

Data-Driven Models Informed by Spatiotemporal Mobility Patterns for Understanding Infectious Disease Dynamics

Abstract
:1. Introduction
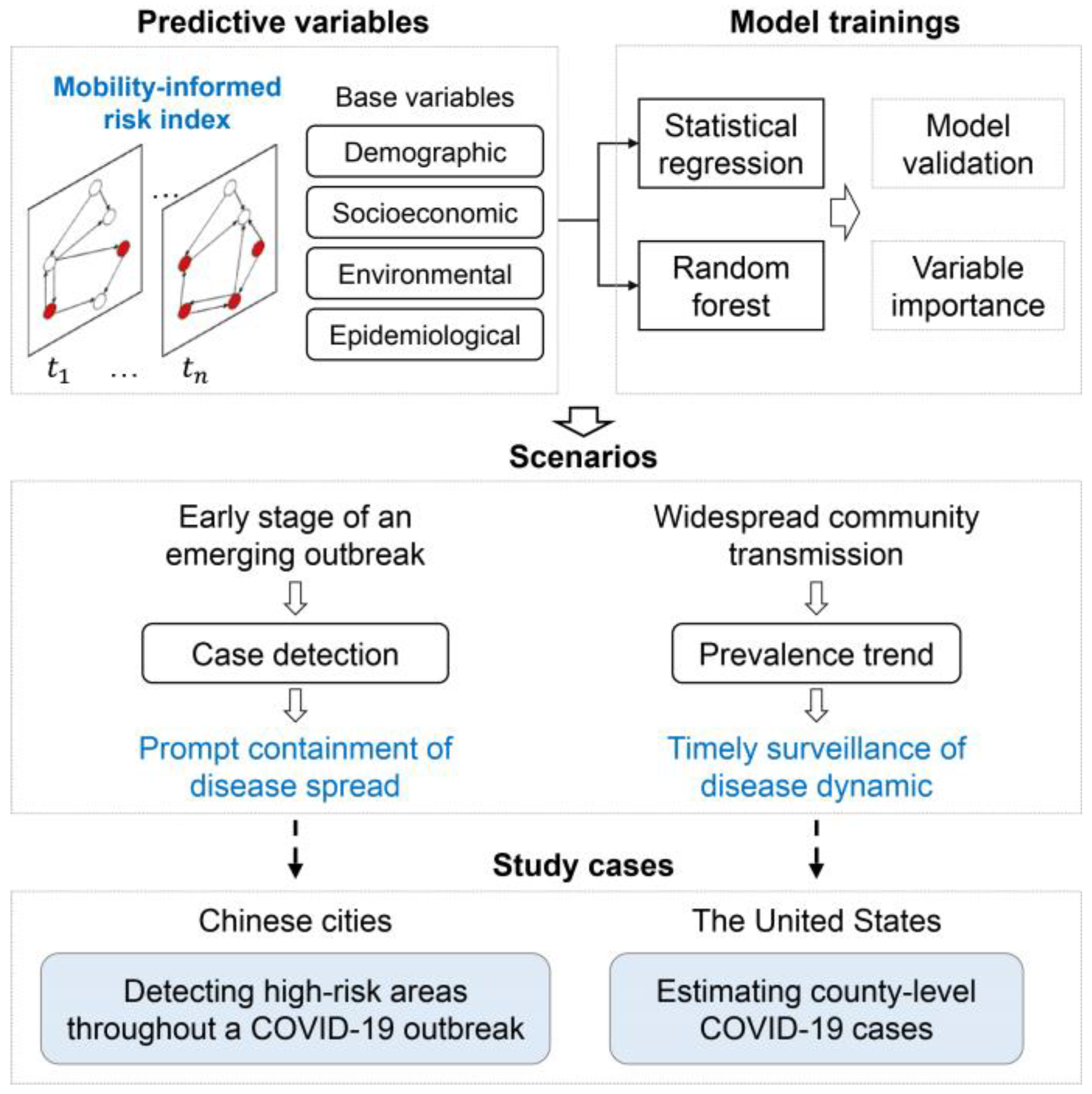
2. Materials and Methods
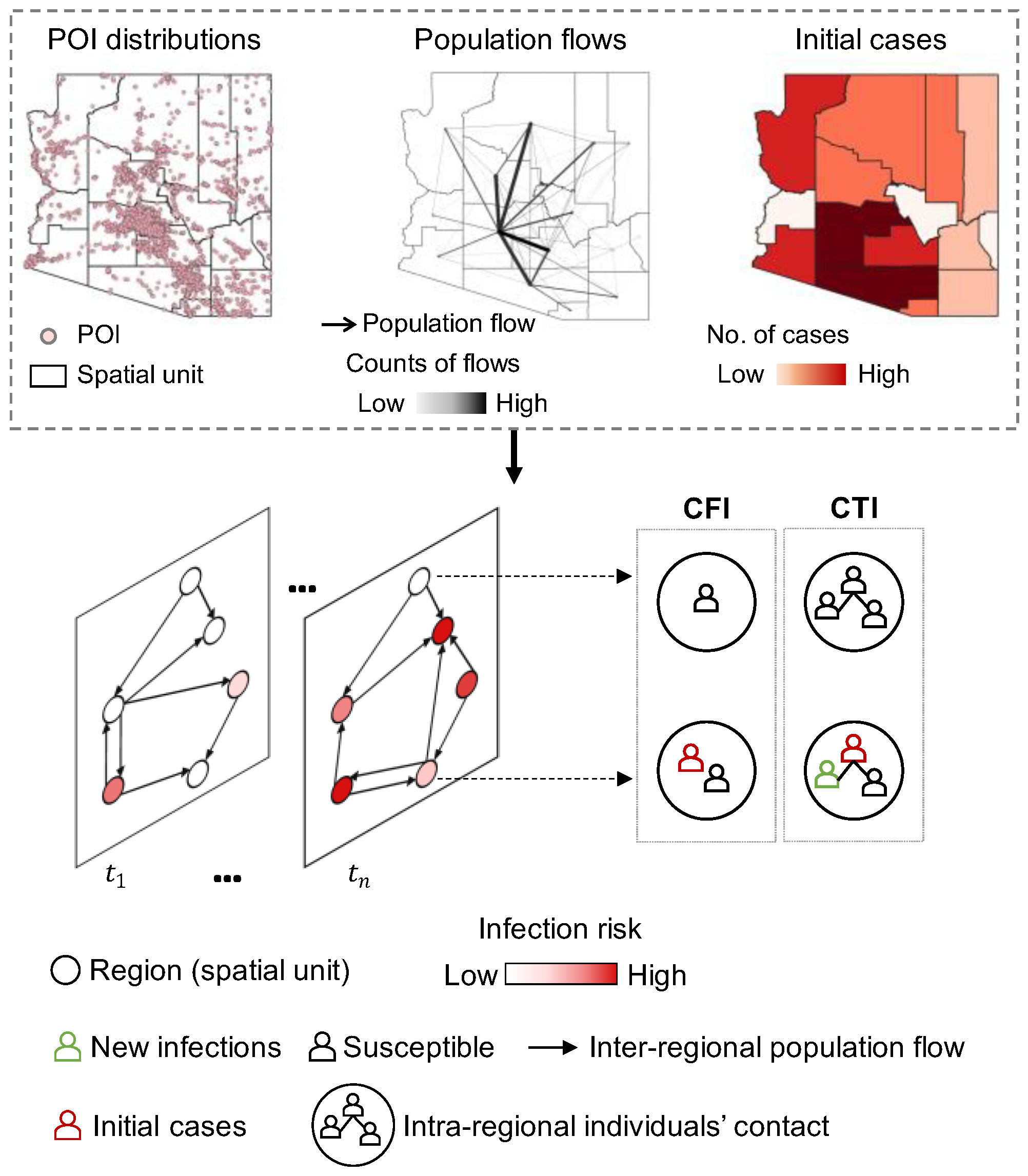
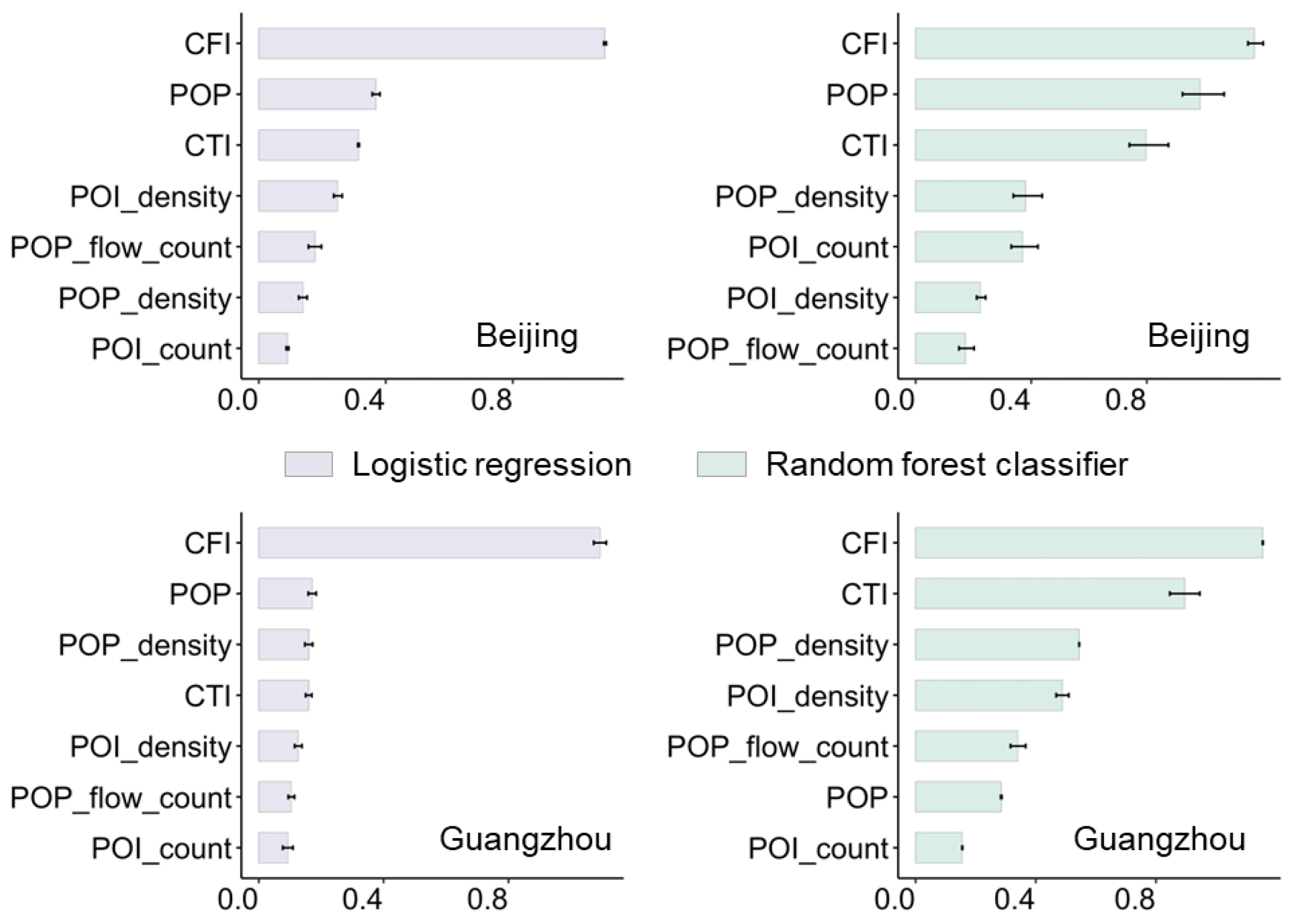
2.1. Mobility-Informed Risk Indices
2.2. Models for Predicting High-Risk Subdistricts in Chinese Cities
2.2.1. Data on COVID-19 Outbreaks
2.2.2. Sample Data Simulated by SEIR Model
2.2.3. Logistic Regression and Random Forest Classifier
2.3. Models for Estimating COVID-19 Cases in the United States
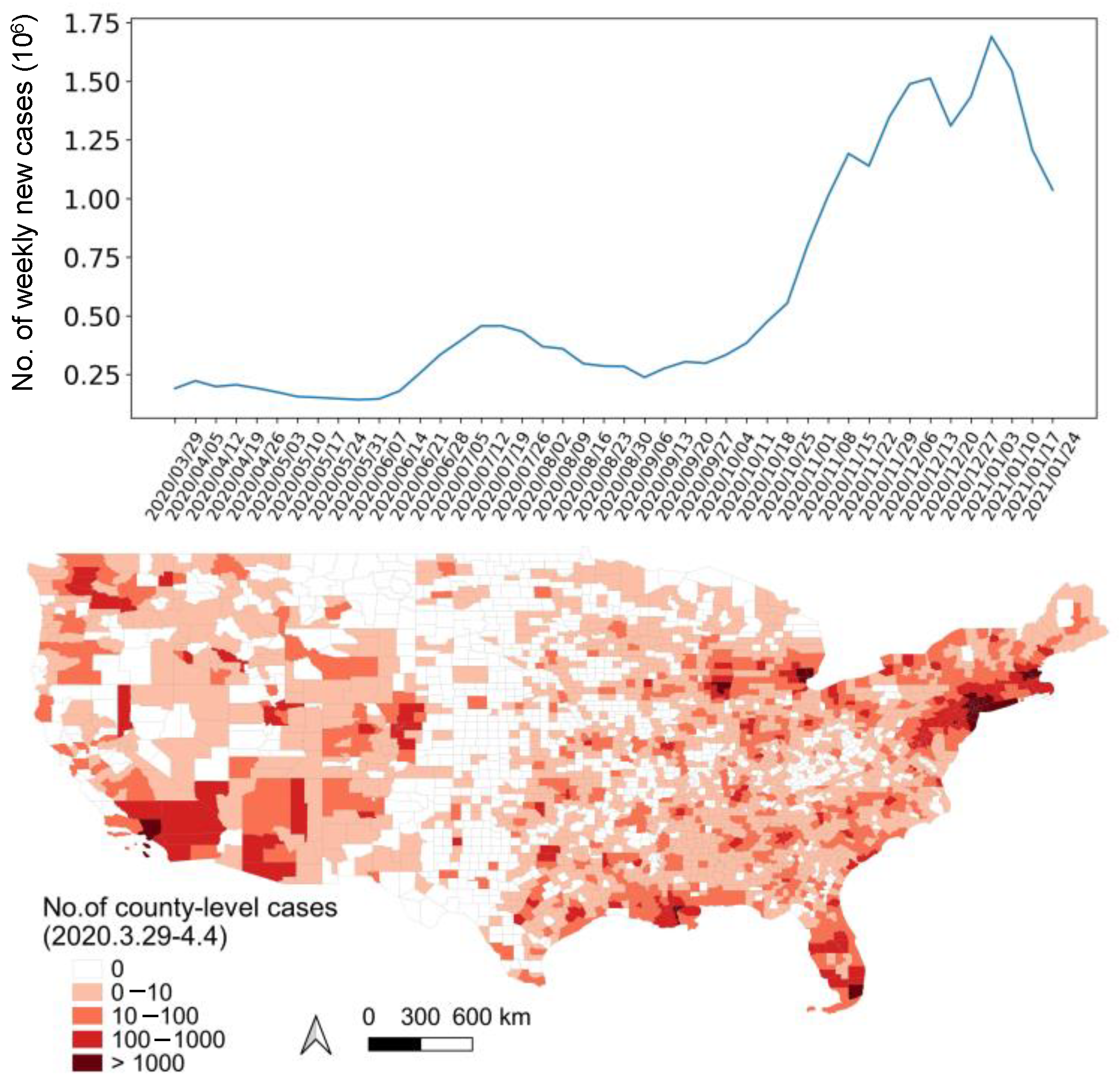
2.3.1. Data on COVID-19 Prevalence
2.3.2. Target and Predictive Variables
2.3.3. Elastic Net and Random Forest Regression
3. Results
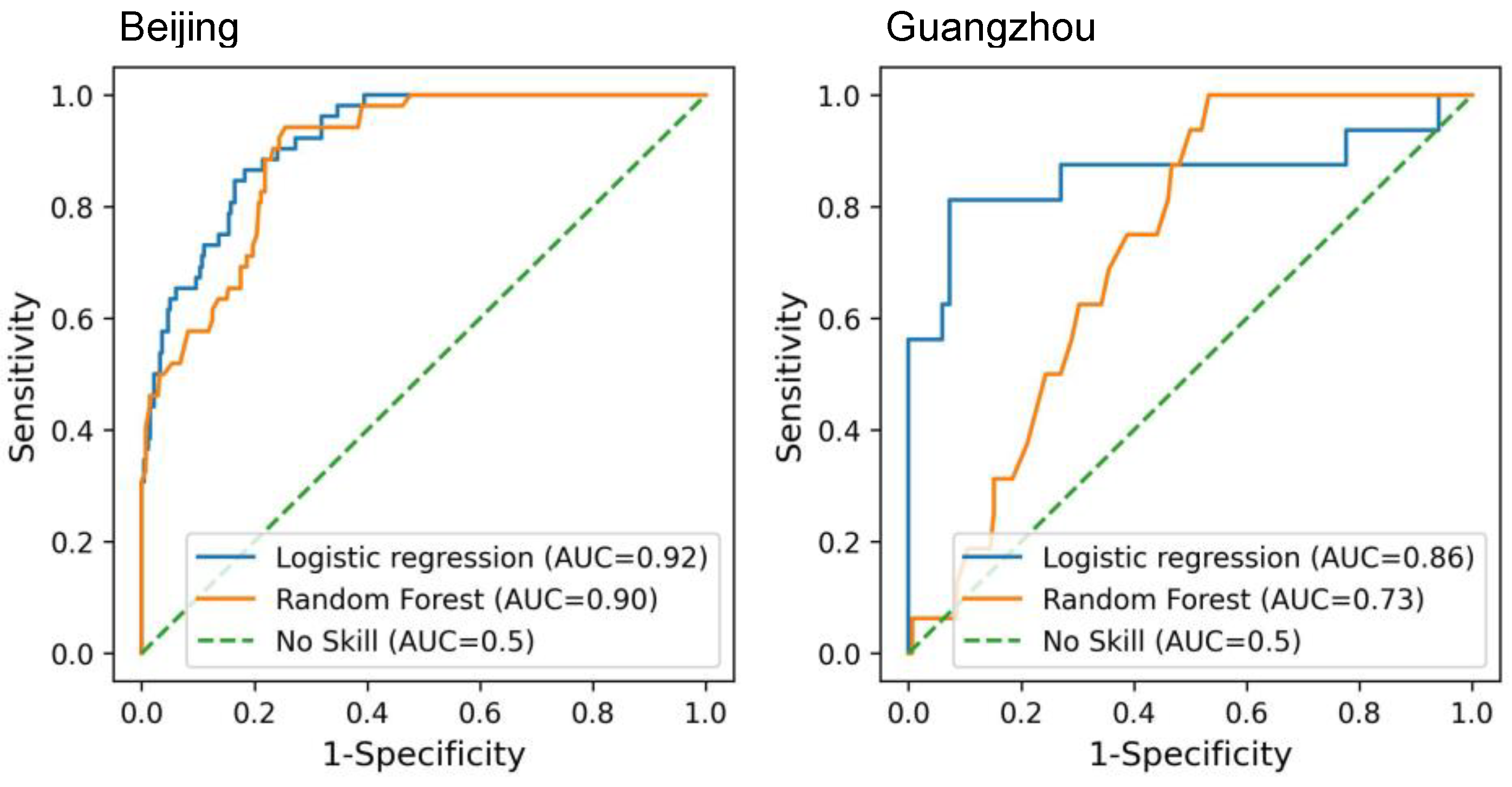
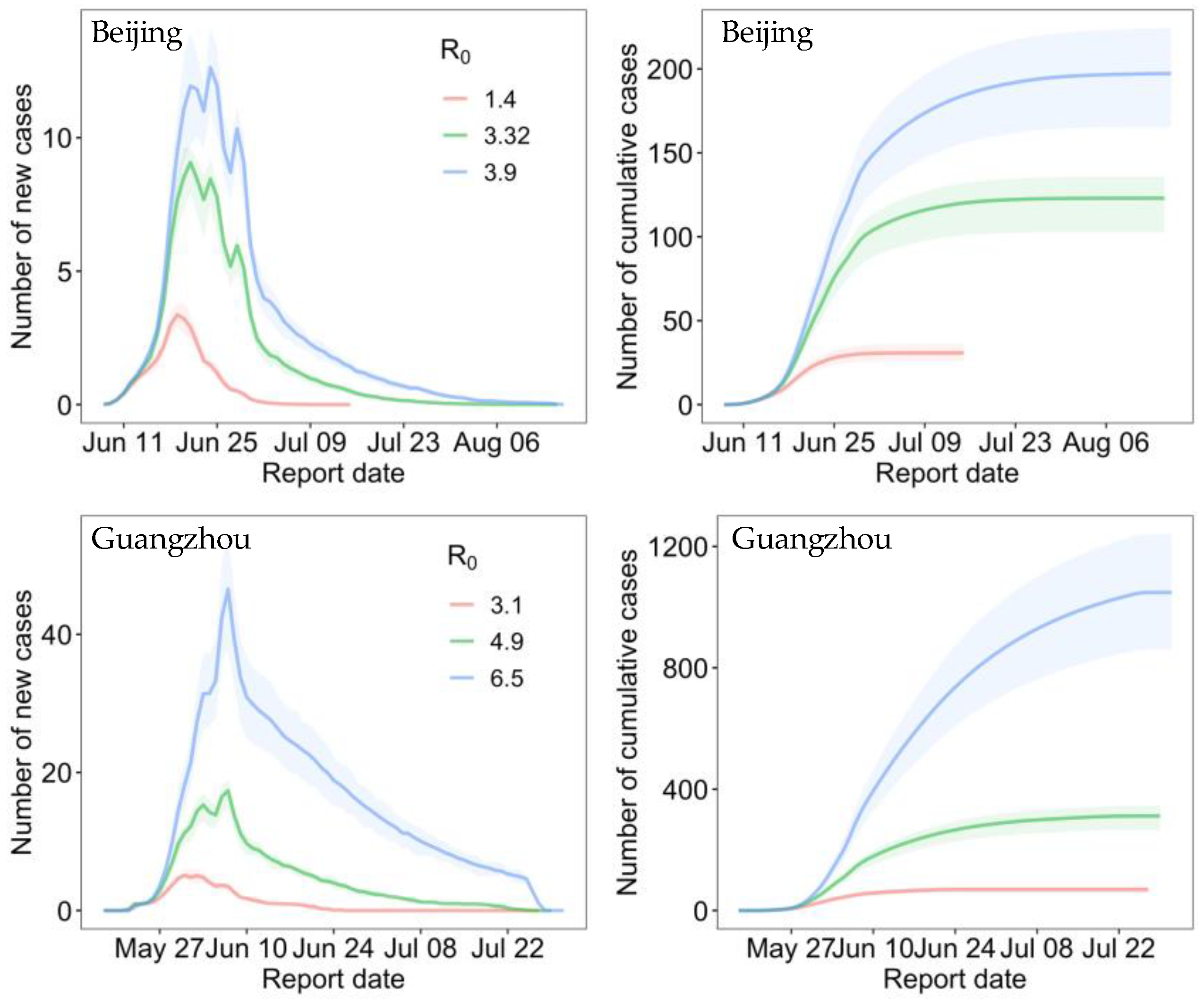
3.1. Risk Deification at the Initial Outbreak Stage
3.2. Forecasts of Weekly Increased Cases
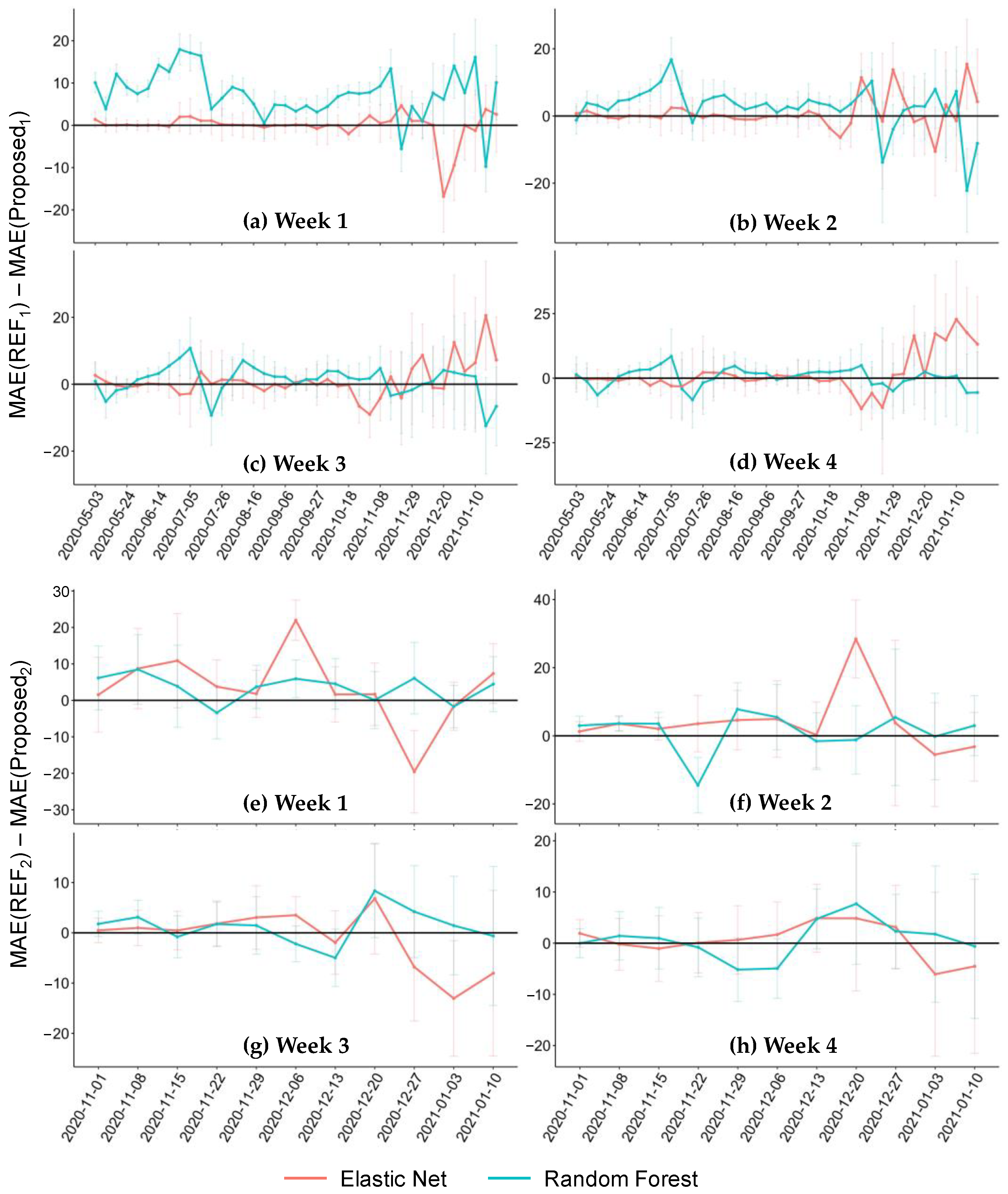
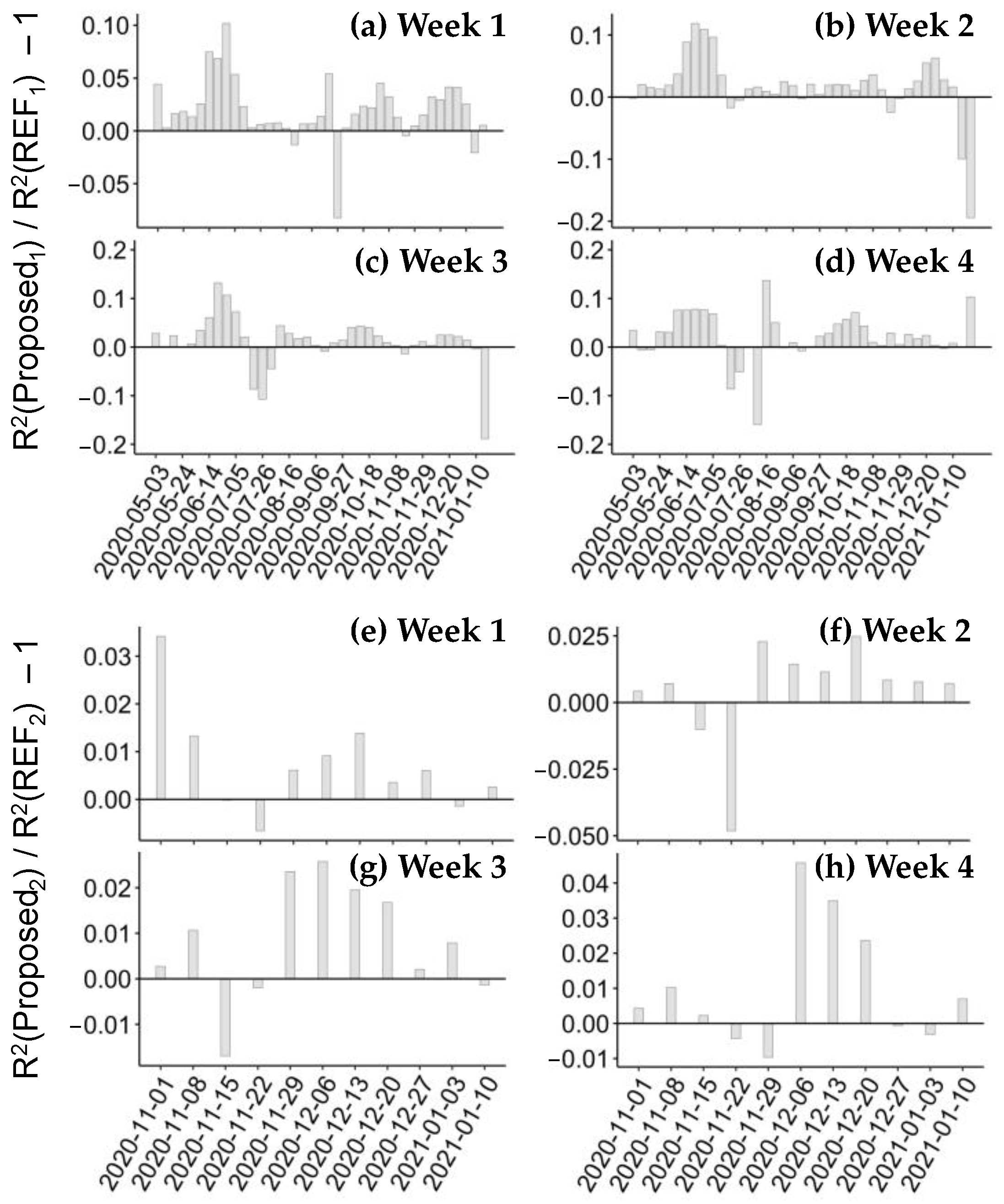
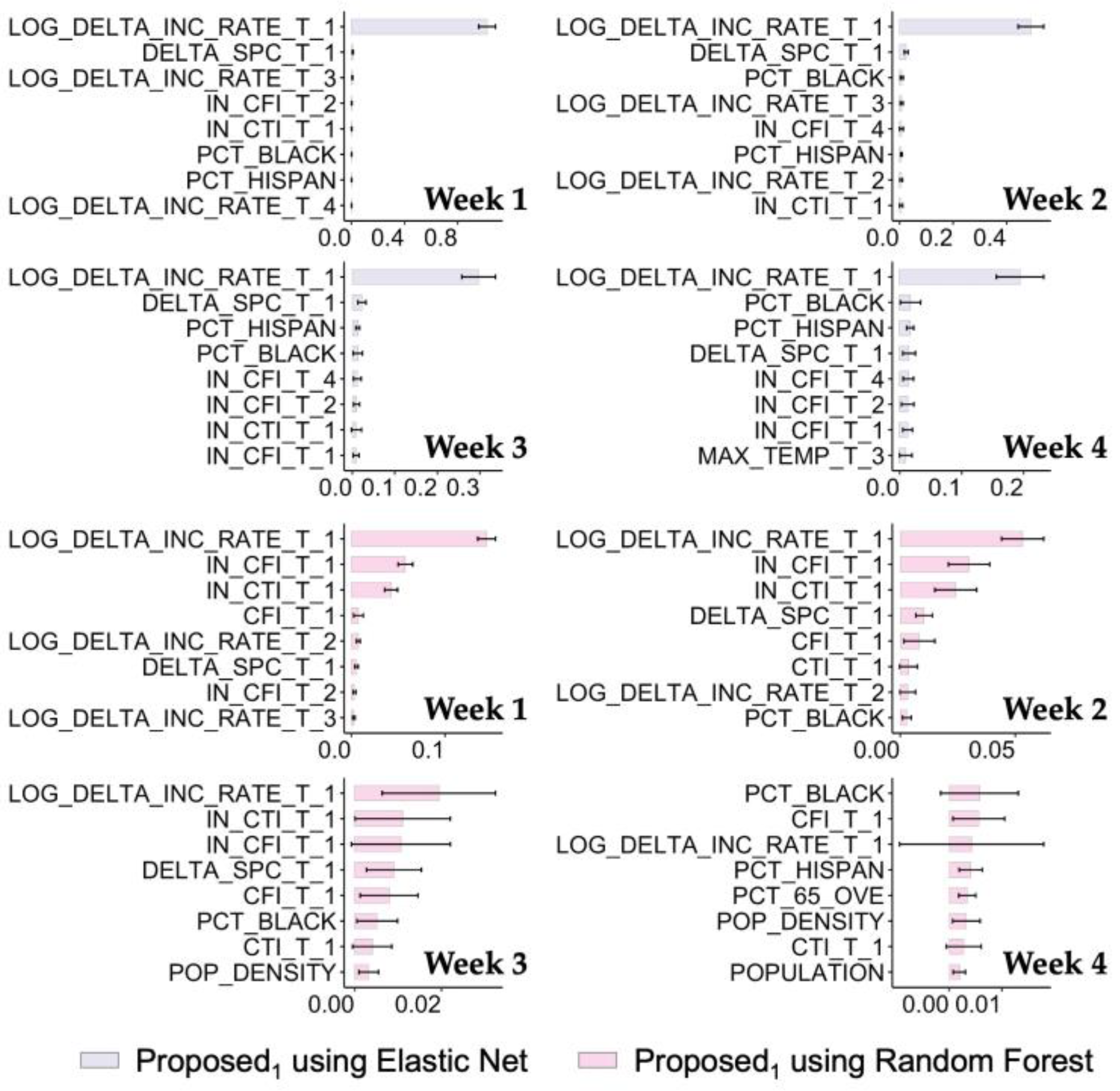
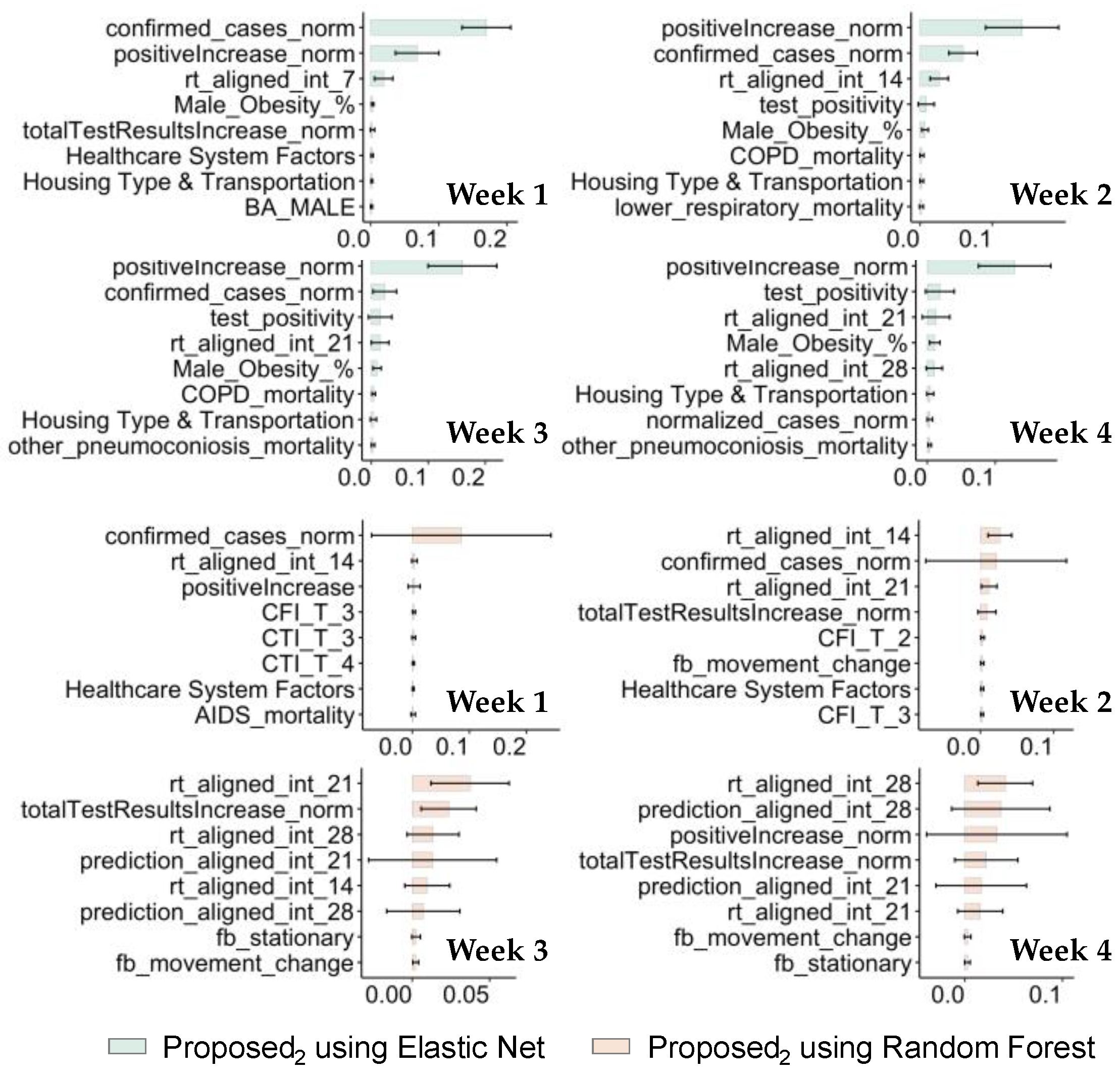
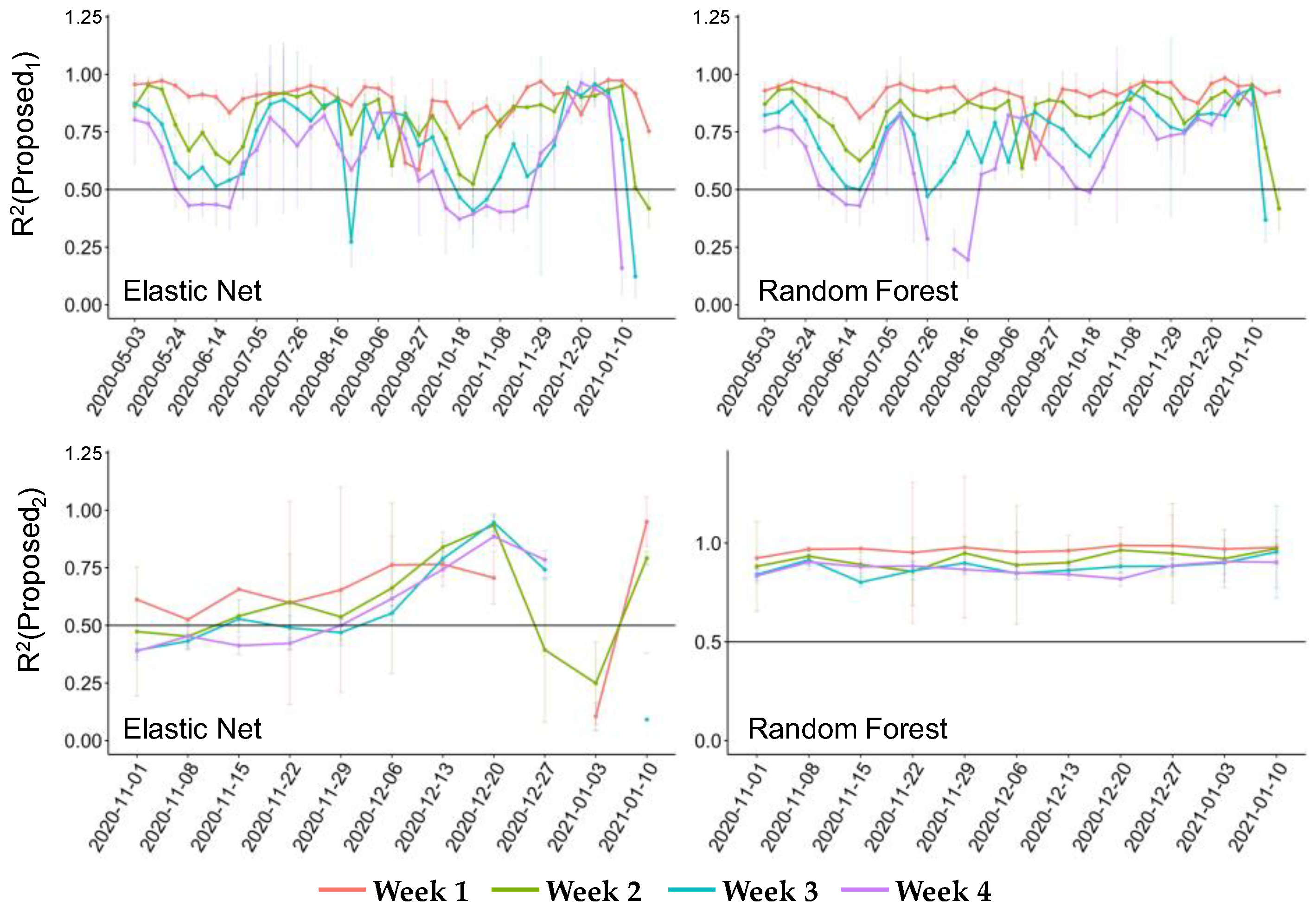
3.2.1. Forecasting Performance
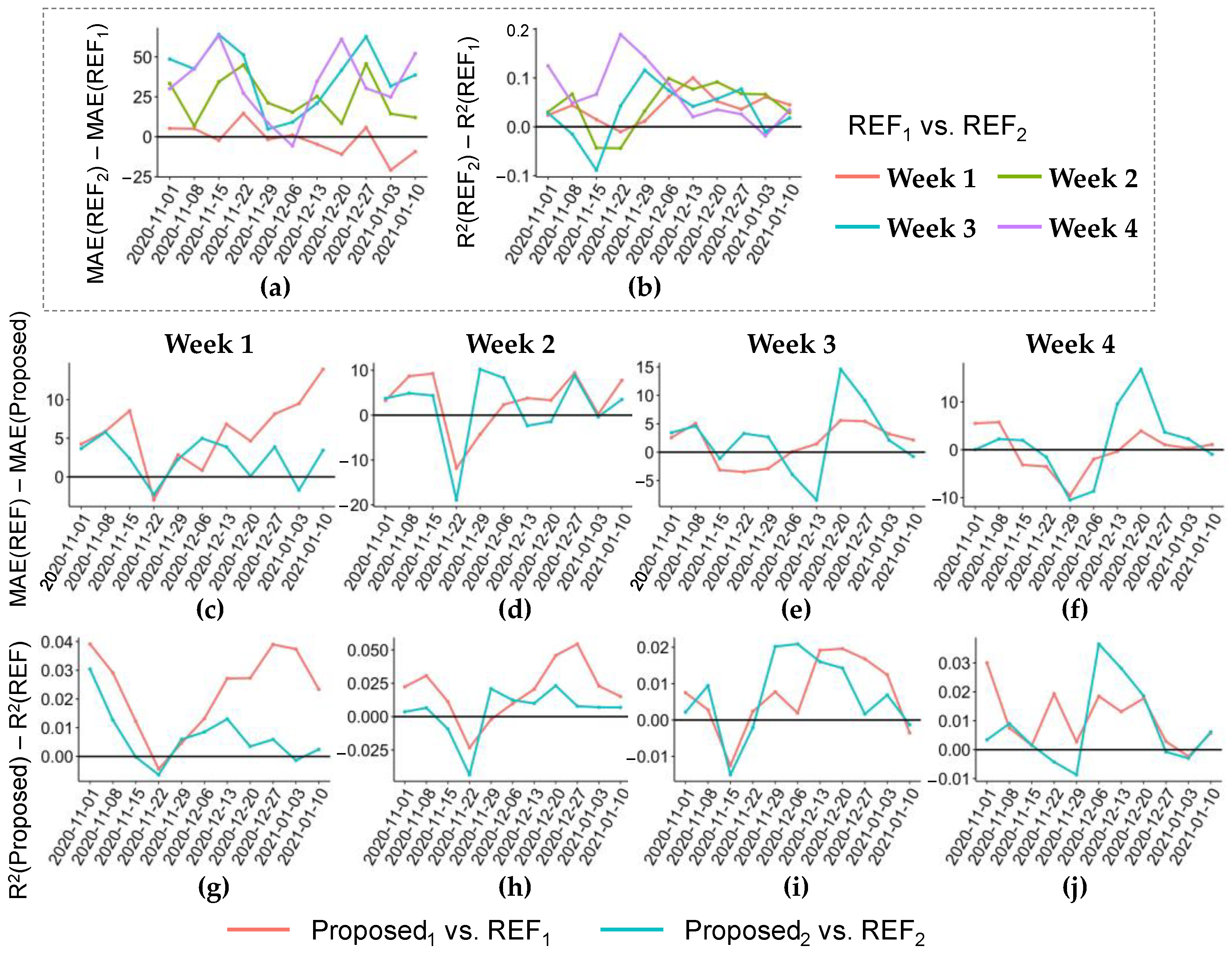
3.2.2. Applicability Analysis
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Extended Figures and Tables




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subdistrict Name | Number of Cases | Subdistrict Name | Number of Cases |
|---|---|---|---|
| Guangzhou (21 May–18 June 2021) | |||
| Baihedong Subdistrict | 91 | Longjin Subdistrict | 2 |
| Zhongnan Subdistrict | 29 | Taihe Town | 1 |
| Zhujiang Subdistrict | 10 | Changgang Subdistrict | 1 |
| Ruibao Subdistrict | 4 | Haichuang Subdistrict | 1 |
| Dongjiao Subdistrict | 3 | Nanhuaxi Subdistrict | 1 |
| Dashi Subdistrict | 2 | Beijing Subdistrict | 1 |
| Luopu Subdistrict | 2 | Dongsha Subdistrict | 1 |
| Yongping Subdistrict | 2 | Chongkou Subdistrict | 1 |
| Beijing (11 June–5 July 2020) | |||
| Huaxiang Area | 192 | Changxindian town | 1 |
| Xihongmen Area | 25 | Changxindian Subdistrict | 1 |
| Xincun Subdistrict | 21 | Yuetan Subdistrict | 1 |
| Huangcun Area | 17 | Youanmen Subdistrict | 1 |
| Yongdinglu Subdistrict | 10 | Yongdingmenwai Subdistrict | 1 |
| Qingyuan Subdistrict | 9 | Yizhuang Area | 1 |
| Lugouqiao Area | 8 | Xingfeng Subdistrict | 1 |
| Majiabao Subdistrict | 7 | Xiaohongmen Area | 1 |
| Tiancunlu Subdistrict | 6 | Wanshoulu Subdistrict | 1 |
| Nanyuan Subdistrict | 6 | Tiantan Subdistrict | 1 |
| Changyang town | 4 | Taipingqiao Subdistrict | 1 |
| Qingyundian town | 4 | Sijiqing Area | 1 |
| Xiluoyuan Subdistrict | 3 | Shibalidian Area | 1 |
| Weishanzhuang town | 3 | Qinglongqiao Subdistrict | 1 |
| Nanyuan Area | 3 | Panggezhuang town | 1 |
| Lugouqiao Subdistrict | 3 | Lixian town | 1 |
| Dahongmen Subdistrict | 3 | Jiugong Area | 1 |
| Zhanlan Road Subdistrict | 2 | Jinrong Street Subdistrict | 1 |
| Yongding Area | 2 | Huilongguan Area | 1 |
| Tiangongyuan Subdistrict | 2 | Hepingli Subdistrict | 1 |
| Linxiao Road Subdistrict | 2 | Guang’anmenwai Subdistrict | 1 |
| Guanyinsi Subdistrict | 2 | Guang’anmennei Subdistrict | 1 |
| Fengtai Subdistrict | 2 | Beizangcun town | 1 |
| Beiyuan Subdistrict | 2 | Balizhuang Subdistrict | 1 |
| Beixinqiao Subdistrict | 2 | Babaoshan Subdistrict | 1 |
| Baizhifang Subdistrict | 2 | Anding town | 1 |
| Category | Variable | Abbreviation |
|---|---|---|
| Socioeconomic and demographic | Population density | POP_DENSITY |
| Pct. of African American population | PCT_BLACK | |
| Pct. of the male population | PCT_MALE | |
| Pct. of the population aged > 65 | PCT_65_OVE | |
| Pct. of Hispanic population | PCT_HISPAN | |
| Pct. of the rural population | PCT_RURAL | |
| Pct. of Native American population | PCT_AMIND | |
| Median household income | MED_HOS_IN | |
| Pct. of the population with a college degree | PCT_COL_DE | |
| Pct. of the population who voted republican | PCT_TRUMP_ | |
| Temperature | Average of daily minimum temperature in one week | MIN_TEMP_T |
| Average of daily maximum temperature in one week | MAX_TEMP_T | |
| COVID-19 incidence rate | Natural logarithm of cumulative incidence rate in one week | LOG_DELTA_INC_RATE |
| Features derived from Facebook | Intra-county movement features | RATIO_MOB_T, REL_MOB_T |
| Inter-county features | SPC_T | |
| Features derived from SafeGraph | Intra-county movement features | distance_traveled_from_home, median_home_dwell_time, pct_completely_home_device_count, pct_delivery_behavior_devices, pct_full_time_work_behavior_devices, pct_part_time_work_behavior_devices |
| Inter-county features | FPC_T |
| Category | Variable | Abbreviation |
|---|---|---|
| Population health | Infectious disease mortality rates (tuberculosis, AIDS, diarrheal disease, lower respiratory disease, meningitis, hepatitis) | AIDS_mortality, diarrheal_mortality, hepatitis_mortality, tubercolosis_mortality, meningitis_mortality, hepatitis_mortality |
| Respiratory disease mortality rates (interstitial lung disease, asthma, coal pneumoconiosis, asbestosis, silicosis, pneumoconiosis, COPD, chronic respiratory disease, other pneumoconiosis, other respiratory diseases) | COPD_mortality, asbestosis_mortality, asthma_mortality, chronic_respiratory_mortality, coal_pneumoconiosis_mortality, lower_respiratory_mortality, other_resp_mortality, interstitial_lung_mortality, other_pneumoconiosis_mortality, silicosis_mortality, pneumoconiosis_mortality | |
| Mortality risk (0–5, 5–25, 25–45, 45–65, and 65–85 age groups) | mortality_risk | |
| Life expectancy | life_expectancy | |
| Diabetes prevalence rates | Diabetes_Prevalence_Both_Sexes | |
| U.S. Census (2018 estimates) | Population density | POP_DENSITY |
| Population | TOT_POP | |
| African Americans | BA_MALE, BA_FEMALE | |
| Native Americans | NA_MALE, NA_FEMALE | |
| Multiracial Americans | TOM_MALE, TOM_FEMALE | |
| Hispanic Americans | H_MALE, H_FEMALE | |
| Individuals over 65 years of age | ELDERLY_POP | |
| Land area | Land Area | |
| Metric that assesses the vulnerability to COVID-19, taking into account socioeconomic, epidemiological, and healthcare system risk factors | Socioeconomic Status | Socioeconomic Status |
| Household Composition and Disability | Household Composition and Disability | |
| Minority Status and Language | Minority Status and Language | |
| Housing Type and Transportation | Housing Type and Transportation | |
| Epidemiological Factors | Epidemiological Factors | |
| Healthcare System Factors | Healthcare System Factors | |
| Features derived from Facebook | Daily mobility relative to average baseline | fb_movement_change |
| Proportion of users staying in same location | fb_stationary | |
| Epidemiological related Features | Weekly case increase | confirmed_cases, confirmed_cases_norm, normalized_cases_norm |
| Daily tests increase, test positivity | positiveIncrease, positiveIncrease_norm, test_positivity, totalTestResultsIncrease, totalTestResultsIncrease_norm | |
| Projection of case | prediction_aligned_int | |
| Projection of Rt | rt_aligned_int |
Appendix B. SEIR Model
| Parameter | Beijing | Guangzhou |
|---|---|---|
| Basic reproduction number | 3.32 (95% CI: 1.4–3.9) | 4.9 (3.1–6.5) |
| Incubation period | 5.2 days (4.1–7.0) | 5.8 days (5.1–6.5) |
| Days from illness onset to isolation | 5 | 4 |
| Infectious period | 7.5 (Initial) | 6 (Initial) |
| Shortened with the implementation of large-scale nucleic acid testing | ||
| Start date of the SEIR model simulation | 3 June 2020 | 18 May 2021 |
| Intervention intensity | Relative level of daily contact based on Baidu movement data | |
References
- Khan, M.; Adil, S.F.; Alkhathlan, H.Z.; Tahir, M.N.; Saif, S.; Khan, M.; Khan, S.T. COVID-19: A Global Challenge with Old History, Epidemiology and Progress So Far. Molecules 2021, 26, 39. [Google Scholar] [CrossRef] [PubMed]
- Islam, S.; Islam, T.; Islam, M.R. New Coronavirus Variants are Creating More Challenges to Global Healthcare System: A Brief Report on the Current Knowledge. Clin. Pathol. 2022, 15, 2632010X221075584. [Google Scholar] [CrossRef]
- Smith, K.F.; Guégan, J.-F. Changing Geographic Distributions of Human Pathogens. Annu. Rev. Ecol. Evol. Syst. 2010, 41, 231–250. [Google Scholar] [CrossRef] [Green Version]
- Daszak, P.; Cunningham, A.A.; Hyatt, A.D. Emerging Infectious Diseases of Wildlife—Threats to Biodiversity and Human Health. Science 2000, 287, 443–449. [Google Scholar] [CrossRef]
- Hasan, A.; Putri, E.R.M.; Susanto, H.; Nuraini, N. Data-driven modeling and forecasting of COVID-19 outbreak for public policy making. ISA Trans. 2022, 124, 135–143. [Google Scholar] [CrossRef]
- He, S.; Peng, Y.; Sun, K. SEIR modeling of the COVID-19 and its dynamics. Nonlinear Dyn. 2020, 101, 1667–1680. [Google Scholar] [CrossRef]
- Hethcote, H.W. The Mathematics of Infectious Diseases. SIAM Rev. 2000, 42, 599–653. [Google Scholar] [CrossRef] [Green Version]
- Getz, W.M.; Salter, R.; Mgbara, W. Adequacy of SEIR models when epidemics have spatial structure: Ebola in Sierra Leone. Philos. Trans. R. Soc. B Biol. Sci. 2019, 374, 20180282. [Google Scholar] [CrossRef] [Green Version]
- Sannigrahi, S.; Pilla, F.; Basu, B.; Basu, A.S.; Molter, A. Examining the association between socio-demographic composition and COVID-19 fatalities in the European region using spatial regression approach. Sustain. Cities Soc. 2020, 62, 102418. [Google Scholar] [CrossRef]
- Kumar, P.; Hama, S.; Omidvarborna, H.; Sharma, A.; Sahani, J.; Abhijith, K.V.; Debele, S.E.; Zavala-Reyes, J.C.; Barwise, Y.; Tiwari, A. Temporary reduction in fine particulate matter due to ‘anthropogenic emissions switch-off’ during COVID-19 lockdown in Indian cities. Sustain. Cities Soc. 2020, 62, 102382. [Google Scholar] [CrossRef]
- Qu, G.; Li, X.; Hu, L.; Jiang, G. An Imperative Need for Research on the Role of Environmental Factors in Transmission of Novel Coronavirus (COVID-19). Environ. Sci. Technol. 2020, 54, 3730–3732. [Google Scholar] [CrossRef] [PubMed]
- Xie, J.; Zhu, Y. Association between ambient temperature and COVID-19 infection in 122 cities from China. Sci. Total Environ. 2020, 724, 138201. [Google Scholar] [CrossRef] [PubMed]
- Mansour, S.; Al Kindi, A.; Al-Said, A.; Al-Said, A.; Atkinson, P. Sociodemographic determinants of COVID-19 incidence rates in Oman: Geospatial modelling using multiscale geographically weighted regression (MGWR). Sustain. Cities Soc. 2021, 65, 102627. [Google Scholar] [CrossRef]
- Mollalo, A.; Vahedi, B.; Rivera, K.M. GIS-based spatial modeling of COVID-19 incidence rate in the continental United States. Sci. Total Environ. 2020, 728, 138884. [Google Scholar] [CrossRef]
- Javad, N.; Parnia-Sadat, F.; Nahid, S.; Majid, T.; Payam, A.; Amir, A.-H. Evaluating Measles Incidence Rates Using Machine Learning and Time Series Methods in the Center of Iran, 1997–2020. Iran. J. Public Health 2022, 51, 904. [Google Scholar] [CrossRef]
- Hasan, M.K.; Jawad, M.T.; Dutta, A.; Awal, M.A.; Islam, M.A.; Masud, M.; Al-Amri, J.F. Associating Measles Vaccine Uptake Classification and its Underlying Factors Using an Ensemble of Machine Learning Models. IEEE Access 2021, 9, 119613–119628. [Google Scholar] [CrossRef]
- Kane, M.J.; Price, N.; Scotch, M.; Rabinowitz, P. Comparison of ARIMA and Random Forest time series models for prediction of avian influenza H5N1 outbreaks. BMC Bioinform. 2014, 15, 276. [Google Scholar] [CrossRef]
- Lucas, B.; Vahedi, B.; Karimzadeh, M. A spatiotemporal machine learning approach to forecasting COVID-19 incidence at the county level in the USA. Int. J. Data Sci. Anal. 2022, 15, 247–266. [Google Scholar] [CrossRef]
- Jin, W.; Dong, S.; Yu, C.; Luo, Q. A data-driven hybrid ensemble AI model for COVID-19 infection forecast using multiple neural networks and reinforced learning. Comput. Biol. Med. 2022, 146, 105560. [Google Scholar] [CrossRef]
- Maiti, A.; Zhang, Q.; Sannigrahi, S.; Pramanik, S.; Chakraborti, S.; Cerda, A.; Pilla, F. Exploring spatiotemporal effects of the driving factors on COVID-19 incidences in the contiguous United States. Sustain. Cities Soc. 2021, 68, 102784. [Google Scholar] [CrossRef]
- Zhou, Y.; Xu, R.; Hu, D.; Yue, Y.; Li, Q.; Xia, J. Effects of human mobility restrictions on the spread of COVID-19 in Shenzhen, China: A modelling study using mobile phone data. Lancet Digit. Health 2020, 2, e417–e424. [Google Scholar] [CrossRef]
- Xiong, C.; Hu, S.; Yang, M.; Luo, W.; Zhang, L. Mobile device data reveal the dynamics in a positive relationship between human mobility and COVID-19 infections. Proc. Natl. Acad. Sci. USA 2020, 117, 27087–27089. [Google Scholar] [CrossRef]
- Alessa, A.; Faezipour, M. A review of influenza detection and prediction through social networking sites. Theor. Biol. Med. Model. 2018, 15, 2. [Google Scholar] [CrossRef] [Green Version]
- Lu, F.S.; Hou, S.; Baltrusaitis, K.; Shah, M.; Leskovec, J.; Sosic, R.; Hawkins, J.; Brownstein, J.; Conidi, G.; Gunn, J.; et al. Accurate Influenza Monitoring and Forecasting Using Novel Internet Data Streams: A Case Study in the Boston Metropolis. JMIR Public Health Surveill 2018, 4, e4. [Google Scholar] [CrossRef] [Green Version]
- Ginsberg, J.; Mohebbi, M.H.; Patel, R.S.; Brammer, L.; Smolinski, M.S.; Brilliant, L. Detecting influenza epidemics using search engine query data. Nature 2009, 457, 1012–1014. [Google Scholar] [CrossRef] [PubMed]
- Chang, S.; Pierson, E.; Koh, P.W.; Gerardin, J.; Redbird, B.; Grusky, D.; Leskovec, J. Mobility network models of COVID-19 explain inequities and inform reopening. Nature 2021, 589, 82–87. [Google Scholar] [CrossRef] [PubMed]
- Vahedi, B.; Karimzadeh, M.; Zoraghein, H. Spatiotemporal prediction of COVID-19 cases using inter- and intra-county proxies of human interactions. Nat. Commun. 2021, 12, 6440. [Google Scholar] [CrossRef] [PubMed]
- Galasso, J.; Cao, D.M.; Hochberg, R. A random forest model for forecasting regional COVID-19 cases utilizing reproduction number estimates and demographic data. Chaos Solitons Fractals 2022, 156, 111779. [Google Scholar] [CrossRef]
- Kang, Y.; Gao, S.; Liang, Y.; Li, M.; Rao, J.; Kruse, J. Multiscale dynamic human mobility flow dataset in the U.S. during the COVID-19 epidemic. Sci. Data 2020, 7, 390. [Google Scholar] [CrossRef]
- Valdano, E.; Okano, J.T.; Colizza, V.; Mitonga, H.K.; Blower, S. Using mobile phone data to reveal risk flow networks underlying the HIV epidemic in Namibia. Nat. Commun. 2021, 12, 2837. [Google Scholar] [CrossRef]
- Psyllidis, A.; Gao, S.; Hu, Y.; Kim, E.-K.; McKenzie, G.; Purves, R.; Yuan, M.; Andris, C. Points of Interest (POI): A commentary on the state of the art, challenges, and prospects for the future. Comput. Urban Sci. 2022, 2, 20. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Wu, W.; Thakuriah, P.; Wang, J. The geography of human activity and land use: A big data approach. Cities 2020, 97, 102523. [Google Scholar] [CrossRef]
- Yue, Y.; Zhuang, Y.; Yeh, A.G.O.; Xie, J.-Y.; Ma, C.-L.; Li, Q.-Q. Measurements of POI-based mixed use and their relationships with neighbourhood vibrancy. Int. J. Geogr. Inf. Sci. 2016, 31, 658–675. [Google Scholar] [CrossRef] [Green Version]
- Xia, C.; Yeh, A.G.-O.; Zhang, A. Analyzing spatial relationships between urban land use intensity and urban vitality at street block level: A case study of five Chinese megacities. Landsc. Urban Plan. 2020, 193, 103669. [Google Scholar] [CrossRef]
- Cui, H.; Wu, L.; Hu, S.; Lu, R.; Wang, S. Recognition of Urban Functions and Mixed Use Based on Residents’ Movement and Topic Generation Model: The Case of Wuhan, China. Remote Sens. 2020, 12, 2889. [Google Scholar] [CrossRef]
- Lai, S.; Ruktanonchai, N.W.; Zhou, L.; Prosper, O.; Luo, W.; Floyd, J.R.; Wesolowski, A.; Santillana, M.; Zhang, C.; Du, X.; et al. Effect of non-pharmaceutical interventions to contain COVID-19 in China. Nature 2020, 585, 410–413. [Google Scholar] [CrossRef]
- Hawkins, D.M. The Problem of Overfitting. J. Chem. Inf. Comput. Sci. 2004, 44, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Marom, N.D.; Rokach, L.; Shmilovici, A. Using the confusion matrix for improving ensemble classifiers. In Proceedings of the 2010 IEEE 26th Convention of Electrical and Electronics Engineers in Israel, Eilat, Israel, 17–20 November 2010; pp. 000555–000559. [Google Scholar]
- Zeng, G. On the confusion matrix in credit scoring and its analytical properties. Commun. Stat.—Theory Methods 2020, 49, 2080–2093. [Google Scholar] [CrossRef]
- Moulaei, K.; Shanbehzadeh, M.; Mohammadi-Taghiabad, Z.; Kazemi-Arpanahi, H. Comparing machine learning algorithms for predicting COVID-19 mortality. BMC Med. Inform. Decis. Mak. 2022, 22, 2. [Google Scholar] [CrossRef]
- Jahangiri, M.; Jahangiri, M.; Najafgholipour, M. The sensitivity and specificity analyses of ambient temperature and population size on the transmission rate of the novel coronavirus (COVID-19) in different provinces of Iran. Sci. Total Environ. 2020, 728, 138872. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Li, D.; Gaynor, S.M.; Quick, C.; Chen, J.T.; Stephenson, B.J.K.; Coull, B.A.; Lin, X. Identifying US County-level characteristics associated with high COVID-19 burden. BMC Public Health 2021, 21, 1007. [Google Scholar] [CrossRef] [PubMed]
- Andersen, L.M.; Harden, S.R.; Sugg, M.M.; Runkle, J.D.; Lundquist, T.E. Analyzing the spatial determinants of local Covid-19 transmission in the United States. Sci. Total Environ. 2021, 754, 142396. [Google Scholar] [CrossRef]
- Alex, R.A.; Bernadette, B.M.; Claire, B.; Lilian, B.; Daniel, K.; Robert, W. Timing of onset of symptom for COVID-19 from publicly reported confirmed cases in Uganda. Pan Afr. Med. J. 2021, 38, 168. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2005, 67, 301–320. [Google Scholar] [CrossRef] [Green Version]
- Franch-Pardo, I.; Desjardins, M.R.; Barea-Navarro, I.; Cerdà, A. A review of GIS methodologies to analyze the dynamics of COVID-19 in the second half of 2020. Trans. GIS 2021, 25, 2191–2239. [Google Scholar] [CrossRef] [PubMed]
- Franch-Pardo, I.; Napoletano, B.M.; Rosete-Verges, F.; Billa, L. Spatial analysis and GIS in the study of COVID-19. A review. Sci. Total Environ. 2020, 739, 140033. [Google Scholar] [CrossRef] [PubMed]
- Persson, J.; Parie, J.F.; Feuerriegel, S. Monitoring the COVID-19 epidemic with nationwide telecommunication data. Proc. Natl. Acad. Sci. USA 2021, 118, e2100664118. [Google Scholar] [CrossRef]
- Badr, H.S.; Du, H.; Marshall, M.; Dong, E.; Squire, M.M.; Gardner, L.M. Association between mobility patterns and COVID-19 transmission in the USA: A mathematical modelling study. Lancet Infect. Dis. 2020, 20, 1247–1254. [Google Scholar] [CrossRef]
- Luo, T.; Wang, J.; Wang, Q.; Wang, X.; Zhao, P.; Zeng, D.D.; Zhang, Q.; Cao, Z. Reconstruction of the Transmission Chain of COVID-19 Outbreak in Beijing’s Xinfadi Market, China. Int. J. Infect. Dis. 2022, 116, 411–417. [Google Scholar] [CrossRef]
- Li, Q.; Guan, X.; Wu, P.; Wang, X.; Zhou, L.; Tong, Y.; Ren, R.; Leung, K.S.M.; Lau, E.H.Y.; Wong, J.Y.; et al. Early Transmission Dynamics in Wuhan, China, of Novel Coronavirus–Infected Pneumonia. N. Engl. J. Med. 2020, 382, 1199–1207. [Google Scholar] [CrossRef] [PubMed]
- Byrne, A.W.; McEvoy, D.; Collins, A.B.; Hunt, K.; Casey, M.; Barber, A.; Butler, F.; Griffin, J.; Lane, E.A.; McAloon, C.; et al. Inferred duration of infectious period of SARS-CoV-2: Rapid scoping review and analysis of available evidence for asymptomatic and symptomatic COVID-19 cases. BMJ Open 2020, 10, e039856. [Google Scholar] [CrossRef] [PubMed]
- Byambasuren, O.; Cardona, M.; Bell, K.; Clark, J.; McLaws, M.-L.; Glasziou, P. Estimating the extent of asymptomatic COVID-19 and its potential for community transmission: Systematic review and meta-analysis. Off. J. Assoc. Med. Microbiol. Infect. Dis. Can. 2020, 5, 223–234. [Google Scholar] [CrossRef]
- He, X.; Lau, E.H.Y.; Wu, P.; Deng, X.; Wang, J.; Hao, X.; Lau, Y.C.; Wong, J.Y.; Guan, Y.; Tan, X.; et al. Temporal dynamics in viral shedding and transmissibility of COVID-19. Nat. Med. 2020, 26, 672–675. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kang, M.; Xin, H.; Yuan, J.; Ali, S.T.; Liang, Z.; Zhang, J.; Hu, T.; Lau, E.H.; Zhang, Y.; Zhang, M.; et al. Transmission dynamics and epidemiological characteristics of SARS-CoV-2 Delta variant infections in Guangdong, China, May to June 2021. Eurosurveillance 2022, 27, 2100815. [Google Scholar] [CrossRef]









| City | R0 | Number of Affected Subdistricts |
|---|---|---|
| Beijing | 3.32 | 43 (95% CI: 37–49) |
| 1.4 | 14 (12–17) | |
| 3.9 | 52 (38–67) | |
| Guangzhou | 4.9 | 26 (22–29) |
| 3.1 | 4 (3–5) | |
| 6.5 | 93 (81–104) |
| Mobility-Informed Risk Index | Temporal Lag | Duration for Mobility Data | Duration for Case Data |
|---|---|---|---|
| CFI_T_1 | One-week | ||
| CFI_T_2 | Two-week | ||
| CFI_T_3 | Three-week | ||
| CFI_T_4 | Four-week |
| Experiment | Predictive Variables Used | Forecast Date | Model |
|---|---|---|---|
| REF1 | See Table A2 | 39 weekly intervals from 3 May 2020 to 24 January 2021 | Elastic net and random forest regression |
| Proposed1 | Variables in REF1 and mobility-informed risk indices | ||
| REF2 | See Table A3 | 11 weekly intervals from 1 November 2020 to 10 January 2021 | |
| Proposed2 | Variables in REF2 and mobility-informed risk indices |
| Model | Subdistrict | Actual COVID-19 Outbreak | ||||
|---|---|---|---|---|---|---|
| Beijing | Guangzhou | |||||
| Logistic regression | Reported | Affected | Unaffected | Affected | Unaffected | |
| Estimated | ||||||
| Affected | 45 | 53 | 14 | 58 | ||
| Unaffected | 7 | 226 | 2 | 94 | ||
| SE: 0.87 (0.83–0.90) SP: 0.81 (0.80–0.81) | SE: 0.87 (0.84–0.90) SP: 0.62 (0.61–0.62) | |||||
| Random forest classifier | Affected | Unaffected | Affected | Unaffected | ||
| Affected | 47 | 71 | 8 | 50 | ||
| Unaffected | 5 | 208 | 8 | 102 | ||
| SE: 0.90 (0.88–0.93) SP: 0.75 (0.74–0.75) | SE: 0.50 (0.47–0.53) SP: 0.67 (0.66–0.68) | |||||
| SEIR model | Affected | Unaffected | Affected | Unaffected | ||
| Affected | 28 | 13 | 13 | 12 | ||
| Unaffected | 24 | 266 | 3 | 140 | ||
| SE: 0.54 (0.50–0.56) SP: 0.95 (0.93–0.96) | SE: 0.81 (0.79–0.83) SP: 0.92 (0.90–0.94) | |||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, D.; Ge, Y.; Wu, X.; Liu, H.; Zhang, W.; Lai, S. Data-Driven Models Informed by Spatiotemporal Mobility Patterns for Understanding Infectious Disease Dynamics. ISPRS Int. J. Geo-Inf. 2023, 12, 266. https://doi.org/10.3390/ijgi12070266
Zhang D, Ge Y, Wu X, Liu H, Zhang W, Lai S. Data-Driven Models Informed by Spatiotemporal Mobility Patterns for Understanding Infectious Disease Dynamics. ISPRS International Journal of Geo-Information. 2023; 12(7):266. https://doi.org/10.3390/ijgi12070266
Chicago/Turabian StyleZhang, Die, Yong Ge, Xilin Wu, Haiyan Liu, Wenbin Zhang, and Shengjie Lai. 2023. "Data-Driven Models Informed by Spatiotemporal Mobility Patterns for Understanding Infectious Disease Dynamics" ISPRS International Journal of Geo-Information 12, no. 7: 266. https://doi.org/10.3390/ijgi12070266