

A Novel Variable Selection Method Based on Ordered Predictors Selection and Successive Projections Algorithm for Predicting Gastrodin Content in Fresh Gastrodia elata Using Fourier Transform Near-Infrared Spectroscopy and Chemometrics
 , , ,
, , ,
Abstract
:1. Introduction
2. Materials and Methods
2.1. G. elata Samples
2.2. FT-NIR Spectroscopic Acquisition
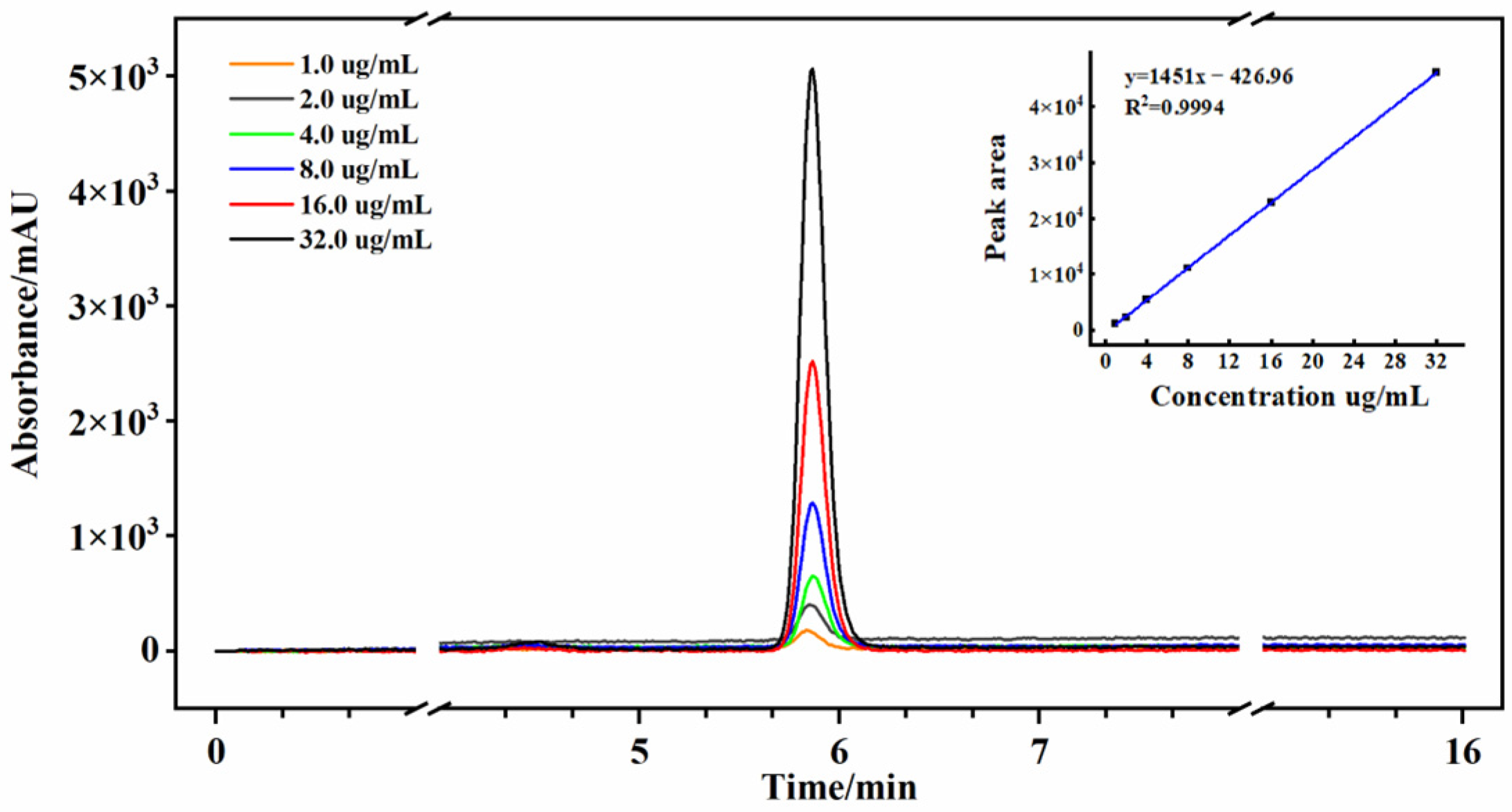
2.3. Gastrodin Content Measurement
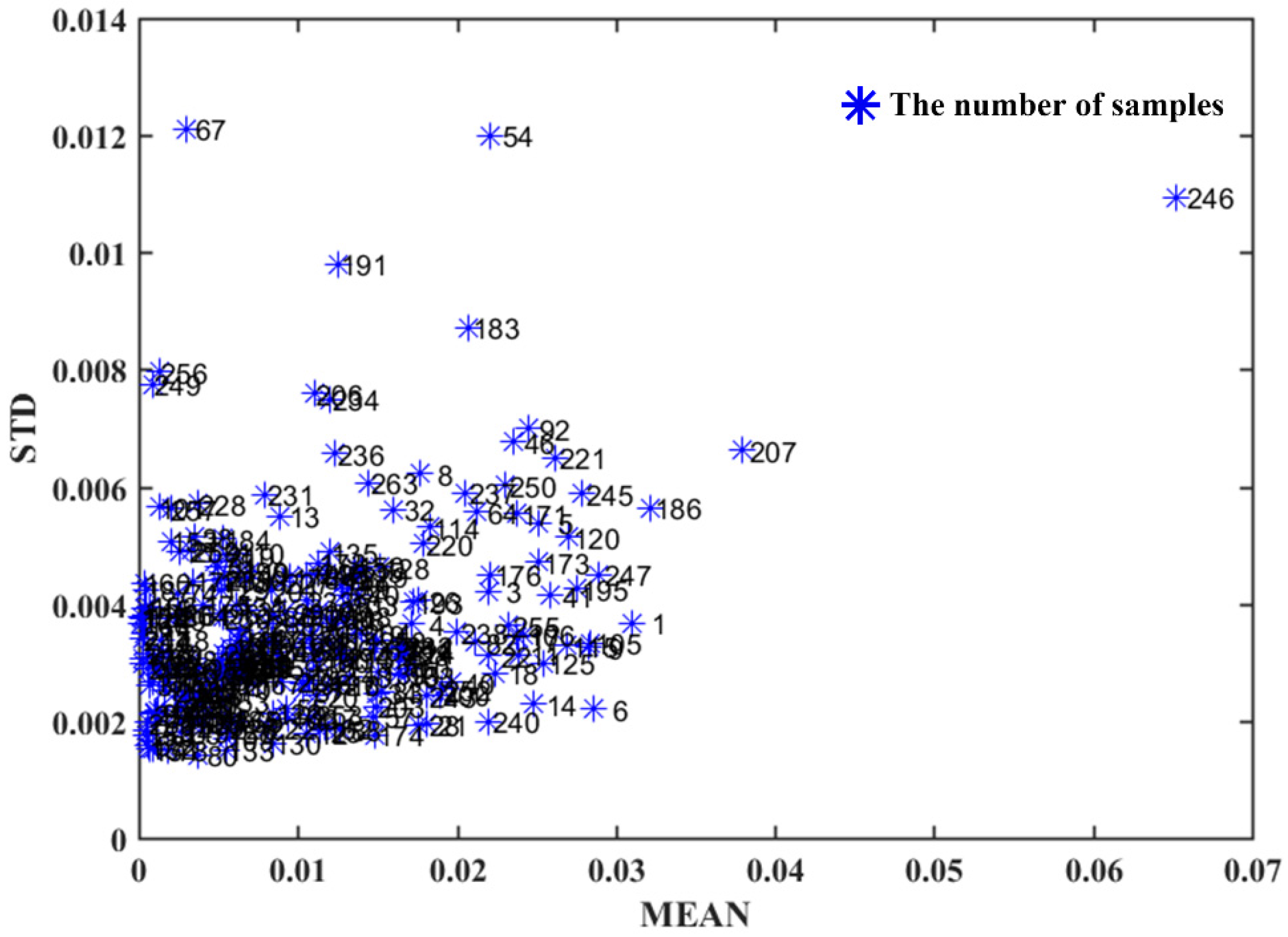
2.4. Outlier Detection
2.5. Chemometrics and Modeling Evaluation
2.5.1. Spectra Pre-Processing
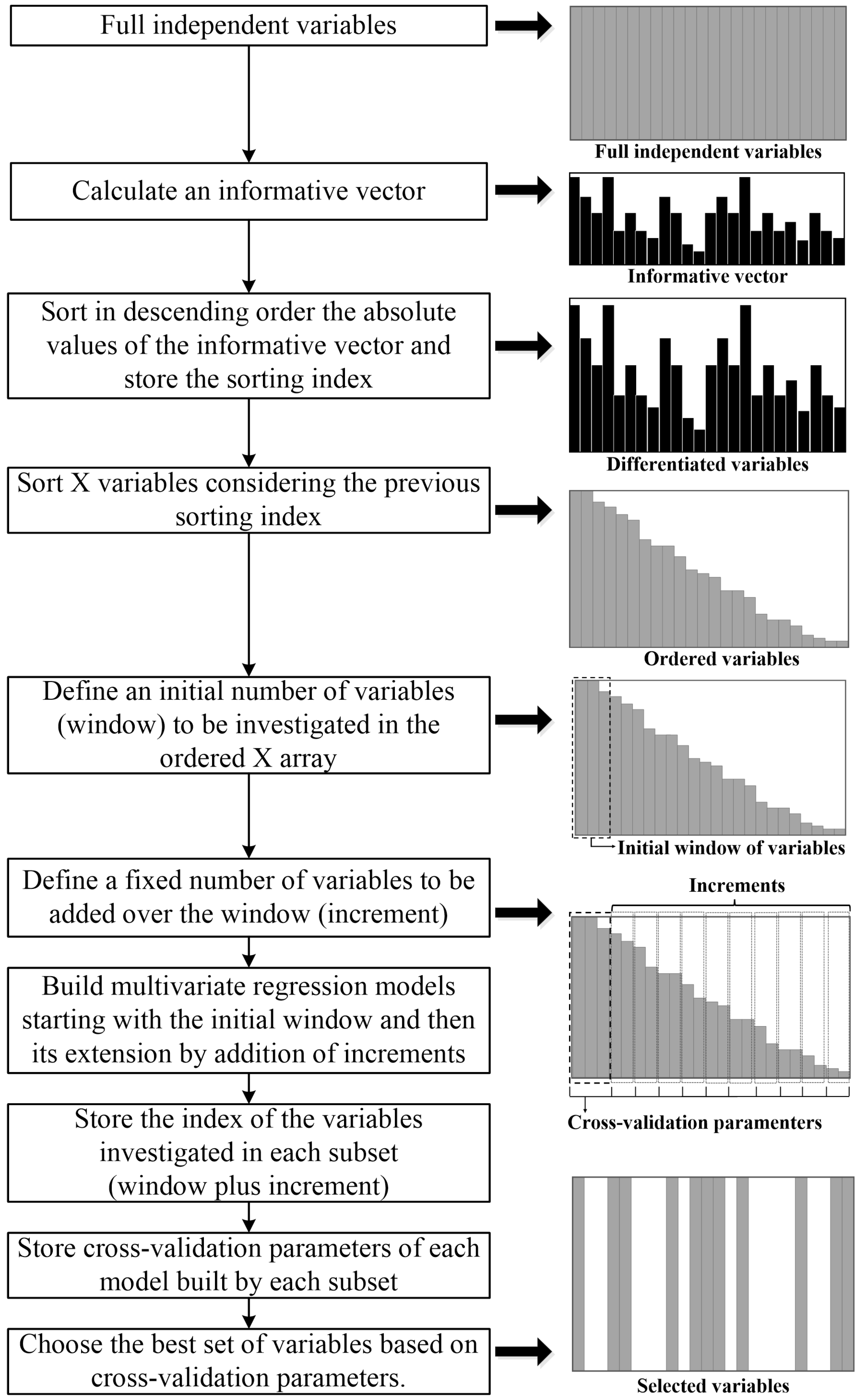
2.5.2. Variable Selection
2.5.3. Multivariate Regression Models and Model Evaluation
2.5.4. Software
3. Results
3.1. Gastrodin Content
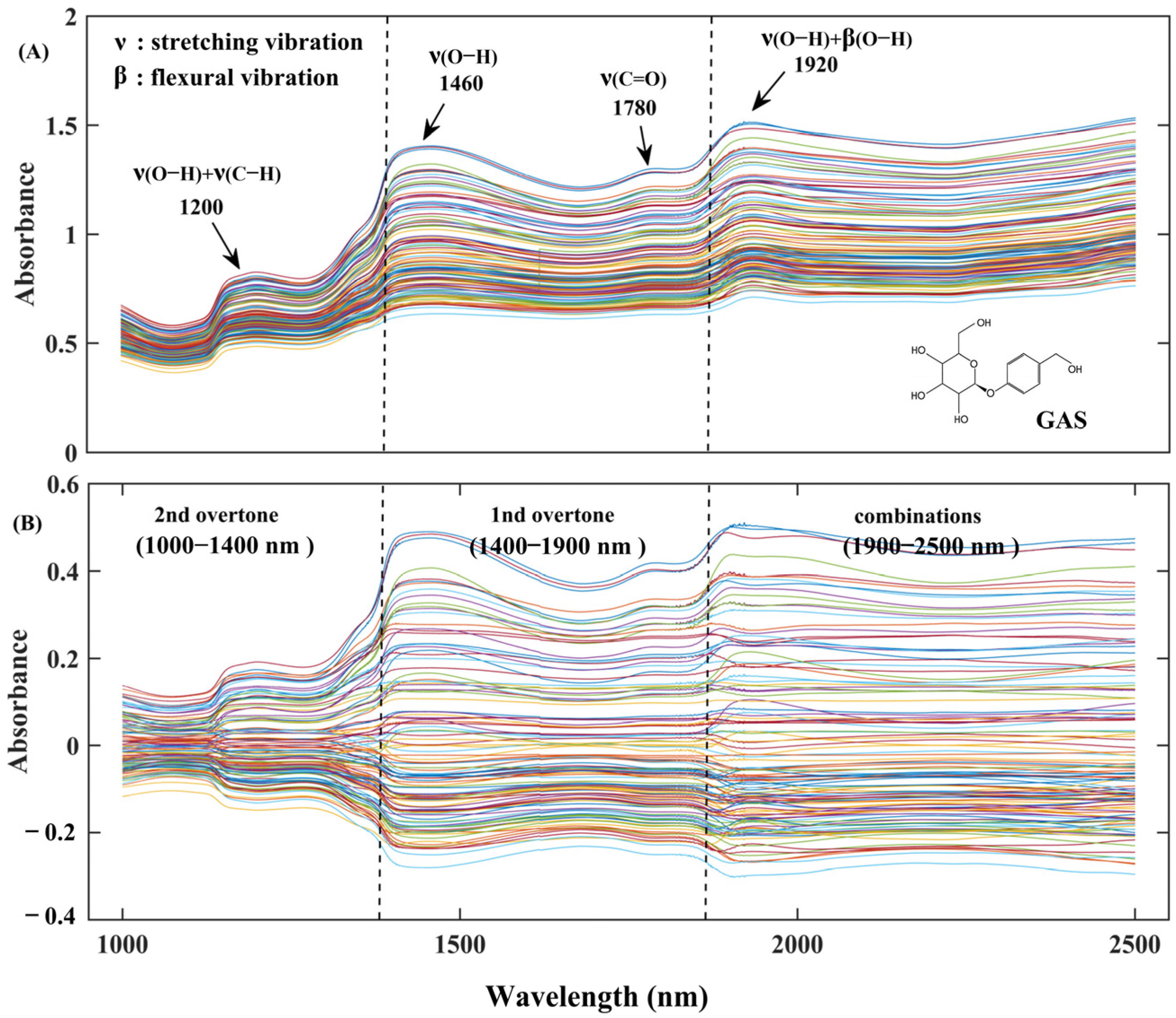
3.2. Spectral Interpretation
3.3. Multivariate Analysis
3.3.1. Spectral Preprocessing Methods and Modeling Based on PLSR
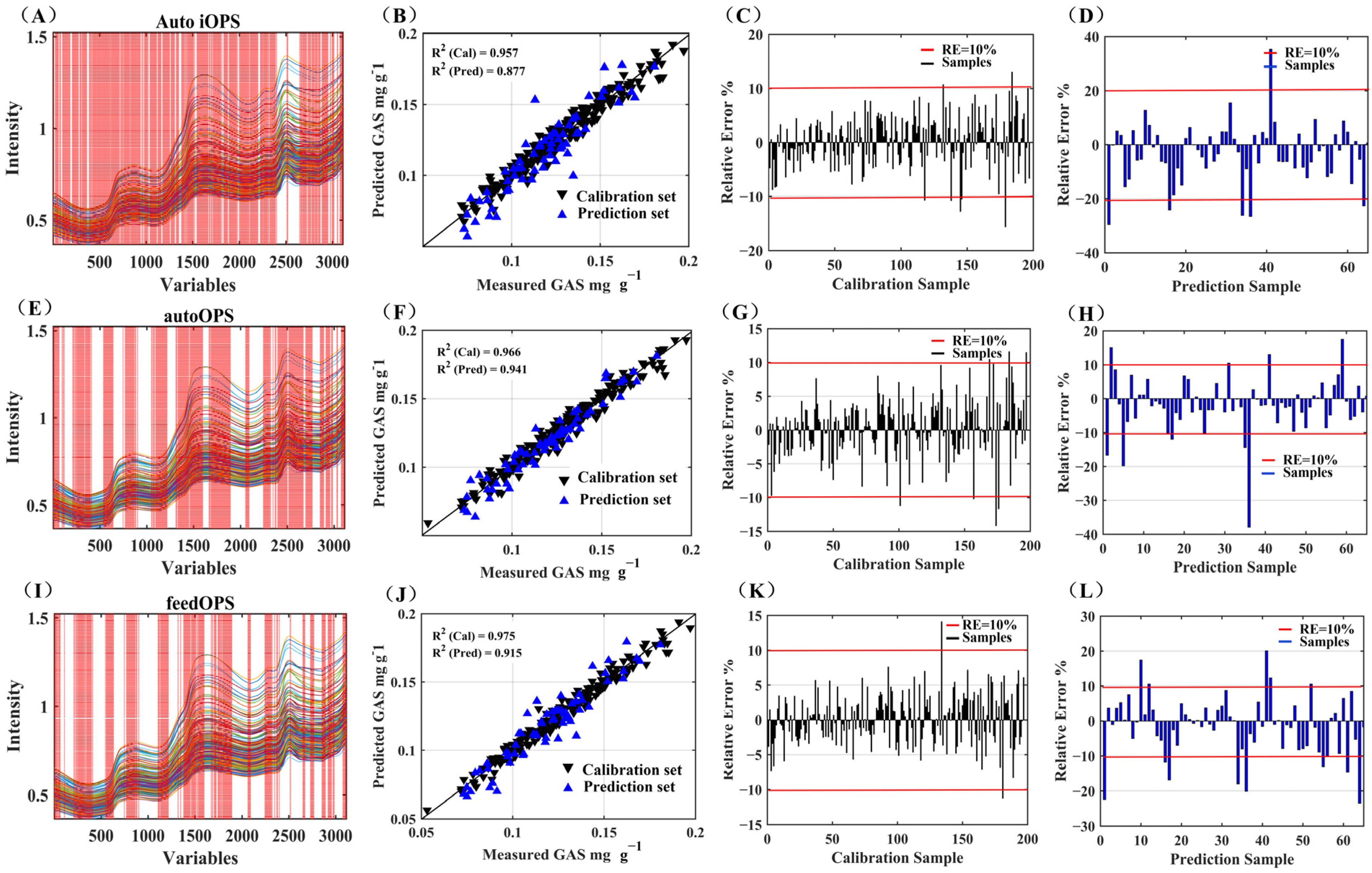
3.3.2. Effects of OPS Variable Selection Methods and Modeling Based on PLSR
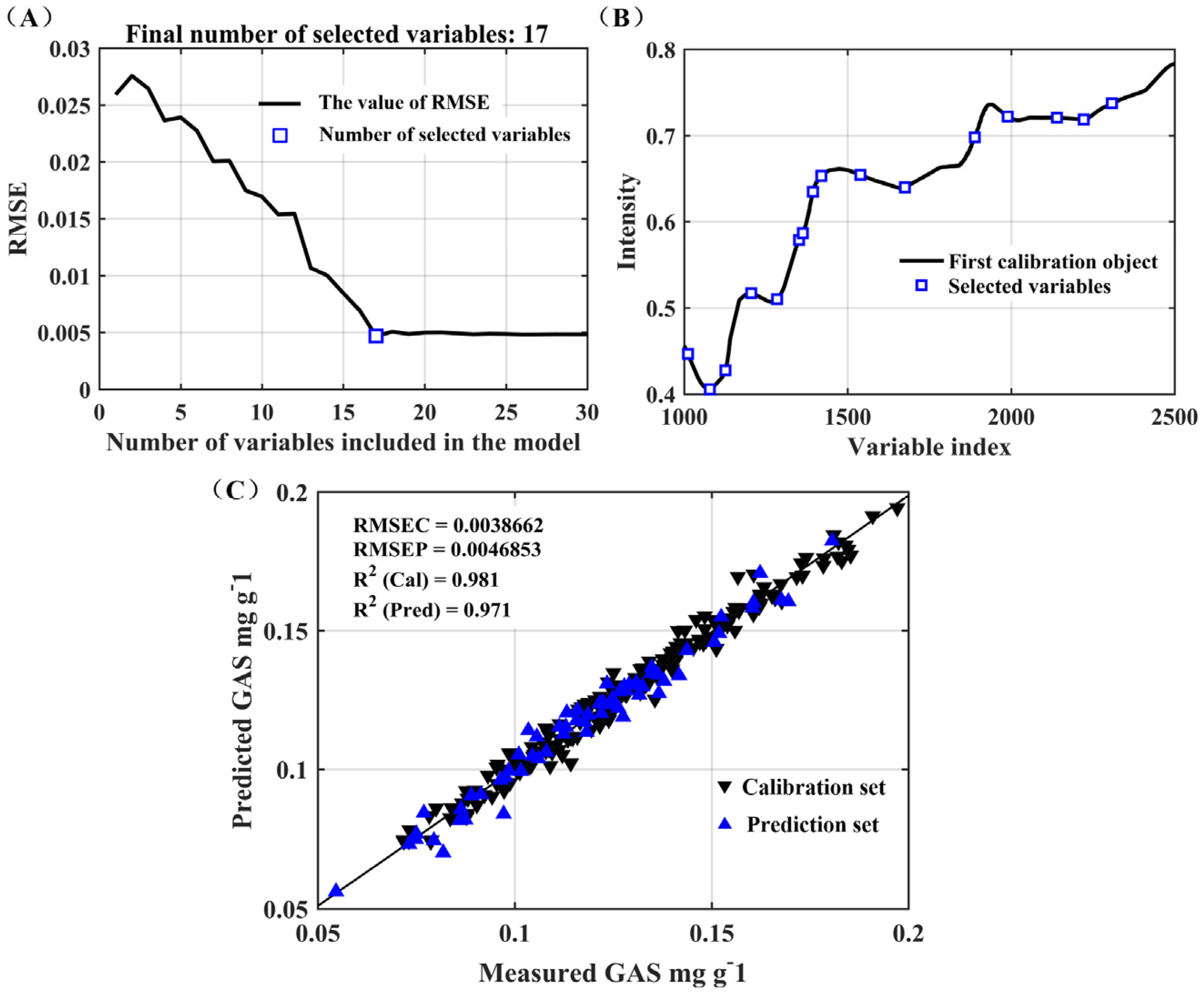
3.3.3. Multiple Linear Regression at Selected Wavelengths Based on SPA
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhan, H.-D.; Zhou, H.-Y.; Sui, Y.-P.; Du, X.-L.; Wang, W.; Dai, L.; Sui, F.; Huo, H.-R.; Jiang, T.-L. The Rhizome of Gastrodia elata Blume—An Ethnopharmacological Review. J. Ethnopharmacol. 2016, 189, 361–385. [Google Scholar] [CrossRef]
- Ojemann, L.M.; Nelson, W.L.; Shin, D.S.; Rowe, A.O.; Buchanan, R.A. Tian Ma, an Ancient Chinese Herb, Offers New Options for the Treatment of Epilepsy and Other Conditions. Epilepsy Behav. 2006, 8, 376–383. [Google Scholar] [CrossRef] [PubMed]
- Lin, Y.-E.; Lin, S.-H.; Chen, W.-C.; Ho, C.-T.; Lai, Y.-S.; Panyod, S.; Sheen, L.-Y. Antidepressant-like Effects of Water Extract of Gastrodia elata Blume in Rats Exposed to Unpredictable Chronic Mild Stress via Modulation of Monoamine Regulatory Pathways. J. Ethnopharmacol. 2016, 187, 57–65. [Google Scholar] [CrossRef]
- Ma, J.; Deng, Y.; Wang, Y.; Liu, Q.; An, J.; Li, M.; Song, N.; Zhang, J.; Cheng, L.; Ma, K. A Comparative Study on Ingredient and Efficiency Difference between Fresh and Steamed Gastrodia elata Blume: An Herbal Material to a Novel Functional Food. J. Funct. Foods. 2021, 82, 104512. [Google Scholar] [CrossRef]
- Yang, H.; Li, Q.; Li, L.; Chen, S.; Zhao, Y.; Hu, Y.; Wang, L.; Lan, X.; Zhong, L.; Lu, D. Gastrodin Modified Polyurethane Conduit Promotes Nerve Repair via Optimizing Schwann Cells Function. Bioact. Mater. 2022, 8, 355–367. [Google Scholar] [CrossRef] [PubMed]
- Pasquini, C. Near Infrared Spectroscopy: A Mature Analytical Technique with New Perspectives—A Review. Anal. Chim. Acta 2018, 1026, 8–36. [Google Scholar] [CrossRef]
- Wafula, E.N.; Onduso, M.; Wainaina, I.N.; Buvé, C.; Kinyanjui, P.K.; Githiri, S.M.; Saeys, W.; Sila, D.N.; Hendrickx, M. Antinutrient to Mineral Molar Ratios of Raw Common Beans and Their Rapid Prediction Using Near-Infrared Spectroscopy. Food Chem. 2022, 368, 130773. [Google Scholar] [CrossRef]
- Cortés, V.; Blasco, J.; Aleixos, N.; Cubero, S.; Talens, P. Monitoring Strategies for Quality Control of Agricultural Products Using Visible and Near-Infrared Spectroscopy: A Review. Trends Food Sci. Technol. 2019, 85, 138–148. [Google Scholar] [CrossRef]
- Shao, Q.-S.; Zhang, A.; Ye, W.-W.; Guo, H.-P.; Hu, R.-H. Fast Determination of Two Atractylenolides in Rhizoma atractylodis macrocephalae by Fourier Transform Near-Infrared Spectroscopy with Partial Least Squares. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2014, 120, 499–504. [Google Scholar] [CrossRef]
- Li, W.; Han, H.; Zhang, L.; Zhang, Y.; Qu, H. A Feasibility Study on the Non-Invasive Analysis of Bottled Compound E Jiao Oral Liquid Using near Infrared Spectroscopy. Sens. Actuators B Chem. 2015, 211, 131–137. [Google Scholar] [CrossRef]
- Wang, Y.; Qin, M.; Qi, J.; Yu, B.; Tang, L. Determination of Polysaccharide Content in Ophiopogon Japonicus by near Infrared Diffuse Reflectance Spectroscopy. Spectrosc. Spectr. Anal. 2009, 29, 2677–2680. [Google Scholar]
- Xue, J.; Wu, C.; Wang, L.; Jiang, S.; Huang, G.; Zhang, J.; Wen, S.; Ye, L. Dynamic Prediction Models for Alkaloid Content Using NIR Technology for the Study and Online Analysis of Parching in Areca Seed. Food Chem. 2011, 126, 725–730. [Google Scholar] [CrossRef]
- Oliveira, U.F.; Costa, A.M.; Roque, J.V.; Cardoso, W.; Motoike, S.Y.; Barbosa, M.H.P.; Teofilo, R.F. Predicting Oil Content in Ripe Macaw Fruits (Acrocomia aculeata) from Unripe Ones by near Infrared Spectroscopy and PLS Regression. Food Chem. 2021, 351, 129314. [Google Scholar] [CrossRef]
- Vohland, M.; Ludwig, M.; Thiele-Bruhn, S.; Ludwig, B. Determination of Soil Properties with Visible to Near- and Mid-Infrared Spectroscopy: Effects of Spectral Variable Selection. Geoderma 2014, 223–225, 88–96. [Google Scholar] [CrossRef]
- Biancolillo, A.; Marini, F.; Ruckebusch, C.; Vitale, R. Chemometric Strategies for Spectroscopy-Based Food Authentication. Appl. Sci. 2020, 10, 6544. [Google Scholar] [CrossRef]
- de Araújo Gomes, A.; Azcarate, S.M.; Diniz, P.H.G.D.; de Sousa Fernandes, D.D.; Veras, G. Variable Selection in the Chemometric Treatment of Food Data: A Tutorial Review. Food Chem. 2022, 370, 131072. [Google Scholar] [CrossRef] [PubMed]
- Roque, J.V.; Cardoso, W.; Peternelli, L.A.; Teófilo, R.F. Comprehensive New Approaches for Variable Selection Using Ordered Predictors Selection. Anal. Chim. Acta 2019, 1075, 57–70. [Google Scholar] [CrossRef]
- Soares, S.F.C.; Gomes, A.A.; Araujo, M.C.U.; Filho, A.R.G.; Galvão, R.K.H. The Successive Projections Algorithm. TrAC Trends Anal. Chem. 2013, 42, 84–98. [Google Scholar] [CrossRef]
- Kennard, R.W.; Stone, L.A. Computer Aided Design of Experiments. Technometrics 1969, 11, 137–148. [Google Scholar] [CrossRef]
- Shen, X.; Jin, C.; Xu, F.; Li, B.; Hu, Y. Determination of Gastrodin and Gastrogenin in Gastrodia elata by High Performance Liquid Chromatography. J. Anhui Univ. Chin. Med. 2014, 33, 70–72. [Google Scholar]
- Li, H.-D.; Xu, Q.-S.; Liang, Y.-Z. libPLS: An Integrated Library for Partial Least Squares Regression and Linear Discriminant Analysis. Chemom. Intell. Lab. Syst. 2018, 176, 34–43. [Google Scholar] [CrossRef]
- Rinnan, Å.; van den Berg, F.; Engelsen, S.B. Review of the Most Common Pre-Processing Techniques for near-Infrared Spectra. TrAC Trends Anal. Chem. 2009, 28, 1201–1222. [Google Scholar] [CrossRef]
- Wang, L.-L.; Lin, Y.-W.; Wang, X.-F.; Xiao, N.; Xu, Y.-D.; Li, H.-D.; Xu, Q.-S. A Selective Review and Comparison for Interval Variable Selection in Spectroscopic Modeling. Chemom. Intell. Lab. Syst. 2018, 172, 229–240. [Google Scholar] [CrossRef]
- Goodarzi, M.; Freitas, M.P.; Jensen, R. Ant Colony Optimization as a Feature Selection Method in the QSAR Modeling of Anti-HIV-1 Activities of 3-(3,5-Dimethylbenzyl) Uracil Derivatives Using MLR, PLS and SVM Regressions. Chemom. Intell. Lab. Syst. 2009, 98, 123–129. [Google Scholar] [CrossRef]
- Olivieri, A.C. Practical Guidelines for Reporting Results in Single- and Multi-Component Analytical Calibration: A Tutorial. Anal. Chim. Acta 2015, 868, 10–22. [Google Scholar] [CrossRef] [PubMed]
- Workman, J.; Weyer, L. Practical guide to interpretive near-infrared spectroscopy. Angew. Chem. Int. Ed. 2008, 47, 4628–4629. [Google Scholar] [CrossRef]
- Han, Z.; Cai, S.; Zhang, X.; Qian, Q.; Huang, Y.; Dai, F.; Zhang, G. Development of Predictive Models for Total Phenolics and Free P-Coumaric Acid Contents in Barley Grain by near-Infrared Spectroscopy. Food Chem. 2017, 227, 342–348. [Google Scholar] [CrossRef] [PubMed]
- Frizon, C.N.T.; Oliveira, G.A.; Perussello, C.A.; Peralta-Zamora, P.G.; Camlofski, A.M.O.; Rossa, Ü.B.; Hoffmann-Ribani, R. Determination of Total Phenolic Compounds in Yerba Mate (Ilex paraguariensis) Combining near Infrared Spectroscopy (NIR) and Multivariate Analysis. LWT 2015, 60, 795–801. [Google Scholar] [CrossRef]
- Saeys, W.; Nguyen Do Trong, N.; Van Beers, R.; Nicolaï, B.M. Multivariate Calibration of Spectroscopic Sensors for Postharvest Quality Evaluation: A Review. Postharvest Biol. Technol. 2019, 158, 110981. [Google Scholar] [CrossRef]
- Mariani, N.C.T.; de Almeida Teixeira, G.H.; de Lima, K.M.G.; Morgenstern, T.B.; Nardini, V.; Júnior, L.C.C. NIRS and iSPA-PLS for Predicting Total Anthocyanin Content in Jaboticaba Fruit. Food Chem. 2015, 174, 643–648. [Google Scholar] [CrossRef]
- Yang, X.; Guang, P.; Xu, G.; Zhu, S.; Chen, Z.; Huang, F. Manuka Honey Adulteration Detection Based on Near-Infrared Spectroscopy Combined with Aquaphotomics. LWT 2020, 132, 109837. [Google Scholar] [CrossRef]
- Ammari, F.; Redjdal, L.; Rutledge, D.N. Detection of Orange Juice Frauds Using Front-Face Fluorescence Spectroscopy and Independent Components Analysis. Food Chem. 2015, 168, 211–217. [Google Scholar] [CrossRef]
- Tomar, M.; Bhardwaj, R.; Kumar, M.; Singh, S.P.; Krishnan, V.; Kansal, R.; Verma, R.; Yadav, V.K.; dahuja, A.; Ahlawat, S.P.; et al. Development of NIR Spectroscopy Based Prediction Models for Nutritional Profiling of Pearl Millet (Pennisetum glaucum (L.)) R.Br: A Chemometrics Approach. LWT 2021, 149, 111813. [Google Scholar] [CrossRef]
- Lei, X.; Wang, X.; Li, G.; Fu, H.; Zhang, X.; Chen, F. Rapid Determination of Seven Components in Ahgelica sihehsis Based on near Infrared Spectroscopy. Chin. Herb. Med. 2019, 50, 3947–3954. [Google Scholar]
- Yin, L.; Zhou, J.; Chen, D.; Han, T.; Zheng, B.; Younis, A.; Shao, Q. A Review of the Application of Near-Infrared Spectroscopy to Rare Traditional Chinese Medicine. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2019, 221, 117208. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.-W.; Sun, S.-Q.; Zhou, Q.; Leung, H.-W. Fourier Transform Mid-Infrared (MIR) and near-Infrared (NIR) Spectroscopy for Rapid Quality Assessment of Chinese Medicine Preparation Honghua Oil. J. Pharm. Biomed. Anal. 2008, 46, 498–504. [Google Scholar] [CrossRef] [PubMed]
- Pissard, A.; Marques, E.J.N.; Dardenne, P.; Lateur, M.; Pasquini, C.; Pimentel, M.F.; Fernández Pierna, J.A.; Baeten, V. Evaluation of a Handheld Ultra-Compact NIR Spectrometer for Rapid and Non-Destructive Determination of Apple Fruit Quality. Postharvest Biol. Technol. 2021, 172, 111375. [Google Scholar] [CrossRef]
- Liu, K.; Chen, X.; Li, L.; Chen, H.; Ruan, X.; Liu, W. A Consensus Successive Projections Algorithm—Multiple Linear Regression Method for Analyzing near Infrared Spectra. Anal. Chim. Acta 2015, 858, 16–23. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Sample Size | Range | Mean ± SD |
|---|---|---|---|
| Calibration | 197 | 0.0531–0.1972 | 0.1276 ± 0.0279 |
| Prediction | 65 | 0.0547–0.1806 | 0.1171 ± 0.0274 |
| Pretreatment | LVs | Calibration Set | Cross-Validation Sets | ||
|---|---|---|---|---|---|
| RMSEC | RMSECV | ||||
| Raw | 10 | 0.8713 | 0.010 | 0.8405 | 0.0111 |
| MC | 10 | 0.9176 | 0.008 | 0.9010 | 0.0088 |
| Autoscale | 10 | 0.9168 | 0.0079 | 0.9002 | 0.011 |
| SG | 10 | 0.8576 | 0.0105 | 0.8276 | 0.0158 |
| 1st Derivative | 10 | 0.9355 | 0.0071 | 0.8711 | 0.01 |
| MSC | 10 | 0.8817 | 0.0096 | 0.8496 | 0.011 |
| SNV | 10 | 0.8818 | 0.0096 | 0.8495 | 0.011 |
| Methods | LVs | nVars | Calibration Set | Prediction Set | RPD | RER | SEP/SEC | ||
|---|---|---|---|---|---|---|---|---|---|
| RMSEC | RMSEP | ||||||||
| Full | 10 | 3112 | 0.9176 | 0.008 | 0.8363 | 0.0135 | 2.03 | 9.63 | 1.69 |
| autoOPS | 10 | 1305 | 0.9656 | 0.0052 | 0.9413 | 0.0074 | 3.70 | 17.57 | 1.42 |
| FeedOPS | 8 | 730 | 0.9748 | 0.0044 | 0.9148 | 0.0091 | 3.01 | 14.29 | 2.07 |
| iOPS | 10 | 1140 | 0.9574 | 0.0058 | 0.8772 | 0.0115 | 2.38 | 11.30 | 1.98 |
| Model | Method | nVars | RMSEC | RMSEP | RPD | RER | ||
|---|---|---|---|---|---|---|---|---|
| PLSR | autoOPS-SPA | 1011, 1078, 1125, 1200, 1283, 1351, 1362, 1393, 1420, 1538, 1675, 1888, 1959, 2140, 2221, 2307, 2500 nm | 0.9235 | 0.0077 | 0.8904 | 0.0096 | 2.85 | 13.54 |
| MLR | 0.9808 | 0.0039 | 0.9712 | 0.0047 | 5.83 | 27.65 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Zuo, C.; Chen, M.; Song, J.; Tu, K.; Lan, W.; Li, C.; Pan, L. A Novel Variable Selection Method Based on Ordered Predictors Selection and Successive Projections Algorithm for Predicting Gastrodin Content in Fresh Gastrodia elata Using Fourier Transform Near-Infrared Spectroscopy and Chemometrics. Foods 2023, 12, 4435. https://doi.org/10.3390/foods12244435
Wang Z, Zuo C, Chen M, Song J, Tu K, Lan W, Li C, Pan L. A Novel Variable Selection Method Based on Ordered Predictors Selection and Successive Projections Algorithm for Predicting Gastrodin Content in Fresh Gastrodia elata Using Fourier Transform Near-Infrared Spectroscopy and Chemometrics. Foods. 2023; 12(24):4435. https://doi.org/10.3390/foods12244435
Chicago/Turabian StyleWang, Zhenjie, Changzhou Zuo, Min Chen, Jin Song, Kang Tu, Weijie Lan, Chunyang Li, and Leiqing Pan. 2023. "A Novel Variable Selection Method Based on Ordered Predictors Selection and Successive Projections Algorithm for Predicting Gastrodin Content in Fresh Gastrodia elata Using Fourier Transform Near-Infrared Spectroscopy and Chemometrics" Foods 12, no. 24: 4435. https://doi.org/10.3390/foods12244435