

Generalized Partially Functional Linear Model with Unknown Link Function

1
School of Science, North China University of Technology, Beijing 100144, China
2
Department of Statistics, University of Leeds, Leeds LS2 9JT, UK
*
Author to whom correspondence should be addressed.
Axioms 2023, 12(12), 1089; https://doi.org/10.3390/axioms12121089
Submission received: 13 October 2023
/
Revised: 16 November 2023
/
Accepted: 22 November 2023
/
Published: 28 November 2023
(This article belongs to the Special Issue Advances in Mathematics: Theory and Applications)
Abstract
:In existing models with an unknown link function, the issue of predictors containing both multiple functional data and multiple scalar data has not been studied. To fill this gap, we propose a generalized partially functional linear model, which not only models the relationship between multiple scalar and functional predictors and responses, but also automatically estimates the link function. Specifically, we use the functional principal component analysis method to reduce the dimensionality of functional predictors, estimate the regression coefficients using the maximum likelihood estimation method, estimate the link function using the method of local linear regression, iteratively obtain the final estimator, and establish the asymptotic normality of the estimator. The asymptotic normality is illustrated through simulation experiments. Finally, the proposed model is applied to study the influence of environmental, economic, and medical levels on life expectancy in China. In the study, functional predictors are the daily air quality index, temperature, and humidity of 58 cities in 2020, and scalar predictors are GDP and the number of beds in hospitals. The experimental results indicate that the unknown link function model has a smaller prediction error and better performance than both the model with the known link function and the model without a link function.
1. Introduction
In 1982, Ramsay [1] first proposed the definition of functional data, laying a foundation for the development of functional data analysis. In 2005, Ramsay and Silverman provided a detailed introduction to the general methods and steps of functional data analysis, including functional principal component analysis and functional linear regression models in their book [2]. In 2012, Horváth and Kokoszka [3] focused on the inferential methods in functional data analysis.
In 2009, Shin [4] proposed a partial functional linear model (PFLM), which explores the relationship between a scalar response variable and mixed-type predictors. In 2012, Shin and Lee [5] derived the asymptotic prediction rate of PFLM and compared it with that of other functional regression models.
In 2002, James [6] proposed generalized linear models with functional predictors and applied them to standard missing data problems. In 2005, Müller and Stadtmüller [7] proposed a generalized functional linear regression model where the response variable is a scalar and the predictor is a random function. They also considered the situation where the link and variance functions were unknown. In 2015, Shang and Cheng [8] proposed a roughness regularization approach in making nonparametric inference for generalized functional linear models with known link functions. In 2019, Wong et al. [9] investigated a class of partially linear functional additive models that predict a scalar response by both the parametric effects of a multivariate predictor and the non-parametric effects of a multivariate functional predictor.
In a generalized linear model, sometimes the link function may not be known exactly, but can be assumed to be of some general ‘parametric’ form. In 1984, Scallan et al. [10] showed how generalized linear models can be extended to fit models with such link functions.
In 1994, Weisberg and Welsh [11] used kernel smoothing estimation to estimate the link function and estimated regression coefficients through the link function, then alternated between these two steps, which effectively solves the fitting problem when the link function is unknown. However, kernel smoothing estimation may have problems at the boundary, so local polynomial fitting is introduced, which performs better near the boundary.
In 1998, Chiou and Müller [12] considered the condition of the link and the variance functions to be unknown but smooth. Consistency results for the link and the variance function estimators, as well as the sampling distribution of the regression coefficients, were obtained. In 2005, Chiou and Müller [13] introduced a flexible marginal modeling approach for statistical inference for clustered and longitudinal data under minimal assumptions. The predictor was longitudinal data in the model. The estimated estimating equation approach was semi-parametric. The semi-parametric model proposed was fitted by quasi-likelihood regression. The consistency of the estimates of the link and variance functions and the asymptotic limit distribution of regression coefficients were given. In addition, there are other methods to estimate unknown functions. In 2009, Bai et al. [14] focused on single-index models for longitudinal data. They proposed a procedure to estimate the single-index component and the unknown link function based on the combination of the penalized splines and quadratic inference functions. In 2012, Pang and Xue [15] generalized the single-index models to the scenarios with random effects. The link function was estimated by using the local linear smoother. A new set of estimating equations modified for the boundary effects was proposed to estimate the index coefficients. In 2017, Yuan and Diao [16] developed a sieve maximum likelihood estimation for generalized linear models, in which the estimator of the unknown link function was assumed to lie in a sieve space. Various methods of sieves including the B-spline and P-spline-based methods were introduced.
In 2017, Kokoszka and Reimherr [17] wrote a book that introduced the basic concepts, methods, and applications of functional data analysis. The book provided a clear and systematic overview, covering key areas such as representation, smoothing, interpolation, statistical modeling, and inference for functional data. It also included detailed explanations of practical examples and computational methods. In 2023, Rao and Reimherr [18] introduced a novel neural network-based nonlinear model of functional data designed to exploit the structure of functional data and fit it with a derived function gradient optimization algorithm, demonstrating the effectiveness of these methods in dealing with complex functional models and providing new breakthroughs for deep learning applications in the field of functional data analysis.
The relationship between environmental factors and human health has been a topic of significant research interest in recent years. In 2012, Huang et al. [19] explored the relationship between temperature and years of life lost (YLL). The study found that both high and low temperatures lead to an increase in YLL, with high temperatures having a greater impact. In 2020, Yang et al. [20] applied a generalized additive model to assess the associations between daily PM2.5 exposure and YLL due to respiratory diseases in 96 Chinese cities during 2013–2016. They further estimated the avoidable YLL and potential gains in life expectancy under the assumption that daily PM2.5 level met World Health Organization standards. In 2021, Deryugina and Molitor [21] explored the factors influencing life expectancy across the United States. The study found that individuals living in areas with severe air pollution, poor water quality, and inadequate healthcare facilities generally had shorter life expectancy and poorer health conditions.
In summary, the existing models with unknown link functions have not addressed the issue of the generalized partially functional regression model, which involves regressing the response variable on multiple functional and scalar predictors. To fill this gap, this study proposes a generalized partially functional linear model with an unknown link function. The proposed model avoids the problem of decreased model accuracy caused by selecting an incorrect link function. The predictors in the proposed model include both multiple functional data and multiple scalar data. It reveals the complex relationships between variables and provides a flexible and effective modeling approach. It can achieve better prediction and explanation.
The paper is organized as follows. All the published works and definitions that are referred to in the process of theorem proving are introduced in Section 2. The abbreviations used in the article are introduced in the Section 3.1. The generalized partial functional linear model with unknown link function is proposed in Section 3.2. The estimation of the regression coefficients and the link function is discussed in Section 3.3. In Section 4, asymptotic normality of estimators are derived. Simulation results are reported in Section 5. The average life expectancy study in 58 cities in China is given in Section 6. In Section 7, a brief summary and limitations of the research are provided. Possible applications and future directions are presented in Section 7.
2. Preliminaries
In this section, we provide an overview of the published works and definitions that are relevant to our research. These preliminary concepts and references lay the foundation for a better understanding of the subsequent discussion.
(1) In 1982, Mack and Silverman [22] provided a comprehensive analysis of the weak and strong uniform consistency properties of kernel regression estimates, highlighted their theoretical properties and practical significance in non-parametric regression modeling. In this paper, we directly apply the results of Proposition 4 as Lemma 1 for Theorem 1 in this paper.
(2) In 1995, Masry and Tjøstheim [23] discussed the estimation and identification of nonlinear time series of ARCH type. They provided an estimation method to obtain consistent estimates of the parameters and proved the asymptotic normality. They also explored model identification methods. Their studies are of significant importance for modeling and analyzing financial time series. Theorem 3.3 in their work is used to prove Theorem 1 in this paper.
(3) In 1999, Chiou and Müller [24] focused on the study of non-parametric quasi-likelihood methods. They provided the theoretical derivation process of this method, and explored its applications in statistical inference. Theorem 4.1 in their paper is used to prove Lemma 2 and Lemma 3 for Theorem 2 in this paper.
(4) In 2021, Xiao et al. [25] proposed a generalized partially functional linear regression model where the response variable is 0 or 1 and the predictors were multiple functional and scalar, and the asymptotic property of the estimated coefficients in the model was established. The proof method of Theorem 1 in [25] is used to prove Theorem 2 in this work.
3. Model and Estimation
The data we observe for the i-th subject are We assume that these data are independent, identically distributed (i.i.d) copies of . For the functional predictor is a random curve. are samples of and are square integrable on a real bounded interval T, i.e., . refers to the space of square integrable functions defined on T. And the scalar predictor vector is a q dimensional random vector. The response Y is a real-valued random variable that may be binary or count.
3.1. Abbreviation Introduction
Table 1 is a list of the abbreviations we use in this work along with their corresponding full forms:
3.2. Model
We establish a model for the relationship between the response variable and the predictors and :
where is the regression coefficient function that needs to be estimated for the functional predictors ; is a q dimensional vector with the elements to be the regression coefficients for the scalar predictors that need to be estimated, i.e., . Here is i.i.d copies of , which is the random error variable and , , where
The relationship between the response variable Y and is established through , i.e., . is the link function that is unknown and needs to be estimated in this paper.
Let be a variance function that satisfies for a constant , such that
To reduce the dimensionality of the functional predictors , we adopt the method of FPCA in this paper. First, we need to standardize the original data by centering them, so that and .
By KL expansion and Mercer’s theorem, can be expanded as
where represents the functional principal component scores, and are called functional principal components, which are the eigenfunctions of the covariance operator of . Notice that form an orthonormal basis for the function space . Then regression coefficient function can be expanded as
where represents the functional principal component scores.
After plugging the above two expansions into (1), we have
In (4), we truncated the predictors at (depending on sample size n), and increases asymptotically with .
3.3. Estimation
Define a parameter vector , where
For the estimation of the parameter vector and the link function g, we use an iterative estimation method to obtain the final estimates. Let there exist a constant ; with this c and n, we can define . The norm of finite dimensional spaces used in this paper is the Euclidean norm. The overall iterative process is briefly described below:
Step 1 To obtain the estimate of by solving Equation (5), it is assumed that the link function is known. The link function is required to be second-order continuously differentiable to ensure the existence of the Hessian matrix, moreover, for the variance function is defined on the range of link function and is strictly positive.
where , near , near , and
Here, and represent the corresponding estimated value in step 1 but not the final estimate.
We introduce the following matrix:
Then, Equation (5) can be expressed in matrix form, i.e.,
We can solve it by the weighted least squares method. A Taylor expansion of , where
and then we can get
where . Simplification yields estimates
where , .
Let
Step 2 By local linear regression, the estimates , of the link functions g, are obtained.
Let the bandwidth of the kernel function converge to zero and define . Since the convergence rates of and are different, their bandwidth choices should also be different. Let denote the bandwidth of , and denote the bandwidth of , but in this paper, for simplicity, the bandwidth is chosen. Let the distributions of both the functional predictors and the scalar predictors Z belong to a compact support set U, and we have . To simplify the expression, we let , . For a fixed , apply the method of local linear regression to obtain an initial estimate of and for g and , respectively. We minimize the weighted sum of squares at any point u, and the formula for calculating the weighted sum of squares is
Step 3 Using the method of Step 1, the link function is replaced by the estimated link functions and , where . To update , solve the estimation equation (5) for . From this we can obtain the estimated value of
Step 4 Using the method in Step 2, the parameter vector is replaced by the estimated , where From this we obtain the estimates and for g and , where
Step 5 Repeat the above steps until converge, and stop the iteration.
Step 6 The final estimate of the regression coefficient is obtained as , and the estimate of the link function g is obtained as .
4. Asymptotic Properties
To derive the asymptotics of the estimates of the link function and the regression coefficients , some additional assumptions are required:
- (C1)
- There exists for a constant , such that
- (C2)
- Let the density function of be strictly positive, and satisfies the first-order Lipschitz condition when .
- (C3)
- The kernel function satisfies the first-order Lipschitz condition and is a bounded and continuous symmetric probability density function and satisfies
- (C4)
- . Here, h is the bandwidth of the kernel function.
- (C5)
- For , as .
Remark 1.
(C1) It is a necessary condition for the asymptotic normality of the estimator. (C2) Ensures that , are far from 0 when is close enough to θ. (C3) The usual assumptions about the kernel function. (C4) The usual assumptions about the bandwidth. (C5) Some controls are applied to m in order to make the convergence faster.
4.1. Asymptotic Convergence of
Lemma 1.
Let be independent and identically distributed random vectors. Furthermore, assume that for any , there exist , and such that is the joint density function of . Let be a bounded and strictly positive kernel function that satisfies the Lipschitz condition, we have
Proof.
See Proposition 4 in Mack and Silverman (1982) [22]. □
Theorem 1.
If we assume that (C1)–(C5) holds, for , then we have
where , , and for the kernel function, let
Proof.
where
By expanding , , we obtain that
From Lemma 1, it can be proved that for
Then
where , ⊗ indicates the Kronecker product.
Inverting the matrix , we get
Let
where , and
By expanding , we obtain when
The Taylor expansion of at u is
where , .
Since , (10) can be transformed into
Corollary 1.
If we further refine the condition in assumption (C4) such that , then it follows that
4.2. Asymptotic Convergence of
First, we need to provide some more specific explanations for the estimation iteration process mentioned in “Estimation”, which makes some preparation for Theorem 2.
(1) solving by Equation (5) given the assumption that the link function is known. Assume , then it follows that
Let , where
and satisfies , . Similarly, we can obtain
(2) Solving given the link function is unknown by
where . Similarly, we can obtain
where .
Lemma 2.
If the assumptions (C1)–(C5) hold, we have
Proof.
Let , , By Theorem 4.1 of Chiou and Müller [24], we know that and , then
where A, B, and C can be expressed as
Then. by (14) we can get
□
Lemma 3.
If the assumptions (C1)–(C5) hold, we have
Proof.
Combining Theorem 1 and in Lemma 2, we can prove that
□
Theorem 2.
If we assume that (C1)–(C5) hold, we have
In the case of truncated models for , let be the estimator of , , where . We define = . Therefore, we have the following expression:
Furthermore, let , where . Here, I represents a dimensional identity matrix.
Proof.
By using the Taylor expansion with a suitable mean value , we can obtain
Then, by Lemmas 2 and 3, (15) can be deformed as
Then, we can get
By combining the above equation with
we can get
By (16), it can be seen that it transforms the relationship between and in the case of unknown link functions into the relationship between and in the case of known link functions, and then combined with Theorem 1 in [25], the proof of Theorem 2 can be obtained. □
4.3. Asymptotic Convergence of
Theorem 3.
If we assume that (C1)–(C5) hold, for , then we have
Proof.
The above expression transforms the relationship between and g into the relationship between and g (i.e., Theorem 1). Therefore, by Theorem 1, we can get Theorem 3. □
Corollary 2.
If we further refine the condition in assumption (C4) such that , then it follows that
Remark 2.
Let represent the eigenvalues and eigenvectors of Ω, where
Then, the 95% confidence band for the regression coefficient function can be expressed as
where , , .
5. Simulation
We consider a binary response and two functional predictors as well as three scalar predictors. The functional predictors and () are observed at 50 equal distant time points on the interval .
The sample sizes are . Let the score coefficients for each functional predictor satisfy the following assumptions:
where .
where .
We define the orthonormal basis functions and , , which satisfy
Then, can be represented through Karhunen–Loeve expansion as follows:
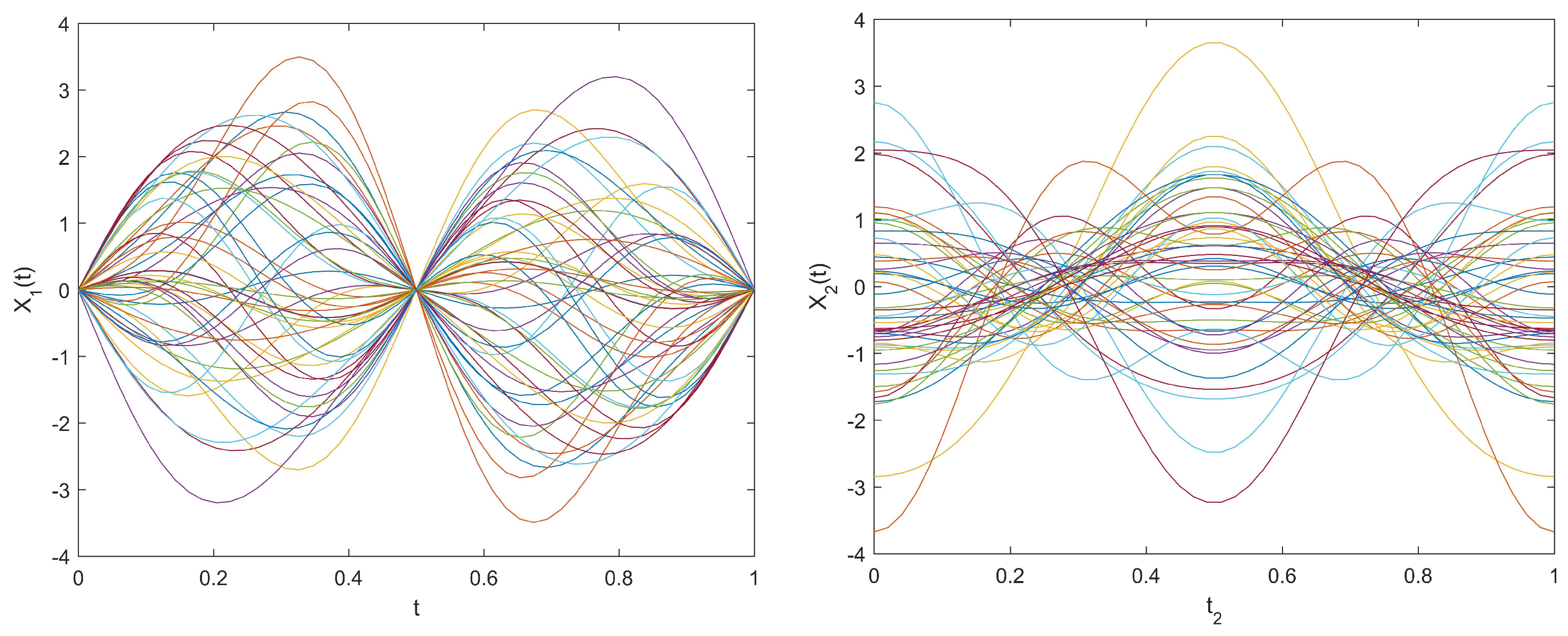
Figure 1 shows the 50 trajectories of the two functional predictors and .
The scalar predictor satisfies the following assumption
We assume that the regression coefficient functions of the functional predictors satisfy the following assumption
where and . Moreover, we assume that the regression coefficients of the scalar predictors satisfy , , .
Define
And we select the link function as
We generate binary response
as pseudo random sequence.
We obtain a sample
where n is the sample size. The number of functional principal components that explain 85% of cumulative variation contribution are , , respectively. We run 100 simulations.
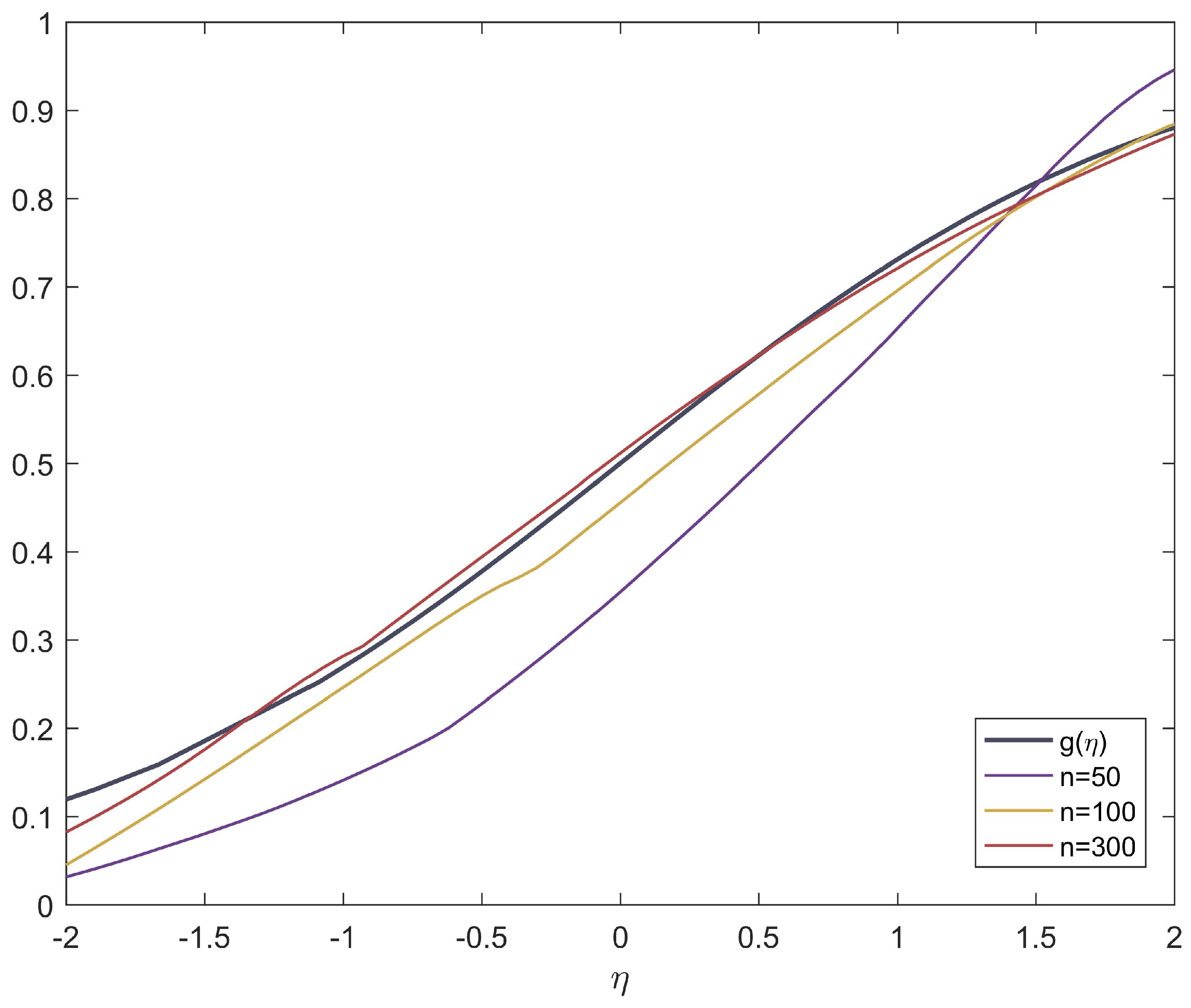
Figure 2 shows the asymptotic behavior of the link function under different sample sizes. The black lines in Figure 2 shows the relationship between and , where
The additional colored lines shown in Figure 2 represent the estimated link function for different sample sizes. These lines are obtained through iterative processes, starting with an initial value of g set to . The iterative process continues until one of the following conditions is met: 100 iterations have been performed, or the error in the regression coefficients is less than 0.01. The purpose of these lines is to illustrate the relationship between and , where
Since in this case, both and are in , we denote the argument of g and by , and the x-axis in Figure 2 is denoted by and is shown in the interval . Table 2 presents the estimates of evaluated through RMISE under different sample sizes. The RMISE is defined as follows:
where is the number of simulations here. In summary, Figure 2 and Table 2 demonstrate that as the sample size increases, the estimated link function becomes closer and closer to the true link function g.
In Table 3, it can be seen that both the SD and RMISE of the estimated regression coefficient functions and decrease as the sample size n increases.
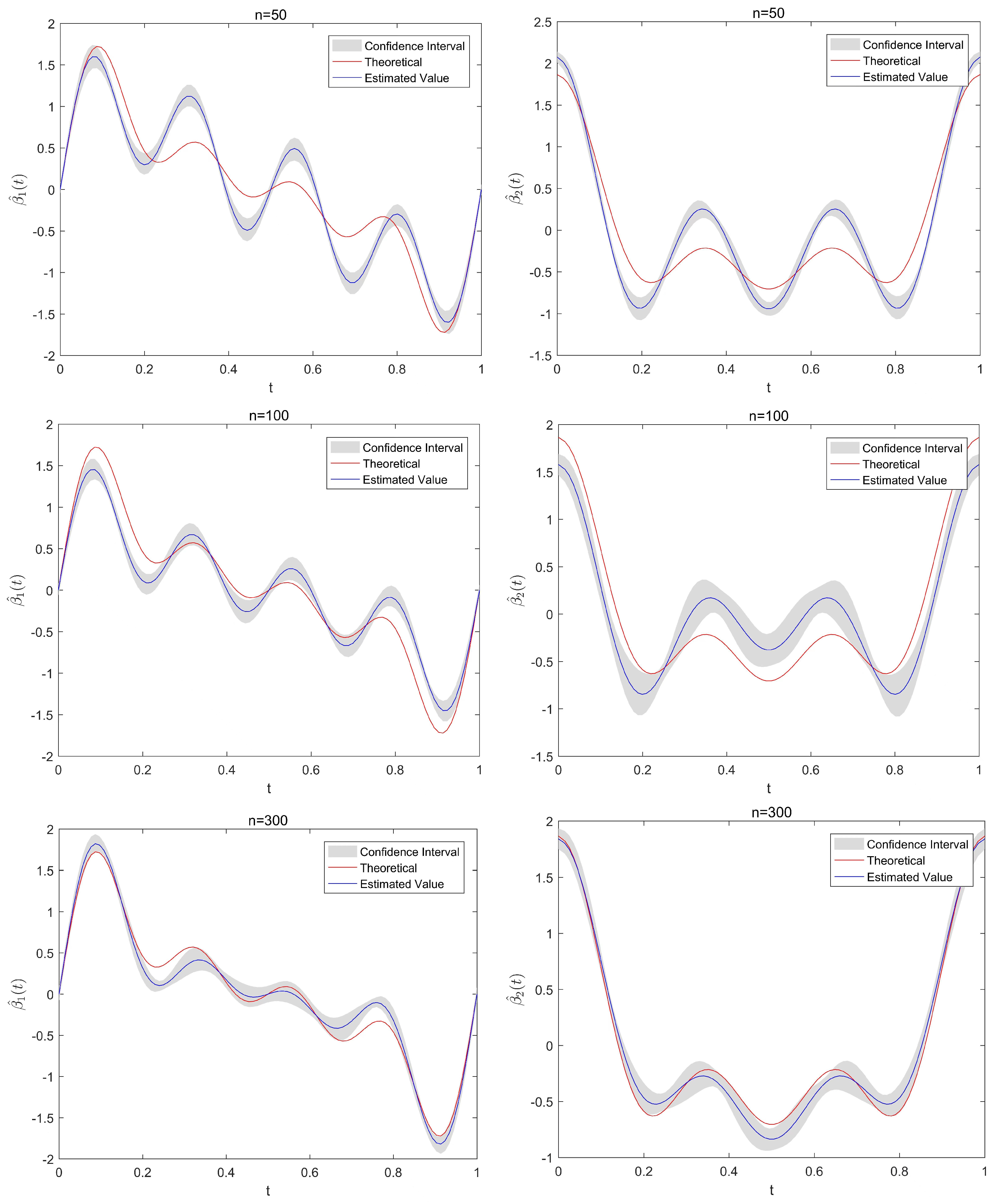
Figure 3 displays the estimated functional regression coefficients and , as well as their 95% confidence intervals under different sample sizes. The red curve in the figure represents the theoretical values of and , while the blue curve represents the estimated values and . The gray shaded area represents the 95% confidence interval of the estimates. It can be seen that as the sample size increases, the estimated values become closer to the true values.
Table 4 presents the estimated scalar regression coefficient and corresponding standard deviation under different sample sizes. It can be seen that as the sample size n increases, becomes closer to the true values . Moreover, as the sample size n increases, the SD becomes smaller, indicating that the estimated values have more certainty.
Table 5 presents the M1 and M2 values for different sample sizes, where , MAE= , , MSE = , and and represent the real and the predicted values of the response variable, respectively. We can find that as the sample size increases, the values of M1 and M2 become smaller, indicating that the predictive performance of the model improves.
6. Application
As is well known, research on average life expectancy is crucial for social development, health policies, and population management. Studies on average life expectancy can help governments, health departments, and social institutions develop relevant policies and plans to improve people’s quality of life and health conditions. By understanding people’s life expectancy, the efficiency of healthcare systems and the effectiveness of social welfare and public health policies can be evaluated, providing a basis for resource allocation and planning. Additionally, research on average life expectancy can also help people understand population structure and trends, providing references for social-economic development, pension systems, and labor market planning. Therefore, in the application of our proposed model, we investigate factors that influence average life expectancy, including air quality index (AQI), temperature, GDP, and number of beds in hospitals.
6.1. Data Description
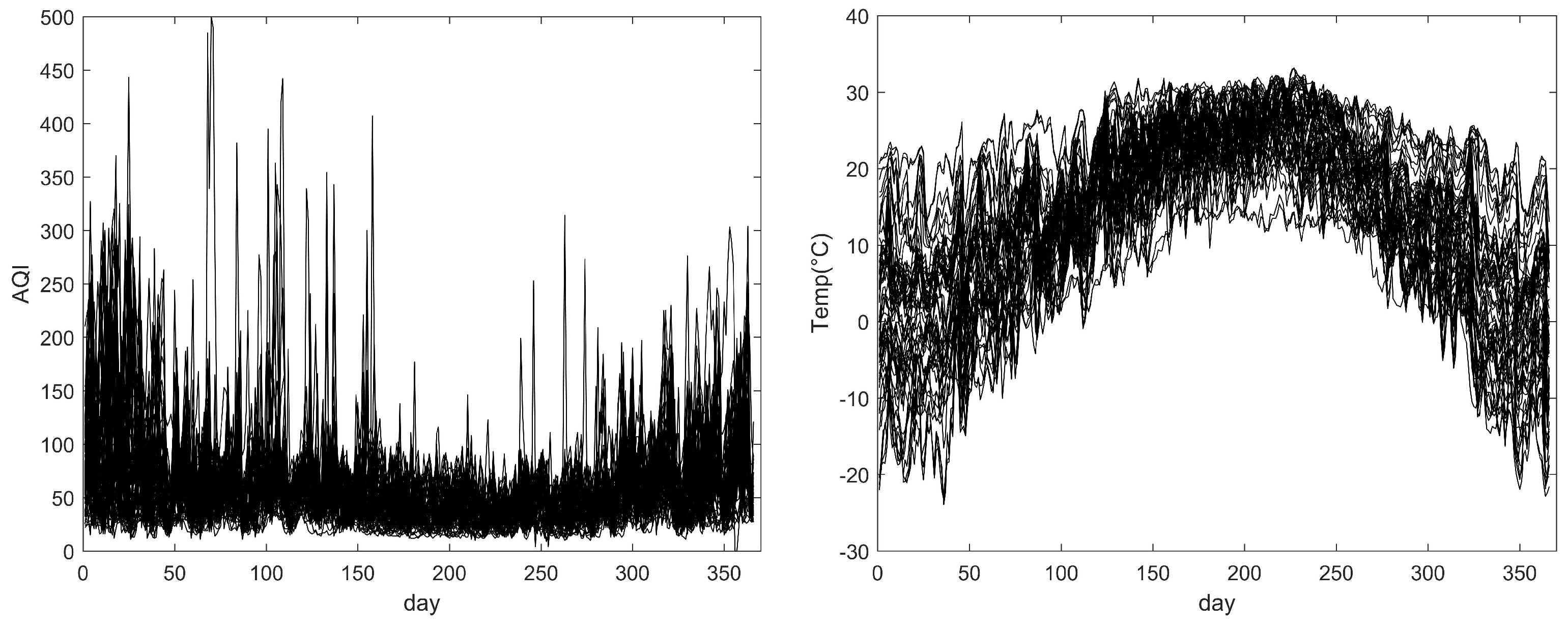
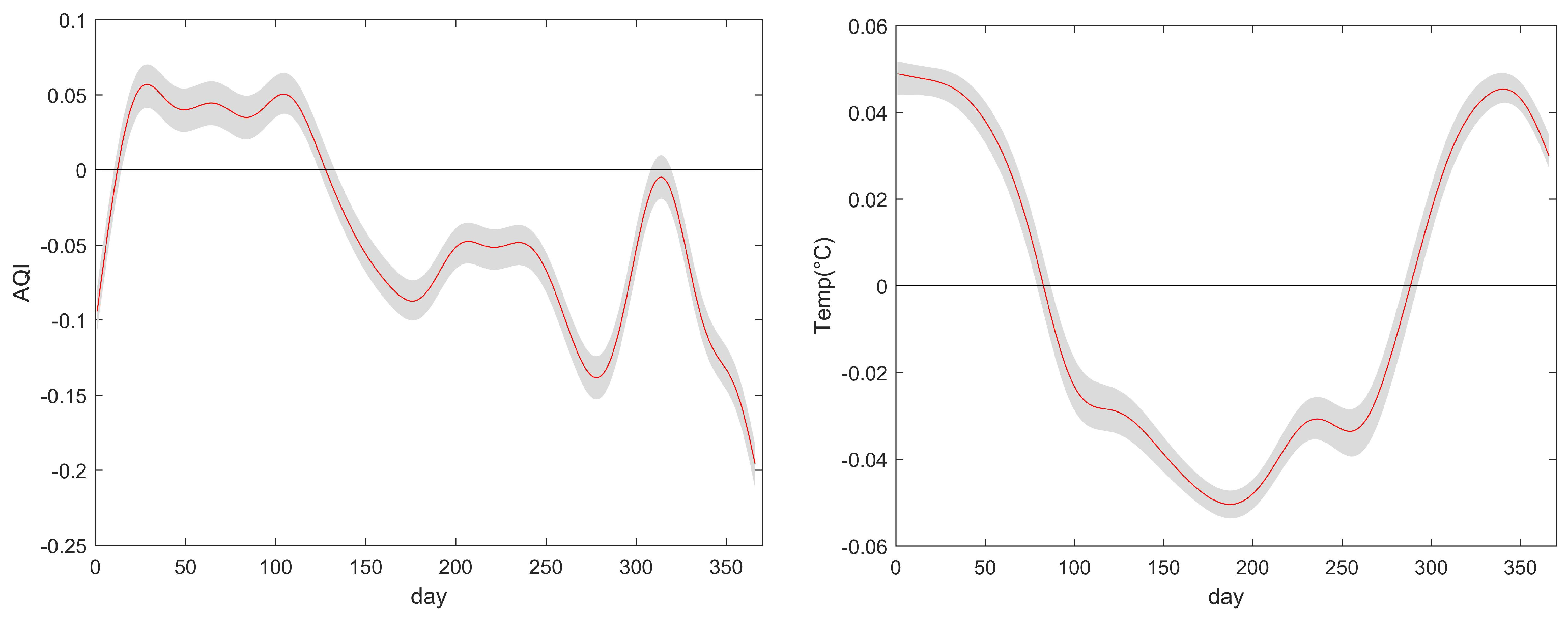
We collected average daily temperature (Temp) data for 58 cities in China in 2020 from the National Meteorological Science Data Sharing Service Platform, and average daily Air Quality Index (AQI) data from the National Environmental Monitoring Station. We also collected GDP, number of beds in hospitals, and life expectancy data for each city from local statistical bulletins and government documents. Among them, there are two functional predictive variables, which are daily AQI and temperature from 1 January to 31 December 2020, for 366 days in 58 cities. There are also two scalar predictive variables, which are GDP and number of beds in hospitals for the 58 cities in 2020. The response variable is the life expectancy of residents in each city in 2020.
Figure 4 shows the daily AQI and temperature for 58 cities in 2020.
6.2. Data Analysis
According to a report released by the National Health Commission, the average life expectancy of Chinese residents in 2020 was 77.9 years. Therefore, we divide the response variable as follows: when the life expectancy of a city is greater than 77.9 years, we represent it as 1; otherwise, when the life expectancy is less than 77.9 years, we represent it as 0. For the functional predictors, we first centralize the data. Second, we conduct FPCA and select the number of functional principal components that explain 75% of the variation. The number of components for AQI and temperature is and , respectively. We use GCV to demonstrate the predictive accuracy of the estimators. In this application, .
6.3. Results Analysis
By inputting the data into the generalized partially functional linear model, we obtain the regression coefficient function for the functional predictors and the regression coefficients for the scalar predictors. The results are shown in Table 6 and Figure 5, respectively.
Table 6 presents the estimated values of the regression coefficient for scalar predictor variables. We can see that both GDP and number of beds in hospitals have a positive relationship with life expectancy, and are significant at the 5% level. This means that when a region has a higher GDP and more hospital beds, the life expectancy in that region is longer. In other words, the better the economic development and medical resources of a region, the longer the life expectancy.
In Figure 5, we see the estimated values of the regression coefficient function . For AQI, we can find a negative relationship between AQI and life expectancy in general. The higher the value of AQI, the more serious the air pollution is, and the lower the life expectancy corresponding to it. However, there is a more obvious positive relationship trend in February to April, which may be influenced by some other external factors. For temperature, we can find that the effect of temperature on life expectancy varies with the change of seasons. In spring, summer, and fall (March to October), the effect of temperature on life expectancy is negatively correlated, and in winter (November to February), it is positively correlated, which is consistent with the conclusion in Huang et al. [19].
To confirm the necessity of considering the unknown link function model, we choose models without a link function and with the logit link function (i.e., ) and compare them with our proposed models with unknown link functions. In order to evaluate the prediction performance of the three models, we use MAE, MSE, and . Additionally, we calculate the accuracy using the confusion matrix, where we define TP as the number of samples correctly classified as positive, TN as the number of samples correctly classified as negative, FP as the number of samples incorrectly classified as positive, and FN as the number of samples incorrectly classified as negative (missed detections). We obtain the model’s accuracy using the formula
When the values of MAE and MSE are smaller, it indicates that the model has a smaller prediction error and better performance. When is closer to 1, it indicates that the model has a stronger ability to explain the response variable. The experimental results are shown in Table 7. It can be seen that the model we proposed has the best performance.
7. Conclusions
This article proposes a generalized partially functional linear model for scalar response and predictor variables that include both functional and scalar components, without specifying a link function. We use functional principal component analysis to reduce the dimensionality of functional data, estimate the regression coefficients using the maximum likelihood estimation method, estimate the link function using the method of local linear regression, iteratively obtain the final estimator, and establish the asymptotic normality of the estimator. The accuracy of the proposed model is validated through simulation studies.
The article applies the proposed model to the study of average life expectancy. Using daily AQI, temperature, GDP, and number of beds in hospitals for 58 cities in China in 2020, the study explores the impact of environmental, economic, and medical factors on life expectancy. The results indicate that GDP and number of beds in hospitals have a positive correlation with the life expectancy, while the AQI has an overall negative correlation. Temperature has a negative correlation with the average life expectancy in spring, summer, and autumn, and a positive correlation in winter. Overall, the study concludes that the average life expectancy is higher in areas with better environmental, economic, and medical development.
This model can be used in various fields, including economics, bio-medicine, engineering, etc. However, this model still has certain limitations. For example, the relationship between air quality and temperature needs to be further considered. There is a certain correlation between temperature and air quality. Generally, an increase in temperature can lead to the intensified volatilization and diffusion of pollutants in the air, thereby causing a decline in air quality. In the next phase of research, we will consider the interactions between functional predictors to make results more accurate. In addition, the algorithms and optimization methods of the model can be further improved to enhance computational efficiency. Combining this model with other machine learning methods can further improve predictive performance.
Author Contributions
W.X.: methodology, software, validation, writing—review, supervision, funding acquisition. S.L.: methodology, software, data curation, writing—original draft. H.L.: writing—review, supervision. All authors have read and agreed to the published version of the manuscript.
Funding
This research is supported by the Yujie Talent Project of North China University of Technology (Grant No. 107051360023XN075-04).
Data Availability Statement
The original data supporting the results of this study can be obtained from the National Meteorological Science Data Sharing Service Platform, the National Environmental Monitoring Station, and local statistical bulletins.
Acknowledgments
The authors would like to thank the referees and the editor for their useful suggestions, which helped us improve the paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ramsay, J.O. When the data are functions. Psychometrika 1982, 47, 379–396. [Google Scholar] [CrossRef]
- Ramsay, J.O.; Silverman, B.W. Functional Data Analysis, 2nd ed.; Springer: New York, NY, USA, 2005. [Google Scholar]
- Horváth, L.; Kokoszka, P. Inference for Functional Data with Application; Springer: New York, NY, USA, 2012. [Google Scholar]
- Shin, H. Partial functional linear regression. J. Stat. Plan. Inference 2009, 139, 3405–3418. [Google Scholar] [CrossRef]
- Shin, H.; Lee, M.H. On prediction rate in partial functional linear regression. J. Multivar. Anal. 2012, 103, 93–106. [Google Scholar] [CrossRef]
- James, G.M. Generalized linear models with functional predictors. J. R. Stat. Soc. Ser. B 2002, 64, 411–432. [Google Scholar] [CrossRef]
- Müller, H.G.; Stadtmüller, U. Generalized functional linear models. Ann. Stat. 2005, 33, 774–805. [Google Scholar] [CrossRef]
- Shang, Z.F.; Cheng, G. Nonparametric inference in generalized functional linear models. Ann. Stat. 2015, 43, 1742–1773. [Google Scholar] [CrossRef]
- Wong, R.K.W.; Li, Y.; Zhu, Z.Y. Partially Linear Functional Additive Models for Multivariate Functional Data. J. Am. Stat. Assoc. 2019, 114, 406–418. [Google Scholar] [CrossRef]
- Scallan, A.; Gilchrist, R.; Green, M. Fitting Parametric Link Functions in Generalized Linear Models. Comput. Stat. Data Anal. 1984, 2, 37–49. [Google Scholar] [CrossRef]
- Weisberg, S.; Welsh, A.H. Adapting for the missing link. Ann. Stat. 1994, 22, 1674–1700. [Google Scholar] [CrossRef]
- Chiou, J.M.; Müller, H.G. Quasi-likelihood regression with unknown link and variance functions. J. Am. Stat. Assoc. 1998, 93, 1376–1387. [Google Scholar] [CrossRef]
- Chiou, J.M.; Müller, H.G. Estimated estimating equations: Semiparametric inference for clustered and longitudinal data. J. R. Stat. Soc. Ser. B 2005, 67, 531–553. [Google Scholar] [CrossRef]
- Bai, Y.; Fung, W.K.; Zhu, Z.Y. Penalized quadratic inference functions for single-index models with longitudinal data. J. Multivar. Anal. 2009, 100, 152–161. [Google Scholar] [CrossRef]
- Pang, Z.; Xue, L. Estimation for the single-index models with random effects. Comput. Stat. Data Anal. 2012, 56, 1837–1853. [Google Scholar] [CrossRef]
- Yuan, M.; Diao, G. Sieve maximum likelihood estimation in generalized linear models with an unknown link function. Wiley Interdiscip. Rev. Comput. Stat. 2017, 10, e1425. [Google Scholar] [CrossRef]
- Kokoszka, P.; Reimherr, M. Introduction to Functional Data Analysis; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar] [CrossRef]
- Rao, A.R.; Reimherr, M. Nonlinear Functional Modeling Using Neural Networks. J. Comput. Graph. Stat. 2023, 32, 1248–1257. [Google Scholar] [CrossRef]
- Huang, C.; Barnett, A.G.; Wang, X.; Tong, S. The impact of temperature on years of life lost in Brisbane, Australia. Nat. Clim. Chang. 2012, 2, 265–270. [Google Scholar] [CrossRef]
- Yang, Y.; Qi, J.L.; Ruan, Z.L.; Yin, P.; Zhang, S.Y.; Liu, J.M.; Liu, Y.N.; Li, R.; Wang, L.J.; Lin, H.L. Changes in Life Expectancy of Respiratory Diseases from Attaining Daily PM2.5 Standard in China: A Nationwide Observational Study. Innovation 2020, 1, 100064. [Google Scholar] [CrossRef] [PubMed]
- Deryugina, T.; Molitor, D. The Causal Effects of Place on Health and Longevity. J. Econ. Perspect. 2021, 35, 147–170. [Google Scholar] [CrossRef]
- Mack, Y.P.; Silverman, B.W. Weak and strong uniform consistency of kernel regression estimates. Probab. Theory Relat. Fields 1982, 63, 405–415. [Google Scholar] [CrossRef]
- Masry, E.; Tjøstheim, D. Estimation and Identification of Nonlinear ARCH Time Series: Strong Convergence and Asymptotic Normality. Econom. Theory 1995, 11, 258–289. [Google Scholar] [CrossRef]
- Chiou, J.M.; Müller, H.G. Nonparametric quasi-likelihood. Ann. Stat. 1999, 27, 36–64. [Google Scholar] [CrossRef]
- Xiao, W.W.; Wang, Y.X.; Liu, H.Y. Generalized partially functional linear model. Sci. Rep. 2021, 11, 23428. [Google Scholar] [CrossRef] [PubMed]
Figure 1.
The predictors and .

Figure 2.
Asymptotic properties of the link function g. The black line in the graph represents the true link function . The purple, yellow, and red lines in the graph represent the estimated link functions under sample sizes of , , and , respectively.
Figure 2.
Asymptotic properties of the link function g. The black line in the graph represents the true link function . The purple, yellow, and red lines in the graph represent the estimated link functions under sample sizes of , , and , respectively.

Figure 3.
Estimated values of regression coefficient function , (blue curves) and their 95% confidence intervals (grey area) for difference sample size, where the red curves are the theoretical regression coefficient functions , .
Figure 3.
Estimated values of regression coefficient function , (blue curves) and their 95% confidence intervals (grey area) for difference sample size, where the red curves are the theoretical regression coefficient functions , .

Figure 4.
Daily AQI (left plot) and daily temperatures (right plot) for 58 cities in 2020; each curve represents one city.
Figure 4.
Daily AQI (left plot) and daily temperatures (right plot) for 58 cities in 2020; each curve represents one city.

Figure 5.
Estimated values of regression coefficient function and their 95% confidence intervals.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
The abbreviations and their corresponding full forms.
| Abbreviation | Full Form |
|---|---|
| FPCA | Functional principal component analysis |
| KL expansion | Karhunen–Loeve expansion |
| RMISE | Root Mean Integrated Square Error |
| SD | Standard Deviation |
| GCV | Generalized Cross Validation |
| MAE | Mean Absolute Error |
| MSE | Mean Squared Error |
| TP | True Positive |
| TN | True Negative |
| FP | False Positive |
| FN | False Negative |
Table 2.
RMISE of g and for different sample size n.
| n | RMISE |
|---|---|
| 50 | 0.3540 |
| 100 | 0.2734 |
| 300 | 0.1449 |
Table 3.
SD and RMISE of the estimated values of and for different sample sizes n.
| n | SD | RMISE | |
|---|---|---|---|
| 50 | 0.2475 | 0.3405 | |
| 100 | 0.1344 | 0.2517 | |
| 300 | 0.0552 | 0.1204 | |
| 50 | 0.2536 | 0.3232 | |
| 100 | 0.1261 | 0.2863 | |
| 300 | 0.0239 | 0.1033 |
Table 4.
Estimated values of scalar regression coefficients and their SD in brackets for different sample sizes n.
Table 4.
Estimated values of scalar regression coefficients and their SD in brackets for different sample sizes n.
| n | |||
|---|---|---|---|
| 50 | 0.7298 (0.191) | 0.5928 (0.177) | 0.5307 (0.232) |
| 100 | 0.6892 (0.092) | 0.5832 (0.071) | 0.4894 (0.096) |
| 300 | 0.7105 (0.019) | 0.5732 (0.018) | 0.4988 (0.016) |
Table 5.
The M1 and M2 values for different sample sizes n.
| n | M1 | M2 |
|---|---|---|
| 50 | 0.3182 | 0.1579 |
| 100 | 0.3028 | 0.1498 |
| 300 | 0.2921 | 0.1406 |
Table 6.
Regression coefficients and their significance levels.
| Estimate | Std.Error | t Value | Pr (>) | |
|---|---|---|---|---|
| 0.6776 | 0.339 | 1.9988 | 0.04639 | |
| 0.7354 | 0.367 | 2.0038 | 0.04585 |
Table 7.
Comparison between Unknown Link Function Model, Logit Link Function Model, and Model without a Link Function.
Table 7.
Comparison between Unknown Link Function Model, Logit Link Function Model, and Model without a Link Function.
| Link Function | MAE | MSE | Accuracy | |
|---|---|---|---|---|
| Unknown | 0.2584 | 0.1399 | 0.8916 | 81.03% |
| Logit | 0.2872 | 0.2511 | 0.6673 | 75.86% |
| Without | 0.4777 | 0.3146 | 0.4118 | 74.14% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Xiao, W.; Li, S.; Liu, H. Generalized Partially Functional Linear Model with Unknown Link Function. Axioms 2023, 12, 1089. https://doi.org/10.3390/axioms12121089
AMA Style
Xiao W, Li S, Liu H. Generalized Partially Functional Linear Model with Unknown Link Function. Axioms. 2023; 12(12):1089. https://doi.org/10.3390/axioms12121089
Chicago/Turabian StyleXiao, Weiwei, Songxuan Li, and Haiyan Liu. 2023. "Generalized Partially Functional Linear Model with Unknown Link Function" Axioms 12, no. 12: 1089. https://doi.org/10.3390/axioms12121089
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.