
The Absence of a Weak-Tie Effect When Predicting Large-Weight Links in Complex Networks
by
 , , , , , and
, , , , , and
Chengjun Zhang
1,2,3,
Qi Li
1,2,3,
Yi Lei
1,2,3,
Ming Qian
1,2,3,
Xinyu Shen
1,2,3,
Di Cheng
1,2,3 and
Wenbin Yu
1,2,3,* 1
School of Computer and Software, Nanjing University of Information Science and Technology, Nanjing 210044, China
2
Jiangsu Collaborative Innovation Center of Atmospheric Environment and Equipment Technology (CI-CAEET), Nanjing University of Information Science and Technology, Nanjing 210044, China
3
Jiangsu Engineering Center of Network Monitoring, Nanjing University of Information Science and Technology, Nanjing 210044, China
*
Author to whom correspondence should be addressed.
Entropy 2023, 25(3), 422; https://doi.org/10.3390/e25030422
Submission received: 28 January 2023
/
Revised: 22 February 2023
/
Accepted: 23 February 2023
/
Published: 26 February 2023
(This article belongs to the Special Issue Complexity, Entropy and the Physics of Information)
Abstract
:Link prediction is a hot issue in information filtering. Link prediction algorithms, based on local similarity indices, are widely used in many fields due to their high efficiency and high prediction accuracy. However, most existing link prediction algorithms are available for unweighted networks, and there are relatively few studies for weighted networks. In the previous studies on weighted networks, some scholars pointed out that links with small weights play a more important role in link prediction and emphasized that weak-ties theory has a significant impact on prediction accuracy. On this basis, we studied the edges with different weights, and we discovered that, for edges with large weights, this weak-ties theory actually does not work; Instead, the weak-ties theory works in the prediction of edges with small weights. Our discovery has instructive implications for link predictions in weighted networks.
1. Introduction
Complex networks play an increasingly important role in the era of information explosion, and the relationships between individuals can be simplified into the form of a network, which is a collection of nodes and edges. A typical network is composed of many nodes and some edges. The nodes are used to represent different individuals in the real system, and the edges are used to represent the relationship between individuals [1,2]. In 1961, Erdős and Rényi proposed the ER network, which features a low clustering coefficient, a short average distance, and a Poisson degree distribution [3,4]. In 1998, Watts and Strogatz proposed a network called the WS network, which has a high clustering coefficient, a small average distance, and a trend of exponential decay of the probability of large-degree nodes [5]. In 1999, Barabá and Albert proposed the BA network, which enjoys a small clustering coefficient and average distance [6,7]. The application of complex networks is reflected in all aspects of life. For instance, brain systems can be viewed as complex networks that can interact dynamically. Japp et al. studied the correlation between the structural properties of networks and the dynamic of networks, and they demonstrated that both functional and anatomical connectivity of the healthy brains share many features with small-world networks, but only to a limited extent, with scale-free networks [8]. Cats et al. developed a public transport robustness assessment model that computes ridership distribution and network performance metrics under planned capacity reductions [9].
Link prediction in the network refers to predicting the possibility of a connection between two nodes in the network that have not yet connected based on the network structure, such as their common neighbors [10]. Link prediction can be used to predict both unknown links (links that actually exist in the network, but which have not been detected), as well as future links (links that do not currently exist in the network, but which should exist or are likely to exist in the future) [11,12]. Research on link prediction can not only promote the theoretical development of network science and information science, but it also has great practical application value [13]. In recent years, with the rapid development of network science, its theoretical achievements have built a research platform for link prediction, making the research of link prediction closely related to the structure and evolution of the network. Therefore, the results of link prediction can be explained more theoretically [14,15,16,17].
Link prediction has very important practical implications and has been widely applied in many industries [18,19]. For example, link prediction can be used to predict potential academic partnerships [20,21], the number of citations of scientists [22] and the risk of diseases [23], recommend new friends/collaborators to people in social networks [24,25], the detection of anomalous emails [26,27], to analyze terrorist networks [28], and it can also be applied to the recommendation system to efficiently recommend suitable products to users [29,30]. Currently, link prediction research has attracted increasing attention from researchers [31]. Some scholars propose using a Markov chain for link prediction. In 2000, Sarukkai proposed and evaluated the notion of probabilistic link prediction and path analysis using Markov chains [32]. In 2002, Zhu et al. proposed a method for constructing a Markov model of a website based on past visitor behavior, and they used the Markov model for link prediction to help new users browse the site [33]. Additionally, some scholars propose using statistical relationships for link prediction. In 2002, Albert et al. proposed applying their statistical relational learning method to build a link prediction model [34]. In recent years, an increasing number of link prediction algorithms have been proposed. In 2006, Hasan et al. used supervised learning for link prediction [35,36], and machine learning methods have also been applied to link prediction [37,38,39]. Since traditional machine learning methods require massive preprocessing of data, Abbas et al. proposed a broad range of machine learning methods to predict the outcome of biomedical interactions and evaluated the performance of the traditional methods with more recent network-based methods [40]. Xian et al. presented a novel link prediction algorithm called GraphLP, which is based on network reconstruction theory [41]. Zhang et al. calculated the prediction accuracy of each edge in the network and found that the accuracy of edges with low edge betweenness is high, while the accuracy of edges with high edge betweenness is low. Therefore, they proposed an prediction algorithm, called RA-LP, to address this issue. This algorithm not only improves the accuracy of the edges with high edge betweenness, but it also improves the overall performance [42]. Shabaz et al. proposeed a method to predict future diseases based on existing health status using link prediction, and this explores how long the link survives [43]. In 2007, David and Jon developed a link prediction method based on analyzing the proximity measurement of nodes in the networks [44]. In 2008, Aaron Clauset et al. presented a general technique for inferring hierarchical structure from network data, and they further showed that knowledge of hierarchical structure can be used to predict missing connections in partially known networks with high accuracy [45,46].
In 2009, Guimer and Marta first mentioned the concept of a network error link, which means that the link that already exists in the network may be incorrect, and they presented a general mathematical and computational framework to address the problem of data reliability in complex networks [47,48]. In 2012, Almansoori et al. pointed out that prediction is one of the most appealing aspects in data mining, but none of the previous work in this domain has explored the prediction of links that may disappear in the future. Therefore, they proposed a link prediction model capable of predicting both links that might exist and links that may disappear in the future [49]. Recently, some scholars have used the link prediction method to infer important factors that have affected aviation network evolution. In the US aviation network, Liu et al. used the analysis of abnormal links in link prediction to find that, although some airports have a large number of common neighbors (simultaneously connected to two or more airports), there are no flights between them, and the reason is that they are limited by the factor of geographical location [50]. Inspired by link prediction, Wang et al. proposed a general framework for evaluating network evolution models, showing that link prediction has an important impact on revealing the network structure and evolution mechanism [51].
In terms of link prediction in weighted networks, some researchers have also conducted a series of studies. Murata and Moriyasu proposed three weighted similarity indices; they applied these indices to the networks of the question-answer bulletin boards system, and the results show that the prediction accuracy can be enhanced [52] with the consideration of weights. Lü et al. introduced these weighted similarity indices into a parameter , and the parameter was used to adjust the effect of the weight in the prediction. Link prediction in three real-world networks was carried out using this weighted index. As a result, they found that the optimal parameter in the link prediction is mostly less than 0. This means that the edges with small weights play a more important role in link prediction [53,54]. On this basis, we found that, when predicting edges with large weights, the larger the parameter is, the higher the accuracy of the prediction. On the other hand, when predicting edges with small weights, a smaller parameter is better, as we can see in Figure 1.
2. Data and Methods
This section mainly introduces the data and link prediction methods used in our research. This research involves four undirected weighted empirical networks: (a) USAir: American Air Transportation Network. Each node in the network represents an airport, and, if there is a direct flight route between the two airports, then there is an edge between the two nodes corresponding to the two airports. The network contains a total of 332 airports and 2126 routes, and the frequency of flights between two airports is called the edge weight [55]. (b) Email: email communication network. The nodes in the network represent users. If there is an email exchange between two users, then an edge exists. The weight of the edge indicates the number of email exchanges between users, and there are 710 users and 5996 emails in this network [56]. (c) CGScience: computer geometry collaboration network. This network represents the cooperative relationship of scientists in the field of computational geometry and contains 3621 authors and 9461 cooperative relationships. Only two authors who have collaborated on articles will be connected. Therefore, the weight of the network is the number of papers the two authors have collaborated on [55]. (d) NetScience: network science collaboration network. This network is composed of scientists who have published papers. In this network, nodes represent scientists, and connected edges represent the cooperative relationship between scientists. It has 1589 nodes and 268 components, and we only consider the giant component in this paper, which contains 379 nodes and 914 connected edges. Obviously, the greater the number of collaborations between two scientists, the greater the weight of the connection between them [57]. If the connectivity of the network is not good, we use the giant component of the network to represent it. The characteristics of these networks are shown in Table 1.
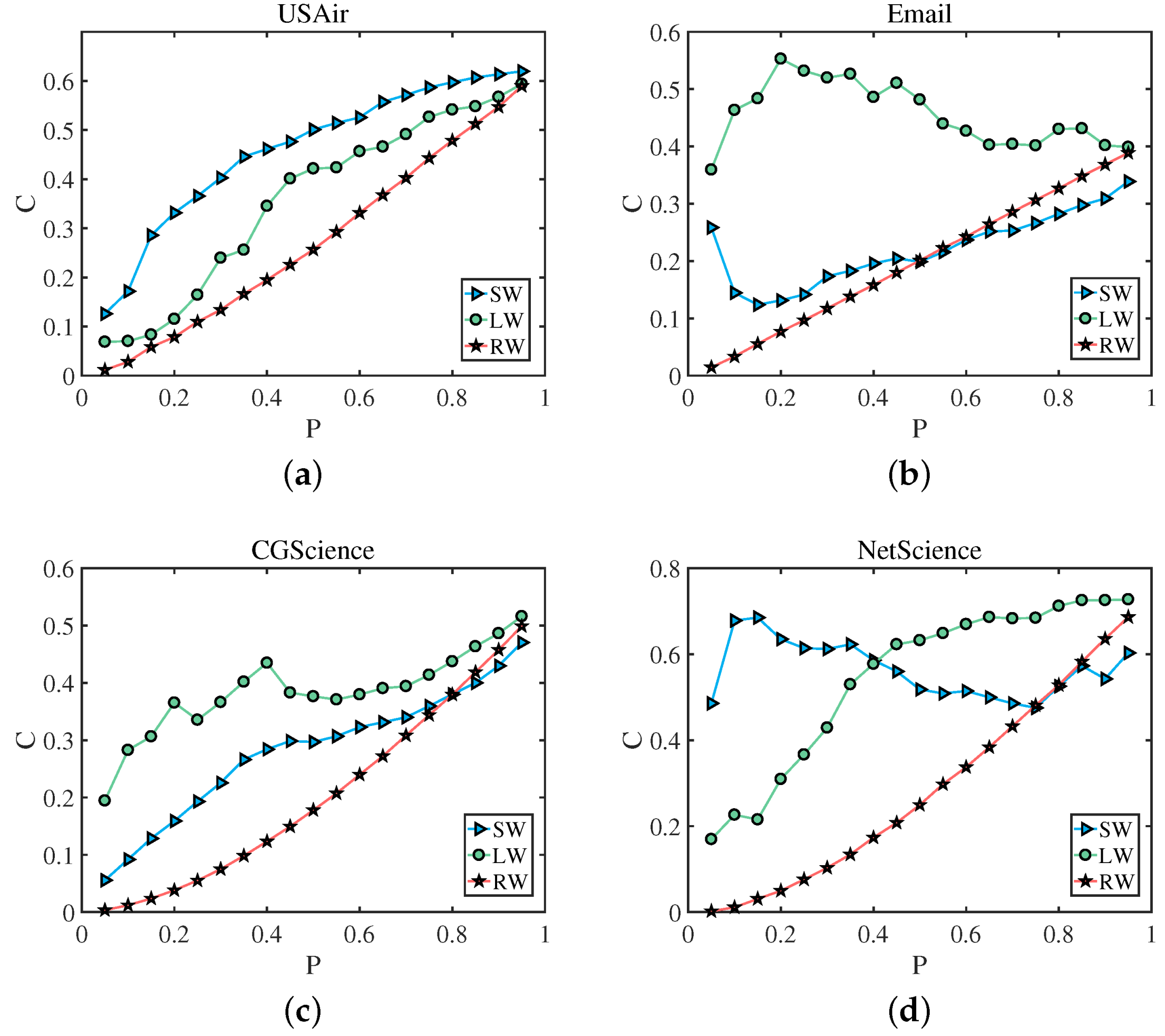
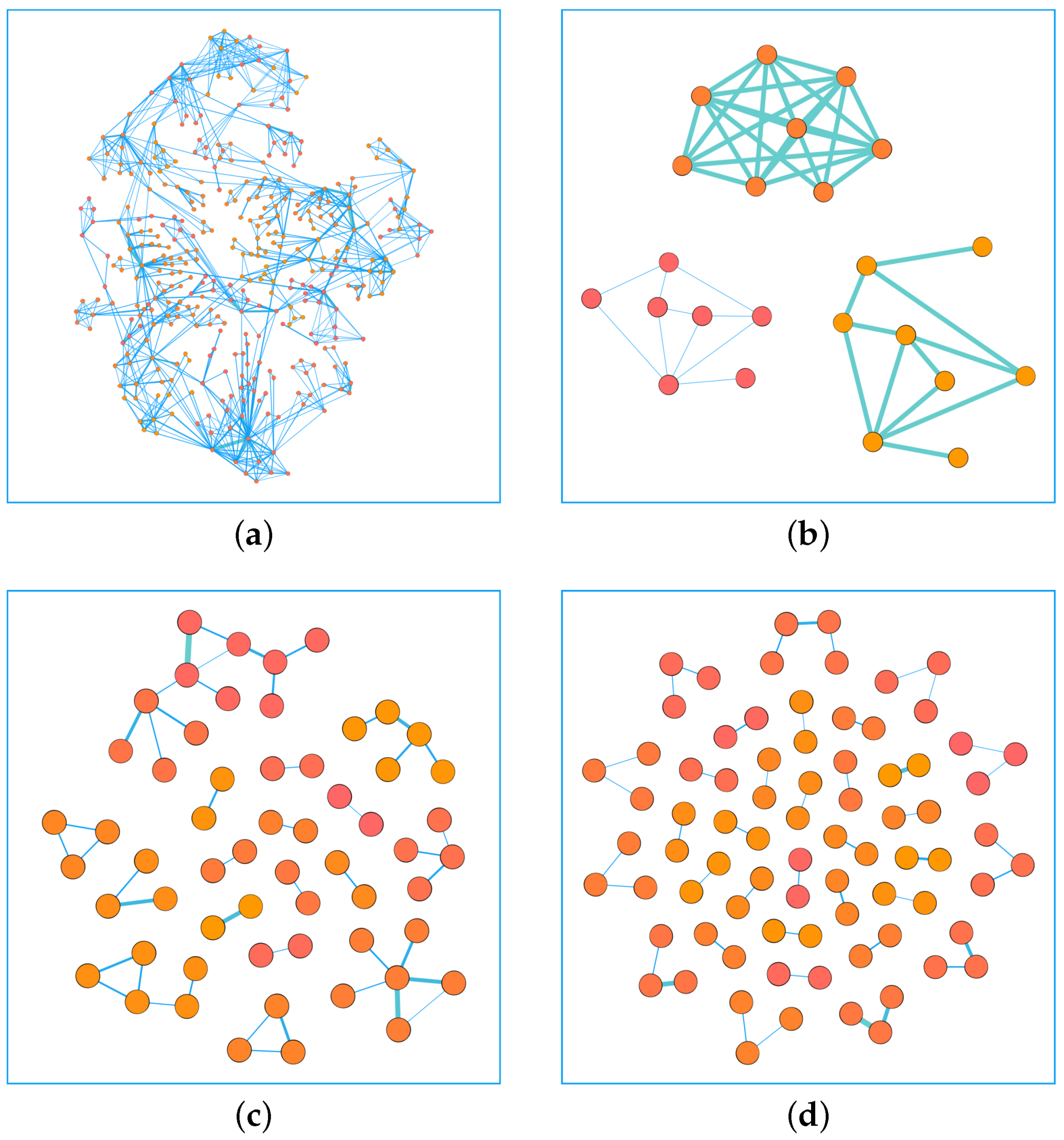
As mentioned above, in a weighted network, the edges with large weights tend to cluster together. Similarly, the edges of small weights tend to cluster together. Among all the edges of a network, we take out a certain percentage of the edges, P, and we calculate the clustering coefficient of the network composed of P. After we sort the edges in ascending order according to weights, we remove the edges with the top proportion P, which can be regarded as the edges with small weights (). Similarly, after sorting the edges in descending order according to weights, we take the edges with the top proportion P, which can be regarded as the edges with large weights (). We randomly select the edges of the proportion P from all the edges, and this part of the edges can represent the edges of the weights of the entire network (). Finally, we calculate the clustering coefficient C of the network composed of the corresponding edges. We found that the clustering coefficient of the network composed of the edges with large weights and small weights is larger than the clustering coefficient of a network composed of random edges. That is, the edges with large weights tend to cluster together, and the edges with small weights also cluster together. The result showing this phenomenon is given in Figure 2. Among them, (a) represents the clustering coefficient of a network formed by edges with high and low weights is greater than that of a network formed by random edges in USAir network, (b) shows edges with high weights have a tendency to cluster with each other in Email network, (c) and (d) denote the same result in CGScience network and NetScience neteork. We can use visualization software to draw a network, such as the NetScience network, and the result showing this phenomenon is given in Figure 3. Among them, (a) represents the structure of the entire network, (b) shows the edges with small weights in the network, (c) denotes the connected edges with large weights, the number of their edges is all 5% of the entire network, and (d) represents randomly selected edges. We use precision to evaluate the performance of the link prediction algorithms [58]. Precision is defined after sorting the link prediction results. Define l as the number of accurately predicted edges and L as the the amount of predicted edges. If l of the first L edges belong to the test set, the precision can be defined as:
The four networks we use are undirected weighted networks. Define as the similarity between node x and node y. The larger the value of is, the more similar the node x and the node y is. In the experiment, the entire network was randomly divided into a training set and a test set . The training set contains 90% of the entire network, and the test set contains 10% of the entire network. The test set is used to verify the accuracy of the prediction. To reduce the impact of randomness, the result is an average of 100 random divisions. We performed the experiment according to the following steps:
(i) First, we sort the links between the test set by their weight, and then we take 10% of the links with the largest weights from the sorted links and mark these links as . Similarly, we take 10% of the links with the smallest weights from the sorted links and mark these links as . Finally, we randomly take 10% of the links from the test set and note these links as . In the following, we study the precision for , and .
(ii) We sort the links between the test set by their weight, and then we divide these links evenly into 10 groups according to their weights, namely, , …, in which contains links with the smallest weight, and contains links with the largest weight. In the following, we study the best precision and the corresponding parameter for these 10 groups.
3. Link Prediction Algorithms
Our research uses three similarity indices, the Common Neighbors (CN), Adamic-Adar (AA) index, and Resource Allocation (RA) index, whose definitions are as follows.
(i) CN. Let denote the neighbor of node x and denote the neighbor of node y; then, can be expressed as the number of common neighbors of node x and node y, which can be expressed as follows:
where is the cardinality of the set B.
(ii) AA index. The idea of the algorithm is that the contribution of the common neighbor node with a high degree is less than that of the common neighbor node with a low degree [59], and can be expressed as:
where is the degree of node z.
(iii) RA index. Some scholars were inspired by the process of resource allocation in the network, and they proposed a new similarity measure [17], which can be expressed as:
However, in the real world, most networks are weighted. For example, in airline networks, the distance between cities can be defined as the weight of this link; in social networks, the relationship between individuals is also weighted. Some scholars proposed a weighted similarity definition [52], so the weighted CN index, weighted AA index, and the weighted RA index (we regard them as WCN, WAA and WRA, respectively) can be expressed as:
where is the weight of the link between nodes x and z, .
A parameter was introduced by researchers for these formulas [53], and is used to control the relative contributions of weak ties to the similarity measures. The parameter-dependent indices for WCN, WAA, and WRA can be expressed as:
where . Their research shows that the optimal value of is mostly less than 1. That is, for some weighted networks, weak links play a more important role in link prediction. Our further research revealed an interesting conjecture, for edges with large weights in the test set, we should use a larger to obtain a better prediction accuracy. For edges with small weights, we should use a smaller to obtain a higher prediction accuracy. This phenomenon would have a great impact on the accuracy of weighted network link prediction.
4. Experiments and Results
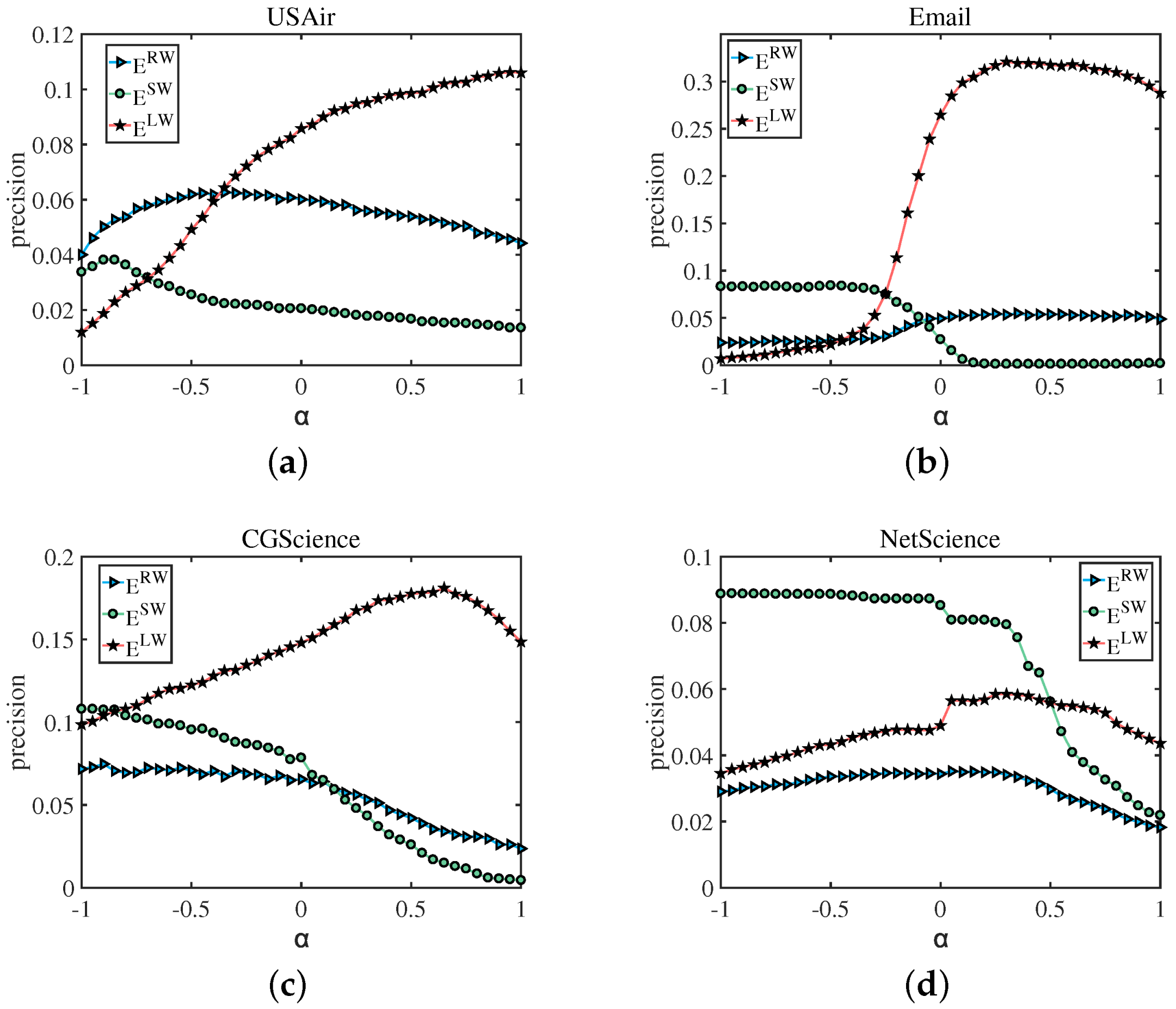
Based on Formula (8), we first calculated the precision of , , and , with ranging from −1 to 1, which aims to explore the different effects of weak-tie on predicting edges with small weights and large weights. The result is shown in the Figure 4. The precision of (links with the larger weight) increases with the increase of , while the precision of (links with the smaller weight) increases with the decrease of . For (links are randomly picked from the test set), the best normally ranges from −0.5 to 0. For example, (a) in Figure 4, for the USAir network, when predicting edges with large weights, with the parameter ranging from −1 to 1, the prediction accuracy increases from 0 to 0.12, showing a significant positive correlation, and, when predicting small weight edges, as the parameter increases from −1 to 1, the prediction accuracy drops from 0.03 to about 0.02, showing an obvious negative correlation effect, and while predicting random weight edges, when the prediction accuracy reaches the optimum the value is 0.06, the parameter at this moment is around −0.5. In Figure 4b–d represent the same result that in order to achieve better prediction accuracy, it is advisable to use a smaller value of for edges that have lower weights. We discovered that the optimal parameter value is negative, indicating that, in the context of link prediction, sometimes the ability of strong connections to promote connections is not as good as that of weak connections. That is, weak connections play a more important role than strong connections, which is the “weak connection” effect of link prediction. The results verified our conjecture: for links with a large weight, a larger guarantees a high precision; for links with a small weight, a smaller is more reasonable.
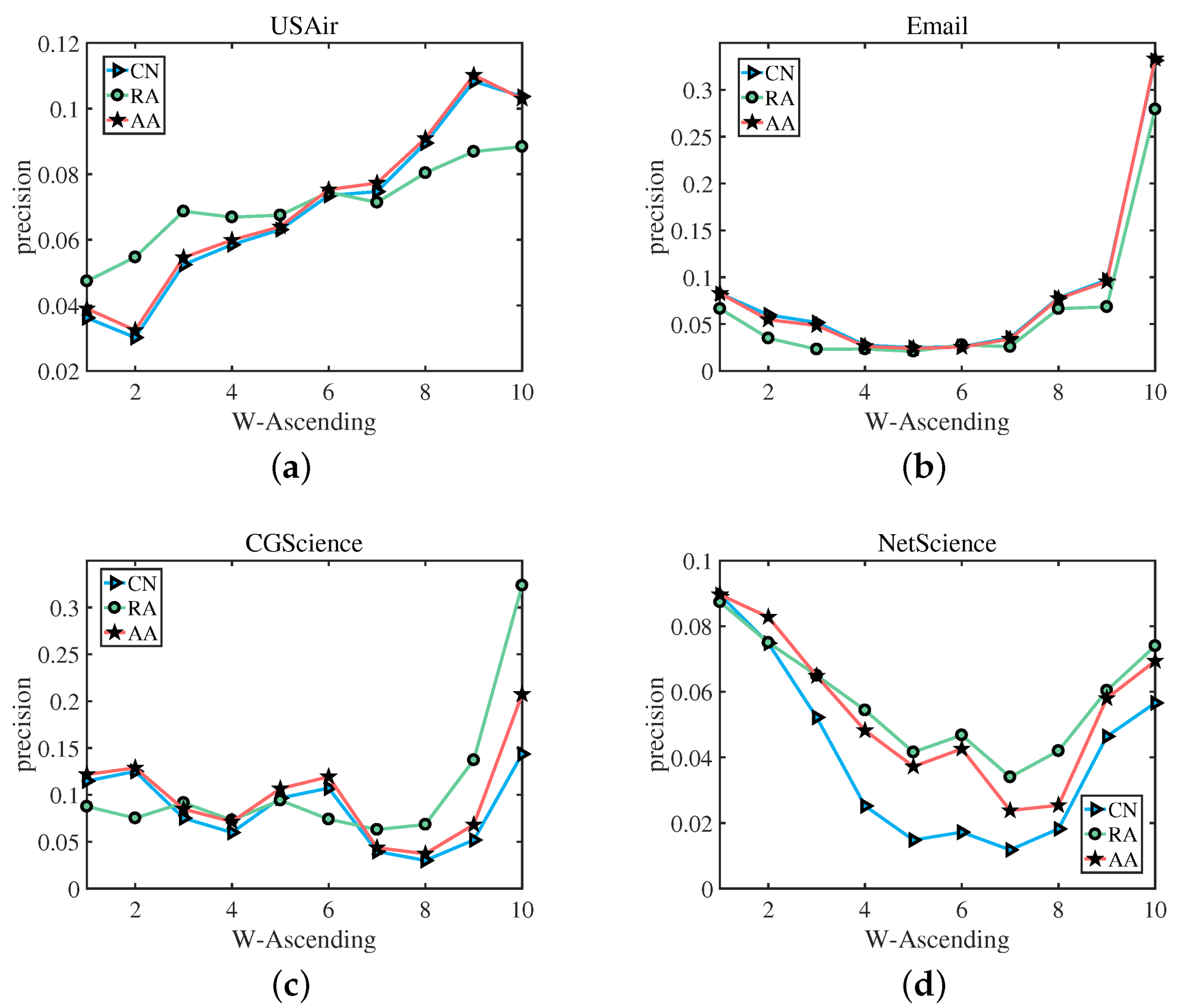
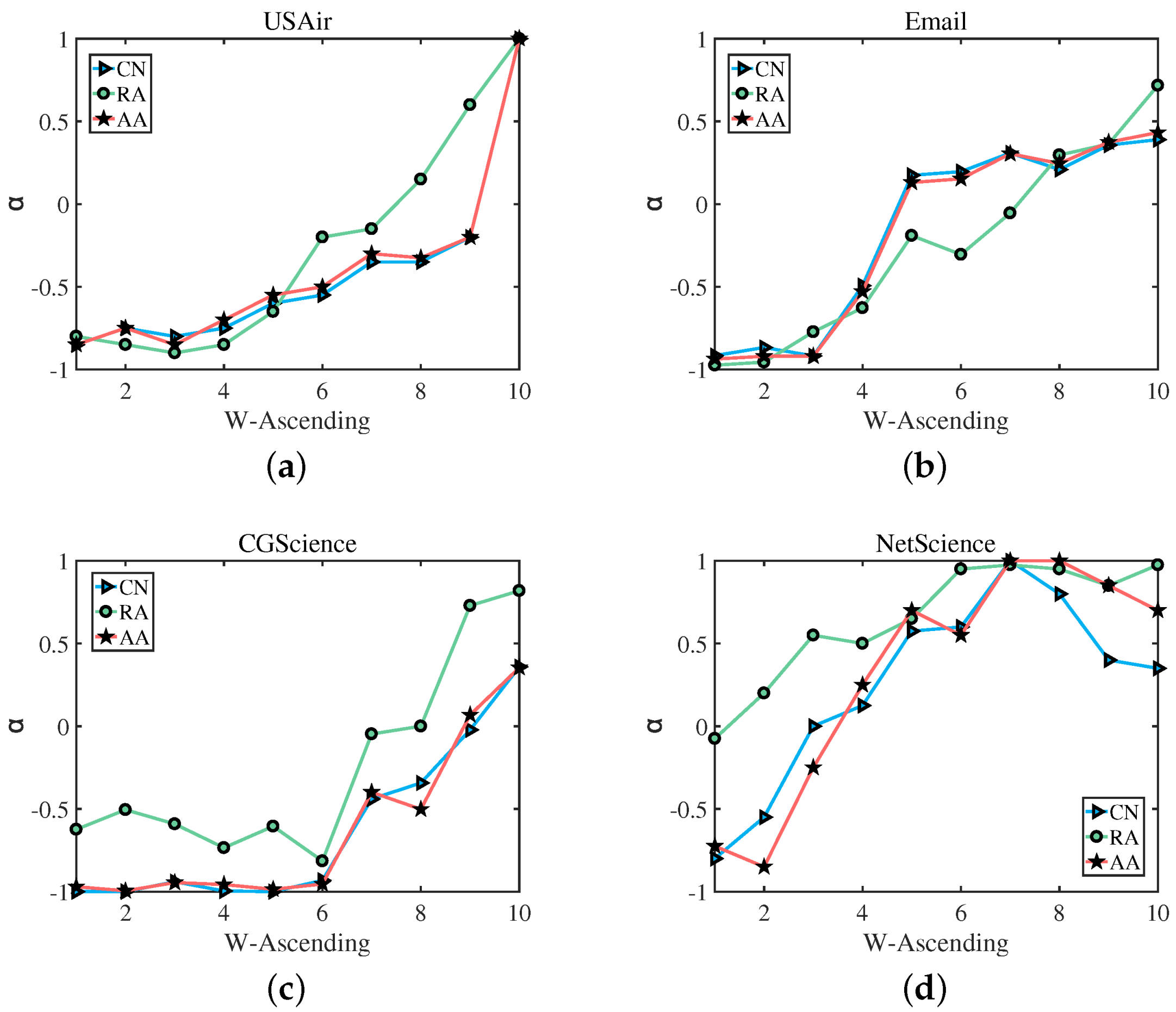
In the following, based on Formulas (8)–(10), we divided the links in the test set into 10 groups according to their weight, namely, , …, in which contains links with the smallest weight, and contains links with the largest weight. Then, for each group , we computed its best precision, as well as its corresponding . Figure 5 shows the best precision of different groups . We can clearly observe that, In Figure 5a,c, for the USAir network and the CGScience network, with the weight of the edges increasing, the accuracy results obtained by the two link prediction indices of CN and AA are almost the same, and the prediction trends of CN and the former two are also the same. For Email and NetScience networks, with the increase of edge weight, these three indices have almost the same accuracy to predict the trend, when CN increases, AA and RA increase; when CN decreases, AA and RA decrease simultaneously. Figure 6 shows the corresponding to the best precision of different groups . The green straight line indicates the RA index, the blue straight line represents the CN index, and the red straight line denotes the AA index. We select USAir, CGScience, Email, and NetScience as the experimental networks. As we can see, (a) in Figure 6, from to , for the link prediction algorithm CN, RA and AA, with the increase of weight, the value of also increases, and (b), (c), (d) have the same result that the value of increases as the weight increases. which also verifies our assumption: for links with a small weight, we should use a small to achieve a better precision, while for links with a large weight, a large is required.
5. Summary and Discussion
In the past, most studies on link prediction focused on unweighted networks, and a great number of link prediction algorithms has been proposed. In recent years, some scholars have emphasized the important role of weak ties in link prediction [53], and some studies have developed the link prediction algorithms from unweighted networks of weighted networks. However, we believe that the weight of the links is as important as the prediction of existence of a missing link. Focusing on weak ties can significantly improve the prediction accuracy, which has certain implications for the development of link prediction. The weights of edges in the network are large or small, and overemphasizing edges with small weights will obviously ignore edges with large weights. Just because the weight of the network is large or small, we should still classify and explore the weight when we perform link prediction. Our research shows that, for links with different weights, the parameter should be adjusted accordingly to achieve better precision. The results also show that, in link prediction for weighted networks, if we want to predict links with large weights, we should use a large parameter , and if we want to predict links with small weights, we should use a small parameter . By adjusting parameter , our method enables the algorithms to work more accurately for links with different weights to improve the overall performance.
Our research discusses the impact of weights on prediction accuracy in detail. In a sense, it has a pivotal role in promoting the development of link prediction, and it may also provides a research direction for researchers. The conclusions drawn from experimentation on several empirical networks verified our research results, but we did not conduct a theoretical verification. We hope that scholars find inspiration on the basis of our current research and contribute further to the development of link prediction.
Author Contributions
Data curation, M.Q. and X.S.; Formal analysis, C.Z. and Q.L.; Investigation, W.Y.; Methodology, W.Y.; Software, C.Z., Q.L., M.Q., and X.S.; Supervision, W.Y.; Validation, C.Z., Q.L., Y.L., and D.C.; Visualization, C.Z., Q.L., M.Q., X.S., Y.L. and D.C.; Writing—original draft, C.Z. and Q.L.; Writing—review and editing, W.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National Natural Science Foundation of China grant number 61703212 and National Science Foundation of Jiangsu Province of China grant number BK20160971.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Boccaletti, S.; Latora, V.; Moreno, Y.; Chavez, M.; Hwang, D.U. Complex networks: Structure and dynamics. Phys. Rep. 2006, 424, 175–308. [Google Scholar] [CrossRef]
- Wellman, B. Computer networks as social networks. Science 2001, 293, 2031–2034. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gilbert, E.N. Random graphs. Ann. Math. Stat. 1959, 30, 1141–1144. [Google Scholar] [CrossRef]
- Erdos, P.; Rényi, A. On the evolution of random graphs. Publ. Math. Inst. Hung. Acad. Sci 1960, 5, 17–60. [Google Scholar]
- Watts, D.J.; Strogatz, S.H. Collective dynamics of ‘small-world’networks. Nature 1998, 393, 440–442. [Google Scholar] [CrossRef]
- Barabási, A.L.; Ravasz, E.; Vicsek, T. Deterministic scale-free networks. Phys. A Stat. Mech. Its Appl. 2001, 299, 559–564. [Google Scholar] [CrossRef] [Green Version]
- Barabási, A.L. Scale-free networks: A decade and beyond. Science 2009, 325, 412–413. [Google Scholar] [CrossRef] [Green Version]
- Reijneveld, J.C.; Ponten, S.C.; Berendse, H.W.; Stam, C.J. The application of graph theoretical analysis to complex networks in the brain. Clin. Neurophysiol. 2007, 118, 2317–2331. [Google Scholar] [CrossRef]
- Cats, O.; Koppenol, G.J.; Warnier, M. Robustness assessment of link capacity reduction for complex networks: Application for public transport systems. Reliab. Eng. Syst. Saf. 2017, 167, 544–553. [Google Scholar] [CrossRef] [Green Version]
- Hwang, S.Y.; Wei, C.P.; Liao, Y.F. Coauthorship networks and academic literature recommendation. Electron. Commer. Res. Appl. 2010, 9, 323–334. [Google Scholar] [CrossRef]
- Folino, F.; Pizzuti, C. A comorbidity-based recommendation engine for disease prediction. In Proceedings of the 2010 IEEE 23rd International Symposium on Computer-Based Medical Systems (CBMS), Bentley, WA, Australia, 12–15 October 2010; pp. 6–12. [Google Scholar]
- Zhou, Q.; Cai, S.; Zhang, Y. Detecting overlapping community structure with node influence. IEEE Access 2019, 7, 171223–171234. [Google Scholar] [CrossRef]
- Krebs, V.E. Mapping networks of terrorist cells. Connections 2002, 24, 43–52. [Google Scholar]
- Jafari, S.H.; Abdolhosseini-Qomi, A.M.; Asadpour, M.; Rahgozar, M.; Yazdani, N. An information theoretic approach to link prediction in multiplex networks. Sci. Rep. 2021, 11, 1–21. [Google Scholar]
- Scellato, S.; Noulas, A.; Mascolo, C. Exploiting place features in link prediction on location-based social networks. In Proceedings of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining, San Diego, CA, USA, 21–24 August 2011; pp. 1046–1054. [Google Scholar]
- Yang, Y.; Lichtenwalter, R.N.; Chawla, N.V. Evaluating link prediction methods. Knowl. Inf. Syst. 2015, 45, 751–782. [Google Scholar] [CrossRef] [Green Version]
- Zhou, T.; Lü, L.; Zhang, Y.C. Predicting missing links via local information. Eur. Phys. J. B 2009, 71, 623–630. [Google Scholar] [CrossRef] [Green Version]
- Kefalas, P.; Symeonidis, P.; Manolopoulos, Y. A graph-based taxonomy of recommendation algorithms and systems in LBSNs. IEEE Trans. Knowl. Data Eng. 2015, 28, 604–622. [Google Scholar] [CrossRef]
- Bütün, E.; Kaya, M. A pattern based supervised link prediction in directed complex networks. Phys. A Stat. Mech. Its Appl. 2019, 525, 1136–1145. [Google Scholar] [CrossRef]
- Guns, R.; Rousseau, R. Recommending research collaborations using link prediction and random forest classifiers. Scientometrics 2014, 101, 1461–1473. [Google Scholar] [CrossRef]
- Yeung, Y.Y.; Liu, T.C.Y.; Ng, P.H. A social network analysis of research collaboration in physics education. Am. J. Phys. 2005, 73, 145–150. [Google Scholar] [CrossRef]
- Bütün, E.; Kaya, M.; Alhajj, R. A supervised learning method for prediction citation count of scientists in citation networks. In Proceedings of the 2017 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), Sydney, NSW, Australia, 1 July–3 August 2017; pp. 952–958. [Google Scholar]
- Gül, S.; Kaya, M.; Kaya, B. Predicting links in weighted disease networks. In Proceedings of the 2016 3rd International Conference on Computer and Information Sciences (ICCOINS), Kuala Lumpur, Malaysia, 15–17 August 2016; pp. 77–81. [Google Scholar]
- Yao, L.; Wang, L.; Pan, L.; Yao, K. Link prediction based on common-neighbors for dynamic social network. Procedia Comput. Sci. 2016, 83, 82–89. [Google Scholar] [CrossRef] [Green Version]
- Huang, S.; Zhang, J.; Wang, L.; Hua, X.S. Social friend recommendation based on multiple network correlation. IEEE Trans. Multimed. 2015, 18, 287–299. [Google Scholar] [CrossRef] [Green Version]
- Huang, Z.; Zeng, D.D. A link prediction approach to anomalous email detection. In Proceedings of the 2006 IEEE International Conference on Systems, Man and Cybernetics, Taipei, Taiwan, 8–11 October 2006; Volume 2, pp. 1131–1136. [Google Scholar]
- Yu, W.; Feng, H.; Xu, Y.; Yin, N.; Chen, Y.; Yang, Z. A Phase Estimation Algorithm for Quantum Speed-Up Multi-Party Computing. Cmc-Comput. Mater. Contin. 2021, 67, 241–252. [Google Scholar] [CrossRef]
- Anil, A.; Kumar, D.; Sharma, S.; Singha, R.; Sarmah, R.; Bhattacharya, N.; Singh, S.R. Link prediction using social network analysis over heterogeneous terrorist network. In Proceedings of the 2015 IEEE International Conference on Smart City/SocialCom/SustainCom (SmartCity), Chengdu, China, 19–21 December 2015; pp. 267–272. [Google Scholar]
- Li, J.; Zhang, L.; Meng, F.; Li, F. Recommendation algorithm based on link prediction and domain knowledge in retail transactions. Procedia Comput. Sci. 2014, 31, 875–881. [Google Scholar] [CrossRef] [Green Version]
- Xie, F.; Chen, Z.; Shang, J.; Feng, X.; Li, J. A link prediction approach for item recommendation with complex number. Knowl.-Based Syst. 2015, 81, 148–158. [Google Scholar] [CrossRef]
- Lü, L.; Zhou, T. Link prediction in complex networks: A survey. Phys. A Stat. Mech. Its Appl. 2011, 390, 1150–1170. [Google Scholar] [CrossRef] [Green Version]
- Sarukkai, R.R. Link prediction and path analysis using markov chains. Comput. Netw. 2000, 33, 377–386. [Google Scholar] [CrossRef]
- Zhu, J.; Hong, J.; Hughes, J.G. Using markov chains for link prediction in adaptive web sites. In Proceedings of the International Conference on Soft Issues in the Design, Development, and Operation of Computing Systems, Belfast, Northern Ireland, 8–10 April 2002; Springer: Berlin/Heidelberg, Germany, 2002; pp. 60–73. [Google Scholar]
- Albert, R.; Barabási, A.L. Statistical mechanics of complex networks. Rev. Mod. Phys. 2002, 74, 47. [Google Scholar] [CrossRef] [Green Version]
- Al Hasan, M.; Chaoji, V.; Salem, S.A. Link prediction using supervised learning. In Proceedings of the SDM06: Workshop on Link Analysis, Counter-Terrorism and Security, Bethesda, USA, 22 April 2006; Volume 30, pp. 798–805. [Google Scholar]
- Chen, M.R.; Huang, P.; Lin, Y.; Cai, S.M. Ssne: Effective node representation for link prediction in sparse networks. IEEE Access 2021, 9, 57874–57885. [Google Scholar] [CrossRef]
- Zhu, L.; Basu, S.; Jarrow, R.A.; Wells, M.T. High-Dimensional Estimation, Basis Assets, and the Adaptive Multi-Factor Model. Q. J. Financ. 2020, 10, 2050017. [Google Scholar] [CrossRef]
- Zhu, L.; Sun, N.; Wells, M.T. Clustering Structure of Microstructure Measures. Appl. Econ. Financ. 2022, 9, 85–95. [Google Scholar] [CrossRef]
- Xian, X.; Wu, T.; Qiao, S.; Wang, X.Z.; Wang, W.; Liu, Y. Netsre: Link predictability measuring and regulating. Knowl.-Based Syst. 2020, 196, 105800. [Google Scholar] [CrossRef]
- Abbas, K.; Abbasi, A.; Dong, S.; Niu, L.; Yu, L.; Chen, B.; Cai, S.M.; Hasan, Q. Application of network link prediction in drug discovery. BMC Bioinform. 2021, 22, 1–21. [Google Scholar] [CrossRef] [PubMed]
- Xian, X.; Wu, T.; Ma, X.; Qiao, S.; Shao, Y.; Wang, C.; Yuan, L.; Wu, Y. Generative Graph Neural Networks for Link Prediction. arXiv 2022, arXiv:2301.00169. [Google Scholar] [CrossRef]
- Zhang, C.; Qian, M.; Shen, X.; Li, Q.; Lei, Y.; Yu, W. Bimodal accuracy distribution of link prediction in complex networks. Int. J. Mod. Phys. C 2022. [Google Scholar] [CrossRef]
- Shabaz, M.; Garg, U. Predicting future diseases based on existing health status using link prediction. World J. Eng. 2022, 19, 29–32. [Google Scholar] [CrossRef]
- Liben-Nowell, D.; Kleinberg, J. The link-prediction problem for social networks. J. Am. Soc. Inf. Sci. Technol. 2007, 58, 1019–1031. [Google Scholar] [CrossRef] [Green Version]
- Clauset, A.; Moore, C.; Newman, M.E. Hierarchical structure and the prediction of missing links in networks. Nature 2008, 453, 98–101. [Google Scholar] [CrossRef] [Green Version]
- Yu, W.; Xiong, Z.; Dong, Z.; Wang, S.; Li, J.; Liu, G.; Liu, A.X. Zero-Error Coding via Classical and Quantum Channels in Sensor Networks. Sensors 2019, 19, 5071. [Google Scholar] [CrossRef] [Green Version]
- Hao, C.; Chen, Y.; Yang, Z.X.; Wu, E. Higher-order potentials for video object segmentation in bilateral space. Neurocomputing 2020, 401, 28–35. [Google Scholar] [CrossRef]
- Guimerà, R.; Sales-Pardo, M. Missing and spurious interactions and the reconstruction of complex networks. Proc. Natl. Acad. Sci. USA 2009, 106, 22073–22078. [Google Scholar] [CrossRef] [Green Version]
- Almansoori, W.; Gao, S.; Jarada, T.N.; Elsheikh, A.M.; Murshed, A.N.; Jida, J.; Alhajj, R.; Rokne, J. Link prediction and classification in social networks and its application in healthcare and systems biology. Netw. Model. Anal. Health Inform. Bioinform. 2012, 1, 27–36. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Zhang, Q.M.; Lü, L.; Zhou, T. Link prediction in complex networks: A local naïve Bayes model. EPL Europhys. Lett. 2011, 96, 48007. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.Q.; Zhang, Q.M.; Zhou, T. Evaluating network models: A likelihood analysis. EPL Europhys. Lett. 2012, 98, 28004. [Google Scholar] [CrossRef] [Green Version]
- Murata, T.; Moriyasu, S. Link prediction of social networks based on weighted proximity measures. In Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence (WI’07), Fremont, CA, USA, 2–5 November 2007; pp. 85–88. [Google Scholar]
- Lü, L.; Zhou, T. Link prediction in weighted networks: The role of weak ties. EPL Europhys. Lett. 2010, 89, 18001. [Google Scholar] [CrossRef] [Green Version]
- Tang, L.; Chen, K.; Wu, C.; Hong, Y.; Jia, K.; Yang, Z.X. Improving semantic analysis on point clouds via auxiliary supervision of local geometric priors. IEEE Trans. Cybern. 2020, 52, 4949–4959. [Google Scholar] [CrossRef]
- Batagelj, V.; Mrvar, A. Pajek Datasets. Available online: http://vlado.fmf.uni-lj.si/pub/networks/data/ (accessed on 24 February 2007).
- Jérôme, K. KONECT—The Koblenz Network Collection. In Proceedings of the Proc. Int. Conf. on World Wide Web Companion, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 1343–1350. [Google Scholar]
- Newman, M.E. Finding community structure in networks using the eigenvectors of matrices. Phys. Rev. E 2006, 74, 036104. [Google Scholar] [CrossRef] [Green Version]
- Herlocker, J.L.; Konstan, J.A.; Terveen, L.G.; Riedl, J.T. Evaluating collaborative filtering recommender systems. ACM Trans. Inf. Syst. 2004, 22, 5–53. [Google Scholar] [CrossRef]
- Adamic, L.A.; Adar, E. Friends and neighbors on the web. Soc. Netw. 2003, 25, 211–230. [Google Scholar] [CrossRef] [Green Version]
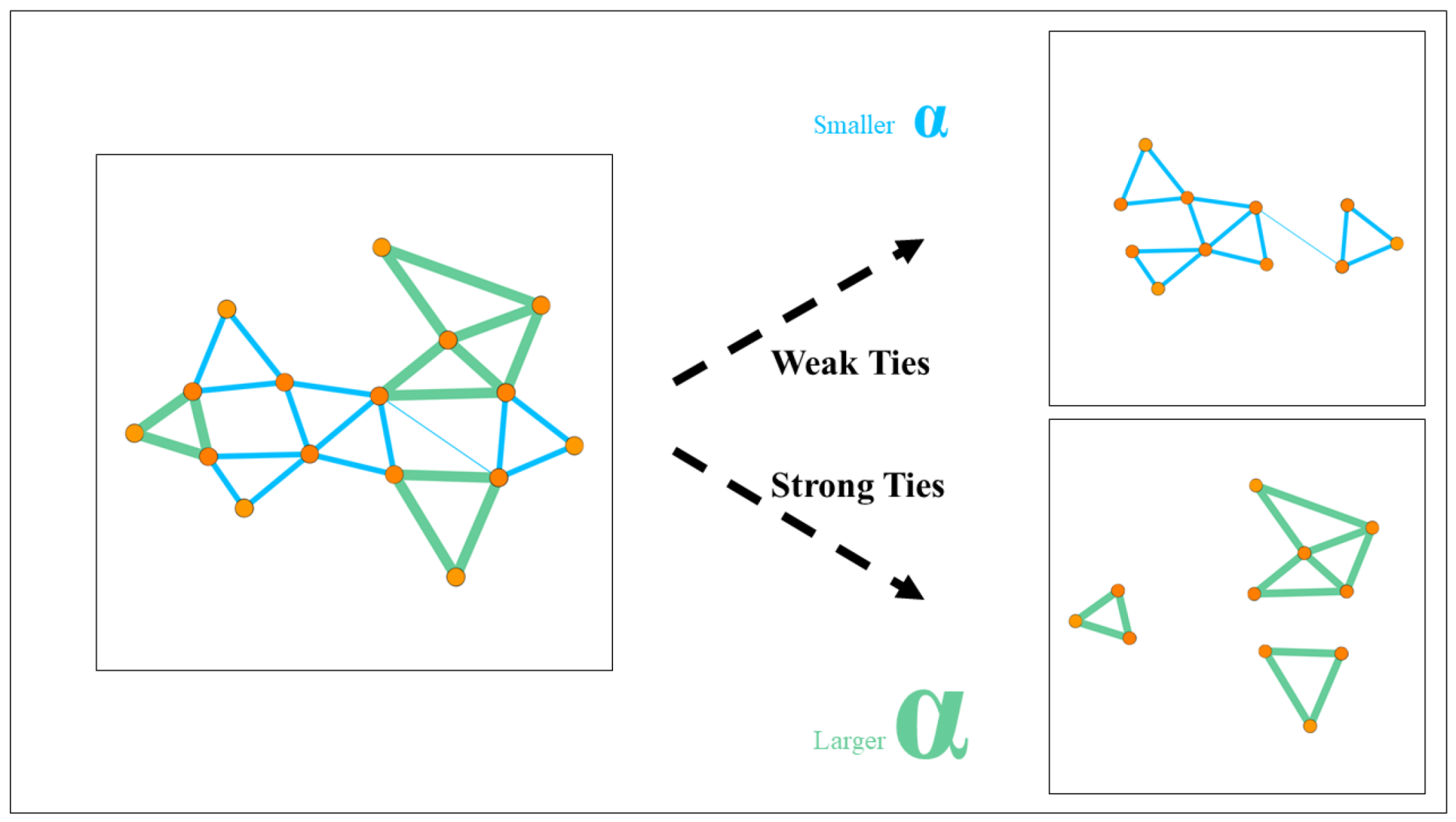
Figure 1.
The graph on the left can be regarded as a weighted network, the edges with the thicker green line can be regarded as the edges with large weights, and the edges with the thinner blue line can be regarded as the edges with small weights. In a weighted network, edges with large weights usually gather together, and similarly, edges with small weights often gather together. For edges with small weights, we use a small to adjust the effects of weights. For edges with large weights, we use a large to adjust the effects of weights. Such a prediction is much more accurate than a prediction that uses the same without distinguishing weights.
Figure 1.
The graph on the left can be regarded as a weighted network, the edges with the thicker green line can be regarded as the edges with large weights, and the edges with the thinner blue line can be regarded as the edges with small weights. In a weighted network, edges with large weights usually gather together, and similarly, edges with small weights often gather together. For edges with small weights, we use a small to adjust the effects of weights. For edges with large weights, we use a large to adjust the effects of weights. Such a prediction is much more accurate than a prediction that uses the same without distinguishing weights.

Figure 2.
The horizontal axis is the edge of the entire network with a ratio of P, and the vertical axis is the average clustering coefficient (C) of the network composed of edges with the corresponding ratio of P. The average clustering coefficient of the network composed of edges with large weights () and edges with small weights () is basically greater than the average clustering coefficient of the network composed of edges with random weights ().
Figure 2.
The horizontal axis is the edge of the entire network with a ratio of P, and the vertical axis is the average clustering coefficient (C) of the network composed of edges with the corresponding ratio of P. The average clustering coefficient of the network composed of edges with large weights () and edges with small weights () is basically greater than the average clustering coefficient of the network composed of edges with random weights ().

Figure 3.
In the NetScience network, the entire network is shown in (a), 5% of the edges with small weights are shown in (b), 5% of the edges with large weights are shown in (c), and 5% of the edges are randomly selected as shown in (d). We can clearly see that the network composed of edges with large weights or edges with small weights has high clustering properties.
Figure 3.
In the NetScience network, the entire network is shown in (a), 5% of the edges with small weights are shown in (b), 5% of the edges with large weights are shown in (c), and 5% of the edges are randomly selected as shown in (d). We can clearly see that the network composed of edges with large weights or edges with small weights has high clustering properties.

Figure 4.
How the precision of links which are randomly picked from the test set (), links with large weight () and links with small weight () change with different , and the range of numbers in bracket in the figure indicates the range of weights. For , the precision reaches the peak at a large . For , the precision reaches the peak at a small . For , the best is between −0.5 and 0.
Figure 4.
How the precision of links which are randomly picked from the test set (), links with large weight () and links with small weight () change with different , and the range of numbers in bracket in the figure indicates the range of weights. For , the precision reaches the peak at a large . For , the precision reaches the peak at a small . For , the best is between −0.5 and 0.

Figure 5.
The best precision corresponds to a network composed of edges with different weight levels. The best precision was calculated using the CN, RA index, and AA index. W-Ascending means sort by weight in ascending order.
Figure 5.
The best precision corresponds to a network composed of edges with different weight levels. The best precision was calculated using the CN, RA index, and AA index. W-Ascending means sort by weight in ascending order.

Figure 6.
The corresponds to the best precision of a network composed of edges with different weight levels. As the weight of links increases, the value of also increases. The result shows that using a large to predict edges with large weights will be more accurate, and using a small to predict edges with small weights will be more accurate.
Figure 6.
The corresponds to the best precision of a network composed of edges with different weight levels. As the weight of links increases, the value of also increases. The result shows that using a large to predict edges with large weights will be more accurate, and using a small to predict edges with small weights will be more accurate.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Characteristics of the empirical network: number of nodes (N) and links (M), average degree (K), average shortest path length (D), clustering coefficient (C), degree assortativity (R).
Table 1.
Characteristics of the empirical network: number of nodes (N) and links (M), average degree (K), average shortest path length (D), clustering coefficient (C), degree assortativity (R).
| Networks | N | M | K | D | C | R |
|---|---|---|---|---|---|---|
| USAir | 332 | 2126 | 12.81 | 2.74 | 0.625 | −0.208 |
| 710 | 5996 | 16.89 | 3.00 | 0.409 | −0.137 | |
| CGScience | 3621 | 9461 | 5.23 | 5.32 | 0.540 | 0.168 |
| NetScience | 379 | 914 | 4.82 | 6.04 | 0.741 | −0.082 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Zhang, C.; Li, Q.; Lei, Y.; Qian, M.; Shen, X.; Cheng, D.; Yu, W. The Absence of a Weak-Tie Effect When Predicting Large-Weight Links in Complex Networks. Entropy 2023, 25, 422. https://doi.org/10.3390/e25030422
AMA Style
Zhang C, Li Q, Lei Y, Qian M, Shen X, Cheng D, Yu W. The Absence of a Weak-Tie Effect When Predicting Large-Weight Links in Complex Networks. Entropy. 2023; 25(3):422. https://doi.org/10.3390/e25030422
Chicago/Turabian StyleZhang, Chengjun, Qi Li, Yi Lei, Ming Qian, Xinyu Shen, Di Cheng, and Wenbin Yu. 2023. "The Absence of a Weak-Tie Effect When Predicting Large-Weight Links in Complex Networks" Entropy 25, no. 3: 422. https://doi.org/10.3390/e25030422
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.