1. Introduction
With the development of unmanned combat air vehicles (UCAVs), the role of UCAVs is becoming increasingly significant in the field of combat [
1]. UCAVs have high efficiency and can perform large overload maneuvers that are otherwise difficult to achieve with manned combat aircrafts. Therefore, it can be predicted that UCAVs will become the main protagonists of future air combats. Most UCAVs are too small to be equipped with medium-range air-to-air missiles (MRAMs). Therefore, within visual range (WVR) air combats are likely to become the main air combat scene of UCAVs [
2]. The UCAV air combat scenario studied in this article is a 1-vs.-1 WVR UCAV air combat scenario using guns. Existing UCAVs can only complete simple military tasks, such as autonomously or semi-autonomously detecting, tracking, and striking ground targets. An example of a UCAV is the RQ-4 “Global Hawk” strategic unmanned reconnaissance aircraft. Although military UCAVs can already perform reconnaissance and ground attack missions, most of these missions rely on the manual decision-making of UCAV ground stations, which operate in the man-in-the-loop control mode. Furthermore, using UCAV ground stations to control UCAVs renders them vulnerable to bad weather conditions and electromagnetic interference, both of which can be problematic in real-time air combat situations. Therefore, it is crucial for UCAVs to be able to make control decisions automatically based on the air combat situations it faces; UCAV autonomous air combat is therefore an important research topic in the field of UAV intelligence.
Owing to the rapidly changing battlefield environments, making autonomous maneuver decisions during air combats is challenging. For example, if one UCAV tracks another UCAV that is steady, and then, if tracked UCAV suddenly slows down, the tracking UCAV may overshoot; this will lead to a sudden change in the air combat situation. Therefore, autonomous maneuver decisions need to be based on mathematical optimization, artificial intelligence, and other technical methods in order to ensure the automatic generation of maneuver strategies in various air combat situations [
3].
Since the early 1960s, a lot of research has been conducted on autonomous air combat, and some key research results have been achieved. At present, several methods have been proposed to enable autonomous maneuver decision-making during air combats, and these methods can be roughly divided into the following three categories: basic fighter maneuvers (BFM)-based methods using library and game theory, optimization-based methods, and artificial intelligence-based methods. First, typical research based on the basic fighter maneuvers (BFMs) using library and game theory are introduced. In [
4], the first systematic study was conducted and a summary of the establishment of BFM expert systems was presented. The design of the maneuver library, control applications, and maneuver recognition based on the BFM expert system were proposed, and various problems that were encountered during maneuver decision-making based on the action library were elaborated in [
5,
6]. Based on a combination of the BFM library, target prediction, and impact point calculations, an autonomous aerial combat framework for two-on-two engagements was proposed in [
7].
Air combat maneuvering methods that are based on the optimization theory include the dynamic programming algorithm [
8], intelligence optimization algorithm [
9], statistical theory [
10] and so on. In [
8], approximate dynamic programming (ADP), a real-time autonomous one-to-one air combat method was studied, and the results were tested in real-time indoor autonomous vehicle test environments (RAVEN). ADP differs from classical dynamic programming in that it constructs a continuous function to approximate future returns. ADP does not need to perform future reward calculations for each discrete state, therefore, its real-time performance is reliable. In [
11], particle swarm optimization, ant colony optimization, and game theory were applied in a cooperative air combat framework, and the results were compared.
Artificial intelligence methods mainly include the use of neural network methods [
12,
13] and reinforcement learning methods [
3,
14,
15,
16]. Air combat maneuvering decisions based on artificial neural networks are extremely robust and they can be learned from a large number of air combat samples. However, air combat samples comprise multiple sets of time series as well as the results of air combats. Owing to confidentiality, air combat samples are difficult to obtain, and the label of such samples are extremely sparse. Furthermore, manual work required to label samples at every sampling moment. Therefore, the method of generating air combat maneuvering strategy based on neural networks has the problem of insufficient samples. Owing to the aforementioned limitations, air combat maneuvering decisions that are based on reinforcement learning are now garnering significant attention. This is because, with this learning method, the sample insufficiency problem, which exists in the case of supervised learning, can be avoided. In [
3], an algorithm that is based on a deep Q-network and a new training method were proposed to reduce training time and simultaneously obtain sub-optimal but effective training results. A discrete action space was used, and the air combat maneuvering decisions of an enemy UCAV were considered.
Single-agent reinforcement learning has been successfully applied in video games, board games, self-driving cars, etc. [
17]. However, UCAV 1-vs.-1 WVR air combats happen in unstable environments, and the Markov decision process (MDP) is not suitable for modelling them. In most articles [
3,
6,
8], the authors will assume an air combat strategy of the enemy, so that an unstable environment model can be converted into a stable environment model. An air combat strategy obtained using a stable environmental model is therefore of little significance, as the obtained policy may only be effective against the assumed air combat strategy of the enemy and, therefore, it may be invalid or not optimal for other enemy air combat strategies. At the same time, UCAV 1-vs.-1 WVR air combat has high real-time and high confrontation characteristics, so, it is critical to accurately predict the maneuvers and intentions of the other party’s UCAV. In the vast majority of articles, the author only uses the current UCAV motion state as the state space for reinforcement learning, which makes it difficult for a trained UCAV air combat strategy to learn predicted target maneuvering and intentional air combat decisions. This means that an air combat strategy will not consist of the intelligent behavior necessary to be in the dominant position in advance. In order to solve the above mentioned problems, we propose a UCAV 1-vs.-1 WVR air combat strategy generation method that is based on a multi-agent reinforcement learning method with the inclusion of a target maneuver prediction in this article.
The main novelties of this paper are summarized below:
We formulate the UCAV 1-vs.-1 WVR air combat as a two-player zero-sum Markov game (ZSMG).
We propose a UCAV 1-vs.-1 WVR air combat strategy generation algorithm based on multi-agent deep deterministic policy gradient (MADDPG).
The future maneuvering states of the target UCAV are introduced into the state space.
Introducing potential-based reward shaping method to improve the efficiency of maneuver strategy generation algorithm of UCAV.
2. Preliminary
2.1. Zero-Sum Markov Games
This paper uses two-player ZSMG theory [
18] as a modeling framework for UCAV 1-vs.-1 WVR air combat missions. The formal definition of a Markov game (MG) is briefly introduced in the following section.
MG is an extension of MDP, which uses elements of game theory to allow multiple agents to compete with each other in model systems that accomplish specified tasks. In other words, an MG with a set of k agents is defined, as follows:
(1) : environment states.
(2) : the action spaces of k agents. The action space of the ith agent is , .
(3)
: a state transition function, which is determined by the current state and the next actions of all the agents. If the environment is stochastic, its function relationship can be expressed as follows:
(4)
: the reward functions of
k agents. For the
ith agent (
), the function relationship can be given, as follows:
The goal of the
ith agent is to find a policy
that maximizes the discount sum of its rewards
.
where,
is a stationary distribution probability for the policies of a given
k agent,
,
T is the length of each trajectory;
is the discount factor; and
is the reward of the
ith agent at the
tth step in a trajectory.
Two player ZSMG is a special case of MG. It only considers two players, called the agent and the opponent, who have opposite reward functions and symmetrical utility functions. The two player ZSMG can be expressed as a quintile , where, is a set of environment states; is the state transition function, where defines a transition function from state s to state when the agent executes action a and the opponent executes action o in a stochastic environment; and are the action spaces of the agent and the opponent; is the reward function of the agent; and, is the reward function of the opponent.
2.2. Deterministic Policy Gradient (DPG) and Deep Deterministic Policy Gradient (DDPG)
The DPG algorithm is an improved version of the policy gradient (PG) algorithm [
19]. Unlike in the PG algorithm [
20], the policy of the DPG algorithm is deterministic:
. Therefore, in the DPG algorithm, a policy parameter
exists in the value function
, and this function must be derived from the policy. The gradient of the objective
can be expressed, as follows:
In Equation (
4), there are no expectations that are related to actions. Therefore, compared with a stochastic policy, policy strategies need less learning data and exhibit high efficiency, especially in the case of action spaces of large dimensions.
DDPG is an improved version of the DPG algorithm [
21], in which the policy and value functions are approximated with deep neural networks. Similar to the DQN algorithm, experience replay and dual network structures are introduced in the DDPG in order to make the training process more stable and the algorithm more convergent. DDPG is therefore an off-policy algorithm, and the samples trajectories from the experience replay the buffers stored throughout the training.
2.3. Multi-Agent Deep Deterministic Policy Gradient (MADDPG)
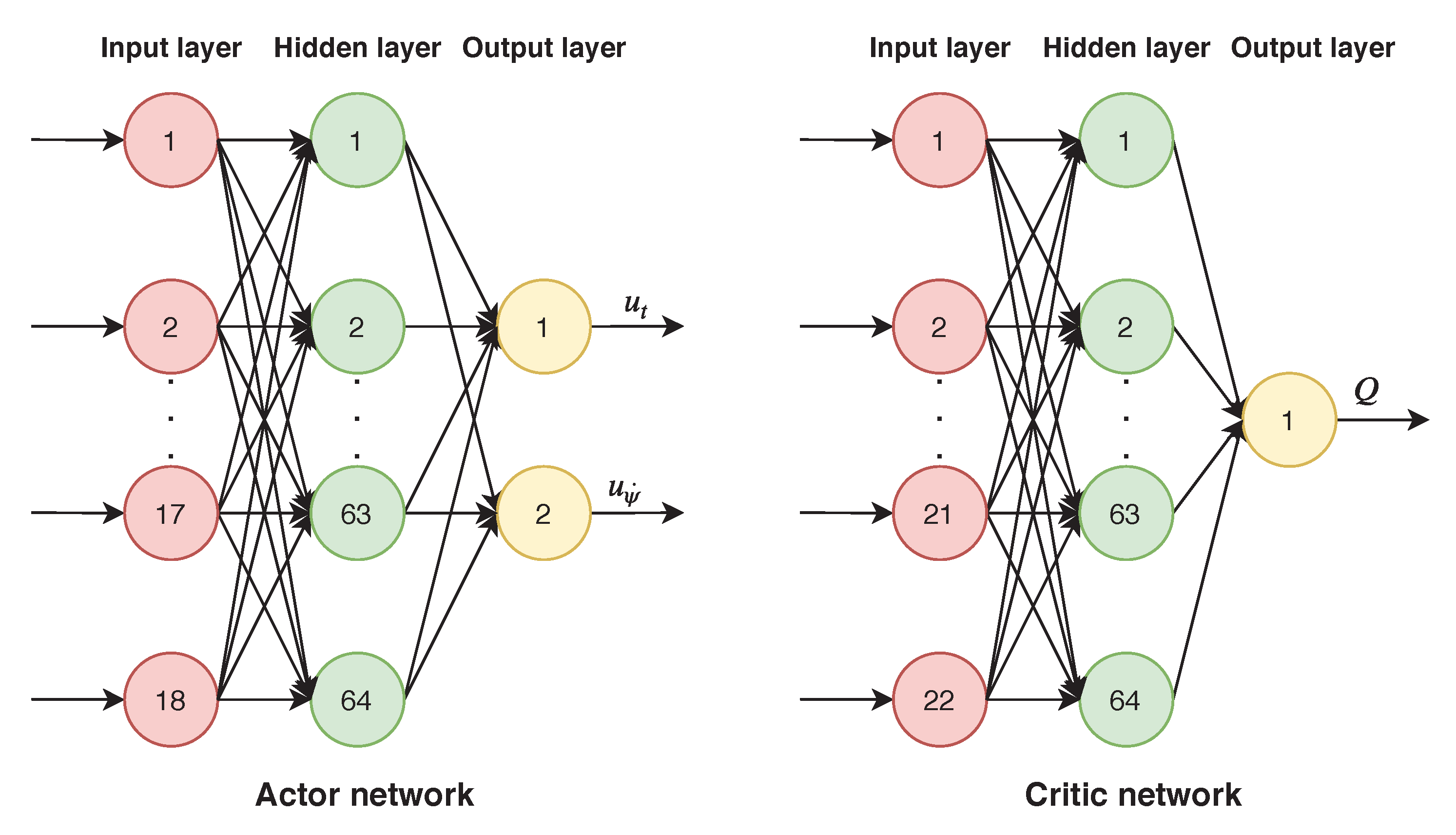
In a multi-agent environment, when other agents are treated as part of the environment, applying the single-agent RL algorithm directly to a multi-agent setting can be problematic, because, from the perspective of an agent, the environment appears to be non-stationary, which violates the Markov assumption that is required for convergence. Especially in DRL, using a neural network as a function approximation, the non-stationary problem is even more serious. In the case of 1-vs.-1 WVR air combat, it is impossible to determine the next state of an enemy UCAV according to the current agent state and its actions, because the opponent UCAV can use different maneuvers to cause the opponent’s next state to differ. Particularly, in a multi-agent competitive environment, the non-stationary problem is serious.
To address the problem of reinforcement learning in a multi-agent environment, Lowe et al. [
22] proposed the MADDPG algorithm and applied the DDPG algorithm to a multi-agent environment. The MADDPG algorithm presents the idea of “centralized training, decentralized execution” and learns a centralized Q function for each agent. A MADDPG algorithm that is based on global information can address the non-stationary problems and stabilize training.
Concretely speaking, the study considers the two-player ZSMG as an example of a multi-agent environment and assumes
to be the agent policy and
to be the opponent policy. Subsequently, we can write the gradient of the expected return for the agent and opponent with polices
and
,
,
as:
where,
is a centralized action-value function of an agent that uses the agent and opponent as input and
is a centralized action-value function of the opponent. The experience replay buffer
contains the tuples
recording experiences of the agent and opponent, where
denotes the next state from
s after taking actions
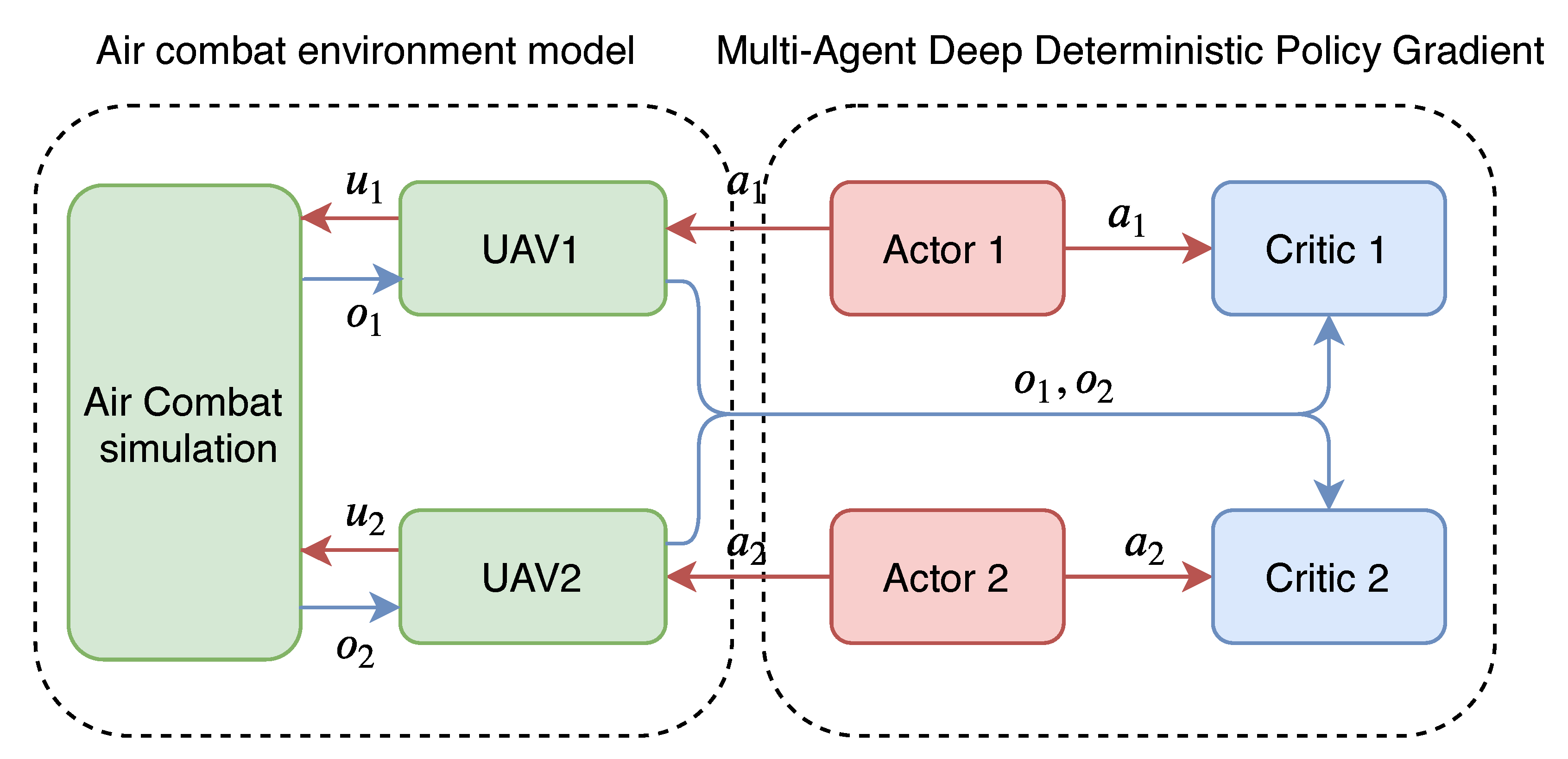
. Centralized action–value functions are updated using the temporal-difference learning. Taking UCAV 1-vs.-1 WVR air combat as an application scenario, both UCAVs will have a Q network and a policy network, respectively. The input of the Q network is the flight status, air combat situation features and action vector of both UCAVs, and the output is Q value of own UCAV. The input of the policy network is the flight status, and the air combat situation features of both UCAVs, and the output is the action vector of own UCAV. A schematic of MADDPG’s idea of “centralized training, distribution execution” of UCAV 1-vs.-1 WVR air combat is illustrated in
Figure 1.
3. 1-vs.-1 WVR Air Combat Engagement Modelling
The two players in a 1-vs.-1 WVR aerial combat engagement, referred to as and , are assumed to be on the same horizontal plane. The objective of each player is to reach the tail of the adversary and track it in a stable manner, in order to satisfy the shooting condition of the guns.
In the following subsection, the 1-vs.-1 WVR aerial combat is modeled by ZSMG. Moreover, the control decisions of each player are taken in the same discrete time interval.
3.1. Air Combat Reward Function and Termination Condition Designing
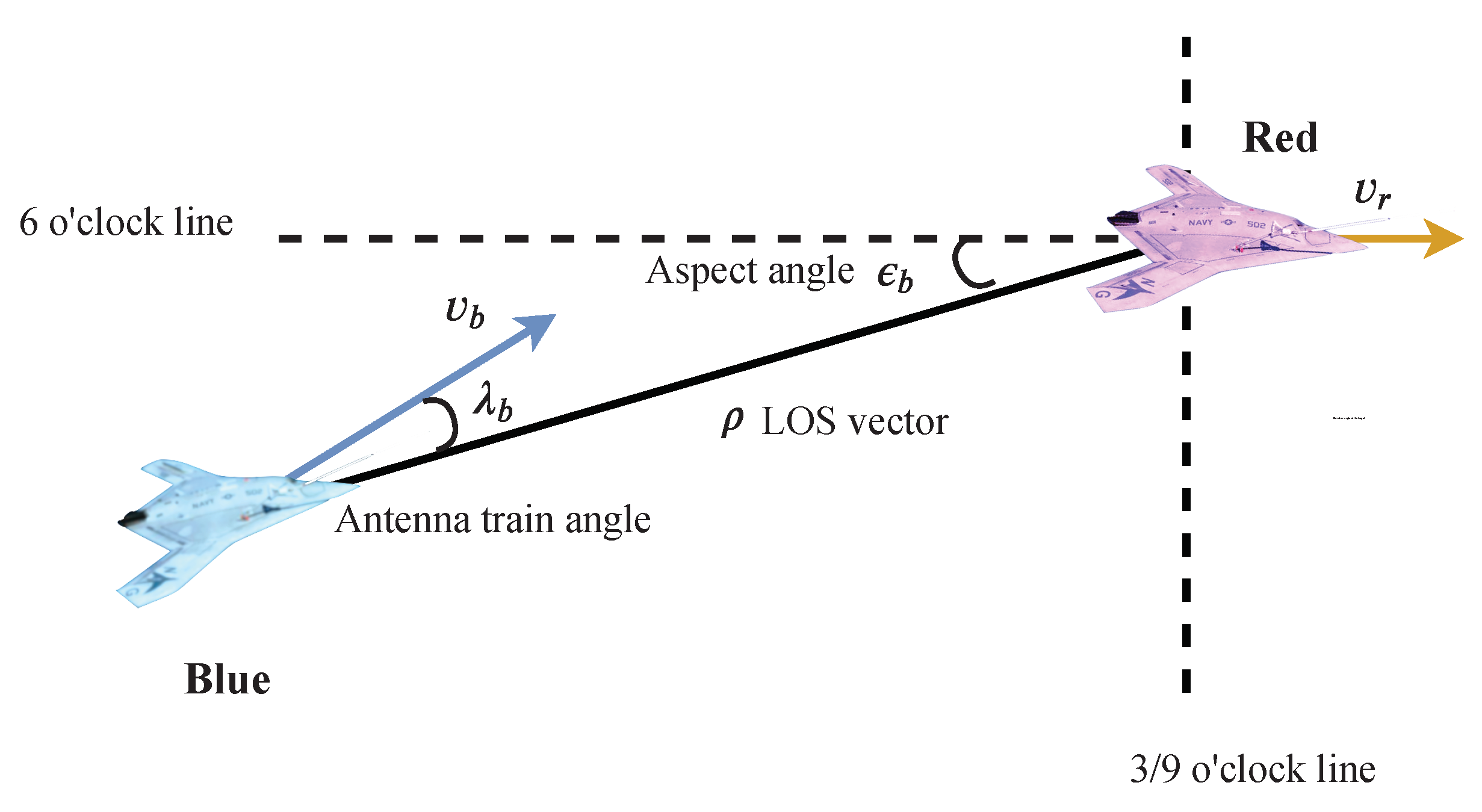
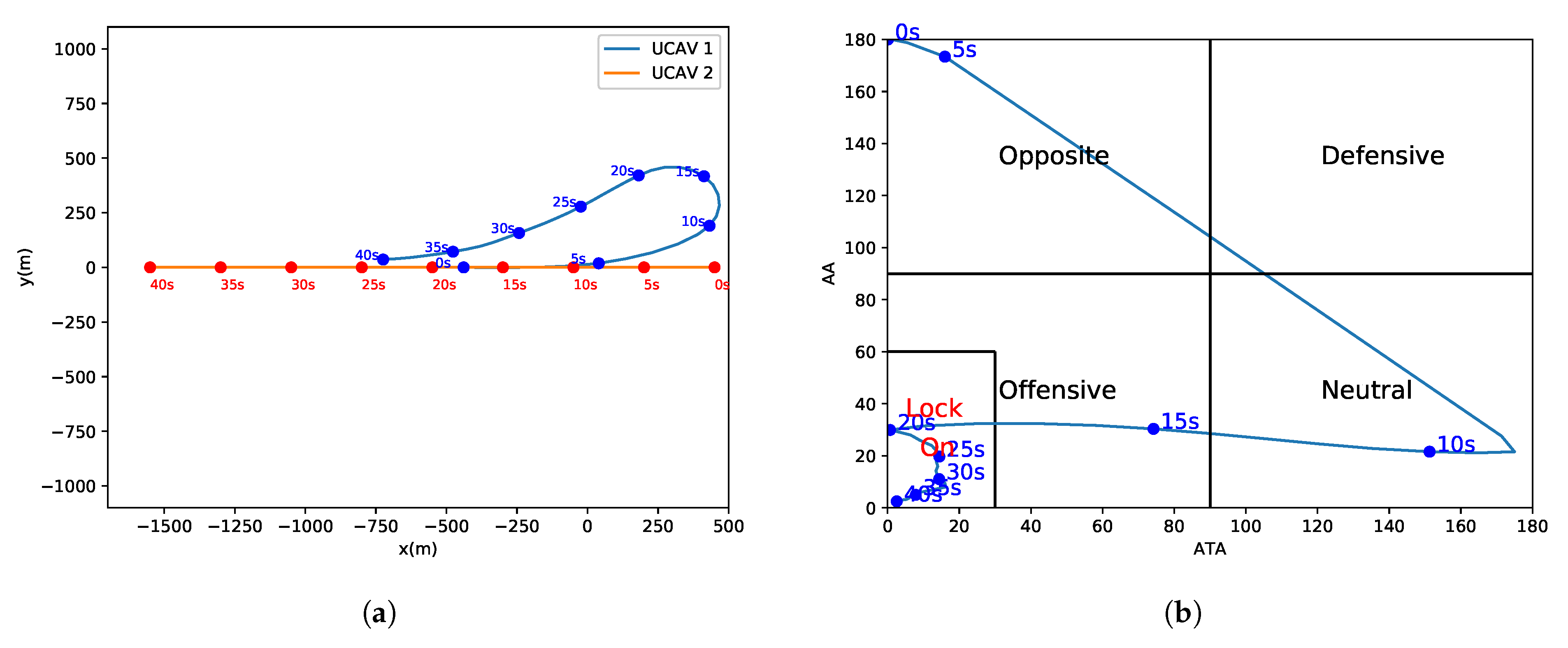
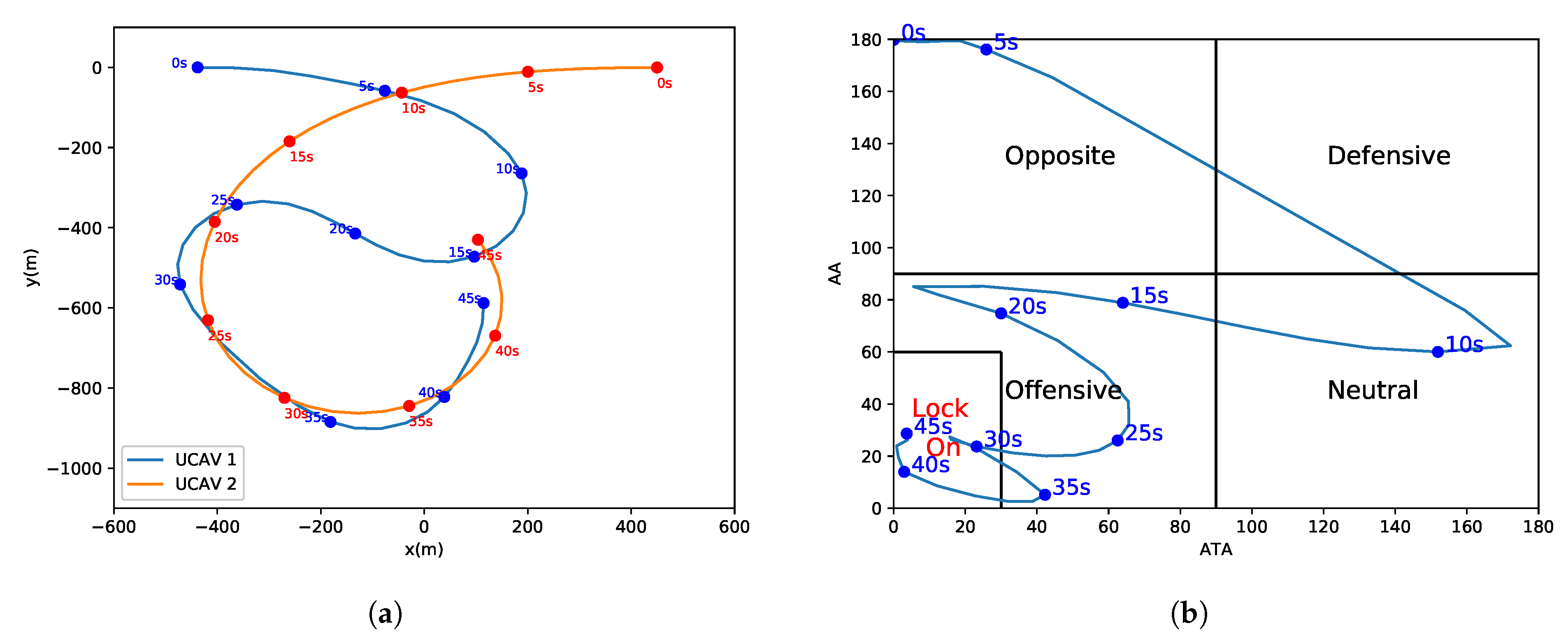
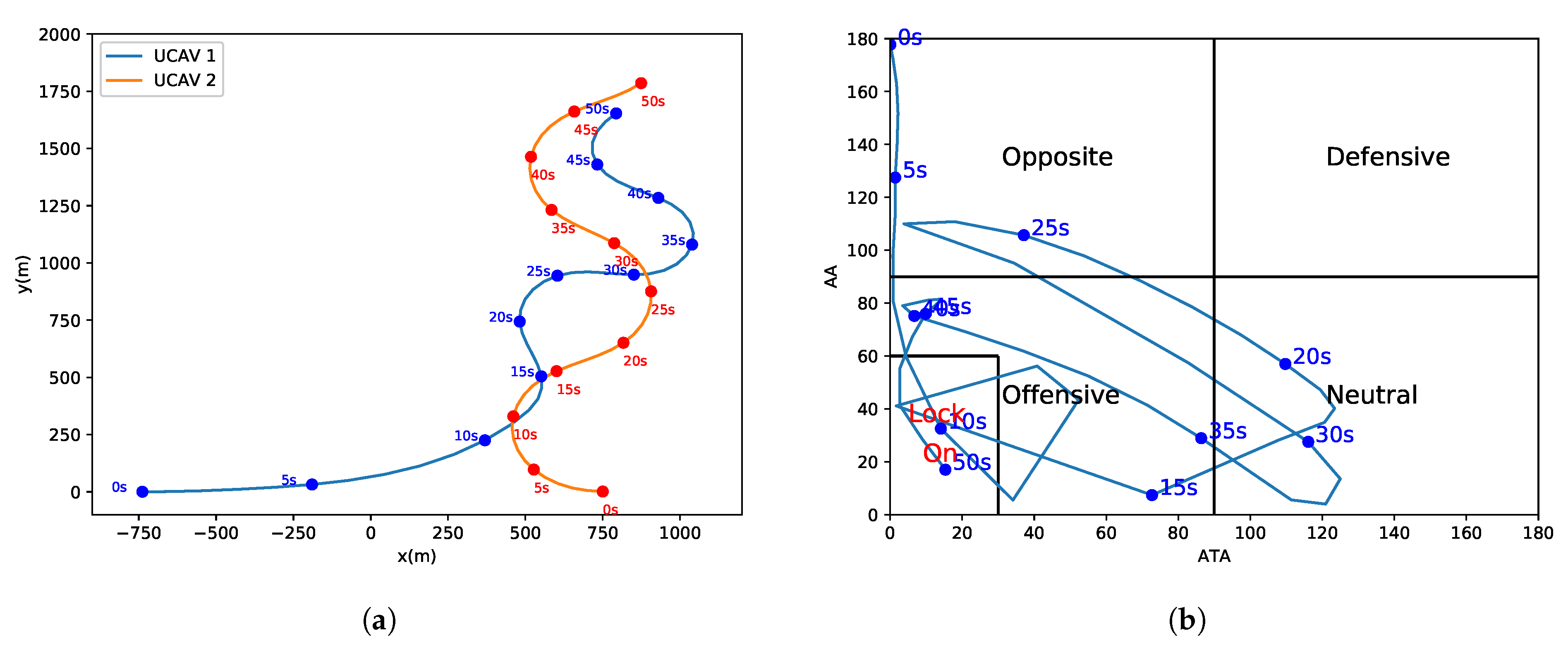
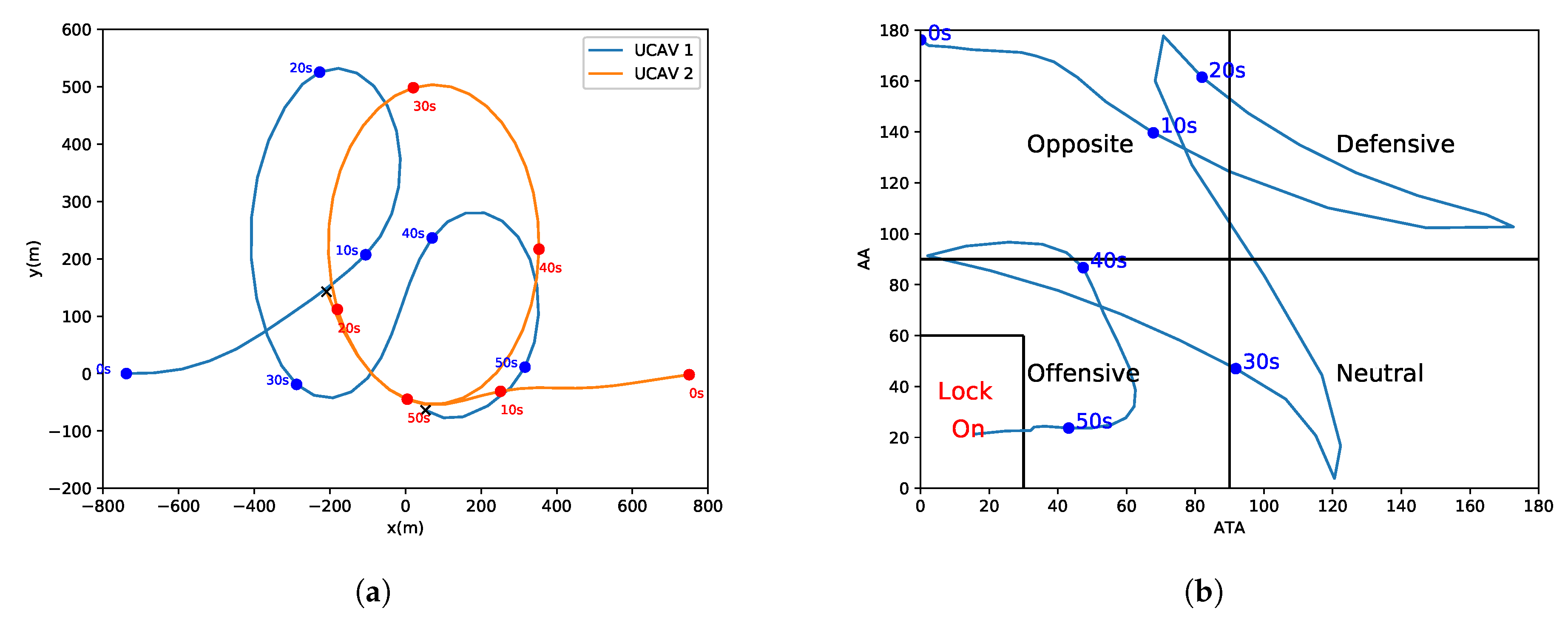
In real 1-vs.-1 WVR air combat scenes, both UCAVs maneuver at the same time and, therefore, one UCAV will be located at the tail of the other UCAV. This ensures stable locking on the other party, then the opponent UCAV is difficult to get rid of the lock and is shot down finally. The combat geometry and parameters shown in
Figure 2 are employed.
In
Figure 2,
is the antenna train angle (ATA) of
, which is the angle between the LOS vector and
’s velocity vector.
is the aspect angle (AA) of
, which is the angle between the LOS vector, and
’s velocity vector.
can be obtained in terms of the velocity of vector
and the line-of-sight (LOS) vector
, where
denotes the LOS vector between
and
. The ATA and AA are allowed to take any value between
. ATA and AA can be obtained from Equations (
6) and (
7).
As can be seen from
Figure 2, a smaller value of
means that
or the gun of
is more accurate at aiming at
, so
is inversely proportional to the shooting chance or offensive advantage. Similarly, a smaller
indicates a smaller probability of being hit by
; therefore,
is inversely proportional to the survival advantage. A termination condition of 1-vs.-1 WVR air combat and rewards can be designed through the abovementioned quantitative analysis of the air combat objectives and related parameters.
This article considers a 1-vs.-1 WVR air combat as a ZSMG problem. Therefore, the rewards of both the UCAVs should be opposite. According to the objective of the 1-vs.-1 WVR air combat, the reward function can be designed using Equation (
8), as follows:
According to the air combat geometry that is shown in
Figure 2, the geometric relationship between AA and ATA of the two UCAVs can be obtained, as follows:
When a UCAV (assumed to be ) satisfies the condition and satisfies this condition for a period of time, it is believed that can maintain the condition and complete the attack and destruction of .
3.2. Action Space of 1-vs.-1 WVR Air Combat
In most previous studies [
3,
4,
8], UCAV’s action space was discrete, and basic fighter maneuvering (BFM) was used as an air combat maneuvering action space, which includes nine actions: left climb, climb, right climb, horizontal left turn, horizontal forward flight, horizontal right turn, dive left, dive, dive right. Although these nine actions cover all common maneuvering actions of a UCAV, the parameters for these maneuvering actions are fixed, and the maneuvering parameters cannot be changed quantitatively, and cannot be combined.
In this paper, a continuous action space is used to control the UCAVs. As air combat is carried out in the same horizontal plane, there are two continuous control variables which control UCAV, namely the thrust and the roll rate. The pitch angular velocity and yaw angular velocity are not considered. Therefore, the action space can be indicated by:
where,
is the thrust of a UCAV and
is the roll rate of a UCAV. They have upper and lower limits, and their upper and lower limits will vary depending on the performance of the UCAV. Together, they will affect the performance of a UCAV’s acceleration and turning maneuvers.
3.3. State Space of 1-vs.-1 WVR Air Combat
System state of air combat is defined by the current motion state parameters of
and
, the relative position and angle parameters and future motion state parameters. Firstly, the current motion state parameters of the two UCAVs in air combat are considered to form the basic state space
:
where,
and
are the current positions of
and
. The positions of UCAVs have no limits, thereby allowing for flight in all directions in the x-y plane. Notably,
and
are the current speeds of both UCAVs,
and
are the current heading angles of both UCAVs, and
and
are the current bank angles of both UCAVs. The bank angle is limited based on the maximum capabilities of the actual UCAV, and based on the need to limit the maximum turning capabilities of the UCAV, the heading angle is allowed to take any value between
.
Subsequently, the distance and relative angle parameters of the two UCAVs are introduced as components of the state space of 1-vs.-1 WVR air combat. The distance parameter is the two-norm of the LOS vector
, and the relative angle parameters are
and
. These components of the state space are depicted in Equation (
12):
Finally, a prediction of the target position is introduced, and the predicted target position is used as a component of the state space. A precise prediction of the target’s future position is crucial for preemptive action. However, accurate predictions can be difficult to achieve owing to uncertainty of the target’s position and intention. The exact model and the characteristics of a combat aircraft are completely hidden. Due to individual differences in the behaviors of the pilots, the combat strategies can contain unpredictable randomness. Furthermore, wrong predictions can worsen the combat situation. Therefore, the target positions should be carefully and precisely predicted.
3.3.1. Prediction Interval Estimation
The size of the prediction interval directly affects the accuracy and computational complexity of the target predictions. If the selected time interval is extremely large, there will be a large difference between the actual position of the target in the future and predicted position; this will impact the obtained air combat countermeasures. If the selected time interval is extremely small, the predicted position will be too close to the current position and, in this case, target prediction cannot be applied. In this study, the flight time required for a bullet to hit the enemy is set to the prediction interval
.
3.3.2. Target Position Prediction
Before predicting the location of a target, it is necessary to assume that the target maneuvering is rational, and that the future control signal of the target only adds a small perturbation
based on the current control signal. The specific calculation of the perturbation
will be explained in
Section 3.3. After calculating the perturbation, the predicted target position can be calculated while using Algorithm 1. Because the value of the perturbation is not strong and the prediction interval is small, the explicit single-step method (Euler’s method) should be used to solve the UCAV motion differential equations.
In Algorithm 1,
is the prediction interval,
are the current motion states of the target UCAV, and
is the step time of solving differential equations,
is the predicted position of the target UCAV. The components of the state space are included in Equation (
14):
In summary, the three state space components of the current motion states, relative to the position and angle states and future motion states, are combined in order to obtain the overall state space:
where, ⊕ is the operator for linking two column vectors.
| Algorithm 1: Target position prediction |
![Applsci 10 05198 i001]() |
6. Conclusions
In this study, a design for a maneuvering strategy generation algorithm for 1-vs.-1 WVR air combat is proposed that is based on the MADDPG algorithm. A 1-vs.-1 WVR air combat is modeled as a two-player zero-sum Markov game. To enable the UCAV to predict the maneuver of the target, a method for predicting the future position of the target is introduced. Inspired by adversarial learning, local minimization is used for solving the Q network to predict the future position of the target. At the same time, a potential-based reward shaping method is designed to improve the efficiency of the maneuvering strategy generation algorithm.
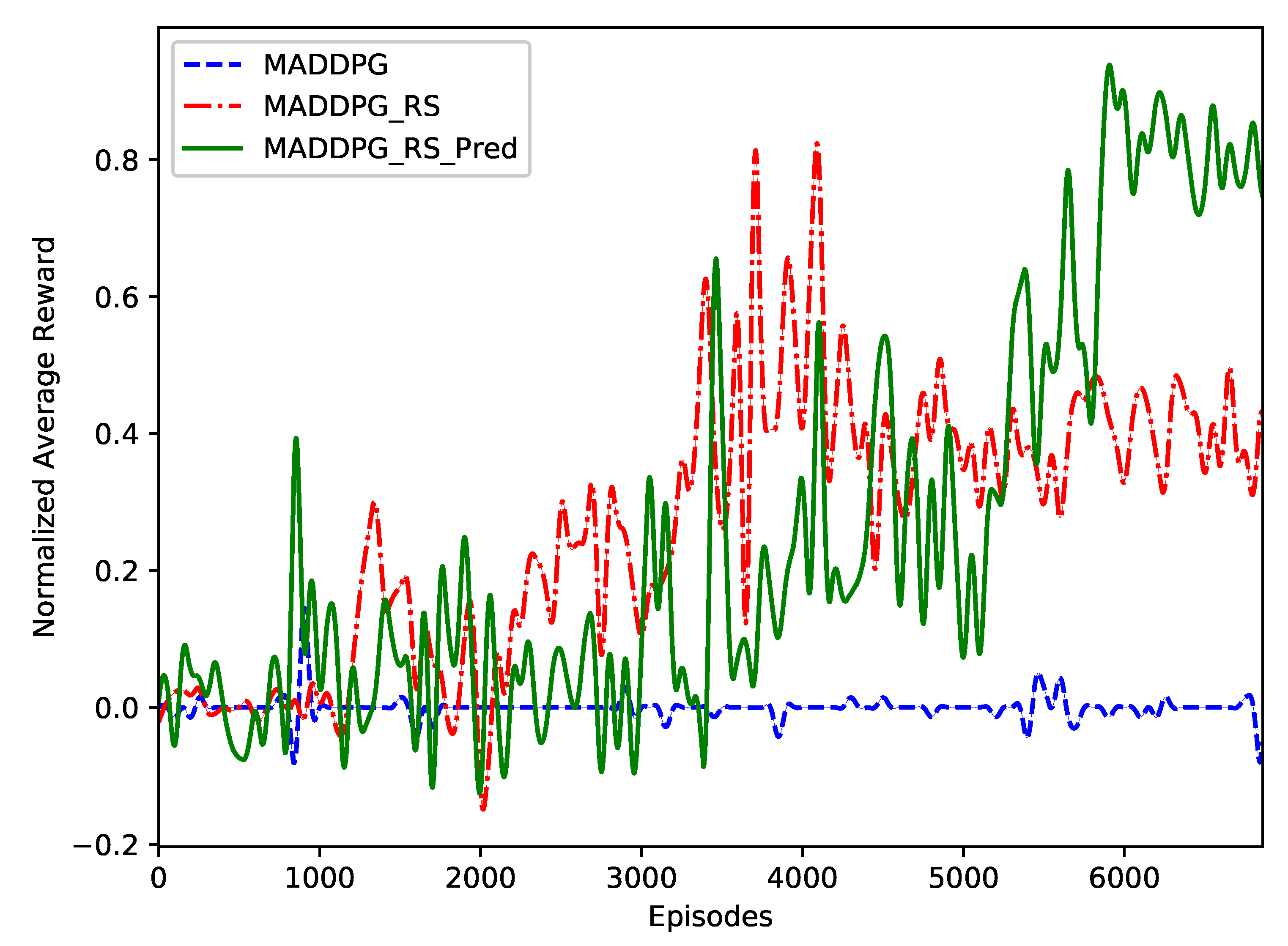
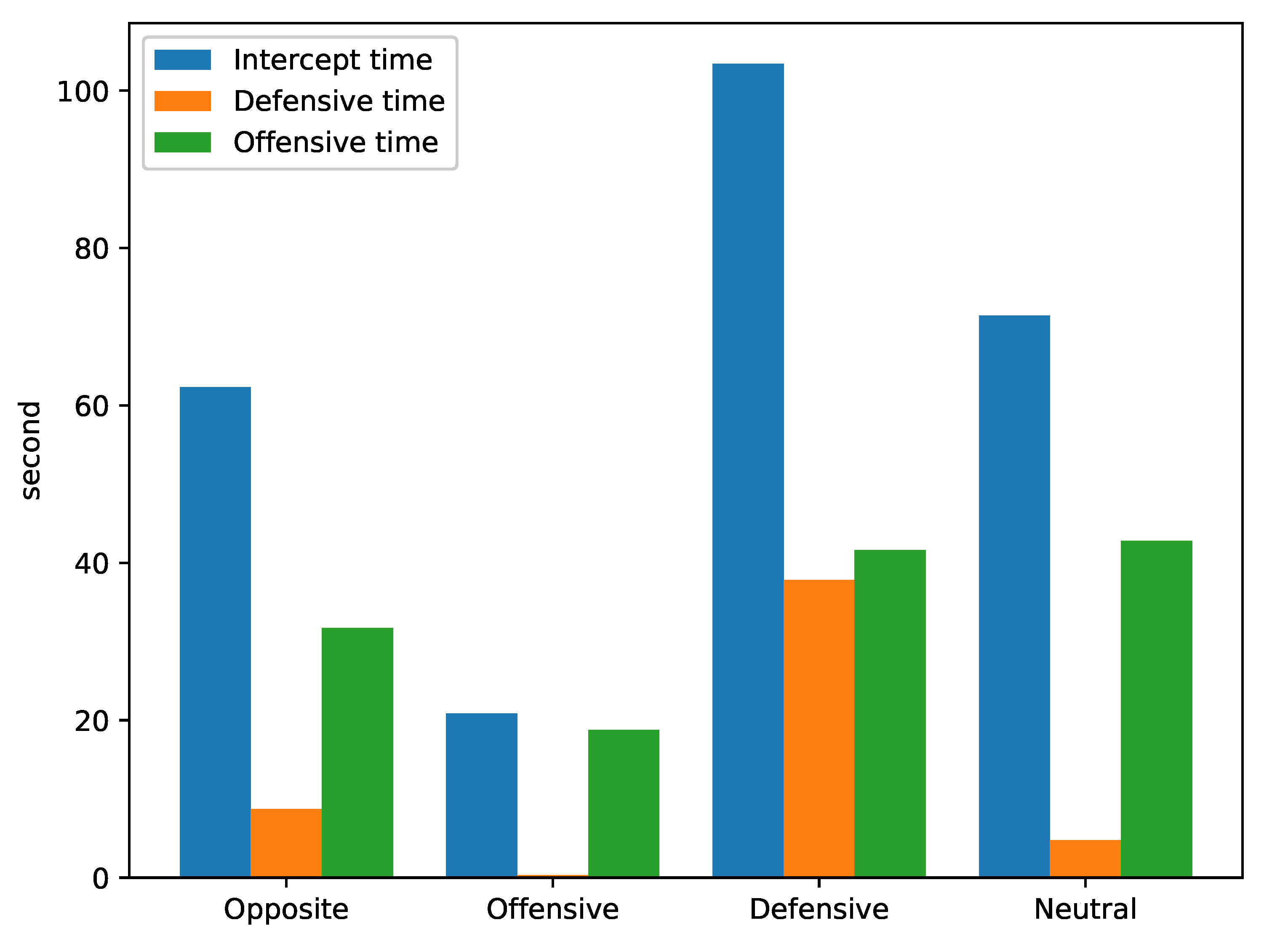
We designed several simulation experiments to verify the effectiveness of the algorithm, as well as the intelligence level of the obtained air combat strategy. The results showed that the strategy obtained while using the PRED-RS-MADDPG algorithm is better than the ones obtained using MADDPG and RS-MADDPG.
In the future, we will focus on applying this method to multi-UCAVs air combat confrontation scenarios. We also intend to use both offline learning and online learning methods in order to obtain a more robust air combat strategy.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}