1. Introduction
The stock market is a lucrative investment avenue that has drawn the sustained interest of many investors and researchers [
1]. The efficient market hypothesis (EMH) posits that stock prices are determined by all available information and relevant news [
2]. Based on this hypothesis, researchers have developed several renowned stock market analysis and prediction theories, such as the Elliott Wave Theory [
3] and Gann Theory, attempting to unveil the intrinsic link between stock price fluctuations and market changes. These theories have paved the way for subsequent stock market prediction research.
Conventional methods for predicting stock prices rely mainly on historical data and time-series analysis techniques [
4]. However, these methods often fail to effectively capture the inherent patterns of stock price movements due to the complexity, randomness, and non-stationarity of stock market data. Artificial intelligence technology has advanced rapidly in recent years, and deep learning methods have achieved remarkable success in multiple fields, such as image recognition, speech analysis, and natural language processing. Many researchers have applied deep learning methods to the financial field, especially stock price or return prediction, and have obtained good results. Among them, the deep neural network (DNN) [
5], recurrent neural network (RNN) [
6,
7,
8,
9,
10,
11,
12,
13], and convolution neural network (CNN) [
14,
15,
16,
17,
18] methods are widely used to mine the complex patterns of stock price changes due to their powerful modeling ability for non-linear data and good adaptability for sequential data. In addition, there are some noteworthy methods. For instance, Zhang et al. improved the cell units of Long Short-Term Memory (LSTM) networks through frequency decomposition [
19]; Feng et al. enhanced the robustness of the model through adversarial training [
20]; Xu et al. improved the model’s anti-interference ability by combining generative models with variational inference [
21]; and Zhang et al. enhanced the predictive performance by combining a transformer with attention networks [
22]. These methods provide beneficial references and lessons for improving models’ structure to enhance their adaptability to financial data features.
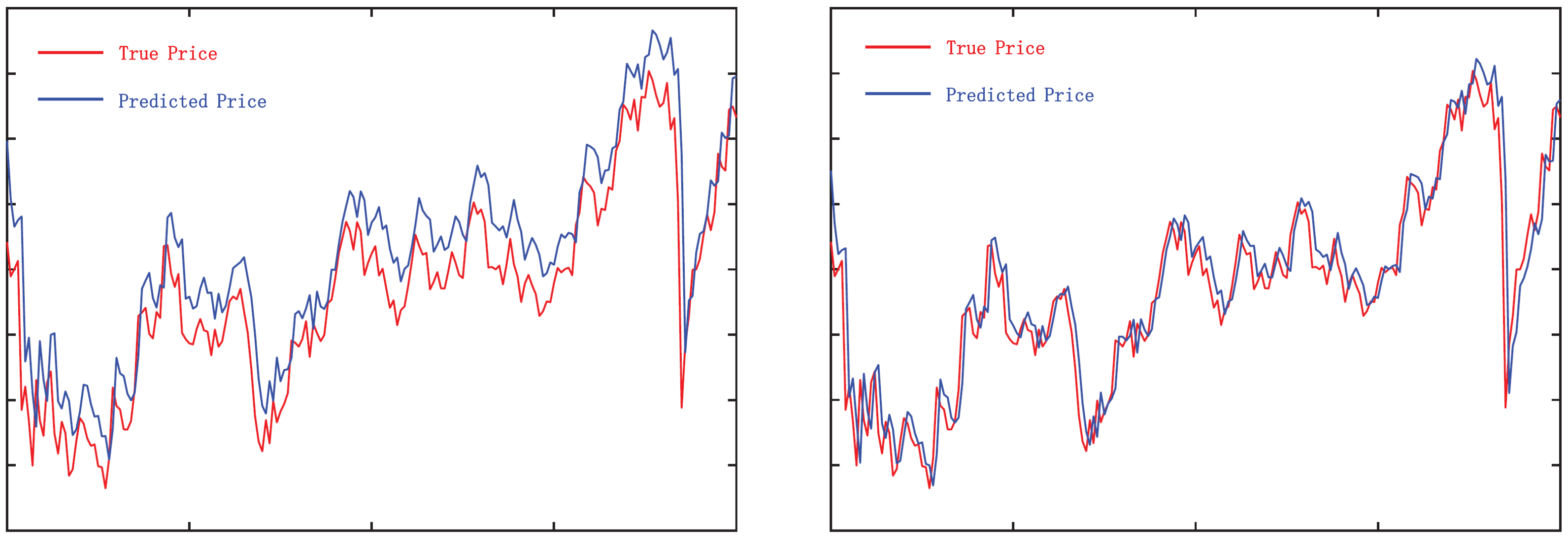
Nevertheless, the direct application of stock price or profit forecasts to real-world stock market transactions does not result in superior returns that align with the models’ projected outcomes, leading to a ‘high model, low return’ scenario. By thoroughly examining the pertinent literature and empirical data, it is evident that the values of significant metrics, such as the Mean Squared Error (MSE) and the Mean Absolute Error (MAE), have exhibited a consistent decline as the depth of the investigation has increased. However, by comparing the predicted curves with the true curves, we found that the prediction results seem to be just a lagged version of the data for the previous trading day, and the models do not capture the trends and turning points of the stock price changes, as shown in
Figure 1. This may be caused by distance-based regression loss functions when training models. This loss function makes models use the value of the nearest time step as the model output after multiple iterations to minimize the model loss. This causes models to fail to predict the turning point when the stock changes, resulting in erroneous judgments and operations and thus losses.
Hence, we need to reconsider the feasibility and necessity of finding a model that can precisely forecast stock prices in real time. Stock prices are affected by both internal factors, such as the company’s performance, and external factors, such as market sentiment, unforeseen events, and government policies. These factors introduce noise and randomness into the stock market data, making it challenging to accurately predict stock prices or returns, even with the advanced capabilities of deep neural networks in handling time-series data. Moreover, minor price fluctuations induced by noise are hard to discern and exploit, while high-return trading opportunities can lead to lower risk and higher returns. Such opportunities often emerge after a period of the accumulation of endogenous driving forces, which result in significant price movements. The optimal trading points are those close to the onset of these movements. Therefore, instead of pursuing accurate price prediction, which may be unattainable, it may be more worthwhile to investigate the endogenous patterns preceding optimal trading points and identify potential high-return trading opportunities.
Significant trading opportunities with high returns usually exist in the medium- and long-term trends of stock price changes rather than short-term fluctuations, which is consistent with the experience of traditional stock market investors. Due to their own limitations, human traders cannot traverse all stocks at any time to find short-term trading opportunities like machines. They use various analytical methods to judge the trend of stock prices and enter the market in advance, holding for a while. Their investment experience usually has the following three characteristics:
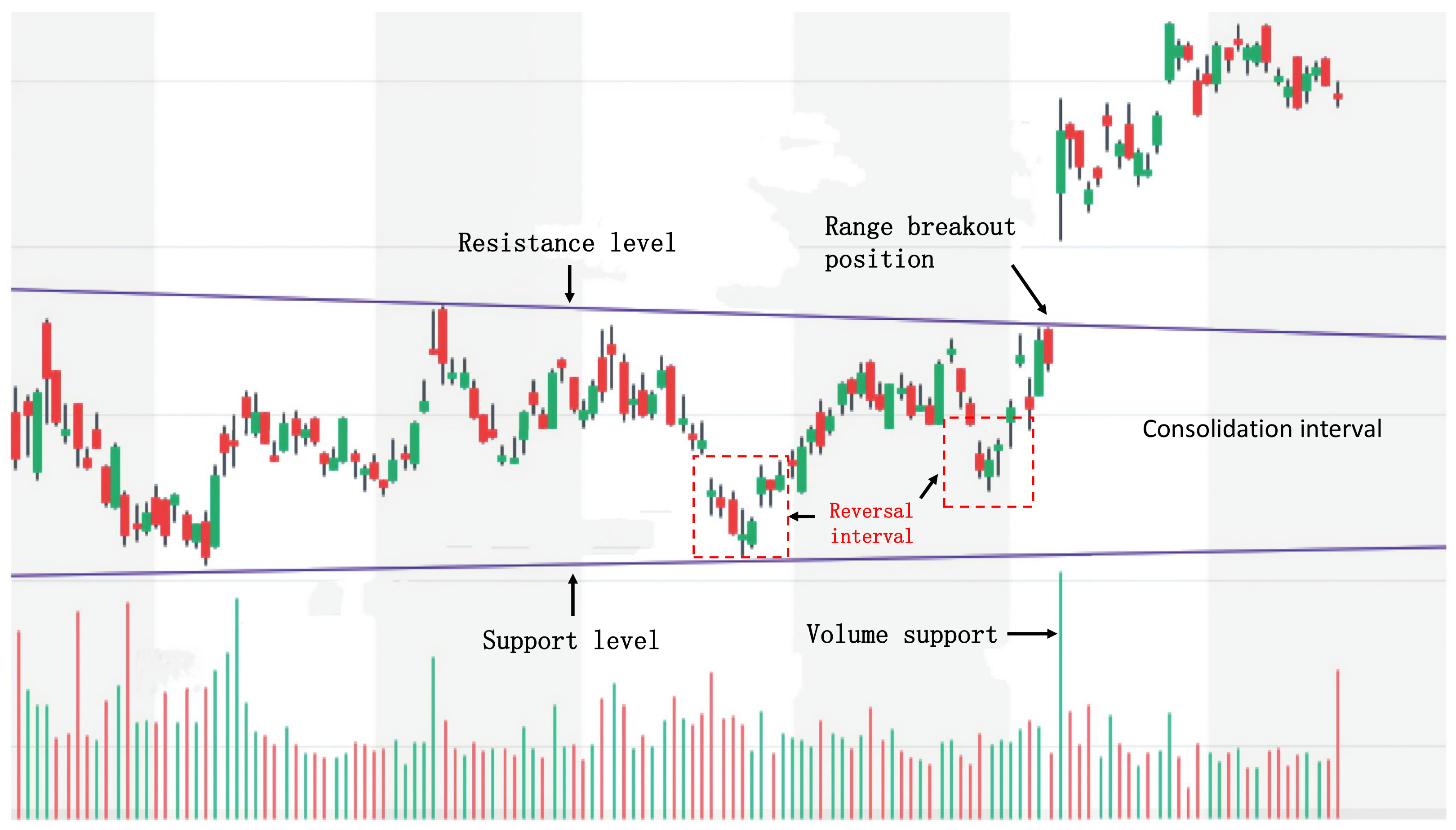
A focus on high-return trading opportunities: Stock investors are not concerned about the price of every moment, but rather the important trading points that can bring high returns. The reason is that predicting stock prices is complex and unstable, and the high transaction cost makes small price fluctuations meaningless. Stock investors prefer trading points with clear signals to achieve higher returns. For example, a widely used trading strategy is Trading Range Breakout (TRB), which regards price breakout points as high-return trading opportunities. According to the experience of stock investors, entering the market when the stock price breaks through the trading range can bring higher returns. As shown in
Figure 2, a breakout occurs when the stock price rises with an increased trading volume, exceeding the set resistance level. At this time, the stock price will break through the price barrier, volatility will increase, and the price will move quickly toward the breakout, forming a high-return trading opportunity favorable for long positions. At the same time, the careful observation of the stock price changes before the range breakout can reveal that before the price breakout, the stock price had already begun to turn and had accumulated momentum for a while. During this time, the changes in stock price and trading volume often hide the inherent change rules before the price breakout. If we can mine and grasp this rule, we can establish long positions in the price range before the breakout and achieve high-return and low-risk trading.
Grasping the changing patterns: The stock price signal at a single moment is often insufficient, and many lucrative trading opportunities emerge when the stock price trend shifts significantly, which necessitates sustained observation for a while to ascertain the stock price movement. Hence, stock investors typically make an integrated assessment based on the trading price, trading volume, and other data over an interval to forecast the stock price’s future trajectory more precisely.
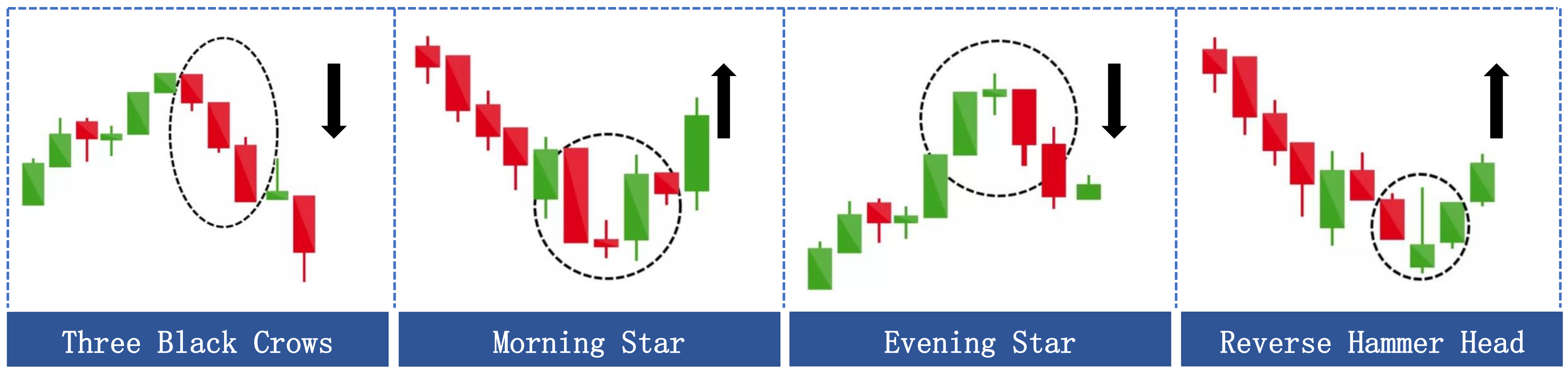
Figure 3 illustrates four prevalent candlestick charts of stock price reversals. It can be observed that these classic candlestick formations are constituted by a sequence of historical data rather than an isolated instant. These data, over time, constitute a coherent signal, revealing the psychological and behavioral alterations of market participants during that span, thereby offering vital clues for the subsequent direction of stock prices.
Diversifying the investment portfolio: The stock market occasionally undergoes a bull market scenario, i.e., the stock price persistently ascends, instilling confidence in investors. Nevertheless, the market trend is not invariably smooth sailing and may invert or plummet unpredictably. Consequently, prudent investors always abide by the "diversifying risk" strategy and allocate their funds across different domains and sectors. The advantage of this is that a diversified portfolio can augment returns and diminish risk levels [
1,
23]. Simultaneously, diversifying investment can also fortify investors’ capacity to handle market fluctuations and unforeseen events and preclude suffering substantial losses due to excessive reliance on one or a few stocks.
To achieve high returns with a certain level of risk by accurately predicting ITPs, three key issues must be addressed: the detection of historical ITPs, the prediction of future ITPs, and the construction of trading strategies. Combined with the practical experience of stock investors, we designed the following solutions.
First, for the detection of historical ITPs, we follow the basic principle that stock investors focus on high-return trading opportunities and use a novel Return-Adaptive Piecewise Linear Representation (RA-PLR) technique to define ITPs as turning points at which stock prices rise or fall sharply. This allows for a trading strategy that not only accurately captures buying opportunities, but also avoids declining returns or even losses due to missed selling points.
Second, for future ITP prediction, by drawing upon the insights gained from researchers who have explored various model structures and methods in financial markets and integrating them with stock investors’ interest in trend reversal patterns, we propose a Batch Attention Multi-Scale Convolution Recurrent Neural Network (Batch-MCRNN). This network combines the advantages of multi-scale convolution networks, stacked LSTM, and time and sample attention mechanisms to explore the potential rules of stock price fluctuations from three dimensions: space, time, and samples. It improves the prediction accuracy of future ITPs. Specifically, we use a Multi-Scale One-Dimension Convolution Neural Network (MS-1DCN) to convolve stock price sequences at different time scales in order to capture the local fluctuation characteristics of stock price changes and help the model focus on local persistent turning patterns. Then, we use Long Short-Term Memory (LSTM) and the temporal attention mechanism, which can perform effective long-sequence learning, to learn the long-term temporal dependency of the raw data and the local features obtained by the CNN. Finally, through the batch attention mechanism for sample interaction, the model itself can explore information between samples and achieve multi-dimensional information mining. In addition, we also introduce residual connections and batch normalization techniques to enhance the stability and generalization ability of the model.
Third, for the construction of trading strategies, the diversification of investment portfolios has been proven effective. We use the CSI 300 Index Constituents, which can reflect the overall situation of China’s stock market and contain numerous mainstream industries, to establish a dataset and achieve overall data diversification. On the one hand, historical data for stocks of the same type are not sufficient to train a robust neural network, which may lead to the overfitting of the model. Using richer data for training can allow neural networks to learn more generalized stock fluctuation rules. On the other hand, the strict definition of ITPs results in their scarcity, leading to an imbalance in the overall dataset. Using more stock data can facilitate subsequent sampling and help reduce the impact of data imbalance. Finally, based on a trading strategy compatible with the overall model, we design a Double Check (DC) method to filter out low-confidence and high-risk predictions and improve the overall performance of trading strategies.
Based on the analysis conducted previously, we propose a framework for ITP prediction based on RA-PLR and Batch-MCRNN with the starting point of improving stock investment returns. The framework aims to accurately define and predict ITPs to identify profitable trading opportunities in the stock market. We evaluated the performance of our method through rigorous and systematic experiments on real-world stock data and contrasted it with several state-of-the-art benchmark methods. The experimental results demonstrated that our method outperformed the baselines in prediction accuracy, return rate, and risk control. Therefore, we contend that it is more advantageous to focus on ITPs rather than the stock price or trend at every time point when developing a trading strategy. The main contributions of this work are summarized as follows:
We propose a novel Return-Adaptive Piecewise Linear Representation for detecting historical ITPs. The method trades off the relationship between the number of ITPs and benefits from a profit-maximization perspective in order to extract reasonably significant trading points that truly satisfy investors’ expectations.
We propose a Batch Attention Multi-Scale Convolution Recurrent Neural Network to forecast future ITPs. This network integrates the benefits of CNN, LSTM, and attention mechanism structures and enhances the prediction accuracy of ITPs.
We propose an adaptive trading strategy that executes buy and sell operations based on ITPs. In addition, to enhance the strategy’s performance and reduce the impact of model prediction errors on the returns, we propose a Double Check method that improves the overall returns of the trading strategy.
We conduct comprehensive and systematic experiments on real-world datasets. The effectiveness and robustness of the method proposed in this work are demonstrated in various aspects, from model prediction performance to simulated trading returns.
The rest of the work is organized as follows:
Section 2 proposes and details a new methodology for improving stock investment returns based on the results of the previous analysis;
Section 3 introduces and discusses the experimental settings and results to demonstrate the comparative advantages of the proposed method;
Section 4 introduces the market simulation situation and analyzes the profitability and risk control capabilities of all methods; and, finally,
Section 5 concludes the work and suggests future research directions.
2. Methodology
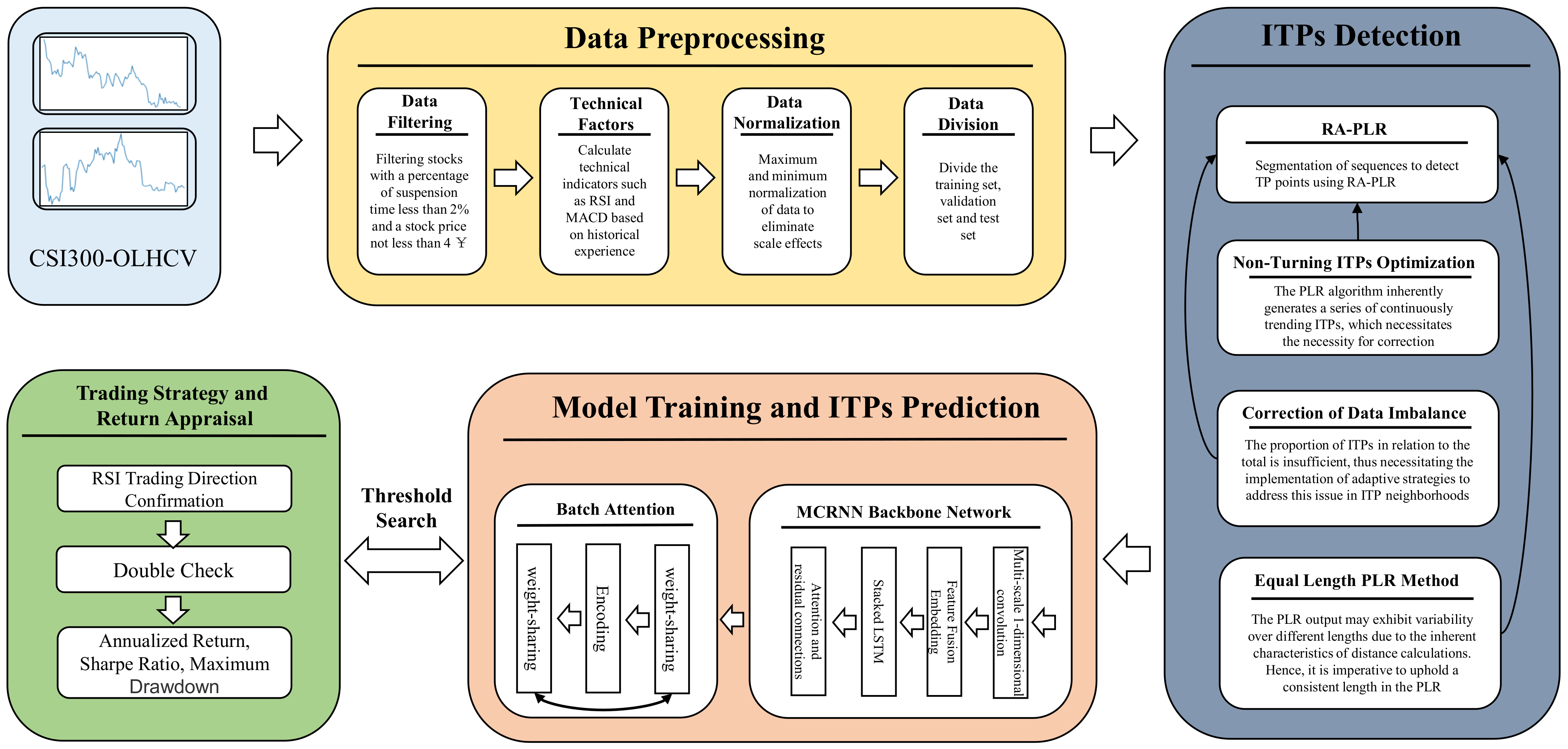
Based on the preceding section’s analysis and discussion, we propose a framework for ITP prediction based on RA-PLR and Batch-MCRNN. The framework comprises four primary components: data preprocessing, ITP detection, model training and ITP prediction, and trading strategy and return appraisal. The general procedure of the framework is illustrated in
Figure 4. This part will focus on the components of the framework related to the detection of ITPs, the training of the model, and the prediction of ITPs. The data preparation technique will be discussed in the experimental portion of
Section 3, while the trading strategy and return evaluation component will be examined in
Section 4.
This work proposes a return evaluation function aligned with the trading strategy’s primary objective: enhancing return. This function aims to achieve effective ITP detection by trading off the number of trading points against the return size. It allows for filtering out high-return trading points that conform to investors’ expectations. In addition, we improve the detection of ITPs to mitigate the problems of sample imbalance and non-turning ITPs. For ITP prediction, this work develops a Batch Attention Multi-Scale Convolution Recurrent Neural Network. This network consists of a multi-scale one-dimension convolution network, a stacked recurrent neural network, and a time and sample attention mechanism, which delve into the latent patterns of stock data in the space, time, and sample dimensions. The multi-scale one-dimension convolution network can detect the fluctuation features of stock data at different scales; the stacked recurrent neural network can model the temporal dependency of stock data; and the time and sample attention mechanism can adaptively distribute the importance of different samples, time steps, and features. The method proposed in this work is elaborated in detail in the following sections.
2.1. Technical Factors
The prediction of the stock market encompasses a consideration of multiple input variables, including historical price data (such as opening, closing, high, and low prices) and trade volume. Nevertheless, it is essential to note that these fundamental characteristics fail to sufficiently encompass the intricate nature and ever-changing dynamics of the market. As a result, some researchers have added technical factors as critical features for their models [
24]. These factors are computed from price and volume data and can effectively indicate the market’s state and behavior regarding trends, volatility, strength, momentum, etc. [
25]. We selected several technical factors to supplement the essential data and improve its quality and information content based on domain experts’ experience and the relevant literature.
Table 1 displays some of the primary technical factors that we employ.
2.2. Return-Adaptive ITP Detection
The successful prediction of future ITPs and the attainment of reliable profits depend on the effective identification of ITPs in historical stock price time series. This work employs PLR to define ITPs as peaks, troughs, and turning points based on an analysis of stock market investors’ behavior, a literature review, and the fundamental objective of trading strategies. Furthermore, we propose a return-adaptive function to trade off the number of trading points against the size of the return. This allows for filtering out high-return trading points that conform to investors’ expectations. Moreover, this work improves the ITP detection process by resolving the issues of sample imbalance and non-turning ITPs. The specific components are as follows.
2.2.1. Piecewise Linear Representation (PLR)
PLR was first developed as a time-series segmentation linear approximation technique for pattern matching and is one of the most commonly used time-series segmentation representations. In financial time-series analysis, researchers often use it to generate turning points [
26], which usually reflect the market’s trading signals. Suppose that
represents financial time-series data, which can be decomposed into
K segments by approximating lines. The segmented description is as follows:
where
is the end time of the
ith segment, and
denotes the approximate linear function of
. Since
indicates the moment when the trend of the time series changes, it is often referred to as a turning point.
2.2.2. Return-Adaptive Threshold Selection
In this work, the top-down PLR algorithm is used to segment stock time-series data for linear approximation in order to minimize the number of segments while controlling the segmentation error so that it does not exceed a preset threshold. In PLR segmentation, the threshold value
is a key parameter affecting the results, and its size is inversely related to the number of segments. Therefore, choosing a reasonable
threshold is essential for identifying turning points and making accurate predictions.
Table 2 shows the number of turning points generated by PLR with different threshold values of
.
In order to achieve accurate ITP detection, a suitable threshold
needs to be chosen. The primary objective of ITP detection is to enhance returns. Hence, this study develops a return-adaptive threshold selection function from the standpoint of returns, considering the actual characteristics of stock market prediction and the identification of ITPs. The function is return-oriented, focusing on medium- and long-term trend changes rather than short-term volatility adjustment, which is consistent with the goal of this work to seek high-return trading opportunities under medium- and long-term trends. The specific form of the function is as follows:
where
is the cumulative return corresponding to the turning point obtained based on the PLR algorithm,
is the penalization factor, and
is the expected time interval of the trade, which is penalized if the time interval between the two turning points is less than this value. The degree of penalty is inversely proportional to the time interval.
is the date of the
ith turning point. Since the data are known during the detection phase, it is possible to trade according to the principle of buying low and selling high. Obviously, the denser the turning points, the higher the cumulative return, i.e., the larger the
. However, at the same time, overly frequent trading will be affected by the penalty term. Therefore, the parameter
of the PLR algorithm can be chosen automatically by maximizing the objective function
, so that the cumulative return is balanced with the number of turning points. Thus, the turning points are converted into ITPs that meet the investors’ expectations.
2.2.3. Non-Turning ITP Optimization
Since the segmentation mechanism of PLR does not require two turning points to have opposite trend directions, lowering the threshold increases the number of ITPs, resulting in some short-term invalid turning points for PLR. These points only reflect short-term price fluctuations rather than medium- or long-term trend changes.
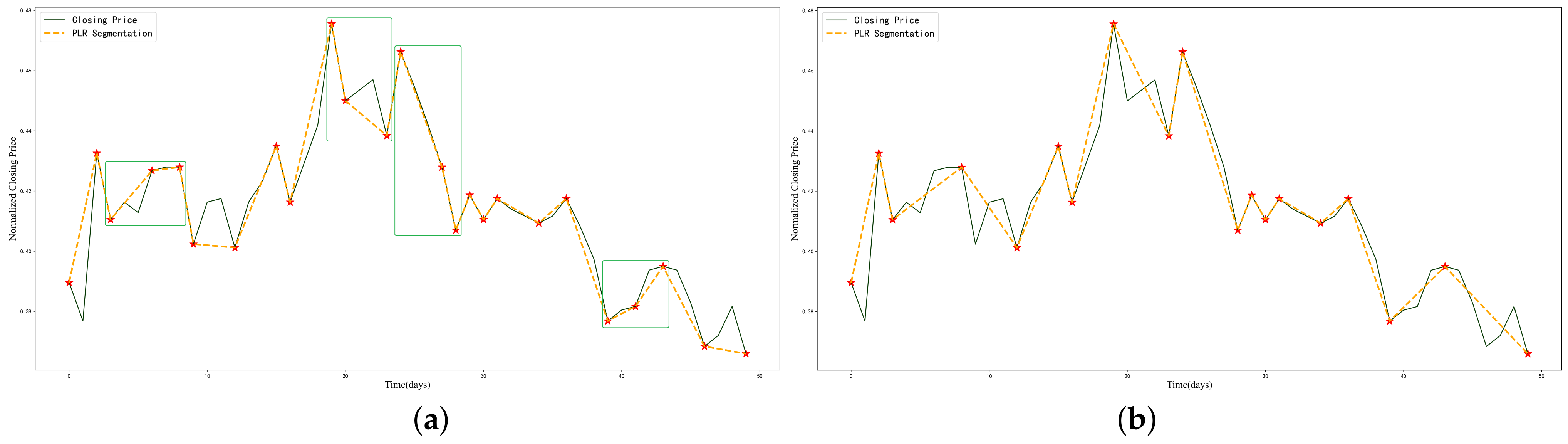
Figure 5 illustrates an example. In
Figure 5a, several groups of ITPs with the same trend appear in a short time span. The ITPs marked with green solid boxes actually belong to the same downward or upward trend and should not be considered as ITPs. Therefore, after removing the short-term fluctuation points,
Figure 5b shows a more reasonable selection of ITPs.
2.2.4. Data Augmentation
This work focuses on the medium- and long-term trends of stock price changes and seeks high-return trading points rather than short-term fluctuations. Therefore, the ITPs focused on in this work pertain to a low proportion of the overall data, less than 10%, leading to a severe data imbalance. Data imbalance affects the learning performance and evaluation accuracy of deep learning methods. A standard solution is to balance the number of samples in each category by undersampling or oversampling. However, undersampling loses much helpful information, while oversampling increases the risk of overfitting. To overcome these problems, we find that the neighborhood features of ITPs are very close to the ITPs themselves, making it difficult to distinguish which neighborhood points are ITPs. Therefore, we combine the experience of domain experts and define ITPs as an interval rather than a point. In this case, the neighborhood points of ITPs generated by the PLR are also labeled as ITPs. Nevertheless, determining the size of the ITP interval is a new problem. The simplest method is to use a fixed-length window. However, as seen in
Figure 6a, there are differences in the change rate within each ITP neighborhood. When the change rate is large, the stock is in a violent fluctuation state, and the neighborhood points should be as close as possible to the original ITPs to maintain the relative consistency of the ITP features. Conversely, the stock price is stable when the change rate is small, and the number of neighborhood points can be slightly increased. In summary, when the change rate of one side of the neighborhood is greater than the threshold
, the sampling window size is
; when the change rate is less than the threshold
, the sampling window size is
.
Figure 6b shows the data points after enhancement.
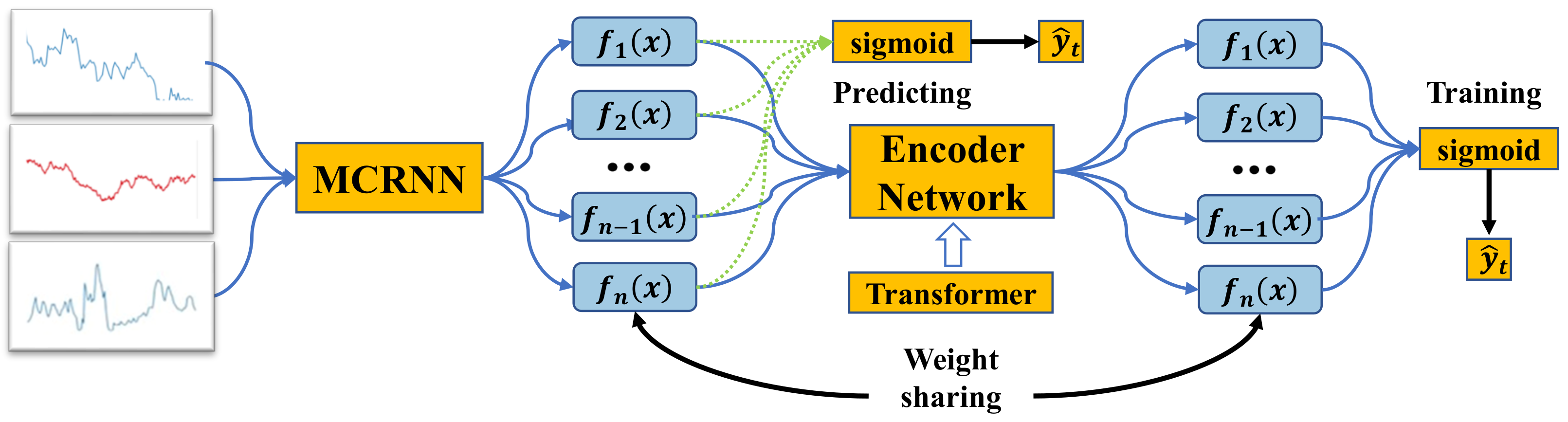
2.3. Batch Attention Multi-Scale Convolution Recurrent Neural Network (Batch-MCRNN)
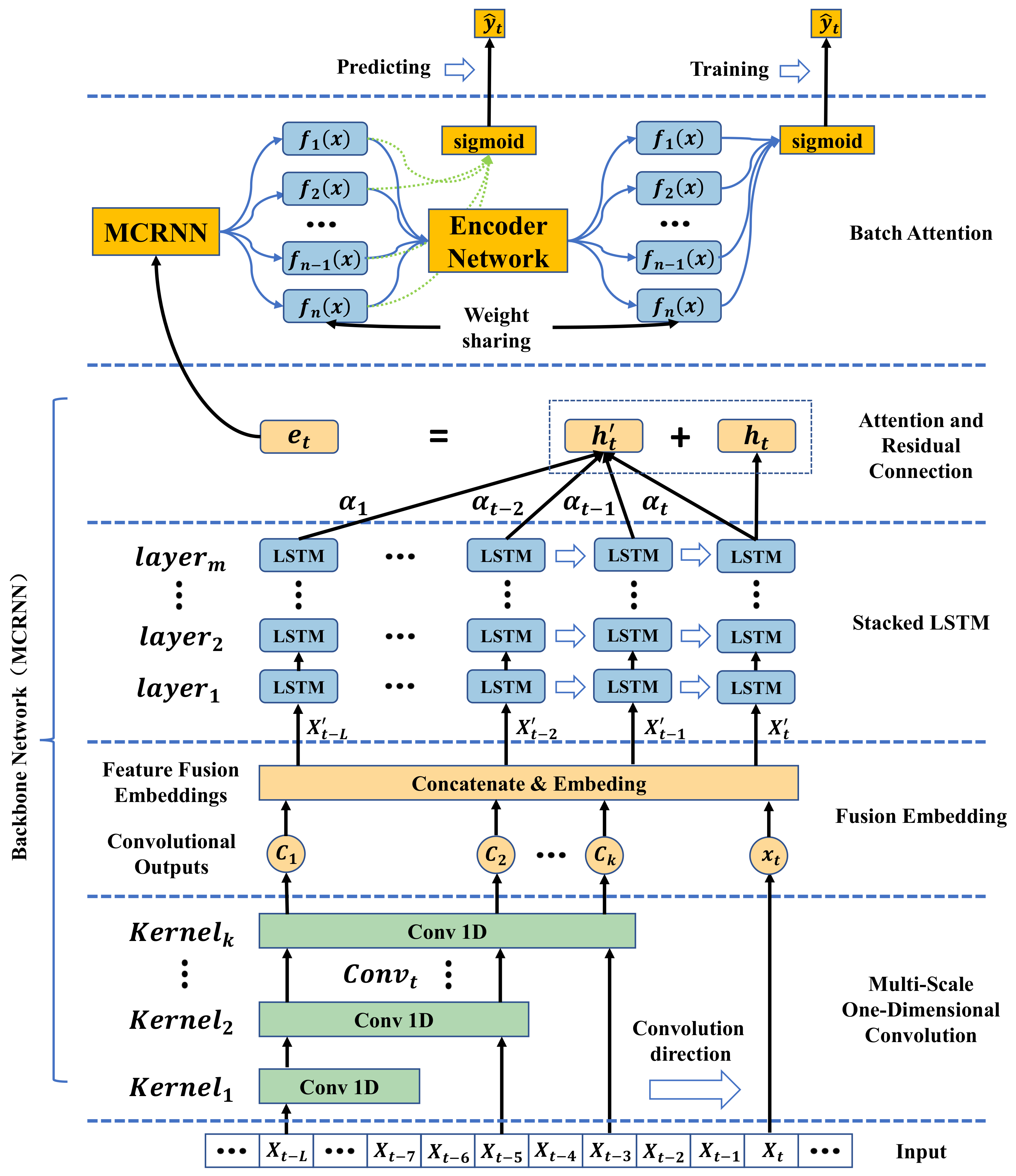
This work proposes a Batch Attention Multi-Scale Convolution Recurrent Neural Network (Batch-MCRNN) model based on the characteristics of stock time series, stock investors’ attention to local turning patterns, and the applicability of deep learning methods in finance. The model comprehensively mines the intrinsic laws of stock data from three dimensions—space, time, and samples—to improve the accuracy of ITP prediction and provide support for improving the returns of trading strategies. The model is mainly composed of the following parts: a multi-scale one-dimension convolution layer for processing local features; a fusion embedding layer for fusing features; a stacked LSTM layer for learning temporal features; an attention and residual connection layer for enhancing sequential attention; and a batch attention layer for reinforcing sample interaction. The overall structure of the model is shown in
Figure 7. Each component is described in detail below.
2.3.1. Multi-Scale One-Dimension Convolution Layer
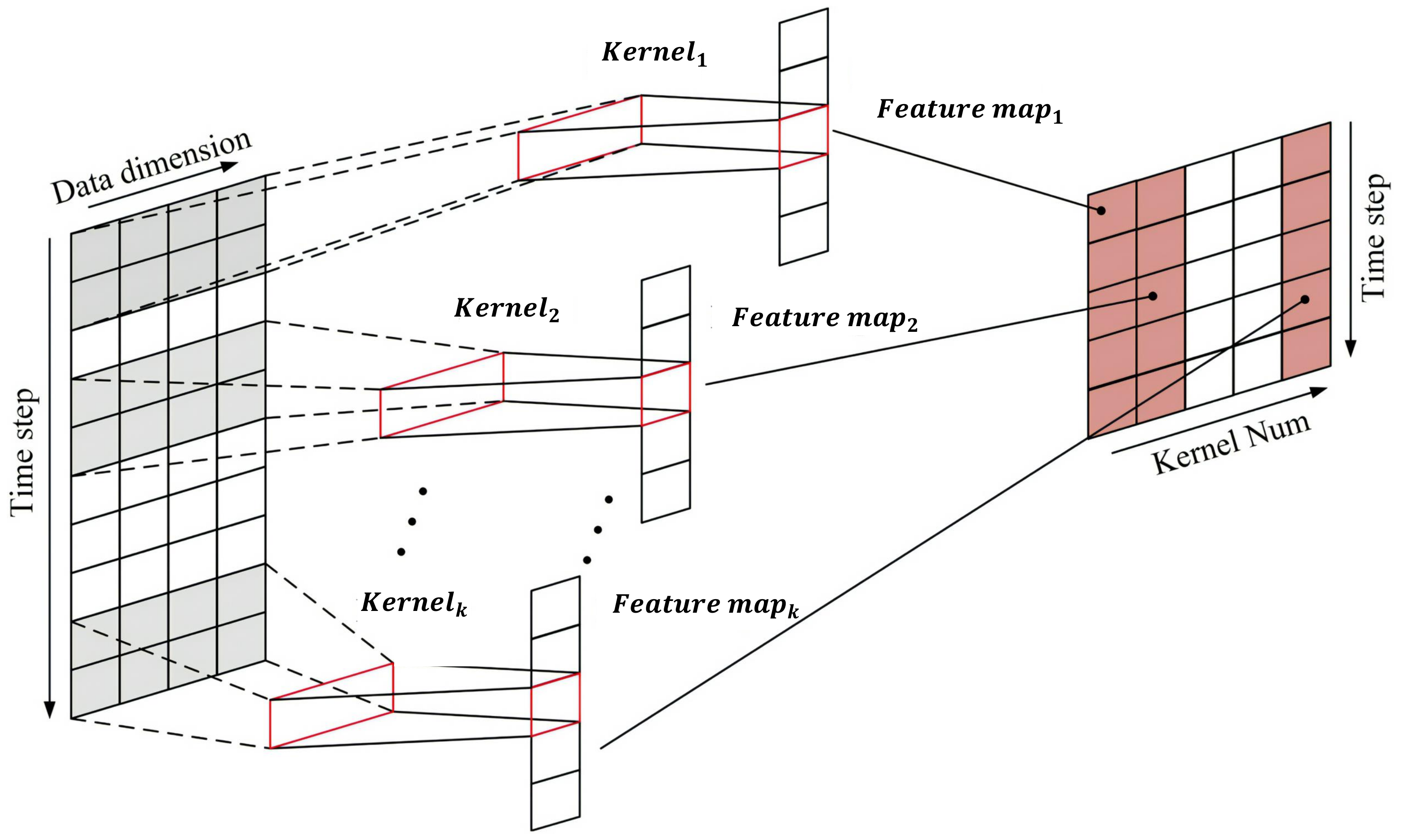
Recent years have witnessed rapid advances in artificial intelligence technology, and CNNs, as an effective method for feature extraction, have shown outstanding performance in various fields besides computer vision. In particular, one-dimension CNNs excel at handling time-series data [
27]. This paper employs an MS-1DCN to capture local fluctuation features in stock sequence data. By applying convolution kernels with different scales, a model can recognize local features across different scopes, thus improving its expressiveness. Moreover, this paper also utilizes cross-channel convolution kernels to enhance the information communication among various features.
Figure 8 illustrates that each one-dimension convolution layer under each convolution scale consists of several same-sized convolution kernels. These convolution kernels move along the time axis with a fixed stride to extract more abstract and representative local features from the stock time series. The extracted features are padded to generate new sequence features, which act as the input for the subsequent convolution layer.
Given a multidimensional stock historical data time series
for a single dimensional sequence
for each input time step
, the following equations show the result of a single convolutional kernel at a single time step under a single channel:
where
denotes the selection of the input mapping;
represents the result of the
jth feature mapping in the
l layer, i.e., the output of the convolution;
represents the
ith feature mapping in the
layer, i.e., the input of the convolutional layer;
represents the weights of the
ith feature mapping in the
l layer;
represents the bias vectors of the convolutional layer; and f(-) is the activation function. In order to perform feature fusion embedding between the convolved local features and the original sequence, we padded the input sequence with 0 of length
(
p is the convolution kernel size) to keep the sequence length constant during convolution. In the subsequent analysis, we will use
to denote the convolutional output of the
bth channel at the
ath scale.
2.3.2. Fusion Embedding Layer
The MS-1DCN consists of S one-dimension convolution layers with different scales, each with M channels, and outputs of S*M new feature sequences reflecting the local fluctuation information at different scales. Then, these new feature sequences are spliced with the original stock sequences to obtain an enhanced feature sequence. Finally, the enhanced feature sequence is converted into input data for LSTM by an embedding network with the following equation:
where
,
. The advantage of the fusion embedding is that the global information in the original stock series is retained while new local volatility features are extracted, thus improving the accuracy and robustness of the prediction.
2.3.3. Stacked LSTM Layer
After the fusion embedding layer, the local features are combined with the original data to aggregate a new vector, and this joint feature is fed into the LSTM layer to learn the long-term temporal dependencies. We employ a multi-layer stacked LSTM structure, which can accelerates the convergence process. To prevent overfitting and improve the generalization ability of the model, we add dropout and batch normalization operations after each LSTM layer. The two-layer stacked LSTM model can be briefly described as follows:
2.3.4. Attention and Residual Connection Layer
In this work, we use the temporal attention mechanism, which is a variant of the standard attention mechanism for sequential data. Temporal attention is a self-attention mechanism that eliminates the need for an extra decoder. Instead, it calculates the alignment scores at each time step
t of the encoder, using the weighted sum of the encoder’s hidden states at the current and other time steps. The formula is as follows:
where
and
are trainable weights called attention weights. The weights
and
are associated with the hidden states of the encoder. For each time step
t, the attention weights
are obtained by normalizing the score
over all time steps of the encoder using the softmax function:
The importance of the output at time step
t is indicated by the attention weight
. The context vector
a is a weighted sum of all hidden values of the encoder, where the weights are determined by the attention weights:
where
,
, and
are the parameters to be learned, and
a is the weighted representation of the complete set of hidden states in the sequence.
To improve the convergence speed and performance of CNN networks, researchers have designed a deep residual network (ResNet) utilizing residual connection, the basic principle of which is to define the objective function of the residual connection through Equation (
9):
where
x is the input,
is the residual function, and
is the objective function. Instead of fitting the objective function
directly, each residual cell fits the residual function
. Based on this idea, we add residual connection after the output of the attention mechanism, which enables the model to learn more effective residual functions and improves the expressive ability of the model. In this work, we connect the attention feature vector
a with the final hidden state
of the stacked LSTM network as a comprehensive representation of the time series, as shown below:
2.3.5. Batch Attention Layer
Inspired by the success of attention mechanisms in various tasks, we propose a batch attention module that enables deep neural networks to learn the relationships among samples within each batch automatically. In this way, the proposed method can achieve collaborative learning among samples.
Figure 9 illustrates the learning framework using the batch attention module. Specifically, a backbone network is first used to learn representations for individual data samples without considering the interactions among different samples within each batch. Then, a batch attention module is introduced, which utilizes the multi-head attention mechanism from the transformer to model the relationships among different samples. The batch attention module’s output serves as the final classifier’s input. To reduce the gap between training and testing, an auxiliary classifier is used before the batch attention module, which shares weights with the final classifier and provides feedback to the batch attention module.
To model relationships between different samples, the batch attention module employs multi-head self-attention (MSA) and MLP blocks of the transformer structure and applies Layernorm(LN) for normalization after each block. Let the input feature sequence be
, where
L is the length of the attentional residual link output sequence, and
C is the dimensionality of the input features. The output of the transformer structure can be expressed as:
where
l is the layer index of the transformer’s multi-head self-attention layer. The multi-head attention layer effectively captures relational information [
28] from the channel and spatial dimensions. Therefore, we believe it can also be extended to the batch dimension to explore interactions between different samples. Unlike the regular application of the transformer, the batch-focused input is first subjected to a reshaping operation that enables the transformer to apply the self-attention mechanism to the batch dimension of the input data. In this way, the self-attention mechanism becomes a cross-following mechanism across samples.
Weight-sharing classifier. The features before and after the batch attention module may be inconsistent due to the uncertainty of the batch size in the testing phase. This prevents us from simply discarding the batch attention module to infer new samples. To solve this problem, we introduce a new auxiliary classifier that can learn knowledge from the final classifier as well as keep consistent with the features before the batch attention module. Specifically, we only have to share weight parameters among the auxiliary and final classifiers. We term this simple and effective approach the “weight-sharing classifier”. With the “weight-sharing classifier”, we can eliminate the batch attention module in the testing phase while still utilizing the sample relation learning performed by the batch attention module. The auxiliary classifier provides the final output of the Batch-MCRNN model, as shown below:
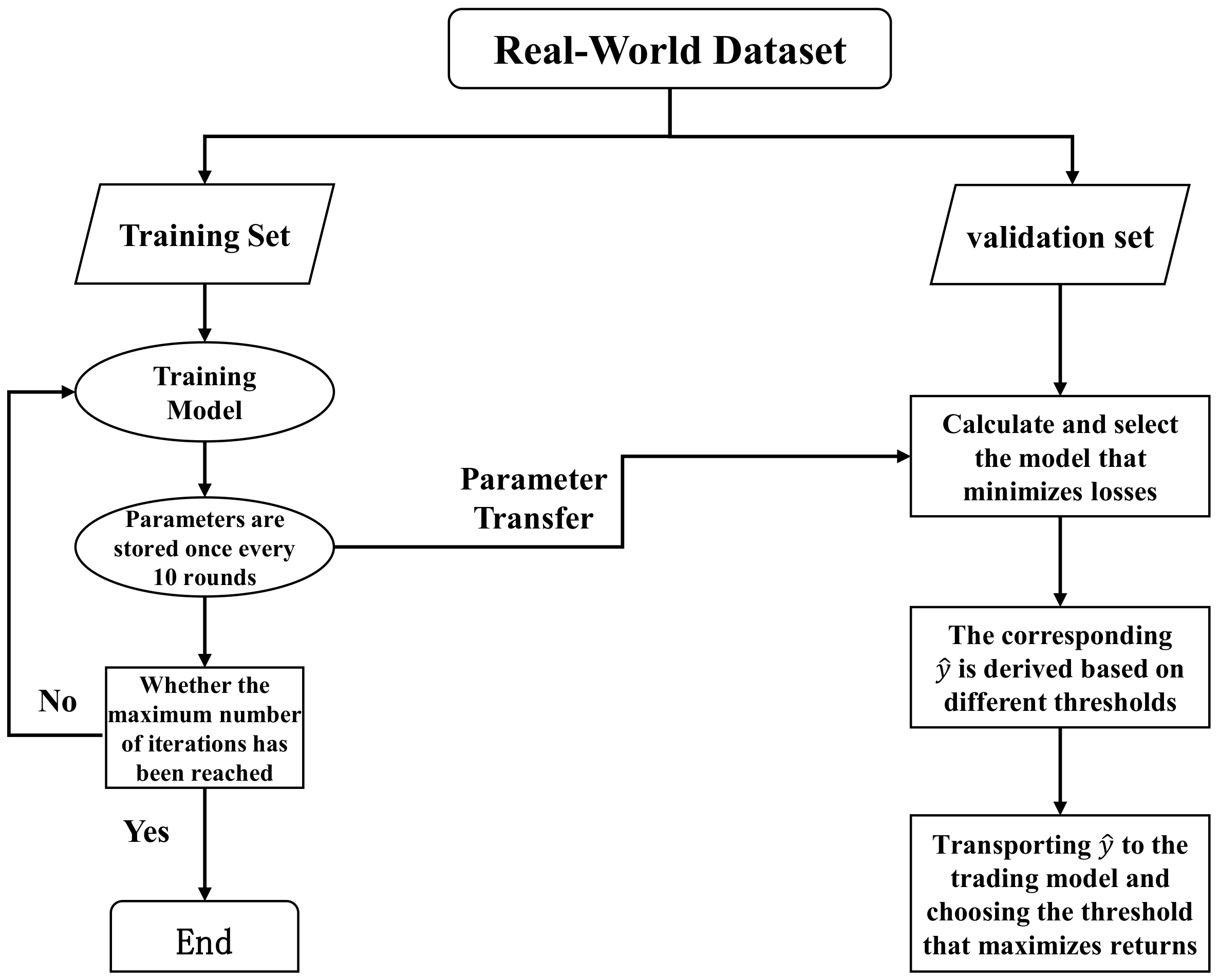
2.4. Returns Retrospective Threshold Search
Classifying ITPs is approached as a binary classification problem in our work. The model’s output is the probability assigned to each time point, indicating its likelihood of belonging to an ITP. It is necessary to establish a threshold
to convert the probability output into classification labels:
The predicted label at time point
t is denoted by
. The prediction is an ITP (“1”) if
; otherwise, it is a non-ITP (“0”). The threshold
plays a crucial role in the model’s predictive performance. We can set
to 0.5 when the dataset has balanced classes. However, our problem involves data imbalance, as the proportion of ITPs remains much lower than that of non-ITPs even after data augmentation. A simple and effective solution is to adjust
according to the ratio of ITPs in the training set. Alternatively, we can optimize
based on the precision–recall or ROC curves. However, these methods may not account for the temporal dependence of time-series data. Therefore, we introduce a returns retrospective threshold search mechanism. It does not target prediction accuracy but returns maximization. The optimal threshold is determined by backtesting the returns of different thresholds in the validation set period. The process is illustrated in
Figure 10.
3. Research Design and Experimental Results Analysis
This section first describes the research design. Then, the performance of the proposed Batch-MCRNN model is evaluated in terms of its ITP prediction ability through comparative experiments on real-world datasets with several state-of-the-art benchmark methods.
3.1. Data Preprocessing
We acquired the trading data from 1 January 2014 to 31 December 2021 from the Tushare website. The dataset was composed of the constituents of the CSI 300 Index as of 31 December 2021. The CSI 300 Index is a composite index of the Shanghai and Shenzhen markets’ overall trends, capturing most of the market size and principal industries, with a high market representativeness and liquidity level. Its constituents are excellent active core investment stocks in various areas, revealing the return condition of the market’s dominant investments.
Since the trading suspension of listed companies interferes with stock prices and causes them to deviate from normal fluctuations, we excluded stocks whose trading days accounted for less than 98% of the total trading days in the experiment to eliminate the impact of outliers caused by frequent trading suspension. Moreover, stock prices that fluctuate at low levels for a long time tend to lack investment attractiveness and affect the model’s ability to identify ITPs. Therefore, we also excluded stocks whose low-level fluctuation ratio exceeded 50%. The specific screening criteria were as follows:
Through the filtering process, we obtained 100 quality stocks. Then, we performed feature scaling on the original stock and technical factor data to eliminate the effects of scale differences among different stocks and enhance the convergence speed before feeding them into the neural network. We used the following formula for feature scaling without a loss of generality:
where
X is the original data;
and
are the maximum and minimum values before normalization, respectively; and
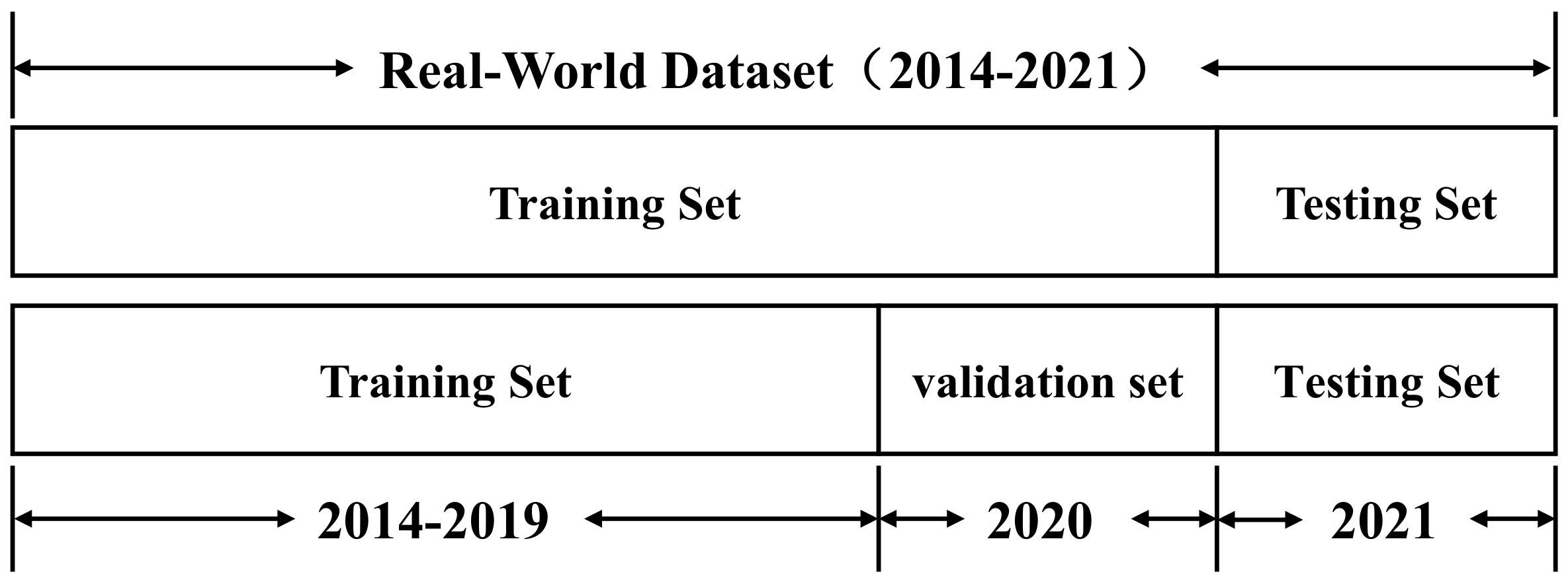
is the normalized dataset. To meet the requirements of time-series prediction, we divide the data into three parts according to the temporal order: the training set, the validation set, and the test set. The diagram of data division is shown in
Figure 11.
3.2. Evaluation Metric
The rarity of ITPs and the stringent detection conditions result in an unbalanced dataset. This renders the accuracy meaningless for evaluating the performance of the classifier, as it cannot effectively identify the ITPs. Therefore, three evaluation metrics robust to unbalanced datasets were used in this work: AUC, F1 score, and MCC. Their definitions and computational formulas are given below.
(1) AUC. The AUC is the area under the ROC curve [
29], which reflects the separability of the classifier. The value of the AUC is in the range of [0, +1]. An AUC of 0.5 indicates that the classifier cannot separate categories. The formula for the AUC is
where TPR indicates the true-positive rate, and FPR indicates the false-positive rate.
(2) MCC. A holistic indicator of a classifier’s quality is the Matthews correlation coefficient (MCC), which synthesizes the information from the four components (ITP, TN, FP, FN) of the confusion matrix. It is stable regardless of the positive and negative sample imbalance across different classes [
30]. The MCC has a value between −1 and +1, with values near +1 signifying an excellent classifier and near −1 signifying a poor classifier. A classifier with an MCC of 0 has no ability to separate classes. The MCC is computed as follows:
where
and
are the numbers of correctly predicted positive and negative samples, and
and
are the number of incorrectly predicted positive and negative samples, respectively.
(3) F1 score. Precision and recall are combined into a single metric called the F1 score, which is the harmonic mean of the two. The F1 score can vary from 0 to 1, with higher values denoting better classifiers, and lower values indicating worse classifiers. The F1 score is more concerned with the predictive effectiveness of positive samples and is insensitive to whether the labels of positive and negative samples are balanced [
31]. The F1 score is calculated using the following formula:
3.3. Compared Methods
This section aims to conduct a comparative analysis between the Batch-MCRNN model and several state-of-the-art benchmark models, while ensuring that all models are evaluated under identical conditions. The comparison models are briefly described below:
(1) MCRNN: MCRNN denotes the removal of the batch attention module in Batch-MCRNN, mapping the output of the residual connection to the labels directly through the fully connected layer and the sigmoid function.
(2) NCNN: NCNN denotes the removal of the MS-1DCN used for local feature extraction in Batch-MCRNN. The input data pass directly to the embedding layer and are fed into the subsequent network after passing through the embedding, and the remaining structure remains unchanged.
(3) SFM: Zhang et al. proposed a novel State Frequency Memory (SFM) recurrent network for capturing multi-frequency trading patterns from past market data and making long-term and short-term stock price forecasts based on these patterns [
19].
(4) AdvNet: Feng et al. proposed a novel machine learning solution using adversarial training to improve the generalization of neural network predictive models for predicting whether stock prices will rise or fall in the future [
20].
(5) StockNet: Xu et al. proposed a novel deep generative model that introduces recurring continuous hidden variables for dealing with the high degree of randomness in the market and uses neural variational inference to address the unsolvability of a posteriori inferences for predicting the rise and fall of stock prices [
21].
(6) TEANet: Zhang et al. proposed a deep learning framework based on transformer and attention networks that utilizes historical text and stock price signals to capture the time-dependence of financial data and predict the rise and fall of stock prices [
22].
3.4. Results Analysis
The purpose of this part is to analyze and discuss the prediction performance of the Batch-MCRNN model along with the other six benchmark models (MCRNN, NCNN, SFM, TEANet, StockNet, and AdvNet) on 100 high-quality stocks selected from the constituents of CSI 300. In order to maintain consistency with the trading strategies in the next section, only the prediction results on 18 stocks with more than one trade are reported in this section. In contrast, the results for the remaining stocks are omitted due to space limitations.
Table 3,
Table 4 and
Table 5 show the prediction results for each metric (AUC, F1 score, and MCC).
As shown in the three tables, the Batch-MCRNN model outperformed the other benchmark models for 15 out of 18 stocks in terms of the AUC metric, with a winning rate of 83.33%. Its mean value was 10.0% higher than the second-best model, and its standard deviation was reduced by 5.7%. In terms of the F1 and MCC scores, the Batch-MCRNN model also won 14 times, with a winning rate of 77.7% for both metrics. Its mean values were 8.8% and 12.8% higher than the second-best scores, respectively. These results indicate that the Batch-MCRNN model significantly surpassed the benchmark models for all metrics, thanks to the advantages of combining convolutional neural networks, recurrent neural networks, attention mechanisms, and residual connections. The Batch-MCRNN model could effectively extract local features, temporal features, and sample interaction information from stock data in three dimensions: space, time, and samples. This enhanced the model’s ability to suppress noise and learn complex patterns and improved its prediction performance without relying on additional data.
Discussion on the role of MS-1DCN. Sequential information in time-series data is effectively learned by most existing methods using RNNs as the primary model. Still, they ignore the local fluctuation features in the data, which are also very important for stock market prediction. We present a novel Batch-MCRNN model that fuses RNNs and CNNs, employing CNNs to extract local fluctuation features at multiple scales and RNNs to learn long-term temporal dependencies, thus achieving the comprehensive modeling of time-series data. The experimental results revealed that the Batch-MCRNN model surpassed the NCNN model on three evaluation metrics, proving that the MS-1DCN could enhance the model’s predictive ability.
Discussion on the role of batch attention. Data imbalance can lead to biased predictions from deep neural networks. Some standard solutions are to adjust the data distribution through sampling techniques in order to make the sample size of each class more balanced. However, these methods can only address the data imbalance problem at the input level and do not change deep neural networks’ internal structure and mechanism. To address the problem with the model itself, we design a batch attention module that allows the deep neural network to interact and propagate information between batch samples so that each sample can contribute to the learning of all classes. By comparing the performance of the Batch-MCRNN model and the MCRNN model on the three evaluation metrics, the Batch-MCRNN model significantly outperformed the MCRNN model. The batch attention module plays a vital role in model prediction.
4. Trading Strategies and Returns Analysis
In this section, we simulate stock trading for 2021 and test the profitability and risk control of the methods based on cumulative return and risk assessment metrics. In the backtest, all methods were traded on a day-by-day basis, with the closing price of the day as the trading price. Meanwhile, the market liquidity was assumed to be sufficient, and the slippage effect was not considered. According to the actual situation of the Chinese market, only long positions were held, and no short positions were held. The total cost per transaction (including stamp duty, commission, etc.) was 0.2%. Details of the evaluation metrics, trading strategies, and returns analysis are provided below.
4.1. Returns Evaluation Metrics
We used three recognized indicators to assess the return–risk characteristics of the various approaches. The first metric was the annualized rate of return (ARR), which is the ratio of annual realizable profit to principal. The second metric was the Sharpe ratio (SR), which reflects the level of excess return of a portfolio relative to a risk-free asset and is calculated as follows:
where
is the return of the portfolio,
is the risk-free rate (we took 3% as the valuation of
), and
is the volatility of the portfolio’s excess return. The higher the value of SR, the higher the excess return of the portfolio.
The third metric was maximum drawdown (MDD), which measures the maximum magnitude of loss experienced by a portfolio before it reaches a new high and is calculated by the formula
4.2. Trading Strategies
ITPs can only indicate the critical moments of price changes and cannot determine their trends. Therefore, we introduced the Relative Strength Index (RSI) as an auxiliary indicator to help the trading strategy determine whether the ITPs were buy points (BPs) or sell points (SPs).
The Relative Strength Index (RSI) is a prevalent momentum indicator that gauges the speed and magnitude of changes in stock prices, as well as the level of overvaluation or undervaluation of stocks. The RSI can show the overbought or oversold status of stocks. The RSI values vary from 0 to 100. Usually, an RSI exceeding 70 implies that stocks are overbought, while an RSI falling below 30 implies that stocks are oversold [
32]. We used the RSI to assess stock trends and trading directions. Due to the inherent predictive error in the model, both excessively high and low RSI thresholds could lead to fewer trading opportunities. Therefore, by analyzing stock data where the balance between upward and downward movements was relatively even, we observed a bimodal distribution of RSI values, with two peaks occurring around 60 and 40. Consequently, we optimized the RSI thresholds for trading direction at 60 and 40. The specific decision rules were as follows:
After determining the ITPs’ trading direction, we designed a comprehensive trading strategy to assess the returns and risk management capabilities of each model. The specific trading strategy was as follows: We allocated a fixed amount to each of the 100 stocks in the CSI 300 and managed their positions separately. In 2021, we slid from the first trading day until we encountered the first buy point, entered a full position, and exited a full position when we encountered the first sell point. We disregarded any other buy signals during this period. If the position was still held at the end of the trading period, we liquidated it on the final day. Finally, we computed the individual metrics for each stock and the aggregate metrics for all stocks.
To mitigate the negative impact of model prediction errors, we propose an improved method based on the Delayed One-Day Strategy (DODS) [
33] called the Double Check (DC) method. This method combines the rate of change of the stock’s prior return
and the RSI indicator to perform a secondary screening of the trading points predicted by the model. The core principle of the DC method is that if the stock price change trend moderates at the time of buying or strengthens at the time of selling, then the trade is made in accordance with the indication of the RSI indicator. Otherwise, the transaction is canceled. The specific steps of the DC method are shown in Algorithm 1, where the formula for the calculation of
is as follows:
| Algorithm 1:Double Check (DC) method |
![Entropy 25 01500 i001]() |
In Algorithm 1, and represent the smoothing coefficients. We employed a grid search approach to determine the optimal alpha and beta values that maximized returns in the validation set after threshold searching using a specific model and threshold. In our experiments, these values were both set to 0.9.
4.3. Returns Analysis
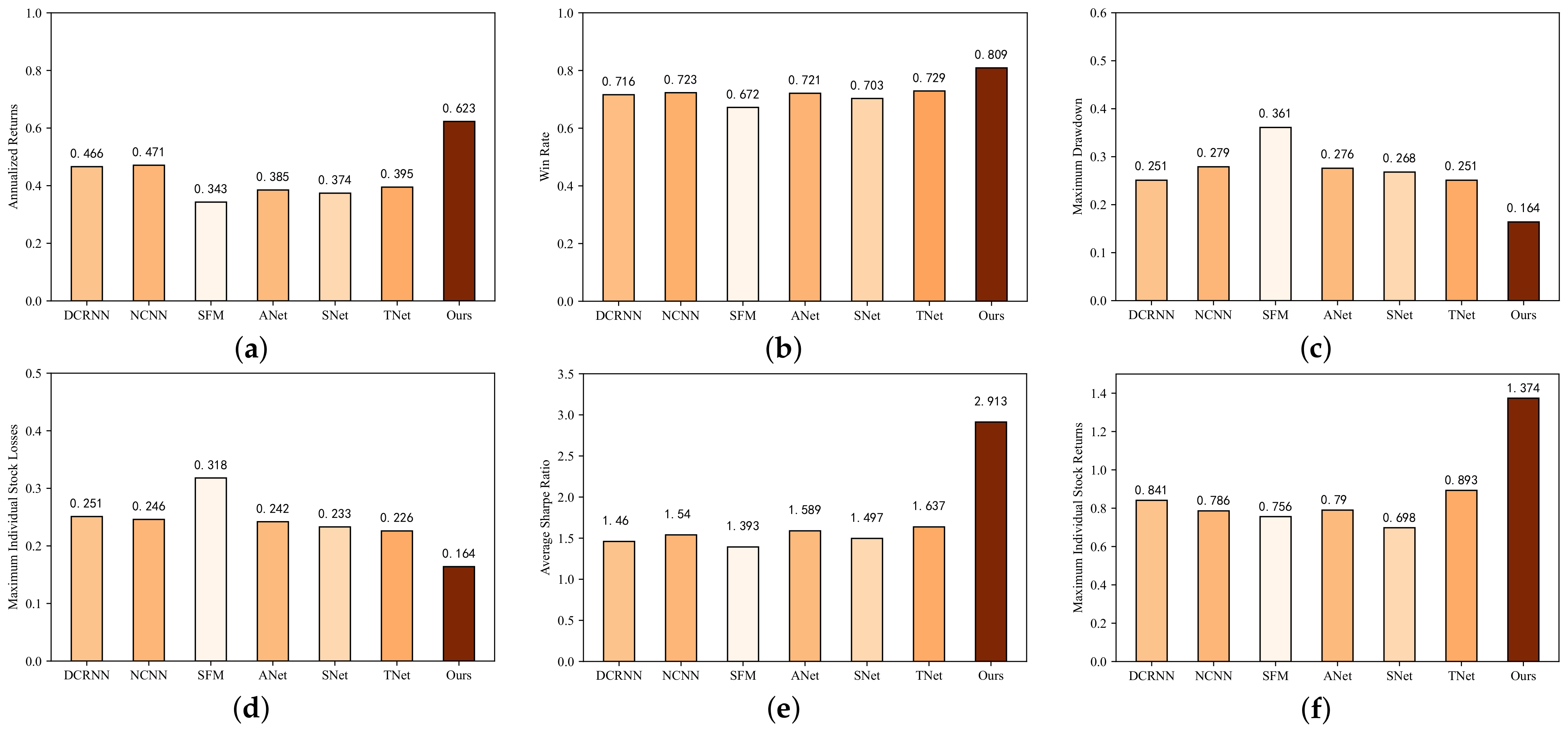
Figure 12 depicts the market backtesting outcomes of all models applied to 100 constituent stocks from the CSI 300 index over 243 trading days in 2021. Three more auxiliary evaluation indicators were introduced to enhance the objectivity of the performance evaluation: the winning rate, maximum individual stock returns, and maximum individual stock losses. This allowed us to analyze and evaluate the forecast results more comprehensively. For ease of presentation, we abbreviate AdvNet, StockNet, and TEANet as ANet, SNet, and TNet, respectively, in the figure.
Overall, the Batch-MCRNN model proposed in this work achieved an annualized return of 62.3%, a winning rate of 80.9%, and a maximum retracement of 16.4% in the framework of ITP prediction. Furthermore, the CSI 300 plunged more than 1000 points over the same period, or 21.3%, in a downward trend, demonstrating the effectiveness of Batch-MCRNN in improving the stock market investment return and reducing the investment risk.
For a trading strategy, there are two critical criteria for evaluation: the net profitability within a certain trading period and the risk control ability of the strategy.
Discussion on profitability. In the introduction, we discussed the methods of predicting stock returns or prices. Although the models seemed to have good predictive performance, they could not achieve a breakthrough in returns, resulting in the strange phenomenon of “high model, low return”. The core of this work was to improve stock investment returns and reduce risk rather than just pursuing the predictive accuracy of the model, although our proposed Batch-MCRNN model performed excellently. From
Figure 12a, we can observe that even considering the trading costs and a long trading period of one year, the worst-performing model achieved a compound return of 34.3% and a win rate of 67%, confirming the feasibility and effectiveness of stock investment by mining the potential change patterns of important trading points.
Discussion on risk control capacity. In the simulation, our approach traded 100 individual types of stocks at the same time, which greatly diversified the trading risk, and made 89 total trades (buys and sells) over a 1-year trading cycle. The win rate (percentage of profitable trades) was more than 80%, implying that there was a high likelihood of a gain on every trade. Regarding the risk–return profile, the overall model had a maximum drawdown of 16.4% and an average Sharpe ratio of 2.913 (calculated only for the 18 stocks traded more than once), which were better than usual. The strategy demonstrated reasonable risk control. Due to the low number of trades and the maximum individual stock loss not exceeding 20%, we did not use additional take-profit and stop-loss strategies to avoid a decline in overall profitability. Overall, the Batch-MCRNN-based trading strategy demonstrated reasonable risk control.
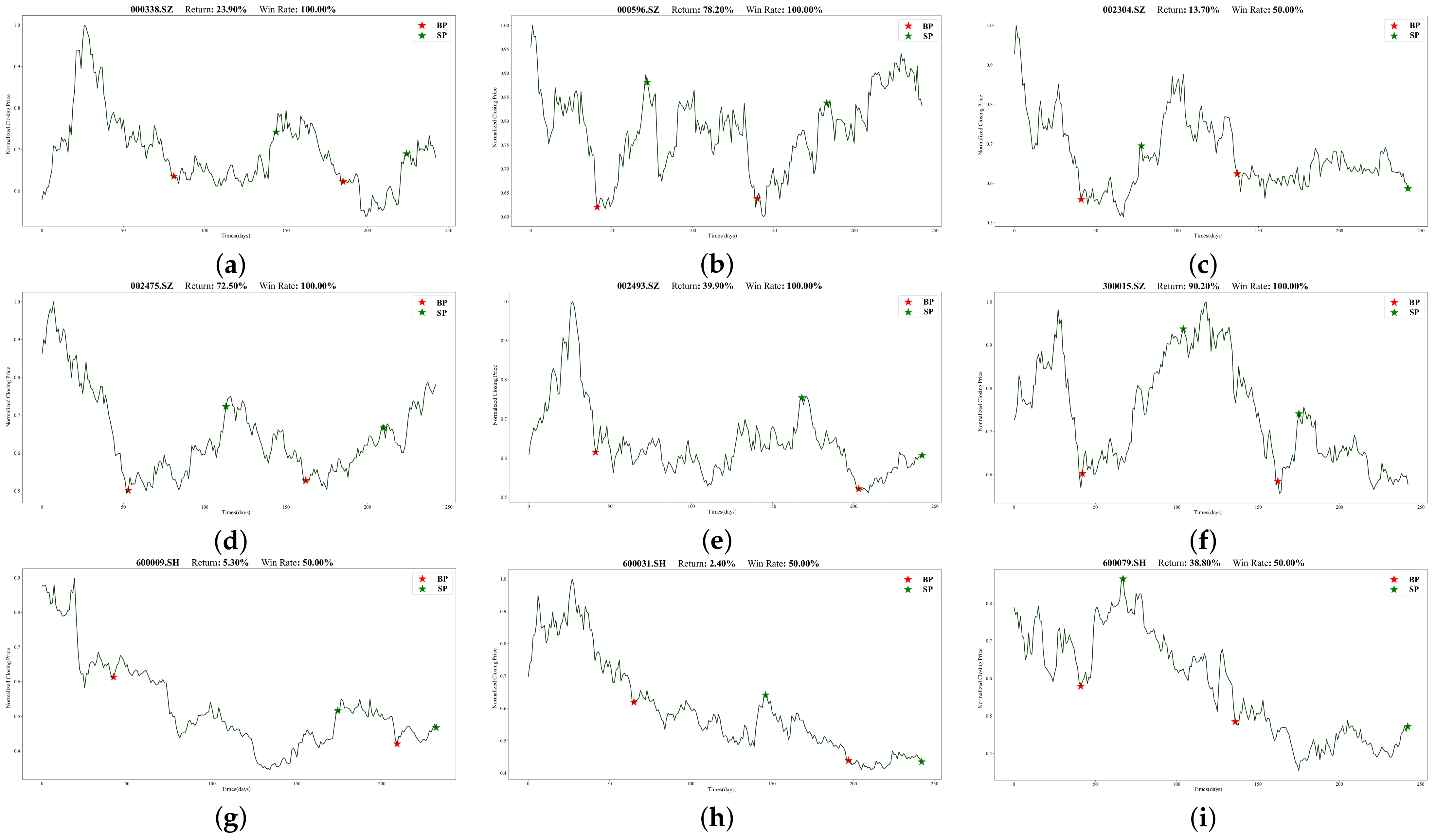
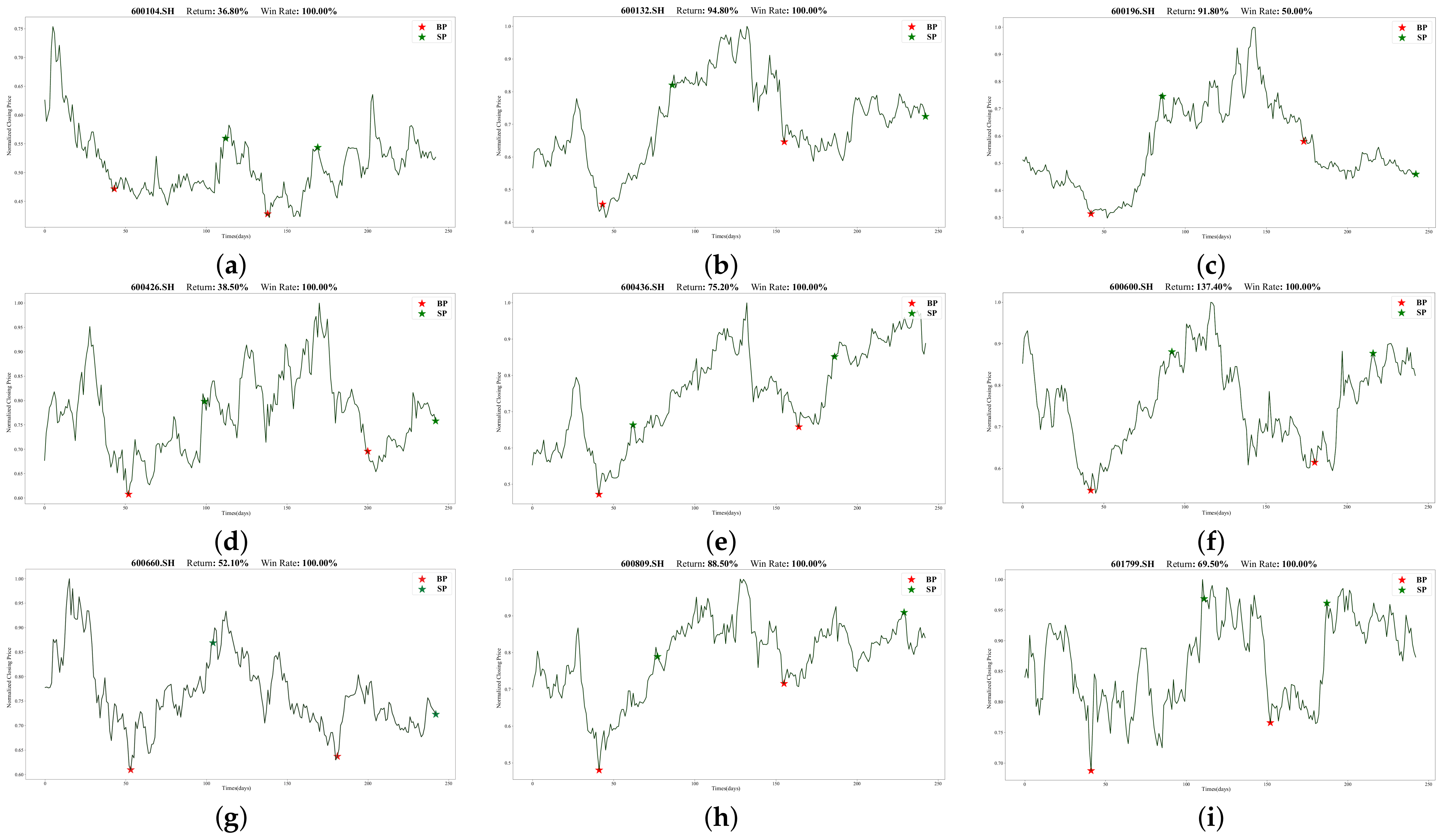
To illustrate Batch-MCRNN’s real-world trading performance more clearly, we chose 18 out of 100 stocks that traded more than once (in line with the previous section’s experimental results).
Figure 13 and
Figure 14 show their specific trading times and prices (red stars mark buying points, and green stars mark selling points). All 18 stocks made profits, ranging from 2.4% to 137.4%. These stocks covered different market trends, such as rising, oscillating, and falling, validating the adaptability and stability of the forecasting framework proposed in this work for various market environments.
Moreover, we observed that for highly volatile stocks like 000596.SZ, 300015.SZ, and 600600.SH, our method had a high predictive power and return rate. These stocks underwent drastic price changes within the year, offering investors lucrative trading opportunities. Our method also effectively detected the start and end of upward trends, entering and exiting promptly, and achieving low-risk and high-return trades. However, our method had some limitations—mainly, its poor prediction performance for long-term declining or mildly fluctuating stocks such as 600009.SH, 600031.SH, and the latter half of 002304.SZ. This may be related to the prediction framework’s design and the trading strategy. Firstly, we did not categorize stocks by volatility and trendiness when identifying ITPs, which significantly affected the model’s performance. Secondly, short-selling is challenging and expensive due to China’s market specificity. Hence, our trading strategy only considered long positions, hampering its downward trend performance.
There were also some interesting results. First, the returns of the 18 stocks exhibited no discernible link with the forecasted outcomes derived from the model discussed in the preceding section. For instance, 002475.SZ performed worse than 600436.SH according to the model’s evaluation metrics, but its return was much higher. We speculate that this was because the model predicted far more ITPs than the actual trading points, and the trading strategy proposed in this work failed to optimally match these predicted points, resulting in some deviations in the actual trading situation. Moreover, since our trading strategy forced close positions at the end of the trading cycle, many stocks suffered losses in the forced closing, as shown in the figures for 600196.SH, 600079.SH, 600031.SH, and so on. The loss was more noticeable when the stock was in a downward trend. These problems prompted us to think about improving our trading strategy, and we will strive to design a more reasonable trading strategy in our future work.
Discussion on the role of the Double Check (DC) method: As shown in
Table 6, we adopted the same evaluation system as the other models to validate the effectiveness of the DC method based on the Batch-MCRNN model. As expected, the DC method conducted a second screening of the trading points, reducing the trading points and thus decreasing the trading frequency. However, indicators such as the win rate, total return, and maximum drawdown all improved to varying degrees. Suffice it to say that using the DC method in trading strategies improved the prediction results of trading points and achieved better profitability.
5. Conclusions
This work focused on improving stock investment returns based on the perspective of important trading points (ITPs). We proposed an ITP prediction framework based on Return-Adaptive Piecewise Linear Representation (RA-PLR) and a Batch Attention Multi-Scale Convolution Recurrent Neural Network (Batch-MCRNN) for three core problems: the detection of historical ITPs, the prediction of future ITPs, and the construction of trading strategies. The framework integrated the experience of stock investors seeking high-return trading opportunities and the advantages of different deep learning structures in dealing with non-linear and non-stationary data, achieving higher prediction accuracy and profitability. The framework consists of four main parts: data preprocessing, ITP detection based on RA-PLR, ITP prediction based on Batch-MCRNN, and a trading strategy combining the Relative Strength Index (RSI) and Double Check (DC) methods. Unlike existing research, this framework always aims to increase trading returns and reduce trading risks, excluding some abnormally performing stocks from the data preprocessing stage; designing a return-adaptive function to balance returns and risks in the ITP detection stage; using the advantages of convolutional neural networks, recurrent neural networks, and attention mechanisms to deeply mine the intrinsic patterns of data from the spatial, temporal, and sample dimensions in the ITP prediction stage; and combining the RSI and DC methods to enhance performance in the trading strategy stage. Extensive experiments on real stock market data showed that the framework could effectively control risk while making sizable profits. In summary, due to the uncertainty and difficulty of stock price prediction tasks, as well as the high transaction costs that make minor price fluctuations irrelevant, focusing on predicting important trading points that are more likely to bring high-return opportunities rather than predicting stock prices or trends at every time point can achieve more profits. This work provides a new perspective on the stock market prediction field, which could help investors develop better trading systems.
The above analysis showed that the input data’s volatility and trend significantly impact the overall return. We plan to solve this problem in the future by either adding an additional discriminant model at the data layer and applying the ITP forecasting framework only to stocks with high volatility or a clear upward trend; or by improving the model structure at the model layer, so that the model can adapt itself to the market conditions and make reasonable decisions. In addition, the simulation trades in this paper were only conducted in the Chinese market, which makes it challenging to execute short trades. In the future, we plan to conduct experiments in the U.S. and other markets in both long and short directions. Finally, time was the only criterion to test the effectiveness of the framework, and a real online rolling test will also be on the agenda.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}