Learning Performance of International Students and Students with Disabilities: Early Prediction and Feature Selection through Educational Data Mining



Abstract
:1. Introduction
2. Background and Related Works
2.1. Educational Data Mining (EDM)
2.2. Student Learning Performance Prediction
2.3. Learning Performance Prediction of Minority Students
2.4. Research Gaps
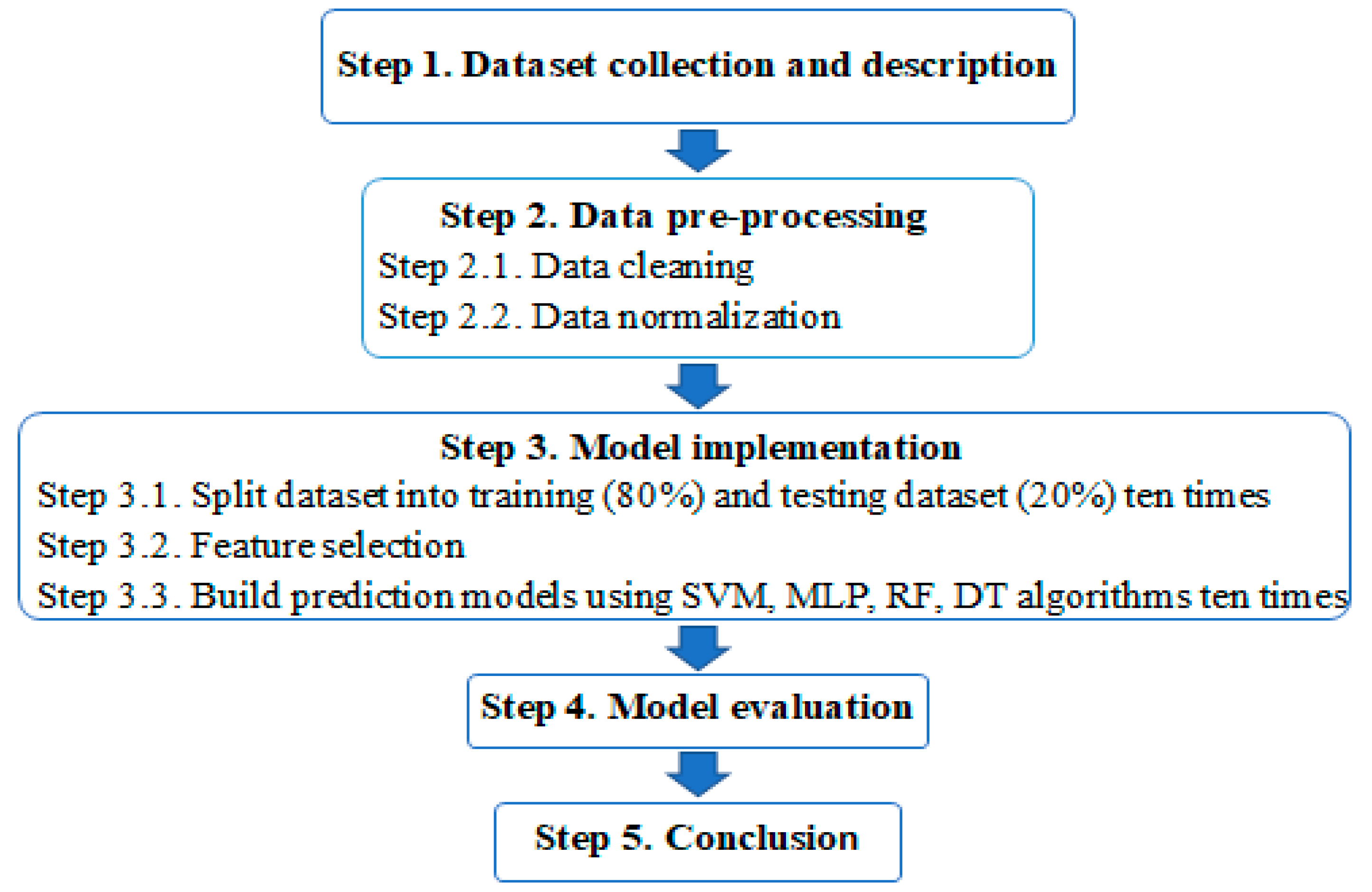
3. Experimental Methodology
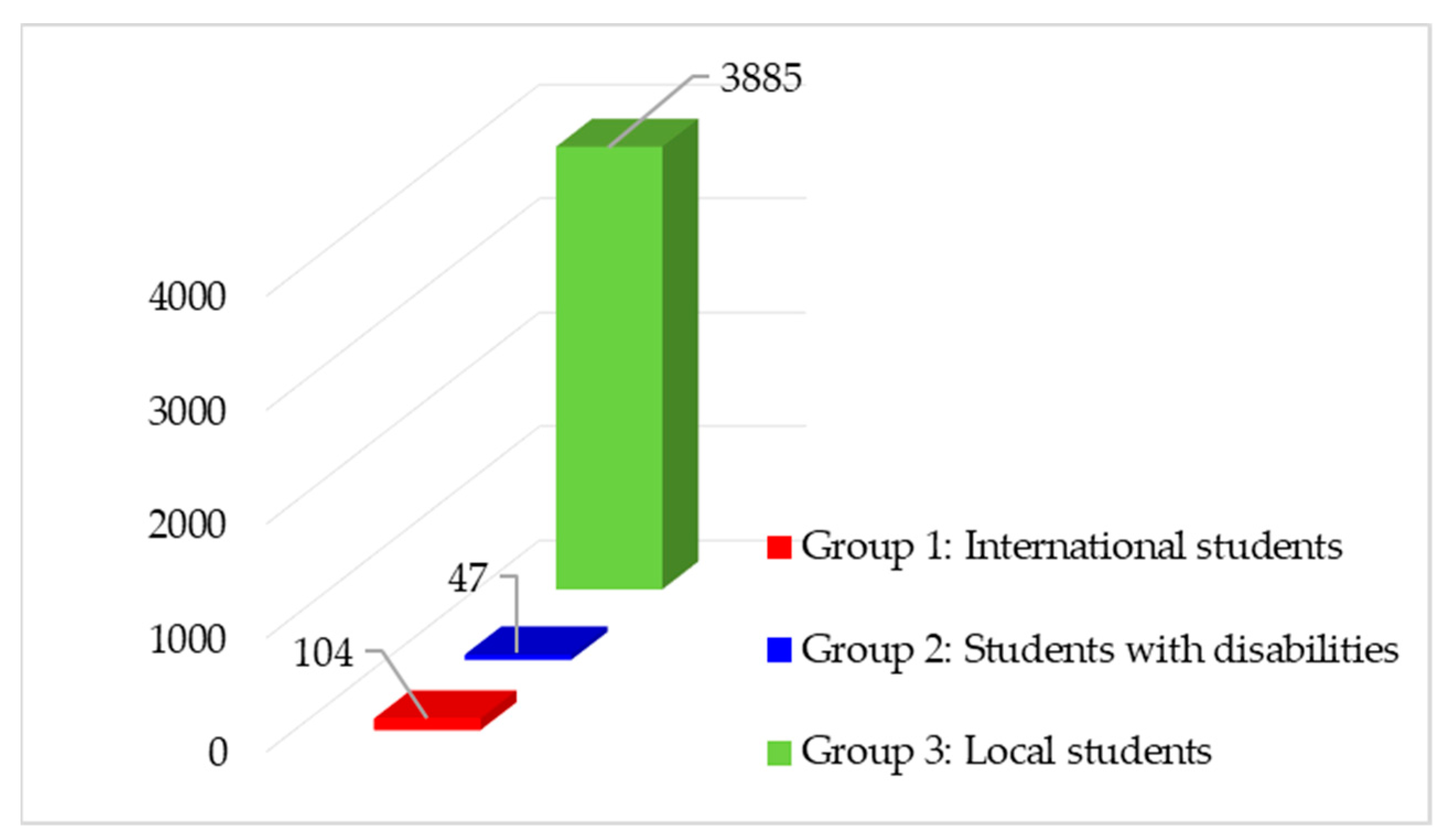
3.1. Step 1. Dataset Collection and Description
3.2. Step 2. Data Pre-Processing
3.3. Model Implementation
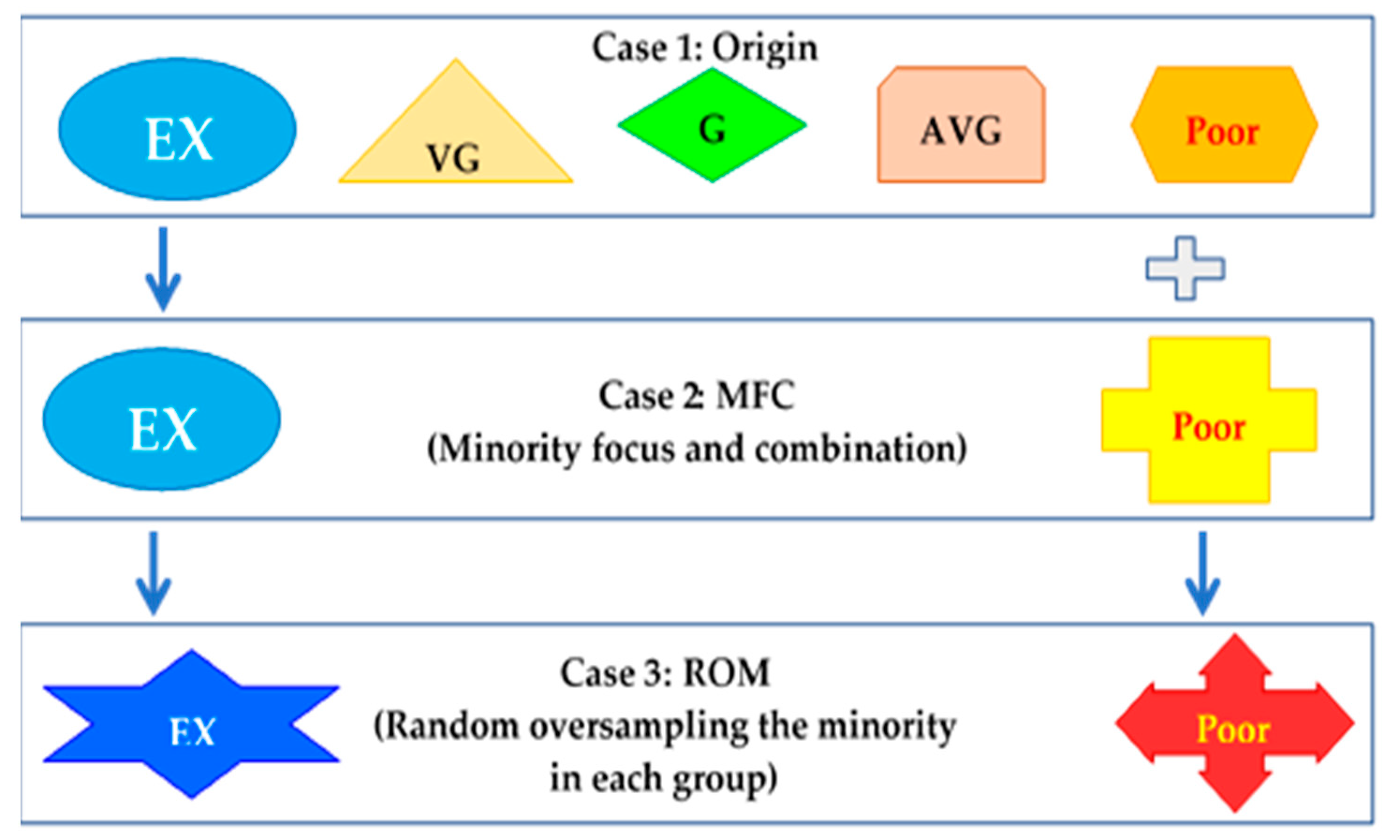
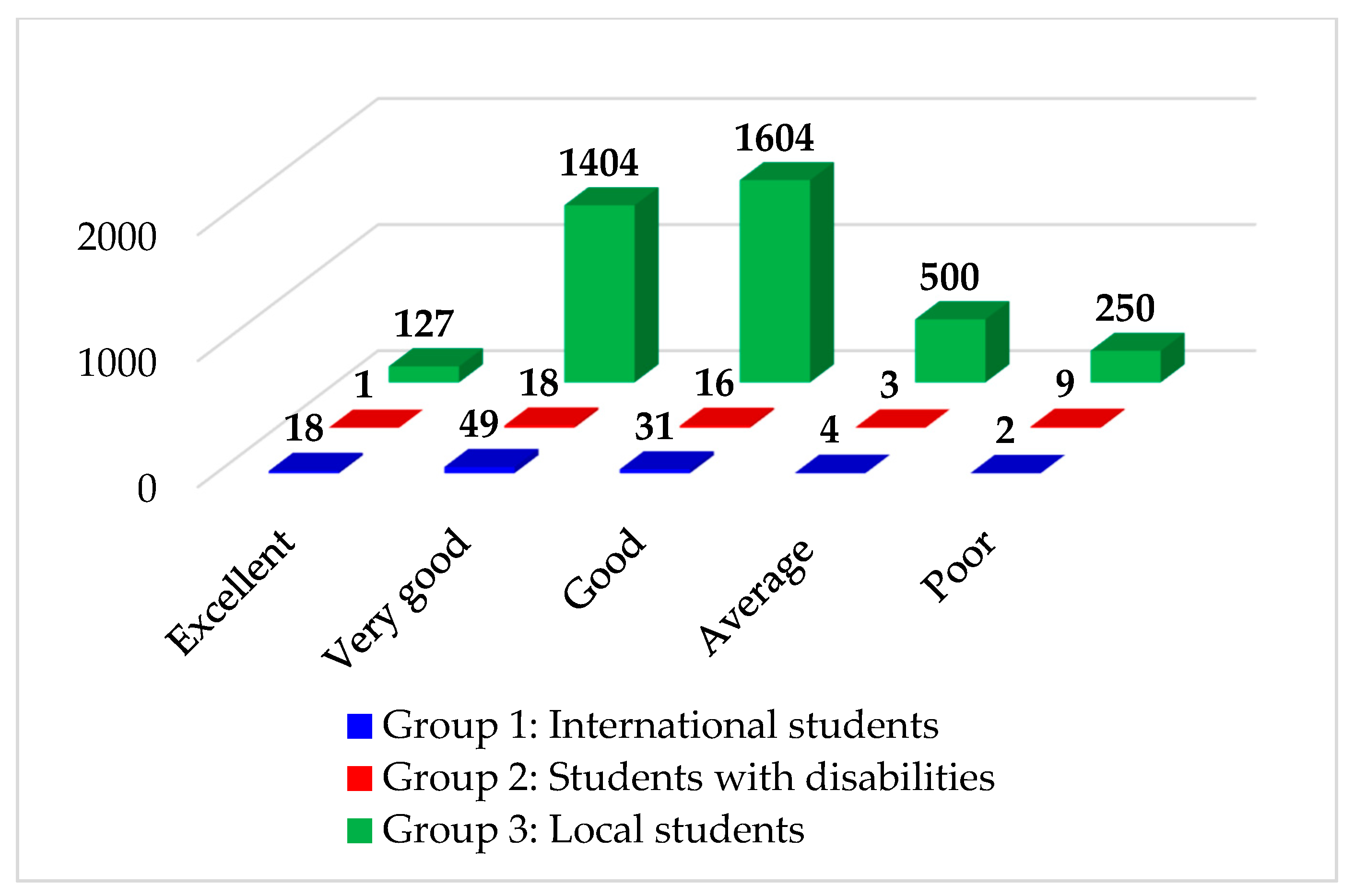
- Case 1: Origin included 5 origin classes: Excellent (EX), Very Good (VG), Good (G), Average (AVG), and Poor. This case was used for investigating if the models predict the minority or not. Figure 4 graphically displays the numbers of employed samples in each group.
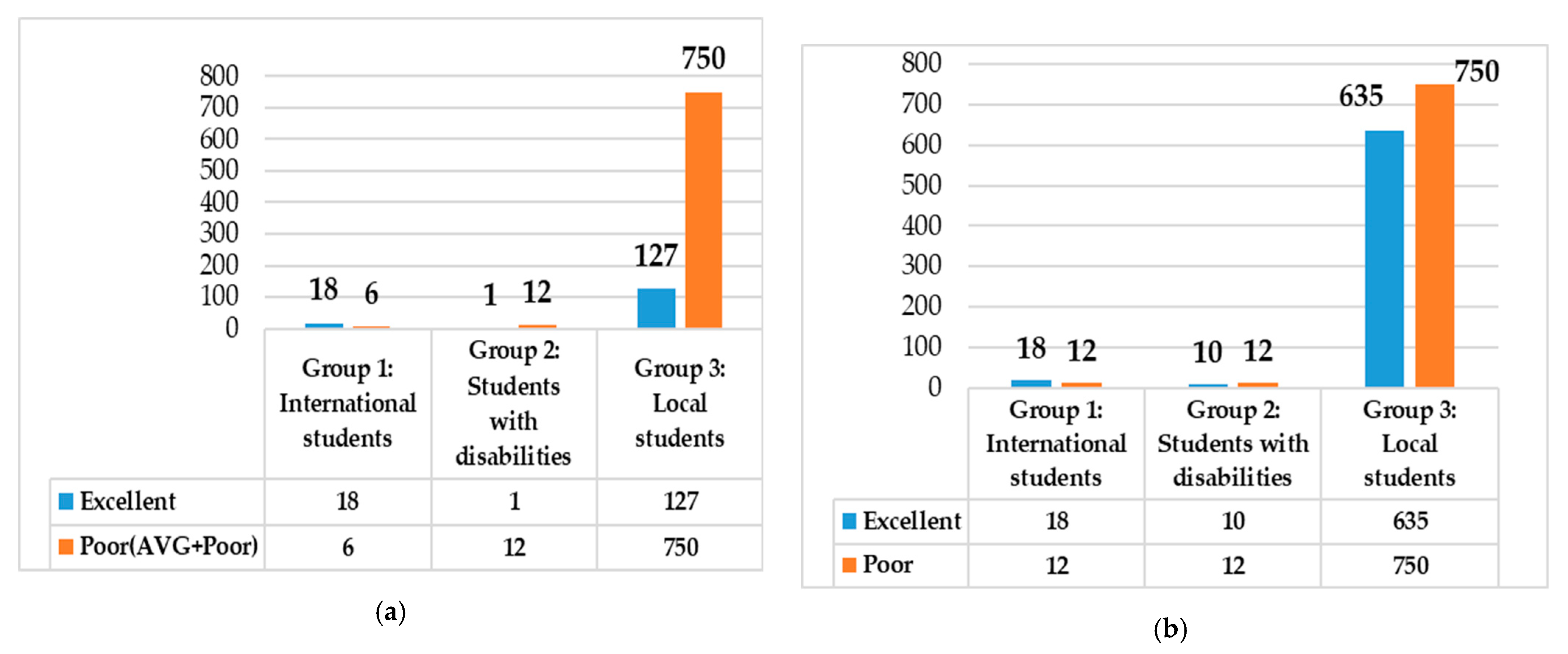
- Case 2: Minority focus and combination (MFC) focused on two minority classes: EX and Poor. The majority classes VG and G were removed. Since the classes “AVG” and “Poor” were very few, we combined the two minority AVG and Poor classes into the Poor class. Therefore, the new combined Poor class (AVG+Poor) included six samples in Group 1, 12 samples in Group 2, and 750 samples in Group 3 (Figure 5a). However, after combining, the imbalanced data problem was present in each group. As shown in Figure 5a, the Poor (AVG+Poor) class remained the minority class in Group 1 (nPoor = 6; nEX = 18); whereas it became the majority class in Group 2 (nPoor = 12; EX = 1) and Group 3 (nPoor = 750; nEX = 127). Therefore, we proposed a resampling method: random oversampling the minority (Case 3) to solve the imbalanced data problem in each group (Figure 5b).
- Case 3: Random oversampling (ROM) was to randomly oversample the minority class in each group by duplicating or generating new minority class instances [49,50]: “EX” and “Poor” classes. As shown in Figure 5b, the numbers of samples in each group are approximately balanced. In the works of Chen et al. [49] and Chang et al. [50], they indicated that oversampling is one of effective solutions for tackling class imbalance problems. Therefore, we employed ROM to deal with class imbalance problems in this study.
3.4. Model Evaluation
- True Positive (TP): instances, which are actually positive, are classified as positive.
- False Positive (FP): instances, which are actually negative, are classified as positive.
- False Negative (FN): instances, which are actually positive, are classified as negative.
- True Negative (TN): instances, which are actually negative, are classified as negative.
4. Experimental Results
4.1. Results of Case 1: Origin
4.2. Results of Case 2: Minority Focus and Combination (MFC)
4.3. Results of Case 3: Random Oversampling the Minority (ROM)
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shahiri, A.M.; Husain, W. A review on predicting student’s performance using data mining techniques. Procedia Comput. Sci. 2015, 72, 414–422. [Google Scholar] [CrossRef]
- Hwang, K.P.; Wang, M.K.; Sodanine, S. The effects of stressors, living support, and adjustment on learning performance of international students in Taiwan. Soc. Behav. Personal. Int. J. 2011, 39, 333–344. [Google Scholar] [CrossRef]
- Hübner, N.; Trautwein, U.; Nagengast, B. Should I stay or should I go? Predictors and effects of studying abroad during high school. Learn. Instr. 2021, 71, 101398. [Google Scholar] [CrossRef]
- Chou, C.P.; Roberts, A.; Ching, G.S. A study on the international students’ perception and norms in Taiwan. Int. J. Res. Stud. Educ. 2012, 1, 71–84. [Google Scholar] [CrossRef]
- Roberts, A.; Chou, P.; Ching, G. Contemporary trends in East Asian higher education: Dispositions of international students in a Taiwan university. High. Educ. 2010, 59, 149–166. [Google Scholar] [CrossRef]
- Ministry of Education, Taiwan (R.O.C.). International Students Come Together to Taiwan, Where the One-Hundred Thirty Thousand Overseas Student Mark Has Been Passed. Available online: https://english.moe.gov.tw/cp-117-25416-d8868-1.html (accessed on 31 May 2022).
- Lewis, A.; Ching, G.S.; Su, Y.N. A case study on the international students’ social adaptability in Taiwan: A qualitative study. Int. J. Res. Stud. Psychol. 2013, 2, 13–24. [Google Scholar] [CrossRef]
- International Students in Taiwan at an All-Time High. Available online: http://www.taipeitimes.com/News/taiwan/archives/2008/02/12/2003400913 (accessed on 31 May 2022).
- Education in Taiwan 2016–2017: Ministry of Education-Republic of China. Available online: https://stats.moe.gov.tw/bookcase/Education_in_Taiwan/105/index.html (accessed on 31 May 2022).
- Romero, C.; Ventura, S. Data mining in education. Wiley Interdis. Rev. Data Min. Know. Disco. 2013, 3, 12–27. [Google Scholar] [CrossRef]
- Baker, R.S.J.D. Data mining for education. Inter. Ency. Educ. 2010, 7, 112–118. [Google Scholar]
- Nguyen, A.; Gardner, L.; Sheridan, D. Data analytics in higher education: An integrated view. J. Inf. Syst. Educ. 2020, 31, 61. [Google Scholar]
- Chakrabarti, S.; Ester, M.; Fayyad, U.; Gehrke, J.; Han, J.; Morishita, S.; Piatetsky-Shapiro, G.; Wang, W. Data mining curriculum: A proposal (Version 1.0). Inten. Work. Group ACM SIGKDD Curricu. Commit. 2006, 140, 1–10. [Google Scholar]
- Asif, R.; Merceron, A.; Ali, S.A.; Haider, N.G. Analyzing undergraduate students’ performance using educational data mining. Comp. Educ. 2017, 113, 177–194. [Google Scholar] [CrossRef]
- Alapont, J.; Bella-Sanjuán, A.; Ferri, C.; Hernández-Orallo, J.; Llopis-Llopis, J.D.; Ramírez-Quintana, M.J. Specialised tools for automating data mining for hospital management. In Proceedings of the First East European Conference on Health Care Modelling and Computation, Craiova, Romania, 31 August–2 September 2005. [Google Scholar]
- Tarik, A.; Aissa, H.; Yousef, F. Artificial Intelligence and Machine Learning to Predict Student Performance during the COVID-19. Procedia Comp. Sci. 2021, 184, 835–840. [Google Scholar] [CrossRef] [PubMed]
- Umadevi, B.; Dhanalakshmi, R. A comprehensive survey of students performance using various data mining techniques. Intern. J. Sci. Res. 2017, 6, 2233–2238. [Google Scholar]
- Zorić, A.B. Benefits of educational data mining. J. Int. Bus. Res. Mark. 2020, 6, 12–16. [Google Scholar] [CrossRef]
- Greller, W.; Drachsler, H. Translating learning into numbers: A generic framework for learning analytics. Educ. Technol. Soc. 2012, 15, 42–57. [Google Scholar]
- Siemens, G.; Baker, R.S.D. Learning analytics and educational data mining: Towards communication and collaboration. In Proceedings of the 2nd International Conference on Learning Analytics and Knowledge, Vancouver, BC, Canada, 29 April–2 May 2012. [Google Scholar]
- Romero, C.; Ventura, S. Educational data mining: A survey from 1995 to 2005. Expert Syst. Appl. 2007, 33, 135–146. [Google Scholar] [CrossRef]
- Baker, R.S.; Yacef, K. The state of educational data mining in 2009: A review and future visions. J. Educ. Data Min. 2009, 1, 3–17. [Google Scholar]
- Upadhyay, N.; Katiyar, V. A survey on the classification techniques in educational data mining. Int. J. Comput. Appl. Technol. Res. 2014, 3, 725–728. [Google Scholar]
- Huynh-Cam, T.T.; Chen, L.S.; Le, H. Using decision trees and random forest algorithms to predict and determine factors contributing to first-year university students’ learning performance. Algorithms 2021, 14, 318. [Google Scholar] [CrossRef]
- Tomasevic, N.; Gvozdenovic, N.; Vranes, S. An overview and comparison of supervised data mining techniques for student exam performance prediction. Comp. Educ. 2020, 143, 103676. [Google Scholar] [CrossRef]
- Namoun, A.; Alshanqiti, A. Predicting student performance using data mining and learning analytics techniques: A systematic literature review. Appl. Sci. 2021, 11, 237. [Google Scholar] [CrossRef]
- Albreiki, B.; Zaki, N.; Alashwal, H. A systematic literature review of student’ performance prediction using machine learning techniques. Educ. Sci. 2021, 11, 552. [Google Scholar] [CrossRef]
- Kabakchieva, D. Student performance prediction by using data mining classification algorithms. Int. J. Comput. Sci. Manag. Res. 2012, 1, 686–690. [Google Scholar]
- Chen, W.K.; Chen, L.S.; Pan, Y.T. A text mining-based framework to discover the important factors in text reviews for predicting the views of live streaming. Appl. Soft Comp. 2021, 111, 107704. [Google Scholar] [CrossRef]
- Al-Barrak, M.A.; Al-Razgan, M. Predicting students final GPA using decision trees: A case study. Int. J. Inf. Educ. Technol. 2016, 6, 528. [Google Scholar] [CrossRef]
- Matzavela, V.; Alepis, E. Decision tree learning through a predictive model for student academic performance in intelligent m-learning environments. Comput. Educ. Artif. Intell. 2021, 2, 100035. [Google Scholar] [CrossRef]
- Khosravi, H.; Shum, S.B.; Chen, G.; Conati, C.; Tsai, Y.-S.; Kay, J.; Knight, S.; Martinez-Maldonado, R.; Sadip, S.; Gašević, D. Explainable Artificial Intelligence in education. Comput. Educ. Artif. Intell. 2022, 3, 100074. [Google Scholar] [CrossRef]
- Chauvin, Y.; Rumelhart, D.E. Backpropagation: Theory, Architectures, and Applications; Psychology Press: London, UK, 2013. [Google Scholar]
- Hamoud, A.; Hashim, A.S.; Awadh, W.A. Predicting student performance in higher education institutions using decision tree analysis. Int. J. Interact. Multimed. Artif. 2018, 5, 26–31. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Abubakar, Y.; Ahmad, N.B.H. Prediction of students’ performance in e-learning environment using random forest. Int. J. Innov. Comput. 2017, 7, 1–5. [Google Scholar]
- Chen, K.Y.; Chen, L.S.; Chen, M.C.; Lee, C.L. Using SVM based method for equipment fault detection in a thermal power plant. Comput. Ind. 2011, 62, 42–50. [Google Scholar] [CrossRef]
- Baashar, Y.; Alkawsi, G.; Ali, N.A.; Alhussian, H.; Bahbouh, H.T. Predicting student’s performance using machine learning methods: A systematic literature review. In Proceedings of the 2021 International Conference on Computer & Information Sciences (ICCOINS), Kuching, Malaysia, 13–15 July 2021. [Google Scholar]
- Niyogisubizo, J.; Liao, L.; Nziyumva, E.; Murwanashyaka, E.; Nshimyumukiza, P.C. Predicting student’s dropout in university classes using two-layer ensemble machine learning approach: A novel stacked generalization. Comput. Educ. Artif. Intell. 2022, 3, 100066. [Google Scholar] [CrossRef]
- Ren, J.; Hagedorn, L.S. International graduate students’ academic performance: What are the influencing factors? J. Int. Stud. 2012, 2, 135–143. [Google Scholar] [CrossRef]
- Huang, B.; Lu, H.; Zhu, R. Disabled peers and student performance: Quasi-experimental evidence from China. Econ. Educ. Rev. 2021, 82, 102121. [Google Scholar] [CrossRef]
- Balestra, S.; Eugster, B.; Liebert, H. Peers with special needs: Effects and policies. Rev. Econ. Stat. 2022, 104, 602–618. [Google Scholar] [CrossRef]
- Griffiths, L.; Worth, P.; Scullard, Z.; Gilbert, D. Supporting disabled students in practice: A tripartite approach. Nurse Educ. Pract. 2010, 10, 132–137. [Google Scholar] [CrossRef] [PubMed]
- Hersh, M. Evaluation framework for ICT-based learning technologies for disabled people. Comput. Educ. 2014, 78, 30–47. [Google Scholar] [CrossRef]
- Zainudin, N.; Abu, N.H.; Mansor, M.F.; Malaysia, K.; Perlis, K. Exploring “Backbone” Factors associated to Academic Performance among Disability Student’s in E-learning: An Empirical Analysis during Pandemic COVID-19. In Proceedings of the 3rd Conference on Technology & Operations Management, Sintok, Malaysia, 24–25 August 2021. [Google Scholar]
- Koutri, M.; Avouris, N.; Daskalaki, S. A survey on web usage mining techniques for web-based adaptive hypermedia systems. In Adaptable and Adaptive Hypermedia Systems; Idea Group Inc. (IGI): Calgary, AB, Canada, 2005; pp. 125–149. [Google Scholar]
- Zorrilla, M.E.; Menasalvas, E.; Marin, D.; Mora, E.; Segovia, J. Web usage mining project for improving web-based learning sites. In Computer Aided Systems Theory–EUROCAST 2005; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Chang, J.R.; Liang, H.Y.; Chen, L.S.; Chang, C.W. Novel feature selection approaches for improving the performance of sentiment classification. J. Ambient. Intell. Humaniz. Comput. 2020, 1–14. [Google Scholar] [CrossRef]
- Chen, M.Y.; Chang, J.R.; Chen, L.S.; Chuang, Y.J. Identifying the key success factors of movie projects in crowdfunding. Multi. Tools Appl. 2022, 81, 27711–27736. [Google Scholar] [CrossRef]
- Chang, J.R.; Chen, L.S.; Lin, L.W. A Novel Cluster based Over-sampling Approach for Classifying Imbalanced Sentiment Data. IAENG Int. J. Comput. Sci. 2021, 48, 1118–1128. [Google Scholar]
- Rodríguez-Hernández, C.F.; Musso, M.; Kyndt, E.; Cascallar, E. Artificial neural networks in academic performance prediction: Systematic implementation and predictor evaluation. Comput. Educ. Artif. Intell. 2021, 2, 100018. [Google Scholar] [CrossRef]
- Powers, D.M. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv 2020, arXiv:2010.16061. [Google Scholar]
- Iqbal, A.; Aftab, S. A classification framework for software defect prediction using multi-filter feature selection technique and MLP. Int. J. Mod. Educ. Comput. Sci. 2020, 12, 18–25. [Google Scholar] [CrossRef]
- Muschelli, J. ROC and AUC with a binary predictor: A potentially misleading metric. J. Classif. 2020, 37, 696–708. [Google Scholar] [CrossRef]
- Ching, G.S.; Wang, W.L.; Wen, T.S. Study abroad tales: Experiences of international students in Taiwan. Int. J. Res. Stud. Psychol. 2016, 5, 63–79. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Feature Name | Feature Description and Transferred Values | No. | Feature Name | Feature Description and Transferred Values |
|---|---|---|---|---|---|
| 1 | Department | 1 = TCA, 2 = TCJ, 3 = CK, 4 = TCL, 5 = TDJ, 6 = TDN, 7 = TD4, 8 = TD5, 9 = TD6, 10 = TD7, 11 = TC6, 12 = TC7, 13 = TC8, 14 = TC9, 15 = TE1, 16 = TE2, 17 = TE3, 18 = TE4, 19 = TE5, 20 = TQ1, 21 = TF1, 22 = TJ2, 23 = TJ4, 24 = TF2, 25 = TF3, 26 = TF4, 27 = TJ9 | 9 | Main source of living expenses | 1 = Parents 2 = Family and friends support 3 = Self-earning 4 = Grants in- or outside the school 5 = Income from full-time job 6 = Family provided 7 = Income from part-time job 8 = Scholarships 9 = Student loans |
| 2 | Gender | 1 = Male, 2 = Female | 10 | Student loan | 1 = Yes, 0 = No |
| 3 | Numbers of required credits | 0–23 | 11 | Tuition waiver | 1 = Yes, 0 = No |
| 4 | Numbers of elective credits | 1–14 | 12 | Father’s occupations | 1 = Military 2 = Education 3 = Public 4 = Service 5 = Industry 6 = Business 7 = Agriculture 8 = Others |
| 5 | Sick leave | 0–36 | 13 | Father’s education | 1 = Junior high school and below 2 = High school 3 = Bachelor 4 = Master 5 = Specialist 6 = PhD |
| 6 | Personal leave | 0–33 | 14 | Mother’s occupations | 1 = Military 2 = Education 3 = Public 4 = Service 5 = Industry 6 = Business 7 = Agriculture 8 = Others |
| 7 | Parent Average income per month | 1 = 25,000 NTD, 2 = 40,000 NTD, 3 = 60,000 NTD, 4 = 80,000~100,000 NTD, 5 = Above 100,000 NTD | 15 | Mother’s education | 1 = Junior high school and below 2 = High school 3 = Bachelor 4 = Master 5 = Specialist 6 = PhD |
| 8 | On-campus accommodation | 1 = Yes, 0 = No | 16 | Grade Point Average (GPA) | 1 = Excellent (90–100 points), 2 = Very Good (80–89 points), 3 = Good (70–79 points), 4 = Average (60–69 points), 5 = Poor (0–59 points) |
| Performance | Accuracy (%) | Precision | Recall | F1-Score | ||||
|---|---|---|---|---|---|---|---|---|
| Mean | SD | Mean | SD | Mean | SD | Mean | SD | |
| Methods | Group 1: International students | |||||||
| SVM | 43.00 | 0.00 | 0.23 | 0.00 | 0.26 | 0.00 | 0.24 | 0.00 |
| MLP | 35.60 | 4.06 | 0.26 | 0.02 | 0.26 | 0.02 | 0.26 | 0.02 |
| RF | 40.00 | 3.50 | 0.30 | 0.02 | 0.30 | 0.02 | 0.30 | 0.02 |
| DT | 40.00 | 4.83 | 0.38 | 0.07 | 0.47 | 0.11 | 0.41 | 0.08 |
| Group 2: Students with disabilities | ||||||||
| SVM | 24.00 | 10.75 | 0.18 | 0.23 | 0.24 | 0.14 | 0.16 | 0.13 |
| MLP | 36.00 | 8.43 | 0.33 | 0.14 | 0.30 | 0.08 | 0.30 | 0.10 |
| RF | 40.00 | 14.14 | 0.43 | 0.20 | 0.41 | 0.19 | 0.38 | 0.16 |
| DT | 30.00 | 6.67 | 0.22 | 0.10 | 0.25 | 0.11 | 0.58 | 1.20 |
| Group 3: Local students | ||||||||
| SVM | 51.00 | 0.00 | 0.46 | 0.00 | 0.26 | 0.00 | 0.24 | 0.00 |
| MLP | 48.80 | 1.23 | 0.38 | 0.03 | 0.31 | 0.01 | 0.32 | 0.01 |
| RF | 53.10 | 1.97 | 0.46 | 0.04 | 0.32 | 0.01 | 0.33 | 0.01 |
| DT | 45.20 | 1.23 | 0.35 | 0.01 | 0.35 | 0.02 | 0.35 | 0.01 |
| Performance | Accuracy (%) | Precision | Recall | F1-Score | ||||
|---|---|---|---|---|---|---|---|---|
| Mean | SD | Mean | SD | Mean | SD | Mean | SD | |
| Methods | Group 1: International students | |||||||
| SVM | 80.00 | 26.67 | 0.70 | 0.39 | 0.80 | 0.26 | 0.73 | 0.35 |
| MLP | 92.00 | 13.98 | 0.94 | 0.10 | 0.93 | 0.12 | 0.92 | 0.14 |
| RF | 90.00 | 17.00 | 0.94 | 0.11 | 0.91 | 0.15 | 0.89 | 0.88 |
| DT | 94.00 | 9.66 | 0.95 | 0.08 | 0.94 | 0.10 | 0.94 | 0.10 |
| Group 2: Students with disabilities | ||||||||
| SVM | 100.00 | 0.00 | 1.00 | 0.00 | 1.00 | 0.00 | 1.00 | 0.00 |
| MLP | 96.30 | 11.10 | 0.94 | 0.17 | 0.93 | 0.22 | 0.93 | 0.20 |
| RF | 96.30 | 11.10 | 0.94 | 0.17 | 0.93 | 0.22 | 0.93 | 0.20 |
| DT | 96.30 | 11.10 | 0.94 | 0.17 | 0.93 | 0.22 | 0.93 | 0.20 |
| Group 3: Local students | ||||||||
| SVM | 88.10 | 3.54 | 0.84 | 0.07 | 0.71 | 0.07 | 0.74 | 0.07 |
| MLP | 87.50 | 5.87 | 0.81 | 0.07 | 0.75 | 0.06 | 0.77 | 0.07 |
| RF | 92.10 | 2.02 | 0.89 | 0.04 | 0.81 | 0.07 | 0.84 | 0.06 |
| DT | 85.60 | 3.84 | 0.75 | 0.08 | 0.77 | 0.08 | 0.76 | 0.08 |
| True Positive Rate | False Negative Rate | False Positive Rate | True Negative Rate | |
|---|---|---|---|---|
| (a) Group 1: International students (SVM) | 1 | 0 | 0 | 1 |
| (b) Group 2: Students with disabilities (SVM) | 1 | 0 | 0 | 1 |
| (c) Group 3: Local students (RF) | 0.412 | 0.588 | 0.069 | 0.931 |
| Performance | Accuracy (%) | Precision | Recall | F1 | ||||
|---|---|---|---|---|---|---|---|---|
| Mean | SD | Mean | SD | Mean | SD | Mean | SD | |
| Methods | Group 1: International students | |||||||
| SVM | 100.00 | 0.00 | 1.00 | 0.00 | 1.00 | 0.00 | 1.00 | 0.00 |
| MLP | 100.00 | 0.00 | 1.00 | 0.00 | 1.00 | 0.00 | 1.00 | 0.00 |
| RF | 96.60 | 7.17 | 0.97 | 0.06 | 0.97 | 0.06 | 0.97 | 0.07 |
| DT | 100.00 | 0.00 | 1.00 | 0.00 | 1.00 | 0.00 | 1.00 | 0.00 |
| Group 2: Students with disabilities | ||||||||
| SVM | 100.00 | 0.00 | 1.00 | 0.00 | 1.00 | 0.00 | 1.00 | 0.00 |
| MLP | 96.00 | 12.65 | 0.98 | 0.08 | 0.97 | 0.10 | 0.96 | 0.13 |
| RF | 98.00 | 6.32 | 0.98 | 0.05 | 0.98 | 0.05 | 0.98 | 0.06 |
| DT | 94.00 | 13.50 | 0.96 | 0.09 | 0.95 | 0.11 | 0.94 | 0.14 |
| Group 3: Local students | ||||||||
| SVM | 91.90 | 1.45 | 0.92 | 0.02 | 0.92 | 0.01 | 0.92 | 0.02 |
| MLP | 94.90 | 0.74 | 0.95 | 0.01 | 0.95 | 0.01 | 0.95 | 0.01 |
| RF | 98.60 | 0.52 | 0.99 | 0.01 | 0.99 | 0.01 | 0.99 | 0.01 |
| DT | 95.20 | 0.79 | 0.95 | 0.01 | 0.96 | 0.01 | 0.95 | 0.01 |
| RF | SVM | MLP | DT | |
|---|---|---|---|---|
| (a) Group 1: International students | 1.00 | 1.00 | 1.00 | 1.00 |
| (b) Group 2: Students with disabilities | 1.00 | 1.00 | 0.83 | 1.00 |
| (c) Group 3: Local students | 1.00 | 1.00 | 0.96 | 0.95 |
| True Positive Rate | False Negative Rate | False Positive Rate | True Negative Rate | |
|---|---|---|---|---|
| (a) Group 1: International students | 1.00 | 0 | 0 | 1.00 |
| (b) Group 2: Students with disabilities | 1.00 | 0 | 0 | 1.00 |
| (c) Group 3: Local students | 1.00 | 0 | 0.066 | 0.934 |
| Performance | Under-sampling | ROM | MFC | |||
|---|---|---|---|---|---|---|
| Accuracy | F1 | Accuracy | F1 | Accuracy | F1 | |
| Methods | Group 1: International students | |||||
| SVM | 86.63 | 0.86 | 100.00 | 1.00 | 80.00 | 0.73 |
| MLP | 83.30 | 0.82 | 100.00 | 1.00 | 92.00 | 0.92 |
| RF | 96.70 | 0.97 | 96.60 | 0.97 | 90.00 | 0.89 |
| DT | 93.40 | 0.93 | 100.00 | 1.00 | 94.00 | 0.94 |
| Group 2: Students with disabilities | ||||||
| SVM | 0.00 | 0.0 | 100.00 | 1.00 | 100.00 | 1.00 |
| MLP | 20.00 | 0.20 | 96.00 | 0.96 | 96.30 | 0.93 |
| RF | 40.00 | 0.40 | 98.00 | 0.98 | 96.30 | 0.93 |
| DT | 0.00 | 0.00 | 94.00 | 0.94 | 96.30 | 0.93 |
| Group 3: Local students | ||||||
| SVM | 86.60 | 0.86 | 91.90 | 0.92 | 88.10 | 0.74 |
| MLP | 85.30 | 0.85 | 94.90 | 0.95 | 87.50 | 0.77 |
| RF | 87.70 | 0.87 | 98.60 | 0.99 | 92.10 | 0.84 |
| DT | 77.40 | 0.76 | 95.20 | 0.95 | 85.60 | 0.76 |
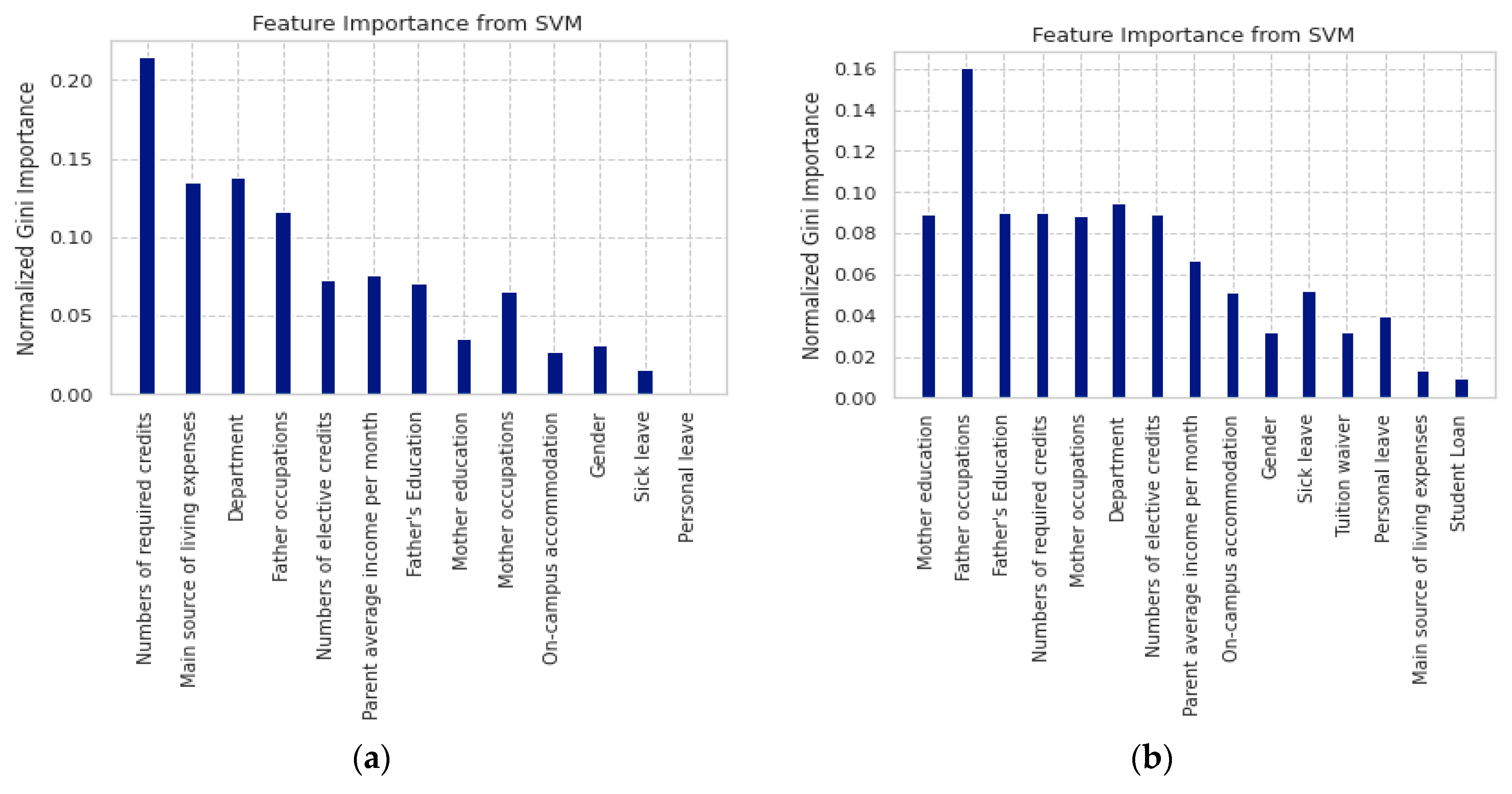
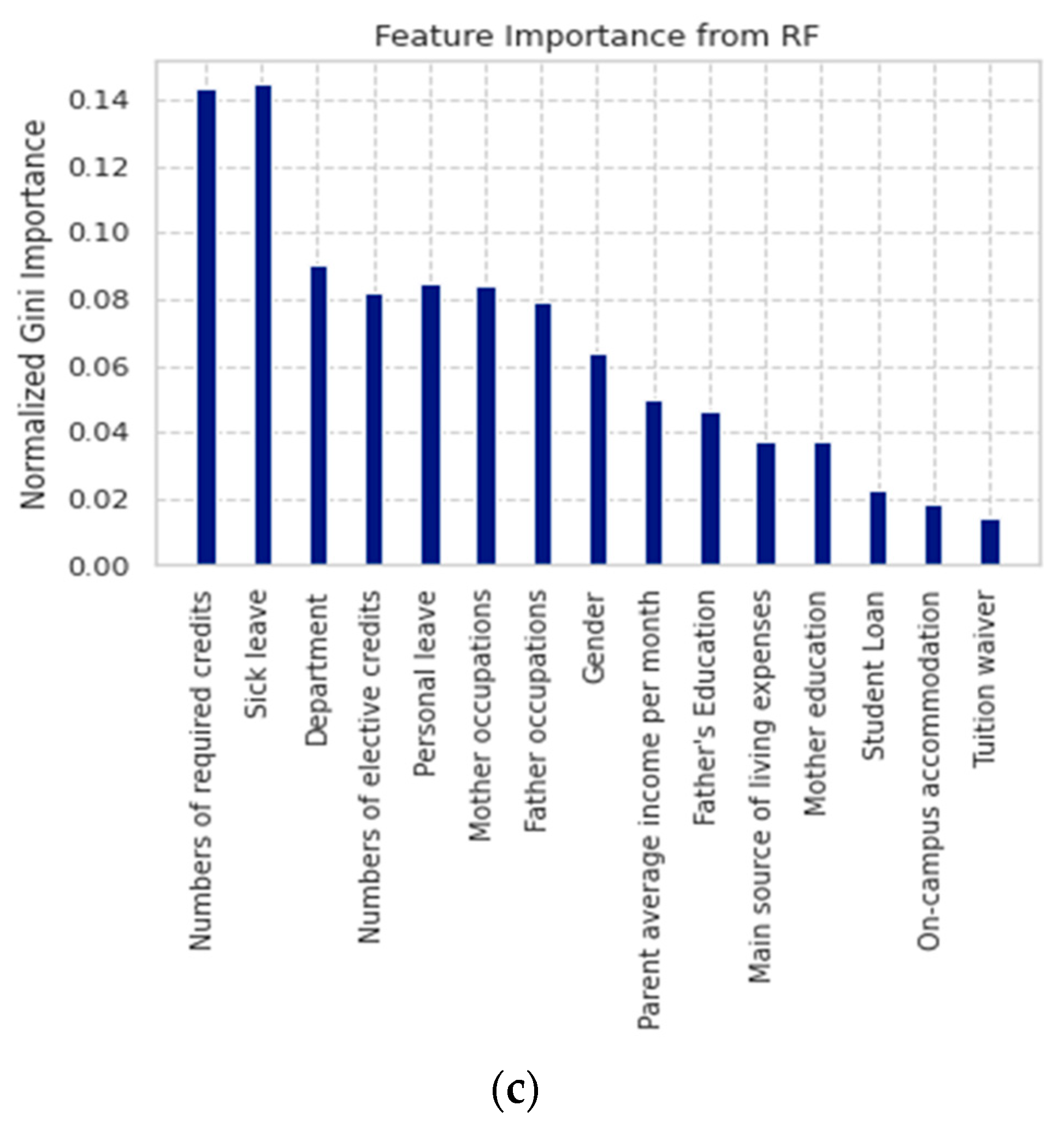
| Group 1: International Students | Group 2: Students with Disabilities | Group 3: Local Students |
|---|---|---|
| 1 No. of required credits | 1 Father occupations | 1 No. of required credits |
| 2 Department | 2 Department | 2 Sick leave |
| 3 Main source of living expenses | 3 Mother education | 3 Department |
| 4 Father occupations | 4 No. of required credits | 4 Personal leave |
| 5 Parent average income per month | 5 No. of elective credits | 5 Mother occupations |
| 6 Numbers of elective credits | 6 Father education | 6 Numbers of elective credits |
| 7 Father’s education | 7 Mother occupations | 7 Father occupations |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huynh-Cam, T.-T.; Chen, L.-S.; Huynh, K.-V. Learning Performance of International Students and Students with Disabilities: Early Prediction and Feature Selection through Educational Data Mining. Big Data Cogn. Comput. 2022, 6, 94. https://doi.org/10.3390/bdcc6030094
Huynh-Cam T-T, Chen L-S, Huynh K-V. Learning Performance of International Students and Students with Disabilities: Early Prediction and Feature Selection through Educational Data Mining. Big Data and Cognitive Computing. 2022; 6(3):94. https://doi.org/10.3390/bdcc6030094
Chicago/Turabian StyleHuynh-Cam, Thao-Trang, Long-Sheng Chen, and Khai-Vinh Huynh. 2022. "Learning Performance of International Students and Students with Disabilities: Early Prediction and Feature Selection through Educational Data Mining" Big Data and Cognitive Computing 6, no. 3: 94. https://doi.org/10.3390/bdcc6030094