
Multilayer Perceptron Network Optimization for Chaotic Time Series Modeling

1
School of Mathematics, Jilin University, Changchun 130021, China
2
Department of Industrial Electronics, School of Engineering, University of Minho, 4800-058 Guimares, Portugal
3
Key Laboratory of Symbol Computation and Knowledge Engineering of the Ministry of Education, College of Computer Science and Technology, Jilin University, 2699 Qianjin Street, Changchun 130012, China
4
School of Computer Science, Zhuhai College of Science and Technology, Zhuhai 519041, China
*
Author to whom correspondence should be addressed.
Entropy 2023, 25(7), 973; https://doi.org/10.3390/e25070973
Submission received: 17 April 2023
/
Revised: 8 June 2023
/
Accepted: 16 June 2023
/
Published: 24 June 2023
(This article belongs to the Special Issue Recent Advances in Statistical Theory and Applications)
Abstract
:Chaotic time series are widely present in practice, but due to their characteristics—such as internal randomness, nonlinearity, and long-term unpredictability—it is difficult to achieve high-precision intermediate or long-term predictions. Multi-layer perceptron (MLP) networks are an effective tool for chaotic time series modeling. Focusing on chaotic time series modeling, this paper presents a generalized degree of freedom approximation method of MLP. We then obtain its Akachi information criterion, which is designed as the loss function for training, hence developing an overall framework for chaotic time series analysis, including phase space reconstruction, model training, and model selection. To verify the effectiveness of the proposed method, it is applied to two artificial chaotic time series and two real-world chaotic time series. The numerical results show that the proposed optimized method is effective to obtain the best model from a group of candidates. Moreover, the optimized models perform very well in multi-step prediction tasks.
1. Introduction
Some nonlinear dynamical systems present a seemingly irregular and random phenomenon, but they are actually produced by deterministic systems. For example, the famous “butterfly effect” concept describes how the flapping of a butterfly’s wings in Brazil could ultimately lead to a tornado in Texas that would not have happened otherwise. In other words, very tiny changes in conditions can result in very large, unpredictable responses, but this follows basic aerodynamic laws. This characteristic of nonlinear dynamical systems is called chaos. Chaotic dynamical systems are ubiquitous in nature, so they have been extensively studied to solve practical problems in different fields, such as financial systems analysis [1,2], power system behavior [3,4], information security [5,6], and the control of nonlinear systems [7,8]. In general, chaotic dynamical systems do not have an explicit dynamical equation and can only be understood through the available time series. Therefore, chaotic time series modeling is of great significance, but it is very difficult due to its complex, chaotic, nonlinear dynamics, such as internal randomness, nonlinearity, and long-term unpredictability.
Various researchers have shown great interest in chaotic time series analysis, finding many results, which could be classified into symbolic regression, polynomial model, model simulation or decomposition, and neural networks. For symbolic regression, Brandejsky used a GPA-ES system to study symbolic regression of deterministic chaotic systems [9], and Senkerik et al. proposed a novel tool for symbolic regression and analytical programming for the evolutionary synthesis of discrete chaotic systems [10]. The polynomial model is a widely used method. Lainscsek et al. used a truncated polynomial expansion involving successive derivatives of the measured time series according to an Ansatz library [11]. This procedure was introduced and improved by [12]. Han et al. utilized genetic programming (GP) and multi-objective optimization to identify chaotic systems using the nonlinear auto-regressive moving average with exogenous inputs (NARMAX) model representing the basis of the hierarchical tree encoding in GP [13]. Model simulation or decomposition is another type of method. Karimov et al. constructed a chaotic circuit from data to identify chaos systems [14]. Yang et al. introduced the Hankel Alternative View of Koopman analysis to decompose chaotic dynamics into a linear model with intermittent forcing [15]. The most widely used methods of chaotic time series analysis are neural network-related methods, which are classified into artificial neural networks (ANN) [16,17,18,19,20], fuzzy neural networks (FNN) [21,22,23,24], optimization algorithms with ANN [25,26,27,28], and wavelet neural networks (WNN) [29,30,31,32]. One can refer to [33] for a comprehensive review. Although there have been many attempts at chaotic time series analysis by neural network methods, including deep learning [16,34,35,36], there are still many issues to be resolved, such as low prediction accuracy and difficulty in determining the network topologies. Therefore, some scholars have studied the network optimization of chaotic time series analysis models. Xie et al. proposed an enhanced grey wolf optimizer (GWO) by designing four distinctive search mechanisms and then developed the evolving convolutional neural network–long short-term memory (CNN-LSTM) networks for time series analysis [37]. Huang et al. proposed an improved differential evolution (IDE) algorithm to optimize the topology of DHNNs consisting of CNN and GRU, including CNNs’ filter size and the number of hidden neurons of the GRU [38]. Focusing on the prediction of short-term traffic flow, Qian et al. found that the RBF neural network is better than the wavelet neural network, and they used the genetic algorithm to optimize the initial parameters [39]. Chen et al. presented a nonlinear ensemble of partially connected neural networks for short-term load forecasting, in which the genetic algorithm is used to generate diverse and effective neural networks, and a novel pruning method was developed to optimize the partially connected neural networks [40]. Kao et al. studied a Takagi-Sugeno-Kang (TSK)-type self-organizing fuzzy neural network, which not only generates and prunes the learning algorithm automatically but also adjusts the parameters of existing fuzzy rules [41]. Though all the above methods work on network structure optimization, they are empirical and have no strict theoretical basis.
The Akaike information criterion (AIC) [42] is a popular tool to evaluate a linear auto-regression model. The idea of AIC has been extended to nonlinear models, especially the neural networks based on the generalized degrees of freedom [43,44,45]. However, when employing the Akaike information criterion based on the generalized degrees of freedom (AICg) to evaluate the MLP network, the generalized degrees of freedom must be estimated. For a linear regression model, the degrees of freedom are the number of variables in the model, which is the sum of the sensitivities of each fitted value with respect to the corresponding observed values. For nonlinear models, Ye [45] defined a new quantity known as the generalized degrees of freedom (GDF) and proved that the GDF provides an unbiased estimation of the error variance. However, it is very difficult to calculate the GDF using the original definition. A Monte Carlo method is therefore suggested to calculate the GDF for a nonlinear model. This approach requires estimating the nonlinear model many times and is therefore time-consuming.
Recently, a new method for the estimation of the generalized degrees of freedom for the RBF-type network has been introduced [44]. Following that method, the generalized hat matrix for the nonlinear model is defined in this study; its trace is an estimation of the generalized degrees of freedom. The proposed estimation method simulates the model procedure once only and therefore is faster than the Monte Carlo method. Using the AICg, the performances of the MLP networks for different network topologies are evaluated, and the optimal MLP network for the chaotic time series is then selected. The model-selecting method is applied to four chaotic time series, two artificial time series and two real-world time series. By estimating the maximal Lyapunov exponents and forecasting the time series, the numerical results show that the MLP network selected by the proposed method behaves better in terms of the analytic and prediction capabilities than other models. The main contributions of the paper are the following three points:
- Present an approximation method to calculate the generalized degree of freedom of MLP, and then obtain its AICg.
- Develop a multilayer perceptron network optimization method for chaotic time series analysis by designing the AICg as the loss function of MLP.
- Propose an overall framework for chaotic time series analysis, including phase space reconstruction, model training, and model selection modules.
This paper is arranged as follows: In Section 2, some backgrounds are introduced, including phase space reconstruction of chaotic systems, the Akaike information criterion of nonlinear systems, and generalized degrees of freedom of MLP. In Section 3, our proposed modeling selection framework for MLP networks is described in detail. In Section 4, the proposed method is applied to four chaotic time series, and the results are presented and analyzed. The last section gives a brief conclusion.
2. Backgrounds
2.1. Phase Space Reconstruction of Chaotic Systems
Suppose that the chaotic system is an n-dimensional system given by
where X = (x1, x2, …, xn) is an n-dimension vector.
In general, the real observed chaotic time series is only one or a few dimensional state sequences. In order to analyze the chaotic time series, it is necessary to reconstruct the phase space of the chaotic system from the observed low-dimensional time series and restore the chaotic attractor of the original phase space in this high-dimensional embedded space. Takens’ theorem is the theoretical basis for phase space reconstruction [46].
Then, Φ (φ, y) is an embedding from M to R2m+1.
Theorem 1.
(Takens’ theorem [46]): Suppose M is an m-dimensional compact manifold, the map φ: M→M is a smooth differential isomorphism, y: M→R is a smooth function, and the map Φ (φ, y): M→R2m+1 is defined by
Φ(φ, y) = (y(x), y(φ(x)), y(φ2(x)), …, y(φ2m (x)))
This theorem states that for an m-dimensional chaotic dynamic system, as long as the embedding dimension is greater than or equal to 2m + 1, the chaotic attractor can be restored in the embedding space; that is, a system with the same dynamic properties as the original chaotic system can be obtained in the embedding space. This mathematically guarantees that a phase space equivalent to the original system in the topological sense can be reconstructed from a lower-dimensional or even one-dimensional chaotic time series. The coordinate delay method is commonly used to reconstruct the phase space of the chaotic system. The essence is to construct m-dimensional phase space vectors from an observed one-dimensional time series {xi} (i ∈ [1, N]) according to a series with different time delays, namely, [47]
where N is the time series length, m the embedding dimension, and τ the time delay. According to Takens’ theorem, if the choice of the embedding dimension m and time delay τ is appropriate, the “orbit” of the reconstructed phase space in the embedded space is equivalent to the dynamics of the original system (Equation (1)) in the sense of differential isomorphism. This method is called the delay coordinate embedding approach. In this approach, the determination of the values of m and τ is the key to phase space reconstruction.
2.2. Akaike Information Criterion of a Nonlinear System
Assume that a nonlinear system is modeled by the function [44]
where X = (x1, x2,…,xd) ∈ Rd is the input, α = (α1, α2,…, αK) ∈ RK is the model parameter, ε∈ R is the random noise, and y ∈ R is the output. Assume also that we have N input samples X = (X1, X2,…, XN) and N output observers Y = (1, 2,…, N), and denote the function output of Xn as yn = f (Xn, α) + ε. Then, the residual sum of squares (RSS) of the MLP network is [44]
For a nonlinear model, the quadratic loss of the model can be estimated by [30]
where σ is the variance of the observation error and ng is the generalized degrees of freedom. The mean of RSS/(N − ng) was proven to be equal to the variance σ2; hence, the quadratic loss can be approximated by [45]
Since ng is much smaller than N and σ is a constant, another criterion G could be obtained by [48]
Taking the logarithm for Equation (6), we can obtain
It should be noted that the above derivation makes use of the Taylor expansion. Then, we arrive at the form of the Akaike information criterion for an MLP network,
which is based on the concept of entropy and able to weigh the complexity of the estimated model and the goodness of the fitted data of the model.
y = f (X, α) + ε,
2.3. Generalized Degrees of Freedom (GDF)
In order to calculate the Akaike information criterion of an MLP network according to Equation (7), the generalized degrees of freedom (GDF) ng should be obtained in advance. Xu et al. developed a fast estimation method for GDF of a nonlinear system [44], which is briefly described in this section for the convenience of the reader.
GDF is defined as “the sum of sensitivity of each fitted value to the perturbation in the corresponding observed value”, which can measure the complexity of a nonlinear model [45]. Xu et al. proposed an approximated method to obtain the GDF of a nonlinear system [44].
Theorem 2.
If a nonlinear model f (X, α) is adequate in fitting the data and has bounded second order derivatives, the generalized degrees of freedom for the nonlinear system can be approximated by
Note that the MLP basis functions clearly have bounded second order derivatives. Hence, Theorem 1 can be applied to calculate the generalized degrees of freedom for an MLP model.
3. Modeling Selection for MLP Networks
3.1. Pipeline of the Modeling Selection
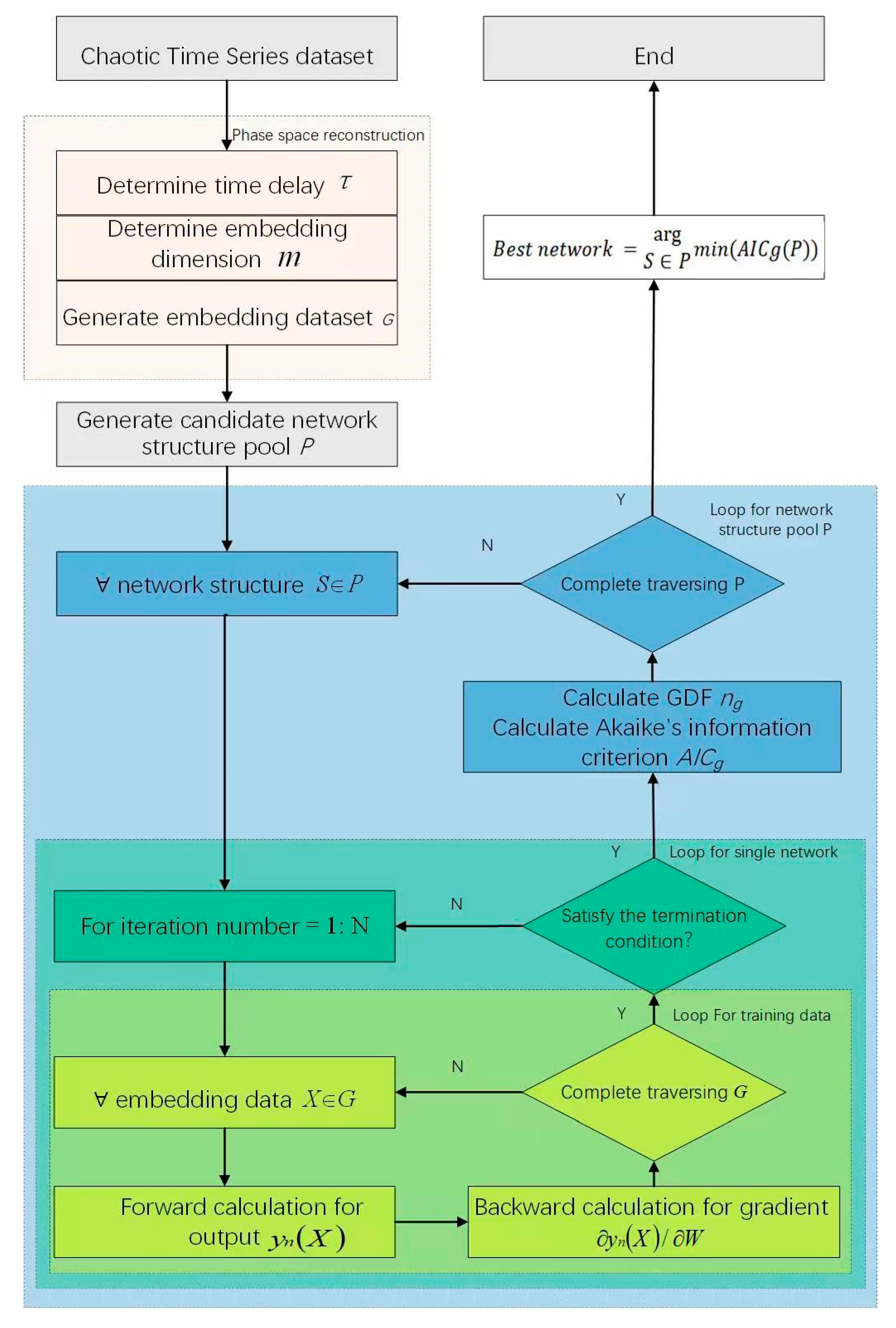
MLP networks are effective tools for chaotic time series predictions. However, the network topology seriously affects the performance of algorithms. Therefore, a pipeline of the modeling selection for MLP networks is proposed in this paper, as shown in Figure 1. For a chaotic time series dataset, the phase space reconstruction should be performed in advance. Next, a candidate MLP structure pool is generated. Then, each structure is trained to determine its parameters. It should be noticed that the Akaike information criterion is used as the loss function for training. When the training process is completed, the MLP network structure with the least Akaike information criterion value is selected as the best one, that is, the final prediction model. The phase space reconstruction process is described in Section 3.2, and the Akaike information criterion computation is detailed in Section 3.3, respectively.
3.2. Phase Space Reconstruction
According to Takens’ theorem, the m-dimensional phase space of the chaotic system could be reconstructed from an observed one-dimensional time series by the delay coordinate embedding approach (Equation (3)). The key to the method is how to determine the embedding dimension m and time delay τ. To address this issue, many algorithms have been proposed: For example, the mutual information method [48] and the autocorrelation coefficients method [49] are two popular approaches to determine the time delay τ; the false nearest neighbor method [50] and its improved version the Cao method [51] are often used to determine the embedding dimension m; and Uzal et al. proposed a noise amplification approach able to handle these two tasks simultaneously [52]. In our pipeline, the time delay τ is determined by the mutual information method [48], and the embedding dimension m is selected by the Cao method [51].
We denote the observed one-dimensional time series {xi} as a discrete system S. The amount of information contained in this system can be characterized in terms of entropy:
where ps represents the probability of s occurring. We denote the delayed time series {xi+τ} as another discrete system Q. Then, the joint entropy of the systems S and Q could be defined by.
where psq represents the joint probability of s and q appearing in systems S and Q. Thereby, the mutual information between the two systems could be defined by
which can be understood as the amount of overlapping information between these two systems. After fixing the original system S, system Q is determined by the time delay τ. Taking the time delay τ as a variable, the mutual information I(S, Q) can be treated as a function of τ, denoted as I(τ). In order to make the correlation between the delayed time series and the original series as small as possible, the minimum point of I(τ) is taken as the final time delay:
Considering that we want a small time delay, the first local minimum point is usually taken as the final result in the real applications. The pseudocode of the time delay determination is given by Algorithm 1.
| Algorithm 1: Time delay determination | |
| Input: one-dimensional time series S = {xi}; time delay max value τmax; iteration number N | |
| Output: best time delay τ* | |
| 1 | |
| 2 | for i = 1: N |
| 3 | time delay τ = i × τmax/N |
| 4 | time delayed system Q = {xi+τ} |
| 5 | |
| 6 | |
| 7 | |
| 8 | end for |
| 9 | τ* |
A chaotic time series is a projection in one- or lower-dimensional space of a deterministic dynamical system’s trajectory in a high-dimensional phase space. The projection modifies the topological properties of the motion trajectory, resulting in “disorder” characteristic of chaotic systems. Thus, we can observe the change in the “nearest neighbor” distances when the embedding dimension increases, and it stops when it no longer changes.
Let xi be a point of the original time series, and Xi(m) = (xi, xi+τ,…, xi+(m−1)τ) and Xi(m+1) = (xi, xi+τ,…, xi+mτ) be its mapping points in the m-dimensional and (m + 1)-dimensional embedding spaces. Denote Xn(i,m) (m) as the nearest neighbor to Xi(m) in the embedding space, i.e.,
Then, the change of the distance of this “nearest neighbor” pair when the embedding dimension increases from m to m + 1 could be represented by
Thus, the average distance change of the “nearest neighbor” pairs could be expressed as
It can be understood as the average scale of the nearest neighbor distance of all mapped points in m-dimensional embedding space after mapping to (m + 1)-dimensional space. Thus, we could define
If the time series is not random, there exists an embedding dimension d* satisfying the Takens’ theorem, such that when m > d*, E1(m) no longer changes; otherwise, E1(m) continues to increase.
To further ensure the reliability of the method, the following judgment criterion has been added:
Since there is no correlation between random sequence data, E2(m) ≡ 1, and for deterministic sequences, there must exist m, such that E2(m) ≠ 1. The pseudocode of the embedding dimension determination is given by Algorithm 2.
| Algorithm 2: Embedding dimension determination | |
| Input: one-dimensional time series S = {xi,…, xn}, time delay τ; max embedding dimension M, threshold ε. | |
| Output: embedding dimension m* | |
| 1 | |
| 2 | for m = 1: M |
| 3 | E(m) = 0; E*(m) = 0; m* = 0; |
| 4 | for i = 1: n − mτ |
| 5 | |
| 6 | |
| 7 | E(m) = E(m) + α(i, m)/(n − mτ) |
| 8 | E* (m) = E* (m) + |x(i + mτ) − x(n(i,m) + mτ)|/(n − mτ) |
| 9 | end for |
| 10 | end for |
| 11 | E1(1) = E(2)/E(1) |
| 12 | E2(1) = E*(2)/E*(1) |
| 13 | for m = 2: M − 1 |
| 14 | E1(m) = E(m + 1)/E(m) |
| 15 | E2(m) = E*(m + 1)/E*(m) |
| 16 | if (|E1(m) − E1(m − 1)| < ε) and (|E2(m) − 1| > ε) |
| 17 | m* = m |
| 18 | end if |
| 19 | end for |
3.3. Calculation of MLP Networks’ Akaike Information Criterion (AICg)
The Akaike information criterion (AICg) offers a relative performance measure when nonlinear models are used to represent the process that actually generates the data. Hence, the AICg provides a means for model selection for an MLP network. In practice, several candidate MLP networks with different neuron sizes are built and trained using the same sample set. The residual sum of squares for every candidate network is then obtained. In order to apply the AICg, the GDF for every candidate network is needed. According to Equation (8), the GDF can be estimated easily by the gradient matrix of the parameters. In this study, using the idea of back-propagation, we introduce a method to calculate the gradient matrix of the parameters for an MLP network.
Consider a multilayer perceptron network with one input layer, K hidden layers, and one output layer. There are Mk neurons in the kth hidden layer. In order to address the bias in the MLP network freely, we first expand the input vector and the neurons. Denote the expanding input vector by
Then, the feed vector in the first hidden layer is
The parameter matrix w(1) is given by
where d is the dimension of the input vector, M1 is the number of the first hidden layer nodes, and βi(1) is the bias of the ith node, respectively.
In the same way, the input vector in the kth hidden layer can be extended by
The feed vector in the kth hidden layer is then given by
Finally, the input vector for the output layer is
The feed value for the output layer is
The output of the MLP network is then given by
Let the activation function f in the hidden layer be the sigmoid function
Then
Let the activation function g in the output layer be the linear function
Then
Denote the MLP network as a function
Let be a matrix with the same dimension as where all its elements are zero except . Furthermore, define matrix by
Then, we have
Hence, the derivative of the MLP function with respect to is given by
Furthermore, the derivative of the MLP function with respect to is given by
By the same discussion, we obtain the derivative with respect to ,
Thus, the gradient matrix of parameters M is obtained, and then the generalized hat matrix H can be calculated according to Equation (9). The trace of the generalized hat matrix is an estimator of the GDF ng for the MLP network according to Equation (8).
Using the GDF estimated by the generalized hat matrix, the AICg for each MLP candidate is calculated by
The pseudocode of the calculation of MLP networks’ Akaike information criterion is given by Algorithm 3.
| Algorithm 3: Calculation of MLP networks’ AICg | |
| Input: ANN model ANN = {wi,m(k)}, embedded time series data G = {X1,…,XN}, iteration number N_Max. | |
| Output: MLP networks’ Akaike’s information criterion AICg | |
| 1 | for i = 1: N_Max |
| 2 | for n = 1: N |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | end for |
| 9 | end for |
4. Experiments
4.1. Benchmark Datasets
In order to verify the effect of the proposed method, it is applied to simulate four chaotic time series: two artificial chaotic time series and two real-world time series. The two artificial benchmarks are the Hénon map [53] and the Lorenz map [54], and the two real ones are sunspots time series [55] and SST data [56], respectively.
Hénon map: The Hénon map [53] is given as
It has a chaotic attractor when a = 1.4 and b = 0.3. A time series of length 1500 is generated with initial conditions y−1 = 1.005 and y0 = −0.3032. The maximal Lyapunov exponent (MLE) of the Henon attractor is about 0.419.
Lorenz equation: The Lorenz map is [54] defined as
It becomes chaotic for σ = 10, r = 28, and b = 8/3. Equation (41) is a three-dimensional differential system, which can be solved numerically using the fourth order Runge-Kutta method with a time step of 0.01 and initial conditions of
A time series of length 1500 is generated with sampling frequency 0.2,
The MLE for the Lorenz attractor is about 0.91. Since the sampling frequency is 0.2, the maximal Lyapunov exponent for the time series is therefore about 0.182.
Sunspots time series: Sunspots are temporary phenomena on the surface of the Sun (the photosphere) that are visible as dark spots compared to the surrounding regions. The sunspots index has been used since 1749. The monthly averaging sunspots index considered in this study is from 1749 to 2009 with a sample size of 3132. The dataset can be downloaded from the website: psl.noaa.gov/gcos_wgsp/Timeseries/SUNSPOT/ (accessed on 5 June 2023). The sunspots data are a nonlinear time series, which have been discussed as a chaotic time series by many authors [55].
SST data: The sign and magnitude of equatorial Pacific sea-surface temperature anomalies (SSTA) provide a measure of the ENSO phase and strength. The El Niño phase produces sea-surface temperatures in the equatorial eastern Pacific that are anomalously warm with respect to the mean seasonal cycle, while La Niña conditions produce anomalously cold sea-surface temperature conditions. The S index of Wright [56] provides a continuous historical record (1881–1986) of SST anomalies averaged over an irregular region of the equatorial Pacific extending for 5° N–5° S and 150°–90° W. The dataset is obtained from Geographic Data Sharing Infrastructure, College of Urban and Environmental Science, Peking University (http://geodata.pku.edu.cn, (accessed on 8 April 2023)).
4.2. Experiment Setup
Generally, a three-layer MLP network structure is selected for experiments. The activation function in the hidden layer is given by the sigmoid function, while the activation function in the output layer is a linear function. Then, we focus on discussing the optimal neuron size in the hidden layer. The Akaike information criterion based on the generalized degrees of freedom (AICg) is employed to evaluate the performance of the MLP networks. During the model training process, the SGD optimization algorithm is used; the momentum is set to 0.9, the weight decay is 0.0005, and the initial learning rate is 0.01.
In the following section, we first describe the results of phase space reconstruction and then give the results of the network model optimization. The performance of the models obtained is also analyzed in detail.
Two measurement methods, the maximum Lyapunov exponent (MLE) and the mean square error (MSE) of the time series, were considered in the experiment for evaluating the experimental results.
Maximum Lyapunov Exponents (MLE):
The Lyapunov exponent can quantitatively characterize the chaotic attractor by measuring the sensitivity of the chaotic orbit to the original condition. In general, a time sequence is considered chaotic only when the MaxLE is positive based on the phase track. Li and Xu proposed an estimation method of MaxLE by the local Jacobian matrix of the nonlinear system [57]. In the reconstructed delay phase space, the local Jacobian matrix at this point is rewritten in the form
where
In this case, the nonlinear function is the three-layer MLP network, and Equation (43) can be rewritten as
Mean square error (MSE)
The mean square error (MSE) is defined by
where yn and are the MLP’s output and expected output of the nth input, and N is the number of samples.
4.3. Phase Space Reconstruction
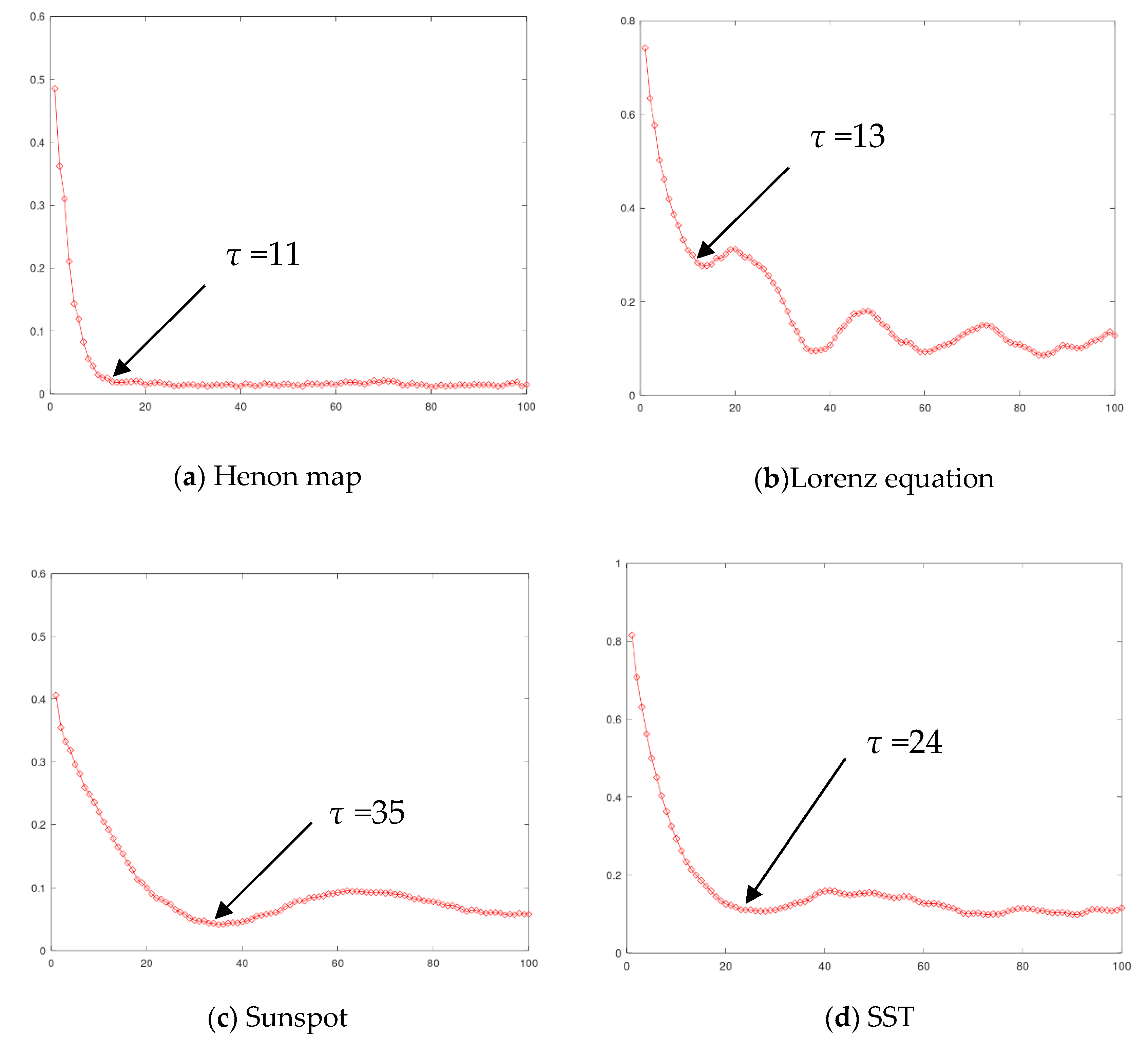
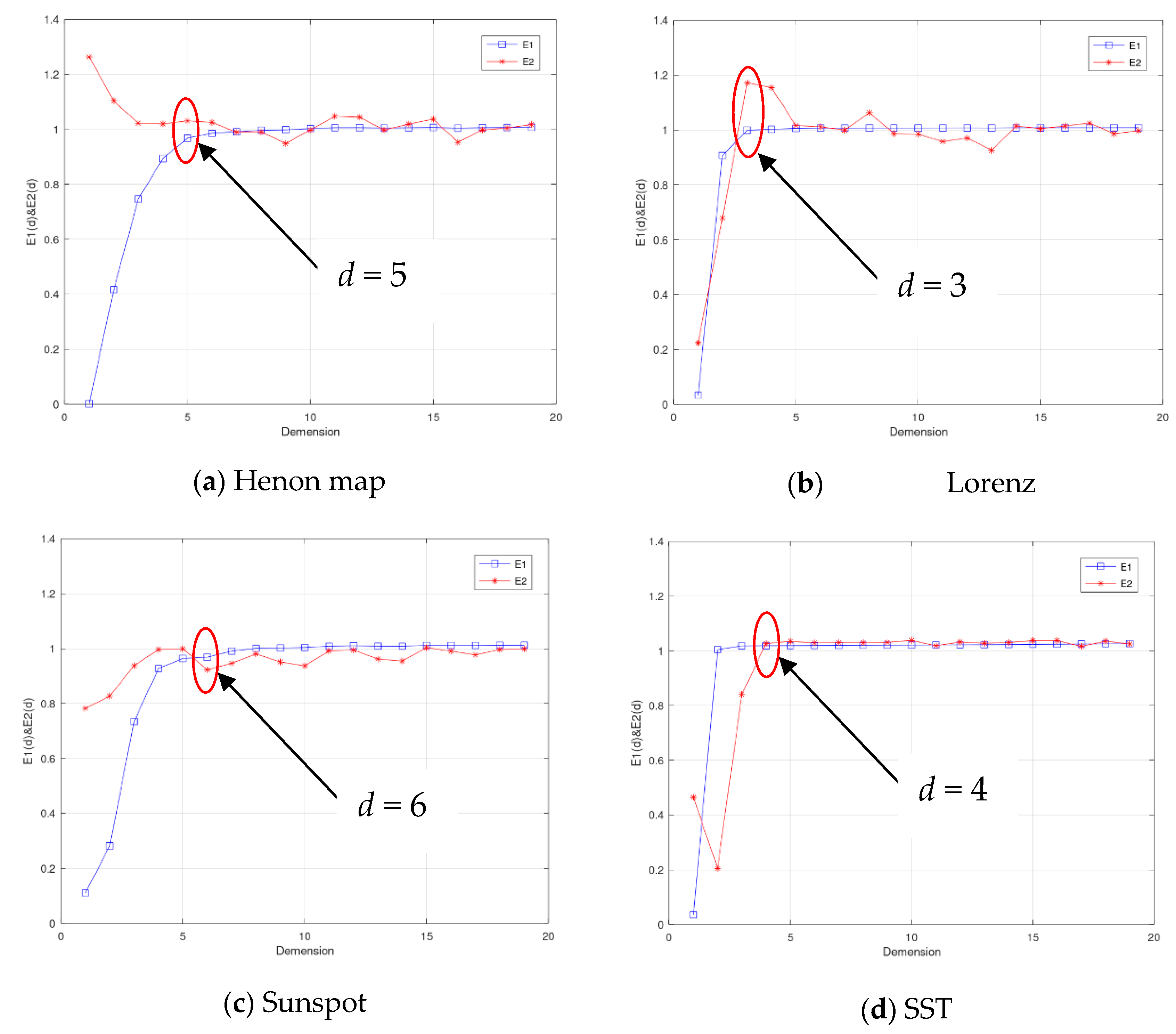
For phase space reconstruction, the two parameters of the delay interval τ* and embedding dimension m* should be determined. The delay interval τ* is determined by the mutual information method, and the embedded dimension m* is selected by the Cao method. Figure 2 shows the variation curve of mutual information with delay interval τ on four datasets. The first minimum point or inflection point of the four curves is selected as the final delay interval. In the Henon map dataset, when τ = 11, the curve enters the stationary region, so the time interval is selected as 11. In the Lorenz dataset, the curve reaches the first minimum point when τ = 13, so the time interval of the Lorenz dataset is selected as 13. In the sunspot dataset and the equatorial Pacific sea-surface temperature dataset, the first minimum is reached at τ = 35 and τ = 24, respectively, so the time interval is chosen as 35 and 24, respectively. Figure 3 shows the change of the two indicators E1 and E2 of the CAO method with the embedding dimension on four datasets, and we select the definite state where E1 reaches a stationary state and E2 does not. As shown in the figure, in the four datasets of the Henon map, Lorenz, sunspots, and equatorial Pacific sea-surface temperature, the embedding dimensions are selected as 5, 3, 7, and 4, respectively.
4.4. Analysis for AICg
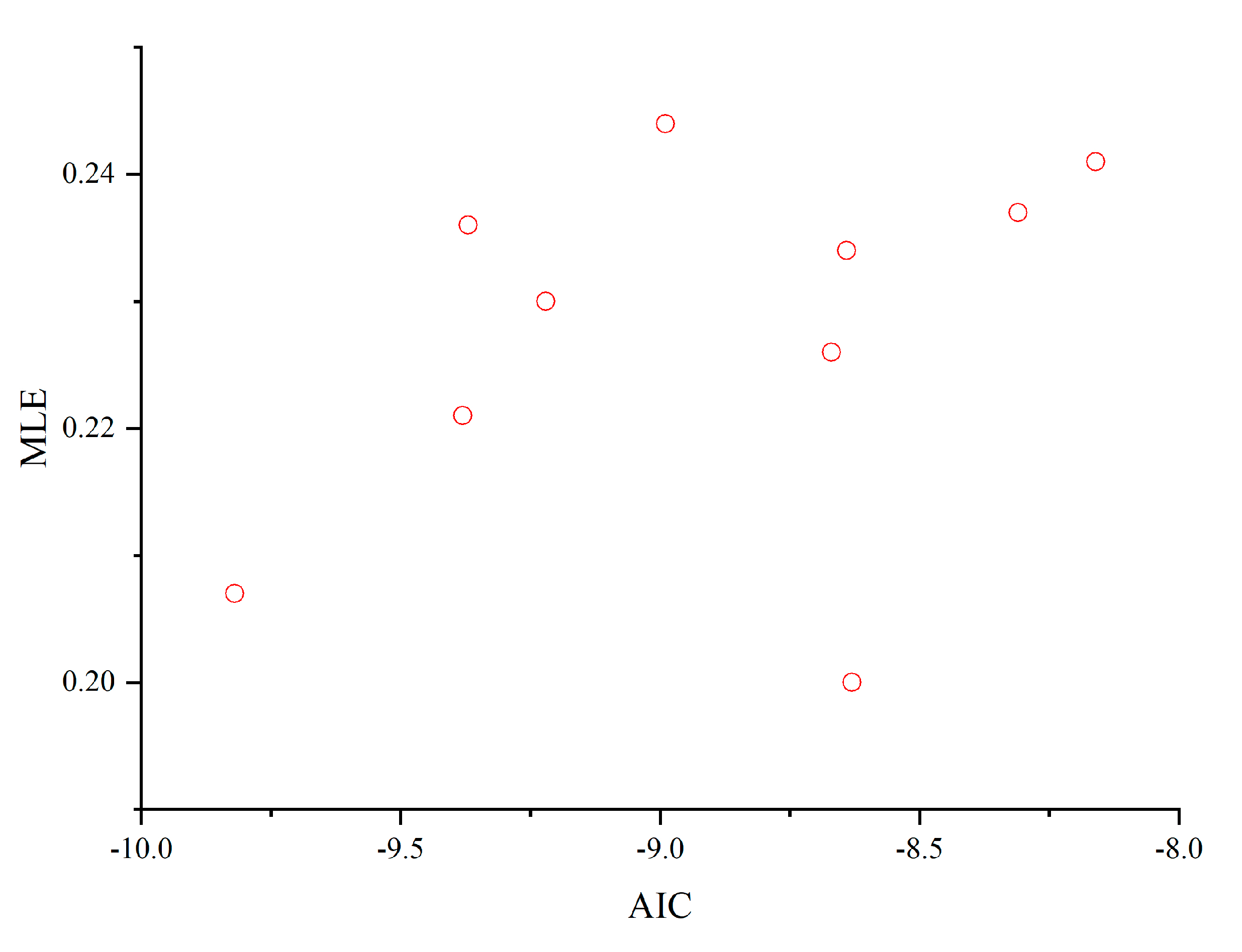
We trained different networks on the Lorentz dataset by randomly initializing the parameters (here, the same network topology is used but with different network weights). The number of nodes in the hidden layer of the network is set to 20, and 10 networks are obtained by training from 10 random initialized parameters. Table 1 shows the comparison results of generalized degrees of freedom (GDF), Akaike information criterion (AICg), and maximum Lyapunov exponents (MLE) for these 10 networks on the Lorenz dataset. The results show that the models with small AICg values prefer small MLE values. The scatterplots for MLE and AICg also show the same trend (Figure 4). In other words, AICg is a good criterion for selecting a good network for chaotic time series.
4.5. Model Optimization
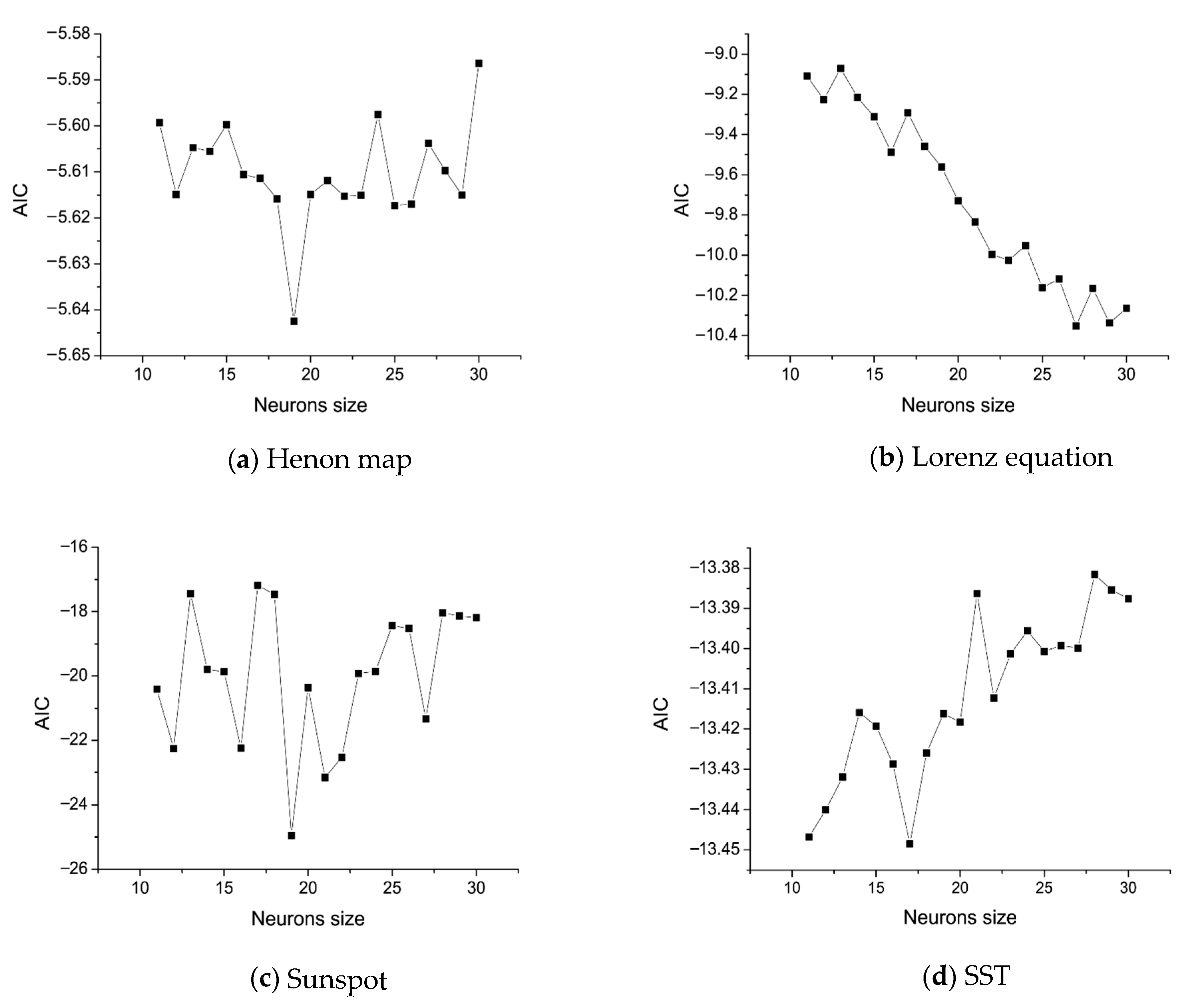
In order to find the optimal network topology for chaotic time series, we select 20 candidate network structures, that is, the number of neurons in the hidden layer from 11 to 30. Each network is trained by randomly selecting initial weights from 10 groups, and the model parameter with the smallest AICg was selected. Figure 5 shows the changes of AICg with hidden layer sizes on the Henon map, Lorenz equation, sunspot, and SST datasets, respectively. For example, as can be seen in Figure 5a, the smallest AICg value is obtained when the number of hidden layer nodes is 19, which is the selected optimal structure. Similarly, for the Lorenz equation, sunspots, and equatorial Pacific sea-surface temperature datasets, the smallest AICg values were obtained with the number of hidden nodes being 27, 19, and 17.
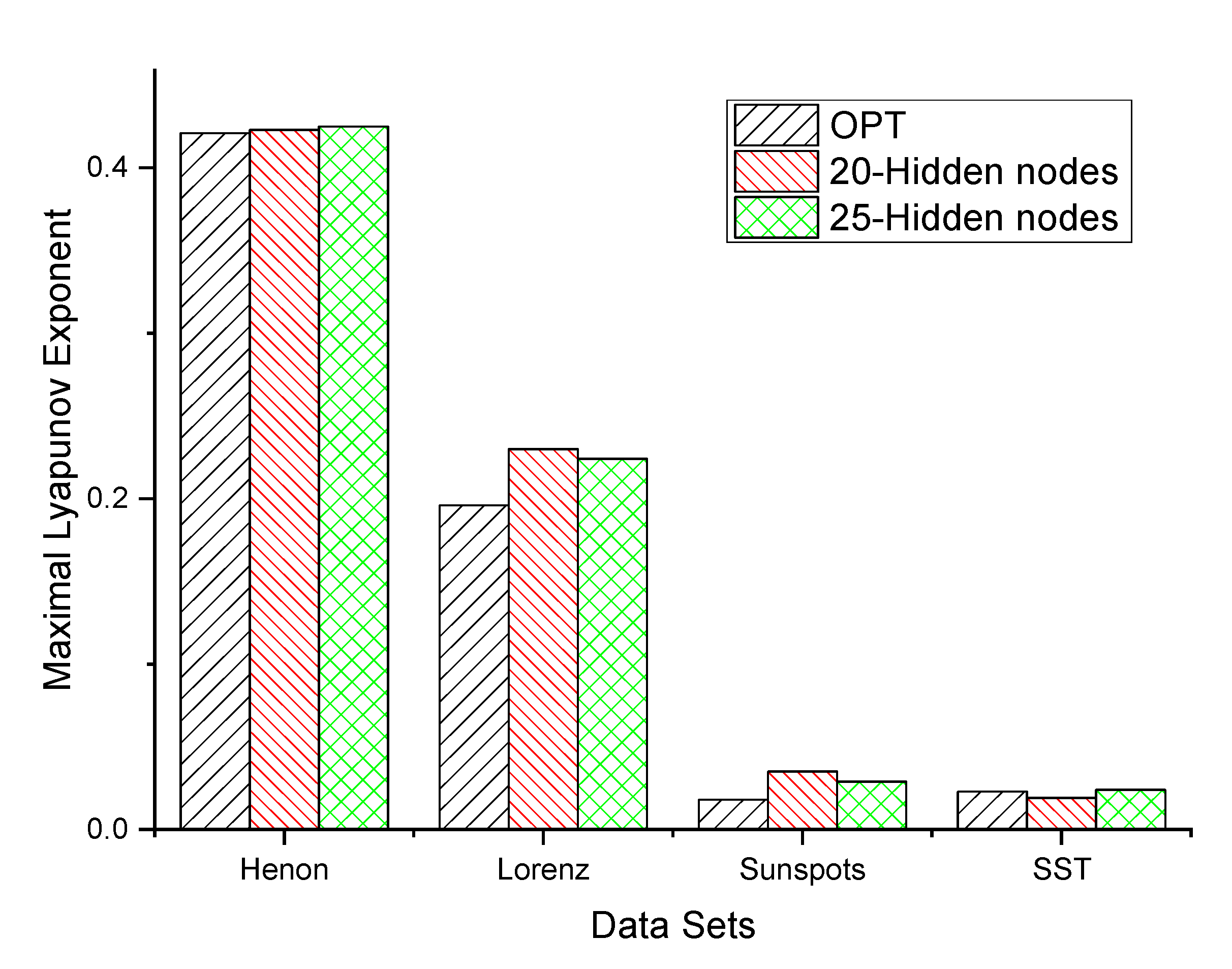
The maximal Lyapunov exponents (MLEs) are calculated by the above method for the four chaotic time series. Three MLP networks—one built by the optimal neuron size and the other two networks built by 20 and 25 neurons, respectively–are employed to estimate the MLE for the four datasets. The two compared networks are optimized by simply minimizing the loss function on MSE. The numerical results are listed in Figure 6. The numerical results show that the network model optimized by our proposed method is significantly better than the two network structures with a fixed number of hidden layer nodes of 20 and 25 on the Lorenz and sunspot datasets, slightly better than the other two types of networks on the Henon map dataset, roughly equivalent to the other two networks on the SST dataset, slightly better than the 25 hidden layer node network, and slightly worse than the 20 hidden layer node network results.
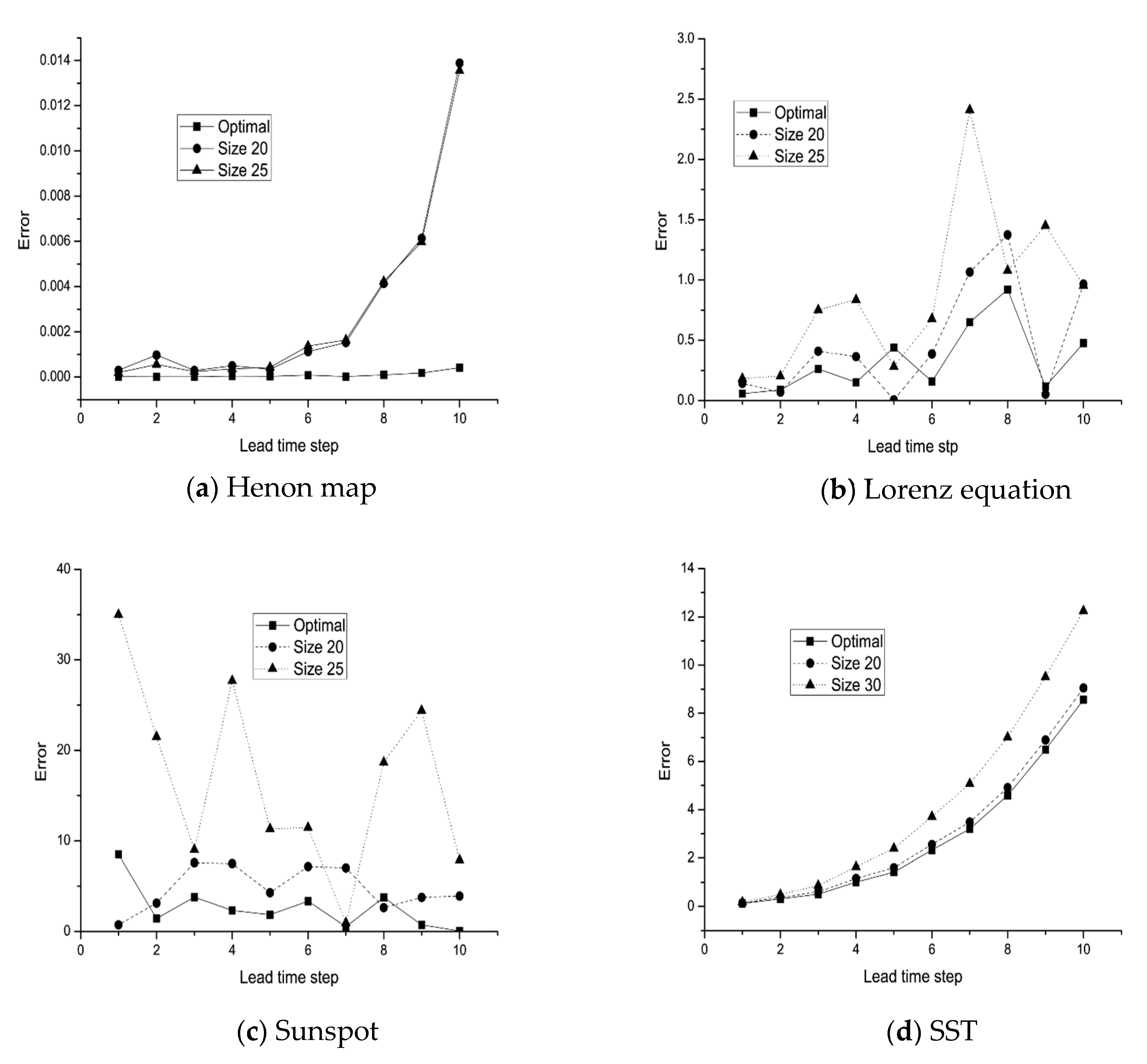
In order to further compare the performance of our proposed method, we investigate the multi-step prediction effect of the above three types of networks on the four datasets, namely, the optimized network by our proposed method, and two MLP networks with 20 and 25 neurons in the hidden layer, respectively. They are trained by the same dataset. The comparison results are shown in Figure 7. In Figure 7a, we show that the optimized MLP network provides significantly better prediction results than the other two MLP networks on the Henon map dataset; the optimized MLP network performs the best on all time steps. It also indicates that the AICg performs well in choosing a good MLP network for a chaotic time series. Figure 7a shows the results of the Lorenz dataset. Except for the fifth time step, the optimized MLP network performs the best among the three networks. The comparison results on two real-world time series are shown in Figure 7c,d. For the first five steps, the MLP networks can predict the time series quite well, but after five steps, the predicting errors become larger. The MLP network selected by the AICg also behaves much better than the other two MLP networks in nearly all cases. It also demonstrates the benefit of using the AICg to choose a good MLP network for a chaotic time series.
5. Conclusions
Focusing on chaotic time series modeling, this paper proposes an MLP network-based framework. First, the generalized degree of freedom approximation method of MLP networks is derived, and then the Akaike information criterion (AICg) can be calculated. Next, a multilayer perceptron network optimization method for chaotic time series analysis is designed according to AICg. Finally, this paper proposes an overall framework for chaotic time series analysis. To verify the effectiveness of the proposed method, it is applied to four chaotic time series datasets, including two artificial datasets and two actual datasets. Experimental results show that the proposed method can effectively optimize the MLP network, and the selected model has obvious performance advantages. At the same time, the results show that the model selected in this paper can obtain good prediction performance on all four datasets. In future work, this approach could be extended to deep neural network models.
Author Contributions
Conceptualization, X.S. and Y.L.; methodology, X.S.; software, M.Q.; validation, M.Q.; formal analysis, A.T. and M.Q.; investigation, A.T. and X.S.; writing—original draft preparation, M.Q.; writing—review and editing, Y.L., A.T. and X.S.; visualization, M.Q.; funding acquisition, Y.L. and X.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded in part by the NSFC grant numbers 61972174 and 62272192, the Science-Technology Development Plan Project of Jilin Province grant number 20210201080GX, the Jilin Province Development and Reform Commission grant number 2021C044-1, the Guangdong Universities’ Innovation Team grant number 2021KCXTD015, and Key Disciplines Projects grant number 2021ZDJS138.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The open-access data that support the findings of this study are made publicly available at psl.noaa.gov/gcos_wgsp/Timeseries/SUNSPOT/ (accessed on 5 June 2023) and http://geodata.pku.edu.cn (accessed on 8 April 2023).
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
References
- Alzaid, S.S.; Kumar, A.; Kumar, S.; Alkahtani, B.S.T. Chaotic behavior of financial dynamical system with generalized fractional operator. Fractals 2023, 31, 2340056. [Google Scholar] [CrossRef]
- Yao, Q.; Jahanshahi, H.; Batrancea, L.M.; Alotaibi, N.D.; Rus, M.-I. Fixed-Time Output-Constrained Synchronization of Unknown Chaotic Financial Systems Using Neural Learning. Mathematics 2022, 10, 3682. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, P.; Li, H.; Zu, W.; Zhang, H. Short-Term Power Prediction of Wind Power Generation System Based on Logistic Chaos Atom Search Optimization BP Neural Network. Int. Trans. Electr. Energy Syst. 2023, 2023, 6328119. [Google Scholar] [CrossRef]
- Wang, M.H.; Lu, S.D.; Liao, R.M. Fault Diagnosis for Power Cables Based on Convolutional Neural Network With Chaotic System and Discrete Wavelet Transform. IEEE Trans. Power Deliv. 2022, 37, 582–590. [Google Scholar] [CrossRef]
- Abuturab, M.R. Multiple-information security system using key image phase and chaotic random phase encoding in Fresnel transform domain. Opt. Lasers Eng. 2020, 124, 105810. [Google Scholar] [CrossRef]
- Liu, Z.Y.; Xia, T.C.; Wang, J.B. Fractional two-dimensional discrete chaotic map and its applications to the information security with elliptic-curve public key cryptography. J. Vib. Control 2017, 24, 4797–4824. [Google Scholar] [CrossRef]
- Yang, G.C.; Yao, J.Y.; Dong, Z.L. Neuroadaptive learning algorithm for constrained nonlinear systems with disturbance rejection. Int. J. Robust Nonlinear Control 2022, 32, 5811–6215. [Google Scholar] [CrossRef]
- Yang, G.C. Asymptotic tracking with novel integral robust schemes for mismatched uncertain nonlinear systems. Int. J. Robust Nonlinear Control 2023, 33, 1407–2507. [Google Scholar] [CrossRef]
- Brandejsky, T. Specific modification of a GPA-ES evolutionary system suitable for deterministic chaos regression. Comput. Math. Appl. 2013, 66, 106–112. [Google Scholar] [CrossRef]
- Senkerik, R.; Oplatková, Z.K.; Zelinka, I.; Chramcov, B.; Davendra, D.; Pluhacek, M. Utilization of analytic programming for the evolutionary synthesis of the robust multi-chaotic controller for selected sets of discrete chaotic systems. Soft Comput. 2014, 18, 651–668. [Google Scholar] [CrossRef]
- Bezruchko, B.P.; Smirnov, D.A. Constructing nonautonomous differential equations from experimental time series. Phys. Rev. E 2000, 63, 016207. [Google Scholar] [CrossRef] [Green Version]
- Lainscsek, C.S.M.; Letellier, C.; Schurrer, F. Ansatz library for global modeling with a structure selection. Phys. Rev. E 2001, 64, 016206. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Han, P.; Zhou, S.L.; Wang, D.F. A Multi-objective Genetic Programming/NARMAX Approach to Chaotic Systems Identification. In Proceedings of the 6th World Congress on Intelligent Control and Automation (2006), Dalian, China, 21–23 June 2006; pp. 1735–1739. [Google Scholar]
- Karimov, A.; Rybin, V.; Kopets, E.; Karimov, T.; Nepomuceno, E.; Butusov, D. Identifying empirical equations of chaotic circuit from data. Nonlinear Dyn. 2023, 111, 871–886. [Google Scholar] [CrossRef]
- Yang, J.; Zhao, J.; Song, J.; Wu, J.; Zhao, C.; Leng, H. A Hybrid Method Using HAVOK Analysis and Machine Learning for Predicting Chaotic Time Series. Entropy 2022, 24, 408. [Google Scholar] [CrossRef] [PubMed]
- Sarveswararao, V.; Ravi, V.; Vivek, Y. ATM cash demand forecasting in an Indian bank with chaos and hybrid deep learning networks. Expert Syst. Appl. 2023, 211, 118645. [Google Scholar] [CrossRef]
- Raubitzek, S.; Neubauer, T. Taming the Chaos in Neural Network Time Series Predictions. Entropy 2021, 23, 1424. [Google Scholar] [CrossRef]
- Yang, G.; Yao, J.; Ullah, N. Neuroadaptive control of saturated nonlinear systems with disturbance compensation. ISA Trans. 2022, 122, 49–62. [Google Scholar] [CrossRef]
- Xu, Y.Q.; Zhen, X.X.; Tang, M. Dynamical System in Chaotic Neurons with Time Delay Self-Feedback and Its Application in Color Image Encryption. Complexity 2022, 2022, 2832104. [Google Scholar] [CrossRef]
- Cheng, W.; Feng, J.B.; Wang, Y. High precision reconstruction of silicon photonics chaos with stacked CNN-LSTM neural networks. Chaos 2022, 32, 053112. [Google Scholar] [CrossRef]
- Lee, J.; Huang, Z.; Lin, L.; Guo, Y.; Lee, R. Chaotic Bi-LSTM and attention HLCO predictor-based quantum price level fuzzy logic trading system. Soft Comput. 2022. [Google Scholar] [CrossRef]
- Nasiri, H.; Ebadzadeh, M.M. MFRFNN: Multi-Functional Recurrent Fuzzy Neural Network for Chaotic Time Series Prediction. Neurocomputing 2022, 507, 292–310. [Google Scholar] [CrossRef]
- Lee, R.S. Chaotic Type-2 Transient-Fuzzy Deep Neuro-Oscillatory Network (CT2TFDNN) for Worldwide Financial Prediction. IEEE Trans. Fuzzy Syst. 2020, 28, 731–745. [Google Scholar] [CrossRef]
- Chai, S.H.; Lim, J.S. Forecasting business cycle with chaotic time series based on neural network with weighted fuzzy membership functions. Chaos Solitons Fractals 2016, 90, 118–126. [Google Scholar] [CrossRef]
- González-Zapata, A.M.; Tlelo-Cuautle, E.; Ovilla-Martinez, B.; Cruz-Vega, I.; De la Fraga, L.G. Optimizing Echo State Networks for Enhancing Large Prediction Horizons of Chaotic Time Series. Mathematics 2022, 10, 3886. [Google Scholar] [CrossRef]
- Mohanty, S.; Dash, R. A novel chaotic flower pollination algorithm for modelling an optimized low-complexity neural network-based NAV predictor model. Prog. Artif. Intell. 2022, 11, 349–366. [Google Scholar] [CrossRef]
- Wang, Y.F.; Fu, Y.C.; Xue, H. Improved prediction method of PV output power based on optimised chaotic phase space reconstruction. IET Renew. Power Gener. 2020, 14, 1831–1840. [Google Scholar] [CrossRef]
- Xu, X.H.; Ren, W.J. A Hybrid Model Based on a Two-Layer Decomposition Approach and an Optimized Neural Network for Chaotic Time Series Prediction. Symmetry 2019, 11, 610. [Google Scholar] [CrossRef] [Green Version]
- Ong, P.; Zainuddin, Z. Optimizing wavelet neural networks using modified cuckoo search for multi-step ahead chaotic time series prediction. Appl. Soft Comput. 2019, 80, 374–386. [Google Scholar] [CrossRef]
- Feng, T.; Yang, S.Y.; Han, F. Chaotic time series prediction using wavelet transform and multi-model hybrid method. J. Vibroeng. 2019, 21, 1983–1999. [Google Scholar] [CrossRef] [Green Version]
- Huang, F.; Yin, K.; Zhang, G.; Gui, L.; Yang, B.; Liu, L. Landslide displacement prediction using discrete wavelet transform and extreme learning machine based on chaos theory. Environ. Earth Sci. 2016, 75, 1376. [Google Scholar] [CrossRef]
- Lu, R.; Lei, T. Short-term load forecast using maximum overlap discrete wavelet transform and BP neural network based on chaos theory. In Proceedings of the 2019 31st Chinese Control and Decision Conference (CCDC 2019), Nanchang, China, 3–5 June 2019; pp. 6029–6033. [Google Scholar]
- Ramadevi, B.; Bingi, K. Chaotic time series forecasting approaches using machine learning techniques: A review. Symmetry 2022, 14, 955. [Google Scholar] [CrossRef]
- Srinivasan, K.; Coble, N.; Hamlin, J.; Antonsen, T.; Ott, E.; Girvan, M. Parallel Machine Learning for Forecasting the Dynamics of Complex Networks. Phys. Rev. Lett. 2022, 128, 164101. [Google Scholar] [CrossRef] [PubMed]
- Li, K.F.H.; Deng, P.F. Chaotic time series prediction using DTIGNet based on improved temporal-inception and GRU. Chaos Solitons Fractals 2022, 159, 112183. [Google Scholar]
- Sangiorgio, M.; Dercole, F.; Guariso, G. Forecasting of noisy chaotic systems with deep neural networks. Chaos Solitons Fractals 2021, 153, 11570. [Google Scholar] [CrossRef]
- Xie, H.L.; Zhang, L.; Lim, C.P. Evolving CNN-LSTM Models for Time Series Prediction Using Enhanced Grey Wolf Optimizer. IEEE Access 2020, 8, 161519–161541. [Google Scholar] [CrossRef]
- Huang, W.T.; Li, Y.T.; Huang, Y. Deep Hybrid Neural Network and Improved Differential Neuroevolution for Chaotic Time Series Prediction. IEEE Access 2020, 8, 159552–159565. [Google Scholar] [CrossRef]
- Qian, Y.S.; Zeng, J.W.; Zhang, S.F. Short-Term Traffic Prediction Based on Genetic Algorithm Improved Neural Network. Tech. Gaz. 2020, 27, 1270–1276. [Google Scholar]
- Chen, L.G.; Chiang, H.D.; Dong, N. Group-based chaos genetic algorithm and non-linear ensemble of neural networks for short-term load forecasting. IET Gener. Transm. Distrib. 2016, 10, 1440–1447. [Google Scholar] [CrossRef]
- Kao, C.H.; Hsu, C.F.; Don, H.S. Design of an adaptive self-organizing fuzzy neural network controller for uncertain nonlinear chaotic systems. Neural Comput. Appl. 2012, 21, 1243–1253. [Google Scholar] [CrossRef]
- Akaike, H. Information theory and the maximum likelihood principle. In International Symposium on Information Theory; Petrov, V., Csaki, F., Eds.; Akademiai Kiado: Budapest, Hungary, 1973. [Google Scholar]
- Jayawardena, A.W.; Xu, P.C.; Tsang, F.L.; Li, W.K. Determining the structure of a radial basis function network for prediction of nonlinear hydrological time series. Hydrol. Sci. J. 2006, 51, 21–44. [Google Scholar] [CrossRef]
- Xu, P.; Jayawardena, A.; Li, W.K. Model selection for RBF network via generalized degree of freedom. Neurocomputing 2013, 99, 163–171. [Google Scholar] [CrossRef]
- Ye, J. On measuring and correcting the effects of data mining and model selection. J. Am. Stat. Assoc. 1998, 93, 120–131. [Google Scholar] [CrossRef]
- Takens, F. Detecting Strange Attractors in Turbulence. In Dynamical Systems and Turbulence, Warwick 1980; Springer: Berlin/Heidelberg, Germany, 1981; pp. 366–381. [Google Scholar]
- Chen, K.; Han, B.T. A survey of state space recognition of chaotic time series analysis. Comput. Sci. 2005, 32, 67–70. (In Chinese) [Google Scholar]
- Graven, P.; Wahba, G. Smoothing noisy data with Spine function. Numer. Math. 1979, 31, 377–403. [Google Scholar]
- Carruba, V.; Aljbaae, S.; Domingos, R.C.; Huaman, M.; Barletta, W. Chaos identification through the autocorrelation function indicator ACFI. Celest. Mech. Dyn. Astron. 2021, 133, 38. [Google Scholar] [CrossRef]
- Kennel, M.B.; Brown, R.; Abarbanel, H.D.I. Determining embedding dimension for phase-space reconstruction using a geometrical construction. Phys. Rev. A 1992, 45, 3403. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cao, L.Y. Practical method for determining the minimum embedding dimension of a scalar time series. Phys D 1997, 110, 43–50. [Google Scholar] [CrossRef]
- Uzal, L.C.; Grinblat, G.L.; Verdes, P.F. Optimal reconstruction of dynamical systems: A noise amplification approach. Phys. Rev. E 2011, 84, 016223. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Keogh, E.J.; Chakrabarti, K.; Pazzani, M.J. Dimensionality reduction for fast similarity search in large time series databases. Knowl. Inf. Syst. 2001, 3, 263–286. [Google Scholar] [CrossRef]
- Chen, Z.; Zuo, W.; Hu, Q.; Lin, L. Kernel sparse representation for time series classification. Inf. Sci. 2015, 292, 15–26. [Google Scholar] [CrossRef]
- Rosas-Romero, R.; Diaz-Torres, A.; Etcheverry, G. Forecasting of stock return prices with sparse representation of financial time series over redundant dictionaries. Expert Syst. Appl. 2016, 57, 37–48. [Google Scholar] [CrossRef]
- Kotteti, C.M.M.; Dong, X.S.; Qian, L.J. Ensemble deep learning on time-series representation of tweets for rumor detection in social media. Appl. Sci. 2020, 10, 7541. [Google Scholar] [CrossRef]
- Li, Q.; Xu, P. Estimation of Lyapunov spectrum and model selection of a chaotic time series. Appl. Math. Model. 2012, 36, 6090–6099. [Google Scholar] [CrossRef]
Figure 1.
Pipeline of the modeling selection.

Figure 2.
Variation curve of mutual information with delay interval τ on datasets of the (a) Henon map, the (b) Lorenz equation, (c) sunspot, and (d) SST.
Figure 2.
Variation curve of mutual information with delay interval τ on datasets of the (a) Henon map, the (b) Lorenz equation, (c) sunspot, and (d) SST.

Figure 3.
The E1 and E2 indicators change curves with the embedded dimension d on datasets of the (a) Henon map, (b) Lorenz equation, (c) sunspot, and (d) SST.
Figure 3.
The E1 and E2 indicators change curves with the embedded dimension d on datasets of the (a) Henon map, (b) Lorenz equation, (c) sunspot, and (d) SST.

Figure 4.
Scatterplot of AICg and MLE on 10 different networks.

Figure 5.
AICg curves of hidden layer scales on the datasets of the (a) Henon map, (b) Lorenz equation, (c) sunspot, and (d) SST.
Figure 5.
AICg curves of hidden layer scales on the datasets of the (a) Henon map, (b) Lorenz equation, (c) sunspot, and (d) SST.

Figure 6.
Lyapunov exponent estimation using the MLP model.

Figure 7.
MSE error comparisons on datasets of the (a) Henon map, (b) Lorenz equation, (c) sunspot, and (d) SST.
Figure 7.
MSE error comparisons on datasets of the (a) Henon map, (b) Lorenz equation, (c) sunspot, and (d) SST.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Comparison results of AICg, GDF, and MLE on 10 networks.
| GDF | AIC | MLE | |
|---|---|---|---|
| 1 | 76.00 | −9.22 | 0.230 |
| 2 | 76.00 | −9.37 | 0.236 |
| 3 | 69.93 | −8.31 | 0.237 |
| 4 | 74.01 | −8.67 | 0.226 |
| 5 | 76.00 | −8.99 | 0.244 |
| 6 | 73.60 | −9.38 | 0.221 |
| 7 | 75.98 | −8.64 | 0.234 |
| 8 | 76.00 | −9.82 | 0.207 |
| 9 | 76.00 | −8.63 | 0.200 |
| 10 | 76.00 | −8.16 | 0.241 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Qiao, M.; Liang, Y.; Tavares, A.; Shi, X. Multilayer Perceptron Network Optimization for Chaotic Time Series Modeling. Entropy 2023, 25, 973. https://doi.org/10.3390/e25070973
AMA Style
Qiao M, Liang Y, Tavares A, Shi X. Multilayer Perceptron Network Optimization for Chaotic Time Series Modeling. Entropy. 2023; 25(7):973. https://doi.org/10.3390/e25070973
Chicago/Turabian StyleQiao, Mu, Yanchun Liang, Adriano Tavares, and Xiaohu Shi. 2023. "Multilayer Perceptron Network Optimization for Chaotic Time Series Modeling" Entropy 25, no. 7: 973. https://doi.org/10.3390/e25070973
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.