


A Secure and Privacy-Preserving Blockchain-Based XAI-Justice System
by
 , , ,
, , ,
Konstantinos Demertzis
1,* ,
,
Konstantinos Rantos
1,
Lykourgos Magafas
2,
Charalabos Skianis
3 and
Lazaros Iliadis
4 1
Department of Computer Science, School of Science, Kavala Campus, International Hellenic University, 65404 Kavala, Greece
2
Department of Physics, School of Science, Kavala Campus, International Hellenic University, 65404 Kavala, Greece
3
Department of Information and Communication Systems Engineering, School of Engineering, University of Aegean, 83200 Samos, Greece
4
Department of Civil Engineering, School of Engineering, Democritus University of Thrace, 67100 Xanthi, Greece
*
Author to whom correspondence should be addressed.
Information 2023, 14(9), 477; https://doi.org/10.3390/info14090477
Submission received: 25 May 2023
/
Revised: 20 August 2023
/
Accepted: 28 August 2023
/
Published: 28 August 2023
(This article belongs to the Special Issue Machine Learning for the Blockchain)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Pursuing “intelligent justice” necessitates an impartial, productive, and technologically driven methodology for judicial determinations. This scholarly composition proposes a framework that harnesses Artificial Intelligence (AI) innovations such as Natural Language Processing (NLP), ChatGPT, ontological alignment, and the semantic web, in conjunction with blockchain and privacy techniques, to examine, deduce, and proffer recommendations for the administration of justice. Specifically, through the integration of blockchain technology, the system affords a secure and transparent infrastructure for the management of legal documentation and transactions while preserving data confidentiality. Privacy approaches, including differential privacy and homomorphic encryption techniques, are further employed to safeguard sensitive data and uphold discretion. The advantages of the suggested framework encompass heightened efficiency and expediency, diminished error propensity, a more uniform approach to judicial determinations, and augmented security and privacy. Additionally, by utilizing explainable AI methodologies, the ethical and legal ramifications of deploying intelligent algorithms and blockchain technologies within the legal domain are scrupulously contemplated, ensuring a secure, efficient, and transparent justice system that concurrently protects sensitive information upholds privacy.
1. Introduction
Technology has significantly advanced many aspects of our lives, and the judicial system is no exception [1]. The concept of justice has evolved over the years, and the need for an “intelligent justice” system is paramount in the modern era. A technology-based justice system has the potential to bring about transparency, efficiency, and objectivity in the administration of justice [2,3].
The traditional judicial system, relying on paper-based processes and manual decision making, has several shortcomings that technology can address. For instance, the use of technology can help streamline the entire legal process, from filing cases to delivering judgments. This will help reduce the backlog of cases and ensure justice is delivered promptly.
Furthermore, technology can help eliminate subjective decision making by providing judges and lawyers with data-driven insights and analytical tools. This will help ensure that decisions are based on facts and evidence rather than personal biases or opinions. Overall, an intelligent, technology-based justice system can help restore trust and confidence in the justice system. It will help ensure that justice is delivered fairly and efficiently and that the rights of individuals are protected [4].
To address these issues, this paper proposes a system that leverages advanced technologies such as AI, blockchain, and privacy-preserving methods to deliver an objective, efficient, and transparent justice system. Specifically, the proposed system uses natural language processing, ontology matching, and semantic web technologies to analyze legal documents and judicial texts in a machine-readable format. This allows for more efficient and accurate analysis and conclusion of cases [5].
Moreover, incorporating blockchain technology provides a secure and transparent platform for managing legal documents and transactions while ensuring data privacy. Privacy methods, including differential privacy and homomorphic encryption, are also used to protect sensitive information and maintain confidentiality. Explainable AI methodologies ensure that the ethical and legal implications of using intelligent algorithms and blockchain technologies in the legal system are carefully considered [6].
The benefits of this proposed system are extensive. They include increased efficiency and speed in the delivery of justice, reduced error rates, a more consistent approach to judicial decision making, and enhanced security and privacy. By using a transparent and secure platform, this proposed system will create greater trust and confidence in the justice system, increasing access to justice.
In conclusion, this proposed system has the potential to revolutionize the justice delivery process by providing greater access to justice while protecting sensitive information and maintaining privacy.
2. Legal and Ethical Aspects
Deploying an electronic Justice system raises important legal and ethical considerations. To ensure compliance with relevant regulations, data protection laws, and ethical guidelines, it is essential to address the following implications:
- Data Protection and Privacy: A blockchain-based XAI-Justice system involves the processing and storage of personal and sensitive legal data. Compliance with data protection laws, such as the European Union’s General Data Protection Regulation (GDPR), is crucial. The system should adhere to principles such as data minimization, purpose limitation, and lawful processing. Measures such as pseudonymization, access controls, and privacy techniques such as differential privacy should be implemented to protect user rights and privacy.
- Security and Integrity: Blockchain technology provides inherent security and integrity features, but it is essential to address potential vulnerabilities and ensure the system’s resilience against attacks. Compliance with relevant security standards and best practices is necessary to protect legal data from unauthorized access, tampering, or malicious activities. Regular security audits, robust encryption mechanisms, and secure key management protocols should be implemented.
- Legal Compliance: The deployment of an XAI-Justice system must adhere to existing legal frameworks and regulatory requirements. It should comply with laws pertaining to electronic signatures, data retention, admissibility of electronic records, and jurisdictional aspects. Additionally, legal professionals should review and validate the system’s compliance with legal principles, including fairness, non-discrimination, and due process.
- Ethical Considerations: The use of AI and blockchain in the justice system raises ethical concerns related to bias, fairness, accountability, and transparency. Biases present in training data or algorithms must be identified and mitigated to ensure fairness and prevent discrimination. Ethical guidelines, such as those outlined in the EU’s Ethics Guidelines for Trustworthy AI, should be followed to promote transparency, explainability, and human oversight of the system’s decision-making processes.
- User Consent and Control: Users should have control over their data and be provided with clear information regarding the collection, processing, and storage of their information within the XAI-Justice system. Informed consent mechanisms should be in place, allowing users to make choices regarding their data sharing and the system’s usage. Users should have the ability to access, rectify, and erase their data in accordance with applicable data protection laws.
- Human Oversight and Intervention: While the XAI-Justice system utilizes AI algorithms, human oversight and intervention remain crucial. The system should be designed to facilitate human–technology collaboration, where legal professionals have the ability to challenge, verify, or override the system’s decisions. Clear mechanisms for human review and intervention should be in place to prevent undue reliance on the system and maintain accountability.
- Transparency, Explainability, and Accountability: The XAI-Justice system should be transparent and provide explanations for its decisions. Users should be able to understand the basis of the system’s recommendations or determinations. Explainable AI methodologies, such as providing decision logs, reasoning chains, or justifications, should be implemented to enhance transparency and enable users to evaluate the system’s outcomes. This not only promotes transparency but also enables accountability. Users and stakeholders should be able to trace the reasoning and logic behind the system’s determinations. It is important to establish clear mechanisms for auditing, oversight, and accountability to ensure that the system’s decisions align with legal and ethical standards.
- Jurisdictional and Cross-Border Considerations: Deploying a blockchain-based XAI-Justice system may involve cross-border data flows and jurisdictional challenges. Compliance with international data transfer regulations and agreements, such as the GDPR’s provisions for data transfers outside the EU, should be ensured. Clarifying the legal framework and addressing jurisdictional issues is vital to facilitate the system’s deployment across different legal systems.
- Bias Mitigation: It is essential to address and mitigate biases that may exist within the XAI-Justice system. Bias can emerge from the training data, algorithmic design, or contextual factors. Regular audits and assessments should be conducted to identify and rectify any biases. Transparency in the system’s decision-making process can help expose and rectify biases, ensuring fair treatment and equal access to justice for all individuals.
- User Empowerment and Inclusion: Users should have the opportunity to actively engage with the XAI-Justice system and provide feedback on its performance. Incorporating user perspectives and involving stakeholders in the development and evaluation processes can help address concerns, identify limitations, and enhance user trust. Inclusive design principles should be applied to ensure that the system is accessible to individuals with diverse needs and abilities.
- Continuous Monitoring and Evaluation: A blockchain-based XAI-Justice system should undergo regular monitoring and evaluation to assess its impact, effectiveness, and adherence to legal and ethical requirements. Ongoing monitoring can help identify potential risks, biases, or unintended consequences. User feedback, performance metrics, and feedback from legal experts should be collected and analyzed to inform system improvements and ensure its alignment with legal principles.
- Regulatory Compliance and Standards: Compliance with relevant regulations, standards, and legal frameworks is critical. The XAI-Justice system should align with legal requirements specific to the jurisdiction it operates in. Collaboration with regulatory authorities and legal professionals is necessary to navigate complex legal landscapes and ensure compliance with evolving legal and ethical guidelines.
- Ethical Review Boards and Governance: Establishing ethical review boards or similar governance structures can help oversee the deployment and operation of the XAI-Justice system. These boards can provide guidance, conduct ethical impact assessments, and address emerging ethical concerns. They can also ensure that the system operates in a manner consistent with ethical principles and societal values.
- Public Trust and Communication: Building public trust is essential for the successful deployment of a blockchain-based XAI-Justice system. Transparent communication about the system’s purpose, capabilities, limitations, and safeguards is necessary to manage expectations and address concerns. Engaging with the public, legal professionals, and relevant stakeholders through public consultations, educational initiatives, and open dialogues can help foster trust and promote understanding of the system’s benefits and limitations.
By considering these legal and ethical implications, the deployment of a blockchain-based XAI-Justice system can aim to uphold legal requirements, respect user rights, mitigate biases, ensure transparency and accountability, and maintain public trust. It is essential to adopt a multidisciplinary approach that involves legal experts, technologists, ethicists, and policymakers to address these considerations and establish a robust framework for deploying and governing such systems within the legal domain.
3. Literature Review
Intelligent justice is a response to the increasing demand for more efficient, transparent, and fair justice systems. Intelligent justice systems seek to revolutionize the legal domain by automating and optimizing various facets of judicial decision making, made possible by advances in AI, machine learning, and NLP [5,7,8]. This literature review investigates the current state of intelligent justice systems, focusing on their underlying methodologies, applications, and obstacles. Several goals provide foundational knowledge on the application of artificial intelligence and machine learning in the legal domain.
For example, Kira [9] program that employs machine learning to extract data, clauses, and other provisions from texts Similarly, Casetext has developed CARA A.I., an A.I. research instrument that evaluates cases discovered in court documents. In addition, efforts are being made to develop software capable of predicting court selections to assist justices in making case decisions. Another illustration is Machina’s software, a legal analytics instrument for predicting the outcomes of lawsuits [10]. Lastly, programs oriented toward the general people, such as LegalZoom [11] or DoNotPay [12], have emerged to enhance access to justice for individuals.
As opportunities expand, however, so does critical thinking. In light of this, the scientific community and legal authorities have highlighted the malpractice risk associated with legal and technical black box practices that are linked to AI applications. A second debate concentrates on the barrier that some of these services encounter in the form of laws governing the unauthorized provision of legal services. Concurrently, there is an ongoing discussion regarding the use of artificial intelligence in the field of justice and the right to a fair prosecution. Several authors have discussed the ethical issues arising from decreased human oversight and increased reliance on these “black box” technologies [13,14,15].
Compensating for the opaqueness of such systems with activities aimed at explainability and user inclusion may aid in the integration and utilization of artificially intelligent systems. Ridley [16] Recognizes that the risk of relying on artificially intelligent systems is not so much in the increased delegation of cognitive tasks to these systems as it is in information professionals and information consumers being oblivious of the nature, precise mechanisms, and consequences of that delegation. In addition, Henry [17] argues that implementing policies that require accountability, mandating not only access to the algorithms themselves and the processes followed when using the data, but also an accessible explanation of the extent to which the data was used, is a crucial element of future governance and regulatory frameworks that promote ethically responsible behaviors in the use of intelligent systems.
Ridley [16] explores the topic of explainable artificial intelligence, which is defined as a variety of strategies, approaches, and procedures that render artificially intelligent systems interpretable and accountable. The two pillars of explainable artificial intelligence are trust and accountability, and Ridley emphasizes user-centered explainability as a prerequisite for an opaque technology. He describes the strategies, approaches, and procedures that research libraries can employ to influence the development, dissemination, and utilization of artificially intelligent systems in ways that are consistent with scholarly and librarianship principles. Turner [18] proposes three broad characteristics required for transparency in artificially intelligent systems: data provenance, data repeatability, and data versioning. Forms of explicable artificial intelligence may vary. According to Verheij [19], investigate how programming rules and inferences are linked and influence one another can be used to manage the integration of knowledge and data. Until then, the criteria for explainability and the responsibilities of proprietary intelligent systems cannot be effectively managed. Turner [18] focuses on semantic association to enhance the explicability of artificially intelligent systems. This method seeks to use explanation techniques to provide a narrative for customized options in order to educate artificially intelligent systems’ decision-making processes on semantic connections.
AI systems can be taught a primary cognitive task followed by a secondary task of linking computational or decision-making events with words. This method, also known as AI rationalization, attempts to provide justifications for autonomous system behavior as if an individual were being questioned about their actions. This process may involve natural language explanation in the form of labeled actions from a technical standpoint; however, given the complexity of artificially intelligent systems and machine learning, there may be inconsistencies in correlating all computational and algorithmic operations with semantic associations. The concept of explainable artificial intelligence is consistent with Wang’s [20] how to avoid situations in which legal practitioners and legal information professionals must deal with issues they do not fully understand due to rapid technological development or entrenching the mismatch between skills taught and skills needed in practice, a proposal is made to develop a basic understanding of the operational principles of various technologies. Explainable AI may also aid in developing the computational reasoning skills of legal information practitioners [21].
According to Aman [22], to continue contributing value to their organizations, legal information professionals can humanize the technology transforming the legal information industry. According to Coleman [23], intelligent information systems can be co-created and facilitated by law librarians and legal information specialists. In a perfect world, these systems and their creators would respect and evaluate diverse data sources, recognizing any inherent biases or flaws; encourage human engagement through experimentation and critical inquiry; foster innovation and the possibilities associated with socially responsible and transparent technological advancements; and support human learning and knowledge creation.
According to Araszkiewicz and RodrguezDoncel [24], the influence and prevalence of advanced technologies in the legal information profession pique the curiosity of various stakeholders regarding the accountability, explainability, dependability, and openness of these emergent intelligent systems. Ridley [16] argues that research libraries have the potential to influence the development, implementation, and use of intelligent systems in ways compatible with the objectives of scholarship and librarianship.
Based on Stevenson and Beatson study [25], although the future of algorithms and artificially intelligent technologies in the legal information field raises significant concerns, those who develop a proficiency in their use will be better able to respond and adapt. These interests motivate ongoing research aimed at enhancing the legal information, data, and algorithmic literacy of both legal information practitioners and the information consumers they serve.
On the other hand, this article [26] offers a review of the decentralized justice industry and of the key players participating in it. It presents a number of key dimensions of the industry and reviews the mechanism design choices made by these different platforms. Moreover, it discusses a growth hypothesis for the industry and how it may grow in the future. In this chapter [27], it is argued that blockchain technologies undermine the conventional, state-centric ideas of jurisdiction and enforcement by structurally tending towards “judicialization”. This paper [28] reviews the main theoretical principles underlying the nascent field of decentralized justice and the early empirical experience in real life use cases. In addition, this study [29] discusses using blockchain technology to streamline legal processes. I start by introducing the ideas behind blockchain technology and cryptocurrencies. Next, we talk about the current legal services. It is determined how blockchain technology can be used in legal procedures. The most prevalent legal systems worldwide are civil and common law. It is assessed how blockchain may affect legal systems. The final section of the paper provides a summary of the effects and applicability of using blockchain technology in legal systems and services.
Finally, personal information protection and privacy interact in diverse ways, especially in the contemporary information age. This study [30] discusses the definition of privacy itself and allied concepts such as information privacy and data protection in justice systems. Moreover, this paper [31] explores the legal construction of personal information protection and privacy under Chinese legal orders, including the differences, similarities, and interplay between the two rights. By distinguishing the legal value, contents and remedial approaches, this paper concludes that the two rights are distinct but overlap. This research [32] propose the best practices for court privacy policy formulation. Moreover, this article [33] answers the following questions: what does the federal statutory approach to regulating privacy from the police look like, and in what ways does it mimic, overlap with, or differ from the Fourth Amendment constitutional approach? In answering these questions, this article also engages the deeper democratic debate over constitutional versus statutory approaches to controlling the police, using the lessons garnered from examining existing privacy regulations to better inform the secondary argument about who does it best.
4. Proposed Approach
Given that the reasonable time of the delivery of justice as a necessary element of the quality of the judicial system is a permanent concept and a central goal of all judicial officers, it is proposed to develop a new methodology of analysis, decision, and auxiliary recommendation, which effective, innovative AI technologies will support. The aim is to use the semantic web, ontologies, blockchain, and AI technologies to leverage legislative documents, which will be interconnected with highly secure and privacy-preserving methods, to produce recommendations to facilitate and speed up justice delivery processes.
Specifically, the proposed system will use NLP technology to understand judicial texts in a machine-readable format. Natural language processing is an interdisciplinary branch of AI and computational linguistics concerned with the syntactic, semantic, and pragmatic analysis of text or natural speech.
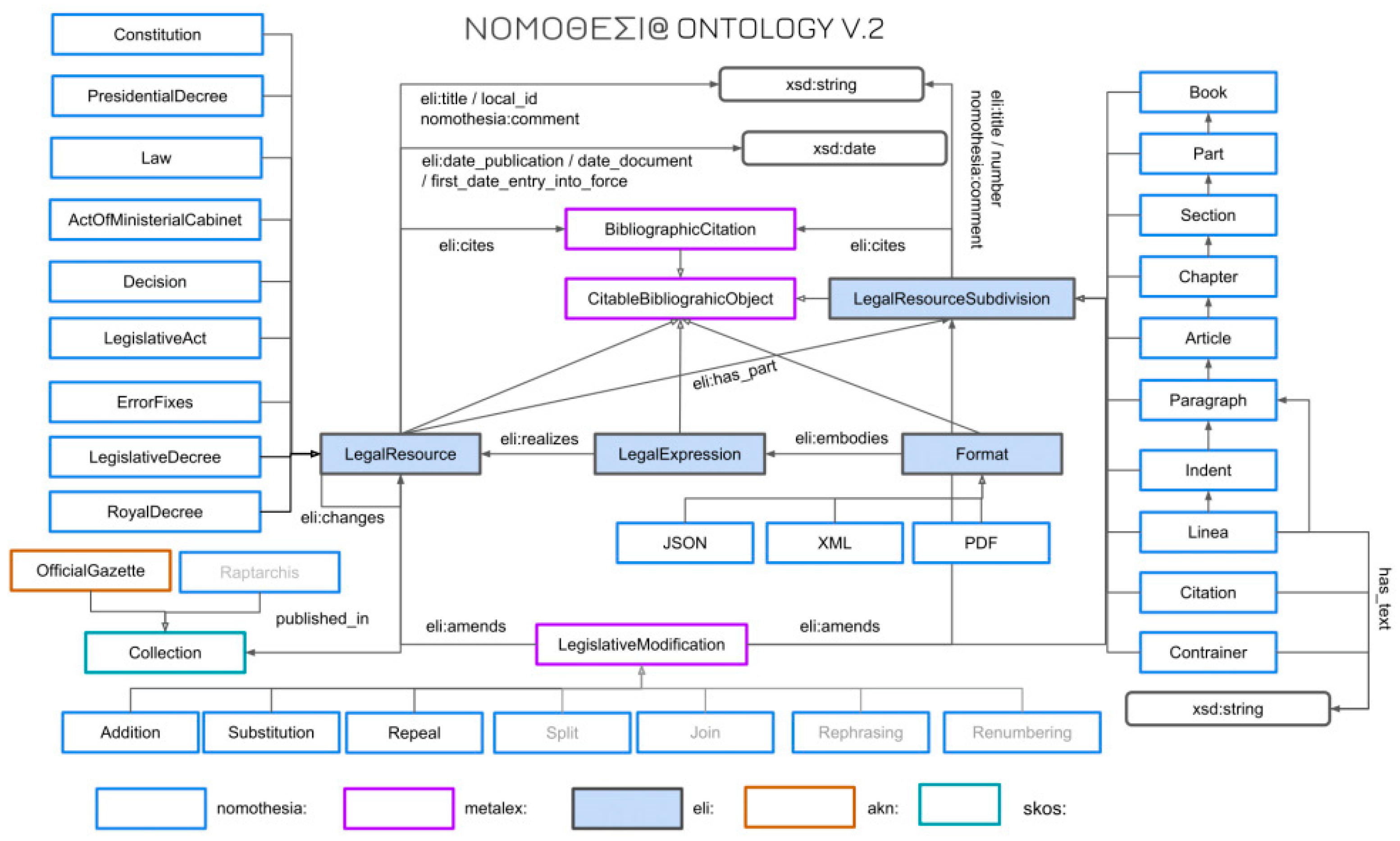
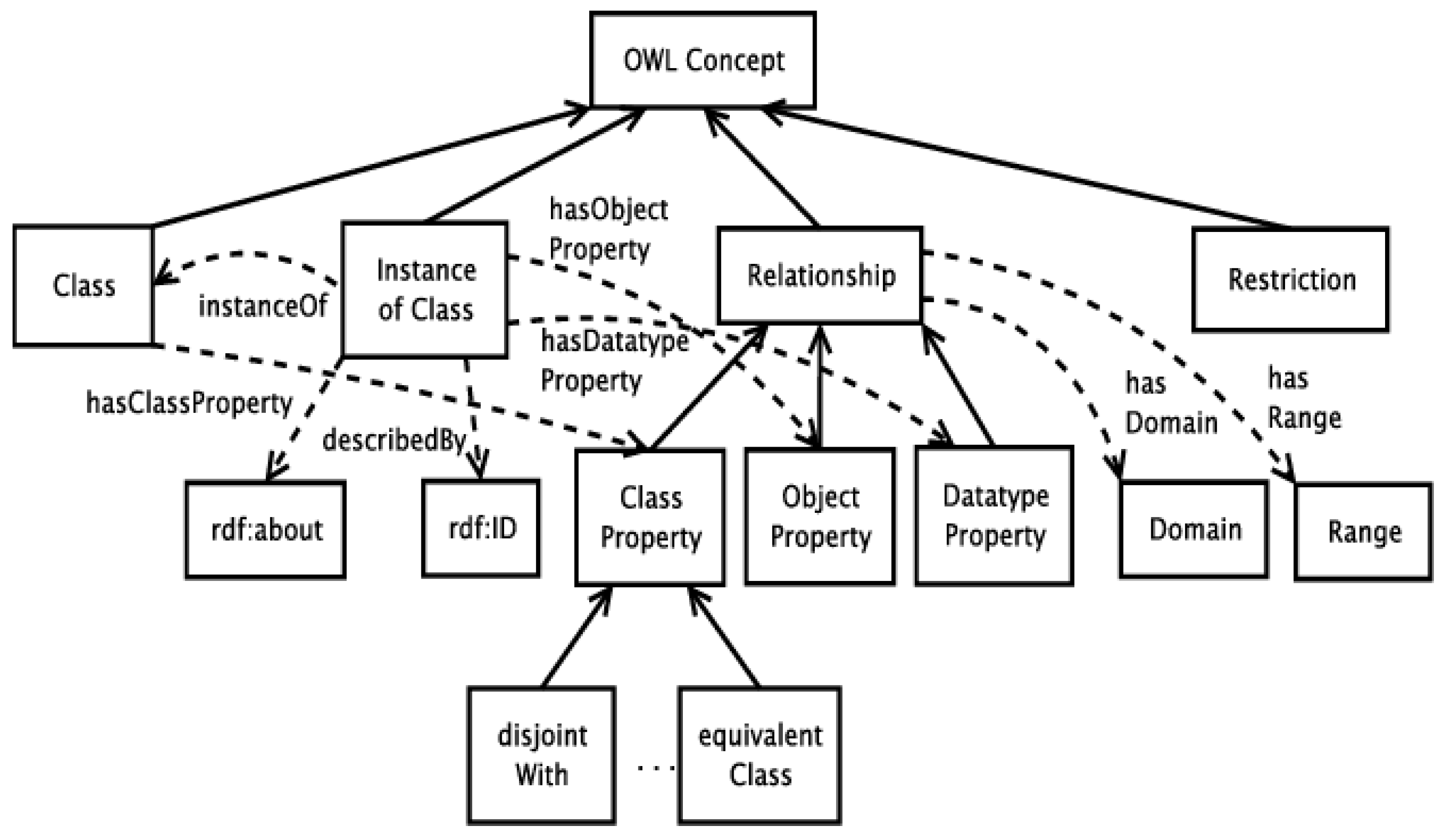
The judicial documents in question will be linked to other legislative documents concerning types of primary national legislation, the Constitution, presidential decrees, laws, acts of the cabinet, corresponding court decisions, and secondary sources of Greek legislation, such as legislative acts and regulatory provisions. All these data, which will have been arranged accordingly to take into account the changes that occur over time, such as new introductions, replacements, and repeals of articles, laws, etc., so that there are pending versions of the current legislation, are arranged in similar ontologies that will cover the various types of legislation. An ontology is a high-level description of a domain of interest that clearly defines the relationships between a domain’s entities and their related properties. Figure 1 below shows an example of the legislation ontology, specifically for the legal resource entity [34].
There are the categories constitution, presidential decree, laws, etc., and the process of changes they may undergo in different editions has been modeled. For each judicial decision, there can be instances, i.e., snapshots of this ontology, which will indicate: the law, the articles, and paragraphs on which the decision was based, any additional elements that demonstrate guilt or mitigating factors, etc., as well as other meta-data records that can explain more fully the judicial incident. Meta-data is information that relates to or explains the data. They can be descriptive, structural, or administrative data and relate to the content, variability, and logical function of the data in question. Based on the layout of an ontology, each legislative document has an identifier, which can be used to refer to a designation uniquely. Accordingly, the interconnection of the proposed entity with other existing ones can describe any case file of the Greek and not only legislation. With the semantic distribution and arrangement, it is possible to describe all the relevant case files.
Using machine learning techniques, ontology matching [35] can be performed, i.e., determination of correspondences between different ontologies, even concepts within ontologies. In this way, relevant legislation can be recognized between ontologies; ontologies can be related to form a temporary conceptual set, and named entities can be recognized within a legal document, for example, a minister who signs the law or an organization or a geographical entity, etc.
Accordingly, for each entity, e.g., a legislative document or a court decision, it will be possible to make a semantic connection with other legislative works, with other related data, and even with European legislation so that the representation of each entity meets the specifications of corresponding data, to queries can be written in SPARQL language, for immediate retrieval of knowledge or relevant information. For example, the following SPARQL query retrieves a legislative document or court decision from a legislation ontology, focusing on the legal resource entity [36]:
| PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> |
| PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> |
| PREFIX owl: <http://www.w3.org/2002/07/owl#> |
| PREFIX xsd: <http://www.w3.org/2001/XMLSchema#> |
| PREFIX leg: <http://example.org/legislation-ontology#> |
| SELECT ?legalResource ?title ?documentType ?dateIssued |
| WHERE { |
| ?legalResource rdf:type leg:LegalResource . |
| ?legalResource rdfs:label ?title . |
| ?legalResource rdfs:label ?title . |
| ?legalResource leg:documentType ?documentType . |
| ?legalResource leg:dateIssued ?dateIssued . |
| FILTER(?documentType = "Legislative Document" || ?documentType = "Court Decision") |
| } |
| LIMIT 10 |
This query uses a fictional legislation ontology with the following namespace: http://example.org/legislation-ontology#. It retrieves the legal resources with their title, document type, and date issued. The FILTER clause limits the results to resources of type “Legislative Document” or “Court Decision”. The LIMIT clause restricts the number of results to 10.
Predictions/recommendations [37] will be made after analyzing the behavioral characteristics of a court decision and relevant legislative information at various levels. For example, it will be possible to suggest to a judicial officer the three most relevant or corresponding judicial cases that he or she could consult for the case under consideration. Moreover, it could recommend the range of punishment (e.g., imprisonment 6–9 months), any additional sanctions (confiscation of driver’s license for two years), administrative sanctions (referral to military court), etc.
Finally, a recommendation system will be developed, that will perform algorithmic filtering (e.g., Collaborative Filtering (CF) algorithm [38]) of information and essentially be a prediction based on the relativity of corresponding situations. Collaborative filtering generally relies on user–item interactions or user-user similarity. In the following example, we will use a simple user-based collaborative filtering approach, where users are judicial officers, and items are court decisions. We will use cosine similarity to measure the similarity between judicial officers based on their decision-making behavior across multiple dimensions [39,40].
| import numpy as np |
| from scipy.spatial.distance import cosine |
| from sklearn.metrics.pairwise import cosine_similarity |
| # Mock data: rows represent judicial officers, columns represent court decisions |
| # Each value indicates the officer’s decision on a specific case (0 = not involved, 1 = favorable, −1 = unfavorable) |
| decision_matrix = np.array([ |
| [1, 0, −1, 1, 1], |
| [1, 1, 0, 1, −1], |
| [0, 1, −1, −1, 1], |
| [−1, 1, 1, 0, 1], |
| ]) |
| def recommend_cases(officer_index, decision_matrix, top_k = 3): |
| officer_decisions = decision_matrix[officer_index] |
| similarities = cosine_similarity([officer_decisions], decision_matrix) |
| # Find the most similar officer (excluding the officer themselves) |
| most_similar_officer_index = np.argmax(similarities [0, :officer_index] + similarities [0, officer_index + 1:]) + 1 |
| # Find the top_k cases where the most similar officer made a decision and the officer in question did not |
| most_similar_officer_decisions = decision_matrix[most_similar_officer_index] |
| candidate_cases = np.where((officer_decisions == 0) & (most_similar_officer_decisions ! = 0))[0] |
| recommendations = candi-date_cases[np.argsort(np.abs(most_similar_officer_decisions[candidate_cases]))[::−1][:top_k]] |
| return recommendations |
| # Test the recommendation function for a specific judicial officer (index 0) |
| officer_index = 0 |
| recommendations = recommend_cases(officer_index, decision_matrix) |
| print(f“Recommended cases for officer {officer_index}: {recommendations}”) |
In this example, we create a mock decision_matrix where rows represent judicial officers and columns represent court decisions. The values in the matrix indicate the officer’s decision on a specific case (0 = not involved, 1 = favorable, −1 = unfavorable). The recommend_cases function takes an officer_index, decision_matrix, and top_k recommendations as input. It computes the cosine similarity between the given officer and all other officers, then finds the most similar officer. Based on the most similar officer’s decisions, it recommends the top_k-cases where the given officer has not made a decision.
Based on modern AI analysis methods, we will develop and evaluate advanced technologies and analysis tools that will significantly facilitate the work of judicial officials. In this process, the ethical, legal, and social aspects will be taken into account from the beginning, in close cooperation with the legal bodies, who will also validate the technologies developed in the pilot activities [41,42].
Special attention will be given to eliminating biases that could arise at all stages of AI-based decision-making processes, namely the collection of data, how algorithms are integrated into decision-making processes, and the results of decisions the proposed system will use [43,44]. The intention is beyond the optimization of algorithmic standardizations to incorporate ethical and legal principles into the training, design, and development of AI algorithms to ensure the efficiency, speed, and independence of judicial decisions while documenting the overall process of origination and transparency of data and processes [45,46].
5. Materials and Methods
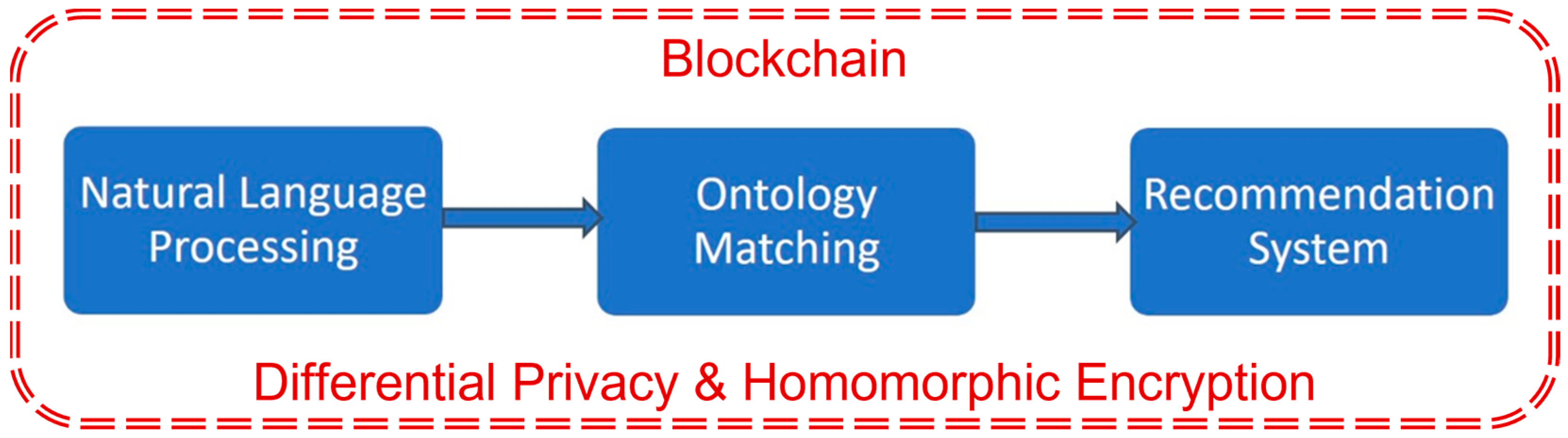
A hybrid AI model capable of operating in the complex environment of the judiciary will be created. The model in question will include three main subsystems, as shown in Figure 2 below.
The proposed subsystems are described in detail below:
5.1. Natural Language Processing (NLP)
Understanding written speech as an extension of natural language processing includes a wide range of tasks, the most basic of which is Named Entity Recognition (NER), which enables Machine Reading Comprehension (MRC). The nominal entities are directly related to the purpose and the application field implemented (legislative documents, court cases, jurisprudence, etc.). In this particular application, the language model Bidirectional Encoder Representations from Transformers (BERT) will be used to fine-tune it for the classification of the nominal entities contained in it to understand the legislative texts related to court cases [8,47].
BERT [48] is a pre-trained model designed to understand a word at the sentence level and relative to its position from both sides (back and front). It is a very accurate model, which utilizes pre-training (transfer learning) and perfecting the basics of the problem it is called to address (fine-tuning, optimization). It is a deep learning neural network architecture adapted as a language model based on the architecture of Autoencoders. Autoencoder is an artificial neural network used to learn efficient encodings of unlabeled data. The encoding is validated and improved by trying to regenerate the input from the encoding. In BERT specifically, a bidirectional model is applied, which produces deep contextualized embeddings. These integrations need little adaptation to achieve excellent results in complex problems in natural language processing, e.g., entailment, question-answering, and reading comprehension.
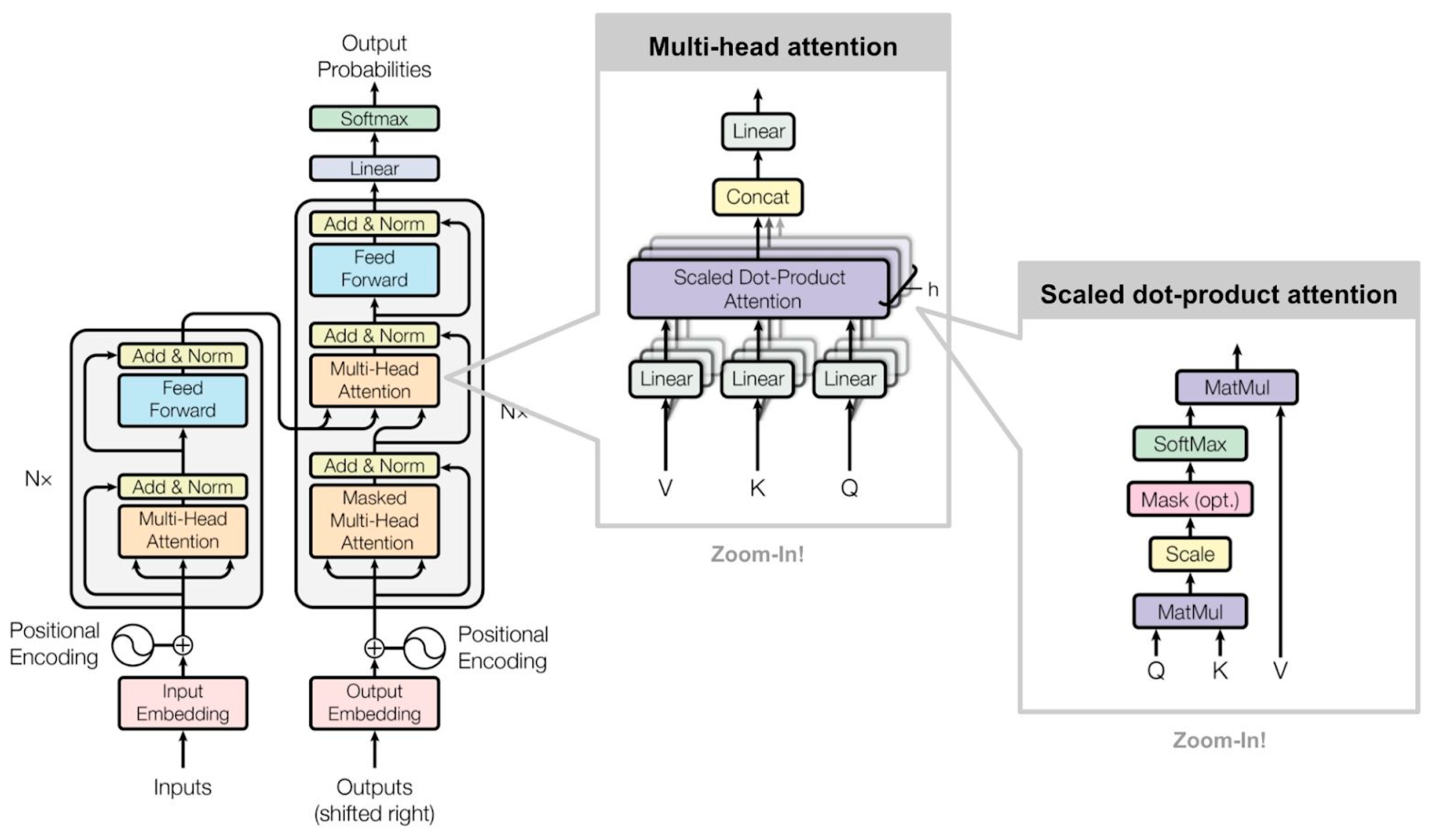
A sample of BERT’s architecture is shown in the Figure 3 below.
The architecture of the transformer includes the encoder that reads the input text and the decoder that produces a prediction for the specific problem at a time. As the goal of the BERT model is to produce a language model, it uses only the encoder component, thus, to some extent differentiating its architecture from that of the transformer. However, it can read the entire sequence of words directly rather than sequentially, which makes it bidirectional and allows it to learn the content of each word based on the words to its left and right (backward and forward).
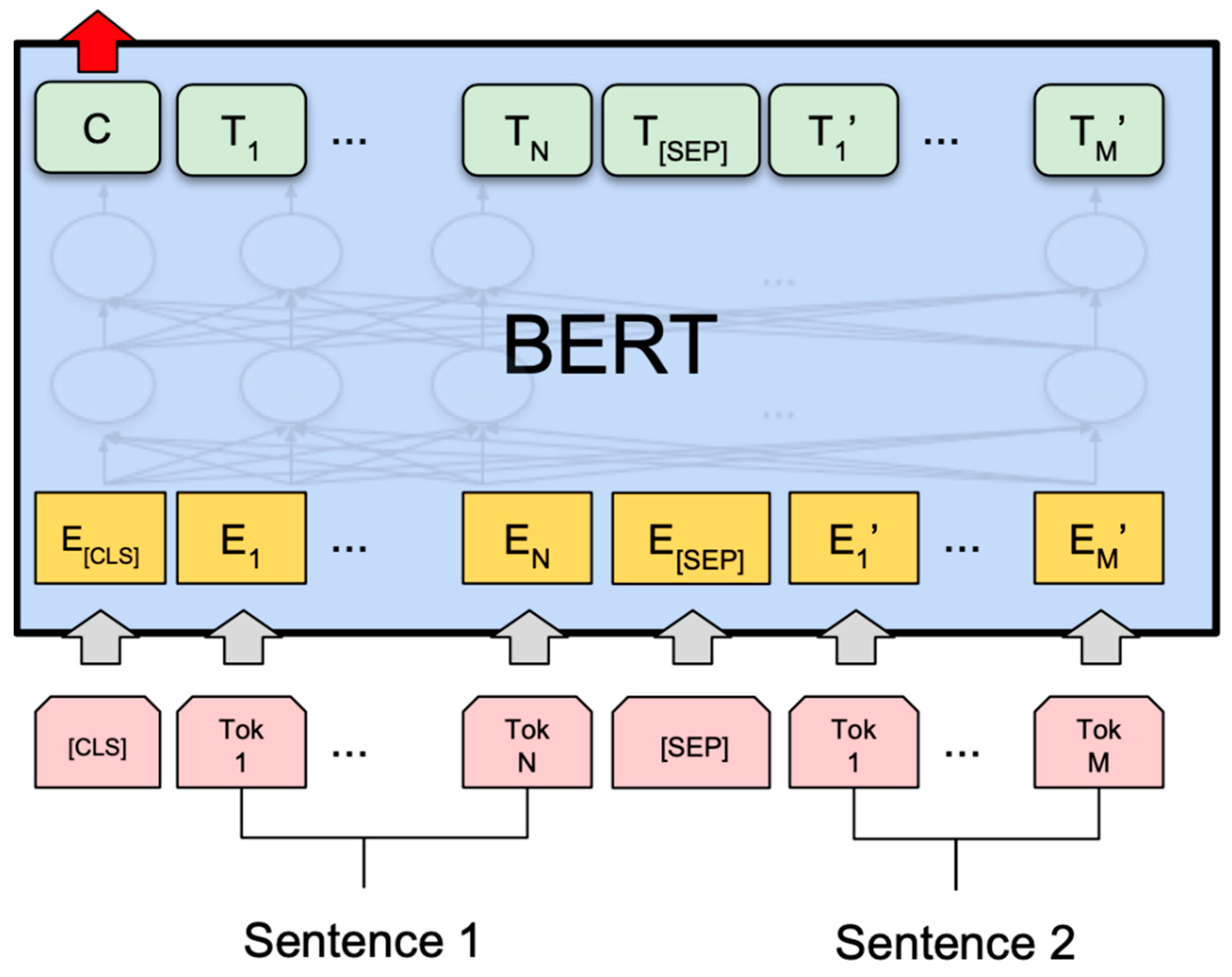
BERT provides a multi-layered architecture with additional self-attention mechanisms, each of which is followed by a Feed Forward Neural Network (FFNN). Specifically, it includes 24 layers, 1024 hidden layers, 16 headers, and 340 M parameters. The bidirectional architecture allows the model to handle many different problems as the representation input is designed so that it is feasible and clear to represent a pair of sentences in a sequence of symbols. The first symbol in any input sequence is always the special symbol [CLS]. It is a sorting symbol whose last hidden states are used as the cumulative sequence representation in sorting problems. As for sentence pairs, they are placed together in a sequence and separated in two ways. First, they are separated by the special symbol [SEP], and then a learned embedding is added to each symbol, indicating whether that symbol belongs to sentence A or B. For each symbol, the input representation is constructed by summing the symbol’s embedding vectors, the embedding vectors of the segment/sentence it belongs to, and the embedding vectors of the position it is in within the sequence. An abstract approach to the process is shown in Figure 4 below.
Two unsupervised strategies are used to pre-train BERT. Specifically, the first one is the Masked Language Model, where the model replaces 15% of the words in the sequence randomly each time, and the objective is for the model to predict all those replaced words based on all the remaining words in the following. While the second is Next Sentence Prediction, where the objective is for the model to predict the existence of a relationship or not between two sentences. A data set consisting of sentence pairs is used to train the model. In 50% of the cases, the second sentence of the pair is exactly that sentence that follows the first one according to the original text, while in the remaining 50% of the cases, its selection is made randomly. Accordingly, during the fine-tuning process, the model is initialized with the parameters obtained from the pre-training and then follows re-training, with the difference that the data are now labeled and of a specific type, depending on the problem under consideration, as each problem has separate fitting models, even though they are initialized with the same pre-trained parameters.
In addition, ChatGPT [49] is a NLP model that can understand human language and generate human-like responses. This means it can be trained to read and understand legal documents, case files, and other relevant sources of legal information and provide insights based on that analysis. One of the key areas where ChatGPT could be used is to improve the accuracy and efficiency of legal analysis. For example, the system could use ChatGPT to summarize legal cases or extract relevant information from legal documents. Let us say the system analyzes a complex legal case with many different legal documents, including contracts, briefs, and court filings. The system could use ChatGPT to read and analyze those documents and then summarize the key points of each document in a concise and easy-to-understand manner. This would help legal professionals save time and make more informed decisions.
Another way that ChatGPT could be used is to provide assistance and guidance to users of the system, such as legal professionals or individuals seeking justice. The system could use ChatGPT to answer questions or provide recommendations based on the analysis of legal documents and case files. For example, a user could ask, “What is the likelihood that I will win this case?” ChatGPT could use its understanding of legal concepts and precedents to provide a data-driven answer based on the available evidence.
ChatGPT could also be used to explain the recommendations and decisions made by the system. For example, if the system recommends a particular course of action, ChatGPT could clearly and concisely explain why that recommendation was made. This would help legal professionals and individuals understand the reasoning behind the system’s decisions. This is important for transparency and accountability in the legal system.
Finally, ChatGPT could be used to improve the overall user experience of the system. This could include answering questions, providing status updates on legal cases, or facilitating communication between legal professionals and their clients. For example, a user could ask a question such as “What is the status of my case?” ChatGPT could provide an up-to-date answer based on the latest information available.
In summary, ChatGPT can be a valuable tool in the proposed model for “intelligent justice”. It can be used to improve the accuracy and efficiency of legal analysis, provide assistance and guidance to users, explain the reasoning behind recommendations and decisions, and improve the overall user experience of the system.
5.2. Ontology Matching (OM)
Ontologies were developed in AI to accommodate knowledge sharing and reuse. They provide machine-processable semantics of information sources that can be communicated between agents. An ontology is an explicit, formal specification of a shared conceptualization. The term explicit means that the type of concepts used and the restrictions regarding using these concepts are clearly defined. The term formal refers to the fact that the ontology must be machine-readable. The term shared refers to the fact that the ontology must capture knowledge shared by the community. Finally, the term conceptualization refers to an abstract model of phenomena of the world in which the concepts related to these phenomena have been determined [42].
Although there are several ontology description languages, implementing the proposed system will use the Web Ontology Language (OWL), which is designed and widely used in SemanticWeb, providing a rich collection of operators for forming concept descriptions. It is a W3C standard that promotes interoperability and sharing between applications and is designed to be compatible with existing web standards. Its syntax is an extension of RDF and RDFS, which are written using XML standardization. With the RDFS vocabulary, we can describe classes and properties; however, with OWL, we can also describe the relationships between classes and properties and their attributes. Moreover, classes and properties can have annotations [50,51,52]. Figure 5 depicts an ontology concept.
To facilitate the processing of the ontologies data during the development of our application, the OWL API will be used, a library for java where it is used to process and read OWL files. It offers various features and programming interfaces related to ontologies. Its use is mainly focused on being able to extract, through the parser it has, the classes and properties of an OWL/XML file together with the additional information required while analyzing the axioms defined for the information of interest [53]. Specifically, data model mapping involves translating concepts, instances, relationships, properties, and constraints. The process includes pre-processing, mapping ontologies, concepts, instances, relations, properties, and rules/axioms. However, restrictions and rules are expressed in OWL, which is currently being extended towards first-order logic expressivity [54].
The main purpose of the subsystem is to identify the associations between different ontologies. For this reason, the Ontology Alignment Tool will be used, which accepts two OWL ontologies and produces mapping rules that will be used to achieve semantic inference. Most of the rules are generated semi-automatic, but there is the possibility to edit, add, remove, and optimize rules.
In each rule, there is the concept of Ontologies Patterns to map the elements (e.g., classes, and properties) of one ontology to another. Such a pattern describes precisely the parameters of the ontology participating in the rule and the role of each one. It can refer to an existing element of an ontology (e.g., a class) or to a new one derived from existing elements (such as the case in which a parameter can be used to describe the entities that belong to a prescribed class) or generally contain any combination of elements of an ontology. Figure 6 depicts an ontology matching workflow.
Such a pattern can consist of other such patterns. Automatic and predefined patterns can be defined depending on the nature of the rule. For example, Simple Relation Patterns can be defined, which define a relation of a specific Object Property of an ontology. Accordingly, Relation Path Patterns define a new property resulting from the combination of one or more relations followed by a property.
Moreover, ChatGPT can assist in this process by providing natural language understanding capabilities to identify and disambiguate the concepts and relationships being compared. Let us consider an example to understand how ChatGPT can assist in ontology matching. Let us say we have two ontologies: one describing concepts related to “criminal law” and another describing concepts related to “cybersecurity law”. We want to align these two ontologies to identify common concepts and relationships, such as “cybercrime” and “penalties”. The first step in ontology matching is to extract concepts and relationships from each ontology. This can be carried out using NLP techniques such as named entity recognition and relationship extraction. ChatGPT can assist in this process by identifying relevant concepts and relationships from natural language text.
For example, let us say we have a document describing a cybercrime case. ChatGPT can read and understand the text, identify relevant concepts and relationships, and extract them as structured data. It can then compare these extracted concepts and relationships with the concepts and relationships in the “criminal law” and “cybersecurity law” ontologies to identify potential matches.
ChatGPT can also assist in the disambiguation of concepts and relationships. In natural language, many words can have multiple meanings depending on the context in which they are used. For example, the word “penalty” could refer to a financial or criminal penalty. ChatGPT can use its understanding of context and semantics to disambiguate these concepts and relationships and match them accurately between ontologies. In addition to ontology matching, ChatGPT can also assist in ontology development and maintenance. For example, it can suggest new concepts and relationships based on analysis of natural language text or identify inconsistencies and errors in an existing ontology.
Overall, ChatGPT’s natural language understanding capabilities can be a valuable tool in the ontology matching process by assisting in identifying, extracting, and disambiguating concepts and relationships from natural language text.
5.3. Recommendation System (RS)
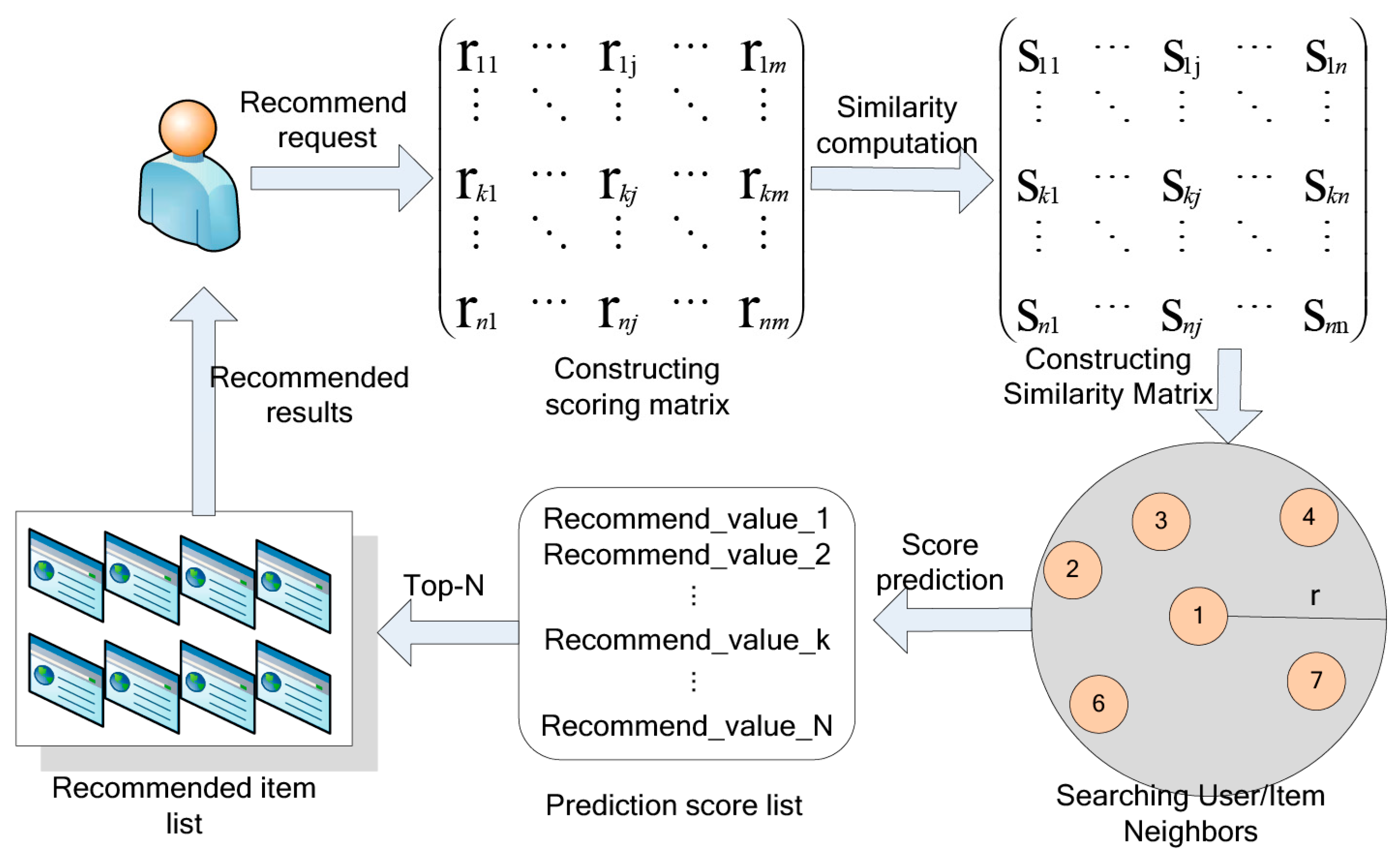
Recommender Systems [37,55] are AI systems that are the idealization of information filtering systems, as their goal is to present the user with the information that interests them personally. Recommender systems were created to solve the basic problems of text-based systems. These problems stem from a large amount of data available for searching.
Personalization results from interaction and intelligent control of possible relevant outcomes. The results in question are also the result of an intelligent confidence management process for any bias in certain subjects. For this reason, the most efficient and reliable recommendation systems are based on CF algorithm [38]. More generally, RS is related to specialized search and information retrieval systems, allowing the user to optimize the list of personalized results.
The reasoning behind CF methods is that if the active user has agreed with some users in the past, then the other recommendations should be relevant and close to their interests. Other important recommender system technologies are content-based filtering and the hybrid approach. In the case of content-based, the system learns to recommend a user based on his past actions. In producing recommendations, the content-based system matches the features—including its preferences—present in the user’s profile with the features of the content of the features that he has not yet interacted with. In the hybrid approach, systems are based on combining various RS techniques. A hybrid system combines content-based and CF to use the advantages of one to correct the disadvantages of the other. For example, suitable filtering methods suffer from the “new cases” problem, i.e., they cannot recommend users without any ratings after they have been rated little or not. This is not considered a limitation for content-based approaches since the prediction of new cases is based on their characteristics which are most often readily available. On the other hand, CF techniques can suggest cases with very different content to users—all that is sufficient is that similar users have shown interest in them—which is not the case in content-based ones.
This proposal proposes a new hybrid recommender system using innovative algorithmic approaches. Specifically, we compute a personalized ranking vector, exploiting both the direct associations between objects and the decomposability of their state space. The logic of the methodology in question is based on the fact that the large systems that appear in nature, in the majority of them, are not as complex as their size implies. Instead, their state space tends to be sparse and “structured”. This inherent sparsity is intertwined with these systems’ evolutionary viability and structural organization. The majority of hierarchically structured complex systems share the property of Nearly Completely Decomposable (NCD), where their states are organized into hierarchical levels of blocks, sub-blocks, sub-sub-blocks, and so on, in such a way that interactions between elements belonging to the same block are much stronger than interactions between elements belonging to different blocks. The fact that a complex system can possess the NCD property indicates the appropriate modeling approach.
A mathematical analysis, which emphasizes the endemic features of the system, can help alleviate problems arising from the sparsity of the underlying state space, gives a deeper knowledge of its behavior, and therefore provides a conceptual framework for the development of algorithms and methods that exploit this knowledge from a qualitative and computational perspective. In addition, it successfully manages to resolve the bias of new incoming cases. An illustrative depiction of how the proposed hybrid model works is shown in Figure 7 below.
The sparse representations adopted by this particular hybrid methodology allow a model to be constructed in which the existence of many parameters is indicated. Still, each observation of the phenomenon under consideration can be explained using only a small part of the set of parameters in question. Extensive statistical and semantic inference measures are used to evaluate the method regarding the concepts of a sample, unknown population parameters and statistical function, measure estimation, estimator selection criteria, completeness of estimators, independence of sample means, and confidence intervals.
The proposed Recommendation System can leverage ChatGPT’s natural language processing capabilities to provide personalized recommendations to users-legal officers based on their legal needs and preferences. First, the system could use ChatGPT to understand the user’s needs and preferences by analyzing natural language queries or input from the user. For example, the user may ask, “What are the legal rights in a case of wrongful termination of a signed contract?” ChatGPT can analyze this input and extract the relevant legal concepts. ChatGPT could also be used to explain the recommendations made by the system. For example, if the system recommends a particular law, ChatGPT could provide information about revisions, relevant provisions, and legal exceptions. This would help the user make an informed decision and understand the reasoning behind the recommendation.
In addition to personalized recommendations, ChatGPT could also provide users with more general legal information, for example, explanations of legal concepts in the supreme or highest court in similar cases, to improve their work’s accuracy and efficiency. Let us say a legal officer is working on a complex legal case related to environmental law. They are struggling to find relevant case law and precedent to support their arguments. ChatGPT can understand the request and analyze relevant legal documents and cases from supreme court files to provide personalized recommendations based on the user’s request.
It can also provide recommendations for using the case law in their arguments and suggest potential counterarguments that the opposing counsel may raise. ChatGPT can provide additional insights and educational recommendations based on the user’s previous work. For example, it can analyze previous legal documents and case files to identify patterns and trends in the user’s work and provide recommendations for improving their argumentation or strategy. In addition, ChatGPT can also assist in the overall user experience of the Recommendation System. It can provide a conversational interface for users to interact with the system, making it more intuitive and user-friendly.
Overall, ChatGPT’s natural language understanding capabilities can be a valuable tool in the Recommendation System for legal officers by providing personalized recommendations and insights to improve the accuracy and efficiency of their work.
5.4. Blockchain
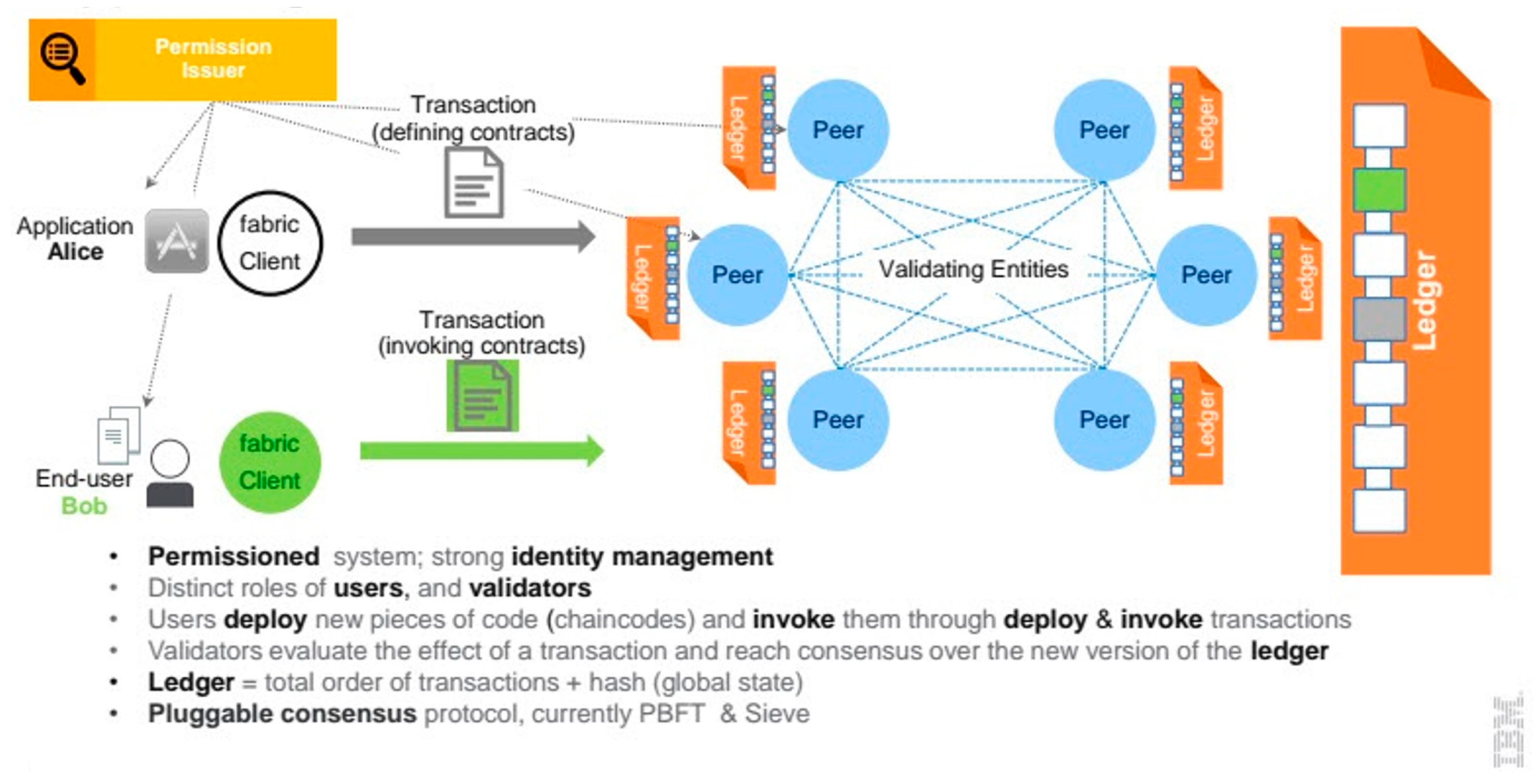
In order to offer a permissioned blockchain infrastructure that can be secure and reliable for building decentralized applications, we chose the Hyperledger Fabric [56,57,58]. Hyperledger Fabric is an open-source, enterprise-grade, permissioned blockchain technology that provides a secure and reliable platform for building decentralized applications. It is one of the projects hosted by the Linux Foundation’s Hyperledger consortium, which aims to advance cross-industry blockchain technologies. It provides several features that make it suitable for enterprise-level blockchain applications. These features include:
- Permissioned Network: Hyperledger Fabric is a permissioned blockchain technology, meaning that only authorized participants can access the network. This makes it suitable for applications where privacy and security are critical, such as in the financial and healthcare industries.
- Modular Architecture: Hyperledger Fabric has a modular architecture that allows for flexibility and customization. Developers can choose the components they need and customize them according to their specific requirements.
- Smart Contracts: Hyperledger Fabric supports the execution of smart contracts, which are self-executing contracts that can automate the enforcement of terms and conditions. Smart contracts can help to reduce the need for intermediaries and streamline business processes.
- Consensus Mechanism: Hyperledger Fabric uses a consensus mechanism that allows for multiple types of consensus algorithms to be used, depending on the specific requirements of the application. This flexibility allows developers to choose the most suitable consensus algorithm for their application.
- Privacy and Confidentiality: Hyperledger Fabric provides privacy and confidentiality features that can help to protect sensitive information and maintain confidentiality. This is achieved through the use of private channels, which allow for secure communication between selected network participants.
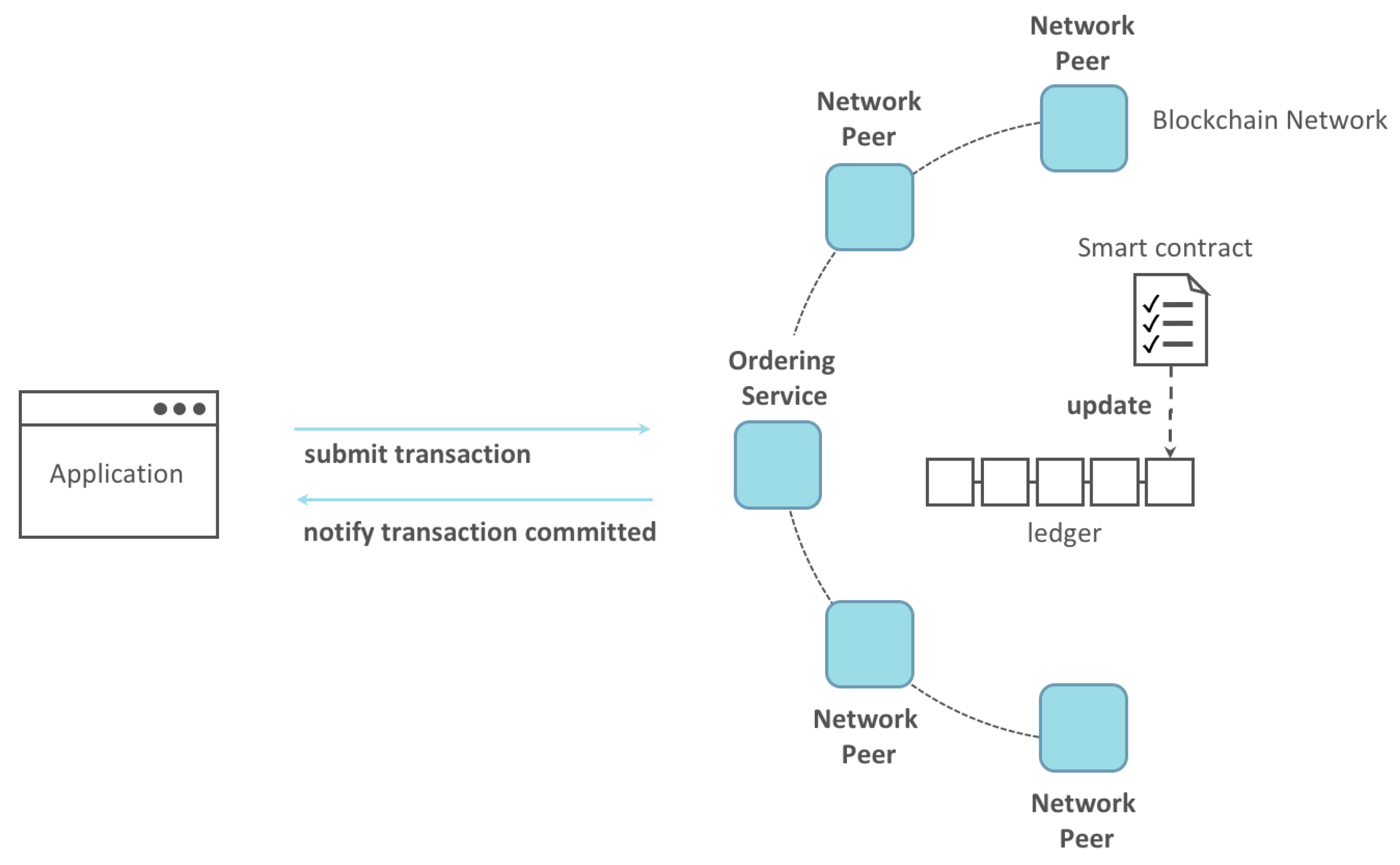
Hyperledger Fabric is being used in various industries, including finance, healthcare, and supply chain management. Its features make it a suitable choice for building enterprise-level decentralized applications that require high levels of security, privacy, and scalability. The Hyperledger-blockchain-architecture is depicted in the following Figure 8.
Hyperledger Fabric can be integrated into the proposed system to enhance its security, privacy, and transparency features. Here are some ways in which Hyperledger Fabric can be used in this architecture model:
- 1.
- Secure and Transparent Document Management: Hyperledger Fabric can be used to securely store and manage legal documents, contracts, and transactions. By leveraging the immutability and tamper-proof features of the blockchain, it can ensure that all documents and transactions are recorded and verified and cannot be altered or deleted without the consent of all parties involved. The architecture employs cryptographic techniques to ensure the integrity and authenticity of legal documents and transactions. Each document or transaction is cryptographically signed by the parties involved and verified by the blockchain network, making it tamper-proof and immutable. Here are some of the cryptographic techniques that can be used in this architecture:
- a.
- Digital Signatures: Digital signatures can be used to verify the authenticity and integrity of legal documents and transactions. Each document or transaction can be cryptographically signed by the parties involved, ensuring that it cannot be altered or tampered with.
- b.
- Hash Functions: Hash functions can be used to create a unique digital fingerprint of legal documents and transactions. This can be used to verify the integrity of the document or transaction, ensuring that it has not been modified or tampered with.
- c.
- Public-Key Cryptography: Public-key cryptography can be used to ensure secure communication between parties involved in legal transactions. Each party can generate a public and private key pair, with the public key used for encryption and the private key used for decryption.
- This ensures that all documents and transactions are recorded and verified and cannot be altered or deleted without all parties’ consent. Moreover, the architecture also employs privacy-enhancing technologies to ensure the confidentiality of sensitive information. Here are some of the privacy-enhancing technologies that can be used in this architecture:
- a.
- Differential Privacy: Differential privacy can be used to add noise to statistical data to protect the privacy of individual data points while still allowing for useful analysis. This can be used to ensure that sensitive information is protected while still allowing for necessary analysis and decision making.
- b.
- Homomorphic Encryption: Homomorphic encryption can be used to enable computation on encrypted data, without requiring the decryption of the data. This can help to ensure the privacy and confidentiality of sensitive information while still allowing for necessary computations.
- c.
- Access Controls: Access controls can be used to restrict access to sensitive information only to authorized users. This helps to prevent unauthorized access to confidential data and ensures that only those with a need-to-know have access to sensitive information.
- 2.
- Consensus Mechanism: Hyperledger Fabric can provide a consensus mechanism that ensures that all parties involved in a legal transaction or decision agree. This can help to prevent disputes and ensure that all parties are held accountable for their actions. The proposed system can use one of the following consensus mechanisms, depending on the requirements and use case:
- a.
- Practical Byzantine Fault Tolerance (PBFT): PBFT is a consensus mechanism that ensures that all nodes in the network agree on the validity of a transaction or decision. It is commonly used in permissioned blockchain networks and provides fast confirmation times, making it suitable for the proposed system.
- b.
- Raft Consensus Algorithm: Raft is another consensus mechanism that is commonly used in permissioned blockchain networks. It ensures that all nodes in the network agree on the validity of a transaction or decision and provides fast confirmation times.
- c.
- Kafka-based Consensus: Kafka-based consensus is a consensus mechanism that is based on Apache Kafka, a distributed streaming platform. It provides fast confirmation times and ensures that all nodes in the network agree on the validity of a transaction or decision.
- Ultimately, the choice of consensus mechanism for the proposed system will depend on the specific requirements and use case. However, all of these consensus mechanisms provide fast confirmation times and ensure that all parties in the network agree on the validity of a transaction or decision, making them suitable for the proposed system.
- 3.
- Smart Contracts: Hyperledger Fabric can enable the development and execution of smart contracts, which can help to automate legal processes and enforce the terms of agreements. This can help reduce the time and cost of traditional legal processes. An example of a Hyperledger Fabric application based on a smart contract is presented in Figure 9.
- Here is an example of a smart contract that can be used in the proposed system for lease agreements:
| pragma solidity ^0.8.0; |
| contract LeaseContract { |
| address public owner; |
| address public tenant; |
| uint public rentAmount; |
| uint public depositAmount; |
| uint public leaseDuration; |
| uint public startDate; |
| uint public endDate; |
| bool public leaseSigned; |
| constructor(address _owner, address _tenant, uint _rentAmount, uint _depositAmount, uint _leaseDuration, uint _startDate) public { |
| owner = _owner; |
| tenant = _tenant; |
| rentAmount = _rentAmount; |
| depositAmount = _depositAmount; |
| leaseDuration = _leaseDuration; |
| startDate = _startDate; |
| endDate = startDate + leaseDuration; |
| leaseSigned = false; |
| } |
| function signLease() public { |
| require(msg.sender == tenant, "Only tenant can sign the lease"); |
| require(block.timestamp <= startDate, "Lease has already started"); |
| leaseSigned = true; |
| } |
| function payRent() public payable { |
| require(msg.sender == tenant, "Only tenant can pay rent"); |
| require(msg.value == rentAmount, "Invalid rent amount"); |
| require(block.timestamp < endDate, "Lease has ended, rent payment not accepted"); |
| owner.transfer(msg.value); |
| } |
| function refundDeposit() public { |
| require(msg.sender == owner, "Only owner can refund deposit"); |
| require(block.timestamp >= endDate, "Lease has not ended, deposit refund not al-lowed"); |
| tenant.transfer(depositAmount); |
| } |
| function getLeaseDetails() public view returns (address, address, uint, uint, uint, uint, uint, bool) { |
| return (owner, tenant, rentAmount, depositAmount, leaseDuration, startDate, endDate, leaseSigned); |
| } |
| } |
- It is written in the Solidity [59] programming language, commonly used for creating smart contracts on the Ethereum blockchain. This smart contract represents a lease agreement between an owner and a tenant. It includes the following functions:
- a.
- Constructor: Initializes the lease agreement with the details provided by the owner and tenant, such as the rent amount, deposit amount, lease duration, and start date.
- b.
- SignLease: Allows the tenant to sign the lease agreement, indicating they agree to the terms.
- c.
- PayRent: Allows the tenant to pay the rent amount to the owner. It verifies that the rent amount is correct and that the lease has not ended.
- d.
- RefundDeposit: This allows the owner to refund the deposit amount to the tenant once the lease has ended.
- e.
- GetLeaseDetails: Returns the details of the lease agreement, including the owner and tenant’s addresses, the rent and deposit amounts, the lease duration, the start and end dates, and whether the lease has been signed.
Using this smart contract, the lease agreement can be automated, and the terms can be enforced automatically. This can help to reduce the time and cost associated with traditional legal processes and ensure that the lease agreement is fair and transparent for both parties involved.
- 4.
- Privacy and Confidentiality: Hyperledger Fabric provides privacy and confidentiality features that can help to protect sensitive information and maintain confidentiality. For example, zero-knowledge proofs can be used to enable selective disclosure of information, allowing only authorized parties to access specific data and information. Hyperledger Fabric also provides privacy and confidentiality features such as private channels, which allow a subset of network participants to conduct transactions without revealing the details to other participants.
Incorporating Hyperledger Fabric into the proposed system can help to provide a more secure, transparent, and efficient platform for legal processes, thus improving the delivery of justice. For example, the study [60] propose a hybrid storage architecture with a global blockchain in the cloud service layer and a local blockchain on the Internet of Things terminals. Regeneration coding enhances data storage reliability and a mechanism for periodically validating hash values ensures data integrity in the global blockchain. Another example is the study [61] to improve cybersecurity is blockchain technology is used to store and connect data in smart networks. However, limited blockchain storage space and slow transaction speeds present challenges. This paper proposes an identity-based proxy aggregate signature (IBPAS) scheme to address these issues by improving signature verification efficiency and compressing storage space. The IBPAS scheme achieves better storage performance than the blockchain itself and only accounts for 12% to 39% of the communication cost of an ordinary signature scheme, according to experiments.
In the proposed system that leverages blockchain technology, ChatGPT can be used to assist the blockchain module in several ways.
- Natural Language Querying: ChatGPT can provide a natural language interface to interact with the blockchain module. Instead of using complex commands and APIs to interact with the blockchain, users can simply ask questions in natural language, and ChatGPT can generate the appropriate response. For example, a user can ask, “What is the most relevant legal case in the last five years?” ChatGPT can query the blockchain module to provide the case.
- Legal Document Analysis: ChatGPT can be trained to analyze legal documents such as contracts, agreements, and court decisions. By analyzing legal documents using NLP techniques, ChatGPT can identify relevant clauses, extract relevant information, and make recommendations for judicial decision making. For example, ChatGPT can analyze a contract to identify the key terms and conditions and verify whether they have been met without privacy leakages.
- Legal Compliance Monitoring: ChatGPT can monitor legal compliance by analyzing legal documents and transactions on the blockchain in real time. By monitoring transactions on the blockchain, ChatGPT can identify potential compliance issues and alert the relevant parties. For example, ChatGPT can analyze a transaction to ensure it complies with relevant regulations and policies.
- Smart Contract Development: ChatGPT can assist in developing and testing smart contracts by generating test cases and providing feedback on the performance of the contracts. By generating test cases using natural language, ChatGPT can help to ensure that the contracts are robust and reliable. For example, ChatGPT can generate test cases to ensure that a smart contract executes the terms of an agreement correctly.
- Data Analysis: ChatGPT can be used to analyze data on the blockchain and provide insights into legal trends and patterns. By analyzing data using NLP techniques, ChatGPT can identify patterns and trends useful for judicial decision making. For example, ChatGPT can analyze court decisions to identify common legal arguments and reasoning used by judges.
In general, ChatGPT can assist the blockchain module in the proposed system by providing a natural language interface, analyzing legal documents, monitoring legal compliance, developing smart contracts, and analyzing data on the blockchain. By doing so, ChatGPT can help improve the legal system’s efficiency, transparency, and accuracy.
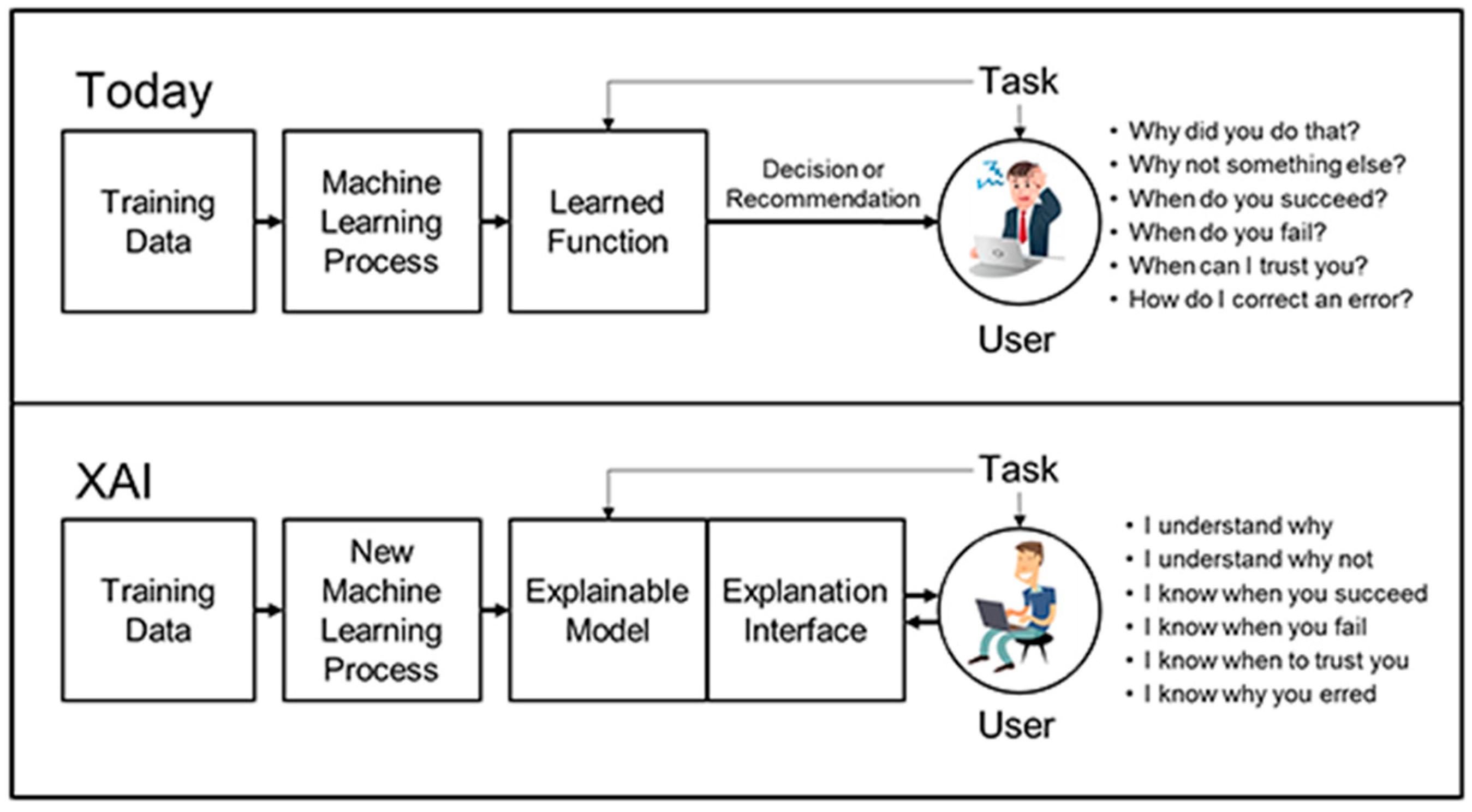
5.5. Explainable AI (XAI)
Explainable AI (XAI) [16,62,63] refers to the set of techniques and methods used to make AI (AI) models and algorithms more transparent and understandable to humans. The goal of XAI is to provide insights into how AI systems work, how they make decisions, and what factors influence their decisions. XAI techniques aim to bridge the gap between the “black box” nature of many AI models and human understanding. The importance of XAI stems from the fact that AI models and algorithms are increasingly being used in critical decision-making tasks, such as healthcare, finance, and justice. These decisions can have a significant impact on individuals and society as a whole, and it is therefore important that these decisions are transparent and understandable. An example of XAI is presented in Figure 10.
XAI techniques can be classified into two broad categories: model-agnostic and model-specific. Model-agnostic techniques are independent of the specific AI model or algorithm and can be applied to any AI system. Model-specific techniques are designed for specific types of AI models or algorithms.
Some examples of XAI techniques include:
- 1.
- Interpretable Models: Interpretable models are a type of AI model that is designed to be easily understood and explainable. These models are built in a way that enables humans to interpret the decision-making process and understand the factors that influence the model’s output. Interpretable models are particularly important in domains where the model’s decisions can significantly impact people’s lives, such as healthcare, finance, and justice. There are several types of interpretable models, each with strengths and weaknesses. Here are a few examples:
- a.
- Decision Trees: Decision trees are a type of interpretable model commonly used in decision-making tasks. Decision trees represent the decision-making process as a tree structure, with each node representing a decision based on a particular input feature. Decision trees are easy to interpret and can provide insights into which features are most important in making a decision.
- b.
- Linear Models: Linear models are a type of interpretable model used to make predictions based on linear relationships between input features and output. Linear models are easy to interpret and can provide insights into how individual input features influence the model’s output.
- c.
- Rule-Based Models: Rule-based models are a type of interpretable model that use a set of rules to make decisions. Rule-based models are easy to interpret and can provide insights into the specific rules that the model uses to make decisions.
- d.
- Bayesian Networks: Bayesian networks are a type of interpretable model that represent the relationships between input features and output using a probabilistic graphical model. Bayesian networks are easy to interpret and can provide insights into the probabilistic relationships between input features and output.
Interpretable models are beneficial because they provide transparency into the decision-making process, essential for ensuring that AI systems are used ethically and responsibly. By making AI models more interpretable, it is possible to identify biases and errors that may be present in the model and to ensure that the decisions made are fair and unbiased. Interpretable models can also provide insights into the factors that influence the model’s output, which can be useful for improving the model’s performance and accuracy.
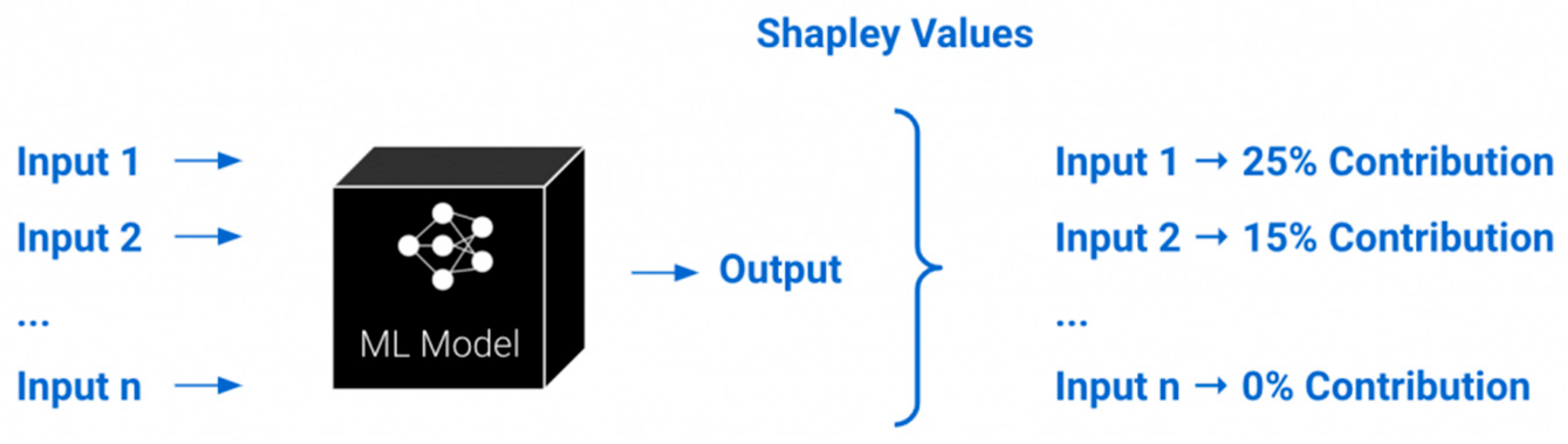
- 2.
- Feature Importance Analysis: Feature importance analysis is a technique used to identify the input features that are most important in making a decision in an AI model. The goal of feature importance analysis is to identify the specific input features that have the most significant impact on the model’s output. By identifying the most important features, it is possible to gain insights into the decision-making process and to understand which factors are most influential in the model’s output. There are several techniques that can be used to perform feature importance analysis, including:
- a.
- Correlation-based Feature Selection: This technique involves selecting input features that are most strongly correlated with the output. The features that have the highest correlation with the output are considered to be the most important.
- b.
- Recursive Feature Elimination: This technique involves recursively removing input features from the model and evaluating the model’s performance after each removal. The features that have the most significant impact on the model’s performance are considered to be the most important.
- c.
- Permutation Importance: This technique involves randomly shuffling the values of an input feature and evaluating the impact on the model’s output. The features that have the most significant impact on the model’s output are considered to be the most important.
- d.
- Information Gain: This technique involves calculating the reduction in entropy that is achieved by including an input feature in the model. The features that have the highest information gain are considered to be the most important.
Feature importance analysis can provide insights into the factors that influence the decision-making process in an AI model. By identifying the most important input features, it is possible to gain a better understanding of the model’s behavior and to ensure that the model is making decisions that are fair and unbiased. Additionally, feature importance analysis can be used to improve the performance of the model by focusing on the most important input features and optimizing them for better performance.
- 3.
- Visualization: Visualization is a technique used to represent data in a way that is more intuitive and understandable to humans. In the context of AI, visualization can be used to represent the decision-making process of a model or to provide insights into the factors that influence the model’s output. Visualization techniques can help to make AI models more interpretable and understandable to humans, which is important for ensuring that they are used ethically and responsibly. There are several visualization techniques that can be used in AI, including:
- a.
- Heat Maps: Heat maps are a type of visualization that can be used to highlight the areas of an image that are most important in making a classification decision. Heat maps use color to represent the importance of each pixel in the image, with brighter colors indicating more important pixels.
- b.
- Visual Trees: Visual trees can be visualized as a tree structure, with each node representing a decision based on a particular input feature. Visual trees can be visualized using different shapes and colors to represent different types of nodes and branches.
- c.
- Scatter Plots: Scatter plots can be used to visualize the relationship between two input features and the output. Scatter plots can be used to identify patterns and relationships that may not be immediately apparent from the data.
- d.
- Bar Charts: Bar charts can be used to visualize the importance of different input features in making a decision. Bar charts can be used to compare the importance of different input features and to identify the most important features.
Visualization can help to make AI models more transparent and interpretable. By representing the decision-making process in a way that is more intuitive and understandable to humans, it is possible to identify biases and errors that may be present in the model, and to ensure that the decisions made by the model are fair and unbiased. Additionally, visualization can provide insights into the factors that influence the model’s output, which can be useful for improving the model’s performance and accuracy.
- 4.
- Counterfactual Explanations: Counterfactual explanations are a type of explanation that shows how a different decision would have been made by an AI model if the input data had been different. Counterfactual explanations can be used to provide insights into the decision-making process of the model and to identify the specific factors that led to a particular decision. There are several techniques that can be used to generate counterfactual explanations, including:
- a.
- Perturbation-based Methods: Perturbation-based methods involve modifying the input data in a way that changes the model’s output. The modifications can be made to a single feature or multiple features. The counterfactual explanation shows how the model’s output would have changed if the input data had been modified in a particular way.
- b.
- Optimization-based Methods: Optimization-based methods involve finding the input data that result in a different output from the model. The optimization can be performed using different algorithms, such as gradient descent or genetic algorithms. The counterfactual explanation shows the modified input data that would have resulted in a different output from the model.
- c.
- Contrastive Explanations: Contrastive explanations involve comparing the input data to a counterfactual input that would have resulted in a different output from the model. The contrastive explanation shows the specific differences between the input data and the counterfactual input, which can provide insights into the factors that led to the model’s decision.
Counterfactual explanations can be used to identify biases and errors that may be present in an AI model. By identifying the specific factors that led to a particular decision, it is possible to ensure that the decisions made by the model are fair and unbiased. Additionally, counterfactual explanations can be used to improve the performance of the model by identifying the specific input features that are most influential in the decision-making process. Overall, counterfactual explanations can help to make AI models more transparent and interpretable, which is important for ensuring that they are used ethically and responsibly.
- 5.
- Natural Language Explanations: Natural language explanations are a type of explanation that is presented in natural language, making it easy for humans to understand. Natural language explanations can be used to explain the decision-making process of an AI model and to provide insights into the factors that influence the model’s output. There are several techniques that can be used to generate natural language explanations, including:
- a.
- Rule-based Methods: Rule-based methods involve encoding the decision-making process of the model as a set of rules. The rules are then used to generate natural language explanations that describe the decision-making process in a way that is easy to understand.
- b.
- Text Generation: Text generation techniques involve using deep learning algorithms to generate natural language explanations based on the input data and the output of the model. The text generation algorithms can be trained on large datasets of human-generated text to ensure that the explanations are natural and easy to understand.
- c.
- Dialog Systems: Dialog systems involve using a chatbot or virtual assistant to provide natural language explanations. The chatbot can be trained on a large corpus of human-generated text and can use natural language processing techniques to understand the user’s queries and provide relevant explanations.
Natural language explanations can be used to make AI models more transparent and interpretable. By providing explanations in a way that is easy to understand, it is possible to ensure that the decisions made by the model are fair and unbiased. Additionally, natural language explanations can be used to improve the performance of the model by identifying the specific input features that are most influential in the decision-making process. Overall, natural language explanations can help to ensure that AI models are used ethically and responsibly, and that the decisions made by the models are understandable and trustworthy.
Overall, XAI techniques aim to provide transparency and understanding of AI models and algorithms, enabling humans to make informed decisions and ensuring that AI systems are used in an ethical and responsible manner. How to work the most reliable model of XAI (Shapley Values [62,64]) is depicted in Figure 11.
ChatGPT, as NLP model, can be used to assist the XAI module in the proposed system by generating natural language explanations of the decision-making process of the AI model. ChatGPT can be trained on a large corpus of human-generated text to ensure that the explanations are natural and easy to understand. Additionally, ChatGPT can use the context of the input data to generate more relevant and accurate explanations. Here is an example of how ChatGPT can assist the XAI module in the proposed system:
Let us say that the AI model in the proposed system is a decision tree model used to make decisions based on various input features. The XAI module could use feature importance analysis to identify the input features that are most important in making a decision. Then, the XAI module could use ChatGPT to generate natural language explanations that describe how the decision tree model uses these input features to make a decision. For example, if the most important input feature is age, ChatGPT could generate an explanation such as “The decision tree model considers age to be the most important factor in making a decision. If the person is older than 50, the model is more likely to make a certain decision, whereas if the person is younger than 50, the model is more likely to make a different decision”.
ChatGPT could also be used to generate natural language explanations of counterfactual examples. For example, if the XAI module identifies that the decision tree model is biased towards a certain demographic group, ChatGPT could generate natural language explanations of how the model’s decision-making process would change if the input data were modified to be more representative of the demographic group.
Overall, ChatGPT can assist the XAI module in the proposed system by generating natural language explanations that are easy to understand and provide insights into the decision-making process of the AI model. This can help to make the AI model more transparent and interpretable, which is important for ensuring that it is used ethically and responsibly.
6. Discussion
The proposed scholarly composition suggests a framework for achieving “intelligent justice” by leveraging various technical advancements. The components of this framework and their potential implications are presented below:
- AI and NLP: The integration of AI, particularly NLP, plays a crucial role in the proposed framework. NLP techniques enable the analysis of vast amounts of legal data, including case law, statutes, and legal documents. These techniques involve extracting relevant information, identifying patterns, and understanding legal language. Through AI and NLP, the framework can enhance the efficiency of legal research, aid in the interpretation of complex legal texts, and provide valuable insights to support judicial determinations. By leveraging AI algorithms, the framework can process and analyze legal texts, identifying key concepts, legal principles, and precedents. Machine learning models can be trained on extensive legal datasets to recognize patterns and extract meaningful information. NLP techniques can further assist in understanding the context, syntax, and semantics of legal language, enabling more accurate analysis and interpretation.
- ChatGPT and Explainable AI: The ChatGPT model, as a conversational AI tool, can be utilized to interact with users and provide legal guidance or explanations. Users, including judges, lawyers, or individuals seeking legal information, can engage in conversations with the AI system to clarify legal concepts, ask questions, or seek assistance with legal research. Explainable AI methodologies are crucial to ensure transparency and interpretability in the decision-making process of intelligent algorithms. By adopting these techniques, the framework can provide explanations and justifications for the AI system’s recommendations or decisions. This promotes accountability, as users can understand the reasoning behind the AI’s output and assess its reliability. Explainable AI can also assist in identifying any biases or limitations in the AI model’s training data or algorithm. This allows for ongoing evaluation and improvement of the system, mitigating potential biases and ensuring fairness in the administration of justice.
- Ontological Alignment and the Semantic Web: Ontological alignment and semantic web technologies enable the organization and linking of legal knowledge within the framework. An ontology is a structured representation of legal concepts, relationships, and rules. By aligning ontologies with legal texts, the framework can establish a comprehensive and structured knowledge base. Through ontological alignment, legal concepts can be connected with relevant legal cases, statutes, and other related information. This facilitates efficient retrieval and analysis of legal information, allowing the system to provide comprehensive insights and recommendations for judicial determinations. The semantic web technologies further enhance this process by enabling automated reasoning and inference, supporting more accurate and consistent decision making.
- Blockchain Technology: Blockchain technology is integrated into the framework to provide a secure and transparent infrastructure for managing legal documentation and transactions. The decentralized and distributed nature of blockchain ensures the integrity and immutability of legal records. Within the framework, legal documents, such as contracts, judgments, and evidence, can be securely stored on the blockchain, ensuring their authenticity and tamper resistance. Transactions related to legal processes, such as property transfers or dispute resolutions, can also be recorded on the blockchain, creating an auditable and transparent trail of activities. Blockchain’s decentralized consensus mechanisms provide trust and transparency, as multiple parties validate and agree on the accuracy of the stored information. Smart contracts, self-executing code stored on the blockchain, can automate certain legal processes, further enhancing efficiency and reducing the need for intermediaries.
- Privacy Techniques: Privacy techniques, including differential privacy and homomorphic encryption, are employed to address the sensitivity of legal data and uphold confidentiality within the framework. Differential privacy adds noise to the data, ensuring individual privacy while still allowing meaningful analysis. By incorporating differential privacy mechanisms, the framework can protect sensitive personal information while enabling aggregated analysis of legal data for research or statistical purposes. Homomorphic encryption is employed within the framework to ensure privacy while processing legal data. With homomorphic encryption, computations can be performed on encrypted data without the need for decryption, maintaining the confidentiality of sensitive information. This technique allows the framework to securely analyze and process legal data while protecting the privacy of individuals involved. By utilizing privacy techniques such as differential privacy and homomorphic encryption, the framework ensures that sensitive legal data are protected throughout the various stages of data analysis, knowledge extraction, and decision making.
The advantages of this proposed framework include:
- Efficiency and Expediency: AI and NLP techniques can streamline legal research and analysis, saving time and effort. Automated processes can assist in managing legal documentation and transactions, reducing administrative burdens.
- Diminished Error Propensity: By leveraging AI technologies, the framework can minimize human errors and biases in legal decision making. Consistent application of legal principles and access to comprehensive legal knowledge can contribute to more accurate determinations.
- Uniform Approach to Judicial Determinations: The integration of AI and ontological alignment promotes consistency in interpreting and applying legal concepts. This can reduce discrepancies in legal outcomes and enhance the predictability of judicial decisions.
- Augmented Security and Privacy: Blockchain technology ensures the security and integrity of legal records, while privacy techniques protect sensitive data. This combination provides a robust framework for maintaining confidentiality, authenticity, and transparency in the justice system.
- Ethical and Legal Considerations: The use of explainable AI methodologies ensures that the ethical and legal implications of deploying intelligent algorithms and blockchain technologies in the legal domain are carefully examined. This scrutiny helps address concerns related to bias, accountability, and fairness.
While the proposed framework has several advantages, it is important to consider its limitations. Here are some potential drawbacks:
- Complexity and Technical Challenges: Implementing and maintaining the proposed framework requires significant technical expertise and resources. Integrating AI, NLP, ontological alignment, blockchain, and privacy techniques can be complex and may involve challenges such as data integration, system interoperability, and algorithmic development. It may also require training and updating AI models to ensure their accuracy and reliability.
- Legal Interpretation and Contextual Understanding: Although AI and NLP techniques can assist in analyzing legal texts, understanding the nuances of legal language, context, and legal precedent is a complex task. Legal interpretation often requires human judgment, as laws can be subject to different interpretations based on the specific circumstances. AI models may struggle with capturing the full range of legal reasoning and the subjective elements involved in legal decision making.
- Limited Generalization: AI models, including ChatGPT, have limitations in their ability to generalize and adapt to novel situations or legal scenarios outside their training data. They rely heavily on patterns and data they were trained on, which may not encompass the full complexity of legal issues. This can lead to inaccuracies or biases in the system’s recommendations or decisions.
- Ethical and Bias Concerns: While efforts are made to ensure explainability and address biases, AI models are susceptible to inheriting biases present in the training data. If legal data used for training the AI system contains biases, such as historical discriminatory practices, it can perpetuate or amplify those biases in the recommendations or decisions. It is crucial to regularly assess and mitigate biases to ensure fairness and equity in the justice system.
- Security and Privacy Risks: While blockchain technology offers advantages in terms of security and transparency, it is not immune to vulnerabilities. The implementation of blockchain systems requires careful consideration of potential security risks, such as 51% attacks or smart contract vulnerabilities. Additionally, while privacy techniques such as differential privacy and homomorphic encryption protect sensitive data, they may introduce computational overhead or reduce the utility of the data for analysis.
- Human–Technology Interaction and Trust: The framework’s success relies on effective human–technology interaction and the trust placed in the system. Users, including judges, lawyers, and the public, need to understand the limitations and capabilities of the technology to make informed decisions. Building trust in AI-based systems within the legal domain may require time, education, and establishing clear mechanisms for human oversight and intervention.
- Legal and Regulatory Challenges: Integrating AI and blockchain technologies into the legal domain raises legal and regulatory challenges. There may be concerns about liability, accountability, and the legality of automated decision-making processes. Developing appropriate legal frameworks, addressing jurisdictional issues, and ensuring compliance with data protection and privacy regulations are essential considerations.
Overall, while the proposed framework offers potential benefits for the administration of justice, it is crucial to address these limitations and challenges to ensure the system’s effectiveness, fairness, and adherence to legal principles. It requires ongoing research, collaboration between legal and technical experts, and careful consideration of the societal and ethical implications of deploying such technologies in the legal domain.
It must be noted that the above study proposal does not explicitly include experiments and results because it focuses on presenting a conceptual framework and the integration of various technologies to achieve “intelligent justice”. It outlines the components, methodologies, and potential advantages of the proposed framework, aiming to provide a comprehensive overview of how these technologies can be applied in the legal domain.
The absence of experiments and results is not uncommon in scholarly composition proposals, especially in the early stages of research or when presenting a conceptual framework, such as the proposed. The proposal primarily focus on outlining the theoretical foundations, methodologies, and potential benefits of the proposed approach. That serve as a starting point for further research and empirical validation.
7. Scenario: Intelligent Justice in DUI (Driving under the Influence) Cases
The scenario is a carefully constructed hypothetical scenario that illustrates the potential application and verification of the proposed “intelligent justice” framework in the context of DUI cases. It serves as a starting point for designing experiments and tests to assess the effectiveness of the various technologies integrated into the framework. The synthetic data generation ensures a diverse and representative dataset, which is essential for training and evaluating AI and NLP models. These models, specifically tailored to the criminal justice domain and DUI cases, enable efficient analysis and interpretation of legal texts related to DUI offenses. The integration of ChatGPT as a conversational AI tool allows users to interact with the system and seek legal guidance or assistance with their DUI cases. The use of explainable AI methodologies ensures transparency and interpretability in the AI system’s decision-making process, instilling trust and accountability in its recommendations. Ontological alignment and semantic web technologies facilitate the organization and linkage of legal knowledge, streamlining the retrieval of relevant legal information to support judicial determinations in DUI cases. The integration of blockchain technology provides a secure and tamper-resistant infrastructure for managing DUI case documentation and transactions, while privacy techniques such as differential privacy and homomorphic encryption protect sensitive DUI data throughout the system’s operations. The scenario sets the stage for conducting performance evaluations, user interaction testing, transparency and explainability assessments, ontological alignment analyses, blockchain security validations, and privacy preservation assessments, all of which are crucial steps in the experimental validation of the proposed intelligent justice framework.
By exploring this scenario, researchers and practitioners can gain insights into the practical implementation and benefits of leveraging these cutting-edge technologies to achieve intelligent justice in specific legal domains such as DUI cases. Specifically:
- 1.
- Scenario:
- (a)
- Data Generation and Simulation: To develop and experimentally validate the proposed “intelligent justice” framework, we focus on DUI (Driving Under the Influence) cases. For data generation, we utilize publicly available legal documents, statutes, and case law related to DUI offenses. Additionally, we create synthetic DUI cases, each with unique circumstances, involving individuals arrested for driving with a blood alcohol content (BAC) of 0.08 or above. These synthetic cases are generated using AI algorithms to ensure realistic language patterns and legal complexities.
- (b)
- AI and NLP Integration: The synthetic dataset is used to train AI and NLP models specifically tailored to DUI cases. Advanced NLP techniques are applied to extract relevant information, identify patterns, and understand the legal language used in DUI cases. The AI models are trained to analyze and interpret DUI-related legal texts, such as statutes, precedents, and court decisions.
- (c)
- Training ML Models for Pattern Recognition: Machine learning models, including neural networks and decision trees, are trained on the synthetic DUI dataset to recognize patterns and extract meaningful insights. These models are designed to identify key elements in DUI cases, such as BAC levels, field sobriety test results, and mitigating factors.
- (d)
- ChatGPT and Explainable AI: The ChatGPT model is integrated into the DUI justice framework to allow users, including judges, lawyers, and individuals facing DUI charges, to interact with the AI system. Users can seek legal guidance, ask questions about DUI laws, or request assistance with legal research related to their cases. The framework employs explainable AI methodologies to provide transparent and justifiable explanations for the AI’s recommendations or decisions. Users can understand the factors considered by the AI in determining the appropriate legal actions.
- (e)
- Ontological Alignment and Semantic Web: A DUI-specific ontology is developed to represent legal concepts, relationships, and rules specific to DUI offenses. The synthetic DUI dataset is aligned with this ontology to establish a structured knowledge base for DUI cases. Legal concepts related to DUI, such as “BAC levels”, “field sobriety tests”, and “penalties”, are linked to relevant statutes, case precedents, and related legal information. Semantic web technologies are employed to support automated reasoning and inference, leading to more accurate and consistent decision making in DUI cases.
- (f)
- Blockchain Integration: Blockchain technology is integrated into the DUI justice framework to ensure the secure and transparent management of DUI case documentation and related transactions. All DUI case documents, including arrest records, breathalyzer results, and court judgments, are stored on the blockchain to guarantee their authenticity and immutability. Transactions related to DUI proceedings, such as plea bargains or sentencing decisions, are recorded on the blockchain, creating a tamper-resistant and auditable trail of activities. The decentralized consensus mechanisms of blockchain instill trust and confidence in the accuracy of recorded information.
- (g)
- Privacy Techniques: Given the sensitivity of DUI data and the need to protect individuals’ privacy, privacy techniques such as differential privacy and homomorphic encryption are employed within the framework. Differential privacy is utilized to add noise to the data, protecting individual identities while enabling meaningful analysis of aggregated DUI data for research or statistical purposes. Homomorphic encryption ensures that DUI data can be securely processed and analyzed without compromising the confidentiality of personal information.
The scenarios demonstrate how the framework can assist judges, lawyers, and other stakeholders in making well-informed and just decisions, ultimately contributing to a more intelligent and fair DUI justice system.
- 2.
- Experimental Validation:
- (a)
- Performance Evaluation: The performance of AI and NLP components in processing and analyzing the synthetic DUI dataset is evaluated. Metrics such as accuracy, precision, recall, and F1 score are measured to assess the model’s ability to identify relevant legal concepts, DUI precedents, and key elements in DUI cases.
- (b)
- User Interaction Testing: User interaction testing is conducted with judges, lawyers, and individuals involved in DUI cases to assess ChatGPT’s usability and the quality of its legal guidance. Feedback from users is collected to understand the effectiveness and usefulness of the AI system in the context of DUI cases.
- (c)
- Transparency and Explainability Assessment: The explainable AI techniques are evaluated to ensure that the AI system provides transparent and interpretable explanations for its recommendations or decisions in DUI cases. Users’ understanding of the reasoning behind the AI’s outputs is analyzed to verify the framework’s accountability.
- (d)
- Ontological Alignment and Semantic Web Analysis: The effectiveness of ontological alignment and semantic web technologies is measured based on the system’s ability to retrieve relevant legal information and provide comprehensive insights for judicial determinations in DUI cases.
- (e)
- Blockchain Security and Trustworthiness: The security and trustworthiness of the blockchain-based infrastructure are evaluated by testing the resistance to tampering and verifying the integrity of DUI case documents and related transactions.
- (f)
- Privacy Preservation Assessment: The privacy techniques employed in the framework are assessed for their ability to protect sensitive DUI data while allowing meaningful analysis and decision making. Measures such as privacy loss and data utility are considered to ensure the confidentiality of individuals involved in DUI cases.
The experimental validation process enhances the efficiency, transparency, accountability, and privacy in DUI proceedings.
8. Conclusions
The paper presents a comprehensive approach to pursuing “intelligent justice” by leveraging AI, NLP, ontological alignment, blockchain, and privacy techniques. By incorporating these technologies, the framework aims to enhance efficiency, accuracy, transparency, and privacy in the administration of justice, while also addressing ethical and legal considerations.
Future research can focus on addressing the limitations and advancing the proposed framework. Here are some areas that warrant further investigation:
- Bias and Fairness: Continued research is needed to address bias in AI systems, improve transparency, and incorporate diverse perspectives in decision making.
- Interdisciplinary Collaboration: Interdisciplinary research is crucial for bridging the gap between AI systems and legal requirements, ensuring alignment with principles, ethical standards, and societal needs, and understanding the implications of intelligent algorithms and blockchain technologies.
- Contextual Understanding and Legal Interpretation: Advancements in natural language processing and machine learning enhance contextual understanding of legal texts, enabling AI models to capture language intricacies, interpret context, and provide nuanced explanations, improving accuracy and reliability in decision making.
- Explainability and Transparency: Research should focus on improving AI model explainability and interpretability, enabling clear explanations for recommendations, building trust, facilitating oversight, and engaging stakeholders in the legal system.
- Data Privacy and Security: Further research is needed to address privacy and security concerns in blockchain technology integration, ensuring data confidentiality and robust security measures.
- User Experience and Human–Technology Interaction: Understanding legal professionals’ needs and expectations is crucial for successful AI adoption. Research should focus on user experience, interface design, and AI’s impact on decision-making processes, social acceptance, trust, and ethical implications.
- Legal and Regulatory Frameworks: Research on AI and blockchain technologies in the justice system must address legal and regulatory challenges, develop appropriate frameworks, examine liability, accountability, and ethical implications, and collaborate with policymakers and experts.
Focusing on the above research areas can advance intelligent justice frameworks, ensuring ethical soundness, legal compliance, and benefit society. However, it is important to note that technology alone cannot solve all the problems of the justice system. It should be used as a tool to support and enhance the work of legal professionals and ensure that justice is delivered in a manner consistent with the rule of law.
Author Contributions
Conceptualization, K.D., K.R., L.M., L.I., C.S. and L.M.; methodology, K.D., K.R., L.I. and L.M.; software, C.S.; validation, K.D., K.R., L.M., C.S. and L.M.; formal analysis, K.D., K.R. and L.M.; investigation, K.D., L.I. and L.M.; resources, L.I. and C.S.; data curation, K.D., K.R., L.M., C.S. and L.M.; writing—original draft preparation, K.D.; writing—review and editing, K.D., K.R., L.M., L.I., C.S. and L.M.; visualization, K.D., K.R., L.M., C.S. and L.M.; supervision, K.D., K.R., L.M., C.S. and L.M.; project administration, L.M.; funding acquisition, C.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The data used in this study are available from the author upon request.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Butt, F.A.; Chattha, J.N.; Ahmad, J.; Zia, M.U.; Rizwan, M.; Naqvi, I.H. On the Integration of Enabling Wireless Technologies and Sensor Fusion for Next-Generation Connected and Autonomous Vehicles. IEEE Access 2022, 10, 14643–14668. [Google Scholar] [CrossRef]
- Lizzi, O. Towards a social and epistemic justice approach for exploring the injustices of English as a Medium of Instruction in basic education. Educ. Rev. 2022, 74, 927–941. [Google Scholar]
- Cano, J.; Jimenez, C.E.; Hernandez, R.; Ros, S. New tools for e-justice: Legal research available to any citizen. In Proceedings of the 2015 Second International Conference on eDemocracy & eGovernment (ICEDEG), Quito, Ecuador, 8–10 April 2015; pp. 108–111. [Google Scholar] [CrossRef]
- Emmert-Streib, F.; Yang, Z.; Feng, H.; Tripathi, S.; Dehmer, M. An Introductory Review of Deep Learning for Prediction Models With Big Data. Front. Artif. Intell. 2020, 3, 4. [Google Scholar] [CrossRef] [PubMed]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef]
- Datta, G.; Joshi, N.; Gupta, K. Study of NMT: An Explainable AI-based approach[C]//2021. In Proceedings of the International Conference on Information Systems and Computer Networks (ISCON), Mathura, India, 22–23 October 2021; pp. 1–4. [Google Scholar]
- Ren, W.; Ji, B.; Guan, Y.; Cao, L.; Ni, R. Recent technical advances in accelerating the clinical translation of small animal brain imaging: Hybrid imaging, deep learning, and transcriptomics. Front. Med. 2022, 9, 771982. [Google Scholar] [CrossRef]
- Boorugu, R.; Ramesh, G. A Survey on NLP based Text Summarization for Summarizing Product Reviews. In Proceedings of the 2020 Second International Conference on Inventive Research in Computing Applications (ICIRCA), Coimbatore, India, 15–17 July 2020; pp. 352–356. [Google Scholar] [CrossRef]
- Machine Learning Contract Search, Review and Analysis Software. Available online: https://kirasystems.com/ (accessed on 26 May 2023).
- Legal Analytics by Lex Machina. Available online: https://lexmachina.com/ (accessed on 26 May 2023).
- LegalZoom|Start a Business, Protect Your Family: LLC Wills Trademark Incorporate & More Online|LegalZoom. Available online: https://www.legalzoom.com/country/gr (accessed on 26 May 2023).
- Save Time and Money with DoNotPay! Available online: https://donotpay.com/ (accessed on 26 May 2023).
- Callister, P.D. Law, Artificial Intelligence, and Natural Language Processing: A Funny Thing Happened on the Way to My Search Results. Law Libr. J. 2020, 112, 161. [Google Scholar]
- Nayyer, K.P.; Rodriguez, M.; Sutherland, S.A. Artificial Intelligence & Implicit Bias: With Great Power Comes Great Responsibility, CanLII Authors Program. 2020. Available online: https://www.canlii.org/en/commentary/doc/2020CanLIIDocs1609#!fragment/zoupio-_Toc3Page1/BQCwhgziBcwMYgK4DsDWszIQewE4BUBTADwBdoAvbRABwEtsBaAfX2zgGYAFMAc0ICMASgA0ybKUIQAiokK4AntADkykREJhcCWfKWr1m7SADKeUgCElAJQCiAGVsA1AIIA5AMK2RpMACNoUnYhISA (accessed on 26 May 2023).
- Wojcik, M.A. Machine-Learnt Bias? Algorithmic Decision Making and Access to Criminal Justice: Overall Winner, Justis International Law & Technology Writing Competition 2020, by Malwina Anna Wojcik of the University of Bologna. Leg. Inf. Manag. 2020, 20, 99–100. [Google Scholar] [CrossRef]
- Ridley, M. Explainable Artificial Intelligence (XAI). Inf. Technol. Libr. 2022, 41, 2. [Google Scholar] [CrossRef]
- Research Librarians as Guides and Navigators for AI Policies at Universities. LaLIST, 23 September 2019. Available online: https://lalist.inist.fr/?p=41259 (accessed on 26 May 2023).
- Turner, J. Robot Rules: Regulating Artificial Intelligence; Springer International Publishing: Cham, Switzerland, 2019. [Google Scholar] [CrossRef]
- Verheij, B. Artificial intelligence as law: Presidential address to the seventeenth international conference on artificial intelligence and law. Artif. Intell. Law 2020, 28, 181–206. [Google Scholar] [CrossRef]
- Wang, Z.J. Between Constancy and Change: Legal Practice and Legal Education in the Age of Technology. Law Context 2019, 36, 64–79. [Google Scholar] [CrossRef]
- Garingan, D.; Pickard, A.J. Artificial Intelligence in Legal Practice: Exploring Theoretical Frameworks for Algorithmic Literacy in the Legal Information Profession. Leg. Inf. Manag. 2021, 21, 97–117. [Google Scholar] [CrossRef]
- Aman, H. The Legal Information Landscape: Change is the New Normal. Leg. Inf. Manag. 2019, 19, 98–101. [Google Scholar] [CrossRef]
- Artificial Intelligence and the Library of the Future, Revisited|Stanford Libraries. Available online: https://library.stanford.edu/blogs/digital-library-blog/2017/11/artificial-intelligence-and-library-future-revisited (accessed on 26 May 2023).
- Legal Knowledge and Information Systems. IOS Press: Amsterdam, The Netherlands, 2010. Available online: https://www.iospress.com/catalog/books/legal-knowledge-and-information-systems-8 (accessed on 26 May 2023).
- Litigating Artificial Intelligence. Emond Publishing: Toronto, ON, Canada, 2020. Available online: https://emond.ca/Store/Books/Litigating-Artificial-Intelligence (accessed on 26 May 2023).
- Aouidef, Y.; Ast, F.; Deffains, B. Decentralized Justice: A Comparative Analysis of Blockchain Online Dispute Resolution Projects. Front. Blockchain 2021, 4, 3. [Google Scholar] [CrossRef]
- Ortolani, P. The Judicialization of the Blockchain. In Regulating Blockchain: Techno-Social and Legal Challenges; Hacker, P., Lianos, I., Dimitropoulos, G., Eich, S., Eds.; Oxford University Press: Oxford, UK, 2019; p. 289. [Google Scholar] [CrossRef]
- Ast, F.; Deffains, B. When Online Dispute Resolution Meets Blockchain: The Birth of Decentralized Justice. Stanf. J. Blockchain Law Policy 2021, 4, 1. [Google Scholar]
- Zhuk, A. Applying blockchain to the modern legal system: Kleros as a decentralised dispute resolution system. Int. Cybersecurity Law Rev. 2023, 4, 351–364. [Google Scholar] [CrossRef]
- Marshall, D.; Thomas, T. Introduction. In Privacy and Criminal Justice; Marshall, D., Thomas, T., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 1–12. [Google Scholar] [CrossRef]
- Cui, S.; Qi, P. The legal construction of personal information protection and privacy under the Chinese Civil Code. Comput. Law Secur. Rev. 2021, 41, 105560. [Google Scholar] [CrossRef]
- Lindauer, M.; Hutter, F. Best Practices for Scientific Research on Neural Architecture Search. arXiv 2020, arXiv:1909.02453. [Google Scholar]
- Murphy, E. The Politics of Privacy in the Criminal Justice System: Information Disclosure, the Fourth Amendment, and Statutory Law Enforcement Exemptions. Mich. Law Rev. 2013, 111, 485–546. [Google Scholar]
- Angelidis, I.; Chalkidis, I.; Nikolaou, C.; Soursos, P.; Koubarakis, M. Nomothesia: A Linked Data Platform for Greek Legislation. 2018. Available online: https://www.semanticscholar.org/paper/Nomothesia-%3A-A-Linked-Data-Platform-for-Greek-Angelidis-Chalkidis/365f1283d60a5ecbe787a90efe972f37caea61fa (accessed on 26 May 2023).
- Demertzi, V.; Demertzis, K. A Hybrid Adaptive Educational eLearning Project based on Ontologies Matching and Recommendation System. arXiv 2020, arXiv:200714771. [Google Scholar]
- Makris, K.; Gioldasis, N.; Bikakis, N.; Christodoulakis, S. Ontology Mapping and SPARQL Rewriting for Querying Federated RDF Data Sources. In On the Move to Meaningful Internet Systems, OTM 2010; Meersman, R., Dillon, T., Herrero, P., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2010; pp. 1108–1117. [Google Scholar] [CrossRef]
- Al-Hadi, I.A.A.-Q.; Sharef, N.M.; Sulaiman, N.; Mustapha, N. Review of the temporal recommendation system with matrix factorization. Int. J. Innov. Comput. Inf. Control 2017, 13, 1579–1594. [Google Scholar]
- Aggarwal, C.C. Neighborhood-Based Collaborative Filtering. In Recommender Systems: The Textbook; Aggarwal, C.C., Ed.; Springer International Publishing: Cham, Switzerland, 2016; pp. 29–70. [Google Scholar] [CrossRef]
- Bai, M.L.; Pamula, R.; Jain, P.K. Tourist Recommender System using Hybrid Filtering. In Proceedings of the 2019 4th International Conference on Information Systems and Computer Networks (ISCON), Mathura, India, 21–22 November 2019; pp. 746–749. [Google Scholar] [CrossRef]
- Cui, G.; Luo, J.; Wang, X. Personalized travel route recommendation using collaborative filtering based on GPS trajectories. Int. J. Digit. Earth 2018, 11, 284–307. [Google Scholar] [CrossRef]
- Alieksieiev, V.; Andrii, B. Information Analysis and Knowledge Gain within Graph Data Model. In Proceedings of the 2019 IEEE 14th International Conference on Computer Sciences and Information Technologies (CSIT), Lviv, Ukraine, 17–20 September 2019; pp. 268–271. [Google Scholar] [CrossRef]
- Alkhalil, A.; Abdallah, M.A.E.; Alogali, A.; Aljaloud, A. Applying big data analytics in higher education: A systematic mapping study. Int. J. Inf. Commun. Technol. Educ. 2021, 17, 29–51. [Google Scholar] [CrossRef]
- Fan, C.; Chen, M.; Wang, X.; Wang, J.; Huang, B. A Review on Data Preprocessing Techniques Toward Efficient and Reliable Knowledge Discovery from Building Operational Data. Front. Energy Res. 2021, 9, 652801. [Google Scholar] [CrossRef]
- Kotsiantis, S.B.; Kanellopoulos, D.; Pintelas, P.E. Data Preprocessing for Supervised Leaning. Int. J. Comput. Inf. Eng. 2007, 1, 4104–4109. [Google Scholar]
- Anil, R.; Gupta, V.; Koren, T.; Singer, Y. Memory-Efficient Adaptive Optimization. arXiv 2019, arXiv:1901.11150. [Google Scholar]
- Anantathanavit, M.; Munlin, M.-A. Radius Particle Swarm Optimization. In Proceedings of the 2013 International Computer Science and Engineering Conference (ICSEC), Nakhonpathom, Thailand, 4–6 September 2013; pp. 126–130. [Google Scholar] [CrossRef]
- Ferrari, A.; Zhao, L.; Alhoshan, W. NLP for Requirements Engineering: Tasks, Techniques, Tools, and Technologies. In Proceedings of the 2021 IEEE/ACM 43rd International Conference on Software Engineering: Companion Proceedings (ICSE-Companion), Madrid, Spain, 25–28 May 2021; pp. 322–323. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Liu, Y.; Han, T.; Ma, S.; Zhang, J.; Yang, Y.; Tian, J.; He, H.; Li, A.; He, M.; Liu, Z.; et al. Summary of ChatGPT/GPT-4 Research and Perspective Towards the Future of Large Language Models. arXiv 2023, arXiv:2304.01852. [Google Scholar]
- Aksenov, A.; Borisov, V.; Shadrin, D.; Porubov, A.; Kotegova, A.; Sozykin, A. Competencies Ontology for the Analysis of Educational Programs. In Proceedings of the 2020 Ural Symposium on Biomedical Engineering, Radioelectronics and Information Technology (USBEREIT), Yekaterinburg, Russia, 14–15 May 2020; pp. 368–371. [Google Scholar] [CrossRef]
- Ali, M.; Falakh, F.M. Semantic Web Ontology for Vocational Education Self-Evaluation System. In Proceedings of the 2020 Third International Conference on Vocational Education and Electrical Engineering (ICVEE), Surabaya, Indonesia, 3–4 October 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Allemang, D.; Hendler, J. Chapter 2—Semantic modeling. In Semantic Web for the Working Ontologist, 2nd ed.; Allemang, D., Hendler, J., Eds.; Morgan Kaufmann: Boston, MA, USA, 2011; pp. 13–25. [Google Scholar] [CrossRef]
- Semantic Web—W3C. Available online: https://www.w3.org/standards/semanticweb/ (accessed on 26 May 2023).
- Nadarajan, G.; Chen-Burger, Y.H. An ontology-based conceptual mapping framework for translating FBPML to the Web services ontology. In Proceedings of the Sixth IEEE International Symposium on Cluster Computing and the Grid (CCGRID’06), Singapore, 16–19 May 2006; pp. 8–165. [Google Scholar] [CrossRef]
- Deschênes, M. Recommender systems to support learners’ Agency in a Learning Context: A systematic review. Int. J. Educ. Technol. High. Educ. 2020, 17, 50. [Google Scholar] [CrossRef]
- Aich, S.; Chakraborty, S.; Sain, M.; Lee, H.; Kim, H.-C. A Review on Benefits of IoT Integrated Blockchain based Supply Chain Management Implementations across Different Sectors with Case Study. In Proceedings of the 2019 21st International Conference on Advanced Communication Technology (ICACT), PyeongChang, Republic of Korea, 17–20 February 2019; pp. 138–141. [Google Scholar]
- Ampel, B.; Patton, M.; Chen, H. Performance Modeling of Hyperledger Sawtooth Blockchain. In Proceedings of the 2019 IEEE International Conference on Intelligence and Security Informatics (ISI), Shenzhen, China, 1–3 July 2019; pp. 59–61. [Google Scholar] [CrossRef]
- Aleksieva, V.; Valchanov, H.; Huliyan, A. Implementation of Smart-Contract, Based on Hyperledger Fabric Blockchain. In Proceedings of the 2020 21st International Symposium on Electrical Apparatus Technologies (SIELA), Bourgas, Bulgaria, 3–6 June 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Solidity—Solidity 0.8.20 Documentation. Available online: https://docs.soliditylang.org/en/v0.8.20/ (accessed on 26 May 2023).
- Ren, Y.J.; Leng, Y.; Cheng, Y.P.; Wang, J. Secure data storage based on blockchain and coding in edge computing. Math. Biosci. Eng. MBE 2019, 16, 1874–1892. [Google Scholar] [CrossRef]
- Ren, Y.; Leng, Y.; Qi, J.; Sharma, P.K.; Wang, J.; Almakhadmeh, Z.; Tolba, A. Multiple cloud storage mechanism based on blockchain in smart homes. Future Gener. Comput. Syst. 2021, 115, 304–313. [Google Scholar] [CrossRef]
- Demertzis, K.; Iliadis, L.; Kikiras, P. A Lipschitz—Shapley Explainable Defense Methodology Against Adversarial Attacks. In Artificial Intelligence Applications and Innovations, AIAI 2021 IFIP WG 12.5 International Workshops; Maglogiannis, I., Macintyre, J., Iliadis, L., Eds.; IFIP Advances in Information and Communication Technology; Springer International Publishing: Cham, Switzerland, 2021; pp. 211–227. [Google Scholar] [CrossRef]
- Demertzis, K.; Iliadis, L.; Kikiras, P.; Pimenidis, E. An explainable semi-personalized federated learning model. Integr. Comput. Aided Eng. 2022, 29, 335–350. [Google Scholar] [CrossRef]
- Hou, D.; Driessen, T.; Sun, H. The Shapley value and the nucleolus of service cost savings games as an application of 1-convexity. IMA J. Appl. Math. 2015, 80, 1799–1807. [Google Scholar] [CrossRef]
Figure 1.
Nomothesia ontology.

Figure 2.
Workflow of the proposed system.

Figure 3.
BERT model architecture.

Figure 4.
BERT application.

Figure 5.
OWL ontology concept.

Figure 6.
Ontology matching workflow.

Figure 7.
Collaborative Filtering algorithm.

Figure 8.
Hyperledger-blockchain-architecture.

Figure 9.
Hyperledger Fabric application based on a smart contract.

Figure 10.
Explainable AI.

Figure 11.
Explainable AI using Shapley values.

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Demertzis, K.; Rantos, K.; Magafas, L.; Skianis, C.; Iliadis, L. A Secure and Privacy-Preserving Blockchain-Based XAI-Justice System. Information 2023, 14, 477. https://doi.org/10.3390/info14090477
AMA Style
Demertzis K, Rantos K, Magafas L, Skianis C, Iliadis L. A Secure and Privacy-Preserving Blockchain-Based XAI-Justice System. Information. 2023; 14(9):477. https://doi.org/10.3390/info14090477
Chicago/Turabian StyleDemertzis, Konstantinos, Konstantinos Rantos, Lykourgos Magafas, Charalabos Skianis, and Lazaros Iliadis. 2023. "A Secure and Privacy-Preserving Blockchain-Based XAI-Justice System" Information 14, no. 9: 477. https://doi.org/10.3390/info14090477
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.