
Natural Language Processing Adoption in Governments and Future Research Directions: A Systematic Review

1
Faculty of Applied Sciences, Macao Polytechnic University, Rua de Luís Gonzaga Gomes, Macao 999078, China
2
Department of Computer Science, State University of New York, Incheon 22012, Republic of Korea
3
Centre for Continuing Education, Macao Polytechnic University, Rua de Luís Gonzaga Gomes, Macao 999078, China
*
Author to whom correspondence should be addressed.
Appl. Sci. 2023, 13(22), 12346; https://doi.org/10.3390/app132212346
Submission received: 14 October 2023
/
Revised: 1 November 2023
/
Accepted: 3 November 2023
/
Published: 15 November 2023
(This article belongs to the Special Issue Natural Language Processing (NLP) and Applications)
Abstract
:Natural language processing (NLP), which is known as an emerging technology creating considerable value in multiple areas, has recently shown its great potential in government operations and public administration applications. However, while the number of publications on NLP is increasing steadily, there is no comprehensive review for a holistic understanding of how NLP is being adopted by governments. In this regard, we present a systematic literature review on NLP applications in governments by following the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) protocol. The review shows that the current literature comprises three levels of contribution: automation, extension, and transformation. The most-used NLP techniques reported in government-related research are sentiment analysis, machine learning, deep learning, classification, data extraction, data mining, topic modelling, opinion mining, chatbots, and question answering. Data classification, management, and decision-making are the most frequently reported reasons for using NLP. The salient research topics being discussed in the literature can be grouped into four categories: (1) governance and policy, (2) citizens and public opinion, (3) medical and healthcare, and (4) economy and environment. Future research directions should focus on (1) the potential of chatbots, (2) NLP applications in the post-pandemic era, and (3) empirical research for government work.
1. Introduction
Artificial intelligence (AI) is being applied extensively by governments globally to initiate more achievement in political affairs [1]. NLP, as a branch of AI research, has also been studied and applied to public administration gradually, and people become familiar with NLP with the rapid development of generative NLP technologies like ChatGPT. NLP refers to the techniques of programming computers to process and analyse vast volumes of natural language data. Putting it simply, the goal of NLP is to make a computer “understand” the contents of documents. NLP is becoming a need of every sector nowadays, especially for governments or institutions in the public sector that need to process a large number of documents. For instance, governments can use NLP technologies to improve the quality of public services [2,3,4], to build citizens’ trust [5], and to increase efficiency and effectiveness in government work [6]. Such technologies have already created considerable value in multiple government functional areas, such as healthcare [7], education [8], e-government services [9], and decision-making [10].
But why has NLP become more and more popular among governments worldwide? It can be explained that amidst the recent global pandemic that made a social virtue out of maintaining physical distance, our main domain of life has moved online. The concept of digital life is not new, but as a result of societal transformation over the past several decades, this phenomenon also applies to the public sector, known as the digital transformation in government. E-governance has become an active topic and has been embraced in many countries to improve traditionally dysfunctional government services and to enable more effective governance arrangements [11]. According to the 2018 United Nations E-Government Survey, the number of countries that provide information and services through government websites has increased to 176 countries from 154 out of 193 member states [12]. Driven by behavioural changes due to the pandemic and the ongoing effort of digital government services, the use of NLP technology in government affairs will be an inevitable trend in the near future.
The growing popularity of NLP in government not only leads to an increase in the number of publications in the research domain but also broader and fragmented literature. Thus, the research domain needs a comprehensive review of extant literature for a holistic understanding [13]. In the extant literature, previous researchers have attempted to offer review papers on NLP from a generic perspective; however, those kinds of experiences cannot directly be duplicated in the government sector, which needs context-specific approaches to expand the knowledge to feasible digital implementations. In a wider context, there are context-specific literature reviews on NLP applications in health [14,15], marketing [16], and engineering [17], but little research focuses on NLP’s adoption by governments and public administration. Earlier studies are mainly to provide a generic review in mapping analytical processes or applications of NLP in other domains, and a thorough understanding of NLP in government is still missing.
To fill this research gap, this systematic literature review is designed with the aims of (1) discovering what NLP techniques are applied in governments, (2) identifying the most discussed purposes of using NLP techniques in governments, and (3) understanding the trending NLP topics in government research and presenting suggestions for future research directions. We have reviewed 1032 articles collected from three databases, i.e., Scopus, Web of Science (WoS), and the Digital Government Reference Library (DGRL), which are recognised for systematic reviews in both technological and governmental fields. Our work successfully identified three main contributions (namely: automation, extension, and transformation) and four types of application (namely: governance and policy, citizens and public opinion, medical and healthcare, as well as economy and environment) from the literature. These insights can help researchers and practitioners refine and apply their work in government and public administration settings.
This paper is structured as follows: Section 2 introduces the current status of the research area, and Section 3 discusses the research methodology, which leads to the retrieval and analysis of our literature collection. Section 4 provides an overview of the findings, Section 5 discusses the results and makes some suggestions for further research directions, and Section 6 makes concluding remarks about our research.
2. Background
2.1. Natural Language Processing
To achieve human-like language processing for a variety of activities or applications, Gelbukh [18] defines NLP as a theoretically motivated set of computational approaches for evaluating and modelling naturally occurring text at one or more levels of linguistic analysis. It explores how text or speech in natural language may be read by computers and then used to perform beneficial tasks [19]. As a result of the linguistics and AI nexus [20], NLP was initially created in the 1950s. But currently, NLP derives its inspiration from a variety of disciplines, necessitating a large mental knowledge base expansion among researchers and developers. To be specific, linguistics, mathematics, computer and information sciences, electrical and electronic engineering, AI and robotics, psychology, etc., are some of the disciplines that constitute the basis of NLP [19].
NLP was created to facilitate user tasks and meet the demand for natural language computer interaction [21]. Since its inception in the 1950s, NLP research has focused on topics such as machine translation, question answering, information extraction, topic modelling, information retrieval, and opinion mining more recently [22]. Over the past 20 years, NLP has developed into a fascinating field of scientific study and practical technology. Its application can serve a variety of purposes: human–human communication can be facilitated by machine translation (MT), human–machine interaction can be facilitated by conversational agents, or both humans and machines can gain from the massive amount of human language content that is currently available online by examining and learning from it [23]. NLP is particularly useful for people or children who do not have the time to learn new specific languages or become proficient in them because it is impossible to force users to learn the machine-specific language if they want to communicate with the computer [24].
With the rapid development of NLP, a series of algorithms and models came into people’s eyesight. For instance, by comparing the relative frequency of terms in a given document with the inverse proportion of that word in the entire document corpus, Term Frequency–Inverse Document Frequency (TF-IDF) analyses the relevance of a word in a given document [25], which is viewed as a classical method in the field. Other NLP techniques that are often applied include topic modelling [26], text classification [27], and text sentiment analysis [28]. Support Vector Machine (SVM) is another conventional algorithm that can be created as a classifier [29,30]. Different from TF-IDF, SVM learns by example to assign labels to objects to accomplish the task [31]. Word2Vec distinguishes itself and demonstrates its advantage when working with a large dataset. It creates a vocabulary from a training text corpus, learns the vector representation of each word, and computes the cosine distance between each word. The original feature dimension is projected into a new lower dimension by grouping similar words based on their distances, reducing the time and challenge of classification [32].
2.2. Natural Language Processing in Governments
As part of this study’s focus on the application of NLP in government, a literature analysis was conducted to determine the current level of research on using NLP to improve the quality of government work. NLP is a subfield of computer science and AI [33]; in other words, it is similar to machine learning, computer vision, and others. NLP is also one of the fundamental technologies of AI. Since AI has been widely employed in governments for a while, a preliminary survey of the literature reveals that earlier works have mainly concentrated on comprehending and describing the status of AI in public administration rather than concentrating on a particular technology. For example, Zuiderwijk and others [1] conducted and introduced a systematic review of AI use in government. They concluded that multidisciplinary, theory-driven research on AI use in public governance is required. There is additional research that discusses the state of the art in current research, looks at the challenges of implementing AI in the public sector, and presents the impacts of some of the major policy initiatives throughout the world in relation to AI in government [34,35]. Researchers discovered a rising trend of interest in AI in the public sector in 2019, with India and the US being the two most active countries [36].
In terms of NLP, it is hard to find any review or summary research about NLP use in governments. Even so, as mentioned in the introduction section, various NLP approaches have been introduced to the public sector: a method was proposed to automatically construct a large-scale annotated dataset for the classification of government documents using an information retrieval approach [6]. For the demands of public administration, Lommatzsch [37] presented a chatbot framework that can respond to all types of questions about the services and offices that are provided. Moreover, the framework can facilitate complex dialogues and encourage citizens by providing hints and recommendations after improvement [38]. Similar to chatbots, Schwarzer and others [2] proposed a question-answering (QA) system that successfully managed ambiguous questions by integrating retrieval methods, task trees, and a rule-based strategy. For most queries about German government services, it provided high-quality responses. In order to improve e-government management, Alguliyev [39] identified latent social networks through the study of user comments via opinion and text mining algorithms. Furthermore, NLP has also been applied to assess public opinion and give government feedback or assist the public sector in improving pertinent policies [8,40,41,42]. Especially during the COVID-19 period, many researchers have used data from social media platforms such as Twitter and Facebook to extract comments or posts from the public to identify various insights [43].
In conclusion, there have been numerous studies on AI applications in governments, but the status quo of the research on NLP applications in governments presents a gap. NLP technologies are being used in governments increasingly and diversely, and what is missing from the past studies is a comprehensive understanding and structured analysis of the applications of NLP in government and the public sector. Therefore, this study aims to analyse and summarise the existing NLP literature in the context of governance and public administration, which is deemed necessary and informative for relevant researchers.
3. Material and Methods
The data collection step followed the strict system review protocol called the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) process to collect literature, as it has been used in disciplines related to our work, including social sciences, public administration, and health and medical sciences. In the area of software engineering, Kitchenham et al.’s protocol of systematic literature review is also widely used [44], and a recent work suggests that it is comparable with the PRISMA protocol [45]. Due to the interdisciplinary nature of this research, we have ensured that our systematic review is consistent with both protocols.
Since PRISMA is a complete process for meta-analysis, it requires going through the assessment of full texts for eligibility [46]. A literature analysis differs from a systematic review in that complete text screening is only carried out when essential [47]. Since the abstracts of original papers are informative and accurate [48], they can concisely and clearly describe one’s work; therefore, this study utilised the abstracts of the collected papers to conduct the literature analysis. For this reason, we refer to the first two steps of this method for data collection. Further, in this study, we applied a computer-aided literature analysis method to analyse the research data, which is based on NLP and network analysis approaches with steps of data pre-processing, word frequency calculation, word extraction, word classification, co-word analysis, and network visualisation [49].
3.1. Search Strategy
The search terms used for this literature analysis are defined in Table 1. We used the advanced search option for each database, if available, which enabled us to use Boolean operators (“OR” and “AND”). The search results were limited to (1) peer-reviewed journal articles and conference proceedings (2) published between January 2012 and December 2022 (3) in the English language (4) reporting on NLP related to governments at any level and (5) indexed in any of the three international databases: Scopus, WoS, or DGRL. These databases were selected because the first two databases cover mostly scientific conferences and journal articles, and the last one includes specific domain knowledge of the disciplines of government and public administration.
The search was undertaken in January 2023, and a total of 1558 records were initially found (6 results in the DGRL, 460 results in Web of Science, and 1092 results in Scopus). We particularly examined whether any additional, relevant sources were available through Google Scholar. The top 100 search results were examined using the same search terms as in Table 1 due to the fact that the relevancy of the first 50 records was highest and subsequently rapidly decreased [1]. The Google Scholar database contained some of the search results that were already found in the above-mentioned databases; nevertheless, no new record was produced by this database. In addition, DGRL is a published open-access library that can be downloaded for reference. The search in DGRL was first started in November 2022. Scholl and their colleagues [50] published Version 18.0 of the DGRL on 15 December 2022, so we updated the search in December 2022 to be as inclusive as possible. Nevertheless, this search turned up no new information. After removing the duplicates, 1203 records remained for the next screening procedure.
3.2. Screening Strategy
This step aims to assess the relevance and quality of the selected studies. Different from a systematic review, a literature analysis only needs to screen the complete text when necessary. In this paper, the relevance of each article was assessed by looking at its title and abstract. Articles found in this stage that did not meet the following two screening criteria were excluded from the analysis [1]:
- The use of NLP should play a significant or major part in the study (its research objective, questions, etc.). Studies with an unrelated or secondary focus on the usage of NLP were excluded from this phase. For example, those articles may use other methods in AI but merely mention NLP technologies and do not use them in their research.
- NLP use in government (or the public sector) should be the main focus of the study, and the study’s objective should directly serve or benefit governments. For example, if NLP was not applied in the context of a government, or the authors only used the open data source from the government to conduct research in other fields, these articles were excluded.
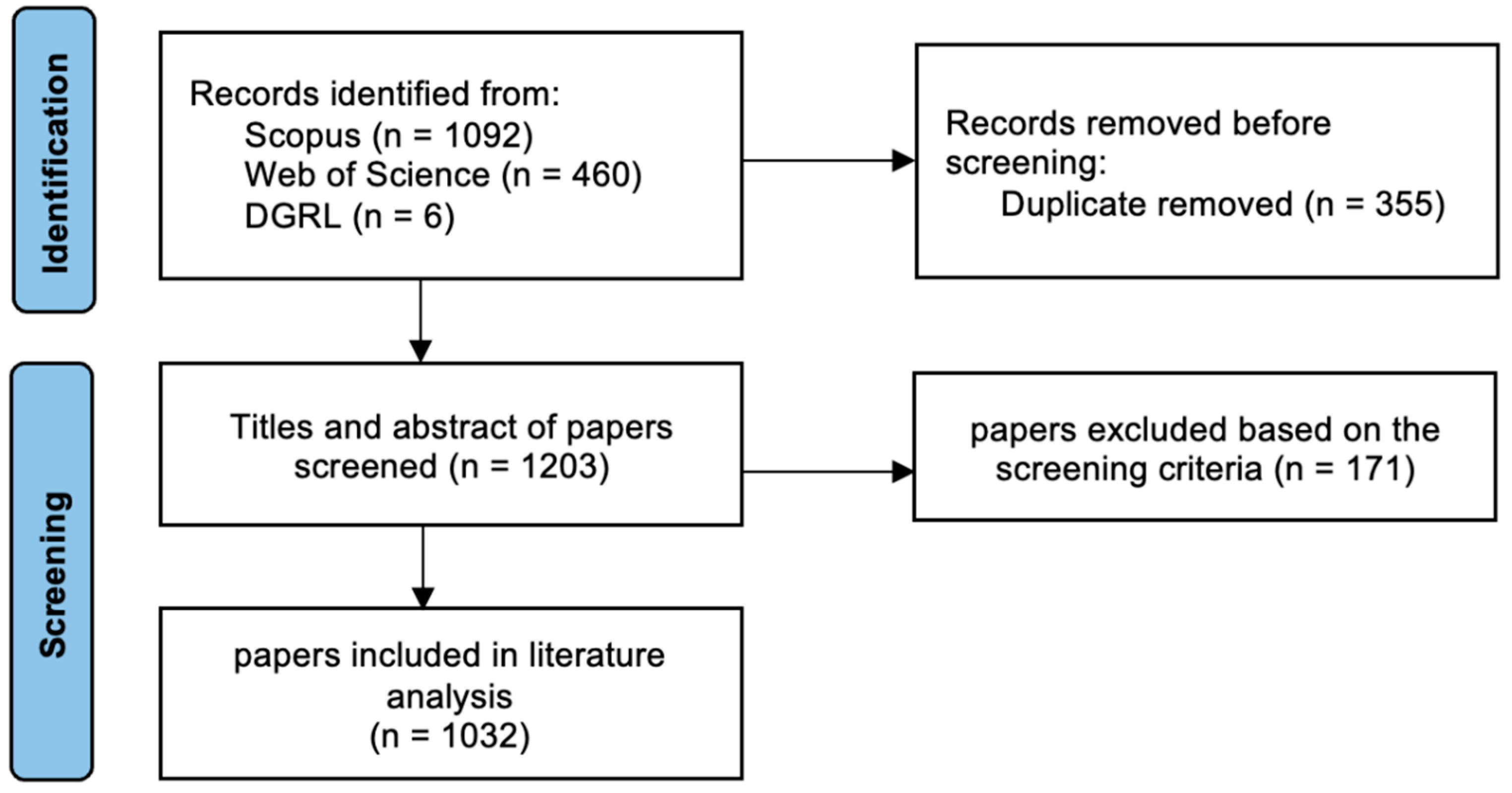
The screening of 1203 titles and abstracts was carried out by the authors and an expert in the NLP area independently. When there were different views, papers were included rather than excluded to ensure that all potential records could be examined. The screening criteria resulted in the exclusion of 114 publications. Finally, 1032 papers were included for literature analysis (Figure 1), and the abstracts of these papers were the data used to conduct the research. The full list of the literature before and after screening is provided in the Supplementary Materials.
3.3. Data Analysis
To attain an overview of the research content of the collected data, the abstracts of the collected literature were processed and analysed at the word level. First, we converted all the text to lowercase for consistency. Stop words, which deliver little meaning and punctuation, were filtered, and then identical terms (e.g., “natural language processing” and “nlp”; “chatbots” and “chatbot”) were combined. Generic keywords associated with abstract formatting requirements (such as “method” and “conclusion”) were removed. Verbs, adjectives, adverbs, and nouns were converted into their prototypes. As a result, 19,146 terms were extracted from the dataset in total by using word frequency counting. The minimal number of occurrences for a term in the word extraction process was set to 25, and 614 of the 19,146 words satisfied the inclusion criterion. However, among the 614 words generated, not every word was consistent with the research objectives, so we screened useless words and extracted related words manually. After several rounds of screening and extraction, the result contained 143 keywords in total. The above tasks were performed with the Python 3.9, NLTK 3.7 [51], NetworkX 2.8 [52], and word_cloud 1.9 [53] packages.
Within these keywords, several topics regarding government management could be seen. Therefore, we performed a manual check to ensure a more accurate classification. Moreover, to explore the relationship between different NLP techniques and different research topics, we first labelled the words related to NLP techniques by following the guide of an expert in the area, including: “nlp”, “sentiment analysis”, “machine learning”, “classification”, “deep learning”, “artificial intelligence”, “nlp technique”, “identification”, “extraction”, “text mining”, “data mining”, “topic modeling”, “prediction”, “recognition”, “information retrieval”, “text classification”, “chatbot”, “opinion mining”, and “question answering”. The remaining words are mainly distributed in the following topics based on the collected articles: governance and policy, citizens and public opinion, medical and healthcare, economy and environment.
In addition to a great proportion of words having clear meanings, the authors then traced back to the collected literature to understand their potential meanings and used such additional information to classify the words that could not be clearly classified. For instance, “quality” referred to the quality of the information [54,55,56], “online” was related to the online discussion of the public [57,58,59,60], “agency” meant the government agency [61,62,63], etc.
4. Results
4.1. Descriptive Results
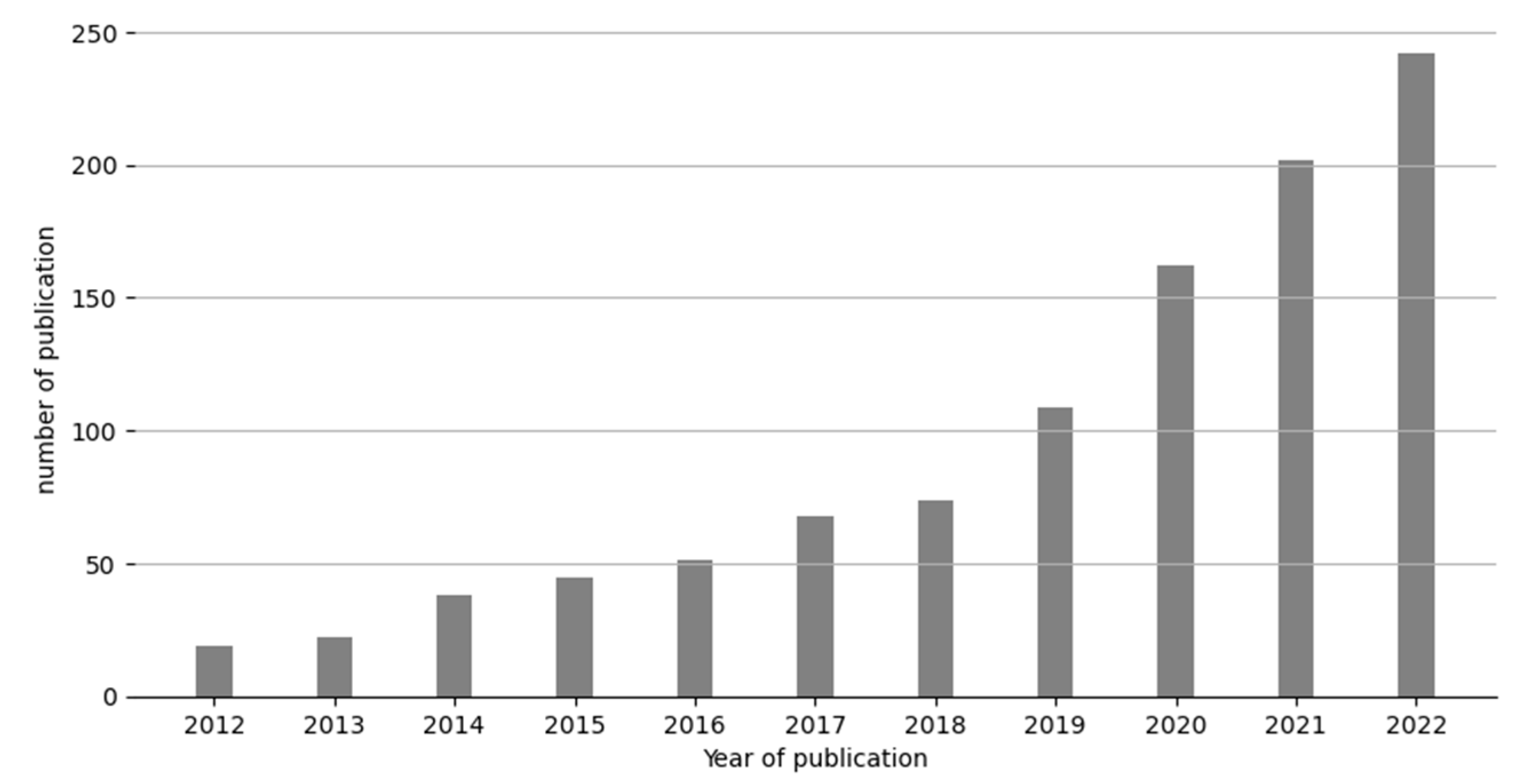
Figure 2 plots the annual trend of the publication numbers of NLP in government. It is noted that the number of publications in the past ten years has increased steadily. Our search was conducted in January 2023, which may not include all publications in the year 2022 (i.e., those that have not yet been published in databases but were accepted); however, the number of publications is already far more than the number from the previous year. From 2012 to 2022, the average growth rate of scientific research papers on government-related NLP research was 30.28%. The number of publications rose steeply between 2017 and 2022, accounting for 83.04% (857 out of 1032) of all included papers.
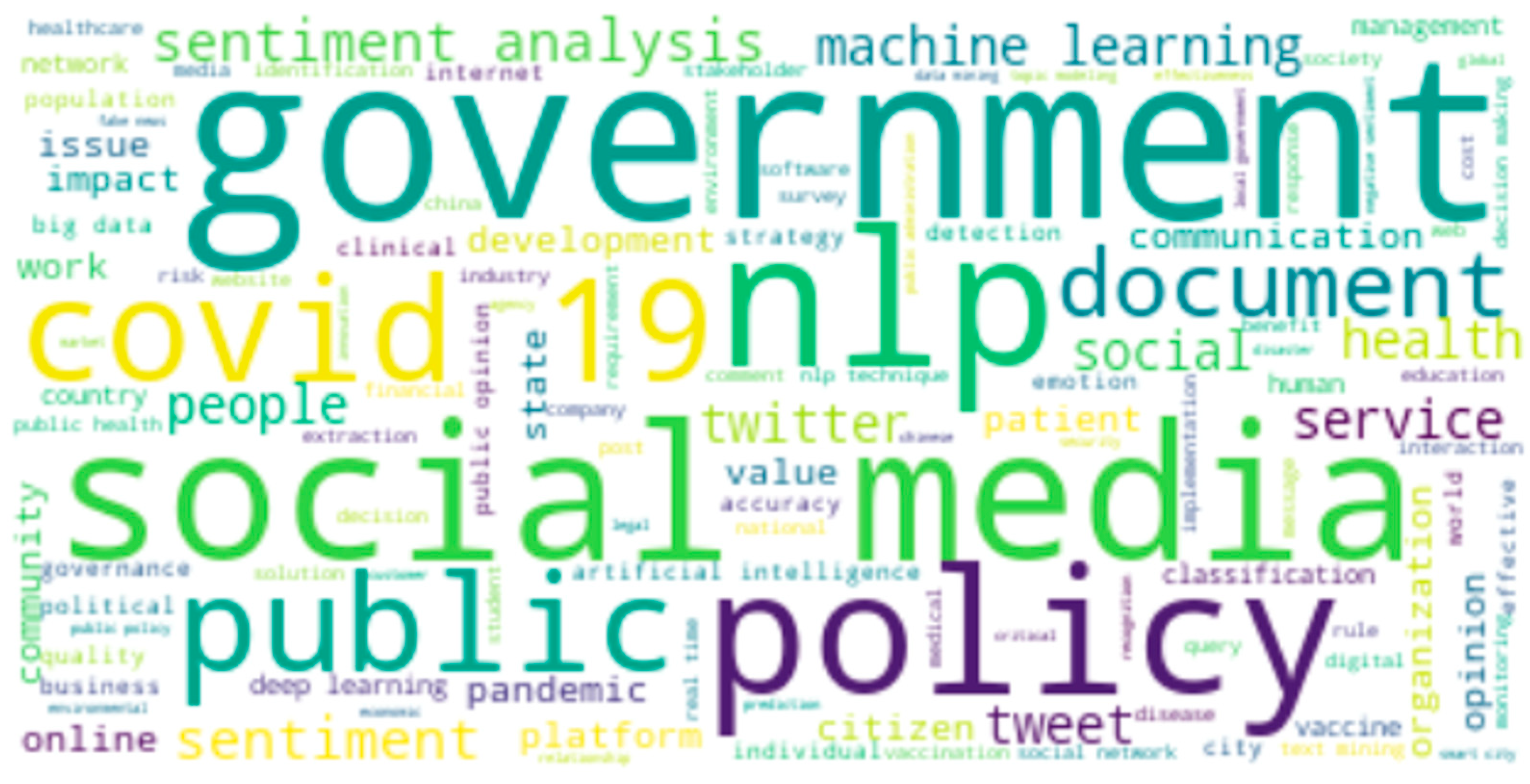
The keywords shown in Figure 3 illustrate the main concepts of NLP in government over these ten years, with the keywords with higher frequency reflected in a bigger size. This word cloud image provides a preliminary overview of the research content among all the articles. Intuitively, “government” occupies the largest position (with a frequency of 603). The keywords “covid 19”, “nlp”, “social media”, “public”, “policy”, “document”, “sentiment analysis”, and “machine learning” occurred many times in the corpus and they are positioned conspicuously. Additionally, “healthcare”, “management”, “global”, “media”, “smart city”, and “environmental” did not appear often, and they are all placed at the corners of the word cloud in smaller sizes.
4.2. Co-Word and Network Analysis
The co-occurrence relationship between two keywords refers to the degree of connection between two concepts when they are represented in a network data structure as source and target nodes. The co-occurrence count depicts the strength of the connection between a pair of words. Table 2 illustrates the top 10 co-occurrence relationships between NLP techniques and the keywords of the literature. Only 10 word pairs are listed due to space constraints. As shown in the table, “sentiment analysis” has a strong relationship with “social media”, “twitter”, “tweet”, showing its applications on social media platforms; “machine learning” is listed with its application areas of “sentiment”, “social media”, “public”, and “tweet”; “deep learning” is associated with “government”; and “classification” is related to “government” and “document”, which illustrates the popular use of deep learning for government document processing.
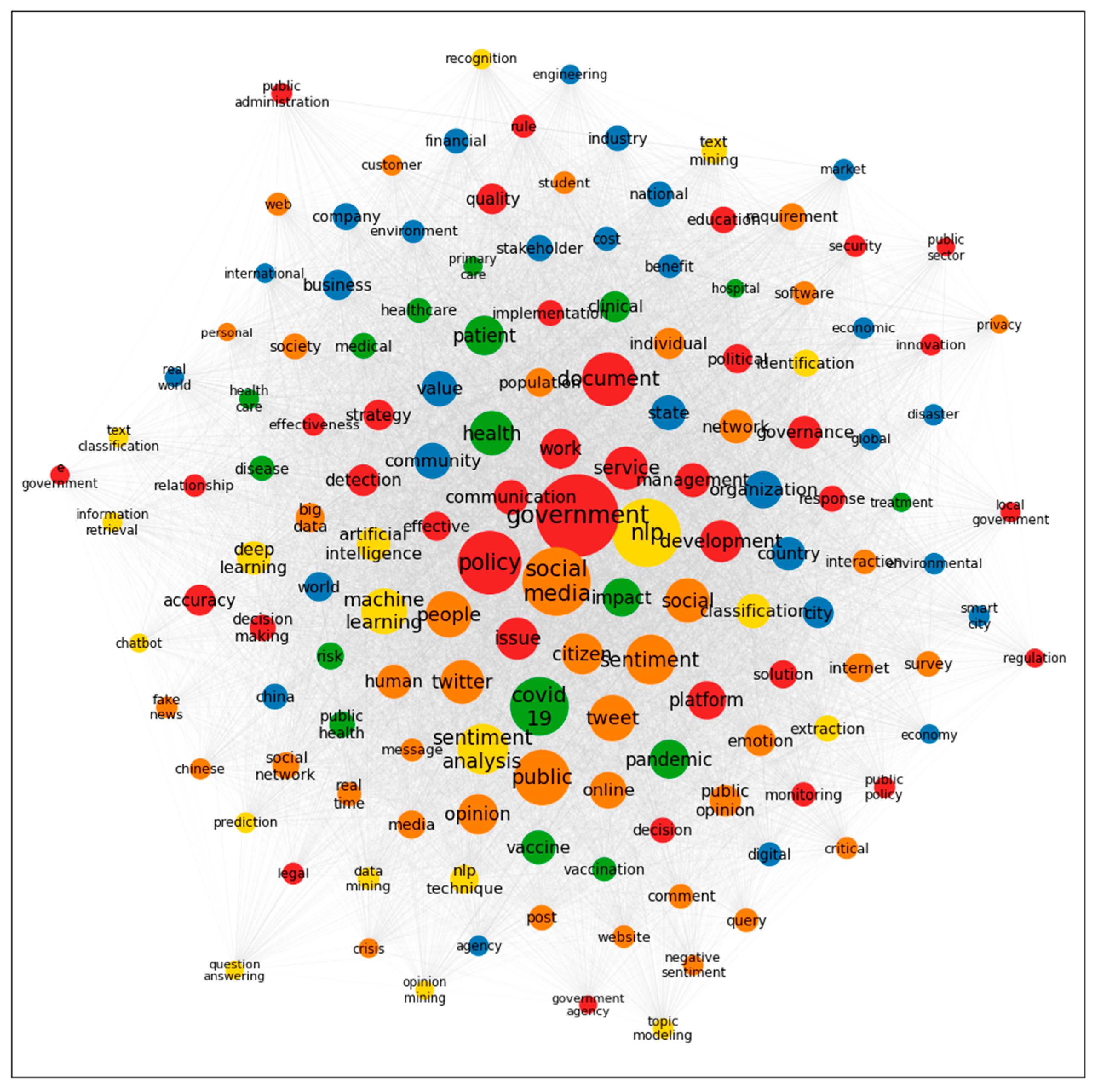
Figure 4 presents the network made with the pairs of co-words, which contained 143 nodes (representing research keywords) and 8293 relations (i.e., edges in the network indicating pairs of keywords co-appearing in all data). The density of the co-word network was measured at 0.831. To better visualise related concepts, several coloured nodes are defined: NLP techniques are represented by yellow nodes, red nodes stand for “governance and policy”, orange nodes refer to “citizens and public opinion”, green nodes are designated for “medical and healthcare”, and blue nodes represent “economy and environment”. The frequencies of words appearing in the dataset determine the sizes of nodes, and the words with larger nodes (such as “government”, “nlp”) reflect the key ideas in the corpus of the literature. The co-word visualisation can clearly show the overview of the NLP-related literature in government and public administration research. As shown in the figure, keywords such as “sentiment analysis”, “machine learning”, “classification”, “deep learning”, “artificial intelligence”, “identification”, “extraction”, “text mining”, “data mining”, “topic modeling”, “prediction”, “recognition”, “information retrieval”, “text classification”, “chatbot”, “opinion mining”, and “question answering” are the NLP techniques mostly found in the literature.
The measurement of the centralities of nodes is another accurate method for determining what is crucial within a network [64]. The results of frequency counts, eigenvector centralities, degree centralities, and closeness centralities of the top 30 keywords are shown in Table 3. The frequency counts were used to order the keywords in the table. When two or more keywords have the same occurrence value, the one with a higher degree of centrality is seen to be more important. Table 3 shows that the most influential concepts include “government”, “social media”, and “nlp”. Moreover, the result demonstrates that the keywords “health”, “social”, “patient”, and “community” have relatively high centrality values, despite their lower frequencies. These can be the research areas connecting other government research areas and NLP techniques in recent years.
Besides the analysis of the overall network (Figure 4), a detailed analysis of different research directions is also significant as it may lead to more undiscovered and interesting insights. The network visualisations and the co-occurrence matrixes between NLP techniques and different research directions are displayed below.
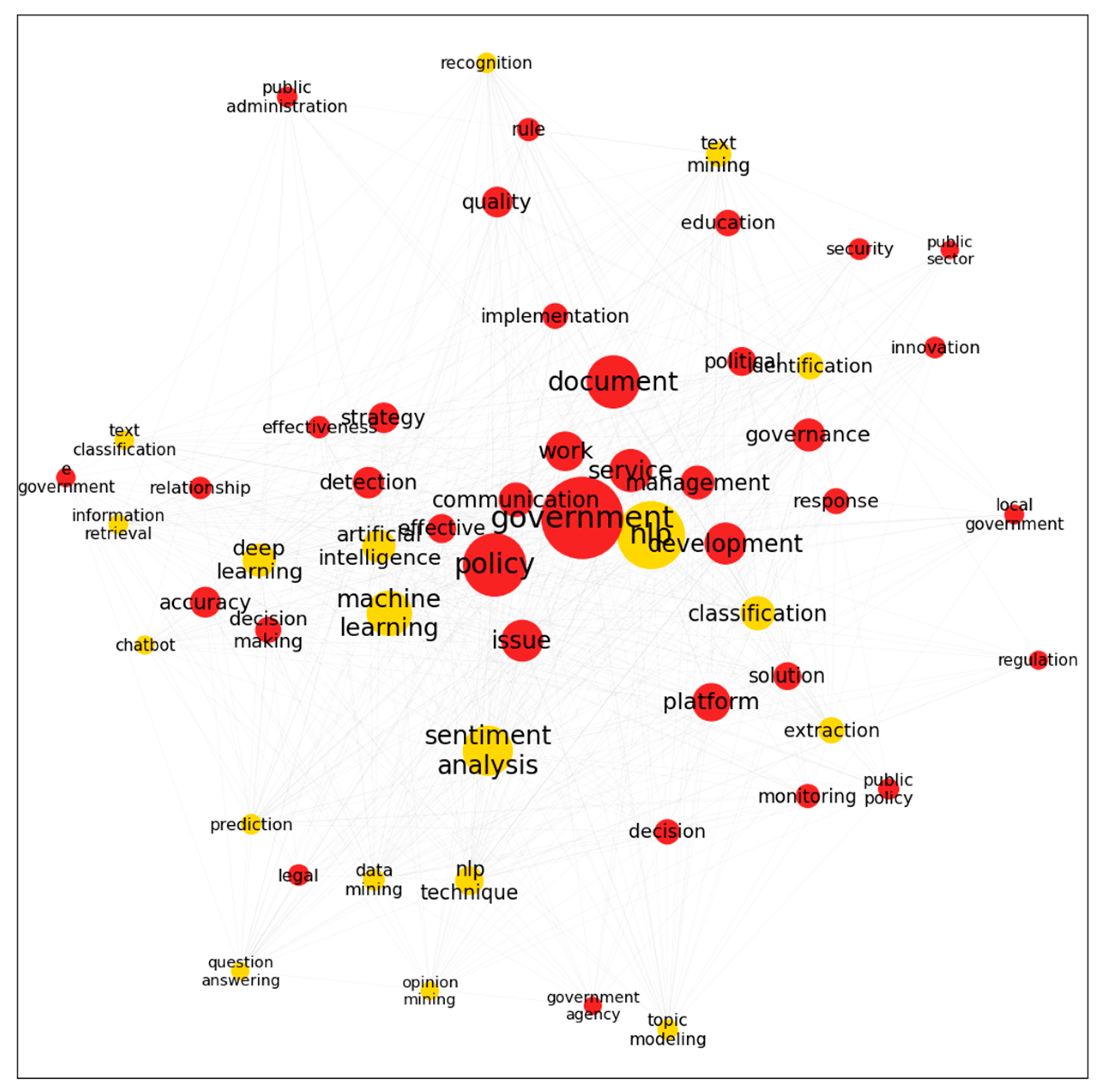
Figure 5 demonstrates the relationships of co-occurrence between the keywords of NLP techniques and the “governance and policy” direction. This research direction contains keywords such as “government”, “policy”, “document”, “service”, “development”, “communication”, “decision-making”, and “response”. Table 4 describes the top 10 popular NLP applications in this direction. Interesting word pairs include “deep learning” with “classification”, “chatbot” with “service”, and “machine learning” with “platform” and “policy”.
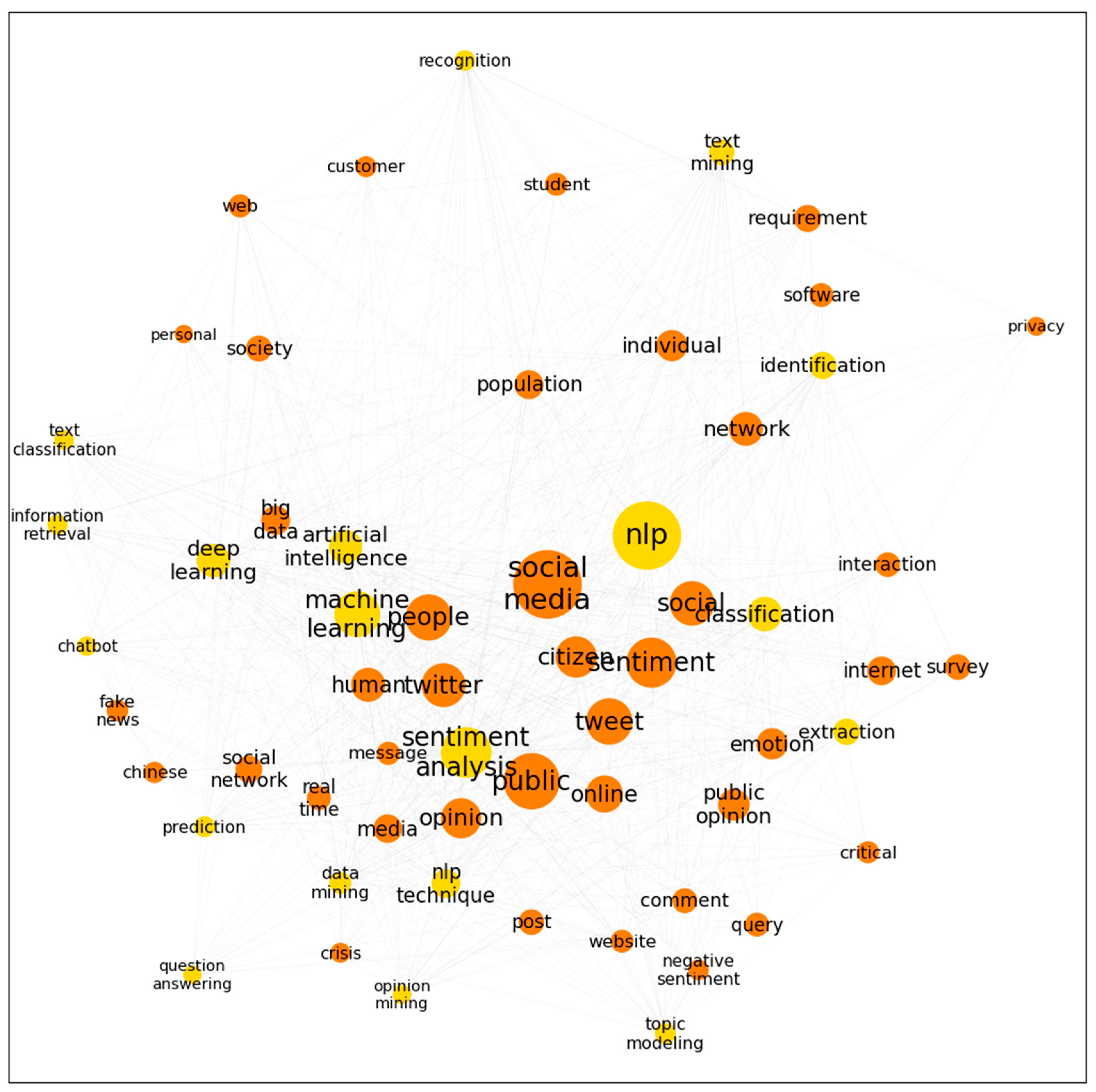
The network of keywords of NLP techniques and the research direction of the “citizens and public opinion” is plotted in Figure 6. This direction contains keywords like “social media”, “public”, “sentiment”, “tweet”, “people”, “social”, “twitter”, “citizen”, “opinion”, “online”, “public opinion”, “emotion”, “fake news”, etc., which are common keywords seen in social media analysis research. As shown in Table 5, the co-occurrence counts of “sentiment analysis” with “social media” rank first in this topic, followed by “sentiment analysis” with “twitter” and “tweet”. These keywords suggest the main research approaches under this research direction.
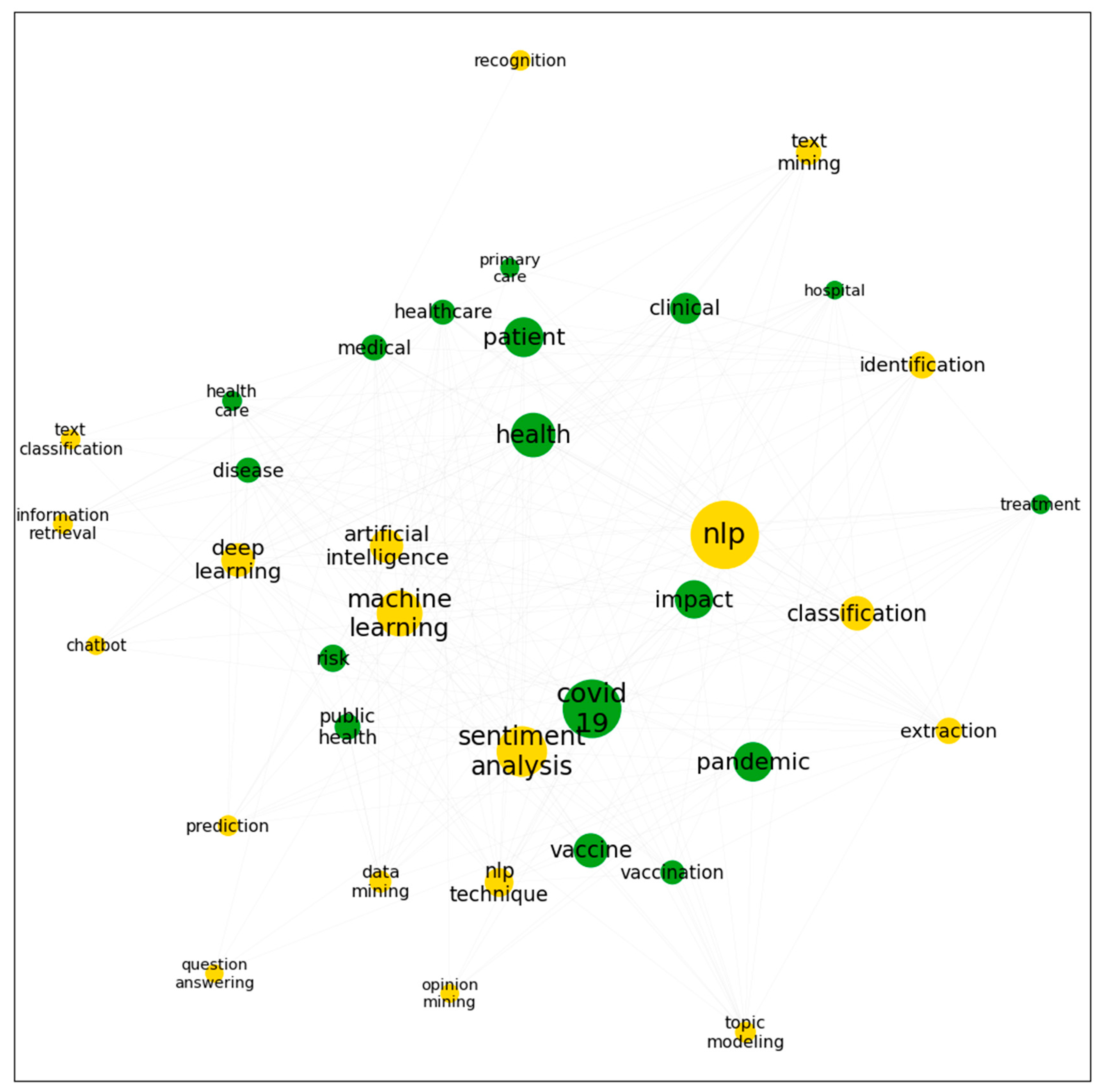
In terms of the “medical and healthcare” direction, it is made up of the following keywords, including “COVID-19”, “health”, “pandemic”, “impact”, “vaccine”, “clinical”, “risk”, “public health”, “medical”, “disease”, “healthcare”, “vaccination”, and “hospital” (Figure 7). By observing the co-occurrence counts in Table 6, it can be learned that governments paid the most attention to the following related research: “identification” with “patient” and “impact”; “topic modeling” with “vaccine”; “sentiment analysis” with “vaccine” or “vaccination”; “deep learning” with “pandemic”; and “machine learning” with “vaccination” and “pandemic”.
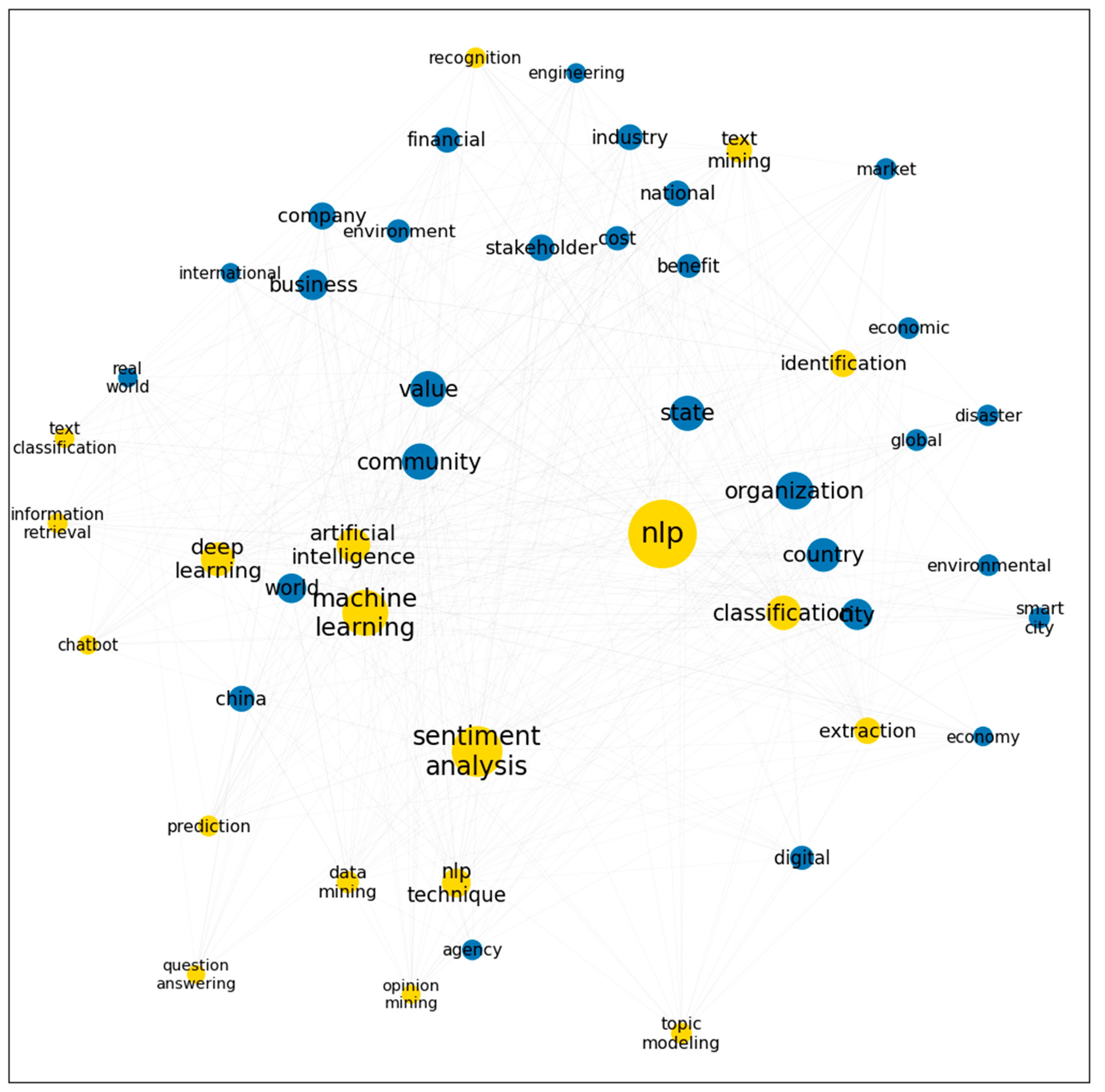
Figure 8 shows the NLP topics discussed in the “economy and environment” direction. Salient keywords in this area include “organization”, “community”, “value”, “state”, “country”, “city”, “business”, “world”, “company”, “stakeholder”, “industry”, “environment”, “disaster”, “smart city”, “agency”, “economy”, and “real world”. As listed in Table 7, under this topic, the linkages between “machine learning” with “organization”, “world”, “state”, and “market”, “identification” with “value” and “state”, as well as “classification” with “disaster” are strong, which shows that these mentioned NLP techniques are usually applied for rectifying these mentioned issues.
5. Discussion
NLP offers new methods for creating and capturing value and has the potential to dramatically change public administration. Based on our analysis, in the past ten years, it can be seen that NLP has contributed greatly and created impacts on governments from all aspects and at all levels. Multiple factors have contributed to this phenomenon. The enormous growth of NLP in government-related research can be attributed to the technological advancements of NLP during this time [21]. Additionally, many advantages of AI applications in the public sector have been widely recognised during this time, notably with regard to e-governance platforms and other NLP solutions [65]. Another contributing factor is that, after sailing through the pandemic, there may be a reduction in face-to-face interactions and an increase in using remote intelligent services with and within governments. Overall, the contributions of the literature can be further summarised into three levels based on an industrial classification of AI applications [66]:
- (1)
- Automation: NLP technologies are leveraged for automating processes and activities under this classification. Exemplar literature includes a discussion of an automatic system to offer COVID-19 information to German citizens [67];
- (2)
- Extension—NLP technologies are being utilised to support novel forms of governance that enhance rather than replace current procedures or activities, such as to enhance the algorithms for fake news identification [68];
- (3)
- Transformation—This category refers to the innovative forms of governance made possible by NLP technologies with the potential to replace or alternate the established ones. For example, chatting robots as a new form of citizen-to-government communication [69].
In the coming sub-sections, we discuss the implications of the use of NLP based on the categories of their application (as summarised in Table 8), followed by the implications of future research redirections inspired by the latest development of NLP and the public administration sector.
5.1. NLP for Governance and Policy
Government departments face thousands of documents to be processed every day [70,71], and how to efficiently extract accurate information from such documents is a vexing problem. As a type of information retrieval model, supervised classification models were suggested to automatically create large-scale annotated datasets for the categorisation of government documents [6]. As an example, the most important terms in the content of twelve national planning documents on AI were extracted and summarised using NLP approaches [72]. Such approaches enable applications to classify information and extract topics from policy documents [70], as well as to discover policy issues [73]. In addition, government services for citizens are frequently intricate and tied to a variety of requirements [2], which is why e-government is still acknowledged as a method for enhancing public services and the efficacy of public policies and partnerships [74]. To facilitate e-government, automatic question-document classification strategies can map pertinent documents and questions to different e-government services [75]. Schwarzer and co-workers provide a retrieval-based question-answering (QA) system for the e-government sector [2]. In general, a majority of the studies discussing the “governance and policy” topic apply NLP techniques to tasks such as text classification, information retrieval, question answering, and topic modelling.
5.2. NLP for Understanding Citizen and Public Opinion
Another common use of NLP in governmental work is to evaluate public sentiment and public opinion. This phenomenon can be explained by how the citizens’ faith in their governments has gradually eroded [5], especially during the tough pandemic period. We observe an increase in such literature during COVID-19, e.g., [76,77]. During such a time, it is important for governments to pay attention to citizens’ voices and make positive responses. Social media platforms are one of the main sources to obtain access to public perspective, as shown by keywords such as “social media”, “twitter”, “tweet”, “comment”, “post”, and “social network” in our analysis. Social media is a convenient and easy-to-use platform for people to express their emotions towards governments. Nevertheless, the data on social media platforms is unstructured and subjective; therefore, NLP techniques are used for exploring the data. For example, the Citizen-Pulse framework [78] performs text analytics on the comments of citizens towards the Indian government using methods like Named Entity Recognition. Meanwhile, when making opinions, people always have their own sentiments. When a government plans to take certain measures, it is important to distinguish whether citizens’ sentiments are positive or negative against the measures. Deep learning, a recent method of NLP analysis, has also gained attention in public administration research. For instance, it is used for evaluating the negativity (toxicity) in citizens’ collective emotions by using a deep learning-based classifier [79]. Researchers also use deep learning techniques to collect tweets and form a multi-class emotion classifier for studying the change in citizen emotions over time during the pandemic [80], which is beneficial to governments for formulating effective pandemic management strategies. Since the happiness of citizens with regard to public policies is crucial from both public and political angles, Rezk and others [81] have presented a predictive analytics framework based on historical citizen attitudes regarding past relevant policies. As a whole, sentiment analysis, deep learning, opinion mining, recognition, and classification are widely combined and used in this research area.
5.3. NLP for Medical and Healthcare
The research about “medical and healthcare” has not attracted much attention in the early years. In the past, governments have utilised a variety of techniques to collect information for any new health rules, such as door-to-door surveys, national census, or hospital records; however, these techniques are constrained and oftentimes time-consuming. In this case, NLP techniques offer practical answers in less time and with the same accuracy as traditional methods [82]. In an effort to reach more veterans with post-traumatic stress disorder (PTSD), the U.S. Government calculated the yearly and cumulative uptake and prevalence rates from 2001 to 2014 for each of the two EBPs for PTSD using NLP [83]. Furthermore, NLP can be used to create applications that can be used by governments to put in place prevention-focused policies and lower the cost of the disease’s total treatment [84]. To summarise, NLP techniques both lower costs and raise the standard of healthcare [7].
On the other hand, there are keywords in our analysis related to COVID-19, which has been discussed since its outbreak at the beginning of 2020. There is no doubt that public health has moved to the top of the priority list in many countries across the globe [82]. Researchers examined the changes in public opinion on social media based on NLP in 2021 [85]. Liew and Lee [86] use structural topic modelling to comprehend the challenges and opportunities for effective COVID-19 vaccination, which can inform the development of comprehensive policies for governments to encourage the uptake of the COVID-19 vaccine. NLP techniques can also be used to evaluate public health measures and supportive policies during the pandemic [87]. In order to help governments better comprehend the situation and assist them in putting suitable policies into place, this analysis intends to identify the public’s concerns and their responses to COVID-19 [43].
5.4. NLP for Economy and Environment
The direction of “economy and environment” is a typical one that has been discussed by governments, since they are quite related to the living quality of the public. Also related to the public health lens, COVID-19 had a significant negative impact on global health and the global economy due to the precautions taken to restrict its transmission [88]. To understand the impact of the pandemic, the publicly accessible work reports from governments are often analysed with NLP and sentiment analysis. One of those findings suggests that one should give local governments in China’s inland regions extra attention because of debt risks [89]. Apart from disease, natural disasters such as forest fires, earthquakes, and droughts also have a significant influence on people’s lives and the social economy, which makes governments attach great importance to it [90]. Taking one study as an example, a model system for unstructured social media data mining was developed to assist the Indonesian government in determining the impact of floods, landslides, and tornadoes [91]. The Spanish government has also made similar efforts. A social sensing application was created to crawl micro messages and evaluate them using NLP methods, which creates fresh opportunities for developing warning systems for the management, early identification, and avoidance of natural disasters [92]. NLP approaches are also applied to enhance practical areas like incident response management [93]. Recently, Lydiri and others [94] have developed an effective tool for detecting people’s perspectives on climate change based on an NLP model called BERT. These projects suggest that, even though NLP has little relativity with the economy and environment, the emergence of rising NLP technologies used in these traditional research areas can bring convenience.
5.5. Implications for Future Research
Based on the tendency of the current exponential growth of the NLP literature, it is expected that there will be more publications in government-related NLP in the future, where the publication volume will double every two years if the growth rate of the previous five years is sustained. To help researchers sailing through the rapid wave of NLP development, this study would like to put forward the following directions, which are noteworthy for future work:
- (1)
- The Potential of Chatbots: The literature analysis reveals a lack of interest in chatbots, though government agencies have gradually shown their interest in chatbots recently, such as [65,95]. Chatbot research is an active NLP research subfield, but the same may not be true in governmental research, given that “the development of chatbots for public administration services has received very little attention” [96]. In fact, chatbots are being used to perform a wide variety of tasks, for instance, placing orders for meals, making product recommendations, providing customer support, setting up meetings, etc. During the pandemic, chatbots’ ability to “chat” with people caught the focus of governments, and they are used as a solution for maintaining conversational engagements under social distancing policies [97]. However, there are few chatbot applications developed for local administrative services [96]. With the introduction of ChatGPT, the conversational capabilities of AI-driven tools have reached the eyesight of the public. It can carry on a conversation by picking up and comprehending human languages and engaging in dialogues in accordance with the chat’s context. One of ChatGPT’s first models can successfully talk with its users in English and other languages on a variety of topics, which has generated both excitement and controversy [98]. This relaxed conversation mode is friendly to the elderly and those who do not know how to use electronic devices well. If governments and researchers plan to use chatbots, the emergence of large language models like ChatGPT will bring benefits since they are suitable for answering questions and providing solutions for citizens, which can enable citizens to easily access government services.
- (2)
- NLP Applications in the Post-Pandemic Era: Another finding of ours is that COVID-19 became a topic of concern studied by many governments. Governments around the world have organised much of their work around the pandemic, and NLP can gauge the effectiveness of government policies [87]. As the illness appears less severe and has turned into a type of respiratory infection, the post-pandemic era has begun, and the emphases of governments’ work have also transformed. The disease has warned and reminded people of the importance of health and lifestyle, and therefore governments need to strengthen the management and the response to public health in the near future. Set against this background, what would be the public health issues that are worth following up on? This is a noteworthy question in the post-pandemic era. NLP approaches such as sentiment analysis and keyword summarisation can be used by governments for monitoring potential reports of infections. In addition, NLP techniques have been found to be useful in the reform of public health systems to collect citizens’ feedback and their sentiments towards the changes [99]. This can serve as a potential future research direction as healthcare systems continue to evolve after the pandemic.
- (3)
- NLP Empirical Research for Government Work: Governance and policy formulation can be viewed as the main functions of governments, and researchers have conducted different NLP studies to tackle the issues in these areas, for instance, creating a contemporary government early warning system and public policy monitoring system to assess government credit in real-time [100]. Other governance-related research includes an NLP-based e-governance platform [101,102] and decision-making systems [82,103]. Our work has identified that some government departments such as health and finance have started using NLP, and it has the potential to bring convenience to other departments, too. To this end, researchers can investigate how to discover novel approaches to improve the effectiveness or accuracy of NLP models to better assist government work, with the aim of eliminating heavy workloads and manual work in the future. To bring NLP into practice, governments must develop novel strategies and guidelines to evaluate the genuine qualitative advantages of various NLP models.
On the other hand, although AI technologies and theories concerning their effects on society have received considerable attention, contributing to empirical research is uncommon today [104]. NLP’s effects on public governance should therefore be empirically tested in future studies, which should go beyond the conceptual and speculative levels. For instance, future work can investigate the design and integration of NLP applications, as well as their integrations with other existing e-government infrastructures, which can create an impact beyond the performance of computational models. Finally, our findings show that NLP in government is still in its infancy and needs more research on how to apply different NLP concepts and approaches to various problems and issues in public administration. It is notable that many studies only use open-sourced NLP tools or software packages that can be directly applied, and future research should move to a higher level by sharing the experience and technical tricks that can be added to the body of knowledge. In general, automation should be built to improve productivity and better assist governmental work. For the public administration sector, NLP models and related information systems will need to go beyond laboratory experiments and should be able to be used in real-time in practical settings.
6. Conclusions
This study concludes that NLP adoption in governments is still a relatively unexplored area, and the emerging technologies and NLP applications in governments are worth further discussing and researching. On the other hand, we present a thorough investigation to identify the widely used NLP techniques and topics that are frequently discussed in governments. With co-word analysis, it can be seen that there are several NLP techniques that are being adopted often, and governments’ attentions and interests in NLP vary. Thus, our work can serve as evidence to help the researchers who need to understand the current research and obtain knowledge in this field. In practice, the study is a useful and current resource for advancing the knowledge of policymakers and practitioners while aiding them in organising and supporting initiatives related to NLP. However, it cannot be denied that our analysis suffered a degree of disturbance due to the presence of COVID-19-related keywords. Moreover, since some applications and practices of governments may not be published as journal and conference articles, we recommend future research to complement the literature review with a search for non-scientific literature, such as government reports, promotional materials, and websites.
Supplementary Materials
The supplementary materials can be downloaded at: https://www.mdpi.com/article/10.3390/app132212346/s1.
Author Contributions
Author Y.J. conducted the data collection, analysis, visualisation and wrote the first draft of the article. P.C.-I.P. was responsible for the initial analytical software, conceptualisation and made substantial revisions. D.W. and H.Y.K. supervised the research, provided funding and made contributions to manuscript writing and revision. All authors have read and agreed to the published version of the manuscript.
Funding
PC-IP was supported by Macao Polytechnic University and the Macao Science and Technology Development Fund (funding ID 0048/2021/APD). The Article Processing Charge of this paper was funded by Macao Polytechnic University.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The datasets used and/or analysed during the current study are available from the corresponding author on reasonable request.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zuiderwijk, A.; Chen, Y.-C.; Salem, F. Implications of the Use of Artificial Intelligence in Public Governance: A Systematic Literature Review and a Research Agenda. Gov. Inf. Q. 2021, 38, 101577. [Google Scholar] [CrossRef]
- Schwarzer, M.; Düver, J.; Ploch, D.; Lommatzsch, A. An Interactive E-Government Question Answering System. In Proceedings of the Lernen, Wissen, Daten, Analysen 2016, Potsdam, Germany, 12–14 September 2016; Volume 1670, pp. 74–82. [Google Scholar]
- Nasseef, O.A.; Baabdullah, A.M.; Alalwan, A.A.; Lal, B.; Dwivedi, Y.K. Artificial Intelligence-Based Public Healthcare Systems: G2G Knowledge-Based Exchange to Enhance the Decision-Making Process. Gov. Inf. Q. 2022, 39, 101618. [Google Scholar] [CrossRef]
- Ju, J.; Meng, Q.; Sun, F.; Liu, L.; Singh, S. Citizen Preferences and Government Chatbot Social Characteristics: Evidence from a Discrete Choice Experiment. Gov. Inf. Q. 2023, 40, 101785. [Google Scholar] [CrossRef]
- Parent, M.; Vandebeek, C.A.; Gemino, A.C. Building Citizen Trust Through E-Government. Gov. Inf. Q. 2005, 22, 720–736. [Google Scholar] [CrossRef]
- Song, Y.; Li, Z.; He, J.; Li, Z.; Fang, X.; Chen, D. Employing Auto-Annotated Data for Government Document Classification. In Proceedings of the 2019 3rd International Conference on Innovation in Artificial Intelligence (ICIAI ‘19), Association for Computing Machinery, New York, NY, USA, 15–18 March 2019; Part F148152. pp. 121–125. [Google Scholar]
- Iroju, O.G.; Department of Computer Science, Adeyemi College of Education, Ondo, Nigeria; Olaleke, J. O. A Systematic Review of Natural Language Processing in Healthcare. Int. J. Inf. Technol. Comput. Sci. 2015, 7, 44–50. [Google Scholar] [CrossRef]
- Zhang, D.; Zhang, J.; Zhang, Y.; Wu, Y. Sentiment Analysis of China’s Education Policy Online Opinion Based on Text Mining. In Proceedings of the 2021 9th International Conference on Information and Education Technology (ICIET), Okayama, Japan, 27–29 March 2021; pp. 73–77. [Google Scholar]
- Iriberri, A.; Navarrete, C.J. E-Government Services: Design and Evaluation of Crime Reporting Alternatives. Electron. Gov. 2013, 10, 171–188. [Google Scholar] [CrossRef]
- Anand, T.; Singh, V.; Bali, B.; Sahoo, B.M.; Shivhare, B.D.; Gupta, A.D. Survey Paper: Sentiment Analysis for Major Government Decisions. In Proceedings of the 2020 International Conference on Intelligent Engineering and Management (ICIEM), London, UK, 17–19 June 2020; pp. 104–109. [Google Scholar]
- Addo, A.; Senyo, P.K. Advancing E-Governance for Development: Digital Identification and Its Link to Socioeconomic Inclusion. Gov. Inf. Q. 2021, 38, 101568. [Google Scholar] [CrossRef]
- Lee, T.; Lee-Geiller, S.; Lee, B.-K. A Validation of the Modified Democratic E-Governance Website Evaluation Model. Gov. Inf. Q. 2021, 38, 101616. [Google Scholar] [CrossRef]
- Verma, S. Sentiment Analysis of Public Services for Smart Society: Literature Review and Future Research Directions. Gov. Inf. Q. 2022, 39, 101708. [Google Scholar] [CrossRef]
- Sheikhalishahi, S.; Miotto, R.; Dudley, J.T.; Lavelli, A.; Rinaldi, F.; Osmani, V. Natural Language Processing of Clinical Notes on Chronic Diseases: Systematic Review. JMIR Med. Inform. 2019, 7, e12239. [Google Scholar] [CrossRef]
- Locke, S.; Bashall, A.; Al-Adely, S.; Moore, J.; Wilson, A.; Kitchen, G.B. Natural Language Processing in Medicine: A Review. Trends Anaesth. Crit. Care 2021, 38, 4–9. [Google Scholar] [CrossRef]
- Bozyiit, F.; Kln, D. Practices of Natural Language Processing in the Finance Sector; Springer: Berlin/Heidelberg, Germany, 2022; Volume 2, pp. 157–170. [Google Scholar]
- Nazir, F.; Butt, W.H.; Anwar, M.W.; Khan Khattak, M.A. The Applications of Natural Language Processing (NLP) for Software Requirement Engineering—A Systematic Literature Review. In Proceedings of the Information Science and Applications 2017; Kim, K., Joukov, N., Eds.; Springer: Singapore, 2017; pp. 485–493. [Google Scholar]
- Gelbukh, A. Natural Language Processing. In Proceedings of the Fifth International Conference on Hybrid Intelligent Systems (HIS’05), Rio de Janerio, Brazil, 6–9 November 2005; p. 1. [Google Scholar]
- Chowdhury, G.G. Natural Language Processing. Annu. Rev. Inf. Ence Technol. 2003, 37, 51–89. [Google Scholar] [CrossRef]
- Nadkarni, P.M.; Ohno-Machado, L.; Chapman, W.W. Natural Language Processing: An Introduction. J. Am. Med. Inform. Assoc. 2011, 18, 544–551. [Google Scholar] [CrossRef] [PubMed]
- Khurana, D.; Koli, A.; Khatter, K.; Singh, S. Natural Language Processing: State of the Art, Current Trends and Challenges. Multimed. Tools Appl. 2022, 82, 3713–3744. [Google Scholar] [CrossRef]
- Cambria, E.; White, B. Jumping NLP Curves: A Review of Natural Language Processing Research [Review Article]. IEEE Comput. Intell. Mag. 2014, 9, 48–57. [Google Scholar] [CrossRef]
- Hirschberg, J.; Manning, C.D. Advances in Natural Language Processing. Science 2015, 349, 261–266. [Google Scholar] [CrossRef]
- Chopra, A.; Prashar, A.; Sain, C. Natural Language Processing. Int. J. Technol. Enhanc. Emerg. Eng. Res. 2013, 1, 131–134. [Google Scholar]
- Ramos, J. Using TF-IDF to Determine Word Relevance in Document Queries. Proc. First Instr. Conf. Mach. Learn. 2003, 242, 29–48. [Google Scholar]
- Grootendorst, M. BERTopic: Neural Topic Modeling with a Class-Based TF-IDF Procedure. arXiv 2022, arXiv:2203.05794. [Google Scholar]
- Zhou, H. Research of Text Classification Based on TF-IDF and CNN-LSTM. J. Phys. Conf. Ser. 2022, 2171, 012021. [Google Scholar] [CrossRef]
- Liu, H.; Chen, X.; Liu, X. A Study of the Application of Weight Distributing Method Combining Sentiment Dictionary and TF-IDF for Text Sentiment Analysis. IEEE Access 2022, 10, 32280–32289. [Google Scholar] [CrossRef]
- Lin, K.-P.; Chen, M.-S. On the Design and Analysis of the Privacy-Preserving SVM Classifier. IEEE Trans. Knowl. Data Eng. 2011, 23, 1704–1717. [Google Scholar] [CrossRef]
- Yang, Y.; Li, J.; Yang, Y. The Research of the Fast SVM Classifier Method. In Proceedings of the 2015 12th International Computer Conference on Wavelet Active Media Technology and Information Processing (ICCWAMTIP), Chengdu, China, 18–20 December 2015; pp. 121–124. [Google Scholar]
- Noble, W.S. What Is a Support Vector Machine? Nat. Biotechnol. 2006, 24, 1565–1567. [Google Scholar] [CrossRef] [PubMed]
- Ma, L.; Zhang, Y. Using Word2Vec to Process Big Text Data. In Proceedings of the 2015 IEEE International Conference on Big Data (Big Data), Santa Clara, CA, USA, 29 October—1 November 2015; pp. 2895–2897. [Google Scholar]
- Reshamwala, A.; Mishra, D.; Pawar, P. Review on Natural Language Processing. IRACST Eng. Sci. Technol. Int. J. 2013, 3, 113–116. [Google Scholar]
- Mutawa, M.A.; Rashid, H. Comprehensive Review on the Challenges That Impact Artificial Intelligence Applications in the Public Sector. In Proceedings of the 5th NA International Conference on Industrial Engineering and Operations Management, Detroit, MI, USA, 10–14 August 2020; Volume 10. [Google Scholar]
- Medaglia, R.; Gil-Garcia, J.R.; Pardo, T.A. Artificial Intelligence in Government: Taking Stock and Moving Forward. Soc. Sci. Comput. Rev. 2021, 41, 123–140. [Google Scholar] [CrossRef]
- Gomes de Sousa, W.; Pereira de Melo, E.R.; De Souza Bermejo, P.H.; Sousa Farias, R.A.; Oliveira Gomes, A. How and Where Is Artificial Intelligence in the Public Sector Going? A Literature Review and Research Agenda. Gov. Inf. Q. 2019, 36, 101392. [Google Scholar] [CrossRef]
- Lommatzsch, A. A next Generation Chatbot-Framework for the Public Administration; Communications in Computer and Information Science. In Proceedings of the Innovations for Community Services: 18th International Conference, I4CS 2018, Žilina, Slovakia, 18–20 June 2018; Springer: Berlin/Heidelberg, Germany, 2018; Volume 863, pp. 127–141. [Google Scholar]
- Lommatzsch, A.; Katins, J. An Information Retrieval-Based Approach for Building Intuitive Chatbots for Large Knowledge Bases. In Proceedings of the Conference on “Lernen, Wissen, Daten, Analysen”, Berlin, Germany, 30 September–2 October 2019; Volume 2454. [Google Scholar]
- Alguliyev, R.M.; Aliguliyev, R.M.; Niftaliyeva, G.Y. Extracting Social Networks from E-Government by Sentiment Analysis of Users’ Comments. Electron. Gov. Int. J. 2019, 15, 91–106. [Google Scholar] [CrossRef]
- Corallo, A.; Fortunato, L.; Matera, M.; Alessi, M.; Camillò, A.; Chetta, V.; Giangreco, E.; Storelli, D. Sentiment Analysis for Government: An Optimized Approach. In Proceedings of the Machine Learning and Data Mining in Pattern Recognition; Perner, P., Ed.; Springer International Publishing: Cham, Switzerland, 2015; pp. 98–112. [Google Scholar]
- Mahadzir, N.H.; Omar, M.F.; Nawi, M.N.M. Towards Sentiment Analysis Application in Housing Projects. In Proceedings of the International Conference on Applied Science and Technology 2016 (ICAST’16), Kedah, Malaysia, 11–13 April 2016; AIP Publishing: College Park, MD, USA; 2016; p. 020060. [Google Scholar]
- Tayal, D.K.; Yadav, S.K. Sentiment Analysis on Social Campaign “Swachh Bharat Abhiyan” Using Unigram Method. AI Soc. 2017, 32, 633–645. [Google Scholar] [CrossRef]
- Madanian, S.; Airehrour, D.; Samsuri, N.A.; Cherrington, M. Twitter Sentiment Analysis in Covid-19 Pandemic. In Proceedings of the 2021 IEEE 12th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), Online (Virtual), 27–30 October 2021; pp. 399–405. [Google Scholar]
- Kitchenham, B.; Pearl Brereton, O.; Budgen, D.; Turner, M.; Bailey, J.; Linkman, S. Systematic Literature Reviews in Software Engineering—A Systematic Literature Review. Inf. Softw. Technol. 2009, 51, 7–15. [Google Scholar] [CrossRef]
- Kitchenham, B.; Madeyski, L.; Budgen, D. SEGRESS: Software Engineering Guidelines for REporting Secondary Studies. IEEE Trans. Softw. Eng. 2023, 49, 1273–1298. [Google Scholar] [CrossRef]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 Statement: An Updated Guideline for Reporting Systematic Reviews. Syst. Rev. 2021, 10, 89. [Google Scholar] [CrossRef] [PubMed]
- Guo, Y.; Hao, Z.; Zhao, S.; Gong, J.; Yang, F. Artificial Intelligence in Health Care: Bibliometric Analysis. J. Med. Internet Res. 2020, 22, e18228. [Google Scholar] [CrossRef] [PubMed]
- Vrijhoef, H.; Steuten, L. How to Write an Abstract. Eur. Diabetes Nurs. 2007, 4, 124–127. [Google Scholar] [CrossRef]
- Jiang, Y.; Pang, P.C.-I.; Ang, W.W.; Lau, Y. A Proposed Method of Literature Analysis Based on Natural Language Processing and Network Analysis. In Proceedings of the 2022 10th International Conference on Information Technology: IoT and Smart City; Association for Computing Machinery: New York, NY, USA, 2023; pp. 29–35. [Google Scholar]
- Scholl, H.J. The Digital Government Reference Library (DGRL) and Its Potential Formative Impact on Digital Government Research (DGR). Gov. Inf. Q. 2021, 38, 101613. [Google Scholar] [CrossRef]
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2009. [Google Scholar]
- Hagberg, A.; Swart, P.S.; Chult, D. Exploring Network Structure, Dynamics, and Function Using NetworkX; Los Alamos National Lab. (LANL): Los Alamos, NM, USA, 2008. [Google Scholar]
- Andreas Mueller. WordCloud for Python Documentation. Available online: http://amueller.github.io/word_cloud/ (accessed on 13 October 2023).
- Hagen, L.; Uzuner, O.; Kotfila, C.; Harrison, T.M.; LaManna, D. Understanding Citizens’ Direct Policy Suggestions to the Federal Government: A Natural Language Processing and Topic Modeling Approach. In Proceedings of the 2015 48th Hawaii International Conference on System Sciences, Kauai, HI, USA, 5–8 January 2015; pp. 2134–2143. [Google Scholar]
- Iriberri, A. Natural Language Processing and Psychology in E-Government Services: Evaluation of a Crime Reporting and Interviewing System. Int. J. Electron. Gov. Res. 2015, 11, 1–17. [Google Scholar] [CrossRef]
- Metsker, O.; Trofimov, E.; Grechishcheva, S. Natural Language Processing of Russian Court Decisions for Digital Indicators Mapping for Oversight Process Control Efficiency: Disobeying a Police Officer Case. In Communications in Computer and Information Science; CCIS; Springer: Berlin/Heidelberg, Germany, 2020; Volume 1135, p. 307. [Google Scholar]
- Aitamuro, T.; Chen, K.; Cherif, A.; Saldivar, J.; Santana, L. Civic CrowdAnalytics: Making Sense of Crowdsourced Civic Input with Big Data Tools. In Proceedings of the ACM Academic Mindtrek’16: Proceedings of the 20th International Academic Mindtrek Conference, Tampere, Finland, 17 October 2016; pp. 86–94. [Google Scholar] [CrossRef]
- Garg, S.; Panwar, D.S.; Gupta, A.; Katarya, R. A Literature Review on Sentiment Analysis Techniques Involving Social Media Platforms. In Proceedings of the 2020 Sixth International Conference on Parallel, Distributed and Grid Computing (PDGC), Waknaghat, India, 6–8 November 2020; pp. 254–259. [Google Scholar]
- Hasbullah, S.S.; Maynard, D.; Wan Chik, R.Z.; Mohd, F.; Noor, M. Automated Content Analysis: A Sentiment Analysis on Malaysian Government Social Media. 2016.
- Messaoudi, C.; Guessoum, Z.; Ben Romdhane, L. Opinion Mining in Online Social Media: A Survey. Soc. Netw. Anal. Min. 2022, 12, 25. [Google Scholar] [CrossRef]
- Alzamil, Z.; Appelbaum, D.; Nehmer, R. An Ontological Artifact for Classifying Social Media: Text Mining Analysis for Financial Data. Int. J. Account. Inf. Syst. 2020, 38, 100469. [Google Scholar] [CrossRef]
- Eckhard, S.; Patz, R.; Schönfeld, M.; van Meegdenburg, H. International Bureaucrats in the UN Security Council Debates: A Speaker-Topic Network Analysis. J. Eur. Public Policy 2021, 30, 214–233. [Google Scholar] [CrossRef]
- Vannoni, M.; Ash, E.; Morelli, M. Measuring Discretion and Delegation in Legislative Texts: Methods and Application to US States. Polit. Anal. 2021, 29, 43–57. [Google Scholar] [CrossRef]
- Prell, C. Social Network Analysis: History, Theory and Methodology; Sage Publications Ltd.: Thousand Oaks, CA, USA, 2012. [Google Scholar]
- Androutsopoulou, A.; Karacapilidis, N.; Loukis, E.; Charalabidis, Y. Transforming the Communication between Citizens and Government through AI-Guided Chatbots. Gov. Inf. Q. 2019, 36, 358–367. [Google Scholar] [CrossRef]
- Darko, A.; Chan, A.P.; Adabre, M.A.; Edwards, D.J.; Hosseini, M.R.; Ameyaw, E.E. Artificial Intelligence in the AEC Industry: Scientometric Analysis and Visualization of Research Activities. Autom. Constr. 2020, 112, 103081. [Google Scholar] [CrossRef]
- Both, A.; Heinze, P.; Perevalov, A.; Bartsch, J.R.; Iudin, R.; Herkner, J.R.; Schrader, T.; Wunsch, J.; Gürth, R.; Falkenhain, A.K. Quality Assurance of a German COVID-19 Question Answering Systems Using Component-Based Microbenchmarking. In Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining, Tempe, AZ, USA, 21–25 February 2022; pp. 1561–1564. [Google Scholar]
- Samadi, M.; Mousavian, M.; Momtazi, S. Deep Contextualized Text Representation and Learning for Fake News Detection. Inf. Process. Manag. 2021, 58, 102723. [Google Scholar] [CrossRef]
- Segura-Tinoco, A.; Holgado-Sánchez, A.; Cantador, I.; Cortés-Cediel, M.E. A Conversational Agent for Argument-Driven e-Participation. In Proceedings of the Conference: DG.O 2022: The 23rd Annual International Conference on Digital Government Research, Online (Virtual), 15–17 June 2022; pp. 191–205. [Google Scholar] [CrossRef]
- Futia, G.; Cairo, F.; Morando, F.; Leschiutta, L. Exploiting Linked Open Data and Natural Language Processing for Classification of Political Speech; Edition Donau-Universität Krems; Danube University: Krems, Austria, 2014; pp. 349–360. [Google Scholar]
- Guo, K.; Jiang, T.; Zhang, H. Knowledge Graph Enhanced Event Extraction in Financial Documents. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 1322–1329. [Google Scholar]
- Papadopoulos, T.; Charalabidis, Y. What Do Governments Plan in the Field of Artificial Intelligence? Analysing National AI Strategies Using NLP. In Proceedings of the ICEGOV 2020: 13th International Conference on Theory and Practice of Electronic Governance, Athens, Greece, 23–25 September 2020; pp. 100–111. [Google Scholar] [CrossRef]
- Ha, S.; Marchetto, D.J.; Dharur, S.; Asensio, O.I. Topic Classification of Electric Vehicle Consumer Experiences with Transformer-Based Deep Learning. Patterns 2021, 2, 100195. [Google Scholar] [CrossRef] [PubMed]
- Pardo, T.A.; Nam, T.; Burke, G.B. E-Government Interoperability: Interaction of Policy, Management, and Technology Dimensions. Soc. Sci. Comput. Rev. 2012, 30, 7–23. [Google Scholar] [CrossRef]
- Nikoli, V.; Markoski, B.; Kuk, K.; Ranelovi, D.; Isar, P. Modelling the System of Receiving Quick Answers for E-Government Services: Study for the Crime Domain in the Republic of Serbia. Acta Polytech. Hung. 2017, 14, 143–163. [Google Scholar] [CrossRef]
- Misra, A.; Misra, D.P.; Mahapatra, S.S.; Biswas, S. Digital Transformation Model: Analytic Approach on Participatory Governance & Community Engagement in India. In Proceedings of the 19th Annual International Conference on Digital Government Research, Delft, The Netherlands, 30 May–1 June 2018. [Google Scholar] [CrossRef]
- Gupta, P.; Kumar, S.; Suman, R.R.; Kumar, V. Sentiment Analysis of Lockdown in India during COVID-19: A Case Study on Twitter. IEEE Trans. Comput. Soc. Syst. 2021, 8, 939–949. [Google Scholar] [CrossRef]
- Lamba, A.; Yadav, D.; Lele, A. CitizenPulse: A Text Analytics Framework for Proactive e-Governance—A Case Study of Mygov. in. In Proceedings of the IKDD Conference on Data Science, 2016, Pune, India, 13–16 March 2016. [Google Scholar] [CrossRef]
- Adikari, A.; Alahakoon, D. Understanding Citizens’ Emotional Pulse in a Smart City Using Artificial Intelligence. IEEE Trans. Ind. Inform. 2020, 17, 2743–2751. [Google Scholar] [CrossRef]
- Choudrie, J.; Patil, S.; Kotecha, K.; Matta, N.; Pappas, I. Applying and Understanding an Advanced, Novel Deep Learning Approach: A COVID-19, Text Based, Emotions Analysis Study. Inf. Syst. Front. 2021, 23, 1431–1465. [Google Scholar] [CrossRef]
- Rezk, M.A.; Ojo, A.; Khayat, G.; Hussein, S. A Predictive Government Decision Based on Citizen Opinions: Tools & Results. In Proceedings of the 11th International Conference, ICEGOV ‘18: Proceedings of the 11th International Conference on Theory and Practice of Electronic Governance; Galway, Ireland, 4–6 April 2018, pp. 712–714. [CrossRef]
- Shah, N.; Srivastava, G.; Savage, D.W.; Mago, V. Assessing Canadians Health Activity and Nutritional Habits Through Social Media. Front. Public Health 2020, 7, 400. [Google Scholar] [CrossRef]
- Maguen, S.; Holder, N.; Madden, E.; Li, Y.; Seal, K.H.; Neylan, T.C.; Lujan, C.; Patterson, O.V.; DuVall, S.L.; Shiner, B. Evidence-Based Psychotherapy Trends among Posttraumatic Stress Disorder Patients in a National Healthcare System, 2001–2014. Depress. Anxiety 2020, 37, 356–364. [Google Scholar] [CrossRef]
- Lima, S.; Teran, L.; Portmann, E. A Proposal for an Explainable Fuzzy-Based Deep Learning System for Skin Cancer Prediction. In Proceedings of the 2020 Seventh International Conference on eDemocracy & eGovernment (ICEDEG), Buenos Aires, Argentina, 22–24 April 2020; pp. 29–35. [Google Scholar]
- Tan, H.; Peng, S.-L.; Zhu, C.-P.; You, Z.; Miao, M.-C.; Kuai, S.-G. Long-Term Effects of the COVID-19 Pandemic on Public Sentiments in Mainland China: Sentiment Analysis of Social Media Posts. J. Med. Internet Res. 2021, 23, e29150. [Google Scholar] [CrossRef]
- Liew, T.M.; Lee, C.S. Examining the Utility of Social Media in COVID-19 Vaccination: Unsupervised Learning of 672,133 Twitter Posts. JMIR Public Health Surveill. 2021, 7, e29789. [Google Scholar] [CrossRef]
- Pang, P.C.-I.; Jiang, W.; Pu, G.; Chan, K.-S.; Lau, Y. Social Media Engagement in Two Governmental Schemes during the COVID-19 Pandemic in Macao. Int. J. Environ. Res. Public. Health 2022, 19, 8976. [Google Scholar] [CrossRef]
- Greyling, T.; Rossouw, S. Positive Attitudes towards COVID-19 Vaccines: A Cross-Country Analysis. PLoS ONE 2022, 17, e0264994. [Google Scholar] [CrossRef]
- Guo, Y.; Li, Y.; Qian, Y. Local Government Debt Risk Assessment: A Deep Learning-Based Perspective. Inf. Process. Manag. 2022, 59, 102948. [Google Scholar] [CrossRef]
- Li, C.; Jiang, Y. Joint Learning for Disaster Event Extraction. In Proceedings of the 6th International Workshop on Advanced Algorithms and Control Engineering (IWAACE 2022), Qingdao, China, 8–10 July 2022; SPIE: Bellingham, WA, USA, 2022; Volume 12350, pp. 745–752. [Google Scholar]
- Arianto, R.; Warnars, H.L.H.S.; Gaol, F.L.; Trisetyarso, A. Mining Unstructured Data in Social Media for Natural Disaster Management in Indonesia. In Proceedings of the 2018 Indonesian Association for Pattern Recognition International Conference (INAPR), Jakarta, Indonesia, 7–8 September 2018; pp. 192–196. [Google Scholar]
- Cecilia, J.M.; Cano, J.-C.; Calafate, C.T.; Manzoni, P.; Perinan-Pascual, C.; Arcas-Tunez, F.; Munoz-Ortega, A. WATERSensing: A Smart Warning System for Natural Disasters in Spain. IEEE Consum. Electron. Mag. 2021, 10, 89–96. [Google Scholar] [CrossRef]
- Kosaka, N.; Koyama, A.; Kokogawa, T.; Maeda, Y.; Koumoto, H.; Suzuki, S.; Yamaguchi, K.; Inui, K. Disaster Information System Using Natural Language Processing. J. Disaster Res. 2017, 12, 67–78. [Google Scholar] [CrossRef]
- Lydiri, M.; El Mourabit, Y.; El Habouz, Y.; Fakir, M. A Performant Deep Learning Model for Sentiment Analysis of Climate Change. Soc. Netw. Anal. Min. 2022, 13, 8. [Google Scholar] [CrossRef]
- Adamopoulou, E.; Moussiades, L. Chatbots: History, Technology, and Applications. Mach. Learn. Appl. 2020, 2, 100006. [Google Scholar] [CrossRef]
- Nirala, K.K.; Singh, N.K.; Purani, V.S. A Survey on Providing Customer and Public Administration Based Services Using AI: Chatbot. Multimed. Tools Appl. 2022, 81, 22215–22246. [Google Scholar] [CrossRef]
- Amiri, P.; Karahanna, E. Chatbot Use Cases in the COVID-19 Public Health Response. J. Am. Med. Inform. Assoc. 2022, 29, 1000–1010. [Google Scholar] [CrossRef] [PubMed]
- van Dis, E.A.M.; Bollen, J.; Zuidema, W.; van Rooij, R.; Bockting, C.L. ChatGPT: Five Priorities for Research. Nature 2023, 614, 224–226. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Pang, P.C.-I.; Xiao, Y.; Wong, D. Changes in Doctor–Patient Relationships in China during COVID-19: A Text Mining Analysis. Int. J. Environ. Res. Public. Health 2022, 19, 13446. [Google Scholar] [CrossRef] [PubMed]
- Li, Z. Forecast and Simulation of the Public Opinion on the Public Policy Based on the Markov Model. Complexity 2021, 2021, 9936965. [Google Scholar] [CrossRef]
- Leelavathy, S.; Nithya, M. Public Opinion Mining Using Natural Language Processing Technique for Improvisation towards Smart City. Int. J. Speech Technol. 2021, 24, 561–569. [Google Scholar] [CrossRef]
- Sovrano, F.; Palmirani, M.; Vitali, F. Combining Shallow and Deep Learning Approaches against Data Scarcity in Legal Domains. Gov. Inf. Q. 2022, 39, 101715. [Google Scholar] [CrossRef]
- Ittoo, A.; Szirbik, N.B.; Huitema, G.B.; Wortmann, J.C. Simulation Gaming and Natural Language Processing for Modelling Stakeholder Behavior in Energy Investments. In Proceedings of the ISC 2013, the 11th Industrial Simulation Conference, Ghent, Belgium, 22–24 May 2013; pp. 23–27. [Google Scholar]
- Aoki, N. An Experimental Study of Public Trust in AI Chatbots in the Public Sector. Gov. Inf. Q. 2020, 37, 101490. [Google Scholar] [CrossRef]
Figure 1.
Flowchart detailing the data collection, assessment, and inclusion processes.

Figure 2.
Research publications on NLP in government over time.

Figure 3.
Word cloud of the literature on NLP in government.

Figure 4.
Co-word network showing the relationships between the words in the literature. Colours represent different categories of concepts.
Figure 4.
Co-word network showing the relationships between the words in the literature. Colours represent different categories of concepts.

Figure 5.
Co-word network in the research area of “governance and policy” (red) and NLP techniques (yellow).
Figure 5.
Co-word network in the research area of “governance and policy” (red) and NLP techniques (yellow).

Figure 6.
Co-word network in the research area of “citizens and public opinion” (orange) and NLP techniques (yellow).
Figure 6.
Co-word network in the research area of “citizens and public opinion” (orange) and NLP techniques (yellow).

Figure 7.
Co-word network in the research area of “medical and healthcare” (green) and NLP techniques (yellow).
Figure 7.
Co-word network in the research area of “medical and healthcare” (green) and NLP techniques (yellow).

Figure 8.
Co-word network in the research area of “economy and environment” (blue) and NLP techniques (yellow).
Figure 8.
Co-word network in the research area of “economy and environment” (blue) and NLP techniques (yellow).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Search terms used in the literature search.
| Topic | Search Terms |
|---|---|
| Natural language processing | “Natural Language Processing” OR “NLP” |
| AND | |
| Government | “government” OR “governance” OR “public sector” OR “public administration” OR “public policy” |
Table 2.
Top 10 co-occurrence relationships between NLP techniques and all topics.
| Keyword 1 | Keyword 2 | Co-Occurrence Count |
|---|---|---|
| sentiment analysis | social media | 199 |
| sentiment analysis | 135 | |
| sentiment analysis | tweet | 120 |
| machine learning | sentiment | 92 |
| machine learning | social media | 86 |
| deep learning | government | 75 |
| classification | government | 65 |
| machine learning | public | 64 |
| classification | document | 61 |
| machine learning | tweet | 58 |
Table 3.
Centrality values of top 30 high-frequency words.
| Word | Frequency | Eigenvector Centrality | Degree Centrality | Closeness Centrality |
|---|---|---|---|---|
| government | 603 | 0.216 | 1.000 | 1.000 |
| social media | 410 | 0.183 | 0.972 | 0.973 |
| nlp | 406 | 0.135 | 1.000 | 1.000 |
| policy | 354 | 0.185 | 0.986 | 0.986 |
| COVID-19 | 298 | 0.161 | 0.901 | 0.910 |
| public | 270 | 0.132 | 0.986 | 0.986 |
| document | 248 | 0.065 | 0.901 | 0.910 |
| sentiment analysis | 218 | 0.085 | 0.951 | 0.953 |
| sentiment | 216 | 0.107 | 0.944 | 0.947 |
| tweet | 184 | 0.105 | 0.880 | 0.893 |
| people | 182 | 0.133 | 0.993 | 0.993 |
| machine learning | 179 | 0.063 | 1.000 | 1.000 |
| health | 169 | 0.352 | 0.958 | 0.959 |
| social | 169 | 0.255 | 0.972 | 0.973 |
| 164 | 0.084 | 0.930 | 0.934 | |
| service | 161 | 0.150 | 0.937 | 0.940 |
| development | 152 | 0.079 | 0.993 | 0.993 |
| issue | 152 | 0.082 | 0.986 | 0.986 |
| citizen | 144 | 0.068 | 0.972 | 0.973 |
| opinion | 136 | 0.066 | 0.915 | 0.922 |
| work | 135 | 0.137 | 0.965 | 0.966 |
| patient | 134 | 0.362 | 0.810 | 0.840 |
| pandemic | 129 | 0.087 | 0.859 | 0.877 |
| platform | 126 | 0.057 | 0.965 | 0.966 |
| impact | 124 | 0.059 | 0.944 | 0.947 |
| organization | 118 | 0.040 | 0.958 | 0.959 |
| online | 114 | 0.051 | 0.937 | 0.940 |
| community | 109 | 0.245 | 0.951 | 0.953 |
| value | 106 | 0.197 | 0.930 | 0.934 |
| communication | 102 | 0.082 | 0.937 | 0.940 |
Table 4.
Top 10 co-occurrence relationships in the research area of “governance and policy”.
| Keyword 1 | Keyword 2 | Co-Occurrence Count |
|---|---|---|
| deep learning | government | 75 |
| classification | government | 65 |
| classification | document | 61 |
| sentiment analysis | work | 44 |
| deep learning | detection | 35 |
| chatbot | service | 33 |
| machine learning | policy | 31 |
| extraction | government | 30 |
| machine learning | platform | 28 |
| chatbot | government | 26 |
Table 5.
Top 10 co-occurrence relationships in the research area of “citizens and public opinion”.
| Keyword 1 | Keyword 2 | Co-Occurrence Count |
|---|---|---|
| sentiment analysis | social media | 199 |
| sentiment analysis | 135 | |
| sentiment analysis | tweet | 120 |
| machine learning | sentiment | 92 |
| machine learning | social media | 86 |
| machine learning | public | 64 |
| machine learning | tweet | 58 |
| opinion mining | social | 48 |
| machine learning | 48 | |
| classification | social media | 46 |
Table 6.
Top 10 co-occurrence relationships in the research area of “medical and healthcare”.
| Keyword 1 | Keyword 2 | Co-Occurrence Count |
|---|---|---|
| identification | patient | 55 |
| topic modeling | vaccine | 35 |
| identification | impact | 31 |
| sentiment analysis | vaccine | 28 |
| deep learning | pandemic | 24 |
| machine learning | vaccination | 22 |
| machine learning | pandemic | 20 |
| sentiment analysis | vaccination | 19 |
| data mining | health | 17 |
| extraction | health | 16 |
Table 7.
Top 10 co-occurrence relationships in the research area of “economy and environment”.
| Keyword 1 | Keyword 2 | Co-Occurrence Count |
|---|---|---|
| machine learning | organization | 28 |
| identification | value | 24 |
| machine learning | world | 23 |
| deep learning | real world | 22 |
| sentiment analysis | value | 18 |
| machine learning | state | 18 |
| classification | disaster | 18 |
| sentiment analysis | world | 13 |
| identification | state | 13 |
| machine learning | market | 13 |
Table 8.
Summary of NLP applications in governments.
| # | Category | Description |
|---|---|---|
| 1 | Governance and Policy | Efficiently extract and analyse documents and policies; obtain insights for better governances and services |
| 2 | Understanding Citizen and Public Opinion | Evaluating citizens’ sentient and public opinions; understanding attitudes regarding policies |
| 3 | Medical and Healthcare | Measuring the reception of health policies; clarifying the situations and the efficiency of public health measures during the pandemic |
| 4 | Economic and Environment | Retrieving the reactions of markets; identifying risks and threats in economics |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Jiang, Y.; Pang, P.C.-I.; Wong, D.; Kan, H.Y. Natural Language Processing Adoption in Governments and Future Research Directions: A Systematic Review. Appl. Sci. 2023, 13, 12346. https://doi.org/10.3390/app132212346
AMA Style
Jiang Y, Pang PC-I, Wong D, Kan HY. Natural Language Processing Adoption in Governments and Future Research Directions: A Systematic Review. Applied Sciences. 2023; 13(22):12346. https://doi.org/10.3390/app132212346
Chicago/Turabian StyleJiang, Yunqing, Patrick Cheong-Iao Pang, Dennis Wong, and Ho Yin Kan. 2023. "Natural Language Processing Adoption in Governments and Future Research Directions: A Systematic Review" Applied Sciences 13, no. 22: 12346. https://doi.org/10.3390/app132212346
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.