When the Best Pandemic Models are the Simplest


1
Department of Mathematics and Statistics, University of New Brunswick, Fredericton, NB E3B 5A3, Canada
2
Institute for Physical Science and Technology, University of Maryland, College Park, MD 20742, USA
3
Department of Mathematics, University of Maryland, College Park, MD 20742, USA
4
Department of Physics, University of Maryland, College Park, MD 20742, USA
*
Author to whom correspondence should be addressed.
†
These authors contributed equally to this work.
Biology 2020, 9(11), 353; https://doi.org/10.3390/biology9110353
Submission received: 5 July 2020
/
Revised: 2 October 2020
/
Accepted: 16 October 2020
/
Published: 23 October 2020
(This article belongs to the Special Issue Theories and Models on COVID-19 Epidemics)
Abstract
:Simple Summary
There is a large variety of data available about the coronavirus pandemic, but we still lack data about some important factors. Who is likely to infect whom and under what conditions and how long after becoming infected? These factors are the essence of transmission dynamics. Two groups using identical complex models can be expected to make different predictions simply because they make different choices for such transmission parameters in the model. A policy setter has no way to choose between their predictions. Simple models are not good for assessing contact tracing and detecting asymptomatic carriers, and do not replace agent-based models. However, we explain how simple models can be used to answer complex questions by adding what we call satellite equations, addressing questions involving age groups, death rates, and likelihood of transmission to nursing homes and to uninfected, isolated populations. Simple models are ideal for showing policy setters who are not mathematically sophisticated the kinds of interventions that are needed to achieve public goals.
Abstract
As the coronavirus pandemic spreads across the globe, people are debating policies to mitigate its severity. Many complex, highly detailed models have been developed to help policy setters make better decisions. However, the basis of these models is unlikely to be understood by non-experts. We describe the advantages of simple models for COVID-19. We say a model is “simple” if its only parameter is the rate of contact between people in the population. This contact rate can vary over time, depending on choices by policy setters. Such models can be understood by a broad audience, and thus can be helpful in explaining the policy decisions to the public. They can be used to evaluate the outcomes of different policies. However, simple models have a disadvantage when dealing with inhomogeneous populations. To augment the power of a simple model to evaluate complicated situations, we add what we call “satellite” equations that do not change the original model. For example, with the help of a satellite equation, one could know what his/her chance is of remaining uninfected through the end of an epidemic. Satellite equations can model the effects of the epidemic on high-risk individuals, death rates, and nursing homes and other isolated populations. To compare simple models with complex models, we introduce our “slightly complex” Model J. We find the conclusions of simple and complex models can be quite similar. However, for each added complexity, a modeler may have to choose additional parameter values describing who will infect whom under what conditions, choices for which there is often little rationale but that can have big impacts on predictions. Our simulations suggest that the added complexity offers little predictive advantage.
1. Introduction
People can sometimes overlook the power of exponential growth, as did the king in an old parable about a servant who had provided a great service. As a reward, the servant asked the king for 64 days of rice, one grain on the first day, two on the second day, four on the third, doubling each day. Initially, the king was delighted with the request, but eventually the king began to understand. The total would be more than kg, so he cut the servant’s head off. Many people would like to cut the head off a pandemic as it slowly spreads, increasing exponentially.
The spread of a virus is reminiscent of Edward Lorenz’s observation that the flap of a butterfly’s wings in Brazil might set off a tornado in Texas. Perhaps a bat in China played the butterfly’s role in the COVID-19 outbreak.
A key concept for the transmission of a human infectious disease is “a contact.” A contact is defined as an interaction between two people where if the first one is infectious and the other is susceptible, the susceptible person becomes exposed and after a latent period becomes infectious and finally removed, either through death or recovery with at least temporary immunity. Mathematical models which are used to describe individuals transitioning between the stages are usually called SEIR models or SIR models. For basic references on epidemic modeling refer to [1,2,3,4].
We refer to an infection’s generation time, i.e., the mean time between being exposed and exposing other individuals, as one period [5]. It seems to be approximately 1 week for COVID-19, but reliable data is lacking.
For each time period n, the average number of contacts that an infectious person has is called the contact rate, . The contact rate varies with time, depending on interventions such as social distancing and seasonal fluctuations. Small changes in can result in large changes in the number of cases, due to multiplicative effects [6]. In our models, we assume that infected people are immune after recovery and remain immune for the duration of the simulations.
Model E (E stands for exponential): When almost everyone is susceptible, we can model the early stages of an outbreak by as follows.
where is the fraction of the population that is infectious in period n and is the disease multiplier for each period. When is a constant, we write it as . When , Model E has pure exponential growth, and it has exponential decay when .
For Model E, is the only parameter that must be chosen by the modeler. We say a model is simple if the model’s equation has only one parameter, namely, the contact rate. Model E above and Model E+ below are “simple.”
We can think of as being the fraction of the population that is infectious in the generation of the disease. That view is an oversimplification since infectiousness can last a few days or more than a month. This simplification is eliminated in our Model J below. The shortcoming does create small errors in but the errors are small compared with expected errors or uncertainties in the values of
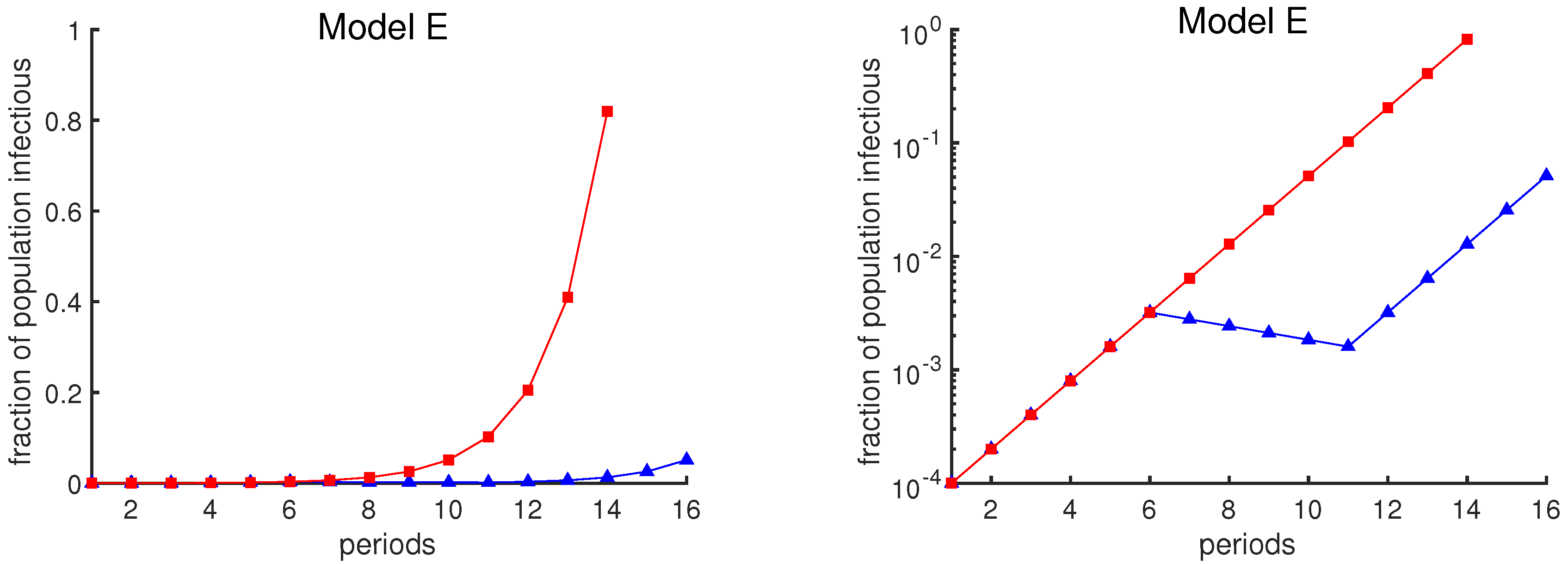
The graphical depiction of case loads can also affect one’s interpretation of the data. The red curves in Figure 1 show the exponential growth of case rates in Model E as a function of time, assuming that the contact rate remains constant at (i.e., no mitigation strategy is attempted). The blue curves show the case rates assuming a policy intervention from week 6 to week 11 that temporarily reduces the contact rate. The same data are plotted in two different ways: a linear scale on the left and a logarithmic scale on the right. The plot in the left panel may suggest that the intervention has been a great success, due to the apparent large reduction in infection rates. However, the logarithmic plot shows that the course of the outbreak simply has been delayed by 5 weeks.
Infectious diseases can eventually deplete the susceptible population and so do not increase exponentially forever. Hence, we should consider a more realistic model. When proposing a model, epidemiologists should have in mind that policymakers should understand a model so that they can make reasonable plans. There are wildly varying sources of advice available. Policymakers are less likely to adopt advice based on models they do not understand and have not participated in [7].
In the following we have proposed two models, a simple model, Model E+, and a slightly complex model, Model J. We will compare the outputs of these two models and we will show that Model E+ can follow the outbreak as closely as Model J. However, any complex model will have additional transmission parameters for intra-group transmission rates for which there are insufficient data, so if plausible choices are used, a wide variety of predictions is inevitable. For example, refer to Figures 5 and 6. Now we introduce the Model E+.
It is all about contact rates. The purpose of Model E+ is for long-term predictions, and short-term, overcoming the limitation that Model E can only be used when the susceptible fraction remains large, greater than perhaps 0.9, for example. The uncertainty in the contact rate is probably much greater than 10%.
Model E+ is designed for a “homogeneous” region; i.e., it assumes that at each moment in time the fraction of the population that is infectious is uniform throughout the region. This hypothesis is an approximation, since, for example, a susceptible who is living with an infectious person has an elevated probability of becoming infected. However, we do not know what that probability is, so we neither include that nor any other non-homogeneities in our model.
The probability of having no contacts in a particular week; If the expected or average number of events in a time period is , and the events are independent, the Poisson probability that no events occur is . The events in question here are contacts in one-week periods. In week n, susceptibles have an average of infectious contacts, so according to Poisson distribution, the probability of remaining uninfected is , so the probability of becoming infectious is .
Some fraction of the population is exposed during period n. It is precisely these people who will be infectious in period . Hence, .
The above discussion motivated us to use the following for “Model E+”.
where we usually take , and is the fraction of the population that is susceptible at the beginning of period n, is the fraction of the population that is infectious during period n, and is the contact rate in week n. People exposed in period n are infectious in period and are removed after that, either becoming immune for the duration of the simulation or dying.
Now that by Model E+ we know the number of infected individuals, what is the simplest way to predict the number of deaths due to infection? The number of deaths that will result from an epidemic depends on two quantities: The total fraction of the population who will eventually become infected and the fraction of infected people who succumb to disease (the death rate).
This formula emphasizes how every model’s long-term predictions of deaths will be determined. The COVID-19 death rate is likely to be in the range to . For a hypothetical population of 100 million, with half getting infected, the model says there will be between and 5 million deaths.
While deaths might be estimated during an epidemic, estimating the number of cases is impossible without antibody tests. A detailed model might predict the peak rate of cases, but it cannot use currently available human interaction data to estimate how many of the cases are asymptomatic. Determining the death rate requires both.
The example of New York City. New York City is heavily dependent on public transportation and perhaps as a result was struck with a massive outbreak. As of May 2020, there were over 185,000 confirmed COVID-19 cases in New York City and an estimated 20,200 deaths. Hence, 11% of confirmed cases were fatal. However, it was not known what fraction of total cases were confirmed. If the fraction were close to 1, and if half of New York City’s population of 8.4 million eventually were infected, then according to Equation (3) the total deaths from the epidemic would be 462,000.
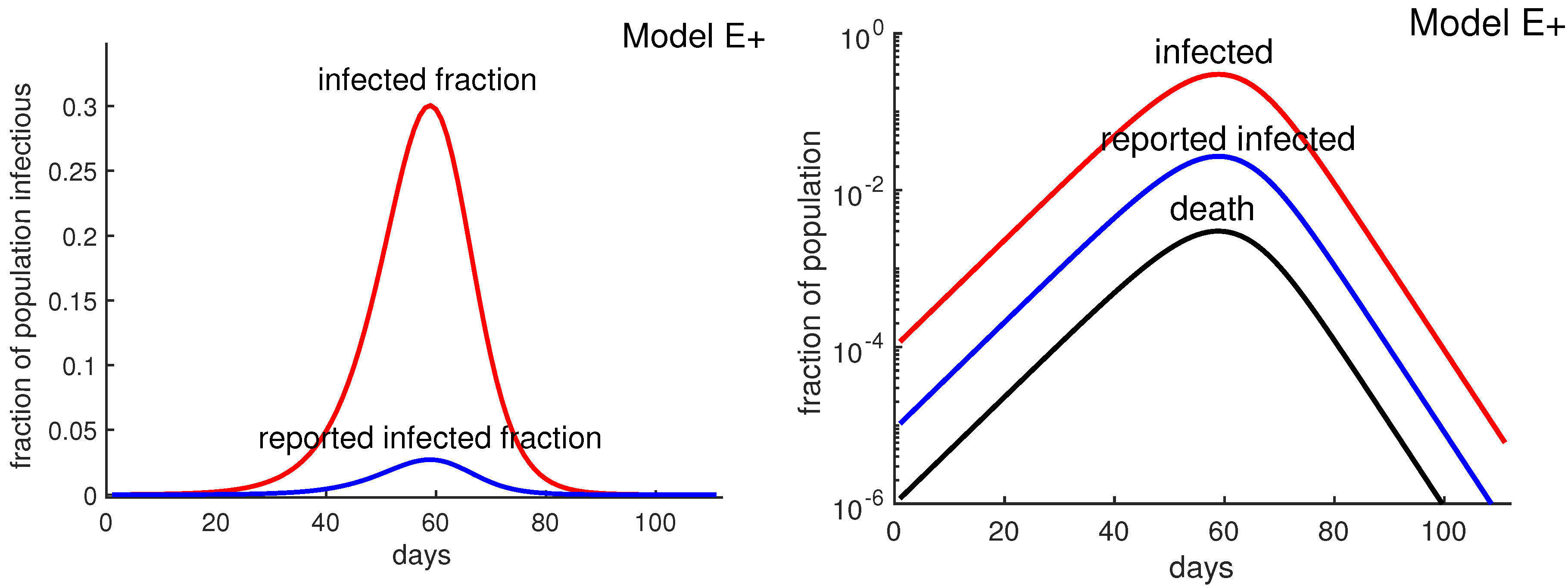
Assuming that the antibody survey results are accurate, the confirmed cases represent less than 9% of the actual cases, which would imply that the death rate is about 1%. Figure 2 shows that reported infected fraction can be quite different from the actual infected fraction. Thus, if half the population were eventually infected, Equation (3) would predict about 40,000 deaths. Such estimates are not possible without antibody tests, and it is not possible to know how high the New York City death toll might have risen if “lockdown” policies had not been implemented. Lockdown policies include social distancing, stay-at-home, closing non-essential businesses, etc.
Estimating for the current COVID-19 outbreak. Covid-19 began spreading perhaps in early November 2019 and 22 weeks later (April 2) reached 1,201,186 confirmed cases worldwide, which in turn is undoubtedly far below the actual number of people infected. Of course these are noisy data with errors. These data imply that the number of confirmed cases grew by at least a factor of approximately 1.9 per week, so the contact rate is at least 1.9. During this time China made major efforts to reduce contacts among its population, making smaller than in areas without such efforts.
We took to be 2 or 3 in most of our simulations. In large cities whose transportation is dominated by mass transit, the growth rate may be much higher. Two recent papers [8,9] estimated early growth rates as a factor of about 10 or more per week.
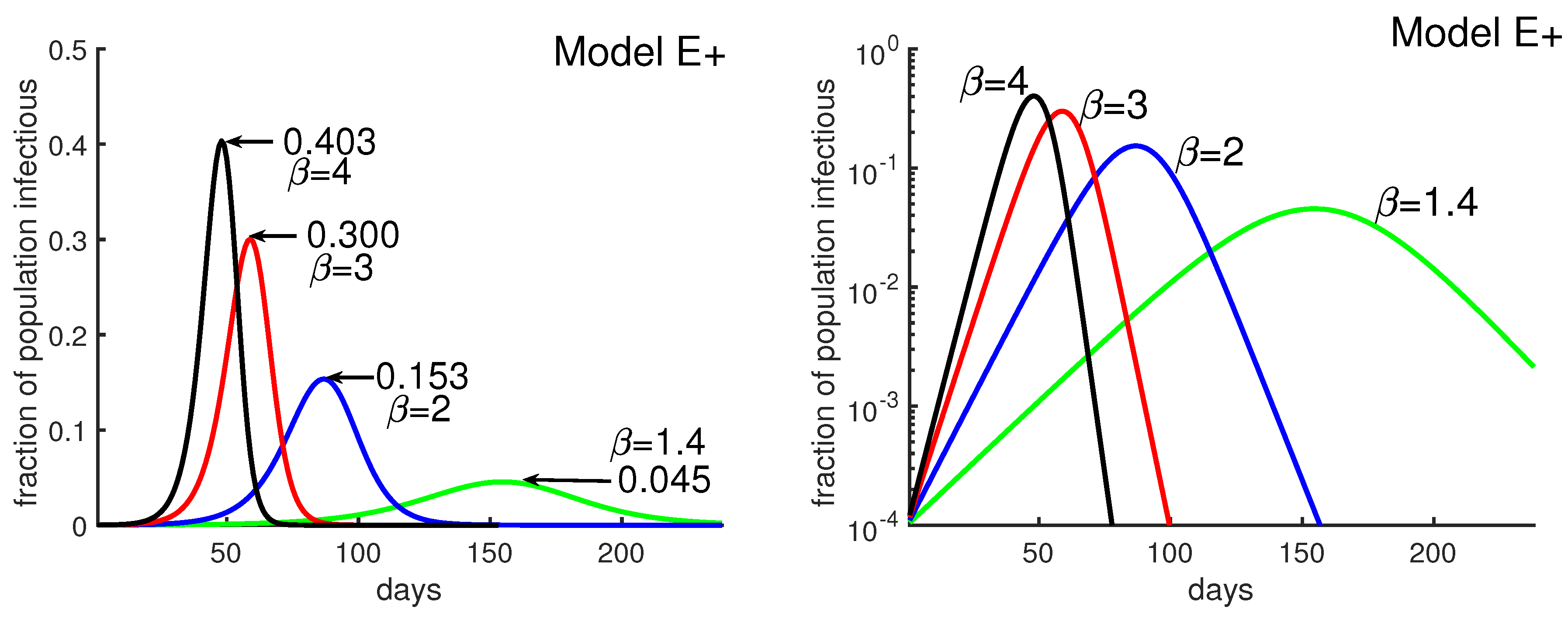
Figure 3 was obtained by running four different simulations of Model E+ for contact rate . It shows how the outbreak’s peak depends upon the contact rate. The figure illustrates that a higher contact rate causes a more severe outbreak with a higher and earlier peak. Figure 3 also explains how to produce the outbreak daily using Model E+.
Using Model E+ to determine what happens during an outbreak: The Washington Post reported that from 25 May to 24 June 2020 (30 days), a group of states in the United States had increasing COVID-19 cases. The United States had relaxed social distancing following the earlier lockdown. New confirmed cases per day rose from 5000 to 20,000. That means that during that period, cases increased by a factor of about per week. That is, 1.4 assuming most people were still susceptible. There is a combined population of 121 million for these states, Arizona, Arkansas, California, Florida, North Carolina, Oregon, South Carolina, Texas, and Utah, together about 37% of the total U.S. population. Figure 3 says that if people do not take greater precautions, we can expect 4.5% of the population to be infectious at the peak for . We assume the number of confirmed cases is about of actual cases. Then the peak daily, confirmed cases would peak at 78,000(∼0.045 × 121,000,000 × (1/10) × (1/7)), almost quadruple the June 24 number. Of course the peaks in the different regions might not coincide but this calculation can be thought of as an estimate of the sum of the peak weeks of the different states.
Models E and E+ with “satellite” equations: Model E and perhaps Model E+ are simple enough to communicate to many policy setters, but there are many questions that cannot be answered with those models. Our goal here is to answer more questions while preserving Model E or E+. Satellite equations allow policy recommenders to increase intelligibility of models for policy setters. Model E or E+ gives us , the infectious fraction for each period n. We add additional “satellite equations” that use and do not change the basic models. Our hope is that many policy setters can understand the logic and the work of policy recommenders. Examples of questions that we want to answer include the following.
- What will happen to those with pre-existing conditions or older populations or those with different contact rates?
- How will nursing homes and long-term care facilities be affected?
Each of the above of course requires additional data, such as, for the nursing home question, the many people including employees that visit the nursing homes each day from the external population.
A satellite equation for predicting deaths: If hospitals become overloaded and overwhelmed with seriously ill covid patients, the probability that a hospitalized patient may die is probably elevated. We now outline a scenario that would have to be refined using actual data of hospitalized covid cases. Suppose some fraction h of infected people will be hospitalized. To be specific, suppose for example the average hospitalized patient enters a hospital one week after exposure and stays in the hospital for three weeks.
Then the number in the hospital in week n would be . Then deaths in week n would be predicted by
for some nonlinear function F. To use this approach, the modeler must determine how long after exposure deaths occur, what h is, and what F is. Then this satellite equation can be used to compute deaths per week, even though Model E+ does not include deaths.
A satellite equation for people with a different contact rate. Suppose person A is isolated most of the time, but about once a week, goes out to lunch with a person B, a different B every time. Suppose the luncheon is in a confined space such that if B is infectious, A has a 50% chance of being exposed. What are A’s chances of becoming infected during the entire outbreak? Our answer is Equation (6), which is the result of a simple calculation.
Model E+ uses an average contact rate. To investigate an individual whose contact rate differs from the average person’s, we can adapt Model E+ by adding a satellite equation. A person may have a very low contact rate, due to wearing protective gear or staying at home, or perhaps the rate is very high due to being in crowds frequently. We denote this person’s contact rate in week n by , which can vary weekly. Let denote the person’s probability of not being infected by week n. Here we use Model E+ to determine and . We use that in a satellite equation for determining ; as above, the probability of remaining uninfected for period n is , where we have replaced the general with the person’s contact rate . Hence,
Notice that , which equals provided the person maintains a constant Since , choosing yields the probability of remaining uninfected at the end of the epidemic,
where denotes the final fraction of susceptible people at the end of the period simulated. To decrease the risk of getting infected, Equation (6) suggests keeping low.
Now we return to the life of A. We have in effect said that A has 0.5 contacts per week and is otherwise isolated. That means .
It is likely that some of the Bs that A has contact with will become infected at some point during the outbreak. However, A will be exposed only if some B is infectious during the week they have lunch. Suppose at the end of the epidemic of the population has become infected. Then Equation (6) says , the probability of remaining uninfected at the end of the outbreak, is , or a 28% chance of becoming infected as a result of these lunches.
A satellite equation for a population with no infections, e.g., a nursing home or an island: Let A denote a relatively isolated population with no cases currently, such as the resident population of a nursing home or a small country or region. Suppose a population A has N visitors per infectious period (which we can think of as one week), and the visitors come from a place B that is experiencing an outbreak. Assume the infectious fraction in B is in period There are different types of visits. Consider the “long-term” visitor, who might be staying more than one period or equivalently is a resident who returned home after a long visit elsewhere. Here “long” means more than one period. A “short-term” visitor might stay for a day.
We can show under reasonable hypotheses that such a person will on average have had half his or her contacts before arrival and half after. The probability that such a visitor is infectious is . The expected number of transmissions per period is . Over the duration of the outbreak, the expected number of primary introduced transmissions T is the sum as in Equation (6).
Suppose, for example, that during the outbreak, 2% of the external population was infected and the number of visitors was 200 per period, and the transmission rate was then primary infections from visitors. If the outbreak has infections transmitted primarily by superspreaders, while most infectious people infect almost no one, then we would expect few new outbreaks but the clusters would be big.
Model E+, fixing deficiencies of predictions from complex models: As we show below, when someone receives predictions of covid cases or deaths from a model, they would really like some context of what is behind the prediction. If predictions vary significantly between models, they would like a better understanding of what is going on. Here we provide an example of how that might be done.
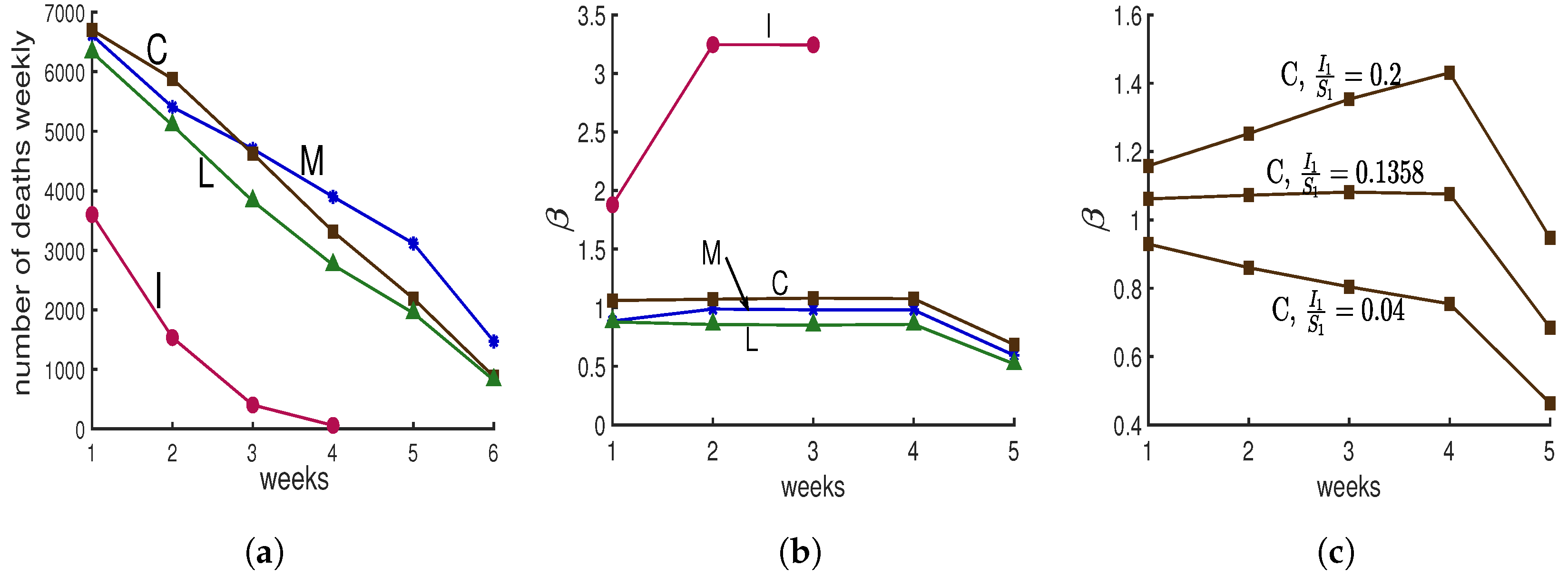
Following the beginning of the lockdown, The New York Times [10] asked several modeling groups for predictions of covid deaths in New York City. Four groups provided predictions for four or more weeks; they are labeled “C”, “I”, “M”, and “L”, for Columbia University’s team [11], IHME Institution’s response to covid [12], MIT University’s team [13], and Los Alamos National lab’s projections [14], in Figure 4a. Predictions “C”, “M”, and “L” show progressive decreases in deaths. Prediction “I” shows a more dramatic decrease. Here we would like to determine what makes it different.
We compute for each prediction as follows. Model E+ concerns infectious fractions, not deaths. Deaths are often used as a more accurate record of how total cases vary than verified cases. For each prediction, we treat the deaths as proportional to the total infectious fraction; i.e., for week . Hence once is chosen, all are known. If we choose , then can be computed from Equation (2b) for .
We do not know or , but for each choice, we can solve Equation (2a) for each for that prediction.
That means that with the computed s, the prediction curves will be reproduced exactly by Model E+. To compute for s, we choose ; notice that this ratio is also the ratio of the total number of infectious individuals in week 1 over susceptible individuals in week 1. From data we know the total number of infectious individuals; therefore, by choosing the ratio , we can calculate first the total number of susceptible individuals and then the total number of population which has been studied. Now we can calculate and , and then using Model E+ we can reproduce each prediction.
We do not expect to change much during a lockdown, so we chose the value of for which the curve is nearly constant during the middle of the run, yielding Figure 4b. To illustrate how we chose the value of , in Figure 4c, we show three choices of for the “C” data.
Those values for “C”, “L”, “M”, and “I” were . Hence the value for the “I” prediction was 12 to 27 times larger than for the other three. Only “I” yields a result with To simplify the presentation, the results shown in Figure 4 have been created for the case . If instead we choose for some , our conclusions are unchanged, as are the above four values . The values of are the same as the plotted values for with .
Why is prediction “I” so different from the rest? Does its rapid decline in deaths simply mean the contact rate was chosen extremely low? No. Figure 4b shows that their contact rate is much higher than for the other three. Thus, why was there such a rapid drop in deaths?
Our findings: The predictions of the four groups give us cases or deaths, but no indication of the susceptible fraction. Model E+ allows us to determine likely values for the susceptibles needed to reproduce the predictions. In order for Model E+ to reproduce the “I” predictions, it is necessary for to be huge. Deaths dropped because almost everyone had been infected and almost no one was left to become infected.
An alternative hypothesis to explain prediction “I” is that at this time when we expect the contact rate to be constant; while the other groups provide predictions consistent with nearly constant contacts, the modelers of “I” predicted the contact rate, , would change quickly, dropping rapidly to near 0, thereby stopping the outbreak. No outbreak will persist if the modelers assume the contact rate is near 0.
Any policy setter should want to know why either the infection rate is so high, with more infectious people than susceptibles at the beginning of the prediction period, or alternatively what made the contact rate drops to near 0.
2. A Mildly Complex “Model J”
In order to compare Models E and E+ we need a somewhat standard SIR or SEIR complex model. In this section we describe a complex model. By definition, complex models have multiple transmission parameters. We will see that uncertainty in those parameters yields a broad range of predictions, making the predictions less valuable. See Figure 5, Figure 6 and Figure 9.
We create our Model J by adding two reasonable and common complications: contact rates that vary from group to group within the population and infectiousness that depends on how much earlier the infected person was exposed. They improve the realism—provided we have the data to accurately set the parameters of the model. The downside of this added complexity is that the system is harder to work with, and the results are more difficult to communicate to the people being advised. To overcome this downside, here we propose an approach that can make complex models more manageable: only one constant must be determined absolutely after other constants determined relative to each other. For example, we are more likely to believe that A has about twice as many contacts as B than what those actual contact rates are.
The elements of this model are the following.
- Some people have more contacts than others. The population is partitioned into K equal-sized groups that can have different contact rates. Usually we take K to be 10. and are the fractions of the people in group m who are susceptible and possibly exposed on day d, respectively. Hence, and and initially we can expect for all m. Note that we always take m to be between 1 and K. The number of contacts of people in group m per unit of time is proportional to . The number of contacts between people in groups i and m is proportional to For example we might have or more generally for some .
- The level of infectiousness depends on how long a person has been infected. The “infectiousness” or likelihood of transmitting the infection on day j after being exposed is proportional to the constant . The collective infectiousness of people in group i who were exposed j days earlier is proportional to . Hence, the collective infectiousness also depends on the contact rates.
- is the fraction of susceptible people in group m being exposed on day d by people from group i who were infected j days earlier. The following proportionality is useful.Summing over all i and j, is proportional toThe term is proportional to the size of the total infectious population on day d; therefore, it is proportional to the level of danger to the community on day d.
- The novel feature of this model is that only one parameter must be determined absolutely in the model while other parameters have relative values. We can make proportionality 9 an equality by multiplying the right-hand side by the appropriate value, The actual transmission rate isJ is independent of and j. Below we show how to select J so that the outbreak has an initial growth rate Typically we choose J is time independent if there is no intervention, but interventions can make depend on day d.
In summary, the resulting Model J follows. For each group , we have
Tuning Model J to achieve a specific growth rate .
David Adam, an editor of Nature, reported in a News article [15] that two very different models produced estimates of the number of deaths that differed by 1%. That similarity gives the illusion of reliability and robustness, but the fraction of infected people who die is unknown. As shown by the evolving New York City data, estimates of the total number of deaths can be uncertain by a factor of 10. Modelers must tune their models to reflect reality. In simple models, that means choosing and the initial fractions of the population that are infected and perhaps susceptible (for Model E+). All these choices should be under discussion with the policy setters.
Suppose we are observing an outbreak that grows by a factor of for a time period , and suppose we want to tune Model J so that it has the same growth rate initially. There is a value of J such that for any constant C, the following is a solution of Equation (12a):
Substitute into Equation (12a) with for all d. Then after factoring out , for each m we obtain the following equation for J.
It is independent of and d.
Parameter sets for Model J: The main purpose of introducing Model J is to show how additional transmission parameters can be included in a complex model. Each transmission parameter that is added increases the choices of the modeler. Transmission parameters can be very hard to estimate accurately. We also show how a model with relative parameters can be tuned by choosing one parameter, J, for the whole system.
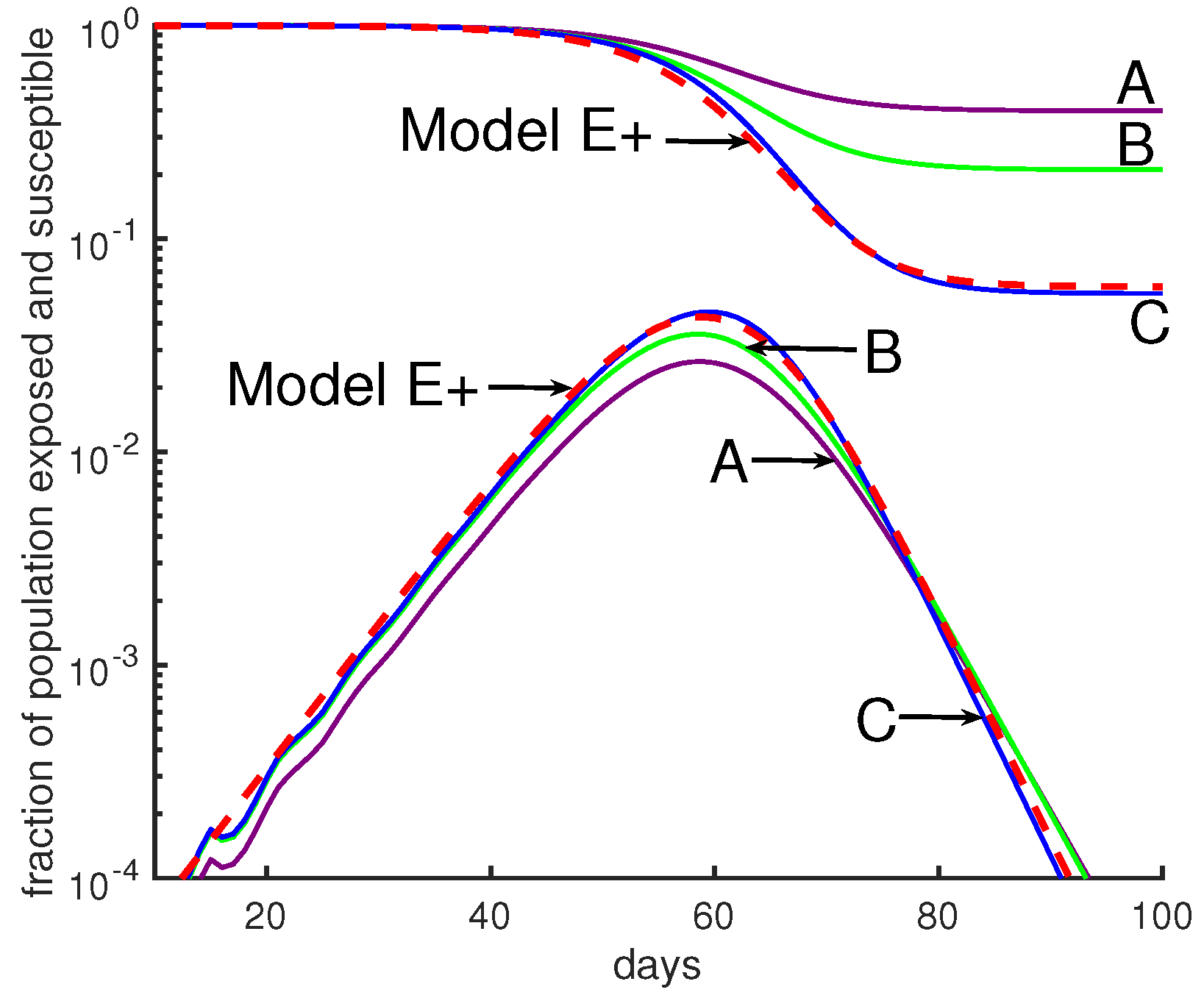
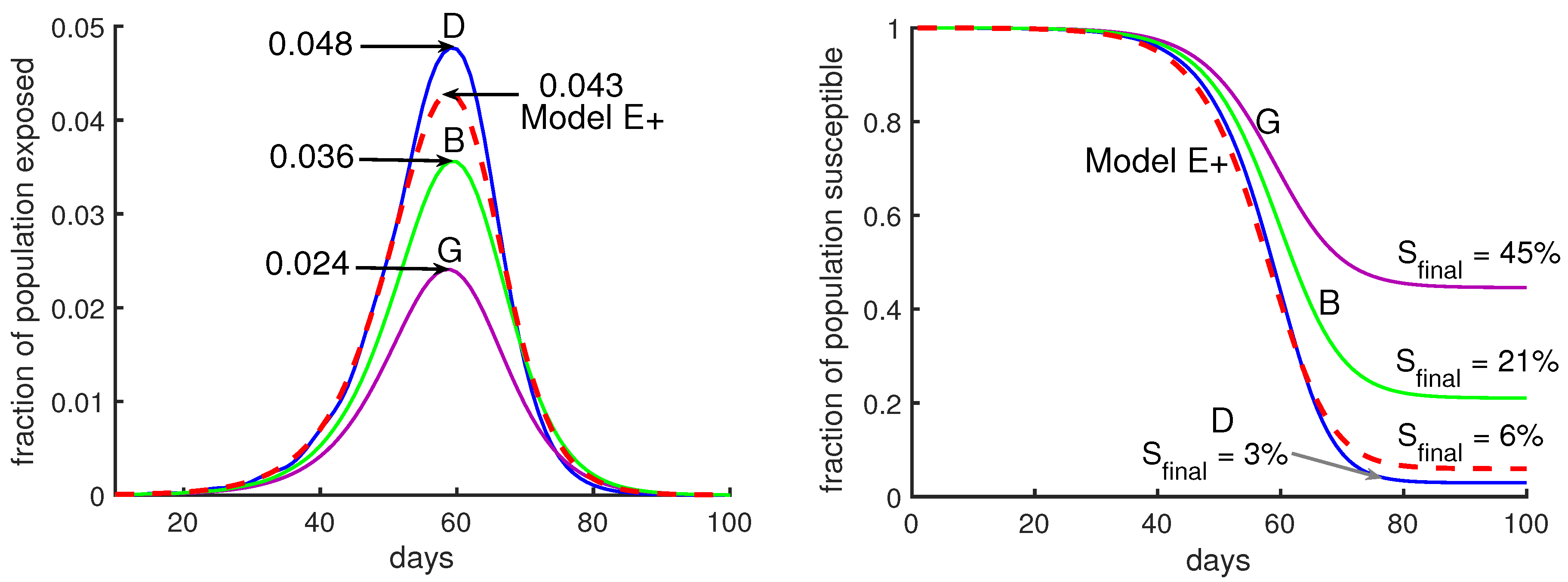
Five examples illustrate the behavior of the model: A, B, C, D, and G in Figure 5 and Figure 6. For each, we divide the population into 10 groups that can have different contact rates, and exposed people are infectious for 5 days, and they are equally infectious for each of those days. Which days they are infectious depends on the case; see Table 1 for more details. For most cases we set the five days to be 5–9 days after exposure.
When there is no intervention, for example, in simulations of Model J in Figure 5, the parameter J is chosen to be constant (independent of d) so that initially the epidemic grows by a factor of three per week. That corresponds to using and days in Equation (13).
The outbreaks of Model J can be quite similar to Model E+’s, as seen in Figure 5, but reasonable changes in the s and s can produce big variations in the predictions of the Model J, as seen in Figure 6.
Figure 5 shows outbreaks from our Model J (Equation (12)). We draw the reader’s attention to the fact that there is more variation between the three Model J curves than there is between their average and the Model E+ curve. We suggest that it is quite difficult to determine which of the three Model J simulations best represents reality. Uncertainty in produces uncertainty in the epidemic peak and in the total number infected during the outbreak. See Figure 3. Though not shown in our figures, the response of Model J to changes in is quite similar to Model E+’s. However, J has additional uncertainties due to its extra transmission parameters, as is shown in Figure 5 and Figure 6.
Hence we believe little is gained by using more complex models, like Model J, for setting policy. In addition, increasing the complexity will decrease intelligibility for most policy setters.
One model by researchers from Imperial College is described as having 15,000 lines of code; see the url Code Review of Ferguson’s Model [16]. That model has a great deal of geographic detail, with infections transmitted from region to region. Uncertainties in transmission rates make prediction difficult, like trying to predict the chaos of billiards when we do not know the properties of the billiards.
In Figure 6 we show two cases where the mean infectious time is either day 6 after exposure (using infectious period days 4–8, case G) or day 8 (using days 6–10, case D). See Table 1. In each case, Model J has been calibrated through the choice of its parameter J so that the initial growth rate per period is 3. Initial conditions have been chosen so that during the early parts of the outbreak, the curves are close together. Small changes in the initial fraction of infected shift each curve to the left or right without otherwise changing it.
Our main choice of s assumes people are infectious for five days, days 5 through 9, and they are equally infectious each of those days; that is, except for when .
Model J is useful because we can test its sensitivity to a variety of choices of parameters. In such a comparison, the exponential growth rate early in the epidemic should be the same for both models.
We found the differences in predictions between Model E+ and Model J are small compared with the uncertainties of the parameters such as the initial growth rate or the death rate.
Reasonable variations in choices of parameters yield big impacts on model J outbreaks. The average time a person is infectious is now known. However, we do not know what the values of and should be. For example, there is much discussion of superspreaders who are rare but quite significant for transmission.
Suppose we want to model a city with a complex model like Model J. We have to choose values for ’s and ’s. Figure 6 shows outbreaks using several choices. It would be difficult to know which choice is most appropriate. However, in the right panel of Figure 6, the fraction of the total population remaining uninfected at the end of the outbreak, , is 15 times higher for case G (purple curve) than for case D (blue curve). Case D has a peak that is twice as high as case G’s.
3. Results
3.1. The Effect of Intervention
We model two policies to mitigate the severity of the outbreak using Model E+ and Model J.
- Policy I: During an intervention period, the contact rate is reduced by a fixed factor.
- Policy II: We reduce the contact rate weekly to keep the maximum fraction of infectious people below a certain threshold, so as not to exceed the capacity of the healthcare system.
3.2. Policy I: A Short-Term Intervention
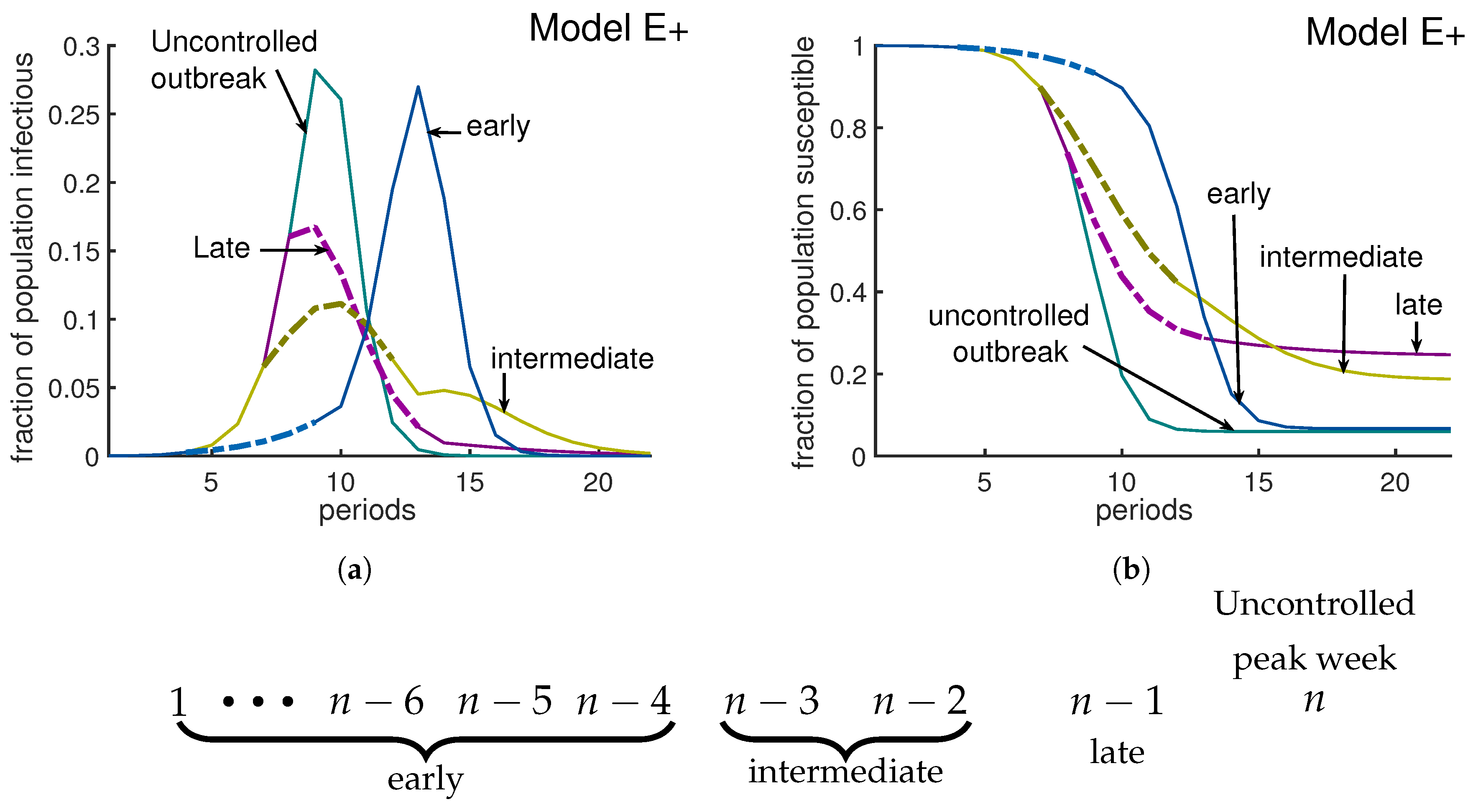
We investigate the effect of a 6-week intervention during which the effective contact rate is reduced from 3 to 1.6. Such interventions in an influenza epidemic can delay the growth of the epidemic [17]. Our simulations show this delay for an early intervention. By an “early intervention” we mean an intervention implemented more than three weeks before the uncontrolled outbreak would peak. Our simulations suggest that an early intervention only delays the epidemic (blue curves in Figure 7a,b). A late intervention is being implemented one week before the uncontrolled outbreak peaks. A late intervention will not have a large impact on reducing the peak, but it will decrease cases after the peak and therefore will increase slightly; (see the purple curves in Figure 7a,b). According to our simulations, a policy I type intervention has an optimum impact on reducing the severity of an outbreak if it starts either two or three weeks before the uncontrolled outbreak peaks. An intervention which starts two to three weeks before uncontrolled outbreak peaks is called an intermediate intervention. For Model E+ when , the uncontrolled outbreak peaks at week 12, with a and . An intermediate intervention can reduce the peak by and the fraction of people who do not experience the disease will increase by more than . (Golden curves in Figure 7a,b).
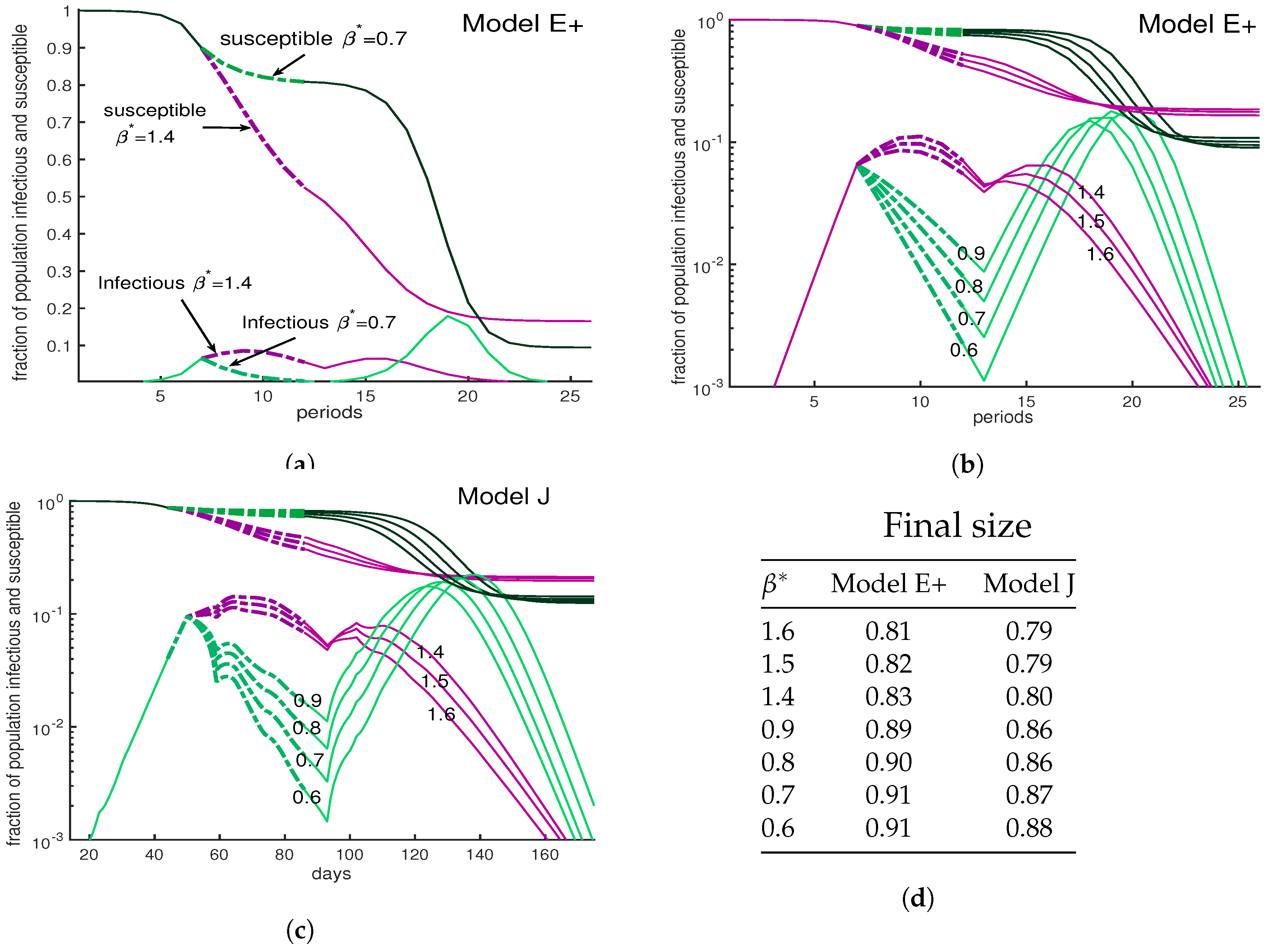
One might think that harsher restrictions will stop an outbreak. The three panels of Figure 8 show a variety scenarios for interventions, all lasting from weeks 7–12, during which the contact rate is reduced. Panels (a) and (b) show Model E+ simulations. The two in (a) are among the seven in (b) but the vertical scale in (b) is logarithmic. Panel (c) is the same as (b) except that Model J is used. In all three panels, the numbers tell the value of used during the interventions.
The green curves show a severe intervention for various choices of from 0.6 to 0.9 while purple curves have values 1.4 to 1.6. All reduce the initial peak of infections below what would have occurred if there was no intervention. The milder interventions here allow the number of infections to grow and approach herd immunity. The severe interventions (green) cause a bigger drop in cases, which is followed by a large peak.
The mild interventions result in more cases during the intervention but fewer in total, because the population reaches a herd immunity level during the intervention. The most important point of Figure 8 is that the complex Model J and the simple Model E+ display the same behavior.
3.3. Policy II: Put a Cap on the Number of Infectious Cases
When facing a new pandemic, due to our lack of knowledge, even experts cannot predict the longevity of the pandemic without a vaccine.
As an article in the New York Times reported [10], most models do not suggest how long a lockdown should continue, or under which conditions we can get back to our regular life routine. A common concern is that a long recession will cause a huge economic downturn. Then what metrics should governors use to allow people to return to their work?
Our policy II allows authorities to keep the maximum fraction of people who are infectious under a certain level, varying interventions week by week to achieve desired contact rates. It could be applied by putting a cap on the fraction of infectious people or exposed people, reducing the pressure on the hospitals.
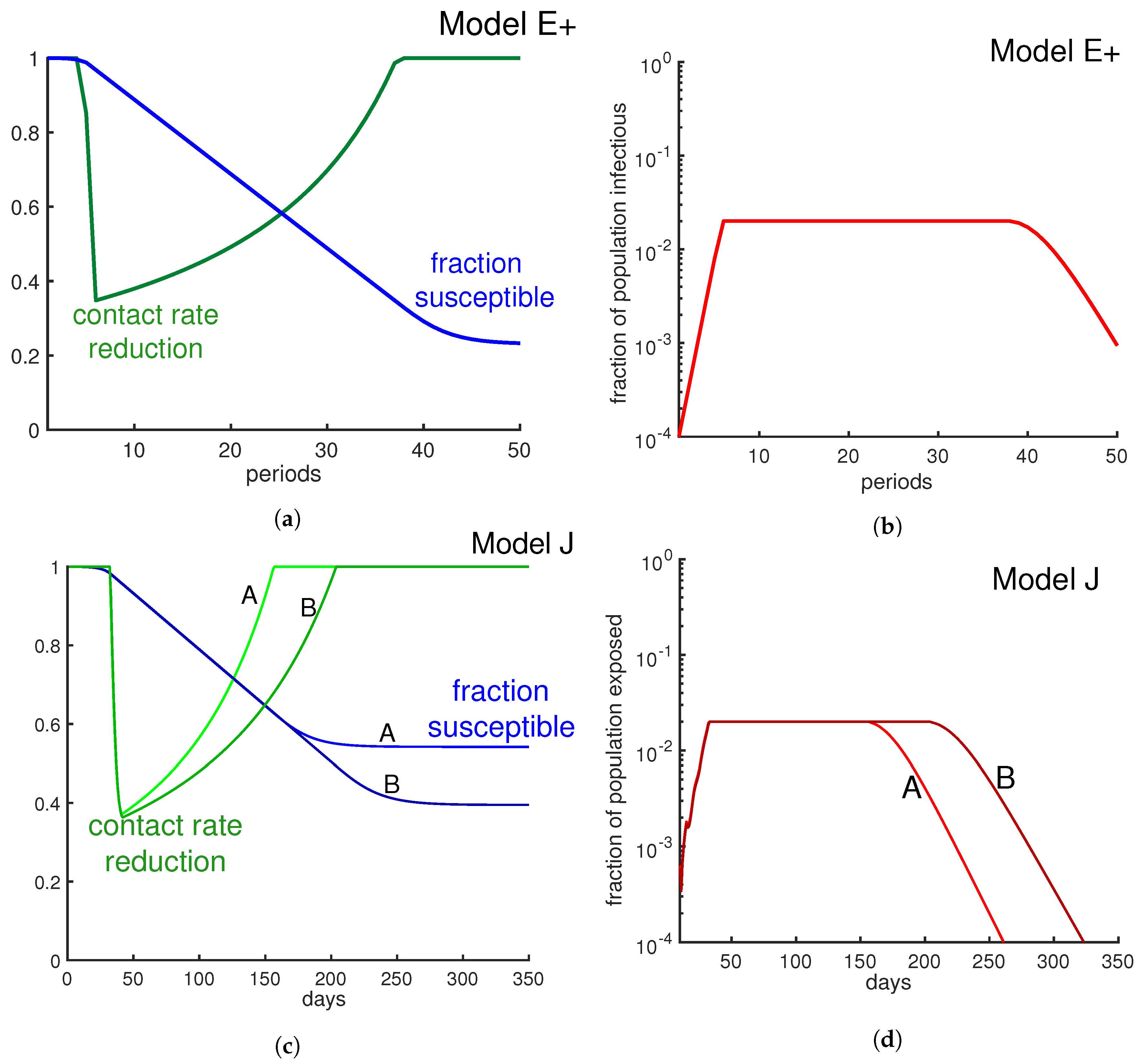
Tuning Model E+ to limit the fraction of infectious weekly: Let us assume we want to keep the maximum fraction of infectious people at a target level. When Model E+ first predicts , we solve for to get . Equation (2a) yields . Solving this for the weekly contact rate gives
In Figure 9b, we keep the number of infectious individuals lower than . As Figure 9a illustrates, by applying this policy about of individuals remain uninfected at the end of outbreak, which has been increased by almost in comparison with the otherwise uncontrolled outbreak.
Tuning Model J to limit the fraction exposed daily: We will denote the fraction of the total population that is exposed on day d by . Hence,
To keep below some daily exposure rate that we call “target”, we have to adjust J dynamically, and in practice that means interventions are needed. When would exceed that level without intervention, we decrease as follows:
In Figure 9d by using Equation (15) we keep the total exposed under weekly. To make Model E+, which has a time step of 7 days, comparable with Model J, which has a time step of one day, we plot the exposures per week for both models. Note that for Model E+ exposures in week n equals the infectious in week . As Figure 9d illustrates, depending on the set of chosen parameters, that the desired result can be achievable in shorter (case A) or longer (case B) time. When facing a pandemic, there are lots of uncertainties in the choice of parameters. Choosing the wrong parameters means obtaining an incorrect prediction. Reporting all possible predictions from all possible choices results in a very uncertain prediction.
4. Discussion
What policy setters should want. During an outbreak, policy setters will have a variety of advisers giving advice. Models that are understandable have a clear advantage, especially when delivering unpopular advice.
As we show in the introduction’s “Model E+, fixing deficiencies of predictions from complex models”, complex model predictions may fail to provide key determinants of their predictions, like the fraction of susceptibles infected each period.
As we have said above, we believe policy setters are more likely to adopt recommendations of models if they understand how the models make predictions. The policy setters are likely to want to know what assumptions determine the model’s behavior. That includes explanations of how the parameter values are determined or estimated. The policy setters are more likely to understand simple models than complex. Model E is sufficient when the great majority of people are still susceptible.
Simple models for an outbreak in a limited region are applicable to many other actual and potential pandemics.
Limitations of modeling: Complex models seem to benefit from the common belief in the power of data. In a world-wide outbreak there is plenty of data. However, when dealing with a deadly disease, reliable experiments are few. Much of the data are worthless to modelers. Complex models can include many parameters that are precise, such as the typical traffic on highways or the number of people taking mass transit. Their weaknesses is the uncertainty in the parameters that describe transmissions between groups.
Complex models are likely to have parameters that describe how many contacts people have in the many specific situations. The most accurately known parameter for transmissions between groups of people is the value of (or ). The rate is not estimated by examining the individual contacts between people. It is estimated from large amounts of data about the growth in the numbers of infected people or hospitalizations or deaths. This most accurate number is likely quite uncertain. If appears to be 2.5, it may be 2 or 3.5. However, there is much less data to determine the transmission parameters or contact rates between subgroups. Hence, complex models must be saddled by transmission parameters between subgroups that are less accurate than .
While people are infectious and perhaps asymptomatic, they can encounter many people. How can a model predict on average how many of these encounters would constitute a contact that transmits infection? We may know the fractions of the populations that are in their 40s or 60s, but we do not know the contact rates for disease transmission between the two groups.
The following example illustrates how epidemics are chains of events whose probabilities are hard to compute because each interaction modeled requires its own (unknown) contact rate. The uncertainty in that contact rate exceeds the benefit of including the interaction in the model.
Consider a chain of contacts. When two people live together, and one, “A”, becomes infected, what is the probability that the other, “B”, will be infected? If an answer to this is obtained in one country, will it be valid for others? New York City apartments might be different from Arizona ranches. Without considerable accurate data, there is a large range of possible parameter values that must be investigated when making predictions with no way to choose between them.
Suppose the probability of the housemate, “B”, being infected, P, is between and with .
If “B” now is infectious and might ride on a standing-room-only bus or train, how many will become exposed as a result? Suppose the number, N, is between and with . The uncertainty factor is about . The possibly infectious person “B” might take a ride on crowded public transportation. (We may have a good estimate as to how often that happens). The uncertainty factor of how many people are likely to be infected is by “B” during the ride.
Next suppose that some uncertain fraction F, between and , of the people on the bus go to a football game or similar crowded event. Each infected person is likely to infect an uncertain number M, which is between and of attendees. Again, the uncertain factors multiply.
This chain of events has a probability . The uncertainty in that product could be estimated as . These ever-compounding uncertainties will contribute to errors in the average contact rate Since the above chain of infections involves three stages of transmissions, it creates uncertainty in if we are using this chain as part of an estimation of .
Technically, one might argue that we should be discussing standard deviations or variances of each event of the chain. That would require assigning a probability distribution to each step. Then the variance of the log of the number of people infected in such a chain of events is the sum of the variances of logarithms. However, we prefer to keep the discussion less technical.
Tuning complex models so that they get “reasonable” predictions. Of course all the uncertainties should be tuned so that the resulting is in agreement with the data. Our Model J was designed with that in mind. To minimize the problem of tuning, we use a single parameter J which is introduced in Equation (12). could be chosen to be constant to represent an outbreak without interventions. Even then, the relative parameters like and must be selected. The numbers must be set by the modeler so that the overall outbreak meets expectations; can change with d, reflecting what the modeler thinks will happen as a result of interventions. That includes estimates of how people will react to imposed conditions.
Undoubtedly, modelers calibrate their complex models against reality as an outbreak progresses. That means they alter the uncertain values of numbers like the above so that a is obtained that agrees with observations. The alterations raise the question of why someone should use a model that requires so many estimates. Why not just pick a model like Model E+ in which the outbreak depends only on one parameter, the contact rate ? Different choices lead to different realizations of the course of the outbreak.
Adding features to complex models. It is attractive to include many features when modeling an outbreak. Each added feature enhances the appearance of reality. There are many possible refinements. Models can split the population into many small groups, perhaps by age, sex, location, individuals’ propensities [18] or population density. Models may also include gatherings for sports, music, movies, religion, politics, or holiday and beach festivities. How many people at such a gathering will be exposed by one infectious person? It depends on the type of gathering, and in any case the answers are not known.
A model must describe how each feature or category affects transmission. Modelers caution against including phenomena with unknown values [19]. Often no data are available. Then the modelers must build in their speculations.
Before a model’s predictions are released, its numbers will be adjusted so that the epidemic’s growth rate will be in agreement with the observed growth rate. The current growth rate is hard to estimate because of the lack of consistent random screening data. However, the current growth rate is the aspect for which the most data are available, even if those data are inadequate. It cannot be derived from collections of model features for which there is less data.
We believe that the fewer the features a model has, the more intelligible it and its assumptions are. We find that the difference between Model E+ and Model J is small compared with changes in
Our approach. To run a simulation using Model E+, Equation (2a), a modeler chooses and . Those who set policy can choose what should be; then can choose and vary policies aimed at achieving the target .
We do not predict the future of an outbreak. Instead, we only discuss what will happen for different choices of We select directly. That will determine when the outbreak peaks, if a large enough fraction of the population is infected. The policy maker makes choices that determine . The contact rate will vary week by week as interventions change the contact rate.
5. Conclusions
Computing . We believe the most important factors in predicting the severity of an outbreak are the contact rate, the hospitalization rate, and the death rate. A higher contact rate leads to a higher peak. Modeling interactions between people will not reveal the death rate. The contact rate can be estimated from data. The overall contact rate of the population is the easiest interaction parameter to evaluate.
Policies I and II. Suppose the goal is to reduce the susceptible population so as to approach herd immunity. We offered two different control policies. In policy I, we only apply lockdown restrictions for a short period of time, and then relax the restrictions. All our simulations were done only for 6-week-long interventions. Of course a longer intervention will reduce infection levels more, but at a higher economic cost.
The benefit of policy I might be to provide enough time for supplying the medical establishment. If that is the goal, it would be best to apply inexpensive interventions early, like requiring business personnel to wear masks and applying social distancing. For example Eikenberry et al. in [20] discussed the impact of wearing face masks in preventing contacts. In the United States, during the covid outbreak, nonessential businesses would not have been closed (high economic cost) if the use of masks (low cost) was recommended.
According to our simulations, an excellent control for policy I is an intervention implemented two to three weeks before the uncontrolled outbreak peaks. It can reduce the peak by and increase the people who remain uninfected at the end of outbreak by . A strong intervention will be more likely to be followed by a larger peak than a milder intervention.
When we face a situation in an outbreak where we lack healthcare staff and space in our hospitals, it is especially important to keep the total fraction of infectious individuals under a target percentage. We suggest implementing policy II in which authorities change the social-distancing policies weekly to maintain the maximum number of infectious individuals under the bearable target.
Interventions, their costs, and their effectiveness. When choosing between interventions, it would be advantageous to evaluate each intervention and estimate how many contacts will be disrupted by its implementation and the cost per interrupted contact. The costs include jobs lost, and businesses being closed temporarily or permanently. Interrupting contacts with people at high risk has extra importance. Complex models and simple models with satellite equations take into account some of these types of contacts. The data for such models may not allow us to use the model to determine , but it may be beneficial to categorize interventions by cost/benefit ratios. Many of the features of complex models can be achieved using satellite equations with Models E or E+.
Author Contributions
Conceptualization, S.J. and J.A.Y.; methodology, S.J. and J.A.Y.; formal analysis, S.J. and J.A.Y.; investigation, S.J. and J.A.Y.; writing—original draft preparation, S.J. and J.A.Y.; writing—review and editing, S.J. and J.A.Y.; visualization, S.J. and J.A.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Acknowledgments
We thank Ishan Saha, Eric Kostelich, Aleksey Zimin, Louise Raphael, and James Watmough for their input. The referees’ comments have helped us significantly to clarify the paper’s main message.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Anderson, R.M.; May, R.M. Infectious Diseases of Humans: Dynamics and Control; OUP Oxford: Oxford, UK, 1991. [Google Scholar]
- Nowak, M.; May, R. Virus Dynamics: Mathematical Principles of Immunology Additionally, Virology; OUP: New York, NY, USA, 2001. [Google Scholar]
- Brauer, F.; van den Driessche, P.; Wu, J. Mathematical Epidemiology; Lecture Notes in Mathematics; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Murray, J.D. Mathematical Biology; Springer: Berlin, Germany, 1989. [Google Scholar]
- Svensson, Å. A Note on Generation Times in Epidemic Models. Math. Biosci. 2007, 208, 300–311. [Google Scholar] [CrossRef] [PubMed]
- London, W.P.; Yorke, J. Recurrent outbreaks of measles, chickenpox and mumps. Seasonal variations in contact rates. Am. J. Epidemiol. 1973, 98, 453–468. [Google Scholar] [CrossRef] [PubMed]
- Kalibala, S.; Nutley, T. Engaging Stakeholders, from Inception and Throughout the Study, is Good Research Practice to Promote use of Findings. AIDS Behav. 2019, 23, 214–219. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hsiang, S.; Allen, D.; Annan-Phan, S.; Bell, K.; Bolliger, I.; Chong, T.; Druckenmiller, H.; Hultgren, A.; Huang, L.Y.; Krasovich, E.; et al. The Effect of Large-Scale Anti-Contagion Policies on the Coronavirus (COVID-19) Pandemic. Nature 2020, 584, 262–267. [Google Scholar] [CrossRef] [PubMed]
- Imperial College COVID-19 Response Team; Flaxman, S.; Mishra, S.; Gandy, A.; Unwin, H.J.T.; Mellan, T.A.; Coupland, H.; Whittaker, C.; Zhu, H.; Berah, T.; et al. Estimating the Effects of Non-Pharmaceutical Interventions on COVID-19 in Europe. Nature 2020, 584, 257–261. [Google Scholar] [CrossRef] [PubMed]
- Quoctrung, B.; Josh, K.; Alicia, P.; Margot, S.-K. What 5 Coronavirus Models Say the Next Month Will Look Like? The New York Times. Available online: https://www.nytimes.com/interactive/2020/04/22/upshot/coronavirus-models.html (accessed on 23 June 2020).
- Columbia University, Mailman School of Public Health, Epidemiology. Forecasts of Covid-19 Cases. 2020. Available online: https://columbia.maps.arcgis.com (accessed on 23 June 2020).
- The Institute for Health Metrics and Evaluation (IHME), Covid-19 Projections. Available online: https://covid19.healthdata.org (accessed on 23 June 2020).
- Massachusetts Institute of Technology, DELPHI Epidemiological Case Predictions. 2020. Available online: https://www.covidanalytics.io/projections (accessed on 23 June 2020).
- Los Alamos National laboratory. COVID-19 Confirmed and Forecasted Case Data. 2020. Available online: https://covid-19.bsvgateway.org (accessed on 23 June 2020).
- Adam, D. Special Report: The Simulations Driving the World’s Response to COVID-19. Nature 2020, 580, 316–318. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Code Review of Ferguson’s Model. Lockdown Sceptics. 6 May 2020. Available online: https://lockdownsceptics.org/code-review-of-fergusons-model/ (accessed on 23 June 2020).
- Dembek, Z.F.; Chekol, T.; Wu, A. Best practice assessment of disease modelling for infectious disease outbreaks. Epidemiol. Infect. 2018, 146, 1207–1215. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sayarshad, Hamid R. An optimal control policy for COVID-19 pandemic until a vaccine deployment. medRxiv 2020. [CrossRef]
- Arino, J.; Brauer, F.; van den Driessche, P.; Watmough, J.; Wu, J. Simple models for containment of a pandemic. J. R. Soc. Interface 2006, 3, 453–457. [Google Scholar] [CrossRef] [Green Version]
- Steffen, E. Eikenberry and Marina Mancuso and Enahoro Iboi and Tin Phan and Keenan Eikenberry and Yang Kuang and Eric Kostelich and Abba B. Gumel. To mask or not to mask: Modeling the potential for face mask use by the general public to curtail the COVID-19 pandemic. Infect. Dis. Model. 2020, 5, 293–308. [Google Scholar]
Figure 1.
Fraction of the population that is infectious using Model E. Both curves show the fraction of the population that is infectious. One period is the average time interval between successive infection generations. The red curve assumes a contact rate of . The blue curve illustrates the effect of an intervention, undertaken between periods 6 and 11, that temporarily reduces the contact rate below 1. The same data are plotted in both panels; the vertical axis is a linear scale on the left and a logarithmic scale on the right.
Figure 1.
Fraction of the population that is infectious using Model E. Both curves show the fraction of the population that is infectious. One period is the average time interval between successive infection generations. The red curve assumes a contact rate of . The blue curve illustrates the effect of an intervention, undertaken between periods 6 and 11, that temporarily reduces the contact rate below 1. The same data are plotted in both panels; the vertical axis is a linear scale on the left and a logarithmic scale on the right.

Figure 2.
A1l cases vs. reported (confirmed) cases. The higher curve (red curve) represents all infectious cases as a fraction of the population for a hypothetical COVID-19 outbreak with using Model E+. The lower curve (blue) is “reported cases” assuming 9% of cases are reported. The horizontal axis starts at week 0 when the fraction of all cases reach about . The lowest curve (black curve) represents all deaths, assuming death rate is 1%. There is a time delay between being infected and being tested, having the test developed, and then posting the results. Similarly there is typically a delay between being reported and dying. These delays would shift the blue and black curves to the right. We have not shifted the curves and leave it to the reader to decide how much they should be shifted.
Figure 2.
A1l cases vs. reported (confirmed) cases. The higher curve (red curve) represents all infectious cases as a fraction of the population for a hypothetical COVID-19 outbreak with using Model E+. The lower curve (blue) is “reported cases” assuming 9% of cases are reported. The horizontal axis starts at week 0 when the fraction of all cases reach about . The lowest curve (black curve) represents all deaths, assuming death rate is 1%. There is a time delay between being infected and being tested, having the test developed, and then posting the results. Similarly there is typically a delay between being reported and dying. These delays would shift the blue and black curves to the right. We have not shifted the curves and leave it to the reader to decide how much they should be shifted.

Figure 3.
Obtaining daily reports from Model E+. Model E+ was run for , and 4. Each point on the curves is the infectious fraction for the preceding 7 days, with the horizontal axis being the number of days. The numbers in the graph show each outbreak’s peak-week infectious fraction. To get a smooth curve here and in the previous figure with daily results, we have run Model E+ seven times for each curve, as follows. Early in the outbreak, the fraction of infectious increases by the factor per week, i.e., per day. For each , the simulation was run seven times with initial infectious , , and the plot was shifted to the right by days, i.e., weeks.
Figure 3.
Obtaining daily reports from Model E+. Model E+ was run for , and 4. Each point on the curves is the infectious fraction for the preceding 7 days, with the horizontal axis being the number of days. The numbers in the graph show each outbreak’s peak-week infectious fraction. To get a smooth curve here and in the previous figure with daily results, we have run Model E+ seven times for each curve, as follows. Early in the outbreak, the fraction of infectious increases by the factor per week, i.e., per day. For each , the simulation was run seven times with initial infectious , , and the plot was shifted to the right by days, i.e., weeks.

Figure 4.
Four simulations from The New York Times. Panel (a) Following the beginning of the lockdown in New York City, The New York Times [10] reported on four simulations of deaths with projections for 4 to 6 weeks, shown here with weekly totals. The simulations included large uncertainty intervals that are not shown here. Write Dn for deaths in week n. Panel (b) Contact rates βn. We assume that deaths are a constant fraction of actual cases, so Dn+1/Dn = In+1/In. Hence, if one has the initial fraction, I1, of susceptibles who are infectious and the contact rates βn, then Model E+ will exactly reproduce the curves in panel (a). See the text for a description of the computation of β and the values for I1s. Panel (c) Here three different choices for ratio I1/S1, for the case “C” are represented. As the figure represents only when I1/S1 = 0.1358, the contact rate β will be constant during the middle of the run.
Figure 4.
Four simulations from The New York Times. Panel (a) Following the beginning of the lockdown in New York City, The New York Times [10] reported on four simulations of deaths with projections for 4 to 6 weeks, shown here with weekly totals. The simulations included large uncertainty intervals that are not shown here. Write Dn for deaths in week n. Panel (b) Contact rates βn. We assume that deaths are a constant fraction of actual cases, so Dn+1/Dn = In+1/In. Hence, if one has the initial fraction, I1, of susceptibles who are infectious and the contact rates βn, then Model E+ will exactly reproduce the curves in panel (a). See the text for a description of the computation of β and the values for I1s. Panel (c) Here three different choices for ratio I1/S1, for the case “C” are represented. As the figure represents only when I1/S1 = 0.1358, the contact rate β will be constant during the middle of the run.

Figure 5.
Comparing Model E+’s outbreaks with Model J’s. All simulations in this figure and the next were chosen so that the initial growth rate was a factor of 3 per week. See Table 1 for parameter choices. The initial conditions were chosen so that the 4 curves would be close together initially. Changes in initial data will shift a curve to the left or right. Model E+: The red dashed curve is for Model E+ with a constant contact rate . Model J: The curves are from Model J.
Figure 5.
Comparing Model E+’s outbreaks with Model J’s. All simulations in this figure and the next were chosen so that the initial growth rate was a factor of 3 per week. See Table 1 for parameter choices. The initial conditions were chosen so that the 4 curves would be close together initially. Changes in initial data will shift a curve to the left or right. Model E+: The red dashed curve is for Model E+ with a constant contact rate . Model J: The curves are from Model J.

Figure 6.
Moderate changes in Model J parameter values make a huge difference. Model J simulations are shown for three sets of parameters, B (green), D (blue), and G (purple). (See Table 1). In both panels the red dashed curve is for Model E+ with a constant contact rate .
Figure 6.
Moderate changes in Model J parameter values make a huge difference. Model J simulations are shown for three sets of parameters, B (green), D (blue), and G (purple). (See Table 1). In both panels the red dashed curve is for Model E+ with a constant contact rate .

Figure 7.
Timing an intervention for optimal effect. In this simulation, the rate of contact was β = 3 before and after intervention; during an intervention β∗ = 1.6. The green curves represent the uncontrolled outbreak without any intervention; the peak is about 28% and Sfinal is about 6%. Panel (a) represents the fraction of infectious individuals and panel (b) shows the susceptible fraction of population. Here we have implemented three different 6-week long interventions. An early intervention (blue curves) that starts at week 5 is not very interesting compared to an intermediate intervention. If the uncontrolled outbreak peaks at week n, then an intervention will be called early, intermediate, or late if it is implemented at least 4 weeks earlier than, 2 to 3 weeks earlier than, or exactly one week before week n, respectively. As the figure illustrates, an early intervention only delays the outbreak. A late intervention (purple curves) that starts at week 8 considerably increases the fraction of people who remain uninfected at the end of the outbreak. A middle intervention (golden curves) should be applied two weeks before the uncontrolled outbreak peaks. According to this figure, the optimal effect, which is a 50% reduction in the peak and a 50% increase in fraction of left susceptible, is achievable by the middle intervention.
Figure 7.
Timing an intervention for optimal effect. In this simulation, the rate of contact was β = 3 before and after intervention; during an intervention β∗ = 1.6. The green curves represent the uncontrolled outbreak without any intervention; the peak is about 28% and Sfinal is about 6%. Panel (a) represents the fraction of infectious individuals and panel (b) shows the susceptible fraction of population. Here we have implemented three different 6-week long interventions. An early intervention (blue curves) that starts at week 5 is not very interesting compared to an intermediate intervention. If the uncontrolled outbreak peaks at week n, then an intervention will be called early, intermediate, or late if it is implemented at least 4 weeks earlier than, 2 to 3 weeks earlier than, or exactly one week before week n, respectively. As the figure illustrates, an early intervention only delays the outbreak. A late intervention (purple curves) that starts at week 8 considerably increases the fraction of people who remain uninfected at the end of the outbreak. A middle intervention (golden curves) should be applied two weeks before the uncontrolled outbreak peaks. According to this figure, the optimal effect, which is a 50% reduction in the peak and a 50% increase in fraction of left susceptible, is achievable by the middle intervention.

Figure 8.
A severe intervention is more likely than a mild intervention to be followed by a large peak. Outside the intervention period, β = 3. During intervention the contact rate is shown by β∗. The curves are dashed during the intervention period. (a) This figure compares a mild intervention with a strong intervention using Model E+. The uncontrolled outbreak with no intervention (not shown) has a peak about 28% and Sfinal ∼6%; i.e., 94% of the population is infected during the entire outbreak. Mild intervention, β∗ = 1.6, raises Sfinal to ∼25%. The severe intervention raises the Sfinal to ∼18%. (b,c). We show an outbreak with a 6-week intervention with a variety of contact rates for both Model E+ (panel b) and Model J (panel c). The intervention period begins when the susceptible population S(d) is ≈ 0.9. The vertical axis is showing the fraction of the population susceptible (upper curves) in week n for Model E+ or in day d for Model J. The lower curves are In for Model E+ and Infec(d) for Model J. Mild interventions (magenta) reduce β to 1.4 to 1.6 and severe ones (green) reduce β to 0.6 to 0.9. Model J changes β by changing Jβ using Equation (13). For Model J, exposed individuals are infectious on days 7 through 12 and they are equally infectious. (d) The final sizes are shown for both Model E+ and Model J. The final size is the total fraction infected during the entire outbreak. According to the table in (d), the strong intervention results in more infected cases during the entire outbreak than the mild one.
Figure 8.
A severe intervention is more likely than a mild intervention to be followed by a large peak. Outside the intervention period, β = 3. During intervention the contact rate is shown by β∗. The curves are dashed during the intervention period. (a) This figure compares a mild intervention with a strong intervention using Model E+. The uncontrolled outbreak with no intervention (not shown) has a peak about 28% and Sfinal ∼6%; i.e., 94% of the population is infected during the entire outbreak. Mild intervention, β∗ = 1.6, raises Sfinal to ∼25%. The severe intervention raises the Sfinal to ∼18%. (b,c). We show an outbreak with a 6-week intervention with a variety of contact rates for both Model E+ (panel b) and Model J (panel c). The intervention period begins when the susceptible population S(d) is ≈ 0.9. The vertical axis is showing the fraction of the population susceptible (upper curves) in week n for Model E+ or in day d for Model J. The lower curves are In for Model E+ and Infec(d) for Model J. Mild interventions (magenta) reduce β to 1.4 to 1.6 and severe ones (green) reduce β to 0.6 to 0.9. Model J changes β by changing Jβ using Equation (13). For Model J, exposed individuals are infectious on days 7 through 12 and they are equally infectious. (d) The final sizes are shown for both Model E+ and Model J. The final size is the total fraction infected during the entire outbreak. According to the table in (d), the strong intervention results in more infected cases during the entire outbreak than the mild one.

Figure 9.
Limit β to limit the infectious fraction. Here we change the contact rate weekly in order to keep the fraction of infectious individuals below 2%. The green curves in panel (a) and panel (c) represent weekly contact rate reduction. As the panels (b) and (d) illustrate, the fraction of infectious individuals never goes beyond 2% per week. Panel (b) is derived from Model E+ and panel (d) is derived from Model J. Alternative strategies include minimizing the contacts of those with risk factors.
Figure 9.
Limit β to limit the infectious fraction. Here we change the contact rate weekly in order to keep the fraction of infectious individuals below 2%. The green curves in panel (a) and panel (c) represent weekly contact rate reduction. As the panels (b) and (d) illustrate, the fraction of infectious individuals never goes beyond 2% per week. Panel (b) is derived from Model E+ and panel (d) is derived from Model J. Alternative strategies include minimizing the contacts of those with risk factors.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Jahedi, S.; Yorke, J.A. When the Best Pandemic Models are the Simplest. Biology 2020, 9, 353. https://doi.org/10.3390/biology9110353
AMA Style
Jahedi S, Yorke JA. When the Best Pandemic Models are the Simplest. Biology. 2020; 9(11):353. https://doi.org/10.3390/biology9110353
Chicago/Turabian StyleJahedi, Sana, and James A. Yorke. 2020. "When the Best Pandemic Models are the Simplest" Biology 9, no. 11: 353. https://doi.org/10.3390/biology9110353
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.