1. 引言
路径规划是移动机器人相关应用研究的一个重要研究方向,它的任务是找到在给定环境中从起始位置到目标位置的无碰撞可行路径。路径规划在许多领域都有广泛的应用,比如无人驾驶、机器人导航、物流管理等。随着移动机器人的及其应用的快速发展,路径规划算法也在不断演进,以应对现实应用中更加复杂的问题。本文将现有一些路径规划算法分为四类,如表1所示。
传统的路径规划算法中,最常见的是基于图搜索的方法,如Dijkstra算法和A*算法。Dijkstra算法通过计算起点到所有其他点的最短路径来寻找目标点的最优路径,但随着计算图的规模增大时,其开销也会与之增加。A*算法则结合了启发式信息,通过计算每个节点到目标点的代价,来优化搜索过程。此外,还有基于采样的方法,如Rapidly-exploring Random Trees (RRT) [1] 算法、RRT*算法以及一些RRT*算法的变体 [2] [3] 。除了基于图搜索和采样的方法,还有一类称为演化算法 [4] [5] 的路径规划方法,这类算法受自然界的生物进化现象启发,通过模拟生物进化的过程来优化路径规划问题。其中,遗传算法是应用最广泛的一种演化算法。它通过模拟基因的交叉和变异来生成新的路径规划解,并根据适应度函数来评估解的优劣,从而逐代演化出较优的路径规划策略。上述这些算法虽然简单高效,但在复杂的实际场景中,尤其是高维度的3D场景中可能存在一些局限性。
近年来,随着机器学习和深度学习技术的迅速兴起,基于智能的路径规划方法也成为了研究热点。通过使用大量的训练数据,可以让智能体从已有经验中学习到知识去执行规划路径任务。事实上,早在上个世纪70、80年代就有利用神经网络进行路径规划的相关研究 [6] [7] ,由于受到当时硬件设备运算能力的局限,神经网络的路径规划算法并没有取得特别优秀的性能。目前,硬件设备运算能力的大幅提升,这为神经网络在路径规划中的应用提供了硬件基础。最近几年,基于神经网络的路径规划的相关工作有MPNet [8] 、GrMPN [9] 和 [10] ,它们在完成实验中的路径规划任务时都取得了不错的结果。
然而,由于基于神经网络的路径规划方法需要大量的训练样本,训练数据的收集并不容易,使用少量数据训练的模型可能无法令人满意。因此,本文提出了两种数据增强的方法,分别在训练环境编码器和神经规划器过程中应用。本文的方法旨在丰富训练样本,弥补训练数据不足的问题,让模型能够学习到更多的经验。实验评估显示,采用本文提出的方法后,其训练的模型较于之前的模型,拥有更高的规划成功率以及较少的规划时间,更适应路径规划任务需求。

Table 1. Advantages and disadvantages of four classes of path planning algorithms
表1. 四种类别路径规划算法的优缺点
2. 基于神经网络的路径规划模型结构
基于神经网络的路径规划算法通常采用端到端的方式。端到端的含义是:网络模型自原始数据输入,到结果输出,从输入端到输出端,整个过程都时在模型中完成,而不是将模型分为多个模块完成。
端到端的神经网络路径规划算法的规划流程如图1所示。该算法包含两部分:
1) 环境编码器。环境编码器用于直接编码任务场景。
2) 神经规划器。神经规划器以环境编码信息和任务(当前位置、目标位置)作为输入,输出的结果是下一时刻的位置。

Figure 1. Schematic diagram of the end-to-end neural network path planning process
图1. 端到端的神经网络路径规划流程示意图
算法流程如下:
步骤1:将环境编码信息与当前位置、目标位置拼接成规划任务信息。
步骤2:将规划任务信息输入神经规划器,输出下一时刻位置。
步骤3:判断神经规划器预测的位置是否发生碰撞。否,执行步骤4;是,重复步骤2。
步骤4:判断神经网络规划器预测的位置是否到达目标位置。否,执行步骤5;是执行步骤6。
步骤5:更新可行节点集合及当前位置后重复步骤1。
步骤6:输出可行节点集合,完成规划任务。
2.1. 环境编码器
在深度学习中,编码器常常被用来降低高维数据的维度,它的本质是将高维度的数据映射到一个低维空间,而后用低维的数据来表示原来的高维数据,这种操作一般被称作特征提取。编码器的实现思路有多种,如常见的图片分类,其使用卷积网络或者多层感知机进行特征提取。
本文中的环境编码器采用自编码器(AutoEncoder) [12] 结构,这是一种无监督学习神经网络模型,用于降低数据维度、特征提取或生成类似输入数据的重构数据。自编码器由一个编码器(Encoder)和一个解码器(Decoder)组成,两者都是神经网络。自编码器的训练目标是使解码器能够将编码器产生的隐藏表示转换回原始输入数据,其结构示意图如图2所示。
1) 编码器:接受输入数据
,d表示数据维度,并X映射到一个低维的表示空间,得到原始数据X在低维空间的隐藏表示
,h表示低维空间的维度,且
。
2) 隐藏表示:编码器的输出一个低维的表示
,其中包含输入数据的关键特征。这种编码操作也可以看作是一个数据压缩。
3) 解码器:输入隐藏表示
,并试着将其还原回原始输入数据的维度,输出简称为
。解码器的目标是学习一种映射,使得从隐藏表示到重构数据的转换能够尽可能地还原输入数据的信息。
4) 损失函数:在训练自编码器的过程中,需要一个评估标准来评估原始输入数据与解码器重构数据之间的差异,这个评估标准常称作损失函数。数据重构任务的常见损失函数是均方误差(Mean Squared Error),其计算方式如式1所示。
(1)
式中
表示数据个数,
分别表示原始数据和重构数据的第
个数据。

Figure 2. Schematic diagram of the autoencoder structure
图2. 自编码器结构示意图
2.2. 神经规划器
神经规划器期望智能体从已有经验中学习到在任务场景中如何规划路径能力。定义函数
代表规划路径操作,设有函数
(2)
式2中
表示规划任务,
为下一时刻的位置。神经网络的目的就是学习到一个模型去拟合函数
。
神经规划器结构如图3所示,其输入为规划任务
,
由环境编码信息
、当前位置(简写为
)和目标位置(简写为
)构成,环境编码信息由环境编码器对任务场景的点云数据编码后得到,将
输入到一个多层感知机网络,网络输出一个预测结果。
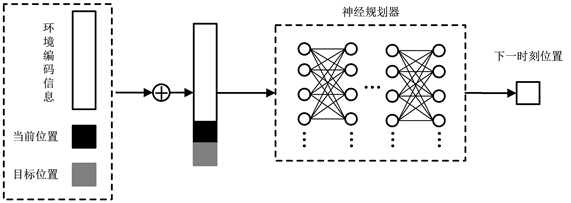
Figure 3. Schematic diagram of neural planner structure
图3. 神经规划器结构示意图
3. 基于数据增强的神经网络路径规划算法
3.1. 基于数据增强的环境编码器训练方法
假设原环境编码器训练数据集由少量任务场景构成,为了丰富训练样本,我们采用平移的方法,将每个场景中的障碍物随机移动,从而生成新的任务场景。具体方法如算法1所示。
环境编码器采用自编码器结构,训练示意图如图4所示。编码器输入为任务场景的原始点云表示,输出任务场景的低维表示。解码器输入为任务场景的低维表示,输出为还原的任务场景的原始点云表示。将还原的任务场景点云表示与原始的任务场景点云表示计算重构误差,然后在反向传播后更新网络参数。重构误差可表示为:
(3)
式3中
分别代表编码器和解码器的网络参数;
代表点云的个数,即一个任务场景由多少个点云表示;
分别代表重建的点云和真实的点云;
代表其后正则化项的权重参数。环境编码器训练时的目标是最小化
,其训练流程如算法2所示。

Figure 4. Diagram of the practical teaching system of automation major
图4. 环境编码器训练示意图
3.2. 基于数据增强的神经规划器训练方法
我们将一条可行路径看作一个有序列表,那么一条可行路径
可以表示为由t个时刻节点构成的有序列表,即
。由于有序列表对列表成员的顺序敏感,有序列表任意成员的顺序发生变化都可视为生成了一个新的列表。于是我们将可行路径
进行反转操作,结果得到一个新的有序列表
。如果只是将
看作两个集合,那么其成员可视为完全等同的,有
,但事实上针对于路径规划任务而言,
应当是两个有序列表,则有
。本节基于上述新的可行路径
构造出训练神经规划器的数据增强数据,神经规划器训练集构造的过程如算法3所示。
神经规划器通过一个多层感知机来拟合路径规划操作函数
,其训练示意图如图5所示。将环境编码信息和当前位置、目标位置拼接成一个向量,输入到神经规划器,预测下一时刻位置,而后将预测结果与真实结果计算预测误差,然后在反向传播后更新网络参数。预测误差可表示为:
(4)
式4中
代表神经规划器的网络参数;
分别代表神经规划器预测的
时刻位置和真实的
时刻位置。神经规划器训练时的目标是最小化
,其训练过程如算法4所示。

Figure 5. Diagram of the practical teaching system of automation major
图5. 神经规划器训练示意图
4. 实验结果与分析
4.1. 数据集准备
本文使用MPNet开放的数据集C3D作为实验的任务环境,其任务场景如图6所示。该数据集包含两部分,一部分是任务场景的点云数据,每个任务场景拥有10个障碍物,一共有30000个场景的点云数据;另一部分是可行路径数据,数据集提供了110个场景的可行路径,其中前100个场景,每个场景有5000条由RRT*算法生成的路径,后10个场景,每个场景有2000条由RRT*算法生成的路径。在训练环境编码器时,30000个场景的点云数据都会参与训练;在训练神经规划器时,我们将数据分为见过的场景(Seen)和未见过的场景(Unseen),Seen的数据包括可行路径数据中前100个场景和与之对应的可行路径,Unseen的数据包括可行路径数据中后10个场景和与之对应的可行路径。
在上述数据集的基础上,我们基于本文提出的两种数据增强方法分别构建了环境编码器和神经规划器的数据增强数据。我们取出C3D中30000个任务场景的点云数据,然后将场景中的障碍物在其三个维度上进行随机移动,得到了30000个新的任务场景点云数据。接下来,我们将C3D中提供的每条路径进行反转操作,得到新的可行路径。
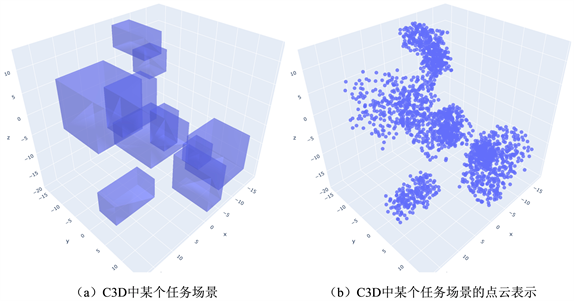
Figure 6. Diagram of the practical teaching system of automation major
图6. C3D场景点云数据集中某一场景的可视化
4.2. 实现细节
本文所涉及编程的实验,均采用Python语言实现,网络模型由pytorch深度学习框架实现。在具体实验中,采用经典的自编码器结构作为环境编码器。编码器的网络结构是一个拥有四层全连接层的多层感知机网络,其大小为786 × 512 × 256 × 60,输入大小是6000,输出大小为60。解码器的网络结构与编码器的网络结构是对称的,其大小为256 × 512 × 786 × 6000,输入大小是60,输出大小为6000。训练时的batchsize设置为100,epoch设置为400,使用Adagrad作为优化器,学习率设置为1e-2。计算重建误差时正则化项的权重参数
设置为1。
在实现神经规划器时,其网络由12层全连接层组成,并对前11层的每一层输出进行PReLU操作,前10层进行Dropout [11] 操作,Dropout的激活概率设置为0.5。网络的输入大小是66,输出大小为3。训练时的batchsize设置为100,epoch设置为500,使用Adagrad作为优化器,学习率设置为1e-2。
为了验证本文提出的方法,我们以MPNet为主要模型框架,并在实验部分将RRT*和Informed-RRT* (下文简写为IRRT) [13] 两种传统方法以及我们的方法在Seen和Unseen场景下完成路径规划任务,比较了四种方法的规划时间、规划路径长度。
4.3. 结果分析
在下文中,为了方便区分及比较旧模型和新模型,我们将使用仅一种数据增强方法训练的模型称作MPNet (E*),MPNet (P*),分别代表仅在环境编码器训练使用数据增强方法和仅在神经规划器训练使用数据增强方法;将使用两种数据增强方法训练的模型称作MPNet*。
实验结果表明,我们的方法提高了MPNet在Seen和Unseen场景中的规划成功率,并且在规划时间上也有改善。图7展示了IRRT算法和MPNet*在Seen和Unseen两种场景下规划路径的情况。

Figure 7. Diagram of the practical teaching system of automation major
图7. IRRT和MPNet*在C3D场景中规划的路径
在表2中,旧方法训练的MPNet在两种场景的规划成功率分别为97.0%和93.7%,采用本文提出的方法训练的MPNet*在Seen和Unseen场景下的规划成功率分别为97.7%和96.5%。MPNet*比MPNet在两种场景下分别高出0.7%和2.8%。同时,在仅采用一种数据增强方法的情况下,本文的方法在保证Seen场景规划成功率稳定的情况下,对Unseen场景的规划成功率相较旧模型也具有一定优势。例如,仅采用数据增强方法的情况下训练出模型MPNet (P*),其在Unseen场景中的规划成功率为95.8%,较于旧模型提高2.1%。
Table 2. MPNet and MPNet* planning success in two scenarios
表2. 两种场景下MPNet和MPNet*规划成功率
在表3中展示了MPNet、MPNet*与另外两种传统算法在Seen、Unseen场景下的规划时间比较。旧方法训练的MPNet在两种场景,结果表明神经网络规划器的规划效率是明显优于两种传统算法的,并且使用本文提出的方法训练的模型相较于旧模型也有一定优势,MPNet*的规划时间较于MPNet减少了0.20 s左右。
Table 3. Planning time of MPNet, MPNet* and traditional algorithms for both scenarios
表3. 两种场景下MPNet、MPNet*及传统算法的规划时间
表4展示了两种场景下四种方法的规划路径的长度比较,对比结果时以RRT*算法规划的路径为基线,比较了另外三种算法与其结果的优劣。评估标准如下:在某场景的某个规划任务中,算法A与RRT*各规划出三条可行路径,若算法A平均的规划长度小于等于RRT*的平均的规划长度,则判定算法A在此次任务中的规划长度优于RRT*。若算法A和RRT*比较了K个规划任务,并在N个任务中优于RRT*,则算法A最后的评估表示为A优于RRT*算法N/K%。我们在Seen和Unseen场景分别选取了100个规划任务,每个任务规划三次,计算平均长度。实验结果表明,虽然神经网络规划器在规划速度上具有一定优势,但在规划路径长度指标上并不如传统算法。
Table 4. Lengths of planned paths for MPNet, MPNet* and traditional algorithms for both scenarios
表4. 两种场景下MPNet、MPNet*及传统算法的规划路径的长度
5. 结束语
路径规划作为机器人学的重要研究方向之一,一直在不断发展。从传统的图搜索算法到基于人工智能的方法和演化算法,各种不同的技术在不同应用场景下展现出强大的优势。随着技术的进步和研究的深入,我们有理由相信神经路径规划算法将在更多领域发挥巨大作用,为人类带来更加智能高效的解决方案。本文提出的两种数据增强的方法,旨在解决训练神经路径规划器所需数据不易收集、数据不足的问题。通过在训练环境编码器以及神经规划器时对训练数据分别采用平移,反转操作,凭此达到丰富训练样本的目的,缓解数据不足的问题。实验对比评估表明,与对比方法相比,本文提出的方法在各个任务场景中都强于对比方法,在规划成功率和时间耗费两个评估指标上都明显优于对比方法。因此,本论文方法满足路径规划任务的需求,具有重要的应用价值。
参考文献