

Large-Scale Date Palm Tree Segmentation from Multiscale UAV-Based and Aerial Images Using Deep Vision Transformers

 ,
,  , , ,
, , ,
Abstract
:1. Introduction
2. Materials
2.1. Study Area
2.2. Data Acquisition
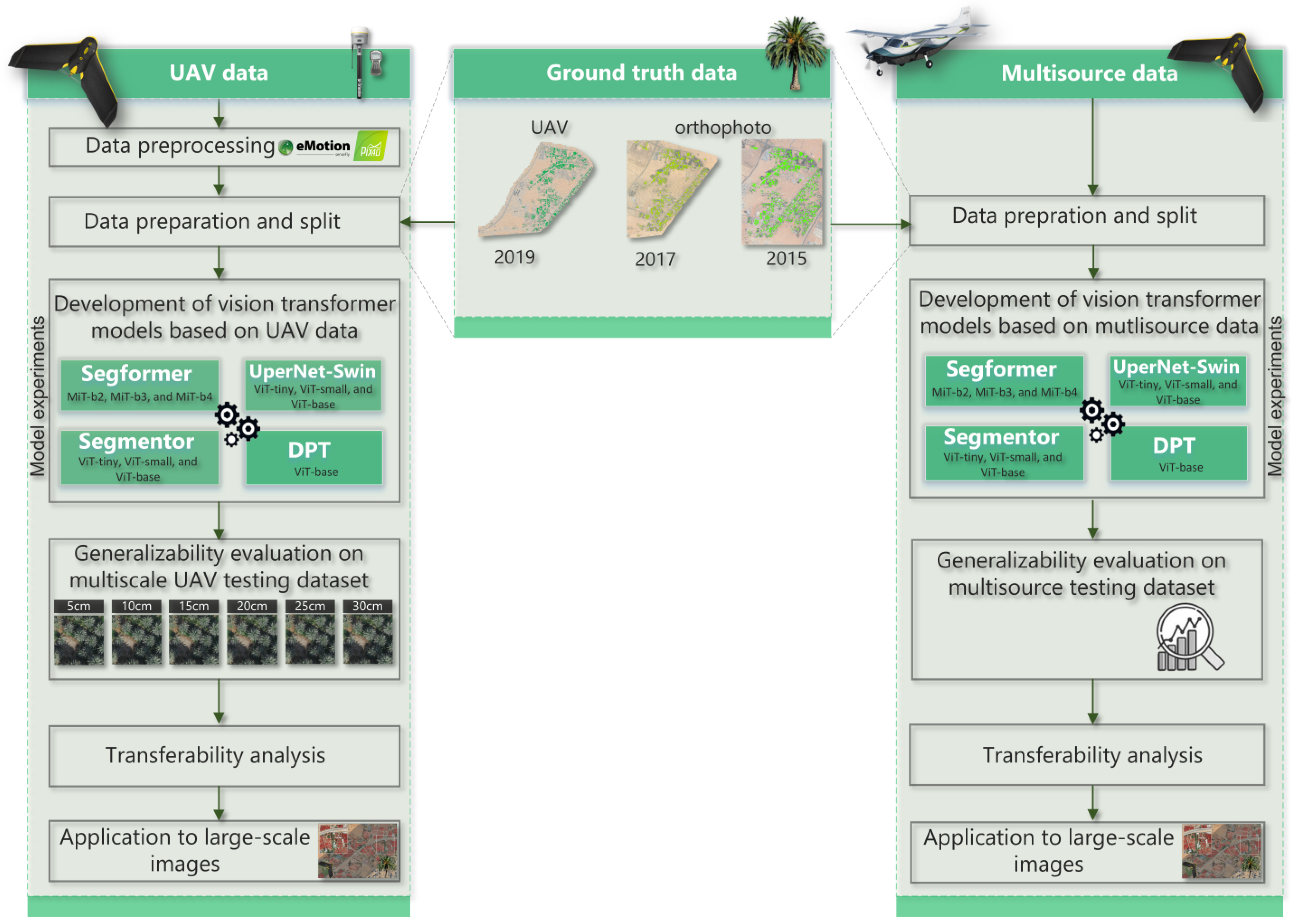
3. Methodology
3.1. Data Preprocessing
3.2. Data Preparation and Split
3.3. Semantic Segmentation Models
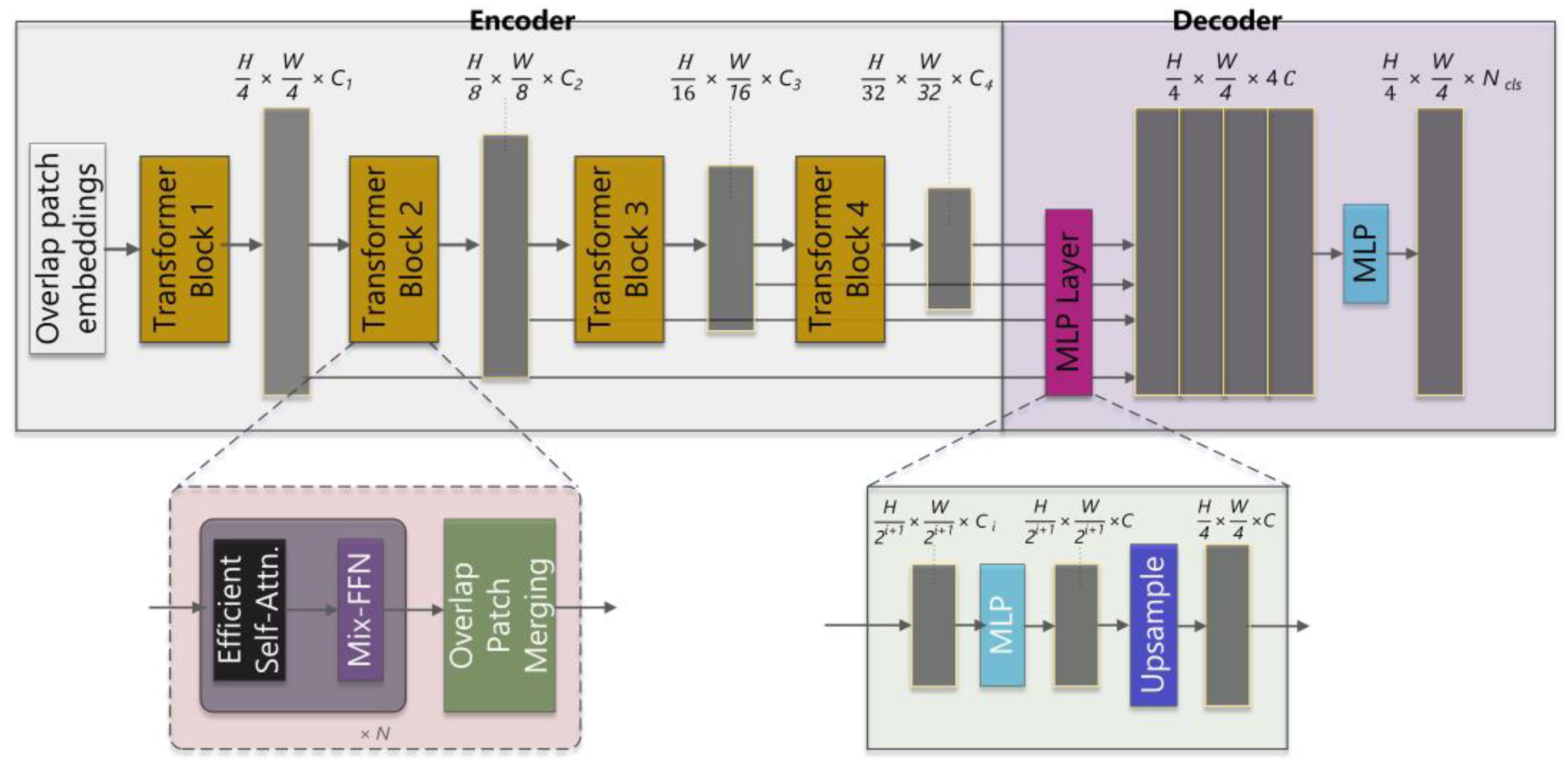
3.3.1. Segformer
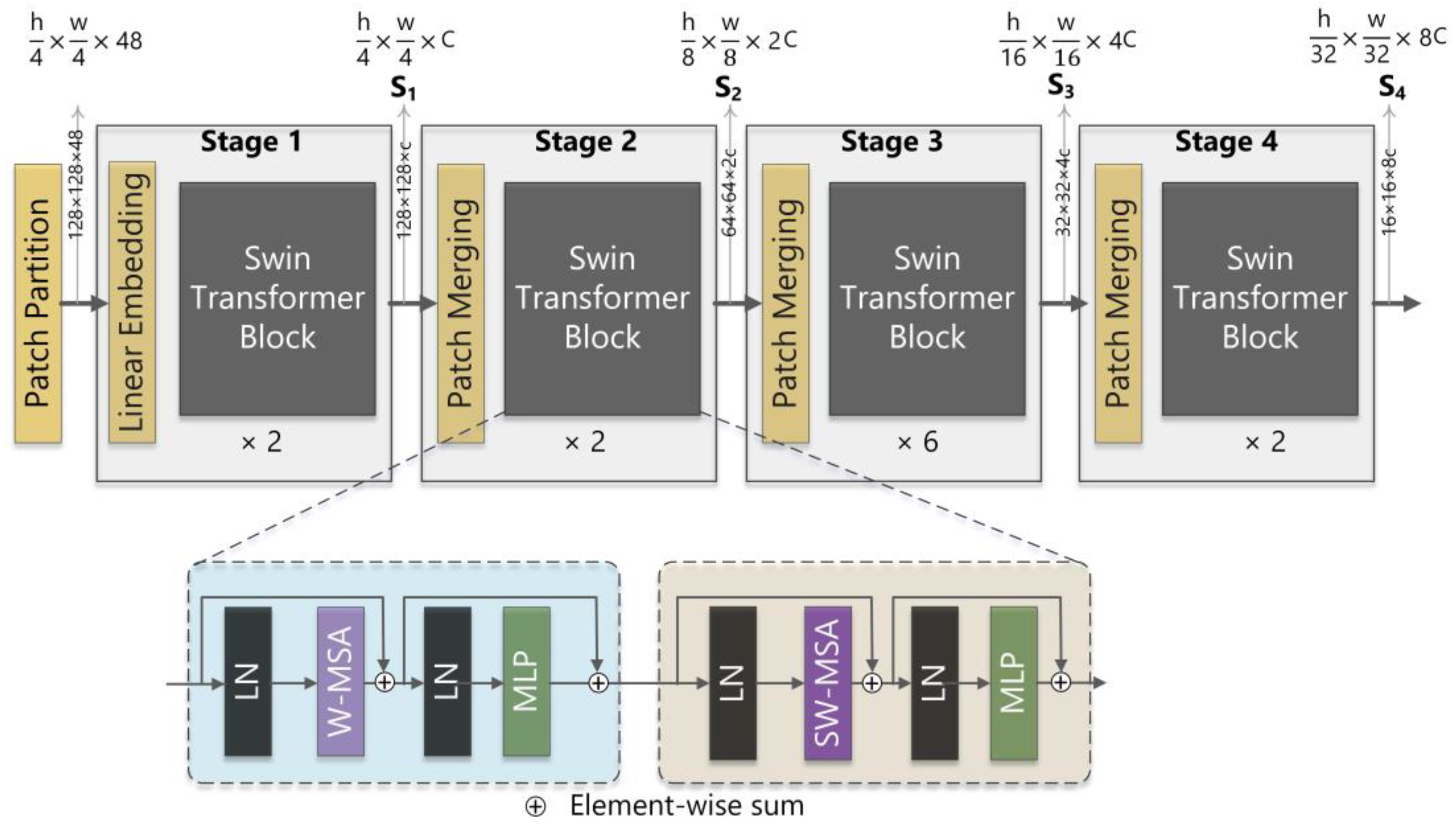
3.3.2. UperNet-Swin Transformer
3.3.3. Segmenter
3.3.4. Dense Prediction Transformer
3.4. Evaluation Metrics
3.5. Experimental Setup
3.6. Generalization Capability Analysis
3.7. Transferability Analysis
3.8. Model Application to Large-Scale Images
4. Results
4.1. Evaluation of Vision Transformers Based on UAV Data
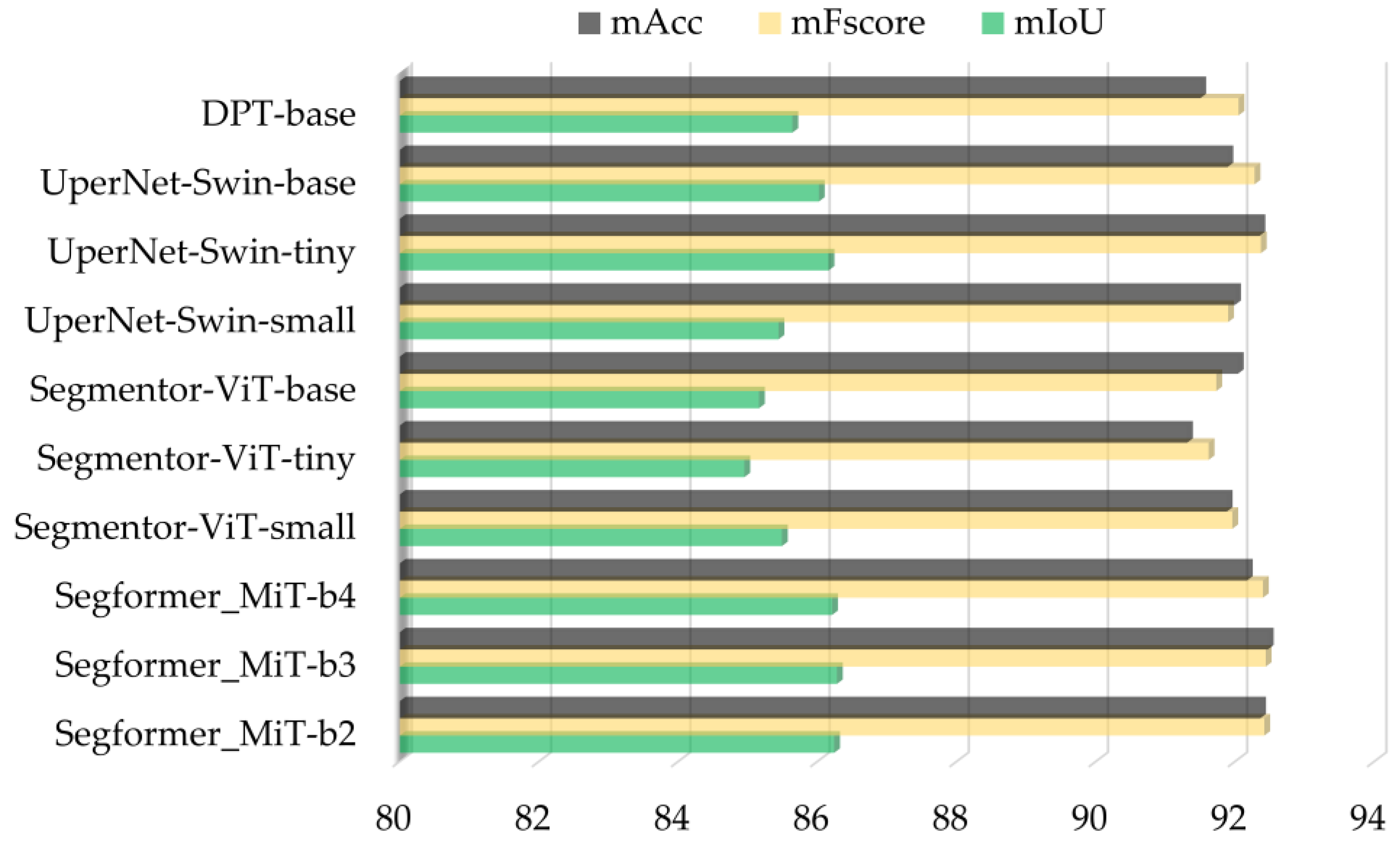
4.1.1. Results of Date Palm Tree Segmentation
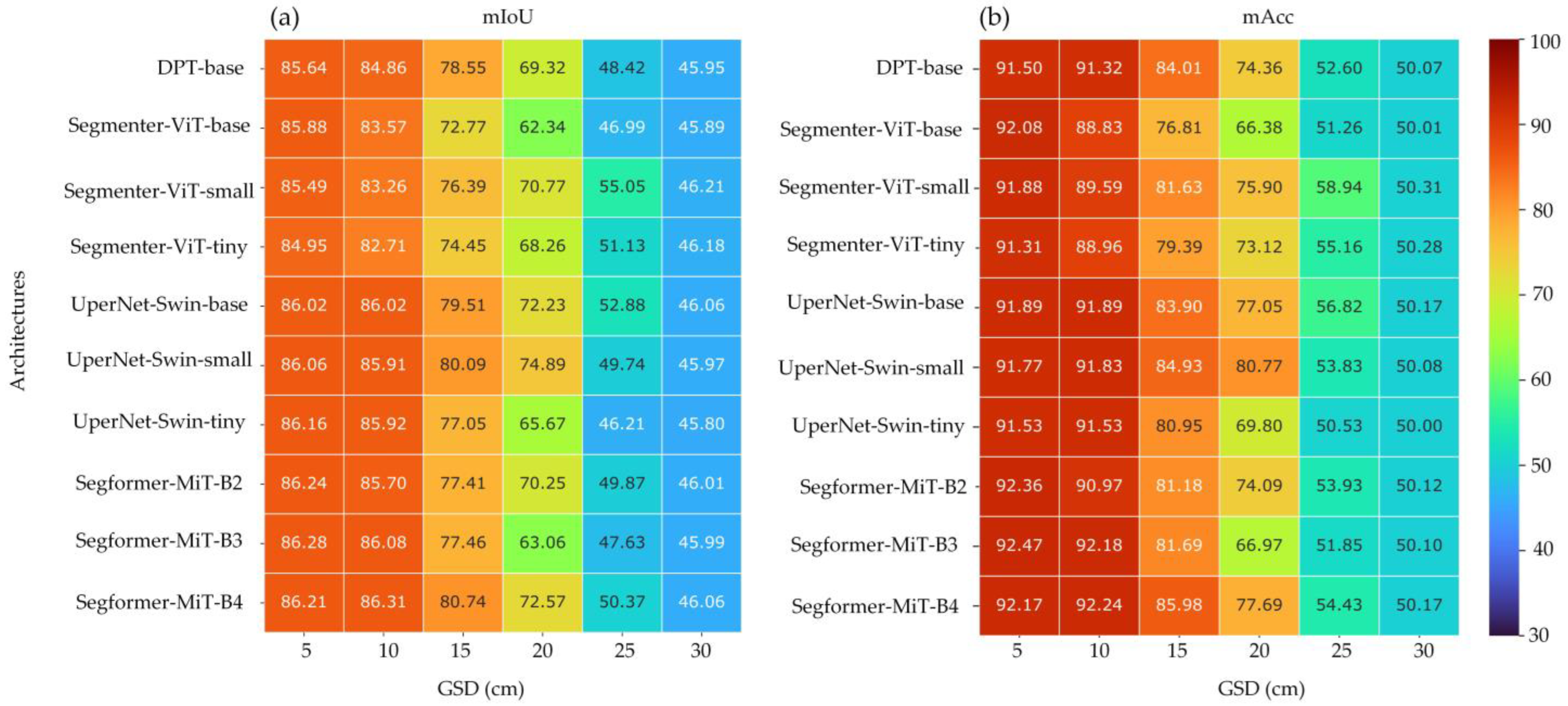
4.1.2. Results of Generalizability Evaluation
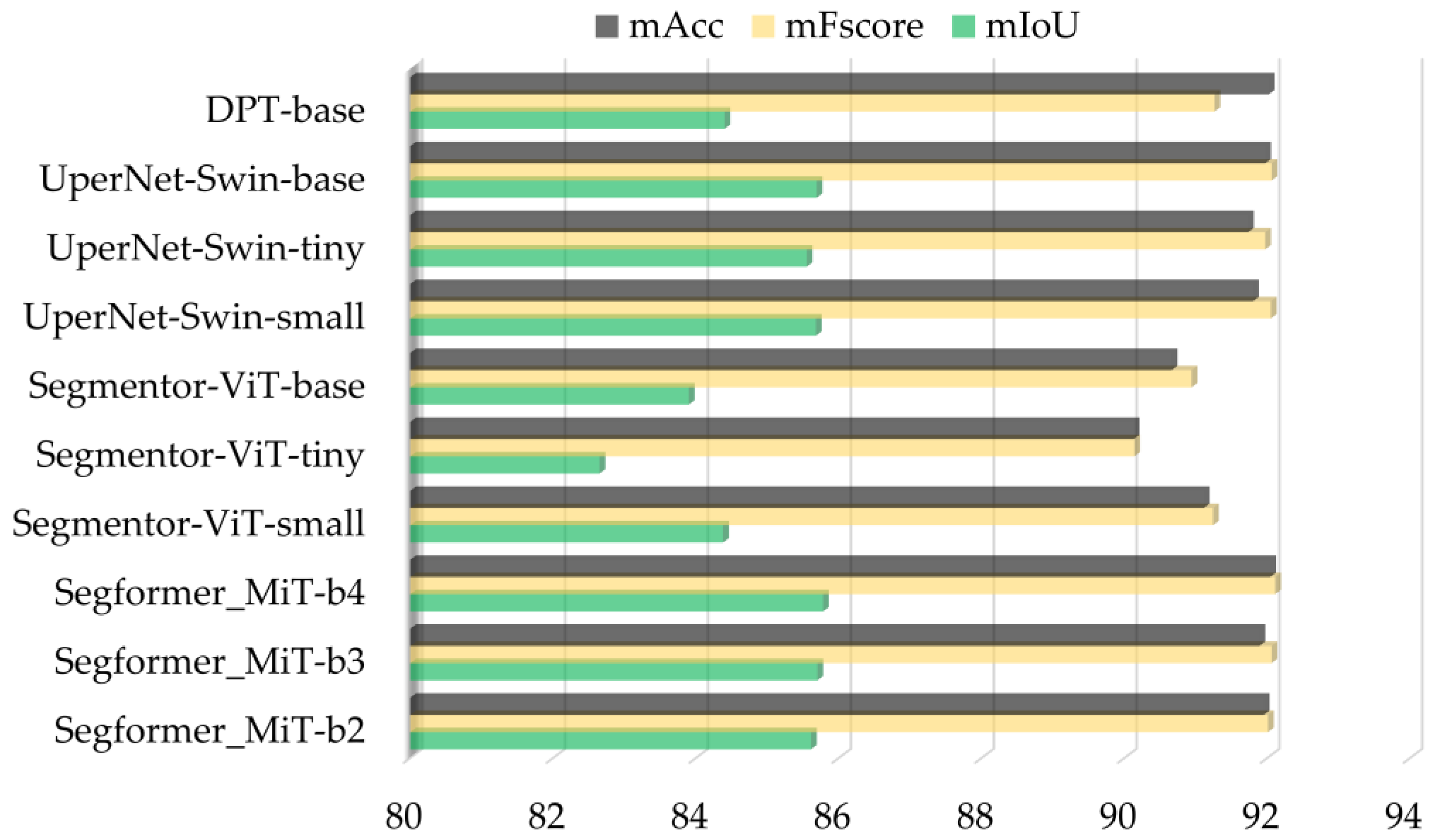
4.2. Results of Vision Transformers Developed on Multisource Data
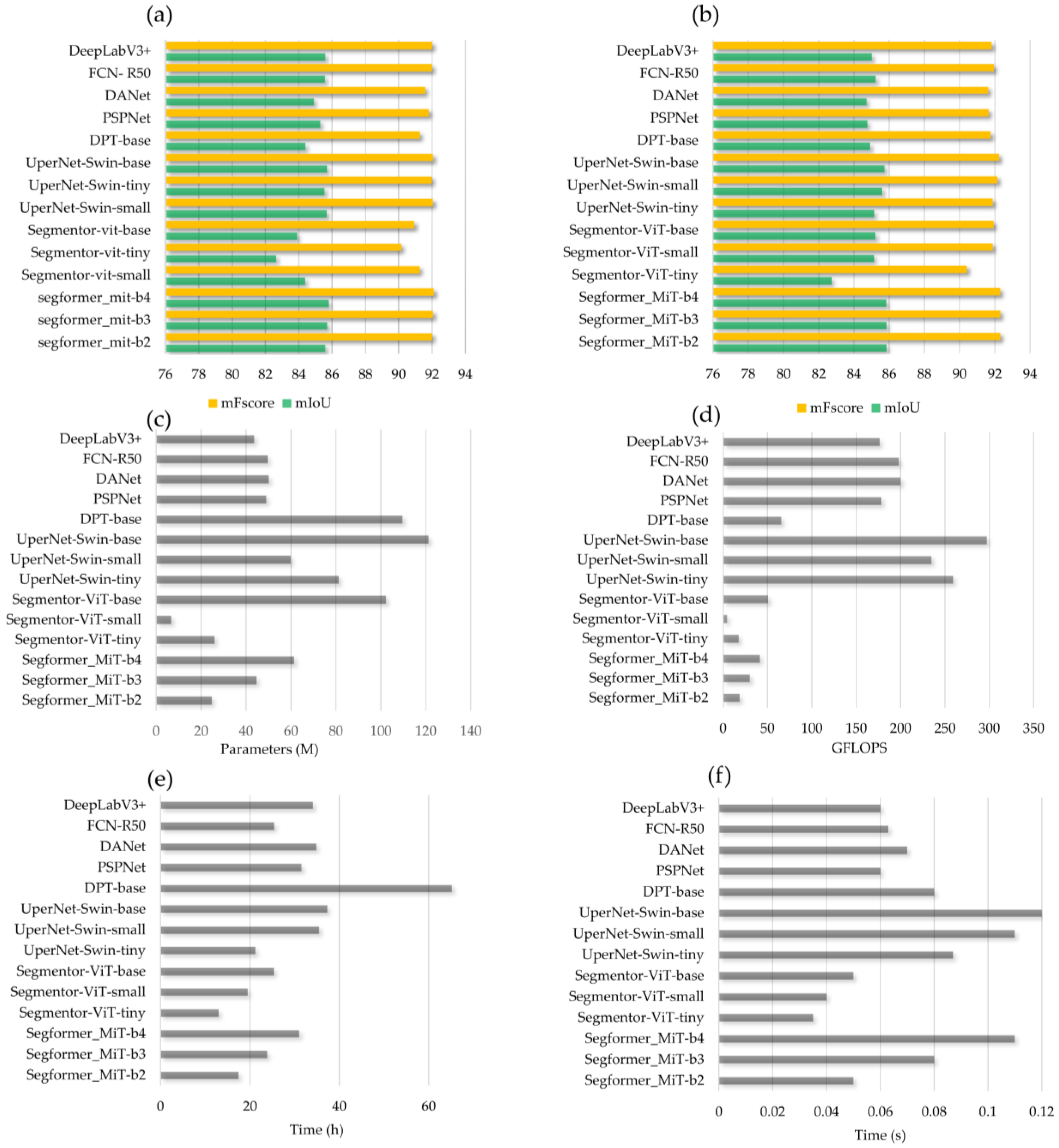
4.3. Results of the Transferability Evaluation
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zaid, A.; Wet, P.F. Chapter I: Botanical and Systematic Description of the Date Palm; FAO: Rome, Italy, 2002; Available online: http://www.fao.org/docrep/006.Y4360E/y4360e05.htm (accessed on 31 March 2018).
- Spennemann, D.H.R. Review of the vertebrate-mediated dispersal of the Date Palm, Phoenix dactylifera. Zool. Middle East 2018, 64, 283–296. [Google Scholar] [CrossRef]
- Krueger, R.R. Date palm (Phoenix dactylifera L.) biology and utilization. In The Date Palm Genome; Springer: Cham, Switzerland, 2021; Volume 1, pp. 3–28. [Google Scholar]
- Food and Agriculture Organization. FAOSTAT. Available online: http://www.fao.org/faostat/en/#data/QC (accessed on 9 March 2021).
- Mohan, M.; Silva, C.A.; Klauberg, C.; Jat, P.; Catts, G.; Cardil, A.; Hudak, A.T.; Dia, M. Individual tree detection from unmanned aerial vehicle (UAV) derived canopy height model in an open canopy mixed conifer forest. Forests 2017, 8, 340. [Google Scholar] [CrossRef] [Green Version]
- Xi, X.; Xia, K.; Yang, Y.; Du, X.; Feng, H. Evaluation of dimensionality reduction methods for individual tree crown delineation using instance segmentation network and UAV multispectral imagery in urban forest. Comput. Electron. Agric. 2021, 191, 106506. [Google Scholar] [CrossRef]
- Safonova, A.; Hamad, Y.; Dmitriev, E.; Georgiev, G.; Trenkin, V.; Georgieva, M.; Dimitrov, S.; Iliev, M. Individual tree crown delineation for the species classification and assessment of vital status of forest stands from UAV images. Drones 2021, 5, 77. [Google Scholar] [CrossRef]
- Miraki, M.; Sohrabi, H.; Fatehi, P.; Kneubuehler, M. Individual tree crown delineation from high-resolution UAV images in broadleaf forest. Ecol. Inform. 2021, 61, 101207. [Google Scholar] [CrossRef]
- Komárek, J.; Klápště, P.; Hrach, K.; Klouček, T. The Potential of Widespread UAV Cameras in the Identification of Conifers and the Delineation of Their Crowns. Forests 2022, 13, 710. [Google Scholar] [CrossRef]
- Malek, S.; Bazi, Y.; Alajlan, N.; AlHichri, H.; Melgani, F. Efficient framework for palm tree detection in UAV images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 4692–4703. [Google Scholar] [CrossRef]
- Chowdhury, P.N.; Shivakumara, P.; Nandanwar, L.; Samiron, F.; Pal, U.; Lu, T. Oil palm tree counting in drone images. Pattern Recognit. Lett. 2022, 153, 1–9. [Google Scholar] [CrossRef]
- Han, P.; Ma, C.; Chen, J.; Chen, L.; Bu, S.; Xu, S.; Zhao, Y.; Zhang, C.; Hagino, T. Fast Tree Detection and Counting on UAVs for Sequential Aerial Images with Generating Orthophoto Mosaicing. Remote Sens. 2022, 14, 4113. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhou, J.; Yang, Y.; Liu, L.; Liu, F.; Kong, W. Rapid Target Detection of Fruit Trees Using UAV Imaging and Improved Light YOLOv4 Algorithm. Remote Sens. 2022, 14, 4324. [Google Scholar] [CrossRef]
- Bazi, Y.; Malek, S.; Alajlan, N.; Alhichri, H. An automatic approach for palm tree counting in UAV images. In Proceedings of the 2014 IEEE Geoscience and Remote Sensing Symposium, Quebec City, QC, Canada, 13–18 July 2014; pp. 537–540. [Google Scholar]
- Ecke, S.; Dempewolf, J.; Frey, J.; Schwaller, A.; Endres, E.; Klemmt, H.J.; Tiede, D.; Seifert, T. UAV-Based Forest Health Monitoring: A Systematic Review. Remote Sens. 2022, 14, 3205. [Google Scholar] [CrossRef]
- Viera-Torres, M.; Sinde-González, I.; Gil-Docampo, M.; Bravo-Yandún, V.; Toulkeridis, T. Generating the baseline in the early detection of bud rot and red ring disease in oil palms by geospatial technologies. Remote Sens. 2020, 12, 3229. [Google Scholar] [CrossRef]
- Li, W.; Dong, R.; Fu, H.; Yu, L. Large-scale oil palm tree detection from high-resolution satellite images using two-stage convolutional neural networks. Remote Sens. 2019, 11, 11. [Google Scholar] [CrossRef] [Green Version]
- Hartling, S.; Sagan, V.; Sidike, P.; Maimaitijiang, M.; Carron, J. Urban tree species classification using a worldview-2/3 and liDAR data fusion approach and deep learning. Sensors 2019, 19, 1284. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pearse, G.D.; Watt, M.S.; Soewarto, J.; Tan, A.Y.S. Deep learning and phenology enhance large-scale tree species classification in aerial imagery during a biosecurity response. Remote Sens. 2021, 13, 1789. [Google Scholar] [CrossRef]
- Kolanuvada, S.R.; Ilango, K.K. Automatic Extraction of Tree Crown for the Estimation of Biomass from UAV Imagery Using Neural Networks. J. Indian Soc. Remote Sens. 2021, 49, 651–658. [Google Scholar] [CrossRef]
- Liu, X.; Ghazali, K.H.; Han, F.; Mohamed, I.I. Automatic Detection of Oil Palm Tree from UAV Images Based on the Deep Learning Method. Appl. Artif. Intell. 2021, 35, 13–24. [Google Scholar] [CrossRef]
- Zamboni, P.; Junior, J.M.; Silva, J.d.A.; Miyoshi, G.T.; Matsubara, E.T.; Nogueira, K.; Gonçalves, W.N. Benchmarking anchor-based and anchor-free state-of-the-art deep learning methods for individual tree detection in rgb high-resolution images. Remote Sens. 2021, 13, 2482. [Google Scholar] [CrossRef]
- Moura, M.M.; de Oliveira, L.E.S.; Sanquetta, C.R.; Bastos, A.; Mohan, M.; Corte, A.P.D. Towards Amazon Forest Restoration: Automatic Detection of Species from UAV Imagery. Remote Sens. 2021, 13, 2627. [Google Scholar] [CrossRef]
- Xia, K.; Wang, H.; Yang, Y.; Du, X.; Feng, H. Automatic Detection and Parameter Estimation of Ginkgo biloba in Urban Environment Based on RGB Images. J. Sens. 2021, 2021, 668934. [Google Scholar] [CrossRef]
- Veras, H.F.P.; Ferreira, M.P.; da Cunha Neto, E.M.; Figueiredo, E.O.; Corte, A.P.D.; Sanquetta, C.R. Fusing multi-season UAS images with convolutional neural networks to map tree species in Amazonian forests. Ecol. Inform. 2022, 71, 101815. [Google Scholar] [CrossRef]
- Sun, Q.; Zhang, R.; Chen, L.; Zhang, L.; Zhang, H.; Zhao, C. Semantic segmentation and path planning for orchards based on UAV images. Comput. Electron. Agric. 2022, 200, 107222. [Google Scholar] [CrossRef]
- Ji, Y.; Yan, E.; Yin, X.; Song, Y.; Wei, W.; Mo, D. Automated extraction of Camellia oleifera crown using unmanned aerial vehicle visible images and the ResU-Net deep learning model. Front. Plant Sci. 2022, 13, 958940. [Google Scholar] [CrossRef]
- Lassalle, G.; Ferreira, M.P.; La Rosa, L.E.C.; de Souza Filho, C.R. Deep learning-based individual tree crown delineation in mangrove forests using very-high-resolution satellite imagery. ISPRS J. Photogramm. Remote Sens. 2022, 189, 220–235. [Google Scholar] [CrossRef]
- Zhang, C.; Zhou, J.; Wang, H.; Tan, T.; Cui, M.; Huang, Z.; Wang, P.; Zhang, L. Multi-Species Individual Tree Segmentation and Identification Based on Improved Mask R-CNN and UAV Imagery in Mixed Forests. Remote Sens. 2022, 14, 874. [Google Scholar] [CrossRef]
- Yang, M.; Mou, Y.; Liu, S.; Meng, Y.; Liu, Z.; Li, P.; Xiang, W.; Zhou, X.; Peng, C. Detecting and mapping tree crowns based on convolutional neural network and Google Earth images. Int. J. Appl. Earth Obs. Geoinf. 2022, 108, 102764. [Google Scholar] [CrossRef]
- Li, Y.; Chai, G.; Wang, Y.; Lei, L.; Zhang, X. ACE R-CNN: An Attention Complementary and Edge Detection-Based Instance Segmentation Algorithm for Individual Tree Species Identification Using UAV RGB Images and LiDAR Data. Remote Sens. 2022, 14, 3035. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Handa, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for robust semantic pixel-wise labelling. arXiv 2015, arXiv:1505.07293. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2015; Volume 9351, pp. 234–241. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Gibril, M.B.A.; Shafri, H.Z.M.; Shanableh, A.; Al-Ruzouq, R.; Wayayok, A.; Hashim, S.J. Deep convolutional neural network for large-scale date palm tree mapping from uav-based images. Remote Sens. 2021, 13, 2787. [Google Scholar] [CrossRef]
- Anagnostis, A.; Tagarakis, A.C.; Kateris, D.; Moysiadis, V.; Sørensen, C.G.; Pearson, S.; Bochtis, D. Orchard Mapping with Deep Learning Semantic Segmentation. Sensors 2021, 21, 3813. [Google Scholar] [CrossRef] [PubMed]
- Ferreira, M.P.; Lotte, R.G.; D’Elia, F.V.; Stamatopoulos, C.; Kim, D.H.; Benjamin, A.R. Accurate mapping of Brazil nut trees (Bertholletia excelsa) in Amazonian forests using WorldView-3 satellite images and convolutional neural networks. Ecol. Inform. 2021, 63, 101302. [Google Scholar] [CrossRef]
- Freudenberg, M.; Nölke, N.; Agostini, A.; Urban, K.; Wörgötter, F.; Kleinn, C. Large scale palm tree detection in high resolution satellite images using U-Net. Remote Sens. 2019, 11, 312. [Google Scholar] [CrossRef] [Green Version]
- Kentsch, S.; Caceres, M.L.L.; Serrano, D.; Roure, F.; Diez, Y. Computer vision and deep learning techniques for the analysis of drone-acquired forest images, a transfer learning study. Remote Sens. 2020, 12, 1287. [Google Scholar] [CrossRef] [Green Version]
- Wagner, F.H.; Sanchez, A.; Tarabalka, Y.; Lotte, R.G.; Ferreira, M.P.; Aidar, M.P.M.; Gloor, E.; Phillips, O.L.; Aragão, L.E.O.C. Using the U-net convolutional network to map forest types and disturbance in the Atlantic rainforest with very high resolution images. Remote Sens. Ecol. Conserv. 2019, 5, 360–375. [Google Scholar] [CrossRef] [Green Version]
- Wagner, F.H.; Sanchez, A.; Aidar, M.P.M.; Rochelle, A.L.C.; Tarabalka, Y.; Fonseca, M.G.; Phillips, O.L.; Gloor, E.; Aragão, L.E.O.C. Mapping Atlantic rainforest degradation and regeneration history with indicator species using convolutional network. PLoS ONE 2020, 15, e0229448. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Wang, X.; Wang, T. Classification of tree species and stock volume estimation in ground forest images using Deep Learning. Comput. Electron. Agric. 2019, 166, 105012. [Google Scholar] [CrossRef]
- Kentsch, S.; Karatsiolis, S.; Kamilaris, A.; Tomhave, L.; Lopez Caceres, M.L. Identification of Tree Species in Japanese Forests based on Aerial Photography and Deep Learning. In Advances and New Trends in Environmental Informatics; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Schiefer, F.; Kattenborn, T.; Frick, A.; Frey, J.; Schall, P.; Koch, B.; Schmidtlein, S. Mapping forest tree species in high resolution UAV-based RGB-imagery by means of convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2020, 170, 205–215. [Google Scholar] [CrossRef]
- Shang, G.; Liu, G.; Zhu, P.; Han, J.; Xia, C.; Jiang, K. A deep residual U-type network for semantic segmentation of orchard environments. Appl. Sci. 2021, 11, 322. [Google Scholar] [CrossRef]
- Ayhan, B.; Kwan, C. Tree, shrub, and grass classification using only RGB images. Remote Sens. 2020, 12, 1333. [Google Scholar] [CrossRef] [Green Version]
- Ferreira, M.P.; de Almeida, D.R.A.; Papa, D.d.A.; Minervino, J.B.S.; Veras, H.F.P.; Formighieri, A.; Santos, C.A.N.; Ferreira, M.A.D.; Figueiredo, E.O.; Ferreira, E.J.L. Individual tree detection and species classification of Amazonian palms using UAV images and deep learning. For. Ecol. Manag. 2020, 475, 118397. [Google Scholar] [CrossRef]
- Cheng, Z.; Qi, L.; Cheng, Y. Cherry Tree Crown Extraction from Natural Orchard Images with Complex Backgrounds. Agriculture 2021, 11, 431. [Google Scholar] [CrossRef]
- Morales, G.; Kemper, G.; Sevillano, G.; Arteaga, D.; Ortega, I.; Telles, J. Automatic segmentation of Mauritia flexuosa in unmanned aerial vehicle (UAV) imagery using deep learning. Forests 2018, 9, 736. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Kolesnikov, A.; Dosovitskiy, A.; Weissenborn, D.; Heigold, G.; Uszkoreit, J.; Beyer, L.; Minderer, M.; Dehghani, M.; Houlsby, N.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Dai, X.; Chen, Y.; Xiao, B.; Chen, D.; Liu, M.; Yuan, L.; Zhang, L. Dynamic head: Unifying object detection heads with attentions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2021), Nashville, TN, USA, 20–25 June 2021; pp. 7373–7382. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.S.; et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2021), Nashville, TN, USA, 20–25 June 2021; pp. 6881–6890. [Google Scholar]
- Xia, Z.; Pan, X.; Song, S.; Li, L.E.; Huang, G. Vision Transformer with Deformable Attention. arXiv 2022, arXiv:2201.00520. [Google Scholar]
- Jamali, A.; Mahdianpari, M. Swin Transformer and Deep Convolutional Neural Networks for Coastal Wetland Classification Using Sentinel-1, Sentinel-2, and LiDAR Data. Remote Sens. 2022, 14, 359. [Google Scholar] [CrossRef]
- Jamali, A.; Mahdianpari, M.; Brisco, B.; Mao, D.; Salehi, B.; Mohammadimanesh, F. 3DUNetGSFormer: A deep learning pipeline for complex wetland mapping using generative adversarial networks and Swin transformer. Ecol. Inform. 2022, 72, 101904. [Google Scholar] [CrossRef]
- Mekhalfi, M.L.; Nicolo, C.; Bazi, Y.; Al Rahhal, M.M.; Alsharif, N.A.; Maghayreh, E. Al Contrasting YOLOv5, Transformer, and EfficientDet Detectors for Crop Circle Detection in Desert. IEEE Geosci. Remote Sens. Lett. 2022, 19, 19–23. [Google Scholar] [CrossRef]
- Chen, G.; Shang, Y. Transformer for Tree Counting in Aerial Images. Remote Sens. 2022, 14, 476. [Google Scholar] [CrossRef]
- Gao, L.; Liu, H.; Yang, M.; Chen, L.; Wan, Y.; Xiao, Z.; Qian, Y. STransFuse: Fusing Swin Transformer and Convolutional Neural Network for Remote Sensing Image Semantic Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 10990–11003. [Google Scholar] [CrossRef]
- Zhang, C.; Wang, L.; Cheng, S.; Li, Y. SwinSUNet: Pure Transformer Network for Remote Sensing Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5224713. [Google Scholar] [CrossRef]
- Chen, X.; Qiu, C.; Guo, W.; Yu, A.; Tong, X.; Schmitt, M. Multiscale Feature Learning by Transformer for Building Extraction from Satellite Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 2503605. [Google Scholar] [CrossRef]
- Abozeid, A.; Alanazi, R.; Elhadad, A.; Taloba, A.I.; Abd El-Aziz, R.M. A Large-Scale Dataset and Deep Learning Model for Detecting and Counting Olive Trees in Satellite Imagery. Comput. Intell. Neurosci. 2022, 2022, 1549842. [Google Scholar] [CrossRef] [PubMed]
- Yang, L.; Wang, X.; Zhai, J. Waterline Extraction for Artificial Coast with Vision Transformers. Front. Environ. Sci. 2022, 10, 799250. [Google Scholar] [CrossRef]
- Panboonyuen, T.; Jitkajornwanich, K.; Lawawirojwong, S.; Srestasathiern, P.; Vateekul, P. Transformer-based decoder designs for semantic segmentation on remotely sensed images. Remote Sens. 2021, 13, 5100. [Google Scholar] [CrossRef]
- Fan, F.; Zeng, X.; Wei, S.; Zhang, H.; Tang, D.; Shi, J.; Zhang, X. Efficient Instance Segmentation Paradigm for Interpreting SAR and Optical Images. Remote Sens. 2022, 14, 531. [Google Scholar] [CrossRef]
- Gibril, M.B.A.; Shafri, H.Z.M.; Shanableh, A.; Al-Ruzouq, R.; Wayayok, A.; bin Hashim, S.J.; Sachit, M.S. Deep convolutional neural networks and Swin transformer-based frameworks for individual date palm tree detection and mapping from large-scale UAV images. Geocarto Int. 2021, 1–31. [Google Scholar] [CrossRef]
- Lan, Y.; Lin, S.; Du, H.; Guo, Y.; Deng, X. Real-Time UAV Patrol Technology in Orchard Based on the Swin-T YOLOX Lightweight Model. Remote Sens. 2022, 14, 5806. [Google Scholar] [CrossRef]
- Alshammari, H.H.; Shahin, O.R. An Efficient Deep Learning Mechanism for the Recognition of Olive Trees in Jouf Region. Comput. Intell. Neurosci. 2022, 2022, 9249530. [Google Scholar] [CrossRef]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. Adv. Neural Inf. Process. Syst. 2021, 15, 12077–12090. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.-P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions. arXiv 2021, arXiv:2102.12122. [Google Scholar]
- Islam, M.A.; Jia, S.; Bruce, N.D.B. How Much Position Information Do Convolutional Neural Networks Encode? arXiv 2020, arXiv:2001.08248. [Google Scholar]
- Xiao, T.; Liu, Y.; Zhou, B.; Jiang, Y.; Sun, J. Unified Perceptual Parsing for Scene Understanding. In Proceedings of the European Conference on Computer Vision (ECCV); Springer: Cham, Switzerland, 2018; pp. 432–448. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 9992–10002. [Google Scholar]
- Strudel, R.; Garcia, R.; Laptev, I.; Schmid, C. Segmenter: Transformer for Semantic Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision; pp. 7242–7252. Available online: https://openaccess.thecvf.com/content/ICCV2021/papers/Strudel_Segmenter_Transformer_for_Semantic_Segmentation_ICCV_2021_paper.pdf (accessed on 6 December 2022).
- Ranftl, R.; Bochkovskiy, A.; Koltun, V. Vision Transformers for Dense Prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision; pp. 12159–12168. Available online: https://openaccess.thecvf.com/content/ICCV2021/papers/Ranftl_Vision_Transformers_for_Dense_Prediction_ICCV_2021_paper.pdf (accessed on 6 December 2022).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8024–8035. [Google Scholar]
- MMS Contributors. {MMSegmentation}: OpenMMLab Semantic Segmentation Toolbox and Benchmark. 2020. Available online: https://github.com/open-mmlab/mmsegmentation (accessed on 6 December 2022).
- Al-Saad, M.; Aburaed, N.; Al Mansoori, S.; Ahmad, H. Al Autonomous Palm Tree Detection from Remote Sensing Images—UAE Dataset. In Proceedings of the IGARSS 2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 2191–2194. [Google Scholar]
- Labelme/Examples/Semantic_Segmentation at Main Wkentaro/Labelme. Available online: https://github.com/wkentaro/labelme/tree/main/examples/semantic_segmentation (accessed on 6 December 2022).
- Ammar, A.; Koubaa, A.; Benjdira, B. Deep-learning-based automated palm tree counting and geolocation in large farms from aerial geotagged images. Agronomy 2021, 11, 1458. [Google Scholar] [CrossRef]
- Jintasuttisak, T.; Edirisinghe, E.; Elbattay, A. Deep neural network based date palm tree detection in drone imagery. Comput. Electron. Agric. 2022, 192, 106560. [Google Scholar] [CrossRef]
- Culman, M.; Delalieux, S.; Van Tricht, K. Palm Tree Inventory From Aerial Images Using Retinanet. In Proceedings of the 2020 Mediterranean and Middle-East Geoscience and Remote Sensing Symposium (M2GARSS), Tunis, Tunisia, 9–11 March 2020; pp. 314–317. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2019), Long Beach, CA, USA, 15–20 June 2019; pp. 3141–3149. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Tang, X.; Tu, Z.; Wang, Y.; Liu, M.; Li, D.; Fan, X. Automatic Detection of Coseismic Landslides Using a New Transformer Method. Remote Sens. 2022, 14, 2884. [Google Scholar] [CrossRef]
- Guo, F.; Qian, Y.; Liu, J.; Yu, H. Pavement crack detection based on transformer network. Autom. Constr. 2023, 145, 104646. [Google Scholar] [CrossRef]
- Gonçalves, D.N.; Marcato, J.; Carrilho, A.C.; Acosta, P.R.; Ramos, A.P.M.; Gomes, F.D.G.; Osco, L.P.; da Rosa Oliveira, M.; Martins, J.A.C.; Damasceno, G.A.; et al. Transformers for mapping burned areas in Brazilian Pantanal and Amazon with PlanetScope imagery. Int. J. Appl. Earth Obs. Geoinf. 2023, 116, 103151. [Google Scholar] [CrossRef]
- Jiang, K.; Afzaal, U.; Lee, J. Transformer-Based Weed Segmentation for Grass Management. Sensors 2023, 23, 65. [Google Scholar] [CrossRef] [PubMed]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| UAV Data | Orthophoto | Orthophoto | Total | |
|---|---|---|---|---|
| Acquisition | 2019 | 2017 | 2015 | - |
| Spatial resolution | 5 cm | 20 cm | 15 cm | - |
| Training samples | 21,045 | 5687 | 16,531 | 43,263 |
| Validation samples | 3784 | 221 | 682 | 4687 |
| Testing samples | 3491 | 218 | 657 | 4366 |
| UAV-Based Models | Generic Multisource Models | |||||
|---|---|---|---|---|---|---|
| mIoU | mF-Score | mAcc | mIoU | mF-Score | mAcc | |
| Segformer_MiT-b2 | 86 | 92.39 | 92.53 | 85.84 | 92.31 | 92.96 |
| Segformer_MiT-b3 | 86.2 | 92.52 | 93.15 | 85.84 | 92.31 | 92.96 |
| Segformer_MiT-b4 | 86.36 | 92.61 | 92.69 | 85.83 | 92.3 | 92.91 |
| Segmenter-ViT-tiny | 84.7 | 91.61 | 91.34 | 82.72 | 90.41 | 90.01 |
| Segmenter-ViT-small | 85.5 | 92.09 | 92.06 | 85.13 | 91.88 | 91.92 |
| Segmenter-ViT-base | 85.64 | 92.18 | 92.7 | 85.22 | 91.93 | 92.5 |
| UperNet-Swin-tiny | 85.57 | 92.14 | 92.51 | 85.14 | 91.88 | 91.62 |
| UperNet-Swin-small | 85.87 | 92.31 | 91.87 | 85.6 | 92.15 | 92.29 |
| UperNet-Swin-base | 85.9 | 92.34 | 92.82 | 85.73 | 92.24 | 92.63 |
| DPT-base | 85.45 | 92.06 | 91.69 | 84.92 | 91.76 | 92.37 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gibril, M.B.A.; Shafri, H.Z.M.; Al-Ruzouq, R.; Shanableh, A.; Nahas, F.; Al Mansoori, S. Large-Scale Date Palm Tree Segmentation from Multiscale UAV-Based and Aerial Images Using Deep Vision Transformers. Drones 2023, 7, 93. https://doi.org/10.3390/drones7020093
Gibril MBA, Shafri HZM, Al-Ruzouq R, Shanableh A, Nahas F, Al Mansoori S. Large-Scale Date Palm Tree Segmentation from Multiscale UAV-Based and Aerial Images Using Deep Vision Transformers. Drones. 2023; 7(2):93. https://doi.org/10.3390/drones7020093
Chicago/Turabian StyleGibril, Mohamed Barakat A., Helmi Zulhaidi Mohd Shafri, Rami Al-Ruzouq, Abdallah Shanableh, Faten Nahas, and Saeed Al Mansoori. 2023. "Large-Scale Date Palm Tree Segmentation from Multiscale UAV-Based and Aerial Images Using Deep Vision Transformers" Drones 7, no. 2: 93. https://doi.org/10.3390/drones7020093