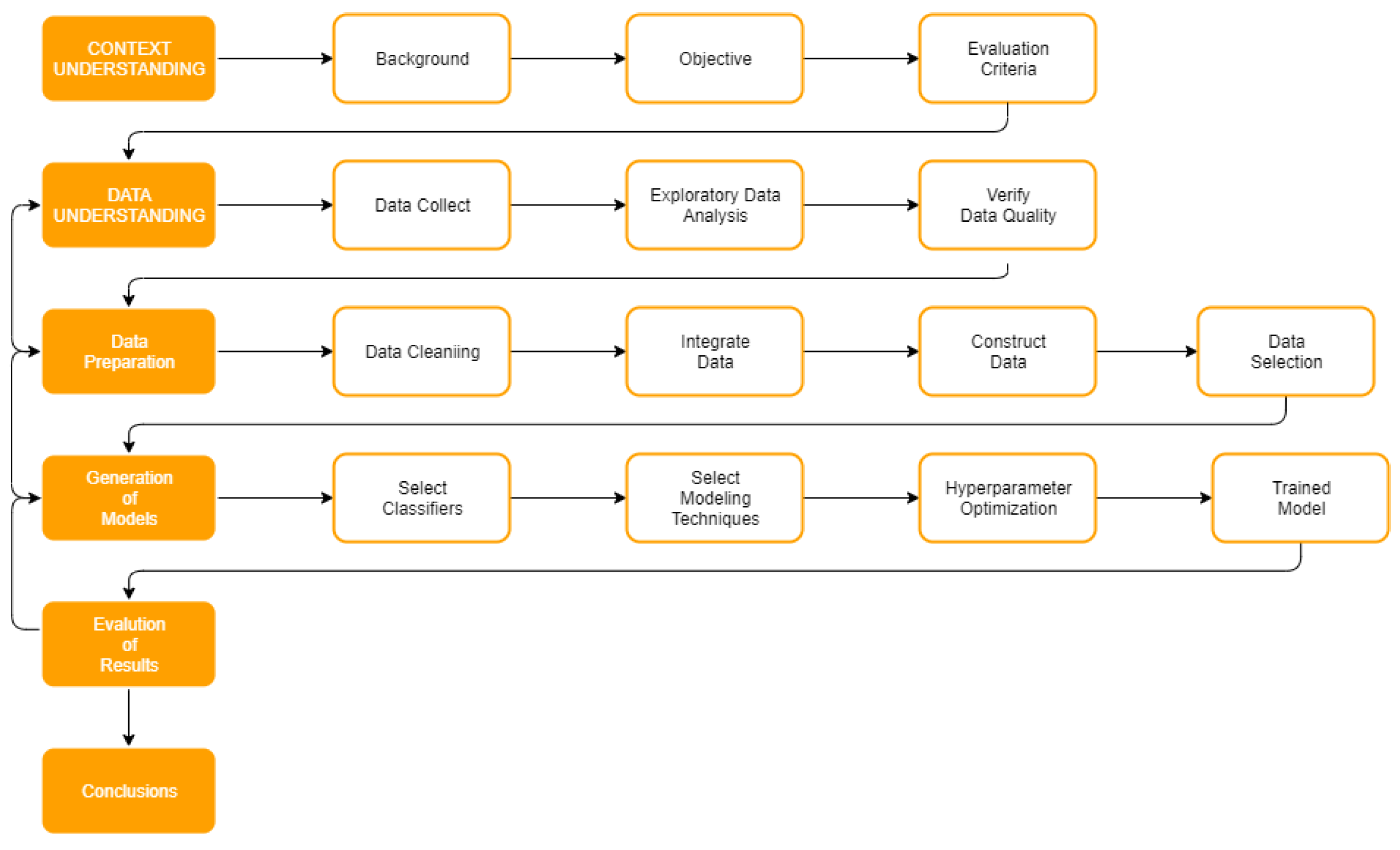
This section presents an overview of the research methodology and the general context of the case study.
3.4. Data Understanding
Data from students enrolled in three bachelor programs from three different faculties of Udelar were collected. The programs are Biology (BIO), Communication (COM), and Nursing (NUR).
Table 2 shows the number of subjects used in each program, the total number of interactions inside the VLE for each subject, the total number of students enrolled in, and the following: students that had success without retaking exams, students that had success after the final exams, and students that failed.
It is important to highlight that it is not mandatory for the student to attend the classes to take or retake the final exams. This particularity affects the way students use VLE, especially during the first year when a large number of students drop out of university as this public university does not have entrance exams. This is the main reason for choosing data from second-year students as it tends to be stable in terms of dropout. In this sense, we believe that we have a clearer picture of the use of the VLE by the students, which was intended to keep them enrolled in the courses.
Two different output variables (targets) were defined for our study: the prediction of success in the course (students who passed without the need of exams) and the prediction of success in the final exams. For the first target, the models predict whether a given student will be approved directly or if they will need to take exams. For the second target, the models predict whether a given student will pass or fail after taking the exams. Together with the students’ interactions inside Moodle, we also used data from the university’s academic system and the FormA-Students survey database.
Students’ interactions within VLE in its raw state were collected. These data were separated by students, day of interaction, and type of content. We collected, from the academic system, the subjects enrolled in by each student, the academic performance in the subjects, and the number of previous failures in each subject. The third data’s source was the continuous survey called FormA-Students. This survey is completed by students annually, and it collects 111 attributes distributed in sections referring to socio-demographic and socio-economic background, pre-university and further university studies, employment status, language proficiency, motivation and expectations about career, academic mobility, and scholarships.
According to the dean of Udelar [
37], the survey data can enable the institution to think about itself in the long term and in strategies that require the prediction of the state of affairs of the different actors to achieve specific objectives. For example, it has the education and occupational category of the father and mother, marital status, family income, ethnic self-perception, disabilities, employment status, occupation classification, scholarship receptions, place of birth, and the place where they live and with whom.
The exploratory data analysis step sought to visualize the different datasets before integration to identify database sizes, become familiar with the data, and gain insights for the transformation of target features, as well as identify visible behavioral patterns.
Figure 3 shows the distribution of interactions in VLE by age. A possible observation is that the older the student, the lower their use of the VLE. This may represent an acceptance trend where younger students tend to adhere more to the use of Moodle. Still the right sidebar of the graph shows the distribution of students by age, and the top bar shows the distribution by interactions. As seen, the highest concentration of interactions was found in students between 20 and 25 years of age.
Another important analysis of the
Figure 3 is that a significant part of the dispersion was located between 0 and 200 interactions. In this range, 52 students were identified who had 0 interactions with the VLE during the courses, of which 16 passed the course (without exam), 23 passed the exam, and 13 failed. In addition to that, only two students took the course for the first time, and both failed.
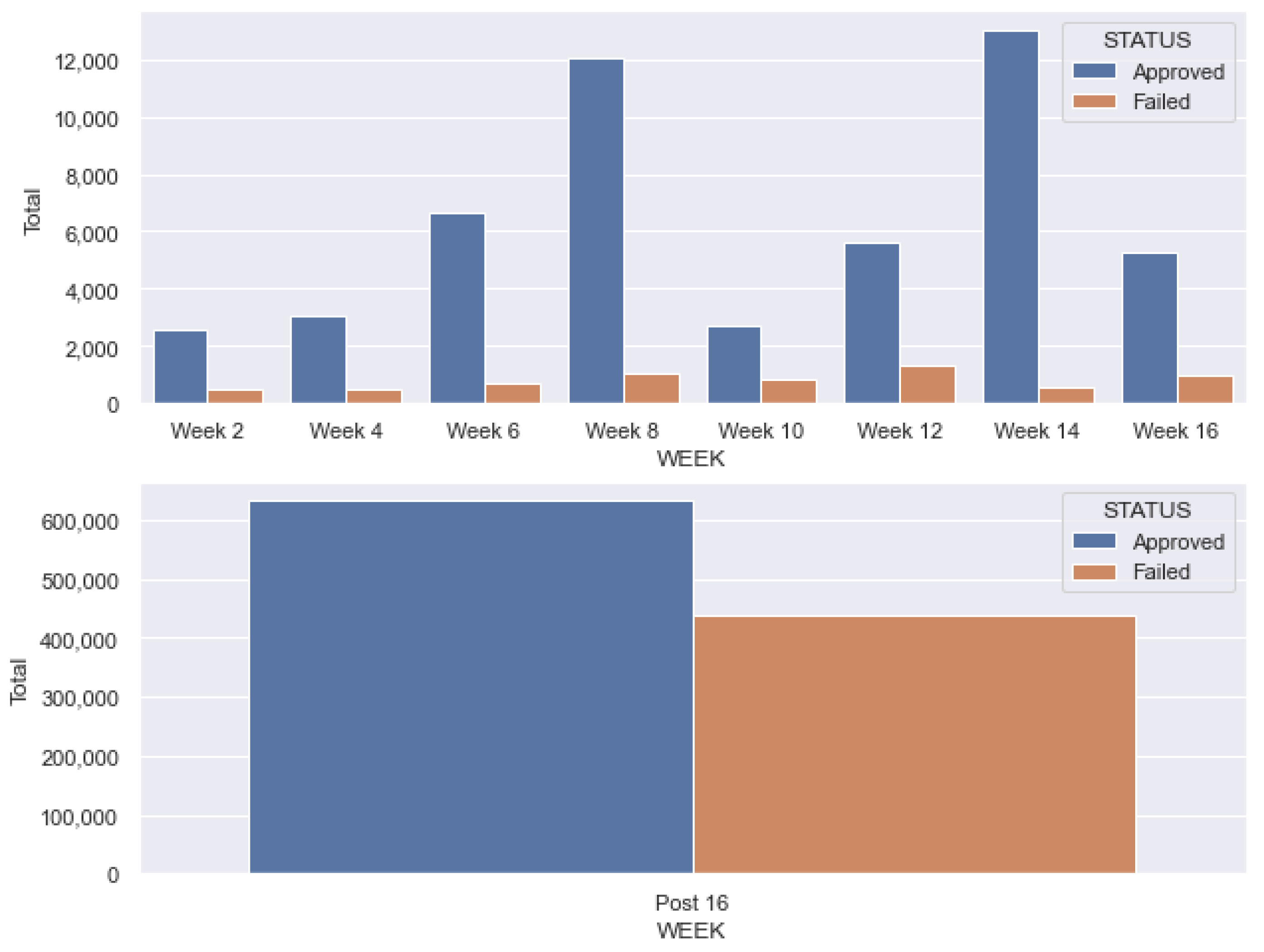
Figure 4 shows the difference of interactions between students who had success versus students who failed the subjects. In the upper part of the figure, interactions are presented during the 16 weeks of the subjects, where notably the students who had success demonstrate a higher engagement in VLE compared to those who failed. The bottom part of the figure shows the total number of interactions after the end of the semester (after the 16 weeks and the final exam) and before students retake the exams. It must be noticed that the failing students had higher engagement compared to the course progress but less than the successful students.
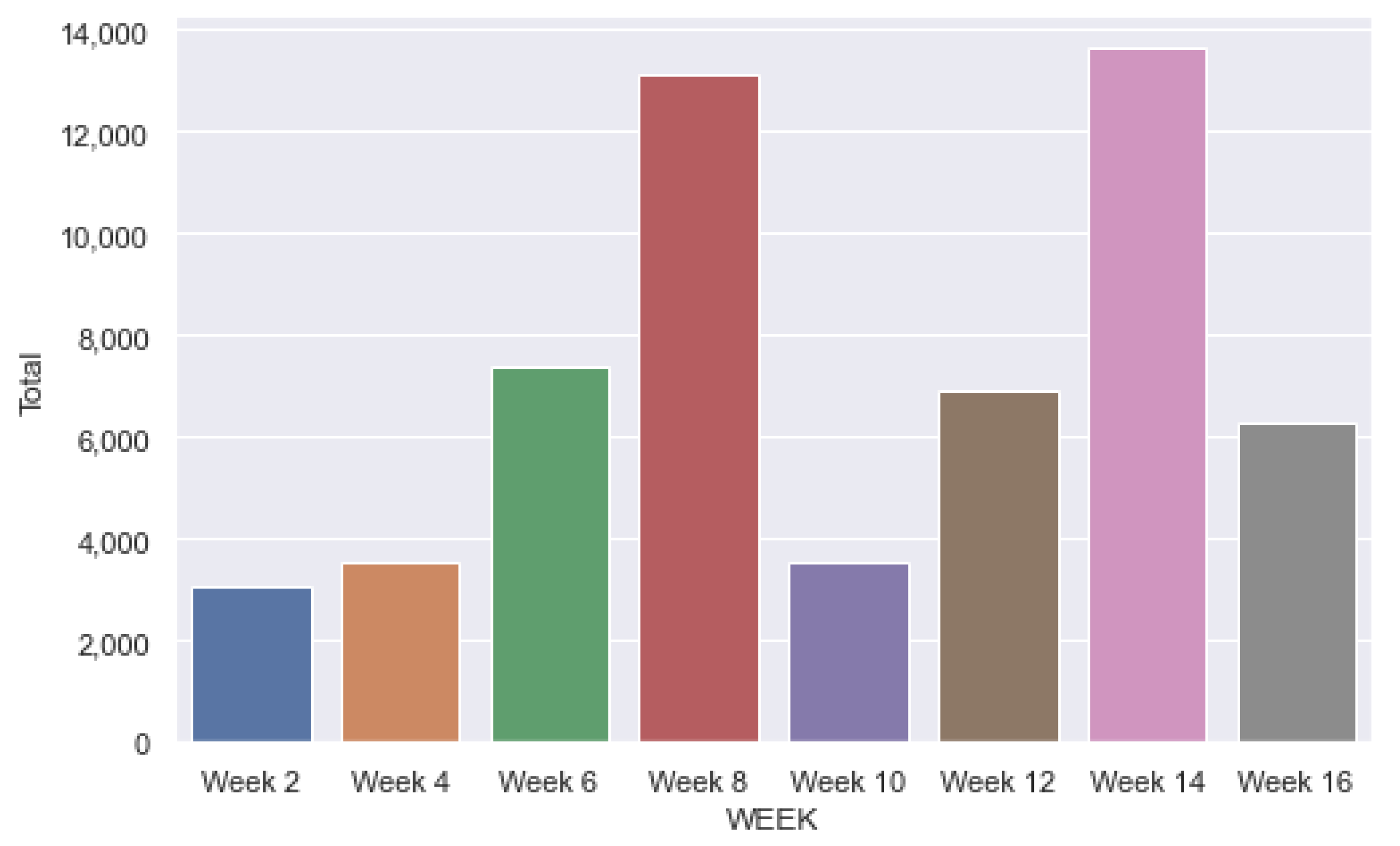
Figure 5 shows the distribution of interactions during the weeks of the course. The interactions grew until the partial exams (in weeks 8 and 14/16). This movement is an indication that the closer the exams/tests are in a given subject, the higher the students access to the VLE to consult the materials.
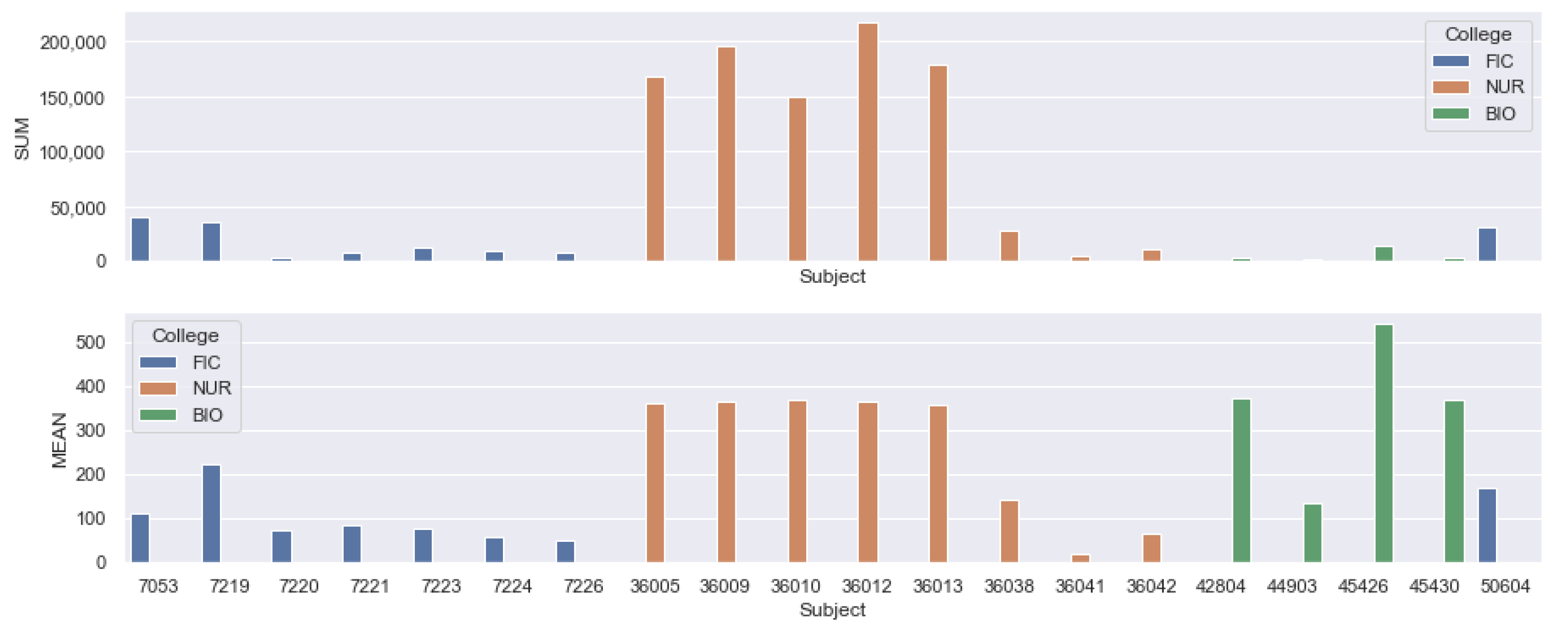
Figure 6 shows the total number of interactions per subject (upper) and the average number of interactions for each of the analyzed subjects (bellow). It is possible to analyze that, even within a program, the use of VLE was considerably different between subjects.
Analyzing the VLE subjects’ didactic design, it was possible to characterize them as mainly organized as repositories of resources to support face-to-face classes, where professors upload materials, such as text, images, and videos, and provide online assessments and self-assessments. Forums are used mainly as a place for coordination and information dissemination rather than for the discussion of content-related issues.
The two main uses of a quiz are as follows: first, as a form of assessment evaluation of learning instruments, generally mandatory, by a single attempt, for all active students and carried out on a pre-established date; and second, as an interactive activity oriented to education and training over a long period and allowing multiple attempts. Rodés et al. [
38] defined a typology of didactic designs according to the type of resources and activities supported by VLE. The courses analyzed here fall mainly under the repository and self-assessment types.
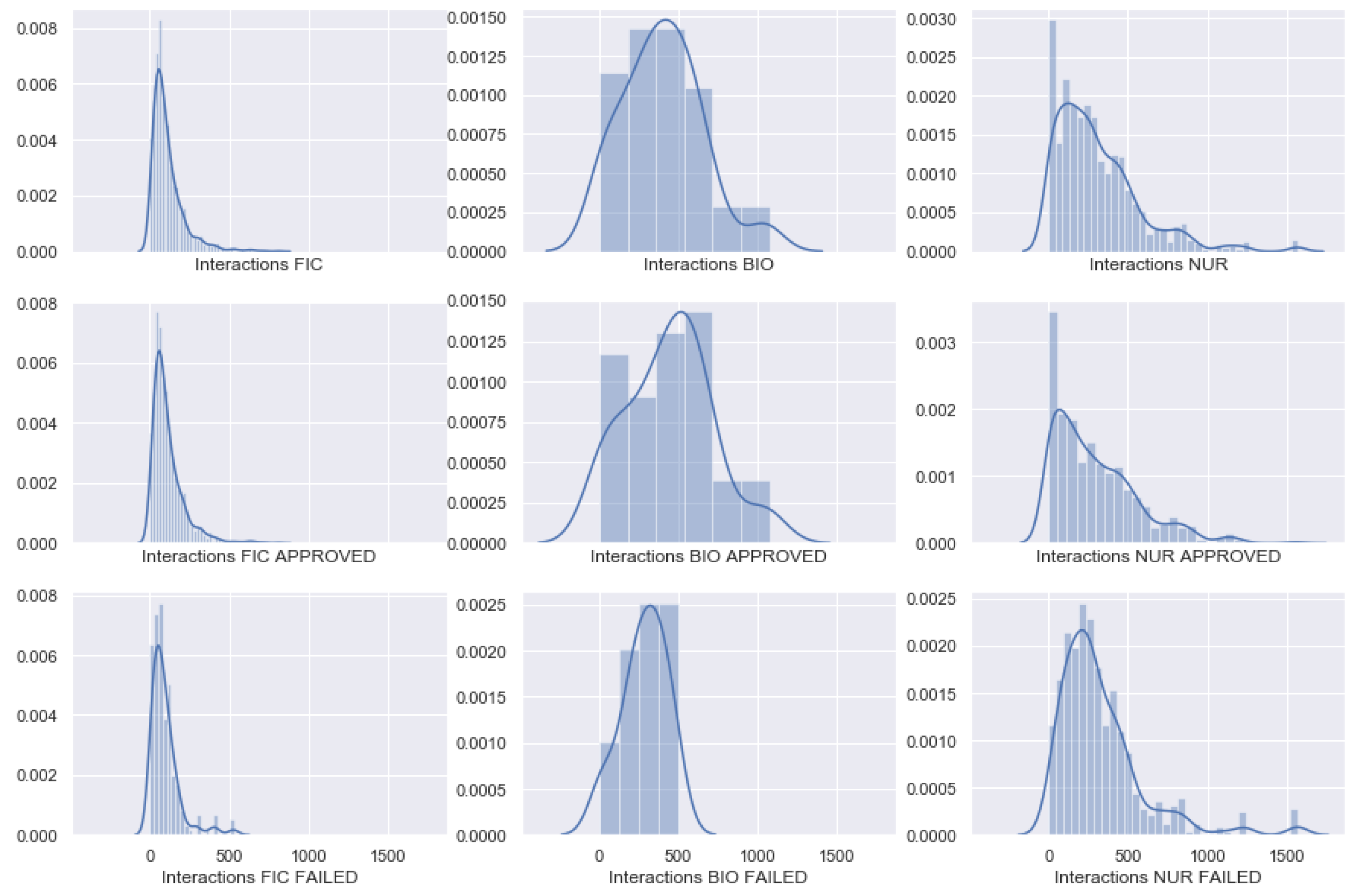
Figure 7 displays the frequencies of the distribution of total interactions by programs and the students’ final status. In FIC and NUR, both categories have their peak of interaction near zero and do not seem to present a different distribution. On the other hand, BIO presents a different distribution of interactions between the categories, with the peak of interactions for the success category near 500 and for the failed category near 300.
To evaluate whether the VLE’s students’ interactions were associated with their final status in the subjects, we performed a statistical analysis. First, we used the Shapiro–Wilk test to verify whether interactions from both groups (success and failure) of each course followed a normal distribution. For the groups that follow a normal distribution, we performed a
t-test and for the others, we applied the Mann–Whitney non-parametric test. The goal was to check whether the means/medians (depending on the test) of the groups present statistically significant differences. This analysis was performed for three different periods of the semester: week 4, week 8, and week 16 (all weeks). The results are shown in
Table 3.
As shown in
Table 3, the only case where the distribution was normal was for the Biology course considering all 16 weeks. In this case, the T-Test showed a statistical difference between the means of the two groups. For the other cases, the Mann–Whitney test showed statistical differences between the medians of the two groups. These results allowed us to conclude that the students’ usage of VLE was associated with their subjects’ final status: success or fail.
Another interesting observed attribute is the number of subjects the student was enrolled in and the relation with their final status.
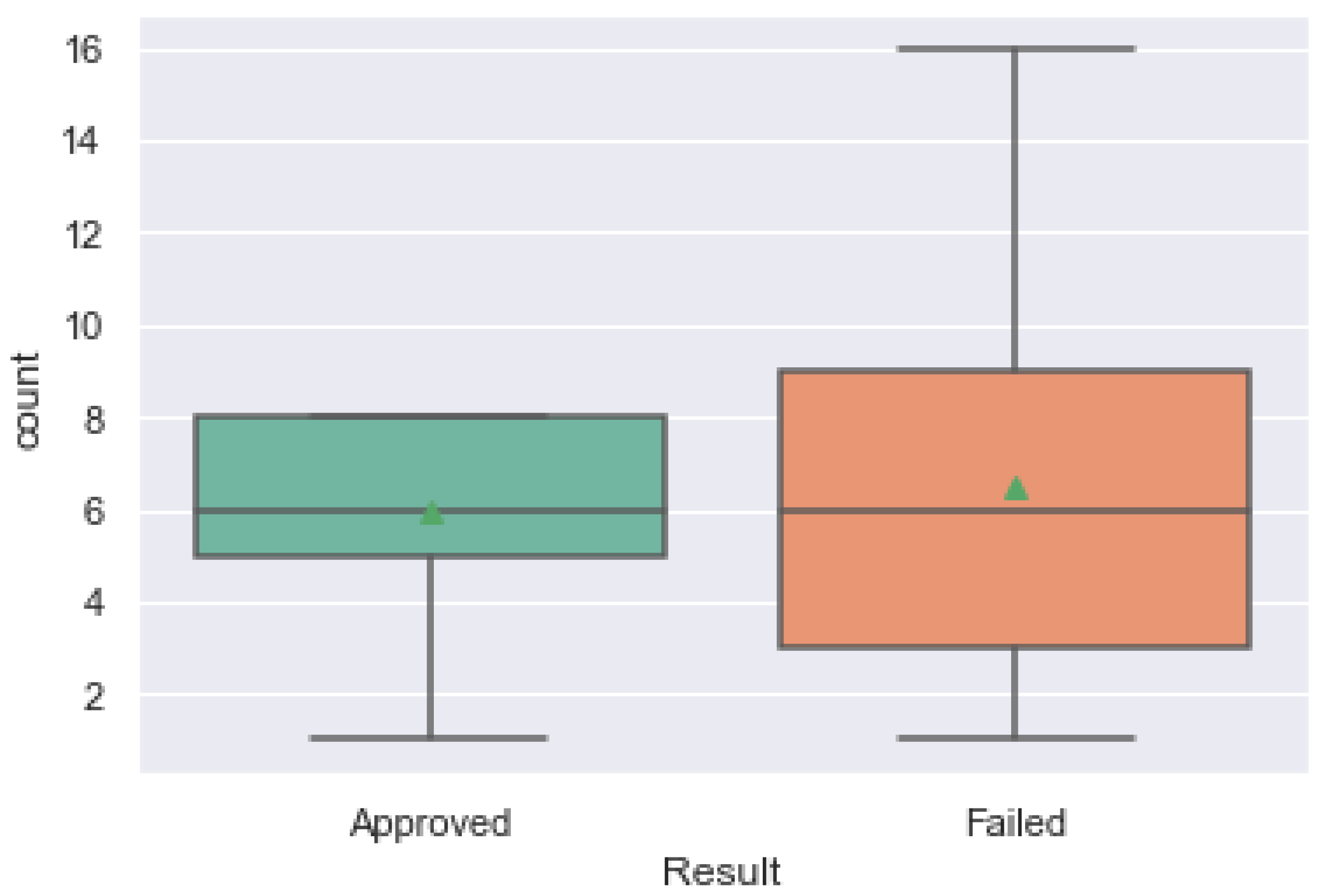
Figure 8 shows a box-plot for both groups of students versus the number of subjects enrolled. Even though the mean and median of subjects for both groups were the same (Success: median = 6.0 and mean = 5.93; Fail: median = 6.0; and mean = 6.47), a Mann–Whitney test showed a significant statistical difference between them (statistic = 2,138,630.0,
p-value < 0.05).
Figure 8 shows that students who failed in the subjects presented a wider dispersion in the number of subjects. Students who had success, tended to enroll in five to eight subjects, while students who failed tended to enroll in three to nine subjects. One of the possible reasons for this discrepancy may be related to the fact that students may enroll in subjects that they are not necessarily interested in taking (as they are allowed to take the final exams without attending classes for those subjects).
This may contribute to the fact that some subjects have a high number of students enrolled although they are not effectively participating. For instance, one given subject from the Nursing course had 590 students enrolled. This is a relatively common practice in Udelar; however, the data seem to show that students regularly attend the subjects in which they have success. This flexibility may also reflect in the engagement of the students in the subjects with students enrolling in more subjects than they are able to attend.
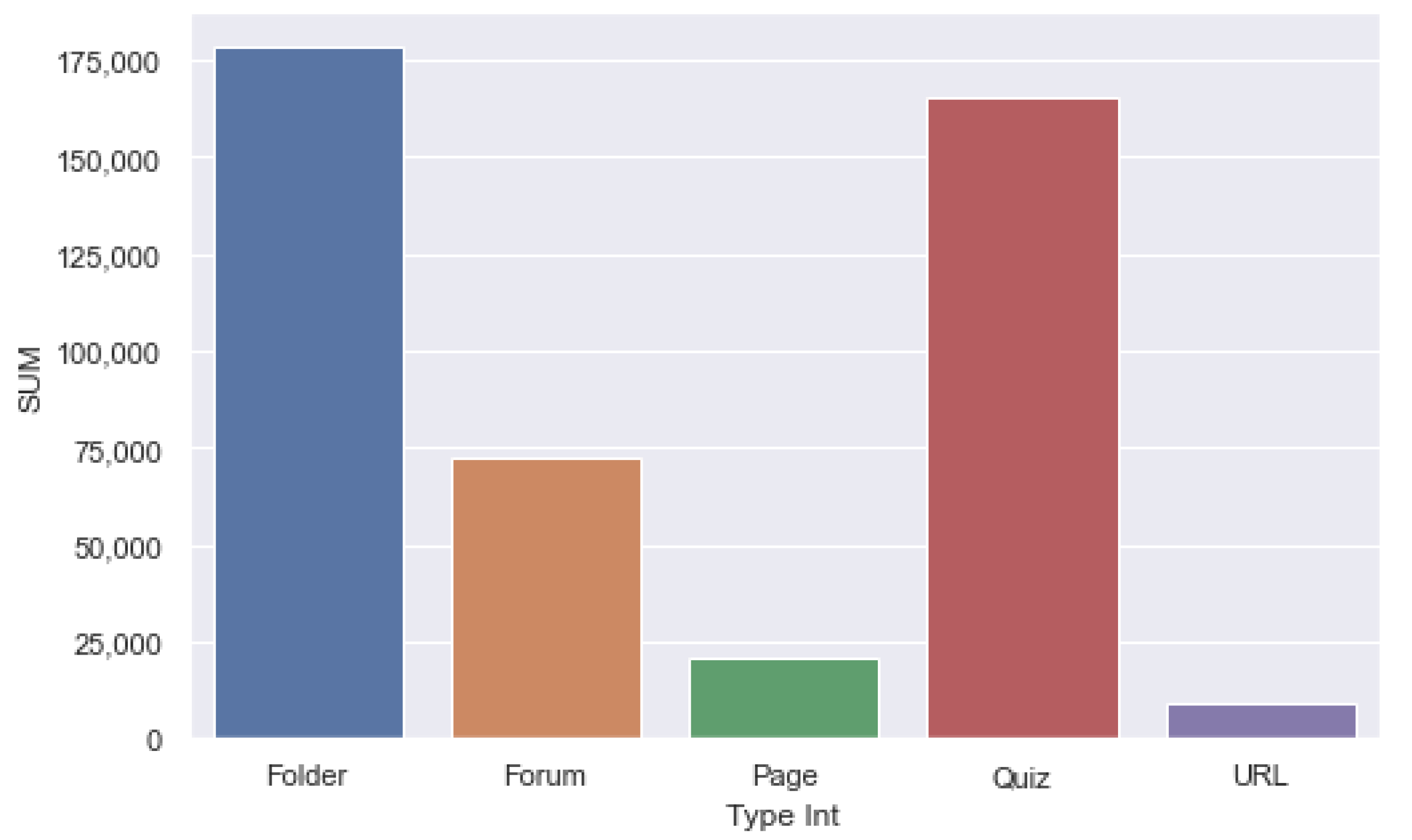
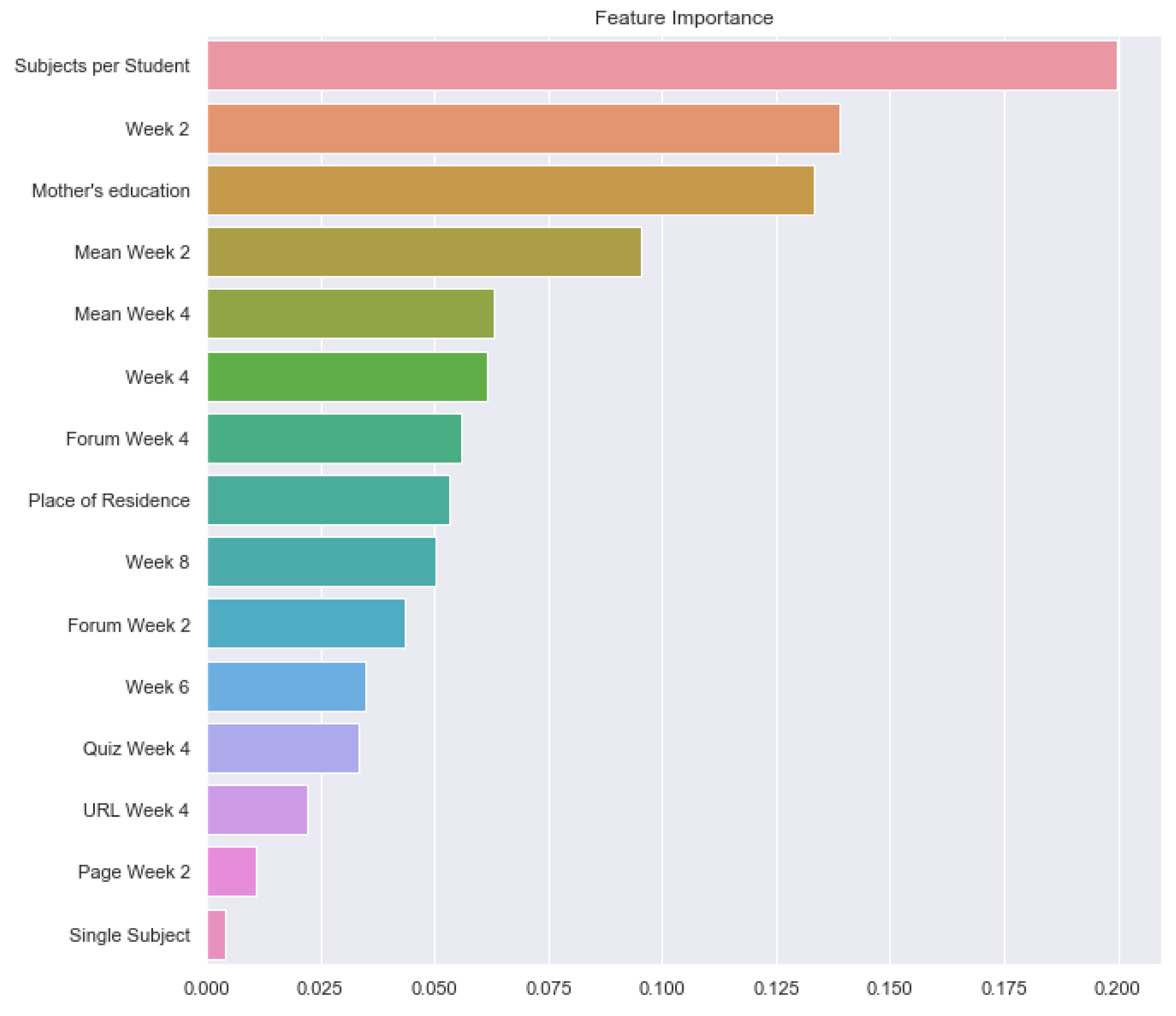
The analysis of the features used in Moodle (
Figure 9) showed that Folder, Forum, Page, Quiz, and URL represented around 90% of the students’ environment interactions. From these, most were interactions with folders and quizzes.
Although they are all asynchronous tools, they can be separated into two categories: interactive and non-interactive. First, there are methods that do not interact with students or professors and are basically used as a content repository, such as Folder, Page, and URL. Second, there are others with interactions, such as forums and quizzes, but no synchronous communication was found, such as conferencing or chat.
3.6. Modeling
This step consists of finding the best combinations of input data to generate predictive models, as well as to fine tune the hyperparameters of the algorithms used to generate the models. Data selection and data preparation were performed together with the modeling. An essential task in data mining and predictive modeling is choosing the performance evaluation metric. For this work, we chose the Area Under the Receiver Operating Characteristic Curve (AUC) [
42].
The AUC is calculated from the size of the area under the plotted curve where the Y-axis is represented by the True Positive Rate (TPR) or Sensitivity (or Recall) (
A1) and the
X-axis is the True Negative Rate (TNR) or Specificity (
A2) [
43]. In order to provide a general overview of the results, the following metrics are also presented for comparison: the Accuracy (
A5), F1-score (
A3), and Precision (
A4).
Among the classifiers initially tested, AdaBoost [
44], logistic regression [
45], and random forest [
46] obtained the best results. However, random forest exceeded the others in practically all tested scenarios, and it was chosen for the work sequence. SKlearn’s GridSearchCV was chosen as the hyperparameter selection technique. GridSearchCV is a parameter selector that tests a combination of hyperparameters initially set and that returns the one that obtained the best results in the tested set. The data normalization technique with the best results was SKlearn’s StandardScaler.
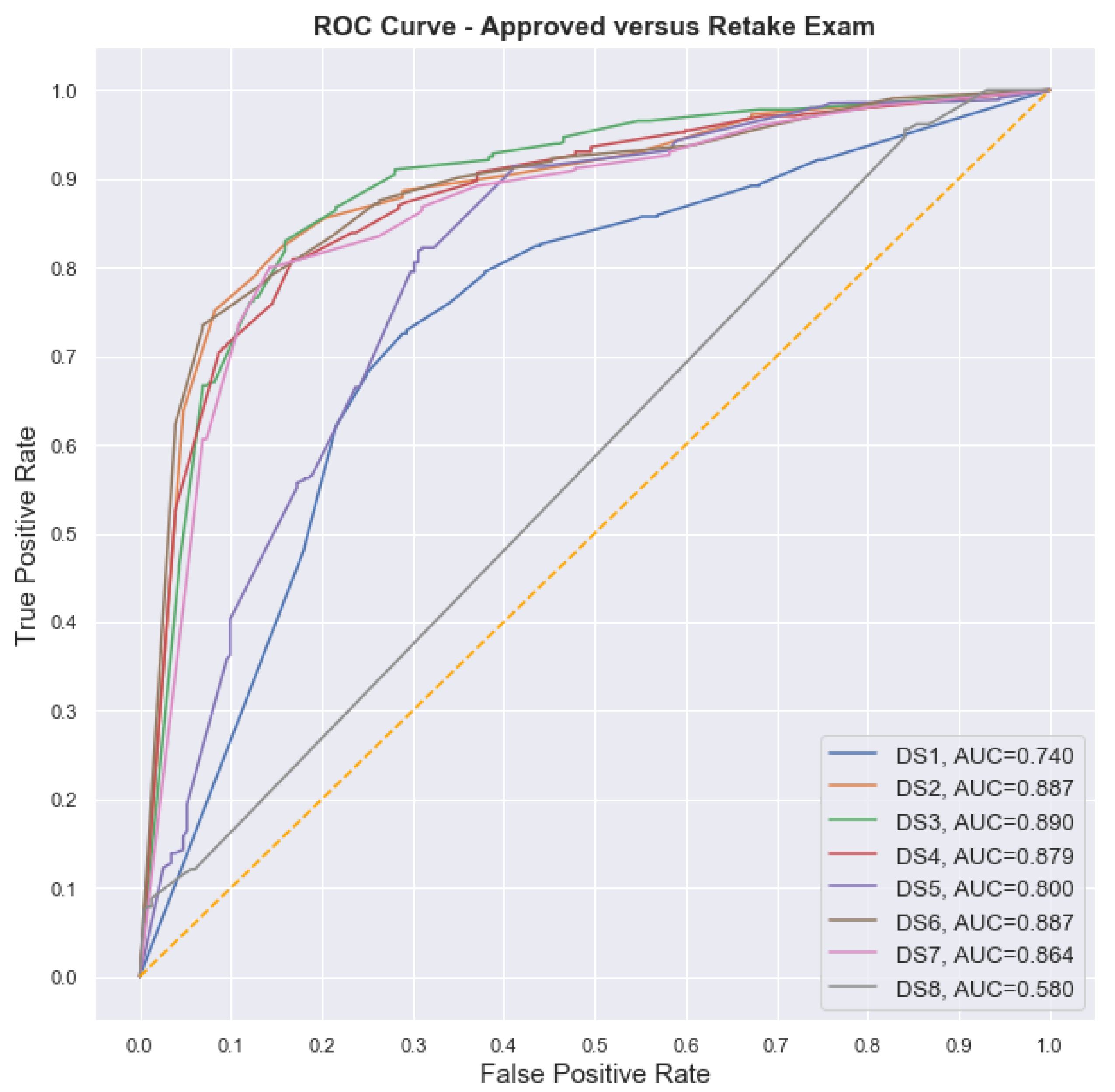
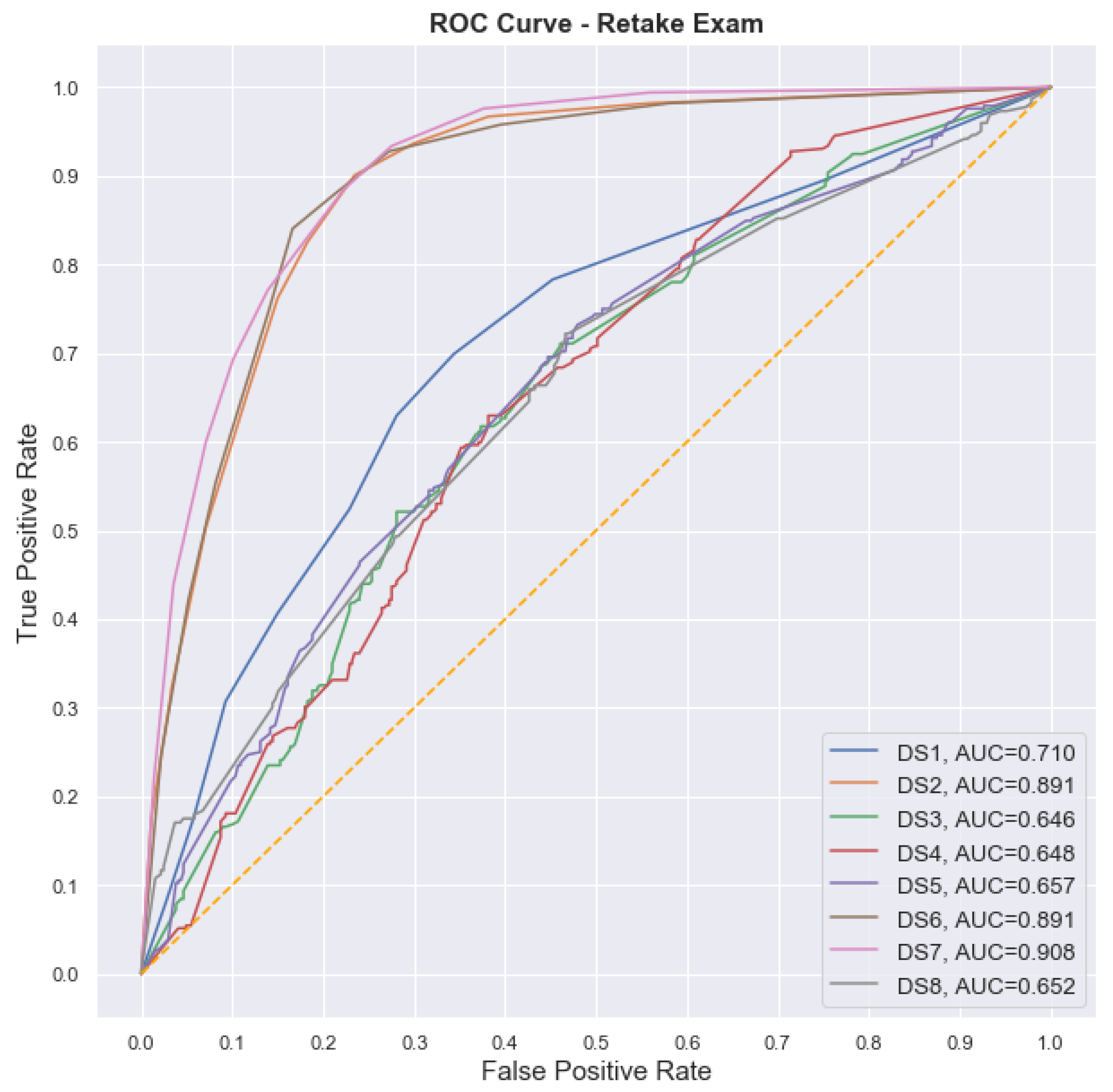
We generated eight different datasets to evaluate the extent to which the different configurations could help to improve the models’ performance, as shown in
Table 4. The main idea of these configurations is to evaluate how the combination of different datasets may interfere in the models’ performance, thus, showing the importance of each database for a better prediction.
The use of DS1 seeks to assess the potential for prediction presented by the survey without any other information besides academic. DS2 is generated by adding the count of total interactions to the survey data. After the EDA, the evaluation shows that this base would be the one with the highest predictive power, being able to be considered the maximum value that can be predicted with the available data. In this way, DS2 is used to compare the gains of using information from the survey along with the information related to the count of interactions.
DS3 and DS4 contain the total count of interactions within the VLE, and DS4 also contains the type of each interaction. DS5, DS6, DS7, and DS8 aim to verify the extent to which it is possible to early predict the performance of the students, so that there is time to perform pedagogical interventions. For that, the count of interactions is performed for a limited number of weeks. All datasets that used VLE data contained the derived attributes earlier described according to the number of weeks covered by the dataset and the inclusion of the type of the interaction or not.
After defining the datasets, a random forest classifier was executed in GridSearchCV to obtain the most optimized configuration for the predictive model. The 10-fold cross-validation was used to evaluate the models. The approach to deal with unbalanced data was the Synthetic Minority Oversampling Technique (SMOTE), which generated new synthesized cases on the training datasets.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











