
Utilization of Explainable Machine Learning Algorithms for Determination of Important Features in ‘Suncrest’ Peach Maturity Prediction

 , , ,
, , ,  and
and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Physicochemical Properties of Fruits
2.1.1. Ground (GC) and Additional (AC) Fruit Skin Color
2.1.2. Fruit Weight, Endocarp Weight, and Flesh Ration
2.1.3. Fruit Width, Length, Shape Index, Diameter, Volume, and Density
2.1.4. Fruit Firmness, Soluble Solids Content (SSC), Titratable Acidity (TA), and SSC/TA Ratio
2.2. Dataset and Building a ML Model
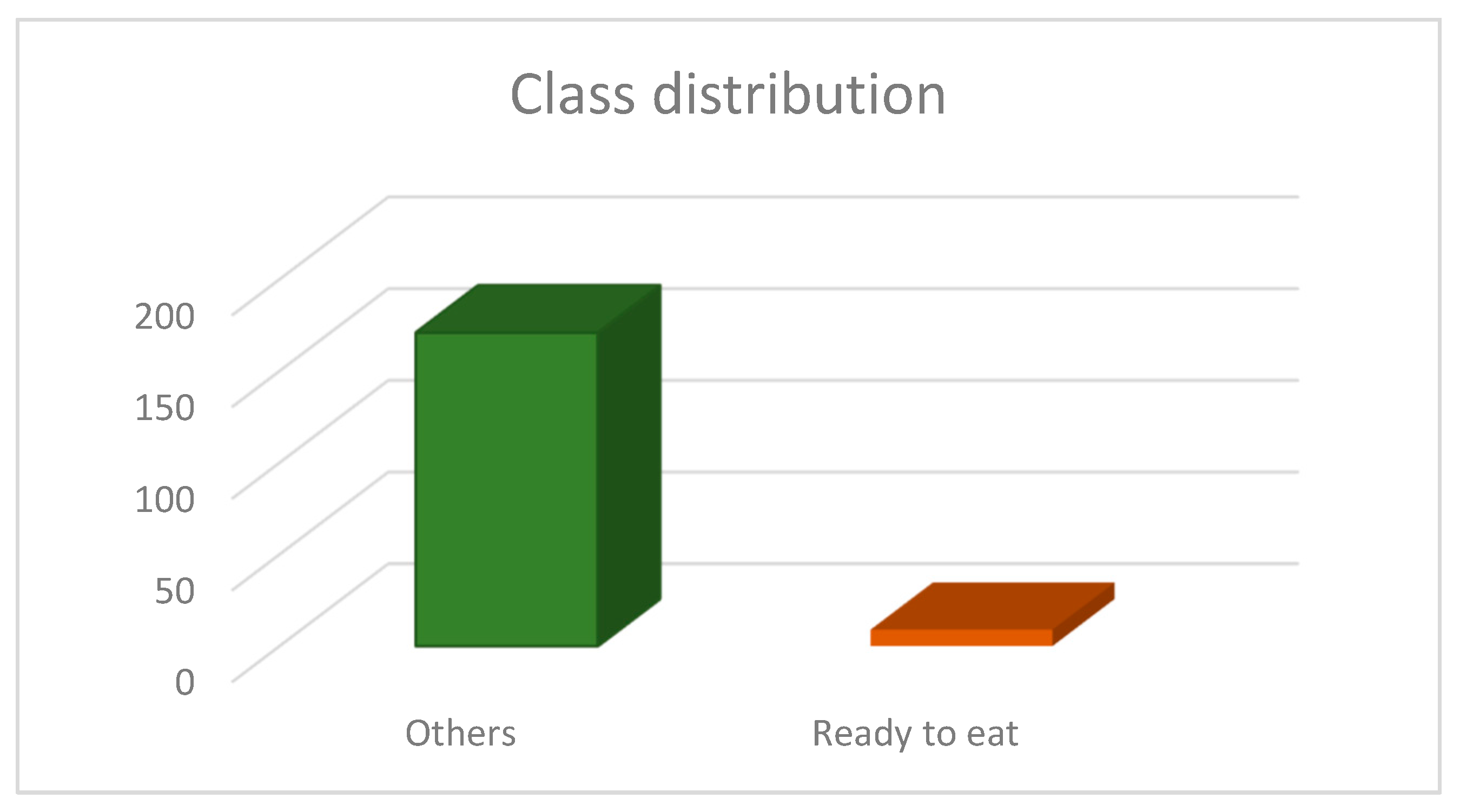
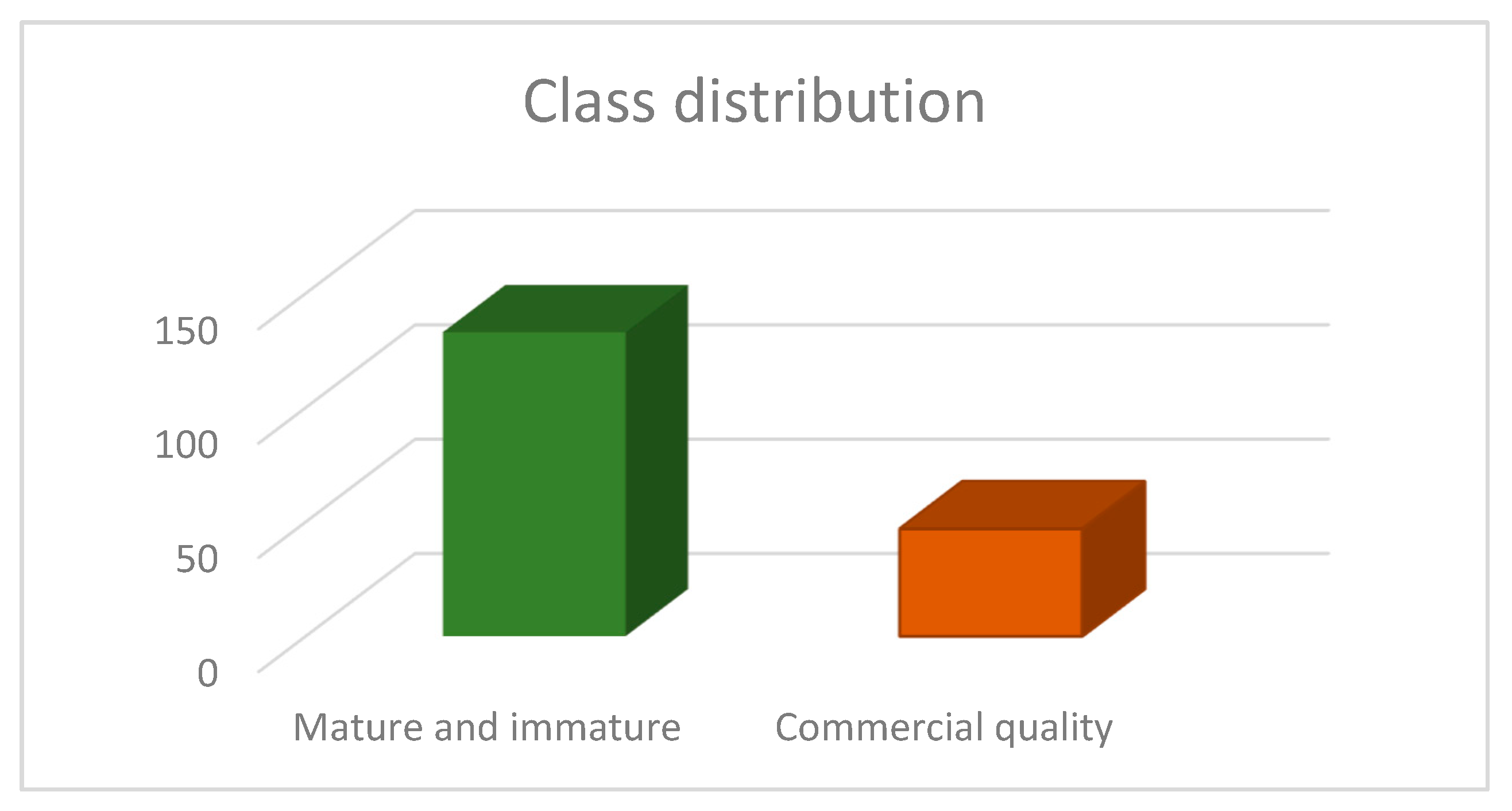
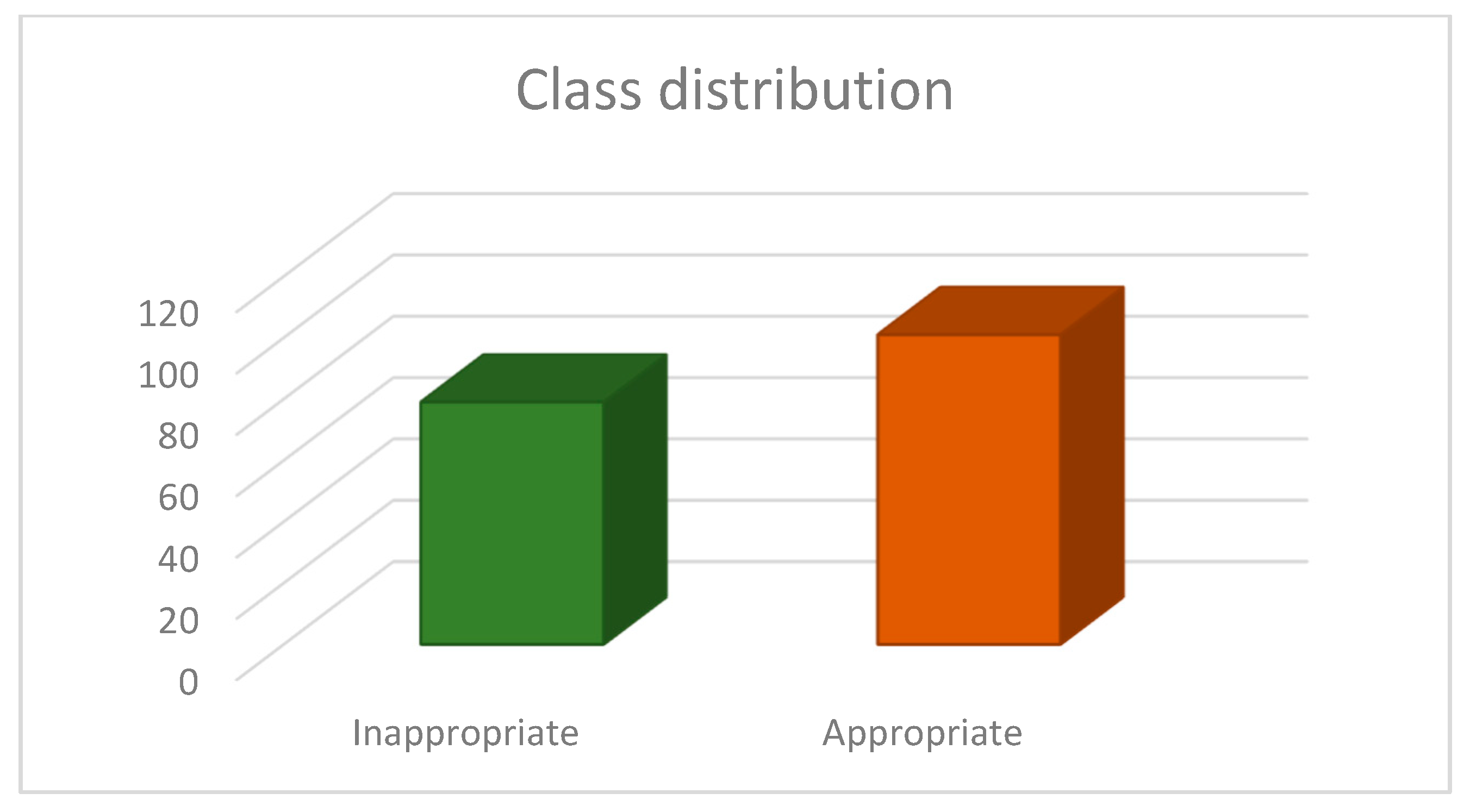
2.2.1. Balancing the Imbalanced Datasets
2.2.2. Training Random Forest Model
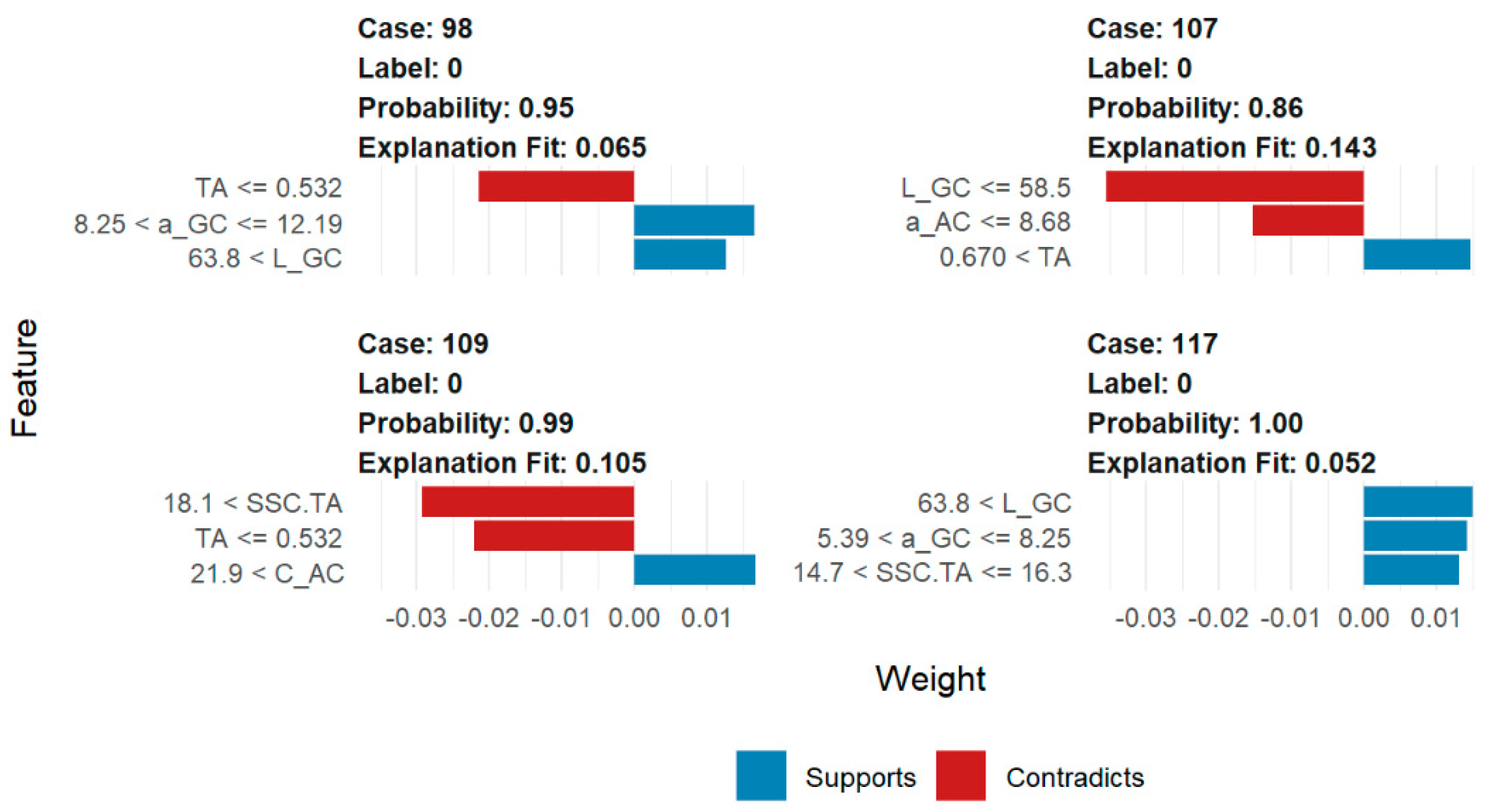
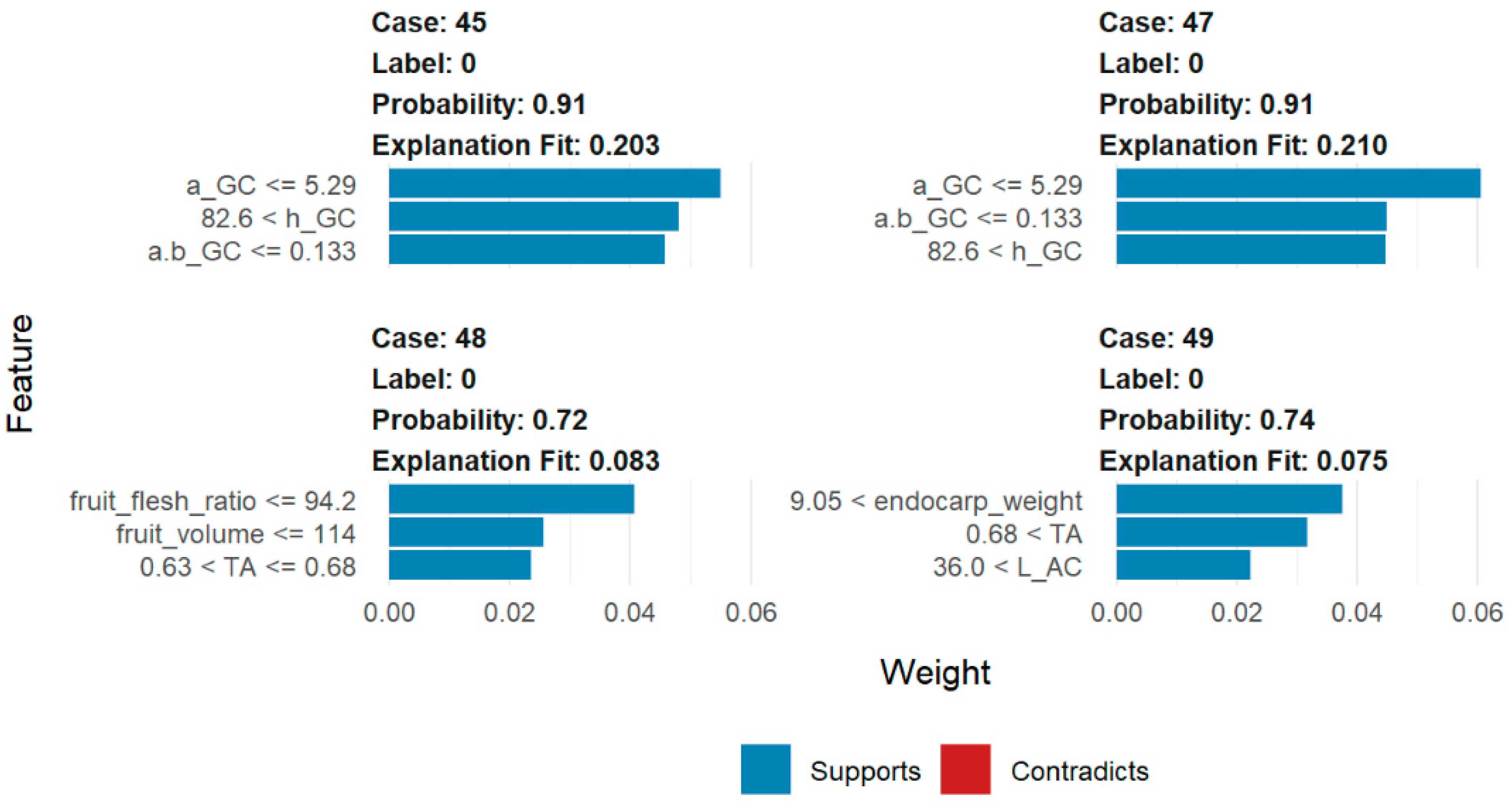
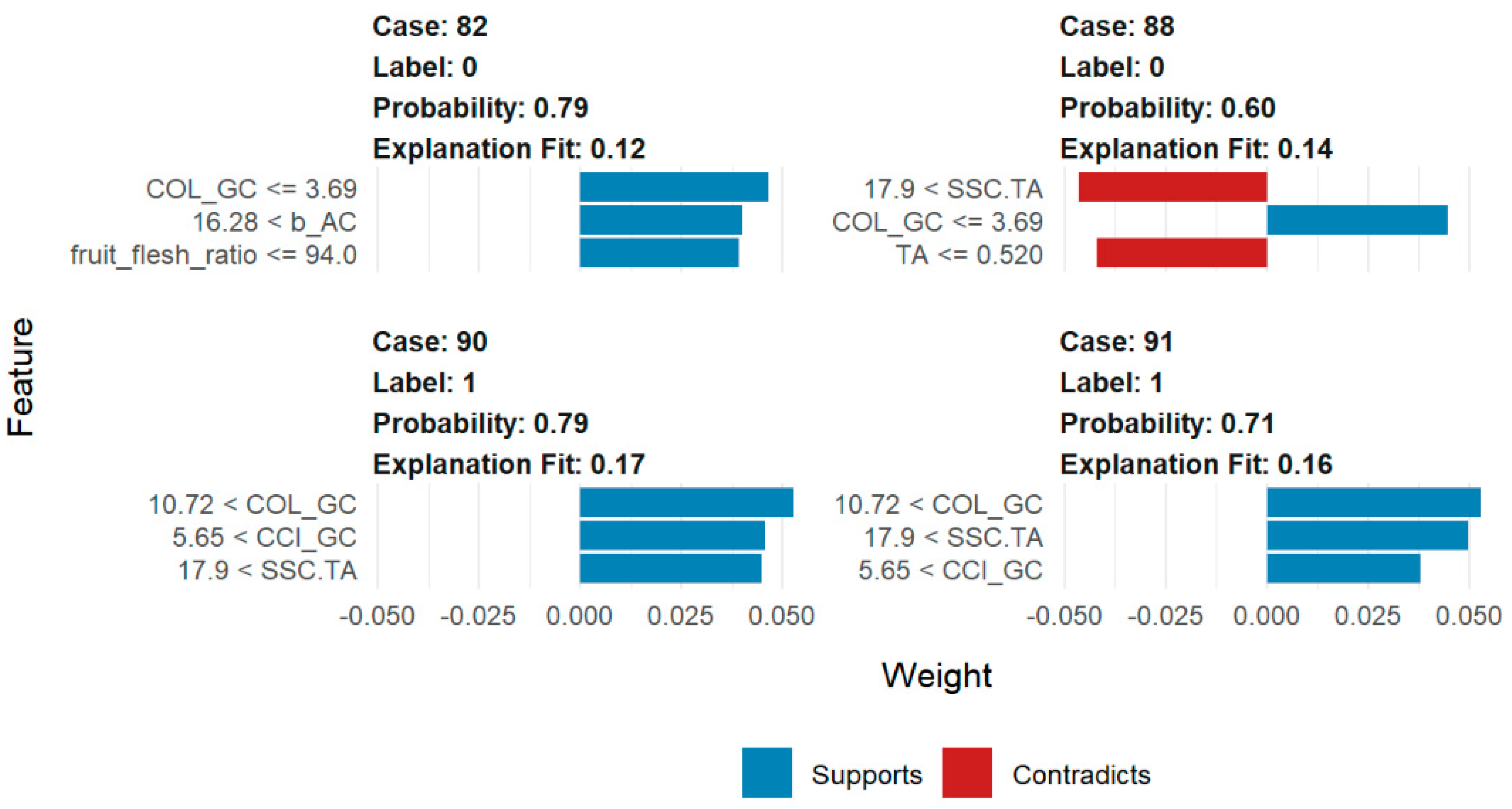
2.2.3. Interpreting Black Box Model Results
3. Results
3.1. The Model A Peaches (Firmness Less Than < 1.84 kg·cm−2)
3.2. The Model B Peaches (Firmness Less Than 3.57 kg·cm−2)
3.3. The Model C Peaches (Firmness Less Than 4.59 kg·cm−2)
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Nomenclature
| Acronym | Definition |
| ACC | Additional color index |
| CCI | Citrus Color Index |
| CI | Confidence Interval |
| CIELAB | Color space defined by the International Commission on Illumination |
| CIRG | Red grape color index |
| DNN | Deep Neural Network |
| GC | Ground color index |
| LIME | Local Interpretable Model-agnostic Explanations |
| ML | Machine Learning |
| NIR | No Information Rate |
| PCA | Principal Component Analysis |
| PFI | Permutation Feature Importance |
| RF | Random forest |
| ROSE | Random Over-Sampling Examples |
| SMOTE | Synthetic Minority Over-Sampling Technique |
| SSC | Soluble Solid Content |
| TA | Titratable Acidity |
| VI | Variable Importance |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Variable Name | Description |
|---|---|---|
| firmness | firmness | / |
| SSC | SSC | soluble solid content |
| TA | TA | titratable acidity |
| SSC/TA | SSC.TA | soluble solid content/titratable acidity |
| fruit weight | fruit_weight | / |
| endocarp weight | endocarp_weight | / |
| fruit flesh ratio | fruit_flesh_ratio | / |
| fruit width | fruit_width | / |
| fruit length | fruit_length | / |
| fruit shape index | fruit_shape_index | / |
| fruit diameter | fruit_diameter | / |
| fruit volume | fruit_volume | / |
| Fruit density | fruit_density | / |
| L*—AC | L_AC | L* variable of additional fruit color |
| a*—AC | a_AC | a* variable of additional fruit color |
| b*—AC | b_AC | b* variable of additional fruit color |
| C*—AC | C_AC | C* variable of additional fruit color |
| h°—AC | h_AC | h° variable of additional fruit color |
| a*/b*—AC | a.b_AC | a*/b* additional color index |
| CCI—AC | CCI_AC | CCL additional color index |
| COL—AC | COL_AC | COL additional color index |
| CIRG1—AC | CIRG1_AC | CIRG1 additional color index |
| CIRG2—AC | CIRG2_AC | CIRG2 additional color index |
| L*—GC | L_GC | L* variable of ground fruit color |
| a*—GC | a_GC | a* variable of ground fruit color |
| b*—GC | b_GC | b* variable of ground fruit color |
| C*—GC | c_GC | C* variable of ground fruit color |
| h°—GC | h_GC | h° variable of ground fruit color |
| a*/b*—GC | a.b_GC | a*/b* ground color index |
| CCI—GC | CCI_GC | CCL ground color index |
| COL—GC | COL_GC | COL ground color index |
| CIRG1—GC | CIRG1_GC | CIRG1 ground color index |
| CIRG2—GC | CIRG2_GC | CIRG2 ground color index |
References
- Encyclopaedia Britannica Peach, Tree and Fruit. Available online: https://www.britannica.com/plant/peach (accessed on 30 June 2021).
- Miserius, M.; Behr, D.H.-C. European Statistics Handbook; Fruitnet: London, UK, 2021; p. 3. [Google Scholar]
- Konopacka, D.; Jesionkowska, K.; Kruczyńska, D.; Stehr, R.; Schoorl, F.; Buehler, A.; Egger, S.; Codarin, S.; Hilaire, C.; Höller, I.; et al. Apple and peach consumption habits across European countries. Appetite 2010, 55, 478–483. [Google Scholar] [CrossRef]
- Crisosto, C.H. How do we increase peach consumption? Acta Hortic. 2002, 592, 601–605. [Google Scholar] [CrossRef]
- Wang, X.; Matetić, M.; Zhou, H.; Zhang, X.; Jemrić, T. Postharvest quality monitoring and variance analysis of peach and nectarine cold chain with multi-sensors technology. Appl. Sci. 2017, 7, 133. [Google Scholar] [CrossRef] [Green Version]
- Robertson, J.A.; Meredith, F.I.; Forbus, W.R. Changes in Quality Characteristics During Peach (Cv. ‘Majestic’) Maturation. J. Food Qual. 1991, 14, 197–207. [Google Scholar] [CrossRef]
- Infante, R. Harvest maturity indicators in the stone fruit industry. Stewart Postharvest Rev. 2012, 1, 1–6. [Google Scholar] [CrossRef]
- Shewfelt, R.L.; Myers, S.C.; Resurreccion, A.V.A. Effect of physiologycal maturity at harvest on peach quality during low temperature storage. J. Food Qual. 1987, 10, 9–20. [Google Scholar] [CrossRef]
- Ceccarelli, A.; Farneti, B.; Frisina, C.; Allen, D.; Donati, I.; Cellini, A.; Costa, G.; Spinelli, F.; Stefanelli, D. Harvest maturity stage and cold storage length influence on flavour development in peach fruit. Agronomy 2019, 9, 10. [Google Scholar] [CrossRef] [Green Version]
- Salunkhe, D.K.; Deshpande, P.B.; Do, J.Y. Effects of Maturity and Storage on Physical and Biochemical Changes in Peach and Apricot Fruits. J. Hortic. Sci. 1968, 43, 235–242. [Google Scholar] [CrossRef]
- Vanoli, M.; Bianchi, G.; Rizzolo, A.; Lurie, S.; Spinelli, L.; Torricelli, A. Electronic nose pattern, sensory profile and flavor components of cold stored ‘Spring Belle’ peaches: Influence of storage temperatures and fruit maturity assessed at harvest by time-resolved reflectance spectroscopy. Acta Hortic. 2015, 1084, 687–694. [Google Scholar] [CrossRef]
- Ramina, A.; Tonutti, P.; McGlasson, W.; McGlasson, B. Ripening, nutrition and postharvest physiology. In The Peach, Botany, Production and Uses; Layne, D.R., Bassi, D., Eds.; CAB International: Wallingford, UK, 2008; pp. 550–574. ISBN 9781845933869. [Google Scholar]
- Crisosto, C.H.; Costa, G. Preharvest factors affecting peach quality. In The Peach: Botany, Production and Uses; CABI: Wallingford, UK, 2008; pp. 536–549. ISBN 9781845933869. [Google Scholar]
- Shinya, P.; Contador, L.; Predieri, S.; Rubio, P.; Infante, R. Peach ripening: Segregation at harvest and postharvest flesh softening. Postharvest Biol. Technol. 2013, 86, 472–478. [Google Scholar] [CrossRef]
- Valero, C.; Crisosto, C.H.; Slaughter, D. Relationship between nondestructive firmness measurements and commercially important ripening fruit stages for peaches, nectarines and plums. Postharvest Biol. Technol. 2007, 44, 248–253. [Google Scholar] [CrossRef] [Green Version]
- Crisosto, C.H.; Kader, A. Peach Postharvest Quality Maintenance Guidelines; Department of Pomology, University of California: Davis, CA, USA, 2000. [Google Scholar]
- Scalisi, A.; Pelliccia, D.; O’connell, M.G. Maturity prediction in yellow peach (Prunus persica L.) cultivars using a fluorescence spectrometer. Sensors 2020, 20, 6555. [Google Scholar] [CrossRef]
- De-la-Torre, M.; Zatarain, O.; Avila-George, H.; Muñoz, M.; Oblitas, J.; Lozada, R.; Mejía, J.; Castro, W. Multivariate analysis and machine learning for ripeness classification of cape gooseberry fruits. Processes 2019, 7, 928. [Google Scholar] [CrossRef] [Green Version]
- Zhang, G.; Fu, Q.; Fu, Z.; Li, X.; Matetić, M.; Bakaric, M.B.; Jemrić, T. A comprehensive peach fruit quality evaluation method for grading and consumption. Appl. Sci. 2020, 10, 1348. [Google Scholar] [CrossRef] [Green Version]
- Hyun Cho, W.; Kyoon Kim, S.; Hwan Na, M.; Seop Na, I. Fruit Ripeness Prediction Based on DNN Feature Induction from Sparse Dataset. Comput. Mater. Contin. 2021, 69, 4003–4024. [Google Scholar] [CrossRef]
- Varga, L.A.; Makowski, J.; Zell, A. Measuring the Ripeness of Fruit with Hyperspectral Imaging and Deep Learning. arXiv 2021, arXiv:2104.09808. [Google Scholar]
- Ljubobratović, D.; Guoxiang, Z.; Bakarić, M.B.; Jemrić, T.; Matetić, M. Predicting peach fruit ripeness using explainable machine learning. In Proceedings of the 31st International DAAAM Virtual Symposium ‘Intelligent Manufacturing & Automation’, Mostar, Bosnia and Herzegovina, 21–24 October 2020; Katalinić, B., Ed.; DAAAM International: Vienna, Austria, 2020; pp. 717–723. [Google Scholar]
- Taylor, R. Interpretation of the Correlation Coefficient: A Basic Review. J. Diagn. Med. Sonogr. 1990, 6, 35–39. [Google Scholar] [CrossRef]
- Ryo, M.; Rillig, M.C. Statistically reinforced machine learning for nonlinear patterns and variable interactions. Ecosphere 2017, 8, e01976. [Google Scholar] [CrossRef]
- Song, C.; Kwan, M.P.; Song, W.; Zhu, J. A Comparison between spatial econometric models and random forest for modeling fire occurrence. Sustainability 2017, 9, 819. [Google Scholar] [CrossRef] [Green Version]
- Auret, L.; Aldrich, C. Interpretation of nonlinear relationships between process variables by use of random forests. Miner. Eng. 2012, 35, 27–42. [Google Scholar] [CrossRef]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Turini, F.; Giannotti, F.; Pedreschi, D. A survey of methods for explaining black box models. ACM Comput. Surv. 2018, 51, 1–45. [Google Scholar] [CrossRef] [Green Version]
- Krpina, I.; Vrbanek, J.; Asić, A.; Ljubičić, M.; Ivković, F.; Ćosić, T.; Štambuk, S.; Kovačević, I.; Perica, S.; Nikolac, N.; et al. Voćarstvo; Nakladni Zavod Globus: Zagreb, Croatia, 2004. [Google Scholar]
- Miljković, I. Suvremeno Voćarstvo; Nakladni zavod Znanje: Zagreb, Croatia, 1991. [Google Scholar]
- Hunter Associates Laboratory Inc. AN 1005.00 Measuring Color Using Hunter L, a, b Versus CIE 1976 L*a*b*. 2012, p. 4. Available online: https://www.hunterlab.com/media/documents/duplicate-of-an-1005-hunterlab-vs-cie-lab.pdf (accessed on 29 October 2021).
- Carreño, J.; Martínez, A.; Almela, L.; Fernández-López, J.A. Proposal of an index for the objective evaluation of the colour of red table grapes. Food Res. Int. 1995, 28, 373–377. [Google Scholar] [CrossRef]
- Gao, Y.; Liu, Y.; Kan, C.; Chen, M.; Chen, J. Changes of peel color and fruit quality in navel orange fruits under different storage methods. Sci. Hortic. 2019, 256, 108522. [Google Scholar] [CrossRef]
- López Camelo, A.F.; Gómez, P.A. Comparison of color indexes for tomato ripening. Hortic. Bras. 2004, 22, 534–537. [Google Scholar] [CrossRef]
- Little, A.C. A Research note: Off on a Tangent. J. Food Sci. 1975, 40, 410–411. [Google Scholar] [CrossRef]
- Jimenez-Cuesta, M.; Cuquerella, J.; Martinez-Javaga, J.M. Determination of a color index for citrus fruit degreening. Proc. Int. Soc. Citric. 1981, 2, 750–753. [Google Scholar]
- Hobson, G.E. Low-temperature injury and the storage of ripening tomatoes. J. Hortic. Sci. 1987, 62, 55–62. [Google Scholar] [CrossRef]
- AOAC. AOAC Official Methods of Analysis of AOAC International, 16th ed.; 5th Rev.; Association of Official Analytical Chemists: Gaithersburg, MD, USA, 1999. [Google Scholar]
- Crisosto, C.; Slaughter, D.; Garner, D.; Boyd, J. Stone fruit critical bruising tresholds. J. Am. Pomol. Soc. 2001, 55, 76–81. [Google Scholar]
- Neri, F.; Brigati, S. Sensory and objective evaluation of peaches. In Proceedings of the Cost 94: The Postharvest Treatment of Fruit and Vegetables; De Jager, A., Jhonson, A., Hohn, E., Eds.; European Comission: Brussels, Belgium, 1994; pp. 107–115. [Google Scholar]
- Viloria, A.; Lezama, O.B.P.; Mercado-Caruzo, N. Unbalanced data processing using oversampling: Machine learning. Procedia Comput. Sci. 2020, 175, 108–113. [Google Scholar] [CrossRef]
- Douzas, G.; Bacao, F.; Last, F. Improving imbalanced learning through a heuristic oversampling method based on k-means and SMOTE. Inf. Sci. 2018, 465, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Juanjuan, W.; Mantao, X.; Hui, W.; Jiwu, Z. Classification of imbalanced data by using the SMOTE algorithm and locally linear embedding. In Proceedings of the 2006 8th international Conference on Signal Processing, Guilin, China, 16–20 November 2006; Volume 3, pp. 1–4. [Google Scholar] [CrossRef]
- Sáez, J.A.; Luengo, J.; Stefanowski, J.; Herrera, F. SMOTE-IPF: Addressing the noisy and borderline examples problem in imbalanced classification by a re-sampling method with filtering. Inf. Sci. 2015, 291, 184–203. [Google Scholar] [CrossRef]
- Lunardon, N.; Menardi, G.; Torelli, N. ROSE: A package for binary imbalanced learning. R J. 2014, 6, 79–89. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Carvalho, D.V.; Pereira, E.M.; Cardoso, J.S. Machine learning interpretability: A survey on methods and metrics. Electronics 2019, 8, 832. [Google Scholar] [CrossRef] [Green Version]
- Molnar, C. Interpretable Machine Learning. A Guide for Making Black Box Models Explainable. 2019, p. 247. Available online: https://christophm.github.io/interpretable-ml-book/ (accessed on 29 October 2021).
- Vilone, G.; Longo, L. Classification of explainable artificial intelligence methods through their output formats. Mach. Learn. Knowl. Extr. 2021, 3, 615–661. [Google Scholar] [CrossRef]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling; Springer: New York, NY, USA, 2013; ISBN 978-1-4614-6849-3. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the KDD’ 16: The 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar] [CrossRef]
- Infante, R.; Aros, D.; Contador, L.; Rubio, P. Does the maturity at harvest affect quality and sensory attributes of peaches and nectarines? N. Z. J. Crop Hortic. Sci. 2012, 40, 103–113. [Google Scholar] [CrossRef]
- Crisosto, C.H.; Mitcham, E.J.; Kader, A.A. Peach and Nectarine: Recommendations for Maintaining Postharvest Quality; Postharvest Technology Center, University of California: Davis, CA, USA, 1996. [Google Scholar]
- Crisosto, C.H.; Valero, D. Harvesting and postharvest handling of peaches for the fresh market. In The Peach: Botany, Production and Uses; Layne, D.R., Bassi, D., Eds.; CAB International: Wallingford, UK, 2008; pp. 575–596. ISBN 9781845933869. [Google Scholar]
- Fruk, G.; Fruk, M.; Vuković, M.; Buhin, J.; Jatoi, M.A.; Jemrić, T. Colouration of apple cv. ‘Braeburn’ grown under anti-hail nets in Croatia. Acta Hortic. Regiotect. 2016, 19, 1–4. [Google Scholar] [CrossRef] [Green Version]
- Ferrer, A.; Remón, S.; Negueruela, A.I.; Oria, R. Changes during the ripening of the very late season Spanish peach cultivar Calanda: Feasibility of using CIELAB coordinates as maturity indices. Sci. Hortic. 2005, 105, 435–446. [Google Scholar] [CrossRef]
- Orazem, P.; Mikulic-Petkovsek, M.; Stampar, F.; Hudina, M. Changes during the last ripening stage in pomological and biochemical parameters of the “Redhaven” peach cultivar grafted on different rootstocks. Sci. Hortic. 2013, 160, 326–334. [Google Scholar] [CrossRef]
- Westwood, M.N. Temperate-Zone Pomology: Physiology and Culture; Timber Press: Portland, OR, USA, 1993; ISBN 0881922536, ISBN 9780881922530. [Google Scholar]
- Cecilia, M.; Nunes, N. Color Atlas of Postharvest Quality of Fruits and Vegetables; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2008; Volume 44, ISBN 9780813817521. [Google Scholar]
- Selli, R.; Sansavini, S. Sugar, acid and pectin content in relation to ripening and quality of peach and nectarine fruits. Acta Hortic. 1995, 379, 345–358. [Google Scholar] [CrossRef]
- Wu, B.H.; Quilot, B.; Génard, M.; Kervella, J.; Li, S.H. Changes in sugar and organic acid concentrations during fruit maturation in peaches, P. davidiana and hybrids as analyzed by principal component analysis. Sci. Hortic. 2005, 103, 429–439. [Google Scholar] [CrossRef]
- Famiani, F.; Casulli, V.; Baldicchi, A.; Battistelli, A.; Moscatello, S.; Walker, R.P. Development and metabolism of the fruit and seed of the Japanese plum Ozark premier (Rosaceae). J. Plant Physiol. 2012, 169, 551–560. [Google Scholar] [CrossRef] [PubMed]
- Crisosto, C.H.; Crisosto, G.M. Relationship between ripe soluble solids concentration (RSSC) and consumer acceptance of high and low acid melting flesh peach and nectarine (Prunus persica (L.) Batsch) cultivars. Postharvest Biol. Technol. 2005, 38, 239–246. [Google Scholar] [CrossRef]
- Crisosto, C.H.; Crisosto, G. Searching for consumer satisfaction: New trends in the California peach industry. In Proceedings of the Ist Mediterranea Peach Symposium, Agrigento, Italy, 10 September 2003. [Google Scholar]
- Crisosto, C.H.; Crisosto, G.; Bowerman, E. Understanding consumer acceptance of peach, nectarine and plum cultivars. Acta Hortic. 2003, 604, 115–119. [Google Scholar] [CrossRef]
- Kader, A.A. Fruit maturity, ripening, and quality relationships. Acta Hortic. 1999, 485, 203–208. [Google Scholar] [CrossRef]
- Bae, H.; Yun, S.K.; Jun, J.H.; Yoon, I.K.; Nam, E.Y.; Kwon, J.H. Assessment of organic acid and sugar composition in apricot, plumcot, plum, and peach during fruit development. J. Appl. Bot. Food Qual. 2014, 87, 24–29. [Google Scholar] [CrossRef]
- Zheng, B.; Zhao, L.; Jiang, X.; Cherono, S.; Liu, J.J.; Ogutu, C.; Ntini, C.; Zhang, X.; Han, Y. Assessment of organic acid accumulation and its related genes in peach. Food Chem. 2021, 334, 127567. [Google Scholar] [CrossRef]
- Crisosto, C.H.; Day, K.R.; Crisosto, G.M.; Garner, D. Quality attributes of white flesh peaches and nectarines grown under California conditions. Fruit Var. J. 2001, 55, 45–51. [Google Scholar]






| Original Dataset | SMOTE | ROSE | |
|---|---|---|---|
| Accuracy: | 0.963 | 0.9815 | 0.8333 |
| 95% CI: | (0.8725, 0.9955) | (0.9011, 0.9995) | (0.7071, 0.9208) |
| p-Value [Acc > NIR]: | 0.6767 | 0.4009 | 1.0000 |
| Kappa: | 0 | 0.6582 | 0.129 |
| Variable Importance | Permutation Feature Importance | ||
|---|---|---|---|
| TA | 18.3138 | L*—GC | 0.076420 |
| L*—GC | 17.1416 | SSC/TA | 0.058790 |
| SSC/TA | 16.8870 | TA | 0.057410 |
| a*—GC | 12.1816 | a*—GC | 0.048530 |
| a*—AC | 12.0051 | h°—GC | 0.037430 |
| a*/b*—GC | 11.5375 | CIRG1—GC | 0.036020 |
| CIRG1—GC | 11.3332 | COL—GC | 0.032580 |
| CCI—GC | 11.1145 | a*/b*—GC | 0.031630 |
| COL—GC | 10.6117 | CCI—GC | 0.031470 |
| h°—AC | 10.2312 | a*—AC | 0.028260 |
| Original Dataset | SMOTE | ROSE | |
|---|---|---|---|
| Accuracy | 0.8148 | 0.8148 | 0.7407 |
| 95% CI | (0.6857, 0.9075) | (0.6857, 0.9075) | (0.6035, 0.8504) |
| p-Value [Acc > NIR] | 0.1372 | 0.1372 | 0.5712 |
| Kappa | 0.4398 | 0.5588 | 0.4075 |
| Variable Importance | Permutation Feature Importance | ||
|---|---|---|---|
| a*—GC | 11.476141 | a*—GC | 0.0395 |
| fruit flesh ratio | 10.786159 | fruit flesh ratio | 0.0351 |
| endocarp weight | 10.418169 | h°—GC | 0.0302 |
| a*/b*—GC | 9.482998 | endocarp weight | 0.0291 |
| h°—GC | 8.188623 | a*/b*—GC | 0.0273 |
| CCI—GC | 7.494602 | COL—GC | 0.0218 |
| CIRG1—GC | 7.446273 | CCI—GC | 0.0196 |
| SSC/TA | 7.318091 | SSC/TA | 0.0155 |
| COL—GC | 7.209811 | TA | 0.0134 |
| h°—AC | 5.78866 | CIRG1—GC | 0.0114 |
| Original Dataset | SMOTE | ROSE | |
|---|---|---|---|
| Accuracy | 0.7037 | 0.7593 | 0.7778 |
| 95% CI | (0.5639, 0.8202) | (0.6236, 0.8651) | (0.644, 0.8796) |
| p-Value [Acc > NIR] | 0.01867 | 0.00158 | 0.0005795 |
| Kappa | 0.379 | 0.514 | 0.561 |
| Variable Importance | Permutation Feature Importance | ||
|---|---|---|---|
| COL—GC | 6.5321168 | COL—GC | 0.0188 |
| h°—GC | 6.0635186 | h°—GC | 0.0144 |
| SSC | 5.9438302 | fruit flesh ratio | 0.0128 |
| CCI—GC | 5.5208861 | CCI—GC | 0.0080 |
| fruit flesh ratio | 5.3963784 | SSC/TA | 0.0066 |
| TA | 4.2983678 | TA | 0.0062 |
| a*—GC | 3.6590949 | a*—GC | 0.0061 |
| L*—AC | 3.6097366 | SSC | 0.0057 |
| SSC/TA | 3.0672675 | CCI—AC | 0.0055 |
| CIRG2—AC | 2.8661167 | L*—AC | 0.0053 |
| Variable Importance | Permutation Feature Importance |
|---|---|
| a*—GC (4) | h°—GC (3.33) |
| CCI—GC (6) | a*—GC (4) |
| COL—GC (6.33) | COL—GC (4.66) |
| SSC/TA (6.66) | SSC/TA (5) |
| TA (6) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ljubobratović, D.; Vuković, M.; Brkić Bakarić, M.; Jemrić, T.; Matetić, M. Utilization of Explainable Machine Learning Algorithms for Determination of Important Features in ‘Suncrest’ Peach Maturity Prediction. Electronics 2021, 10, 3115. https://doi.org/10.3390/electronics10243115
Ljubobratović D, Vuković M, Brkić Bakarić M, Jemrić T, Matetić M. Utilization of Explainable Machine Learning Algorithms for Determination of Important Features in ‘Suncrest’ Peach Maturity Prediction. Electronics. 2021; 10(24):3115. https://doi.org/10.3390/electronics10243115
Chicago/Turabian StyleLjubobratović, Dejan, Marko Vuković, Marija Brkić Bakarić, Tomislav Jemrić, and Maja Matetić. 2021. "Utilization of Explainable Machine Learning Algorithms for Determination of Important Features in ‘Suncrest’ Peach Maturity Prediction" Electronics 10, no. 24: 3115. https://doi.org/10.3390/electronics10243115