1. 引言
党的二十大的顺利召开进一步明确了国家实施科教兴国、人才强国战略的坚定决心。高等教育作为承担教育图强、创新制胜、人才引领光荣使命的重要一环,需要在日常教学中坚持以学生为中心、以成果为导向、以持续改进为重点的教育理念。落实到高校计算机专业的日常教学工作层面,针对学生理论知识的实践化能力培养尤为重要。
《数据结构》作为计算机专业极其重要的专业基础课,对学生的逻辑思维、编程能力、算法设计能力起到奠基意义。国内高校许多优秀教师对该课程的教学方法进行了深入的探究。于真 [1] 制定了“学习产出”式教学目标,依据教学目标制定相应教学内容并开展灵活多变的教学活动,同时,他也探讨了过程性考核的实施方法。王霞 [2] 等探讨了构建基于CDT (案例驱动教学)的数据结构教学内容体系和学教结合的梯进式教学过程体系,通过满意度调查证明了所提教学改革方案的有效性。徐航 [3] 等以线上教学平台为基础,以实际教学经验为参考,提出了一种有助于提高学生的学习效率和积极性的教学改革方案。司国东 [4] 等分析了《数据结构》课程教学中存在的问题,提出了基于认知负荷理论的实验题库设计和教学方法,对更新教学案例进行了初步探究。然而,目前针对如何将高校教学团队科研成果与日常教学有机结合,如何利用理论知识解决国家战略发展面临的实际困难等问题研究成果较少。本文结合本教学团队科研成果,结合大数据环境下网络舆情信息分析问题,设计出了一个适用于“串的模式匹配算法”章节学习的教学案例。
2. 案例分析及数据建模
2.1. 案例引入
BP和KMP是串的模式匹配问题中非常经典的两个算法,然而它们均只能实现串的完全匹配,并不能根据相似程度完成串的模糊匹配,在解决实际问题时很难得到准确的结果。本文结合大数据环境下网络舆情信息聚类问题,设计了相关的讲解案例。
案例描述:针对某一网络热点事件报道文章下的3万条用户评论进行识别,根据评论偏好信息将用户进行分类,并根据相关报道的作者观点将评论分为基本赞成、保持中立、基本反对三类,为进一步的舆情信息分析打下基础。
案例分析:由于网络用户表达意见方式存在差异,无法利用串的完全匹配算法来识别主串(用户评论)中是否存在模式串(作者观点)。另外,由于文章及评论中包含了大量与事件态度无关的表述,先对舆情信息进行特征向量提取可以大幅提高信息分析速度及准确率。最后,应先根据特征向量利用聚类算法对评论用户进行识别,再通过设置阈值来判断各分类与作者观点之间的匹配程度,从而完成最终的评论分类。
2.2. 数据建模
实际网络热点事件评论信息进行特征向量抽取,得到一个具有三个事件评判属性的特征向量数据集(此工作由教学团队预先利用Transformer模型进行提取,然后直接下发给学生进行建模)。引导学生将其转换成如图1所示的非线性网络舆情信息串(为了方便表述,该图只取3条信息串,每个串由10个特征值组成,其中黄色串为相关报道作者观点):

Figure 1. Non-linear network public opinion information string
图1. 非线性网络舆情信息串
不同用户观点特征值之间的差异被描述为三维空间中点的距离,距离越大说明用户观点分歧越大,反之亦然。
3. 模型求解
课堂教学中,模型求解需分解成:改进nextval数组生成函数,用户评论信息串聚类,用户评论信息串识别三个部分进行讲解。
3.1. 改进nextval数组生成函数
由于实际问题中,评论用户观点的特征值均存在差异,故需要对改良后的KMP算法(使用nextval数组)进行进一步改进使之可以完成模糊匹配。当两个特征串某一对应位置的特征值点之间的距离小于阈值μ时,即认为两者匹配。修改后的nextval数组求解函数如下所示:
Void get_nextval (String T, int *nextval)
int i = 1;int k = 0;
float d = 0; //不同特征值之间的距离
nextval [1] = 0;
while (I < T[0])
D = get_distance (T[i], T[k]);//此为距离求解函数,求解不同特征值之间的距离
if (k == 0 || d ≤ 0.35) //本例中模糊匹配阈值为0.35
++ i;
++ k;
if (d > 0.35)
nextval [i] = k;
else
nextval [i] = nextval [k];
else
k = nextval [k];
3.2. 用户评论信息串聚类
首先,让学生理解最优集结点(聚类中心)的定义。
定义1:设n维空间闭区域内点集
有m个带权重的点
,
的权重
,且
。若存在点
与Q内所有点之间的加权Euclidean距离之和
最小,即
(1)
则称
为点集Q的n维空间最优集结点。三维空间最优集结点如图2所示:
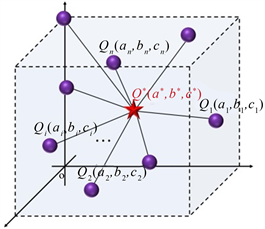
Figure 2. Optimal assembly point in three-dimensional space
图2. 三维空间最优集结点
在此基础上,向学生下发教学团队开发的自适应算法 [5] [6] [7] 代码,让学生结合改进后的KMP算法对自适应算法进行修改,计算出如图3所示的实际案例中网络用户的综合评论信息串:

Figure 3. Web user comprehensive review information string
图3. 网络用户综合评论信息串
根据本项目所选案例的要求及实际情况,设置2个阈值,将用户评论信息串与综合评论信息串之间的距离与阈值进行比较,将用户评论信息划分为3类,并再次调用改进后的自适应算法求解出如图4所示每一类的综合评论信息串:
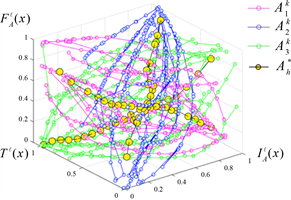
Figure 4. Three types of user comprehensive comment information string
图4. 三类用户综合评论信息串
3.3. 用户信息评论串识别
选取2.2中各类综合评论信息串与报道作者信息串进行比对,利用基于投影理论的模糊信息投影公式计算出各类综合评论信息串在报道作者信息串上的投影,投影值越大,证明此类评论信息对作者观点的赞成度越高。计算过程如下:
定义2:设
和
是两个向量,则
(2)
称为向量α在向量β上的投影,其中
和
是向量α和β的模。显然,
的值越大,向量α和向量β越接近。投影过程如图5所示:
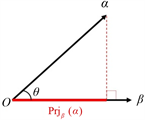
Figure 5. The projection of α vector onto β vector
图5. 向量α在向量β上的投影
定义3:设
和
是两个矩阵,则
(3)
称为矩阵
在矩阵
上的投影。显然,
越大,矩阵
和矩阵
越接近。
4. 案例仿真
4.1. 实验指导过程
教学团队成员选取自媒体平台上的网络热点事件报道文章及其评论信息为研究对象,利用transformer对文章本身及2万条评论信息进行特征提取并将特征值做成txt文档,作为教学数据集发放给学生。要求学生分组讨论,利用理论课上学习到的知识对KMP算法代码进行修改,形成改进后的可以完成模糊匹配的模糊KMP算法。完成对所有小组代码检查工作后,由教师下发高维聚类自适应算法代码,让学生们将自己开发的模糊KMP算法嵌入到高位聚类算法中,并对数据集进行处理得到最终结果。各组展开实验结果横向比对,由指导老师进行点评,同时带领同学们进行实验总结。
4.2. 部分仿真结果
利用2.1与2.2中提到的算法对数据集进行处理,得出的三个评论类的综合评论矩阵和报道作者信息向量如下所示:
利用公式(2)和公式(3)计算出各类评论信息与文章观点相似度如下所示:
显然,A2类持基本赞同观点,A1类持基本反对观点,A3类持中立观点。
5. 结语
《数据结构》是计算机科学与技术、软件工程、数据与大数据科学等专业的一门极其重要的基础课,课程所涉及的知识点是人工智能、大数据计算等前沿技术的理论基础,在工程实际问题中应用非常广泛。传统授课过程中讲解的案例较为陈旧,与现实中的新兴问题存在脱节现象。本文基于OBE教学理念,结合教学团队科研成果,对融入课程思政元素、紧跟国家发展战略需求的案例教学方式进行探索,提出了一个“串的模式匹配算法”的教学案例。
基金项目
1) 江苏理工学院2022年校教学改革与研究项目“OBE视域下课程思政素材库与案例库的建设研究——以数据结构课程为例”。项目号:11610312306;
2) 江苏省高等教育教改研究项目“新工科背景下计算机公共基础课程教学改革与探索”。项目号:2021JSJG658;
3) 江苏省高等教育学会专项课题“基于产教融合的计算机类本科专业综合实训教学探索与研究”。项目号:2020JDKT135;
4) 江苏理工学院校级一流课程、课程思政示范课、产教融合课程——数据结构。
NOTES
*通讯作者。