
A Pore Classification System for the Detection of Additive Manufacturing Defects Combining Machine Learning and Numerical Image Analysis †

Abstract
:1. Introduction
1.1. General Motivation
1.2. Related Work
1.3. Contribution of Our Research
2. Materials and Methods
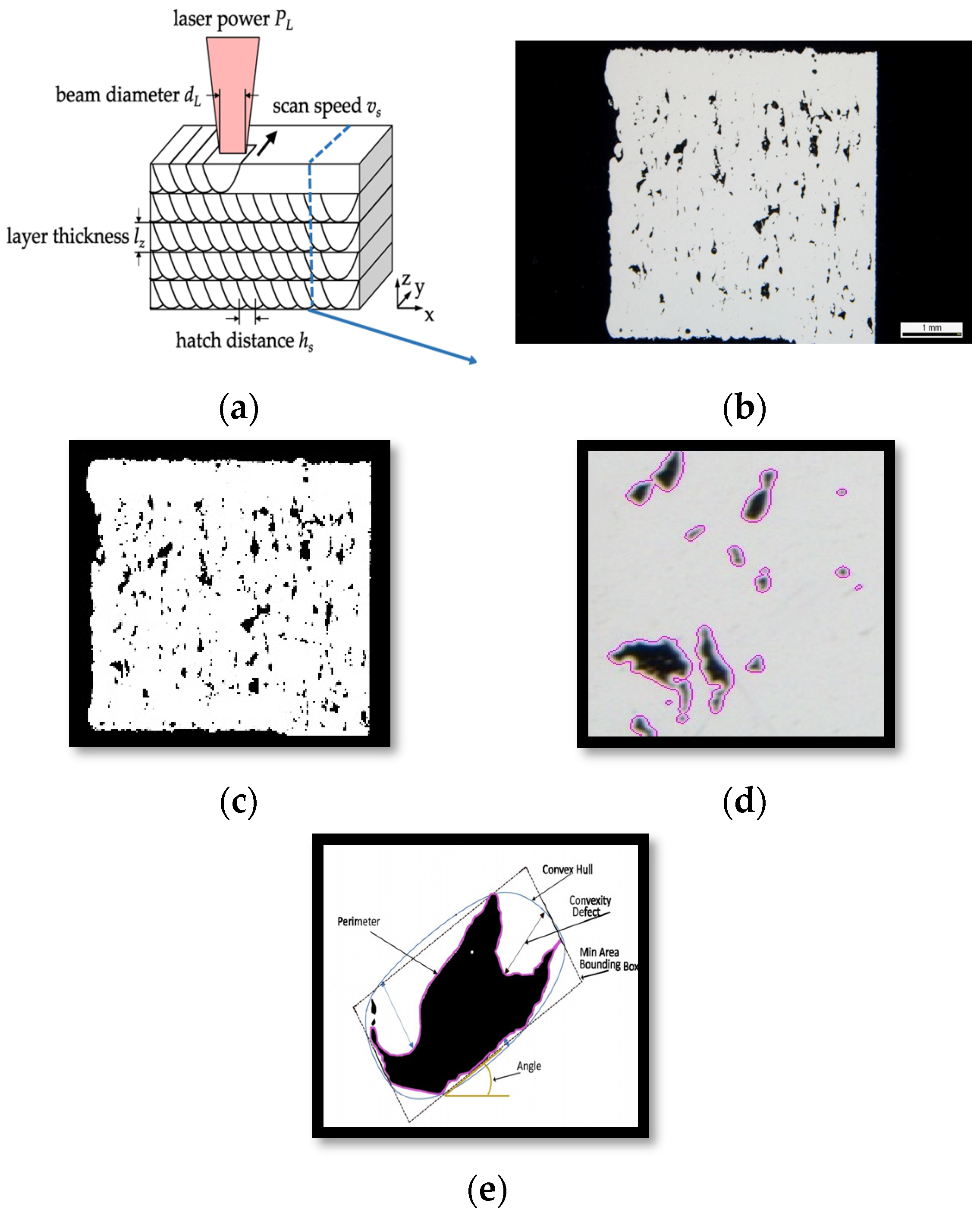
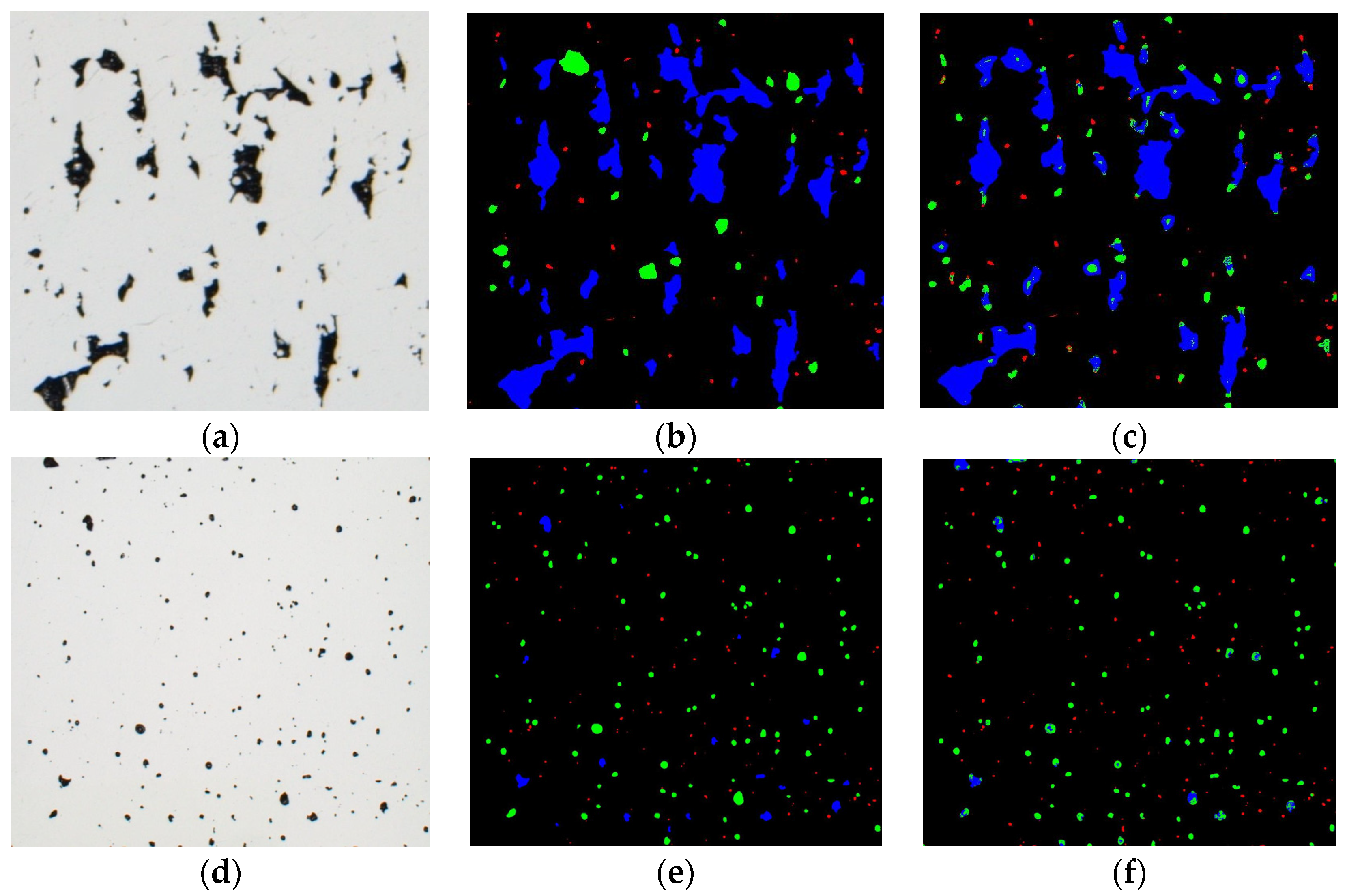
2.1. Dataset
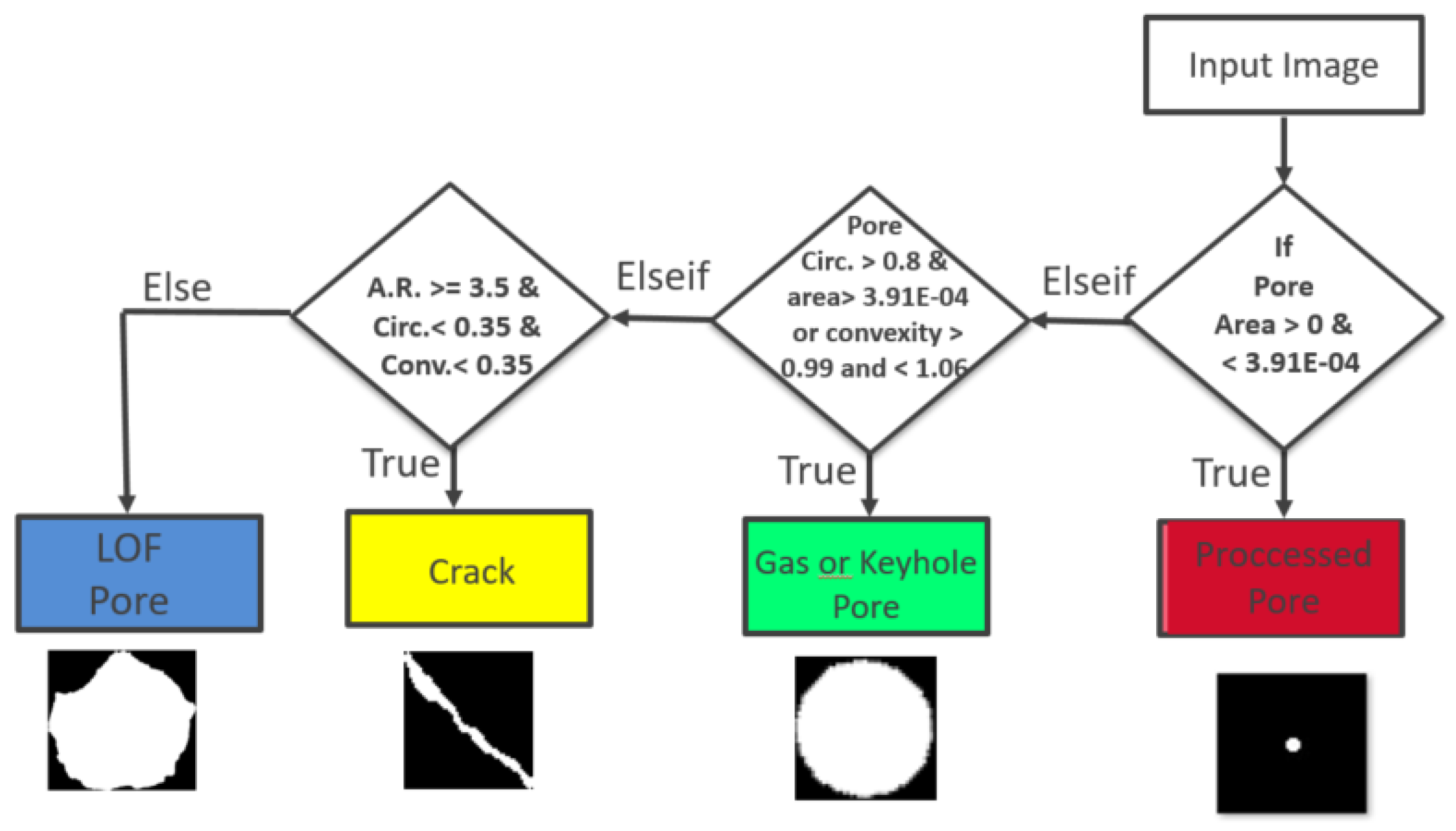
2.2. Preprocessing and Feature Extraction
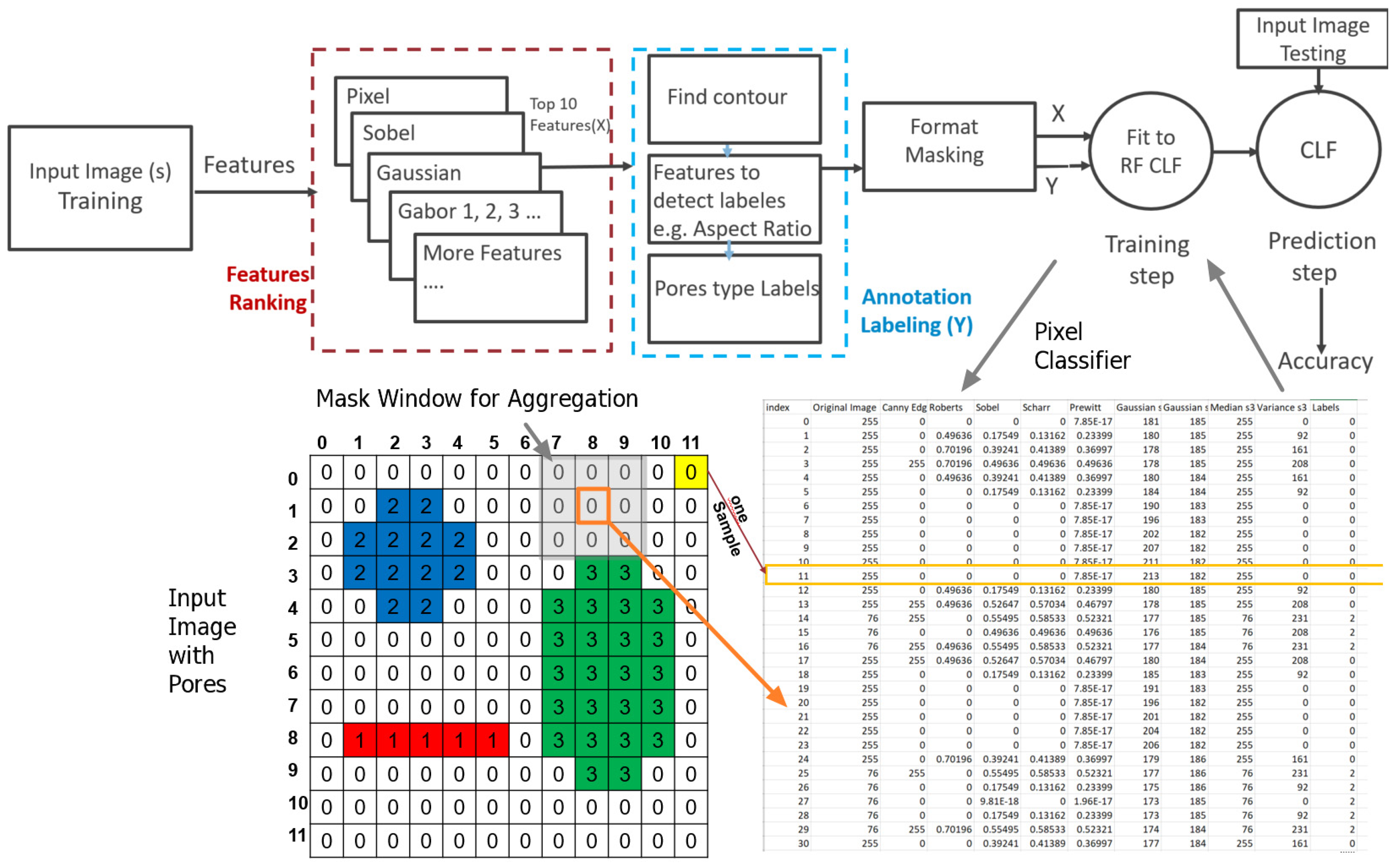
2.3. Machine Learning Classifiers
2.3.1. Random Forest Classifier (RF)
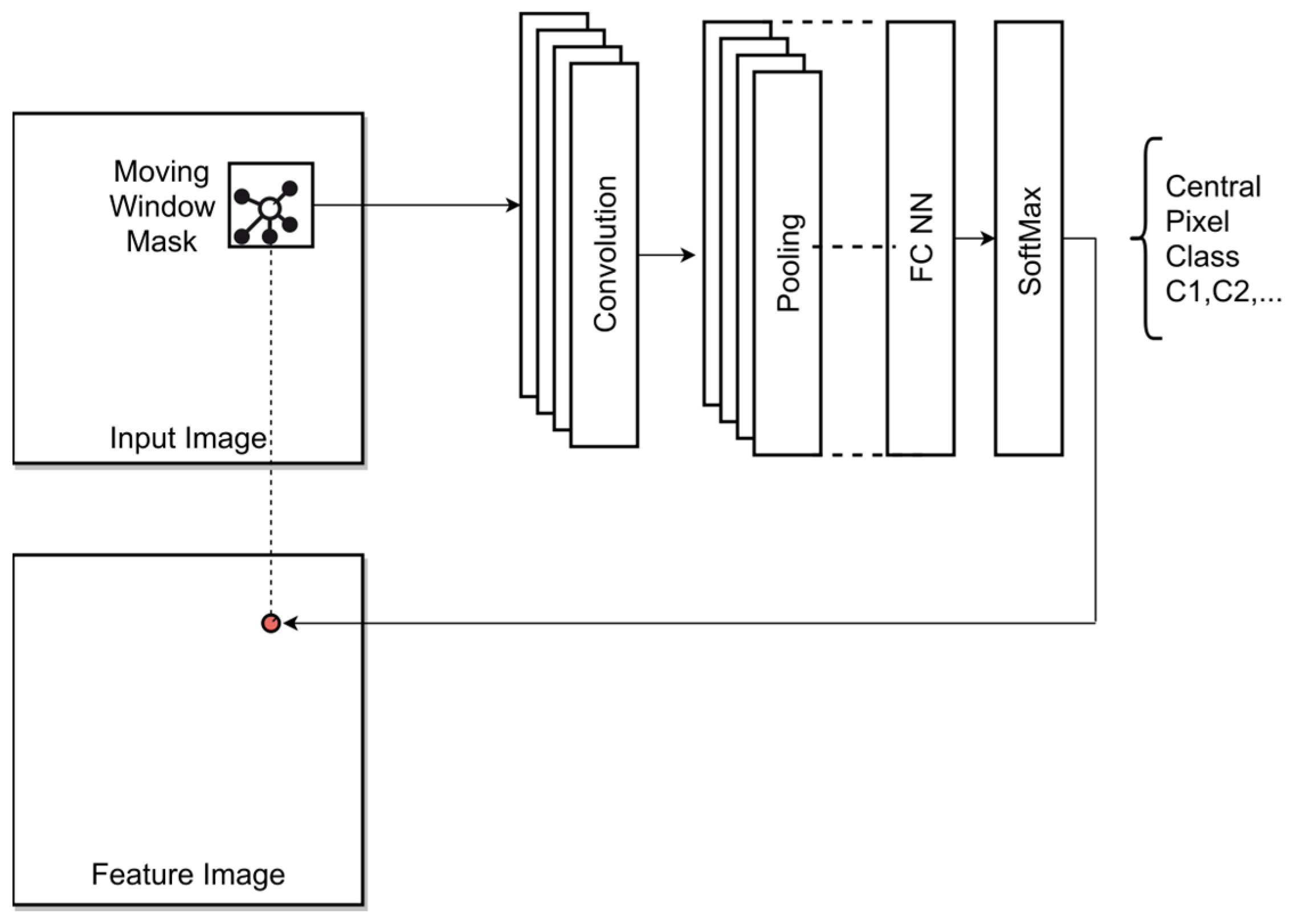
2.3.2. Semantic Pixel Classifier
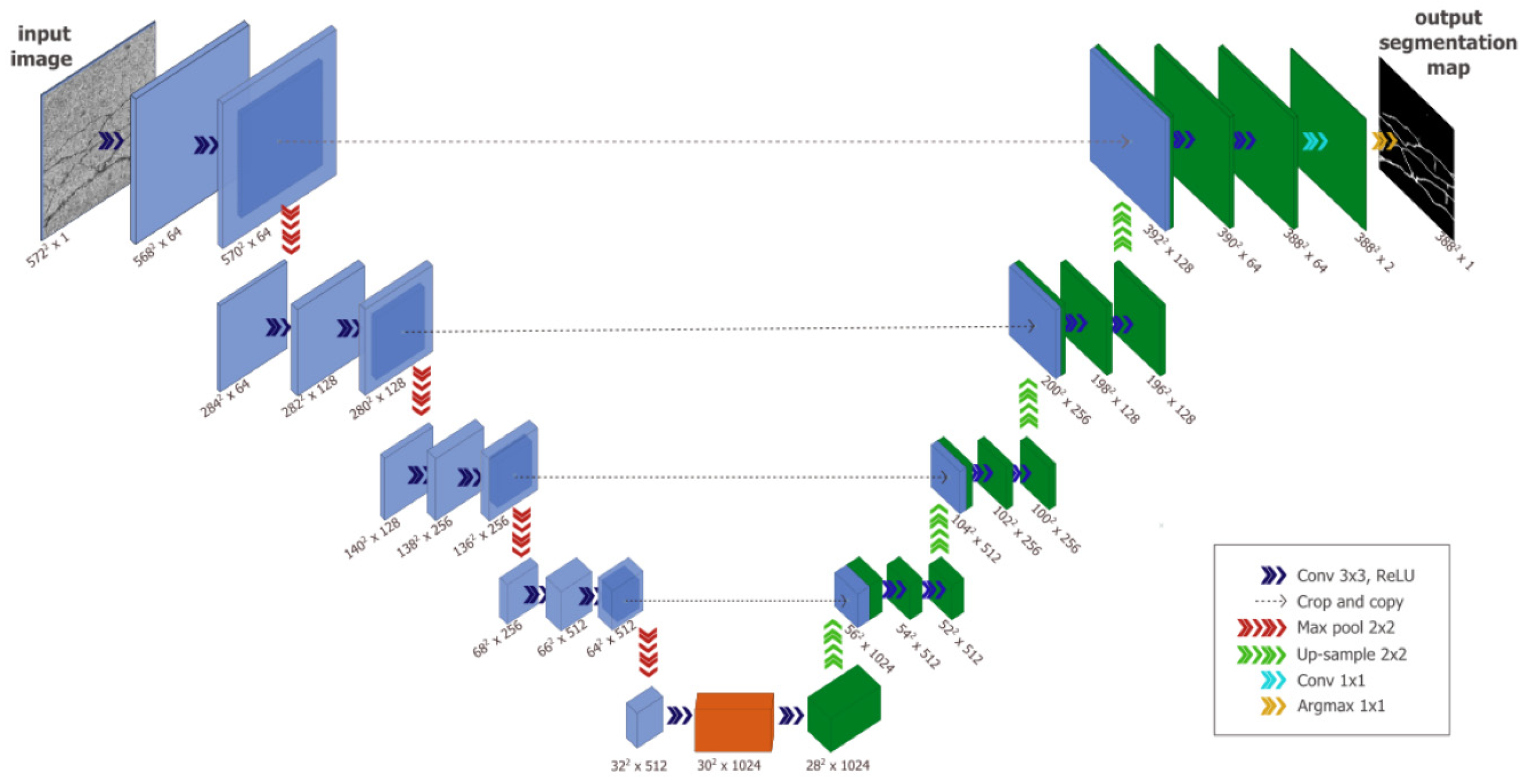
2.3.3. Convolutional Neural Network (CNN) and U-Shaped Neural Network (U-Net)
2.4. Performance Metrics
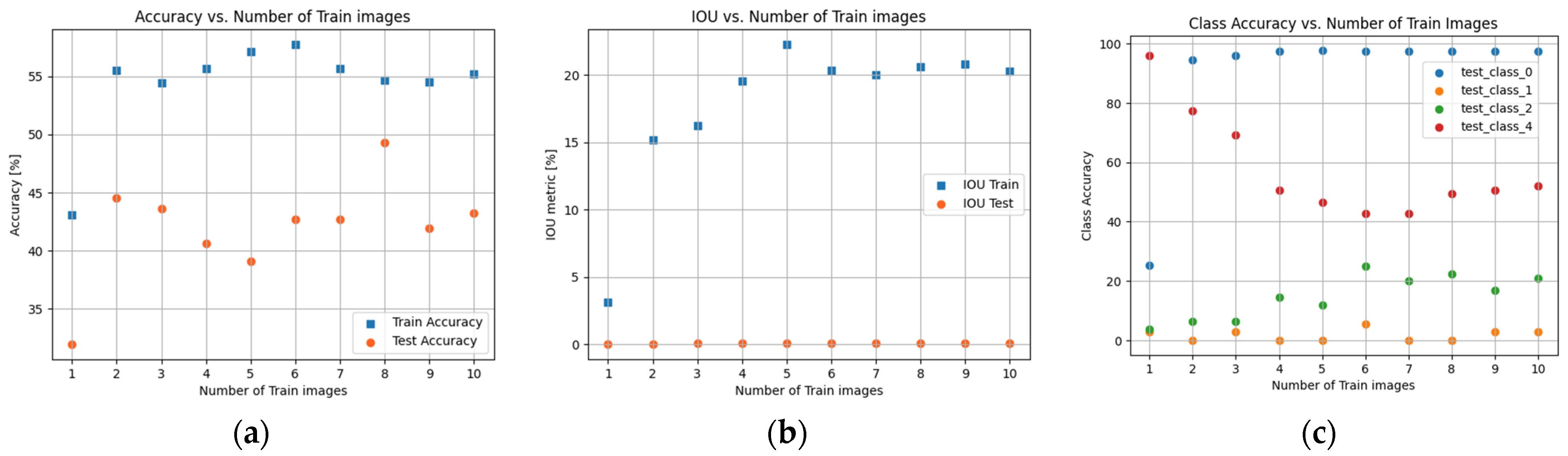
3. Experimental Design
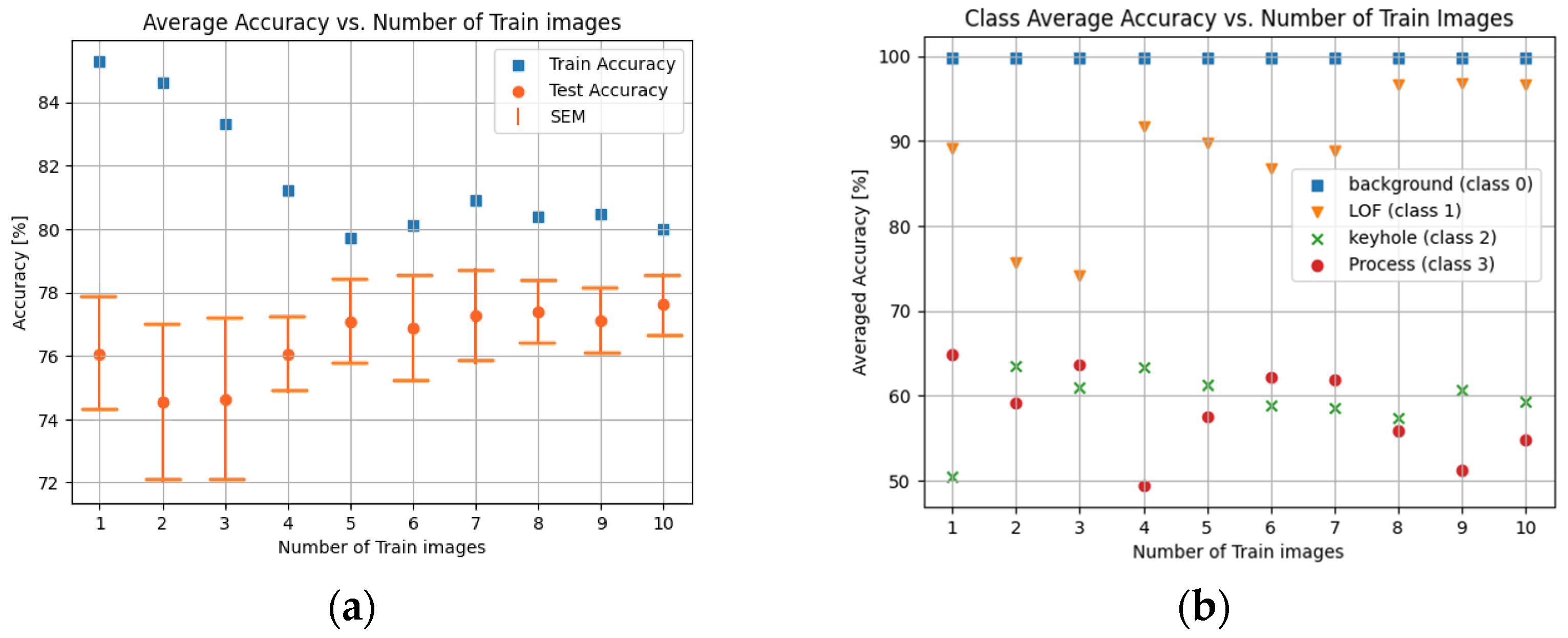
4. Results and Discussion
5. Conclusions and Future Work
- Use a semantic pixel clustering based on DBSCAN to improve pore classification by majority decision and to derive ROI boundaries of the pores;
- Enhance the RF- and CNN-based micrograph data classification model, finally fusing these models to create a more robust meta model;
- Develop a forward ML model for predicting mechanical properties;
- Create an inverse ML model for predicting AM process parameters.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Defect Type | Characteristics | Geometric Features | Material and Mechanical Properties | |
|---|---|---|---|---|
 | Keyhole pore [6,7] | Vapor bubbles trapped in melt pool during printing and vaporized metal at high local temperatures or merge process pores | Keyhole-like voids, channeling | Reduced mechanical strength, reduced fatigue resistance, susceptibility to crack initiation |
 | Gas pore (circular keyhole) [8] | Vapor bubbles trapped in melt pool during printing (or merge process pores) | Irregular distribution, spherical | Decreased fatigue life, lowered mechanical strength, compromised surface finish |
 | Lake of Fusion (LOF) [8,9] | Due to insufficiently melted material | Interlayer gaps, unfused regions, not necessarily spherical | Starting point for cracks which may grow further due to stress |
 | Unmelted particle (LOF) [8,10,11] | Due to insufficiently melted material (inclusion of unmelted powder) | Same as above but with unmelted powder trapped inside | Starting point for cracks which may grow further due to stress |
 | Process pore [9] | Low packing density of the powder, hollow powder particles, and entrapped inert gas | Irregular distribution, spherical with smallest area | Less effect on the material |
 | Crack [3] | Fractures in printed layers or at interfaces or can be caused due to failure induced by other pores | Large aspect ratio | Biggest risk for initiating mechanical failure |
Appendix B


| Pore Type | Mean Area mm | Convexity Defects | Aspect Ratio |
|---|---|---|---|
| Process | 8.59 × 10−5 | 1.135 | 1.397 |
| Keyhole | 0.018 | 23.750 | 1.211 |
| LOF | 0.029 | 12.517 | 1.972 |
Appendix C



References
- Khorasani, A.; Gibson, I.; Veetil, J.K.; Ghasemi, A.H. A review of technological improvements in laser-based powder bed fusion of metal printers. Int. J. Adv. Manuf. Technol. 2020, 108, 191. [Google Scholar] [CrossRef]
- Kruth, J.-P.; Mercelis, P.; van Vaerenbergh, J.; Froyen, L.; Rombouts, M. Binding mechanisms in selective laser sintering and selective laser melting. Rapid Prototyp. J. 2005, 11, 26. [Google Scholar] [CrossRef]
- Gong, H.; Rafi, K.; Gu, H.; Ram, G.D.J.; Starr, T.; Stucker, B. Influence of defects on mechanical properties of Ti-6Al-4V components produced by selective laser melting and electron beam melting. Mater. Des. 2015, 86, 545–554. [Google Scholar] [CrossRef]
- Keshavarzkermani, A.; Marzbanrad, E.; Esmaeilizadeh, R.; Mahmoodkhani, Y.; Ali, U.; Enrique, P.D.; Zhou, N.Y.; Bonakdar, A.; Toyserkani, E. An investigation into the effect of process parameters on melt pool geometry, cell spacing, and grain refinement during laser powder bed fusion. Opt. Laser Technol. 2019, 116, 83. [Google Scholar] [CrossRef]
- Cepeda-Jiménez, C.M.; Potenza, F.; Magalini, E.; Luchin, V.; Molinari, A.; Pérez-Prado, M.T. Effect of energy density on the microstructure and texture evolution of Ti-6Al-4V manufactured by laser powder bed fusion. Mater. Charact. 2020, 163, 110238. [Google Scholar] [CrossRef]
- Wang, T.; Dai, S.; Liao, H.; Zhu, H. Pores and the formation mechanisms of SLMed AlSi10Mg. Rapid Prototyp. J. 2020, 26, 1657–1664. [Google Scholar] [CrossRef]
- Martin, A.A.; Calta, N.P.; Khairallah, S.A.; Wang, J.; Depond, P.J.; Fong, A.Y.; Thampy, V.; Guss, G.M.; Kiss, A.M.; Stone, K.H.; et al. Dynamics of pore formation during laser powder bed fusion additive manufacturing. Nat. Commun. 2019, 10, 1987. [Google Scholar] [CrossRef]
- Ellendt, N.; Fabricius, F.; Toenjes, A. PoreAnalyzer—An Open-Source Framework for the Analysis and Classification of Defects in Additive Manufacturing. Appl. Sci. 2021, 11, 6086. [Google Scholar] [CrossRef]
- Altmann, M.L.; Benthien, T.; Ellendt, N.; Toenjes, A. Defect Classification for Additive Manufacturing with Machine Learning. Materials 2023, 16, 6242. [Google Scholar] [CrossRef]
- Kruth, J.P.; Froyen, L.; Van Vaerenbergh, J.; Mercelis, P.; Rombouts, M.; Lauwers, B. Selective laser melting of iron-based powder. J. Mater. Process. Technol. 2004, 149, 616–622. [Google Scholar] [CrossRef]
- Wang, W.; Ning, J.; Liang, S.Y. Prediction of lack-of-fusion porosity in laser powder-bed fusion considering boundary conditions and sensitivity to laser power absorption. Int. J. Adv. Manuf. Technol. 2021, 112, 61–70. [Google Scholar] [CrossRef]
- Zhang, Y.; Hong, G.S.; Ye, D.; Zhu, K.; Fuh, J.Y. Extraction and evaluation of melt pool, plume and spatter information for powder-bed fusion AM process monitoring. Mater. Des. 2018, 156, 458–469. [Google Scholar] [CrossRef]
- Scime, L.; Beuth, J. Anomaly detection and classification in a laser powder bed additive manufacturing process using a trained computer vision algorithm. Addit. Manuf. 2018, 19, 114–126. [Google Scholar] [CrossRef]
- Wong VW, H.; Ferguson, M.; Law, K.H.; Lee YT, T.; Witherell, P. Automatic volumetric segmentation of additive manufacturing defects with 3D U-Net. arXiv 2021, arXiv:2101.08993. [Google Scholar]
- Bradski, G. The openCV library. Dr. Dobb’s J. Softw. Tools Prof. Program. 2000, 25, 120–123. [Google Scholar]
- Suzuki, S. Topological structural analysis of digitized binary images by border following. Comput. Vis. Graph. Image Process. 1985, 30, 32–46. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Cutler, A.; Cutler, D.R.; Stevens, J.R. Random forests. Ensemble Mach. Learn. Methods Appl. 2012, 157–175. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Fabian, P.; Gael, V.; Alexandre, G.; Vincent, M.; Bertrand, T.; Olivier, G.; Mathieu, B.; Peter, P.; Ron, W.; Vincent, D.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Bosse, S.; Lehmhus, D. Automated Detection of hidden Damages and Impurities in Aluminum Die Casting Materials and Fibre-Metal Laminates using Low-quality X-ray Radiography, Synthetic X-ray Data Augmentation by Simulation, and Machine Learning. arXiv 2023, arXiv:2311.12041. [Google Scholar] [CrossRef]
- Shah, C.; Bosse, S.; von Hehl, A. Taxonomy of Damage Patterns in Composite Materials, Measuring Signals, and Methods for Automated Damage Diagnostics. Materials 2022, 15, 4645. [Google Scholar] [CrossRef] [PubMed]
- Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D.; Laboratories, H.Y.L.B.; Zhu, Z.; Cheng, J.; Zhao, Y.; et al. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar]
- Jenkins, M.D.; Carr, T.A.; Iglesias, M.I.; Buggy, T.; Morison, G. A deep convolutional neural network for semantic pixel-wise segmentation of road and pavement surface cracks. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; pp. 2120–2124. [Google Scholar] [CrossRef]
- Al-Zaidawi, S.M.K. Machine Learning Classification of User Attributes via Eye Movements. Ph.D. Thesis, Universität Bremen, Bremen, Germany, 2022. [Google Scholar] [CrossRef]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, California, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]





| Class\Method | RF | CNN | U-NET |
|---|---|---|---|
| Process Pore Class | 54% (40% Keyhole FC) | 93% | 50% |
| LOF Class | 99% | 60% (25% Keyhole FC) | 5% |
| Keyhole Class | 75% (20% Pro FC) | 65% (25% LOF FC) | 20% |
| Total | 76% | 73% | 25% (failed) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Zaidawi, S.M.K.; Bosse, S. A Pore Classification System for the Detection of Additive Manufacturing Defects Combining Machine Learning and Numerical Image Analysis. Eng. Proc. 2023, 58, 122. https://doi.org/10.3390/ecsa-10-16024
Al-Zaidawi SMK, Bosse S. A Pore Classification System for the Detection of Additive Manufacturing Defects Combining Machine Learning and Numerical Image Analysis. Engineering Proceedings. 2023; 58(1):122. https://doi.org/10.3390/ecsa-10-16024
Chicago/Turabian StyleAl-Zaidawi, Sahar Mahdie Klim, and Stefan Bosse. 2023. "A Pore Classification System for the Detection of Additive Manufacturing Defects Combining Machine Learning and Numerical Image Analysis" Engineering Proceedings 58, no. 1: 122. https://doi.org/10.3390/ecsa-10-16024