
A Spatial–Temporal Causal Convolution Network Framework for Accurate and Fine-Grained PM2.5 Concentration Prediction

 , ,
, ,
Abstract
:1. Introduction
- (1)
- Based on the important influence of air pollutants and meteorological factors on PM2.5 diffusion and evolution, a large number of studies incorporated atmospheric data monitored by stations into PM2.5 prediction modeling. These atmospheric data mainly include meteorological factors (atmospheric pressure, temperature, humidity, wind direction, etc.) and air pollutants (PM2.5, PM10, CO, NO2, etc.).
- (2)
- The temporal and spatial correlation among monitoring stations should be incorporated into PM2.5 modeling. Due to the existence of many influencing factors, the PM2.5 sequence of the target station and surrounding stations is interdependent in spatial and temporal dimensions. How to effectively capture the temporal and spatial correlation between different stations is the key to improving the prediction performance.
- (1)
- In order to capture the nonlinear influencing factors, this study not only considers the spatial–temporal correlation between stations, but also adopts meteorological factors and air pollutants that have a strong correlation with the diffusion evolution of PM2.5.
- (2)
- In terms of fine-grained prediction, the proposed model occupies a fine resolution both in spatial and temporal dimensions. The hourly prediction shows a more elaborate depiction of PM2.5 concentration distribution and trend via station-level analysis.
- (3)
- Convolutional neural network and causal convolutional network are employed to extract the spatial–temporal features of air pollutants with spatial–temporal attention mechanism. It overcomes the problems existing in typical deep learning methods, such as time-consuming iteration propagation, gradient vanishing, etc.
- (4)
- We combine ST-CCN-PM2.5 model with end-to-end Bayesian optimizer. It cannot only avoid obtaining local optimal solution, but also automatically and efficiently extract the optimal hyperparameters of the model, providing a promising research direction for PM2.5 prediction.
2. Related Works
2.1. On Modeling of Fine-grained PM2.5 Prediction
2.1.1. Linear Models and Time Series Models
2.1.2. Shallow Neural Networks
2.1.3. Deep Learning Based Models
2.1.4. Specialized Models
2.2. On Selection of Impact Factors
2.2.1. Spatial–Temporal Influence Factors
2.2.2. Other Influencing Factors
3. Methodology
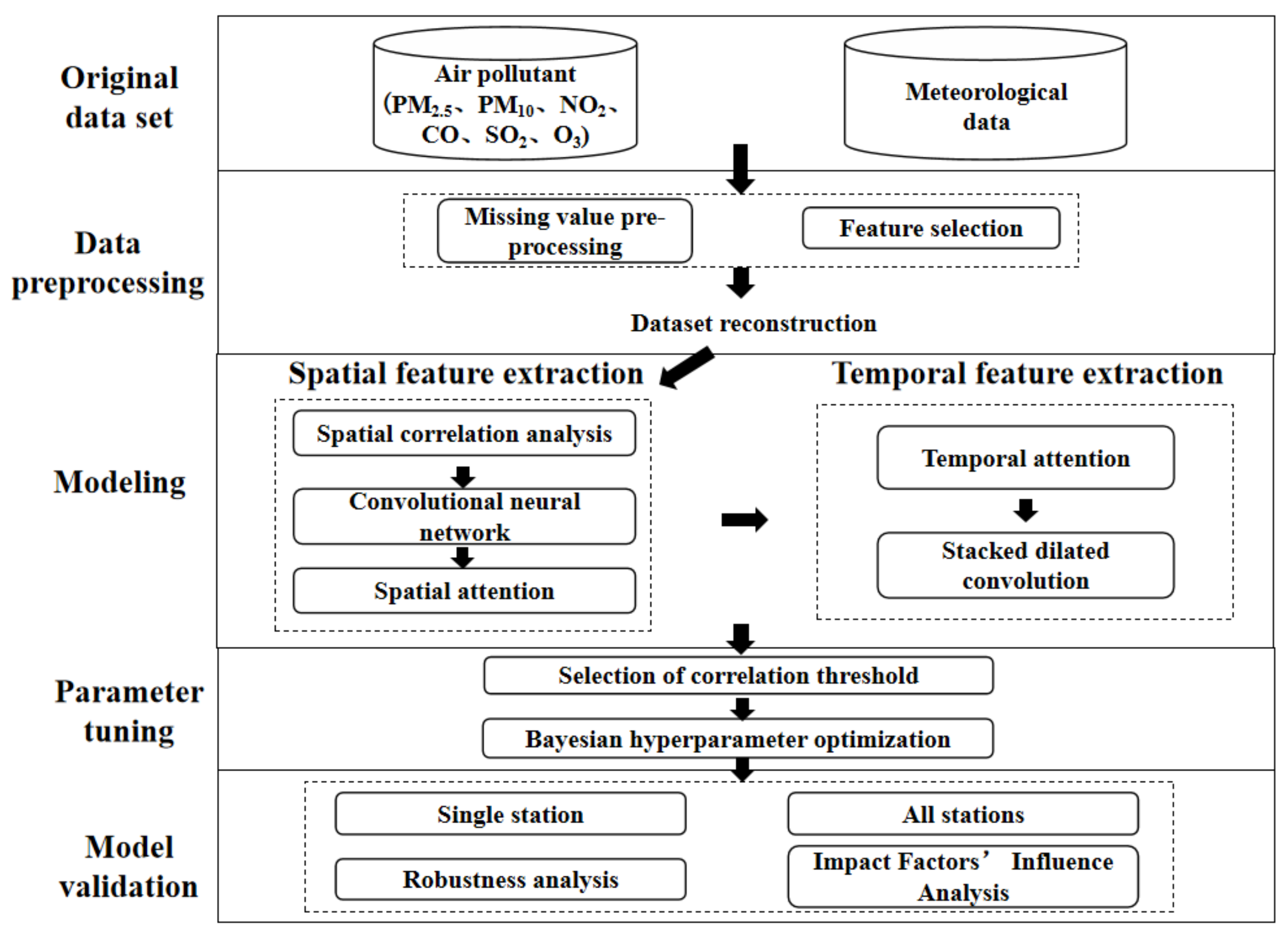
3.1. ST-CCN-PM2.5 Architecture
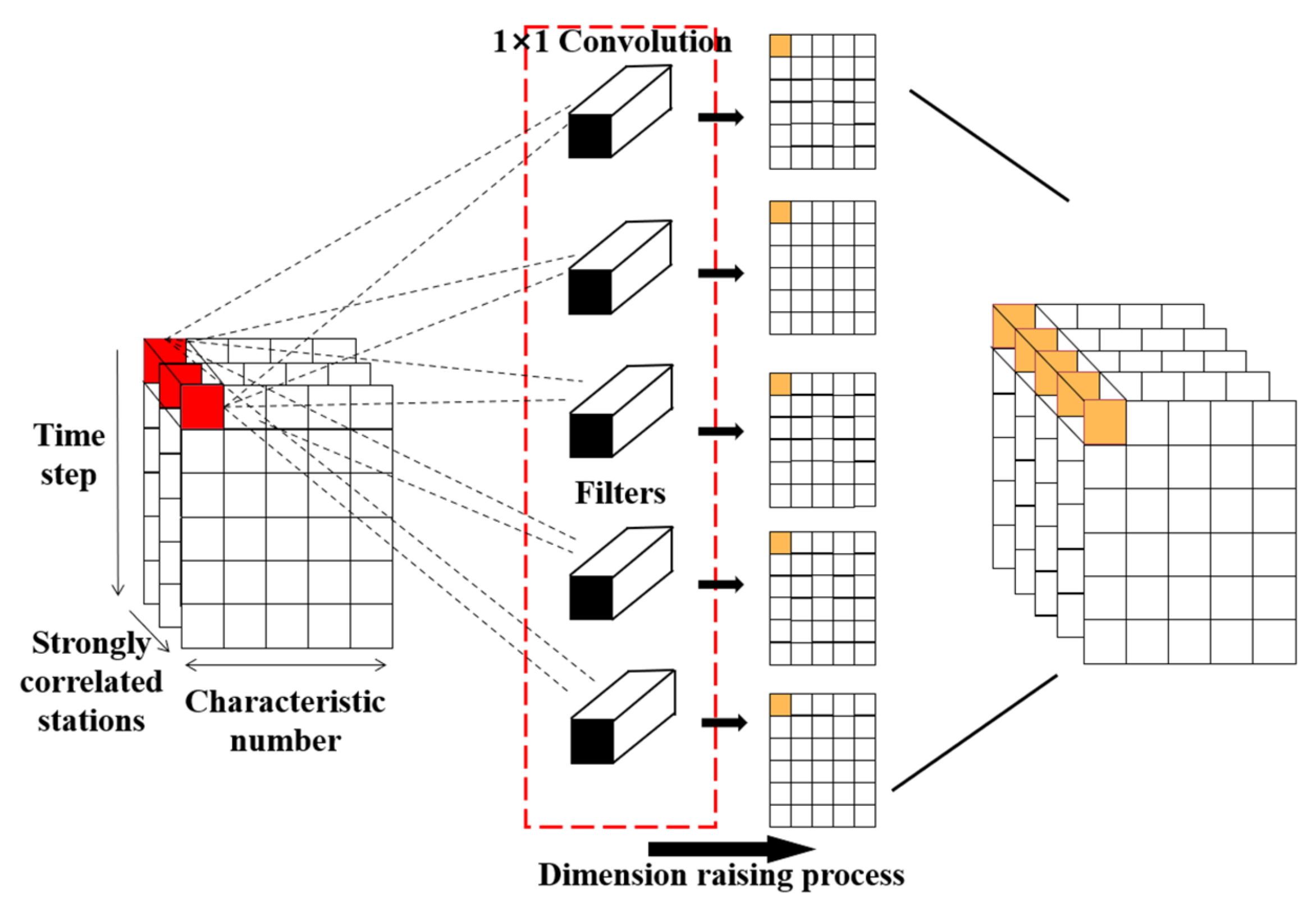
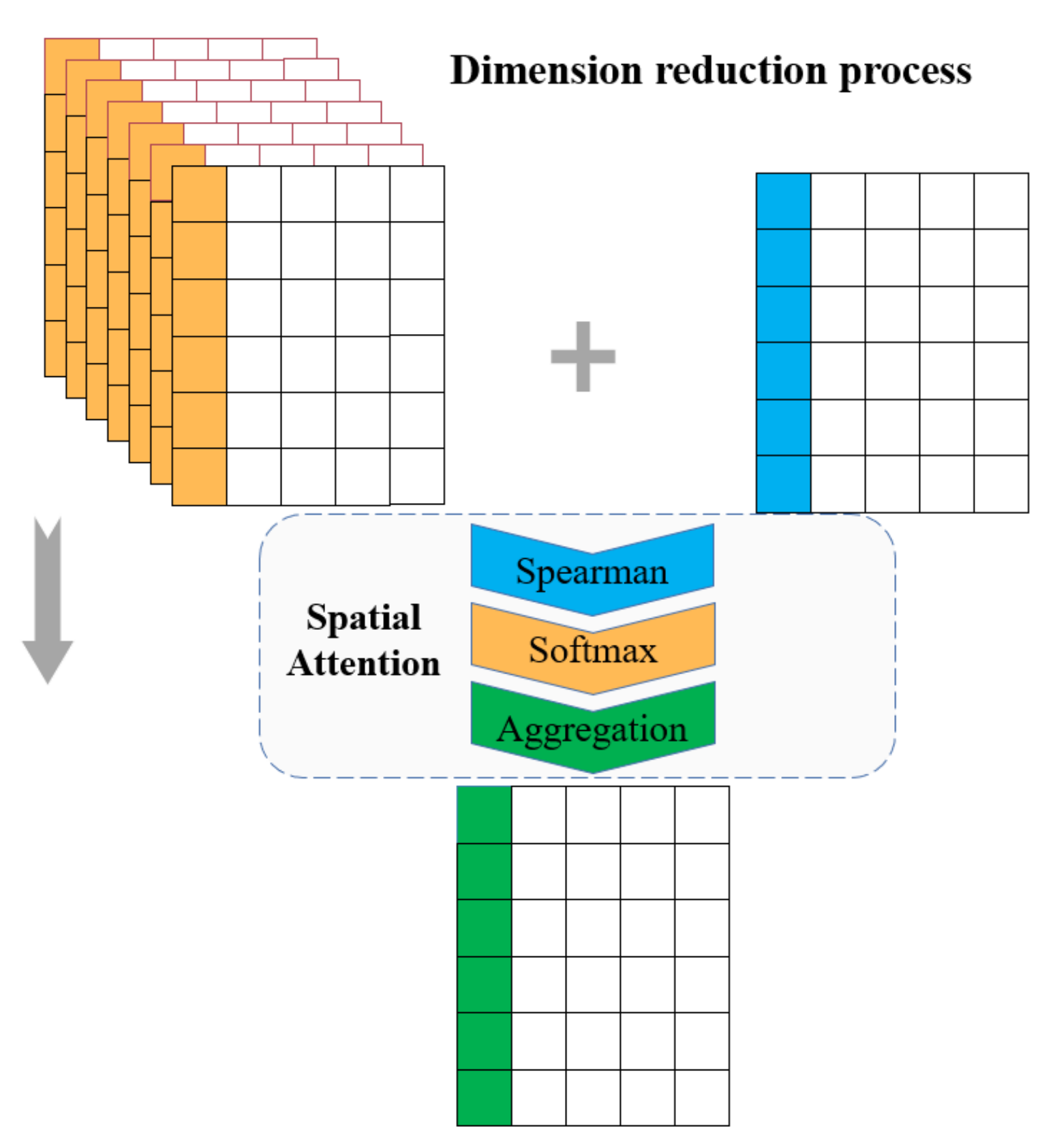
3.2. Spatial Feature Extraction
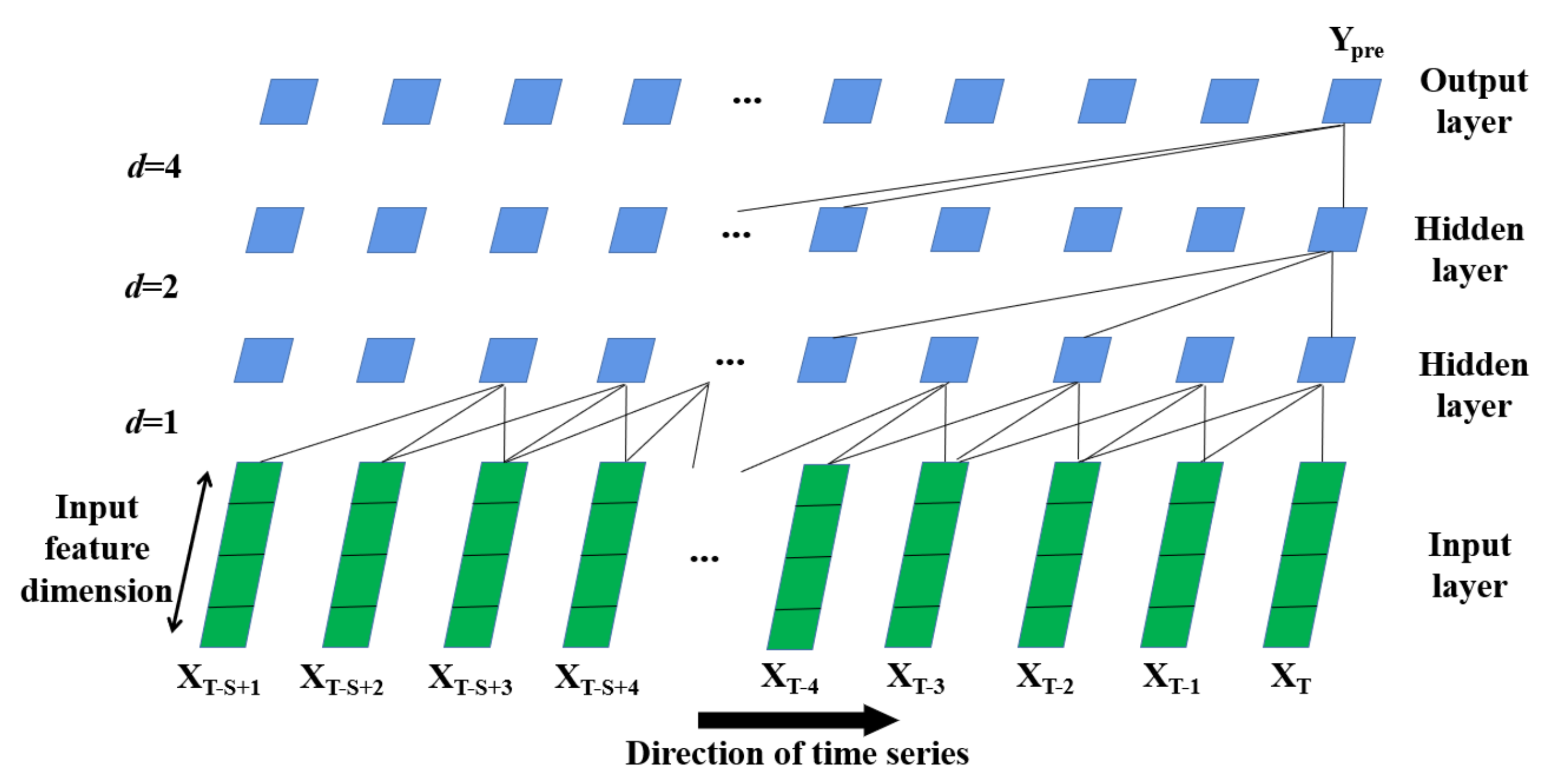
3.3. Temporal Feature Extraction
4. Experiment
4.1. Study Area and Dataset Description
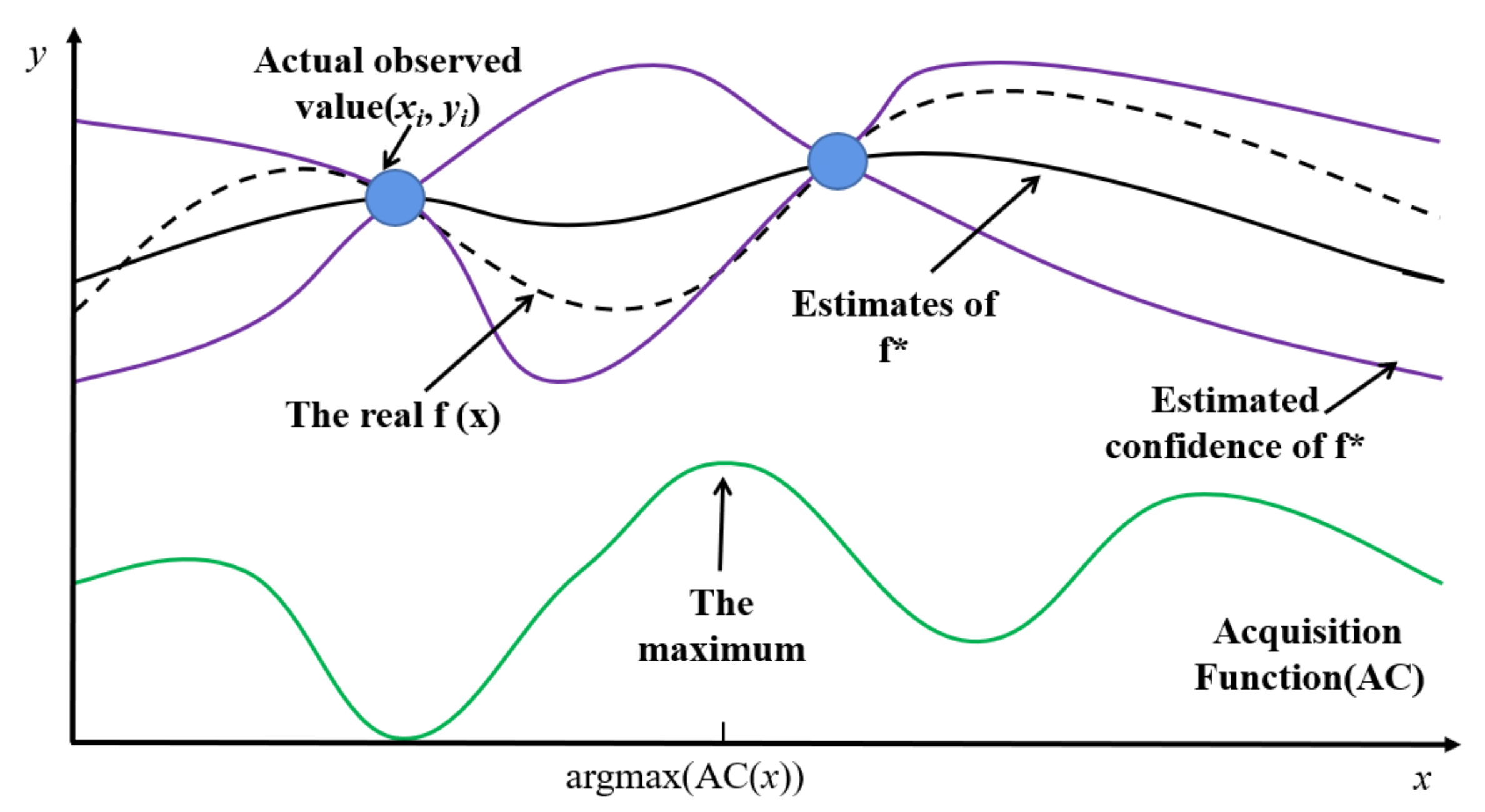
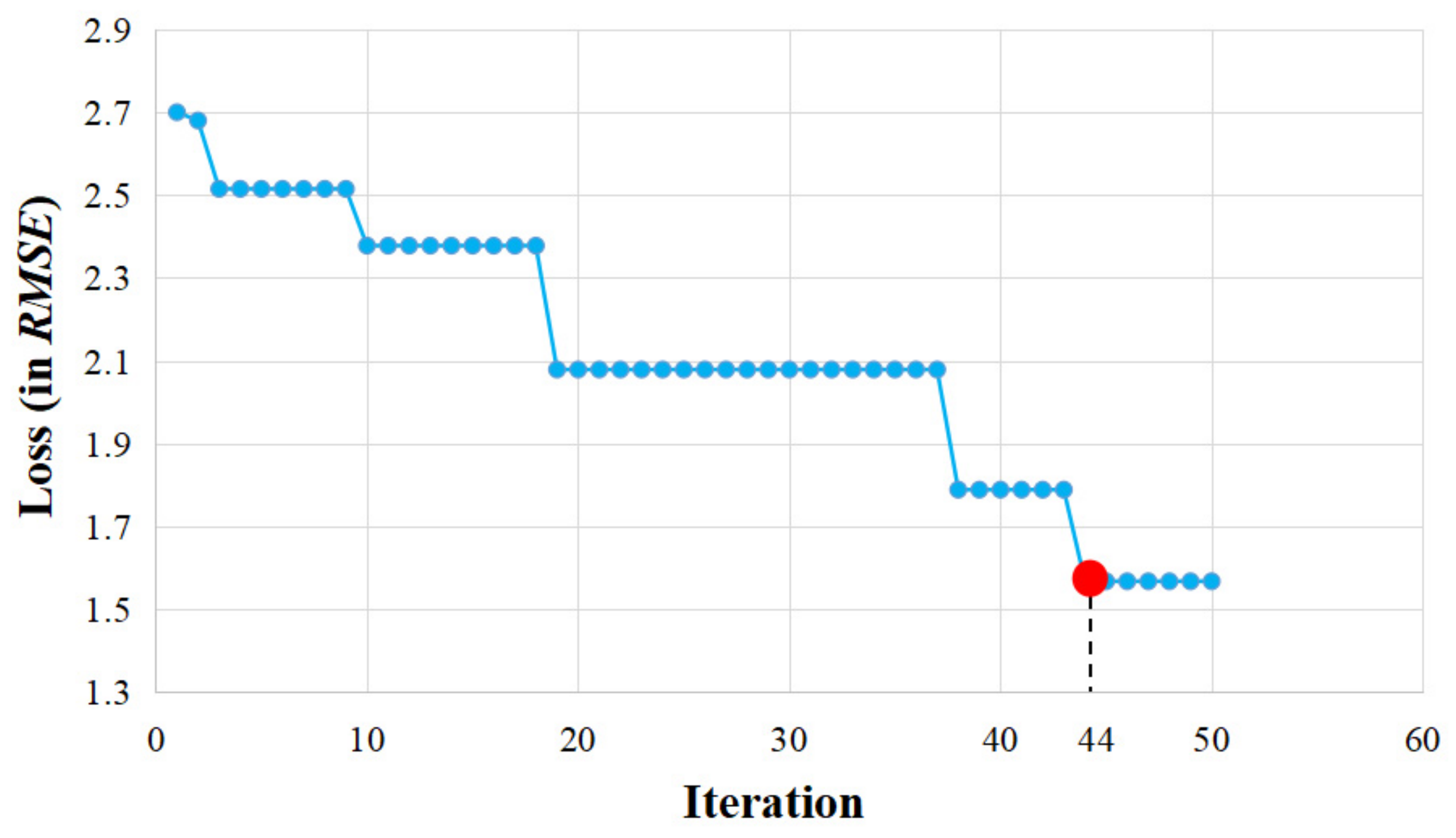
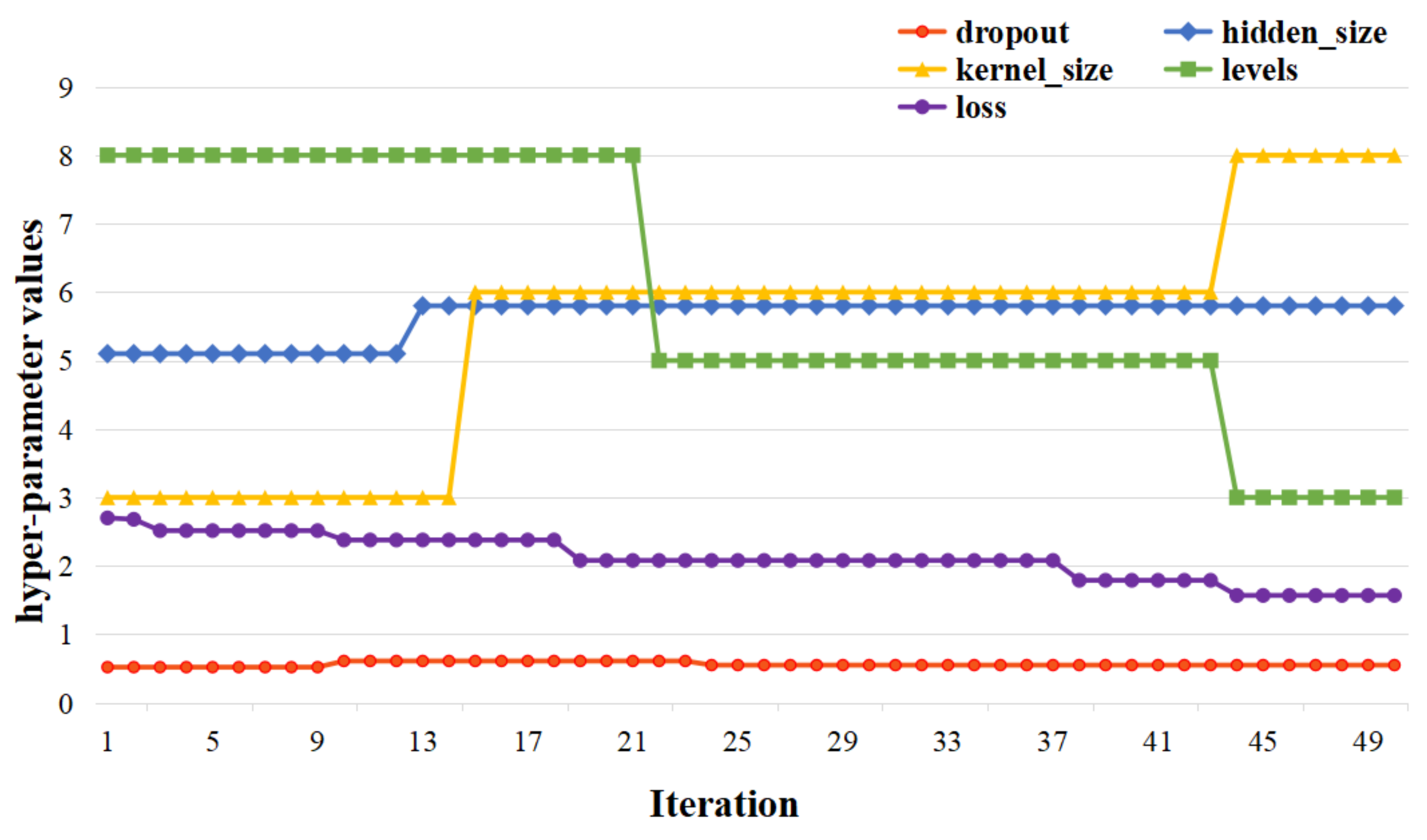
4.2. Hyperparameter Tuning Based on Bayesian Optimization
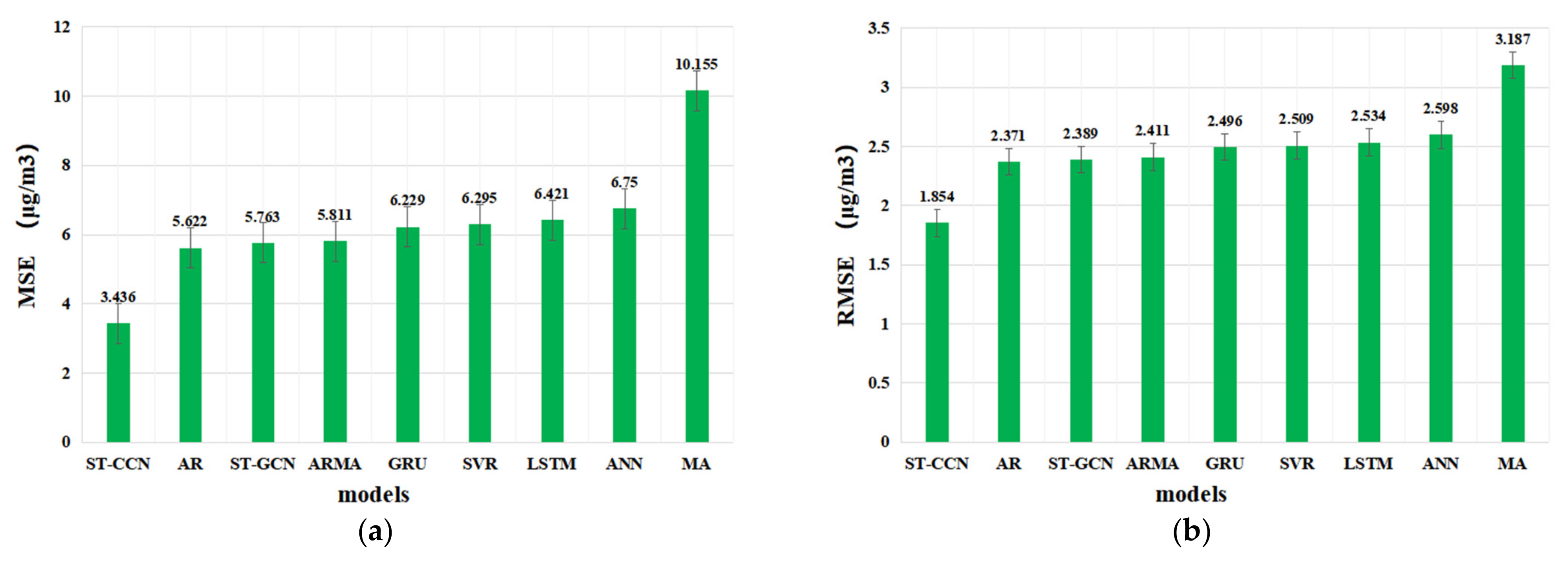
4.3. Prediction Performance Analysis
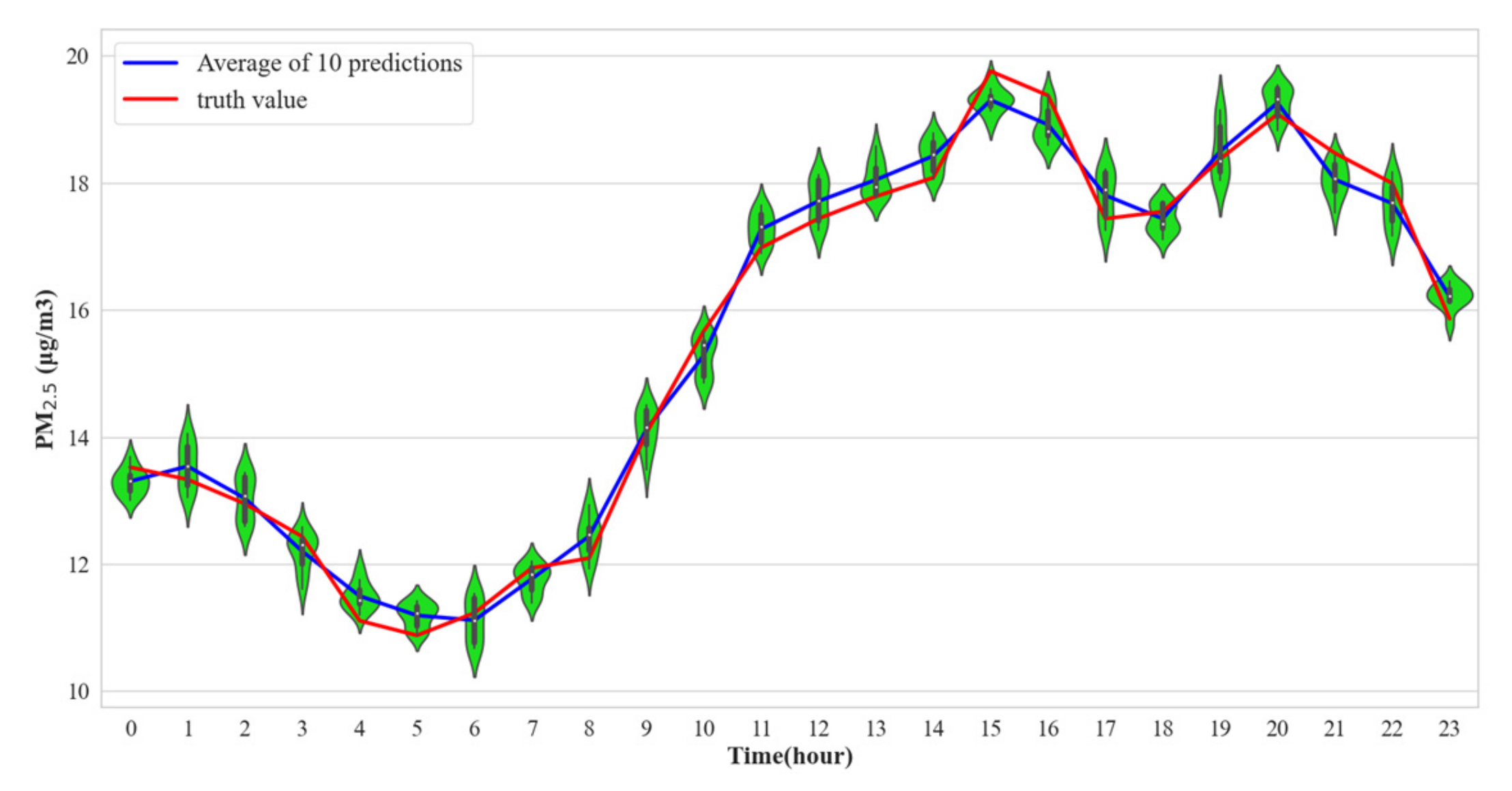
4.3.1. Target Station Performance Analysis
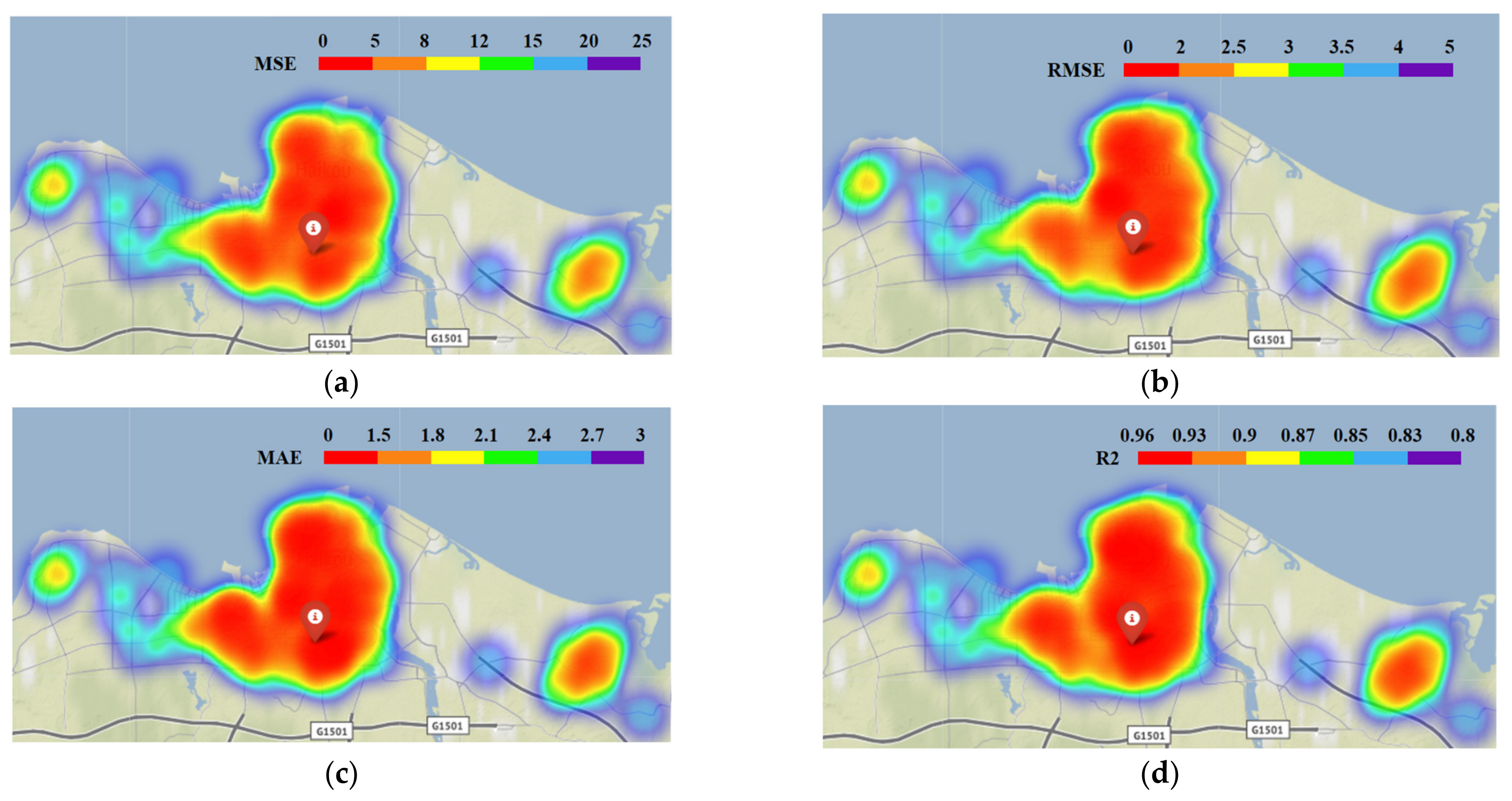
4.3.2. All Stations’ Performance Analysis
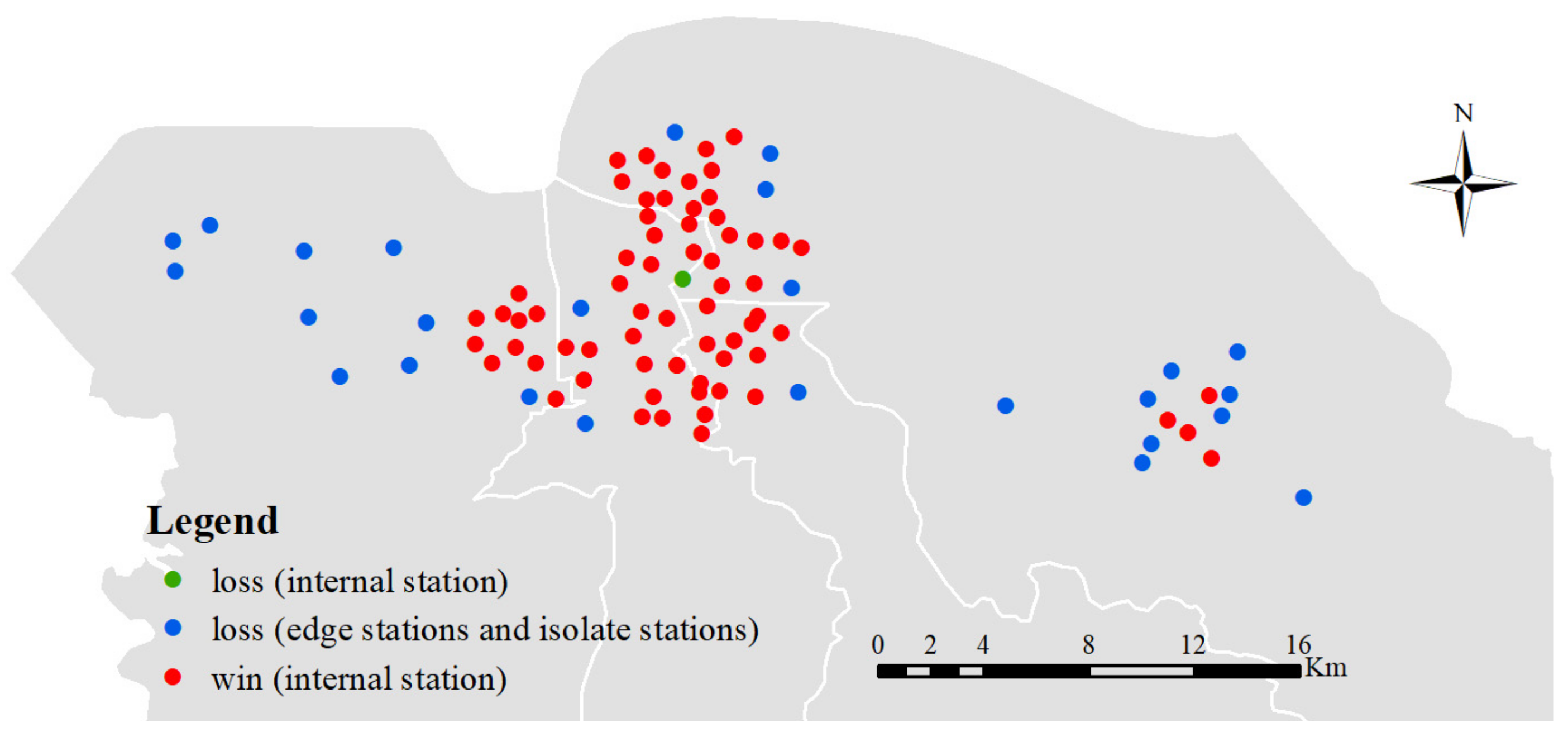
4.4. Robustness Analysis
4.4.1. Significance via the Friedman Test

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | AR | MA | ARMA | ANN | SVR | GRU | LSTM | STGCN | STCCN |
|---|---|---|---|---|---|---|---|---|---|
| data_25% | 2.39(2) | 3.22(9) | 2.43(4) | 2.61(8) | 2.54(6) | 2.51(5) | 2.56(7) | 2.41(3) | 1.83(1) |
| data_50% | 2.27(2) | 3.17(9) | 2.38(4) | 2.58(8) | 2.52(7) | 2.46(5) | 2.52(7) | 2.35(3) | 1.76(1) |
| data_75% | 2.33(2) | 3.13(9) | 2.41(4) | 2.55(8) | 2.44(6) | 2.43(5) | 2.44(6) | 2.37(3) | 1.92(1) |
| Average | 2 | 9 | 4 | 8 | 6.3 | 5 | 6.3 | 3 | 1 |
4.4.2. Model Generalization Analysis
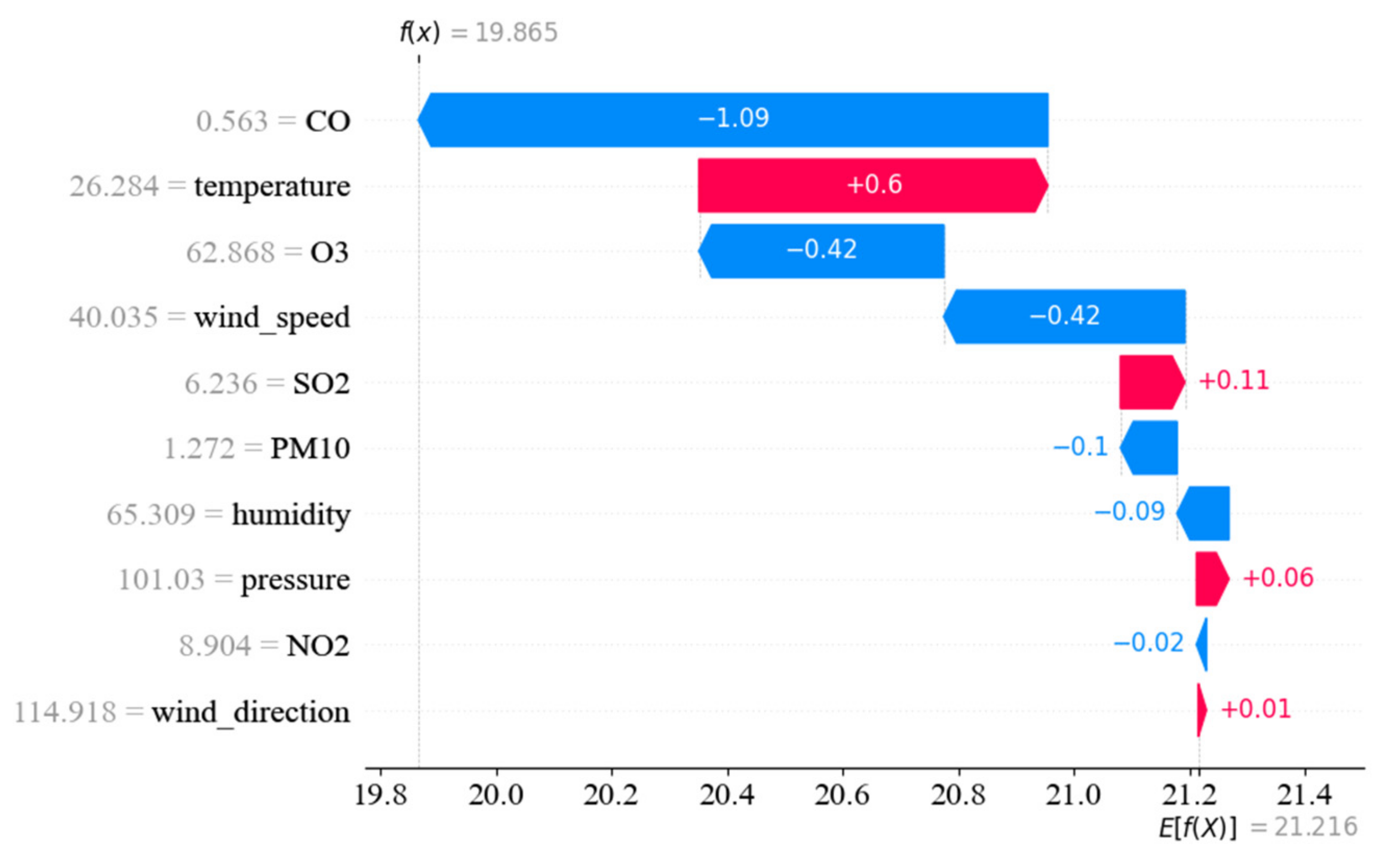
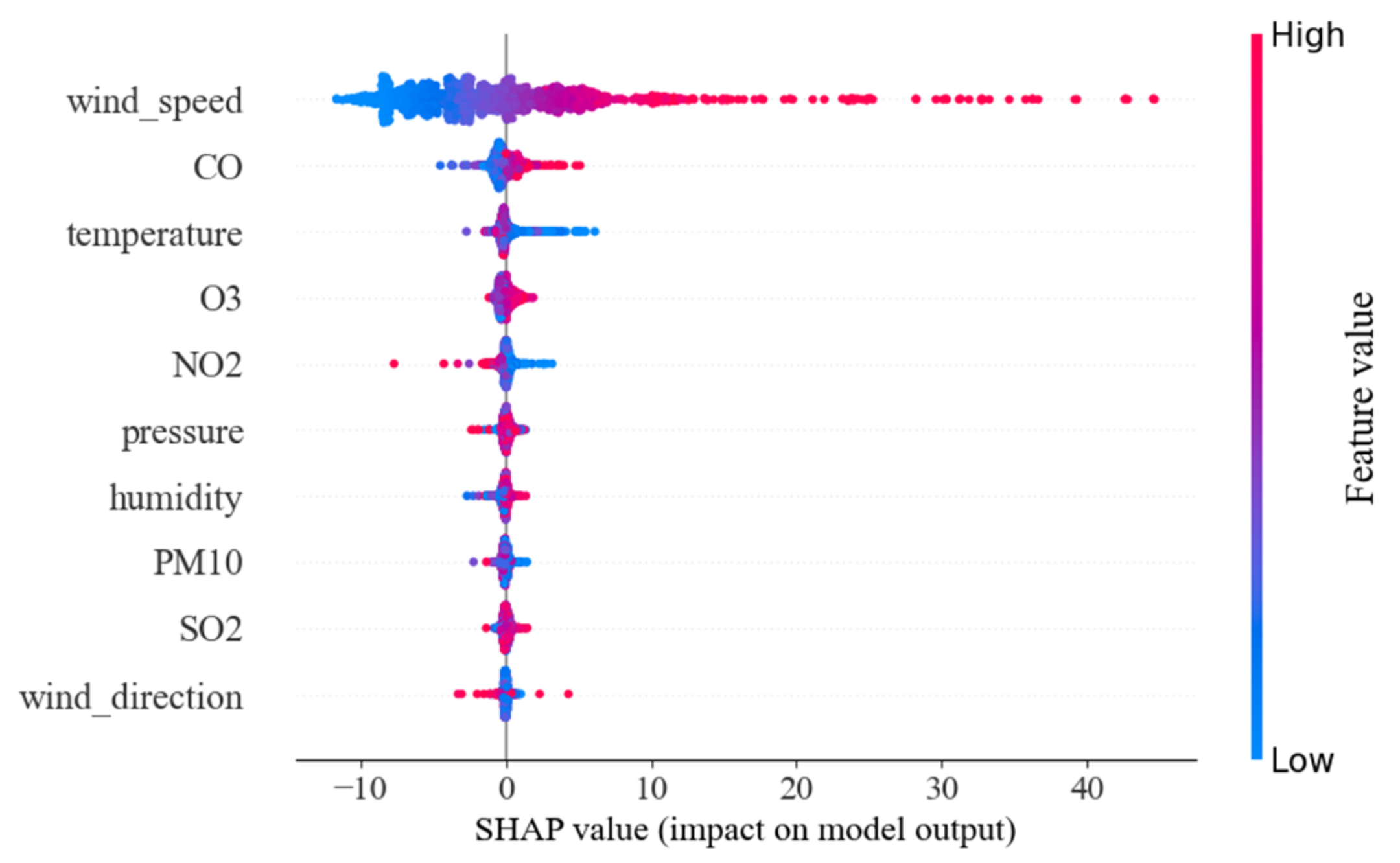
4.5. Impact Factors’ Influence Analysis
5. Discussion
5.1. The Influence of Spatial Effect
5.2. The Influence of Multi-Source Factors
5.3. Advantages of ST-CCN-PM2.5 Compared with Other Typical Deep Learning Models
6. Conclusions
6.1. Summary of Experimental Results
6.2. Caveats and Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hong, C.; Zhang, Q.; Zhang, Y.; Schellnhuber, H.J. Impacts of climate change on future air quality and human health in China. Proc. Natl. Acad. Sci. USA 2019, 116, 17193–17200. [Google Scholar] [CrossRef] [PubMed]
- Ai, S.; Wang, C.; Qian, Z.M.; Cui, Y.; Liu, Y.; Acharya, B.K.; Sun, X.; Hinyard, L.; Jansson, D.R.; Qin, L.; et al. Hourly associations between ambient air pollution and emergency ambulance calls in one central Chinese city: Implications for hourly air quality standards. Sci. Total Environ. 2019, 696, 133956. [Google Scholar] [CrossRef] [PubMed]
- Loomis, D.; Grosse, Y.; Lauby-Secretan, B.; el Ghissassi, F.; Bouvard, V.; Benbrahim-Tallaa, L.; Guha, N.; Baan, R.; Mattock, H.; Straif, K. The carcinogenicity of outdoor air pollution. Lancet Oncol. 2013, 14, 1262. [Google Scholar] [CrossRef]
- Hu, J.; Yang, B.; Guo, C.; Jensen, C.S.; Xiong, H. Stochastic origin-destination matrix forecasting using dual-stage graph convolutional, recurrent neural networks. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering (ICDE), Dallas, TX, USA, 20–24 April 2020; pp. 1417–1428. [Google Scholar] [CrossRef]
- Seo, Y.; Defferrard, M.; Vandergheynst, P.; Bresson, X. Structured sequence modeling with graph convolutional recurrent networks. In Proceedings of the International Conference on Neural Information Processing, Siem Reap, Cambodia, 13–16 December 2018; pp. 362–373. [Google Scholar] [CrossRef]
- Wu, Z.; Pan, S.; Long, G.; Jiang, J.; Zhang, C. Graph WaveNet for Deep Spatial-Temporal Graph Modeling. In Proceedings of the International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 1907–1913. [Google Scholar] [CrossRef]
- Yu, B.; Yin, H.; Zhu, Z. Spatio-temporal graph convolutional networks: A deep learning framework for traffic forecasting. In Proceedings of the International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 3634–3640. [Google Scholar] [CrossRef]
- Gu, Y.; Li, B.; Meng, Q. Hybrid interpretable predictive machine learning model for air pollution prediction. Neurocomputing 2022, 468, 123–136. [Google Scholar] [CrossRef]
- Donnelly, A.; Misstear, B.; Broderick, B. Real time air quality forecasting using integrated parametric and non-parametric regression techniques. Atmos. Environ. 2015, 103, 53–65. [Google Scholar] [CrossRef]
- Barthwal, A.; Acharya, D. An IoT based Sensing System for Modeling and Forecasting Urban Air Quality. Wirel. Pers. Commun. 2021, 116, 3503–3526. [Google Scholar] [CrossRef]
- Zhu, H.; Lu, X. The Prediction of PM2.5 Value Based on ARMA and Improved BP Neural Network Model. In Proceedings of the 2016 International Conference on Intelligent Networking and Collaborative Systems (INCoS), Ostrava, Czech Republic, 27 October 2016; pp. 515–517. [Google Scholar] [CrossRef]
- Reisen, V.A.; Sarnaglia, A.J.Q.; CostaReis, N., Jr.; Lévy-Leduc, C.; MériSantos, J. Modeling and forecasting daily average PM10 concentrations by a seasonal long-memory model with volatility. Environ. Model. Softw. 2014, 51, 286–295. [Google Scholar] [CrossRef]
- Li, J.; Li, X.; Wang, K.; Cui, G. Atmospheric PM2.5 Prediction Based on Multiple Model Adaptive Unscented Kalman Filter. Atmosphere 2021, 12, 607. [Google Scholar] [CrossRef]
- Wood, D.A. Trend decomposition aids forecasts of air particulate matter (PM2.5) assisted by machine and deep learning without recourse to exogenous data. Atmos. Pollut. Res. 2022, 13, 101352. [Google Scholar] [CrossRef]
- Hung, W.; Lu, C.; Alessandrini, S.; Kumar, R.; Lin, C.-A. Estimation of PM2.5 concentrations in New York State: Understanding the influence of vertical mixing on surface PM2.5 using machine learning. Atmosphere 2020, 11, 1303. [Google Scholar] [CrossRef]
- Nidzgorska-Lencewicz, J. Application of Artificial Neural Networks in the Prediction of PM10 Levels in the Winter Months: A Case Study in the Tricity Agglomeration, Poland. Atmosphere 2018, 9, 203. [Google Scholar] [CrossRef]
- Bera, B.; Bhattacharjee, S.; Sengupta, N.; Saha, S. PM2.5 concentration prediction during COVID-19 lockdown over Kolkata metropolitan city, India using MLR and ANN models. Environ. Chall. 2021, 4, 100155. [Google Scholar] [CrossRef]
- Zhou, Y.; Chang, F.-J.; Chen, H.; Li, H. Exploring Copula-based Bayesian Model Averaging with multiple ANNs for PM2.5 ensemble forecasts. J. Clean. Prod. 2020, 263, 121528. [Google Scholar] [CrossRef]
- Araujo, L.N.; Belotti, J.T.; Alves, T.A.; Tadano, Y.d.; Siqueira, H. Ensemble method based on Artificial Neural Networks to estimate air pollution health risks. Environ. Model. Softw. 2020, 123, 104567. [Google Scholar] [CrossRef]
- Stafoggia, M.; Bellander, T.; Buccia, S.; Davoli, M.; de Hoogh, K.; de’ Donato, F.; Gariazzo, C.; Lyapustin, A.; Michelozzi, P.; Renzi, M.; et al. Estimation of daily PM10 and PM2.5 concentrations in Italy, 2013–2015, using a spatiotemporal land-use random-forest model. Environ. Int. 2019, 124, 170–179. [Google Scholar] [CrossRef]
- Wei, J.; Huang, W.; Li, Z.; Xue, W.; Peng, Y.; Sun, L.; Cribb, M. Estimating 1-km-resolution PM2.5 concentrations across China using the space-time random forest approach. Remote Sens. Environ. 2019, 231, 111221. [Google Scholar] [CrossRef]
- Sun, W.; Liu, M. Prediction and analysis of the three major industries and residential consumption CO2 emissions based on least squares support vector machine in China. J. Clean. Prod. 2016, 122, 144–153. [Google Scholar] [CrossRef]
- Liu, W.; Guo, G.; Chen, F.; Chen, Y. Meteorological pattern analysis assisted daily PM2.5 grades prediction using SVM optimized by PSO algorithm. Atmos. Pollut. Res. 2019, 10, 1482–1491. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Hopfield, J.J. Neurons with graded response have collective computational properties like those of two-state neurons. Proc. Natl. Acad. Sci. USA 1984, 81, 3088–3092. [Google Scholar] [CrossRef]
- Zhao, J.; Lin, S.; Liu, X.; Chen, J.; Zhang, Y.; Mei, Q. ST-CCN-PM2.5: Fine-grained PM2.5 concentration prediction via spatial-temporal causal convolution network. In Proceedings of the 4th ACM SIGSPATIAL International Workshop on Advances in Resilient and Intelligent Cities, Beijing, China, 2 November 2021; pp. 48–55. [Google Scholar] [CrossRef]
- Hong, H.; Jeon, H.; Youn, C.; Kim, H. Incorporation of Shipping Activity Data in Recurrent Neural Networks and Long Short-Term Memory Models to Improve Air Quality Predictions around Busan Port. Atmosphere 2021, 12, 1172. [Google Scholar] [CrossRef]
- Jiang, X.; Luo, Y.; Zhang, B. Prediction of PM2.5 Concentration Based on the LSTM-TSLightGBM Variable Weight Combination Model. Atmosphere 2021, 12, 1211. [Google Scholar] [CrossRef]
- Dai, H.; Huang, G.; Wang, J.; Zeng, H.; Zhou, F. Prediction of Air Pollutant Concentration Based on One-Dimensional Multi-Scale CNN-LSTM Considering Spatial-Temporal Feature: A Case Study of Xi’an, China. Atmosphere 2021, 12, 1626. [Google Scholar] [CrossRef]
- Park, D.; Yoo, G.-W.; Park, S.-H.; Lee, J.-H. Assessment and Calibration of a Low-Cost PM2.5 Sensor Using Machine Learning (HybridLSTM Neural Network): Feasibility Study to Build an Air Quality Monitoring System. Atmosphere 2021, 12, 1306. [Google Scholar] [CrossRef]
- Shi, L.; Zhang, H.; Xu, X.; Han, M.; Zuo, P. A balanced social LSTM for PM2.5 concentration prediction based on local spatiotemporal correlation. Chemosphere 2022, 291, 133124. [Google Scholar] [CrossRef]
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Yang, G.; Lee, H.M.; Lee, G. A hybrid deep learning model to forecast particulate matter concentration levels in Seoul, South Korea. Atmosphere 2020, 11, 348. [Google Scholar] [CrossRef]
- Weerakody, P.B.; Wong, K.W.; Wang, G.; Ela, W. A review of irregular time series data handling with gated recurrent neural networks. Neurocomputing 2021, 441, 161–178. [Google Scholar] [CrossRef]
- Zhang, G.; Lu, H.; Dong, J.; Poslad, S.; Li, R.; Zhang, X.; Rui, X. A framework to predict high-resolution spatiotemporal PM2.5 distributions using a deep-learning model: A case study of Shijiazhuang, China. Remote Sens. 2020, 12, 2825. [Google Scholar] [CrossRef]
- Huang, C.J.; Kuo, P.H. A deep CNN-LSTM model for particulate matter (PM2.5) forecasting in smart cities. Sensors 2018, 18, 2220. [Google Scholar] [CrossRef]
- Wang, S.; Li, Y.; Zhang, J.; Meng, Q.; Meng, L.; Gao, F. PM2.5-GNN: A Domain Knowledge Enhanced Graph Neural Network For PM2.5 Forecasting. In Proceedings of the 28th International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 3–6 November 2020; pp. 163–166. [Google Scholar] [CrossRef]
- Bai, S.; Kolter, J.Z.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Van den Oord, A.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. Wavenet: A generative model for raw audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Grell, G.A.; Peckham, S.E.; Schmitz, R.; McKeen, S.A.; Frost, G.; Skamarock, W.C.; Eder, B. Fully coupled “online” chemistry within the WRF model. Atmos. Environ. 2005, 39, 6957–6975. [Google Scholar] [CrossRef]
- Kim, Y.; Fu, J.S.; Miller, T.L. Improving ozone modeling in complex terrain at a fine grid resolution: Part I—Examination of analysis nudging and all PBL schemes associated with LSMs in meteorological model. Atmos. Environ. 2010, 44, 523–532. [Google Scholar] [CrossRef]
- Zheng, M.; Yan, C.; Wang, S.; He, K.; Zhang, Y. Understanding PM2.5 sources in China: Challenges and perspectives. Natl. Sci. Rev. 2017, 4, 801–803. [Google Scholar] [CrossRef]
- Herrmann, M.; Gutheil, E. Simulation of the Air Quality in Southern California, USA in July and October of the Year 2018. Atmosphere 2022, 13, 548. [Google Scholar] [CrossRef]
- Sharma, A.; Valdes, A.C.F.; Lee, Y. Impact of Wildfires on Meteorology and Air Quality (PM2.5 and O3) over Western United States during September 2017. Atmosphere 2022, 13, 262. [Google Scholar] [CrossRef]
- Tobler, W.R. A computer movie simulating urban growth in the Detroit region. Econ. Geogr. 1970, 46 (Suppl. S1), 234–240. [Google Scholar] [CrossRef]
- Wen, C.; Liu, S.; Yao, X.; Peng, L.; Li, X.; Hu, Y.; Chi, T. A novel spatiotemporal convolutional long short-term neural network for air pollution prediction. Sci. Total Environ. 2019, 654, 1091–1099. [Google Scholar] [CrossRef]
- Zhao, J.; Deng, F.; Cai, Y.; Chen, J. Long short-term memory-Fully connected (LSTM-FC) neural network for PM2.5 concentration prediction. Chemosphere 2019, 220, 486–492. [Google Scholar] [CrossRef]
- Bai, K.; Li, K.; Chang, N.-B.; Gao, W. Advancing the prediction accuracy of satellite-based PM2.5 concentration mapping: A perspective of data mining through in situ PM2.5 measurements. Environ. Pollut. 2019, 254, 113047. [Google Scholar] [CrossRef]
- Pak, U.; Ma, J.; Ryu, U.; Ryom, K.; Juhyok, U.; Pak, K.; Pak, C. Deep learning-based PM2.5 prediction considering the spatiotemporal correlations: A case study of Beijing, China. Sci. Total Environ. 2020, 699, 133561. [Google Scholar] [CrossRef]
- Qiao, T.; Xiu, G.; Zheng, Y.; Yang, J.; Wang, L.; Yang, J.; Huang, Z. Preliminary investigation of PM1, PM2.5, PM10 and its metal elemental composition in tunnels at a subway station in Shanghai, China. Transp. Res. Part D Transp. Environ. 2015, 41, 136–146. [Google Scholar] [CrossRef]
- Behera, S.N.; Sharma, M. Transformation of atmospheric ammonia and acid gases into components of PM2.5: An environmental chamber study. Environ. Sci. Pollut. Res. 2012, 19, 1187–1197. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, L.; Li, F.; Du, B.; Choo, K.R.; Hassan, H.; Qin, W. Air quality data clustering using EPLS method. Inf. Fusion 2017, 36, 225–232. [Google Scholar] [CrossRef]
- Mihaljević, B.; Bielza, C.; Larrañaga, P. Bayesian networks for interpretable machine learning and optimization. Neurocomputing 2021, 456, 648–665. [Google Scholar] [CrossRef]
- Marcellino, M.; Stock, J.H.; Watson, M.W. A comparison of direct and iterated multistep AR methods for forecasting macroeconomic time series. J. Econom. 2006, 135, 499–526. [Google Scholar] [CrossRef]
- Lento, C. Forecasting Security Returns with Simple Moving Averages. Int. Bus. Econ. Res. J. IBER 2008, 7, 11–22. [Google Scholar] [CrossRef]
- Li, B.; Zhu, E.; Feng, Q. Statistical Analysis of Changsha PM2.5 Based on Time Series. J. Quant. Econ. 2017, 34, 105–110. [Google Scholar] [CrossRef]
- Huang, G.; Li, X.; Zhang, B.; Ren, J. PM2.5 concentration forecasting at surface monitoring sites using GRU neural network based on empirical mode decomposition. Sci. Total Environ. 2021, 768, 144516. [Google Scholar] [CrossRef]
- Friedman, M. The use of ranks to avoid the assumption of normality implicit in the analysis of variance. J. Am. Stat. Assoc. 1937, 32, 675–701. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. arXiv 2017, arXiv:1705.07874. [Google Scholar]
- Qin, D.S.; Gao, C.Y. Control Measures for Automobile Exhaust Emissions in PM2.5 Governance. Discret. Dyn. Nat. Soc. 2022, 2022, 8461406. [Google Scholar] [CrossRef]
- Xie, Y.; Zhao, B.; Zhang, L.; Luo, R. Spatiotemporal variations of PM2.5 and PM10 concentrations between 31 Chinese cities and their relationships with SO2, NO2, CO and O3. Particuology 2015, 20, 141–149. [Google Scholar] [CrossRef]
- Wallace, J.; Kanaroglou, P. The effect of temperature inversions on ground-level nitrogen dioxide (NO2) and fine particulate matter (PM2.5) using temperature profiles from the Atmospheric Infrared Sounder (AIRS). Sci. Total Environ. 2009, 407, 5085–5095. [Google Scholar] [CrossRef]
- Liu, K.; Gao, S.; Lu, F. Identifying spatial interaction patterns of vehicle movements on urban road networks by topic modelling, Computers. Environ. Urban Syst. 2019, 74, 50–61. [Google Scholar] [CrossRef]
- Cheng, T.; Wang, J. Accommodating spatial associations in DRNN for space–time analysis. Comput. Environ. Urban Syst. 2009, 33, 409–418. [Google Scholar] [CrossRef]
- Zhao, T.; Huang, Z.; Tu, W.; He, B.; Cao, R.; Cao, J.; Li, M. Coupling graph deep learning and spatial-temporal influence of built environment for short-term bus travel demand prediction. Comput. Environ. Urban Syst. 2022, 94, 101776. [Google Scholar] [CrossRef]
- Xu, Y.; Zhou, B.; Jin, S.; Xie, X.; Chen, Z.; Hu, S.; He, N. A framework for urban land use classification by integrating the spatial context of points of interest and graph convolutional neural network method. Comput. Environ. Urban Syst. 2022, 95, 101807. [Google Scholar] [CrossRef]
- Li, S.; Jin, X.; Xuan, Y.; Zhou, X.; Chen, W.; Wang, Y.-X.; Yan, X. Enhancing the Locality and Breaking the Memory Bottleneck of Transformer on Time Series Forecasting. arXiv 2019, arXiv:1907.00235. [Google Scholar]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting. arXiv 2020, arXiv:2012.07436. [Google Scholar]
- Oreshkin, B.N.; Amini, A.; Coyle, L.; Coates, M.J. FC-GAGA: Fully Connected Gated Graph Architecture for Spatio-Temporal Traffic Forecasting. arXiv 2020, arXiv:2007.15531. [Google Scholar]
- Zhan, Q.; Wu, G.; Gan, C. Magcn: A multi-adaptive graph convolutional network for traffic forecasting. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Ye, J.; Zhao, J.; Ye, K.; Xu, C. Multi-stgcnet: A graph convolution based spatial-temporal framework for subway passenger flow forecasting. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar] [CrossRef]















| Type | Feature Name | Data Type | Unit |
|---|---|---|---|
| Air quality data | PM2.5 | Numeric | μg/m3 |
| PM10 | Numeric | μg/m3 | |
| NO2 | Numeric | μg/m3 | |
| CO | Numeric | μg/m3 | |
| O3 | Numeric | μg/m3 | |
| SO2 | Numeric | μg/m3 | |
| Meteorological data | Temperature | Numeric | ℃ |
| Pressure | Numeric | hpa | |
| Humidity | Numeric | % | |
| Wind speed | Numeric | km/h | |
| Wind direction | Categorical (No/E/W/S/N/Unstable/SE/NE/SW/NW) | None |
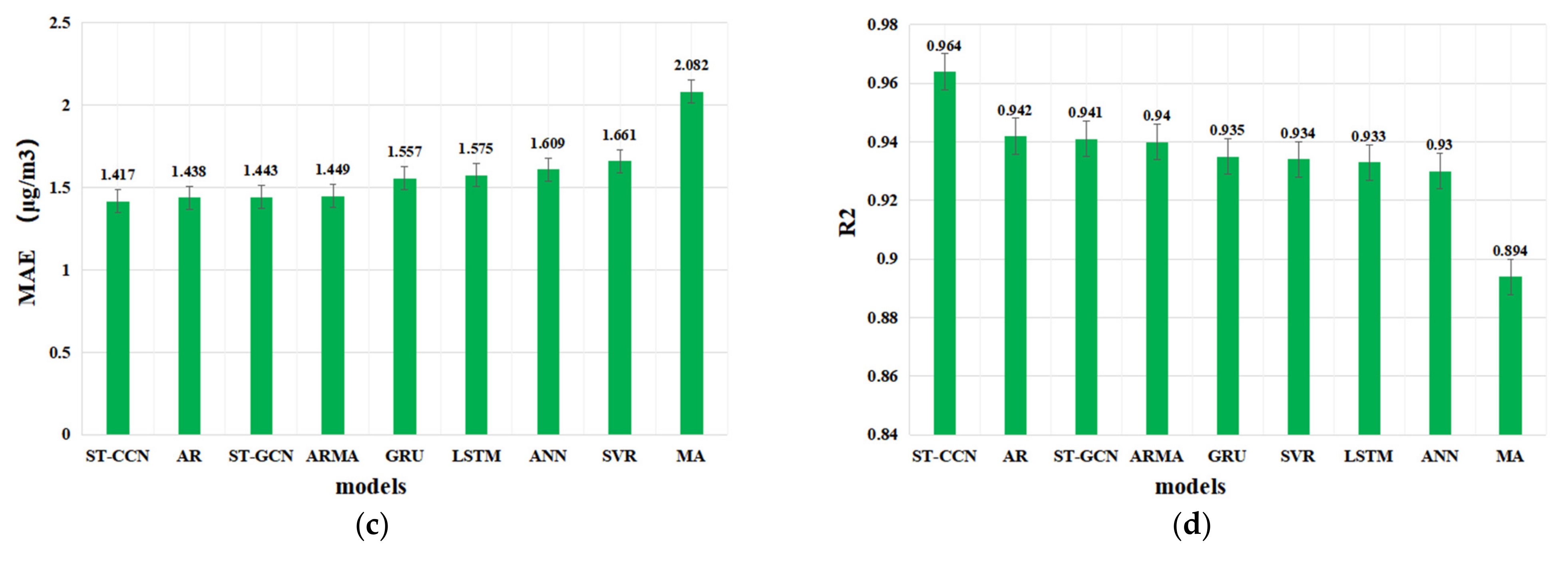
| Models | MSE | RMSE | MAE | R2 |
|---|---|---|---|---|
| AR | 5.622 | 2.371 | 1.438 | 0.942 |
| MA | 10.155 | 3.187 | 2.082 | 0.894 |
| ARMA | 5.811 | 2.411 | 1.449 | 0.940 |
| SVR | 6.295 | 2.509 | 1.661 | 0.934 |
| ANN | 6.750 | 2.598 | 1.609 | 0.930 |
| GRU | 6.229 | 2.496 | 1.557 | 0.935 |
| LSTM | 6.421 | 2.534 | 1.575 | 0.933 |
| ST-GCN | 5.763 | 2.389 | 1.443 | 0.941 |
| ST-CCN-PM2.5 | 3.436 | 1.854 | 1.417 | 0.964 |
| Models | MSE | RMSE | MAE | R2 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Win | Tie | Loss | Win | Tie | Loss | Win | Tie | Loss | Win | Tie | Loss | |
| AR | 5 | 0 | 90 | 5 | 0 | 90 | 12 | 0 | 83 | 14 | 0 | 81 |
| MA | 0 | 0 | 95 | 0 | 0 | 95 | 0 | 0 | 95 | 0 | 0 | 95 |
| ARMA | 4 | 0 | 91 | 4 | 0 | 91 | 3 | 0 | 92 | 6 | 1 | 88 |
| ANN | 0 | 0 | 95 | 0 | 0 | 95 | 0 | 0 | 95 | 0 | 0 | 95 |
| SVR | 0 | 0 | 95 | 0 | 0 | 95 | 0 | 0 | 95 | 0 | 0 | 95 |
| GRU | 1 | 0 | 94 | 1 | 0 | 94 | 2 | 0 | 93 | 1 | 0 | 94 |
| LSTM | 0 | 0 | 95 | 0 | 0 | 95 | 0 | 0 | 95 | 0 | 0 | 95 |
| ST-GCN | 17 | 0 | 78 | 17 | 0 | 78 | 15 | 0 | 80 | 9 | 0 | 86 |
| ST-CCN | 68 | 0 | 27 | 68 | 0 | 27 | 63 | 0 | 32 | 64 | 1 | 30 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, S.; Zhao, J.; Li, J.; Liu, X.; Zhang, Y.; Wang, S.; Mei, Q.; Chen, Z.; Gao, Y. A Spatial–Temporal Causal Convolution Network Framework for Accurate and Fine-Grained PM2.5 Concentration Prediction. Entropy 2022, 24, 1125. https://doi.org/10.3390/e24081125
Lin S, Zhao J, Li J, Liu X, Zhang Y, Wang S, Mei Q, Chen Z, Gao Y. A Spatial–Temporal Causal Convolution Network Framework for Accurate and Fine-Grained PM2.5 Concentration Prediction. Entropy. 2022; 24(8):1125. https://doi.org/10.3390/e24081125
Chicago/Turabian StyleLin, Shaofu, Junjie Zhao, Jianqiang Li, Xiliang Liu, Yumin Zhang, Shaohua Wang, Qiang Mei, Zhuodong Chen, and Yuyao Gao. 2022. "A Spatial–Temporal Causal Convolution Network Framework for Accurate and Fine-Grained PM2.5 Concentration Prediction" Entropy 24, no. 8: 1125. https://doi.org/10.3390/e24081125