


Mapping Cropland Extent in Pakistan Using Machine Learning Algorithms on Google Earth Engine Cloud Computing Framework


Abstract
:1. Introduction
Sentinel-2 Data Literature Study
2. Literature Review
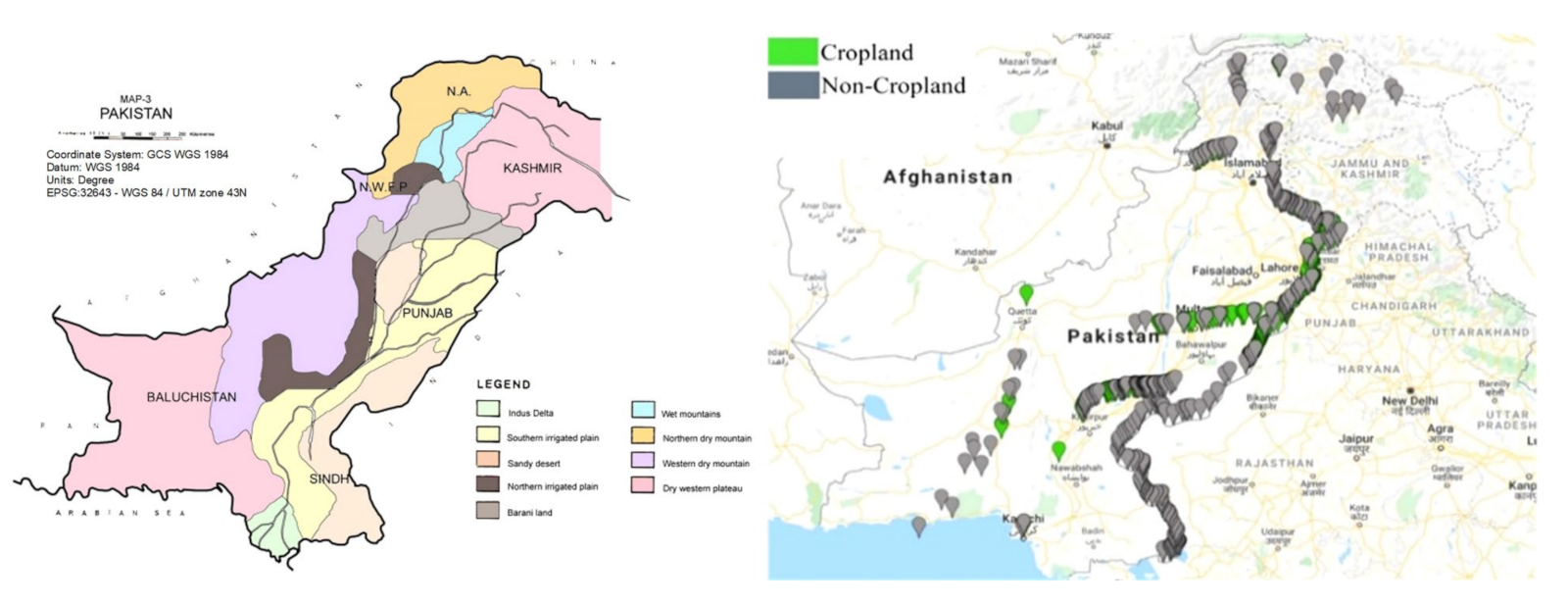
3. Study Area
4. Dataset
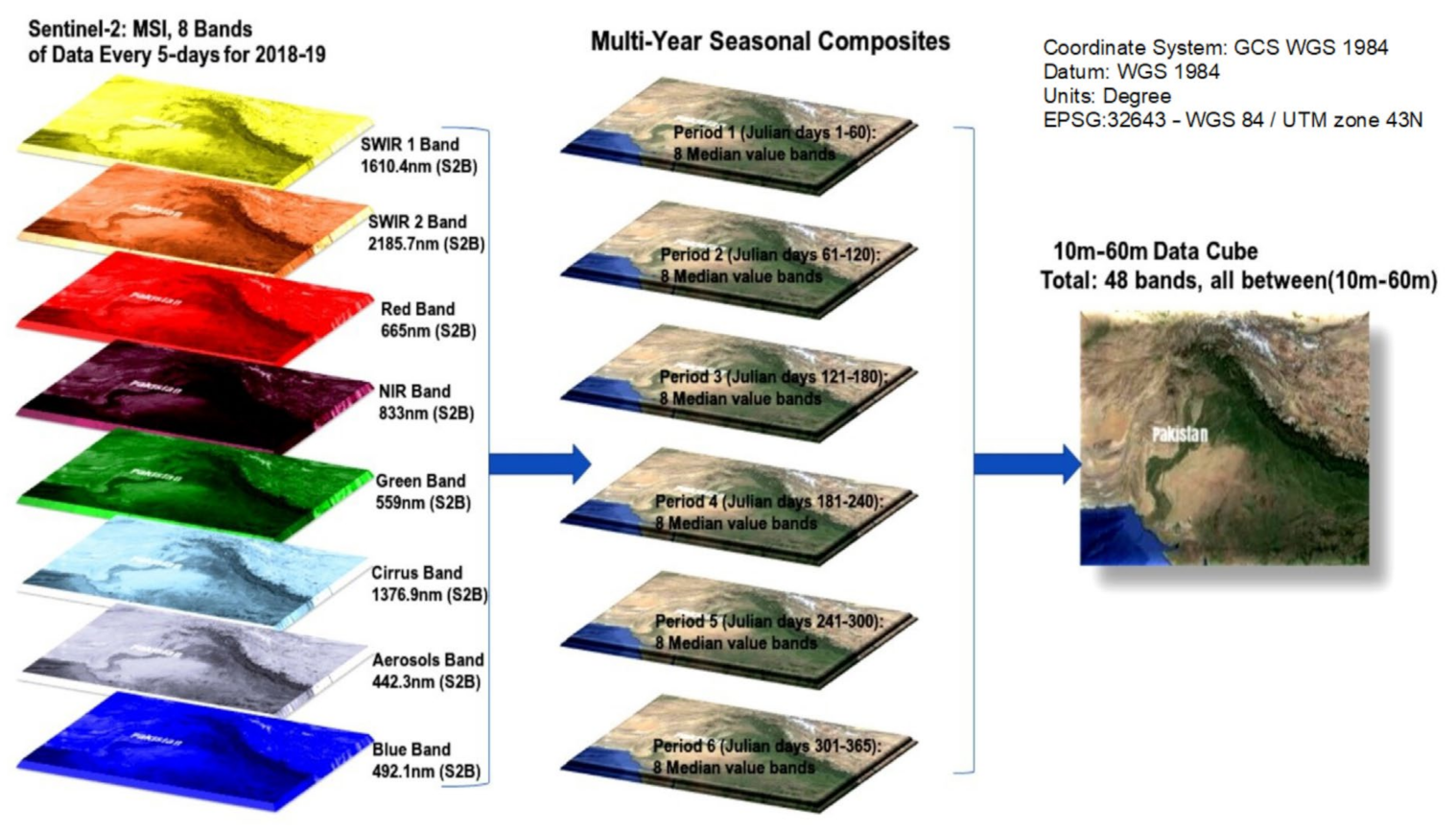
4.1. Sentinel-2 MSI Satellite Imagery Data
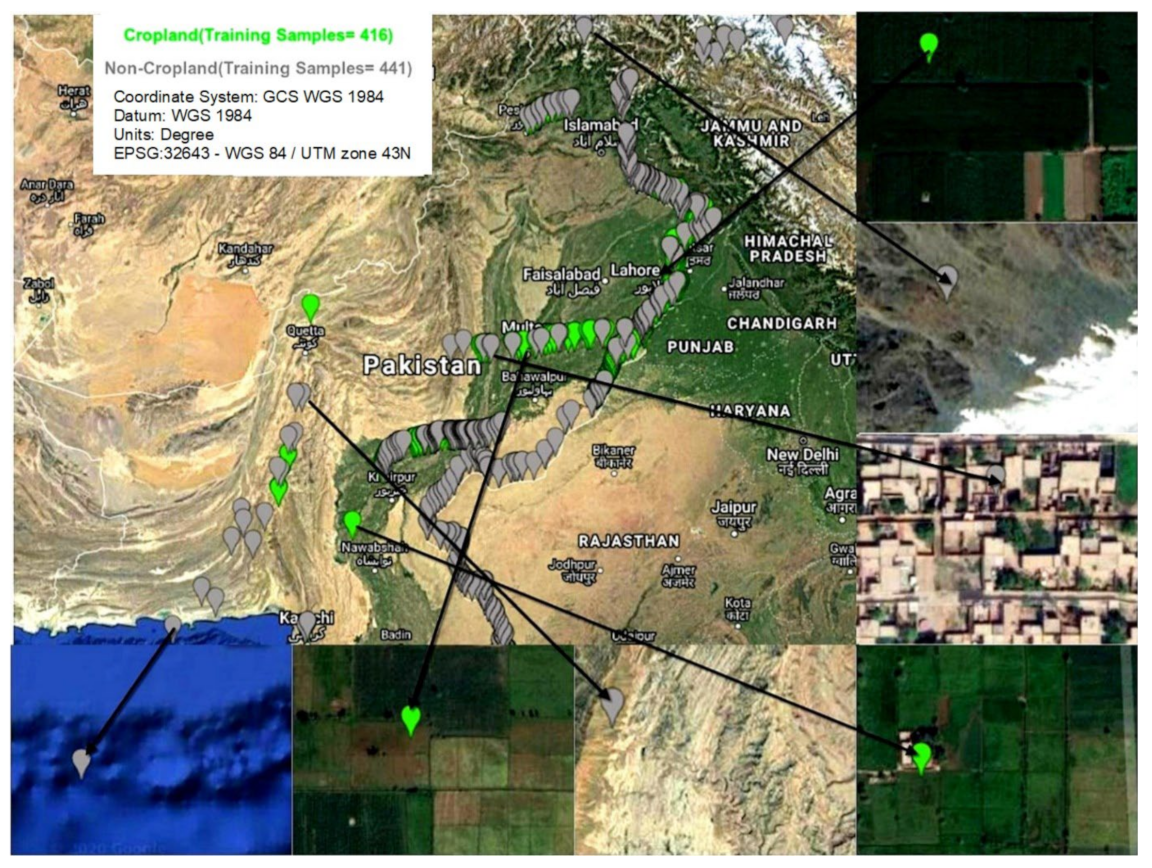
4.2. Training and Validation Sample Croplands
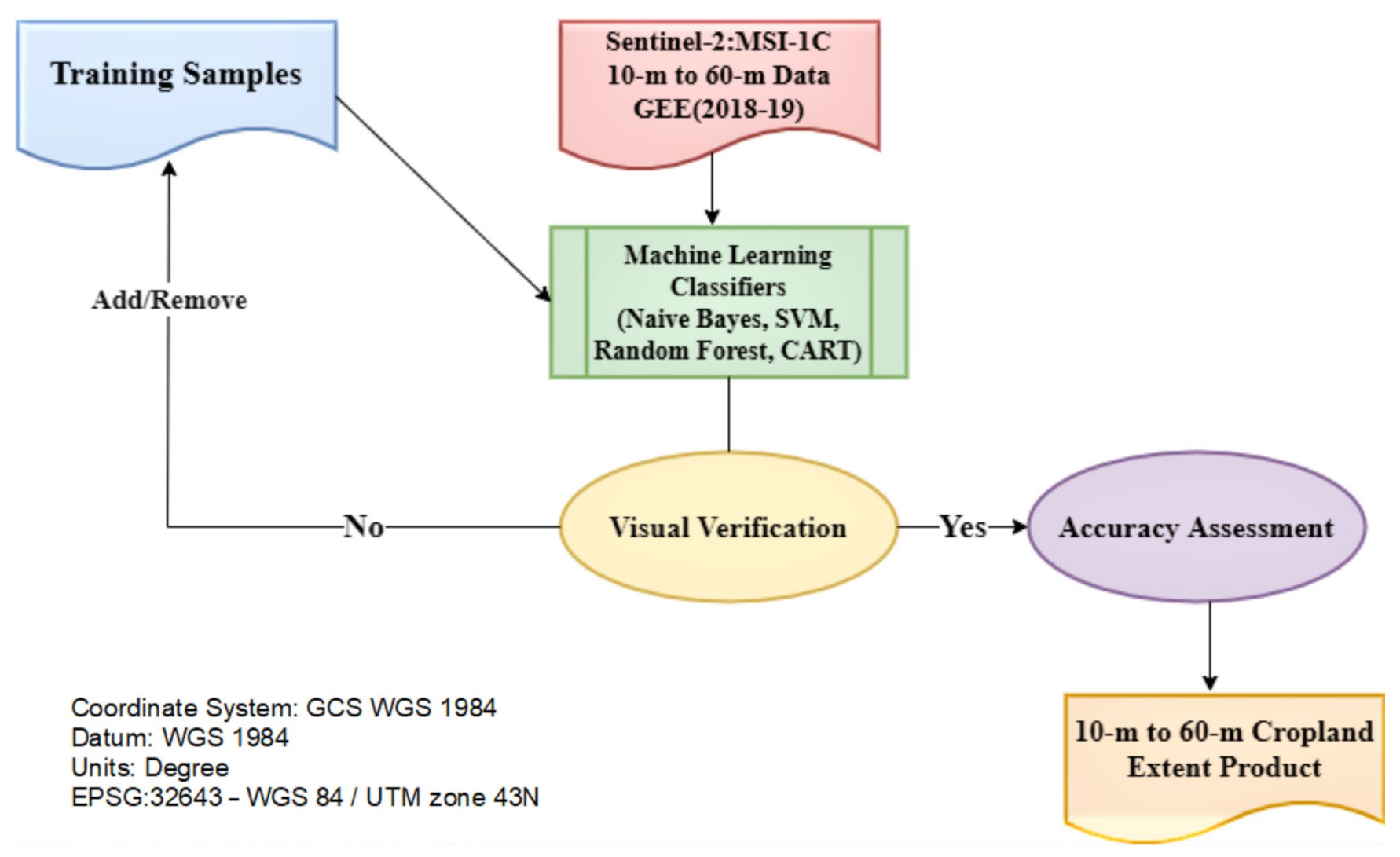
5. Methodology
5.1. Machine Learning Algorithms
- Produce a computer description of current examples in instruction.
- Classify MFDC from 10 m to 60 m based on the existing classification with the GEE cloud on Support Vector Machine, Random Forest, and Naïve Bayes algorithms, as shown in Figure 2.
- Visually examine the categorization tests using current reference maps and sub-meter to 10-m VHRI.
- Connect field samples to designated zones with comparison submeter to 10 m VHRI from Google Earth Imagery.
- Repeat measures 1–4 of the expanded training data collection to optimize classification and obtain high precision.
5.2. Google Earth Platforms Cloud Computing
Remote Sensing Analysis Accuracy on the GEE Platform
- It would help if it was possible to find solutions to the problem of data loss caused by weather conditions (such as clouds and shadows) that were easily accessible.
- Improve existing classifiers, especially the SVM, by incorporating neural network classifiers (through a library such as TensorFlow’s deep learning capabilities).
6. Results and Discussion
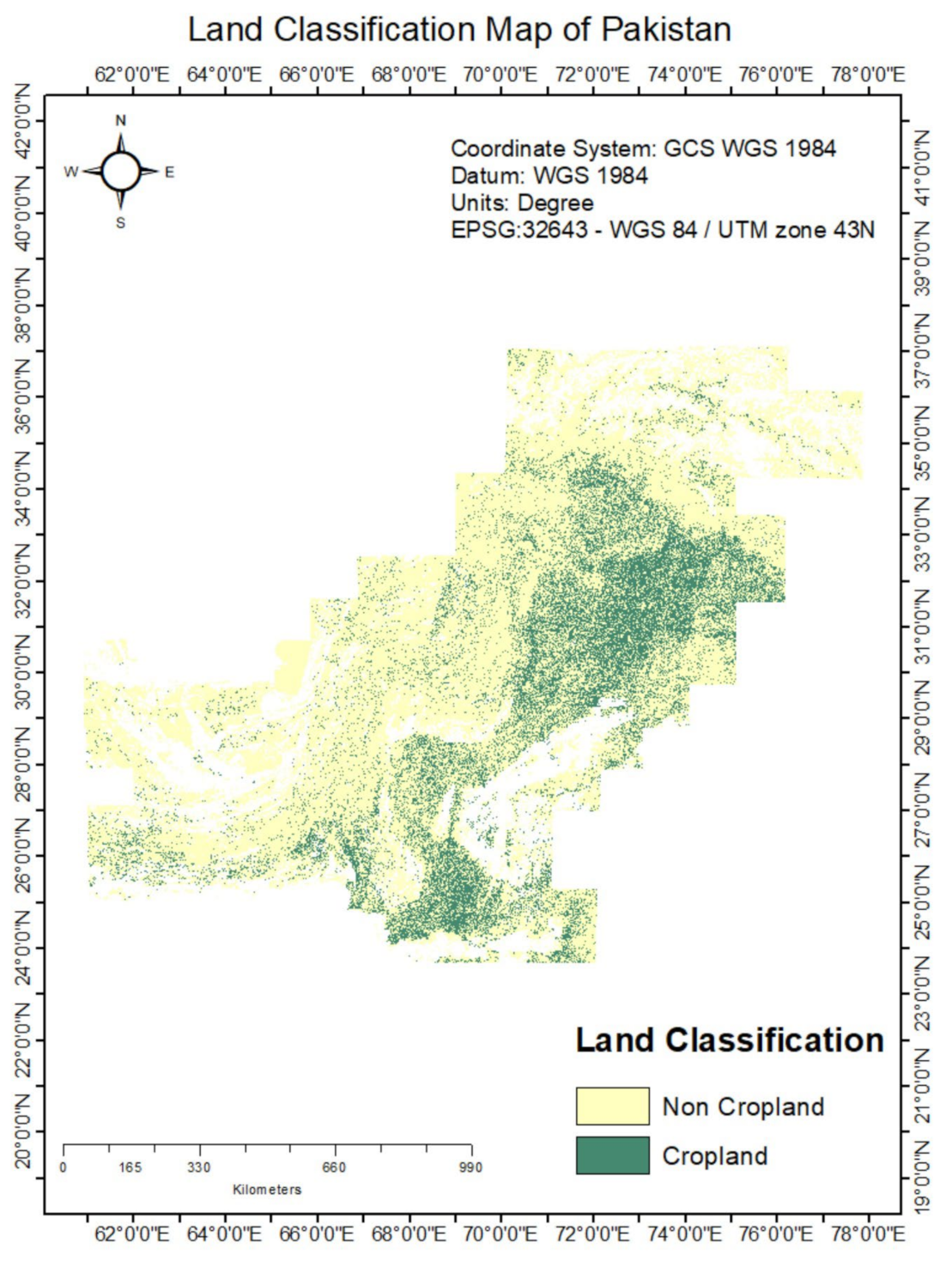
6.1. 10 m to 60 m Cropland Extent Product for Pakistan
6.2. Accuracy Assessment
6.3. The Analogy to Other Datasets and Agricultural Regions
6.4. Input Parameters for Cropland Extent Mapping
7. Conclusions
8. Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
References
- Estévez, J.; Salinero-Delgado, M.; Berger, K.; Pipia, L.; Rivera-Caicedo, J.P.; Wocher, M.; Reyes-Muñoz, P.; Tagliabue, G.; Boschetti, M.; Verrelst, J. Gaussian processes retrieval of crop traits in Google Earth Engine based on Sentinel-2 top-of-atmosphere data. Remote Sens. Environ. 2022, 273, 112958. [Google Scholar] [CrossRef]
- Suni, T.; Guenther, A.; Hansson, H.C.; Kulmala, M.; Andreae, M.O.; Arneth, A.; Artaxo, P.; Blyth, E.; Brus, M.; Ganzeveld, L.; et al. The significance of land-atmosphere interactions in the Earth system—iLEAPS achievements and perspectives. Anthropocene 2015, 12, 69–84. [Google Scholar] [CrossRef] [Green Version]
- Lutter, S.; Pfister, S.; Giljum, S.; Wieland, H.; Mutel, C. Spatially explicit assessment of water embodied in European trade: A product-level multi-regional input-output analysis. Glob. Environ. Chang. 2016, 38, 171–182. [Google Scholar] [CrossRef] [Green Version]
- van Zanten, H.H.; Mollenhorst, H.; Klootwijk, C.W.; van Middelaar, C.E.; de Boer, I.J. Global food supply: Land use efficiency of livestock systems. Int. J. Life Cycle Assess. 2016, 21, 747–758. [Google Scholar] [CrossRef] [Green Version]
- Pfister, S.; Vionnet, S.; Levova, T.; Humbert, S. Ecoinvent 3: Assessing water use in LCA and facilitating water footprinting. Int. J. Life Cycle Assess. 2016, 21, 1349–1360. [Google Scholar] [CrossRef]
- Davis, K.F.; Rulli, M.C.; Seveso, A.; D’Odorico, P. Increased food production and reduced water use through optimized crop distribution. Nat. Geosci. 2017, 10, 919–924. [Google Scholar] [CrossRef]
- Waldner, F.; Canto, G.S.; Defourny, P. Automated annual cropland mapping using knowledge-based temporal features. ISPRS J. Photogramm. Remote Sens. 2015, 110, 1–13. [Google Scholar] [CrossRef]
- Gumma, M.K.; Thenkabail, P.S.; Maunahan, A.; Islam, S.; Nelson, A. Mapping seasonal rice cropland extent and area in the high cropping intensity environment of Bangladesh using MODIS 500 m data for the year 2010. ISPRS J. Photogramm. Remote Sens. 2014, 91, 98–113. [Google Scholar] [CrossRef]
- Estel, S.; Kuemmerle, T.; Alcántara, C.; Levers, C.; Prishchepov, A.; Hostert, P. Mapping farmland abandonment and recultivation across Europe using MODIS NDVI time series. Remote Sens. Environ. 2015, 163, 312–325. [Google Scholar] [CrossRef]
- Shao, Y.; Lunetta, R.S.; Ediriwickrema, J.; Iiames, J. Mapping cropland and major crop types across the Great Lakes Basin using MODIS-NDVI data. Photogramm. Eng. Remote Sens. 2010, 76, 73–84. [Google Scholar] [CrossRef] [Green Version]
- Shao, Y.; Lunetta, R.S. Sub-pixel mapping of tree canopy, impervious surfaces, and cropland in the Laurentian Great Lakes Basin using MODIS time-series data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2010, 4, 336–347. [Google Scholar] [CrossRef]
- He, Y.; Lee, E.; Warner, T.A. A time series of annual land use and land cover maps of China from 1982 to 2013 generated using AVHRR GIMMS NDVI3g data. Remote Sens. Environ. 2017, 199, 201–217. [Google Scholar] [CrossRef]
- Pittman, K.; Hansen, M.C.; Becker-Reshef, I.; Potapov, P.V.; Justice, C.O. Estimating global cropland extent with multi-year MODIS data. Remote Sens. 2010, 2, 1844–1863. [Google Scholar] [CrossRef] [Green Version]
- Thenkabail, P. Global Food Security Support Analysis Data at Nominal 1 km (GFSAD1km) Derived from Remote Sensing in Support of Food Security in the Twenty-First Century: Current Achievements and Future Possibilities. In Land Resources Monitoring, Modeling, and Mapping with Remote Sensing; CRC Press: Boca Raton, FL, USA, 2018; pp. 865–894. [Google Scholar]
- Liang, D.; Zuo, Y.; Huang, L.; Zhao, J.; Teng, L.; Yang, F. Evaluation of the consistency of MODIS Land Cover Product (MCD12Q1) based on Chinese 30 m GlobeLand30 datasets: A case study in Anhui Province, China. ISPRS Int. J. Geo-Inf. 2015, 4, 2519–2541. [Google Scholar] [CrossRef] [Green Version]
- Ran, Y.; Li, X. First comprehensive fine-resolution global land cover map in the world from China—Comments on global land cover map at 30-m resolution. Sci. China Earth Sci. 2015, 58, 1677. [Google Scholar] [CrossRef]
- Arsanjani, J.J.; Tayyebi, A.; Vaz, E. GlobeLand30 as an alternative fine-scale global land cover map: Challenges, possibilities, and implications for developing countries. Habitat Int. 2016, 55, 25–31. [Google Scholar] [CrossRef]
- Yang, Y.; Xiao, P.; Feng, X.; Li, H. Accuracy assessment of seven global land cover datasets over China. ISPRS J. Photogramm. Remote Sens. 2017, 125, 156–173. [Google Scholar] [CrossRef]
- Chen, Z.; Zhao, S. Automatic monitoring of surface water dynamics using Sentinel-1 and Sentinel-2 data with Google Earth Engine. Int. J. Appl. Earth Obs. Geoinf. 2022, 113, 103010. [Google Scholar] [CrossRef]
- Belgiu, M.; Csillik, O. Sentinel-2 cropland mapping using pixel-based and object-based time-weighted dynamic time warping analysis. Remote Sens. Environ. 2018, 204, 509–523. [Google Scholar] [CrossRef]
- Gumma, M.K.; Thenkabail, P.S.; Deevi, K.C.; Mohammed, I.A.; Teluguntla, P.; Oliphant, A.; Xiong, J.; Aye, T.; Whitbread, A.M. Mapping cropland fallow areas in myanmar to scale up sustainable intensification of pulse crops in the farming system. GIScience Remote Sens. 2018, 55, 926–949. [Google Scholar] [CrossRef]
- Vogels, M.F.; de Jong, S.M.; Sterk, G.; Addink, E.A. Agricultural cropland mapping using black-and-white aerial photography, object-based image analysis and random forests. Int. J. Appl. Earth Obs. Geoinf. 2017, 54, 114–123. [Google Scholar] [CrossRef]
- Löw, F.; Prishchepov, A.V.; Waldner, F.; Dubovyk, O.; Akramkhanov, A.; Biradar, C.; Lamers, J.P. Mapping cropland abandonment in the Aral Sea Basin with MODIS time series. Remote Sens. 2018, 10, 159. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Zhu, W.; Cui, X. A shape-matching cropping index (CI) mapping method to determine agricultural cropland intensities in China using MODIS time-series data. Photogramm. Eng. Remote Sens. 2012, 78, 829–837. [Google Scholar] [CrossRef]
- Biradar, C.M.; Thenkabail, P.; Turral, H.; Noojipady, P.; Jie, L.Y.; Velpuri, M.; Dheeravath, V.; Venkateswarlu, V.; Vithanage, J.; Jagath, L.; et al. A global map of rainfed cropland areas (GMRCA) at the end of last millennium using remote sensing. Int. J. Appl. Earth Obs. Geoinf. 2009, 11, 114–129. [Google Scholar] [CrossRef]
- Nellis, M.D.; Price, K.P.; Rundquist, D. Remote sensing of cropland agriculture. In The SAGE Handbook of Remote Sensing; SAGE Publications, Inc.: New York, NY, USA, 2009; Volume 1, pp. 368–380. [Google Scholar]
- Sweeney, S.; Ruseva, T.; Estes, L.; Evans, T. Mapping cropland in smallholder-dominated savannas: Integrating remote sensing techniques and probabilistic modeling. Remote Sens. 2015, 7, 15295–15317. [Google Scholar] [CrossRef] [Green Version]
- Oliphant, A.J.; Thenkabail, P.S.; Teluguntla, P.; Xiong, J.; Gumma, M.K.; Congalton, R.G.; Yadav, K. Mapping cropland extent of Southeast and Northeast Asia using multi-year time-series Landsat 30-m data using a random forest classifier on the Google Earth Engine Cloud. Int. J. Appl. Earth Obs. Geoinf. 2019, 81, 110–124. [Google Scholar] [CrossRef]
- Alberto, R.; Serrano, S.C.; Damian, G.B.; Camaso, E.E.; Celestino, A.B.; Hernando, P.J.C.; Isip, M.F.; Orge, K.M.; Quinto, M.J.C.; Tagaca, R.C.; et al. Object Based Agricultural Land Cover Classification Map of Shadowed Areas from Aerial Image and Lidar Data Using Support Vector Machine. In Proceedings of the 2016 ISPRS Congress, Prague, Czech Republic, 12–19 July 2016; Volume 3. [Google Scholar]
- Sitthi, A.; Nagai, M.; Dailey, M.; Ninsawat, S. Exploring land use and land cover of geotagged social-sensing images using naive bayes classifier. Sustainability 2016, 8, 921. [Google Scholar] [CrossRef] [Green Version]
- Xiong, J.; Thenkabail, P.S.; Gumma, M.K.; Teluguntla, P.; Poehnelt, J.; Congalton, R.G.; Yadav, K.; Thau, D. Automated cropland mapping of continental Africa using Google Earth Engine cloud computing. ISPRS J. Photogramm. Remote Sens. 2017, 126, 225–244. [Google Scholar] [CrossRef] [Green Version]
- Friesz, A.M.; Wylie, B.K.; Howard, D.M. Temporal expansion of annual crop classification layers for the CONUS using the C5 decision tree classifier. Remote Sens. Lett. 2017, 8, 389–398. [Google Scholar] [CrossRef]
- Teluguntla, P.; Thenkabail, P.S.; Xiong, J.; Gumma, M.K.; Congalton, R.G.; Oliphant, A.; Poehnelt, J.; Yadav, K.; Rao, M.; Massey, R. Spectral matching techniques (SMTs) and automated cropland classification algorithms (ACCAs) for mapping croplands of Australia using MODIS 250-m time-series (2000–2015) data. Int. J. Digit. Earth 2017, 10, 944–977. [Google Scholar] [CrossRef] [Green Version]
- Teluguntla, P.; Thenkabail, P.S.; Xiong, J.; Gumma, M.K.; Congalton, R.G.; Oliphant, J.A.; Sankey, T.; Poehnelt, J.; Yadav, K.; Massey, R.; et al. NASA Making Earth System Data Records for Use in Research Environments (MEaSUREs) Global Food Security-support Analysis Data (GFSAD) Cropland Extent 2015 Australia, New Zealand, China, Mongolia 30 m V001. 2017. Available online: http://oar.icrisat.org/10980/ (accessed on 5 December 2022).
- Zhong, L.; Hu, L.; Yu, L.; Gong, P.; Biging, G.S. Automated mapping of soybean and corn using phenology. ISPRS J. Photogramm. Remote Sens. 2016, 119, 151–164. [Google Scholar] [CrossRef] [Green Version]
- Bellón, B.; Bégué, A.; Lo Seen, D.; De Almeida, C.A.; Simões, M. A remote sensing approach for regional-scale mapping of agricultural land-use systems based on NDVI time series. Remote Sens. 2017, 9, 600. [Google Scholar] [CrossRef] [Green Version]
- Xie, Y.; Lark, T.J.; Brown, J.F.; Gibbs, H.K. Mapping irrigated cropland extent across the conterminous United States at 30 m resolution using a semi-automatic training approach on Google Earth Engine. ISPRS J. Photogramm. Remote Sening. 2019, 155, 136–149. [Google Scholar] [CrossRef]
- Useya, J.; Chen, S.; Murefu, M. Cropland Mapping and Change Detection: Toward Zimbabwean Cropland Inventory. IEEE Access 2019, 7, 53603–53620. [Google Scholar] [CrossRef]
- Del Valle, T.M. Comparison of common classification strategies for large-scale vegetation mapping over the Google Earth Engine platform. Int. J. Appl. Earth Obs. Geoinf. 2022, 115, 103092. [Google Scholar] [CrossRef]
- Quang, N.H.; Nguyen, M.N.; Paget, M.; Anstee, J.; Viet, N.D.; Nones, M.; Tuan, V.A. Assessment of Human-Induced Effects on Sea/Brackish Water Chlorophyll-a Concentration in Ha Long Bay of Vietnam with Google Earth Engine. Remote Sens. 2022, 14, 4822. [Google Scholar] [CrossRef]
- Onačillová, K.; Gallay, M.; Paluba, D.; Péliová, A.; Tokarčík, O.; Laubertová, D. Combining Landsat 8 and Sentinel-2 Data in Google Earth Engine to Derive Higher Resolution Land Surface Temperature Maps in Urban Environment. Remote Sens. 2022, 14, 4076. [Google Scholar] [CrossRef]
- Erickson, T. Multi-Source Geospatial Data Analysis with Google Earth Engine; American Geophysical Union (AGU): Fall Meeting Abstracts, Washington, DC, USA, 2014. [Google Scholar]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Praticò, S.; Solano, F.; Di Fazio, S.; Modica, G. Machine learning classification of mediterranean forest habitats in google earth engine based on seasonal sentinel-2 time-series and input image composition optimisation. Remote Sens. 2021, 13, 586. [Google Scholar] [CrossRef]
- Seydi, S.T.; Akhoondzadeh, M.; Amani, M.; Mahdavi, S. Wildfire damage assessment over Australia using sentinel-2 imagery and MODIS land cover product within the google earth engine cloud platform. Remote Sens. 2021, 13, 220. [Google Scholar] [CrossRef]
- Sun, Y.; Qin, Q.; Ren, H.; Zhang, Y. Decameter Cropland LAI/FPAR Estimation from Sentinel-2 Imagery Using Google Earth Engine. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- Ahmad, D.; Chani, M.I.; Humayon, A.A. Major crops forecasting area, production and yield evidence from agriculture sector of Pakistan. Sarhad J. Agric. 2017, 33, 385–396. [Google Scholar] [CrossRef]
- Yan, L.; Roy, D.P.; Li, Z.; Zhang, H.K.; Huang, H. Sentinel-2A multi-temporal misregistration characterization and an orbit-based sub-pixel registration methodology. Remote Sens. Environ. 2018, 215, 495–506. [Google Scholar] [CrossRef]
- Li, J.; Roy, D.P. A global analysis of Sentinel-2A, Sentinel-2B and Landsat-8 data revisit intervals and implications for terrestrial monitoring. Remote Sens. 2017, 9, 902. [Google Scholar] [CrossRef] [Green Version]
- FAO. Pakistan: Review of the Wheat Sector and Grain Storage; Food and Agriculture Organization: Rome, Italy, 2013. [Google Scholar]
- Pakistan Bureau of Statistics. Agricultural Census 2010—Pakistan Report; Pakistan Bureau of Statistics: Islamabad, Pakistan, 2010. [Google Scholar]
- Basso, B.; Cammarano, D.; Carfagna, E. Review of crop yield forecasting methods and early warning systems. In Proceedings of the First Meeting of the Scientific Advisory Committee of the Global Strategy to Improve Agricultural and Rural Statistics, Rome, Italy, 18 July 2013. [Google Scholar]
- Boryan, C.; Yang, Z.; Mueller, R.; Craig, M. Monitoring US agriculture: The US department of agriculture, national agricultural statistics service, cropland data layer program. Geocarto Int. 2011, 26, 341–358. [Google Scholar] [CrossRef]
- Pelletier, C.; Webb, G.I.; Petitjean, F.J.R.S. Temporal convolutional neural network for the classification of satellite image time series. Remote Sens. 2019, 11, 523. [Google Scholar] [CrossRef] [Green Version]
- Pelletier, C.; Valero, S.; Inglada, J.; Champion, N.; Dedieu, G. Assessing the robustness of Random Forests to map land cover with high resolution satellite image time series over large areas. Remote Sens. Environ. 2016, 187, 156–168. [Google Scholar] [CrossRef]
- Xiong, J.; Thenkabail, P.S.; Tilton, J.C.; Gumma, M.K.; Teluguntla, P.; Oliphant, A.; Congalton, R.G.; Yadav, K.; Gorelick, N. Nominal 30-m cropland extent map of continental Africa by integrating pixel-based and object-based algorithms using Sentinel-2 and Landsat-8 data on Google Earth Engine. Remote Sens. 2017, 9, 1065. [Google Scholar] [CrossRef] [Green Version]
- Csillik, O.; Belgiu, M. Cropland mapping from Sentinel-2 time series data using object-based image analysis. In Proceedings of the 20th AGILE International Conference on Geographic Information Science Societal Geo-Innovation Celebrating, Wageningen, The Netherlands, 9 May 2017. [Google Scholar]
- Lebourgeois, V.; Dupuy, S.; Vintrou, É.; Ameline, M.; Butler, S.; Bégué, A. A combined random forest and OBIA classification scheme for mapping smallholder agriculture at different nomenclature levels using multisource data (simulated Sentinel-2 time series, VHRS and DEM). Remote Sens. 2017, 9, 259. [Google Scholar] [CrossRef] [Green Version]
- Castaldi, F.; Hueni, A.; Chabrillat, S.; Ward, K.; Buttafuoco, G.; Bomans, B.; Vreys, K.; Brell, M.; van Wesemael, B. Evaluating the capability of the Sentinel 2 data for soil organic carbon prediction in croplands. ISPRS J. Photogramm. Remote Sens. 2019, 147, 267–282. [Google Scholar] [CrossRef]
- Lambert, M.J.; Traoré, P.C.S.; Blaes, X.; Baret, P.; Defourny, P. Estimating smallholder crops production at village level from Sentinel-2 time series in Mali’s cotton belt. Remote Sens. Environ. 2018, 216, 647–657. [Google Scholar] [CrossRef]
- Kolecka, N.; Ginzler, C.; Pazur, R.; Price, B.; Verburg, P.H. Regional scale mapping of grassland mowing frequency with sentinel-2 time series. Remote Sens. 2018, 10, 1221. [Google Scholar] [CrossRef] [Green Version]
- Van Tricht, K.; Gobin, A.; Gilliams, S.; Piccard, I. Synergistic use of radar Sentinel-1 and optical Sentinel-2 imagery for crop mapping: A case study for Belgium. Remote Sens. 2018, 10, 1642. [Google Scholar] [CrossRef] [Green Version]
- Poortinga, A.; Tenneson, K.; Shapiro, A.; Nquyen, Q.; San Aung, K.; Chishtie, F.; Saah, D. Mapping plantations in Myanmar by fusing landsat-8, sentinel-2 and sentinel-1 data along with systematic error quantification. Remote Sens. 2019, 11, 831. [Google Scholar] [CrossRef] [Green Version]
- Kanjir, U.; Đurić, N.; Veljanovski, T. Sentinel-2 Based Temporal Detection of Agricultural Land Use Anomalies in Support of Common Agricultural Policy Monitoring. ISPRS Int. J. Geo-Inf. 2018, 7, 405. [Google Scholar] [CrossRef] [Green Version]
- Mahdianpari, M.; Salehi, B.; Mohammadimanesh, F.; Homayouni, S.; Gill, E. The first wetland inventory map of newfoundland at a spatial resolution of 10 m using sentinel-1 and sentinel-2 data on the google earth engine cloud computing platform. Remote Sens. 2019, 11, 43. [Google Scholar] [CrossRef] [Green Version]
- Shelestov, A.; Lavreniuk, M.; Kussul, N.; Novikov, A.; Skakun, S. Exploring Google earth engine platform for big data processing: Classification of multi-temporal satellite imagery for crop mapping. frontiers in Earth Science. Environ. Inform. Remote Sens. 2017, 5, 17. [Google Scholar] [CrossRef] [Green Version]
- Kang, B.; Nguyen, T.Q. Random forest with learned representations for semantic segmentation. IEEE Trans. Image Process. 2019, 28, 3542–3555. [Google Scholar] [CrossRef] [Green Version]
- Bihani, A.; Daigle, H.; Santos, J.E.; Landry, C.; Prodanović, M.; Milliken, K. MudrockNet: Semantic segmentation of mudrock SEM images through deep learning. Comput. Geosci. 2022, 158, 104952. [Google Scholar] [CrossRef]
- Ravì, D.; Bober, M.; Farinella, G.M.; Guarnera, M.; Battiato, S. Semantic segmentation of images exploiting DCT based features and random forest. Pattern Recognit. 2016, 52, 260–273. [Google Scholar] [CrossRef]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Shayeganpour, S.; Tangestani, M.H.; Gorsevski, P.V. Machine learning and multi-sensor data fusion for mapping lithology: A case study of Kowli-kosh area, SW Iran. Adv. Space Res. 2021, 68, 3992–4015. [Google Scholar] [CrossRef]
- Du, B.; Mao, D.; Wang, Z.; Qiu, Z.; Yan, H.; Feng, K.; Zhang, Z. Mapping wetland plant communities using unmanned aerial vehicle hyperspectral imagery by comparing object/pixel-based classifications combining multiple machine-learning algorithms. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 8249–8258. [Google Scholar] [CrossRef]
- Jiang, D.; Li, G.; Tan, C.; Huang, L.; Sun, Y.; Kong, J. Semantic segmentation for multiscale target based on object recognition using the improved Faster-RCNN model. Future Gener. Comput. Syst. 2021, 123, 94–104. [Google Scholar] [CrossRef]
- Liu, T.; Abd-Elrahman, A.; Morton, J.; Wilhelm, V.L. Comparing fully convolutional networks, random forest, support vector machine, and patch-based deep convolutional neural networks for object-based wetland mapping using images from small unmanned aircraft system. GIScience Remote Sens. 2018, 55, 243–264. [Google Scholar] [CrossRef]
- Chen, B.; Xia, M.; Huang, J. Mfanet: A multi-level feature aggregation network for semantic segmentation of land cover. Remote Sens. 2021, 13, 731. [Google Scholar] [CrossRef]
- Boulila, W. A top-down approach for semantic segmentation of big remote sensing images. Earth Sci. Inform. 2019, 12, 295–306. [Google Scholar] [CrossRef]
- Mallick, J.; Talukdar, S.; Pal, S.; Rahman, A. A novel classifier for improving wetland mapping by integrating image fusion techniques and ensemble machine learning classifiers. Ecol. Inform. 2021, 65, 101426. [Google Scholar] [CrossRef]
- Balado, J.; Martínez-Sánchez, J.; Arias, P.; Novo, A. Road environment semantic segmentation with deep learning from MLS point cloud data. Sensors 2019, 19, 3466. [Google Scholar] [CrossRef] [Green Version]
- Sun, Y.; Zhang, X.; Xin, Q.; Huang, J. Developing a multi-filter convolutional neural network for semantic segmentation using high-resolution aerial imagery and LiDAR data. ISPRS J. Photogramm. Remote Sens. 2018, 143, 3–14. [Google Scholar] [CrossRef]
- Singh, R.; Goel, A.; Raghuvanshi, D.K. Computer-aided diagnostic network for brain tumor classification employing modulated Gabor filter banks. Vis. Comput. 2021, 37, 2157–2171. [Google Scholar] [CrossRef]
- Vijayan, T.; Sangeetha, M.; Kumaravel, A.; Karthik, B. WITHDRAWN: Gabor filter and machine learning based diabetic retinopathy analysis and detection. In Microprocessors and Microsystems; Elsevier: Amsterdam, The Netherlands, 2020; in press. [Google Scholar]
- More, S.S.; Narain, B.; Jadhav, B. Role of modified gabor filter algorithm in multimodal biometric images. In Proceedings of the 2019 6th International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 13–15 March 2019. [Google Scholar]
- Gumma, M.K.; Thenkabail, P.S.; Teluguntla, P.G.; Oliphant, A.; Xiong, J.; Giri, C.; Pyla, V.; Dixit, S.; Whitbread, A.M. Agricultural cropland extent and areas of South Asia derived using Landsat satellite 30-m time-series big-data using random forest machine learning algorithms on the Google Earth Engine cloud. GIScience Remote Sens. 2020, 57, 302–322. [Google Scholar] [CrossRef] [Green Version]
- Gumma, M.K.; Thenkabail, P.S.; Teluguntla, P.; Rao, M.N.; Mohammed, I.A.; Whitbread, A.M. Mapping rice-fallow cropland areas for short-season grain legumes intensification in South Asia using MODIS 250 m time-series data. Int. J. Digit. Earth 2016, 9, 981–1003. [Google Scholar] [CrossRef] [Green Version]
- Gathala, M.K.; Timsina, J.; Islam, M.S.; Krupnik, T.J.; Bose, T.R.; Islam, N.; Rahman, M.M.; Hossain, M.I.; Harun-Ar-Rashid, M.; Ghosh, A.K.; et al. Productivity, profitability, and energetics: A multi-criteria assessment of farmers’ tillage and crop establishment options for maize in intensively cultivated environments of South Asia. Field Crops Res. 2016, 186, 32–46. [Google Scholar] [CrossRef]
- Maciel, D.A.; Barbosa, C.C.F.; de Moraes Novo, E.M.L.; Júnior, R.F.; Begliomini, F.N. Water clarity in Brazilian water assessed using Sentinel-2 and machine learning methods. ISPRS J. Photogramm. Remote Sens. 2021, 182, 134–152. [Google Scholar] [CrossRef]
- Khan, A.; Hansen, M.C.; Potapov, P.; Stehman, S.V.; Chatta, A.A. Landsat-based wheat mapping in the heterogeneous cropping system of Punjab, Pakistan. Int. J. Remote Sens. 2016, 37, 1391–1410. [Google Scholar] [CrossRef]
- Jayne, T.S.; Chamberlin, J.; Muyanga, M. Global Agro-Ecological Zones (GAEZ v3. 0)-Model Documentation; Technical Report; IIASA: Laxenburg, Austria; FAO: Rome, Italy, 2012. [Google Scholar]
- Sibanda, M.; Mutanga, O.; Rouget, M. Examining the potential of Sentinel-2 MSI spectral resolution in quantifying above ground biomass across different fertilizer treatments. ISPRS J. Photogramm. Remote Sens. 2015, 110, 55–65. [Google Scholar] [CrossRef]
- Sibanda, M.; Mutanga, O.; Rouget, M. Discriminating rangeland management practices using simulated hyspIRI, landsat 8 OLI, sentinel 2 MSI, and VENµs spectral data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 3957–3969. [Google Scholar] [CrossRef]
- Varma, M.K.S.; Rao, N.K.K.; Raju, K.K.; Varma, G.P.S. Pixel-based classification using support vector machine classifier. In Proceedings of the 2016 IEEE 6th International Conference on Advanced Computing (IACC), Bhimavaram, India, 27–28 February 2016. [Google Scholar]
- Li, L.; Solana, C.; Canters, F.; Kervyn, M. Testing random forest classification for identifying lava flows and mapping age groups on a single Landsat 8 image. J. Volcanol. Geotherm. Res. 2017, 345, 109–124. [Google Scholar] [CrossRef] [Green Version]
- Teluguntla, P.; Thenkabail, P.S.; Oliphant, A.; Xiong, J.; Gumma, M.K.; Congalton, R.G.; Yadav, K.; Huete, A. A 30-m landsat-derived cropland extent product of Australia and China using random forest machine learning algorithm on Google Earth Engine cloud computing platform. ISPRS J. Photogramm. Remote Sens. 2018, 144, 325–340. [Google Scholar] [CrossRef]
- Saranya, J.; Sathik, M.M.; Nisha, S.S. Agricultural Crop Classification Models In Data Mining Techniques. Int. Res. J. Eng. Technol. (IRJET) 2019, 6, 282–285. [Google Scholar]
- Shaharum, N.S.N.; Shafri, H.Z.M.; Ghani, W.A.W.A.K.; Samsatli, S.; Al-Habshi, M.M.A.; Yusuf, B. Oil palm mapping over Peninsular Malaysia using Google Earth Engine and machine learning algorithms. Remote Sens. Appl. Soc. Environ. 2020, 17, 100287. [Google Scholar] [CrossRef]
- Teluguntla, P.; Thenkabail, P.S.; Xiong, J.; Gumma, M.K.; Giri, C.; Milesi, C.; Ozdogan, M.; Congalton, R.; Tilton, J.; Sankey, T.T.; et al. Global Cropland Area Database (GCAD) derived from remote sensing in support of food security in the twenty-first century: Current achievements and future possibilities. In Land Resources: Monitoring, Modelling, and Mapping; Taylor & Francis: Oxford, UK, 2015. [Google Scholar]
- Tamiminia, H.; Salehi, B.; Mahdianpari, M.; Quackenbush, L.; Adeli, S.; Brisco, B. Google Earth Engine for geo-big data applications: A meta-analysis and systematic review. ISPRS J. Photogramm. Remote Sens. 2020, 164, 152–170. [Google Scholar] [CrossRef]
- Lebrini, Y.; Boudhar, A.; Laamrani, A.; Htitiou, A.; Lionboui, H.; Salhi, A.; Chehbouni, A.; Benabdelouahab, T. Mapping and characterization of phenological changes over various farming systems in an arid and semi-arid region using multitemporal moderate spatial resolution data. Remote Sens. 2021, 13, 578. [Google Scholar] [CrossRef]
- Murmu, S.; Biswas, S.J.A.P. Application of fuzzy logic and neural network in crop classification: A review. Aquat. Procedia 2015, 4, 1203–1210. [Google Scholar] [CrossRef]
- Li, Q.; Qiu, C.; Ma, L.; Schmitt, M.; Zhu, X.X. Mapping the land cover of Africa at 10 m resolution from multi-source remote sensing data with Google Earth Engine. Remote Sens. 2020, 12, 602. [Google Scholar] [CrossRef] [Green Version]
- Congalton, R.G.; Yadav, K.; McDonnell, K.; Poehnelt, J.; Stevens, B.; Gumma, M.K.; Teluguntla, P.; Thenkabail, P.S. Global Food Security-Support Analysis Data (GFSAD) Cropland Extent 2015 Validation 30 m V001; NASA EOSDIS Land Processes DAAC: Sioux Falls, SD, USA, 2017. [Google Scholar]
- Hansen, M.C.; Potapov, P.; Hancher, M.; Turubanova, S.; Tyukavina, A.; Thau, D.; Stehman, S.V.; Goetz, S.J.; Loveland, T.R.; Kommareddy, A.; et al. High-resolution global maps of 21st-century forest cover change. Science 2013, 342, 850–853. [Google Scholar] [CrossRef] [Green Version]
- Carroll, M.L.; Townshend, J.R.; DiMiceli, C.M.; Noojipady, P.; Sohlberg, R.A. A new global raster water mask at 250 m resolution. Int. J. Digit. Earth 2009, 2, 291–308. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Social Implications/Article Summary |
|---|---|
| (Belgiu&Csillik, 2018) [20] | This paper assesses how the Sentinel-2 approach for time-weighted dynamic time-setting (TWDTW) works in three fields of research (In Romania, Italy, and the US) for pixel- and object-based categorization of various crop varieties. The classification outputs for pixel-and object-based image processing systems are contrasted with Random Forest (RF). Both approaches have been tested for their response to the testing samples. |
| (Xiong, J., Thenkabail, P.S., Tilton, J.C., Gumma, M.K., Teluguntla, P., Oliphant, A., Congalton, R.G., Yadav, K. and Gorelick, N., Xiong, J., 2017) [56] | This work reveals that we use Sentinel-2 (10 m to 20 m) for 10 days, and Google Earth Engine Landsat-8 Data for a mapping approach to cropland in broad spatial resolution (30 m or better). |
| (Csillik&Belgiu, 2017) [57] | This article presents the findings of a study on cropland mapping using artifacts as spatial analysis units from the Sentinel-2 time series information. A multi-resolution segmentation algorithm was automatically divided into the Sentinel-2 data series, and the resulting image artifacts were categorized using the Time-Weighted Time Warping (TWDTW) technique. We used this method in the agricultural region of southeast Romania to chart wheat, corn, rice, sunflower, and trees. The applied cropland mapping system has obtained a cumulative precision of 93.43% and a kappa index of 92%. |
| (Lebourgeois, V., Dupuy, S., Vintrou, É., Ameline, M., Butler, S. and Bégué, A., 2017) [58] | To construct land utilization charts from a smallholder agricultural zone in Madagascar at five different nomenclature rates, we analyzed and enhanced the performance of a hybrid Random Forest classifier/object technique. Step one was to improve the RF classifier by increasing the number of input variables. |
| (Castaldi, F., Hueni, A., Chabrillat, S., Ward, K., Buttafuoco, G., Bomans, B., Vreys, K., Brell, M. and van Wesemael, 2019) [59] | This research aims to use signal-to-noise ratio (SNR) to evaluate the efficacy and importance of spectral and spatial resolution. The capabilities of multi-spectral S2 and hyperspectral airborne remote sensing data are compared in this study. |
| (Lambert, Traoré, Blaes, Baret, & Defourny, 2018) [60] | This paper establishes a method of analyzing crop performance at farm-to-community rates with Sentinel-2 high-resolution series and soil data in the Koningué municipality of Mali. The study is based on the supervised, pixel-dependent classification of crop forms in the current cultivable mask. |
| (Kolecka, Ginzler, Pazur, Price, & Verburg, 2018) [61] | This study examines whether a Sentinel-2 data time series can be used to examine mowing rates in the Swiss Canton of Aargau. Two Cloud Casting techniques and three SPM devices were evaluated for their capacity to detect and track grassland management tasks (pixels, pavement polygons & shrunken pail polygons). |
| (Van Tricht, Gobin, Gilliams, & Piccard, 2018) [62] | This crop map of Belgium was made using optical data from the Sentinel-1 and Sentinel-2 satellites. The excellent accuracy of 82% and a Kappa value of 0.77 were achieved while estimating eight crop forms using an automated random forest classifier. |
| (Poortinga, A., Tenneson, K., Shapiro, A., Nquyen, Q., San Aung, K., Chishtie, F. and Saah, D., 2019) [63] | This method combined the sensors’ data into a unified yearly composite. The south’s water, forests, urban and built-up water, croplands, rubber, palm oil, and mangrove were used as benchmarks against which to analyze and assess several factors. Through this training data, we were able to generate many levels of biophysical probability for each class. In decision-tree logic and Monte Carlo simulations, these fundamental building blocks were used for the base and probability charts. |
| (Kanjir, Đurić, & Veljanovski, 2018) [64] | In this study, we examined the applicability of the Breaks for Additive Season and Trend (BFAST) method for characterizing land-use anomalies in land-use research, and we provided an overview of a time-series approach utilizing Sentinel-2 images. This study examines the relationship between time-defined greenness and the improper use of permanent widows and agricultural fields throughout one growing season (vegetative vigor). |
| (Mahdianpari, Salehi, Mohammadimanesh, Homayouni, & Gill, 2019) [65] | The research provides one of the wealthiest wetland-sized provinces in Canada with a first comprehensive inventory chart of wetlands. Five wetland groups and three non-wetland groups were set up around the island of Newfoundland. Together, they cover about 106,000 km2. |
| (Shelestov, Lavreniuk, Kussul, Novikov, & Skakun, 2017) [66] | The research addresses the benefits and limitations of classification compared to the consistency obtained for various categories for the Ukrainian environment and uses a neural network method to equate it to the classifier. |
| Name of the Data Provider | The Mega-File Data Cube with Total # of Bands | The Time-Composite of Julian Days over Data | Data Years | The Series of Sentinel-2 | Name of the Data Provider | |
|---|---|---|---|---|---|---|
| Pakistan | European Union/ESA/ Copernicus | 48 | C1: 1–60 | 2018, 2019 | Multi-Spectral Instrument, Level-1C | European Union/ESA/ Copernicus |
| C2: 61–120 | ||||||
| C3: 121–180 | ||||||
| C4: 181–240 | ||||||
| C5: 241–300 | ||||||
| C6: 301–365 |
| Class | Training Samples | Validation Samples | |
|---|---|---|---|
| Pakistan | Cropland | 416 | 100 |
| Non-Cropland | 441 | 100 |
| CART Algorithm Accuracy on Training and Validation Datasets | |||||
|---|---|---|---|---|---|
| Cropland | Non-Cropland | Total | User Accuracy | Classification Accuracy: 93% Validation Accuracy: 82% | |
| Cropland | 73 | 27 | 100 | 73% | |
| Non-Cropland | 9 | 91 | 100 | 91% | |
| Total | 82 | 118 | 200 | ||
| Producer Accuracy | 89% | 77% | |||
| Random Forest Algorithm Accuracy on Training and Validation Datasets | |||||
| Cropland | Non-Cropland | Total | User Accuracy | Classification Accuracy: 91% Validation Accuracy: 75% | |
| Cropland | 71 | 29 | 100 | 71% | |
| Non-Cropland | 21 | 79 | 100 | 79% | |
| Total | 92 | 108 | 200 | ||
| Producer Accuracy | 77% | 73% | |||
| Naïve Bayes Algorithm Accuracy on Training and Validation Datasets | |||||
| Cropland | Non-Cropland | Total | User Accuracy | Classification Accuracy: 83% Validation Accuracy: 76% | |
| Cropland | 54 | 46 | 100 | 54% | |
| Non-Cropland | 13 | 87 | 100 | 87% | |
| Total | 67 | 133 | 200 | ||
| Producer Accuracy | 81% | 65% | |||
| Support Vector Machine Algorithm Accuracy on Training and Validation Datasets | |||||
| Cropland | Non-Cropland | Total | User Accuracy | Classification Accuracy: 83% Validation Accuracy: 74% | |
| Cropland | 68 | 32 | 100 | 68% | |
| Non-Cropland | 21 | 79 | 100 | 79% | |
| Total | 89 | 111 | 200 | ||
| Producer Accuracy | 76% | 71% | |||
| Country. | Agriculture Land in Sq. Km (The World Bank Data) | Govt. of Pakistan (Agriculture Census Organization-2010) in Sq. Km. | Net Cropland Area in Sq. Km. (Estimated in the Current Study) | Agriculture Land (Pakistan Bureau of Statistics) in Sq. Km. | % of the Total Agriculture Land Areas |
|---|---|---|---|---|---|
| Pakistan | 368,440 | 274,814 | 370,200 | 303,400 | 47.79% |
| Band Name | Sentinel 2-MSI Wavelength (nm) | Vegetation Index (VI) | Equation |
|---|---|---|---|
| Blue | 496.6 nm (S2A)/492.1 nm (S2B) | EVI | EVI = 2.5 (NIR-red)/(NIR + 6*red–7.5*blue + 1) |
| Green | 560 nm (S2A)/559 nm (S2B) | ||
| Red | 664.5 nm (S2A)/665 nm (S2B) | NDWI | NDWI = (NIR-SWIR1)/(NIR + SWIR1) |
| NIR | 835.1 nm (S2A)/833 nm (S2B) | ||
| SWIR1 | 1613.7 nm (S2A)/1610.4 nm (S2B) | ||
| SWIR2 | 2202.4 nm (S2A)/2185.7 nm (S2B) | NDVI | NDVI = (NIR-red)/(NIR + red) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Latif, R.M.A.; He, J.; Umer, M. Mapping Cropland Extent in Pakistan Using Machine Learning Algorithms on Google Earth Engine Cloud Computing Framework. ISPRS Int. J. Geo-Inf. 2023, 12, 81. https://doi.org/10.3390/ijgi12020081
Latif RMA, He J, Umer M. Mapping Cropland Extent in Pakistan Using Machine Learning Algorithms on Google Earth Engine Cloud Computing Framework. ISPRS International Journal of Geo-Information. 2023; 12(2):81. https://doi.org/10.3390/ijgi12020081
Chicago/Turabian StyleLatif, Rana Muhammad Amir, Jinliao He, and Muhammad Umer. 2023. "Mapping Cropland Extent in Pakistan Using Machine Learning Algorithms on Google Earth Engine Cloud Computing Framework" ISPRS International Journal of Geo-Information 12, no. 2: 81. https://doi.org/10.3390/ijgi12020081