
Travel Characteristics Analysis and Traffic Prediction Modeling Based on Online Car-Hailing Operational Data Sets


Abstract
:1. Introduction
2. Data Overview and Preprocessing
2.1. Data Overview
2.2. Data Preprocessing
3. Online Car-Hailing Travel Characteristics Analysis
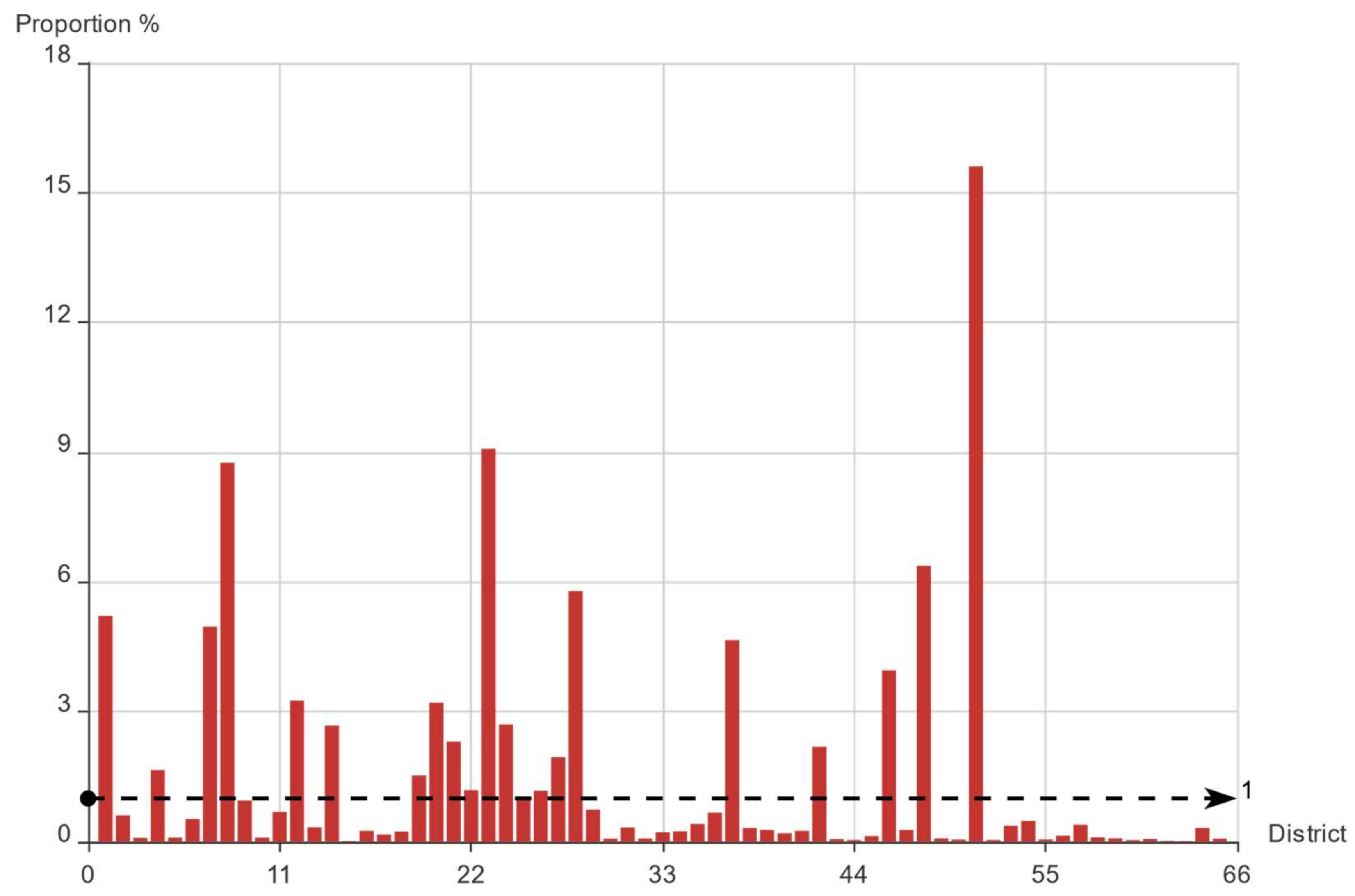
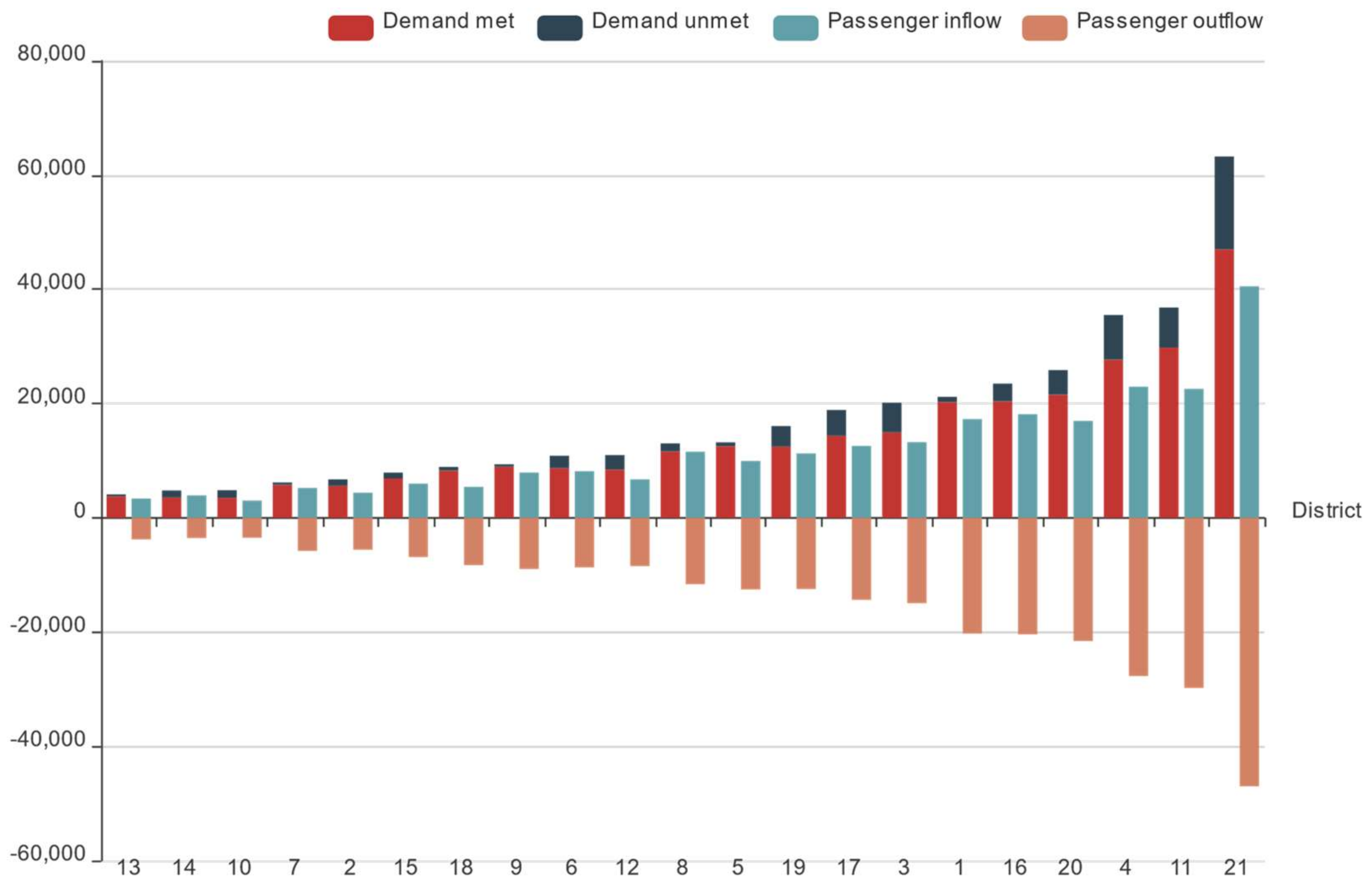
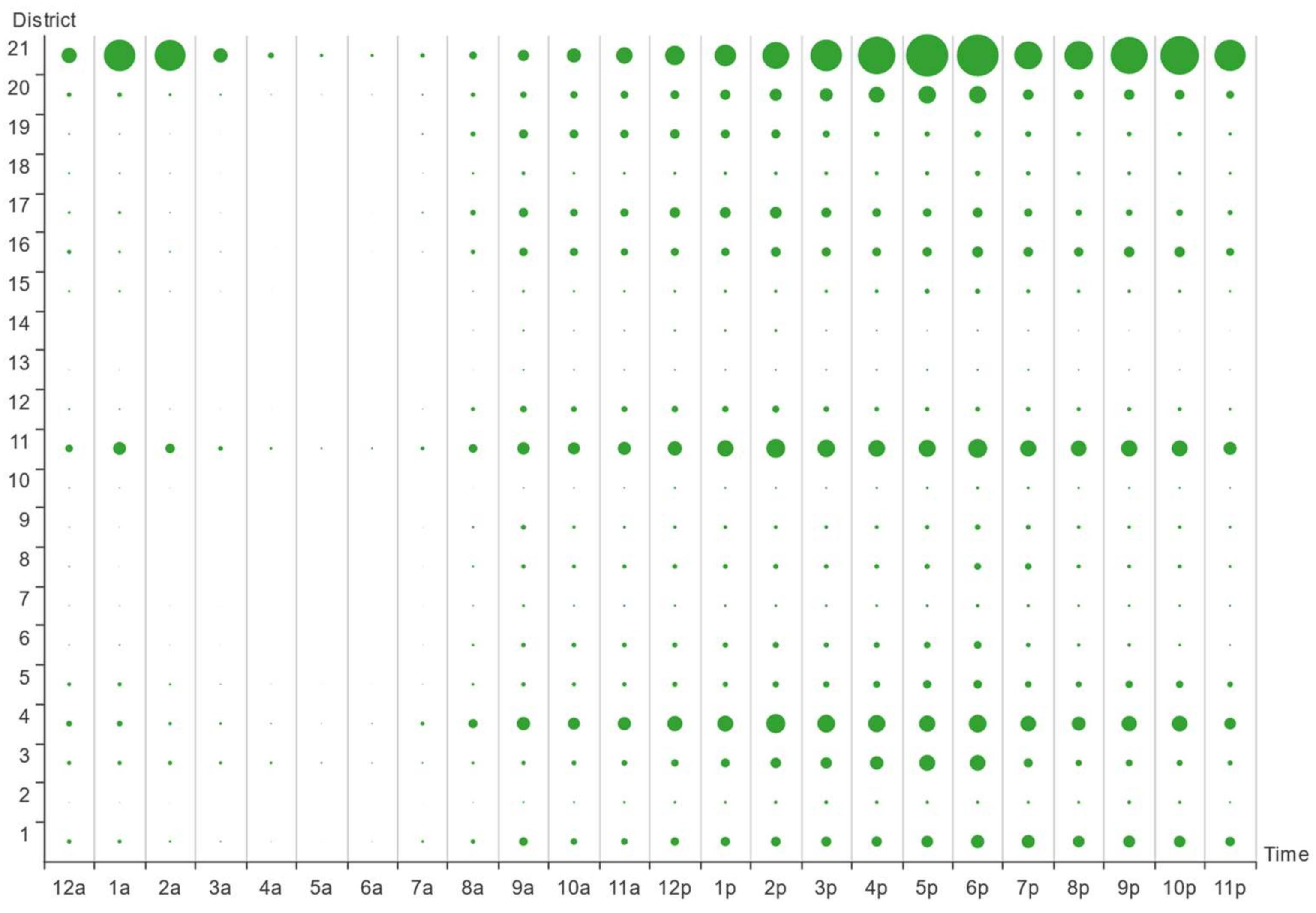
3.1. Online Car-Hailing Travel: District Characteristics Analysis
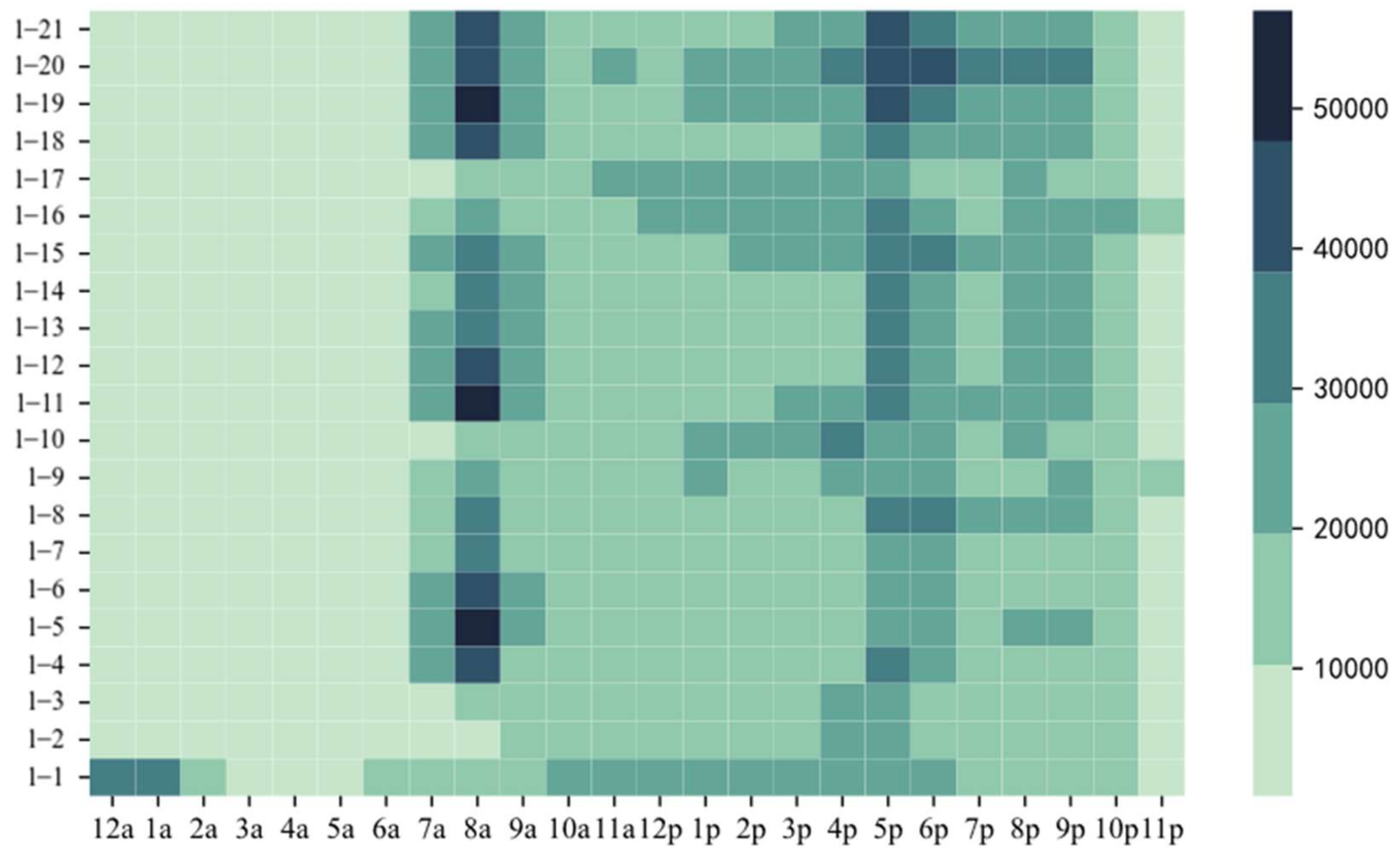
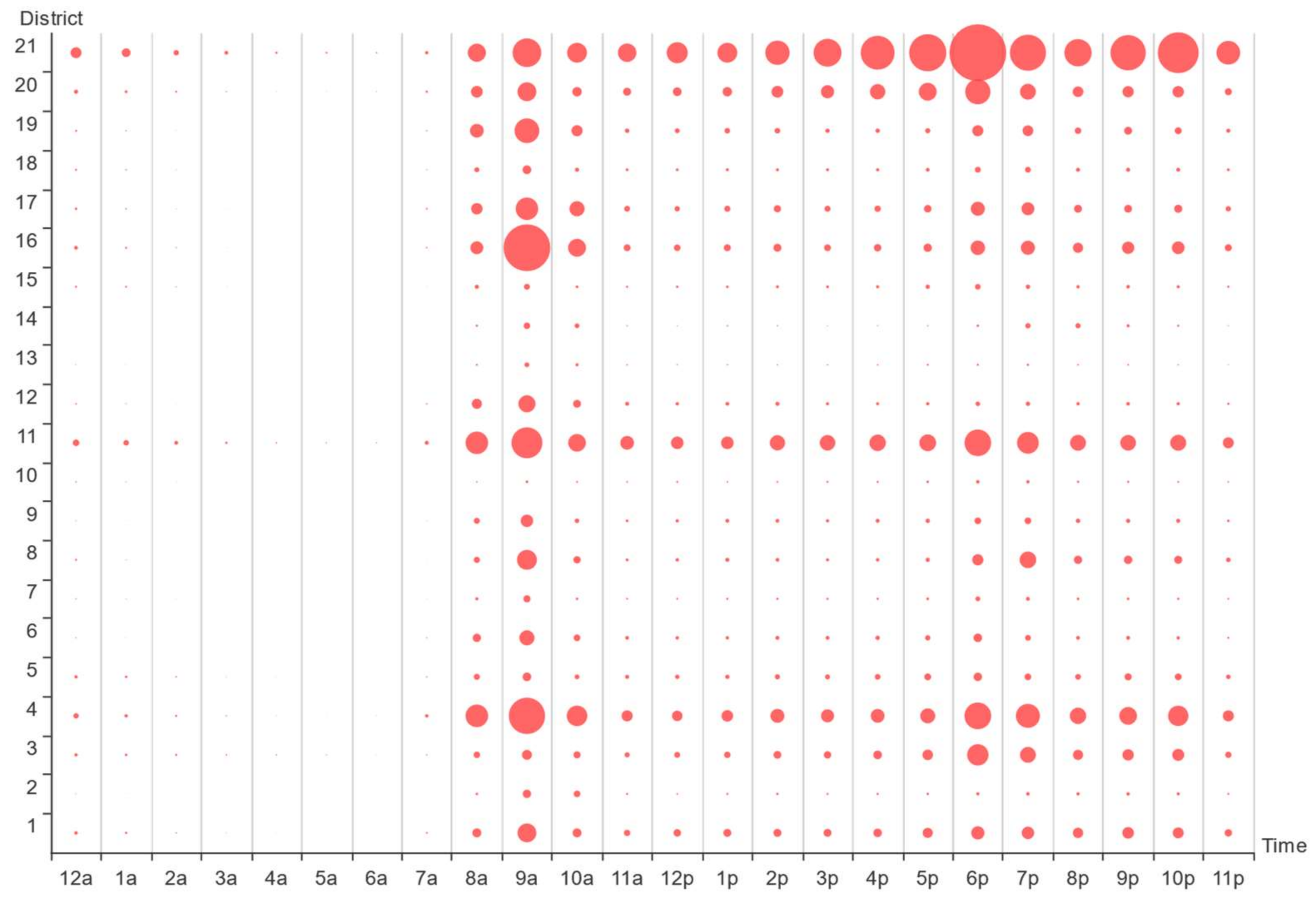
3.2. Online Car-Hailing Travel: Time Characteristics Analysis
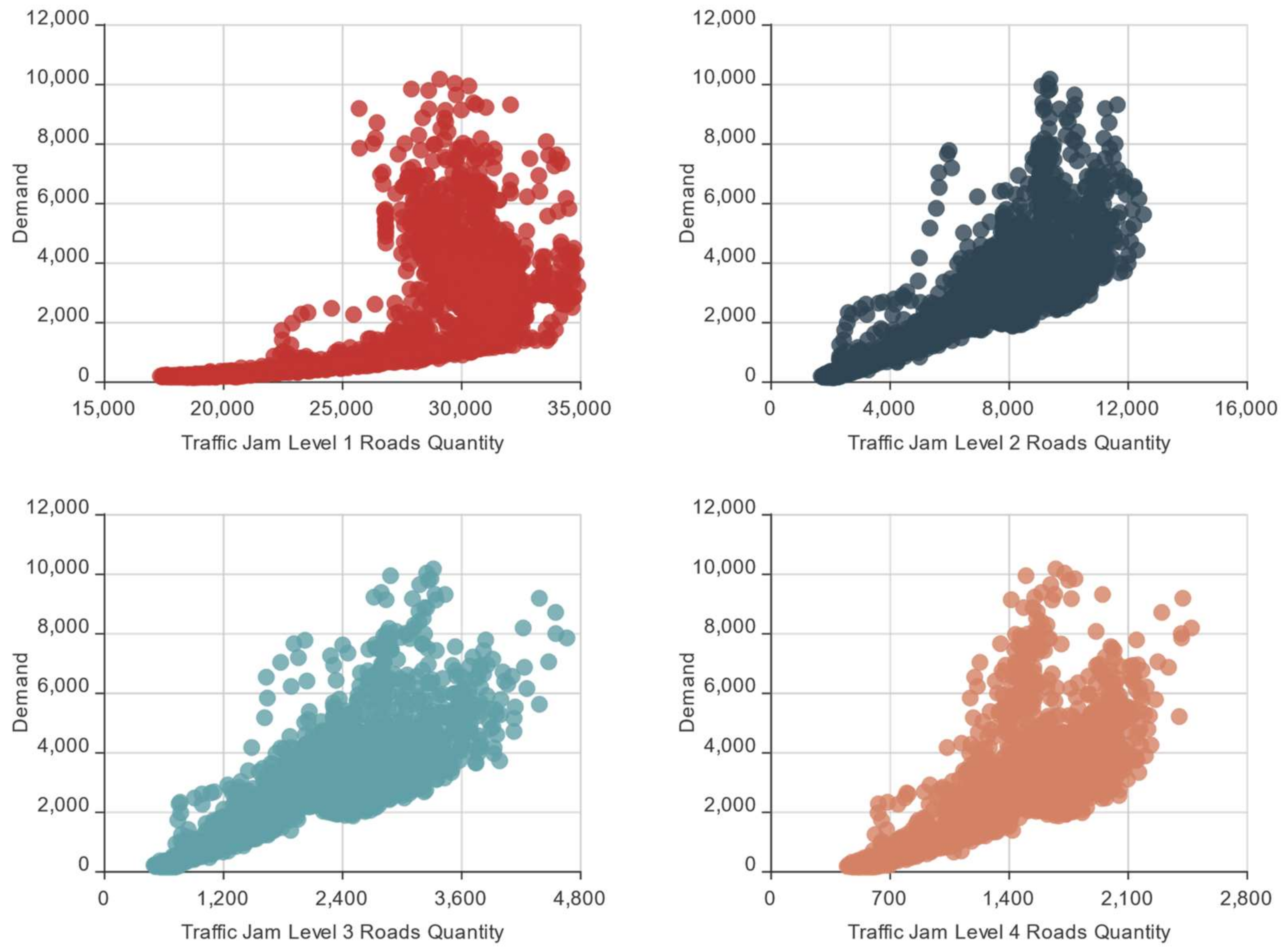
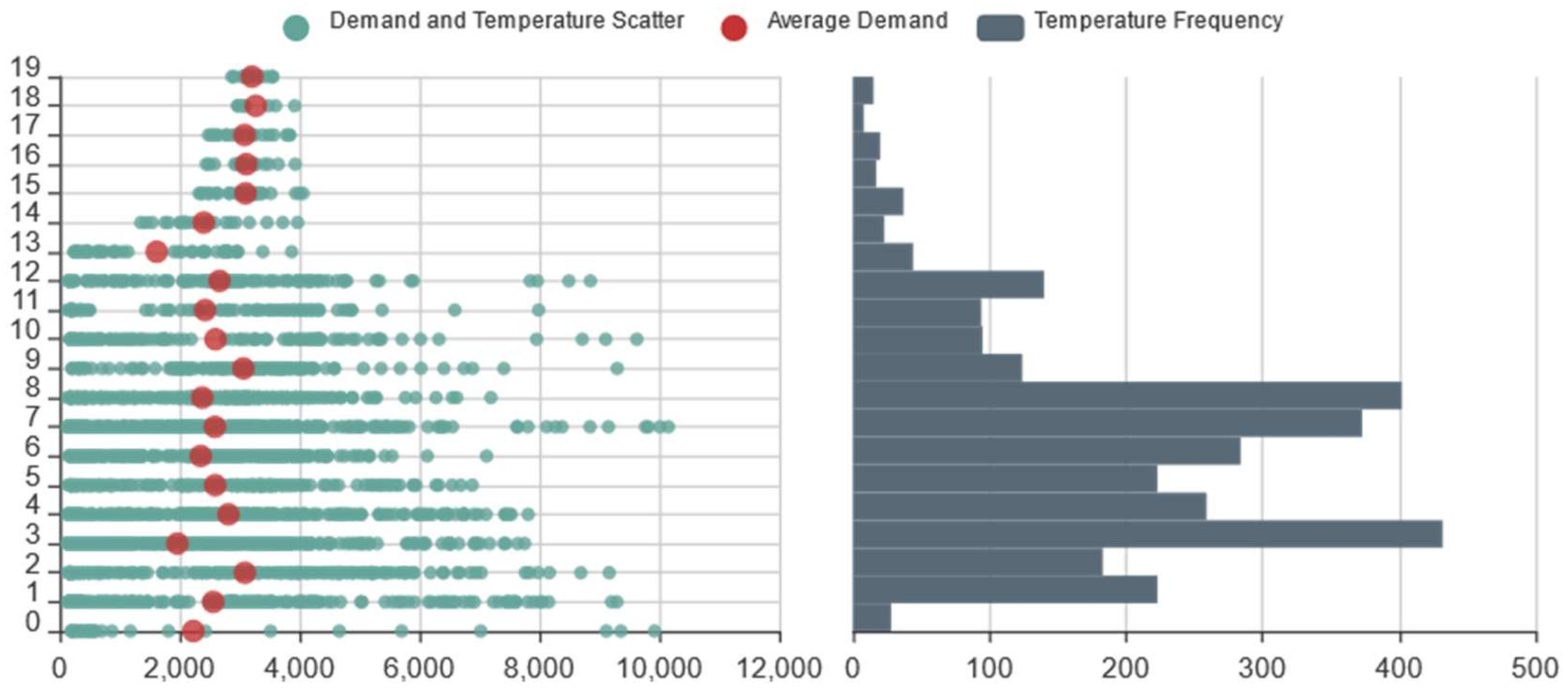
3.3. Online Car-Hailing Travel: Traffic Jam Characteristics Analysis
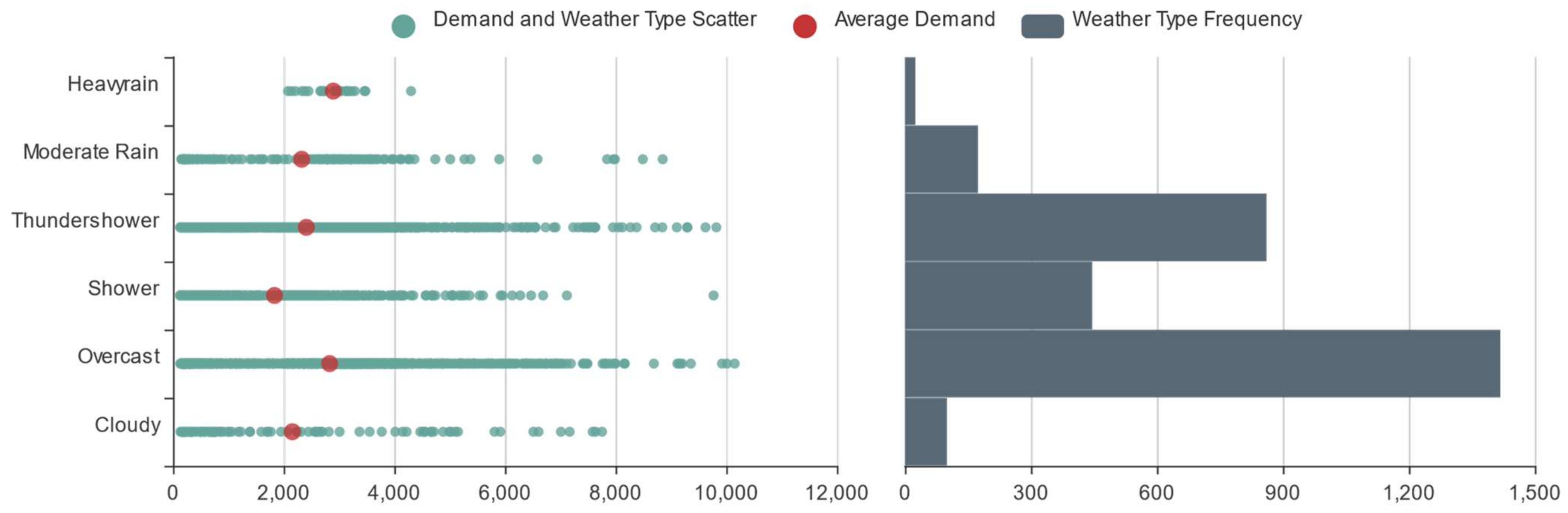
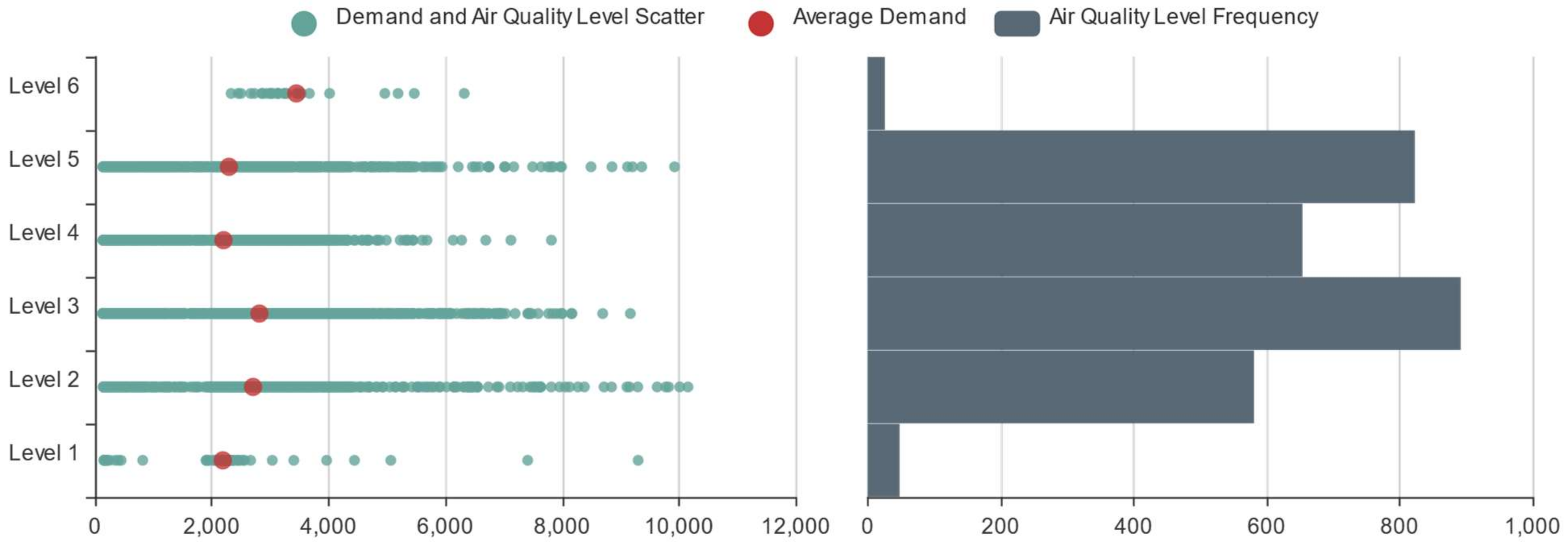
3.4. Online Car-Hailing Travel: Other Characteristics Analysis
4. Online Car-Hailing Demand Prediction Based on a Multivariable Hybrid Time Series Model
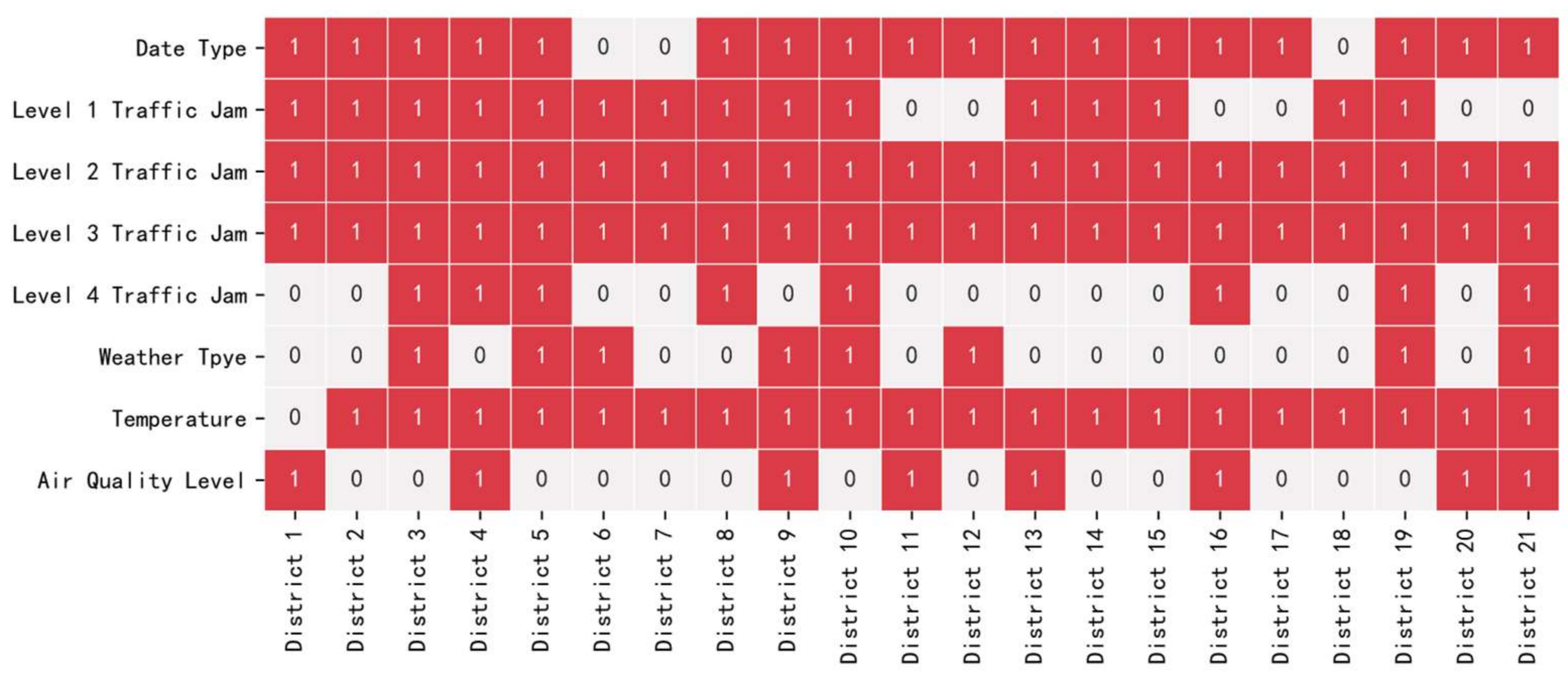
4.1. MIC Feature Selection
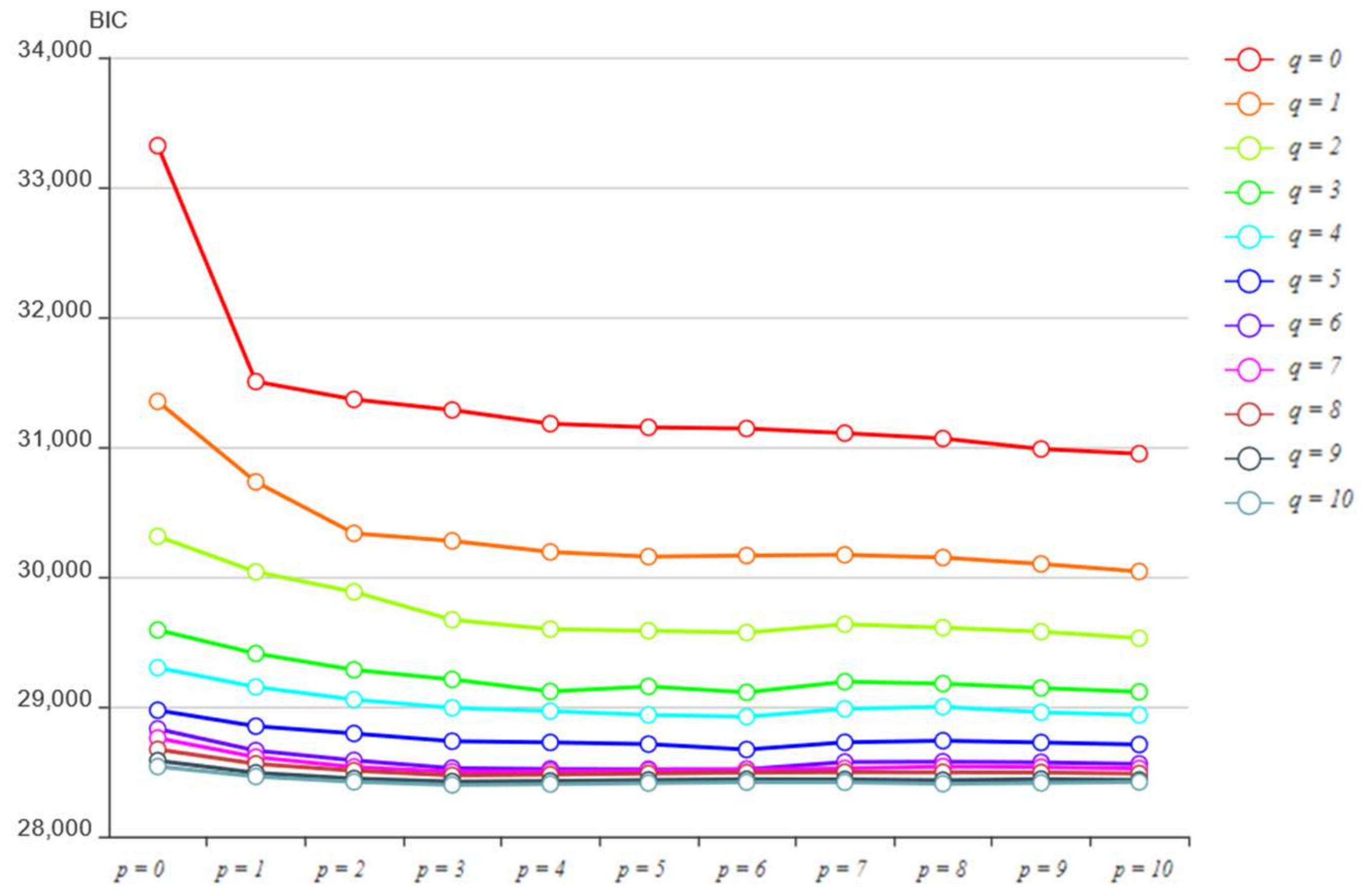
4.2. ARIMAX Linear Time Series Model
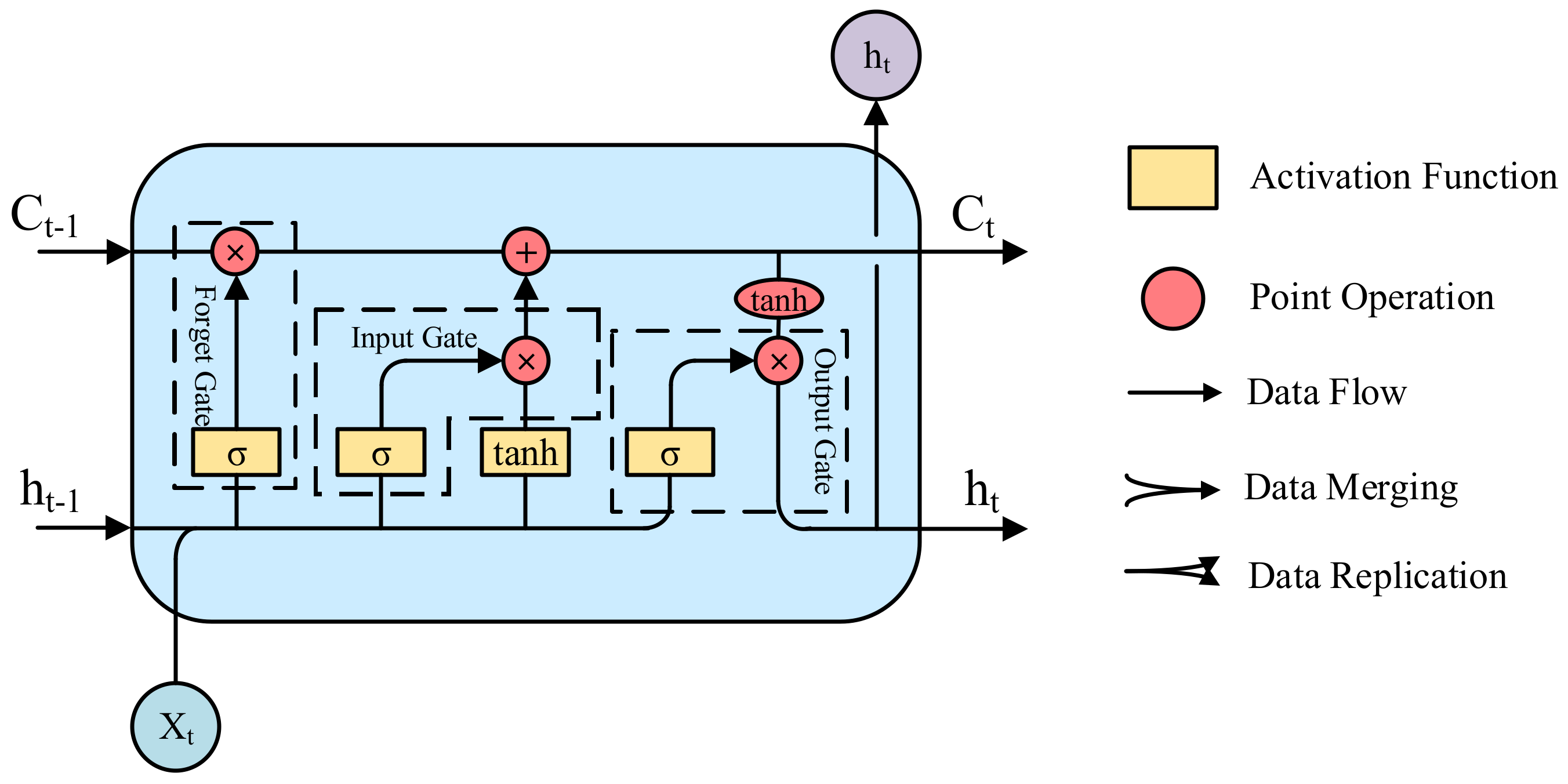
4.3. LSTM Nonlinear Time Series Model
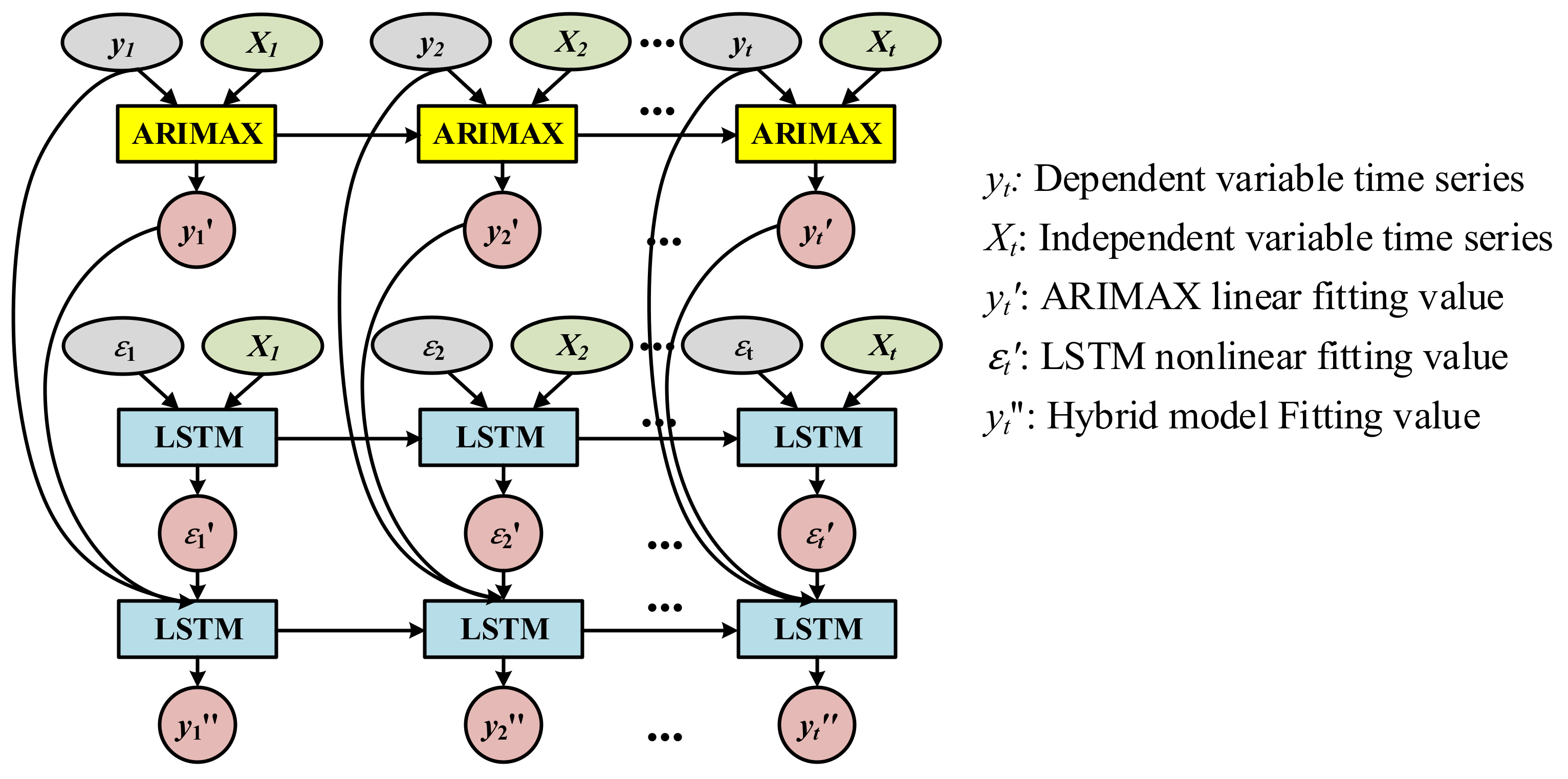
4.4. Multivariable Hybrid Time Series Model
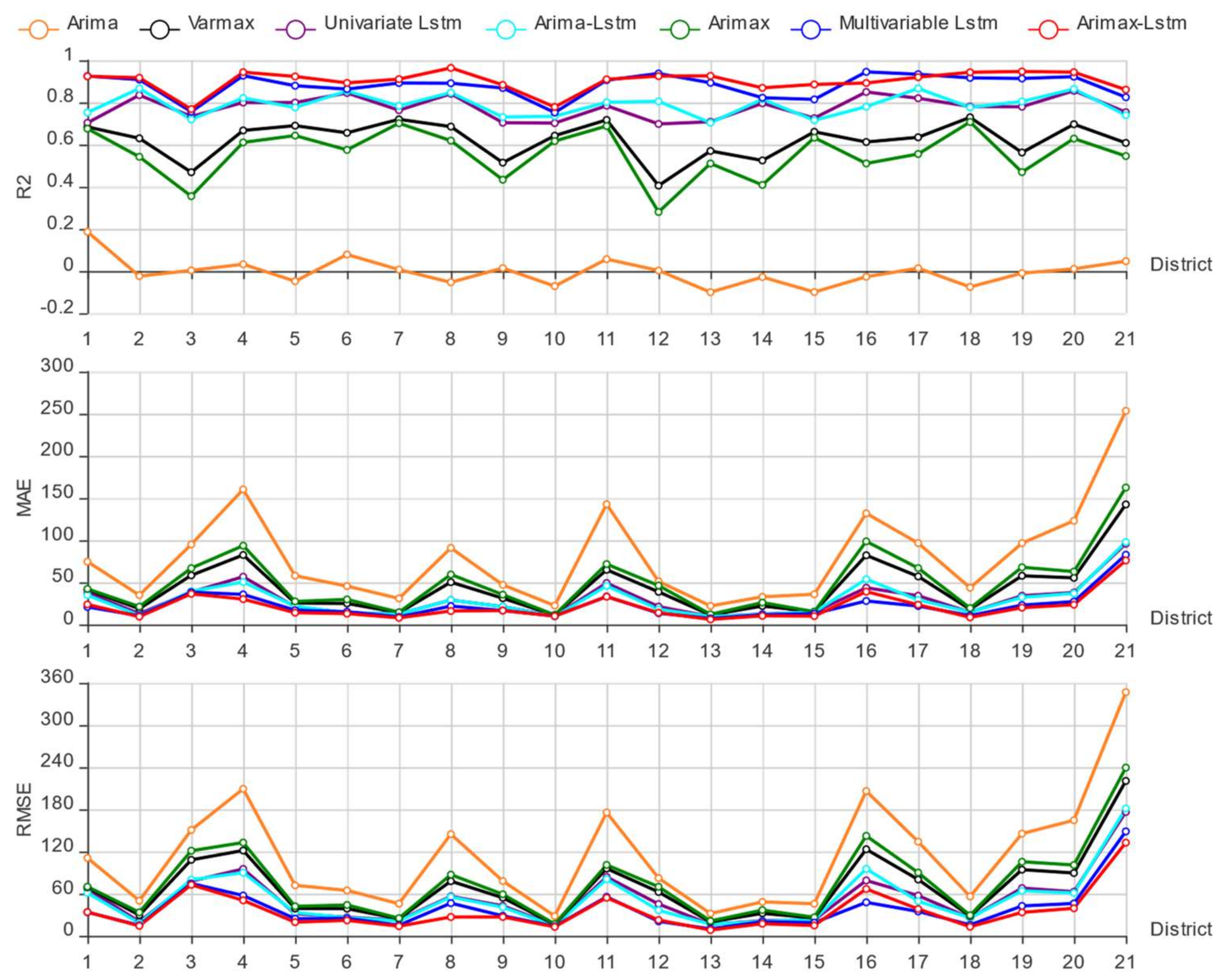
4.5. Verification Experiment and Result Analysis
5. Conclusions
6. Discussion
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yin, C.; Xiong, Z.; Chen, H.; Wang, J.; Cooper, D.; David, B. A literature survey on smart cities. Sci. China Inf. Sci. 2015, 58, 1–18. [Google Scholar] [CrossRef]
- Batty, M.; Axhausen, K.W.; Giannotti, F.; Pozdnoukhov, A.; Bazzani, A.; Wachowicz, M.; Ouzounis, G.; Portugali, Y. Smart cities of the future. Eur. Phys. J. Spec. Top. 2012, 214, 481–518. [Google Scholar] [CrossRef] [Green Version]
- Ismagilova, E.; Hughes, L.; Dwivedi, Y.K.; Raman, K.R. Smart cities: Advances in research—An information systems perspective. Int. J. Inform. Manag. 2019, 47, 88–100. [Google Scholar] [CrossRef]
- Gohar, M.; Muzammal, M.; Ur Rahman, A. SMART TSS: Defining transportation system behavior using big data analytics in smart cities. Sustain. Cities Soc. 2018, 41, 114–119. [Google Scholar] [CrossRef]
- Kuo, Y.; Szeto, W.Y. Smart transportation and analytics. Transp. B Transp. Dyn. 2018, 6, 1–3. [Google Scholar] [CrossRef]
- Yan, J.; Liu, J.; Tseng, F. An evaluation system based on the self-organizing system framework of smart cities: A case study of smart transportation systems in China. Technol. Forecast Soc. 2020, 153, 119371. [Google Scholar] [CrossRef]
- Babar, M.; Arif, F. Real-time data processing scheme using big data analytics in internet of things based smart transportation environment. J. Amb. Intel. Hum. Comp. 2019, 10, 4167–4177. [Google Scholar] [CrossRef]
- Goulet-Langlois, G.; Koutsopoulos, H.N.; Zhao, Z.; Zhao, J. Measuring Regularity of Individual Travel Patterns. IEEE Trans. Intell. Transp. 2018, 19, 1583–1592. [Google Scholar] [CrossRef] [Green Version]
- Xie, X.; Wang, Z.J. Examining travel patterns and characteristics in a bikesharing network and implications for data-driven decision supports: Case study in the Washington DC area. J. Transp. Geogr. 2018, 71, 84–102. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Dai, Z.; Zhu, L.; Liu, X. Analysis of Spatial and Temporal Characteristics of Citizens’ Mobility Based on E-Bike GPS Trajectory Data in Tengzhou City, China. Sustainability 2019, 11, 5003. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Huang, H.; Ni, X.; Zeng, W. Revealing Spatial-Temporal Characteristics and Patterns of Urban Travel: A Large-Scale Analysis and Visualization Study with Taxi GPS Data. Isprs Int. J. Geo-Inf. 2019, 8, 257. [Google Scholar] [CrossRef] [Green Version]
- Yu, C.; He, Z. Analysing the spatial-temporal characteristics of bus travel demand using the heat map. J. Transp. Geogr. 2017, 58, 247–255. [Google Scholar] [CrossRef]
- Goel, R.; Tiwari, G. Access–egress and other travel characteristics of metro users in Delhi and its satellite cities. IATSS Res. 2016, 39, 164–172. [Google Scholar] [CrossRef] [Green Version]
- Jiang, S.; Chen, W.; Li, Z.; Yu, H. Short-Term Demand Prediction Method for Online Car-Hailing Services Based on a Least Squares Support Vector Machine. IEEE Access 2019, 7, 11882–11891. [Google Scholar] [CrossRef]
- Gilibert, M.; Ribas, I.; Rosen, C.; Siebeneich, A. On-demand Shared Ride-Hailing for Commuting Purposes: Comparison of Barcelona and Hanover Case Studies. Transp. Res. Procedia 2020, 47, 323–330. [Google Scholar] [CrossRef]
- Tang, J.; Chen, X.; Hu, Z.; Zong, F.; Han, C.; Li, L. Traffic flow prediction based on combination of support vector machine and data denoising schemes. Phys. A Stat. Mech. Its Appl. 2019, 534, 120642. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhang, H.; An, L.; Liu, Q. Improving the approaches of traffic demand forecasting in the big data era. Cities 2018, 82, 19–26. [Google Scholar] [CrossRef]
- Tang, J.; Liu, F.; Zou, Y.; Zhang, W.; Wang, Y. An Improved Fuzzy Neural Network for Traffic Speed Prediction Considering Periodic Characteristic. IEEE Trans. Intell. Transp. 2017, 18, 2340–2350. [Google Scholar] [CrossRef]
- Hassija, V.; Gupta, V.; Garg, S.; Chamola, V. Traffic Jam Probability Estimation Based on Blockchain and Deep Neural Networks. IEEE Trans. Intell. Transp. 2020, 1–10. [Google Scholar] [CrossRef]
- Parmezan, A.R.S.; Souza, V.M.A.; Batista, G.E.A.P. Evaluation of statistical and machine learning models for time series prediction: Identifying the state-of-the-art and the best conditions for the use of each model. Inform. Sci. 2019, 484, 302–337. [Google Scholar] [CrossRef]
- Klepsch, J.; Klüppelberg, C.; Wei, T. Prediction of functional ARMA processes with an application to traffic data. Econom. Stat. 2017, 1, 128–149. [Google Scholar] [CrossRef] [Green Version]
- Xu, D.; Wang, Y.; Jia, L.; Qin, Y.; Dong, H. Real-time road traffic state prediction based on ARIMA and Kalman filter. Front. Inform. Technol. Electron. Eng. 2017, 18, 287–302. [Google Scholar] [CrossRef]
- Williams, B.M. Multivariate Vehicular Traffic Flow Prediction: Evaluation of ARIMAX Modeling. Transp. Res. Rec. 2001, 1776, 194–200. [Google Scholar] [CrossRef]
- Sun, Y.; Leng, B.; Guan, W. A novel wavelet-SVM short-time passenger flow prediction in Beijing subway system. Neurocomputing 2015, 166, 109–121. [Google Scholar] [CrossRef]
- Hu, W.; Yan, L.; Liu, K.; Wang, H. A Short-Term Traffic Flow Forecasting Method Based on the Hybrid PSO-SVR. Neural Process. Lett. 2016, 43, 155–172. [Google Scholar] [CrossRef]
- Alajali, W.; Zhou, W.; Wen, S.; Wang, Y. Intersection Traffic Prediction Using Decision Tree Models. Symmetry 2018, 10, 386. [Google Scholar] [CrossRef] [Green Version]
- Tian, Y.; Zhang, K.; Li, J.; Lin, X.; Yang, B. LSTM-based traffic flow prediction with missing data. Neurocomputing 2018, 318, 297–305. [Google Scholar] [CrossRef]
- Ming, W.; Bao, Y.; Hu, Z.; Xiong, T.; Bala, P.; Ji, P. Multistep-Ahead Air Passengers Traffic Prediction with Hybrid ARIMA-SVMs Models. Sci. World J. 2014, 2014, 567246. [Google Scholar] [CrossRef]
- Zhang, N.; Zhang, Y.; Lu, H. Seasonal Autoregressive Integrated Moving Average and Support Vector Machine Models: Prediction of Short-Term Traffic Flow on Freeways. Transp. Res. Rec. 2011, 2215, 85–92. [Google Scholar] [CrossRef]
- Liu, B.; Tang, X.; Cheng, J.; Shi, P. Traffic flow combination forecasting method based on improved LSTM and ARIMA. Int. J. Embed. Syst. 2020, 12, 22–30. [Google Scholar] [CrossRef]
- Tamuke, E.; Jackson, E.A.; Sillah, A. Forecasting Inflation in Sierra Leone Using Arima and Arimax: A Comparative Evaluation, Model Building and Analysis Team 4. Theor. Pract. Res. Econ. Fields 2018, 9, 63–74. [Google Scholar] [CrossRef]
- Harvey, H.B.; Sotardi, S.T. The Pareto Principle. J. Am. Coll. Radiol. 2018, 15, 931. [Google Scholar] [CrossRef] [PubMed]
- Zhou, M.; Wang, D.; Li, Q.; Yue, Y.; Tu, W.; Cao, R. Impacts of weather on public transport ridership: Results from mining data from different sources. Transp. Res. Part C Emerg. Technol. 2017, 75, 17–29. [Google Scholar] [CrossRef] [Green Version]
- Wu, J.; Liao, H. Weather, travel mode choice, and impacts on subway ridership in Beijing. Transp. Res. Part A Policy Pract. 2020, 135, 264–279. [Google Scholar] [CrossRef]
- Zhao, P.; Li, S.; Li, P.; Liu, J.; Long, K. How does air pollution influence cycling behaviour? Evidence from Beijing. Transp. Res. Part D Transp. Environ. 2018, 63, 826–838. [Google Scholar] [CrossRef]
- Guo, P.; Fu, J.; Yang, X. Condition Monitoring and Fault Diagnosis of Wind Turbines Gearbox Bearing Temperature Based on Kolmogorov-Smirnov Test and Convolutional Neural Network Model. Energies 2018, 11, 2248. [Google Scholar] [CrossRef] [Green Version]
- Jović, O. Durbin-Watson partial least-squares regression applied to MIR data on adulteration with edible oils of different origins. Food Chem. 2016, 213, 791–798. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Field Name | Description | Example |
|---|---|---|
| order_id | Order ID | 0e0d61fe14b76b59a83c421a720216a5 |
| driver_id | Driver ID | f214b0789124b60ea8e279543da45c78 or Null |
| passenger_id | Passenger ID | a083fd0a2181a13d7a614271edd4a0af |
| start_district_id | Order start district ID | 74c1c25f4b283fa74a5514307b0d0278 |
| dest_district_id | Order destination district ID | dd8d3b9665536d6e05b29c2648c0e69a |
| price | Order price | 10.7 |
| datetime | Order date and time | 2016-01-17 20:15:26 |
| Field Name | Description | Example |
|---|---|---|
| district_id | District ID | 1ecbb52d73c522f184a6fc53128b1ea1 |
| traffic | Road quantity in different traffic jam levels | 1:231 2:33 3:13 4:10 |
| datetime | Records the date and time | 2016-01-01 23:30:22 |
| Field Name | Description | Example |
|---|---|---|
| datetime | Record date and time | 1 January 2016, 09:55:15 |
| weather | Weather type | 2 |
| temperature | Temperature (°C) | 4.0 |
| air_quality | Air quality level | 3 |
| District ID | Date | Time Slice ID | Demand | Traffic Jam Level 3 | Temperature | Air Quality Level |
|---|---|---|---|---|---|---|
| 16 | 1 January 2016 | 1 | 101 | 76 | 3 | 4 |
| 16 | 1 January 2016 | 2 | 116 | 76 | 3 | 4 |
| 16 | 2016-01-01 | 3 | 113 | 86 | 3 | 4 |
| 16 | 21 January 2016 | 142 | 65 | 70 | 1 | 1 |
| 16 | 21 January 2016 | 143 | 64 | 75 | 1 | 1 |
| 16 | 21 January 2016 | 144 | 52 | 70 | 1 | 1 |
| Parameter | Value |
|---|---|
| Time Steps | 6 |
| Input Layer Units Number | 47 |
| Output Layer Units Number | 1 |
| Hide Layer Number | 1 |
| Hide Layer Units Number | 100 |
| Epochs | 60 |
| Batch Size | 16 |
| Activation Function | Rectified linear unit (ReLU) |
| Loss Function | Min mean absolute error (MAE) |
| Optimizer | Adam |
| Dropout | 0.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, S.; Chen, B.; Liu, H.; Ji, X.; Wei, C.; Chang, W.; Xiao, Y. Travel Characteristics Analysis and Traffic Prediction Modeling Based on Online Car-Hailing Operational Data Sets. Entropy 2021, 23, 1305. https://doi.org/10.3390/e23101305
Zhou S, Chen B, Liu H, Ji X, Wei C, Chang W, Xiao Y. Travel Characteristics Analysis and Traffic Prediction Modeling Based on Online Car-Hailing Operational Data Sets. Entropy. 2021; 23(10):1305. https://doi.org/10.3390/e23101305
Chicago/Turabian StyleZhou, Shenghan, Bang Chen, Houxiang Liu, Xinpeng Ji, Chaofan Wei, Wenbing Chang, and Yiyong Xiao. 2021. "Travel Characteristics Analysis and Traffic Prediction Modeling Based on Online Car-Hailing Operational Data Sets" Entropy 23, no. 10: 1305. https://doi.org/10.3390/e23101305