
On the Relationship between Feature Selection Metrics and Accuracy

Department of Computer and Data Sciences, Case Western Reserve University, Cleveland, OH 44106, USA
*
Authors to whom correspondence should be addressed.
†
These authors contributed equally to this work.
Entropy 2023, 25(12), 1646; https://doi.org/10.3390/e25121646
Submission received: 7 October 2023
/
Revised: 2 December 2023
/
Accepted: 8 December 2023
/
Published: 11 December 2023
(This article belongs to the Special Issue Information-Theoretic Criteria for Statistical Model Selection)
Abstract
:Feature selection metrics are commonly used in the machine learning pipeline to rank and select features before creating a predictive model. While many different metrics have been proposed for feature selection, final models are often evaluated by accuracy. In this paper, we consider the relationship between common feature selection metrics and accuracy. In particular, we focus on misorderings: cases where a feature selection metric may rank features differently than accuracy would. We analytically investigate the frequency of misordering for a variety of feature selection metrics as a function of parameters that represent how a feature partitions the data. Our analysis reveals that different metrics have systematic differences in how likely they are to misorder features which can happen over a wide range of partition parameters. We then perform an empirical evaluation with different feature selection metrics on several real-world datasets to measure misordering. Our empirical results generally match our analytical results, illustrating that misordering features happens in practice and can provide some insight into the performance of feature selection metrics.
1. Introduction
In supervised machine learning, many algorithms assume a feature-set representation of the data in which each feature represents a characteristic of the underlying subject being analyzed. However, not all features have the same effect on prediction. When predicting if an animal is a lion, whether the animal has sharp teeth is likely a better indicator than whether the animal has eyes. As the number of features increases, the difficulty of learning a concept increases significantly [1]. This phenomenon is often referred to as the “curse of dimensionality” [1]. Together with this, the chance of overfitting, that is, producing a model that fits the training data very well but does poorly overall, increases as well. In order to mitigate these issues, a common strategy is to filter the feature set that is to try to identify “relevant” features. Relevant features are those that are hypothesized to be used by the underlying target concept we seek. Once a set of candidate-relevant features is identified, concepts may be learned with these features alone. This speeds up the search process and results in the learned concepts being less likely to overfit since they contain fewer (or no) irrelevant features.
After selecting a relevant feature subset, predictive models are built. Such models often optimize the 0–1 loss and are evaluated according to accuracy. While many alternative losses and evaluation metrics exist, the popularity of the 0–1 loss for optimization and accuracy as a metric is due to the simple and intuitive nature of these functions [2]. However, the 0–1 loss is itself rarely used for feature selection. Possible reasons are that finding a set of features that optimizes the 0–1 loss is not tractable in the worst case [3,4,5,6], and optimizing this loss alone may not necessarily yield a small set of features. Instead, feature selection filters use a variety of metrics such as information gain [7,8,9,10,11] and Gini index [12]. Metrics such as these are typically well-correlated with accuracy but do not always produce the same result. Inthis paper, our interest is to specifically analyze and gain insight into cases when feature selection metrics rank features differently than accuracy would. This is of interest because it may provide insight into the downstream performance of a predictive model optimizing the 0–1 loss or evaluated using accuracy as a metric.
As a simple example, consider a toy dataset in Table 1. The task is to learn whether an animal is a lion. If we were to apply information gain as a filter to select the top feature, Loud? will be selected with a gain of . However, a decision stump classifier using either Has Fur? or Lazy? would have a higher accuracy ( vs. ). These features have a lower information gain than Loud? ( and respectively). In this case, we would say that the two pairs (Has Fur?, Loud?) and (Lazy?, Loud?) are misordered by information gain relative to accuracy. A misordering occurs when, without loss of generality, there are two features where feature A has a higher feature selection metric value than feature B, but feature B has a higher accuracy when used as a decision stump classifier. Of course, in this toy example, the impact of misordering may not be very significant. But in real-world tasks, with many features, it is possible that feature selection metrics that are more prone to misordering may lead to poorer performance in downstream models.
The fundamental reason why misorderings may occur is because there is not a one-to-one correspondence between feature selection metrics and accuracy. This was established in prior work [13] which derived bounds on the classification accuracy given information gain and vice versa for the binary classification case. However, the implications of those results in terms of feature selection are not well understood, to our knowledge. Our work is a step to fill this gap.
We make the following assumptions for this work:
- For each feature selection metric, a higher value corresponds to a more relevant feature for the prediction task.
- Feature selection metrics are evaluated in the context of binary classification, where one of two class labels are associated with each example [14]. While our analysis can be generalized to multiclass tasks, our results in this work use data from binary classification.
- We consider each feature to make a binary partition of the data in order to simplify the analysis. This does not impose a loss of generality because continuous or nominal features with many values can still be used to perform binary partitions [12].
- We assume no feature values are missing for the purpose of analytical comparisons.
In the following sections, we first introduce some definitions and notations and then define the conditions under which misordering can happen for for feature selection metrics, in a space parameterized by the characteristics of a partition induced by a feature. Next, we visualize the probability of misordering both locally and globally in this space. Finally, we evaluate a number of feature selection metrics on real-world data to understand the prevalence of misordering in reality.
2. Conditions for Misordering
We define each input example as drawn from an input space . Here, i represents the index of the example in dataset , and j denotes the feature index of the example. Each example has an associated class in the output space , where k represents the class index.
In this representation, N denotes the number of samples, F represents the number of features each sample has and C is the total number of classes in the dataset . In the rest of the paper we focus on binary classification, which can be characterized using two classes.
We further define a partition as a binary split in the dataset, based on a feature j. We identify two feature values corresponding to the canonical feature values 0 and 1, each containing a mixture of positive and negative examples. Feature value 0 has a negative and b positive examples, while feature value 1 has c negative and d positive examples. Mathematically, this can be expressed as where represents the partition on feature j.
We observe that the variables , and d can completely represent both the partitions as well as the original dataset . However, they are not independent. To address this, we introduce two alternate variables p and q. Here, p represents the fraction of examples in the first partition, and q represents the fraction of examples that have positive labels out of examples in the first partition. Additionally, m represents the fraction of negative examples in the dataset . Using p, q, and m, we can completely represent any partition as below:
Using this change of variables (Equation (2)), we can express the accuracy of a partition as:
In these equations represents the max operator. We only provide the final expression for sake of brevity.
2.1. Feature Selection Metrics Used
In this paper, we focus primarily on information gain, Gini index, Hellinger distance, and Bhattacharyya distance to perform an analytical comparison. An empirical comparison of various real datasets with additional feature selection methods is presented in Section 4.
2.1.1. Information Gain
Information gain is a widely used feature selection method [15]. It measures the reduction in uncertainty for predicting the target class when considering feature j. Mathematically, it can be expressed as , where denotes the entropy of a random variable, Y represents the output random variables and j represents the feature.
Information gain can be written in terms of the variables p, q and m as
2.1.2. Gini Index
The Gini index is another important filter method, which can be expressed as [16]. Here, Y is a discrete output random variable, and is the probability of a sample being classified into class k. Essentially, the Gini index measures the impurity of a given dataset. Analogous to information gain, the difference between the Gini index of the dataset and the subsets resulting from splitting using different features are used to rank features. The Gini index can be expressed in terms of the variables p, q, and m as:
2.1.3. Hellinger Distance
Hellinger distance is a statistical measure that quantifies the similarity between two probability distributions. It can be defined in terms of two discrete random variables X and Y as [17]. To utilize the Hellinger distance as a feature selection metric, we calculate the partition weighted average between the Hellinger distance of the original dataset and the partitions. Our goal in feature selection is to choose the partition with maximal distributional distance from the original dataset. Hellinger distance can be expressed in terms of the variables p, q, and m as:
2.1.4. Bhattacharyya Distance
Bhattacharyya distance is another measure of similarity between two probability distributions. Unlike Hellinger distance, Bhattacharyya distance does not obey the triangle inequality, therefore, it is not considered a true distance. It is defined as where X and Y are two discrete random variables defined on the same space, ln denotes the natural logarithm and is the Bhattacharyya distance function [18]. Analogous to Hellinger distance, for its use in feature selection, we compute the partition weighted average between the Bhattacharyya distance of the original dataset with the partitions [19]. Bhattacharyya distance can also be expressed in terms of variables p, q, and m as:
In order to compute the misorderings for a given set of partitions with variables (, ) belonging to partition 0, and (, ) belonging to partition 1 and the fraction of samples in the dataset given by m. Using these variables we can calculate the misorderings as
Here, is a feature selection function that is one of , , or . In the expression, represents the logical and operator, similarly represents the logical or operator.
3. Analytical Comparison and Discussion
In this section, we analyze Equation (8) derived in the previous section to understand to what extent each approach is prone to misordering features. To conduct this we study the behavior of the inequality as a function of its inputs graphically for each feature selection metric.
3.1. A Local View of Misordering
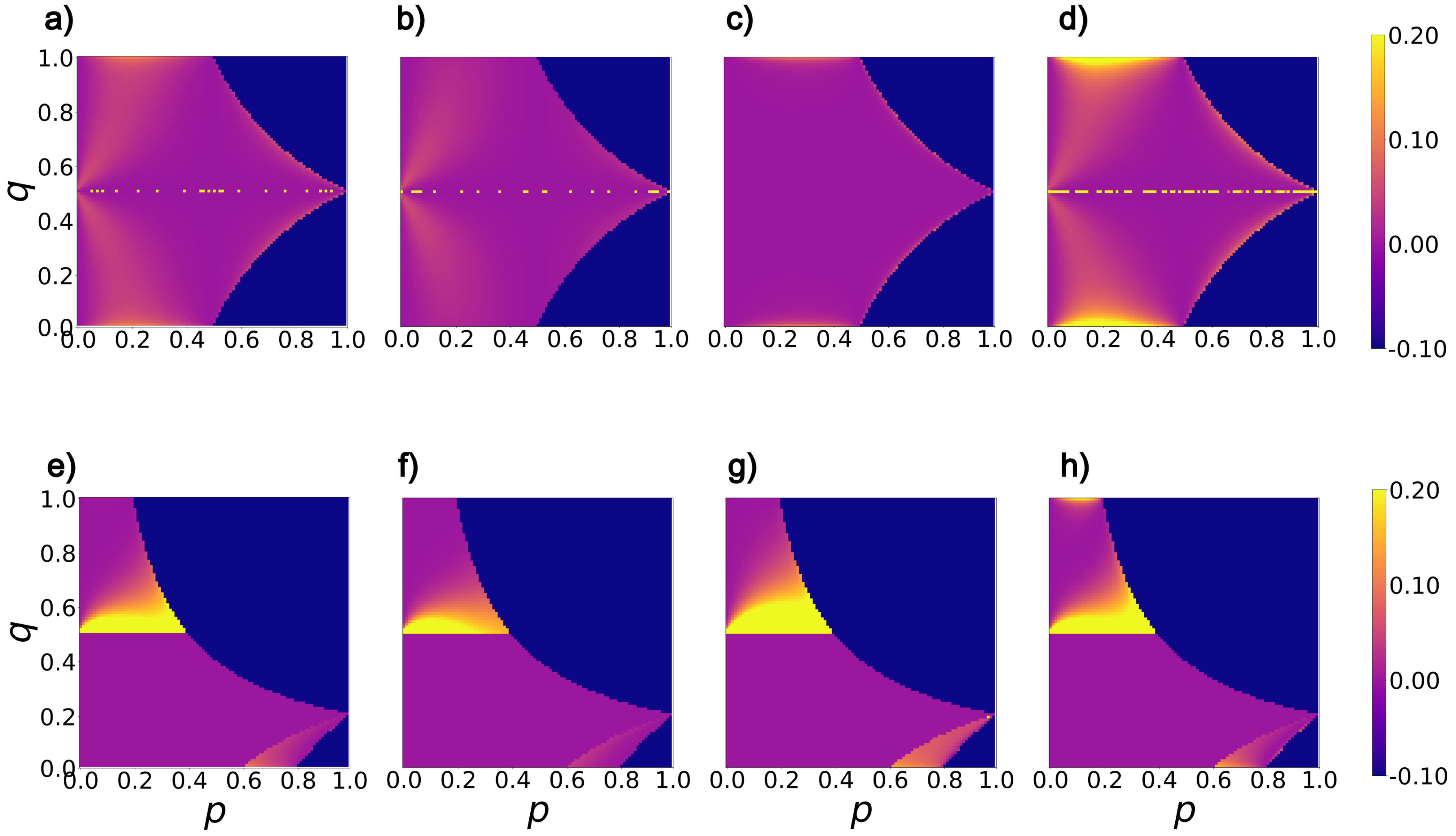
Consider some partition for a given m. How prone is the point to a misordering? For a given feature selector, consider the unit vector along the derivative of the selector with respect to and the unit vector along the derivative of accuracy at . Our hypothesis is that the more aligned these vectors are, the less prone is to misordering. The intuition is that if these vectors are aligned in the local environment around , then both accuracy and the metric are changing in the same way. As they become misaligned, it becomes increasingly possible for a misordering to happen. To quantify this effect, the alignment between the direction of the two vectors is calculated using the cosine of the angle between them. We compute to quantify misalignment between the two vectors. We then plot heat maps of the misalignment in space using small steps in p and q parameters spanning all possible values of p, and q. In our computation, gradient vectors are generated using automatic differentiation to overcome any finite step effects. The results are shown in Figure 1.
In the heat maps shown in Figure 1, bright yellow regions represent significant misalignment between gradient vectors of the corresponding feature selection metric and that of accuracy. The darkest blue region denotes a configuration of that is unachievable for the given m). For (Figure 1a–d), we observe that Bhattacharyya distance (Figure 1d) qualitatively has the highest misalignment with accuracy, while Hellinger distance (Figure 1c) has qualitatively the lowest misalignment with accuracy. Conversely, for skewed datasets (Figure 1e–h) qualitatively Hellinger distance (Figure 1g) has the highest misalignment with accuracy.
Considering the graphs for different values of m, we observe that regions of significant misalignment grow as m increases (the class distribution becomes more skewed) for all metrics. This indicates that the problem of misordering should become more extensive as m grows.
We identify distinct and consistent regions on the heatmaps across all feature selection metrics that have significant dissimilarity with accuracy as a function of m. Such observations indicate it may be possible to characterize these regions and predict when misordering is likely to happen.
3.2. A Global View of Misordering
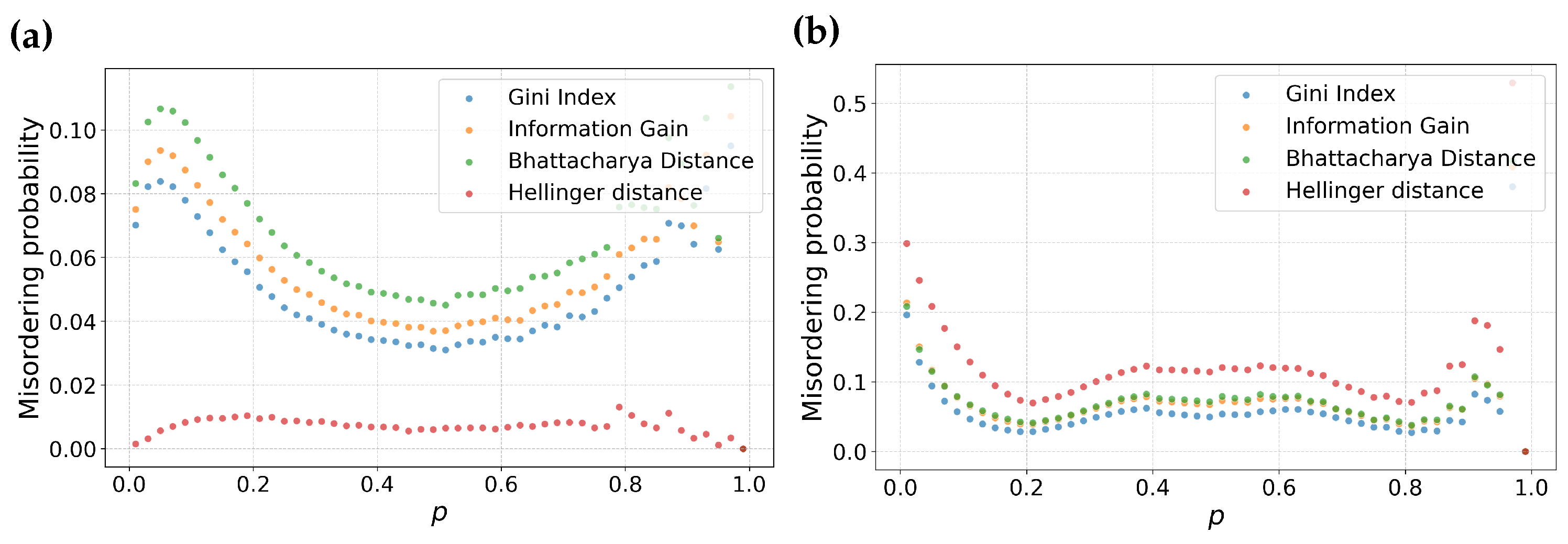
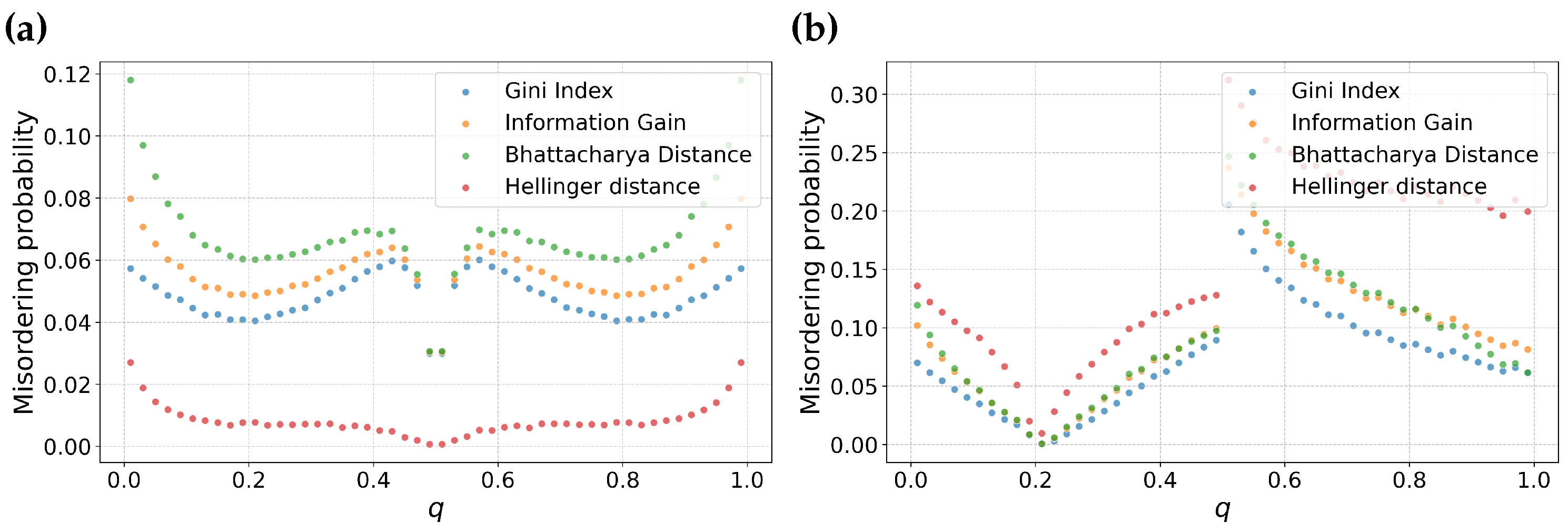
The previous analysis describes the behavior of feature selection metrics around a specific point. In this subsection, we examine the distribution of misordering probability as a function of the individual parameters p and q for different values of m. To do this, we will average over all other parameters. That is, for a fixed m, we will consider all pairs of partitions and for a given value of q. The space of all such partitions will be finely sampled. This approach enables us to calculate the misordering probability as fraction of misorderings over the space of all possible combinations of possible partitions. Note that since the order of the partition pair does not matter, we also include all and pairs in the analysis for a given q. The results are shown in Figure 2 as a function of p and Figure 3 as a function of q.
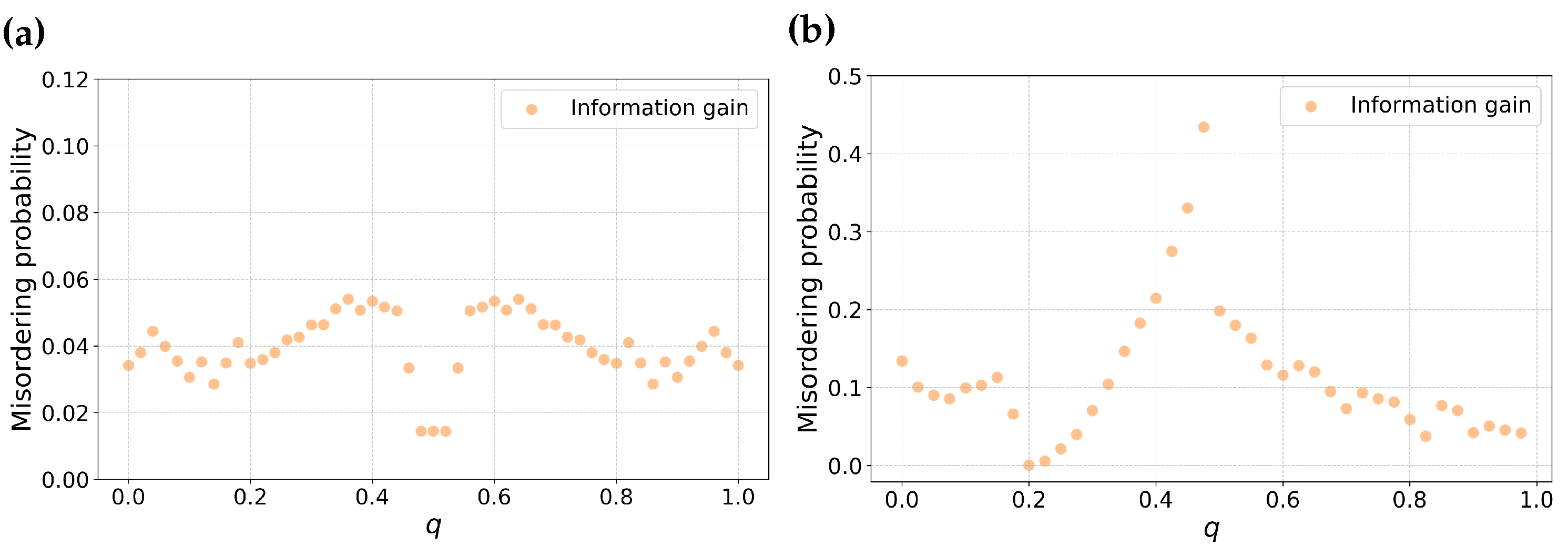
From Figure 3, we make some key observations. Among the feature selection metrics chosen, Bhattacharyya distance, Information gain and Gini have consistent ordering for both balanced (Figure 3a) as well as skewed datasets (Figure 3b). Among these three metrics, Bhattacharyya distance has the highest misordering probability followed by Information gain and Gini, respectively. Particularly, Gini maintains a relatively lower misordering probability across both balanced as well as skewed datasets suggesting resilience to variation in m.
In contrast, Hellinger distance displays interesting behavior. It has the lowest misordering probability for at the same time has the highest misordering probability for a higher value of m. This suggests that Hellinger distance is particularly sensitive to skewness of dataset. This analysis is consistent with our observations in the previous section about the local behavior of this metric.
Examining the misordering probability plotted against the parameter p in Figure 2, we can make analogous statements to misordering against the parameter q. Information gain, Gini and Bhattacharyya distance have consistent ordering in misordering probability across both balanced as well as skewed datasets. Hellinger distance maintains similar divergent behavior between balanced and skewed datasets.
However, in contrast to Figure 3, the plots against the parameter p are flatter, which suggests there is less sensitivity to a fraction of samples in the first partition.
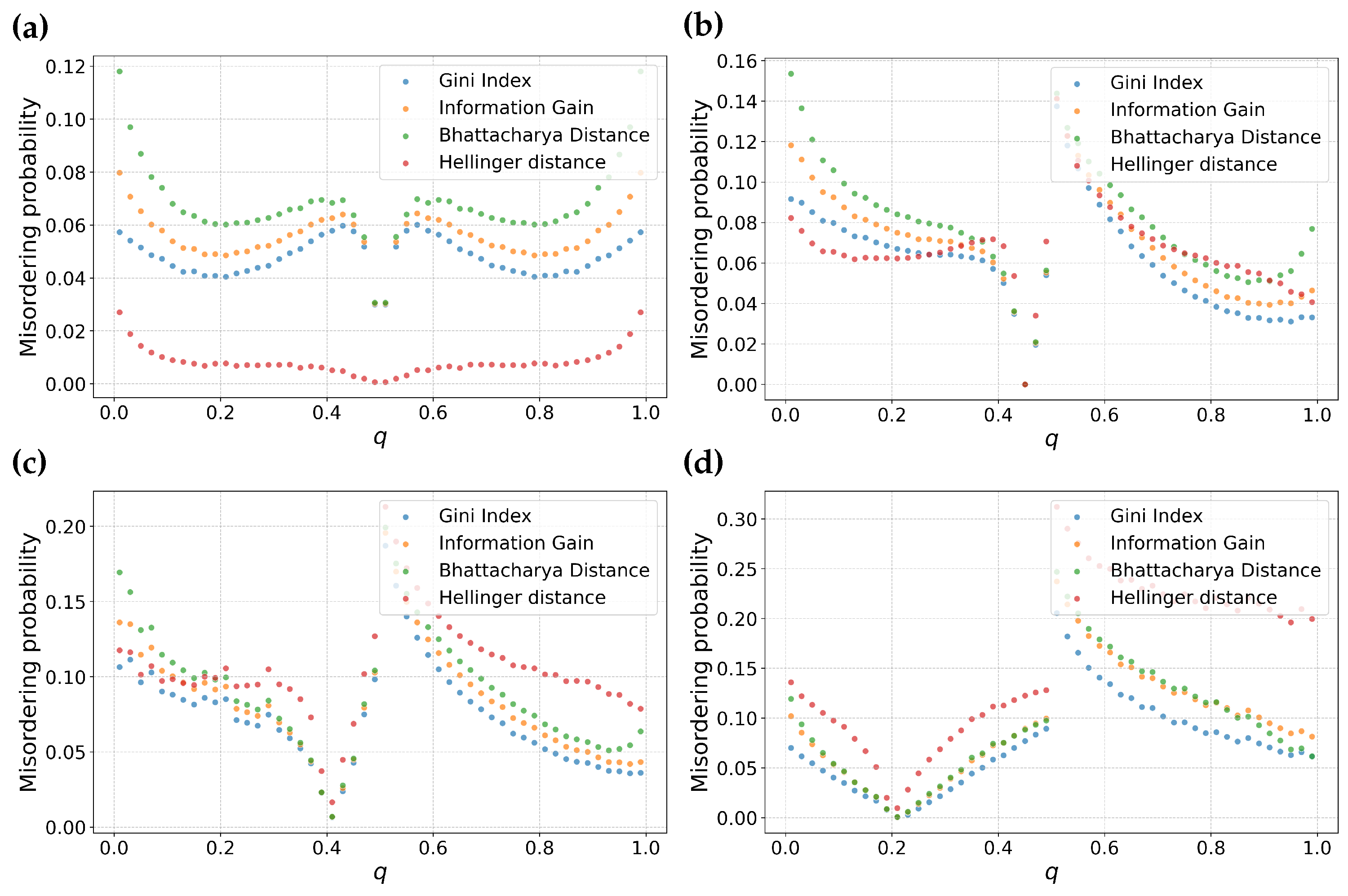
To further highlight the dependence of Hellinger distance on m we conduct an additional experiment. We vary m, using , , , and . This allows us to illustrate the crossover point for Hellinger distance, where the misordering probability of Hellinger distance reverts from having the lowest misordering probability to the highest misordering probability.
From Figure 4 we observe that there is a crossover between Figure 4b and Figure 4c. At this transition point, Hellinger distance has a misordering probability comparable to other feature selection metrics. This suggests that by knowing the skewness of the data distribution, we can make an informed choice to suppress misordering due to feature selection.
In order to verify that the theoretical results shown in Figure 3 are consistent with generated partitions, we created synthetic datasets with the same class skews. We plot the misordering rate of information gain against q as shown in Figure 5. We randomly generated 5000 partitions. The partitions are grouped into groups of q values such that there is a minimum of 30 partitions for each group. For Figure 5a, this results in bins of q values of , while for Figure 5b this results in bins of . From Figure 3 and Figure 5 we see similar shapes for information gain, which suggests that the theoretical results in this section will apply to real data.
3.3. Is Misordering Confined to Narrow Combinations of Error Rates and Feature Selection Metrics?
An important question arises when discussing misorderings—what is the extent of feature selection metrics and accuracy values that can result in misordering? One might naturally assume that misorderings would occur within a confined region of the space of the feature selection metric and accuracy. If true, this would suggest that the issue of misordering is not a widespread phenomenon.
In this experiment, we aim to determine the range of values of the feature selection metric and accuracy that can lead to misordering. To determine this, we sample across the complete space of p and q values. This enables us to examine a range of partitions that can arise for a binary classification task.
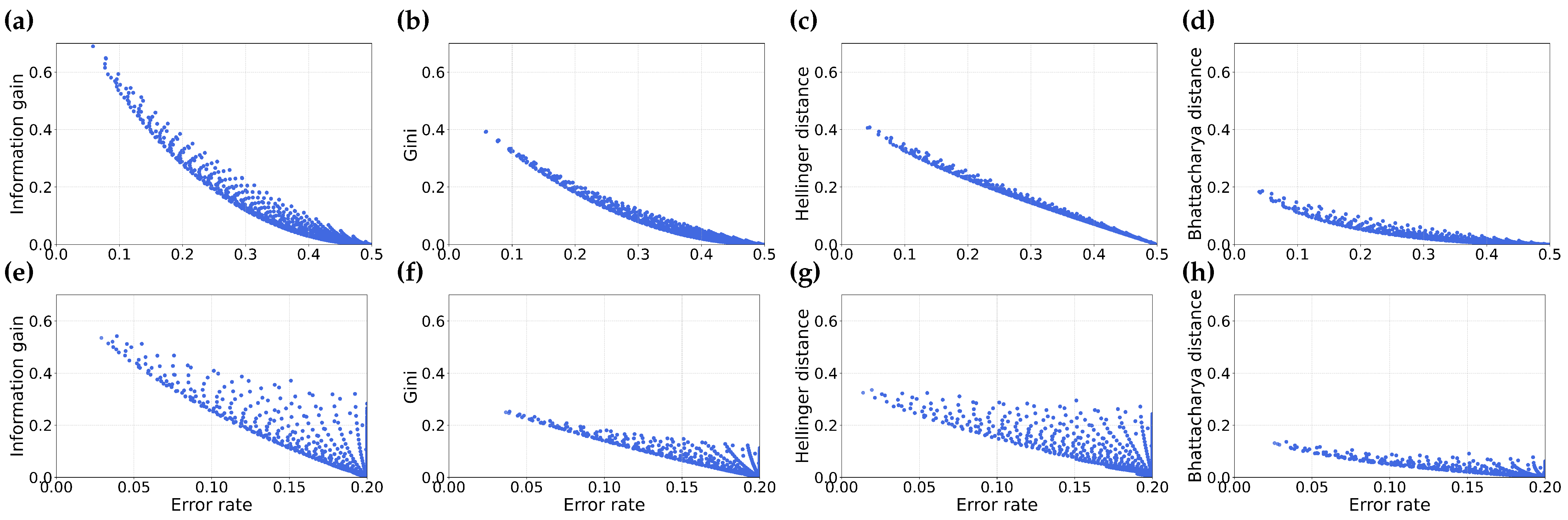
From Figure 6, we observe that the values of information gain, Gini index, Hellinger distance and Bhattacharyya distance and rate span a significant region. This may be due to the fact that misordered pairs arise from the relationship between two partitions, not just a single partition, meaning the misordering region is unlikely to be constrained to a small area in the space of any given feature selection metric and error rate.
We note that as the distribution of negative and positive samples becomes more skewed, the region representing misordering shrinks. This occurs because fewer positive examples in a dataset result in a smaller range of possible error values as well as information gain values.
We also notice that the extent of error values for skewed distribution (as shown in Figure 6e–h) is smaller. This can be attributed to the fact that the maximum possible error in a skewed dataset is determined by the percent of the data in the minority class. In the case of , the skewed distribution of negative to positive samples is .
Misordering of partitions can occur in a wide region of space spanned by the feature selection metric and the error rate. This means that misordering is not localized to specific feature selection metrics or accuracy values.
3.4. Is Misordering Primarily Due to Numerical Issues?
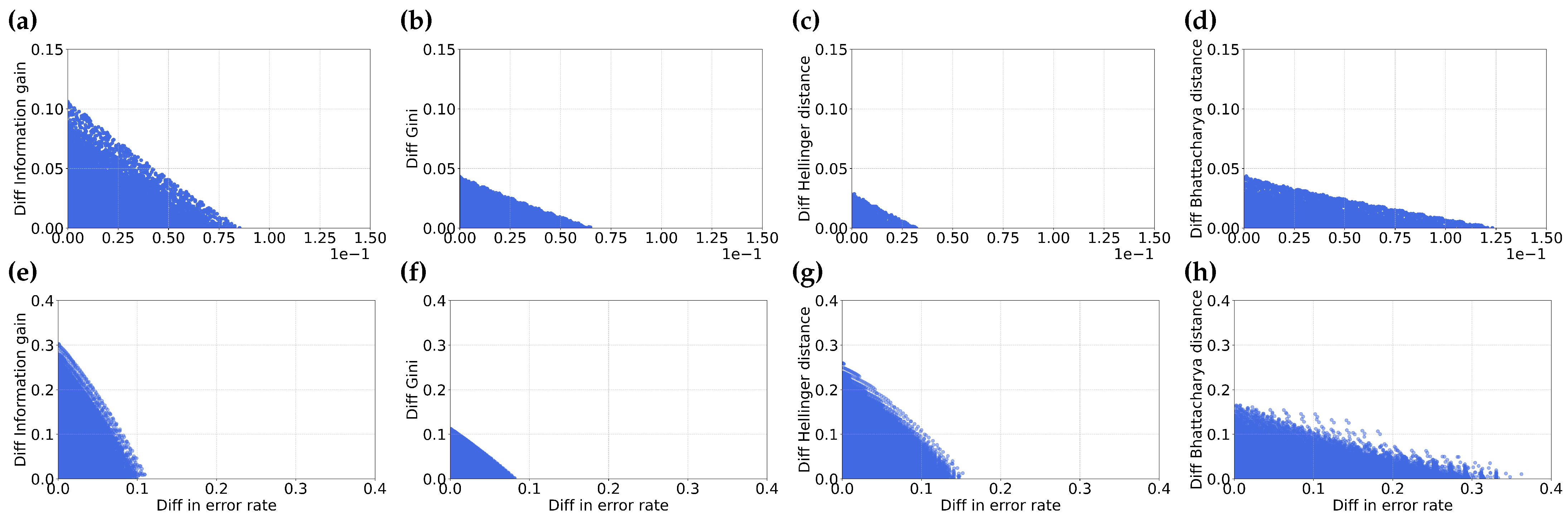
Another possible explanation for the observed misordering could be attributed to rounding errors while ranking features. This is relevant when a pair of partitions exhibits very close values in terms of either information gain or error rate. To verify this hypothesis, we examine the relationship by plotting the difference in various feature selection metrics against the difference in error rate between two partitions. Similar to the previous experiment, we sample across the complete space of p and q values. This enables us to consider a range of partitions that can result in misordering. Note, that unlike Section 3.1, the pairs of partitions we consider here can have very different values.
In Figure 7, we illustrate the relationships between the difference in feature selection metrics and the difference in error. It is important to note that there is a symmetric region of misordered partitions that spans the negative x-y axis in the fourth quadrant, this region is omitted in the illustration for the sake of simplicity.
We note that the extent of values for the difference in the feature selection metric and the difference in error is significant and finite. This observation indicates that misordering cannot be attributed exclusively to rounding errors when a pair of partitions have closely aligned values in either information gain or error.
We further observe a notable difference between skewed and balanced datasets. Specifically, we observe that for skewed datasets (as depicted in Figure 7e–h), the extent of difference in the feature selection metric and error is larger than for the balanced dataset (shown in Figure 7a–d). This suggests a greater probability of misordering in skewed datasets compared to balanced datasets. This is a likely supporting cause for the greater probability of misordering we observed in our prior analysis.
4. Empirical Comparison and Discussion
In the previous section, we considered the probability of misordering analytically. However, this does not establish that misordering can happen in real data, or if it does, what is its prevalence. In this section, we study this question by comparing 13 real-world datasets of varying sizes. Three of these datasets (Arcene, Gisette, and Madelon) are used in the Neural Information Processing Systems 2003 Feature Selection Challenge [20]. We also use biological/text datasets which include ALLAML, Colon, GLI_85, Leukemia, Prostate_GE, SMK_CAN_187, and BASEHOCK which can be retrieved at [21]. The last category of datasets we use are SONAR, Ionosphere, and Congressional Voting from [22]. The characteristics of all of these datasets can be found in Table 2. We chose datasets that span with varying numbers and types of features, class ratios and numbers of examples to get a holistic view of the misordering problem.
4.1. Misordering on Real-World Datasets
We evaluated misordering frequency on the selected datasets using three feature selection metrics information gain, the Gini index and Gain Ratio [15,23]. The gain Ratio is a modification of information gain that attempts to calibrate features that have a large variance in the number of values. Although in our analytical comparisons (Section 3) we have considered features to have two values, real data can have many. To rank such features we must consider all their values. The Gini index generalizes well to such cases. On the other hand, information gain prefers features with a large number of values. To counterbalance this, the Gain Ratio normalizes information gain with the entropy of the feature, . The core idea is that a feature with a large number of values will also have high entropy, so dividing by the entropy will make such a feature less likely to be ranked highly.
The misordering rates for all datasets and these metrics are provided in Table 3. Based on this table, we first observe that misordering does indeed happen in real datasets for all metrics we considered. It ranges from (Voting/Gain Ratio) to (Madelon/Gain Ratio). In the majority of cases, about of the feature pairs are misordered by most of these metrics. Second, when comparing information gain with the Gini index, across all datasets, the Gini index has a lower or equal misordering rate to information gain. This is consistent with our analysis above, where we saw the same behavior. The gain Ratio does not show a clear pattern. In some datasets, its misordering rates are lower than others, and in some, they are the highest.
One interesting observation from this data is that the misordering rates for information gain and the Gini index seem to be relatively stable as the class proportion changes. From the analytical results in Figure 3 and Figure 4, we observe that the misordering rates tend to increase on average as the class proportions become more unbalanced. However, this trend is not reflected in our real-world datasets. Of course, our analytical curves are averages, so this behavior is not ruled out by those results. Second, the most skewed datasets in our comparison are also among the smallest. Such small samples may bias estimates of information gain, Gini, or accuracy which could affect the misordering rate differently.
Another important observation from the empirical results in Section 3 is the effect of class imbalance on the misordering rate of Hellinger distance. The results in Figure 4 show that Hellinger distance has the lowest misordering rate for class-balanced datasets, and the rate increases with class imbalance. Using datasets from Figure Table 2, we plot Hellinger distance vs. class skew in Figure 8a. These results verify the analytical results on real data. Using a linear fit to the data gives which suggests our empirical observations are consistent with our observations from real datasets. For comparison, we examined the percent misordering due to information gain against the class skew in Figure 8b. Here we find no significant correlation between the linear model and data points, which corresponds to our observations regarding information gain.
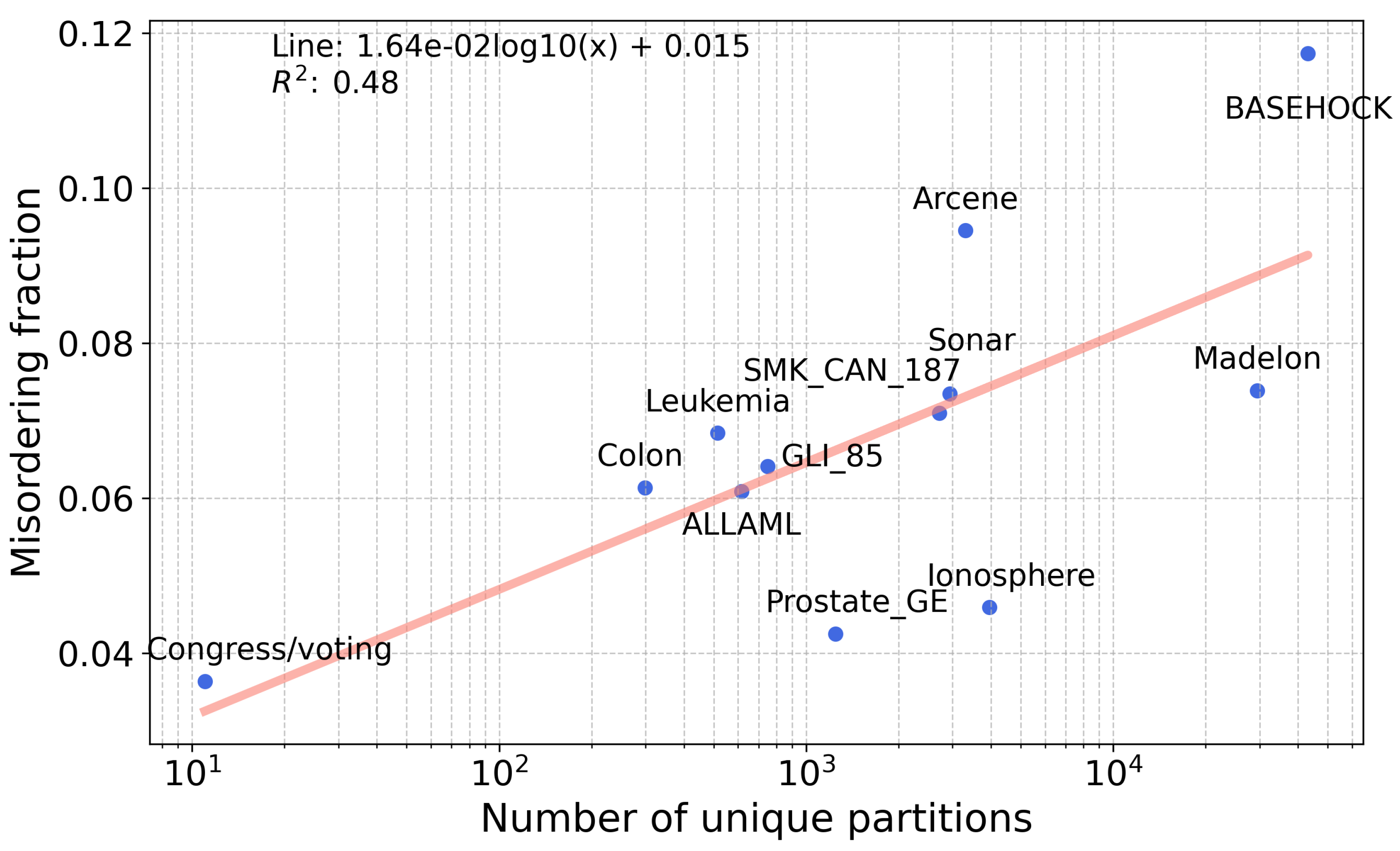
A third relevant hypothesis is that the number of unique partitions in a dataset affects the misordering rate. This is because the more partitions there are, the more pairs there are to compare, resulting in a higher chance that two partitions will have a similar enough value of information gain and error to cause misordering. Note that the number of features in a dataset is not informative since misordering rates are computed by comparing unique partitions, not features. The number of unique partitions for a dataset is computed by creating all possible partitions through splitting features and then removing all duplicate partitions. This constitutes a set of unique partitions that we use to compute misordering rates. We plot the number of features and misordering rates for information gain for the datasets in Table 2 and Figure 9. The trend line has a positive slope (), which is consistent with our hypothesis. However, the slope is inherently small due to the orders of magnitude difference between the values of the axes.
To summarize, our evaluation of real data is broadly consistent with our analytical observations. Different methods do have different misordering rates on different datasets. The ordering of misordering rates on average is broadly consistent across analytical and real-data results, so that, for example, the misordering rate for the Gini index is generally lower than that of information gain. We also observe that Hellinger distance does have an increasing misordering rate as class skew increases, as predicted by our analytical experiments, and the number of features generally increases the misordering rate.
4.2. Potential Misordering in Other Feature Selection Metrics
The literature on feature selection metrics is vast. One could ask if other metrics exhibit the same characteristics as those we have evaluated. While it is infeasible for us to implement and test every such method, we attempt to indirectly answer this question. We collect a number of alternative feature selection metrics and evaluate the correlation between their performance as reported in the literature with information gain. Our hypothesis is that methods that produce downstream classifiers that are highly correlated with those produced by information gain will exhibit the same pattern of misordering as information gain.
The methods we evaluate are as follows:
- Fisher score [24] is a filter method that determines the ratio of the separation between classes and the variance within classes for each feature. The idea is to find a subset of features such that the distances between data points of different classes are as large as possible and the distances between data points of the same class are as small as possible.
- Cons (Consistency Based Filter) [26] is a filter method that measures how much consistency there is in the training data when considering a subset of features [27]. A consistency measure is defined by how often feature values for examples match and the class labels match. A set of features is inconsistent if all of the feature values match, but the class labels differ [28].
- ReliefF [30] randomly samples an example from the data and then determines the two nearest neighbors, where one has the same class label and the other has the opposite class label. These nearest neighbors are determined by using the metric of the p-dimensional Euclidean distance where p is the number of features in the data. The feature values of these neighbors are compared to the example that was sampled and used to update the relevance of each feature to the label. The idea is that a feature that predicts the label well should be able to separate examples with different class labels and predict the same label for examples from the same class [7].
- mRMR [31] chooses features based on the relevance with the target class and also picks features that are minimally redundant with each other. The optimization criteria of minimum redundancy and maximum relevance are based on mutual information [7]. The mutual information between two features represents the dependence between the two variables and thus is used as a measure of redundancy, while the average mutual information over the set of features is used as a measure of relevance. In order to find the minimum redundancy-maximum relevance set of features, these two criteria are optimized simultaneously, which can be done through a variety of heuristics [31].
- FCBF (fast correlation-based filter) [32] first selects a set of features highly correlated with the class label using a metric called Symmetric Uncertainty. Symmetric Uncertainty is the ratio between the information gain and the entropy for two features. Then, three heuristics that keep more relevant features and remove redundant features are applied [7].
To compare the performance of these methods with information gain, we compile results from a large number of papers in the literature (see Appendix A, Table A1 for a list of papers for each method). Each of these papers reports accuracy values for using information gain with a specific model (ex. decision trees) on multiple datasets and then reports the accuracy values for using another feature selection method with the same model and same dataset. We compile all of the information gain accuracy values into one vector and all of the accuracy values for the other feature selection method (ex. chi-squared) in another. For instance, in [37], one experiment was done where the following values were reported: (1) the accuracy using information gained with their Cornell sentiment polarity dataset and training it with a Support Vector Machine and (2) the accuracy using the chi-squared statistic with the same data and training it with a Support Vector Machine. These two entries are paired in the respective performance vectors so that they will be compared when we carry out a correlation.
To ensure that correlation values are valid, the elements within each vector need to be independent. Thus, we avoided using similar classifiers for the same datasets (More details about the specific values used are in the Appendix A and [38]). In order to measure correlation, we use Pearson’s correlation coefficient (r) [39]. X, Y are random variables, if , are sampled, and , are the sample means, the correlation coefficient is computed as:
The results of this analysis are shown in Table 4.
From the table, we see that nearly every approach we evaluate has performance that is significantly correlated with information gain. The only exceptions (to some extent) are the LASSO and SVM-RFE methods. This is not surprising because these methods are embedded and wrapper methods that perform feature selection in the context of a classifier. All other methods are filters that are very highly correlated with information gain. While this is indirect evidence, it suggests that the results of this paper with information gain likely apply to other feature selection metrics to a similar extent.
4.3. Impact of Misordering on Adaboost
In this section and the next, we consider the impact that misordering may have on feature selection and boosting. Adaboost (Adaptive Boosting) [40] is an ensemble algorithm that combines an ensemble of weak learners, into a strong learner. It adaptively weighs data points to generate successive weak learners. Decision stumps using information gain are a common choice as a weak learner for this approach. The theory of boosting suggests that [41], as long as a weak learner that minimizes error can be selected in each iteration, an upper bound of the error of the ensemble will decrease exponentially on the training set. Since we know that information gain can misorder features, thereby not necessarily selecting the lowest error stump, this motivates us to investigate whether using the actual lowest error stump may improve the performance of boosting.
We ran 10 iterations of the Adaboost algorithm on several datasets, using both information gain (normal boosted stumps) and alternatively selecting the stump with the lowest error. We used 80% of the data from each dataset to train and the remaining 20% as a test. The results are summarized in Table 5, which display train and test set error rates of the ensemble over 10 iterations on five datasets.
We observe that of the 50 iterations, over 30 () had a misordered feature selected by information gain. Further, in many cases, the ensemble built by choosing stumps with the lowest error also had better accuracy on these datasets during training and testing. While many factors affect performance in real datasets, this is an indication that reducing misordering may in some cases improve the performance of a downstream classifier or ensemble method.
4.4. Impact of Misordering on Feature Selection Precision and Recall
In this section, we evaluate the efficacy of various feature selection metrics, Information gain, Gini, Hellinger distance, and Bhattacharyya distance in identifying relevant features from a dataset.
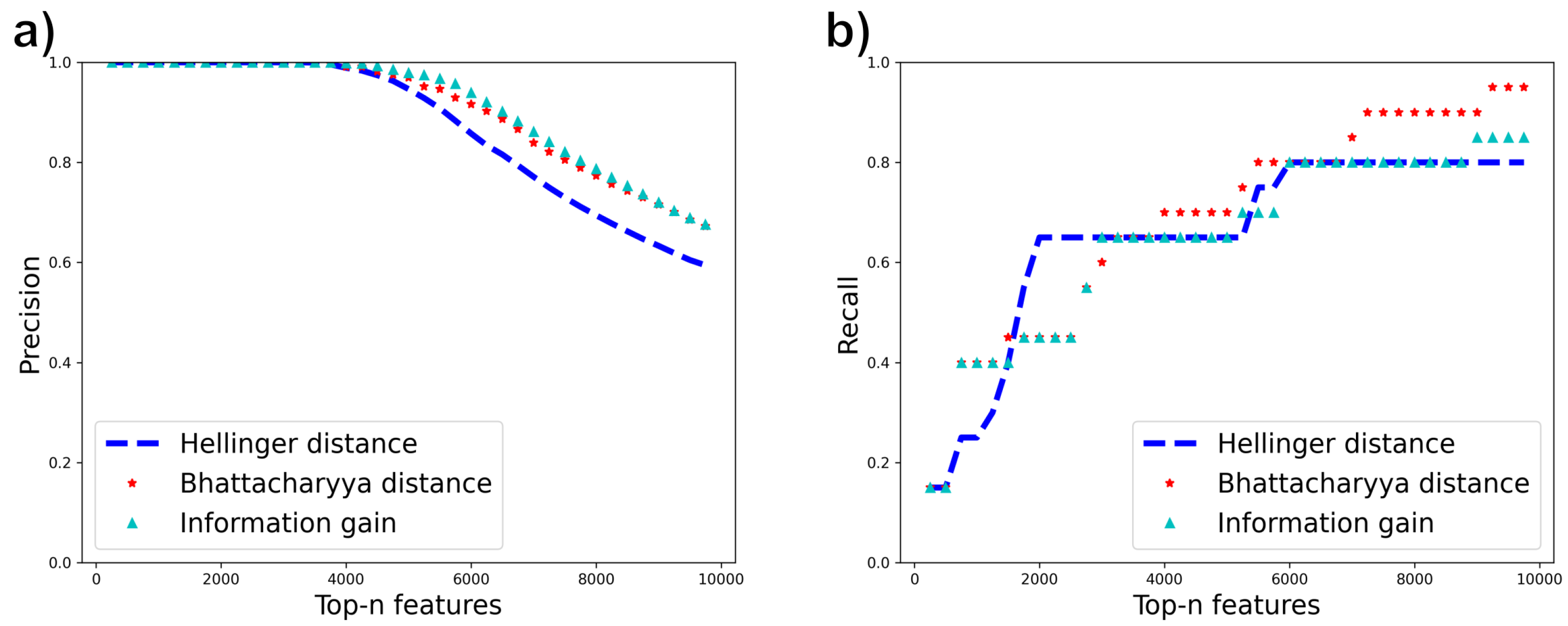
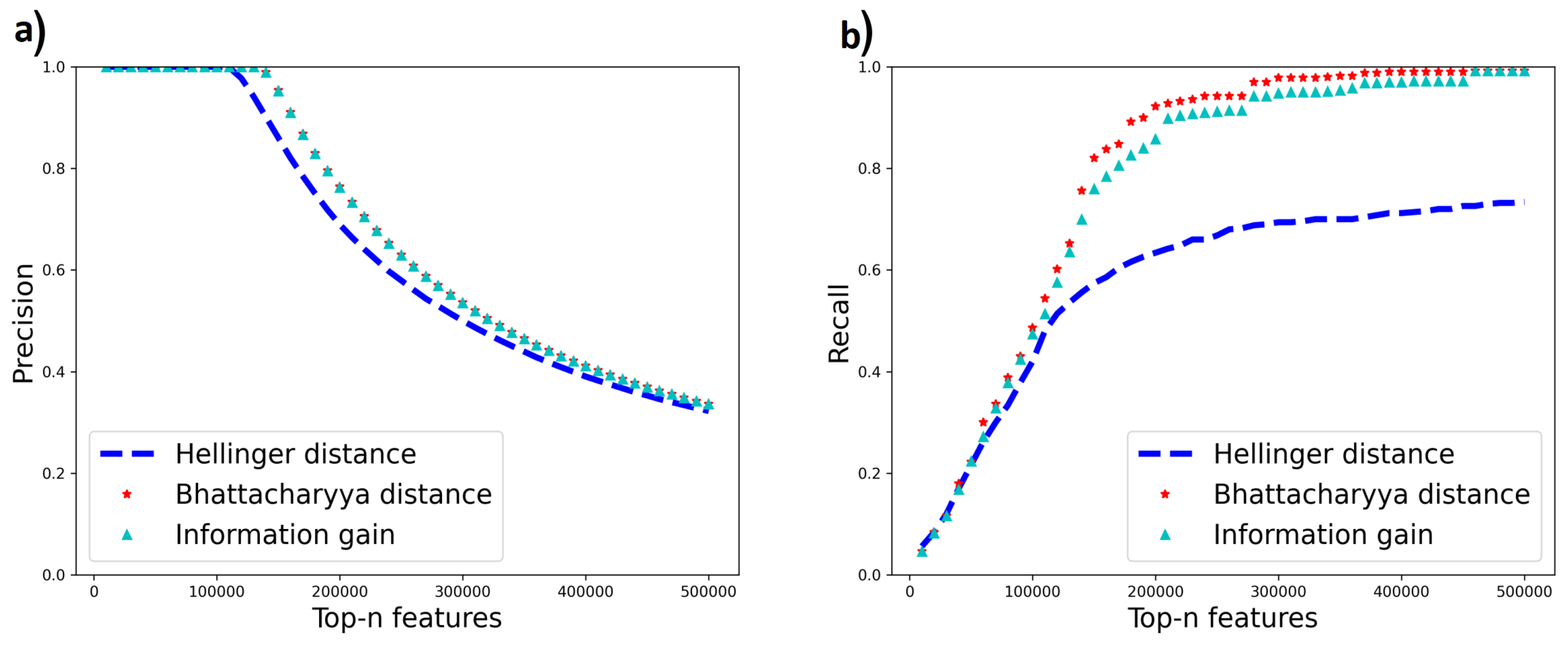
We use two datasets, Madelon [44] and Gisette [45], from the NIPS 2003 feature selection challenge which contain a mixture of relevant and irrelevant features. Each dataset has a set of relevant features augmented with some irrelevant “probe” features. Relevant features for Madelon were extracted using the Boruta method [46], and their relevance was verified using correlation matrix analysis. For Gisette, we found a version of the dataset that identified the probe features explicitly. We then created a more challenging version we call Gisette-small by keeping all irrelevant features but only 500 of the original 2500 relevant features. We then run all feature selection methods on the two datasets. Since the relevant features are known, we plot the precision and recall of selected features using the known relevant features as the ground truth, at different thresholds of the number of selected features (“Top-n features”) on the x-axis. The results are shown in Figure 10 and Figure 11. In these results, the Gini index curve almost completely overlapped with the information gain curve (not surprising as their misordering rates are quite similar), so we did not plot the Gini result.
From the results for Madelon, Hellinger demonstrates a higher recall rate at a lower number of top-n features, followed by Bhattacharya distance and then information gain which shows higher recall at a larger value of top-n features. Bhattacharyya distance has the best overall recall. This trend correlates with the misordering rates (Table 6) which show higher misordering rates for Information gain followed by Bhattacharya distance and Hellinger distance. In Gisette-small, Bhattacharyya distance still has the best overall recall rate and matches the precision of information gain. This is consistent with its lower misordering rate than information gain. However, Hellinger distance does not perform well on this dataset though it has a low misordering rate on this dataset. The reason for this behavior remains to be understood. With this exception, however, the other results indicate that the misordering rate correlates well with true feature selection performance.
5. Limitations
In this study, we have made several assumptions to simplify our analysis. Our focus has been on binary class data with binary features for ease of analysis. Extension to multi-class problems remains for future work. While the approach should be extendable, the selection criteria we have explored may behave differently in that case. Further, our analysis has been primarily based on four feature selection metrics. There are many other feature selection metrics that remain to be analyzed using this approach. We also assumed that no data were missing. Missing feature values would not have allowed us to accurately calculate the variables p and q in our analysis. In the presence of missing values, we would suggest using techniques such as imputation before a feature selection criterion is applied. Finally, we have performed preliminary experiments to evaluate the effect of misordering on downstream classifiers. While we observed differences in performance, our experiments cannot conclusively suggest differences in misordering rates as the cause. Designing additional experiments to understand downstream effects remains a direction for future work.
6. Conclusions
In this paper, we have discussed a not-so-well-studied aspect of the relationship between feature selection metrics and accuracy, and misorderings. We have looked at some common feature selection methods including Information gain, Gini index, Hellinger distance, and Bhattacharya distance and their relationship to misordering. We have shown analytically as well as empirically that misordering is a phenomenon that affects several different feature selection metrics. It is not confined to a narrow range of accuracy values or feature selection metrics and it is not a function of numerical errors introduced during computation. Further, different metrics have different behavior with respect to the parameters that characterize partitions of the data. Empirically, we show that misordering also happens in real-world data. Beyond the feature selection metrics we have tested, performance correlations with other metrics suggest that many metrics will be prone to misordering as well.
Author Contributions
Conceptualization, S.R. and E.E.; methodology, software, validation, analysis, visualization, writing—original draft preparation, E.E. and N.N.; writing—review and editing, all; supervision, project administration, funding acquisition, S.R. All authors have read and agreed to the published version of the manuscript.
Funding
N.N. and S.R. were supported in part by National Science Foundation award SES-2120972.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
Code and data will be made available on github upon publication.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results. The manuscript reflects the opinions of the authors and not those of the National Science Foundation.
Appendix A
In order to calculate the correlation of information gain with a variety of feature methods, data from a variety of papers was compiled. The exact data collected can be found in [38], but Table A1 shows a summary of which feature selection methods appear in which collected papers. In these papers, results for the exact same computations were shown for information gain and other metrics. For each feature selection metric compared with information gain, two arrays of the same length can be produced where one corresponding elements represent data from the same source. In order to make sure that correlation values are valid, the elements within each vector need to be independent since the more similar the entries become, the less reliable the correlation becomes. Thus, similar classifiers for the same datasets are avoided. The following is a list of choices made in order to ensure that similar classifiers for the same datasets are not used:
- When a paper lists 2 values of accuracy for the same classifier and dataset, but the only differing factor is the number of features used and the number of features is relatively small, the larger number of features is used. For instance, in Table 10 of [7], the paper reports accuracy values for both using the top 10 features and the top 50 features for using information gain, ReliefF, SVM-RFE, and mRMR. Using the larger number of features is more likely to encompass the target we are trying to capture due to the relatively small number of features used. Note that this point only applies when both information gain and the metric compared to information gain both select the top k values of their metric.
- When information gain and the other metric do not both select the top k values of their metric, the option which allows the 2 metrics to have the closest number of features used in their models is used. For instance, in Table 10 of [7], there are accuracy values for accuracy for both selecting the top 10 features and selecting the top 50 features. However, correlation-based feature selection (CFS) does not select features based on a specific number of top features, so the different datasets have different numbers of features used in the models. Based on Table 9 of [7], the Breast dataset has 130 features selected for CFS, so when comparing information gain and CFS, the value of accuracy using the top 50 features of information gain is compared to the CFS accuracy since 50 is closer to 130 than 10 is to 130.
- When the choice of the cross-validation method is between (1) regular 5-fold cross-validation and (2) distribution-balanced stratified cross-validation(DOB-SCV) with 5 folds, the former is used as it is a more standard option. One example of this occurring is in Table A1 and Table A2 in [7].
- The Sequential Minimal Optimization (SMO) algorithm is an algorithm that solves the quadratic programming problem that comes from training SVMs (Sequential Vector Machines). SMO is used in Table 5.8 of [47], which uses 3 different polynomial kernels (1, 2, and 3). We choose the kernel of 3 since the choice of features should have the biggest effect on this kernel.
- In order to guarantee that each entry in the compared vectors are different enough to guarantee that the entries are independent, similar classifiers cannot be used together with the same dataset. Data that uses logistic regression as the classifier is not used as a linear SVM is essentially the same as logistic regression with a linear kernel. For instance, this occurs in Table 4 of [48] with results for both SVM and logistic regression being reported.
- In some papers, the C4.5 classifier is used with similar datasets. For instance, in [47], the Corral dataset is used. However, [49] uses both the Corral dataset and a modification of the Corral dataset called Corral-100, which adds 93 irrelevant binary features to the Corral dataset. In the correlation calculations, the Corral-100 dataset is used as the irrelevant features add additional selection opinions that help reveal how good each algorithm is. The Led-100 dataset is also used instead of the Led-25 dataset in [49] for the same reasoning.
- When the options for feature dimensions are large (thousands of features), as in Table 1 of [50], the median value is chosen. Once the number of features gets large, the number of features should not make as big of a difference, so the median value is used. If two values of feature dimension are equally close to the median, then the larger value is used.
- When an algorithm uses a population size, such as in an evolutionary algorithm, the option with the larger population size is used as the algorithm will see more options of what features to select. For instance, in Table 1 of [51], the population size of 50 is used.
- Table 13 of [49] uses 2 ranker methods for some feature selection algorithms: (1) selecting the optimal number of features, (2) selecting 20 features. Since the 20 features better encompasses the feature selection problem since the optimal number of features is 2 features.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table A1.
Summary of feature selection methods and the papers correlating to information gain.
| Feature Selection Method | List of Papers Used for Calculations |
|---|---|
| Fisher score | [35,52,53] |
| CFS(Correlation Based Feature Selection) | [7,26,27,29,47,48,49] |
| INTERACT | [7,27,49] |
| Cons (Consistency Based Filer) | [26,27,29,48,49] |
| Chi-squared statistic | [29,37,50,53] |
| Relief-F | [7,10,26,27,29,35,47,48,49,53,54] |
| mRMR (Minimum-Redundancy Maximum-Relevance) | [7,10,35,49] |
| FCBF (fast correlation-based filter) | [7,27,29,47] |
| LASSO | [29,35,55] |
| SVM-RFE | [7,29,49] |
References
- Hira, Z.M.; Gillies, D.F. A Review of Feature Selection and Feature Extraction Methods Applied on Microarray Data. Adv. Bioinform. 2015, 2015, 198363. [Google Scholar] [CrossRef] [PubMed]
- Dinga, R.; Penninx, B.W.; Veltman, D.J.; Schmaal, L.; Marquand, A.F. Beyond accuracy: Measures for assessing machine learning models, pitfalls and guidelines. bioRxiv 2019, 743138. [Google Scholar] [CrossRef]
- Guyon, I.; Elisseeff, A. An Introduction to Variable and Feature Selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Nguyen, T.; Sanner, S. Algorithms for direct 0–1 loss optimization in binary classification. In Proceedings of the International Conference on Machine Learning, PMLR, Atlanta, GA, USA, 17–19 June 2013; pp. 1085–1093. [Google Scholar]
- Zhou, S.; Pan, L.; Xiu, N.; Qi, H.D. Quadratic convergence of smoothing Newton’s method for 0/1 loss optimization. SIAM J. Optim. 2021, 31, 3184–3211. [Google Scholar] [CrossRef]
- He, X.; Little, M.A. 1248 An efficient, provably exact, practical algorithm for the 0–1 loss linear classification problem. arXiv 2023, arXiv:2306.12344. [Google Scholar]
- Bolón-Canedo, V.; Sánchez-Maroño, N.; Alonso-Betanzos, A.; Benítez, J.; Herrera, F. A review of microarray datasets and applied feature selection methods. Inf. Sci. 2014, 282, 111–135. [Google Scholar] [CrossRef]
- Tangirala, S. Evaluating the Impact of GINI Index and Information Gain on Classification using Decision Tree Classifier Algorithm. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 612–619. [Google Scholar] [CrossRef]
- Mingers, J. An Empirical Comparison of Selection Measures for Decision-Tree Induction; Machine Learning; Springer: Berlin/Heidelberg, Germany, 1989; Volume 3, pp. 319–342. [Google Scholar] [CrossRef]
- Nie, F.; Huang, H.; Cai, X.; Ding, C. Efficient and Robust Feature Selection via Joint ℓ2,1-Norms Minimization. Neural Inf. Process. Syst. 2010, 23. Available online: https://proceedings.neurips.cc/paper_files/paper/2010/file/09c6c3783b4a70054da74f2538ed47c6-Paper.pdf (accessed on 22 November 2023).
- Ferreria, A.J.; Figueuredo, M.A. An unsupervised approach to feature discretization and selection. Pattern Recognit. 2011, 45, 3048–3060. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.; Stone, C.J.; Olshen, R. Classification and Regression Trees; Routledge: London, UK, 1984. [Google Scholar]
- Meyen, S. Relation between Classification Accuracy and Mutual Information in Equally Weighted Classification Tasks. Master’s Thesis, University of Tuebingen, Tubingen, Germany, 2016. [Google Scholar]
- Zhou, Z.H. A brief introduction to weakly supervised learning. Natl. Sci. Rev. 2017, 5, 44–53. [Google Scholar] [CrossRef]
- Quinlan, J.R. C4.5: Programs for Machine Learning; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1993. [Google Scholar]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees. Biometrics 1984, 40, 874. [Google Scholar]
- Hellinger, E. Neue begründung der theorie quadratischer formen von unendlichvielen veränderlichen. J. Reine Angew. Math. 1909, 1909, 210–271. [Google Scholar] [CrossRef]
- Bhattacharyya, A. On a measure of divergence between two multinomial populations. Sankhya Indian J. Stat. 1946, 7, 401–406. [Google Scholar]
- Choi, E.; Lee, C. Feature extraction based on the Bhattacharyya distance. Pattern Recognit. 2003, 36, 1703–1709. [Google Scholar] [CrossRef]
- Guyon, I.; Gunn, S.; Ben-Hur, A.; Dror, G. Result Analysis of the NIPS 2003 Feature Selection Challenge with data retrieved from University of California Irvine Machine Learning Repository. 2004. Available online: https://papers.nips.cc/paper/2004/file/5e751896e527c862bf67251a474b3819-Paper.pdf (accessed on 22 November 2023).
- Li, J. Feature Selection Datasets. Data retrieved from Arizona State University. Available online: https://jundongl.github.io/scikit-feature/datasets.html (accessed on 5 October 2023).
- Dua, D.; Graff, C. UCI Machine Learning Repository. 2017. Available online: https://archive.ics.uci.edu/ (accessed on 22 November 2023).
- Grimaldi, M.; Cunningham, P.; Kokaram, A. An Evaluation of Alternative Feature Selection Strategies and Ensemble Techniques for Classifying Music. Workshop on Multimedia Discovery and Mining. 2003. Available online: https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=22a1a59619809e8ecf7ff051ed262bea0f835f92#page=44 (accessed on 22 November 2023).
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern Classification; Wiley-Interscience Publication: Hoboken, NJ, USA, 2000. [Google Scholar]
- Hall, M.A. Correlation-Based Feature Selection for Machine Learning. Ph.D. Thesis, The University of Waikato, Hamilton, New Zealand, 1999. Available online: https://www.cs.waikato.ac.nz/~mhall/thesis.pdf (accessed on 5 October 2023).
- Hall, M.A.; Holmes, G. Benchmarking Attribute Selection Techniques for Discrete Class Data Mining. IEEE Trans. Knowl. Data Eng. 2003, 15, 1437–1447. [Google Scholar] [CrossRef]
- Bolon-Canedo, V.; Sanchez-Marono, N.; Alonso-Betanzos, A. An ensemble of filters and classifiers for microarray data classification. Pattern Recognit. 2012, 45, 531–539. [Google Scholar] [CrossRef]
- Dash, M.; Liu, H. Consistency-based search in feature selection. Artif. Intell. 2003, 151, 155–176. [Google Scholar] [CrossRef]
- Singh, N.; Singh, P. A hybrid ensemble-filter wrapper feature selection approach for medical data classification. Chemom. Intell. Lab. Syst. 2021, 217, 104396. [Google Scholar] [CrossRef]
- Kononenko, I. Estimating attributes: Analysis and extensions of RELIEF. In European Conference on Machine Learning; Springer: Berlin/Heidelberg, Germany, 1994. [Google Scholar]
- Ding, C.; Peng, H. Minimum Redundancy Feature Selection from Microarray Gene Expression Data. J. Bioinform. Comput. Biol. 2005, 3, 185–205. [Google Scholar] [CrossRef]
- Yu, L.; Liu, H. Feature Selection for High-Dimensional Data: A Fast Correlation-Based Filter Solution. In Proceedings of the Twentieth International Conference on Machine Learning, Washington, DC, USA, 21–24 August 2003. [Google Scholar]
- Zhao, Z.; Liu, H. Searching for Interacting Features. In Proceedings of the 20th International Joint Conference on Artificial Intelligence, Hyderabad, India, 6–12 January 2007. [Google Scholar]
- Tibshirani, R. Regression Shrinkage and Selection via the Lasso. J. R. Stat. Soc. 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Nardone, D.; Ciaramella, A.; Staiano, A. A Sparse-Modeling Based Approach for Class Specific Feature Selection. PeerJ Comput. Sci. 2019, 5, e237. [Google Scholar] [CrossRef] [PubMed]
- Guyon, I.; Weston, J.; Barnhill, S.; Vapnik, V. Gene Selection for Cancer Classification using Support Vector Machines. Mach. Learn. 2002, 46, 389–422. [Google Scholar] [CrossRef]
- Manek, A.S.; Shenoy, P.D.; Mohan, M.C.; R, V.K. Aspect term extraction for sentiment analysis in large movie reviews using Gini Index feature selection method and SVM classifier. World Wide Web 2016, 20, 135–154. [Google Scholar] [CrossRef]
- Epstein, E. The Relationship between Common Feature Selection Metrics and Accuracy. Master’s Thesis, Case Western Reserve University, Cleveland, OH, USA, 2022. [Google Scholar]
- Pearson, K. Notes on the History of Correlation. Biometrika 1920, 13, 25–45. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Schapire, R.E. The Design and Analysis of Efficient Learning Algorithms. Ph.D. Thesis, MIT Press , Cambridge, MA, USA, 1992. [Google Scholar]
- Burl, M.C.; Asker, L.; Smyth, P.; Fayyad, U.; Perona, P.; Crumpler, L.; Aubele, J. Learning to recognize volcanoes on Venus. Mach. Learn. 1998, 30, 165–194. [Google Scholar] [CrossRef]
- Ouyang, T.; Ray, S.; Rabinovich, M.; Allman, M. Can network characteristics detect spam effectively in a stand-alone enterprise? In Proceedings of the Passive and Active Measurement: 12th International Conference, PAM 2011, Atlanta, GA, USA, 20–22 March 2011; Proceedings 12. Springer: Berlin/Heidelberg, Germany, 2011; pp. 92–101. [Google Scholar]
- Guyon, I. Madelon. UCI Machine Learning Repository. 2008. Available online: https://archive.ics.uci.edu/dataset/171/madelon (accessed on 22 November 2023).
- Guyon, I.; Gunn, S.; Ben-Hur, A.; Dror, G. Gisette. UCI Machine Learning Repository. 2008. Available online: https://archive.ics.uci.edu/dataset/170/gisette (accessed on 22 November 2023).
- Kursa, M.B.; Rudnicki, W.R. Feature Selection with the Boruta Package. J. Stat. Softw. 2010, 36, 1–13. [Google Scholar] [CrossRef]
- Sui, B. Information Gain Feature Selection Based On Feature Interactions. Master’s Thesis, University of Houston, Houston, TX, USA, 2013. [Google Scholar]
- Koprinska, I. Feature Selection for Brain-Computer Interfaces. PAKDD 2009 International Workshops. 2009. Available online: https://link.springer.com/content/pdf/10.1007/978-3-642-14640-4.pdf (accessed on 1 October 2023).
- Bolón-Canedo, V.; Sánchez-Maroño, N.; Alonso-Betanzos, A. A Review of Feature Selection Methods on Synthetic Data. Knowl. Inf. Syst. 2013, 34, 483–519. [Google Scholar] [CrossRef]
- Wu, L.; Wang, Y.; Zhang, S.; Zhang, Y. Fusing Gini Index and Term Frequency for Text Feature Selection. In Proceedings of the 2017 IEEE Third International Conference on Multimedia Big Data, Laguna Hills, CA, USA, 19–21 April 2017. [Google Scholar]
- Jirapech-Umpai, T.; Aitken, S. Feature selection and classification for microarray data analysis: Evolutionary methods for identifying predictive genes. BMC Bioinform. 2005, 6, 148. [Google Scholar] [CrossRef]
- Masoudi-Sobhanzadeh, Y.; Motieghader, H.; Masoudi-Nejad, A. FeatureSelect: A software for feature selection based on machine. learning approaches. BMC Bioinform. 2019, 20, 170. [Google Scholar] [CrossRef]
- Phuong, H.T.M.; Hanh, L.T.M.; Binh, N.T. A Comparative Analysis of Filter-Based Feature Selection Methods for Software Fault Prediction. Res. Dev. Inf. Commun. Technol. 2021. [Google Scholar] [CrossRef]
- Taheri, N.; Nezamabadi-pour, H. A hybrid feature selection method for high-dimensional data. In Proceedings of the 4th International Conference on Computer and Knowledge Engineering, Mashhad, Iran, 29–30 October 2014. [Google Scholar]
- Bi, X.; Liu, J.G.; Cao, Y.S. Classification of Low-grade and High-grade Glioma using Multiparametric Radiomics Model. In Proceedings of the IEEE 3rd Information Technology, Networking, Electronic and Automation Control Conference (ITNEC 2019), Chengdu, China, 15–17 March 2019. [Google Scholar]
Figure 1.
Heat maps illustrate the misalignment between the gradient vectors of feature selection metrics and accuracy. (a,e) depict this relationship for Information gain, (b,f) for the Gini index, (c,g) for the Hellinger distance, and (d,h) for the Bhattacharyya distance. (a–d) represent datasets with an equal distribution of negative and positive samples, while (e–h) show datasets with . Here, p represents the fraction of examples in the first partition, and q represents the fraction of positive examples in the first partition.
Figure 1.
Heat maps illustrate the misalignment between the gradient vectors of feature selection metrics and accuracy. (a,e) depict this relationship for Information gain, (b,f) for the Gini index, (c,g) for the Hellinger distance, and (d,h) for the Bhattacharyya distance. (a–d) represent datasets with an equal distribution of negative and positive samples, while (e–h) show datasets with . Here, p represents the fraction of examples in the first partition, and q represents the fraction of positive examples in the first partition.

Figure 2.
Probability of misordering for information gain, Gini index, Hellinger distance, and Bhattacharyya distance as functions of the parameters p. Sub-figure (a) represents these comparisons for balanced datasets, while sub-figure (b) shows a similar comparison for skewed datasets with .
Figure 2.
Probability of misordering for information gain, Gini index, Hellinger distance, and Bhattacharyya distance as functions of the parameters p. Sub-figure (a) represents these comparisons for balanced datasets, while sub-figure (b) shows a similar comparison for skewed datasets with .

Figure 3.
Probability of misordering for information gain, Gini index, Hellinger distance, and Bhattacharyya distance as functions of the parameters q. Sub-figure (a) represents the these comparisons for a balanced dataset, while sub-figure (b) shows similar comparison for a skewed dataset with .
Figure 3.
Probability of misordering for information gain, Gini index, Hellinger distance, and Bhattacharyya distance as functions of the parameters q. Sub-figure (a) represents the these comparisons for a balanced dataset, while sub-figure (b) shows similar comparison for a skewed dataset with .

Figure 4.
Probability of Misordering for Information Gain, Gini Index, Hellinger Distance, and Bhattacharyya Distance as a function of the Parameter q. This figure highlights the dependency of Hellinger Distance on data skew, with sub-figures (a–d) representing data distributions with varying fractions of negative samples (m): (a), (b), (c), and (d), respectively.
Figure 4.
Probability of Misordering for Information Gain, Gini Index, Hellinger Distance, and Bhattacharyya Distance as a function of the Parameter q. This figure highlights the dependency of Hellinger Distance on data skew, with sub-figures (a–d) representing data distributions with varying fractions of negative samples (m): (a), (b), (c), and (d), respectively.

Figure 5.
The empirical probability of misordering for Information gain as a function of the parameter q. Sub-figure (a) represents the empirical misordering probability for balanced datasets, while sub-figure (b) represents the same for skewed datasets with .
Figure 5.
The empirical probability of misordering for Information gain as a function of the parameter q. Sub-figure (a) represents the empirical misordering probability for balanced datasets, while sub-figure (b) represents the same for skewed datasets with .

Figure 6.
This figure illustrates the comparison between the error rate and various feature selection metrics—Information gain (a,e), Gini index (b,f), Hellinger distance (c,g) and Bhattacharyya distance (d,h). Sub-figures (a–d) represent datasets with equal distribution of negative and positive samples, while sub-figures (e–h) show the same comparisons for datasets with .
Figure 6.
This figure illustrates the comparison between the error rate and various feature selection metrics—Information gain (a,e), Gini index (b,f), Hellinger distance (c,g) and Bhattacharyya distance (d,h). Sub-figures (a–d) represent datasets with equal distribution of negative and positive samples, while sub-figures (e–h) show the same comparisons for datasets with .

Figure 7.
This figure illustrates the comparison between the difference in error rate and difference in various feature selection metrics–Information gain (a,e), Gini index (b,f), Hellinger distance (c,g) and Bhattacharyya distance (d,h). Sub-figures (a–d) represent datasets with equal distribution of negative and positive samples, while sub-figures (e–h) show the same comparisons for datasets with .
Figure 7.
This figure illustrates the comparison between the difference in error rate and difference in various feature selection metrics–Information gain (a,e), Gini index (b,f), Hellinger distance (c,g) and Bhattacharyya distance (d,h). Sub-figures (a–d) represent datasets with equal distribution of negative and positive samples, while sub-figures (e–h) show the same comparisons for datasets with .

Figure 8.
Relationship between the class skew in real datasets and the percent misordering for (a) Hellinger distance (b) Information gain. Each data point represents a unique dataset. A line is drawn to show goodness of fit with a linear model.
Figure 8.
Relationship between the class skew in real datasets and the percent misordering for (a) Hellinger distance (b) Information gain. Each data point represents a unique dataset. A line is drawn to show goodness of fit with a linear model.

Figure 9.
Relationship between the number of features in real datasets and the percent misordering. Each data point represents a unique dataset. A line is drawn to show goodness of fit with a linear model.
Figure 9.
Relationship between the number of features in real datasets and the percent misordering. Each data point represents a unique dataset. A line is drawn to show goodness of fit with a linear model.

Figure 10.
(a) Precision (b) Recall of relevant features using Information gain, Hellinger distance and Bhattacharyya distance for Madelon.
Figure 10.
(a) Precision (b) Recall of relevant features using Information gain, Hellinger distance and Bhattacharyya distance for Madelon.

Figure 11.
(a) Precision (b) Recall of relevant features using Information gain, Hellinger distance and Bhattacharyya distance for Gisette-small.
Figure 11.
(a) Precision (b) Recall of relevant features using Information gain, Hellinger distance and Bhattacharyya distance for Gisette-small.

Table 1.
Toy Classification Task to Predict Which Animals Are Lions.
| Sharp Teeth? | Has Fur? | Lazy? | Loud? | Is Lion? (Label) |
|---|---|---|---|---|
| No | No | Yes | No | Yes |
| No | Yes | No | No | No |
| Yes | No | Yes | No | No |
| Yes | Yes | Yes | No | Yes |
| Yes | Yes | No | No | No |
| Yes | No | No | No | No |
| Yes | Yes | Yes | No | Yes |
| Yes | Yes | No | No | Yes |
| Yes | Yes | No | Yes | Yes |
Table 2.
Summary of Real Datasets.
| Dataset | Percent Majority Class | Number of Examples | Number of Features | Number of Unique Feature Splits | Feature Type |
|---|---|---|---|---|---|
| Gisette | 0.500 | 7000 | 5000 | 478,699 | Continuous |
| Madelon | 0.500 | 2600 | 500 | 29,490 | Continuous |
| BASEHOCK | 0.501 | 1993 | 4862 | 43,109 | Discrete |
| Prostate_GE | 0.510 | 102 | 5966 | 1245 | Continuous |
| SMK_CAN_187 | 0.519 | 187 | 19,993 | 2715 | Continuous |
| Sonar | 0.534 | 208 | 60 | 2941 | Continuous |
| Arcene | 0.560 | 200 | 10,000 | 3308 | Continuous |
| Congressional Voting | 0.614 | 435 | 16 | 11 | Binary |
| Ionosphere | 0.641 | 351 | 34 | 3958 | Continuous |
| Colon | 0.645 | 62 | 2000 | 299 | Discrete |
| ALLAML | 0.653 | 72 | 7129 | 615 | Continuous |
| Leukemia | 0.653 | 72 | 7070 | 515 | Discrete |
| GLI_85 | 0.694 | 85 | 22,283 | 749 | Continuous |
Table 3.
Misordering Rates on real datasets for Information Gain, Gain Ratio, Gini Index, Hellinger distance, and Bhattacharyya distance.
Table 3.
Misordering Rates on real datasets for Information Gain, Gain Ratio, Gini Index, Hellinger distance, and Bhattacharyya distance.
| Dataset | Percent Majority Class | Information Gain | Gain Ratio | Gini Index | Hellinger Distance | Bhattacharyya Distance |
|---|---|---|---|---|---|---|
| Gisette | 0.500 | 0.0612 | 0.116 | 0.0572 | 0.0024 | 0.0562 |
| Madelon | 0.500 | 0.0739 | 0.143 | 0.0683 | 0.0001 | 0.0455 |
| BASEHOCK | 0.501 | 0.117 | 0.209 | 0.113 | 0.0097 | 0.1122 |
| Prostate_GE | 0.510 | 0.0425 | 0.0837 | 0.0325 | 0.0115 | 0.0593 |
| SMK_CAN_187 | 0.519 | 0.0710 | 0.127 | 0.0629 | 0.0357 | 0.0805 |
| Sonar | 0.534 | 0.0734 | 0.113 | 0.0686 | 0.0633 | 0.0775 |
| Arcene | 0.560 | 0.0945 | 0.124 | 0.0851 | 0.0943 | 0.1037 |
| Congressional Voting | 0.614 | 0.0364 | 0.0182 | 0.0364 | 0.0364 | 0.0545 |
| Ionosphere | 0.641 | 0.0459 | 0.0263 | 0.0433 | 0.0918 | 0.0454 |
| Colon | 0.645 | 0.0614 | 0.0603 | 0.0490 | 0.0713 | 0.0716 |
| ALLAML | 0.653 | 0.0609 | 0.0564 | 0.0444 | 0.0833 | 0.0738 |
| Leukemia | 0.653 | 0.0684 | 0.0631 | 0.0551 | 0.0936 | 0.0793 |
| GLI_85 | 0.694 | 0.0641 | 0.0480 | 0.0489 | 0.0946 | 0.0745 |
Table 4.
Correlation of Various Feature Selection Metrics With Information Gain.
| Feature Selection Method | Pearson’s Coef. | p-Value | # Data Points |
|---|---|---|---|
| Fisher score | 0.961 | 22 | |
| CFS (Correlation Based Feature Selection) | 0.929 | 213 | |
| INTERACT | 0.913 | 92 | |
| Cons (Consistency Based Filter) | 0.912 | 187 | |
| Chi-squared statistic | 0.899 | 96 | |
| Relief-F | 0.861 | 240 | |
| mRMR | 0.851 | 71 | |
| FCBF (fast correlation-based filter) | 0.836 | 134 | |
| LASSO | 0.726 | 90 | |
| SVM-RFE | 0.660 | 142 |
Table 5.
Train and test set accuracy of Adaboost with decision stumps chosen by information gain (IG/Train and IG/Test) compared with stumps chosen by minimum error (Err/Train and Err/Test). Bold iterations represent where misordering occurs when using IG.
Table 5.
Train and test set accuracy of Adaboost with decision stumps chosen by information gain (IG/Train and IG/Test) compared with stumps chosen by minimum error (Err/Train and Err/Test). Bold iterations represent where misordering occurs when using IG.
| Dataset | Iteration | IG/Train | Err/Train | IG/Test | Err/Test |
|---|---|---|---|---|---|
| Volcanoes [42] | 1 | 0.841 | 0.841 | 0.029 | 0.029 |
| 2 | 0.841 | 0.841 | 0.029 | 0.029 | |
| 3 | 0.841 | 0.841 | 0.029 | 0.029 | |
| 4 | 0.845 | 0.855 | 0.166 | 0.126 | |
| 5 | 0.845 | 0.855 | 0.166 | 0.126 | |
| 6 | 0.845 | 0.842 | 0.164 | 0.235 | |
| 7 | 0.839 | 0.866 | 0.211 | 0.161 | |
| 8 | 0.846 | 0.867 | 0.155 | 0.191 | |
| 9 | 0.840 | 0.864 | 0.211 | 0.112 | |
| 10 | 0.846 | 0.871 | 0.155 | 0.197 | |
| Spam [43] | 1 | 0.663 | 0.712 | 0.668 | 0.707 |
| 2 | 0.663 | 0.712 | 0.668 | 0.707 | |
| 3 | 0.663 | 0.712 | 0.668 | 0.707 | |
| 4 | 0.675 | 0.706 | 0.677 | 0.714 | |
| 5 | 0.721 | 0.715 | 0.715 | 0.716 | |
| 6 | 0.721 | 0.717 | 0.715 | 0.718 | |
| 7 | 0.721 | 0.719 | 0.715 | 0.713 | |
| 8 | 0.711 | 0.722 | 0.706 | 0.720 | |
| 9 | 0.719 | 0.720 | 0.714 | 0.713 | |
| 10 | 0.719 | 0.723 | 0.714 | 0.721 | |
| Ionosphere [22] | 1 | 0.864 | 0.864 | 0.700 | 0.700 |
| 2 | 0.864 | 0.864 | 0.700 | 0.700 | |
| 3 | 0.914 | 0.907 | 0.886 | 0.771 | |
| 4 | 0.893 | 0.907 | 0.771 | 0.714 | |
| 5 | 0.893 | 0.904 | 0.771 | 0.743 | |
| 6 | 0.896 | 0.929 | 0.771 | 0.786 | |
| 7 | 0.925 | 0.907 | 0.800 | 0.786 | |
| 8 | 0.896 | 0.932 | 0.771 | 0.800 | |
| 9 | 0.943 | 0.932 | 0.800 | 0.786 | |
| 10 | 0.911 | 0.946 | 0.771 | 0.857 | |
| Hepatitis [22] | 1 | 0.889 | 0.889 | 0.875 | 0.875 |
| 2 | 0.889 | 0.889 | 0.875 | 0.875 | |
| 3 | 0.889 | 0.905 | 0.875 | 1.000 | |
| 4 | 0.905 | 0.921 | 1.000 | 1.000 | |
| 5 | 0.857 | 0.952 | 1.000 | 1.000 | |
| 6 | 0.952 | 0.968 | 1.000 | 1.000 | |
| 7 | 0.984 | 0.968 | 1.000 | 1.000 | |
| 8 | 0.968 | 0.968 | 1.000 | 1.000 | |
| 9 | 0.984 | 0.984 | 1.000 | 1.000 | |
| 10 | 0.952 | 0.984 | 1.000 | 1.000 | |
| German [22] | 1 | 0.700 | 0.715 | 0.680 | 0.725 |
| 2 | 0.700 | 0.715 | 0.680 | 0.725 | |
| 3 | 0.723 | 0.730 | 0.735 | 0.710 | |
| 4 | 0.717 | 0.741 | 0.715 | 0.740 | |
| 5 | 0.715 | 0.742 | 0.715 | 0.745 | |
| 6 | 0.715 | 0.750 | 0.715 | 0.740 | |
| 7 | 0.725 | 0.751 | 0.735 | 0.725 | |
| 8 | 0.736 | 0.761 | 0.715 | 0.730 | |
| 9 | 0.757 | 0.770 | 0.715 | 0.740 | |
| 10 | 0.762 | 0.760 | 0.715 | 0.730 |
Table 6.
Misordering rates for Madelon and Gisette-small.
| Dataset | Information Gain | Hellinger Distance | Bhattacharyya Distance |
|---|---|---|---|
| Madelon | 0.0739 | 0.0001 | 0.045 |
| Gisette-small | 0.0534 | 0.0007 | 0.034 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Epstein, E.; Nallapareddy, N.; Ray, S. On the Relationship between Feature Selection Metrics and Accuracy. Entropy 2023, 25, 1646. https://doi.org/10.3390/e25121646
AMA Style
Epstein E, Nallapareddy N, Ray S. On the Relationship between Feature Selection Metrics and Accuracy. Entropy. 2023; 25(12):1646. https://doi.org/10.3390/e25121646
Chicago/Turabian StyleEpstein, Elise, Naren Nallapareddy, and Soumya Ray. 2023. "On the Relationship between Feature Selection Metrics and Accuracy" Entropy 25, no. 12: 1646. https://doi.org/10.3390/e25121646
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.