
Measuring 3D Video Quality of Experience (QoE) Using A Hybrid Metric Based on Spatial Resolution and Depth Cues


Abstract
:1. Introduction
2. State-of-the-Art Studies
2.1. Reference-Based Metrics
2.2. NR Metrics
2.3. Evaluation of the State-of-the-Art Studies
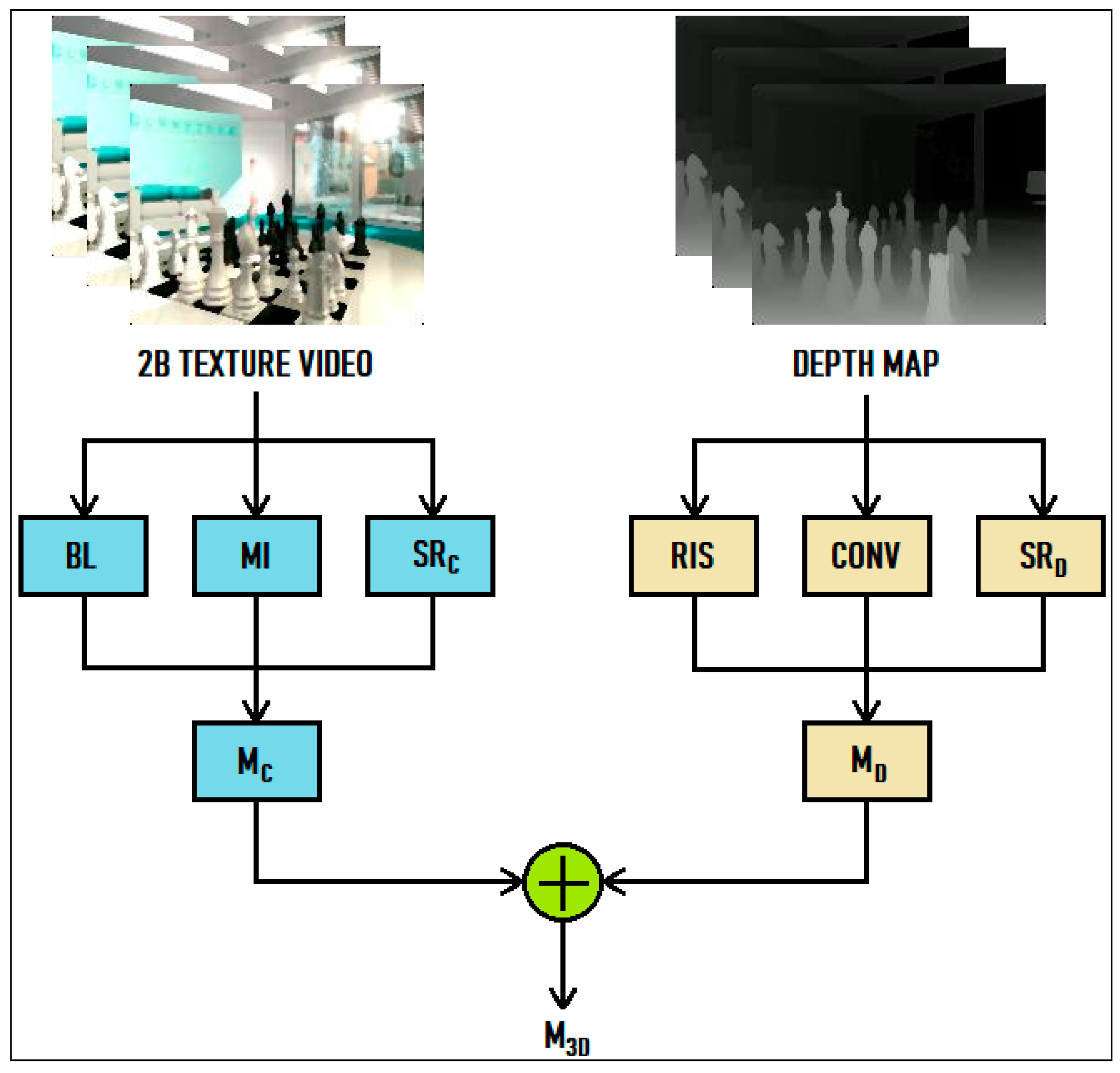
3. Proposed Hybrid 3D-Video QoE Evaluation Method
3.1. Proposed Models for the Depth Cues
3.2. Blurriness
3.3. Motion Information
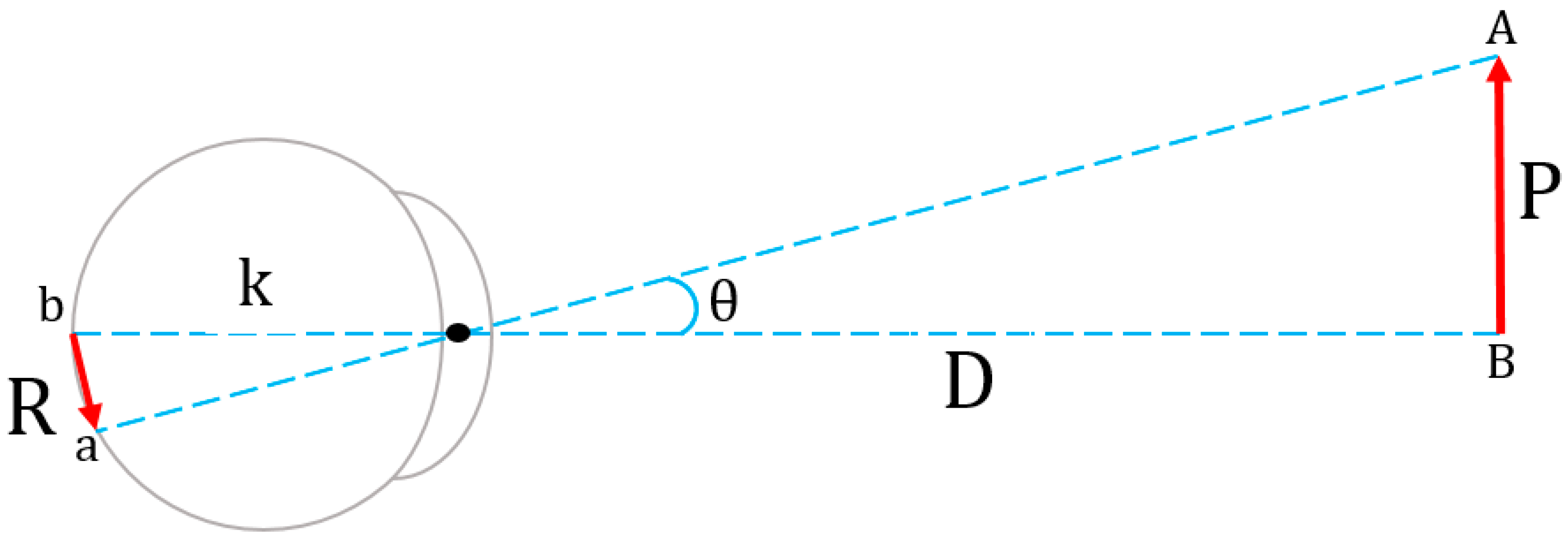
3.4. Retinal-Image Size
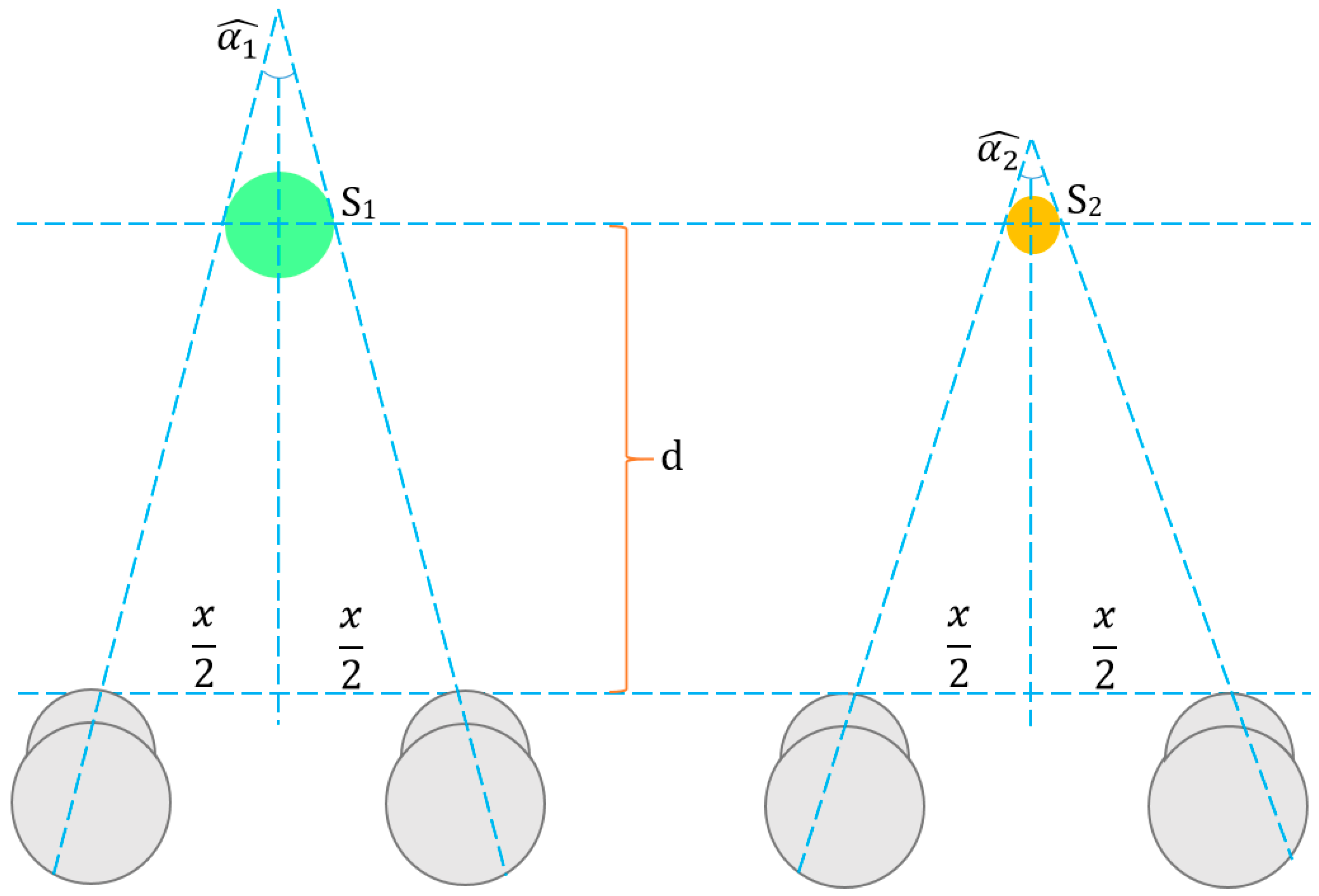
3.5. Convergence
3.6. Subjective Tests
4. Modeling of and
4.1. Modeling of
4.2. Modeling of
5. Results and Discussions
6. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ghadiyaram, D.; Pan, J.; Bovik, A.C. Learning a Continuous-Time Streaming Video QoE Model. IEEE Trans. Image Process. 2018, 27, 2257–2271. [Google Scholar] [CrossRef] [PubMed]
- International Telecommunication Union—Telecommunication Standardization Sector. Vocabulary for performance, quality of service and quality of experience. In Recommendation ITU-T P.10/G.100 (2017)—Amendment 1 (06/2019); International Telecommunication Union: Geneva, Switzerland, 2019. [Google Scholar]
- Suárez, F.J.; García, A.; Granda, J.C.; García, D.F.; Nuño, P. Assessing the QoE in Video Services Over Lossy Networks. J. Netw. Syst. Manag. 2016, 24, 116–139. [Google Scholar] [CrossRef]
- Su, Z.; Li, D.; Ren, H.; Chen, L. Evaluation of depth perception based on binocular stereo vision. In Proceedings of the 13th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery (ICNC-FSKD), Guilin, China, 29–31 July 2017; pp. 2892–2896. [Google Scholar] [CrossRef]
- Chen, Z.; Zhou, W.; Li, W. Blind Stereoscopic Video Quality Assessment: From Depth Perception to Overall Experience. IEEE Trans. Image Process. 2018, 27, 721–734. [Google Scholar] [CrossRef] [PubMed]
- Zhai, G.; Min, X. Perceptual image quality assessment: A survey. Sci. China Inf. Sci. 2020, 63, 211301. [Google Scholar] [CrossRef]
- Barman, N.; Jammeh, E.; Ghorashi, S.A.; Martini, M.G. No-Reference Video Quality Estimation Based on Machine Learning for Passive Gaming Video Streaming Applications. IEEE Access 2019, 7, 74511–74527. [Google Scholar] [CrossRef]
- Vlaović, J.; Vranješ, M.; Grabić, D.; Samardžija, D. Comparison of Objective Video Quality Assessment Methods on Videos with Different Spatial Resolutions. In Proceedings of the International Conference on Systems, Signals and Image Processing (IWSSIP), Osijek, Crotia, 6–7 June 2019; pp. 287–292. [Google Scholar] [CrossRef]
- Yilmaz, G.N. A no reference depth perception assessment metric for 3D video. Multimed. Tools Appl. 2015, 74, 6937–6950. [Google Scholar] [CrossRef]
- Varga, D. No-Reference Image Quality Assessment with Global Statistical Features. J. Imaging 2021, 7, 29. [Google Scholar] [CrossRef] [PubMed]
- Rajchel, M.; Oszust, M. No-reference image quality assessment of authentically distorted images with global and local statistics. SIViP 2021, 15, 83–91. [Google Scholar] [CrossRef]
- Dost, S.; Saud, F.; Shabbir, M.; Khan, A.G.; Shahid, M.; Lovstrom, B. Reduced reference image and video quality assessments: Review of methods. J. Image Video Proc. 2022, 2022, 1. [Google Scholar] [CrossRef]
- Min, X.; Zhai, G.; Gu, K.; Liu, Y.; Yang, X. Blind Image Quality Estimation via Distortion Aggravation. IEEE Trans. Broadcast. 2018, 64, 508–517. [Google Scholar] [CrossRef]
- Min, X.; Zhai, G.; Gu, K.; Liu, Y.; Yang, X.; Chen, C.W. Blind Quality Assessment Based on Pseudo-Reference Image. IEEE Trans. Multimed. 2018, 20, 2049–2062. [Google Scholar] [CrossRef]
- Min, X.; Ma, K.; Gu, K.; Zhai, G.; Wang, Z.; Lin, W.; Chen, C.W. Unified Blind Quality Assessment of Compressed Natural, Graphic, and Screen Content Images. IEEE Trans. Image Process. 2017, 26, 5462–5474. [Google Scholar] [CrossRef] [PubMed]
- Min, X.; Ma, K.; Gu, K.; Zhai, G.; Yang, X.; Zhang, W.; Le Callet, P.; Chen, C.W. Screen Content Quality Assessment: Overview, Benchmark, and Beyond. ACM Comput. Surv. Dec. 2022, 54, 1–36. [Google Scholar] [CrossRef]
- Mahmoudpour, S.; Schelkens, P. On the performance of objective quality metrics for lightfields. Signal Process. Image Commun. 2021, 93, 116179. [Google Scholar] [CrossRef]
- Min, X.; Zhou, J.; Zhai, G.; Le Callet, P.; Yang, X.; Guan, X. A Metric for Light Field Reconstruction, Compression, and Display Quality Evaluation. IEEE Trans. Image Process. 2020, 29, 3790–3804. [Google Scholar] [CrossRef] [PubMed]
- Zhou, S.; Zhu, T.; Shi, K.; Li, Y.; Zheng, W.; Yong, J. Review of light field technologies. Vis. Comput. Ind. Biomed. Art. 2021, 4, 29. [Google Scholar] [CrossRef] [PubMed]
- Adhikarla, V.K.; Vinkler, M.; Sumin, D.; Mantiuk, R.K.; Myszkowski, K.; Seidel, H.; Didyk, P. Towards a Quality Metric for Dense Light Fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3720–3729. [Google Scholar] [CrossRef]
- Min, X.; Zhai, G.; Gu, K.; Yang, X.; Guan, X. Objective Quality Evaluation of Dehazed Images. IEEE Trans. Intell. Transp. Syst. 2019, 20, 2879–2892. [Google Scholar] [CrossRef]
- Min, X.; Zhai, G.; Gu, K.; Zhu, Y.; Zhou, J.; Guo, G.; Yang, X.; Guan, X.; Zhang, W. Quality Evaluation of Image Dehazing Methods Using Synthetic Hazy Images. IEEE Trans. Multimed. 2019, 21, 2319–2333. [Google Scholar] [CrossRef]
- Min, X.; Zhai, G.; Zhou, J.; Farias, M.C.Q.; Bovik, A.C. Study of Subjective and Objective Quality Assessment of Audio-Visual Signals. IEEE Trans. Image Process. 2020, 29, 6054–6068. [Google Scholar] [CrossRef]
- Min, X.; Zhai, G.; Zhou, J.; Zhang, X.; Yang, X.; Guan, X. A Multimodal Saliency Model for Videos with High Audio-Visual Correspondence. IEEE Trans. Image Process. 2020, 29, 3805–3819. [Google Scholar] [CrossRef]
- Min, X.; Zhai, G.; Hu, C.; Gu, K. Fixation prediction through multimodal analysis. In Proceedings of the Visual Communications and Image Processing (VCIP), Singapore, 13–16 December 2015; pp. 1–4. [Google Scholar] [CrossRef]
- Sun, W.; Luo, W.; Min, X.; Zhai, G.; Yang, X.; Gu, K.; Ma, S. MC360IQA: The Multi-Channel CNN for Blind 360-Degree Image Quality Assessment. In Proceedings of the IEEE International Symposium on Circuits and Systems (ISCAS), Sapporo, Japan, 26–29 May 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Zhou, W.; Xu, J.; Jiang, Q.; Chen, Z. No-Reference Quality Assessment for 360-Degree Images by Analysis of Multifrequency Information and Local-Global Naturalness. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 1778–1791. [Google Scholar] [CrossRef]
- Sendjasni, A.; Larabi, M. PW-360IQA: Perceptually-Weighted Multichannel CNN for Blind 360-Degree Image Quality Assessment. Sensors 2023, 23, 4242. [Google Scholar] [CrossRef] [PubMed]
- Joveluro, P.; Malekmohamadi, H.; Fernando, W.A.C.; Kondoz, A.M. Perceptual Video Quality Metric for 3D video quality assessment. In Proceedings of the 3DTV-Conference: The True Vision—Capture, Transmission and Display of 3D Video, Tampere, Finland, 7–9 June 2010; pp. 1–4. [Google Scholar] [CrossRef]
- Jin, L.; Boev, A.; Gotchev, A.; Egiazarian, K. 3D-DCT based perceptual quality assessment of stereo video. In Proceedings of the 18th IEEE International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011; pp. 2521–2524. [Google Scholar] [CrossRef]
- Zeng, K.; Wang, Z. 3D-SSIM for video quality assessment. In Proceedings of the 19th IEEE International Conference on Image Processing, Orlando, FL, USA, 30 September–3 October 2012; pp. 621–624. [Google Scholar] [CrossRef]
- Seo, J.; Liu, X.; Kim, D.; Sohn, K. An Objective Video Quality Metric for Compressed Stereoscopic Video. Circuits Syst. Signal Process 2012, 31, 1089–1107. [Google Scholar] [CrossRef]
- Sun, C.; Liu, X.; Xu, X.; Yang, W. An Efficient Quality Assessment Metric for 3D Video. In Proceedings of the IEEE 12th International Conference on Computer and Information Technology, Chengdu, China, 27–29 October 2012; pp. 209–213. [Google Scholar] [CrossRef]
- Sun, C.; Liu, X.; Yang, W. An Efficient Quality Metric for DIBR-based 3D Video. In Proceedings of the IEEE 14th International Conference on High Performance Computing and Communication & IEEE 9th International Conference on Embedded Software and Systems, Liverpool, UK, 25–27 June 2012; pp. 1391–1394. [Google Scholar] [CrossRef]
- Han, J.; Jiang, T.; Ma, S. Stereoscopic video quality assessment model based on spatial-temporal structural information. In Proceedings of the Visual Communications and Image Processing, San Diego, CA, USA, 27–30 November 2012; pp. 1–6. [Google Scholar] [CrossRef]
- Banitalebi-Dehkordi, A.; Pourazad, M.T.; Nasiopoulos, P. A human visual system-based 3D video quality metric. In Proceedings of the International Conference on 3D Imaging (IC3D), Liege, Belgium, 3–5 December 2012; pp. 1–5. [Google Scholar] [CrossRef]
- Banitalebi-Dehkordi, A.; Pourazad, M.T.; Nasiopoulos, P. 3D video quality metric for mobile applications. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 3731–3735. [Google Scholar] [CrossRef]
- Malekmohamadi, H.; Fernando, W.A.C.; Kondoz, A.M. A new reduced reference objective quality metric for stereoscopic video. In Proceedings of the IEEE Globecom Workshops, Anaheim, CA, USA, 3–7 December 2012; pp. 1325–1328. [Google Scholar] [CrossRef]
- Malekmohamadi, H.; Fernando, W.A.C.; Kondoz, A.M. Reduced reference metric for compressed stereoscopic videos. Electron. Lett. 2013, 49, 701–702. [Google Scholar] [CrossRef]
- Qi, F.; Jiang, T.; Fan, X.; Ma, S.; Zhao, D. Stereoscopic video quality assessment based on stereo just-noticeable difference model. In Proceedings of the IEEE International Conference on Image Processing, Melbourne, VIC, Australia, 15–18 September 2013; pp. 34–38. [Google Scholar] [CrossRef]
- De Silva, V.; Arachchi, H.K.; Ekmekcioglu, E.; Kondoz, A. Toward an Impairment Metric for Stereoscopic Video: A Full-Reference Video Quality Metric to Assess Compressed Stereoscopic Video. IEEE Trans. Image Process. 2013, 22, 3392–3404. [Google Scholar] [CrossRef] [PubMed]
- Banitalebi-Dehkordi, A.; Pourazad, M.T.; Nasiopoulos, P. An efficient human visual system based quality metric for 3D video. Multimed. Tools Appl. 2015, 75, 4187–4215. [Google Scholar] [CrossRef]
- Qi, F.; Zhao, D.; Fan, X.; Jiang, T. Stereoscopic video quality assessment based on visual attention and just-noticeable difference models. SIViP 2015, 10, 737–744. [Google Scholar] [CrossRef]
- Genco, M.L.; Adas, T.; Ozbek, N. Stereo Video Quality assessment using SSIM and depth maps. In Proceedings of the 24th Signal Processing and Communication Application Conference (SIU), Zonguldak, Turkey, 16–19 May 2016; pp. 1325–1328. [Google Scholar] [CrossRef]
- Lee, P.J.; Yang, H.P.; Hsu, C.C. 3D video quality assessment based on visual perception. In Proceedings of the IEEE 6th Global Conference on Consumer Electronics (GCCE), Nagoya, Japan, 24–27 October 2017; pp. 1–2. [Google Scholar] [CrossRef]
- Appina, B.; Manasa, K.; Channappayya, S.S. A full reference stereoscopic video quality assessment metric. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–7 March 2017; pp. 2012–2016. [Google Scholar] [CrossRef]
- Wang, J.; Wang, S.; Wang, Z. Asymmetrically Compressed Stereoscopic 3D Videos: Quality Assessment and Rate-Distortion Performance Evaluation. IEEE Trans. Image Process. 2017, 26, 1330–1343. [Google Scholar] [CrossRef]
- Galkandage, C.; Calic, J.; Dogan, S.; Guillemaut, J. Stereoscopic Video Quality Assessment Using Binocular Energy. IEEE J. Sel. Top. Signal Process. 2017, 11, 102–112. [Google Scholar] [CrossRef]
- Appina, B.; Channappayya, S.S. Full-Reference 3-D Video Quality Assessment Using Scene Component Statistical Dependencies. IEEE Signal Process. Lett. 2018, 25, 823–827. [Google Scholar] [CrossRef]
- Huang, Y.; Zhou, Y.; Hu, B.; Tian, S.; Yan, J. DIBR-synthesised video quality assessment by measuring geometric distortion and spatiotemporal inconsistency. Electron. Lett. 2020, 56, 1314–1317. [Google Scholar] [CrossRef]
- Yilmaz, G.N.; Akar, G.B. 3D Video Quality Evaluation Based on SSIM Model Improvement. In Proceedings of the 6th International Conference on Computer Science and Engineering (UBMK), Ankara, Turkey, 15–17 September 2021; pp. 425–428. [Google Scholar] [CrossRef]
- Solh, M.; AlRegib, G.; Bauza, J.M. 3VQM: A vision-based quality measure for DIBR-based 3D videos. In Proceedings of the IEEE International Conference on Multimedia and Expo, Barcelona, Spain, 11–15 July 2011; pp. 1–6. [Google Scholar] [CrossRef]
- Solh, M.; AlRegib, G. A no-reference quality measure for DIBR-based 3D videos. In Proceedings of the IEEE International Conference on Multimedia and Expo, Barcelona, Spain, 11–15 July 2011; pp. 1–6. [Google Scholar] [CrossRef]
- Ha, K.; Kim, M. A perceptual quality assessment metric using temporal complexity and disparity information for stereoscopic video. In Proceedings of the 18th IEEE International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011; pp. 2525–2528. [Google Scholar] [CrossRef]
- López, J.P.; Rodrigo, J.A.; Jiménez, D.; Menéndez, J.M. Stereoscopic 3D video quality assessment based on depth maps and video motion. EURASIP J. Image Video Proc. 2013, 2013, 62. [Google Scholar] [CrossRef]
- Han, Y.; Yuan, Z.; Muntean, G. No reference objective quality metric for stereoscopic 3D video. In Proceedings of the IEEE International Symposium on Broadband Multimedia Systems and Broadcasting, Beijing, China, 25–27 June 2014; pp. 1–6. [Google Scholar] [CrossRef]
- Hasan, M.M.; Arnold, J.F.; Frater, M.R. No-reference quality assessment of 3D videos based on human visual perception. In Proceedings of the International Conference on 3D Imaging (IC3D), Liege, Belgium, 9–10 December 2014; pp. 1–6. [Google Scholar] [CrossRef]
- Hasan, M.M.; Arnold, J.F.; Frater, M.R. A novel quality assessment of transmitted 3D videos based on binocular rivalry impact. In Proceedings of the Picture Coding Symposium (PCS), Cairns, QLD, Australia, 31 May–3 June 2015; pp. 297–301. [Google Scholar] [CrossRef]
- Han, Y.; Yuan, Z.; Muntean, G. Extended no reference objective Quality Metric for stereoscopic 3D video. In Proceedings of the IEEE International Conference on Communication Workshop (ICCW), London, UK, 8–12 June 2015; pp. 1729–1734. [Google Scholar] [CrossRef]
- Mahmood, S.A.; Ghani, R.F. Objective quality assessment of 3D stereoscopic video based on motion vectors and depth map features. In Proceedings of the 7th Computer Science and Electronic Engineering Conference (CEEC), Colchester, UK, 24–25 September 2015; pp. 179–183. [Google Scholar] [CrossRef]
- Silva, A.R.; Melgar, M.E.V.; Farias, M.C.Q. A no-reference stereoscopic quality metric. In Proceedings of SPIE 9393, Three-Dimensional Image Processing, Measurement (3DIPM), and Applications; Proceedings of Electronic Imaging Science and Technology: San Francisco, CA, USA, 2015; p. 9393. [Google Scholar] [CrossRef]
- Han, Y.; Yuan, Z.; Muntean, G. An Innovative No-Reference Metric for Real-Time 3D Stereoscopic Video Quality Assessment. IEEE Trans. Broadcast. 2016, 62, 654–663. [Google Scholar] [CrossRef]
- Yang, J.; Wang, H.; Lu, W.; Li, B.; Badii, A.; Meng, Q. A no-reference optical flow-based quality evaluator for stereoscopic videos in curvelet domain. Inf. Sci. 2017, 414, 133–146. [Google Scholar] [CrossRef]
- Appina, B.; Jalli, A.; Battula, S.S.; Channappayya, S.S. No-Reference Stereoscopic Video Quality Assessment Algorithm Using Joint Motion and Depth Statistics. In Proceedings of the 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 2800–2804. [Google Scholar] [CrossRef]
- Bayrak, H.; Yilmaz, G.N. No-reference evaluation of 3 dimensional video quality using spatial and frequency domain components. In Proceedings of the 26th Signal Processing and Communications Applications Conference (SIU), Izmir, Turkey, 2–5 May 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Yang, J.; Ji, C.; Jiang, B.; Lu, W.; Meng, Q. No Reference Quality Assessment of Stereo Video Based on Saliency and Sparsity. IEEE Trans. Broadcast. 2018, 64, 341–353. [Google Scholar] [CrossRef]
- Yang, J.; Zhu, Y.; Ma, C.; Lu, W.; Meng, Q. Stereoscopic video quality assessment based on 3D convolutional neural networks. Neurocomputing 2018, 309, 83–93. [Google Scholar] [CrossRef]
- Wang, Y.; Shuai, Y.; Zhu, Y.; Zhang, J.; An, P. Jointly learning perceptually heterogeneous features for blind 3D video quality assessment. Neurocomputing 2019, 332, 298–304. [Google Scholar] [CrossRef]
- Yang, J.; Zhao, Y.; Jiang, B.; Lu, W.; Gao, X. No-Reference Quality Evaluation of Stereoscopic Video Based on Spatio-Temporal Texture. IEEE Trans. Multimed. 2020, 22, 2635–2644. [Google Scholar] [CrossRef]
- Yang, J.; Zhao, Y.; Jiang, B.; Meng, Q.; Lu, W.; Gao, X. No-Reference Quality Assessment of Stereoscopic Videos With Inter-Frame Cross on a Content-Rich Database. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 3608–3623. [Google Scholar] [CrossRef]
- Banitalebi-Dehkordi, A.; Nasiopoulos, P. Saliency inspired quality assessment of stereoscopic 3D video. Multimed. Tools Appl. 2018, 77, 26055–26082. [Google Scholar] [CrossRef]
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing, 4th ed.; Pearson: New York, NY, USA, 2018; ISBN 9780133356724. [Google Scholar]
- Yilmaz, G.N.; Cimtay, Y. Depth Perception Assessment of a 3D Video Based on Spatial Resolution. J. Artif. Intell. Data Sci. 2022, 2, 1–7. [Google Scholar]
- Liu, W.; Ma, L.; Qiu, B.; Cui, M.; Ding, J. An efficient depth map preprocessing method based on structure-aided domain transform smoothing for 3D view generation. PLoS ONE 2017, 12, e0175910. [Google Scholar] [CrossRef] [PubMed]
- Yilmaz, G.N. A Bit Rate Adaptation Model for 3D Video. Multidimens. Syst. Sign Process. 2016, 27, 201–215. [Google Scholar] [CrossRef]
- Emmert, E. Größenverhältnisse der Nachbilder. Klin. Monatsblätter Augenheilkd. Augenärztliche Fortbild. 1881, 19, 443–450. [Google Scholar]
- Zeiss, C.; Goersch, H. Handbuch für Augenoptik, 4th ed.; C. Maurer Druck + Verlag: Geislingen, Germany, 2000. [Google Scholar]
- International Telecommunication Union—Radiocommunication Sector. Methodology for the subjective assessment of the quality of television pictures. In Recommendation ITU-R BT.500-13; Electronic Publication: Geneva, Switzerland, 2012. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 2D Video | Video Size | Quantization Parameter (QP) | ||||
|---|---|---|---|---|---|---|
| 25 | 30 | 35 | 40 | 45 | ||
| Breakdance | Original | 0.260 | 0.259 | 0.258 | 0.256 | 0.236 |
| SD | 0.258 | 0.258 | 0.257 | 0.255 | 0.253 | |
| CIF | 0.258 | 0.257 | 0.256 | 0.255 | 0.253 | |
| QCIF | 0.256 | 0.255 | 0.255 | 0.254 | 0.251 | |
| Butterfly | Original | 0.092 | 0.092 | 0.092 | 0.091 | 0.090 |
| SD | 0.089 | 0.089 | 0.089 | 0.088 | 0.088 | |
| CIF | 0.086 | 0.086 | 0.086 | 0.086 | 0.086 | |
| QCIF | 0.083 | 0.083 | 0.083 | 0.083 | 0.083 | |
| Windmill | Original | 0.200 | 0.200 | 0.199 | 0.199 | 0.197 |
| SD | 0.198 | 0.198 | 0.197 | 0.197 | 0.195 | |
| CIF | 0.196 | 0.196 | 0.196 | 0.195 | 0.194 | |
| QCIF | 0.192 | 0.192 | 0.192 | 0.192 | 0.191 | |
| Chess | Original | 0.335 | 0.335 | 0.335 | 0.335 | 0.335 |
| SD | 0.365 | 0.365 | 0.365 | 0.365 | 0.365 | |
| CIF | 0.379 | 0.379 | 0.379 | 0.379 | 0.379 | |
| QCIF | 0.378 | 0.378 | 0.378 | 0.378 | 0.379 | |
| Interview | Original | 0.199 | 0.199 | 0.199 | 0.198 | 0.197 |
| SD | 0.197 | 0.197 | 0.197 | 0.196 | 0.195 | |
| CIF | 0.190 | 0.190 | 0.190 | 0.190 | 0.189 | |
| QCIF | 0.183 | 0.183 | 0.184 | 0.183 | 0.183 | |
| Advertisement | Original | 0.282 | 0.281 | 0.281 | 0.281 | 0.280 |
| SD | 0.289 | 0.288 | 0.288 | 0.288 | 0.287 | |
| CIF | 0.288 | 0.288 | 0.288 | 0.287 | 0.286 | |
| QCIF | 0.286 | 0.286 | 0.285 | 0.285 | 0.285 | |
| Farm | Original | 0.298 | 0.298 | 0.298 | 0.298 | 0.298 |
| SD | 0.297 | 0.297 | 0.297 | 0.297 | 0.297 | |
| CIF | 0.296 | 0.296 | 0.296 | 0.296 | 0.296 | |
| QCIF | 0.293 | 0.293 | 0.294 | 0.293 | 0.293 | |
| Football | Original | 0.206 | 0.207 | 0.206 | 0.206 | 0.204 |
| SD | 0.205 | 0.205 | 0.205 | 0.204 | 0.203 | |
| CIF | 0.202 | 0.202 | 0.202 | 0.202 | 0.201 | |
| QCIF | 0.197 | 0.197 | 0.198 | 0.198 | 0.197 | |
| Newspaper | Original | 0.278 | 0.278 | 0.278 | 0.278 | 0.278 |
| SD | 0.356 | 0.356 | 0.356 | 0.365 | 0.356 | |
| CIF | 0.363 | 0.363 | 0.363 | 0.362 | 0.362 | |
| QCIF | 0.362 | 0.362 | 0.362 | 0.362 | 0.361 | |
| Ballet | Original | 0.641 | 0.640 | 0.638 | 0.635 | 0.628 |
| SD | 0.655 | 0.653 | 0.650 | 0.644 | 0.631 | |
| CIF | 0.656 | 0.654 | 0.650 | 0.645 | 0.632 | |
| QCIF | 0.657 | 0.654 | 0.651 | 0.645 | 0.632 | |
| 2D Video | Video Size | Quantization Parameter (QP) | ||||
|---|---|---|---|---|---|---|
| 25 | 30 | 35 | 40 | 45 | ||
| Breakdance | Original | 0.311 | 0.333 | 0.309 | 0.282 | 0.224 |
| SD | 0.326 | 0.326 | 0.297 | 0.270 | 0.210 | |
| CIF | 0.265 | 0.260 | 0.240 | 0.222 | 0.169 | |
| QCIF | 0.216 | 0.214 | 0.203 | 0.187 | 0.143 | |
| Butterfly | Original | 1.610 | 1.627 | 1.596 | 1.520 | 1.426 |
| SD | 1.673 | 1.687 | 1.656 | 1.581 | 1.478 | |
| CIF | 1.146 | 1.144 | 1.114 | 1.081 | 1.027 | |
| QCIF | 0.791 | 0.783 | 0.764 | 0.737 | 0.701 | |
| Windmill | Original | 0.153 | 0.152 | 0.145 | 0.137 | 0.110 |
| SD | 0.130 | 0.130 | 0.125 | 0.119 | 0.101 | |
| CIF | 0.067 | 0.067 | 0.067 | 0.067 | 0.061 | |
| QCIF | 0.035 | 0.036 | 0.036 | 0.036 | 0.033 | |
| Chess | Original | 0.280 | 0.281 | 0.279 | 0.276 | 0.301 |
| SD | 0.254 | 0.254 | 0.251 | 0.252 | 0.270 | |
| CIF | 0.168 | 0.170 | 0.170 | 0.168 | 0.172 | |
| QCIF | 0.120 | 0.122 | 0.121 | 0.117 | 0.116 | |
| Interview | Original | 0.114 | 0.109 | 0.101 | 0.090 | 0.078 |
| SD | 0.119 | 0.114 | 0.106 | 0.095 | 0.082 | |
| CIF | 0.066 | 0.064 | 0.061 | 0.057 | 0.050 | |
| QCIF | 0.038 | 0.037 | 0.036 | 0.033 | 0.031 | |
| Advertisement | Original | 0.292 | 0.300 | 0.304 | 0.298 | 0.283 |
| SD | 0.308 | 0.314 | 0.321 | 0.314 | 0.307 | |
| CIF | 0.231 | 0.236 | 0.241 | 0.240 | 0.234 | |
| QCIF | 0.176 | 0.179 | 0.180 | 0.180 | 0.174 | |
| Farm | Original | 1.033 | 1.043 | 1.026 | 0.970 | 0.878 |
| SD | 1.142 | 1.141 | 1.119 | 1.053 | 0.956 | |
| CIF | 0.767 | 0.767 | 0.755 | 0.723 | 0.661 | |
| QCIF | 0.465 | 0.467 | 0.465 | 0.459 | 0.432 | |
| Football | Original | 1.336 | 1.443 | 1.337 | 1.257 | 1.296 |
| SD | 1.466 | 1.520 | 1.319 | 1.172 | 1.170 | |
| CIF | 1.271 | 1.271 | 1.043 | 0.856 | 0.812 | |
| QCIF | 0.636 | 0.640 | 0.566 | 0.468 | 0.440 | |
| Newspaper | Original | 0.465 | 0.455 | 0.437 | 0.400 | 0.347 |
| SD | 0.355 | 0.352 | 0.343 | 0.319 | 0.281 | |
| CIF | 0.192 | 0.192 | 0.191 | 0.185 | 0.169 | |
| QCIF | 0.102 | 0.102 | 0.103 | 0.102 | 0.099 | |
| Ballet | Original | 0.247 | 0.265 | 0.255 | 0.221 | 0.203 |
| SD | 0.248 | 0.239 | 0.232 | 0.210 | 0.190 | |
| CIF | 0.180 | 0.168 | 0.163 | 0.153 | 0.140 | |
| QCIF | 0.119 | 0.114 | 0.114 | 0.103 | 0.090 | |
| DM Sequence | DM Size | Quantization Parameter (QP) | ||||
|---|---|---|---|---|---|---|
| 25 | 30 | 35 | 40 | 45 | ||
| Breakdance | Original | 3.291 × 10−7 | 3.290 × 10−7 | 3.279 × 10−7 | 3.244 × 10−7 | 3.246 × 10−7 |
| SD | 6.364 × 10−7 | 6.361 × 10−7 | 6.343 × 10−7 | 6.278 × 10−7 | 6.282 × 10−7 | |
| CIF | 2.520 × 10−6 | 2.521 × 10−6 | 2.513 × 10−6 | 2.498 × 10−6 | 2.501 × 10−6 | |
| QCIF | 9.979 × 10−6 | 9.979 × 10−6 | 9.939 × 10−6 | 9.861 × 10−6 | 9.893 × 10−6 | |
| Butterfly | Original | 6.835 × 10−8 | 6.857 × 10−8 | 6.952 × 10−8 | 7.076 × 10−8 | 7.245 × 10−8 |
| SD | 9.518 × 10−8 | 9.536 × 10−8 | 9.600 × 10−8 | 9.802 × 10−8 | 1.005 × 10−7 | |
| CIF | 3.767 × 10−7 | 3.793 × 10−7 | 3.810 × 10−7 | 3.918 × 10−7 | 4.019 × 10−7 | |
| QCIF | 1.489 × 10−6 | 1.503 × 10−6 | 1.513 × 10−6 | 1.529 × 10−6 | 1.580 × 10−6 | |
| Windmill | Original | 1.232 × 10−7 | 1.232 × 10−7 | 1.235 × 10−7 | 1.235 × 10−7 | 1.254 × 10−7 |
| SD | 1.573 × 10−7 | 1.582 × 10−7 | 1.579 × 10−7 | 1.578 × 10−7 | 1.604 × 10−7 | |
| CIF | 6.272 × 10−7 | 6.312 × 10−7 | 6.294 × 10−7 | 6.297 × 10−7 | 6.404 × 10−7 | |
| QCIF | 2.495 × 10−6 | 2.509 × 10−6 | 2.502 × 10−6 | 2.509 × 10−6 | 2.550 × 10−6 | |
| Chess | Original | 9.743 × 10−8 | 9.670 × 10−8 | 9.753 × 10−8 | 9.787 × 10−8 | 1.008 × 10−7 |
| SD | 1.252 × 10−7 | 1.243 × 10−7 | 1.252 × 10−7 | 1.253 × 10−7 | 1.291 × 10−7 | |
| CIF | 5.027 × 10−7 | 4.996 × 10−7 | 5.040 × 10−7 | 5.025 × 10−7 | 5.164 × 10−7 | |
| QCIF | 2.030 × 10−6 | 2.009 × 10−6 | 2.032 × 10−6 | 2.022 × 10−6 | 2.065 × 10−6 | |
| Interview | Original | 7.915 × 10−8 | 7.929 × 10−8 | 8.014 × 10−8 | 8.236 × 10−8 | 8.405 × 10−8 |
| SD | 8.240 × 10−8 | 8.259 × 10−8 | 8.340 × 10−8 | 8.556 × 10−8 | 8.731 × 10−8 | |
| CIF | 3.287 × 10−7 | 3.296 × 10−7 | 3.333 × 10−7 | 3.425 × 10−7 | 3.491 × 10−7 | |
| QCIF | 1.309 × 10−6 | 1.320 × 10−6 | 1.337 × 10−6 | 1.369 × 10−6 | 1.389 × 10−6 | |
| Advertisement | Original | 4.246 × 10−8 | 4.285 × 10−8 | 4.348 × 10−8 | 4.451 × 10−8 | 4.577 × 10−8 |
| SD | 6.156 × 10−8 | 6.191 × 10−8 | 6.248 × 10−8 | 6.385 × 10−8 | 6.595 × 10−8 | |
| CIF | 2.470 × 10−7 | 2.474 × 10−7 | 2.492 × 10−7 | 2.567 × 10−7 | 2.632 × 10−7 | |
| QCIF | 1.011 × 10−6 | 1.023 × 10−6 | 1.034 × 10−6 | 1.056 × 10−6 | 1.084 × 10−6 | |
| Farm | Original | 1.217 × 10−7 | 1.214 × 10−7 | 1.206 × 10−7 | 1.203 × 10−7 | 1.226 × 10−7 |
| SD | 1.562 × 10−7 | 1.558 × 10−7 | 1.546 × 10−7 | 1.543 × 10−7 | 1.568 × 10−7 | |
| CIF | 6.233 × 10−7 | 6.216 × 10−7 | 6.167 × 10−7 | 6.156 × 10−7 | 6.254 × 10−7 | |
| QCIF | 2.472 × 10−6 | 2.467 × 10−6 | 2.443 × 10−6 | 2.446 × 10−6 | 2.483 × 10−6 | |
| Football | Original | 1.214 × 10−7 | 1.224 × 10−7 | 1.223 × 10−7 | 1.231 × 10−7 | 1.241 × 10−7 |
| SD | 1.551 × 10−7 | 1.563 × 10−7 | 1.563 × 10−7 | 1.573 × 10−7 | 1.586 × 10−7 | |
| CIF | 6.220 × 10−7 | 6.269 × 10−7 | 6.268 × 10−7 | 6.309 × 10−7 | 6.363 × 10−7 | |
| QCIF | 2.497 × 10−6 | 2.517 × 10−6 | 2.519 × 10−6 | 2.534 × 10−6 | 2.557 × 10−6 | |
| Newspaper | Original | 1.646 × 10−7 | 1.659 × 10−7 | 1.670 × 10−7 | 1.692 × 10−7 | 1.718 × 10−7 |
| SD | 3.258 × 10−7 | 3.268 × 10−7 | 3.278 × 10−7 | 3.311 × 10−7 | 3.354 × 10−7 | |
| CIF | 1.310 × 10−6 | 1.314 × 10−6 | 1.317 × 10−6 | 1.329 × 10−6 | 1.348 × 10−6 | |
| QCIF | 5.285 × 10−6 | 5.298 × 10−6 | 5.312 × 10−6 | 5.358 × 10−6 | 5.438 × 10−6 | |
| Ballet | Original | 4.583 × 10−7 | 4.585 × 10−7 | 4.577 × 10−7 | 4.568 × 10−7 | 4.546 × 10−7 |
| SD | 8.847 × 10−7 | 8.849 × 10−7 | 8.835 × 10−7 | 8.820 × 10−7 | 8.773 × 10−7 | |
| CIF | 3.559 × 10−6 | 3.560 × 10−6 | 3.555 × 10−6 | 3.547 × 10−6 | 3.535 × 10−6 | |
| QCIF | 1.412 × 10−5 | 1.413 × 10−5 | 1.411 × 10−5 | 1.410 × 10−5 | 1.407 × 10−5 | |
| DM Sequence | DM Size | Quantization Parameter (QP) | ||||
|---|---|---|---|---|---|---|
| 25 | 30 | 35 | 40 | 45 | ||
| Breakdance | Original | 2.035 × 10−10 | 2.035 × 10−10 | 2.034 × 10−10 | 2.030 × 10−10 | 2.031 × 10−10 |
| SD | 3.949 × 10−10 | 3.950 × 10−10 | 3.946 × 10−10 | 3.939 × 10−10 | 3.940 × 10−10 | |
| CIF | 1.582 × 10−9 | 1.582 × 10−9 | 1.581 × 10−9 | 1.577 × 10−9 | 1.578 × 10−9 | |
| QCIF | 6.362 × 10−9 | 6.362 × 10−9 | 6.350 × 10−9 | 6.329 × 10−9 | 6.335 × 10−9 | |
| Butterfly | Original | 1.618 × 10−10 | 1.162 × 10−10 | 1.627 × 10−10 | 1.637 × 10−10 | 1.635 × 10−10 |
| SD | 2.138 × 10−10 | 2.140 × 10−10 | 2.145 × 10−10 | 2.162 × 10−10 | 2.157 × 10−10 | |
| CIF | 8.559 × 10−10 | 8.577 × 10−10 | 8.599 × 10−10 | 8.672 × 10−10 | 8.648 × 10−10 | |
| QCIF | 3.420 × 10−9 | 3.433 × 10−9 | 3.442 × 10−9 | 3.452 × 10−9 | 3.448 × 10−9 | |
| Windmill | Original | 2.795 × 10−10 | 2.799 × 10−10 | 2.781 × 10−10 | 2.772 × 10−10 | 2.790 × 10−10 |
| SD | 3.578 × 10−10 | 3.583 × 10−10 | 3.559 × 10−10 | 3.548 × 10−10 | 3.573 × 10−10 | |
| CIF | 1.432 × 10−9 | 1.435 × 10−9 | 1.425 × 10−9 | 1.421 × 10−9 | 1.433 × 10−9 | |
| QCIF | 5.750 × 10−9 | 5.759 × 10−9 | 5.721 × 10−9 | 5.702 × 10−9 | 5.767 × 10−9 | |
| Chess | Original | 3.151 × 10−10 | 3.114 × 10−10 | 3.104 × 10−10 | 3.047 × 10−10 | 3.003 × 10−10 |
| SD | 4.041 × 10−10 | 3.994 × 10−10 | 3.977 × 10−10 | 3.900 × 10−10 | 3.844 × 10−10 | |
| CIF | 1.617 × 10−9 | 1.599 × 10−9 | 1.593 × 10−9 | 1.560 × 10−9 | 1.536 × 10−9 | |
| QCIF | 6.482 × 10−9 | 6.401 × 10−9 | 6.390 × 10−9 | 6.249 × 10−9 | 6.134 × 10−9 | |
| Interview | Original | 1.972 × 10−10 | 1.975 × 10−10 | 1.981 × 10−10 | 1.989 × 10−10 | 1.998 × 10−10 |
| SD | 2.028 × 10−10 | 2.031 × 10−10 | 2.034 × 10−10 | 2.045 × 10−10 | 2.054 × 10−10 | |
| CIF | 8.117 × 10−10 | 8.129 × 10−10 | 8.156 × 10−10 | 8.189 × 10−10 | 8.226 × 10−10 | |
| QCIF | 3.244 × 10−9 | 3.248 × 10−9 | 3.261 × 10−9 | 3.275 × 10−9 | 3.287 × 10−9 | |
| Advertisement | Original | 1.178 × 10−10 | 1.183 × 10−10 | 1.193 × 10−10 | 1.207 × 10−10 | 1.233 × 10−10 |
| SD | 1.524 × 10−10 | 1.530 × 10−10 | 1.542 × 10−10 | 1.560 × 10−10 | 1.594 × 10−10 | |
| CIF | 6.094 × 10−10 | 6.118 × 10−10 | 6.166 × 10−10 | 6.242 × 10−10 | 6.374 × 10−10 | |
| QCIF | 2.437 × 10−9 | 2.449 × 10−9 | 2.469 × 10−9 | 2.497 × 10−9 | 2.553 × 10−9 | |
| Farm | Original | 2.182 × 10−10 | 2.181 × 10−10 | 2.178 × 10−10 | 2.185 × 10−10 | 2.200 × 10−10 |
| SD | 2.799 × 10−10 | 2.800 × 10−10 | 2.795 × 10−10 | 2.804 × 10−10 | 2.823 × 10−10 | |
| CIF | 1.122 × 10−9 | 1.122 × 10−9 | 1.120 × 10−9 | 1.124 × 10−9 | 1.131 × 10−9 | |
| QCIF | 4.518 × 10−9 | 4.517 × 10−9 | 4.504 × 10−9 | 4.520 × 10−9 | 4.551 × 10−9 | |
| Football | Original | 2.694 × 10−10 | 2.685 × 10−10 | 2.681 × 10−10 | 2.666 × 10−10 | 2.646 × 10−10 |
| SD | 3.445 × 10−10 | 3.433 × 10−10 | 3.428 × 10−10 | 3.400 × 10−10 | 3.384 × 10−10 | |
| CIF | 1.378 × 10−9 | 1.373 × 10−9 | 1.371 × 10−9 | 1.364 × 10−9 | 1.353 × 10−9 | |
| QCIF | 5.514 × 10−9 | 5.494 × 10−9 | 5.485 × 10−9 | 5.458 × 10−9 | 5.415 × 10−9 | |
| Newspaper | Original | 7.960 × 10−11 | 7.980 × 10−11 | 7.990 × 10−11 | 8.020 × 10−11 | 8.050 × 10−11 |
| SD | 1.554 × 10−10 | 1.555 × 10−10 | 1.556 × 10−10 | 1.560 × 10−10 | 1.566 × 10−10 | |
| CIF | 6.223 × 10−10 | 6.225 × 10−10 | 6.225 × 10−10 | 6.240 × 10−10 | 6.261 × 10−10 | |
| QCIF | 2.493 × 10−9 | 2.492 × 10−9 | 2.493 × 10−10 | 2.497 × 10−9 | 2.505 × 10−9 | |
| Ballet | Original | 2.313 × 10−10 | 2.316 × 10−10 | 2.315 × 10−10 | 2.313 × 10−10 | 2.316 × 10−10 |
| SD | 4.493 × 10−10 | 4.498 × 10−10 | 4.496 × 10−10 | 4.492 × 10−10 | 4.496 × 10−10 | |
| CIF | 1.803 × 10−9 | 1.805 × 10−9 | 1.804 × 10−9 | 1.803 × 10−9 | 1.805 × 10−9 | |
| QCIF | 7.240 × 10−9 | 7.247 × 10−9 | 7.246 × 10−9 | 7.239 × 10−9 | 7.243 × 10−9 | |
| Video | Quantization Parameter (QP) | Spatial Resolution (2D + DM) | M3D | VQM | PSNR | SSIM | MOS |
|---|---|---|---|---|---|---|---|
| Breakdance | 25 | SD | 3.4401 | 4.8796 | 56.5618 | 0.9989 | 3.032 ± 0.32 |
| 30 | 3.4332 | 4.8291 | 53.5868 | 0.9984 | 2.844 ± 0.29 | ||
| 35 | 3.1140 | 4.7497 | 50.4148 | 0.9975 | 2.688 ± 0.35 | ||
| 40 | 2.8213 | 4.6262 | 47.1143 | 0.9960 | 2.500 ± 0.33 | ||
| 45 | 2.1744 | 4.4271 | 43.6735 | 0.9934 | 2.375 ± 0.28 | ||
| 25 | CIF | 0.7920 | 4.9037 | 56.9623 | 0.9991 | 3.032 ± 0.34 | |
| 30 | 0.7777 | 4.8638 | 54.1026 | 0.9987 | 2.844 ± 0.35 | ||
| 35 | 0.7248 | 4.8078 | 50.9981 | 0.9978 | 2.688 ± 0.31 | ||
| 40 | 0.6745 | 4.7133 | 47.6829 | 0.9962 | 2.500 ± 0.27 | ||
| 45 | 0.5342 | 4.5608 | 44.2103 | 0.9931 | 2.375 ± 0.32 | ||
| 25 | QCIF | 0.5422 | 4.9125 | 56.8838 | 0.9993 | 3.032 ± 0.31 | |
| 30 | 0.5406 | 4.8809 | 54.2220 | 0.9989 | 2.844 ± 0.33 | ||
| 35 | 0.5308 | 4.8346 | 51.3094 | 0.9983 | 2.688 ± 0.36 | ||
| 40 | 0.5156 | 4.7579 | 48.1342 | 0.9969 | 2.500 ± 0.34 | ||
| 45 | 0.4883 | 4.6352 | 44.6945 | 0.9942 | 2.375 ± 0.37 |
| Video | Quantization Parameter (QP) | Spatial Resolution (2D + DM) | M3D | VQM | PSNR | SSIM | MOS |
|---|---|---|---|---|---|---|---|
| Ballet | 25 | SD | 6.6267 | 4.8773 | 53.7605 | 0.9991 | 3.407 ± 0.27 |
| 30 | 6.3759 | 4.8239 | 53.2095 | 0.9987 | 3.250 ± 0.29 | ||
| 35 | 6.1400 | 4.7416 | 49.9250 | 0.9979 | 3.126 ± 0.32 | ||
| 40 | 5.5372 | 4.6091 | 46.4618 | 0.9965 | 3.032 ± 0.35 | ||
| 45 | 4.9082 | 4.4217 | 42.9127 | 0.9941 | 2.907 ± 0.36 | ||
| 25 | CIF | 1.3605 | 4.9039 | 56.5066 | 0.9993 | 3.407 ± 0.42 | |
| 30 | 1.2735 | 4.8588 | 53.5567 | 0.9989 | 3.250 ± 0.39 | ||
| 35 | 1.2735 | 4.7992 | 50.2766 | 0.9981 | 3.126 ± 0.37 | ||
| 40 | 1.1640 | 4.7027 | 46.7613 | 0.9968 | 3.032 ± 0.33 | ||
| 45 | 1.0611 | 4.5688 | 43.2264 | 0.9942 | 2.907 ± 0.35 | ||
| 25 | QCIF | 0.8464 | 4.9150 | 56.5325 | 0.9995 | 3.407 ± 0.29 | |
| 30 | 0.8380 | 4.8773 | 53.6213 | 0.9992 | 3.250 ± 0.32 | ||
| 35 | 0.8354 | 4.8303 | 50.5181 | 0.9987 | 3.126 ± 0.34 | ||
| 40 | 0.8143 | 4.7481 | 46.9328 | 0.9976 | 3.032 ± 0.28 | ||
| 45 | 0.7891 | 4.6356 | 43.4891 | 0.9956 | 2.907 ± 0.35 |
| Video | Quantization Parameter (QP) | Spatial Resolution (2D + DM) | M3D | VQM | PSNR | SSIM | MOS |
|---|---|---|---|---|---|---|---|
| Interview | 25 | SD | 0.9474 | 4.2200 | 41.4998 | 0.9966 | 4.001 ± 0.27 |
| 30 | 0.9075 | 4.1903 | 41.3180 | 0.9959 | 3.907 ± 0.33 | ||
| 35 | 0.8448 | 4.1317 | 40.9247 | 0.9944 | 3.813 ± 0.31 | ||
| 40 | 0.7592 | 4.0538 | 40.1647 | 0.9917 | 3.688 ± 0.29 | ||
| 45 | 0.6530 | 3.8449 | 38.7946 | 0.9864 | 3.625 ± 0.32 | ||
| 25 | CIF | 0.1345 | 4.3272 | 42.7706 | 0.9975 | 4.001 ± 0.28 | |
| 30 | 0.1303 | 4.3058 | 42.5561 | 0.9969 | 3.907 ± 0.26 | ||
| 35 | 0.1253 | 4.2687 | 42.1289 | 0.9958 | 3.813 ± 0.31 | ||
| 40 | 0.1164 | 4.2066 | 41.2602 | 0.9936 | 3.688 ± 0.29 | ||
| 45 | 0.1037 | 4.0760 | 39.7609 | 0.9891 | 3.625 ± 0.33 | ||
| 25 | QCIF | 0.0447 | 4.4151 | 42.3809 | 0.9973 | 4.001 ± 0.34 | |
| 30 | 0.0445 | 4.4017 | 42.2283 | 0.9970 | 3.907 ± 0.31 | ||
| 35 | 0.0443 | 4.3779 | 41.9024 | 0.9962 | 3.813 ± 0.29 | ||
| 40 | 0.0439 | 4.3343 | 41.2490 | 0.9948 | 3.688 ± 0.30 | ||
| 45 | 0.0432 | 4.2470 | 40.0028 | 0.9915 | 3.625 ± 0.28 |
| Video | Quantization Parameter (QP) | Spatial Resolution (2D + DM) | M3D | VQM | PSNR | SSIM | MOS |
|---|---|---|---|---|---|---|---|
| Newspaper | 25 | SD | 5.1342 | 4.0684 | 35.8210 | 0.9933 | 3.688 ± 0.41 |
| 30 | 5.0837 | 4.0339 | 35.6992 | 0.9918 | 3.626 ± 0.40 | ||
| 35 | 4.9536 | 3.9709 | 35.4685 | 0.9889 | 3.500 ± 0.38 | ||
| 40 | 4.7325 | 3.8708 | 35.0251 | 0.9836 | 3.344 ± 0.36 | ||
| 45 | 4.0618 | 3.7132 | 34.2498 | 0.9765 | 3.250 ± 0.34 | ||
| 25 | CIF | 0.7252 | 4.0660 | 35.6577 | 0.9917 | 3.688 ± 0.33 | |
| 30 | 0.7252 | 4.0507 | 35.5944 | 0.9915 | 3.626 ± 0.29 | ||
| 35 | 0.7252 | 4.0205 | 35.4349 | 0.9902 | 3.500 ± 0.31 | ||
| 40 | 0.6999 | 3.9645 | 35.0834 | 0.9866 | 3.344 ± 0.32 | ||
| 45 | 0.6422 | 3.8515 | 34.4194 | 0.9804 | 3.250 ± 0.30 | ||
| 25 | QCIF | 0.1768 | 4.0558 | 35.2781 | 0.9892 | 3.688 ± 0.29 | |
| 30 | 0.1773 | 4.0504 | 35.2539 | 0.9894 | 3.626 ± 0.31 | ||
| 35 | 0.1781 | 4.0343 | 35.1658 | 0.9892 | 3.500 ± 0.34 | ||
| 40 | 0.1781 | 4.0066 | 34.9285 | 0.9879 | 3.344 ± 0.33 | ||
| 45 | 0.1770 | 3.9303 | 34.9087 | 0.9843 | 3.250 ± 0.36 |
| Video | Quantization Parameter (QP) | Spatial Resolution (2D + DM) | M3D | VQM | PSNR | SSIM | MOS |
|---|---|---|---|---|---|---|---|
| Windmill | 25 | SD | 1.0434 | 4.4358 | 45.1454 | 0.9963 | 3.969 ± 0.26 |
| 30 | 1.0445 | 4.3923 | 43.5693 | 0.9953 | 3.844 ± 0.23 | ||
| 35 | 1.0045 | 4.3052 | 41.6618 | 0.9934 | 3.751 ± 0.28 | ||
| 40 | 0.9569 | 4.1879 | 39.7736 | 0.9902 | 3.594 ± 0.31 | ||
| 45 | 0.8033 | 3.9880 | 37.6751 | 0.9845 | 3.500 ± 0.29 | ||
| 25 | CIF | 0.1566 | 4.4552 | 45.4161 | 0.9961 | 3.969 ± 0.30 | |
| 30 | 0.1570 | 4.4276 | 44.0346 | 0.9955 | 3.844 ± 0.32 | ||
| 35 | 0.1553 | 4.3616 | 42.3003 | 0.9940 | 3.751 ± 0.34 | ||
| 40 | 0.1546 | 4.2743 | 40.4856 | 0.9913 | 3.594 ± 0.36 | ||
| 45 | 0.1433 | 4.1308 | 38.3891 | 0.9859 | 3.500 ± 0.31 | ||
| 25 | QCIF | 0.1079 | 4.4626 | 45.2037 | 0.9955 | 3.969 ± 0.29 | |
| 30 | 0.1091 | 4.4407 | 43.9034 | 0.9950 | 3.844 ± 0.27 | ||
| 35 | 0.1082 | 4.3906 | 42.3530 | 0.9940 | 3.751 ± 0.32 | ||
| 40 | 0.1080 | 4.3181 | 40.7104 | 0.9921 | 3.594 ± 0.33 | ||
| 45 | 0.1089 | 4.2043 | 38.8237 | 0.9879 | 3.500 ± 0.30 |
| Video | Quantization Parameter (QP) | Spatial Resolution (2D + DM) | M3D | VQM | PSNR | SSIM | MOS |
|---|---|---|---|---|---|---|---|
| Advertisement | 25 | SD | 3.6042 | 4.8873 | 56.6045 | 0.9995 | 4.219 ± 0.42 |
| 30 | 3.6778 | 4.8289 | 53.1858 | 0.9990 | 4.063 ± 0.39 | ||
| 35 | 3.7451 | 4.7360 | 49.6790 | 0.9982 | 3.844 ± 0.33 | ||
| 40 | 3.6653 | 4.5838 | 45.7916 | 0.9966 | 3.719 ± 0.35 | ||
| 45 | 3.5679 | 4.3204 | 41.5741 | 0.9932 | 3.563 ± 0.38 | ||
| 25 | CIF | 0.6777 | 4.9107 | 56.7655 | 0.9996 | 4.219 ± 0.36 | |
| 30 | 0.6909 | 4.8654 | 53.4021 | 0.9993 | 4.063 ± 0.33 | ||
| 35 | 0.7072 | 4.7999 | 49.9854 | 0.9986 | 3.844 ± 0.31 | ||
| 40 | 0.7017 | 4.6908 | 46.1555 | 0.9974 | 3.719 ± 0.29 | ||
| 45 | 0.6829 | 4.4971 | 42.0431 | 0.9945 | 3.563 ± 0.27 | ||
| 25 | QCIF | 0.1433 | 4.9176 | 56.5843 | 0.9997 | 4.219 ± 0.34 | |
| 30 | 0.1454 | 4.8774 | 53.2847 | 0.9995 | 4.063 ± 0.37 | ||
| 35 | 0.1461 | 4.8215 | 50.0120 | 0.9990 | 3.844 ± 0.35 | ||
| 40 | 0.1468 | 4.7272 | 46.2116 | 0.9981 | 3.719 ± 0.38 | ||
| 45 | 0.1430 | 4.5706 | 42.2322 | 0.9962 | 3.563 ± 0.33 |
| Video | Quantization Parameter (QP) | Spatial Resolution (2D + DM) | M3D | VQM | PSNR | SSIM | MOS |
|---|---|---|---|---|---|---|---|
| Butterfly | 25 | SD | 6.0256 | 4.8873 | 56.6045 | 0.9995 | 4.219 ± 0.35 |
| 30 | 6.0710 | 4.8289 | 53.1858 | 0.9990 | 4.063 ± 0.38 | ||
| 35 | 5.9588 | 4.7360 | 49.6790 | 0.9982 | 3.844 ± 0.32 | ||
| 40 | 5.6684 | 4.5838 | 45.7916 | 0.9966 | 3.719 ± 0.34 | ||
| 45 | 5.2647 | 4.3204 | 41.5741 | 0.9932 | 3.563 ± 0.37 | ||
| 25 | CIF | 1.0064 | 4.9107 | 56.7655 | 0.9996 | 4.219 ± 0.40 | |
| 30 | 1.0032 | 4.8654 | 53.4021 | 0.9993 | 4.063 ± 0.42 | ||
| 35 | 0.9786 | 4.7999 | 49.9854 | 0.9986 | 3.844 ± 0.39 | ||
| 40 | 0.9498 | 4.6908 | 46.1555 | 0.9974 | 3.719 ± 0.43 | ||
| 45 | 0.8998 | 4.4971 | 42.0431 | 0.9945 | 3.563 ± 0.37 | ||
| 25 | QCIF | 0.1985 | 4.9176 | 56.5843 | 0.9997 | 4.219 ± 0.35 | |
| 30 | 0.1970 | 4.8774 | 53.2847 | 0.9995 | 4.063 ± 0.33 | ||
| 35 | 0.1936 | 4.8215 | 50.0120 | 0.9990 | 3.844 ± 0.37 | ||
| 40 | 0.1886 | 4.7272 | 46.2116 | 0.9981 | 3.719 ± 0.32 | ||
| 45 | 0.1821 | 4.5706 | 42.2322 | 0.9962 | 3.563 ± 0.30 |
| Video | Quantization Parameter (QP) | Spatial Resolution (2D + DM) | M3D | VQM | PSNR | SSIM | MOS |
|---|---|---|---|---|---|---|---|
| Chess | 25 | SD | 3.7715 | 4.8789 | 54.5879 | 0.9991 | 4.407 ± 0.33 |
| 30 | 3.7714 | 4.8166 | 50.9710 | 0.9982 | 4.188 ± 0.30 | ||
| 35 | 3.7181 | 4.7283 | 47.3275 | 0.9965 | 4.032 ± 0.29 | ||
| 40 | 3.7373 | 4.5733 | 43.5673 | 0.9929 | 3.875 ± 0.32 | ||
| 45 | 4.0090 | 4.3055 | 39.6801 | 0.9859 | 3.751 ± 0.35 | ||
| 25 | CIF | 0.6665 | 4.9000 | 54.7785 | 0.9993 | 4.407 ± 0.36 | |
| 30 | 0.6731 | 4.8405 | 51.2166 | 0.9986 | 4.188 ± 0.38 | ||
| 35 | 0.6718 | 4.7685 | 47.6791 | 0.9973 | 4.032 ± 0.41 | ||
| 40 | 0.6663 | 4.6611 | 44.0473 | 0.9944 | 3.875 ± 0.37 | ||
| 45 | 0.6809 | 4.4613 | 40.2214 | 0.9886 | 3.751 ± 0.39 | ||
| 25 | QCIF | 0.1987 | 4.9089 | 54.6848 | 0.9996 | 4.407 ± 0.33 | |
| 30 | 0.1984 | 4.8524 | 51.1796 | 0.9990 | 4.188 ± 0.31 | ||
| 35 | 0.1982 | 4.7830 | 47.6853 | 0.9980 | 4.032 ± 0.35 | ||
| 40 | 0.1923 | 4.6834 | 44.1676 | 0.9959 | 3.875 ± 0.34 | ||
| 45 | 0.1913 | 4.5261 | 40.4934 | 0.9915 | 3.751 ± 0.38 |
| Video | Quantization Parameter (QP) | Spatial Resolution (2D + DM) | M3D | VQM | PSNR | SSIM | MOS |
|---|---|---|---|---|---|---|---|
| Farm | 25 | SD | 13.7420 | 4.8592 | 55.3304 | 0.9989 | 4.063 ± 0.31 |
| 30 | 13.7356 | 4.3882 | 44.3243 | 0.9956 | 3.938 ± 0.34 | ||
| 35 | 13.4822 | 4.6924 | 49.1877 | 0.9969 | 3.844 ± 0.36 | ||
| 40 | 12.6759 | 4.5258 | 45.9308 | 0.9944 | 3.719 ± 0.29 | ||
| 45 | 11.5130 | 4.2681 | 42.2888 | 0.9897 | 3.563 ± 0.35 | ||
| 25 | CIF | 2.3161 | 4.8730 | 53.6109 | 0.9990 | 4.063 ± 0.32 | |
| 30 | 2.3176 | 4.4372 | 44.6049 | 0.9957 | 3.938 ± 0.29 | ||
| 35 | 2.3176 | 4.7578 | 49.1674 | 0.9974 | 3.844 ± 0.35 | ||
| 40 | 2.1857 | 4.6416 | 46.3153 | 0.9954 | 3.719 ± 0.31 | ||
| 45 | 2.0014 | 4.4426 | 42.9054 | 0.9910 | 3.563 ± 0.28 | ||
| 25 | QCIF | 0.4162 | 4.8496 | 51.0768 | 0.9988 | 4.063 ± 0.32 | |
| 30 | 0.4179 | 4.4530 | 44.4586 | 0.9955 | 3.938 ± 0.33 | ||
| 35 | 0.4156 | 4.7571 | 47.6791 | 0.9976 | 3.844 ± 0.29 | ||
| 40 | 0.4109 | 4.6676 | 45.5833 | 0.9958 | 3.719 ± 0.27 | ||
| 45 | 0.3928 | 4.5059 | 42.8398 | 0.9920 | 3.563 ± 0.30 |
| Video | Quantization Parameter (QP) | Spatial Resolution (2D + DM) | M3D | VQM | PSNR | SSIM | MOS |
|---|---|---|---|---|---|---|---|
| Football | 25 | SD | 12.1641 | 4.8734 | 55.2868 | 0.9987 | 3.407 ± 0.23 |
| 30 | 12.6200 | 4.8057 | 52.1508 | 0.9976 | 3.251 ± 0.26 | ||
| 35 | 10.9462 | 4.7125 | 49.0173 | 0.9959 | 3.157 ± 0.28 | ||
| 40 | 9.6997 | 4.5733 | 45.7945 | 0.9935 | 2.969 ± 0.22 | ||
| 45 | 9.6318 | 4.3229 | 41.9282 | 0.9890 | 2.844 ± 0.25 | ||
| 25 | CIF | 2.6262 | 4.9018 | 55.9488 | 0.9991 | 3.407 ± 0.27 | |
| 30 | 2.6288 | 4.8516 | 53.0047 | 0.9984 | 3.251 ± 0.25 | ||
| 35 | 2.6288 | 4.7890 | 49.9781 | 0.9973 | 3.157 ± 0.22 | ||
| 40 | 1.7745 | 4.6903 | 46.7740 | 0.9953 | 2.969 ± 0.24 | ||
| 45 | 1.6785 | 4.5151 | 44.4051 | 0.9916 | 2.844 ± 0.28 | ||
| 25 | QCIF | 0.4051 | 4.9066 | 55.8213 | 0.9993 | 3.407 ± 0.30 | |
| 30 | 0.4077 | 4.8604 | 53.0627 | 0.9988 | 3.251 ± 0.32 | ||
| 35 | 0.3708 | 4.8119 | 50.2311 | 0.9980 | 3.157 ± 0.35 | ||
| 40 | 0.3219 | 4.7342 | 47.1955 | 0.9965 | 2.969 ± 0.38 | ||
| 45 | 0.3076 | 4.5929 | 43.4736 | 0.9935 | 2.844 ± 0.37 |
| 3D Video | Spatial Resolution | Correlation between the M3D and the MOS | Correlation between the M3D and VQM | Correlation between the M3D and PSNR | Correlation between the M3D and SSIM |
|---|---|---|---|---|---|
| Breakdance | SD | 0.924 | 0.994 | 0.953 | 0.996 |
| CIF | 0.919 | 0.994 | 0.952 | 0.998 | |
| QCIF | 0.920 | 0.996 | 0.956 | 0.998 | |
| Ballet | SD | 0.956 | 0.998 | 0.990 | 0.993 |
| CIF | 0.956 | 0.984 | 0.971 | 0.970 | |
| QCIF | 0.925 | 0.992 | 0.957 | 0.995 | |
| Windmill | SD | 0.887 | 0.979 | 0.916 | 0.987 |
| CIF | 0.785 | 0.920 | 0.840 | 0.952 | |
| QCIF | 0.255 | 0.273 | 0.260 | 0.332 | |
| Newspaper | SD | 0.907 | 0.982 | 0.991 | 0.978 |
| CIF | 0.854 | 0.976 | 0.981 | 0.986 | |
| QCIF | 0.286 | 0.106 | 0.282 | 0.264 | |
| Interview | SD | 0.977 | 0.978 | 0.985 | 0.983 |
| CIF | 0.962 | 0.993 | 0.994 | 0.990 | |
| QCIF | 0.944 | 0.998 | 0.997 | 0.993 | |
| Advertisement | SD | 0.134 | 0.450 | 0.239 | 0.513 |
| CIF | 0.328 | 0.007 | 0.228 | 0.106 | |
| QCIF | 0.111 | 0.187 | 0.033 | 0.289 | |
| Butterfly | SD | 0.880 | 0.984 | 0.922 | 0.989 |
| CIF | 0.940 | 0.997 | 0.966 | 0.992 | |
| QCIF | 0.959 | 0.998 | 0.982 | 0.987 | |
| Chess | SD | 0.525 | 0.783 | 0.601 | 0.826 |
| CIF | 0.562 | 0.684 | 0.590 | 0.699 | |
| QCIF | 0.876 | 0.926 | 0.905 | 0.912 | |
| Farm | SD | 0.939 | 0.675 | 0.646 | 0.936 |
| CIF | 0.901 | 0.540 | 0.651 | 0.914 | |
| QCIF | 0.862 | 0.405 | 0.620 | 0.855 | |
| Football | SD | 0.911 | 0.880 | 0.914 | 0.880 |
| CIF | 0.906 | 0.902 | 0.882 | 0.903 | |
| QCIF | 0.959 | 0.939 | 0.959 | 0.925 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Coskun, S.; Nur Yilmaz, G.; Battisti, F.; Alhussein, M.; Islam, S. Measuring 3D Video Quality of Experience (QoE) Using A Hybrid Metric Based on Spatial Resolution and Depth Cues. J. Imaging 2023, 9, 281. https://doi.org/10.3390/jimaging9120281
Coskun S, Nur Yilmaz G, Battisti F, Alhussein M, Islam S. Measuring 3D Video Quality of Experience (QoE) Using A Hybrid Metric Based on Spatial Resolution and Depth Cues. Journal of Imaging. 2023; 9(12):281. https://doi.org/10.3390/jimaging9120281
Chicago/Turabian StyleCoskun, Sahin, Gokce Nur Yilmaz, Federica Battisti, Musaed Alhussein, and Saiful Islam. 2023. "Measuring 3D Video Quality of Experience (QoE) Using A Hybrid Metric Based on Spatial Resolution and Depth Cues" Journal of Imaging 9, no. 12: 281. https://doi.org/10.3390/jimaging9120281