
Machine Learning for Prediction of the International Roughness Index on Flexible Pavements: A Review, Challenges, and Future Directions



Abstract
:1. Introduction
2. Background
2.1. Pavement Performance Models
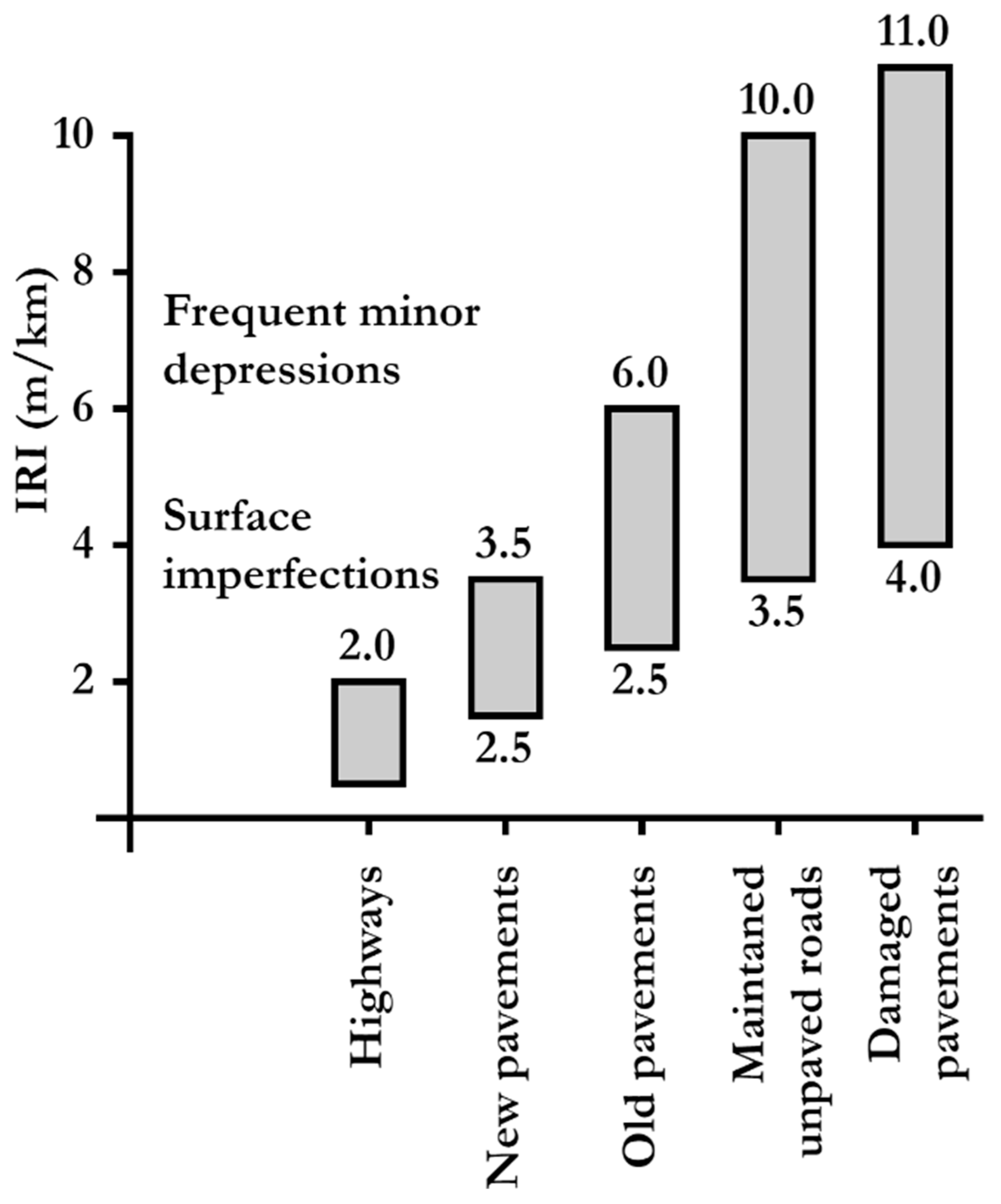
2.2. International Roughness Index (IRI)
2.3. Road Pavement Databases
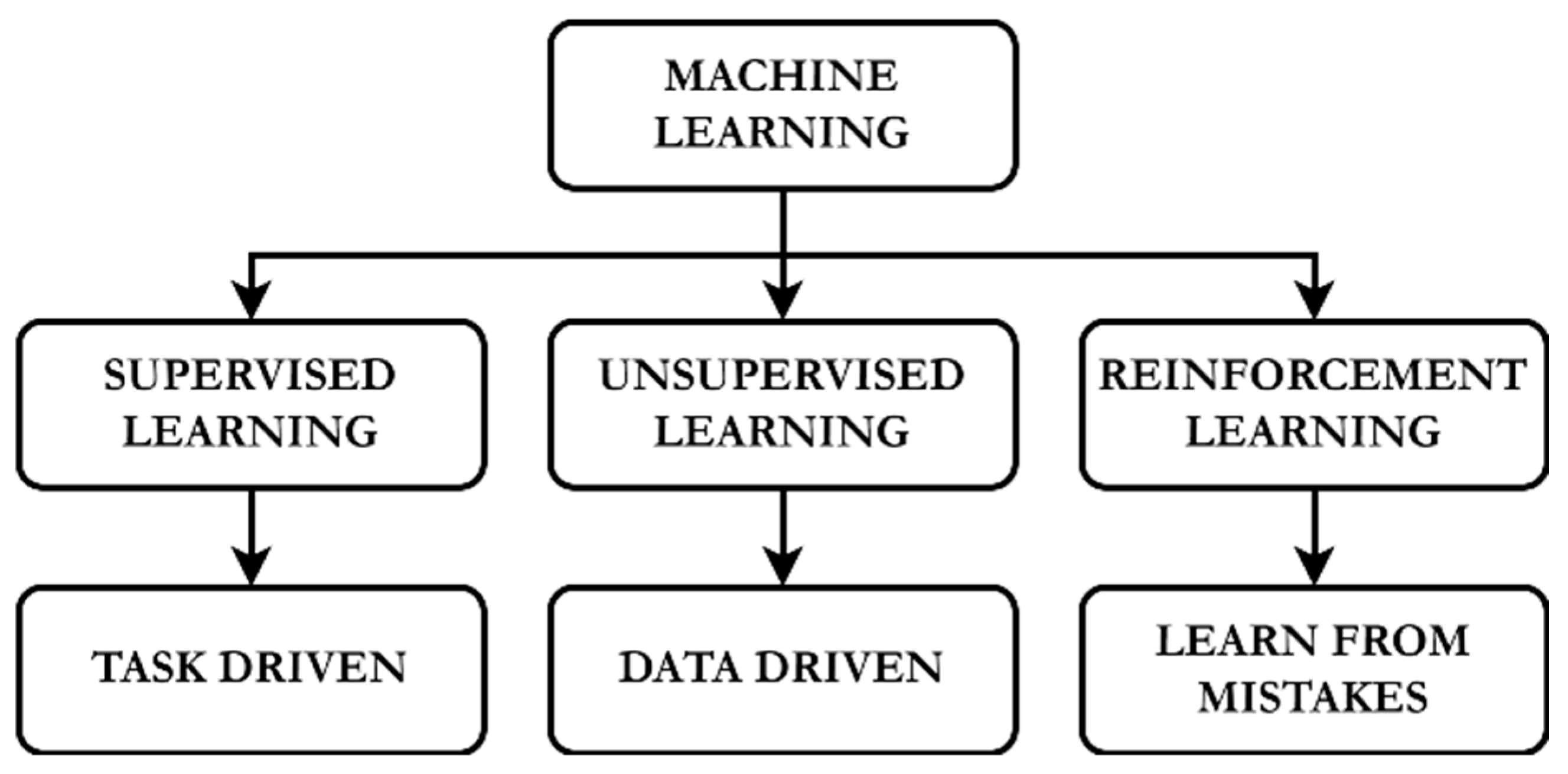
2.4. Fundamentals of Machine Learning
Popular Algorithms in Pavement Analysis
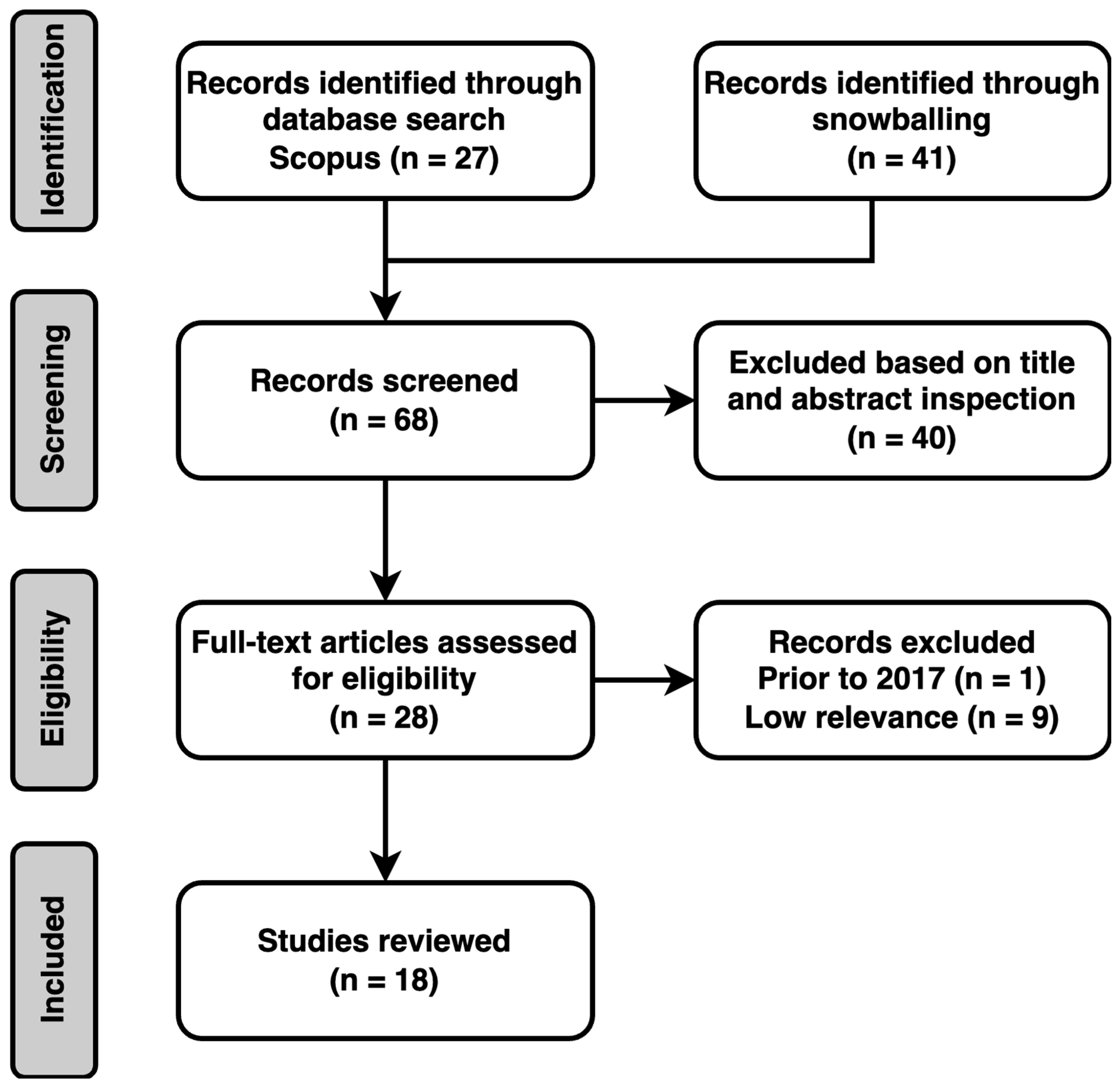
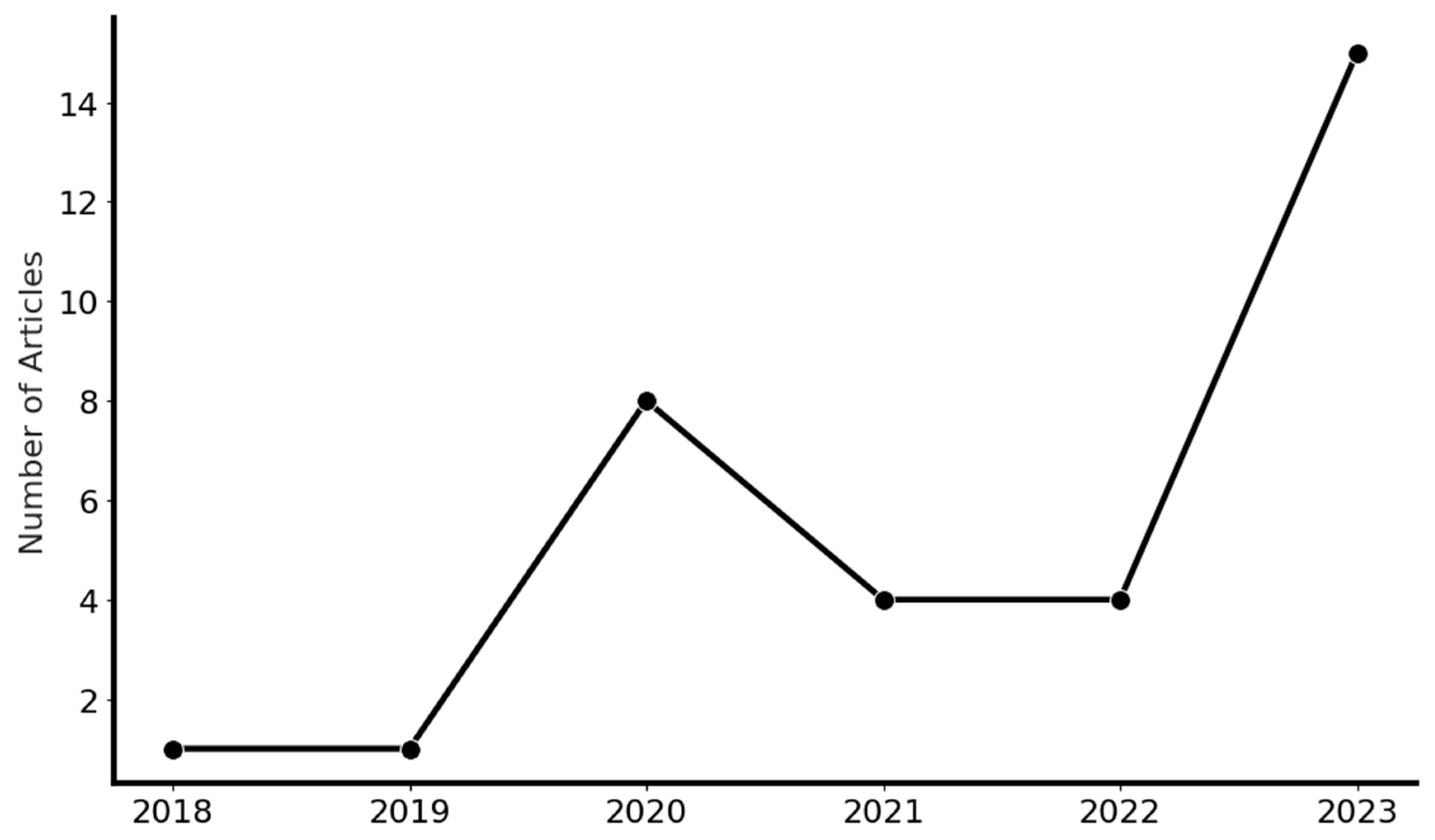
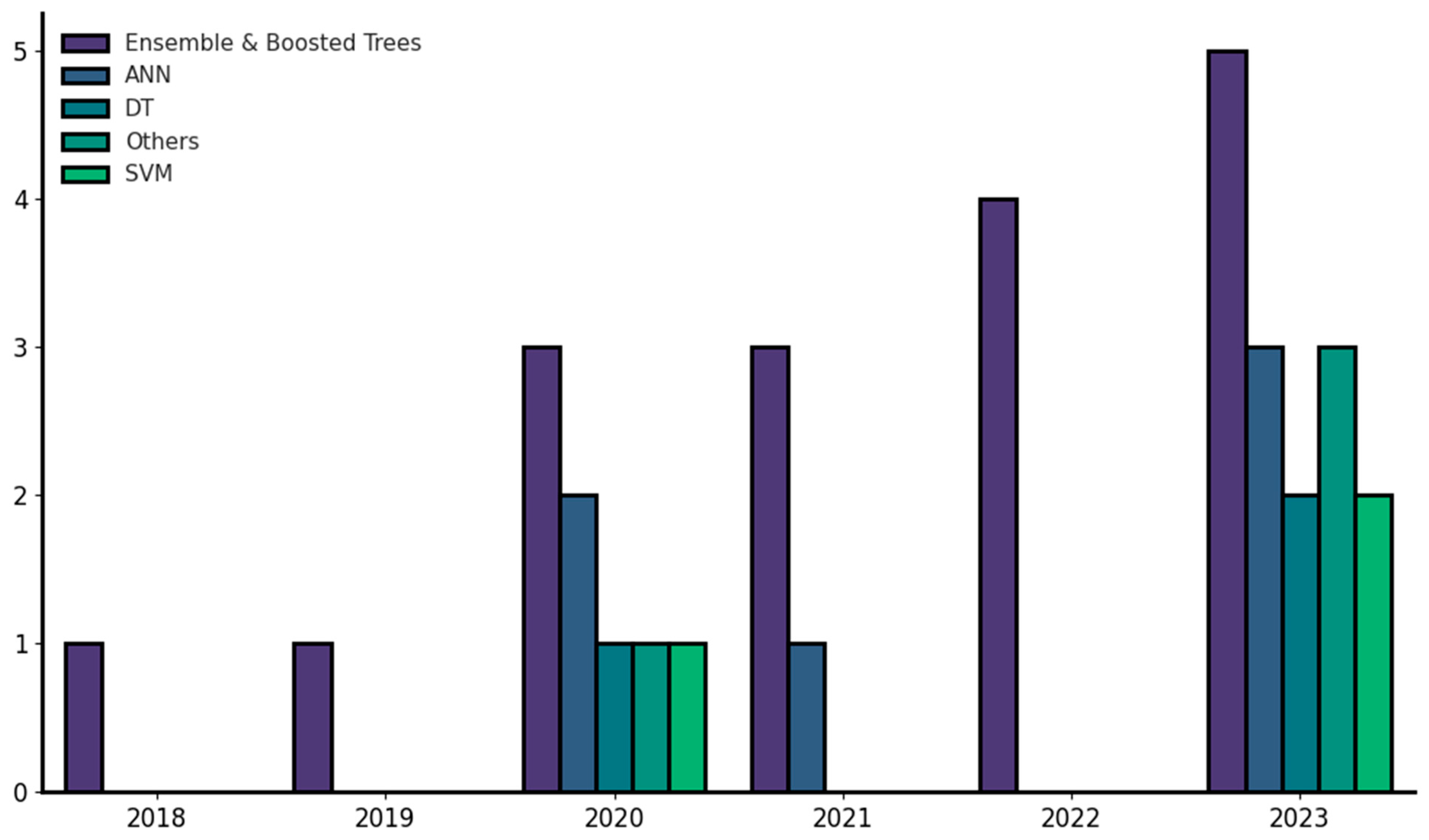
3. Methodology
- Pavement*;
- Predict* or model* or perform*;
- Machine learning or artificial intelligence or deep learning or neural network*;
- International roughness index or IRI;
- Flexible or asphalt.
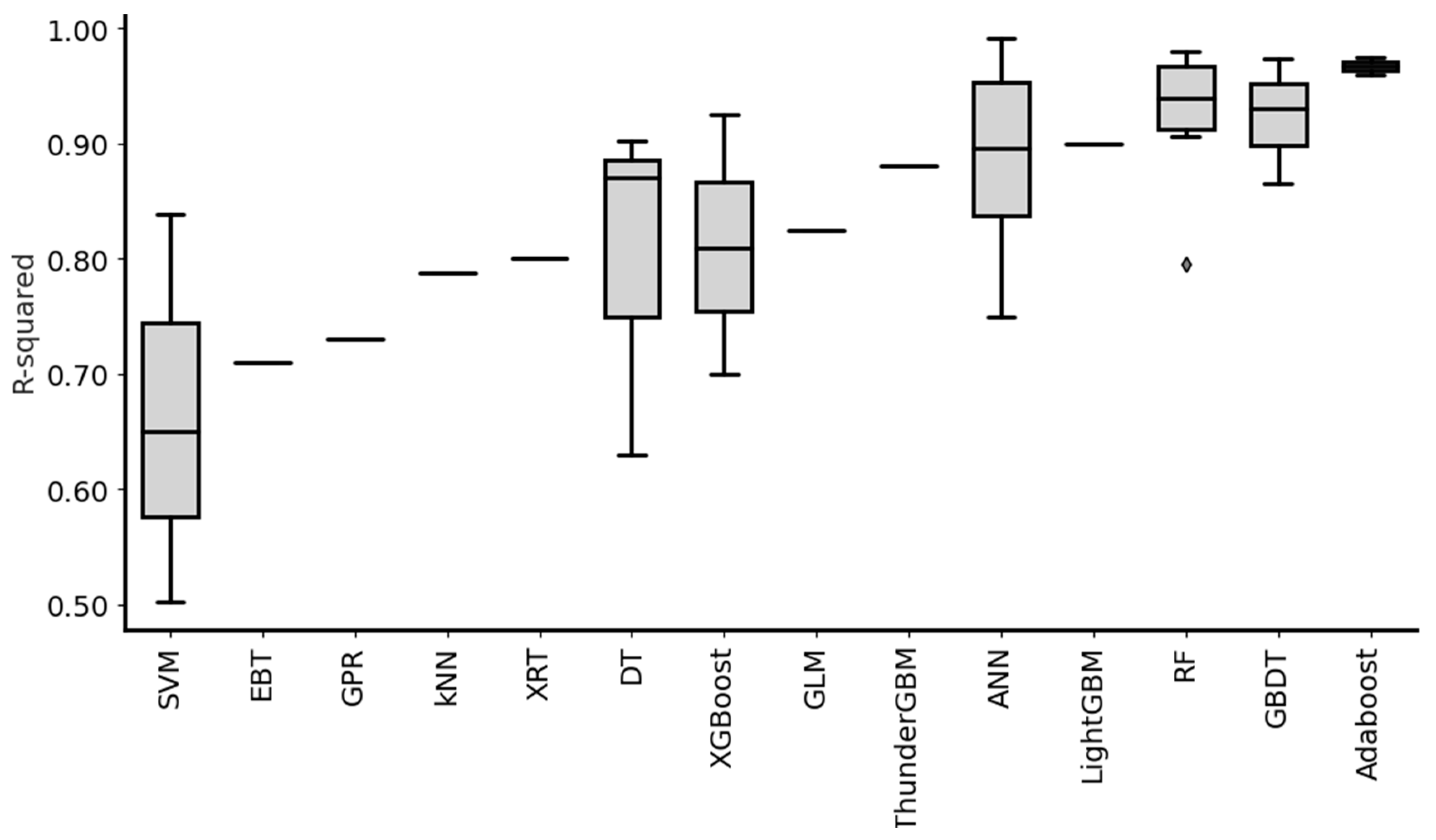
4. Machine Learning for IRI Prediction
- It includes only test sample results;
- Each study considered may have different contexts and scopes;
- Models may have diverse training data;
- Only the best results are represented, as specifically cited in the studies;
- The sample of studies analyzed is relatively small (17 articles).
4.1. Challenges in IRI Prediction with Machine Learning
4.2. Future Research
- High-quality and standardized datasets: One of the major challenges in using ML for pavement performance prediction is the availability of high-quality data for benchmark models. Future research should focus on developing an extensive, standardized, high-quality database.
- Interpretable models: Research should focus on developing interpretable models that provide insight into the relationships between the inputs and the outputs.
- Variability of pavement performance: The variability from diverse environmental factors presents a significant challenge. Future research should focus on developing models proficient at managing and adapting to the complexity and variability inherent in pavement performance.
- Computational efficiency: Research should focus on developing computationally efficient models that can handle large datasets and consume less resources.
- Complexity: Different stakeholders have shown interest in using AI. However, complexity is a limiting factor. Future research should focus on simplifying the use of the models and improving their explainability.
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Uddin, W. Pavement Management Systems; Fwa, T., Ed.; Taylor & Francis: Abingdon, UK, 2006. [Google Scholar]
- Kulkarni, R.B.; Miller, R.W. Pavement Management Systems: Past, Present, and Future. Transp. Res. Rec. 2003, 349, 65–71. [Google Scholar] [CrossRef]
- Gupta, A.; Kumar, P.; Rastogi, R. Critical Review of Flexible Pavement Performance Models. KSCE J. Civ. Eng. 2014, 18, 1455–1462. [Google Scholar] [CrossRef]
- Santos, J.; Ferreira, A. Pavement Design Optimization Considering Costs and Preventive Interventions. J. Transp. Eng. 2012, 138, 911–923. [Google Scholar] [CrossRef]
- Huang, M.H.; Rust, R.T. Artificial Intelligence in Service. J. Serv. Res. 2018, 21, 155–172. [Google Scholar] [CrossRef]
- Wang, W.; Siau, K. Artificial Intelligence, Machine Learning, Automation, Robotics, Future of Work and Future of Humanity: A Review and Research Agenda. J. Database Manag. 2019, 30, 61–79. [Google Scholar] [CrossRef]
- Ioannides, A.M.; Tallapragada, P.K. An Overview and a Case Study of Pavement Performance Prediction. Int. J. Pavement Eng. 2013, 14, 629–644. [Google Scholar] [CrossRef]
- Premkumar, L.; Vavrik, W.R. Enhancing Pavement Performance Prediction Models for the Illinois Tollway System. Int. J. Pavement Res. Technol. 2016, 9, 14–19. [Google Scholar] [CrossRef]
- Marcelino, P.; de Lurdes Antunes, M.; Fortunato, E.; Gomes, M.C. Transfer Learning for Pavement Performance Prediction. Int. J. Pavement Res. Technol. 2019, 13, 154–167. [Google Scholar] [CrossRef]
- Yao, L.; Leng, Z.; Jiang, J.; Ni, F. Modelling of Pavement Performance Evolution Considering Uncertainty and Interpretability: A Machine Learning Based Framework. Int. J. Pavement Eng. 2022, 23, 5211–5226. [Google Scholar] [CrossRef]
- van Wijk, I. Highway Maintenance. In The Handbook of Highway Engineering; Fwa, T., Ed.; Taylor & Francis: Abingdon, UK, 2006; pp. 488–555. [Google Scholar]
- Paterson, W.D.O. Road Deterioration and Maintenance Effects: Models for Planning and Management; The Highway Design and Maintenance Standards Series; World Bank Group: Washington, DC, USA, 1987. [Google Scholar]
- Markow, M.J. Highway Management Systems: State of the Art. J. Infrastruct. Syst. 1995, 1, 186–191. [Google Scholar] [CrossRef]
- Hoque, Z. Highway Condition Surveys and Serviceability Evaluation; Fwa, T., Ed.; Taylor & Francis: Abingdon, UK, 2006. [Google Scholar]
- Jordan, M.; Mitchell, T. Machine Learning: Trends, Perspectives, and Prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef] [PubMed]
- Abduljabbar, R.; Dia, H.; Liyanage, S.; Bagloee, S.A. Applications of Artificial Intelligence in Transport: An Overview. Sustainability 2019, 11, 189. [Google Scholar] [CrossRef]
- Géron, A. Hands-on Machine Learning with Scikit-Learn and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems; O’Reilly Media: Sebastopol, CA, USA, 2017. [Google Scholar]
- Justo-Silva, R.; Ferreira, A.; Flintsch, G. Review on Machine Learning Techniques for Developing Pavement Performance Prediction Models. Sustainability 2021, 13, 5248. [Google Scholar] [CrossRef]
- Gong, H.; Sun, Y.; Hu, W.; Polaczyk, P.A.; Huang, B. Investigating Impacts of Asphalt Mixture Properties on Pavement Performance Using LTPP Data through Random Forests. Constr. Build. Mater. 2019, 204, 203–212. [Google Scholar] [CrossRef]
- Schnebele, E.; Tanyu, B.F.; Cervone, G.; Waters, N. Review of Remote Sensing Methodologies for Pavement Management and Assessment. Eur. Transp. Res. Rev. 2015, 7, 7. [Google Scholar] [CrossRef]
- Peraka, N.S.P.; Biligiri, K.P. Pavement Asset Management Systems and Technologies: A Review. Autom. Constr. 2020, 119, 103336. [Google Scholar] [CrossRef]
- Benmhahe, B.; Chentoufi, J.A. Automated Pavement Distress Detection, Classification and Measurement: A Review. Int. J. Adv. Comput. Sci. Appl. 2021, 12. [Google Scholar] [CrossRef]
- Castanier, B.; Yeung, T.G. Optimal Highway Maintenance Policies under Uncertainty. In Proceedings of the 2008 Annual Reliability and Maintainability Symposium, Las Vegas, NV, USA, 28–31 January 2008; IEEE: Las Vegas, NV, USA, 2008; pp. 25–30. [Google Scholar]
- Bashar, M.Z.; Torres-Machi, C. Performance of Machine Learning Algorithms in Predicting the Pavement International Roughness Index. Transp. Res. Rec. 2021, 2675, 226–237. [Google Scholar] [CrossRef]
- Choi, J.; Adams, T.M.; Bahia, H.U. Pavement Roughness Modeling Using Back-Propagation Neural Networks. Comput. Aided Civ. Infrastruct. Eng. 2004, 19, 295–303. [Google Scholar] [CrossRef]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 Statement: An Updated Guideline for Reporting Systematic Reviews. BMJ 2021, 372, n71. [Google Scholar] [CrossRef]
- Park, S.H.; Kim, J.H. Comparative Analysis of Performance Prediction Models for Flexible Pavements. J. Transp. Eng. Part B Pavements 2019, 145, 04018062. [Google Scholar] [CrossRef]
- Hall, K.; Muñoz, C. Estimation of Present Serviceability Index from International Roughness Index. Transp. Res. Rec. 1999, 1655, 93–99. [Google Scholar] [CrossRef]
- Sayers, M.W.; Gillespie, T.D.; Queiroz, C.A.V. The International Road Roughness Experiment (IRRE): Establishing Correlation and a Calibration Standard for Measurements; World Bank Group: Washington, DC, USA, 1986. [Google Scholar]
- Abdelaziz, N.; Abd El-Hakim, R.T.; El-Badawy, S.M.; Afify, H.A. International Roughness Index Prediction Model for Flexible Pavements. Int. J. Pavement Eng. 2020, 21, 88–99. [Google Scholar] [CrossRef]
- U.S. Government Publishing Office. Title 23–Highways, Part 490–National Performance Management Measures; Assessments of Performance for the Interstate and Non-Interstate NHS, §490.313 2023. Available online: https://www.ecfr.gov/current/title-23/part-490 (accessed on 20 September 2023).
- Miranda, L.J. Towards Data-Centric Machine Learning: A Short Review. 2021. Available online: https://ljvmiranda921.github.io/notebook/2021/07/30/data-centric-ml/ (accessed on 1 April 2023).
- Clemente, F.; Ribeiro, G.M.; Quemy, A.; Santos, M.S.; Pereira, R.C.; Barros, A. Ydata-Profiling: Accelerating Data-Centric AI with High-Quality Data. Neurocomputing 2023, 554, 126585. [Google Scholar] [CrossRef]
- FHWA. The Long-Term Pavement Performance Program; Federal Highway Administration: Washington, DC, USA, 2015. [Google Scholar]
- Russell, S.J.; Norvig, P. Artificial Intelligence: A Modern Approach, 3rd ed.; Prentice Hall Series in Artificial Intelligence; Pearson: Upper Saddle River, NJ, USA, 2016; ISBN 978-0-13-604259-4. [Google Scholar]
- Sen, P.C.; Hajra, M.; Ghosh, M. Supervised Classification Algorithms in Machine Learning: A Survey and Review. In Emerging Technology in Modelling and Graphics; Advances in Intelligent Systems and Computing; Mandal, J.K., Bhattacharya, D., Eds.; Springer: Singapore, 2020; Volume 937, pp. 99–111. ISBN 9789811374029. [Google Scholar]
- Mohri, M.; Rostamizadeh, A.; Talwalkar, A. Foundations of Machine Learning—Adaptive Computation and Machine Learning, 2nd ed.; The MIT Press: Cambridge, MA, USA; London, UK, 2018; ISBN 978-0-262-03940-6. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction. IEEE Trans. Neural Netw. 1998, 9, 1054. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Drucker, H.; Burges, C.J.C.; Kaufman, L.; Smola, A.; Vapnik, V. Support Vector Regression Machines. In Proceedings of the 9th International Conference on Neural Information Processing Systems (NIPS’96), Denver, CO, USA, 2–5 December 1996; MIT Press: Cambridge, MA, USA, 1996; pp. 155–161. [Google Scholar]
- McCulloch, W.S.; Pitts, W. A Logical Calculus of the Ideas Immanent in Nervous Activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Song, L.; Wang, X. Faster Region Convolutional Neural Network for Automated Pavement Distress Detection. Road Mater. Pavement Des. 2021, 22, 23–41. [Google Scholar] [CrossRef]
- Song, W.; Jia, G.; Zhu, H.; Jia, D.; Gao, L. Automated Pavement Crack Damage Detection Using Deep Multiscale Convolutional Features. J. Adv. Transp. 2020, 2020, 6412562. [Google Scholar] [CrossRef]
- Tamagusko, T.; Ferreira, A. Optimizing Pothole Detection in Pavements: A Comparative Analysis of Deep Learning Models. Eng. Proc. 2023, 36, 11. [Google Scholar] [CrossRef]
- Gopalakrishnan, K. Deep Learning in Data-Driven Pavement Image Analysis and Automated Distress Detection: A Review. Data 2018, 3, 28. [Google Scholar] [CrossRef]
- Tamagusko, T.; Correia, M.G.; Huynh, M.A.; Ferreira, A. Deep Learning Applied to Road Accident Detection with Transfer Learning and Synthetic Images. Transp. Res. Procedia 2022, 64, 90–97. [Google Scholar] [CrossRef]
- Tamagusko, T.; Gomes Correia, M.; Rita, L.; Bostan, T.-C.; Peliteiro, M.; Martins, R.; Santos, L.; Ferreira, A. Data-Driven Approach for Urban Micromobility Enhancement through Safety Mapping and Intelligent Route Planning. Smart Cities 2023, 6, 2035–2056. [Google Scholar] [CrossRef]
- Quinlan, J.R. Induction of Decision Trees. Mach Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Dietterich, T.G. Ensemble Methods in Machine Learning. In Multiple Classifier Systems; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2000; Volume 1857, pp. 1–15. ISBN 978-3-540-67704-8. [Google Scholar]
- Elith, J.; Leathwick, J.R.; Hastie, T. A Working Guide to Boosted Regression Trees. J. Anim. Ecol. 2008, 77, 802–813. [Google Scholar] [CrossRef]
- Gong, H.; Sun, Y.; Shu, X.; Huang, B. Use of Random Forests Regression for Predicting IRI of Asphalt Pavements. Constr. Build. Mater. 2018, 189, 890–897. [Google Scholar] [CrossRef]
- Wang, C.; Xu, S.; Yang, J. Adaboost Algorithm in Artificial Intelligence for Optimizing the IRI Prediction Accuracy of Asphalt Concrete Pavement. Sensors 2021, 21, 5682. [Google Scholar] [CrossRef]
- Hossain, M.I.; Gopisetti, L.S.P.; Miah, M.S. International Roughness Index Prediction of Flexible Pavements Using Neural Networks. J. Transp. Eng. Part B Pavements 2019, 145, 04018058. [Google Scholar] [CrossRef]
- Zeiada, W.; Dabous, S.A.; Hamad, K.; Al-Ruzouq, R.; Khalil, M.A. Machine Learning for Pavement Performance Modelling in Warm Climate Regions. Arab. J. Sci. Eng. 2020, 45, 4091–4109. [Google Scholar] [CrossRef]
- Damirchilo, F.; Hosseini, A.; Mellat Parast, M.; Fini, E.H. Machine Learning Approach to Predict International Roughness Index Using Long-Term Pavement Performance Data. J. Transp. Eng. Part B Pavements 2021, 147, 04021058. [Google Scholar] [CrossRef]
- Guo, R.; Fu, D.; Sollazzo, G. An Ensemble Learning Model for Asphalt Pavement Performance Prediction Based on Gradient Boosting Decision Tree. Int. J. Pavement Eng. 2021, 23, 3633–3646. [Google Scholar] [CrossRef]
- Gharieb, M.; Nishikawa, T.; Nakamura, S.; Thepvongsa, K. Modeling of pavement roughness utilizing artificial neural network approach for laos national road network. J. Civ. Eng. Manag. 2022, 28, 261–277. [Google Scholar] [CrossRef]
- Marcelino, P.; de Lurdes Antunes, M.; Fortunato, E.; Gomes, M.C. Machine Learning Approach for Pavement Performance Prediction. Int. J. Pavement Eng. 2021, 22, 341–354. [Google Scholar] [CrossRef]
- Naseri, H.; Jahanbakhsh, H.; Foomajd, A.; Galustanian, N.; Karimi, M.M.D.; Waygood, E.O. A Newly Developed Hybrid Method on Pavement Maintenance and Rehabilitation Optimization Applying Whale Optimization Algorithm and Random Forest Regression. Int. J. Pavement Eng. 2022, 1–13. [Google Scholar] [CrossRef]
- Luo, Z.; Wang, H.; Li, S. Prediction of International Roughness Index Based on Stacking Fusion Model. Sustainability 2022, 14, 6949. [Google Scholar] [CrossRef]
- Song, Y.; Wang, Y.D.; Hu, X.; Liu, J. An Efficient and Explainable Ensemble Learning Model for Asphalt Pavement Condition Prediction Based on LTPP Dataset. IEEE Trans. Intell. Transport. Syst. 2022, 23, 22084–22093. [Google Scholar] [CrossRef]
- Sandamal, K.; Shashiprabha, S.; Muttil, N.; Rathnayake, U. Pavement Roughness Prediction Using Explainable and Supervised Machine Learning Technique for Long-Term Performance. Sustainability 2023, 15, 9617. [Google Scholar] [CrossRef]
- Abdualaziz Ali, A.; Heneash, U.; Hussein, A.; Khan, S. Application of Artificial Neural Network Technique for Prediction of Pavement Roughness as a Performance Indicator. J. King Saud Univ. Eng. Sci. 2023, in press. [CrossRef]
- Naseri, H.; Shokoohi, M.; Jahanbakhsh, H.; Karimi, M.M.; Waygood, E.O.D. Novel Soft-Computing Approach to Better Predict Flexible Pavement Roughness. Transp. Res. Rec. J. Transp. Res. Board 2023, 2677, 246–259. [Google Scholar] [CrossRef]
- Sharma, A.; Sachdeva, S.N.; Aggarwal, P. Predicting IRI Using Machine Learning Techniques. Int. J. Pavement Res. Technol. 2023, 16, 128–137. [Google Scholar] [CrossRef]
- Zhang, M.; Gong, H.; Jia, X.; Xiao, R.; Jiang, X.; Ma, Y.; Huang, B. Analysis of Critical Factors to Asphalt Overlay Performance Using Gradient Boosted Models. Constr. Build. Mater. 2020, 262, 120083. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A Decision-Theoretic Generalization of on-Line Learning and an Application to Boosting. In Computational Learning Theory; Lecture Notes in Computer Science; Vitányi, P., Ed.; Springer: Berlin/Heidelberg, Germany, 1995; Volume 904, pp. 23–37. ISBN 978-3-540-59119-1. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Statist. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased Boosting with Categorical Features. In Proceedings of the Advances in Neural Information Processing Systems, Red Hook, NY, USA, 3–8 December 2008; Curran Associates, Inc.: Red Hook, NY, USA, 2018; Volume 31. [Google Scholar]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely Randomized Trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef]
- Breslow, N.E. Generalized Linear Models: Checking Assumptions and Strengthening Conclusions. Stat. Appl. 1996, 8, 23–41. [Google Scholar]
- Cover, T.; Hart, P. Nearest Neighbor Pattern Classification. IEEE Trans. Inform. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S. A Unified Approach to Interpreting Model Predictions. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 4768–4777. [Google Scholar]
- Liu, J.; Wang, Y.; Zhang, Z.; Mo, Y. Multi-View Moving Objects Classification via Transfer Learning. In Proceedings of the First Asian Conference on Pattern Recognition. 2011 First Asian Conference on Pattern Recognition (ACPR 2011), Beijing, China, 28 November 2011. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; p. 398. [Google Scholar]
- Wen, Z.; Liu, H.; Shi, J.; Li, Q.; He, B.; Chen, J. ThunderGBM: Fast GBDTs and Random Forests on GPUs. J. Mach. Learn. Res. 2020, 21, 4389–4393. [Google Scholar]
- Shwartz-Ziv, R.; Armon, A. Tabular Data: Deep Learning Is Not All You Need. Inf. Fusion 2022, 81, 84–90. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 3149–3157. [Google Scholar]
- Roscher, R.; Bohn, B.; Duarte, M.F.; Garcke, J. Explainable Machine Learning for Scientific Insights and Discoveries. IEEE Access 2020, 8, 42200–42216. [Google Scholar] [CrossRef]
- Linardatos, P.; Papastefanopoulos, V.; Kotsiantis, S. Explainable AI: A Review of Machine Learning Interpretability Methods. Entropy 2020, 23, 18. [Google Scholar] [CrossRef] [PubMed]
- Carvalho, D.V.; Pereira, E.M.; Cardoso, J.S. Machine Learning Interpretability: A Survey on Methods and Metrics. Electronics 2019, 8, 832. [Google Scholar] [CrossRef]
- Zwaan, R.A.; Etz, A.; Lucas, R.E.; Donnellan, M.B. Making Replication Mainstream. Behav. Brain Sci. 2017, 41, e120. [Google Scholar] [CrossRef] [PubMed]
- Ioannidis, J.P. How to Make More Published Research True. PLoS Med. 2014, 11, e1001747. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Condition | IRI (m/km) | IRI (in/mi) |
|---|---|---|
| Good | <1.5 | <95 |
| Fair | 1.5–2.7 | 95–170 |
| Poor | >2.7 | >170 |
| Inclusion | Exclusion |
|---|---|
| Related to pavement performance prediction | Not written in English |
| Use IRI as a quality index | Published before 2018 |
| Train an ML model | |
| Study focused on flexible pavements | |
| Peer reviewed article |
| Author | Title | Contributions |
|---|---|---|
| Gong et al. [52] | Use of random forests regression for predicting IRI of asphalt pavements. | Recommends using RF to predict IRI values and shows its accuracy with high R2 and low RMSE scores compared to LR. Highlights the initial IRI as the critical factor. |
| Marcelino et al. [9] | Transfer learning for pavement performance prediction. | Proposes a transfer learning method with the AdaBoost algorithm for pavement performance prediction with scarce data. |
| Wang et al. [53] | Adaboost algorithm in artificial intelligence for optimizing the IRI prediction accuracy of asphalt concrete pavement | Developed an AdaBoost model to improve IRI predictions, surpassing the MEPDG’s linear regression approach. |
| Hossain et al. [54] | International roughness index prediction of flexible pavements using neural networks. | Introduces an ANN model for IRI prediction using climate and traffic data. Results demonstrate low RMSE and accurate prediction in various United States climates. |
| Abdelaziz et al. [30] | International roughness index prediction model for flexible pavements. | Introduces an improved IRI prediction model for flexible pavements using regression analysis and neural networks. |
| Zeiada et al. [55] | Machine learning for pavement performance modelling in warm climate regions. | The study demonstrates ANN modeling’s superior accuracy over other ML methods and traditional regression, emphasizing distinct environmental impacts between warm and cold regions. |
| Damirchilo et al. [56] | Machine learning approach to predict international roughness index using long-term pavement performance data. | An XGBoost based approach is introduced to predict IRI and its performance was superior compared to SVR and RF. The study used LTPP data and found key factors affecting predictions, such as No.-200-passing, hydraulic conductivity, and KESAL. |
| Zhang et al. [67] | Analysis of critical factors to asphalt overlay performance using gradient boosted models | The research identified the critical variables for the evolution of overlay performance using GBDT. |
| Guo et al. [57] | An ensemble learning model for asphalt pavement performance prediction based on gradient boosting decision tree. | The study introduces an ensemble learning model using LightGBM to predict two functional indices, IRI and RD. This model performs better than ANN and RF. |
| Gharieb et al. [58] | Modeling of pavement roughness utilizing artificial neural network approach for Laos national road network. | Presents two ANN models that accurately forecast the IRI for DBST and AC pavements. |
| Marcelino et al. [59] | Machine learning approach for pavement performance prediction. | Presents a ML method for pavement performance prediction, focusing on making the model applicable in different situations. It includes a case study using RF to predict 5–10 years of IRI using data from the LTPP. |
| Naseri et al. [60] | A newly developed hybrid method on pavement maintenance and rehabilitation optimization applying whale optimization algorithm and random forest regression. | This study presents a novel hybrid method for optimizing pavement maintenance using RF, WOA, and GA, significantly outperforming traditional models in accuracy and cost-efficiency. |
| Luo et al. [61] | Prediction of IRI based on stacking fusion model. | The study suggests a stacking fusion model improves pavement performance prediction. The model combines GBDT and XGBoost with bagging as meta-learners. |
| Song et al. [62] | An efficient and explainable ensemble learning model for asphalt pavement condition prediction based on LTPP dataset. | The paper introduces a model to predict the IRI of asphalt pavements. It uses ThunderGBM and SHAP to achieve higher accuracy and better feature interpretation. |
| Sandamal et al. [63] | Pavement roughness prediction using explainable and supervised machine learning technique for long-term performance | RF offered the most accurate predictions compared to kNN, SVM, DT and XGBoost. Furthermore, these authors introduced SHAP to explain the importance of the resource. |
| Abdualaziz et al. [30] | Application of artificial neural network technique for prediction of pavement roughness as a performance indicator. | Developed ANN models to predict IRI by analyzing pavement distress effects across two climate regions (wet freeze and wet freeze) in North America. |
| Naseri et al. [65] | Novel soft-computing approach to better predict flexible pavement roughness. | Introduced an AOA-SGDR method for features selection from 58 initial variables. |
| Sharma et al. [66] | Predicting IRI using machine learning techniques. | GBDT performs the best. The paper also highlights the importance of weather factors. |
| Author | Year | Models | Data Source | Contributions | |||
|---|---|---|---|---|---|---|---|
| M&R | Traffic | Structure | Climate | ||||
| Gong et al. [52] | 2018 | RF | LTPP | X | X | X | X |
| Marcelino et al. [9] | 2019 | AdaBoost | LTPP | X | X | X | |
| Wang et al. [53] | 2021 | Adaboost | LTPP | X | X | X | |
| Hossain et al. [54] | 2019 | ANN | LTPP | X | X | ||
| Abdelaziz et al. [30] | 2020 | ANN | LTPP | X | X | ||
| Zeiada et al. [55] | 2020 | DT, SVM, EBT, GPR, ANN | LTPP | X | X | X | |
| Damirchilo et al. [56] | 2020 | XGBoost | LTPP | X | X | X | X |
| Zhang et al. [67] | 2020 | GBDT | LTPP | X | X | X | |
| Guo et al. [57] | 2021 | LightGBM | LTPP | X | X | X | |
| Gharieb et al. [58] | 2021 | ANN | NRN | X | |||
| Marcelino et al. [59] | 2021 | RF | LTPP | X | X | X | X |
| Naseri et al. [60] | 2022 | RF | LTPP | X | X | X | X |
| Luo et al. [61] | 2022 | GBDT, XGBoost, SVM | LTPP | X | X | X | |
| Song et al. [62] | 2022 | ThunderGBM | LTPP | X | X | X | X |
| Sandamal et al. [63] | 2023 | kNN, SVM, DT, RF, XGBoost | Proprietary 1 | X | |||
| Abdualaziz et al. [64] | 2023 | ANN | LTPP | ||||
| Naseri et al. [65] | 2023 | DT, SVM, RF, ANN | LTPP | X | X | X | |
| Sharma et al. [66] | 2023 | GBDT, ANN, XRT, GLM, RF | LTPP | X | X | X | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tamagusko, T.; Ferreira, A. Machine Learning for Prediction of the International Roughness Index on Flexible Pavements: A Review, Challenges, and Future Directions. Infrastructures 2023, 8, 170. https://doi.org/10.3390/infrastructures8120170
Tamagusko T, Ferreira A. Machine Learning for Prediction of the International Roughness Index on Flexible Pavements: A Review, Challenges, and Future Directions. Infrastructures. 2023; 8(12):170. https://doi.org/10.3390/infrastructures8120170
Chicago/Turabian StyleTamagusko, Tiago, and Adelino Ferreira. 2023. "Machine Learning for Prediction of the International Roughness Index on Flexible Pavements: A Review, Challenges, and Future Directions" Infrastructures 8, no. 12: 170. https://doi.org/10.3390/infrastructures8120170