
Prediction of Critical Filling of a Storage Area Network by Machine Learning Methods

 , ,
, ,
Abstract
:1. Introduction
2. Related Works
3. Materials and Methods
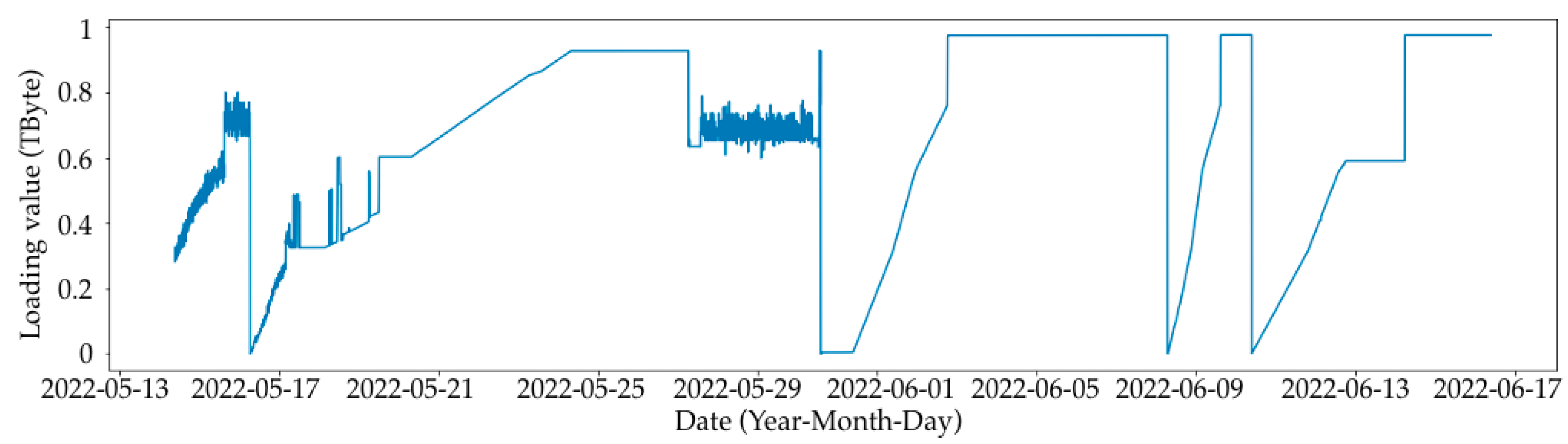
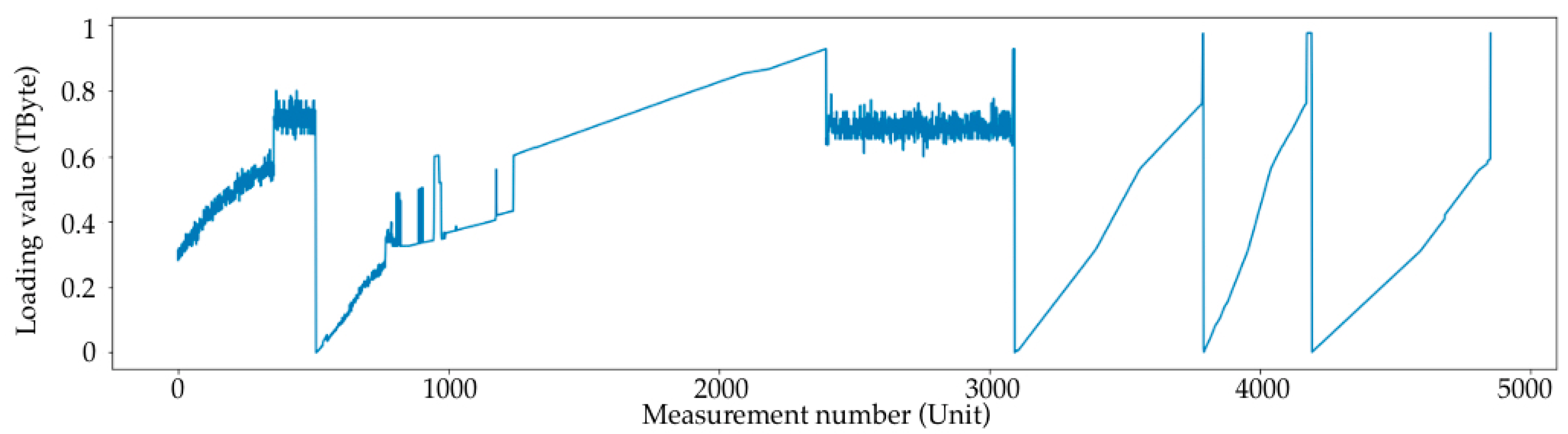
3.1. SAN Loading Simulation
- A binary classification task: it is necessary to predict whether there will be a significant increase in the volume of data at a future point in time.
- A regression task. If the forecast of task 1 will be positive, and thus there will be an increase in data, then it is necessary to forecast this volume (target variable). Otherwise, if there is no growth or it is insignificant (for example, in the normal operation of the system), the regression task will not be solved.
- To solve the regression problem, we pre-processed the data in two variants.
- The basic variant:
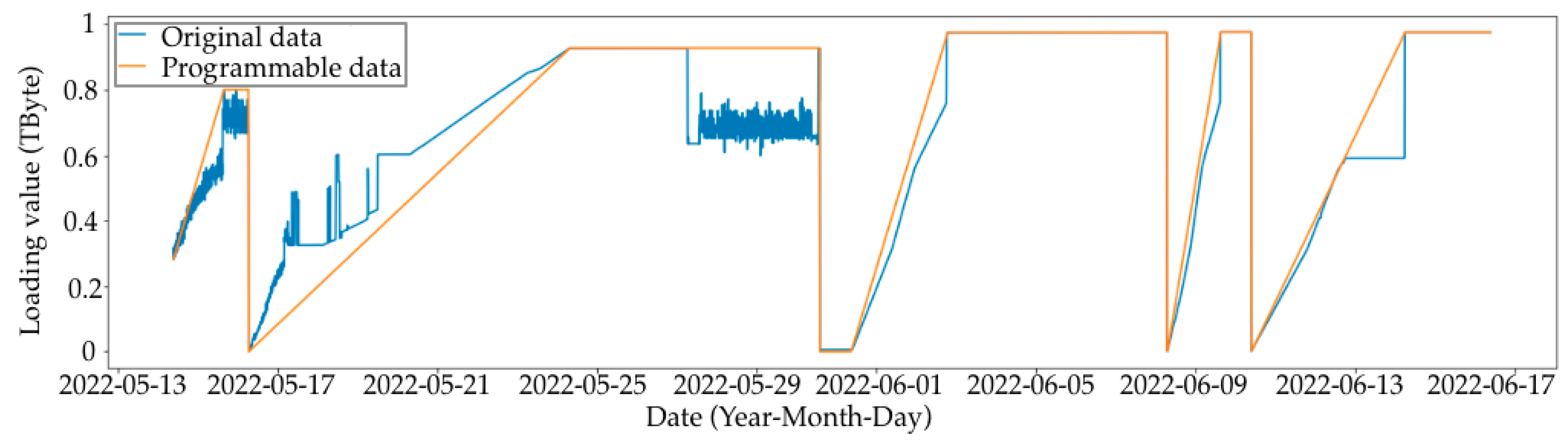
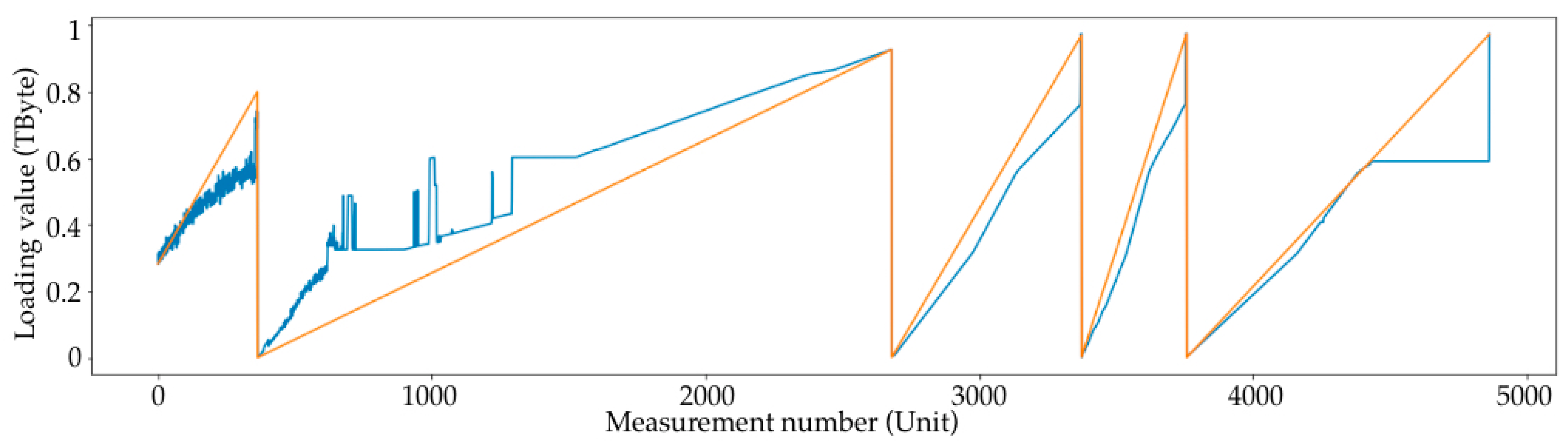
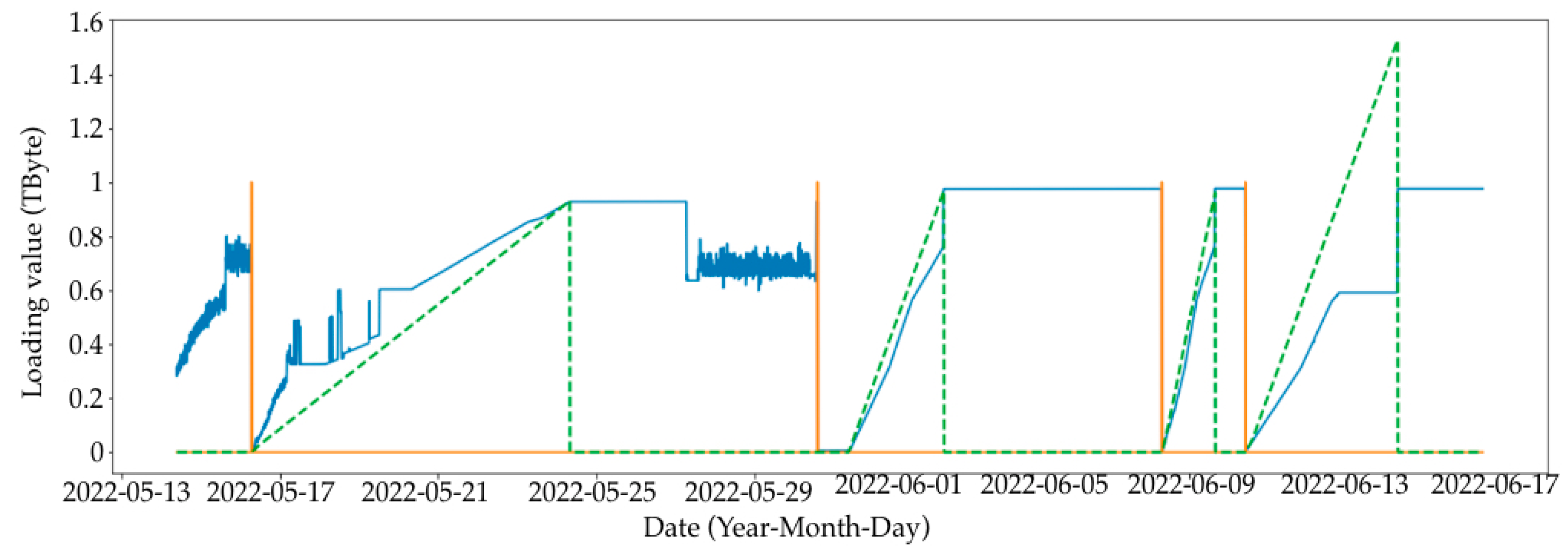
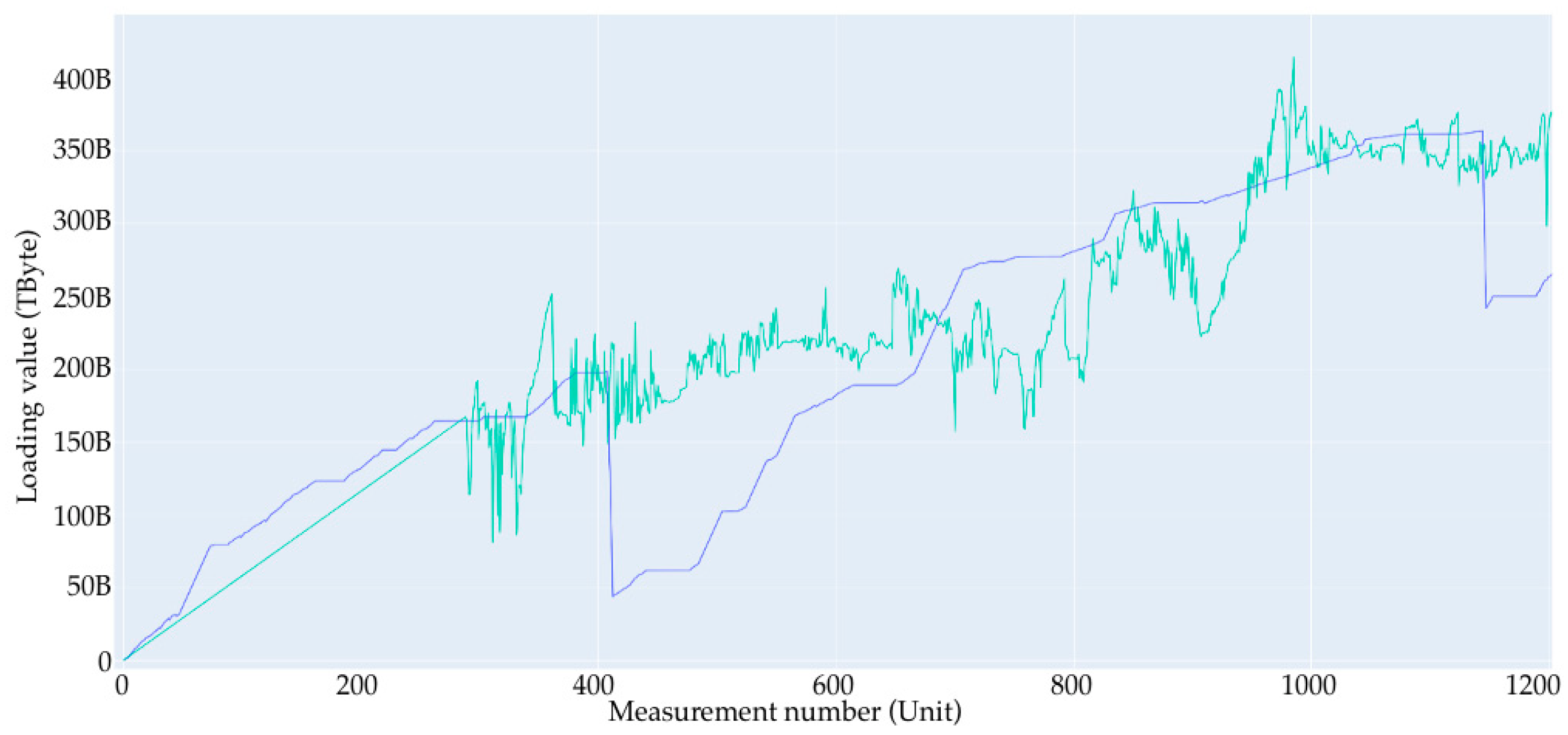
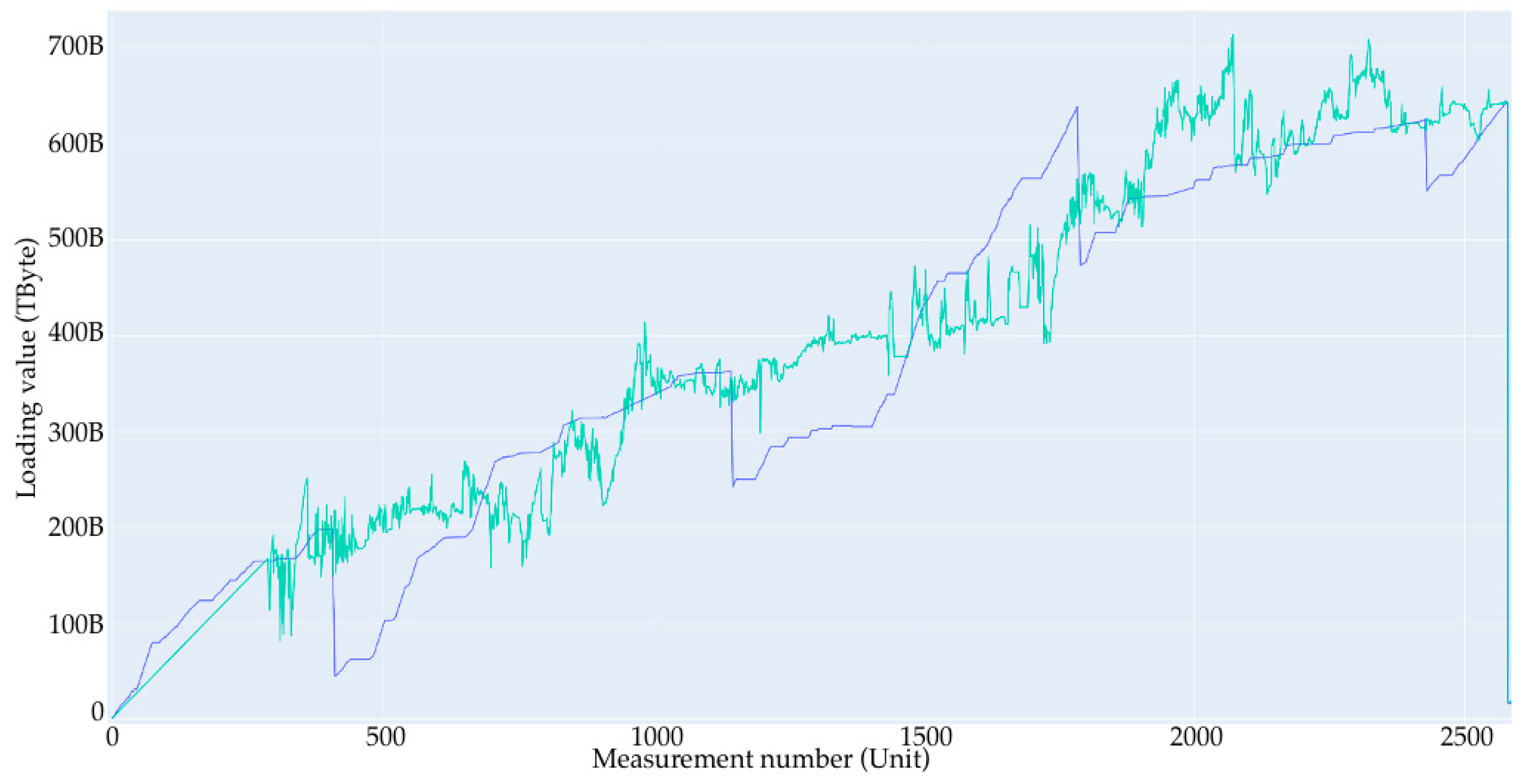
- Removing periods where there is no load, since there is no way to predict the time when the load will start from a small number of data (Figure 2);
- Addition to the basic variant:



- Thus, the following actions with the original dataset were performed:
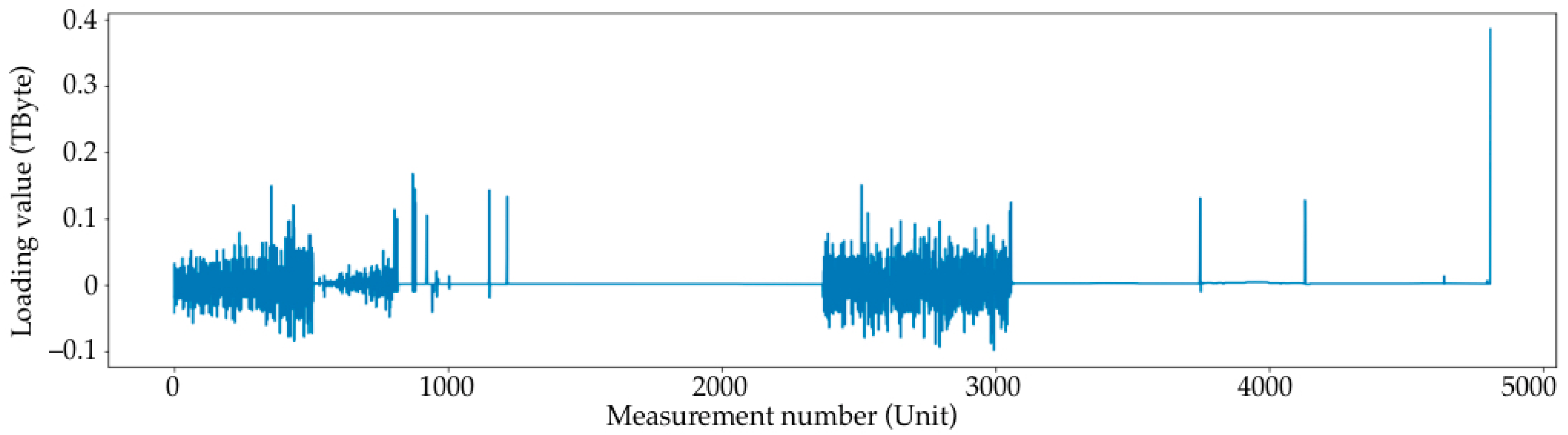
- The variable “Deviation” (diff) was added, which is the difference between the current SAN load value and the previous one;
- SAN downtimes were removed;
- All the sudden SAN load downturns (more than 10%) were removed, since only the SAN load growth prediction was consistent;
- The data were smoothed using a moving average (MA) with a period of 50.




- Here, we define the following notation:
- Diff—the difference between the current value and the previous value;
- MA—moving average;
- Lag—number of observations preceding the current one;
- Shift—shift from the beginning of the loading trend.
- Table 1 compares the results of SAN utilization prediction according to quality criteria.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Score Diff | MAPE Diff | MAPE Value | RMSE Diff | RMSE Value |
|---|---|---|---|---|---|
| NN_(162,512)_MA(50)_Diff Lag_50_Shift_50 | 0.916413 | 12.59 | 0.31 | 0.033401 | 0.950863 |
| NN_(162,512)_MA(50)_Diff Lag_50_Shift_50_Even_trend | 0.858994 | 0.19 | 0.06 | 0.012702 | 0.288143 |
| CatBoost_MA(50)_Diff_Shift_50 | 0.573871 | 12.48 | 0.16 | 0.073646 | 0.480208 |
| CatBoost_MA(50)_Diff Lag_50_Shift_50 | 0.573871 | 12.48 | 0.16 | 0.073646 | 0.480208 |
| KNN_MA(50)_Diff Lag_50_Even_trend | 0.953349 | 0.04 | 0.00 | 0.006142 | 0.084444 |
| KNN_MA(50)_Diff Lag_50_Shift_50_Even_trend | 0.953349 | 0.04 | 0.00 | 0.006142 | 0.084444 |
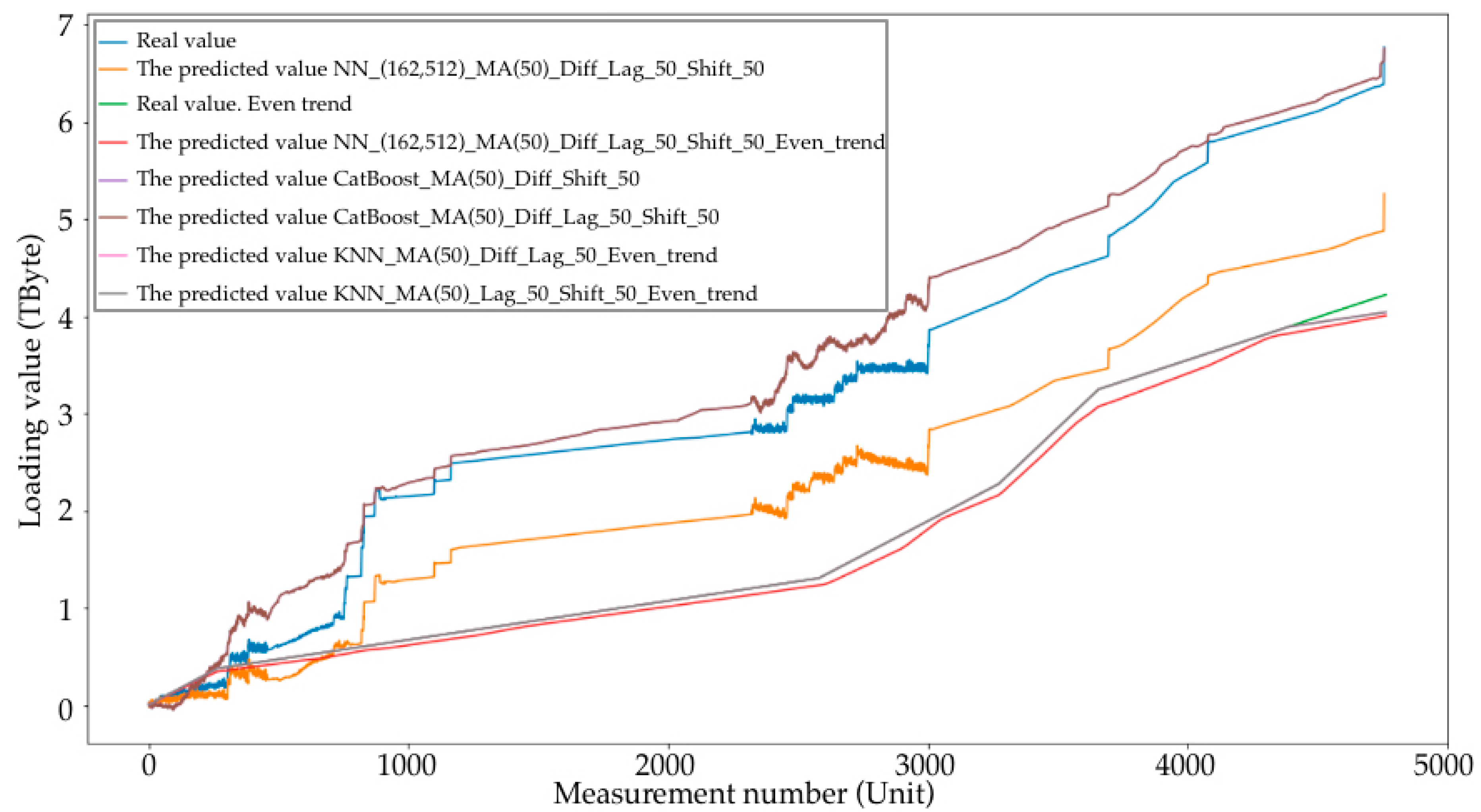
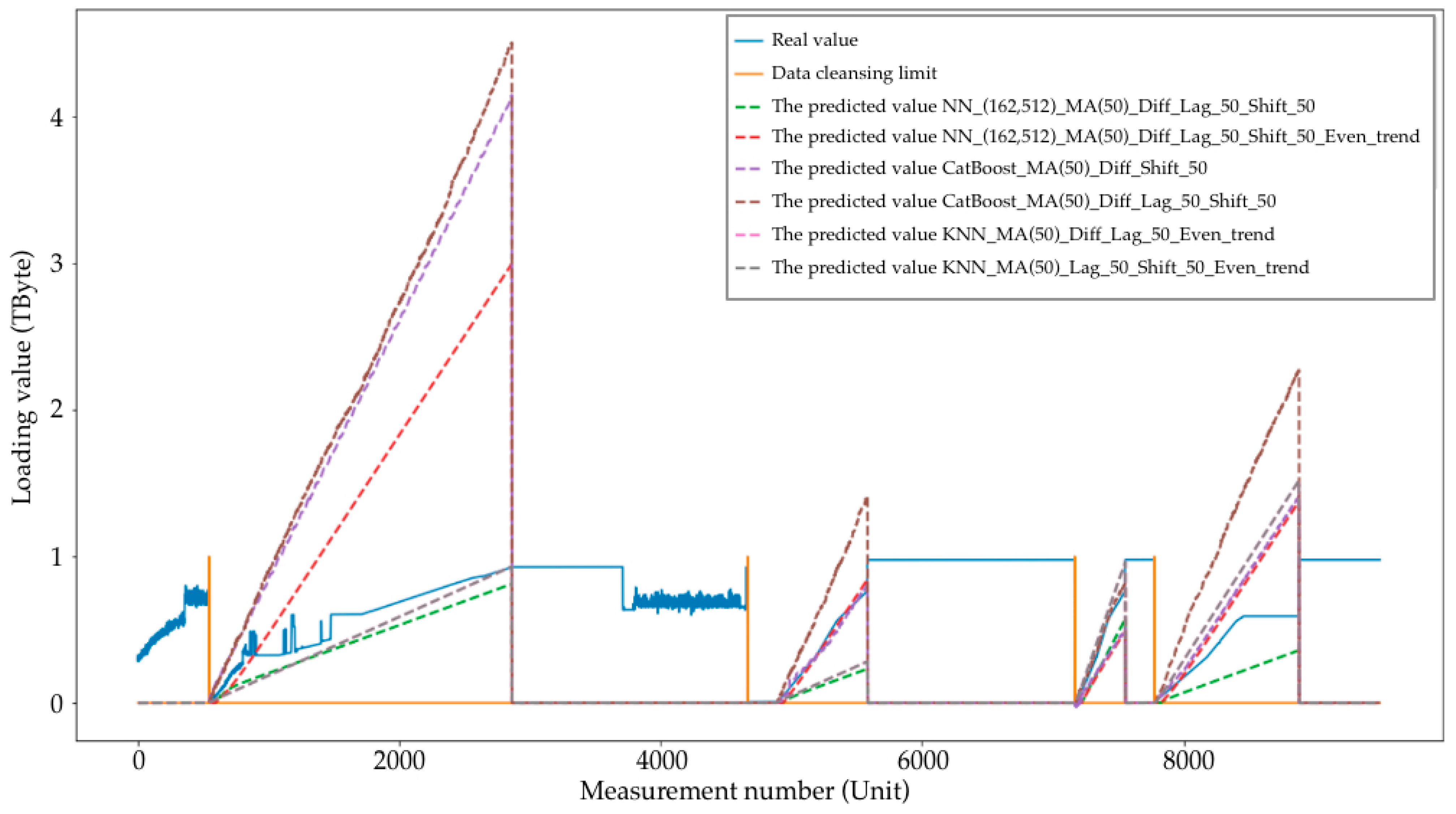
- NN_(162,512)_MA(50)_Diff_Lag_50_Shift_50:
- ○
- Multilayer Perspectron Neural Network;
- ○
- Architecture: 2 hidden layers, namely, 1-162 and 2-512;
- ○
- Input parameters:
- ■
- MA (50);
- ■
- Diff (50)—50 observations back from the current value.
- ○
- From the starting point of the loading stage, 50 observations were “waited out” and the forecast was performed based on their values (this stage was performed only for the graph in Figure 8).
- NN_(162,512)_MA(50)_Diff_Lag_50_Shift_50_Even_trend:
- ○
- Multilayer Perspectron Neural Network;
- ○
- Architecture—2 hidden layers: 1-162 and 2-512;
- ○
- The dataset for training was preprocessed to fully linear loading plots;
- ○
- Input data:
- ■
- MA (50);
- ■
- Diff (50)—50 observations back from the current value.
- ○
- From the starting point of the loading stage 50 observations were “waited out” and the forecast was performed based on their values (this stage was performed only for the graph in Figure 8).
- CatBoost_MA(50)_Diff_Shift_50:
- ○
- CatBoostRegressor model;
- ○
- Hyperparameters by default;
- ○
- Input data:
- ■
- MA (50);
- ■
- Diff;
- ○
- From the starting point of the loading stage 50 observations were “waited out” and the forecast was performed based on their values (this stage was performed only for the graph in Figure 8).
- CatBoost_MA(50)_Diff_Lag_50_Shift_50:
- ○
- CatBoostRegressor model;
- ○
- Hyperparameters by default;
- ○
- Input data:
- ■
- MA (50);
- ■
- Diff (50)—50 observations back from the current value.
- ○
- From the starting point of the loading stage 50 observations were “waited out” and the forecast was performed based on their values (this stage was performed only for the graph in Figure 8).
- KNN_MA(50)_Diff_Lag_50_Even_trend:
- ○
- KNeighborsClassifier model;
- ○
- Hyperparameters:
- ■
- metric = ‘cityblock’;
- ■
- weights = ‘distance’.
- ○
- The dataset for training was preprocessed into fully linear loading sections;
- ○
- Input data:
- ■
- MA (50);
- ■
- Diff (50)—50 observations back from the current value.
- KNN_MA(50)_Lag_50_Shift_50_Even_trend:
- ○
- KNeighborsClassifier model;
- ○
- Hyperparameters:
- ■
- metric = ‘cityblock’;
- ■
- weights = ‘distance’.
- ○
- The dataset for training was preprocessed into fully linear loading sections;
- ○
- Input data:
- ■
- MA (50);
- ■
- Diff (50)—50 observations back from the current value.
- ○
- From the starting point of the loading stage 50 observations were “waited out” and the forecast was performed based on their values (this stage was performed only for the graph in Figure 8).

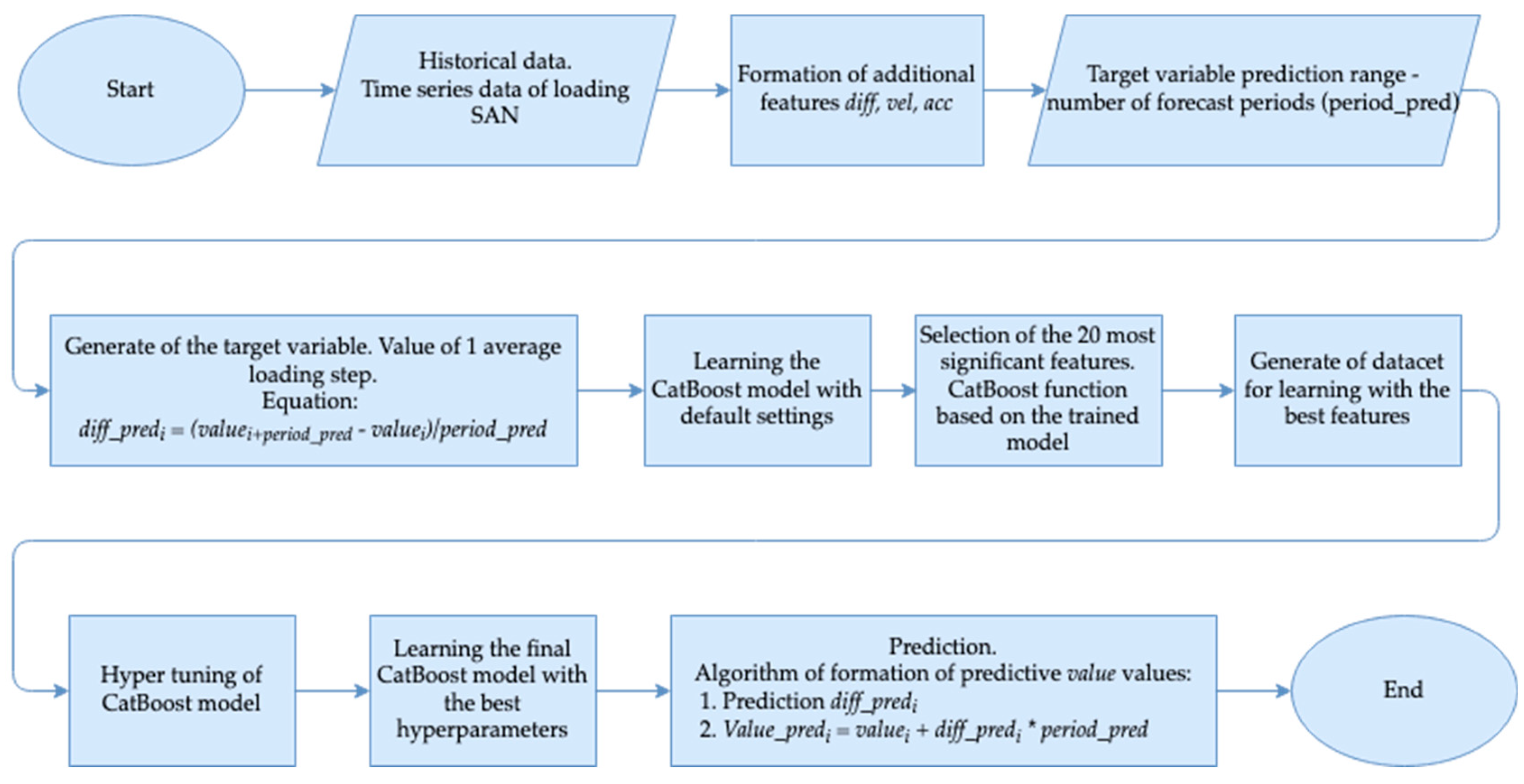
3.2. CatBoost Description
4. Results
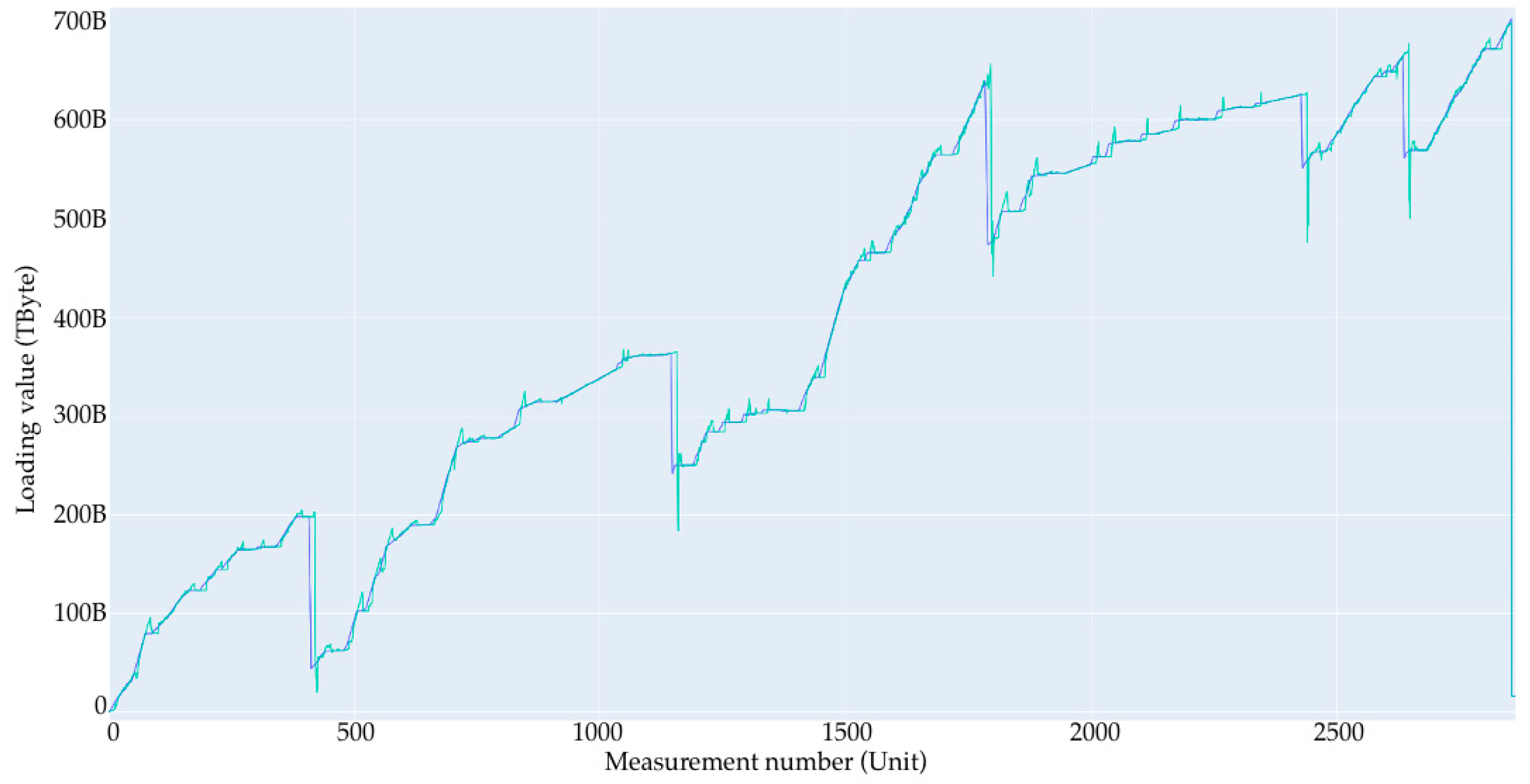
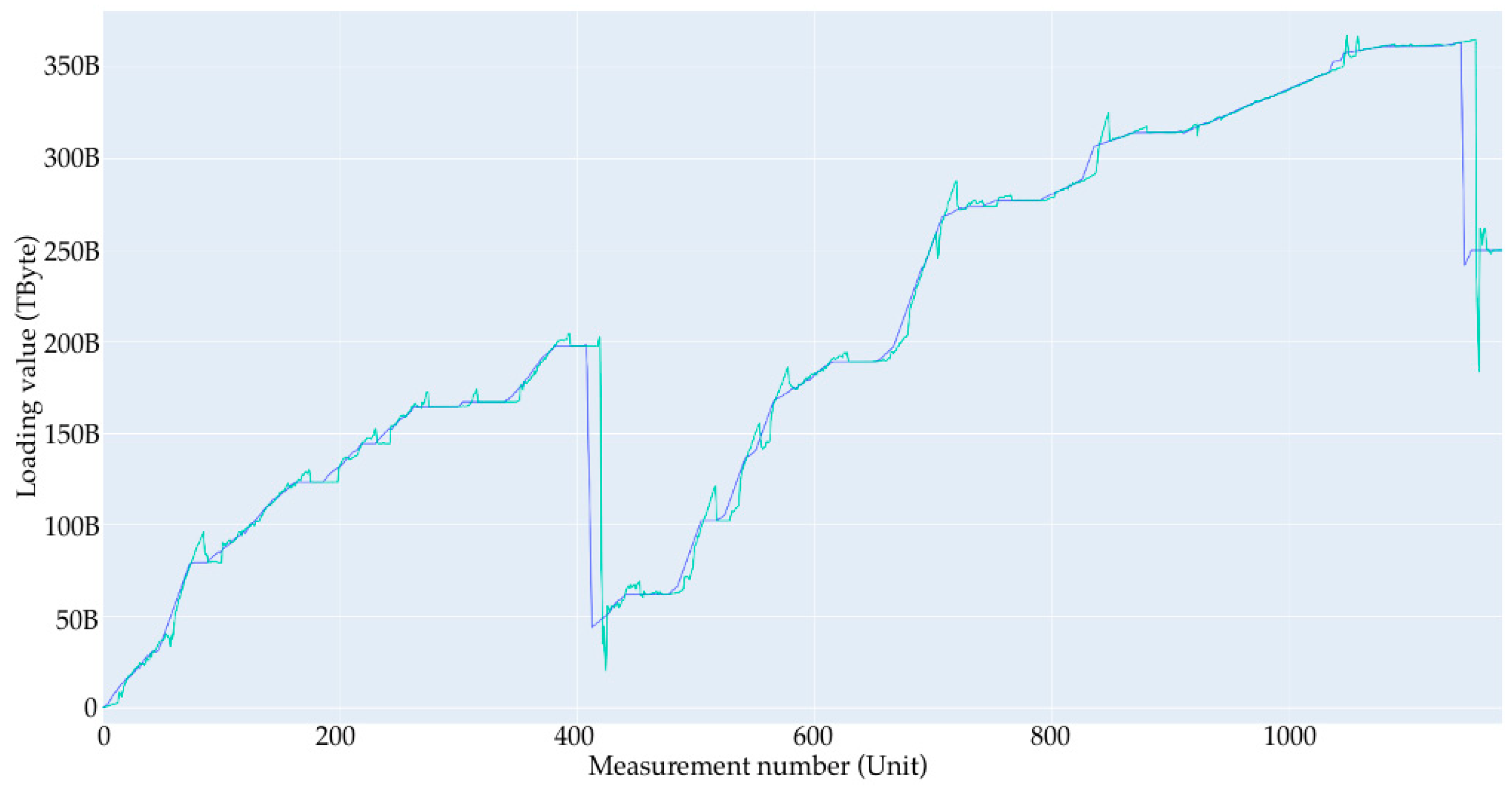
4.1. Initial Data Synthesis
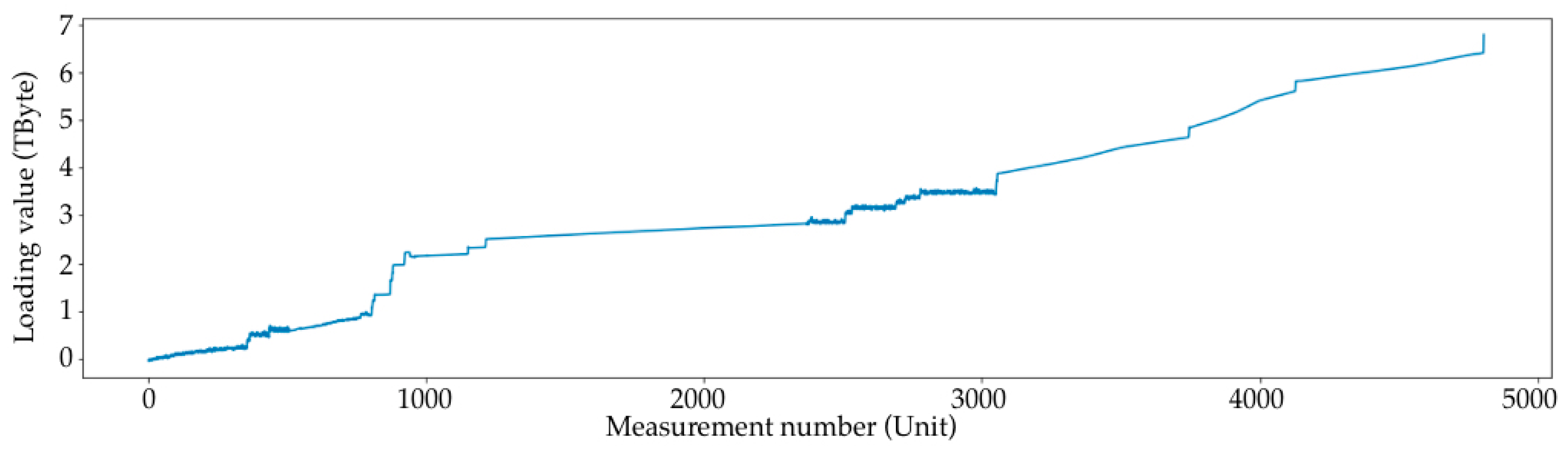
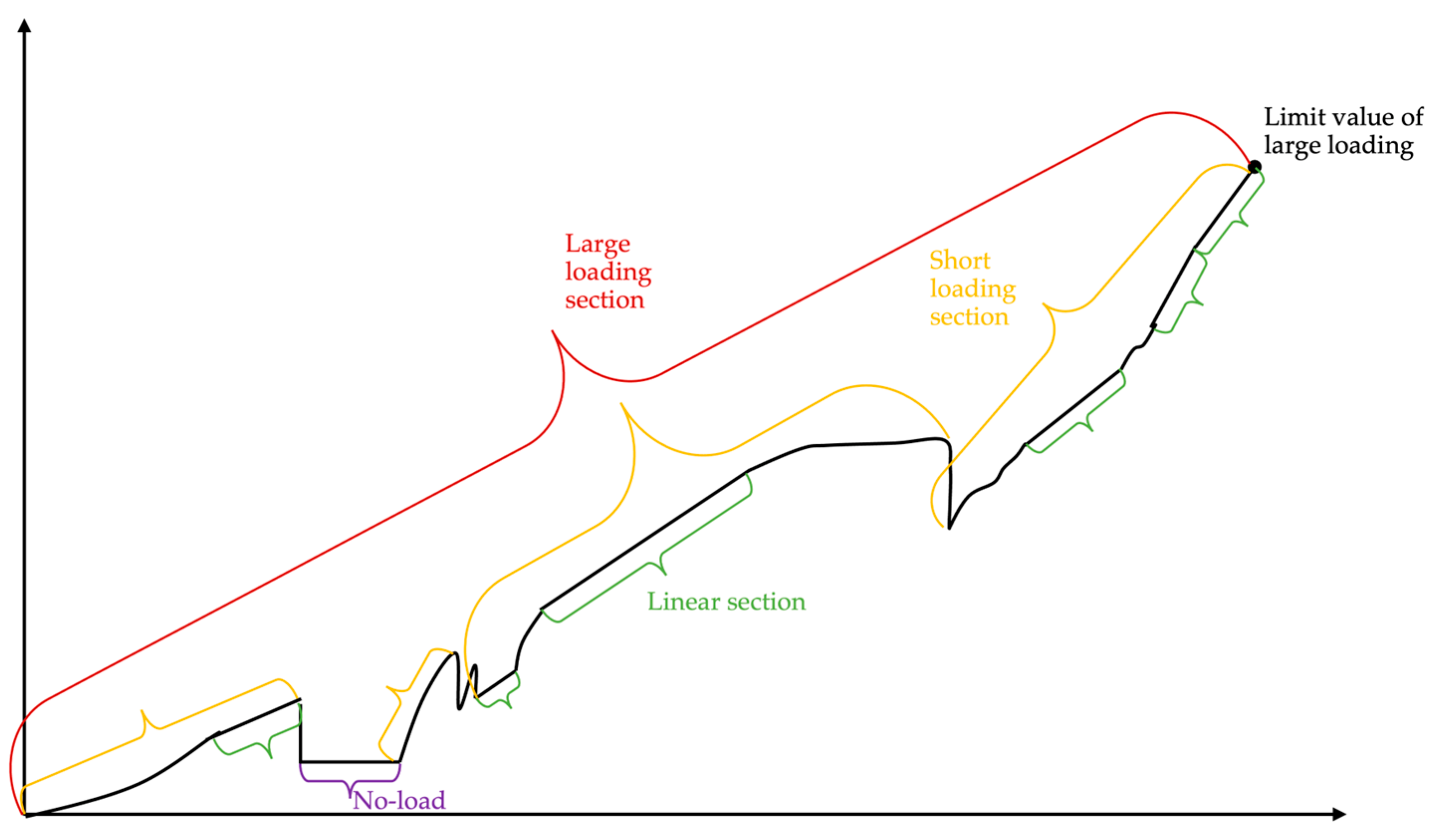
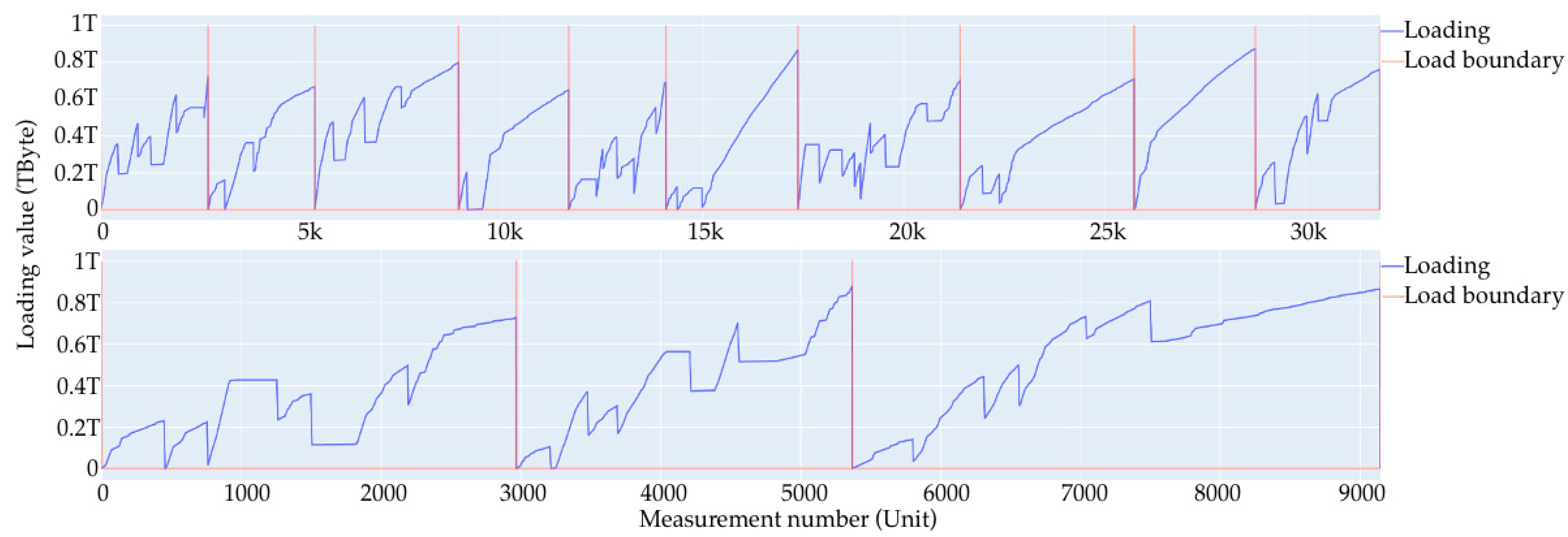
- A large loading section (or large loading stage) is a storage area network loading from 0 to some limit value. In the case of the current data synthesis, the limit value is in the range of 60 to 90% of the total volume. In the current example, the volume is set to 1 Tb. After each large loading step, there is a complete deletion of records to 0 with no small deletion steps. Since the data are generated, the large loading steps are not related to each other, and this deletion is performed only to start a new loading step from a point at 0.
- Short loading section (or small loading stage)—this is a local loading stage, similar to the large one, only inside of it. It is loaded at a smaller percentage, and after stage-by-stage deletion occurs with a simulation of the real values, it obtains one record of removal in the range from 10 Gb to 50 Gb; the range of the limits of removal are from 5 to 25% of the total volume.
- No-load—this is the point at which nothing happens; the value is the same throughout several records.
- Linear section—this is the section that is very close to the linear load, wherein the values of the increment at each step are in the range of ±5% of the average value given for this linear section to move from point A to point B.
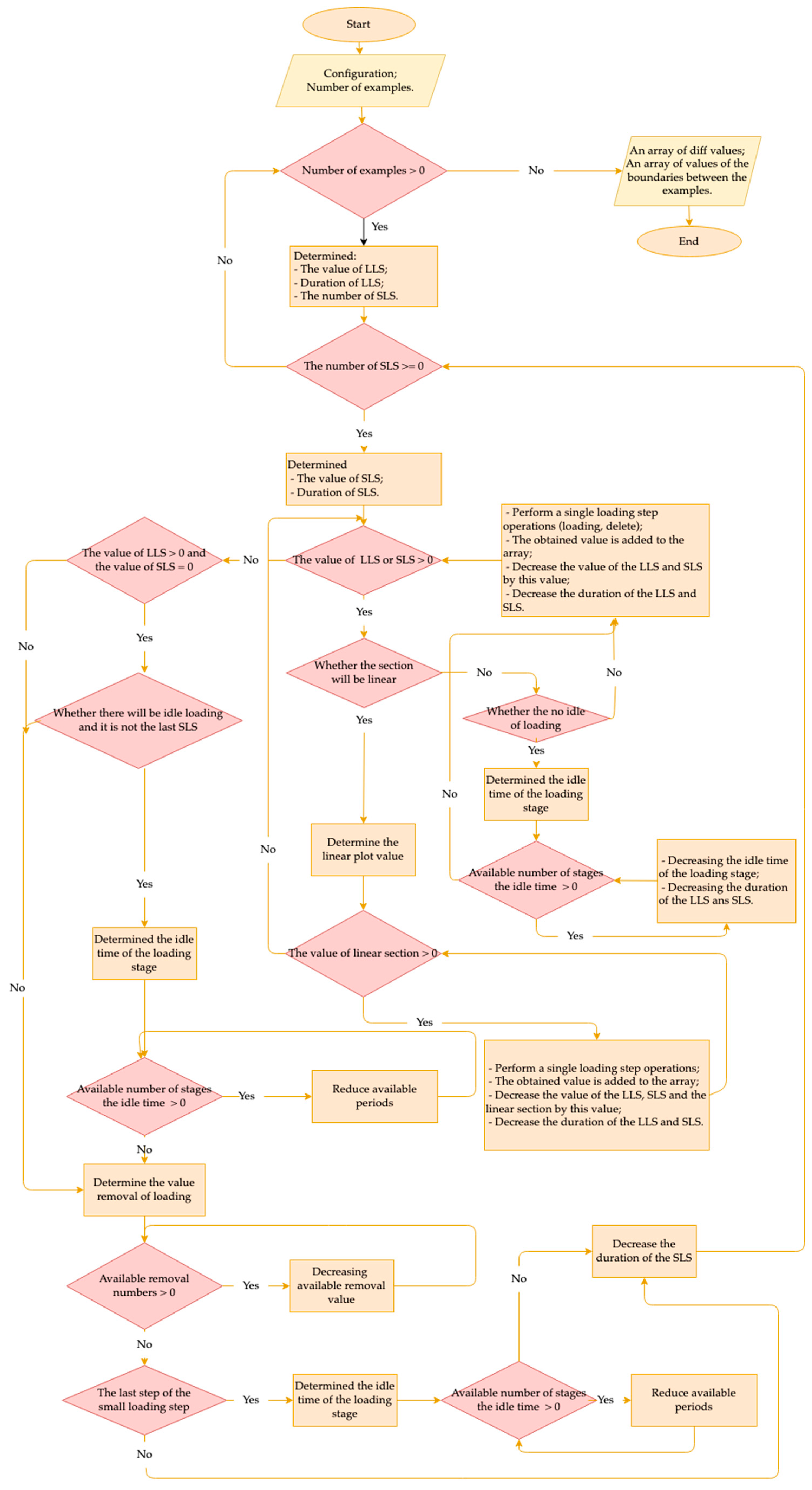
- The value and duration of one large loading step (LLS);
- The number of small loading steps (SLS), inside of the large one.
- An array of diff values (delta function);
- An array of values of the boundaries between the examples;
- The completion of the algorithm.
- The operation of determining a single loading step is performed;
- The obtained value is added to the array;
- The values of the large loading step, the small loading step, and the linear section are decreased by this value;
- The durations of the large loading step and the small loading step are decreased.
- the value of the large loading step, small loading step, and linear section are decreased by that value;
- The durations of the large loading step and the small loading step are decreased.
- An array of delta values;
- An array of boundary values between examples.
4.2. Formation of a Set of Essential Features for Predicting SAN Utilization
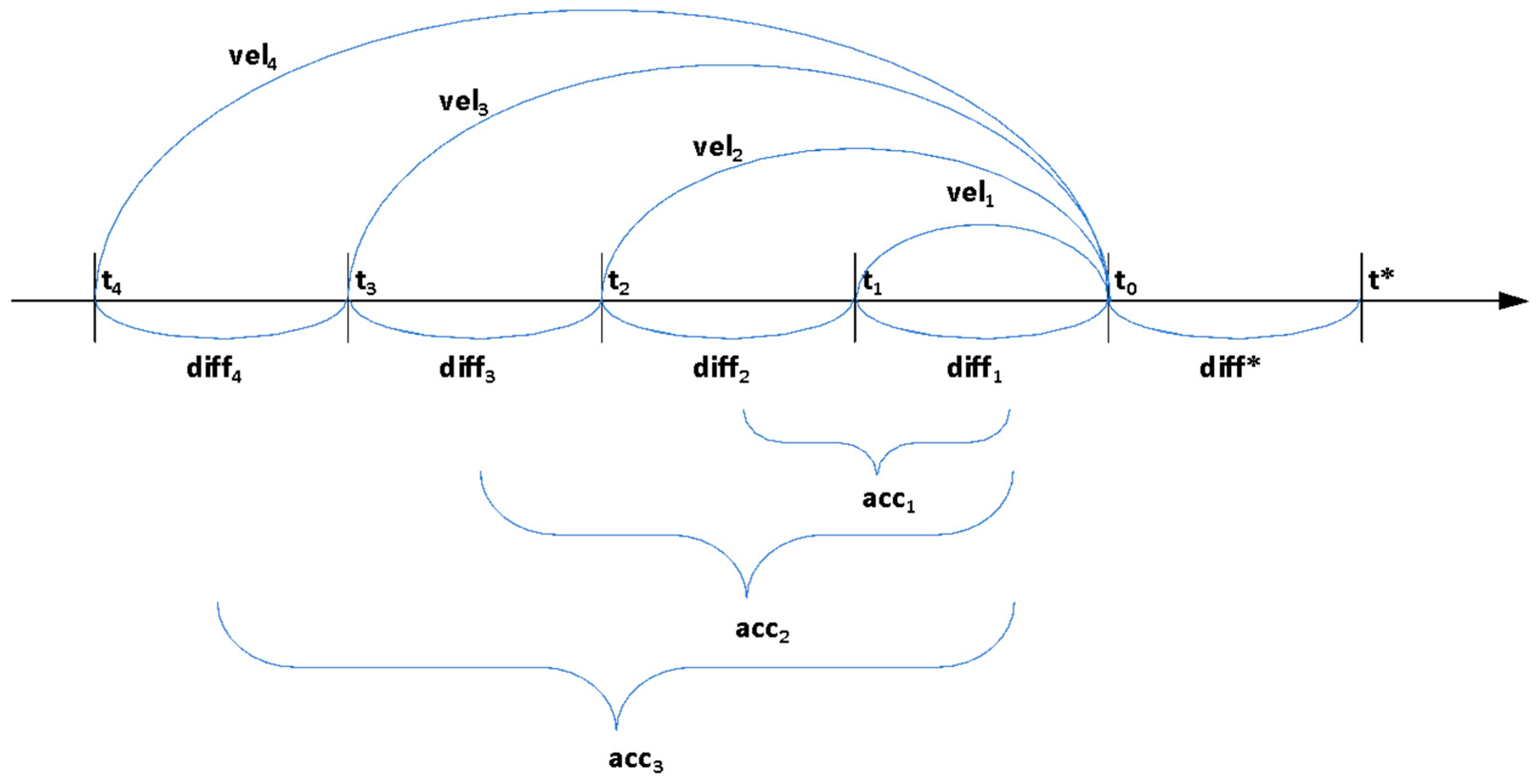
- The value of load increase in the next period of time is close to the current value of load increase diff1 (the principle of “inertia” or stable load increase);
- In the case when the change of the diff value at the current moment is temporary, and when the value of diff was higher or lower during the entirety of the earlier operation, then the average value of loading change at time periods (tj, tj−1, …, t1), j = 1, …, n) should be considered (the principle of the “average speed” of loading corresponds to Equation (1)):
- 3.
- In the case when the loading rate (vel) increases (or decreases) in the process, then this tendency to increase (decrease) should be considered with respect to the values of the change in diff (the principle of accounting for the “acceleration” of the loading is given in Equation (2)):
4.3. Experimental Results
- The model was tested on 576 incoming diff properties.
- The 10 best properties were selected by the CatBoost model function “get_feature_importance”. Testing was conducted on these properties.
- The five best properties were selected by the CatBoost model function “get_feature_importance”. Testing was conducted on these properties.
- The three best properties were selected by the function of the CatBoost model “get_feature_importance”. Testing was conducted on these properties.
- A single best property was selected by the CatBoost model function “get_feature_importance”. Testing was conducted on these properties.
- Testing was performed on 1151 incoming properties. Of these:
- Average velocity (vel)—576;
- Average acceleration (acc)—575.
- The 20 best properties were selected by the CatBoost model function “get_feature_importance”. Tests were conducted on these properties.
- The 10 best properties were selected by function of the CatBoost model “get_feature_importance”. Tests were conducted on these properties.
- The five best properties were selected by the function of the CatBoost model “get_feature_importance”. Tests were conducted on these properties.
- Changing the feature space by introducing the generalizing features velj and accj leads to improved prediction;
- A truncated feature set simplifies the model and accelerates training without incurring a significant loss (or improvement) of prediction accuracy.
5. Experimental Studies on Predicting SAN Loading Using Regression
5.1. Predicting SAN Utilization by Regression One Hour Ahead
- CatBoostRegressor and CatBoost Library;
- KNeighborsRegressor, using the k-nearest neighbor method;
- LinearRegression, linear regression.
- CatBoost model hyperparameter grid search:
- Loss-function MAE average absolute error;
- A test sample size of 20%.
- The following is a list of CatBoost model hyperparameters:
- The best hyperparameters of the CatBoost model are as follows:
- The best hyperparameters of the KneighborsRegressor model are as follows:
5.2. Predicting SAN Load Using Neural Networks
5.3. Predicting SAN Load Using Regression for 24 h Ahead
- CatBoost hyperparameter grid search on top—20 parameters.
- The list of hyperparameters of the CatBoost model:
- The best hyperparameters of the CatBoost model:
- The best results of the CatBoost model prediction:
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Çelik, D.; Meral, M.E.; Waseem, M. Investigation and Analysis of Effective Approaches, Opportunities, Bottlenecks and Future Potential Capabilities for Digitalization of Energy Systems and Sustainable Development Goals. Electr. Power Syst. Res. 2022, 211, 108251. [Google Scholar] [CrossRef]
- Waseem, M.; Lin, Z.; Liu, S.; Jinai, Z.; Rizwan, M.; Sajjad, I.A. Optimal BRA Based Electric Demand Prediction Strategy Considering Instance-Based Learning of the Forecast Factors. Int. Trans. Electr. Energy Syst. 2021, 31, e12967. [Google Scholar] [CrossRef]
- Teggi, P.; Malakreddy, B.; Teggi, P.P.; Harivinod, N. AIOPS Prediction for Server Stability Based on ARIMA Model. Int. J. Eng. Tech. Res. 2021, 10, 128–134. [Google Scholar]
- Nääs Starberg, F.; Rooth, A. Predicting a Business Application's Cloud Server CPU Utilization Using the Machine Learning Model LSTM. DEGREE Proj. Technol. 2021, 1, 1–14. [Google Scholar]
- Nashold, L.; Krishnan, R. Using LSTM and SARIMA Models to Forecast Cluster CPU Usage. arXiv 2020. [Google Scholar] [CrossRef]
- D’souza, R. Optimizing Utilization Forecasting with Artificial Intelligence and Machine Learning. Available online: https://www.datanami.com/2020/ (accessed on 21 October 2022).
- Masich, I.S.; Tyncheko, V.S.; Nelyub, V.A.; Bukhtoyarov, V.V.; Kurashkin, S.O.; Borodulin, A.S. Paired Patterns in Logical Analysis of Data for Decision Support in Recognition. Computation 2022, 10, 185. [Google Scholar] [CrossRef]
- Yoas, D.W. Using Forecasting to Predict Long-Term Resource Utilization for Web Services. Ph.D. Thesis, Retrieved from NSUWorks, Graduate School of Computer and Information Sciences. Nova Southeastern University, Lauderdale, FL, USA, 2013. [Google Scholar]
- Mikhalev, A.S.; Tynchenko, V.S.; Nelyub, V.A.; Lugovaya, N.M.; Baranov, V.A.; Kukartsev, V.V.; Sergienko, R.B.; Kurashkin, S.O. The Orb-Weaving Spider Algorithm for Training of Recurrent Neural Networks. Symmetry 2022, 14, 2036. [Google Scholar] [CrossRef]
- Cheong, C.W.; Way, C.C. Fuzzy Linguistic Decision Analysis for Web Server System Future Planning. In Proceedings of the IEEE Region 10 Annual International Conference (TENCON), Kuala Lumpur, Malaysia, 24–27 September 2000; Volume 1, pp. 367–372. [Google Scholar]
- Cheong, C.W.; Hua, K.Y.W.; Leong, N.K. Web Server Future Planning Decision Analysis—Fuzzy Linguistic Weighted Approach. In Proceedings of the 4th International Conference on Knowledge-Based Intelligent Engineering Systems and Allied Technologies (KES 2000), Brighton, UK, 30 August–1 September 2000; Volume 2, pp. 826–830. [Google Scholar]
- Khosla, N.; Sharma, D. Using Semi-Supervised Classifier to Forecast Extreme CPU Utilization. Int. J. Artif. Intell. Appl. 2020, 11, 45–52. [Google Scholar] [CrossRef]
- Tatarnikova, T.M.; Poymanova, E.D. Differentiated Capacity Extension Method for System of Data Storage with Multilevel Structure. Sci. Tech. J. Inf. Technol. Mech. Opt. 2020, 20, 66–73. [Google Scholar] [CrossRef] [Green Version]
- Poimanova, E.D.; Tatarnikova, T.M.; Kraeva, E.V. Model of Data Traffic Storage Management. J. Instrum. Eng. 2021, 64, 370–375. [Google Scholar] [CrossRef]
- Sovetov, B.Y.; Tatarnikova, T.M.; Poymanova, E.D. Storage Scaling Management Model. Inf.-Upr. Sist. 2020, 1, 43–49. [Google Scholar] [CrossRef]
- Janardhanan, D.; Barrett, E. CPU Workload Forecasting of Machines in Data Centers Using LSTM Recurrent Neural Networks and ARIMA Models. In Proceedings of the 2017 12th International Conference for Internet Technology and Secured Transactions (ICITST), Cambridge, UK, 11–14 December 2017; pp. 55–60. [Google Scholar]
- Tran, V.G.; Debusschere, V.; Bacha, S. Hourly Server Workload Forecasting up to 168 Hours Ahead Using Seasonal ARIMA Model. In Proceedings of the 2012 IEEE International Conference on Industrial Technology (ICIT), Athens, Greece, 19–21 March 2012; pp. 1127–1131. [Google Scholar]
- Zharikov, E.; Telenyk, S.; Bidyuk, P. Adaptive Workload Forecasting in Cloud Data Centers. J. Grid Comput. 2020, 18, 149–168. [Google Scholar] [CrossRef]
- Baldan, F.J.; Ramirez-Gallego, S.; Bergmeir, C.; Herrera, F.; Benitez, J.M. A Forecasting Methodology for Workload Forecasting in Cloud Systems. IEEE Trans. Cloud Comput. 2018, 6, 929–941. [Google Scholar] [CrossRef]
- Tran, V.G.; Debusschere, V.; Bacha, S. Neural Networks for Web Server Workload Forecasting. In Proceedings of the 2013 IEEE International Conference on Industrial Technology (ICIT), Cape Town, South Africa, 25–28 February 2013; pp. 1152–1156. [Google Scholar]
- CatBoost. Available online: https://catboost.ai/ (accessed on 20 October 2022).
- Yao, C.; Dai, Q.; Song, G. Several Novel Dynamic Ensemble Selection Algorithms for Time Series Prediction. Neural Process. Lett. 2019, 50, 1789–1829. [Google Scholar] [CrossRef]
- Dorogush, A.V.; Ershov, V.; Yandex, A.G. CatBoost: Gradient Boosting with Categorical Features Support. arXiv 2018. [Google Scholar] [CrossRef]
- Jabeur, S.B.; Gharib, C.; Mefteh-Wali, S.; Arfi, W.B. CatBoost model and artificial intelligence techniques for corporate failure prediction. Technol. Forecast. Soc. Change 2021, 166, 120658. [Google Scholar] [CrossRef]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. In Proceedings of the 32nd Conference on Neural Information Processing Systems, NEURIPS 2018, Montreal, QC, Canada, 2–7 December 2018; Volume 31, pp. 6638–6648. [Google Scholar]
- Aarthi, B.; Jeenath Shafana, N.; Tripathy, S.; Sampat Kumar, U.; Harshitha, K. Sentiment Analysis Using CatBoost Algorithm on COVID-19 Tweets. Lect. Notes Data Eng. Commun. Technol. 2023, 131, 161–171. [Google Scholar] [CrossRef]
- Chen, S.; Dai, Y.; Ma, X.; Peng, H.; Wang, D.; Wang, Y. Personalized Optimal Nutrition Lifestyle for Self Obesity Management Using Metaalgorithms. Sci. Rep. 2022, 12, 12387. [Google Scholar] [CrossRef] [PubMed]










| Parameters | Min. Value | Max. Value |
|---|---|---|
| Limit value range of one large loading step (% of volume filling) | 60 | 90 |
| The duration of one large loading step (number of hours) | 192 | 384 |
| Range of values, i.e., the number of small loading steps within a large one | 0 | 7 |
| Limit value range of one small loading step within a large one (% of volume filling) | 10 | 50 |
| Duration of one small download step within a large one (number of hours) | 8 | 48 |
| Value range of one download record (5 min/Mb) | 100 | 3500 |
| One deletion record. Only considered when downloading (5 min/Mb) | 500 | 1000 |
| Probability of a deletion record appearing only when downloading (%) | 1 | |
| Limit value range of one deletion step. Follows a small loading step (% volume filling) | 5 | 25 |
| Range of values of one deletion record. Only considered at the moment of large data cleaning (5 min/Mb) | 10,000 | 50,000 |
| Probability of a linear section appearing (approximation to the average value of the loading section) at a small loading step (%) | 1 | |
| Percentage of available values from the average in a linear segment | 5 | |
| Distance of a linear section in a small loading stage (ratio to the remaining value of a small loading stage) (%) | 10 | 30 |
| Length of time of no-volume loading after a small loading step (number of hours) | 1 | 30 |
| Probability of occurrence of downtime after a small loading step (%) | 20 | |
| Duration of volume unloading absence at the moment of loading a small stage (number of hours) | 1 | 3 |
| Probability of the absence of volume unloading at the time of downloading a small stage (%) | 1 | |
| Index | Value | Diff | Diff_Pred | Vel_1 | Vel_2 | Vel_4 | Acc_1 | Vel_3 | Vel_37 | Acc_3 | Acc_2 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2.88 × 108 | 2.88 × 108 | 7.84 × 108 | 287,595,427 | 1.44 × 108 | 7.18 × 107 | 2.88 × 108 | 95,865,142 | 26,145,039 | 95,865,142 | 1.44 × 108 |
| 1 | 4.6 × 108 | 1.73 × 108 | 8.52 × 108 | 172,849,937 | 2.3 × 108 | 1.15 × 108 | −1.1 × 108 | 1.53 × 108 | 38,370,447 | 57,616,646 | 86,424,969 |
| 2 | 1.46 × 109 | 109 | 8.74 × 108 | 1,000,166,779 | 5.87 × 108 | 3.65 × 108 | 8.27 × 108 | 4.87 × 108 | 1.12 × 108 | 3.33 × 108 | 3.56 × 108 |
| 3 | 1.69 × 109 | 2.32 × 108 | 9.11 × 108 | 231,652,134 | 6.16 × 108 | 4.23 × 108 | −7.7 × 108 | 4.68 × 108 | 1.21 × 108 | −1.9 × 107 | 29,401,099 |
| 4 | 1.93 × 109 | 2.34 × 108 | 9.47 × 108 | 233,602,912 | 2.33 × 108 | 4.1 × 108 | 1,950,778 | 4.88 × 108 | 1.28 × 108 | 20,250,992 | −3.8 × 108 |
| 5 | 3.09 × 109 | 1.16 × 109 | 8.87 × 108 | 1,163,185,905 | 6.98 × 108 | 6.57 × 108 | 9.3 × 108 | 5.43 × 108 | 1.93 × 108 | 54,339,709 | 4.66 × 108 |
| 6 | 4.23 × 109 | 1.14 × 109 | 8.45 × 108 | 1,139,444,841 | 1.15 × 109 | 6.92 × 108 | −2.4 × 107 | 8.45 × 108 | 2.49 × 108 | 3.03 × 108 | 4.53 × 108 |
| 7 | 5.25 × 109 | 1.02 × 109 | 8.65 × 108 | 1,022,942,872 | 1.08 × 109 | 8.9 × 108 | −1.2 × 108 | 1.11 × 109 | 2.92 × 108 | 2.63 × 108 | −7 × 107 |
| 8 | 6.23 × 109 | 9.81 × 108 | 8.04 × 108 | 980,959,592 | 109 | 1.08 × 109 | −4.2 × 107 | 1.05 × 109 | 3.28 × 108 | −6.1 × 107 | −7.9 × 107 |
| 9 | 7.49 × 109 | 1.26 × 109 | 7.38 × 108 | 1,258,057,292 | 1.12 × 109 | 1.1 × 109 | 2.77 × 108 | 1.09 × 109 | 3.75 × 108 | 39,537,484 | 1.18 × 108 |
| 10 | 8.46 × 109 | 9.65 × 108 | 7.09 × 108 | 964,858,193 | 1.11 × 109 | 1.06 × 109 | −2.9 × 108 | 1.07 × 109 | 4.03 × 108 | −1.9 × 107 | −8,050,700 |
| Feature | R2_Score | MAE (5 min/Mb) |
|---|---|---|
| top_3_diff | 0.141 | 245.3 |
| top_5_diff | 0.136 | 245.518 |
| top_10_diff | 0.118 | 250.166 |
| diff—diff575 | 0.095 | 251.993 |
| top_1_diff | 0.141 | 245.3 |
| Feature | R2_Score | MAE (5 min/Mb) |
|---|---|---|
| vel576_acc_575 | 0.158 | 241.16 |
| top_20 | 0.164 | 243.976 |
| top_10 | 0.166 | 244.427 |
| top_5 | 0.157 | 245.122 |
| Feature | R2_Score_Test | MAE (5 min/Mb) Test | R2_Score_Train | MAE (5 min/Mb) Train | R2_Score_Value_Train | MAPE Train | R2_Score_Test | MAPE_Test | Time | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | CatBoost | 0.170824 | 278.800098 | 0.208604 | 246.253602 | 0.995776 | 41.662629 | 0.995247 | 47.190251 | 60 s |
| 1 | LinearRegression | 0.103211 | 391.897892 | 0.117591 | 368.547922 | 0.995309 | 48.447350 | 0.994881 | 57.711764 | 1 s |
| 2 | KNeighborsRegressor | 0.181701 | 316.129383 | 0.215314 | 290.157608 | 0.995814 | 41.746353 | 0.995302 | 47.815941 | 240 s |
| Layer (Type) | Output Shape | Param # |
|---|---|---|
| dense_28 (Dense) | (None, 256) | 5376 |
| dense_29 (Dense) | (None, 256) | 5376 |
| dense_30 (Dense) | (None, 256) | 65,792 |
| dense_31 (Dense) | (None, 256) | 65,792 |
| dense_32 (Dense) | (None, 256) | 65,792 |
| dense_33 (Dense) | (None, 256) | 65,792 |
| dense_34 (Dense) | (None, 256) | 65,792 |
| dense_35 (Dense) | (None, 256) | 65,792 |
| dense_36 (Dense) | (None, 256) | 65,792 |
| dense_37 (Dense) | (None, 256) | 65,792 |
| dense_38 (Dense) | (None, 1) | 257 |
| Total params: 597,761 Trainable params: 597,761 Non-trainable params: 0 | ||
| feature | R2_Score_Test | MAE (5 min/Mb) Test | R2_Score_Train | MAE (5 min/Mb) Train | R2_Score_Value_Train | MAPE Train | R2_Score_Test | пpost | Time | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | NN (30) | 0.145156 | 296.460396 | 0.169836 | 272.314980 | 0.995568 | 43.799124 | 0.995092 | 52.625168 | 85 s |
| 1 | NN 10 layers of 30 neurons | 0.132219 | 291.138713 | 0.165863 | 265.017411 | 0.995561 | 40.682488 | 0.995079 | 50.087625 | 100 s |
| 2 | NN (256) | 0.143416 | 300.917126 | 0.166495 | 277.047718 | 0.995546 | 46.452904 | 0.995072 | 55.716560 | 80 s |
| 3 | NN 10 layers of 256 neurons | 0.076478 | 297.920565 | 0.098162 | 273.298865 | 0.995178 | 48.149521 | 0.994680 | 56.919627 | 130 s |
| Model | Diff Train MAE | Diff Test MAE | Diff Train R2 | Diff Test R2 | Value Train MAPE | Value Test MAPE | Value Train R2 | Value Test R2 |
|---|---|---|---|---|---|---|---|---|
| 1 h | 246.25 | 277.8 | 0.21 | 0.17 | 41.66 | 47.19 | 0.996 | 0.995 |
| 2 h | 275.22 | 307.0 | 0.17 | 0.12 | 90.63 | 102.5 | 0.989 | 0.988 |
| 4 h | 275.2 | 300.62 | 0.18 | 0.12 | 178.67 | 217.26 | 0.976 | 0.973 |
| 8 h | 240.15 | 266.05 | 0.24 | 0.15 | 348.02 | 458.5 | 0.948 | 0.943 |
| 24 h | 160.15 | 194.37 | 0.35 | 0.19 | 807.53 | 682.42 | 0.858 | 0.811 |
| 48 h | 106.91 | 129.48 | 0.25 | 0.11 | 921.97 | 270.47 | 0.748 | 0.656 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Masich, I.S.; Tynchenko, V.S.; Nelyub, V.A.; Bukhtoyarov, V.V.; Kurashkin, S.O.; Gantimurov, A.P.; Borodulin, A.S. Prediction of Critical Filling of a Storage Area Network by Machine Learning Methods. Electronics 2022, 11, 4150. https://doi.org/10.3390/electronics11244150
Masich IS, Tynchenko VS, Nelyub VA, Bukhtoyarov VV, Kurashkin SO, Gantimurov AP, Borodulin AS. Prediction of Critical Filling of a Storage Area Network by Machine Learning Methods. Electronics. 2022; 11(24):4150. https://doi.org/10.3390/electronics11244150
Chicago/Turabian StyleMasich, Igor S., Vadim S. Tynchenko, Vladimir A. Nelyub, Vladimir V. Bukhtoyarov, Sergei O. Kurashkin, Andrei P. Gantimurov, and Aleksey S. Borodulin. 2022. "Prediction of Critical Filling of a Storage Area Network by Machine Learning Methods" Electronics 11, no. 24: 4150. https://doi.org/10.3390/electronics11244150