
Online Measurement Error Detection for the ElectronicTransformer in a Smart Grid


 , , and
, , and
Abstract
:1. Introduction
1.1. Related Works
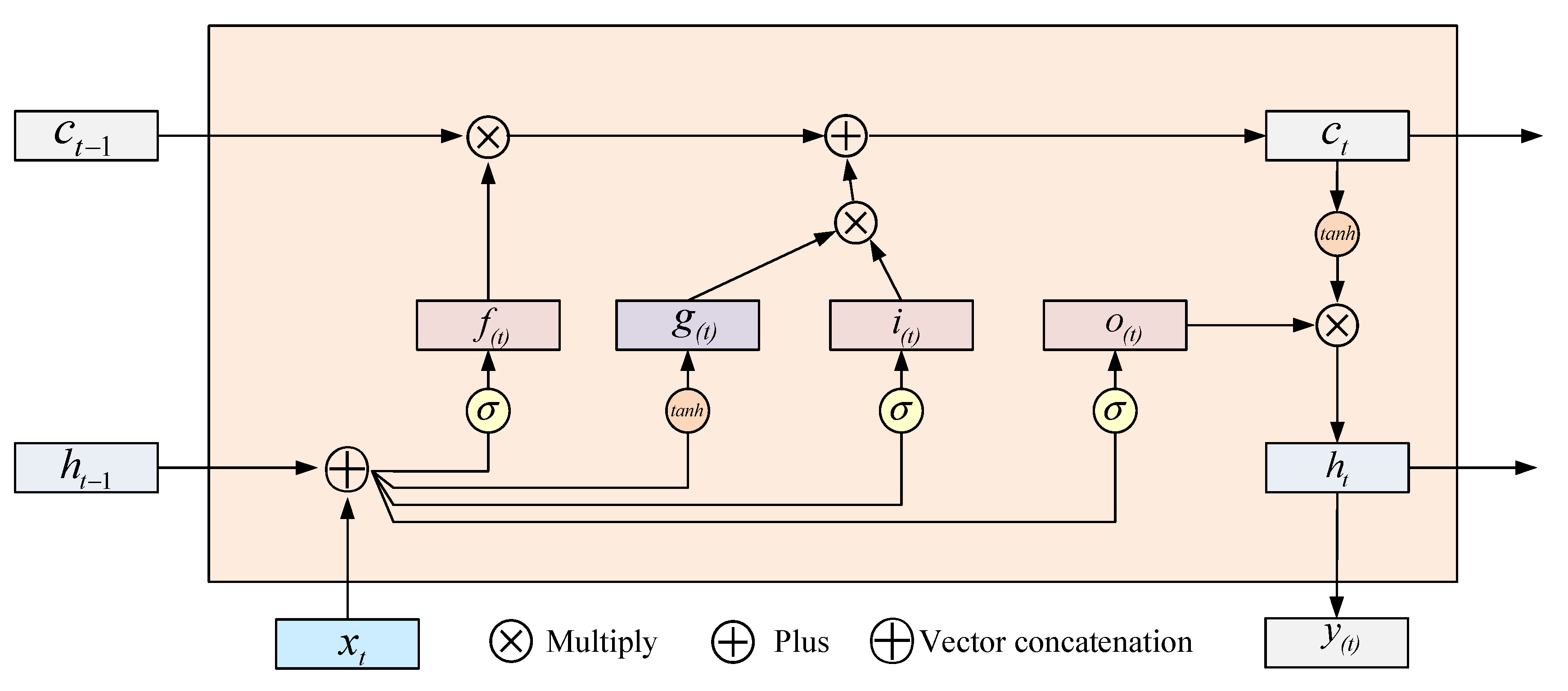
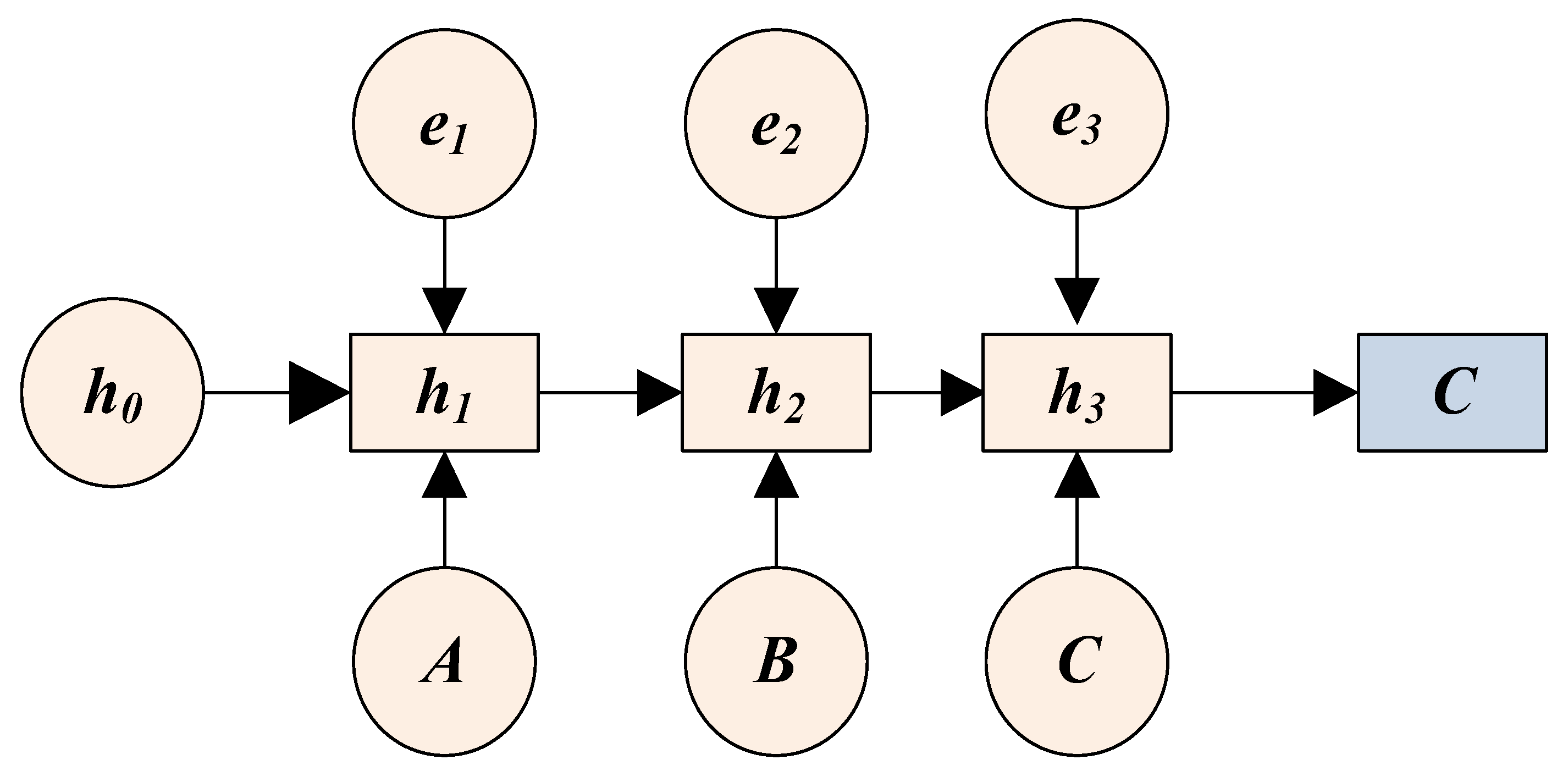
1.1.1. Long Short-Term Memory (LSTM) Network
- (1)
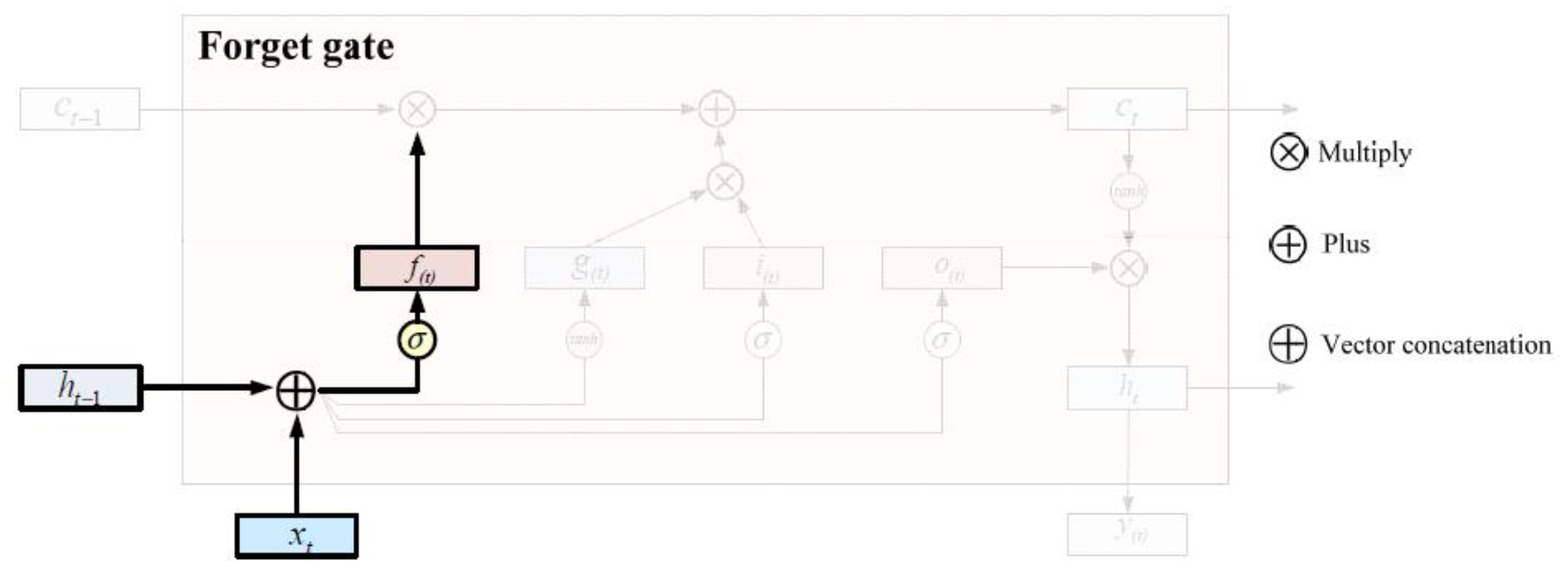
- Forget gate : The forget gate is used to control the proportion of input information, and when the time sequence information passes through the forget gate, part of the information is discarded so that the time span of each batch of data is the same and the data volume is not too large. This ratio control outputs a value between 0 and 1 through the sigmoid layer, with 0 representing “complete abandonment” and 1 representing “complete retention”. The implementation diagram of the forget door is shown in Figure 2.
- (2)
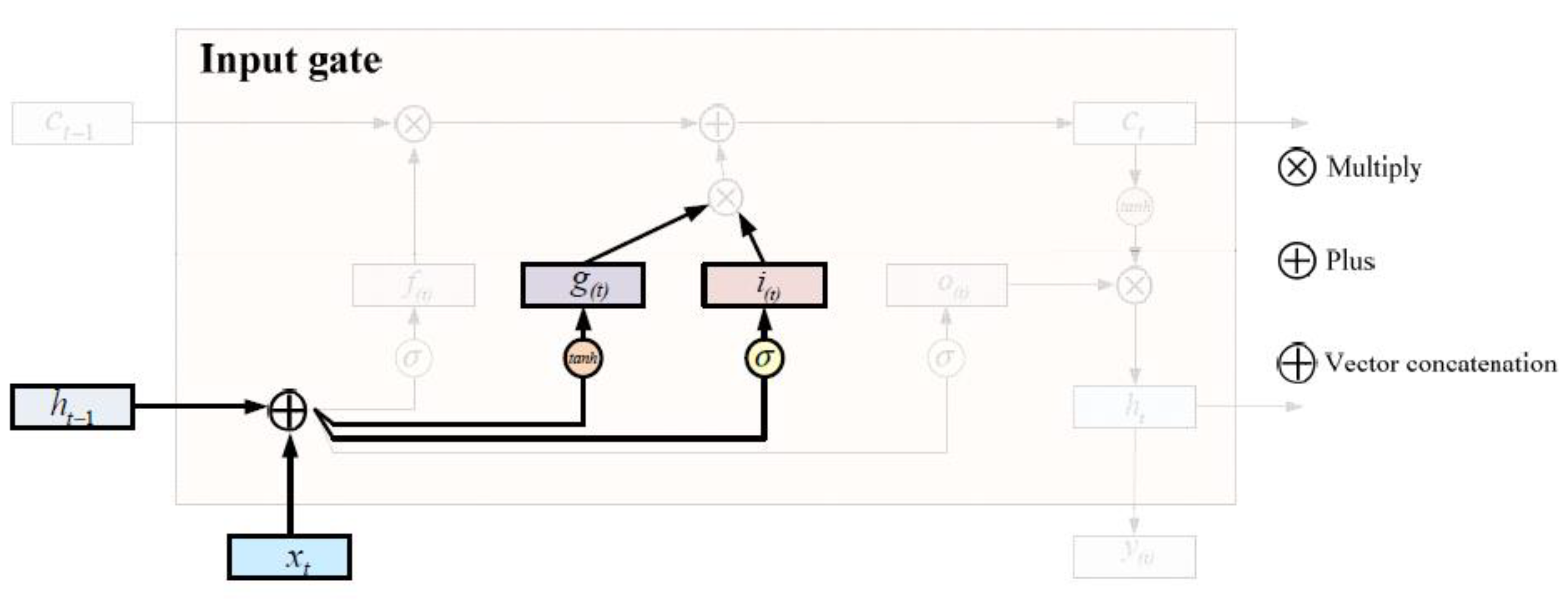
- Input gate The input gate controls the input process of the current moment information. This process includes the input gate completing the updating of the current moment information, and at the same time superimposes the input of a moment on the hidden layer to the current state. The input gate function includes a sigmoid function. The implementation diagram of the input gate is shown in Figure 3.
- (3)
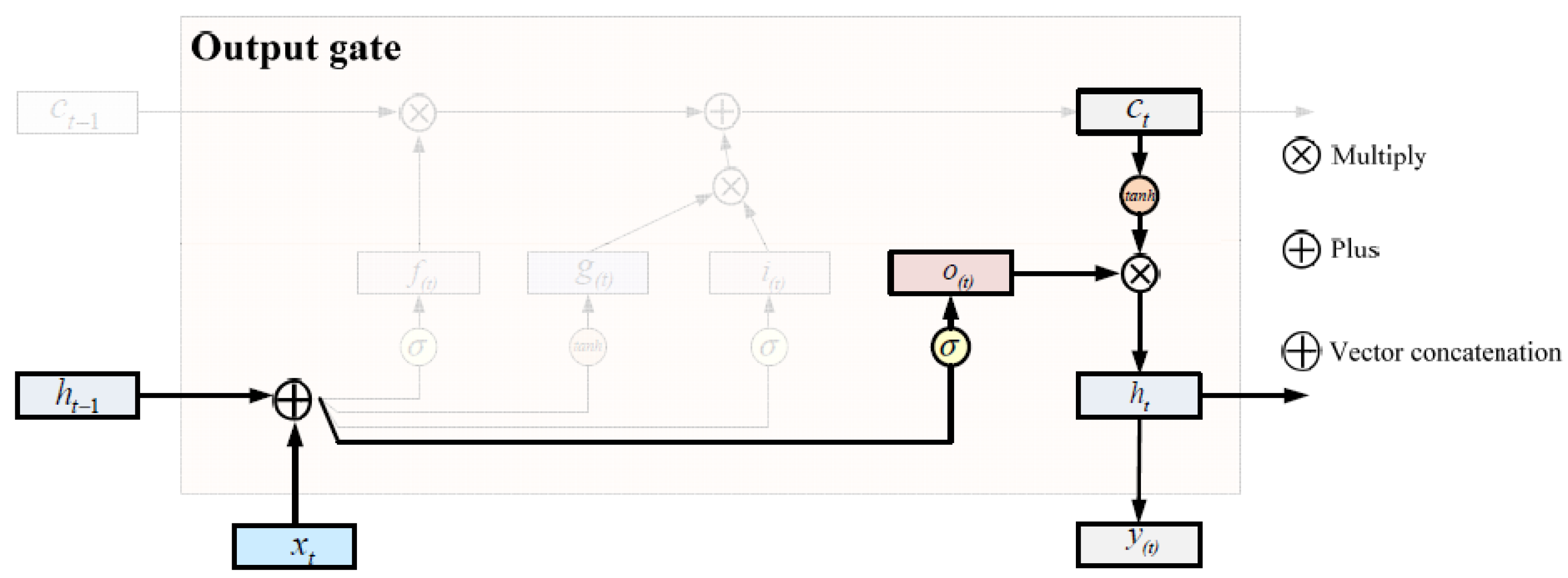
- Output gate The output gate function controls the output information and the timing information returned to the hidden layer before the memory unit information is output. By using the output gate, the state is updated, while the state of ht−1 is retained in the time unit operating under the hidden layer. The implementation diagram of the output gate is shown in Figure 4 below.
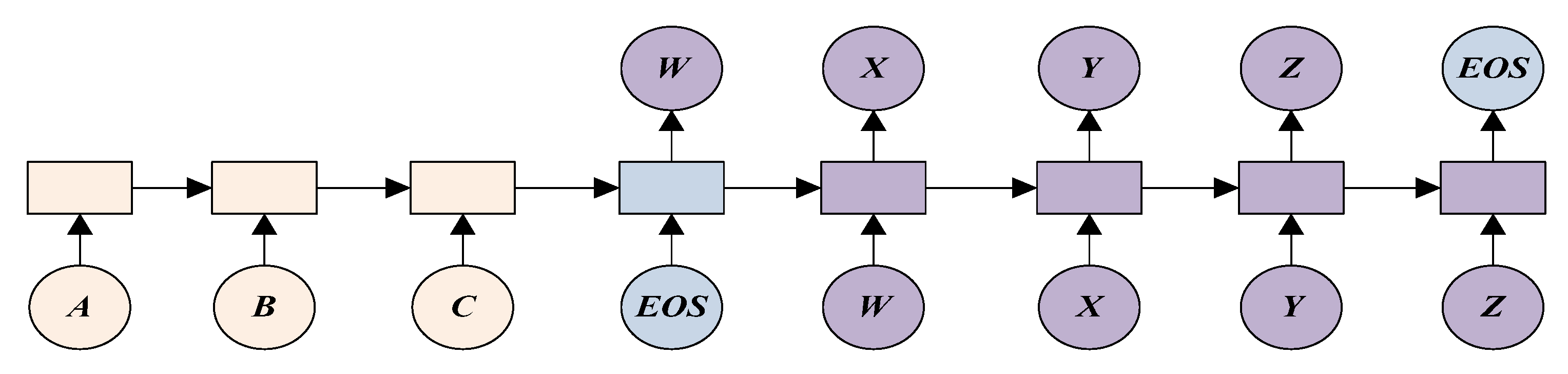
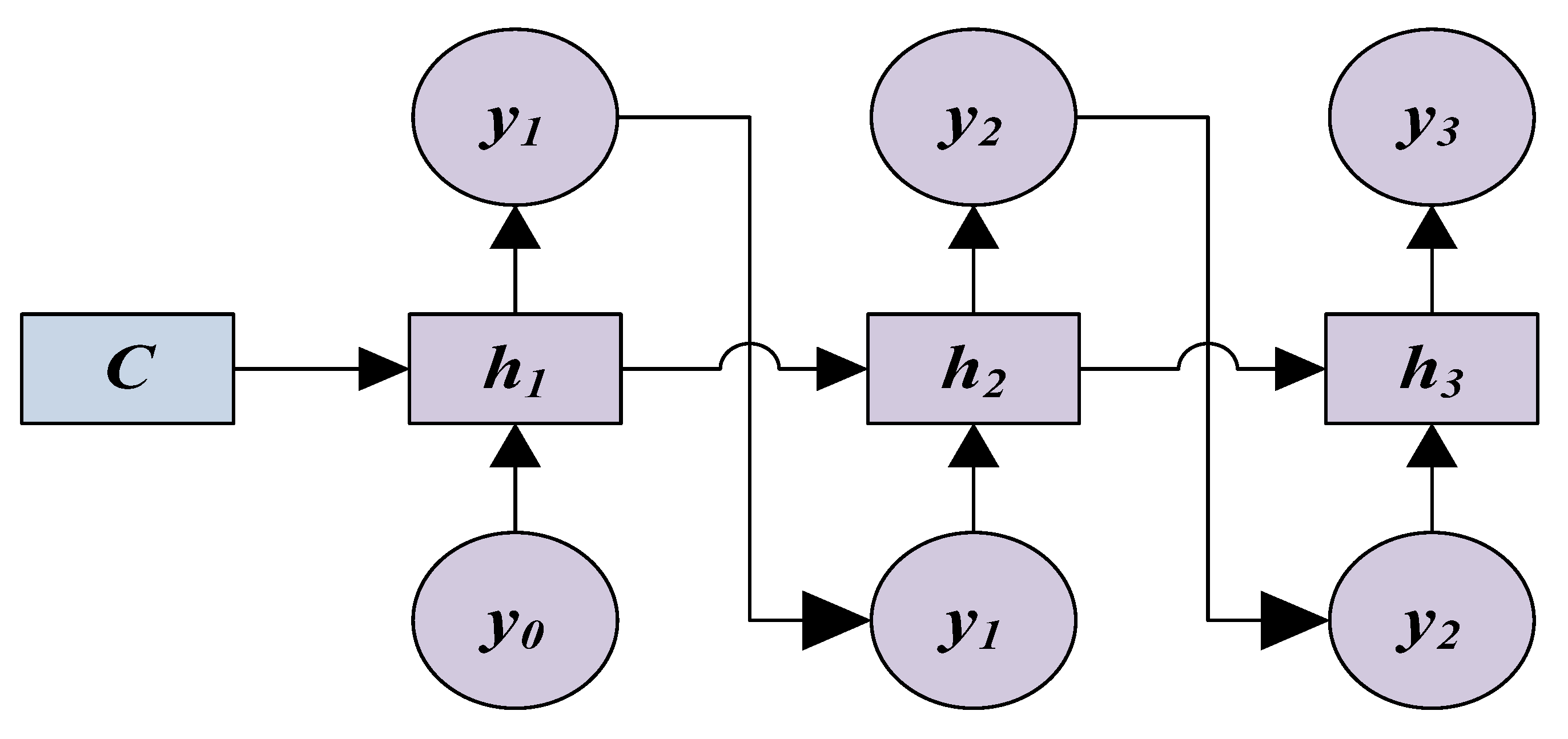
1.1.2. Seq2Seq Network Model
1.2. Construction of Prediction Model Based on Optimized Neural Network
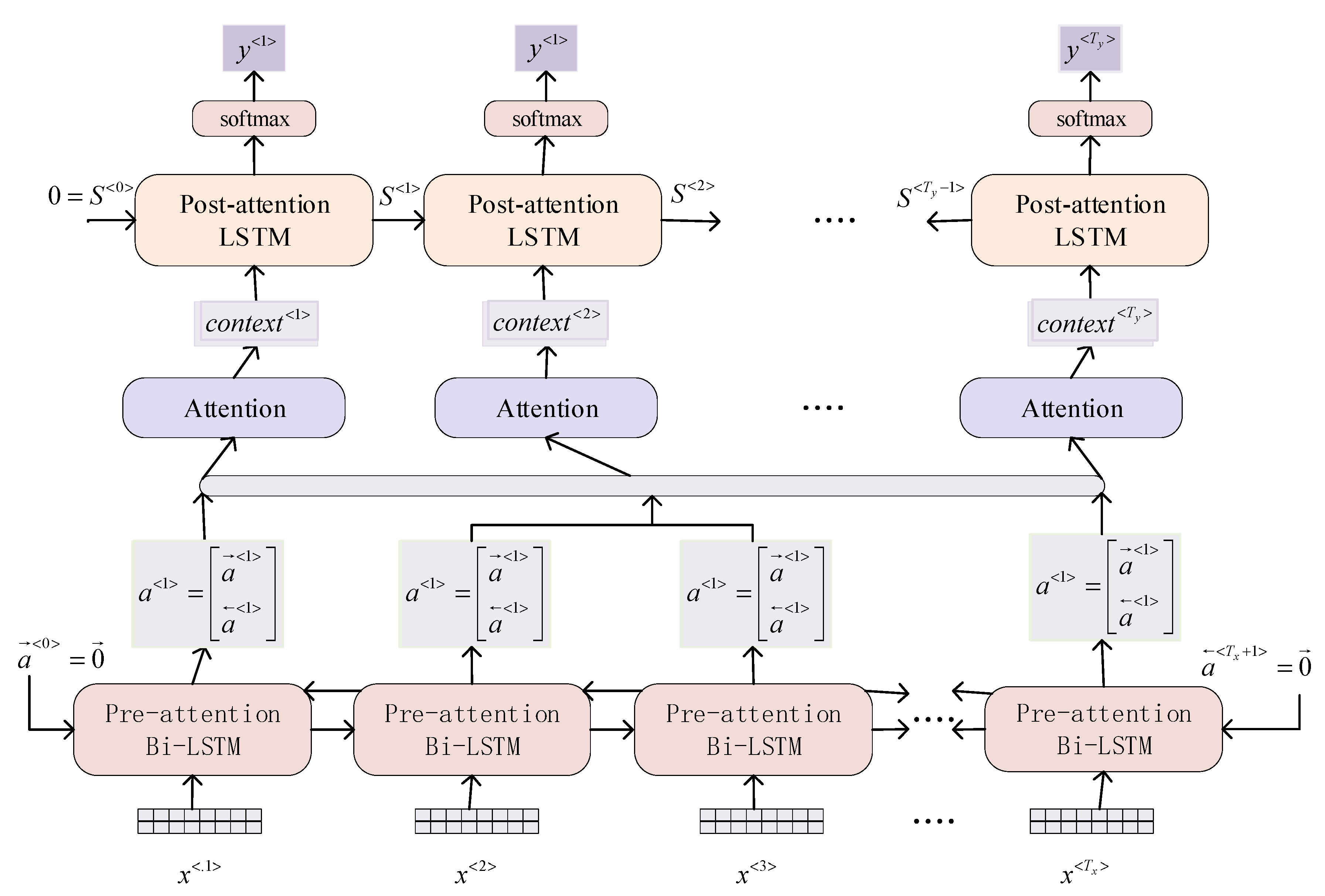
1.2.1. Attention Mechanism (AM)
1.2.2. Construction of Seq2Seq Model
2. Experiment
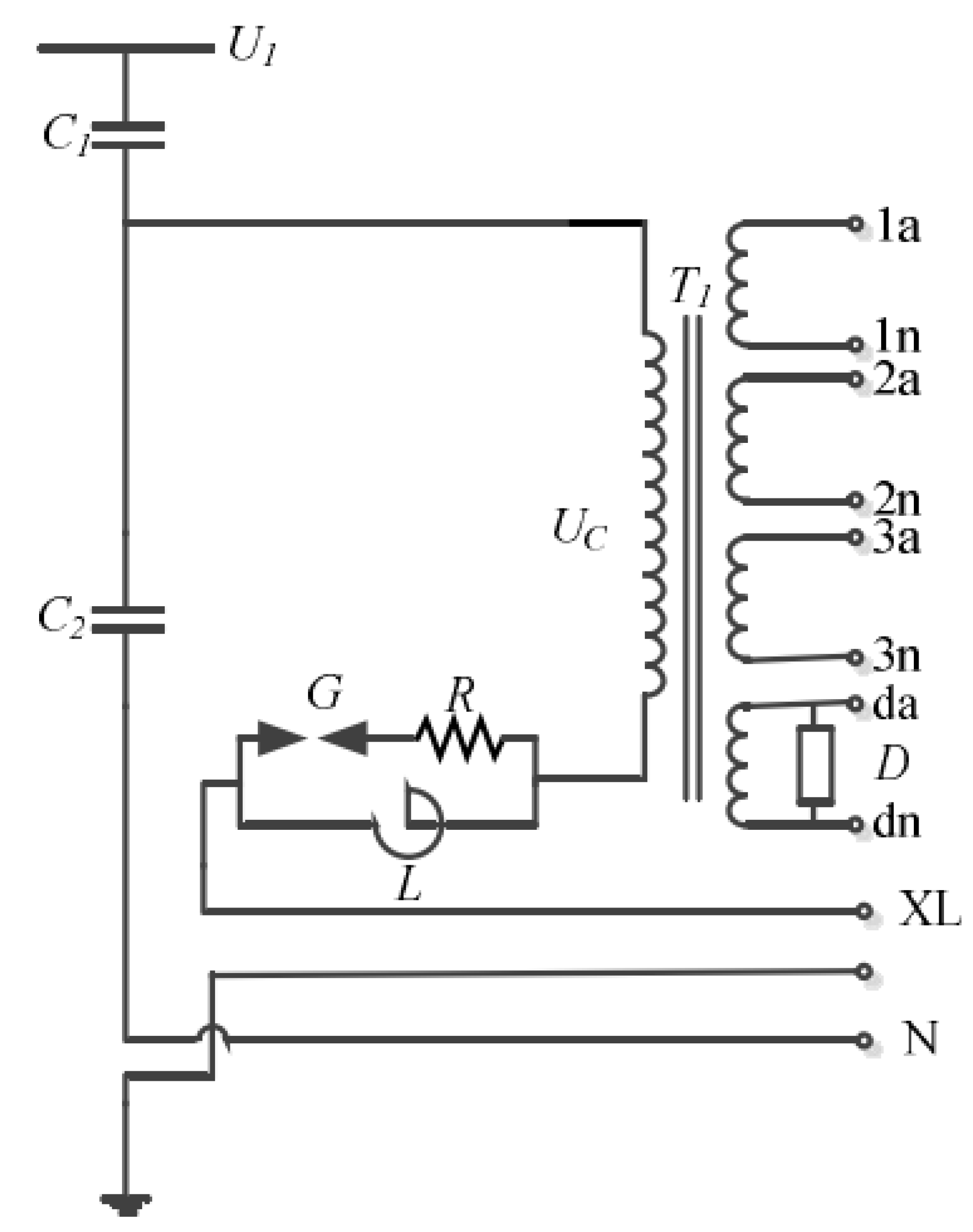
2.1. Experimental Environment and Data Set
2.2. Evaluating Indicator
- (1)
- Mean absolute error (MAE): Refers to the average of the absolute value of the deviation between the predicted value and the real value. MAE reflects the error of the predicted value of the model to a certain extent. The formula to calculate MAE is shown as follows:
- (2)
- Average absolute percentage error (MAPE): Represents the average deviation between the predicted results and the actual results. The formula to calculate MAPE is shown as follows:
- (3)
- Mean square error (MSE): Represents the deviation between each predicted value and the real value is reflected to evaluate the degree of data change. The smaller the MSE is, the higher the accuracy of the experimental data of the prediction model is. The formula to calculate MSE is shown as follows:
- (4)
- Root mean square error (RMSE): Represents the deviation between each predicted value and the true value is reflected to evaluate the extent of variation in the data, and the smaller the RMSE is, the higher accuracy of the model is. The formula to calculate RMSE is shown as follows:
- (5)
- Coefficient of determination : Its range is between [0, 1]. T It represents the deviation between the predicted value and the true value. The formula to calculate is shown as follows:
2.3. Experimental Process and Analysis
- Step 1:
- Divide the original data set into a training set, verification set, and test set according to a certain proportion;
- Step 2:
- Initialize network model hyperparameters;
- Step 3:
- Complete the relevant calculation of Seq2Seq model coding, and work out the attention variable corresponding to the BLSTM unit;
- Step 4:
- Calculate the context variable corresponding to each time step according to the calculated attention variable;
- Step 5:
- Calculate the predicted value of the current time step according to the calculated context variable and the output value of the decoded part of the previous time step;
- Step 6:
- Repeat the above steps until the specified number of iterations is completed, thus ending the training of the network model;
- Step 7:
- Test the model and judge the quality of the model by evaluating indicators;
- Step 8:
- Reverse normalize the predicted results, compare them with real data, and evaluate the prediction performance.
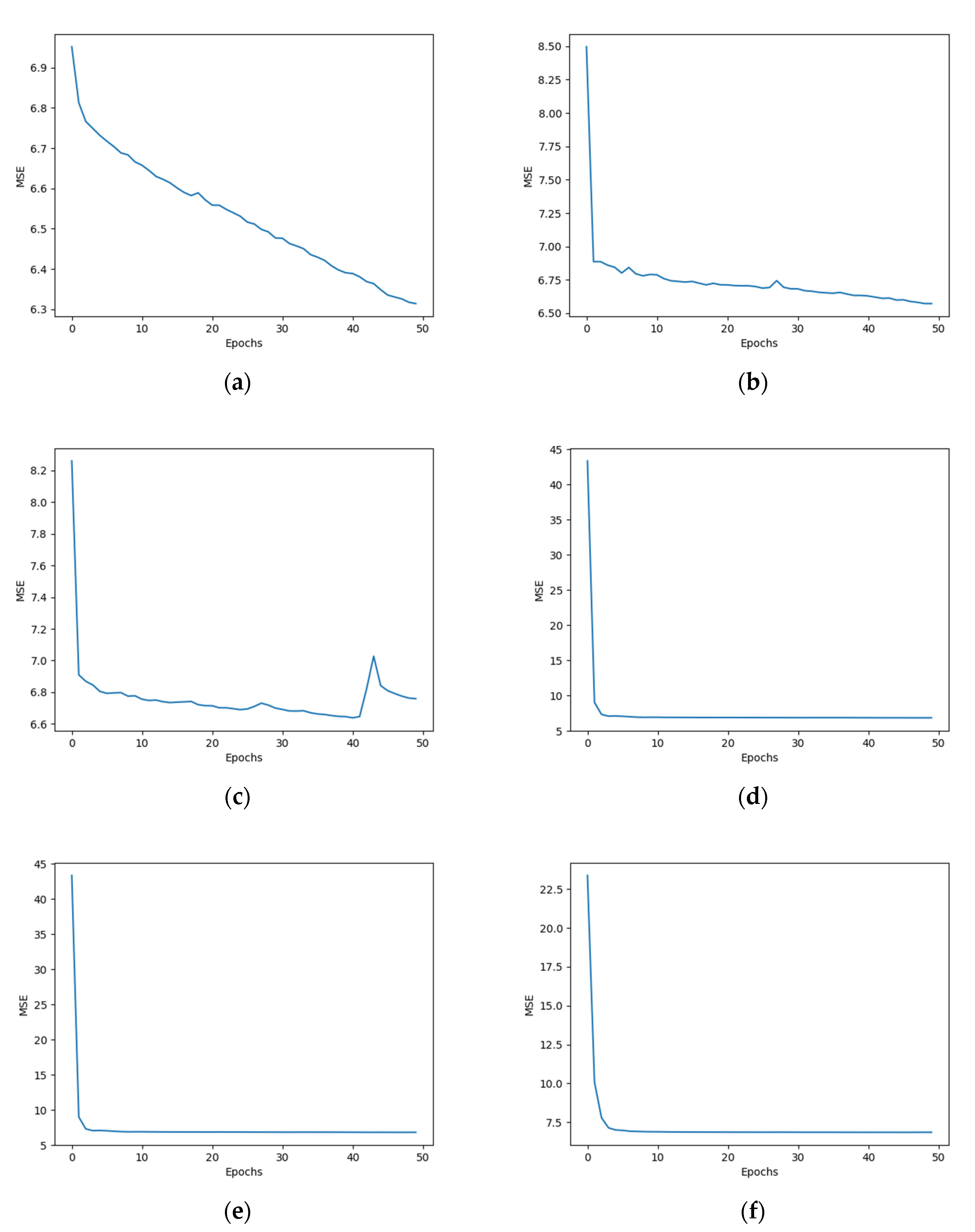
2.3.1. Parameter Selection
- (1)
- Selection of batchsize and epochs
- (2)
- Learning rate
2.3.2. Data Prediction Experiment of Transformer
3. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Joseph, A.; Balachandra, P. Energy Internet, the Future Electricity System: Overview, Concept, Model Structure, and Mechanism. Energies 2020, 13, 4242. [Google Scholar] [CrossRef]
- Li, Z.; Li, H.; Zhang, Z.; Luo, P.; Li, H.; Zhang, W. High-accuracy online calibration system for electronic voltage transformers with digital output. Trans. Inst. Meas. Control. 2014, 36, 734–742. [Google Scholar] [CrossRef]
- Çayci, H. A complex current ratio device for the calibration of current transformer test sets. Metrol. Meas. Syst. 2011, 18, 159–164. [Google Scholar] [CrossRef] [Green Version]
- Xu, Y.; Li, Y.; Xiao, X.; Xu, Z.; Hu, H. Monitoring and analysis of electronic current transformer’s field operating errors. Measurement 2017, 112, 117–124. [Google Scholar] [CrossRef]
- Zhang, Z.; Li, H.; Tang, D.; Hu, C.; Jiao, Y. Monitoring the metering performance of an electronic voltage transformer on-line based on cyber-physics correlation analysis. Meas. Sci. Technol. 2017, 28, 105015. [Google Scholar] [CrossRef] [Green Version]
- Liu, B.; Ye, G.X.; Guo, K.Q.; Mao, A.L.; Wan, G. Calculation method of composite error for electronic current transformers based on Rowgowski coil. High Volt. Eng. 2011, 37, 2391–2397. [Google Scholar]
- Yamada, T.; Kon, S.; Hashimoto, N.; Yamaguchi, T.; Yazawa, K.; Kondo, R.; Kurosawa, K. ECT evaluation by an error measurement system according to IEC 60044-8 and 61850-9-2. IEEE Trans. Power Deliv. 2012, 27, 1377–1384. [Google Scholar] [CrossRef]
- Solovev, D.B.; Gorkavyy, M.A. Current transformers: Transfer functions, frequency response, and static measurement error. In Proceedings of the 2019 International Science and Technology Conference “EastConf”, Vladivostok, Russia, 1–2 March 2019; pp. 1–7. [Google Scholar]
- Lei, T.; Faifer, M.; Ottoboni, R.; Toscani, S. On-line fault detection technique for voltage transformers. Measurement 2017, 108, 193–200. [Google Scholar] [CrossRef]
- Nunes, M.; Gerding, E.; McGroarty, F.; Niranjan, M. The Memory Advantage of Long Short-Term Memory Networks for Bond Yield Forecasting. In Proceedings of the International Conference on Forecasting Financial Markets, Ca’ Foscari University of Venice, Venice, Italy, 19–21 June 2019. [Google Scholar]
- Siami-Namini, S.; Tavakoli, N.; Namin, A.S. A comparative analysis of forecasting financial time series using arima, lstm, and bilstm. arXiv 2019, arXiv:1911.09512. [Google Scholar]
- Jinghang, X.; Wanli, Z.; Shining, L.; Ying, W. Causal Relation Extraction Based on Graph Attention Networks. J. Comput. Res. Dev. 2020, 57, 159–174. [Google Scholar]
- Medeiros, R.P.; Costa, F.B. A wavelet-based transformer differential protection with differential current transformer saturation and cross-country fault detection. IEEE Trans. Power Deliv. 2017, 33, 789–799. [Google Scholar] [CrossRef]
- Ronanki, D.; Williamson, S.S. Evolution of power converter topologies and technical considerations of power electronic transformer-based rolling stock architectures. IEEE Trans. Transp. Electrif. 2017, 4, 211–219. [Google Scholar] [CrossRef]
- Van Der Westhuizen, J.; Lasenby, J. The unreasonable effectiveness of the forget gate. arXiv 2018, arXiv:1804.04849. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. arXiv 2014, arXiv:1409.3215. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the properties of neural machine translation: Encoder-decoder approaches. arXiv 2014, arXiv:1409.1259. [Google Scholar]
- Przystupa, K. Selected methods for improving power reliability. Przegląd Elektrotech. 2018, 94, 270–273. [Google Scholar] [CrossRef]
- Przystupa, K.; Koziel, J. Analysis of the quality of uninterruptible power supply using a UPS. In 2018 Applications of Electromagnetics in Modern Techniques and Medicine (PTZE); IEEE: Piscataway, NJ, USA, 2018; pp. 191–194. [Google Scholar]
- Tylavsky, D.J.; He, Q.; McCulla, G.A.; Hunt, J.R. Sources of error in substation distribution transformer dynamic thermal modeling. IEEE Trans. Power Deliv. 2000, 15, 178–185. [Google Scholar] [CrossRef]
- Mazurek, P.A.; Michałowska, J.; Koziel, J.; Gad, R.; Wdowiak, A. The intensity of electromagnetic fields in the range of GSM 900, GSM 1800 DECT, UMTS, WLAN in built-up areas. Przeglad Elektrotech. 2018, 94, 202–205. [Google Scholar] [CrossRef] [Green Version]
- Sun, S.; Przystupa, K.; Wei, M.; Yu, H.; Ye, Z.; Kochan, O. Fast bearing fault diagnosis of rolling element using Lévy Moth-Flame optimization algorithm and Naive Bayes. Eksploat. Niezawodn. Maint. Reliab. 2020, 22, 730–740. [Google Scholar] [CrossRef]
- Li, L.L.; Yang, B.; Liang, M.; Zeng, W.; Ren, M.; Segal, S.; Urtasun, R. End-to-end contextual perception and prediction with interaction transformer. arXiv 2020, arXiv:2008.05927. [Google Scholar]
- Wu, P.; Lu, Z.; Zhou, Q.; Lei, Z.; Li, X.; Qiu, M.; Hung, P.C. Bigdata logs analysis based on seq2seq networks for cognitive Internet of Things. Future Gener. Comput. Syst. 2019, 90, 477–488. [Google Scholar] [CrossRef]
- Wang, J.; Kochan, O.; Przystupa, K.; Su, J. Information-measuring system to study the thermocouple with controlled temperature field. Meas. Sci. Rev. 2019, 19, 161–169. [Google Scholar] [CrossRef] [Green Version]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Graves, A.; Fernández, S.; Schmidhuber, J. Bidirectional LSTM networks for improved phoneme classification and recognition. In Proceedings of the International Conference on Artificial Neural Networks 2005, Warsaw, Poland, 11–15 September 2005; pp. 799–804. [Google Scholar]
- Jun, S.; Przystupa, K.; Beshley, M.; Kochan, O.; Beshley, H.; Klymash, M.; Wang, J.; Pieniak, D. A Cost-Efficient Software Based Router and Traffic Generator for Simulation and Testing of IP Network. Electronics 2019, 9, 40. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Fan, X.; Zhang, Y.; Zhang, C.; Wang, Z. Aging evaluation and moisture prediction of oil-immersed cellulose insulation in field transformer using frequency domain spectroscopy and aging kinetics model. Cellulose 2020, 27, 7175–7189. [Google Scholar] [CrossRef]
- Kozieł, J.; Przystupa, K. Using the FTA method to analyze the quality of an uninterruptible power supply unitreparation UPS. Przeglad Elektrotech. 2019, 95, 37–40. [Google Scholar] [CrossRef] [Green Version]
- Przystupa, K. An attempt to use FMEA method for an approximate reliability assessment of machinery. In Proceedings of the ITM Web of Conferences, Lublin, Poland, 23–25 November 2017; EDP Sciences: Paris, France, 2017; Volume 15, p. 5001. [Google Scholar]
- Fang, M.T.; Chen, Z.J.; Przystupa, K.; Li, T.; Majka, M.; Kochan, O. Examination of Abnormal Behavior Detection Based on Improved YOLOv3. Electronics 2021, 10, 197. [Google Scholar] [CrossRef]
- Zhang, Y.; Yu, M.; Li, N.; Yu, C.; Cui, J.; Yu, D. Seq2seq attentional siamese neural networks for text-dependent speaker verification. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, CA, USA, 5–9 March 2017; pp. 6131–6135. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Operating System | Windows |
|---|---|
| Development language | Python |
| Development framework | Keras, Numpy, Scikit-learn |
| CPU | Intel Xeon(R)CPU E5-2689 [email protected] |
| GPU | NVIDIA P104-100 |
| Memory | 10G |
| Learning Rate | Coefficient of Determination | Model Convergence Time () |
|---|---|---|
| 0.0459 | 0.9512 | 181.0607 |
| 0.0999 | 0.9506 | 181.1854 |
| 0.7318 | 0.9483 | 180.4176 |
| 0.1635 | 0.9475 | 180.9635 |
| 0.3529 | 0.9471 | 180.7596 |
| 0.2938 | 0.9462 | 181.8128 |
| 0.3121 | 0.9461 | 180.3750 |
| 0.2916 | 0.9457 | 179.7163 |
| 0.3736 | 0.9455 | 180.3897 |
| 0.2337 | 0.9454 | 180.8672 |
| 0.2821 | 0.9449 | 177.7299 |
| 0.3230 | 0.9448 | 181.1029 |
| 0.5124 | 0.9446 | 180.4604 |
| 0.9005 | 0.9442 | 180.7586 |
| 0.5064 | 0.9439 | 185.3993 |
| 0.8575 | 0.9437 | 180.5046 |
| 0.7217 | 0.9435 | 180.8051 |
| 0.8892 | 0.9425 | 180.3878 |
| 0.6537 | 0.9422 | 186.0291 |
| 0.7850 | 0.9401 | 180.4719 |
| Network Model | MAPE | MSE | MAE | RMSE | |
|---|---|---|---|---|---|
| Seq2Seq network model | 13.55 | 5300.98 | 14.01 | 72.61 | 0.947 |
| Seq2Seq network model optimized by AM | 12.96 | 4509.45 | 13.30 | 68.78 | 0.951 |
| Point Number | Mean Absolute Error of Point Position |
|---|---|
| main variant I group A phase | 0.00027497 |
| main variant I group B phase | 0.00002473 |
| main variant I group C phase | 0.00011656 |
| main variant II group A phase | 0.00000826 |
| main variant II group B phase | 0.00000515 |
| main variant II group C phase | 0.00004297 |
| main variant III group A phase | 0.0000099 |
| main variant III group B phase | 0.00007127 |
| main variant III group C phase | 0.00000206 |
| 5449 Line A phase | 0.00569437 |
| 5449 Line B phase | 0.00138136 |
| 5449 Line C phase | 0.00008017 |
| 5450 Line A phase | 0.00001751 |
| 5450 Line B phase | 0.00029623 |
| 5450 Line C phase | 0.00004697 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiong, G.; Przystupa, K.; Teng, Y.; Xue, W.; Huan, W.; Feng, Z.; Qiong, X.; Wang, C.; Skowron, M.; Kochan, O.; et al. Online Measurement Error Detection for the ElectronicTransformer in a Smart Grid. Energies 2021, 14, 3551. https://doi.org/10.3390/en14123551
Xiong G, Przystupa K, Teng Y, Xue W, Huan W, Feng Z, Qiong X, Wang C, Skowron M, Kochan O, et al. Online Measurement Error Detection for the ElectronicTransformer in a Smart Grid. Energies. 2021; 14(12):3551. https://doi.org/10.3390/en14123551
Chicago/Turabian StyleXiong, Gu, Krzysztof Przystupa, Yao Teng, Wang Xue, Wang Huan, Zhou Feng, Xiang Qiong, Chunzhi Wang, Mikołaj Skowron, Orest Kochan, and et al. 2021. "Online Measurement Error Detection for the ElectronicTransformer in a Smart Grid" Energies 14, no. 12: 3551. https://doi.org/10.3390/en14123551