
Analyzing Data Reference Characteristics of Deep Learning Workloads for Improving Buffer Cache Performance

Department of Computer Engineering, Ewha University, Seoul 03760, Republic of Korea
*
Author to whom correspondence should be addressed.
Appl. Sci. 2023, 13(22), 12102; https://doi.org/10.3390/app132212102
Submission received: 6 October 2023
/
Revised: 28 October 2023
/
Accepted: 5 November 2023
/
Published: 7 November 2023
(This article belongs to the Section Computing and Artificial Intelligence)
Abstract
:Due to the recent growing data size of deep learning workloads, loading data from storage is increasingly becoming a performance bottleneck for neural network systems. In this article, we analyze the data reference characteristics of neural network workloads and observe that they are significantly different from conventional desktop workloads. In particular, during the training phase of deep learning, data blocks are referenced in a fully random manner, which significantly degrades the performance of a buffer cache. To handle this situation, this article suggests a new data shuffling scheme that aims to accelerate data loading in deep neural networks. Unlike the default shuffling method used in PyTorch that randomly shuffles full dataset in every epoch, the proposed scheme defines a shuffling unit called bundle, and enhances the locality of data references to improve buffer cache performances. Specifically, the proposed scheme performs data shuffling by the unit of a bundle, and the bundles used in each epoch are arranged alternately, thereby improving the locality of references at the viewpoint of the buffer cache. Based on simulation and measurement studies, we show that the hit rate of the buffer cache is improved by 37.2%, and the data loading time is also shortened by 11.4% without degrading the model’s training efficiency.
1. Introduction
Deep neural networks are increasingly being adopted across a variety of industries, including manufacturing [1], IoT (Internet of Things) [2], automotive [3], and healthcare [4]. It is reported that the market size of deep learning technologies is anticipated to grow with an average annual rate of 36% by 2030 [5,6]. In order for deep neural network models to perform high-precision inference on new data, it is important to train them using sufficiently large datasets [7].
Neural network workloads consist of compute-bound tasks [8,9], but loading data from storage may degrade the performance of the workloads since accessing storage is 105 to 106 times slower than computing in processors [10], and huge amounts of data can be consistently referenced during the training phase of neural network workloads [7]. Because systems do not have sufficient memory space to accommodate the entire dataset [11], traditional systems typically take advantage of the buffer cache for improving the loading time of data from storage [12].
The buffer cache retains data blocks retrieved from secondary storage so that subsequent requests for the same data can be immediately referenced from the buffer cache without needing to search secondary storage [12,13]. Since the capacity of the buffer cache is limited, we should select some victim data to be removed from the buffer cache to add new data [13]. Because there is a property in data references that recently used data are likely to be used again in the future, which we call temporal locality [14], buffer caching is effective by maintaining recently referenced data. The most famous policy used in the buffer cache is the least recently used (LRU) eviction algorithm that removes the data referenced oldest when free space is needed. However, we observe that this is not the case for neural network workloads where temporal locality-based algorithms such as LRU do not perform well [9].
In this article, we extract data reference traces of neural network workloads and observe some special reference characteristics while training is performed. In particular, all data in the dataset are equally referenced in a random manner at each epoch. We observe that these reference characteristics degrade the buffer cache performance significantly when traditional algorithms based on temporal locality are used.
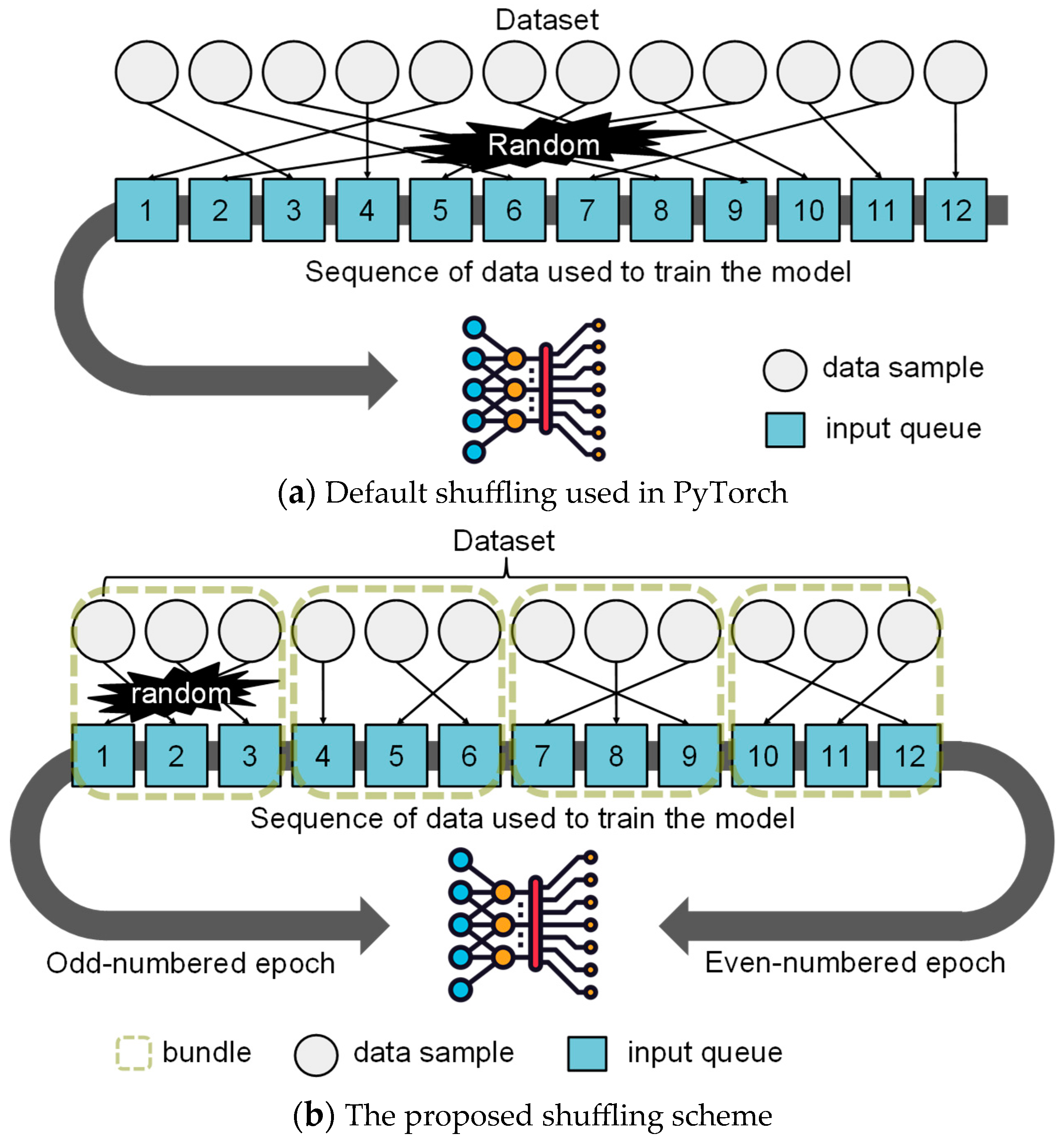
To cope with this situation, we present a new data shuffling scheme for improving buffer cache performance in neural network systems. Unlike traditional shuffling used in neural network training, which randomly shuffles all data in every epoch, the proposed scheme defines shuffling units that we call bundles, to improve the locality of data references without degrading the model’s training efficiency. Our scheme performs data shuffling by the unit of bundle, and the bundles used in each epoch are arranged alternately, thereby improving the locality of data references at the viewpoint of the buffer cache.
Figure 1 shows a brief overview of the proposed shuffling scheme in comparison with the default shuffling used in PyTorch. By utilizing the data shuffling scheme presented in this article, we show that the hit rate of the buffer cache can be improved by 37.2% on average, and the data loading time can also be accelerated by 11.4% while training is being performed.
The main contributions of this article can be summarized as follows.
- First, we analyze the data reference characteristics of deep learning workloads from a buffer cache’s perspective and find out that block references generated during deep learning’s training significantly degrade buffer cache performance.
- Second, we observe that data blocks in deep learning workloads are referenced in a completely random manner in each epoch, which causes performance impairments in current buffer cache systems that focus on temporal locality of references.
- Third, we propose a new data shuffling scheme that groups a portion of data blocks into bundles and performs bundle-based shuffling to improve the locality of data block references. In addition, we alternately select bundles for each epoch to maximize temporal locality.
The remainder of this article is organized as follows. Section 2 discusses the data reference characteristics of neural network workloads based on trace analysis. In Section 3, we describe the proposed data shuffling scheme considering buffer cache performances. Section 4 presents the experimental results to validate the effectiveness of the suggested data shuffling scheme. Section 5 briefly summarizes studies related to this article. Finally, Section 6 concludes this article.
2. Data Reference Characteristics in Neural Network Workloads
We analyze the reference characteristics of data blocks in neural network workloads. To this end, we use the strace utility to collect the system call traces of data block references while neural network workloads run [15]. We make use of PyTorch 2.1.0 [16] for our experiments. The datasets used in our trace collections are as follows.
- Food101: This dataset consists of 101 food categories, and each category contains 1000 images [17]. For each category, 250 manually reviewed test images are provided as well as 750 training images.
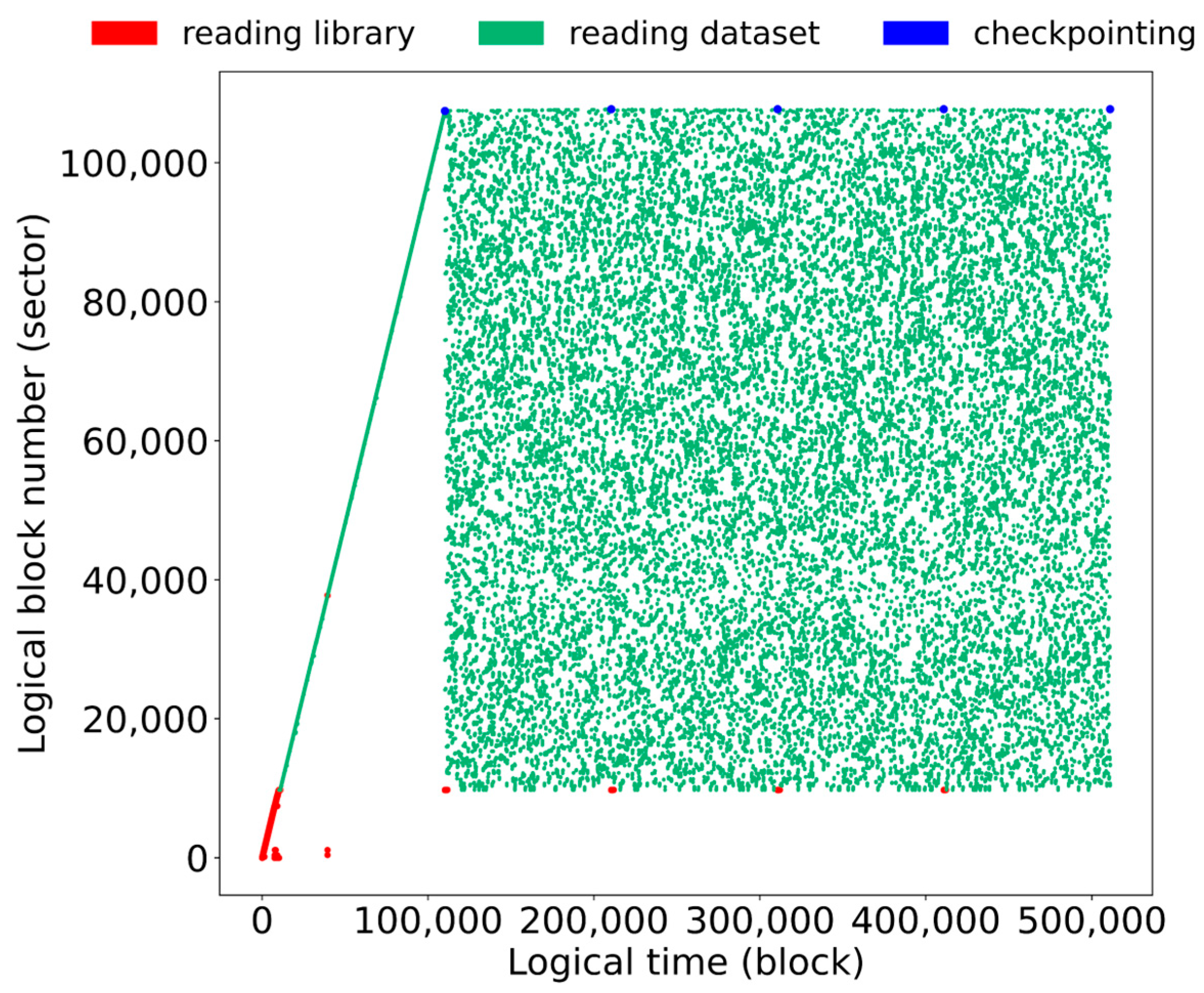
Figure 2 shows the data reference sequences that occur while training with the dataset is being performed. In this figure, the x-axis is logical time, which increases by one whenever a data block is referenced. The y-axis is the data block number, which we assign to 1 when a data block is referenced first and then increase by 1 whenever a new data block appears.
When training starts, libraries such as libc and configuration files are loaded first (denoted as “reading library” in Figure 2). After this phase, the dataset is referenced at each epoch and the training is performed (“reading dataset” in Figure 2). The weights of the model trained are saved at the end of each epoch (“checkpointing” in Figure 2). Such types of reading and writing data blocks occur iteratively at every epoch. However, the reference patterns of “reading dataset” in Figure 2 are varied based on a specific point in time. That is, the reference pattern of “reading dataset” in the first epoch is a completely sequential pattern, whereas it changes to a random pattern from the second epoch.
Note that Figure 2 plots data references over five epochs, and the first epoch and the next four epochs show different reference patterns. Note also that traditional desktop applications do not show such reference patterns, where a sequential pattern, a looping pattern, and a temporally clustered pattern are usually mixed [20]. Due to the existence of temporal locality references, the buffer cache in traditional systems can achieve good performance by maintaining recently referenced data and discarding data blocks that were not recently used.
In contrast, as data blocks are referenced randomly in neural network workloads, it is challenging to improve the performance of data loading by making use of the buffer cache [21]. This is because the training of neural networks typically makes use of a stochastic gradient descent method, which trains the dataset in mini-batches that are randomly generated from the entire dataset at each epoch. Accordingly, data blocks in neural network workloads are randomly referenced as shown Figure 2. Although the reference trend in the first epoch in Figure 2 seems to be sequential, we can also consider it as a random pattern because data blocks are sequentially numbered based on the order of references in our experiments.
3. Data Shuffling in Neural Networks Considering Buffer Cache
In this section, we suggest a new data shuffling scheme for neural network workloads to improve the buffer cache performance. As observed in the previous section, data block references in neural network workloads are totally random, which degrades the effectiveness of the buffer cache. To handle this situation, we present a new data shuffling scheme in bundle units, which improves the locality of data block references.
Our scheme behaves different from conventional neural network training that randomly shuffles a full dataset in every epoch. That is, we define a shuffling unit, called a bundle, and shuffles data within a bundle randomly such as conventional training, but bundles are selected sequentially in each epoch instead of randomly shuffled.
To this end, we inject our code in the components of PyTorch, consisting of Dataset, DataLoader, and Sampler. The Dataset makes use of the __getitem__ method to retrieve a data sample from the corresponding index. The DataLoader loads data samples from a dataset in mini-batches by making use of a worker process. The Sampler extracts a subset of dataset samples during this process [22]. When the shuffle parameter is set to true, the DataLoader invokes RandomSampler to shuffle the entire dataset randomly, and retrieves the dataset based on this sequence.
In this article, we add the BundleRandomSampler to shuffle a dataset in bundle units. The BundleRandomSampler takes the bundle size as an input parameter and obtains the offset index of each bundle in the entire dataset. Then, each bundle is shuffled based on the offsets determined. This is different from RandomSampler that shuffles all indices of the entire dataset and SubsetRandomSampler that shuffles the samples for given indices.
To set the bundle size of BundleRandomSampler, we define a parameter called bundle_ratio that is used as the input parameter to invoke DataLoader. The bundle_ratio can be set between 0 and 1, representing the ratio of the bundle size relative to the entire dataset. For example, if the bundle_ratio is 0.2, each bundle contains 20% of the entire dataset, such that there are 5 bundles in the dataset.
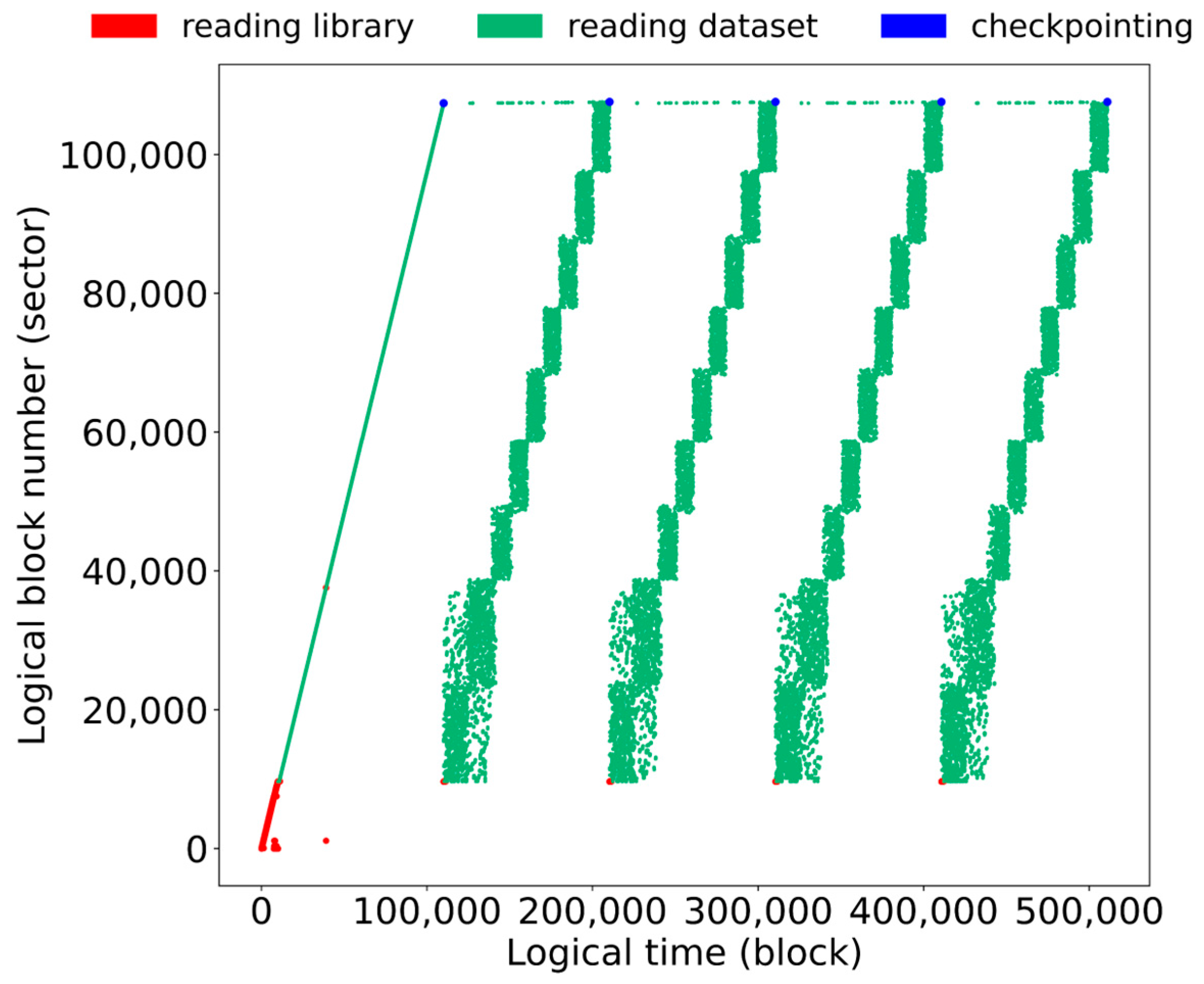
Figure 3 depicts the data block references while training the same dataset shown in Figure 2 with the proposed shuffling scheme. As we see from this figure, intra-bundle references are randomly shuffled, whereas inter-bundle references exhibit sequential patterns from the second epoch of the training.
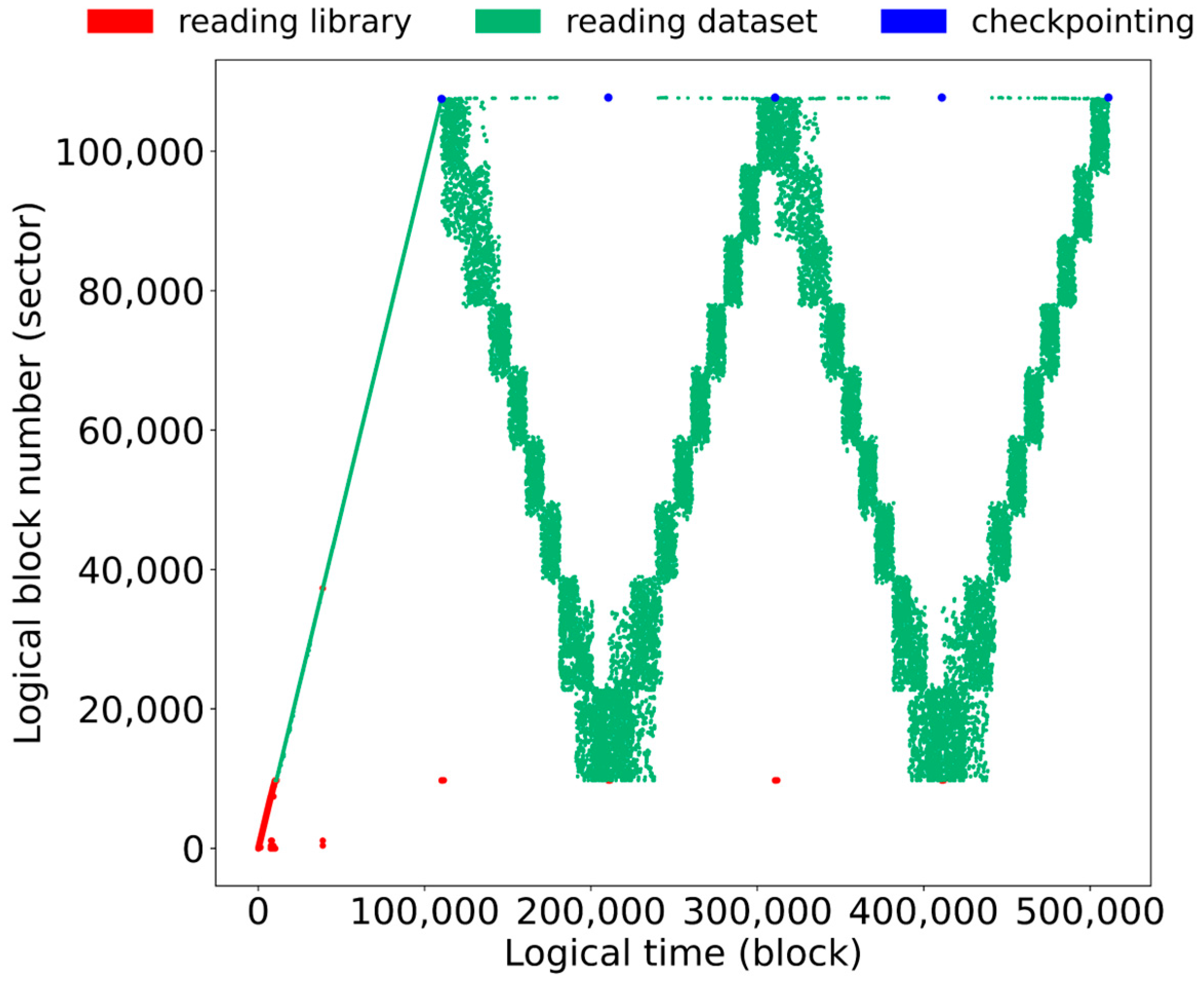
Along with the bundle-based shuffling scheme, we suggest another simple but efficient scheme that can improve the effectiveness of buffer caching. Specifically, in each epoch, the referencing orders of bundles are reversed from the previous epoch, thereby generating the alternating sequence of bundle references. Suppose that there are 9 bundles, B1, B2, …, B9, in the full dataset and the bundles are referenced in increasing order of B1, B2, B3, …, B9 in the n-th epoch. Then, the reference order of the bundles in the (n + 1)-th epoch in our scheme is B9, B8, B7, …, B1. Such an alternating sequence of references is intended to improve the temporal locality effect from the perspective of the buffer cache so that data blocks that were last referenced in the previous epoch are referenced first in the next epoch.
In particular, if the dataset is larger than the size of the buffer cache, data blocks cached in the previous epoch are certain to be discarded from the buffer cache by the eviction algorithm before they are referenced in the current epoch. This significantly degrades the buffer cache performance. However, our bundle alternating scheme resolves this problem by taking advantage of temporal locality to a certain level.
Figure 4 plots the distributions of data blocks referenced when the proposed bundle-based shuffling and bundle alternating schemes are applied with the same dataset used in Figure 2 and Figure 3. As we see from this figure, the first epoch exhibits a purely sequential reference pattern, and then sequential reference patterns are observed in increasing and decreasing orders alternately at an inter-bundle granularity, whereas random reference patterns are consistently observed within bundles.
4. Experimental Results
To validate the effectiveness of the suggested data shuffling scheme, we conduct experiments with data reference traces collected while running neural network workloads introduced in Section 2. Specifically, we capture block reference traces while conducting the classification problem of ImageNet100 and Food101 with the ResNet50 model [23]. For the eviction algorithm of the buffer cache, we use the least recently used (LRU), as it is the most commonly adopted in the buffer cache [12].
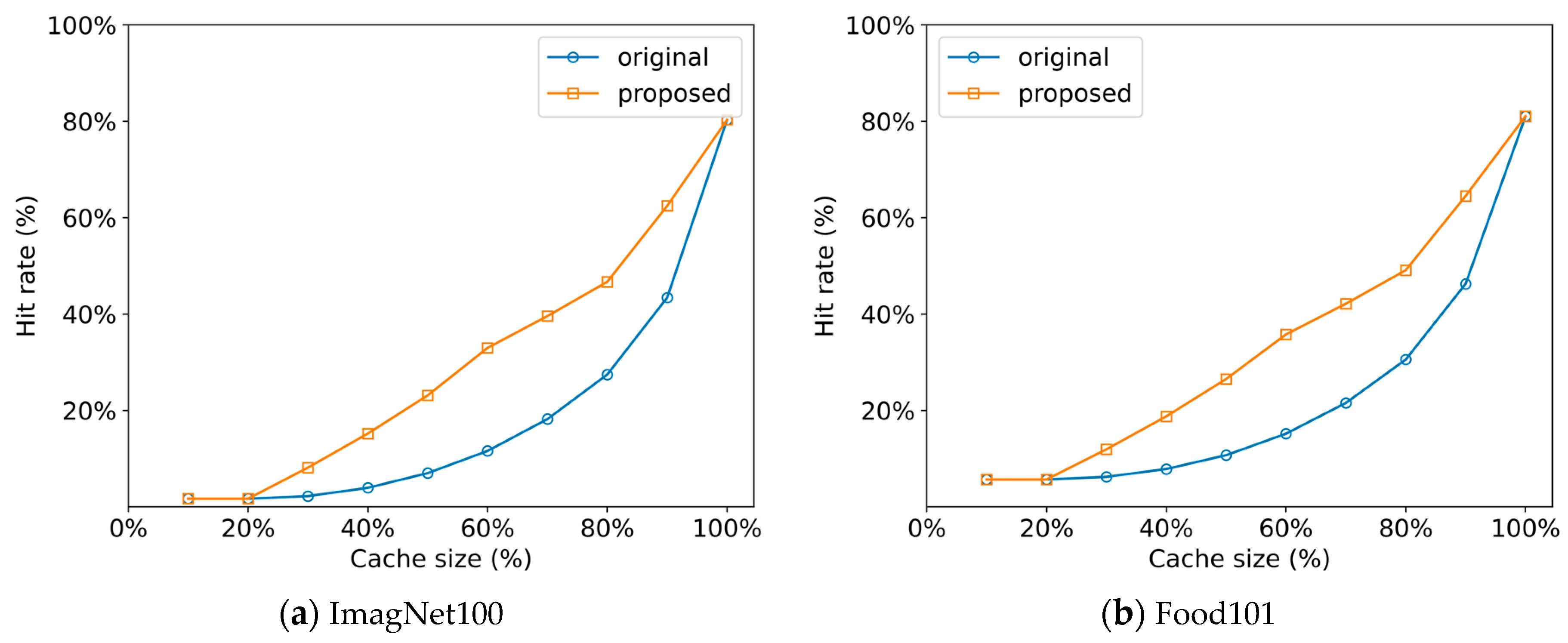
Figure 5 shows the cache hit rate of the buffer cache when the proposed shuffling scheme is used in comparison with the original shuffling used in PyTorch. In the graph, the x-axis is the size of the buffer cache in a relative scale. The 100% cache size implies the capacity that can load all data blocks simultaneously during the full training periods. As can be seen from this figure, the proposed shuffling scheme performs the best regardless of the cache size and workload situation. When the size of the buffer cache is too small, even hot data cannot be accommodated, causing the low cache hit rate regardless of the shuffling method. On the other end, if the size of the buffer cache is very large, all data blocks can be simultaneously loaded into the buffer cache, resulting in the same cache hit rate no matter which shuffling method is used. When considering the conventional system configurations, the results with the cache size of 30–50% represents the most practical situations, and we can observe significant improvement of the proposed scheme in this range. For the ImageNet100 dataset, the proposed shuffling scheme exhibits the improvement of 40.7% on average and up to 74.1% in terms of the cache hit rate. For the Food101 dataset, the improvement is 33.8% on average and up to 59.6%. When considering the two dataset cases together, the average improvement in hit rate is 37.2%.
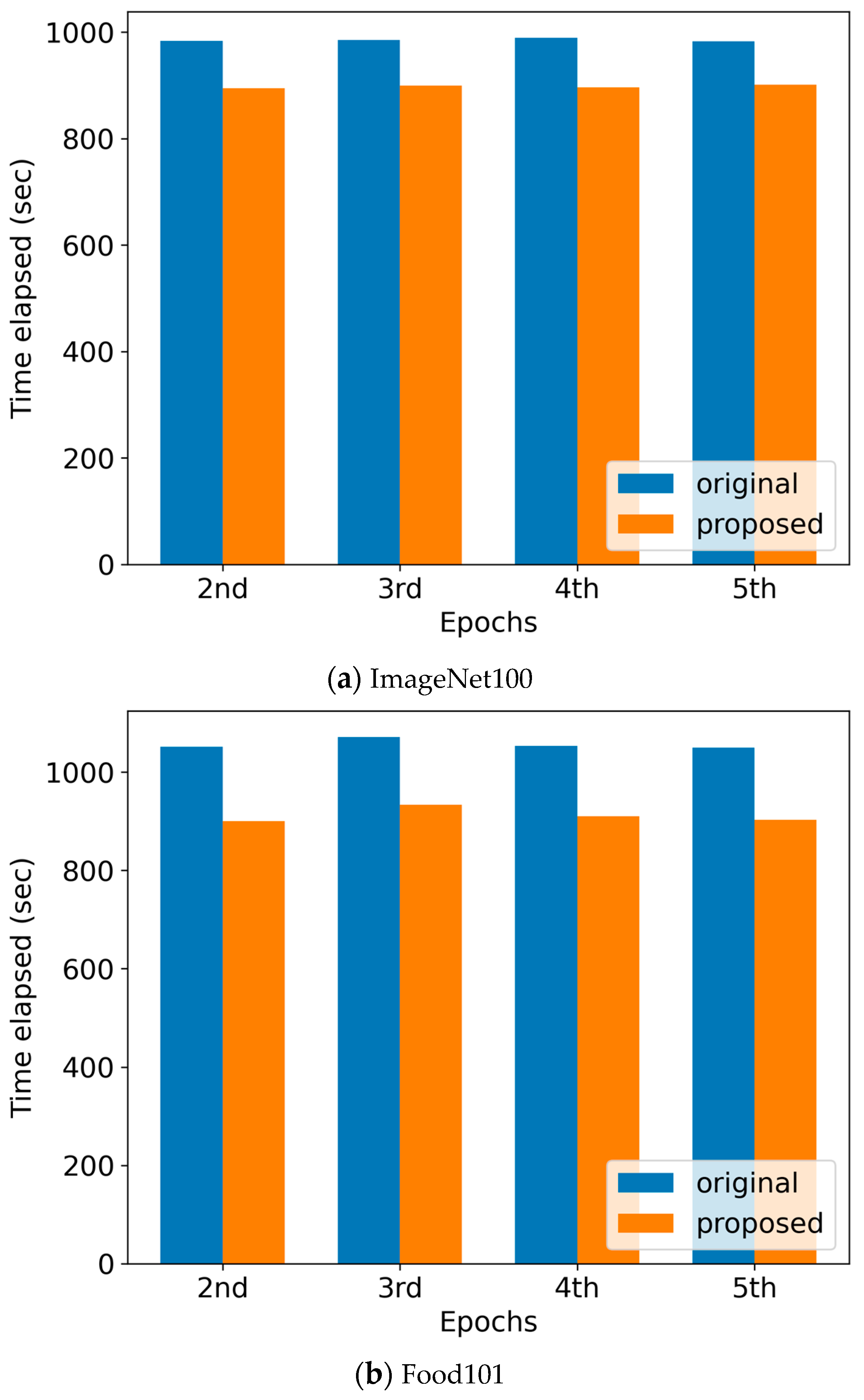
To quantify how the enhancement in the cache hit rate affects the actual I/O time of workloads, we conduct measurement studies. Figure 6 plots the data loading time resulting from the measurement while executing each workload with the proposed shuffling scheme compared to the original data shuffling method used in PyTorch. To see the pure time of data loading, we measure the I/O latency to load the datasets, convert them in Tensor, and resize them, and exclude the time to compute in cores. To see the performance trend while training in neural networks, we measure the loading time as the number of epochs increases. As we see, the proposed shuffling scheme outperforms the original shuffling method of PyTorch throughout the epochs. Specifically, the improvement of the loading time is 8.96% and 13.76% in ImageNet100 and Food101 datasets, respectively, and their average is 11.4%.
By applying the proposed shuffling scheme, we showed that the hit rate of the buffer cache and the data loading time can be improved. However, unlike the original method that pursues complete randomness, the proposed scheme maintains the randomness of data references only within a bundle, which may degrade the model’s training accuracy when the same training process is performed. In the worst case, the model might fail to converge because of biased batches.
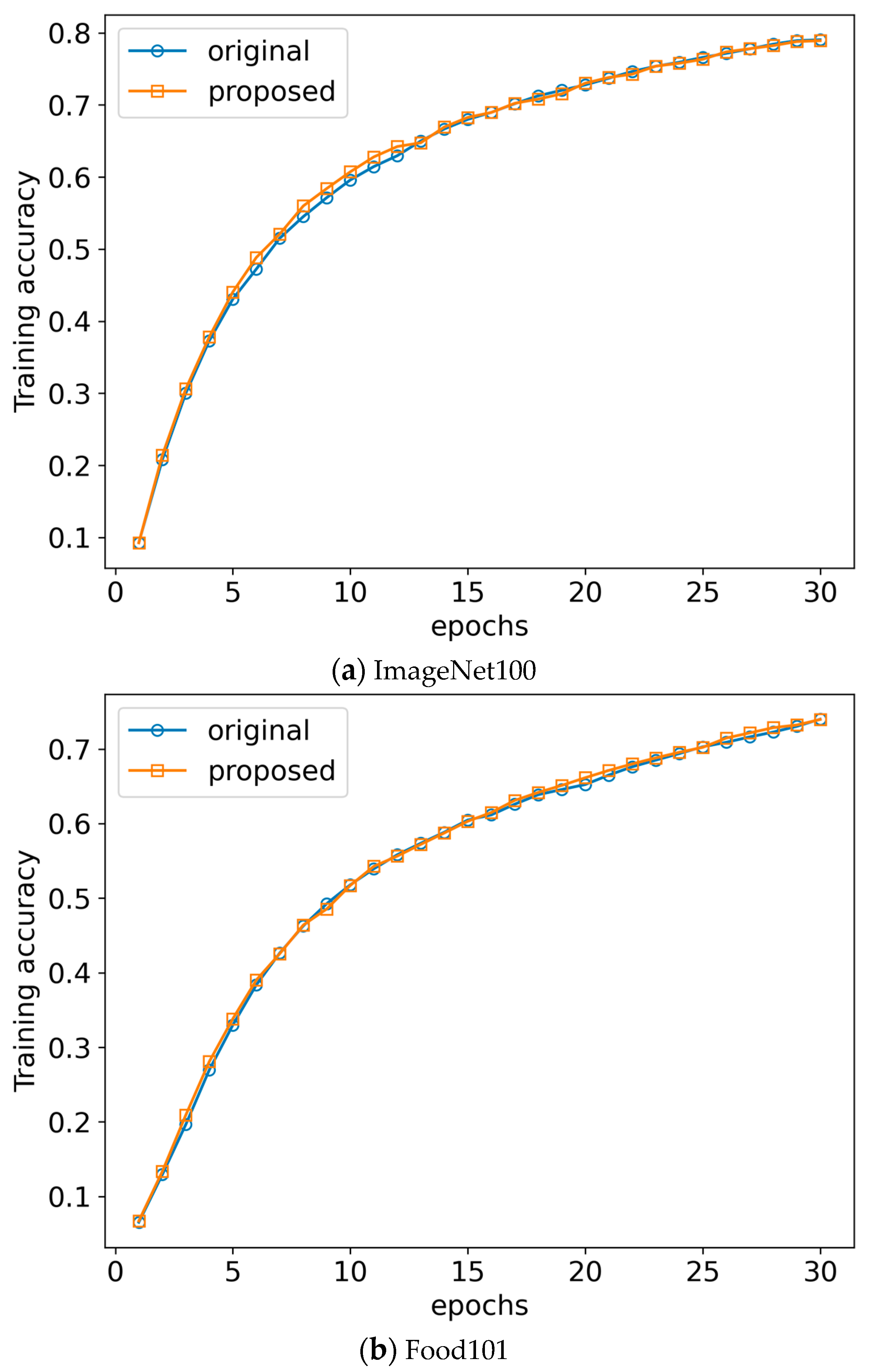
To validate this, we compare the training accuracy of the two models trained by using the proposed shuffling scheme and the original method used in PyTorch as time progresses. Figure 7 shows the training accuracy of the two methods as the number of epochs increases. As shown in the figure, the training accuracy of the proposed scheme is almost the same as that of the original method. Meanwhile, the actual time spent in each epoch will be shortened by applying the proposed scheme since it improves buffer cache performance.
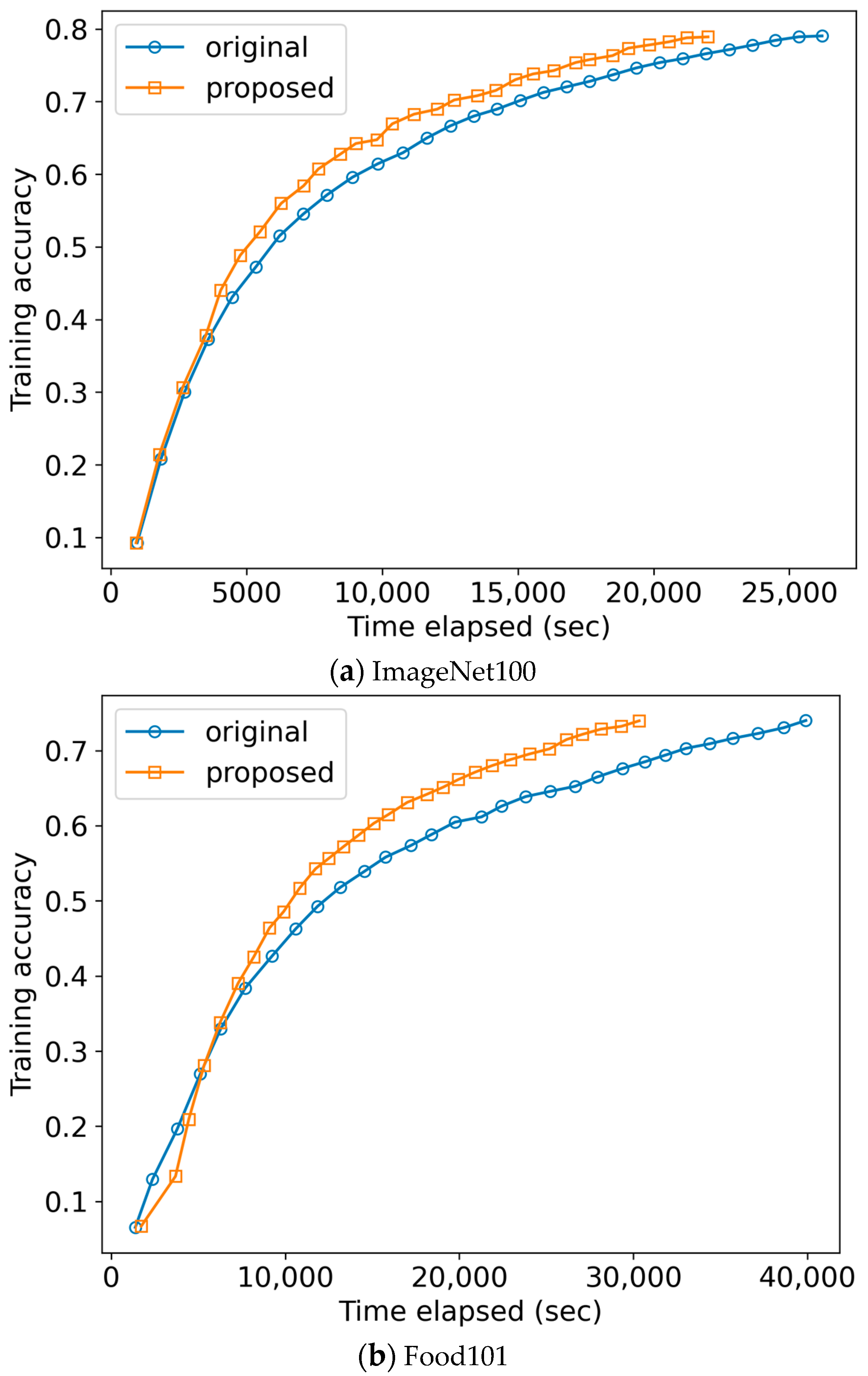
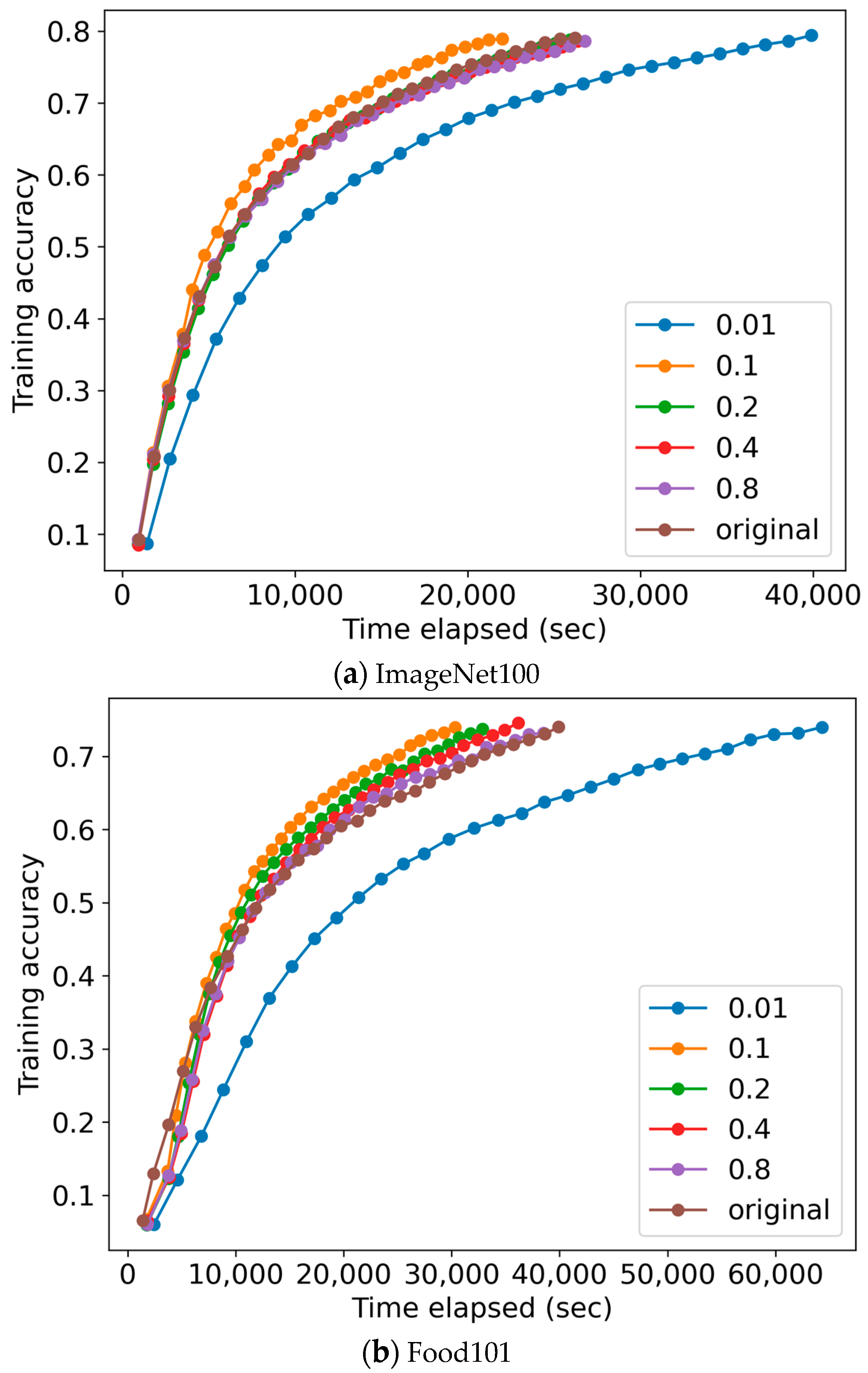
To see this, Figure 8 plots the training accuracy of Figure 7 when the x-axis is changed from the number of epochs to the actual time elapsed. As shown in the figure, the elapsed time to reach the same training accuracy was shortened by 15.4% and 23.7% in Imagenet100 and Food101, respectively, by applying the proposed scheme. This is because our scheme takes less time for each epoch as the data loading time is reduced.
4.1. Sensitivity Analysis on the Bundle Size
Bundle_ratio is an adjustable parameter of the proposed scheme that compromises between randomness and locality of data references. As bundle_ratio increases (i.e., the size of a bundle grows), the randomness of data shuffling increases, thereby improving training efficiency, whereas the locality of data references is degraded from the buffer cache’s perspective. When the bundle_ratio becomes 1, the proposed scheme works exactly the same as the default random shuffling method. Conversely, decreasing the bundle_ratio (i.e., reducing the size of a bundle) can improve the locality of data references from the buffer cache’s perspective, but it degrades the effectiveness of training. If the bundle_ratio becomes extremely small, implying that each bundle consists of a single block, data references will be completely sequential without any randomness. In this case, cache performance can be maximized, but training efficiency degrades significantly over new epochs.
To investigate the effect of the bundle size, we conduct experiments and measure the performance as the bundle_ratio is varied. As shown in Figure 9, the best result was achieved when the bundle_ratio is at some specific point rather than at the extremes of being too large or too small. In this article, we set the default bundle_ratio to 0.1 based on our experimental results as it produces reasonably competitive results regardless of workloads. In reality, determining an optimal bundle_ratio for a given workload is a matter that we are still pursuing as it depends on various parameters including the dataset size and access characteristics. Thus, for now, we need to set a bundle_ratio that performs well for given workloads and will pursue the optimization issue as a future research.
4.2. Effects on Parallel/Distributed Environments
In this subsection, we performed experiments with a large dataset in distributed settings making use of data parallelism. Data parallelism is a deep learning method that replicates the model to multiple machines when a dataset is large and performs training by dividing a batch of data into each machine, calculating gradients in parallel, and then aggregating them [24]. As the shuffling scheme proposed in this article deals with the order in which to train the dataset on a single machine each epoch, it can be performed after data parallelism is adopted.
To see the effects of our scheme on parallel/distributed environments, we performed experiments with a large dataset SUN397 as the number of nodes increases. Note that SUN397 (Scene Understanding 397) is an image database that contains 397 categories of scenes and 108,754 images in total [25].
After assigning a subset of the dataset to each node, we selected data to be trained through local shuffling and examine the performance of the buffer cache during training for five epochs. The size of the buffer cache in this experiment is set to the 50% of the full dataset size, and LRU is used as the caching algorithm. Table 1 shows the hit ratio of the buffer cache with the proposed scheme and the original random shuffling method. As shown in the table, the proposed scheme consistently performs better than the method that does not use it, implying that it scales well. Specifically, the hit rate is in the range of 11.39% to 12.70% in original shuffling, whereas the proposed scheme shows the hit rate of 36.14% to 37.76% regardless of the number of nodes used.
4.3. Sensitivity Analysis on Caching Algorithms
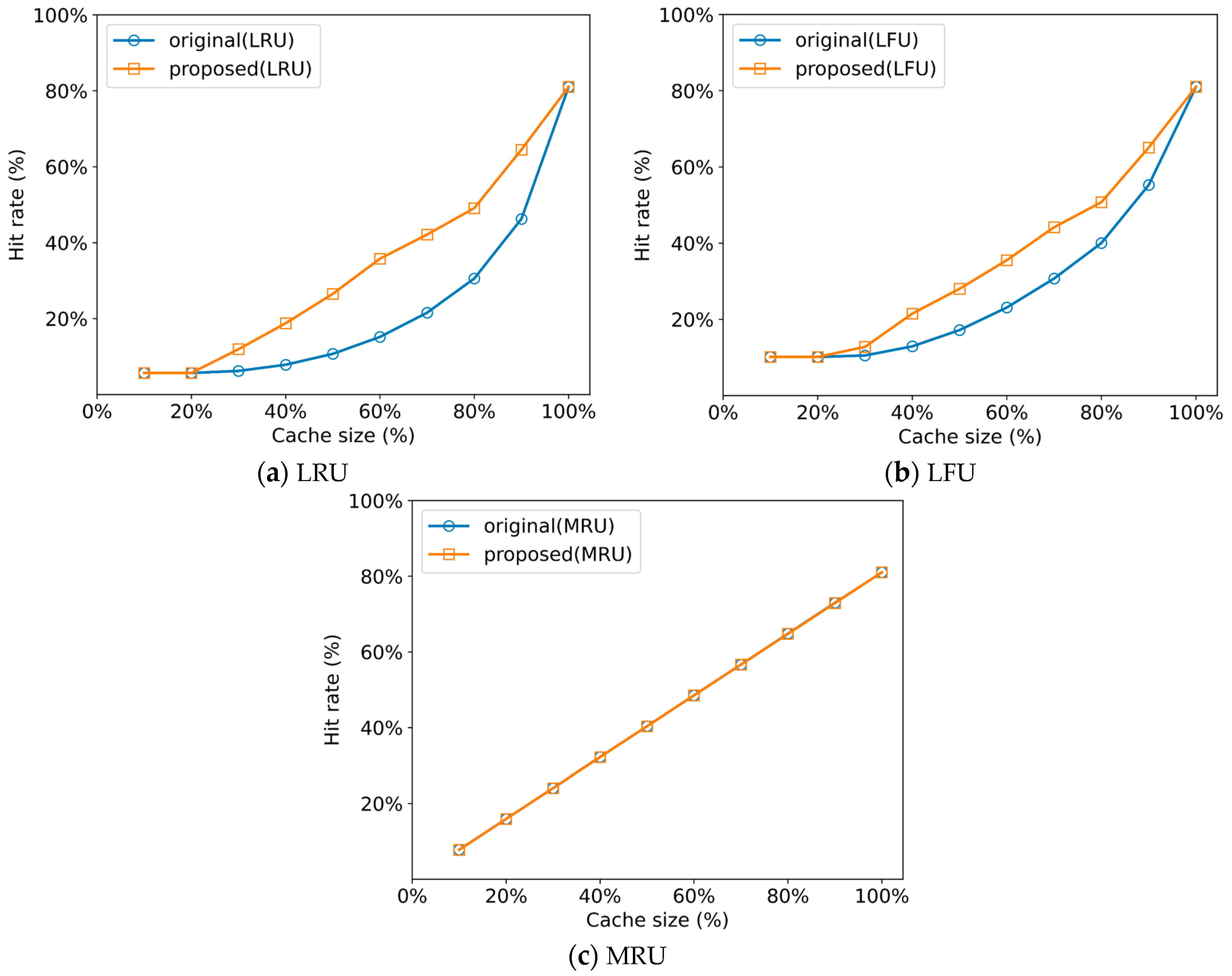
The buffer cache that this article focuses on is equipped at the top of the file system layer, and its algorithm is implemented in the operating system kernel. Since the buffer cache supports not only deep learning workloads but also various kinds of applications, it typically adopts the LRU algorithm that considers temporal locality of data references and the CLOCK algorithm to approximate it. In terms of performance, the LFU (least frequently used) algorithm is often superior to LRU empirically, but due to implementation efficiency, most operating systems adopt variants of LRU. The MRU (most recently used) algorithm does not show good performance in the buffer cache layer in most workload cases, so few operating systems actually adopt it. However, to further validate the effectiveness of the proposed scheme, we perform additional experiments using LFU and MRU in this subsection.
Figure 10 shows the hit rate of the proposed scheme in comparison with the original random shuffling as the caching algorithm is varied. Note that this experiment is performed with the Food101 dataset and similar results can be observed for ImageNet100. As shown in Figure 10b, the performance of the proposed scheme is also improved when the buffer cache is managed by the LFU algorithm although the gap has narrowed. Specifically, the improvement of the proposed scheme is 29.3% on average and up to 66.6% in the buffer cache with LFU.
As shown in Figure 10c, the performance result of the proposed scheme is almost the same as that of the original random shuffling when the buffer cache is managed by MRU. MRU evicts the most recently used block from the cache when free space is needed, so blocks cached in the previous epoch remain in the buffer cache until referenced again. For this reason, the number of hits with the MRU cache is equal to the cache size in each epoch regardless of using the proposed scheme. Actually, the philosophy of the MRU algorithm seems similar to the bundle alternating of the proposed scheme. However, replacing the buffer caching algorithm from LRU to MRU is not a simple matter because it requires the modification of the operating system kernel, raising the issue of compatibility and causes significant performance degradation to most other workloads. Note that the approach of this article is effective in practice as it addresses the performance effect of the buffer cache layer through a cache-friendly shuffling scheme at the application layer without needing to modify the buffer caching algorithm implemented in the operating system kernel, which is also harmful for most workloads.
5. Related Works
Recently, as the size of deep learning models continues to increase, distributed learning methods that perform training by dividing the dataset across multiple nodes are gaining attention. Regarding data shuffling, research has been conducted to improve the efficiency of generating random numbers to obtain a shuffling index for a distributed learning environment.
Nguyen et al. propose a partial-local shuffling method between nodes to compensate for the shortcomings of local shuffling when performing distributed learning on a large number of nodes [26]. Partial-local shuffling refers to a method of partially mixing datasets between nodes by exchanging part of the local dataset within each node. In order to efficiently shuffle data between nodes, Zhu et al. propose DeepIO, which allows remote nodes to access data buffered in the node’s local memory by taking advantage of the RDMA_READ operation [27]. Dryden et al. observe that although each sample is referenced only once per epoch, the number of times the same worker accesses the data sample across multiple epochs is different [28]. By considering this, they propose NoPFS, which stores frequently referenced samples from the worker in fast local storage.
Unlike the aforementioned studies that focus on distributed learning, we address the data shuffling issue within a single node to determine the order of data to train each epoch, and its purpose is to improve the effectiveness of the buffer cache by reducing storage I/Os without degrading the efficiency of training.
Several studies have noted that not all data samples within a dataset have the same effect on model training. These studies mainly pursue training models by selecting datasets using their particular sampling methods rather than full random sampling. Katharopoulos et al. make use of importance sampling techniques to train deep learning models and utilize the loss to calculate the importance of samples [29]. Khan et al. observe that when training a deep learning model using importance sampling, certain data samples are referenced more often than others. They utilize these properties to improve cache performances [22].
Similar to the studies mentioned above, there are also studies that use the loss of each sample to determine hard examples where the model is prone to error and use them for model training. For example, Fast R-CNN [30] and OHEM [31] strengthen the performance of models by sampling hard examples and then reusing them for model training. Schroff et al. [32], Robinson et al. [33], and Tabassum et al. [34] also make use of hard examples to train models. In particular, they perform self-supervised learning with unlabeled datasets by utilizing hard examples.
Meanwhile, some studies focus on the data augmentation phase for efficient file I/O in the model training process. Arazo et al. observe that importance sampling approaches do not provide a consistent improvement under a limited amount of training dataset. To resolve this situation, they introduce an adequate data augmentation method for model training with limited budget environments, thereby balancing high performance with low computational requirements [35]. Lee et al. observe that data augmentation often suffers from heavy CPU overhead [36]. To handle this situation, they split data augmentation into partial and final augmentations, and then reuse partially augmented samples to reduce CPU computation while further transforming them with the final augmentation. By doing so, they preserve the sample diversity obtained by data augmentation with low CPU overhead.
To solve the small file problem that occurs in the Hadoop distributed file system (HDFS), Zhu et al. observed the fact that files in deep learning applications have a strong correlation between batches and merge them into a unit called pile to perform training efficiently [37]. To address the problem of storage write traffic during checkpointing, Chien et al. introduced a burst buffer that absorbs large amounts of checkpoint I/O [38]. In particular, they accelerate storage I/O performance by adopting non-volatile memory with fast write operations as burst buffer. Lee and Bahn analyzed that write access in deep learning makes up the majority of memory accesses, but it shows a low access bias of 0.3 in the Zipf parameter [21]. Based on this observation, they accelerated the write access in deep learning by introducing a non-volatile memory architecture, and present an appropriate memory management policy for this architecture.
6. Conclusions
Data references in neural network workloads exhibit very different trends from those in traditional desktop workloads. Particularly, during the training phase of neural network workloads, all data blocks are referenced randomly. Because of such characteristics, it is challenging to improve the performance of the buffer cache while running neural network workloads. To handle this situation, we suggested a new shuffling scheme that aims to accelerate data loading time in neural networks by improving the buffer cache hit rate. Unlike traditional shuffling used in neural network training that randomly shuffles the entire dataset at every epoch, our shuffling scheme defines a shuffling unit called a bundle, and improves the locality of data references without degrading the training efficiency. We also use a heuristic to improve temporal locality of references by alternating the sequence of bundles to be used for each epoch. By utilizing the proposed shuffling scheme, this article showed that the cache hit rate and the data loading time can be improved by 37.2% and 11.4%, respectively. In addition, we showed that the proposed shuffling scheme does not degrade the training efficiency.
Existing caching optimization research has mainly focused on improving the performance of the cache memory layer above main memory [39]. The shuffling scheme proposed in this article is different in that it seeks to improve performance for the storage layer below the main memory. As the target layers are different, additional performance improvements can be expected by using both approaches together. To fully utilize the effectiveness of cache optimization in different layers, jointly optimizing the two layers may be a good research direction for our future study. Likewise, since there are a lot of studies on data parallelism that address the efficiency of dividing a batch of data on multiple machines, determining the order of data to be trained on each machine considered in this article can be co-optimized with this approach, possibly leading to improved I/O performance. Specifically, we will focus on IoT (Internet of Things) applications with a small buffer cache where hit rate is difficult to improve, and training is performed in distributed environments with data parallelism.
Author Contributions
J.L. implemented the algorithm, and performed the experiments. H.B. designed the work and provided expertise. All authors have read and agreed to the published version of the manuscript.
Funding
This work was partially supported by the Institute of Information & communications Technology Planning & Evaluation (IITP) grant funded by the Korean government (MSIT) (No. 2021-0-02068, Artificial Intelligence Innovation Hub) and (No. RS-2022-00155966, Artificial Intelligence Convergence Innovation Human Resources Development (Ewha University)).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
No new data were created or analyzed in this study. Data sharing is not applicable to this article.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Kotsiopoulos, T.; Sarigiannidis, P.; Ioannidis, D.; Tzovaras, D. Machine Learning and Deep Learning in smart manufacturing: The Smart Grid paradigm. Comput. Sci. Rev. 2021, 40, 100341. [Google Scholar] [CrossRef]
- Li, H.; Ota, K.; Dong, M. Learning IoT in edge: Deep learning for the internet of things with edge computing. IEEE Network 2018, 32, 96–101. [Google Scholar] [CrossRef]
- Muhammad, K.; Ullah, A.; Lloret, J.; Del Ser, J.; de Albuquerque, V.H.C. Deep Learning for Safe Autonomous Driving: Current Challenges and Future Directions. IEEE Trans. Intell. Transp. Syst. 2021, 22, 4316–4336. [Google Scholar] [CrossRef]
- Abdullah, A.A.; Hassan, M.M.; Mustafa, Y.T. A Review on Bayesian Deep Learning in Healthcare: Applications and Challenges. IEEE Access 2022, 10, 36538–36562. [Google Scholar] [CrossRef]
- Fortune Business Insights. Artificial Intelligence Market Size, Share & COVID-19 Impact Analysis. 2023. Available online: https://www.fortunebusinessinsights.com/industry-reports/artificial-intelligence-market-100114 (accessed on 6 October 2023).
- Tam, P.; Math, S.; Nam, C.; Kim, S. Adaptive resource optimized edge federated learning in real-time image sensing classifications. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 10929–10940. [Google Scholar] [CrossRef]
- Park, S.; Bahn, H. Memory Access Characteristics of Neural Network Workloads and Their Implications. In Proceedings of the IEEE Asia-Pacific Conference on Computer Science and Data Engineering, Gold Coast, Australia, 18–20 December 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Rhu, M.; Gimelshein, N.; Clemons, J.; Zulfiqar, A.; Keckler, S.W. vDNN: Virtualized Deep Neural Networks for Scalable, Memory-Efficient Neural Network Design. In Proceedings of the 2016 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Taipei, Taiwan, 15–19 October 2016; pp. 1–13. [Google Scholar] [CrossRef]
- Lee, J.; Bahn, H. Analyzing Memory Access Traces of Deep Learning Workloads for Efficient Memory Management. In Proceedings of the 12th Int’l Conf. Information Technology in Medicine and Education, Xiamen, China, 18–20 November 2022; pp. 389–393. [Google Scholar] [CrossRef]
- Zhang, Z.; Huang, L.; Manor, U.; Fang, L.; Merlo, G.; Michoski, C.; Gaffney, N. FanStore: Enabling efficient and scalable I/O for distributed deep learning. arXiv 2018, arXiv:1809.10799. [Google Scholar] [CrossRef]
- Cheng, G.; Wan, Z.; Ding, W.; Sun, R. Memory Allocation Strategy in Edge Programmable Logic Controllers Based on Dynamic Programming and Fixed-Size Allocation. Appl. Sci. 2023, 13, 10297. [Google Scholar] [CrossRef]
- Zhang, Z.; Shen, Z.; Jia, Z.; Shao, Z. UniBuffer: Optimizing Journaling Overhead with Unified DRAM and NVM Hybrid Buffer Cache. IEEE Trans. Comput. Des. Integr. Circuits Syst. 2019, 39, 1792–1805. [Google Scholar] [CrossRef]
- Bahn, H.; Kim, J. Reducing the Overhead of Virtual Memory Swapping by Considering Application Characteristics and Memory Situations. In Proceedings of the Int’l Conf. Information Technology in Medicine and Education, Xiamen, China, 18–20 November 2022; pp. 434–438. [Google Scholar] [CrossRef]
- Kwon, S.; Bahn, H. Classification and Characterization of Memory Reference Behavior in Machine Learning Workloads. In Proceedings of the IEEE/ACIS 23rd Int’l Conf. Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing (SNPD), Taichung, Taiwan, 7–9 December 2022; pp. 103–108. [Google Scholar] [CrossRef]
- Strace. Available online: https://strace.io/ (accessed on 6 October 2023).
- PyTorch. Available online: https://pytorch.org/ (accessed on 6 October 2023).
- Food101 Dataset. Available online: https://data.vision.ee.ethz.ch/cvl/datasets_extra/food-101/ (accessed on 6 October 2023).
- ImageNet100 Dataset. Available online: https://www.kaggle.com/datasets/ambityga/imagenet100 (accessed on 6 October 2023).
- ImageNet-1k Dataset. Available online: https://www.image-net.org/challenges/LSVRC/2012 (accessed on 6 October 2023).
- Zhou, F.; Behren, J.; Brewer, E. AMP: Program Context Specific Buffer Caching. In Proceedings of the USENIX Annual Technical Conference, Anaheim, CA, USA, 10–15 April 2005; pp. 371–374. [Google Scholar]
- Lee, J.; Bahn, H. Characterization of Memory Access in Deep Learning and Its Implications in Memory Management. Comput. Mater. Contin. 2023, 76, 607–629. [Google Scholar] [CrossRef]
- Khan, R.; Yazdani, A.; Fu, Y.; Paul, A.; Ji, B.; Jian, X.; Cheng, Y.; Butt, A. SHADE: Enable Fundamental Cacheability for Distributed Deep Learning Training. In Proceedings of the 21st USENIX Conference on File and Storage Technologies (FAST), Santa Clara, CA, USA, 21–23 February 2023; pp. 135–152. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Shallue, C.J.; Lee, J.; Antognini, J.; Sohl-Dickstein, J.; Frostig, R.; Dahl, G.E. Measuring the Effects of Data Parallelism on Neural Network Training. J. Mach. Learn. Res. 2019, 20, 1–49. [Google Scholar]
- SUN 397. Available online: https://vision.princeton.edu/projects/2010/SUN/ (accessed on 6 October 2023).
- Nguyen, T.T.; Trahay, F.; Domke, J.; Drozd, A.; Vatai, E.; Liao, J.; Wahib, M.; Gerofi, B. Why Globally Re-shuffle? Revisiting Data Shuffling in Large Scale Deep Learning. In Proceedings of the IEEE Int’l Parallel and Distributed Processing Symposium (IPDPS), Lyon, France, 30 May–3 June 2022; pp. 1085–1096. [Google Scholar]
- Zhu, Y.; Chowdhury, F.; Fu, H.; Moody, A.; Mohror, K.; Sato, K.; Yu, W. Entropy-Aware I/O Pipelining for Large-Scale Deep Learning on HPC Systems. In Proceedings of the IEEE 26th Int’l Symposium on Modeling, Analysis, and Simulation of Computer and Telecommunication Systems (MASCOTS), Milwaukee, WI, USA, 25–28 September 2018; pp. 145–156. [Google Scholar]
- Dryden, N.; Böhringer, R.; Ben-Nun, T.; Hoefler, T. Clairvoyant Prefetching for Distributed Machine Learning I/O. arXiv 2021, arXiv:2101.08734. [Google Scholar] [CrossRef]
- Katharopoulos, A.; Fleuret, F. Not All Samples Are Created Equal: Deep Learning with Importance Sampling. In Proceedings of the 35th Int’l Conference on Machine Learning (PMLR), Stockholm, Sweden, 10–15 July 2018; Volume 80, pp. 2525–2534. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE/CVF Int’l Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Shrivastava, A.; Gupta, A.; Girshick, R. Training Region-Based Object Detectors with Online Hard Example Mining. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 761–769. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A Unified Embedding for Face Recognition and Clustering. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Robinson, J.; Chuang, C.; Sra, S.; Jegelka, S. Contrastive Learning with Hard negative samples. arXiv 2020, arXiv:2010.04592. [Google Scholar] [CrossRef]
- Tabassum, A.; Wahed, M.; Eldardiry, H.; Lourentzou, I. Hard Negative Sampling Strategies for Contrastive Representation Learning. arXiv 2022, arXiv:2206.01197. [Google Scholar] [CrossRef]
- Arazo, E.; Ortego, D.; Albert, P.; O’Connor, N.; McGuinness, K. How Important is Importance Sampling for Deep Budgeted training? arXiv 2021, arXiv:2110.14283. [Google Scholar] [CrossRef]
- Lee, G.; Lee, I.; Ha, H.; Lee, K.; Hyun, H.; Shin, A.; Chun, B. Refurbish Your Training Data: Reusing Partially Augmented Samples for Faster Deep Neural Network Training. In Proceedings of the USENIX Annual Technical Conference, Virtual, 14–16 July 2021; pp. 537–550. [Google Scholar]
- Zhu, Z.; Tan, L.; Li, Y.; Ji, C. PHDFS: Optimizing I/O performance of HDFS in deep learning cloud computing platform. J. Syst. Arch. 2020, 109, 101810. [Google Scholar] [CrossRef]
- Chien, S.; Markidis, S.; Sishtla, C.; Santos, L.; Herman, P.; Narasimhamurthy, S.; Laure, E. Characterizing Deep-Learning I/O Workloads in TensorFlow. In Proceedings of the IEEE/ACM 3rd Int’l Workshop on Parallel Data Storage & Data Intensive Scalable Computing Systems (PDSW-DISCS), Dallas, TX, USA, 12 November 2018; pp. 54–63. [Google Scholar]
- Shi, Z.; Huang, X.; Jain, A.; Lin, C. Applying Deep Learning to the Cache Replacement Problem. In Proceedings of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Columbus, OH, USA, 12–16 October 2019; pp. 413–425. [Google Scholar] [CrossRef]
Figure 1.
An overview of the proposed shuffling scheme in comparison to the default shuffling in PyTorch.
Figure 1.
An overview of the proposed shuffling scheme in comparison to the default shuffling in PyTorch.

Figure 2.
Data references while training of neural networks.

Figure 3.
Data reference after adopting bundle-based shuffling.

Figure 4.
Data references after adopting bundle-based shuffling and bundle alternating.

Figure 5.
Performance comparison with respect to the cache hit rate.

Figure 6.
Performance comparison with respect to the data loading time.

Figure 7.
Comparison of original and proposed schemes with respect to the training accuracy.

Figure 8.
Comparison of original and proposed schemes with respect to training efficiency.

Figure 9.
Effects of the bundle_ratio on training accuracy as time progresses.

Figure 10.
Performance effect of the proposed scheme with different caching algorithms.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Effect of the proposed scheme as the number of nodes increases.
| # of Nodes | Node # | Original | Proposed |
|---|---|---|---|
| 2 nodes | Node 1 | 11.63% | 36.99% |
| Node 2 | 11.64% | 37.52% | |
| 4 nodes | Node 1 | 11.87% | 37.02% |
| Node 2 | 11.90% | 37.33% | |
| Node 3 | 11.60% | 36.93% | |
| Node 4 | 11.59% | 36.98% | |
| 8 nodes | Node 1 | 11.95% | 37.58% |
| Node 2 | 12.35% | 36.27% | |
| Node 3 | 11.43% | 36.81% | |
| Node 4 | 11.82% | 37.55% | |
| Node 5 | 12.01% | 36.35% | |
| Node 6 | 11.82% | 37.55% | |
| Node 7 | 11.70% | 36.14% | |
| Node 8 | 11.87% | 37.26% | |
| 16 nodes | Node 1 | 13.14% | 37.04% |
| Node 2 | 11.62% | 37.60% | |
| Node 3 | 12.70% | 37.53% | |
| Node 4 | 12.17% | 37.75% | |
| Node 5 | 12.21% | 36.46% | |
| Node 6 | 12.59% | 37.51% | |
| Node 7 | 12.34% | 37.40% | |
| Node 8 | 11.57% | 37.45% | |
| Node 9 | 12.49% | 37.52% | |
| Node 10 | 11.49% | 37.11% | |
| Node 11 | 11.39% | 37.57% | |
| Node 12 | 11.80% | 36.78% | |
| Node 13 | 11.66% | 37.49% | |
| Node 14 | 12.05% | 37.48% | |
| Node 15 | 12.20% | 36.96% | |
| Node 16 | 12.38% | 37.39% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Lee, J.; Bahn, H. Analyzing Data Reference Characteristics of Deep Learning Workloads for Improving Buffer Cache Performance. Appl. Sci. 2023, 13, 12102. https://doi.org/10.3390/app132212102
AMA Style
Lee J, Bahn H. Analyzing Data Reference Characteristics of Deep Learning Workloads for Improving Buffer Cache Performance. Applied Sciences. 2023; 13(22):12102. https://doi.org/10.3390/app132212102
Chicago/Turabian StyleLee, Jeongha, and Hyokyung Bahn. 2023. "Analyzing Data Reference Characteristics of Deep Learning Workloads for Improving Buffer Cache Performance" Applied Sciences 13, no. 22: 12102. https://doi.org/10.3390/app132212102
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.