
Extreme Eigenvalues and the Emerging Outlier in Rank-One Non-Hermitian Deformations of the Gaussian Unitary Ensemble

1
Department of Mathematics, King’s College London, London WC2R 2LS, UK
2
School of Mathematical Sciences, Queen Mary University of London, London E1 4NS, UK
*
Authors to whom correspondence should be addressed.
Entropy 2023, 25(1), 74; https://doi.org/10.3390/e25010074
Submission received: 13 November 2022
/
Revised: 28 December 2022
/
Accepted: 28 December 2022
/
Published: 30 December 2022
(This article belongs to the Special Issue Quantum Chaos—Dedicated to Professor Giulio Casati on the Occasion of His 80th Birthday)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Complex eigenvalues of random matrices provide the simplest model for studying resonances in wave scattering from a quantum chaotic system via a single open channel. It is known that in the limit of large matrix dimensions the eigenvalue density of J undergoes an abrupt restructuring at , the critical threshold beyond which a single eigenvalue outlier (“broad resonance”) appears. We provide a detailed description of this restructuring transition, including the scaling with N of the width of the critical region about the outlier threshold and the associated scaling for the real parts (“resonance positions”) and imaginary parts (“resonance widths”) of the eigenvalues which are farthest away from the real axis. In the critical regime we determine the density of such extreme eigenvalues, and show how the outlier gradually separates itself from the rest of the extreme eigenvalues. Finally, we describe the fluctuations in the height of the eigenvalue outlier for large but finite N in terms of the associated large deviation function.
1. Introduction
Rank-one non-normal deformations of the Gaussian and Circular Unitary Ensembles are a useful analytic tool for studying statistics of resonances in quantum scattering from a chaotic domain via a single channel [1,2]. As surveyed in [2,3], these random matrix ensembles are integrable in the sense that the joint probability density of their complex eigenvalues and, in some spectral scaling limits of interest, the eigenvalue correlation functions can be determined in a closed form. Such integrability, which also proves to be useful in other physics contexts, see, e.g., [4], extends to a certain degree to the deformed Gaussian and circular ensembles [5,6], especially to the classical values [7,8], but is lost if the underlying normal random matrix ensemble (Hermitian or unitary) is not integrable, as is the case with, e.g., finite rank non-Hermitian deformations of Wigner matrices [9,10,11] or band matrices [12]. Still, the latter matrices are found to share, in appropriate parameter ranges, some statistical characteristics of their complex eigenvalues and eigenvectors with their integrable counterparts.
In this paper, we aim to investigate complex eigenvalues with extreme imaginary parts for the rank-one non-Hermitian deformations of the Gaussian Unitary Ensemble (GUE) by exploiting the above-mentioned integrability. The latter feature gives access to the asymptotics of the eigenvalue density in the complex plane on mesoscopic scales and allows us to carry out a quantitative analysis of the separation of the eigenvalue outlier (which is known to exist in this model [9,10]) from the rest of the eigenvalues. Eigenvalue outliers in the complex plane have recently attracted renewed interest [11,13,14,15]. Our analysis refines and complements the existing knowledge about the outliers of nearly Hermitian matrices [9,10,11] albeit for arguably the simplest model of its type. As we will demonstrate, despite the simplicity of the model, its extreme eigenvalues exhibit an interesting transition at a certain value of the deformation parameter, with rich critical behaviour which deserves to be studied in more detail.
The non-Hermitian matrices that we consider are of the form
where H is a GUE matrix and is a diagonal matrix with all diagonal entries being zero except the first one,
Denoting the matrix dimension by N, we fix the global spectral scale by the condition that the expected value of is N. Then the joint probability density function (JDPF) of matrix elements of the GUE matrix H is
With this normalisation, the limiting eigenvalue distribution of H, as the matrix dimension is approaching infinity, is supported on the interval , and, inside this interval, the eigenvalue density is .
Note that due to the invariance of the JPDF (3) with respect to unitary rotations one may equivalently replace in (2) with any other rank-one Hermitian matrix. Without loss of generality we may also assume to be positive. Then the eigenvalues of matrices J (1)–(3) are all in the upper half of the complex plane and for N large they all, except possibly one outlier, lie just above the interval of the real line. Whether such an outlier is present or not is determined by the value of . For fixed values of , almost surely, for N sufficiently large, all N eigenvalues lie within distance from the real line, with for every [9]. Furthermore, if then the same is true of all but one eigenvalue. This outlier lies much higher in the complex plane: to leading order in N, its imaginary part (the “height”) is [9,10,14]. For precise statements and proofs we refer the reader to [9,10] where these and similar facts were established for finite rank non-Hermitian deformations of real symmetric matrices with independent matrix entries.
For finite but large matrix dimensions, one would expect to find a transition region of infinitesimal width about the outlier threshold value which captures the emergence of the outlier from the sea of low lying eigenvalues. Questions about the scaling of with N and the corresponding characteristic height and distribution of the eigenvalues that lie farthest away from the real line are natural and interesting in this context. These are open questions in the mathematics and mathematical physics literature on the subject.
Apart from the mathematical curiosity, there is also motivation coming from physics. In the physics literature, the eigenvalues of J are associated with the zeroes of a scattering matrix in the complex energy plane, and their complex conjugates with the poles of the same scattering matrix, known as “resonances”. The latter are obviously the eigenvalues of matrices (1)–(2) with replaced by . In that context the absolute value of the eigenvalue’s imaginary part is associated with the “resonance width”. The eigenvalues close to real axis are called “narrow resonances” and the outlier is called the “broad resonance”. The use of the Gaussian Unitary Ensemble for H is justified by invoking the so-called Bohigas-Giannoni-Schmidt conjecture [16] describing spectral statistics of highly excited energy levels of some classes of systems whose classical counterparts are chaotic. The resulting ensemble J is then an important ingredient in characterising statistical properties of scattering matrices in systems with quantum chaos and no time-reversal invariance, see [1] for description of the associated framework going back to the pioneering paper [17]. In that framework, the phenomenon of the outlier separation and the simultaneous movement of the rest of the eigenvalues towards the real axis was first discussed, albeit at a heuristic level, already in early theoretical works [18,19], the latter work even establishing the correct asymptotic position of the outlier. Later on, this phenomenon got considerable attention under the name “resonance trapping” and eventually was observed in experiments [20].
Very recently, Dubach and Erdős [11] performed a detailed analysis of the eigenvalue trajectories, with respect to changing the parameter , in the random matrix ensemble in the settings when H is assumed to be a Wigner matrix and v a column vector of unit length. It turned out that the evolution of the eigenvalues is governed by a system of deterministic first-order differential equations subject to random initial conditions, with the initial positions and velocities expressed in terms of the eigenvalues and eigenvectors of H. In addition, under suitable conditions on the distribution of matrix entries of H ensuring the validity of the uniform isotropic local law (Theorem 5 in [11]), Dubach and Erdős proved that with high probability the eigenvalue outlier is distinctly separated from the rest of the eigenvalues for all
Moreover, if , i.e., if is asymptotically small, the outlier’s height is and its real part is in the window of width around the origin, whereas all other eigenvalues are no higher than . In addition, with high probability, for all
no eigenvalue reaches the heights
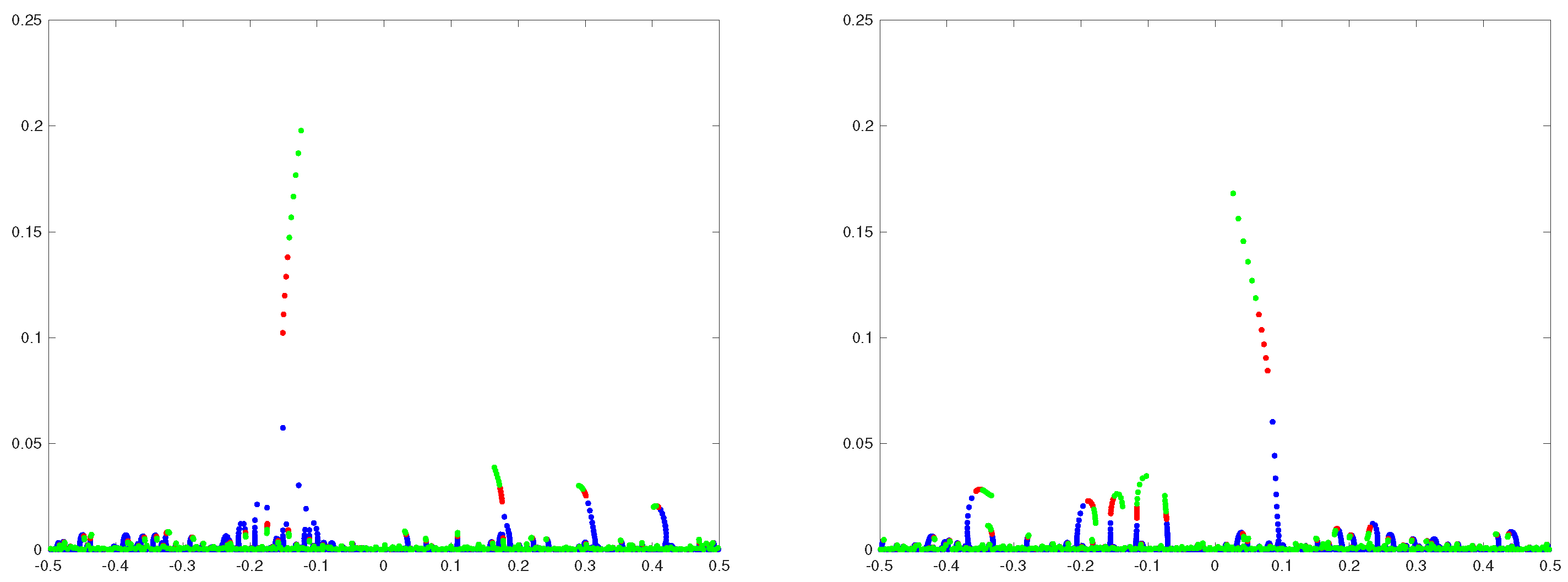
These findings suggest that the width of the transition region around scales with as for N large. Naturally, for inside this region one would expect to find several eigenvalues, including the emerging “atypical” outlier, with imaginary parts on the critical scale (6) much exceeding the height of low lying eigenvalues, as illustrated in Figure 1. One might call such eigenvalues “typical extremes” to emphasise atypicality of the emerging outlier.
To a large extent our paper is motivated by [11] and aims to provide quantitative insights into this picture of the outlier emerging from the cloud of extreme eigenvalues. Whilst the approach of Dubach and Erdős is dynamical (fix matrix H and study eigenvalue trajectories as the magnitude of the deformation increases), our approach is statistical (fix a scale for and count the number of eigenvalues on characterisitc spectral scales in the complex plane averaged over the distribution of H which, for technical reasons, we assume to be GUE). Our present approach is limited to the expected values; analysing higher order moments is left as an interesting problem for future investigations. However, even with such a basic tool we are able to develop rather detailed quantitative understanding of the outlier separation and the associated restructuring transition in the spectra of matrices J.
As such, the two approaches complement each other very well. For example, we prove that for
the expected number of eigenvalues whose height exceeds the level (6) is asymptotically given by the integral with density
This density is the average density of the extreme eigenvalues at height (6). Together with findings in [11] this result establishes that the width of the transition region around indeed scales with . Similarly, we are able to determine the average density of extreme eigenvalues of J near the origin in the complex plane in the critical scaling regime when when . As a function of coordinates q and m, this density, when appropriately rescaled, is given by
It can be verified that , implying that the population of extreme eigenvalues at the critical height (6) which generates the eventual outlier (as is approaching infinity) is constrained to a narrow vertical strip of width about the origin (the centre of the eigenvalue band of H). Thus, our results both confirm and complement the analysis in [11], and show that it indeed touched the optimal scales in (7), both along the real and imaginary axes.
We would like to conclude this section with a short description of the structure of our paper. In Section 2 we develop quantitative heuristic analysis of the outlier separation. This analysis elucidates the emerging critical scaling in and the critical spectral scalings in the complex plane and provides a useful background for rigorous calculations later on. This section also offers our outlook on the universality of the exponent in (7). Section 3 contains the statement of our main results and discussion. In Section 4 we express the expected density of eigenvalues of J and the density of their imaginary parts at finite matrix dimensions in terms of, respectively, Hermite and Laguerre polynomials. These expressions are then used in Section 5 and Section 6 for asymptotic analysis of eigenvalue densities in various scaling limits. The two appendices contain derivations of technical auxiliary results.
2. Low Lying Eigenvalues and Their Extremes: A Heuristic Outlook
Before presenting our main results in the next Section, we would like to offer our quantitative heuristic insights into the outlier separation elucidating the emerging scalings and mechanisms behind them and providing a useful background for rigorous calculations later on.
With standing for the eigenvalues of matrices , the angular brackets standing for averaging over the GUE matrix H (3), and for the Dirac delta-function, the expected number of eigenvalues of J in domain D can be computed by integrating the mean eigenvalue density
over D and multiplying the result by N. For example, the expected number of the eigenvalues of J which lie above the line in the complex plane is given by the integral
where is the mean density of the imaginary parts irrespective of the value of the real part,
Guided by the eigenvalue perturbation theory one can expect that the typical height Y of the eigenvalues whose real part is close to a point in the spectral bulk scales with the mean separation between neighbouring real eigenvalues of the GUE matrix H in the limit . On a more formal level, introducing the scaled version of [21]
one finds that such scaled density is well-defined in the limit of large matrix dimensions [1,2,21,22]: for every
confirming that locally the typical height of low lying eigenvalues scales with .
Globally, the typical height of low lying eigenvalues scales with . Intuitively, this can be understood from the exact sum rule
which follows from the obvious relation . On a more formal level, consider the expected fraction of the eigenvalues of J which lie above the level , and set . In the limit ,
The integral in (15) is the modified Bessel function . Therefore,
From this,
The density is the mean density of the scaled imaginary parts in the limit of large matrix dimensions. Even though it describes low lying eigenvalues it contains some useful information about eigenvalues higher up in the complex plane.
As an example, consider the expected value of the sum of the imaginary parts of low lying eigenvalues. Using definition (10), the sum rule (13) implies that
Upon rescaling , one could naively jump to the conclusion that . However, by making use of (17) and integral 6.623(3) in [23], one actually finds that
Thus, if then the imaginary parts of low lying eigenvalues indeed add up to , in full agreement with the sum rule (19), whereas if they add up only to . The sum rule deficit is exactly the imaginary part of the outlier, and suggests that the rescaled limiting density of low lying eigenvalues, , precisely misses the delta-functional mass .
As another example, consider the asymptotic form of when . It is markedly different depending on whether or not. In the later case, using in (17) the asymptotic expansion for the modified Bessel function of large argument, one finds an exponential decay, whilst in the former case the decay is algebraic:
It is instructive to return to the unscaled imaginary part Y and take a closer look at the expected number of the eigenvalues of J exceeding the level in the limit . It is evident from (16) that
provided . Extending this asymptotic relation to large values of allows one to get insights, even if only heuristically, about the characteristic scale of the highest placed among the low lying eigenvalues. Along these lines, we define the characteristic scale of the height of typical extreme eigenvalues as such level that the expected number of eigenvalues with imaginary part exceeding is of order of unity:
We add the word typical to exclude the atypical eigenvalue (the outlier) which is known to exist when . Now, assuming to be large (but still anticipating ) one can replace the Bessel function in (21) by its corresponding asymptotic expression and approximate:
The condition in (22) then leads to two essentially different scenarios depending on the value of . Namely, for every fixed positive the characteristic scale of the typical extreme values is, to leading order in N, . On the other hand, if then the typical extreme values raise from the sea of low lying eigenvalues to a much higher height of . This change of scale for extreme values is easy to trace back to the emerging power-law decay in the vicinity of which is evident in (20).
In fact, as evident from (23), the typical extreme values scale as not only at , but also as long as . Actually, by setting simultaneously and the asymptotic relation (23) is converted into
an expression that is indeed of order of unity for all fixed values of and . Thus, the width of the transition region about must scale with . Combined with the existence of a distinct outlier at height one may indeed see that our heuristic argument perfectly agrees with the conjecture of Dubach and Erdős about the critical scaling where the separation of typical and atypical extreme values happens.
Before continuing our exposition of the heuristics behind the restructuring of the density of complex eigenvalues we would like to make two remarks.
Remark 1.
To make further contact with the standard subject of extreme value statistics, it is useful to recourse to the classical theory of extreme values for i.i.d. sequences of random variables, a succinct albeit informal summary of which can be found in, e.g., [24]. In that case the probability law of extreme values is characterised by the tail behaviour of the “parent” probability density function (pdf) of and is essentially universal in the limit . In our context, the pertinent case for comparison is that of non-negative continuous i.i.d. random variables with the parent distribution supported on the entire semi-axis . Then only two possibilities may arise. Those sequences which are characterised by the power-law decaying pdf , , as have their extreme values scaling with and the distribution of their maximum, , after rescaling converges to the so-called Fréchet law in the limit . In contrast, if the parent pdf decays faster than any power, e.g., if , , then, to leading order, extreme values scale with , and the distribution of the largest value , converges, after a shift and further rescaling, to the so-called Gumbel law. Although, the imaginary parts of complex eigenvalues in the random matrix ensemble (1)–(3) are not at all independent (as is evident from their JPDF (51) resulting in a non-trivial determinantal two-point and higher order correlation functions at the scale , see [22]), our scaling predictions for the typical extreme eigenvalues are in formal correspondence with the i.i.d. picture: a Gumbel-like scaling (with ) if and a Fréchet-like scaling (with ) if . This is exactly as would have been implied in the i.i.d. picture by the tail behaviour of the mean eigenvalue densities in the two cases in (20). This fact naturally suggests to conjecture Gumbel statistics for the typical largest imaginary part (excluding possible outlier) for any , changing to a Fréchet-like law for , with a possible family of dependent nontrivial extreme value statistics in the crossover critical regime . Although we are not able to shed light on the distribution of typical extreme eigenvalues in the random matrix ensemble (1)–(3), we will discuss some results in that direction for a somewhat related model at the end of the next section.
Remark 2.
The phenomenon of resonance width restructuring with increasing the coupling to continuum (controlled in the present model by the parameter γ) and the emergence of the broad resonance has many features in common with the so-called super-radiant phenomena in optics. This is well known in the physics literature, see [25] and references therein. Here, we would like to point to a similarity of the spectral restructure in the random matrix ensemble (1)–(3) to a process in a different physics context, the so-called “condensation transition” which occurs in models of mass transport when the globally conserved mass M exceeds a critical value, see, e.g., [26] for a review. In such a regime, the excess mass forms a localised in space condensate coexisting with a background fluid in which the remaining mass is evenly distributed over the rest of the system. A particularly simple case for analysing the condensation phenomenon is when the system has a stationary state such that probability of observing a configuration of masses factorises into the form . In that context again the tail behaviour of the “parent” mass density plays important role. Although we would like to stress again that in our model the imaginary parts of the complex eigenvalues are not independent, the analogy with the condensation phenomenon is quite evident.
Essentially the same heuristic analysis as in the above helps to clarify the numerically observed fact of the outlier emerging mostly close to the origin of the spectrum Re z = 0. From this angle it is instructive to ask what should be the scale of extreme values for eigenvalues satisfying , that are sampled in a window of a small widths around the origin (still assuming typically many eigenvalues in the window, so that ). The total mean number of eigenvalues in the window W whose imaginary parts exceed the level Y (but still formally remain of the order of ) is now given by
For the term is exponentially suppressed, while the integral in is dominated by and with required accuracy yields the leading-order expression in the form:
Now, let us assume that both the width W of the window and the parameter scale with N in this non-trivial way as
and again apply the same heuristic procedure to determine the scale of extreme values in the window as for given values of exponents and . A straightforward computation shows that the arising scale of extreme values very essentially depends on whether the parameter satisfies or . In the former case we find
whereas in the latter case
One may say that as long as the system is not fully in the well-developed “critical regime”, and the extreme value scale is growing with the window width, saturating at the Gumbel-like scale . At the same time, as long as exceeds the threshold value , the typical extreme values reach the scale as long as they are sampled in a window of width exceeding the scale , thus containing eigenvalues. This heuristics suggests that only eigenvalues satisfying typically have a nonvanishing probability to reach to the maximum height in the complex plane, and eventually to generate an outlier as increases. It would be also natural to expect the corresponding extreme eigenvalues to follow the Fréchet-type statistics for their imaginary parts, as opposed to the Gumbel statistics in the former case.
We would like to end our heuristic considerations with a brief heuristic outlook on the universality of the scaling factor which is key to the correct description of the transition in question. As is evident from (23) the exponent is implied by the scaling law
in the limit for the expected number of eigenvalues exceeding the level line . Thus, to investigate the extent of universality of this exponent one needs to trace the origin of the scaling law (30). This can be readily done by returning to the asymptotic relation (14) and (15) which was used to obtain (30). On evaluating the integral in (15) for large values of by the Laplace method it becomes immediately apparent that the power on the right-hand side in (30) and, hence, the exponent in question stems from the quadratic shape of the limiting GUE eigenvalue density function in the vicinity of its maximum. It is natural to conjecture that had one started from a random Hermitian matrix H taken from the broad class of invariant ensembles characterised by joint probability density function with a suitable potential (or from the class of Wigner matrices with suitable conditions on the iid entries), the asymptotic expression (12) for the scaled eigenvalue density would retain its validity after replacing in (11) and (12) by the corresponding limiting eigenvalue density of H. For example, as was shown albeit not fully rigorously in [27], such universality of the scaled eigenvalue density near the real line is exhibited by almost Hermitian random matrices which are morally similar to finite rank non-Hermitian deviations as in (1) and (2). Since asymptotic relation (14) and (15) is the immediate corollary of (12), one then concludes that as long as the limiting eigenvalue density of H has a single global parabolic-shaped maximum, an additive rank-one non-Hermitian deformation will demonstrate the same type of critical scaling for its extreme complex eigenvalues, and, most probably, after appropriate rescaling, the same type of critical behaviour of the density of imaginary parts as described in the next section. One can however imagine invariant ensembles where the mean eigenvalue density would have a non-parabolic behaviour close to the maximum point.
From this point of view, the noticed in [11] resemblance of the critical scaling in the present model and the edge scaling of extreme real eigenvalues of GUE, which, e.g., manifests itself in the so-called BBP [28] transition under additive rank-one Hermitian perturbation of the GUE, looks to us purely coincidental. Indeed, the latter is known to have its origin in the square root behaviour of the mean density at the spectral edges where vanishes, and as such seems to have nothing to do with the behaviour of the same density close to its maximal point.
3. Main Results and Discussion
Our first result concerns the mean density of imaginary parts (10) in the large deviation regime . We note that no eigenvalue of J has imaginary part equal or greater than . This is a consequence of the sum rule (13). Therefore we only consider the range of values .
Theorem 1.
Consider the random matrix ensemble (1)–(3) in the scaling regime
Then for every fixed and
with
and
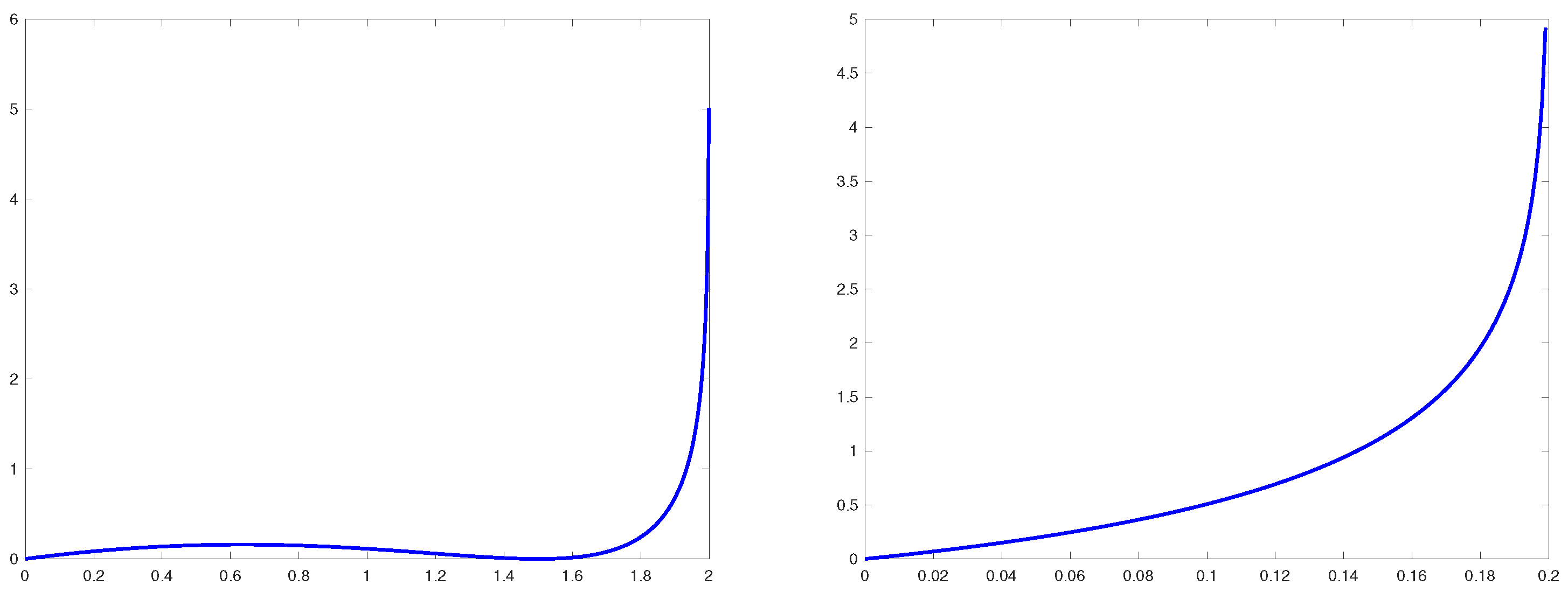
The rate function is a smooth non-negative function of Y on the interval vanishing at . The rate function is monotone increasing on this interval if , whereas if then it has two local extrema: a local minimum at where it vanishes, and a local maximum at .
By the way of discussion of the above Theorem a few remarks are in order.
Remark 3.
The two distinct profiles of the rate function are illustrated in Figure 2. If, the pointwhere the Large Deviation Rate functionvanishes can be identified as the most probable value of the imaginary part in the region, converging in the limitto (the height of) the outlier, see next comment. At the same time, the other extremal point,, can be interpreted as the true boundary, along the imaginary axis in the complex plane, between the bulk of eigenvalues and the spectral outlier. This is because the pre-exponential factorin (32) vanishes at too. Hence, in the scaling limit (31).
Remark 4.
The Large Deviation approximation (32) for describes fluctuations of the imaginary part of the outlier around its most probable value . The law of these fluctuations in the limit can be easily determined from (32). To this end, we first note that for N large the magnitude of fluctuations about scales with . Calculating the second derivative and rescaling the density correspondingly, one finds (in the limit ) that
The integral of the rescaled density on the left-hand side over the entire range of values of u counts the expected number of eigenvalues in the -neighbourhood of . Evidently, this integral is approaching unity as , confirming that the rescaled density on the left-hand side in (36) describes the law of fluctuations of a single eigenvalue - the outlier. Thus, we recover one of the results of [10] where laws of outlier fluctuations were established in greater generality than our assumptions (2) and (3). We note that for finite but large values of N the function
provides an approximation of the probability density function of the outlier in the interval , .
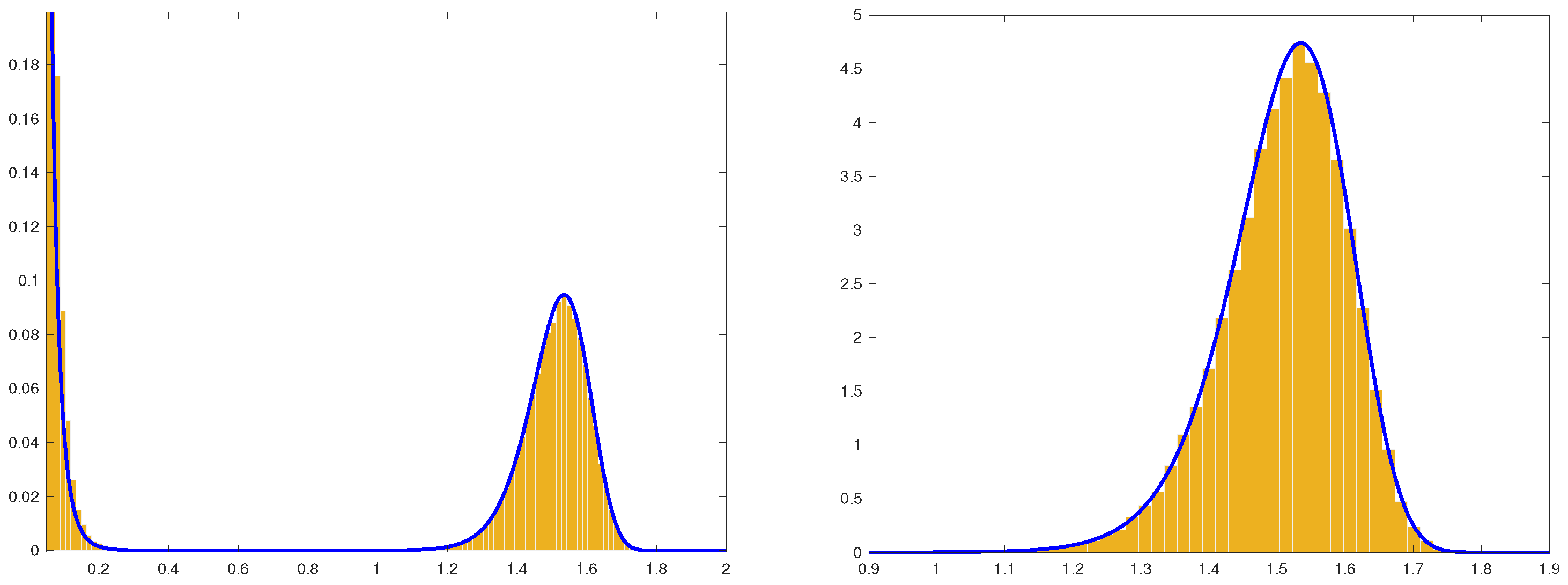
In Figure 3, we plot histograms of the imaginary partsof the eigenvalues and of their maximal valuein the random matrix ensemble (1)–(3) and make comparison with the corresponding Large Deviation approximations. Although the value of is only moderately large, one can observe a good agreement. Furthermore, one can observe that the large-N approximation (37) of the probability density of captures well the skewness of the distribution of for finite matrix dimensions. This skewness disappears in the limit , see Equation (36).
Remark 5.
Consider now the scales with . The expected number of eigenvalues with is given by the integral
The rescaled density in this integral can be found from (32)–(34):
Evidently, if then, away from the boundary point , the integral in (38) vanishes in the limit . Therefore for every fixed and there are no eigenvalues of J whose imaginary part is scaling with . On the other hand, according to the heuristics of Section 2, one should expect finite numbers of eigenvalues whose imaginary part is scaling with . These would be the extremes of the eigenvalues with the typical imaginary part .
By formally lettingin (39) one obtains
This relation reproduces the leading order of the asymptotic form of the density of the rescaled imaginary parts in the region , see the top line in (20). Thus, for a fixed value of Theorem 1 describes a crossover of the density of imaginary parts from the characteristic scale of low lying eigenvalues to larger scales, including which is the scale of the outlier.
Whereas the picture described by Theorem 1 is quite complete for a fixed , it is not detailed enough to accurately describe the typical extreme eigenvalues in the situation when the parameter approaches its critical value as N is approaching infinity. For example, from the heuristics of Section 2 we know that both the width of the transition region about and the height of the typical extreme eigenvalues scale with . The Large Deviation approximation (32), if applied formally in the transition region parametrised by , yields the following approximate expression for the rescaled density of imaginary parts:
Evidently, in the limit of small values of m which corresponds to approaching the scale from above, this expression does not reproduce the correct power of algebraic decay (20) characteristic of this scale when . In contrast, the heuristics based on (21), see the approximations in (23) and (24), do reproduce the correct power. Indeed, by taking the derivative in m of the expression on the right-hand side in (24), one gets
In the limit of small values of m the expression on the right-hand side agrees with the bottom line in (20). One can also arrive at (41) by making the formal substitution and in (20).
Our next Theorem is a refinement of Theorem 1 in that it provides an accurate description of the density of the typical extreme eigenvalues in the transition region between the sea of low lying eigenvalues and the eigenvalue outlier.
Theorem 2.
This theorem confirms that the characteristic scale of the height of the typical extreme eigenvalues of matrix J is . Indeed, the expected number of eigenvalues with imaginary part exceeding the level is given by
which is a finite number in the limit .
Theorem 2 also describes the density in the cross-over from the characteristic scale of low lying eigenvalues to the Large Deviation regime of Theorem 1. Indeed, for small values of m the asymptotic expression (43) matches the one in (41), whilst in the limit of large values of m it matches (40).
The emerging outlier is captured by (43) when both m and are large. Intuitively this is clear from the comparison of (43) and (40). On a more formal level, one can come to the same conclusion by analysing the limiting density of extreme values
Using Wolfram Mathematica one finds
where
Evidently, for all if is negative. Therefore, if (subcritical values of ) then the limiting density is a monotonically decreasing function of m on the entire interval . One can interpret this profile as a population of extreme eigenvalues without an obvious “leader”. By continuity, this profile persevere for small positive . Indeed, at the polynomial has three pairs of complex conjugated roots, none are real. Since the roots of polynomials depend continuously on its coefficients, there exists an such that for all the polynomial in m will still have no real roots and, hence, will take only negative values, implying that is a monotonically decreasing function of m. By computing the roots of in variable m, we can show that .
Once , the polynomial in m acquires real roots. In the limit of large positive there are two real roots: to leading order these are
The larger root, , is the point of local maximum of , where , and the smaller root, , is the point of local minimum , where . In fact, in the limit the larger root is transitioning into , the most probable value of imaginary parts, and, hence, it can be interpreted as the emerging spectral outlier. At the same time, the smaller root is transitioning into the true boundary between the sea of low lying eigenvalues and the outlier. This cross-over can be validated by noticing that in the scaling limit (42) and .
Further insights into the restructuring of the spectrum of J can be obtained by looking at the -dependence of the expected number of the eigenvalues of J with imaginary parts exceeding the level . In the scaling limit (42) this number converges to
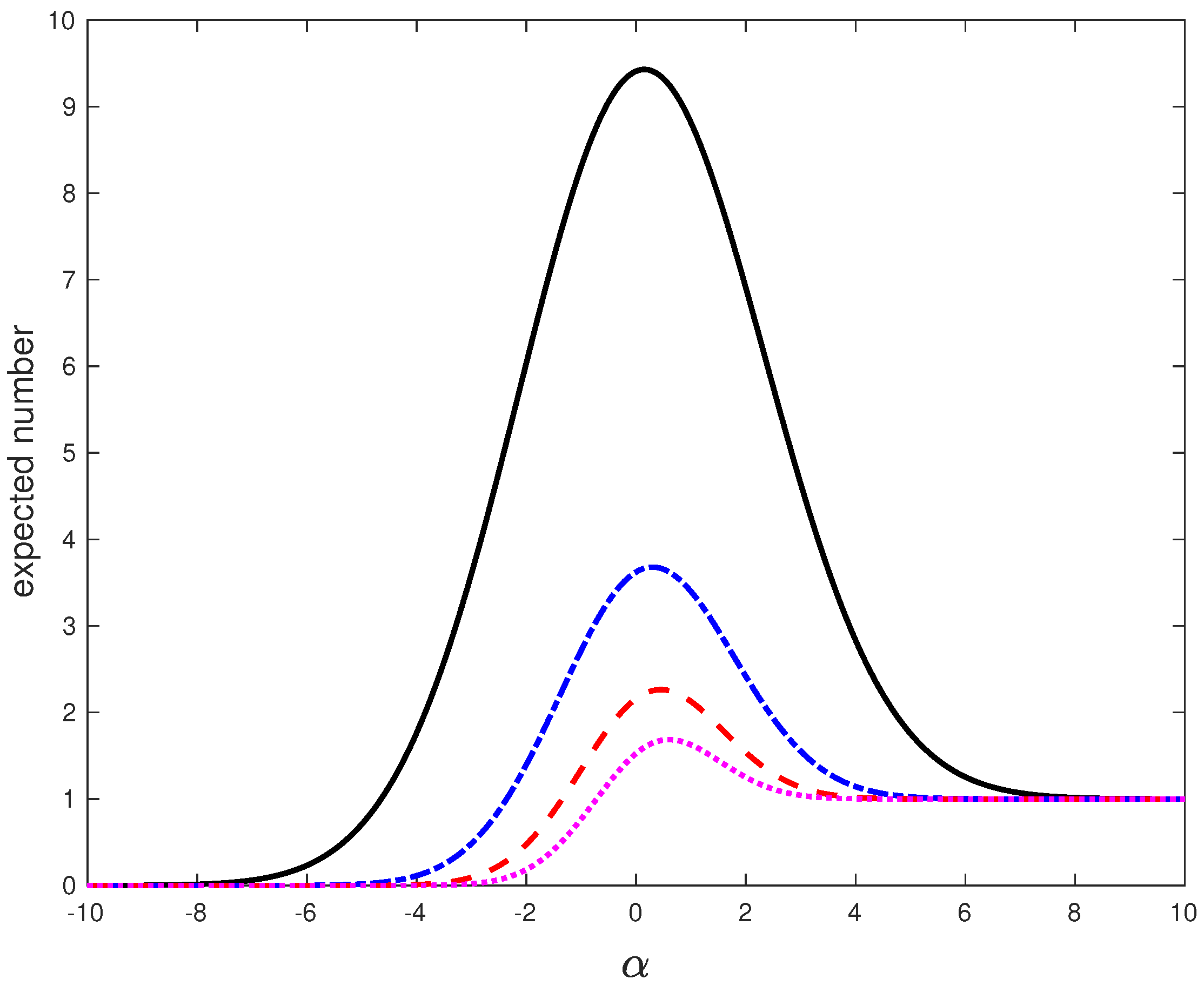
In Figure 4, we plot as function of for several values of m. One can observe that for any fixed the population of the extreme eigenvalues of J that exceed the level is, on average, growing as is approaching the critical value from below. For on the other side of , this population peaks a some point and then it starts to decline as increases further, to a single eigenvalue which is the outlier. All the other extreme eigenvalues are getting closer and closer to the real line with the increase of . One can think of them as being trapped in the sea of low lying eigenvalues. This picture is consistent with the eigenvalue trajectories of Figure 1 and provides a more quantitative description of the “resonance trapping” phenomenon [20] in the framework of random matrix theory.
Our final result aims to clarify the length of the central part of the spectrum of J supporting nontrivial scaling behaviour of the extreme eigenvalues in the vicinity of the separation transition. To this end, let us consider eigenvalues of J in the scaling regime when
On average, eigenvalue numbers in this regime can be counted using the rescaled density
where, as before, the angle brackets stand for the averaging over the GUE matrix H in (1) and is the mean eigenvalue density (8).
Theorem 3.
It is easy to see from (46) that . Thus, Theorem 3 confirms the heuristics of Section 2 in that the population of extreme eigenvalues which generates the eventual outlier (as is approaching infinity) is constrained to a narrow vertical strip of width about the origin.
Our results demonstrate that despite being one of the simplest tools available, the mean eigenvalue density captures the eigenvalue and parameter scales associated with the spectral restructuring in the random matrix ensemble (1)–(3). However, it gives no information about finer details, such as the probability distribution of the extreme eigenvalues during the restructure. Calculating all the higher order eigenvalue correlation functions in the scaling regime (45) would be a significant step towards describing such finer details. Unfortunately, the eigenvalue point process in the random matrix ensemble (1)–(3) is not determinantal at finite matrix dimensions and such a calculation is a considerably more difficult analytic task compared to the mean eigenvalue density.
At this point we want to mention that the probability distribution of extreme eigenvalues can be determined in a related but different random matrix ensemble exhibiting a spectral restructuring not unlike one in (1)–(3). This ensemble consists of subunitary matrices of the form
where the matrix U is taken from the Circular Unitary Ensemble (CUE) of complex unitary matrices uniformly distributed over with the Haar’s measure and is a parameter. The ensemble was originally introduced in [29] and various statistical aspects of their spectra and eigenvectors were addressed in [2,6,30,31] and most recently in [15].
Obviously, if then the matrix is unitary and all of its eigenvalues lie on the unit circle . If and is fixed in the limit then, typically, the eigenvalues of lie at a distance from the unit circle with the farthest away being at a distance with probability close to one. On the other hand, for one of the eigenvalues becomes identically zero, and the rest are distributed inside the unit circle in the same way as eigenvalues of the so-called “truncated” CUE [32].
The similarity between the random matrix ensembles (47) and (1)–(3) can be exemplified by analysing the mean density of the eigenvalue moduli
in the limit of large matrix dimensions . One finds [29] that for every fixed
whereas, on rescaling the radial density near the unit circle [2,32],
Equation (48) is identical, with the obvious correspondence
to Equation (12) considered at the centre of the GUE spectrum. In the limit of large values of y,
The rescaled radial density has an exponentially light tail if , and it is heavy-tailed if which hints at markedly different behaviour of the extreme eigenvalues in the two cases. Reflecting on (50), one can convince themselves that this change occurs in an infinitesimal region near of width . Such a scaling regime was earlier identified and analysed from a somewhat different angle in [15]. The precise relation of our analysis to one in [15] will be given in a separate paper [33].
On setting , , one can investigate this transition region in much detail [33]. For example, the smallest eigenvalue modulus of the subunitary matrices ,
converges in the limit to a random variable X whose cumulative probability distribution function is given by the series
This family of probability distributions interpolates between the Fréchet and Gumbel distributions and is different from the standard family of probability distributions that characterise the extreme values in long sequence of i.i.d. random variables. In the limit of small values of t
whereas
4. Mean Density of Eigenvalues at Finite Matrix Dimensions
Our analysis of various scaling regimes of the random matrix ensemble (1)–(3) is based on finite-N expressions for the mean eigenvalue density and the mean density of imaginary parts in terms of orthogonal polynomials, see Equations (56)–(64). These representations are new and the current Section contains their derivations.
4.1. Joint Eigenvalue Density and Correlation Functions
Our starting point is a closed form expression for the joint density of the eigenvalues of J (1)–(3):
where G(N) is the Barnes G-function. The expression was derived in [22] (see also [5]) and, for obvious reason, it holds for , where
is the upper half of the complex plane
The first key fact that makes our analysis possible is that the eigenvalue correlation functions
can be expressed in terms of averages of products of characteristic polynomials of random matrices having the same structure as (1)–(3) but of smaller dimension and with a different parameter . The relevance of this to our investigation is in that the mean eigenvalue density (8) which is the main object of our interest is
It has been shown in [22] that
where
and are the random matrices (1)–(3) of dimension with N in (3) replaced by and in (2) replaced by ,
The GUE average of the product of the characteristic polynomials of can be performed with the help of the following proposition which we prove in Appendix A.
Proposition 1.
4.2. Mean Density of Complex Eigenvalues
Setting and in (53) and then shifting the variable of integration by making the substitution in the matrix integral, one obtains the following integral representation for the mean density of eigenvalues (52) in the random matrix ensemble (1)–(3):
It is convenient to parametrise the hermitian matrix by diagonalising it:
where is a unitary matrix, which can be parametrised as
Noting that
one arrives, on making the substitution in (54), at
where we have introduced
The integral over can be performed by the substitution . This yields
where
with .
Further, introducing functions
one can rewrite the integral in the following form
Now one observes that are actually a rescaled version of Hermite polynomials. We have that
where are the monic Hermite polynomials
and are the orthonormal Hermite polynomials
satisfying the orthogonality relations
The polynomials also satisfy the recurrence relation
Using the above definitions and the expression for the eigenvalue density in (56) and with the notation we obtain
which, by using the recurrence relation, can be further rewritten as
4.3. Density of the Imaginary Parts
In this section, we present the derivation of the density for the imaginary parts of the eigenvalues, irrespective of their real parts, as defined in (10). We start with an observation, see integral 7.377 in [23]:
Lemma 1.
Let be two non-negative integers and . Then
where is a standard Laguerre polynomial.
Integrating with respect to X expression for the density in (60) one gets the probability density of imaginary parts in the form
with
where we systematically used the recursion relations:
and
5. Proof of Theorems 1 and 2
In both proofs we use the following integral representation for the Laguerre polynomials in terms of the modified Bessel functions (see, e.g., Equation 4.19.13 in [34]):
The integral in (65) can be evaluated in the limit in various scaling regimes for Y using the Laplace method, see Appendix B. The resulting asymptotic expression depends on the scaling of the variable with N.
Proof of Theorem 1.
Consider the scaling regime (31) with being fixed. In this regime the asymptotic form of the mean density of the imaginary parts can be found using the leading order form of which can be read from (A8) as
On substituting (66) into (64) one gets an asymptotic expression for the density (61) precisely in the Large Deviation form (32) with the rate function (33) and the pre-exponential factor in the form
Finally, by exploiting the relation ,
This brings the function in (67) to the form as given in (34).
To analyse the shape of the rate function in (33) it is convenient to parametrise
In this parametrisation, the rate function transforms to
and its derivative in factorises as follows:
Therefore, the stationary points of solve the equations
and
These equations yields two stationary points and . Correspondingly, the rate function has two stationary points
It is evident that if both stationary points and are negative. One can easily check that in this case is monotonically increasing on the interval and is positive on this interval.
If then taking the second derivative in one can easily show that
so that is the point of local minimum of the rate function , and is the point of local maximum. It is also easy to verify that the rate function vanishes in the limit and also at , staying positive at all other , so that that the point is the point of absolute minimum. Finally, to verify that the pre-exponential factor (34) vanishes at it suffices to show that . On noticing that
this relation evidently follows from (68) and (70). □
Proof of Theorem 2.
In the scaling regime (42) the variable Y scales with . As in this case, the required asymptotic expressions for Laguerre polynomials can be read from (A8). It turns out that in order to calculate the density of imaginary parts to leading order in this regime, one has to retain the subleading term in the pre-exponential factor as specified in (A8). On substituting in (A8) we obtain that with the required precision
where with (35) and expanded in powers of :
It is easy to see that the overall exponential behaviour of the mean density (61) will still be given by (33) duly expanded:
Putting in here the scaling form and recalling we find from (75), assuming that the parameters and are fixed, that
This verifies the exponent in (43). To find the pre-exponential terms we find it most convenient to use Equation (63). Substituting there (71)–(73) we first get
After rearranging and collecting the relevant terms in the above expression we arrive at
The expansion (74) together with give the relations
and
which are exact to the subleading order. We can now see that the leading order terms inside the curly brackets in (77) cancel. This also implies that at the leading order it is enough to replace the factor in (77) with . Finally, adding the leading order contribution from
to the terms in (78) and (79) results in
thus verifying the pre-exponential factors in (43). □
Let us finally present the derivation of the marginal density of imaginary parts () pertinent to keeping the product fixed as . This task is straightforwardly achieved by performing the limit in (61) via substituting the corresponding asymptotics of Laguerre polynomials (A3) into the Formula (63) and using the identity .
6. Proof of Theorem 3
Proof.
We will use Equations (56)–(58) which express the mean density of eigenvalues in terms of the rescaled Hermite polynomials (59).
Using the integral representation in (57) it can be shown that in the scaling limit
the rescaled Hermite polynomials are given by the asymptotic equations
where we have introduced the notations
This implies for (58) that
We are here interested in the limit of small (81), and, hence, can use the expansions
and, consequently,
Hence,
Setting here , and one obtains that to leading order in N
With the same precision we have
and, consequently,
On inspecting (56) and (85), one concludes that the overall exponential factor in (56) is given by , where
The leading order form of can be found by expanding in powers of X and Y, in a similar way as before:
Adding all contributions,
Setting here , and , one obtains that to leading order
Combining (88) with (87), and trivially taking into account asymptotic expressions for the remaining multiplicative factors in (56) and (86), one arrives at (46). □
Author Contributions
Conceptualization, Y.V.F. and B.A.K.; Methodology, Y.V.F., B.A.K. and M.P.; Formal analysis, Y.V.F., B.A.K. and M.P.; Investigation, Y.V.F. and B.A.K.; Writing—original draft, Y.V.F. and B.A.K.; Writing—review & editing, Y.V.F. and B.A.K. All authors have read and agreed to the published version of the manuscript.
Funding
Y.V.F. acknowledges financial support from EPSRC Grant EP/V002473/1 “Random Hessians and Jacobians: theory and applications”.
Acknowledgments
The authors are grateful to Guillaume Dubach for highly useful comments on the revised version of the manuscript. The authors are also grateful to Bertrand Lacroix A Chez Toine for bringing their attention to paper [26] and the similarity between the spectral restructure in the random matrix ensemble (1)–(3) and the condensation transition in models of mass transport.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
Abbreviations
The following abbreviations are used in this manuscript:
| GUE | Gaussian Unitary Ensemble |
| JPDF | Joint Probability Density Function |
Appendix A. Proof of Proposition 1
We prove here a more general version of Proposition 1 which holds for rank-M deviations from the GUE (3) with arbitrary real parameters . The Proposition 1 follows as the special case .
Proposition A1.
Let be a diagonal matrix of dimension N with non-zero real entries and
where the average is taken over the GUE distribution (3). Then
where the integration is over the space of Hermitian matrices , is the standard volume element in this space and
Proof of Proposition A1.
The average of the product of the characteristic polynomials over the GUE in in (A1) can be calculated using Grassmann integration. First we use the well-known identity
where M is matrix, and are Grassmann variables vectors of length N and . We also write each square of determinant in the form
Combining the above relations,
Now we interchange the order of integrations and perform the GUE average first:
In the last expression one can see quartic terms in Grassmann variables. To deal with these terms, we use the so-called Hubbard-Stratonovich transformation. Let
and
Then
The quadratic term in the matrix A can be linearised at the expense of the additional integration over hermitian matrices (the Hubbard-Stratonovich transformation):
Now, we can integration over the Grassmann variables. We have
By manipulating terms in the exponentials,
Now, recalling that for we obtain the statement of the Proposition. □
Appendix B. Various Asymptotic Regimes for Laguerre Polynomials
Asymptotic behaviour of the Laguerre polynomials in the limit when and k and are fixed depends on the scale of the variable compared to N. For our investigation we need two scales: (i) is fixed and (ii) . In both cases the desired approximations can be obtained from the integral representation (65) which we rewrite as
We start with simpler case of being fixed in the limit . In this case significant contributions to the integral in (A2) are coming from a neighbourhood of the point which is the point of minimum the function inside the interval of integration. Straightforward evaluation of the integral by the Laplace method together with the Stirling approximation yields that
In the other regime of interest for us, , one can use the following asymptotic expansion for the modified Bessel function (see, e.g., Formula 5.11.10 in [34]):
It reduces the asymptotic analysis of to analysis of the following expression:
In this case significant contributions to the integral in (A5) are coming from a neighbourhood of the point which is the point of minimum the function inside the interval of integration.
Using the relations and we find that
Expanding the integrand in the standard way around and collecting the leading and subleading order terms we get asymptotic expressions for Laguerre polynomials with the precision sufficient for our purposes:
References
- Fyodorov, Y.V.; Sommers, H.-J. Statistics of resonance poles, phase shifts and time delays in quantum chaotic scattering: Random matrix approach for systems with broken time-reversal invariance. J. Math. Phys. 1997, 38, 1918–1981. [Google Scholar] [CrossRef] [Green Version]
- Fyodorov, Y.V.; Sommers, H.-J. Random Matrices Close to Hermitian or Unitary: Overview of Methods and Results. J. Phys. A Math. Gen. 2003, 36, 3303–3347. [Google Scholar] [CrossRef]
- Forrester, P.J. Rank-1 perturbations in random matrix theory—A review of exact results. arXiv 2022, arXiv:2201.00324. [Google Scholar]
- Poplavskyi, M.; Schehr, G. Exact Persistence Exponent for the 2D-Diffusion Equation and Related Kac Polynomials. Phys. Rev. Lett. 2018, 121, 150601. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kozhan, R. Rank One Non-Hermitian Perturbations of Hermitian β-Ensembles of Random Matrices. J. Stat. Phys. 2017, 168, 92–108. [Google Scholar] [CrossRef] [Green Version]
- Killip, R.; Kozhan, R. Matrix Models and Eigenvalue Statistics for Truncations of Classical Ensembles of Random Unitary Matrices. Commun. Math. Phys. 2017, 349, 99–1027. [Google Scholar] [CrossRef] [Green Version]
- Fyodorov, Y.V.; Osman, M. Eigenfunction non-orthogonality factors and the shape of CPA-like dips in a single-channel reflection from lossy chaotic cavities. J. Phys. A Math. Theor. 2022, 55, 224013. [Google Scholar] [CrossRef]
- Fyodorov, Y.V.; Osman, M.; Tublin, R. A Few Results and Conjectures about Rank-One Non-Hermitian Deformations of β-Hermite Ensembles. Manuscript in preparation.
- O’Rourke, S.; Wood, P. Spectra of nearly Hermitian random matrices. Ann. l’Institut Henri Poincare 2017, 53, 1241–1279. [Google Scholar] [CrossRef] [Green Version]
- Rochet, J. Complex Outliers of Hermitian Random Matrices. J. Theor. Probab. 2017, 30, 1624–1654. [Google Scholar] [CrossRef]
- Dubach, G.; Erdős, L. Dynamics of a rank-one perturbation of a Hermitian matrix. arXiv 2022, arXiv:2108.13694. [Google Scholar]
- Shcherbina, M.; Shcherbina, T. Finite-rank complex deformations of random band matrices: Sigma-model approximation. arXiv 2022, arXiv:2112.04455. [Google Scholar]
- Tao, T. Outliers in the spectrum of iid matrices with bounded rank perturbations. Probab. Theory Relat. Fields 2013, 155, 231–263. [Google Scholar] [CrossRef] [Green Version]
- O’Rourke, S.; Renfrew, D. Low rank perturbations of large elliptic random matrices. Electron. J. Probab. 2014, 19, 1–65. [Google Scholar] [CrossRef]
- Forrester, P.J.; Ipsen, J.R. A generalisation of the relation between zeros of the complex Kac polynomial and eigenvalues of truncated unitary matrices. Probab. Theory Relat. Fields 2019, 175, 833–847. [Google Scholar] [CrossRef] [Green Version]
- Bohigas, O.; Giannoni, M.J.; Schmit, C. Characterization of chaotic quantum spectra and universality of level fluctuation laws. Phys. Rev. Lett. 1984, 52, 1–4. [Google Scholar] [CrossRef]
- Verbaarschot, J.J.M.; Weidenmüller, H.A.; Zirnbauer, M.R. Grassmann integration in stochastic quantum physics: The case of compound-nucleus scattering. Phys. Rep. 1985, 129, 367–438. [Google Scholar] [CrossRef]
- Sokolov, V.V.; Zelevinsky, V.G. Dynamics and statistics of unstable quantum states. Nucl. Phys. A 1989, 504, 562–588. [Google Scholar] [CrossRef]
- Dittes, F.-M.; Harney, H.L.; Rotter, I. Formation of fast and slow decay modes in N-level systems coupled to one open channel. Phys. Lett. A 1991, 153, 451–455. [Google Scholar] [CrossRef]
- Persson, E.; Rotter, I.; Stoeckmann, H.-J.; Barth, M. Observation of Resonance Trapping in an Open Microwave Cavity. Phys. Rev. Lett. 2000, 85, 2478–2481. [Google Scholar] [CrossRef] [Green Version]
- Fyodorov, Y.V.; Sommers, H.-J. Statistics of S-matrix poles in few-channel chaotic scattering: Crossover from isolated to overlapping resonances. JETP Lett. 1996, 63, 1026–1030. [Google Scholar] [CrossRef] [Green Version]
- Fyodorov, Y.V.; Khoruzhenko, B.A. Systematic Analytical Approach to Correlation Functions of Resonances in Quantum Chaotic Scattering. Phys. Rev. Lett. 1999, 83, 65–68. [Google Scholar] [CrossRef] [Green Version]
- Gradshteyn, I.S.; Ryzhik, I.M. Table of Integrals, Series, and Products, 7th ed.; Elsevier/Academic Press: Amsterdam, The Netherlands, 2007. [Google Scholar]
- Majumdar, S.N.; Pal, A.; Schehr, G. Extreme value statistics of correlated random variables: A pedagogical review. Phys. Rep. 2020, 840, 1–32. [Google Scholar] [CrossRef] [Green Version]
- Auerbach, N.; Zelevinsky, V. Super-radient dynamics, doorways, and resonances in nuclei and other open mesoscopic systems. Rep. Progr. Phys. 2011, 74, 106301. [Google Scholar] [CrossRef]
- Majumdar, S.N. Real-space Condensation in Stochastic Mass Transport Models. In Exact Methods in Low-dimentional Statistical Physics and Quantum Computing; (Lecture Notes of the Les Houches Summer School); Jacobsen, J., Ed.; Oxford University Press: New York, NY, USA, 2009; Volume 89. [Google Scholar]
- Fyodorov, Y.V.; Khoruzhenko, B.A.; Sommers, H.-J. Universality in the random matrix spectra in the regime of weak non-Hermiticity. Ann. Inst. H Poincaré Phys. Théor. 1998, 68, 449–489. [Google Scholar]
- Baik, J.; Ben Arous, G.; Peche, S. Phase transition of the largest eigenvalue for nonnull complex sample covariance matrices. Ann. Probab. 2005, 33, 1643–1697. [Google Scholar] [CrossRef]
- Fyodorov, Y.V. Spectra of random matrices close to unitary and scattering theory for discrete-time systems. arXiv 2001, arXiv:nlin/0002034. [Google Scholar]
- Fyodorov, Y.V.; Mehlig, B. Statistics of resonances and nonorthogonal eigenfunctions in a model for single-channel chaotic scattering. Phys. Rev. E 2002, 66, 045202(R). [Google Scholar] [CrossRef] [Green Version]
- Fyodorov, Y.V.; Khoruzhenko, B.A. On absolute moments of characteristic polynomials of a certain class of complex random matrices. Commun. Math. Phys. 2007, 273, 561–599. [Google Scholar] [CrossRef] [Green Version]
- Życzkowski, K.; Sommers, H.-J. Truncations of random unitary matrices. J. Phys. A Math. Gen. 2000, 33, 2045–2057. [Google Scholar] [CrossRef]
- Fyodorov, Y.V.; Khoruzhenko, B.A. Extreme eigenvalues of random sub-unitary matrices: From Fréchet to Gumbel. Manuscript in preparation.
- Lebedev, N.N. Special Functions and Their Applications; Dover Publications: New York, NY, USA, 1972. [Google Scholar]
Figure 1.
-trajectories of eigenvalues of matrices (1)–(3) of dimension near the origin. Each plot represents a different sample of H from the GUE (3). The parameter is varying in the interval in the increments of (blue dots), in the interval in the increments of (red dots), and in the interval in the increments of (green dots).
Figure 1.
-trajectories of eigenvalues of matrices (1)–(3) of dimension near the origin. Each plot represents a different sample of H from the GUE (3). The parameter is varying in the interval in the increments of (blue dots), in the interval in the increments of (red dots), and in the interval in the increments of (green dots).

Figure 2.
Plots of the rate function for (plot on the left) and (plot on the right).

Figure 3.
Histograms of the imaginary parts of the eigenvalues in the random matrix ensemble (1)–(3) of dimension with . Plot on the left: Histogram of ’s versus the large deviation approximation of density of the imaginary parts given by (32) (solid line). Plot on the right: Histogram of the largest imaginary part versus the large deviation approximation (37) of the p.d.f. of (solid line). Each plot was produced using 100,000 samples from the GUE distribution (3).
Figure 3.
Histograms of the imaginary parts of the eigenvalues in the random matrix ensemble (1)–(3) of dimension with . Plot on the left: Histogram of ’s versus the large deviation approximation of density of the imaginary parts given by (32) (solid line). Plot on the right: Histogram of the largest imaginary part versus the large deviation approximation (37) of the p.d.f. of (solid line). Each plot was produced using 100,000 samples from the GUE distribution (3).

Figure 4.
Plot of the expected number of the eigenvalues of J with imaginary parts exceeding the level as function of when (black solid line), (blue dashdotted line), (red dashed line), and (magenta dotted line).
Figure 4.
Plot of the expected number of the eigenvalues of J with imaginary parts exceeding the level as function of when (black solid line), (blue dashdotted line), (red dashed line), and (magenta dotted line).

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Fyodorov, Y.V.; Khoruzhenko, B.A.; Poplavskyi, M. Extreme Eigenvalues and the Emerging Outlier in Rank-One Non-Hermitian Deformations of the Gaussian Unitary Ensemble. Entropy 2023, 25, 74. https://doi.org/10.3390/e25010074
AMA Style
Fyodorov YV, Khoruzhenko BA, Poplavskyi M. Extreme Eigenvalues and the Emerging Outlier in Rank-One Non-Hermitian Deformations of the Gaussian Unitary Ensemble. Entropy. 2023; 25(1):74. https://doi.org/10.3390/e25010074
Chicago/Turabian StyleFyodorov, Yan V., Boris A. Khoruzhenko, and Mihail Poplavskyi. 2023. "Extreme Eigenvalues and the Emerging Outlier in Rank-One Non-Hermitian Deformations of the Gaussian Unitary Ensemble" Entropy 25, no. 1: 74. https://doi.org/10.3390/e25010074
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.