
An Unsupervised Graph-Based Approach for Detecting Relevant Topics: A Case Study on the Italian Twitter Cohort during the Russia–Ukraine Conflict

Abstract
:1. Introduction
2. Methods
2.1. Data Preprocessing
- Text tokenization with the aid of Part-of-Speech information;
- Hashtags extraction;
- Lowercasing conversion (optional);
- Links, symbols, emojis and retweets removals (optional);
- Stopwords removals (Italian words most commonly used stored as a list in an external file);
- Text lemmatization (optional): similar to stemming, associates to every word its lemma;
- Numbers removals (optional).
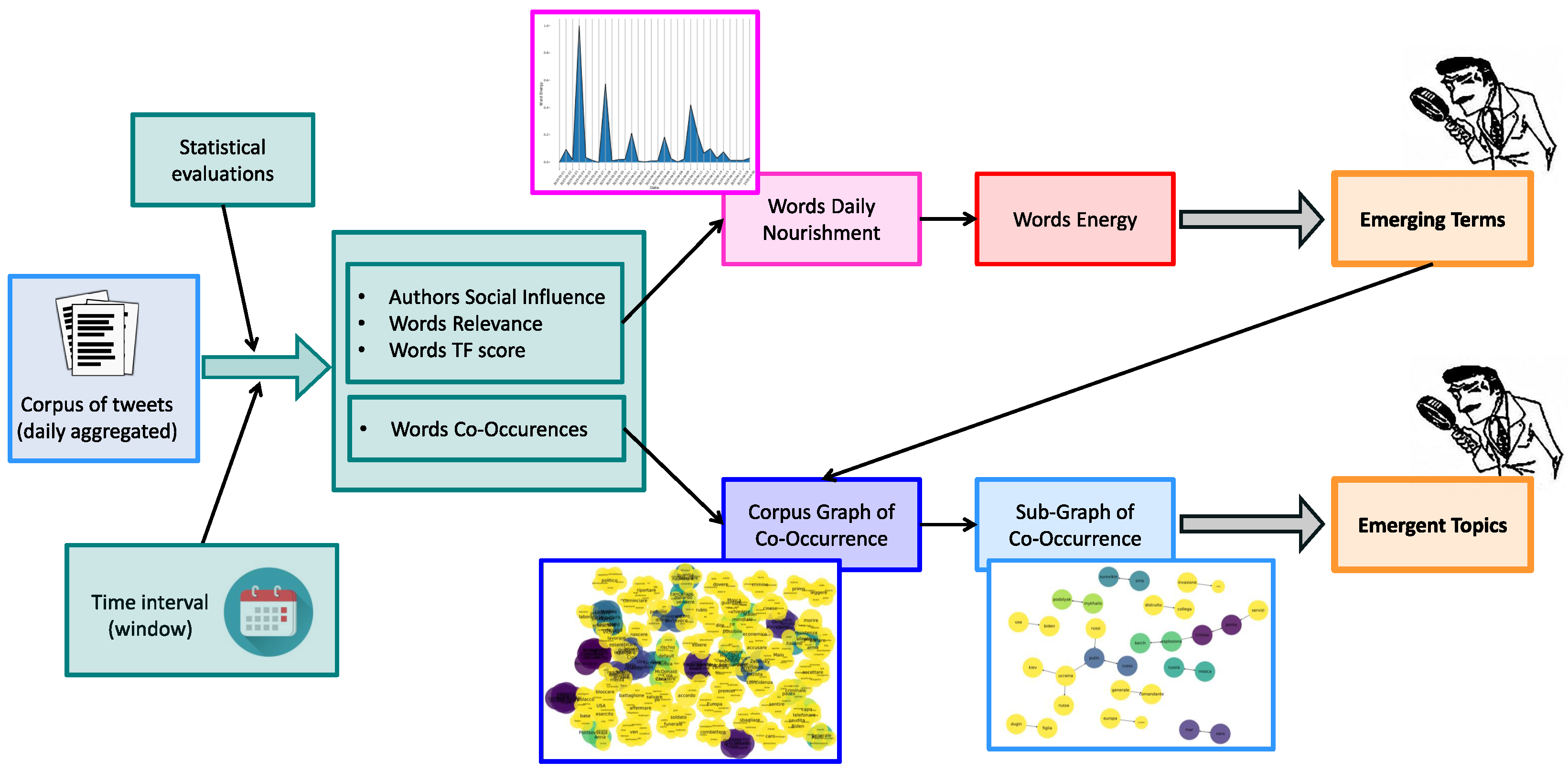
2.2. Topic Detection and Tracking
- How much that word is used within a corpus;
- How socially relevant are the authors who use it in their texts;
- How relevant that word is within a text (e.g., it is a hashtag).
- is the j-th tweet containing word x;
- is a constant that boosts the nutrition if the keyword is also a hashtag;
- is the authority of the author of the —see Equation (5).
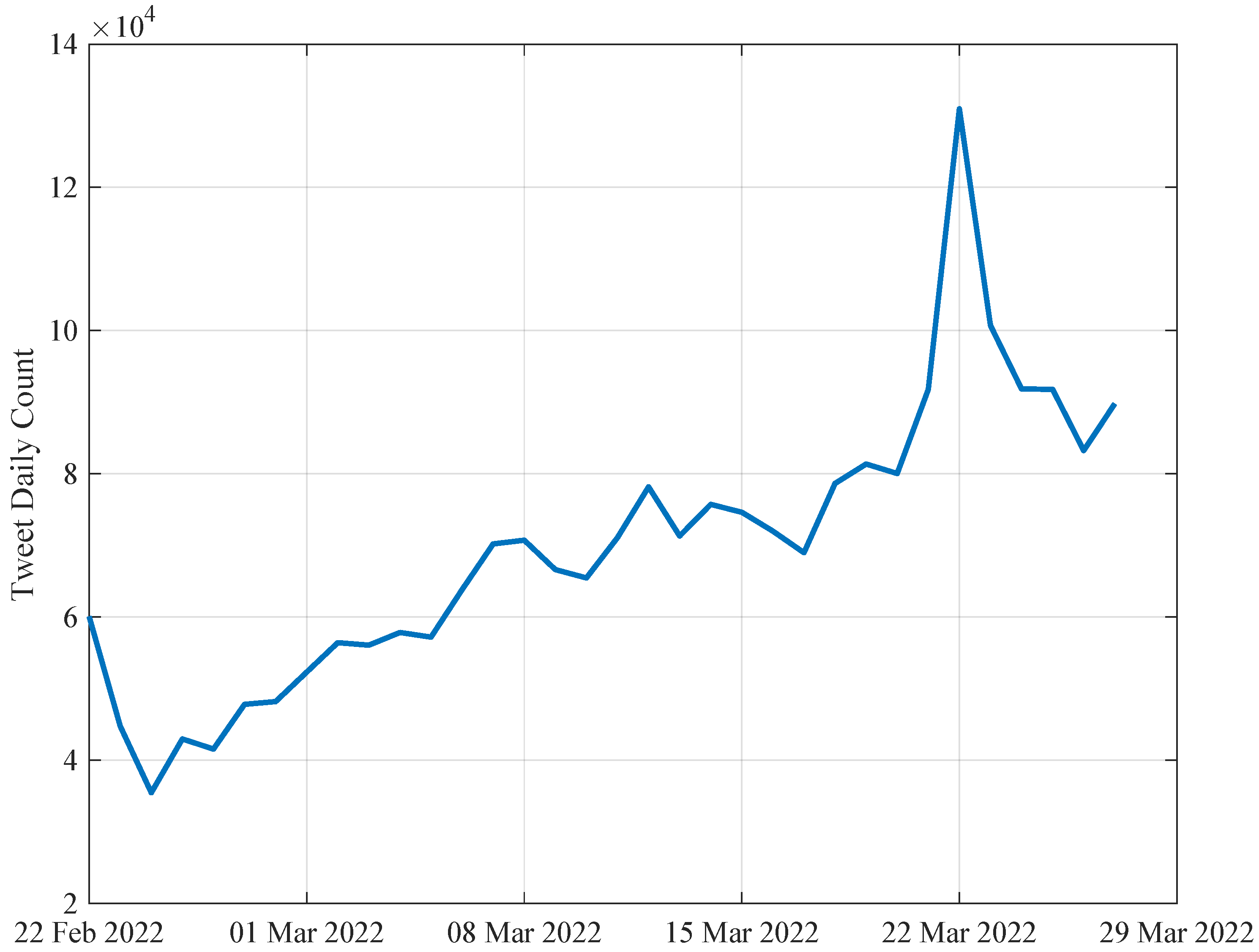
3. Dataset Description
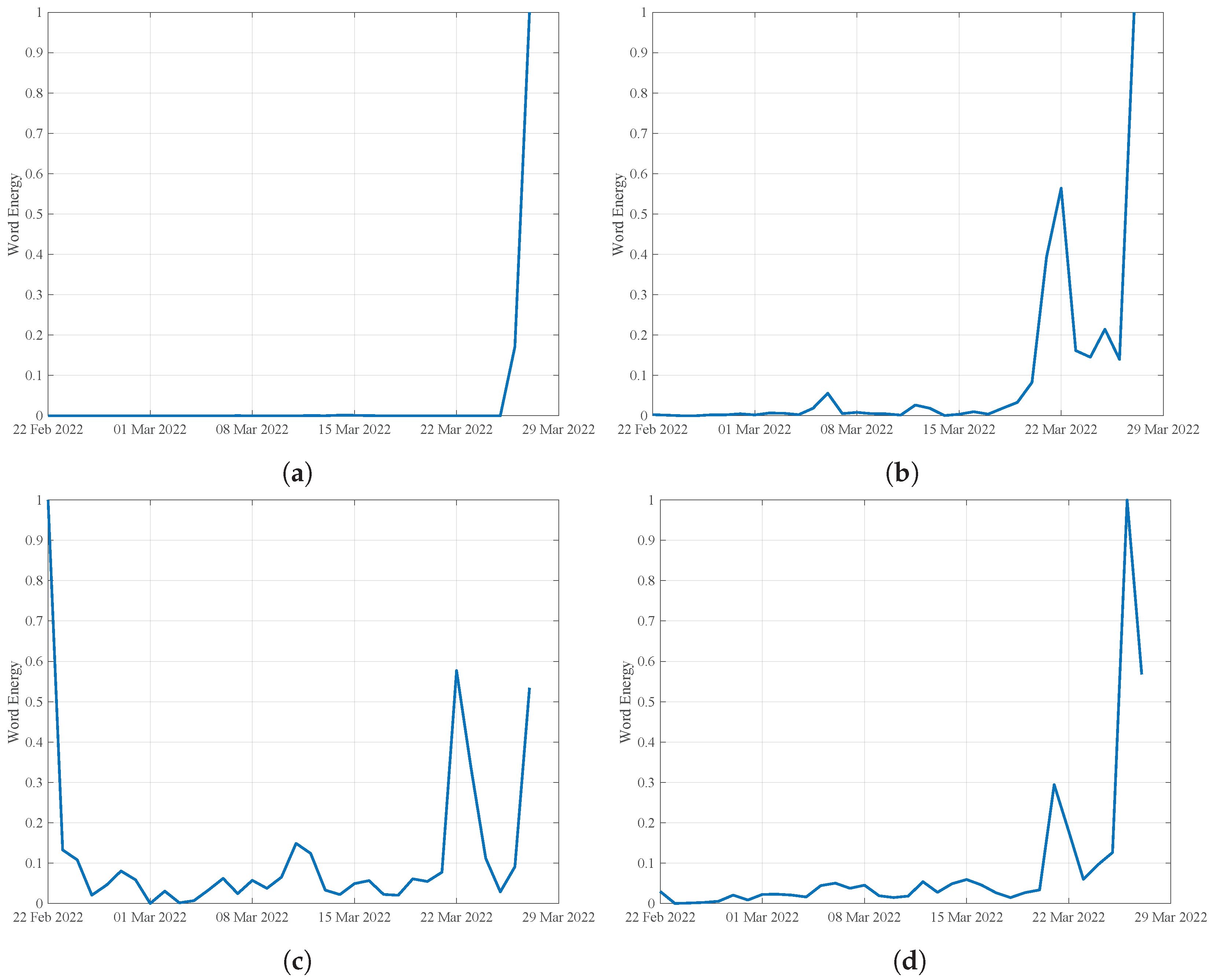
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| EU | European Union |
| NATO | North Atlantic Treaty Organization |
| NLP | Natural Language Processing |
| OSM | Online Social Media |
| U.S. | United States (of America) |
| USA | see U.S. |
Appendix A. Glossary
| Dmitry S. Peskov: | Russian diplomat and Kremlin Press Secretary |
| Dmytro Kuleba: | current Minister for Foreign Affairs of Ukraine |
| Forte dei Marmi: | a sea town in nothern Tuscany, Italy |
| Giuseppe Conte: | Italian politician and current President of the Five-Star Movement (i.e., Movimento 5 Stelle) |
| Hunter Biden: | Joe Biden’s son |
| Joseph Biden: | American politician and current President of the United States of America (also, Joe Biden) |
| La Stampa: | an Italian newspaper |
| Maria V. Zakharova: | spokeswoman for the Ministry of Foreign Affairs of the Russian Federation |
| Mario Draghi: | former Prime Minister of Italy |
| Sergey Lavrov: | Russian diplomat, former Russian Ambassador to the United Nations and current Minister of Foreign Affairs |
| Vladimir V. Putin: | Russian politician and current President of Russia |
| Volodymyr O. Zelenskyy: | Ukrainian politician and current President of Ukraine. |
| Zhao Lijian: | current Director of the Chinese Ministry of Foreign Affairs Information Department |
Appendix B. Sitography
References
- Mardones, C. Economic effects of isolating Russia from international trade due to its ‘special military operation’ in Ukraine. Eur. Plan. Stud. 2022, 31, 663–678. [Google Scholar] [CrossRef]
- Haque, U.; Naeem, A.; Wang, S.; Espinoza, J.; Holovanova, I.; Gutor, T.; Bazyka, D.; Galindo, R.; Sharma, S.; Kaidashev, I.P.; et al. The human toll and humanitarian crisis of the Russia-Ukraine war: The first 162 days. BMJ Glob. Health 2022, 7, e009550. [Google Scholar] [CrossRef] [PubMed]
- GEDI (Ed.) La Russia Cambia il Mondo: Perché Putin ha Aggredito l’Ucraina, lo Spazio Russo Diventerà un Buco Nero? la Guerra Ridisegna la Carta d’Eurasia; Limes, GEDI: Turin, Italy, 2022; OCLC: 1312643216. [Google Scholar]
- Makhortykh, M.; Lyebyedyev, Y. #SaveDonbassPeople: Twitter, propaganda, and conflict in Eastern Ukraine. Commun. Rev. 2015, 18, 239–270. [Google Scholar] [CrossRef]
- Ojala, M.; Pantti, M.; Kangas, J. Professional role enactment amid information warfare: War correspondents tweeting on the Ukraine conflict. Journalism 2018, 19, 297–313. [Google Scholar] [CrossRef] [Green Version]
- Boulianne, S. Revolution in the making? Social media effects across the globe. Inf. Commun. Soc. 2019, 22, 39–54. [Google Scholar] [CrossRef]
- Herrera, L. Revolution in the Age of Social Media: The Egyptian Popular Insurrection and the Internet; Verso Books: London, UK, 2014. [Google Scholar]
- Strandberg, K. A social media revolution or just a case of history repeating itself? The use of social media in the 2011 Finnish parliamentary elections. New Media Soc. 2013, 15, 1329–1347. [Google Scholar] [CrossRef]
- Alhindi, W.A.; Talha, M.; Sulong, G.B. The role of modern technology in arab spring. Arch. Des Sci. 2012, 65, 101–112. [Google Scholar]
- Chen, E.; Ferrara, E. Tweets in Time of Conflict: A Public Dataset Tracking the Twitter Discourse on the War Between Ukraine and Russia. arXiv 2022, arXiv:2203.07488. [Google Scholar]
- Doan, S.; Vo, B.K.H.; Collier, N. An Analysis of Twitter Messages in the 2011 Tohoku Earthquake. In Electronic Healthcare, Proceedings of the 4th International Conference, eHealth 2011, Málaga, Spain, 21–23 November 2011; Kostkova, P., Szomszor, M., Fowler, D., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 58–66. [Google Scholar] [CrossRef] [Green Version]
- Sakaki, T.; Okazaki, M.; Matsuo, Y. Earthquake Shakes Twitter Users: Real-Time Event Detection by Social Sensors. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; Association for Computing Machinery: New York, NY, USA, 2010. WWW ’10. pp. 851–860. [Google Scholar] [CrossRef]
- Mendoza, M.; Poblete, B.; Valderrama, I. Early Tracking of People’s Reaction in Twitter for Fast Reporting of Damages in the Mercalli Scale. In Social Computing and Social Media, Technologies and Analytics, Proceedings of the 10th International Conference, SCSM 2018, Held as Part of HCI International 2018, Las Vegas, NV, USA, 15–20 July 2018; Meiselwitz, G., Ed.; Springer International Publishing: Cham, Switzerland, 2018; pp. 247–257. [Google Scholar] [CrossRef]
- Oh, O.; Agrawal, M.; Rao, H.R. Information control and terrorism: Tracking the Mumbai terrorist attack through twitter. Inf. Syst. Front. 2011, 13, 33–43. [Google Scholar] [CrossRef]
- Cheong, M.; Lee, V.C. A microblogging-based approach to terrorism informatics: Exploration and chronicling civilian sentiment and response to terrorism events via Twitter. Inf. Syst. Front. 2011, 13, 45–59. [Google Scholar] [CrossRef]
- Buntain, C.; Golbeck, J.; Liu, B.; LaFree, G. Evaluating Public Response to the Boston Marathon Bombing and Other Acts of Terrorism through Twitter. Proc. Int. Aaai Conf. Web Soc. Media 2021, 10, 555–558. [Google Scholar] [CrossRef]
- Öztürk, N.; Ayvaz, S. Sentiment analysis on Twitter: A text mining approach to the Syrian refugee crisis. Telemat. Inform. 2018, 35, 136–147. [Google Scholar] [CrossRef]
- Denecke, K.; Krieck, M.; Otrusina, L.; Smrz, P.; Dolog, P.; Nejdl, W.; Velasco, E. How to exploit twitter for public health monitoring? Methods Inf. Med. 2013, 52, 326–339. [Google Scholar] [CrossRef] [PubMed]
- Signorini, A.; Segre, A.M.; Polgreen, P.M. The use of Twitter to track levels of disease activity and public concern in the US during the influenza A H1N1 pandemic. PLoS ONE 2011, 6, e19467. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jain, V.K.; Kumar, S. An Effective Approach to Track Levels of Influenza-A (H1N1) Pandemic in India Using Twitter. Procedia Comput. Sci. 2015, 70, 801–807. [Google Scholar] [CrossRef] [Green Version]
- De Santis, E.; Martino, A.; Rizzi, A. An Infoveillance System for Detecting and Tracking Relevant Topics From Italian Tweets During the COVID-19 Event. IEEE Access 2020, 8, 132527–132538. [Google Scholar] [CrossRef] [PubMed]
- Kumar, S.; Khan, M.B.; Hasanat, M.H.A.; Saudagar, A.K.J.; AlTameem, A.; AlKhathami, M. An Anomaly Detection Framework for Twitter Data. Appl. Sci. 2022, 12, 11059. [Google Scholar] [CrossRef]
- Zafarani, R.; Abbasi, M.A.; Liu, H. Social Media Mining: An Introduction; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Hromic, H.; Prangnawarat, N.; Hulpuş, I.; Karnstedt, M.; Hayes, C. Graph-Based Methods for Clustering Topics of Interest in Twitter. In Engineering the Web in the Big Data Era; Cimiano, P., Frasincar, F., Houben, G.J., Schwabe, D., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 701–704. [Google Scholar]
- Cinque, M.; Della Corte, R.; Moscato, V.; Sperlí, G. A graph-based approach to detect unexplained sequences in a log. Expert Syst. Appl. 2021, 171, 114556. [Google Scholar] [CrossRef]
- Polyzos, E.S. Escalating tension and the war in ukraine: Evidence using impulse response functions on economic indicators and twitter sentiment. SSRN Electron. J. 2022. [Google Scholar] [CrossRef]
- Ibar-Alonso, R.; Quiroga-García, R.; Arenas-Parra, M. Opinion Mining of Green Energy Sentiment: A Russia-Ukraine Conflict Analysis. Mathematics 2022, 10, 2532. [Google Scholar] [CrossRef]
- Pavlyshenko, B.M. Methods of Informational Trends Analytics and Fake News Detection on Twitter. arXiv 2022, arXiv:2204.04891. [Google Scholar]
- Patil, S.; Lokesha, V. Live Twitter Sentiment Analysis Using Streamlit Framework. SSRN Electron. J. 2022. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4119949 (accessed on 4 May 2023). [CrossRef]
- Chen, C.C.; Chen, Y.T.; Sun, Y.; Chen, M.C. Life Cycle Modeling of News Events Using Aging Theory. In Machine Learning: ECML 2003, Proceedings of the 14th European Conference on Machine Learning, Cavtat-Dubrovnik, Croatia, 22–26 September 2003; Lavrač, N., Gamberger, D., Blockeel, H., Todorovski, L., Eds.; Springer: Berlin/Heidelberg, Germany, 2003; pp. 47–59. [Google Scholar] [CrossRef] [Green Version]
- Schmid, H. Probabilistic part-of-speech tagging using decision trees. In Proceedings of the International Conference on New Methods in Language Processing, Manchester, UK, 6–8 July 1994; p. 154. [Google Scholar]
- Schmid, H. Improvements in Part-of-Speech Tagging with an Application to German. In Natural Language Processing Using Very Large Corpora; Armstrong, S., Church, K., Isabelle, P., Manzi, S., Tzoukermann, E., Yarowsky, D., Eds.; Springer: Dordrecht, The Netherlands, 1999; pp. 13–25. [Google Scholar] [CrossRef]
- Cataldi, M.; Di Caro, L.; Schifanella, C. Emerging Topic Detection on Twitter Based on Temporal and Social Terms Evaluation. In Proceedings of the Tenth International Workshop on Multimedia Data Mining, Washington, DC, USA, 25 July 2010; Association for Computing Machinery: New York, NY, USA, 2010. MDMKDD ’10. [Google Scholar] [CrossRef]
- Salton, G.; Buckley, C. Term-weighting approaches in automatic text retrieval. Inf. Process. Manag. 1988, 24, 513–523. [Google Scholar] [CrossRef] [Green Version]
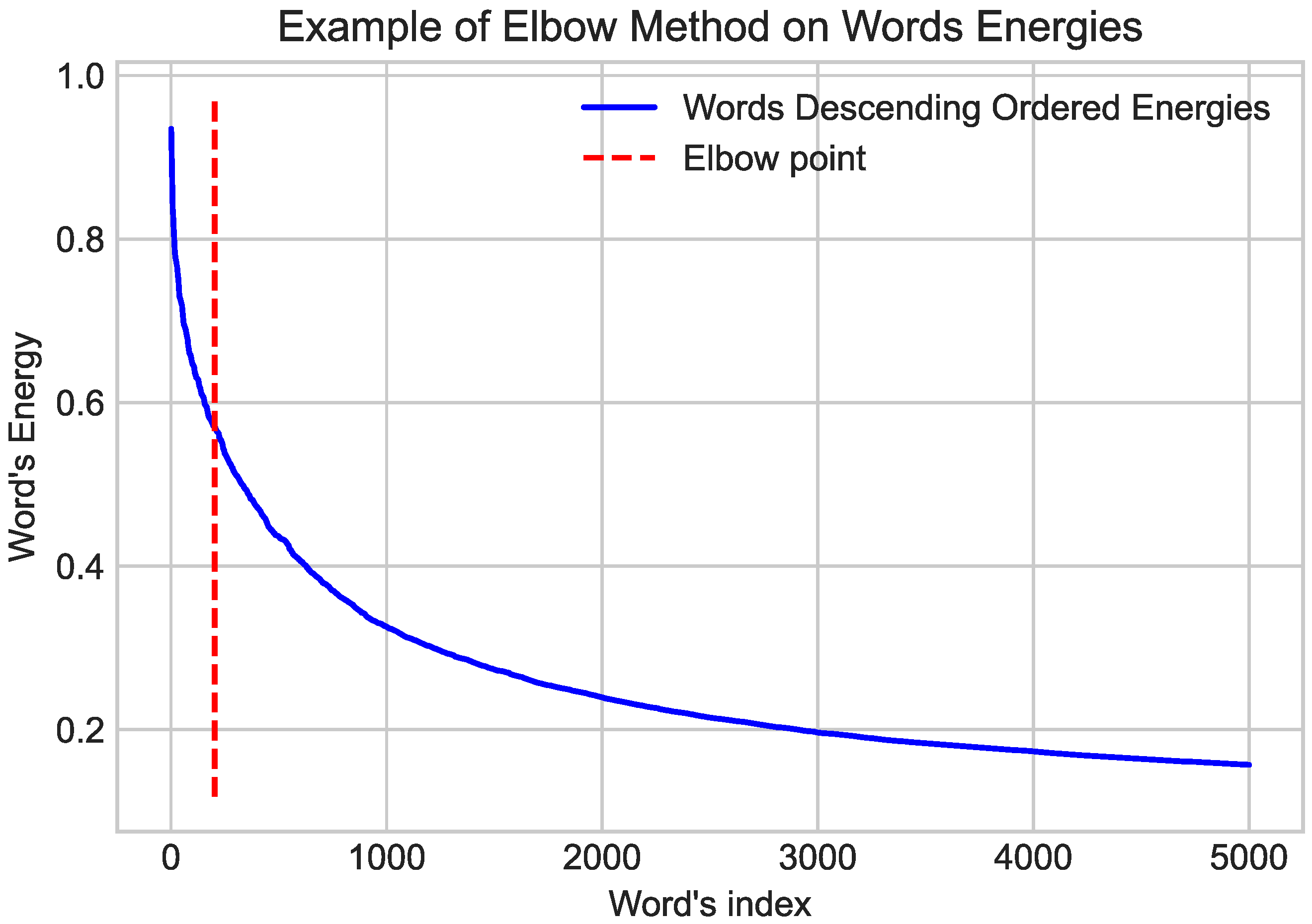
- Satopaa, V.; Albrecht, J.; Irwin, D.; Raghavan, B. Finding a “Kneedle” in a Haystack: Detecting Knee Points in System Behavior. In Proceedings of the 2011 31st International Conference on Distributed Computing Systems Workshops, Minneapolis, MN, USA, 20–24 June 2011; pp. 166–171. [Google Scholar] [CrossRef] [Green Version]
- Troussas, C.; Krouska, A. Path-Based Recommender System for Learning Activities Using Knowledge Graphs. Information 2023, 14, 9. [Google Scholar] [CrossRef]
- Peer, M.; Brunec, I.K.; Newcombe, N.S.; Epstein, R.A. Structuring knowledge with cognitive maps and cognitive graphs. Trends Cogn. Sci. 2021, 25, 37–54. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Topic | Terms | Terms (Translated) |
|---|---|---|
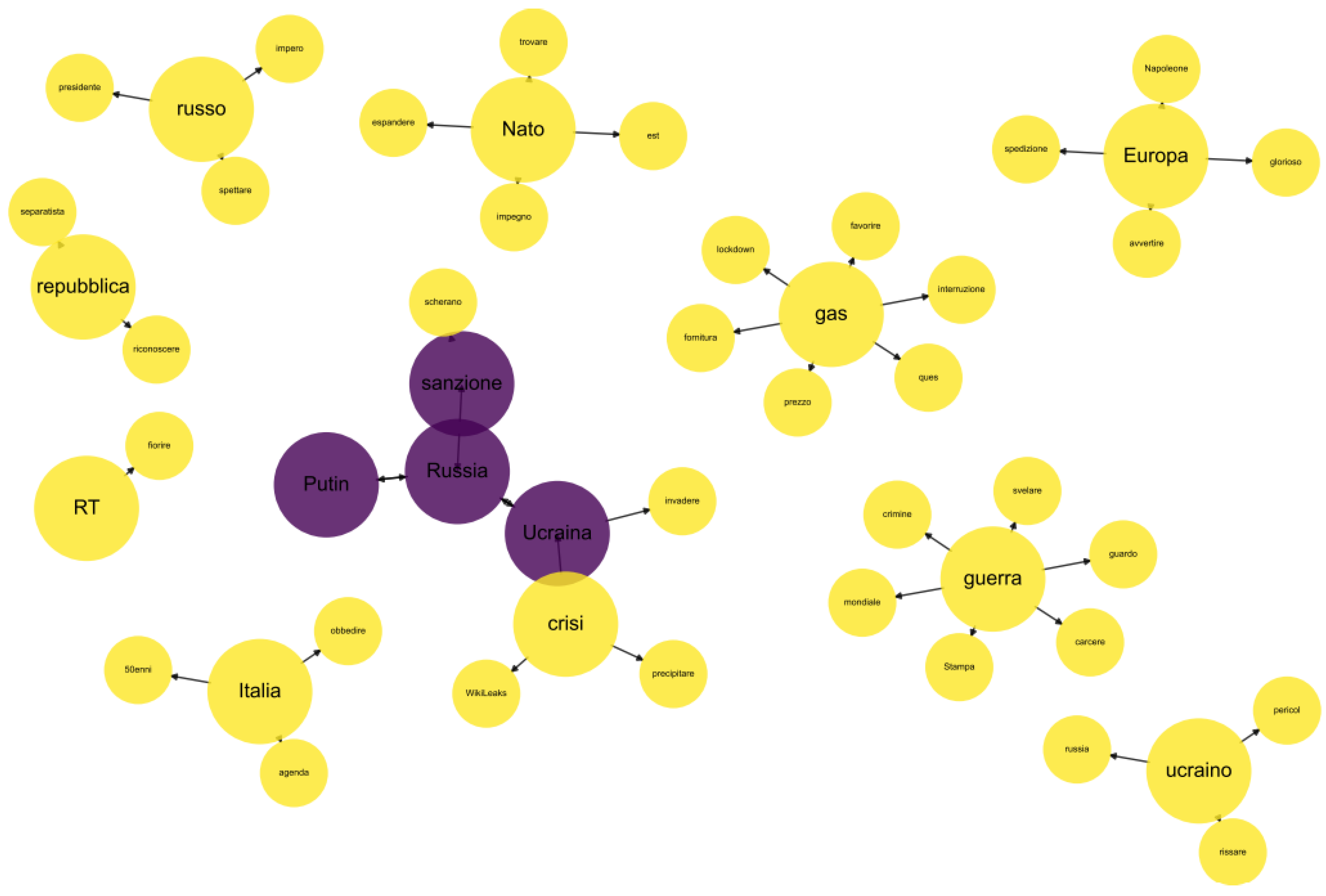
| #1 | Putin, Russia | Putin, Russia |
| #2 | repubblica, separatista, riconoscere | republic, separatist, recognize |
| Topic | Terms | Terms (Translated) |
|---|---|---|
| #1 | ministero, estero, ministro | ministry, foreign affairs, minister |
| #2 | Italia, sanzione, demenziale, Washington | Italy, sanctions, foolish, Washington |
| #3 | gas, energetico, deliberare, crisi | gas, energetic, approve, crisis |
| Topic | Terms | Terms (Translated) |
|---|---|---|
| #1 | raid, sirena, suonare, aereo, capitale, Kiev | raid, siren, sound, airplane, capital, Kyiv |
| #2 | militare, operazione | military, operation |
| #3 | attacco, invasione, attaccare, condannare, civile, conseguenza, esplosione | attack, invasion, to attack, to condemn, civil/civilian, consequence, explosion |
| Topic | Terms | Terms (Translated) |
|---|---|---|
| #1 | spazio, chiudere, aereo, Italy | space, to block, airplane, Italy |
| #2 | trattenere, arrestare, giornalista, russo, polizia | to detain, to arrest, journalist, Russian, police |
| #3 | nucleare, Bielorussia, potere, Cina, negoziato, italiano, NATO | nuclear, Belarus, power, China, negotiation, Italian, NATO |
| #4 | arma, pace, mandare, guerra, soldato, criminale, dichiarare | weapon, peace, to send, war, soldier, criminal, to declare |
| #5 | Putin, Russia | Putin, Russia |
| Topic | Terms | Terms (Translated) |
|---|---|---|
| #1 | Putin, Russia | Putin, Russia |
| #2 | ucraino, popolo | Ukrainian, people |
| #3 | guerra, Ucraina | war, Ukraine |
| #4 | villa, Zelensky, marmo, forte | villa, Zelenskyy, marmo, forte |
| #5 | pausa, evacuare, civile | pause, evacuate, civilian |
| #6 | bambino, governo, scrivere, Vladimir, scuola, spiegare, minuto | children, government, write, Vladimir, school, explain, minute |
| #7 | occidente, cattivo, protesta, cittadino, riuscire, anziano, polizia | West, evil, protest, citizen, be able to, elderly, police |
| Topic | Terms | Terms (Translated) |
|---|---|---|
| #1 | ospedale, pediatrico | hospital, pediatric |
| #2 | conflitto, responsabile, Nato | conflict, responsible, Nato |
| #3 | biologico, ricerca | biological, research |
| Topic | Terms | Terms (Translated) |
|---|---|---|
| #1 | stamattina, ambasciatore, La, Stampa, Sergey | this morning, ambassador, La, Stampa, Sergey |
| #2 | militare, spesa | military, expenses |
| #3 | chimico, arma | chemical, weapon |
| #4 | Joe, Hunter, figlio | Joe, Hunter, son |
| Topic | Terms | Terms (Translated) |
|---|---|---|
| #1 | Putin, Biden, macellaio, presidente, Conte, USA, accusa | Putin, Biden, butcher, president, Conte, USA, accuse |
| #2 | americano, mandare, potere, bar, tiranno, atomico | American, to send, power, bar, tyrant, atomic |
| #3 | Ucraina, USA, Europa, nascere, volere, ucraino, libertà | Ukraine, USA, Europe, to born, willing, Ukrainian, freedom |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
De Santis, E.; Martino, A.; Ronci, F.; Rizzi, A. An Unsupervised Graph-Based Approach for Detecting Relevant Topics: A Case Study on the Italian Twitter Cohort during the Russia–Ukraine Conflict. Information 2023, 14, 330. https://doi.org/10.3390/info14060330
De Santis E, Martino A, Ronci F, Rizzi A. An Unsupervised Graph-Based Approach for Detecting Relevant Topics: A Case Study on the Italian Twitter Cohort during the Russia–Ukraine Conflict. Information. 2023; 14(6):330. https://doi.org/10.3390/info14060330
Chicago/Turabian StyleDe Santis, Enrico, Alessio Martino, Francesca Ronci, and Antonello Rizzi. 2023. "An Unsupervised Graph-Based Approach for Detecting Relevant Topics: A Case Study on the Italian Twitter Cohort during the Russia–Ukraine Conflict" Information 14, no. 6: 330. https://doi.org/10.3390/info14060330