
Numerical Investigation of a Class of Nonlinear Time-Dependent Delay PDEs Based on Gaussian Process Regression

School of Statistics and Mathematics, Zhongnan University of Economics and Law, Wuhan 430073, China
*
Author to whom correspondence should be addressed.
Fractal Fract. 2022, 6(10), 606; https://doi.org/10.3390/fractalfract6100606
Submission received: 27 August 2022
/
Revised: 7 October 2022
/
Accepted: 11 October 2022
/
Published: 17 October 2022
(This article belongs to the Special Issue Novel Numerical Solutions of Fractional PDEs)
Abstract
:Probabilistic machine learning and data-driven methods gradually show their high efficiency in solving the forward and inverse problems of partial differential equations (PDEs). This paper will focus on investigating the forward problem of solving time-dependent nonlinear delay PDEs with multi-delays based on multi-prior numerical Gaussian processes (MP-NGPs), which are constructed by us to solve complex PDEs that may involve fractional operators, multi-delays and different types of boundary conditions. We also quantify the uncertainty of the prediction solution by the posterior distribution of the predicted solution. The core of MP-NGPs is to discretize time firstly, then a Gaussian process regression based on multi-priors is considered at each time step to obtain the solution of the next time step, and this procedure is repeated until the last time step. Different types of boundary conditions are studied in this paper, which include Dirichlet, Neumann and mixed boundary conditions. Several numerical tests are provided to show that the methods considered in this paper work well in solving nonlinear time-dependent PDEs with delay, where delay partial differential equations, delay partial integro-differential equations and delay fractional partial differential equations are considered. Furthermore, in order to improve the accuracy of the algorithm, we construct Runge–Kutta methods under the frame of multi-prior numerical Gaussian processes. The results of the numerical experiments prove that the prediction accuracy of the algorithm is obviously improved when the Runge–Kutta methods are employed.
1. Introduction
In the last decade, more and more attention has been paid on the theoretical studies and practical applications concerned with probabilistic machine learning and data-driven methods [1,2], and some studies have been gradually extended to the fields of differential equations. How to predict the solution of (nonlinear) dynamic systems represented by (delay) partial differential equations (PDEs) has been valued [3,4,5,6,7,8]. However, (deep) neural networks are favored and used more often by researchers [9,10,11,12,13,14,15,16], and the research targets may involve the forward and inverse problem [17].
Machine learning for Gaussian processes (GPs) [18] is not new, and has been wildly employed in many fields, such as geology [19], meteorology [20] and some financial applications [21]. Similar to other machine learning methodologies, Gaussian processes can be utilized in regression problems or classification problems. Moreover, Gaussian processes belong to a set of methods named kernel machines [22]. However, compared with other kernel machine methods, such as support vector machines (SVMs) [23] and relevance vector machines (RVMs) [24], the strict probability deduction of Gaussian processes greatly limits the popularization of this method in industrial circles. Another drawback of Gaussian processes is that the computational cost may be expensive, due to the Cholesky decomposition of the kernel functions. As a kernel machine with very strong learning ability, Gaussian processes (GPs) have been widely used in the forward and inverse problem of ordinary differential equations (ODEs) and PDEs in recent years.
Markus et al. (2021) [25] constructed multi-output Gaussian process priors with realizations in the solution set of the linear PDEs; the construction was fully algorithmic via Gröbner bases. However, the construction for building GP priors by the parametrization of such systems was done via a pullback. Paterne et al. (2022) [26] efficiently inferred inhomogeneous terms modeled as GPs by using a truncated basis expansion of the GP kernel from the perspective of exact conjugate Bayesian inference. Mamikon et al. (2022) [27] proposed a framework which combined co-Kriging with the linear transformation of GPs together with the use of kernels given by spectral expansions in eigenfunctions of the boundary value problem, to infer the solution of a well-posed boundary value problem (BVP). To estimate parameters of nonlinear dynamic systems, represented by ODEs from sparse and noisy data, Yang et al. (2022) [28] bypassed the need for numerical integration, and proposed a fast and accurate method, named manifold-constrained Gaussian process inference (MAGI), explicitly conditioned on the manifold constraint that derivatives of Gaussian processes must satisfy the considered ODEs, based on a GP model over time series data. Raissi et al. (2018) [29] proposed a method for the forward problem of time-dependent PDEs based on GPR, which was named numerical Gaussian processes (NGPs). The method can solve equations with high accuracy, and the frame of the algorithm is flexible for solving different problems. Generally speaking, the study of Gaussian processes is an important branch of probabilistic numerics [30,31,32,33,34,35] in numerical analysis.
On the basis of NGPs, we propose a new method, multi-prior numerical Gaussian processes (MP-NGPs), which is designed to solve complex PDEs. In our known information, most methods based on Gaussian processes do not consider the delay term and high-dimensional problems, and only a few researchers consider fractional derivatives and integro differential derivatives, which obviously cannot meet the requirements of practical application. However, these problems are all considered in MP-NGPs. We also give strict mathematical deduction of MP-NGPs. Several PDEs are solved in the following sections to prove the validity of MP-NGPs.
It is well known that Gaussian processes [18] possess a strict mathematical basis and coincide with the Bayesian method in nature. Unlike traditional methods, including the finite element method [36], spectral method [37], and finite difference method [38], MP-NGPs [29] solve PDEs by means of statistical methods, which is the same as NGPs. In MP-NGPs, the Bayesian method [39] is used to construct an efficient data learning machine, and then infer the solution of the equations.
This paper will mainly exploit the possibility of MP-NGPs to solve the forward problem of a class of time-dependent nonlinear delay partial differential equations with multi-delays (1),
where t is the temporal variable, is the D dimensions spatial vector, () are delay terms (), and , is the boundary of . is the solution of (1), is the inhomogeneous term, , (), , are given functions, and , () are linear operators.
The linear operators considered in this paper will contain three different operators; these are partial differential, integro-differential and fractional-order operators. We should point that the fractional-order operators of (1) are considered in the sense of Caputo [40,41]
where is a constant (, ), is the Gamma function.
Apparently, the boundary conditions of the problem (1) are Dirichlet boundary conditions. As for other types of boundary conditions, we will discuss them and give some solutions in Section 4. In order to certify the high efficiency and flexibility of MP-NGPs again, we will consider another type of time-dependent PDEs, wave equations, which still involve delay terms and inhomogeneous terms, in Section 5.
We arrange the outline of this paper as follows: Section 2 introduces MP-NGPs according to the workflow of solving nonlinear delay PDEs. In Section 3, Runge–Kutta methods based on MP-NGPs are constructed. Section 4 introduces the processing of Neumann and mixed boundary conditions in MP-NGPs. Section 5 gives two methods of how to slove wave equations in MP-NGPs. Finally, we present some discussions and conclusions in Section 6 and Section 7, respectively.
2. Multi-Priors Numerical Gaussian Processes
In this section, we introduce MP-NGPs based on the workflow of solving nonlinear delay PDEs with multi-delays.
2.1. Prior
Use the backward Euler scheme in the first equation of (1) to discretize time, take the time step size as , and then obtain
where , , , , , . We approximate the nonlinear terms and () with and (), respectively, where denotes the predicted solution (posterior mean) of the previous time step. Then introduce notations that , () and , so we can obtain the simplified equation
Equation (4) captures the whole structure of solutions at each time step. We can link the solutions at different time steps by setting reasonable prior assumptions. Assume the following prior hypotheses [29]
to be mutually independent Gaussian processes. Considering the calculation feasibility, we set a prior assumption on rather than . Assume covariance functions to be of the following exponential form [18],
where denotes the hyper-parameters. In Equations (6), , . In short, any information of PDEs, such as delay terms, can be encoded into MP-NGPs through assuming multi-priors, as long as the structure constructed by these priors is feasible.
By Mercer’s theorem [42], given a positive definite covariance function we can decompose it into , where and satisfying . Treat as a set of orthogonal basis and construct a reproducing kernel Hilbert space (RKHS) [43], which is the so-called kernel trick [43]. The covariance function in Equation (6) does not have a finite decomposition. Different covariance functions, such as rational quadratic covariance functions and Matérn covariance functions, can be appropriately selected under different prior information [18].
2.2. Training
It is worth noting that is a symmetry matrix, and elements besides the upper triangular part of are not written in this paper.
Consider additive noise in the observed data, and introduce notations that , , , and (), where , , , and (). Assume and to be mutually independent additive noise. Notice that is equal to . That is, the boundary points can be seen as the known points uses for the next time step, as Dirichlet boundary conditions are considered. For different types of boundary conditions, the corresponding treatment will be introduced in Section 4.
By (5), the hyper-parameters are trained by minimizing the following log marginal likelihood function,
where N is the length of . A Quasi-Newton optimizer [44] is applied for training in this paper. It should be pointed that other optimizer algorithm, such as the whale optimization algorithm [45] (WOA) and the ant colony optimization algorithm [46], can also be used for training.
The training procedure is one of the most important things for exploiting the algorithm, which can be seen as the “regression nature” of MP-NGPs. However, to numerically solve the forward problem of PDEs, the method of MP-NGPs subtly turns algebraic problems into optimization problems, which are more familiar with machine learning methods.
2.3. Posterior
We can easily obtain the following posterior distribution of the prediction solution based on the conditional distribution of Gaussian processes,
where , .
2.4. Propagating Uncertainty
Notice that () and () are generated data, we cannot use the outcome of the conditional distribution (8) in the next time step. We should propagate the uncertainty firstly, marginalize (, ) out by exploiting (when )
to have (when )
where , , and .
Then from (10), we can obtain both the form of and the artificial data of the next time step, where , .
2.5. Basic Workflow
Summing up the above introduction, we have the following algorithm workflow:
- Firstly, we obtain the initial data , delay term data () and the inhomogeneous term data by randomly selecting points on spatial domain , and obtain the boundary data by randomly selecting points on . Then we train the hyper-parameters in (7) by using the obtained data.
- From the obtained hyper-parameters of step 1, (8) is used to predict the solution for the first time step and obtain artificially generated data , where points are randomly sampled from , and is the corresponding random vector. We obtain the delay term data () and the inhomogeneous term data by randomly selecting points on , then obtain the boundary data by randomly selecting points on .
- From , (), and , we train the hyper-parameters for the second time step.
- From the obtained hyper-parameters of step 3, (10) is used to predict the solution for the second time step and obtain artificially generated data , where points are randomly sampled from . We also obtain the delay term data () and the inhomogeneous term data by randomly selecting points on , then obtain the boundary data by randomly selecting points on .
- Steps 3 and 4 are repeated until the last time step.
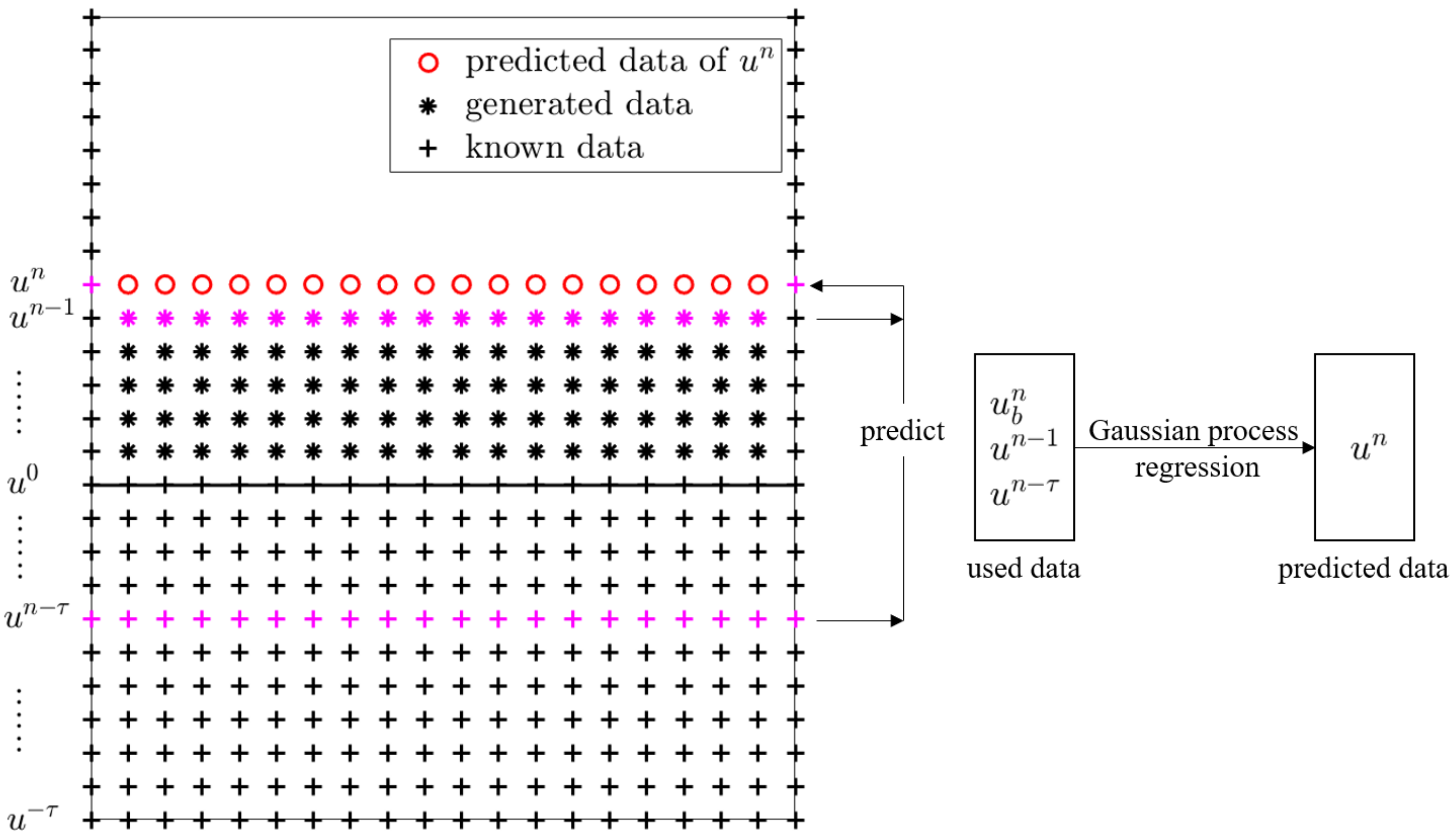
However, we exploit the Gaussian process regression to predict the next solution at each time step. Figure 1 shows the basic idea of MP-NGPs. At each iteration, the optimized hyper-parameters of the current time step are saved and deemed as initial values of the hyper-parameters in the next time step, which can significantly speed up the training process.
2.6. Processing of Fractional-Order Operators
For simplicity, we consider the following delay problem to show the processing of the fractional-order operators,
where continuous real function is absolutely integrable in . Assume arbitrary-order partial derivatives of to be continuous function and absolutely integrable in .
Consider the backward Euler scheme to (11) with and replaced by and , respectively,
We can easily obtain the following results from Section 2.2,
How to deal with the first term on the right side of (15) is one of the most important tasks. Denote , according to [40], the Fourier transform is carried out with respect to the spatial variable on to obtain , as the excellent properties of the squared exponential covariance function obviously assure the feasibility of the Fourier transform of derivatives of , according to which and its partial derivatives vanish for . Then we can obtain the following intermediate kernels:
where , .
At last, the inverse Fourier transform can be performed on and to obtain the kernels and .
2.7. Numerical Tests
To verify the validity of the method proposed, three examples are provided. Firstly, we introduce the maximum absolute error to denote the difference between the conditional posterior mean of the prediction solution and exact solution as follows:
where is the current time, is a point random sampling from , is the exact solution, and is the posterior mean of (prediction solution).
We also introduce a notation that , which can be seen as a measure of the prediction error under a different time step size .
Then we introduce the relative spatial error to represent the relative error of prediction [29],
Example 1.
We fix to be , , and in turn. The exact solution of (30) is , and the inhomogeneous term differs from each other when is changed,
where .
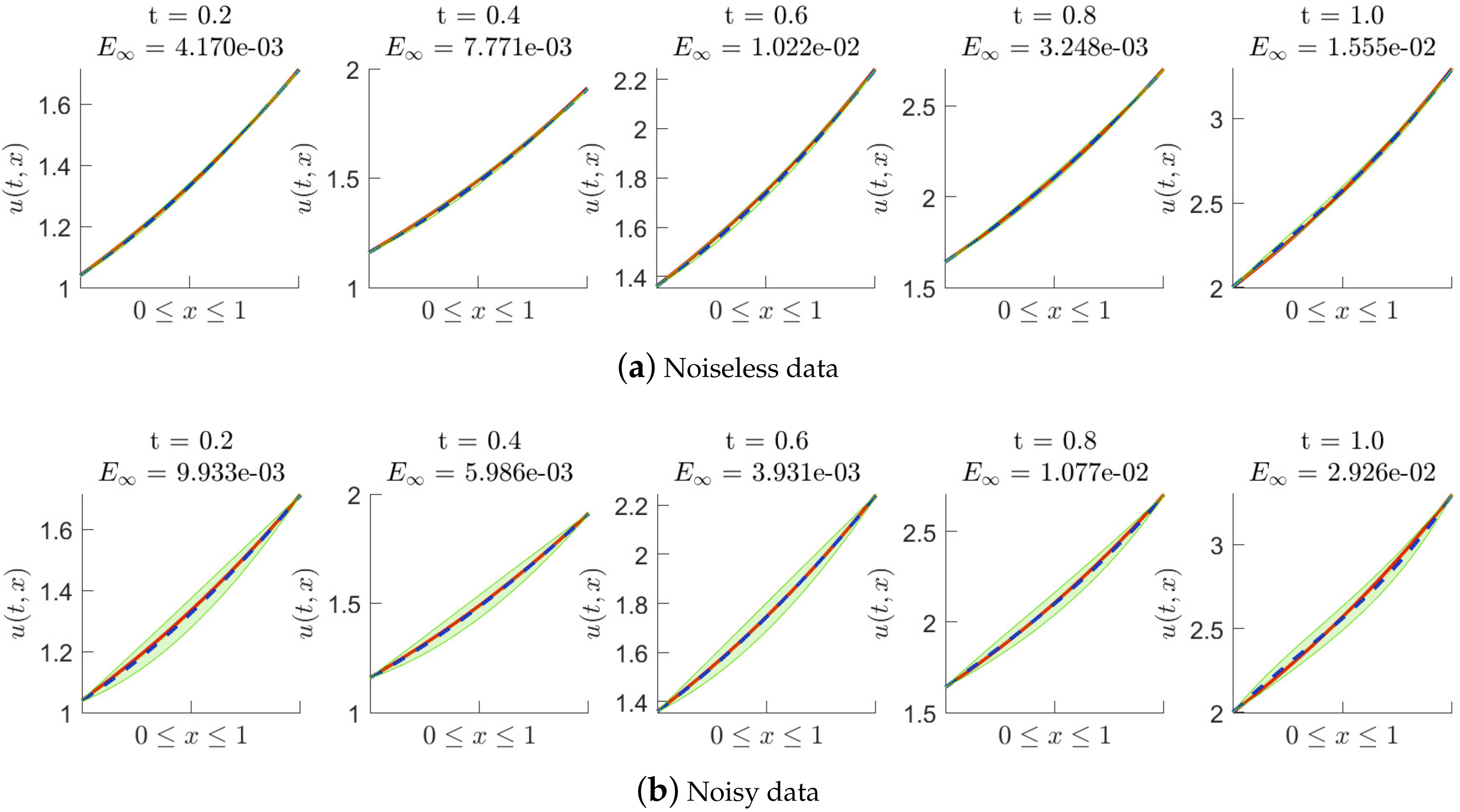
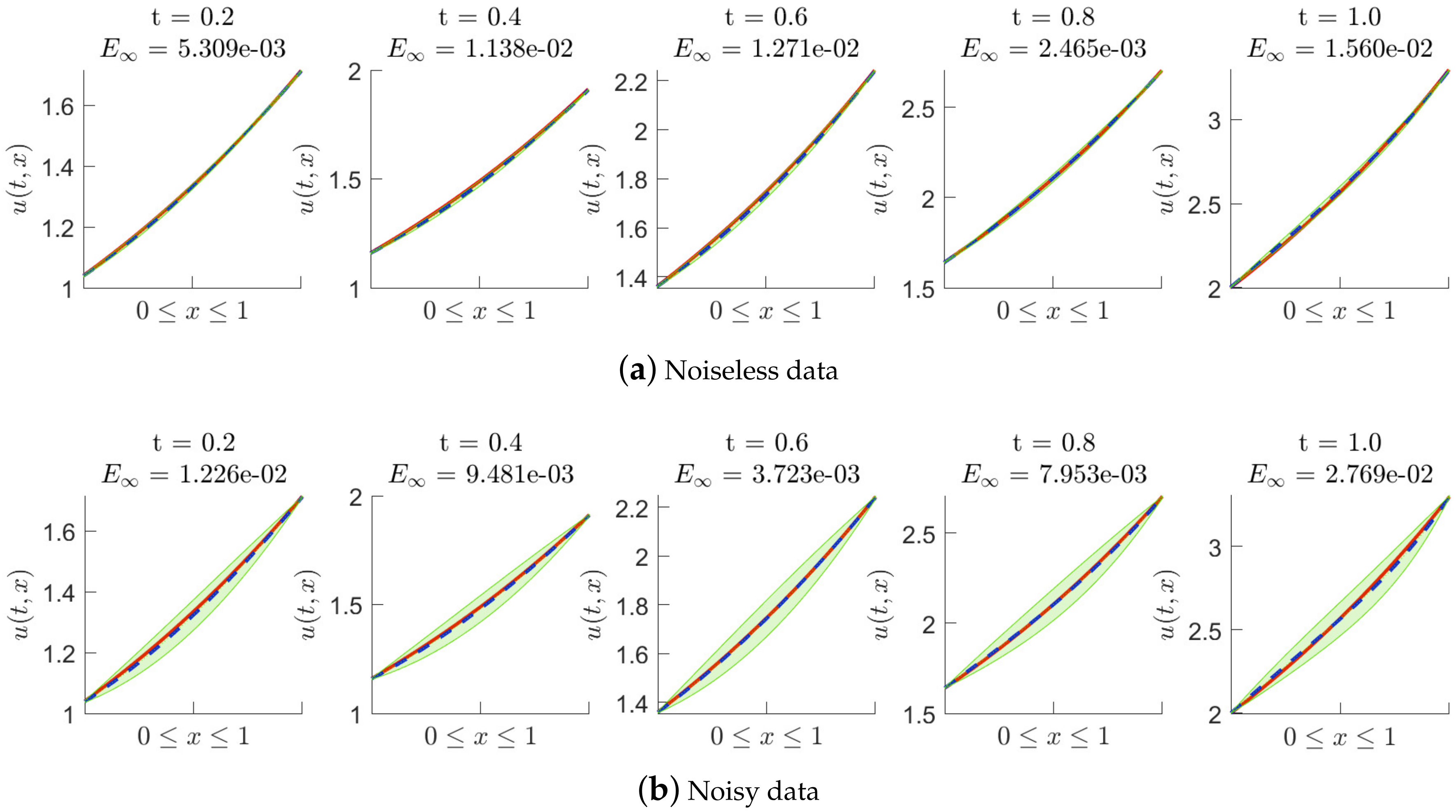
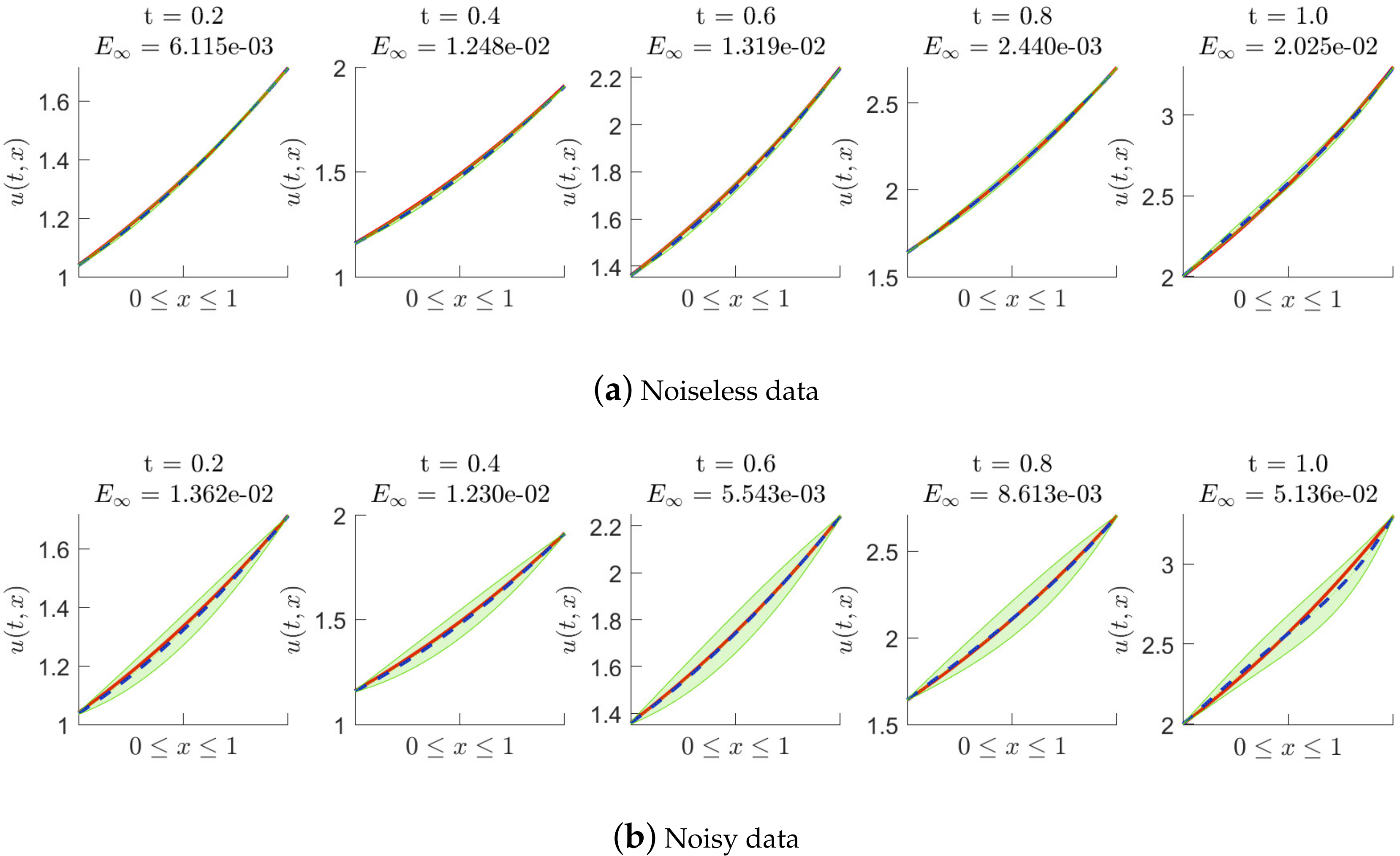
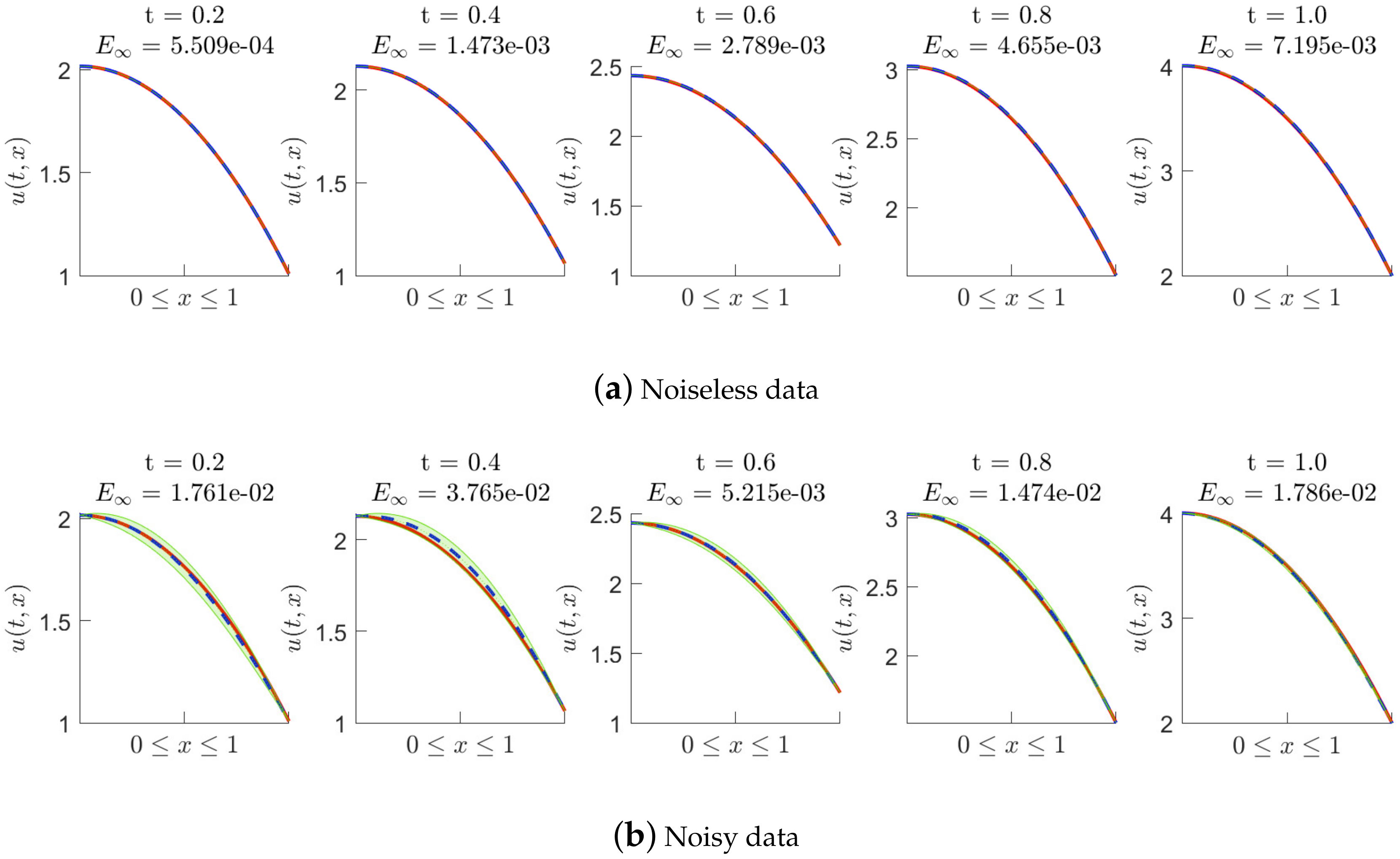
Numerical tests of solving (19) are performed with noiseless data and noisy data, respectively, where the backward Euler scheme is employed. We only add noise into the initial data , and the additive noise of is . Figure 2, Figure 3 and Figure 4 show the posterior distribution of the predicted solution at some time nodes, where we fix the number of initial data points (inhomogeneous term data points, artificially generated data points and delay term data points) to be 20 and to be 0.01, and take to be , , and in turn. In each of these figures, (a) presents the results of the experiments with noiseless data, and (b) presents the results of the experiments with noisy data. Moreover, Table 1 shows us the maximum absolute error between the conditional posterior mean of the prediction solution and the exact solution at some time nodes in detail, where noiseless data is used in the experiments. Table 2 shows us the maximum absolute error at some time nodes, where noisy data are used. It is found that the method works well when solving nonlinear delay fractional equations. It is easy to observe that higher prediction accuracy is obtained by using noiseless data in experimental tests.
Example 2.
Example 2 is a partial integro-differential equation with one delay. The exact solution of (21) is , and the inhomogeneous term is .
Numerical tests of solving (21) are performed with noiseless data and noisy data, respectively, where the backward Euler scheme is employed. We add noise into the initial data and inhomogeneous term data (), and the additive noisy of and is and , respectively. Figure 5 shows the posterior distribution of the predicted solution at different time nodes, where we fix the number of initial data points (inhomogeneous term data points, artificially generated data points and delay term data points) to be 10 and to be 0.01. In Figure 5, the five pictures on the upper side present the results of the experiments with noiseless data, and the other five pictures on the lower side present the results of the experiments with noisy data. Moreover, Table 3 shows us the maximum absolute error at some time nodes in detail, where noiseless data and noisy data are used in the experiments, respectively. It is found that the method works well when solving nonlinear delay integro-differential equations. It is worth noting that the computational accuracy of the prediction solution is not sensitive to noise, as the level of noise added into the data is not low.
Example 3.
Example 3 defines a problem with two delays and three spatial dimensions. The exact solution of (22) is , and the inhomogeneous term is
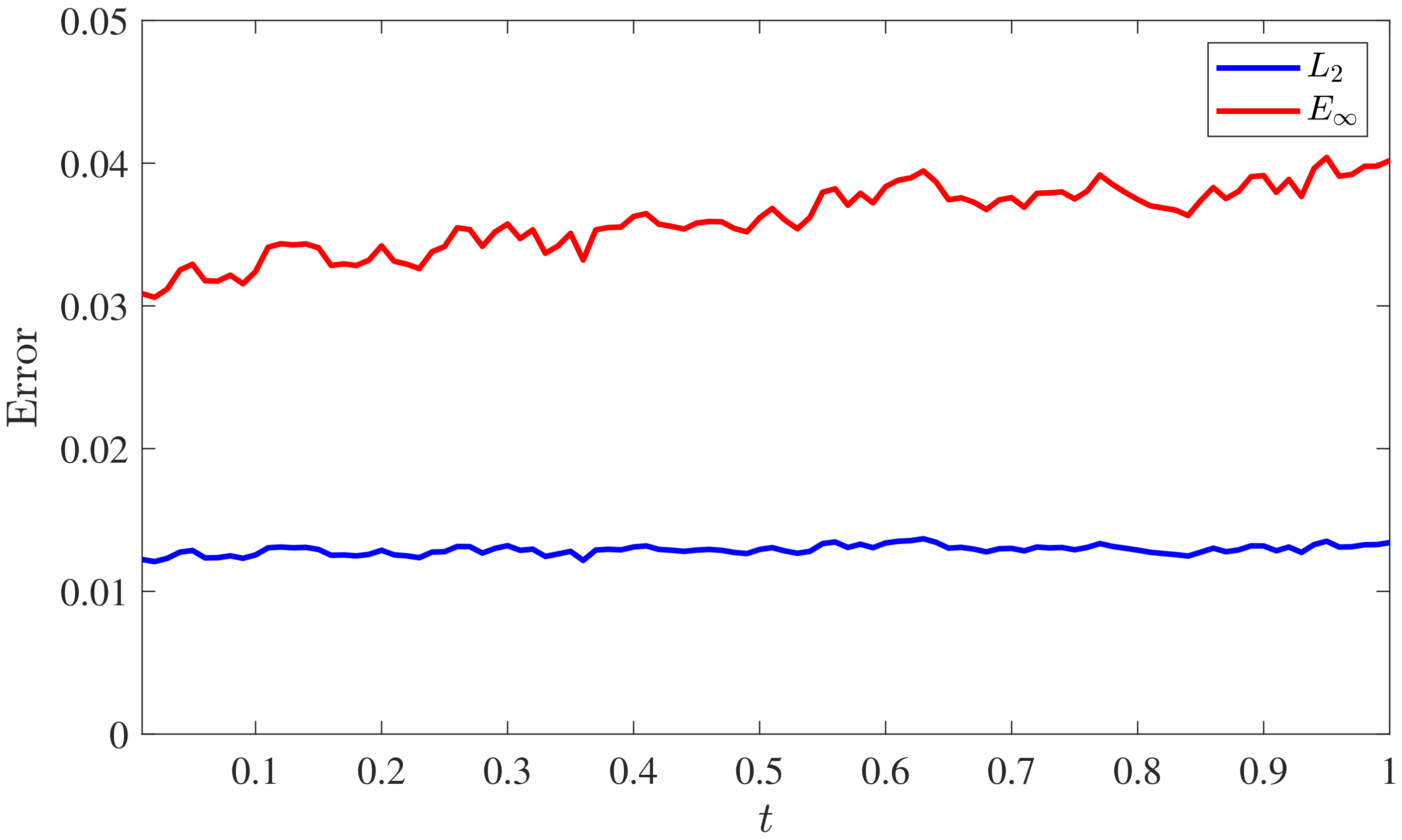
Numerical tests applying the backward Euler scheme to solve (22) will be performed with noiseless data. Figure 6 shows the relative spatial error and the maximum absolute error with the increase in time, where we fix the number of initial data points (inhomogeneous term data points, artificially generated data points and delay term data points) to be 20 and to be 0.01. The number of training data points on each boundary line is fixed to be 5. Furthermore, Table 4 shows the relative spatial error and the maximum absolute error at some time nodes in detail. According to the experimental outcome, we can conclude that the method is still effective when solving nonlinear time-dependent delay equations with high dimensions and multi-delays.
3. Runge–Kutta Methods
For the purpose of improving the accuracy of the methodology considered in Section 2, we will consider Runge–Kutta methods [47,48] based on the frame of MP-NGPs.
3.1. MP-NGPs Based on Runge–Kutta Methods
Apply Runge–Kutta methods with q stages to the first equation of (1) with appropriate approximation of nonlinear terms, and we can obtain [47]
Reforming (24), we have
where , , and . Prior assumptions are set on and Equations (25) turn into a regression problem.
Then directly write the joint distribution of . For simplicity, we introduce the Runge–Kutta methods by solving the following problem:
The trapezoidal rule is applied under the structure of Runge–Kutta methods to (26) with , , and replaced by , , and , respectively. Then we have
Reforming (27), we have
However, Equation (28) coincides with the structure of Runge–Kutta methods when and . Reforming (28), we obtain
where and are linear operators.
Assume the following prior hypotheses:
to be mutually independent Gaussian processes, and assume covariance functions to be the following exponential form of (6). By the properties of the Gaussian processes, we have
where
Other kernels are assumed to be .
We can write the posterior distribution of the prediction as follows:
where , , ,
, , , , , , .
For (), () and () are artificially generated data, we cannot directly use the outcome of the conditional distribution of (32) in the next time step. To propagate the uncertainty, we should marginalize (, ) by employing
to get
where (if , replace by ; if , replace by ), , (if , replace by ; if , replace by ), and .
On the basis of Equation (34), we have , and obtain the artificial data of the next step, where , .
3.2. Numerical Test for the Problem with One Delay Applying the Trapezoidal Rule
In this subsection, the method of applying the backward Euler scheme and the trapezoidal scheme is applied to solve Example 4, and numerical tests are carried out. Moreover, the impact of data noise and the amount of training data on maximum absolute error is investigated in this subsection.
Example 4.
The exact solution of (35) is , and the inhomogeneous term is .
Table 5 presents the maximum absolute error between the conditional posterior mean of the prediction solution and the exact solution at five time nodes for the different time step size under the backward Euler scheme, where the number of initial data points (inhomogeneous term data points, artificially generated data points and delay term data points) is fixed to be 20. It is found that the method applying the backward Euler scheme is first-order accurate in time, which is just in line with the first-order convergence property of the backward Euler scheme we applied. Since calculating the convergence order in time requires the maximum absolute error under two consecutive time steps, we omit the display of the first value in the last column of Table 5 and Table 6.
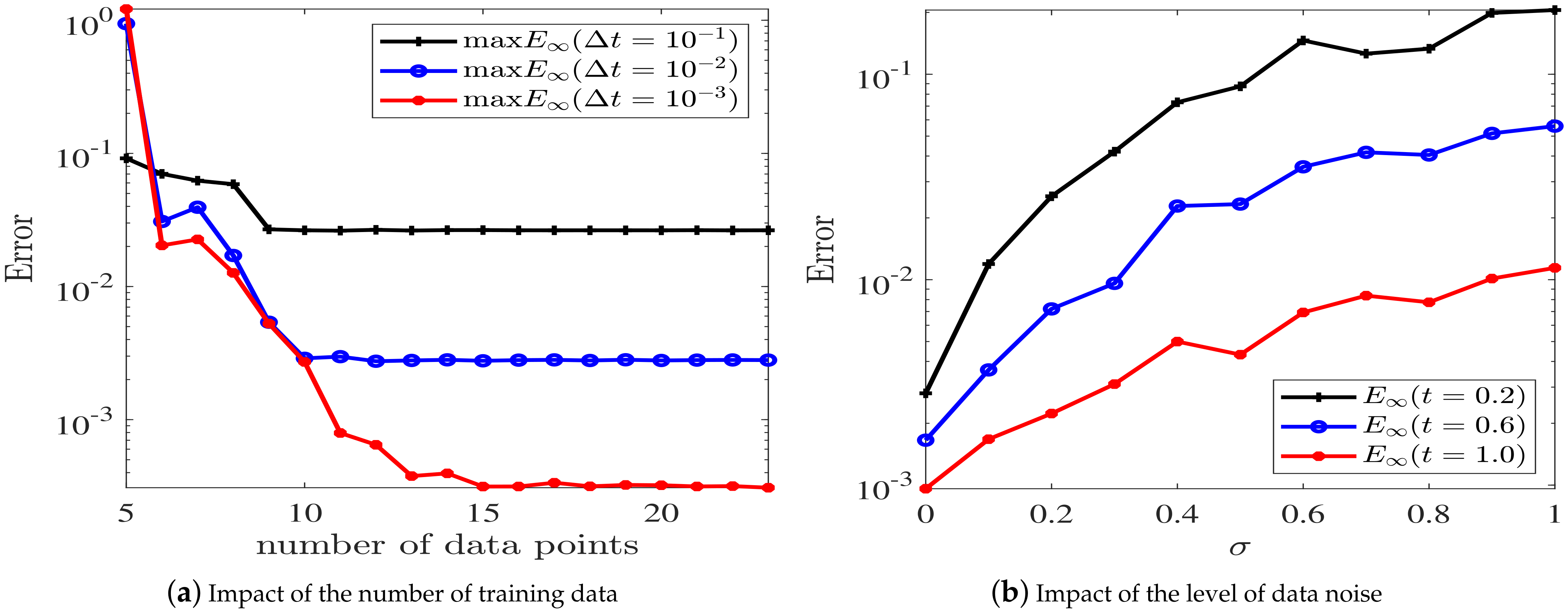
Figure 7a shows the impact of the number of initial data points (inhomogeneous term data points, artificially generated data points and delay term data points) on , where we take as , and in turn. The results show that when is equal to , the prediction accuracy quickly reaches saturation with the increase in the number of training data points, but when is taken smaller, increasing the amount of training data still has the potential to improve the prediction accuracy, and the saturation behavior occurs much later.
Moreover, we investigate the impact of noise on the prediction accuracy. We add noise into the initial data , delay term data () and inhomogeneous term data () to investigate the impact of the level of the noise on the accuracy. The additive noisy of , and is , and , respectively. Take , and observe the change of under different at these time nodes (see Figure 7b). The experiment outcome proves that the bigger , the lower the prediction accuracy. With the progress of the iteration, the impact of the noise on the accuracy of the current time step becomes smaller, and the accuracy gradually tends to increase, as the hyper-parameters that contain the knowledge of the considered problem are trained better and better as the iteration progress continues.
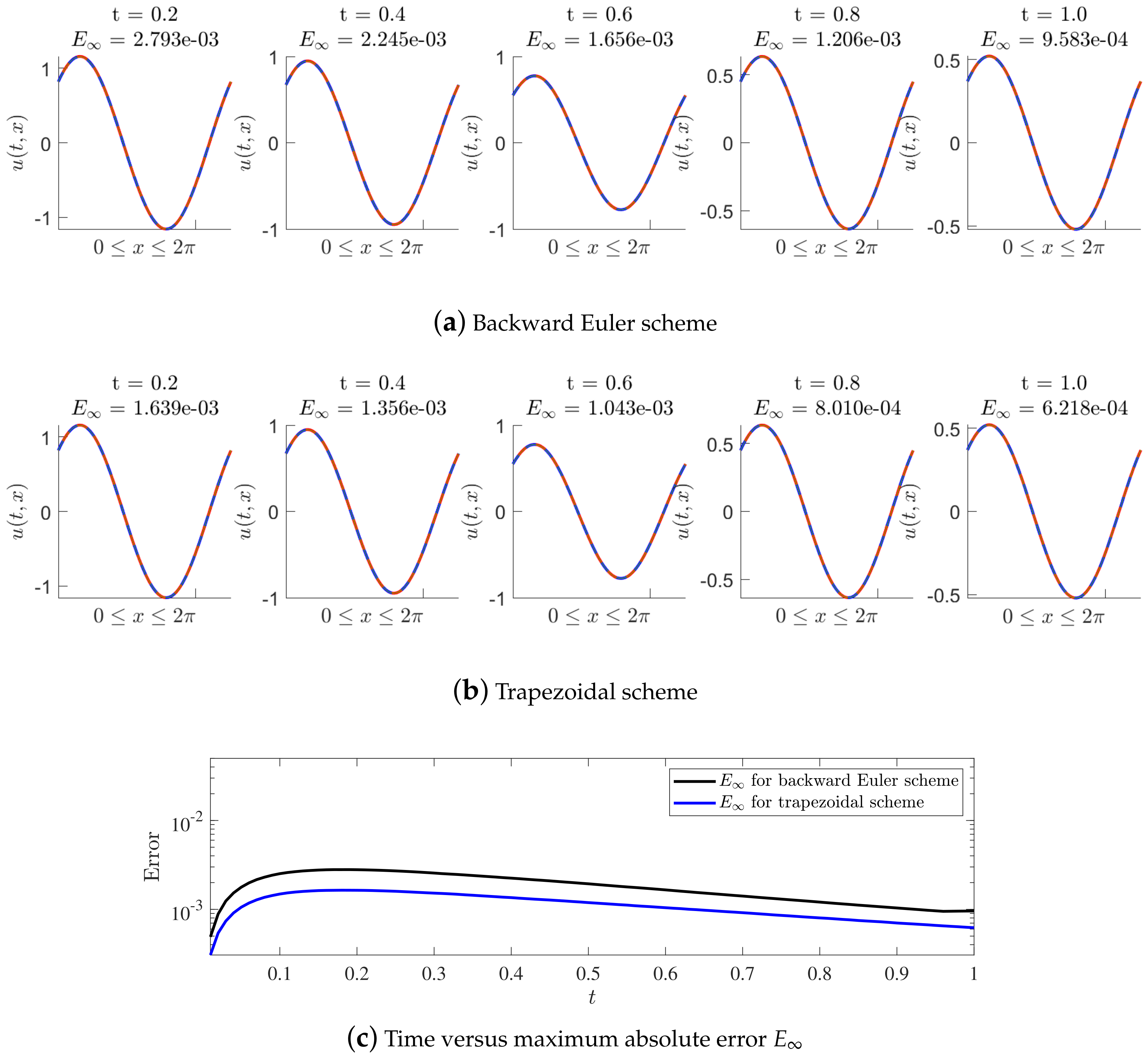
Table 6 shows the maximum absolute error between the conditional posterior mean of the prediction solution and the exact solution at five time nodes for the different time step size under the trapezoidal scheme, where the number of initial data points (inhomogeneous term data points, artificially generated data points and delay term data points) is fixed to be 20. It is found that the method applying the trapezoidal rule is still first-order accurate in time, which is apparently not consistent with the second-order convergence property of the trapezoidal rule. Therefore, we can conclude from these results that the convergence rate of MP-NGPs using Runge–Kutta methods is also the first-order. Fortunately, the accuracy of the method applying the trapezoidal scheme (Runge–Kutta methods) does exceed the backward Euler scheme when other experimental conditions are fixed, which means that applying the Runge–Kutta methods on MP-NGPs is still very useful when the current accuracy is not satisfying. The results of Figure 8 also prove that the Runge–Kutta methods do exceed the backward Euler scheme in prediction accuracy.
4. Processing of Neumann and Mixed Boundary Conditions
In the above sections, we did not mention the processing of other boundary conditions, except Dirichlet boundary conditions. This section will introduce how to solve two-dimensional PDEs with Neumann or mixed boundary conditions. That is, the spatial vector is a one-dimensional variable.
As everyone knows, Dirichlet, Neumann and mixed boundary conditions have the following general form, respectively, in the problem (1) of two dimensions:
where , , are given functions.
In order to avoid the repetitive introduction, we will focus on the processing of Neumann and mixed boundary conditions in this section.
4.1. Neumann Boundary Conditions
For the Neumann boundary conditions (37), introduce , where . Note , and is a linear operator.
Return to the problem (1), then we can get , where
where , . The additive noise is assumed to be independent of other noise.
After the training part, the posterior distribution of can be directly written as
where ,
, .
On the basis of Section 2.4, in order to accurately propagate the uncertainty, marginalize (and perhaps , when ) by employing (assume )
to obtain (assume )
where , , and .
By the posterior distribution (42), obtain the simplified form , and then obtain the artificial data of the next time step, where , and .
Let us return to the problem (11) in Section 2.6, and the operator contains fractional-order operators. Then can be obtained by performing the inverse Fourier transform on , where
4.2. Mixed Boundary Conditions
For the mixed boundary conditions (38), the processing of boundary information is more complicated. Introduce , , where , , , . Note , , where and are linear operators.
Return to the problem (1), then we can obtain , where
where , , , . The additive noise and are assumed to be independent of other noise.
After the training part, the posterior distribution of can be directly written as
where , .
By Section 2.4, in order to accurately propagate the uncertainty, marginalize (and perhaps , when ) by employing (assume )
to obtain (assume )
where , , and .
On the basis of the posterior distribution (49), obtain the simplified form , and then obtain the artificial data of the next time step, where , and .
Return to problem (11) in Section 2.6, and the operator contains fractional-order operators. Then and can be obtained by performing the inverse Fourier transform on and , respectively, where
4.3. Numerical Tests for a Problem with Two Delays and Different Types of Boundary Conditions
In this subsection, we will solve a nonlinear PDE with two delays, and Dirichlet, Neumann and mixed boundary conditions will be considered in this PDE, in turn.
Example 5.
Example 5 is a nonlinear PDE with two delays. The exact solution of (51) is , and the inhomogeneous term is . The Dirichlet, Neumann and mixed boundary conditions of Example 5 are as follows:
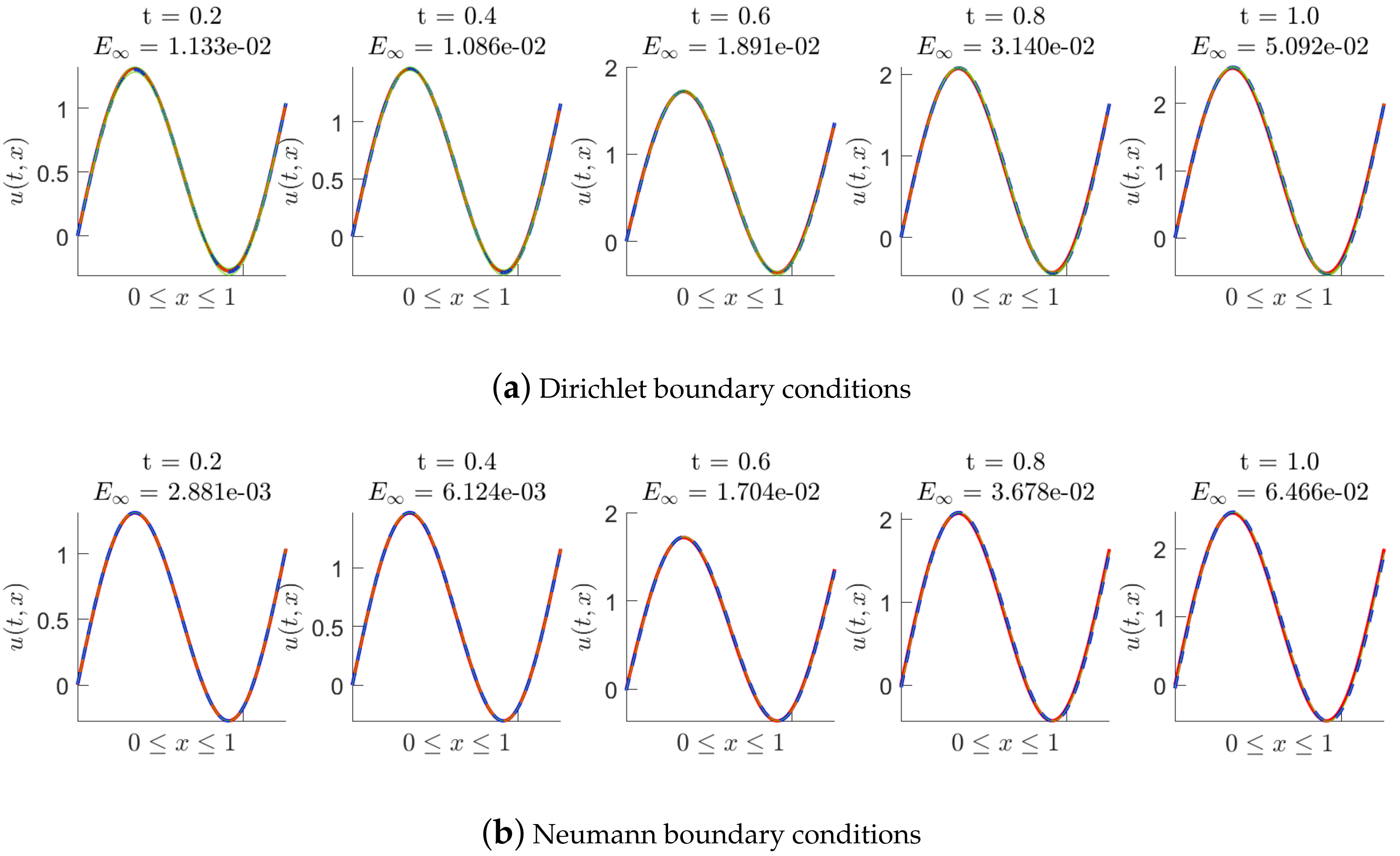
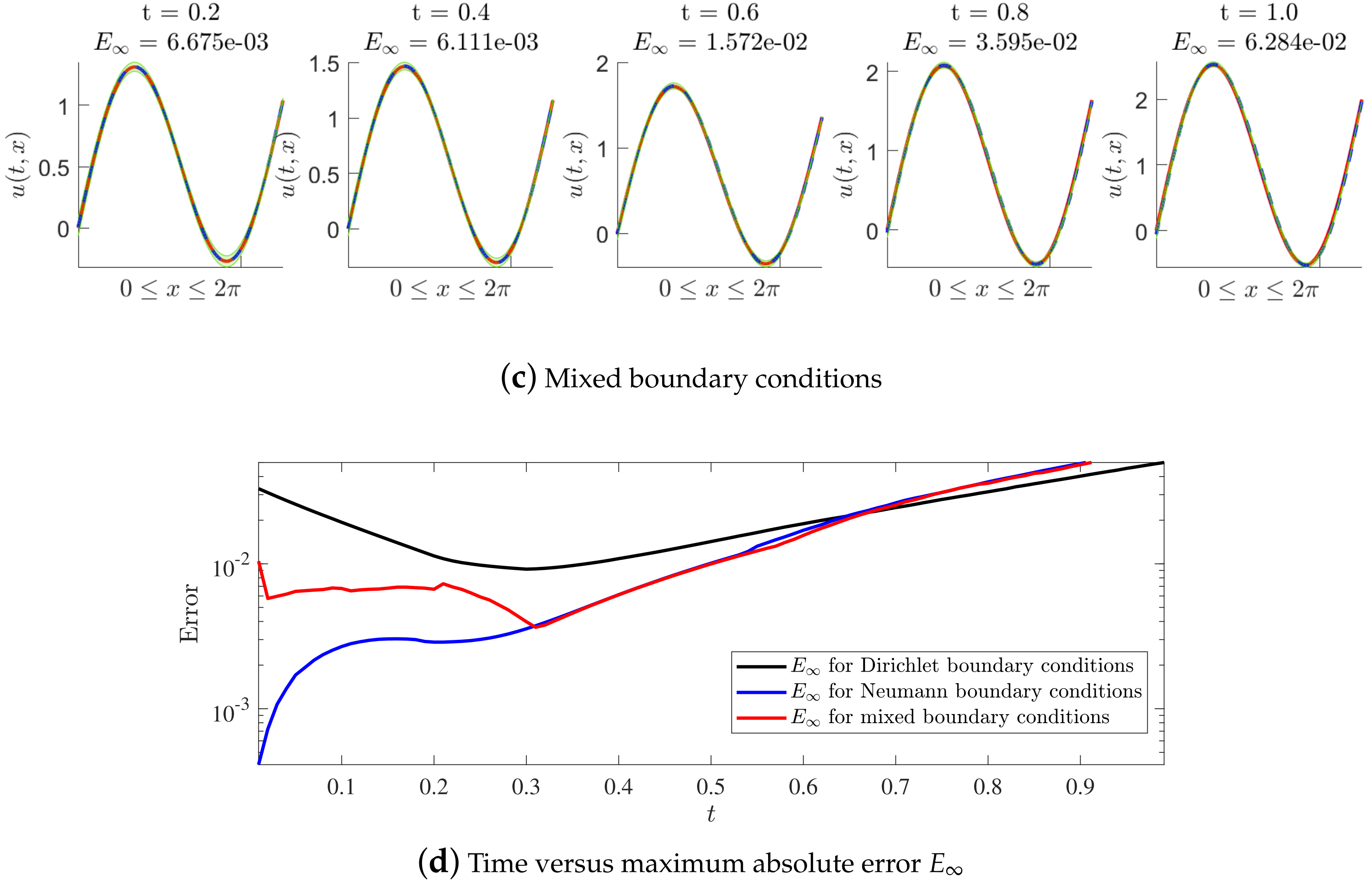
Numerical tests of solving (51) will be performed with noiseless data. Figure 9 shows the posterior distribution of the predicted solution at different time nodes, where we fix the number of initial data points (inhomogeneous term data points, artificially generated data points and delay term data points) to be 10 and fix to be 0.01. Figure 9a–c presents the results of the experiments with Dirichlet, Neumann and mixed boundary conditions, respectively, and Figure 9d shows the maximum absolute error with the increase in time. Moreover, Table 7 shows us the maximum absolute error at some time nodes in detail, where Dirichlet, Neumann and mixed boundary conditions are both considered. It is found that the method based on MP-NGPs works well when solving nonlinear delay PDEs with Dirichlet, Neumann or mixed boundary conditions. The prediction accuracy under different types of boundary conditions is close to each other.
5. Processing of Wave Equations
So as to prove the efficiency of MP-NGPs, we give the processing of another type of time-dependent PDEs, wave equations,
where , , , and are given functions. Apparently, delay terms and inhomogeneous terms are also considered in the wave equations.
We will give two methods of how to solve wave equations by the algorithm of MP-NGPs.
5.1. Second Order Central Difference Scheme
The first method is to apply a second-order central difference scheme of second-order derivatives on the first Equation of (55) to discretize the temporal variable:
where , , , , , .
Rearrange (56) to obtain
Obviously, the scheme (56) is a multi-steps method, while the backward Euler scheme is a one-step method. Then introduce notations that , , and . So, we can obtain the simplified equation
Assume the Gaussian process prior as follows:
According to the properties of Gaussian processes, then we can obtain , where
Any kernel not mentioned above is equal to .
After the training part, the posterior distribution of can be directly written as
where .
On the basis of Section 2.4, in order to accurately propagate the uncertainty, marginalize , (and , when ) by employing
to obtain
where (if , replace by ; if , replace by ; if , replace by ), , and (if , replace by ; if , replace by ; if , replace by ).
By the posterior distribution (63), obtain the simplified form , and then obtain the artificial data of the next time step, where , and .
5.2. Backward Euler Scheme
Firstly, note , then obtain
where . Apply the backward Euler scheme on the first equation of (55) to discretize time,
Rearrange (65) to obtain
Then introduce notations that , , , , , and . Then obtain the simplified form
Assume the Gaussian process prior as follows:
According to the properties of Gaussian processes, we can obtain , where
Any kernel not mentioned above is equal to .
After the training part, the joint posterior distribution of can be directly written as
where
On the basis of Section 2.4, in order to accurately propagate the uncertainty, marginalize , (and , when ) by employing
to obtain
where (if , replace and by and , respectively; if , replace by ), , (if , replace by ; if , replace by ), and .
By the posterior distribution (73), obtain the simplified form , and then obtain the artificial data of the next time step, where , and .
This two methods reflect the flexibility of NGPs and MP-NGPs. Due to the limited space of this paper, we only introduced the processing of wave equations. The other types of time-dependent PDEs can also be solved by the idea of this two methods.
5.3. Numerical Tests
Example 6.
Example 6 is the wave equation with one delay. The exact solution of (74) is , and the inhomogeneous term is .
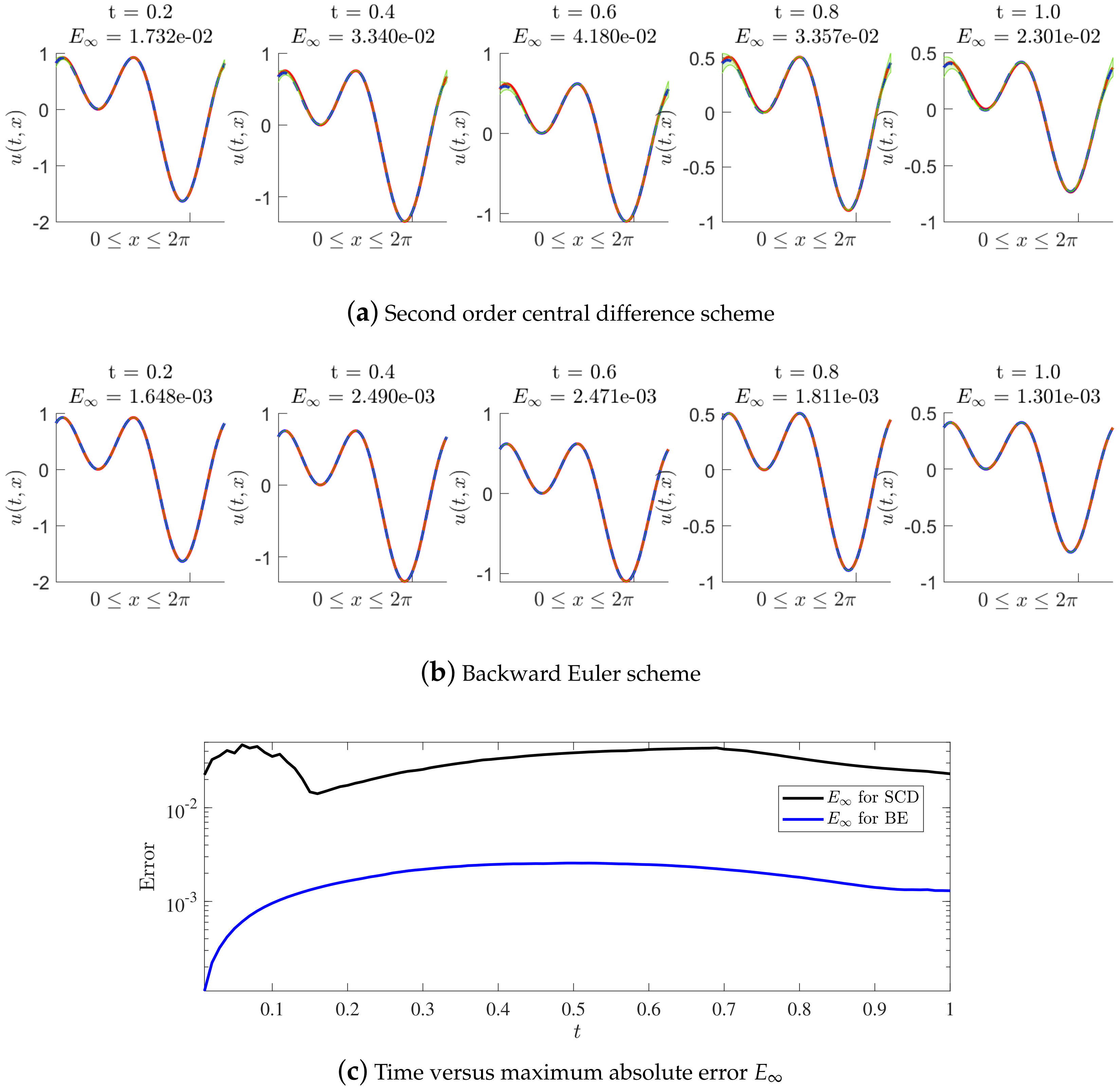
Numerical tests of solving (74) are performed with noiseless data. Figure 10 shows the posterior distribution of the predicted solution at different time nodes, where we fix the number of initial data points (inhomogeneous term data points, artificially generated data points and delay term data points) to be 15 and fix to be 0.01. Figure 9a,b, presents the results of the experiments employing the second-order central difference scheme and the backward Euler scheme, respectively, and Figure 9c shows the maximum absolute error with the increase in time. Moreover, Table 8 shows us the maximum absolute error at some time nodes in detail. According to the results of numerical tests, we conclude that the two methods based on MP-NGPs effectively solve the wave equation with one delay. The second method applying the backward Euler scheme behaves better than the first method, applying the second-order central difference scheme on prediction accuracy.
6. Discussion
In this paper, a new method, called multi-priors numerical Gaussian processes (MP-NGPs), is designed and proposed on the basis of numerical Gaussian processes (NGPs), to solve complex time-dependent PDEs. Compared with NGPs, the MP-NGPs proposed possess a structure with a much stricter mathematical deduction, and the application of MP-NGPs is more flexible. Delay terms and inhomogeneous terms can be introduced on MP-NGPs. The main idea of MP-NGPs is to realize the discretization of time, apply Gaussian process regression to transform the potential information of PDEs into a scheme controlled by several operators, and predict the solution from the statistical perspective. MP-NGPs build a Gaussian process regression at each time step to predict the solution at the next time step. The basic idea of MP-NGPs is very similar to that of NGPs, but the applications of MP-NGPs are explored more deeply than NGPs. Moreover, this methodology of MP-NGPs has natural advantages in handling noisy data and quantifying the uncertainty of the predicted solution. It should be mentioned that MP-NGPs can only solve a class of fractional-order PDEs composed of special fractional-order derivatives (2). Other kinds of fractional-order derivatives still deserve further research in MP-NGPs. Moreover, multi-spatial-dimension irregular domain problems, the inverse problems of PDEs, such as estimating constant or variable coefficients based on Gaussian processes and some specific application problems of MP-NGPs, may be the direction of our future investigation.
7. Conclusions
In this manuscript, the possibility of MP-NGPs in solving nonlinear delay partial differential equations with multi-delays is explored. These equations investigated include partial differential equations, partial integro-differential equations, fractional partial differential equations and wave equations. We also consider Neumann and mixed boundary conditions of PDEs on MP-NGPs. Numerical experiments prove that the method proposed can solve nonlinear delay partial differential equations with satisfactory precision, and the algorithm applying the backward Euler scheme is stably first-order accurate in time. So as to improve the prediction accuracy, Runge–Kutta methods under the frame of MP-NGPs are proposed in this manuscript. The algorithm applying the Runge–Kutta methods can effectively improve the prediction accuracy, although the temporal convergence rate of this algorithm is still of the first order according to the numerical experiments.
Author Contributions
Conceptualization, W.G., W.Z. and Y.H.; methodology, W.G. and W.Z.; software, W.G. and W.Z.; validation, W.G. and Y.H.; formal analysis, W.G. and Y.H.; investigation, W.G., W.Z. and Y.H.; writing—original draft preparation, W.Z.; writing—review and editing, W.G. and Y.H.; visualization, W.G., W.Z. and Y.H.; supervision, W.G. and Y.H. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by National Natural Science Foundation of P.R. China (No. 71974204).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ghahramani, Z. Probabilistic machine learning and artificial intelligence. Nature 2015, 521, 452–459. [Google Scholar] [CrossRef] [PubMed]
- Kempa-Liehr, A.W.; Lin, C.Y.C.; Britten, R.; Armstrong, D.; Wallace, J.; Mordaunt, D.; O’Sullivan, M. Healthcare pathway discovery and probabilistic machine learning. Int. J. Med. Inform. 2020, 137, 104087. [Google Scholar] [CrossRef] [PubMed]
- Maslyaev, M.; Hvatov, A.; Kalyuzhnaya, A.V. Partial differential equations discovery with EPDE framework: Application for real and synthetic data. J. Comput. Sci. 2021, 53, 101345. [Google Scholar] [CrossRef]
- Lorin, E. From structured data to evolution linear partial differential equations. J. Comput. Phys. 2019, 393, 162–185. [Google Scholar] [CrossRef]
- Arbabi, H.; Bunder, J.E.; Samaey, G.; Roberts, A.J.; Kevrekidis, I.G. Linking machine learning with multiscale numerics: Data-driven discovery of homogenized equations. JOM 2020, 72, 4444–4457. [Google Scholar] [CrossRef]
- Martina-Perez, S.; Simpson, M.J.; Baker, R.E. Bayesian uncertainty quantification for data-driven equation learning. Proc. R. Soc. A 2021, 477, 20210426. [Google Scholar] [CrossRef] [PubMed]
- Dal Santo, N.; Deparis, S.; Pegolotti, L. Data driven approximation of parametrized PDEs by reduced basis and neural networks. J. Comput. Phys. 2020, 416, 109550. [Google Scholar] [CrossRef]
- Raissi, M.; Perdikaris, P.; Karniadakis, G.E. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J. Comput. Phys. 2019, 378, 686–707. [Google Scholar] [CrossRef]
- Kremsner, S.; Steinicke, A.; Szölgyenyi, M. A deep neural network algorithm for semilinear elliptic PDEs with applications in insurance mathematics. Risks 2020, 8, 136. [Google Scholar] [CrossRef]
- Guo, Y.; Cao, X.; Liu, B.; Gao, M. Solving partial differential equations using deep learning and physical constraints. Appl. Sci. 2020, 10, 5917. [Google Scholar] [CrossRef]
- Chen, Z.; Liu, Y.; Sun, H. Physics-informed learning of governing equations from scarce data. Nat. Commun. 2021, 12, 6136. [Google Scholar] [CrossRef] [PubMed]
- Gelbrecht, M.; Boers, N.; Kurths, J. Neural partial differential equations for chaotic systems. New J. Phys. 2021, 23, 043005. [Google Scholar] [CrossRef]
- Omidi, M.; Arab, B.; Rasanan, A.; Rad, J.; Parand, K. Learning nonlinear dynamics with behavior ordinary/partial/system of the differential equations: Looking through the lens of orthogonal neural networks. Eng. Comput. 2022, 38, 1635–1654. [Google Scholar] [CrossRef]
- Lagergren, J.H.; Nardini, J.T.; Michael Lavigne, G.; Rutter, E.M.; Flores, K.B. Learning partial differential equations for biological transport models from noisy spatio-temporal data. Proc. R. Soc. A 2020, 476, 20190800. [Google Scholar] [CrossRef]
- Koyamada, K.; Long, Y.; Kawamura, T.; Konishi, K. Data-driven derivation of partial differential equations using neural network model. Int. J. Model Simulat. Sci. Comput. 2021, 12, 2140001. [Google Scholar] [CrossRef]
- Kalogeris, I.; Papadopoulos, V. Diffusion maps-aided Neural Networks for the solution of parametrized PDEs. Comput. Meth. Appl. Mech. Eng. 2021, 376, 113568. [Google Scholar] [CrossRef]
- Kaipio, J.; Somersalo, E. Statistical and Computational Inverse Problems; Springer Science & Business Media: New York, NY, USA, 2006; Volume 160. [Google Scholar] [CrossRef]
- Williams, C.K.; Rasmussen, C.E. Gaussian Processes for Machine Learning; MIT Press: Cambridge, MA, USA, 2006; Volume 2. [Google Scholar] [CrossRef] [Green Version]
- Mahmoodzadeh, A.; Mohammadi, M.; Abdulhamid, S.N.; Ali, H.F.H.; Ibrahim, H.H.; Rashidi, S. Forecasting tunnel path geology using Gaussian process regression. Geomech. Eng. 2022, 28, 359–374. [Google Scholar] [CrossRef]
- Hoolohan, V.; Tomlin, A.S.; Cockerill, T. Improved near surface wind speed predictions using Gaussian process regression combined with numerical weather predictions and observed meteorological data. Renew. Energy 2018, 126, 1043–1054. [Google Scholar] [CrossRef]
- Gonzalvez, J.; Lezmi, E.; Roncalli, T.; Xu, J. Financial applications of gaussian processes and bayesian optimization. arXiv 2019, arXiv:1903.04841. [Google Scholar] [CrossRef] [Green Version]
- Schölkopf, B.; Smola, A.J.; Bach, F. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and beyond; MIT Press: Cambridge, MA, USA, 2002. [Google Scholar]
- Drucker, H.; Wu, D.; Vapnik, V.N. Support vector machines for spam categorization. IEEE Trans. Neural Netw. 1999, 10, 1048–1054. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tipping, M.E. Sparse Bayesian learning and the relevance vector machine. J. Mach. Learn. Res. 2001, 1, 211–244. [Google Scholar]
- Lange-Hegermann, M. Linearly constrained gaussian processes with boundary conditions. In Proceedings of the International Conference on Artificial Intelligence and Statistics, PMLR, San Diego, USA, 13–15 April 2021; pp. 1090–1098. [Google Scholar]
- Gahungu, P.; Lanyon, C.W.; Alvarez, M.A.; Bainomugisha, E.; Smith, M.; Wilkinson, R.D. Adjoint-aided inference of Gaussian process driven differential equations. arXiv 2022, arXiv:2202.04589. [Google Scholar] [CrossRef]
- Gulian, M.; Frankel, A.; Swiler, L. Gaussian process regression constrained by boundary value problems. Comput. Methods Appl. Mech. Eng. 2022, 388, 114117. [Google Scholar] [CrossRef]
- Yang, S.; Wong, S.W.; Kou, S. Inference of dynamic systems from noisy and sparse data via manifold-constrained Gaussian processes. Proc. Natl. Acad. Sci. USA 2021, 118, e2020397118. [Google Scholar] [CrossRef] [PubMed]
- Raissi, M.; Perdikaris, P.; Karniadakis, G.E. Numerical Gaussian processes for time-dependent and nonlinear partial differential equations. SIAM J. Sci. Comput. 2018, 40, A172–A198. [Google Scholar] [CrossRef] [Green Version]
- Oates, C.J.; Sullivan, T.J. A modern retrospective on probabilistic numerics. Stat. Comput. 2019, 29, 1335–1351. [Google Scholar] [CrossRef] [Green Version]
- Hennig, P.; Osborne, M.A.; Girolami, M. Probabilistic numerics and uncertainty in computations. Proc. R. Soc. A 2015, 471, 20150142. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Conrad, P.R.; Girolami, M.; Särkkä, S.; Stuart, A.; Zygalakis, K. Statistical analysis of differential equations: Introducing probability measures on numerical solutions. Stat. Comput. 2017, 27, 1065–1082. [Google Scholar] [CrossRef] [Green Version]
- Kersting, H.; Sullivan, T.J.; Hennig, P. Convergence rates of Gaussian ODE filters. Stat. Comput. 2020, 30, 1791–1816. [Google Scholar] [CrossRef]
- Raissi, M.; Karniadakis, G.E. Hidden physics models: Machine learning of nonlinear partial differential equations. J. Comput. Phys. 2018, 357, 125–141. [Google Scholar] [CrossRef] [Green Version]
- Raissi, M.; Perdikaris, P.; Karniadakis, G.E. Machine learning of linear differential equations using Gaussian processes. J. Comput. Phys. 2017, 348, 683–693. [Google Scholar] [CrossRef] [Green Version]
- Reddy, J.N. Introduction to the Finite Element Method; McGraw-Hill Education: Columbus, OH, USA, 2019. [Google Scholar] [CrossRef] [Green Version]
- Gottlieb, D.; Orszag, S.A. Numerical Analysis of Spectral Methods: Theory and Applications; SIAM: Philadelphia, PA, USA, 1977. [Google Scholar] [CrossRef] [Green Version]
- Strikwerda, J.C. Finite Difference Schemes and Partial Differential Equations; SIAM: Philadelphia, PA, USA, 2004; Available online: https://www.semanticscholar.org/paper/Finite-Difference-Schemes-and-Partial-Differential-Strikwerda/757830fca3a06a8a402efad2d812bea0cf561702 (accessed on 20 August 2022).
- Bernardo, J.M.; Smith, A.F. Bayesian Theory; John Wiley & Sons: Hoboken, NJ, USA, 2009; Volume 405, Available online: https://onlinelibrary.wiley.com/doi/book/10.1002/9780470316870 (accessed on 20 August 2022).
- Podlubny, I. Fractional Differential Equations: An Introduction to Fractional Derivatives, Fractional Differential Equations, to Methods of Their Solution and Some of Their Applications; Elsevier: Amsterdam, The Netherlands, 1998. [Google Scholar]
- Povstenko, Y. Linear Fractional Diffusion-Wave Equation for Scientists and Engineers; Birkhäuser: New York, NY, USA, 2015. [Google Scholar] [CrossRef]
- König, H. Eigenvalue Distribution of Compact Operators; Birkhäuser: Basel, Switzerland, 2013; Volume 16. [Google Scholar] [CrossRef]
- Berlinet, A.; Thomas-Agnan, C. Reproducing Kernel Hilbert Spaces in Probability and Statistics; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2011. [Google Scholar] [CrossRef]
- Zhu, C.; Byrd, R.H.; Lu, P.; Nocedal, J. Algorithm 778: L-BFGS-B: Fortran subroutines for large-scale bound-constrained optimization. ACM Trans. Math. Softw. 1997, 23, 550–560. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. The whale optimization algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Dorigo, M.; Birattari, M.; Stutzle, T. Ant colony optimization. IEEE Comput. Intell. Mag. 2006, 1, 28–39. [Google Scholar] [CrossRef]
- Iserles, A. A First Course in the Numerical Analysis of Differential Equations; Number 44; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar] [CrossRef]
- Butcher, J.C. A history of Runge-Kutta methods. Appl. Numer. Math. 1996, 20, 247–260. [Google Scholar] [CrossRef]
Figure 1.
Basic workflow of MP-NGPs.

Figure 2.
Fractional equation of Example 1: the posterior distribution of the predicted solution at different time nodes, where is fixed to be . The red solid line represents the exact solution. The blue dash line represents the posterior mean. The green shade indicates the two posterior standard deviation centered on the posterior mean. Noiseless data and noisy data are used, respectively.
Figure 2.
Fractional equation of Example 1: the posterior distribution of the predicted solution at different time nodes, where is fixed to be . The red solid line represents the exact solution. The blue dash line represents the posterior mean. The green shade indicates the two posterior standard deviation centered on the posterior mean. Noiseless data and noisy data are used, respectively.

Figure 3.
Fractional equation of Example 1: the posterior distribution of the predicted solution at different time nodes, where is fixed to be . Noiseless data and noisy data are used, respectively.
Figure 3.
Fractional equation of Example 1: the posterior distribution of the predicted solution at different time nodes, where is fixed to be . Noiseless data and noisy data are used, respectively.

Figure 4.
Fractional equation of Example 1: the posterior distribution of the predicted solution at different time nodes, where is fixed to be . Noiseless data and noisy data are used, respectively.
Figure 4.
Fractional equation of Example 1: the posterior distribution of the predicted solution at different time nodes, where is fixed to be . Noiseless data and noisy data are used, respectively.

Figure 5.
Integro-differential equation: the posterior distribution of the predicted solution at different time nodes, where . Noiseless data and noisy data are used, respectively.
Figure 5.
Integro-differential equation: the posterior distribution of the predicted solution at different time nodes, where . Noiseless data and noisy data are used, respectively.

Figure 6.
Problem of Example 3: Time versus the relative spatial error and maximum absolute error until the final time step is reached, where is fixed to be 0.01.
Figure 6.
Problem of Example 3: Time versus the relative spatial error and maximum absolute error until the final time step is reached, where is fixed to be 0.01.

Figure 7.
Results of Example 4, (a) impact of the number of initial data points (inhomogeneous term data points, artificially generated data points and delay term data points) on , when the backward Euler scheme is employed. Fix to be , and in turn. (b) Impact of the level of the additive noise on the maximum absolute error , when the backward Euler scheme is used. Fix the number of initial data points (inhomogeneous term data points, artificially generated data points and delay term data points) to be 20, and take .
Figure 7.
Results of Example 4, (a) impact of the number of initial data points (inhomogeneous term data points, artificially generated data points and delay term data points) on , when the backward Euler scheme is employed. Fix to be , and in turn. (b) Impact of the level of the additive noise on the maximum absolute error , when the backward Euler scheme is used. Fix the number of initial data points (inhomogeneous term data points, artificially generated data points and delay term data points) to be 20, and take .

Figure 8.
Problem of Example 1: (a) The posterior distribution of the predicted solution at different time nodes, where the backward Euler scheme is used. Fix the number of initial data points (inhomogeneous term data points, artificially generated data points and delay term data points) to be 30, and take . (b) The posterior distribution of the predicted solution at different time nodes, where the trapezoidal scheme is used. The other experimental conditions are the same as those with the backward Euler scheme. (c) Time versus maximum absolute error until the final time step is reached, where the backward Euler scheme and the trapezoidal scheme are both considered.
Figure 8.
Problem of Example 1: (a) The posterior distribution of the predicted solution at different time nodes, where the backward Euler scheme is used. Fix the number of initial data points (inhomogeneous term data points, artificially generated data points and delay term data points) to be 30, and take . (b) The posterior distribution of the predicted solution at different time nodes, where the trapezoidal scheme is used. The other experimental conditions are the same as those with the backward Euler scheme. (c) Time versus maximum absolute error until the final time step is reached, where the backward Euler scheme and the trapezoidal scheme are both considered.

Figure 9.
(a) The posterior distribution of the predicted solution at different time nodes, where Dirichlet boundary conditions are employed. (b) The posterior distribution of the predicted solution at different time nodes, where Neumann boundary conditions are employed. (c) The posterior distribution of the predicted solution at different time nodes, where mixed boundary conditions are employed. (d) Time versus the maximum absolute error until the final time step is reached.
Figure 9.
(a) The posterior distribution of the predicted solution at different time nodes, where Dirichlet boundary conditions are employed. (b) The posterior distribution of the predicted solution at different time nodes, where Neumann boundary conditions are employed. (c) The posterior distribution of the predicted solution at different time nodes, where mixed boundary conditions are employed. (d) Time versus the maximum absolute error until the final time step is reached.


Figure 10.
Wave equation of Example 6: (a) The posterior distribution of the predicted solution at different time nodes, where the second order central difference scheme is used. (b) The posterior distribution of the predicted solution at different time nodes, where the backward Euler scheme is used. (c) Time versus maximum absolute error until the final time step is reached, where the second order central difference scheme (SCD) and the backward Euler scheme (BE) are both considered.
Figure 10.
Wave equation of Example 6: (a) The posterior distribution of the predicted solution at different time nodes, where the second order central difference scheme is used. (b) The posterior distribution of the predicted solution at different time nodes, where the backward Euler scheme is used. (c) Time versus maximum absolute error until the final time step is reached, where the second order central difference scheme (SCD) and the backward Euler scheme (BE) are both considered.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Fractional equation of Example 1: maximum absolute error at some time nodes, where , is fixed to be , , and in turn, and noiseless data are used.
Table 1.
Fractional equation of Example 1: maximum absolute error at some time nodes, where , is fixed to be , , and in turn, and noiseless data are used.
| t | ||||||
| t | ||||||
Table 2.
Fractional equation of Example 1: maximum absolute error at some time nodes, where , is fixed to be , , and in turn, and noisy data are used.
Table 2.
Fractional equation of Example 1: maximum absolute error at some time nodes, where , is fixed to be , , and in turn, and noisy data are used.
| t | ||||||
| t | ||||||
Table 3.
Integro-differential equation of Example 2: maximum absolute error at some time nodes, where , where experiments are performed with noiseless data and noisy data, respectively.
Table 3.
Integro-differential equation of Example 2: maximum absolute error at some time nodes, where , where experiments are performed with noiseless data and noisy data, respectively.
| t | |||||
| t | |||||
Table 4.
Problem of Example 3: Relative spatial error and maximum absolute error at some time nodes, where is fixed to be 0.01.
Table 4.
Problem of Example 3: Relative spatial error and maximum absolute error at some time nodes, where is fixed to be 0.01.
| t | |||||
| t | |||||
Table 5.
Problem of Example 4: maximum absolute error at five time nodes for different under the backward Euler scheme and the convergence order in time.
Table 5.
Problem of Example 4: maximum absolute error at five time nodes for different under the backward Euler scheme and the convergence order in time.
| 0.2 | * | ||||||
| 0.1 | 1.966 | ||||||
| 0.05 | 1.951 | ||||||
| 0.025 | 1.966 | ||||||
| 0.0125 | 1.991 | ||||||
| 0.00625 | 1.963 |
Table 6.
Problem of Example 4: maximum absolute error at five time nodes for different under the trapezoidal scheme and the convergence order in time.
Table 6.
Problem of Example 4: maximum absolute error at five time nodes for different under the trapezoidal scheme and the convergence order in time.
| 0.2 | * | ||||||
| 0.1 | 2.573 | ||||||
| 0.05 | 2.135 | ||||||
| 0.025 | 2.002 | ||||||
| 0.0125 | 2.001 | ||||||
| 0.00625 | 1.964 |
Table 7.
Example 5: Maximum absolute error at some time nodes, where , where Dirichlet, Neumann and mixed boundary conditions are used, respectively.
Table 7.
Example 5: Maximum absolute error at some time nodes, where , where Dirichlet, Neumann and mixed boundary conditions are used, respectively.
| t | |||||
| t | |||||
Table 8.
Wave equation of Example 6: Maximum absolute error at some time nodes, where , where the second order central difference scheme (SCD) and the backward Euler scheme (BE) are applied, respectively.
Table 8.
Wave equation of Example 6: Maximum absolute error at some time nodes, where , where the second order central difference scheme (SCD) and the backward Euler scheme (BE) are applied, respectively.
| t | |||||
| t | |||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Gu, W.; Zhang, W.; Han, Y. Numerical Investigation of a Class of Nonlinear Time-Dependent Delay PDEs Based on Gaussian Process Regression. Fractal Fract. 2022, 6, 606. https://doi.org/10.3390/fractalfract6100606
AMA Style
Gu W, Zhang W, Han Y. Numerical Investigation of a Class of Nonlinear Time-Dependent Delay PDEs Based on Gaussian Process Regression. Fractal and Fractional. 2022; 6(10):606. https://doi.org/10.3390/fractalfract6100606
Chicago/Turabian StyleGu, Wei, Wenbo Zhang, and Yaling Han. 2022. "Numerical Investigation of a Class of Nonlinear Time-Dependent Delay PDEs Based on Gaussian Process Regression" Fractal and Fractional 6, no. 10: 606. https://doi.org/10.3390/fractalfract6100606