
Content and Sentiment Analysis of The New York Times Coronavirus (2019-nCOV) Articles with Natural Language Processing (NLP) and Leximancer


Abstract
:1. Introduction
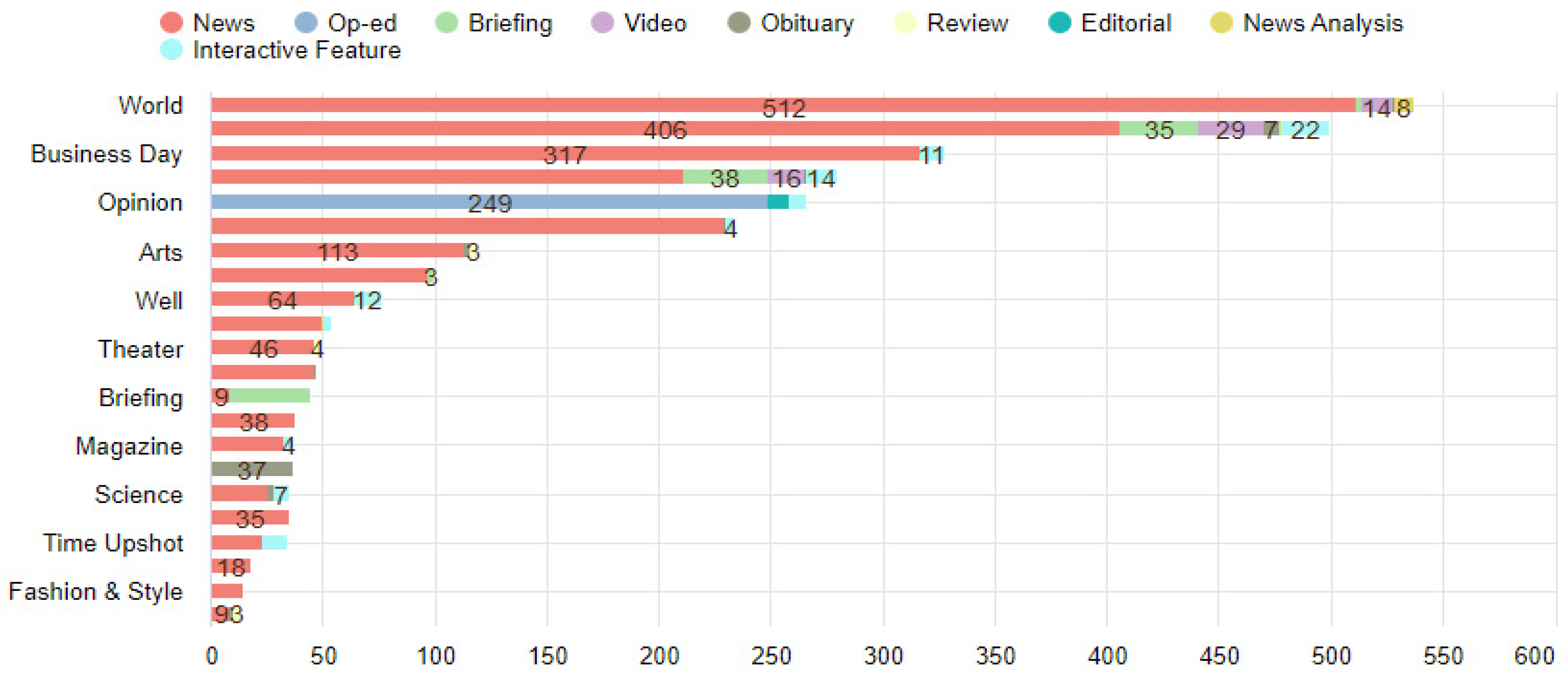
- We gathered information about how the mainstream media (Nytimes.com) sets the agenda for the community.
- To evaluate the debate around the pandemic, we used VADER’s sentiment analysis. The findings provided us with the distance and closeness positions of a few topics connected to the pandemic discourse on Nytimes.com, disclosed in accordance with the conceptual definitions of those themes.
- Using our dataset, we performed text classification, for which we created four alternative machine learning models. In these analysis results, the algorithm that demonstrated the best performance has been determined.
- Concerning crisis communication monitoring, we have presented an overview of the emotions evoked and topics covered by Nytimes.com’s pandemic-related (2019-nCOV) coverage, which should be useful.
2. Related Works
2.1. Theoretical-Related Works
2.2. Practical-Related Works
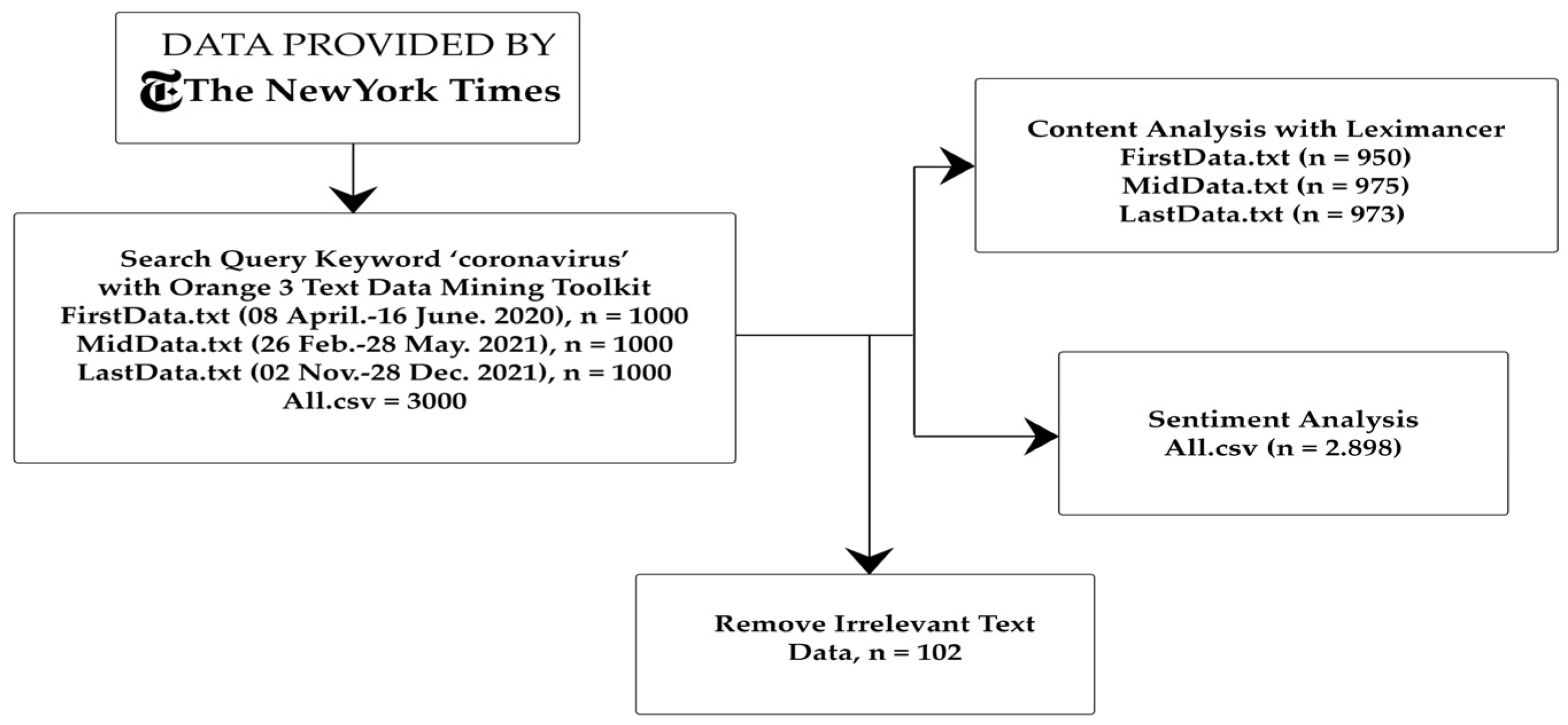
3. Data and Methods
4. Results
4.1. Sentiment Analysis and Results
- It performs very well on text, similar to that seen on social networking platforms, while easily generalizing to a variety of other fields.
- It is developed using a generalizable, valence-based, human-curated gold standard sentiment lexicon, yet it does not need any training data.
- It has a speed that allows it to be utilized online with streaming data, and it does not suffer from a speed–performance tradeoff to a significant degree.
- Analysis is language-specific.
- Discriminating jargon, nomenclature, memes, or turns of phrase may not be recognized.
4.2. Evaluation
4.3. Leximancer Content Analysis and Results
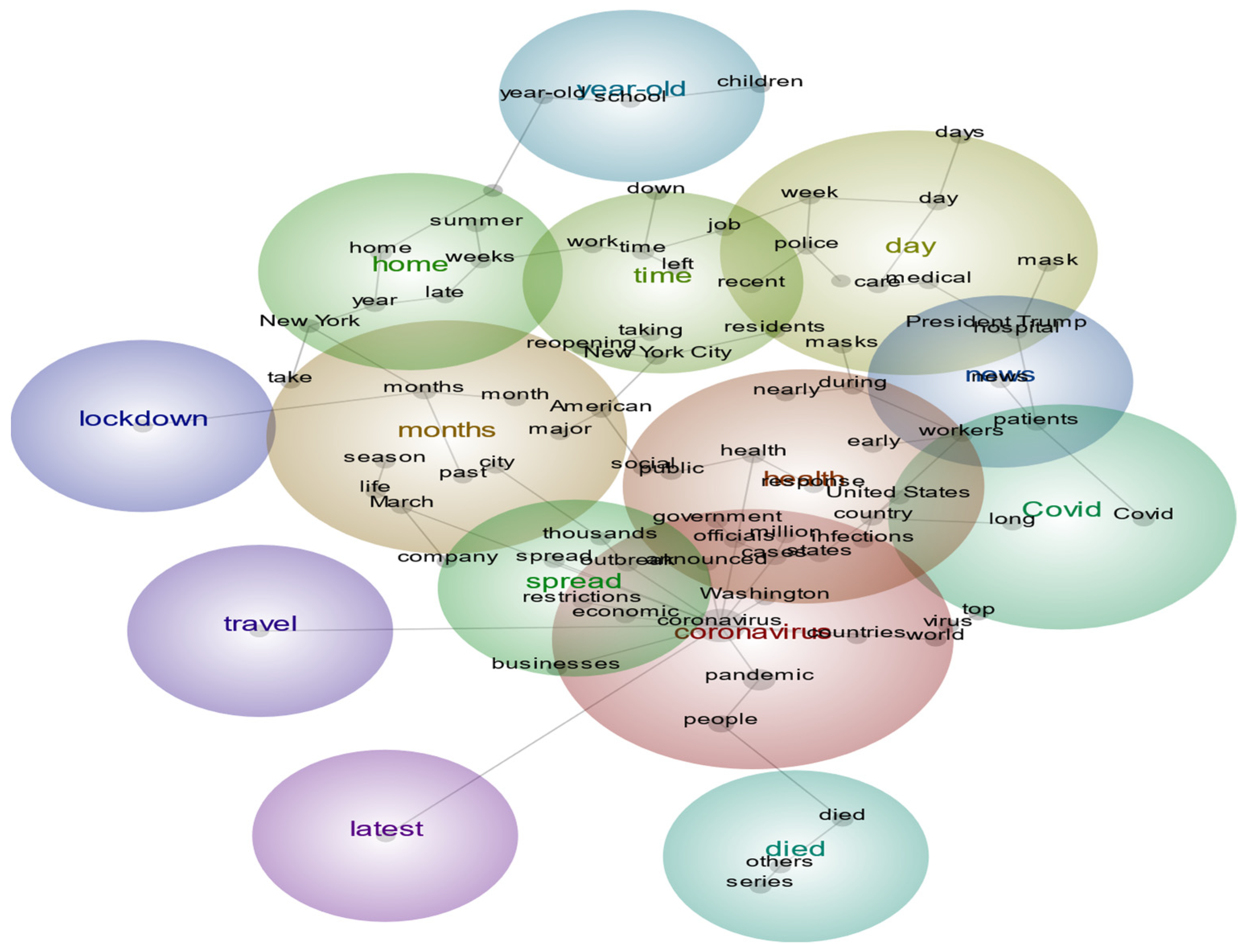
4.3.1. Leximancer First-Term Content (08 April–16 June 2020) Analysis Results
4.3.2. Leximancer Mid-Term Content (26 February–28 May 2021) Analysis Results
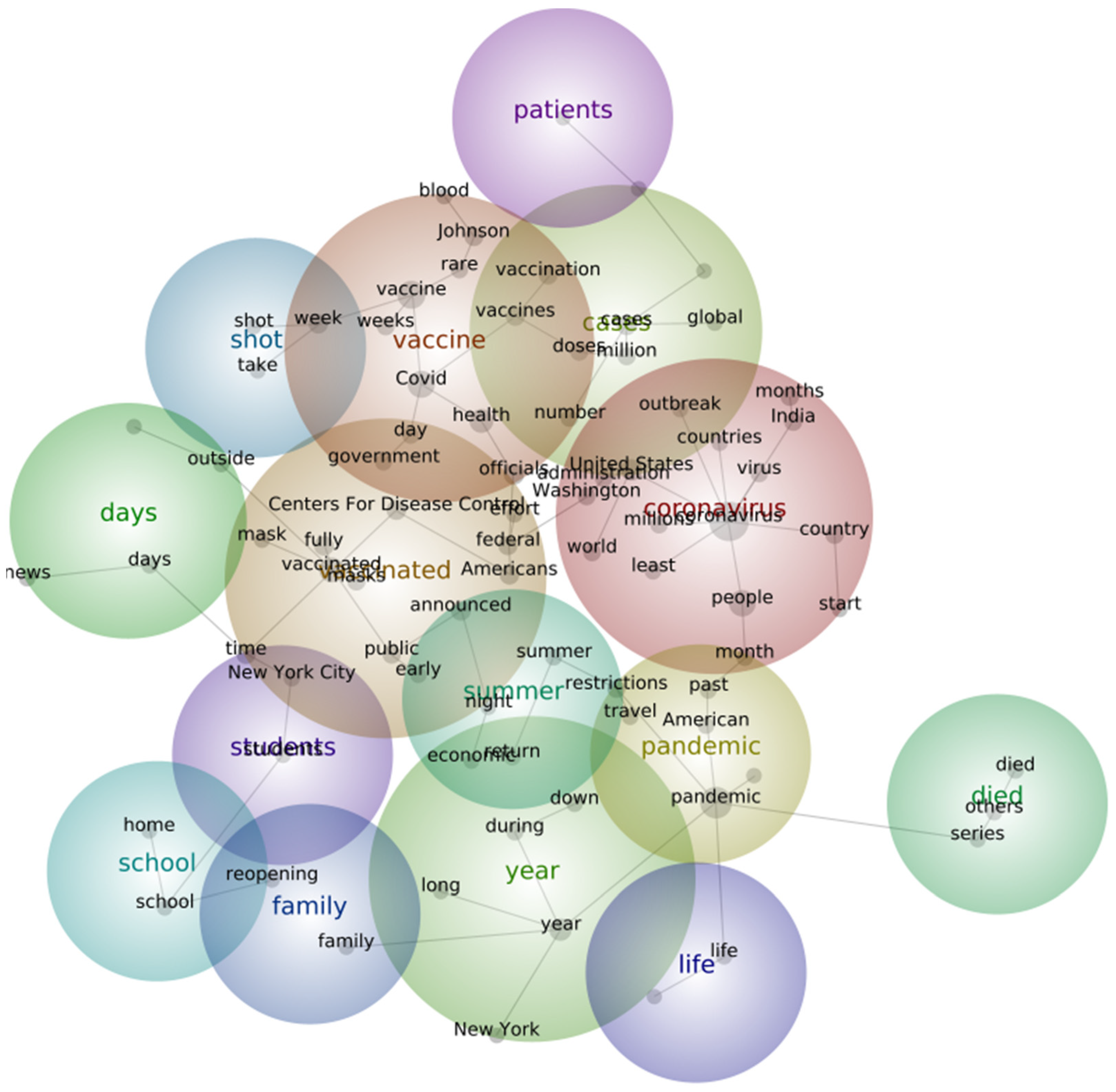
4.3.3. Leximancer Last-Term Content (2 November–28 December 2021) Analysis Results
4.3.4. Leximancer Content Analysis Results for Three Periods, Themes and Concepts
5. Discussion and Implications
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Caduff, C. What Went Wrong: Corona and the World after the Full Stop. Med. Anthropol. Q. 2020, 34, 467–487. [Google Scholar] [CrossRef]
- Cheval, S.; Mihai Adamescu, C.; Georgiadis, T.; Herrnegger, M.; Piticar, A.; Legates, D.R. Observed and Potential Impacts of the COVID-19 Pandemic on the Environment. IJERPH 2020, 17, 4140. [Google Scholar] [CrossRef]
- Wiederhold, B.K. Using Social Media to Our Advantage: Alleviating Anxiety During a Pandemic. Cyberpsychol. Behav. Soc. Netw. 2020, 23, 197–198. [Google Scholar] [CrossRef]
- Viehmann, C.; Ziegele, M.; Quiring, O. Communication, Cohesion, and Corona: The Impact of People’s Use of Different Information Sources on Their Sense of Societal Cohesion in Times of Crises. J. Stud. 2022, 23, 629–649. [Google Scholar] [CrossRef]
- Newman, N. Reuters Institute Digital News Report 2020; Reuters Institute for the study of Journalism: Oxford, England, 2020. [Google Scholar]
- Kim, S.J.; Wang, X.; Malthouse, E.C. Digital News Readership and Subscription in the United States during COVID-19: A Longitudinal Analysis of Clickstream and Subscription Data from a Local News Site. Digit. J. 2022, 10, 1015–1036. [Google Scholar] [CrossRef]
- Andersen, K.; Shehata, A.; Andersson, D. Alternative News Orientation and Trust in Mainstream Media: A Longitudinal Audience Perspective. Digit. J. 2021, 1–20. [Google Scholar] [CrossRef]
- Lucy, L.; Demszky, D.; Bromley, P.; Jurafsky, D. Content Analysis of Textbooks via Natural Language Processing: Findings on Gender, Race, and Ethnicity in Texas U.S. History Textbooks. AERA Open 2020, 6, 233285842094031. [Google Scholar] [CrossRef]
- Leximancer User Guide. 2022, p. 149. Available online: https://www.doc.leximancer.com/ (accessed on 20 March 2022).
- Chen, H.; Huang, X.; Li, Z. A Content Analysis of Chinese News Coverage on COVID-19 and Tourism. Curr. Issues Tour. 2022, 25, 198–205. [Google Scholar] [CrossRef]
- Olagoke, A.A.; Olagoke, O.O.; Hughes, A.M. Exposure to Coronavirus News on Mainstream Media: The Role of Risk Perceptions and Depression. Br. J. Health Psychol. 2020, 25, 865–874. [Google Scholar] [CrossRef]
- Cruz-Cárdenas, J.; Zabelina, E.; Guadalupe-Lanas, J.; Palacio-Fierro, A.; Ramos-Galarza, C. COVID-19, Consumer Behavior, Technology, and Society: A Literature Review and Bibliometric Analysis. Technol. Forecast. Soc. Change 2021, 173, 121179. [Google Scholar] [CrossRef]
- Van Aelst, P.; Toth, F.; Castro, L.; Štětka, V.; Vreese, C.d.; Aalberg, T.; Cardenal, A.S.; Corbu, N.; Esser, F.; Hopmann, D.N.; et al. Does a Crisis Change News Habits? A Comparative Study of the Effects of COVID-19 on News Media Use in 17 European Countries. Digit. J. 2021, 9, 1208–1238. [Google Scholar] [CrossRef]
- Kurten, S.; Beullens, K. #Coronavirus: Monitoring the Belgian Twitter Discourse on the Severe Acute Respiratory Syndrome Coronavirus 2 Pandemic. Cyberpsychol. Behav. Soc. Netw. 2021, 24, 117–122. [Google Scholar] [CrossRef]
- Ellerich-Groppe, N.; Pfaller, L.; Schweda, M. Young for Old—Old for Young? Ethical Perspectives on Intergenerational Solidarity and Responsibility in Public Discourses on COVID-19. Eur. J. Ageing 2021, 18, 159–171. [Google Scholar] [CrossRef]
- Ayalon, L.; Chasteen, A.; Diehl, M.; Levy, B.R.; Neupert, S.D.; Rothermund, K.; Tesch-Römer, C.; Wahl, H.-W. Aging in Times of the COVID-19 Pandemic: Avoiding Ageism and Fostering Intergenerational Solidarity. J. Gerontol. Ser. B 2021, 76, e49–e52. [Google Scholar] [CrossRef]
- Xiang, X.; Lu, X.; Halavanau, A.; Xue, J.; Sun, Y.; Lai, P.H.L.; Wu, Z. Modern Senicide in the Face of a Pandemic: An Examination of Public Discourse and Sentiment About Older Adults and COVID-19 Using Machine Learning. J. Gerontol. Ser. B 2021, 76, e190–e200. [Google Scholar] [CrossRef]
- Pascual-Ferrá, P.; Alperstein, N.; Barnett, D.J. Social Network Analysis of COVID-19 Public Discourse on Twitter: Implications for Risk Communication. Disaster Med. Public Health Prep. 2022, 16, 561–569. [Google Scholar] [CrossRef]
- Xue, J.; Chen, J.; Chen, C.; Zheng, C.; Li, S.; Zhu, T. Public Discourse and Sentiment during the COVID 19 Pandemic: Using Latent Dirichlet Allocation for Topic Modeling on Twitter. PLoS ONE 2020, 15, e0239441. [Google Scholar] [CrossRef]
- Habib, M.A.; Anik, M.A.H. Impacts of COVID-19 on Transport Modes and Mobility Behavior: Analysis of Public Discourse in Twitter. Transp. Res. Rec. 2021, 2, 036119812110299. [Google Scholar] [CrossRef]
- Agenda-Setting Theory. 2022. Available online: https://wikipedia (accessed on 20 March 2022).
- McCombs, M.E.; Shaw, D.L.; Weaver, D.H. New Directions in Agenda-Setting Theory and Research. Mass Commun. Soc. 2014, 17, 781–802. [Google Scholar] [CrossRef]
- Littlejohn, S.W.; Foss, K.A. Theories of Human Communication, 10th ed.; Waveland Press: Long Grove, IL, USA, 2010; ISBN 978-1-4786-0939-1. [Google Scholar]
- Dai, Y.; Li, Y.; Cheng, C.-Y.; Zhao, H.; Meng, T. Government-Led or Public-Led? Chinese Policy Agenda Setting during the COVID-19 Pandemic. J. Comp. Policy Anal. Res. Pract. 2021, 23, 157–175. [Google Scholar] [CrossRef]
- Meutia, I.F.; Sujadmiko, B.; Yulianti, D.; Putra, K.A.; Aini, S.N. The Agenda Setting Policy for Hajj and Umrah in Post Pandemic. In Proceedings of the 2nd International Indonesia Conference on Interdisciplinary Studies (IICIS 2021), Amsterdam, The Netherlands, 28 October 2021; pp. 32–37. [Google Scholar]
- Liu, K.; Geng, X.; Liu, X. The Application of Network Agenda Setting Model during the COVID-19 Pandemic Based on Latent Dirichlet Allocation Topic Modeling. Front. Psychol. 2022, 13, 954576. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q. Using Social Media for Agenda Setting in Chinese Government’s Communications during the 2020 COVID-19 Pandemic. J. Commun. Inq. 2022, 46, 01968599221105099. [Google Scholar] [CrossRef]
- Wikipedia Agenda-Setting Theory-Wikipedia. Available online: https://en.wikipedia.org/wiki/Agenda-setting_theory (accessed on 23 November 2022).
- Manning, C.; Surdeanu, M.; Bauer, J.; Finkel, J.; Bethard, S.; McClosky, D. The Stanford CoreNLP Natural Language Processing Toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Baltimore, MD, USA, 23–24 June 2014; pp. 55–60. [Google Scholar]
- Leximancer. Available online: https://www.leximancer.com/ (accessed on 20 March 2022).
- Orange Data Mining-Text Mining. Available online: https://orangedatamining.com/workflows/Text-Mining/ (accessed on 20 March 2022).
- Kanasa, D.H. An Introduction to Leximancer. Available online: https://www.leximancer.com/ (accessed on 20 March 2022).
- Angus, D.; Rintel, S.; Wiles, J. Making Sense of Big Text: A Visual-First Approach for Analysing Text Data Using Leximancer and Discursis. Int. J. Soc. Res. Methodol. 2013, 16, 261–267. [Google Scholar] [CrossRef]
- Wilk, V.; Cripps, H.; Capatina, A.; Micu, A.; Micu, A.-E. The State of #digitalentrepreneurship: A Big Data Leximancer Analysis of Social Media Activity. Int. Entrep. Manag. J. 2021, 17, 1899–1916. [Google Scholar] [CrossRef]
- Wilk, V.; Soutar, G.N.; Harrigan, P. Tackling Social Media Data Analysis: Comparing and Contrasting QSR NVivo and Leximancer. QMR 2019, 22, 94–113. [Google Scholar] [CrossRef]
- Tunca, S.; Sezen, B.; Wilk, V. An Exploratory Content and Sentiment Analysis of The Guardian Metaverse Articles Using Leximancer and Natural Language Processing. Cyberpsychol. Behav. Soc. Netw. 2022, 26, 56–78. [Google Scholar]
- Pang, B.; Lee, L.; Vaithyanathan, S. Thumbs up? Sentiment Classification Using Machine Learning Techniques. arXiv 2002, arXiv:cs/0205070. [Google Scholar]
- Hutto, C.J.; Gilbert, E. VADER: A Parsimonious Rule-Based Model for Sentiment Analysis of Social Media Text. In Proceedings of the International AAAI Conference on Web and Social Media, Ann Arbor, MI, USA, 1–4 June 2014. [Google Scholar]
- Beri, A. Sentimental Analysis Using Vader. Interpretation and Classification of…|by Aditya Beri|Towards Data Science. Available online: https://towardsdatascience.com/sentimental-analysis-using-vader-a3415fef7664?gi=ee44b81a54cb (accessed on 3 February 2022).
- Qin, Z.; Ronchieri, E. Exploring Pandemics Events on Twitter by Using Sentiment Analysis and Topic Modelling. Appl. Sci. 2022, 12, 11924. [Google Scholar] [CrossRef]
- Zhang, X.; Saleh, H.; Younis, E.M.G.; Sahal, R.; Ali, A.A. Predicting Coronavirus Pandemic in Real-Time Using Machine Learning and Big Data Streaming System. Complexity 2020, 2020, 6688912. [Google Scholar] [CrossRef]
- Sepúlveda, A.; Periñán-Pascual, C.; Muñoz, A.; Martínez-España, R.; Hernández-Orallo, E.; Cecilia, J.M. COVIDSensing: Social Sensing Strategy for the Management of the COVID-19 Crisis. Electronics 2021, 10, 3157. [Google Scholar] [CrossRef]
- Aramaki, E.; Maskawa, S.; Morita, M. Twitter Catches The Flu: Detecting Influenza Pandemics Using Twitter. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, Edinburgh, Scotland, UK, 27–31 July 2011. [Google Scholar]
- Andreadis, S.; Antzoulatos, G.; Mavropoulos, T.; Giannakeris, P.; Tzionis, G.; Pantelidis, N.; Ioannidis, K.; Karakostas, A.; Gialampoukidis, I.; Vrochidis, S.; et al. A Social Media Analytics Platform Visualising the Spread of COVID-19 in Italy via Exploitation of Automatically Geotagged Tweets. Online Soc. Netw. Media 2021, 23, 100134. [Google Scholar] [CrossRef] [PubMed]
- Mahdikhani, M. Predicting the Popularity of Tweets by Analyzing Public Opinion and Emotions in Different Stages of COVID-19 Pandemic. Int. J. Inf. Manag. Data Insights 2022, 2, 100053. [Google Scholar] [CrossRef]
- de Arruda, H.F.; Silva, F.N.; Marinho, V.Q.; Amancio, D.R.; Costa, L. da F. Representation of Texts as Complex Networks: A Mesoscopic Approach. J. Complex Netw. 2018, 6, 125–144. [Google Scholar] [CrossRef]
- Mansoor, M.; Gurumurthy, K.; Prasad, V.R. Global Sentiment Analysis Of COVID-19 Tweets Over Time. arXiv 2020, arXiv:2010.14234. [Google Scholar]
- Corrêa, E.A.; Amancio, D.R. Word Sense Induction Using Word Embeddings and Community Detection in Complex Networks. Phys. A Stat. Mech. Its Appl. 2019, 523, 180–190. [Google Scholar] [CrossRef]
- Pandey, S. Simplifying Sentiment Analysis Using VADER in Python (on Social Media Text)|by Parul Pandey|Analytics Vidhya|Medium. Available online: https://medium.com/analytics-vidhya/simplifying-social-media-sentiment-analysis-using-vader-in-python-f9e6ec6fc52f (accessed on 25 December 2022).
- Quandt, T.; Boberg, S.; Schatto-Eckrodt, T.; Frischlich, L. Pandemic News: Facebook Pages of Mainstream News Media and the Coronavirus Crisis—A Computational Content Analysis. arXiv 2020, arXiv:2005.13290. [Google Scholar]
- Ahmed, S.; Khaium, M.O.; Tazmeem, F. COVID-19 Lockdown in India Triggers a Rapid Rise in Suicides Due to the Alcohol Withdrawal Symptoms: Evidence from Media Reports. Int. J. Soc. Psychiatry 2020, 66, 827–829. [Google Scholar] [CrossRef]
- Lemenager, T.; Neissner, M.; Koopmann, A.; Reinhard, I.; Georgiadou, E.; Müller, A.; Kiefer, F.; Hillemacher, T. COVID-19 Lockdown Restrictions and Online Media Consumption in Germany. IJERPH 2020, 18, 14. [Google Scholar] [CrossRef]
- Jia, W.; Lu, F. US Media’s Coverage of China’s Handling of COVID-19: Playing the Role of the Fourth Branch of Government or the Fourth Estate? Glob. Media China 2021, 6, 8–23. [Google Scholar] [CrossRef]
- Donthu, N.; Gustafsson, A. Effects of COVID-19 on Business and Research. J. Bus. Res. 2020, 117, 284–289. [Google Scholar] [CrossRef]
- Crs, R. Global Economic Effects of COVID-19; Congressional Research Service: Washington, DC, USA, 2020; Volume 84, pp. 20–115. [Google Scholar]
- Apergis, E.; Apergis, N. Inflation Expectations, Volatility and Covid-19: Evidence from the US Inflation Swap Rates. Appl. Econ. Lett. 2021, 28, 1327–1331. [Google Scholar] [CrossRef]
- Coluccia, B.; Agnusdei, G.P.; Miglietta, P.P.; De Leo, F. Effects of COVID-19 on the Italian Agri-Food Supply and Value Chains. Food Control 2021, 123, 107839. [Google Scholar] [CrossRef] [PubMed]
- Wise, J. COVID-19: New Coronavirus Variant Is Identified in UK. BMJ 2020, 371, m4857. [Google Scholar] [CrossRef] [PubMed]
- Babcock, H.M.; Gemeinhart, N.; Jones, M.; Dunagan, W.C.; Woeltje, K.F. Mandatory Influenza Vaccination of Health Care Workers: Translating Policy to Practice. Clin. Infect. Dis. 2010, 50, 459–464. [Google Scholar] [CrossRef]
- Hakim, H.; Gaur, A.H.; McCullers, J.A. Motivating Factors for High Rates of Influenza Vaccination among Healthcare Workers. Vaccine 2011, 29, 5963–5969. [Google Scholar] [CrossRef]
- Douville, L.E.; Myers, A.; Jackson, M.A.; Lantos, J.D. Health Care Worker Knowledge, Attitudes, and Beliefs Regarding Mandatory Influenza Vaccination. Arch. Pediatr. Adolesc. Med. 2010, 164, 33–37. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Row Labes | Count of Text | Percentage (%) |
|---|---|---|
| Positive | 1741 | 60% |
| Negative | 1157 | 40% |
| Total | 2898 | 100% |
| Method | Precision | Recall | F1-Score | Accuracy |
|---|---|---|---|---|
| Random Forest | 0.64 | 0.72 | 0.64 | 0.78 |
| Naïve Bayes | 0.58 | 0.60 | 0.59 | 0.86 |
| Support Vector Machine | 0.59 | 0.61 | 0.60 | 0.85 |
| Multilayer Perceptron | 0.73 | 0.74 | 0.73 | 0.86 |
| Bert | 0.66 | 0.65 | 0.56 | 0.81 |
| Electra | 0.70 | 0.70 | 0.62 | 0.84 |
| Method | Precision | Recall | F1-Score | Accuracy |
|---|---|---|---|---|
| Random Forest | 0.62 | 0.70 | 0.62 | 0.76 |
| Naïve Bayes | 0.56 | 0.58 | 0.57 | 0.84 |
| Support Vector Machine | 0.57 | 0.59 | 0.58 | 0.83 |
| Multilayer Perceptron | 0.71 | 0.72 | 0.71 | 0.84 |
| Bert | 0.65 | 0.67 | 0.62 | 0.83 |
| Electra | 0.69 | 0.68 | 0.59 | 0.82 |
| Class | RF | NB | SVM | MP | Bert | Electra |
|---|---|---|---|---|---|---|
| Positive | 74.5 | 86.1 | 85.7 | 87.3 | 84.6 | 81.2 |
| Negative | 78.2 | 82.6 | 81.3 | 82.5 | 82.2 | 84.3 |
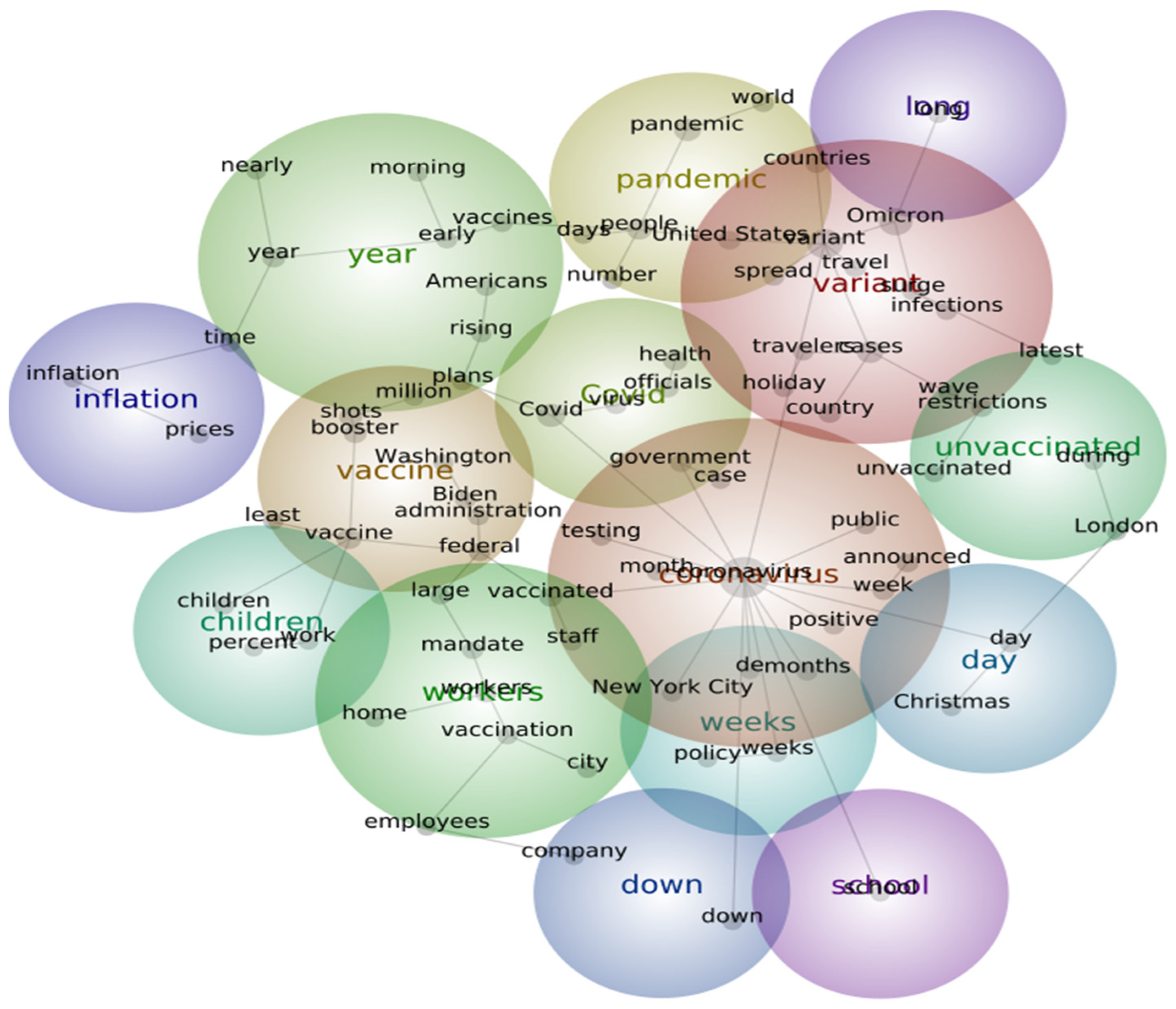
| First-Term Content (8 April–16 June 2020) | Mid-Term Content (26 February–28 May 2021) | Last-Term Content (2 November–28 December 2021) | |||
|---|---|---|---|---|---|
| Themes | Concepts | Themes | Concepts | Themes | Concepts |
| health | country, officials, United States, states, public, spread, announced, outbreak, government, infections, million | Coronavirus | people, United States, country, months, India, world, Washington, millions, virus, administration | Coronavirus | vaccinated, announced, week, positive, testing, months, public |
| Coronavirus | pandemic, people, cases, Washington, world, virus | vaccinated | announced, fully, Centers for Disease Control, Americans, time, federal, public, masks, government, summer | variant | Omicron, cases, country, surge, restrictions, travel, spread, infections |
| months | month, March, city, lockdown | vaccine | Covid, health, officials, week, vaccines, weeks | pandemic | people, United States, world, countries |
| home | year, weeks, New York | cases | Johnson, vaccination, doses, million, number, rare | covid | health, officials, government, virus |
| time | New York City, down, work | pandemic | restrictions, month, past, American, travel | vaccine | booster, shots, federal, administration, Biden |
| day | week, care, days | summer | night, economic | workers | mandate, vaccination, employees |
| spread | outbreak, businesses | died | others, series | day | Christmas |
| during | workers | school | reopening, home, students | down | vaccines, Americans, rising, case |
| died | series, others | year | during, return | children | children, city, company |
| lockdown | lockdown | family | reopening | weeks | policy |
| Covid | long | days | news | inflation | Prices, time |
| businesses | economic, restrictions, company | shot | take | down | nearly |
| President Trump | Washington | students | students | long | Omicron |
| travel | travel | patients | hospital | unvaccinated | During, wave |
| latest | latest | office | life | school | Percent |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tunca, S.; Sezen, B.; Balcioglu, Y.S. Content and Sentiment Analysis of The New York Times Coronavirus (2019-nCOV) Articles with Natural Language Processing (NLP) and Leximancer. Electronics 2023, 12, 1964. https://doi.org/10.3390/electronics12091964
Tunca S, Sezen B, Balcioglu YS. Content and Sentiment Analysis of The New York Times Coronavirus (2019-nCOV) Articles with Natural Language Processing (NLP) and Leximancer. Electronics. 2023; 12(9):1964. https://doi.org/10.3390/electronics12091964
Chicago/Turabian StyleTunca, Sezai, Bulent Sezen, and Yavuz Selim Balcioglu. 2023. "Content and Sentiment Analysis of The New York Times Coronavirus (2019-nCOV) Articles with Natural Language Processing (NLP) and Leximancer" Electronics 12, no. 9: 1964. https://doi.org/10.3390/electronics12091964