
Comparison of Perturbation Strategies for the Initial Ensemble in Ocean Data Assimilation with a Fully Coupled Earth System Model


Abstract
:1. Introduction
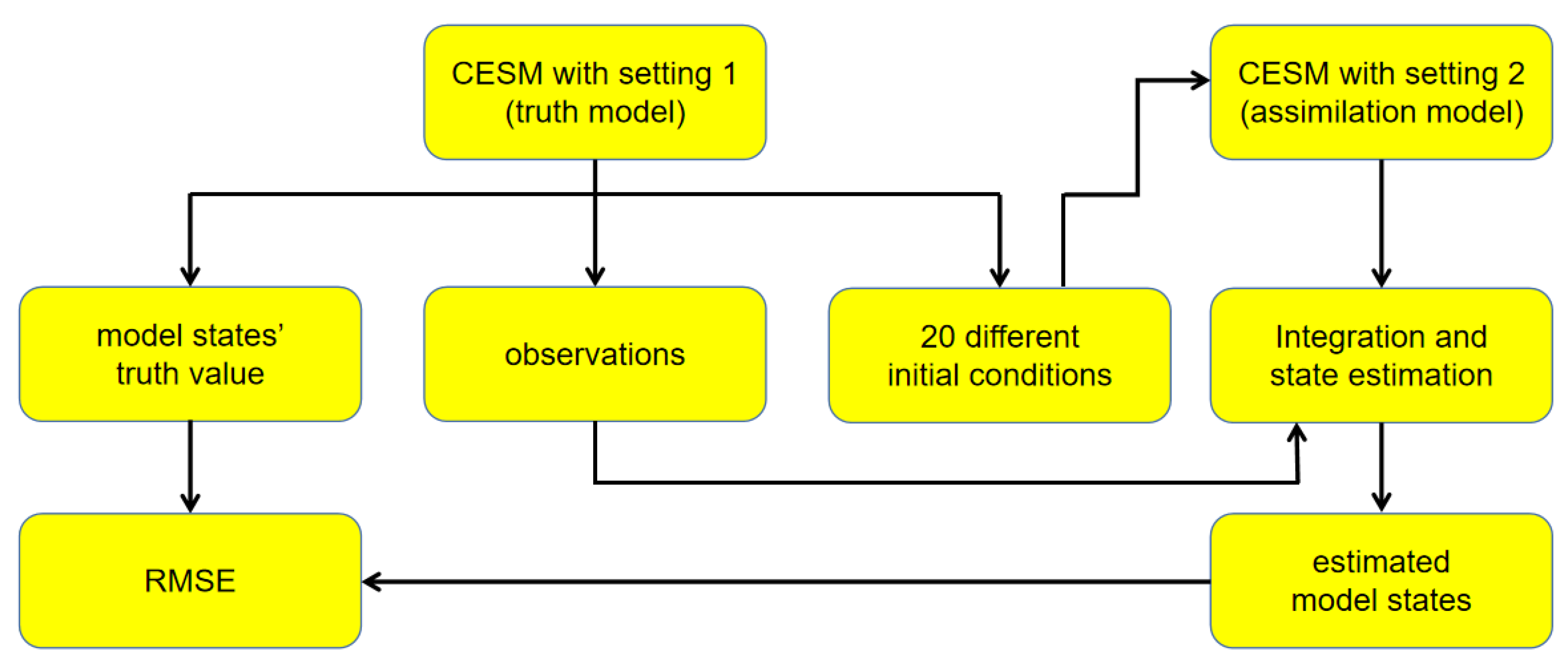
2. The Ensemble DA System and Experiment Design
2.1. Model and Data Assimilation System
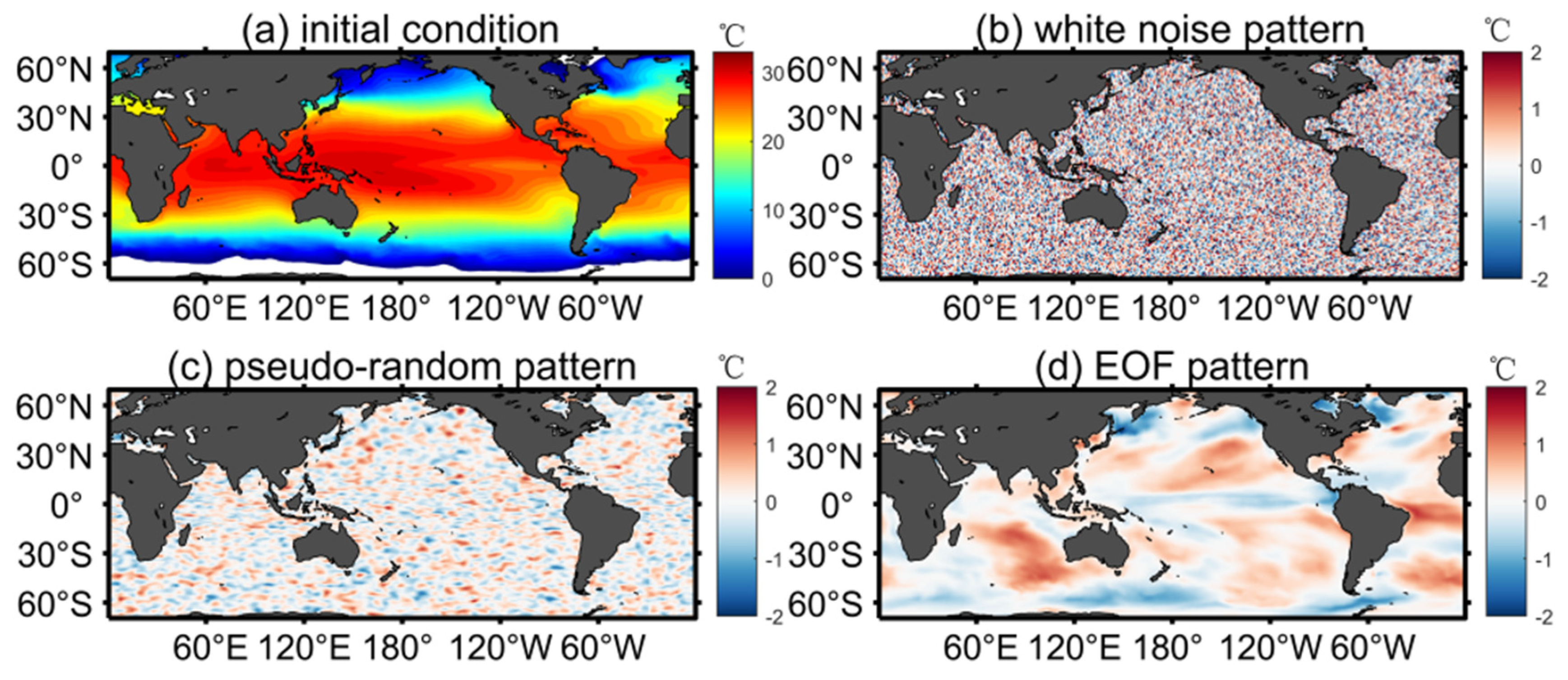
2.2. Initial Perturbation Methods
2.2.1. White Noise Pattern
2.2.2. Pseudo-Random Pattern
2.2.3. EOF Pattern
2.3. Analysis of Variance
2.4. Experiment Design
2.4.1. Design of Observation
2.4.2. Design of Assimilation Experiments
3. Results
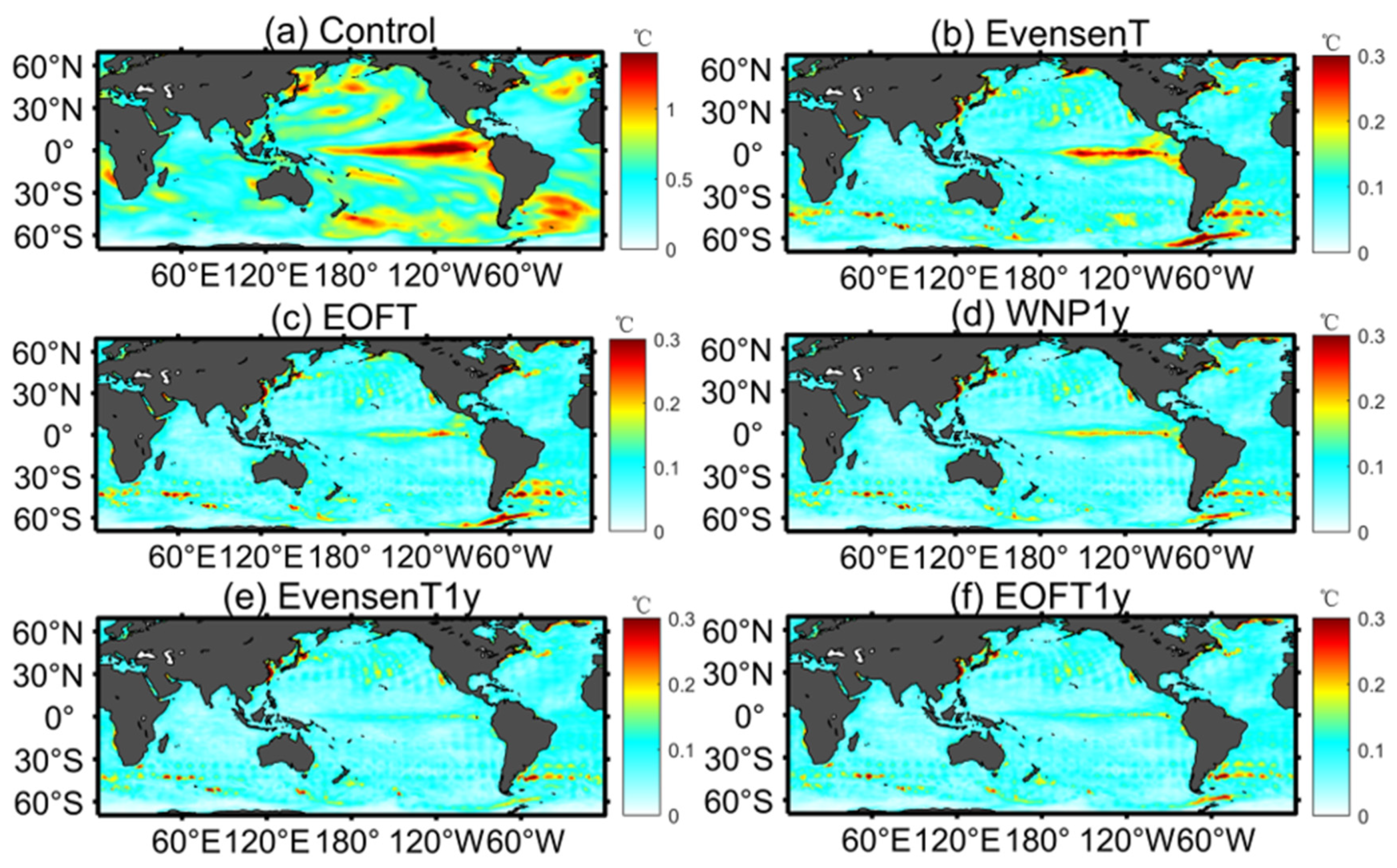
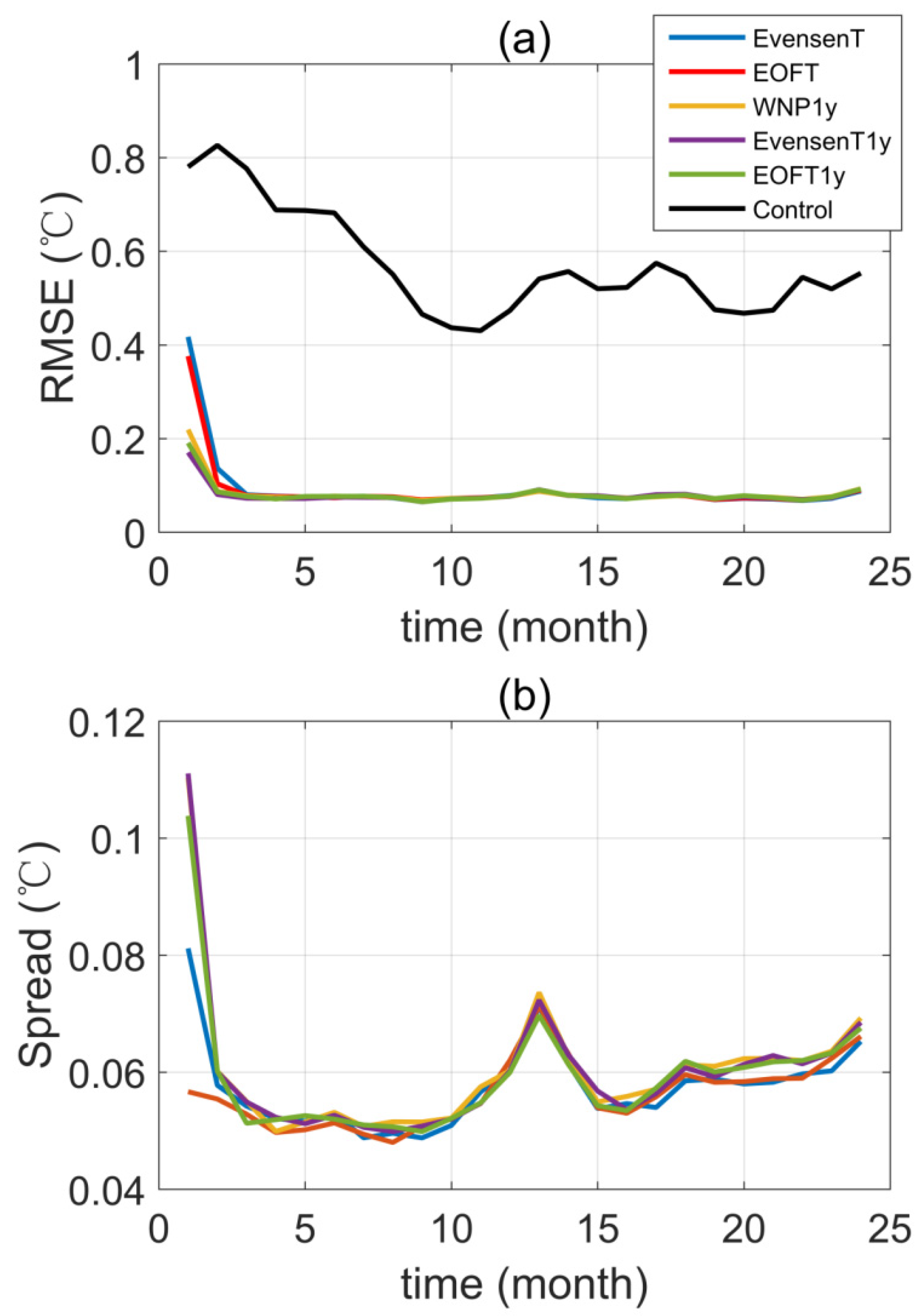
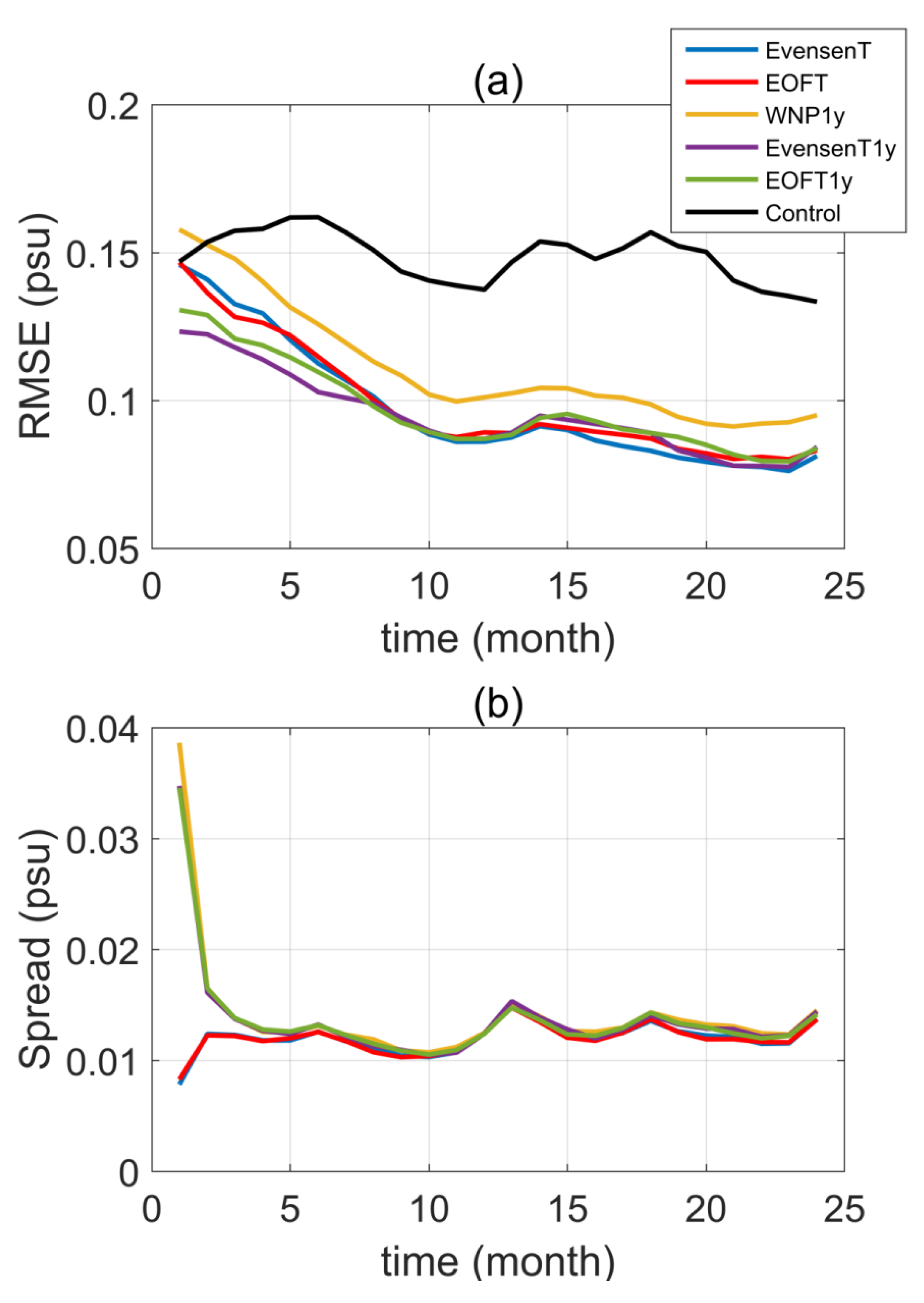
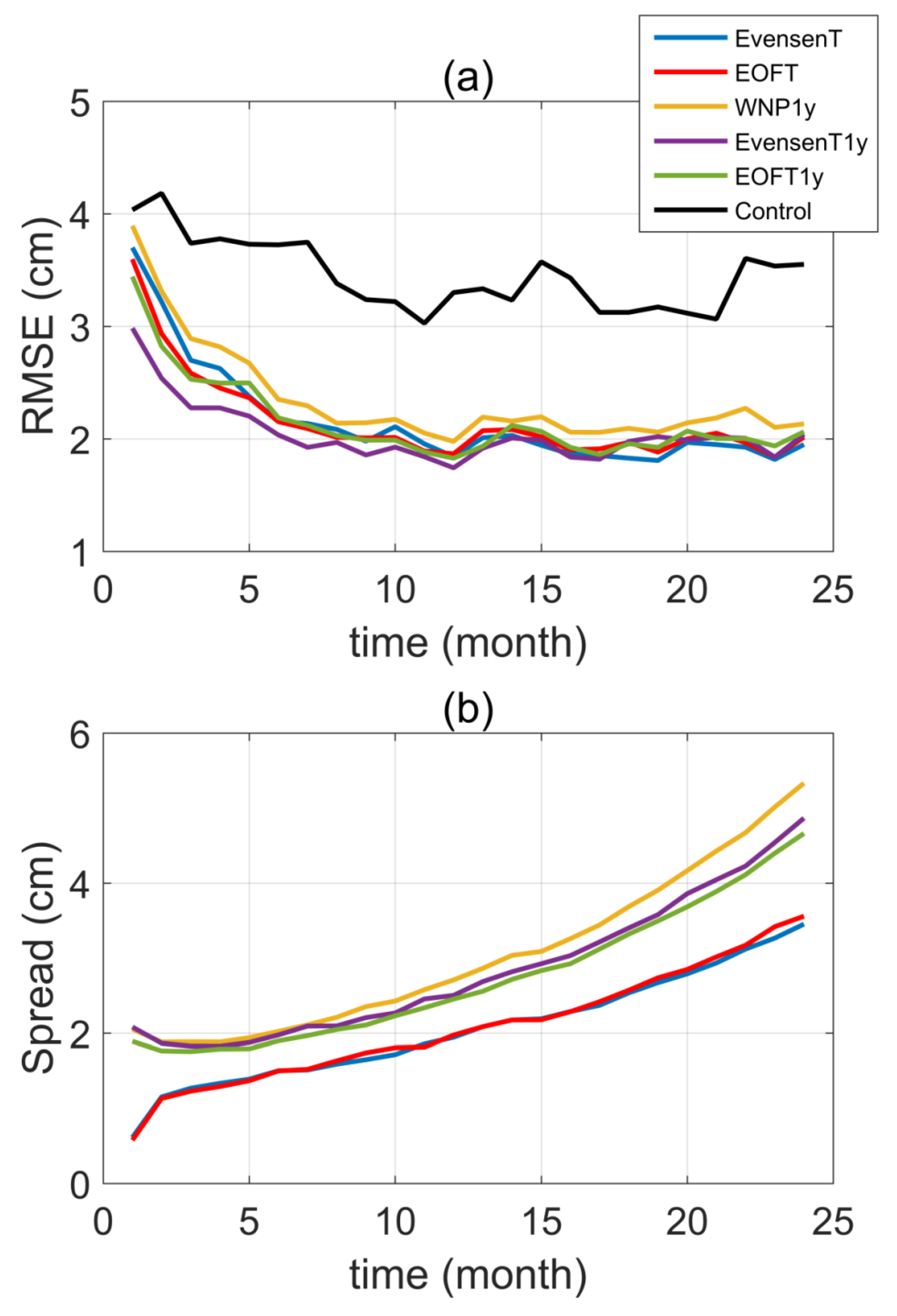
3.1. The Initial Uncertainties and Ensemble Spread
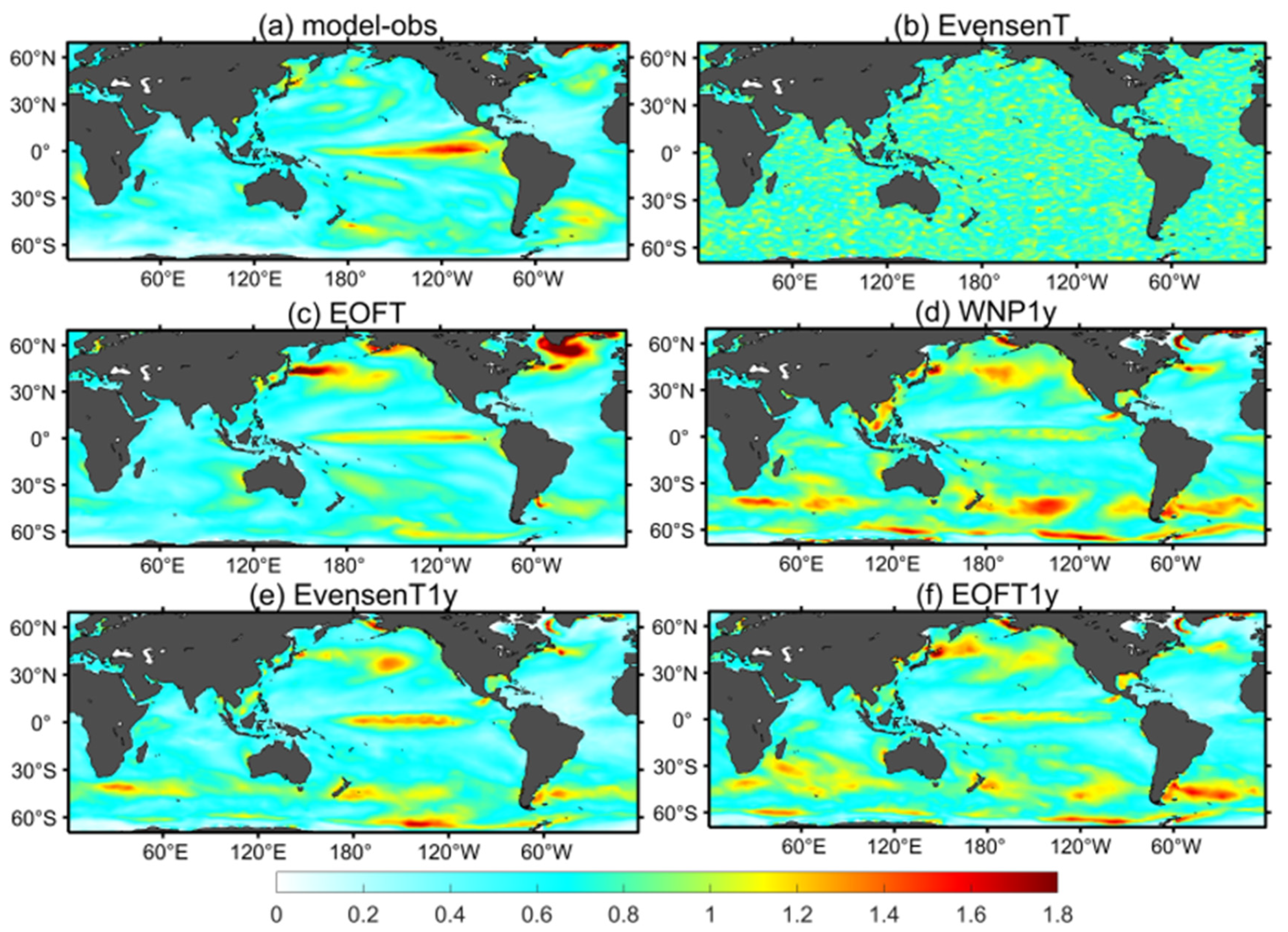
3.2. Assessing Differences between Assimilation Experiments
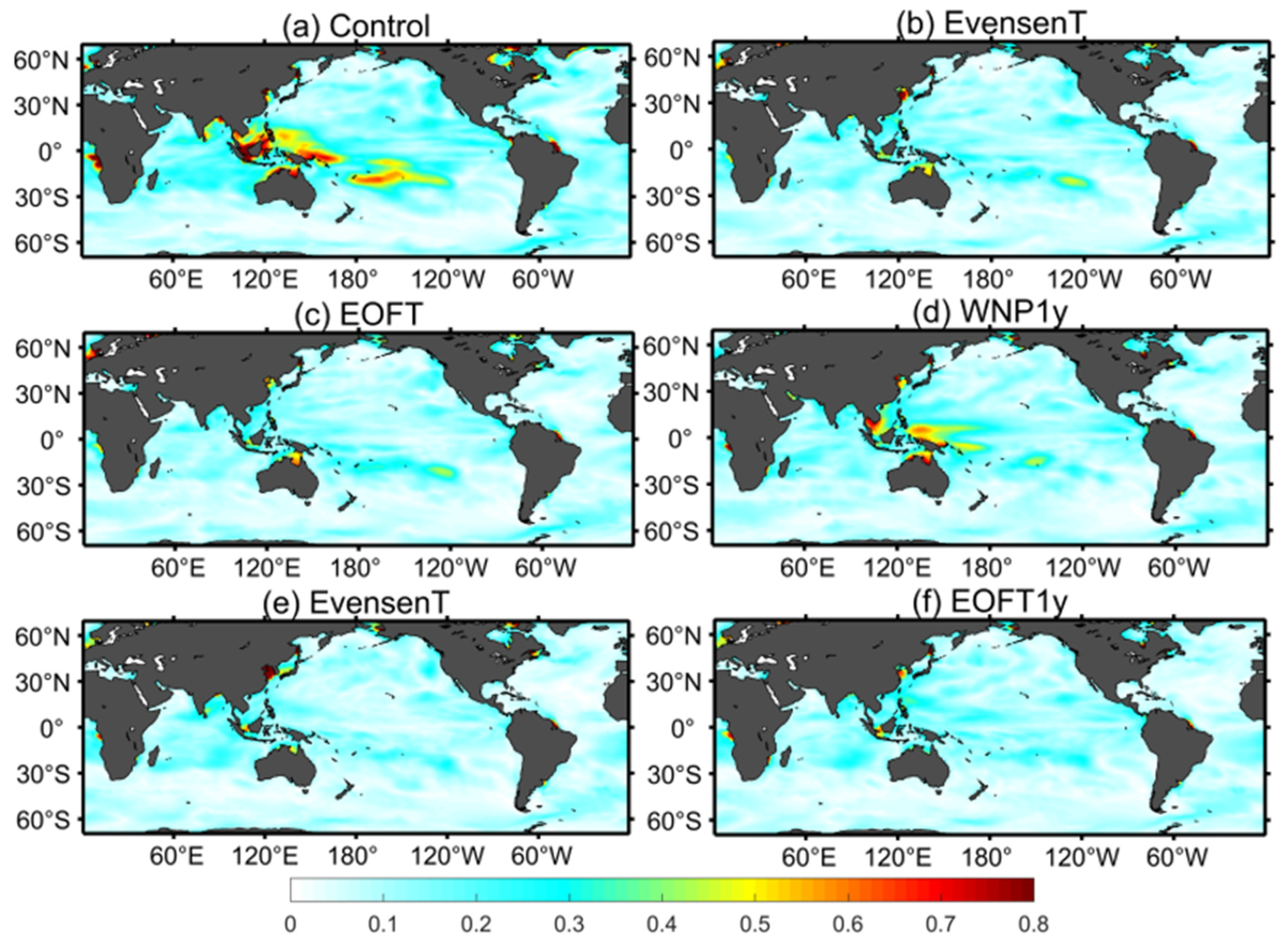
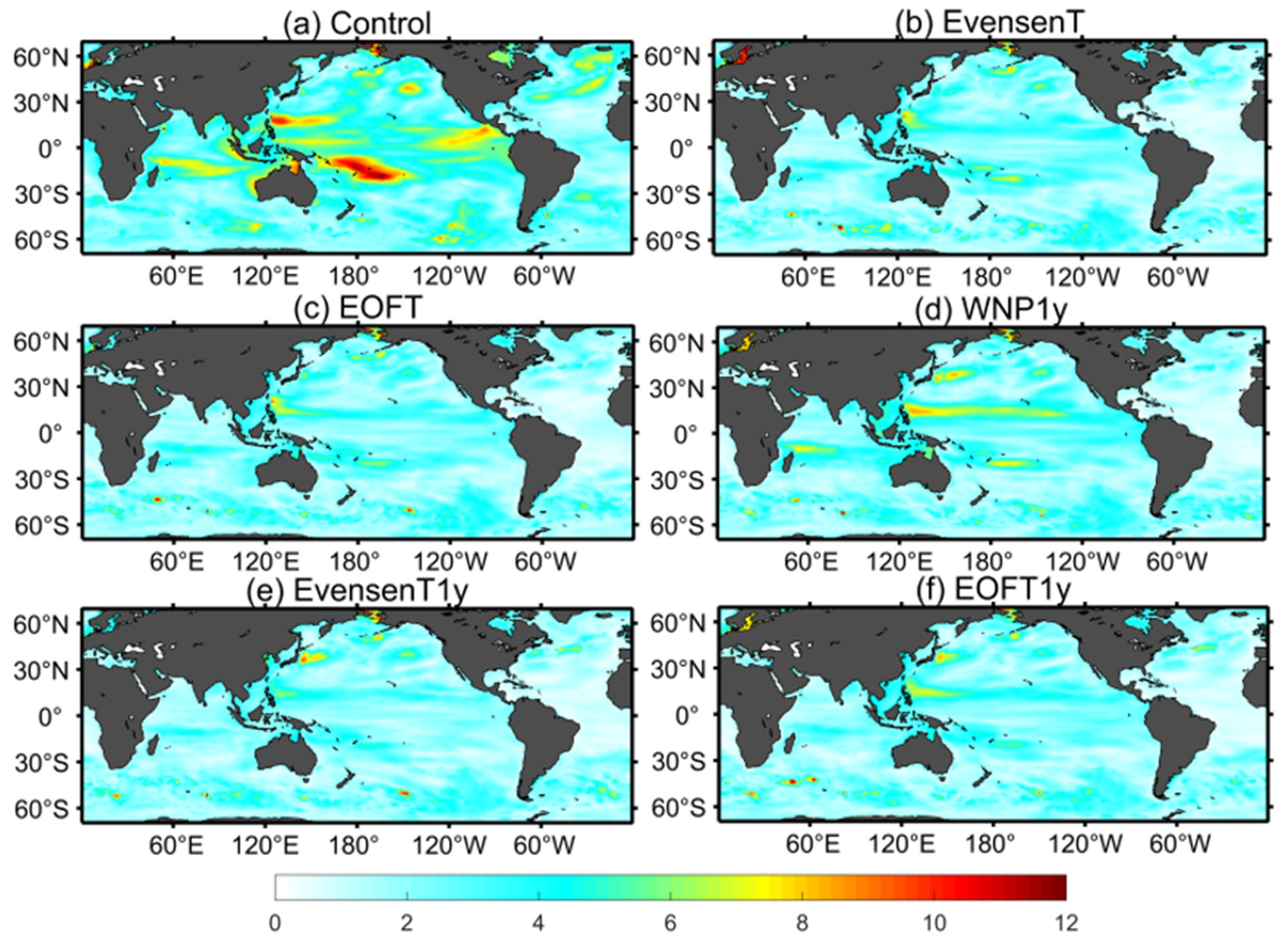
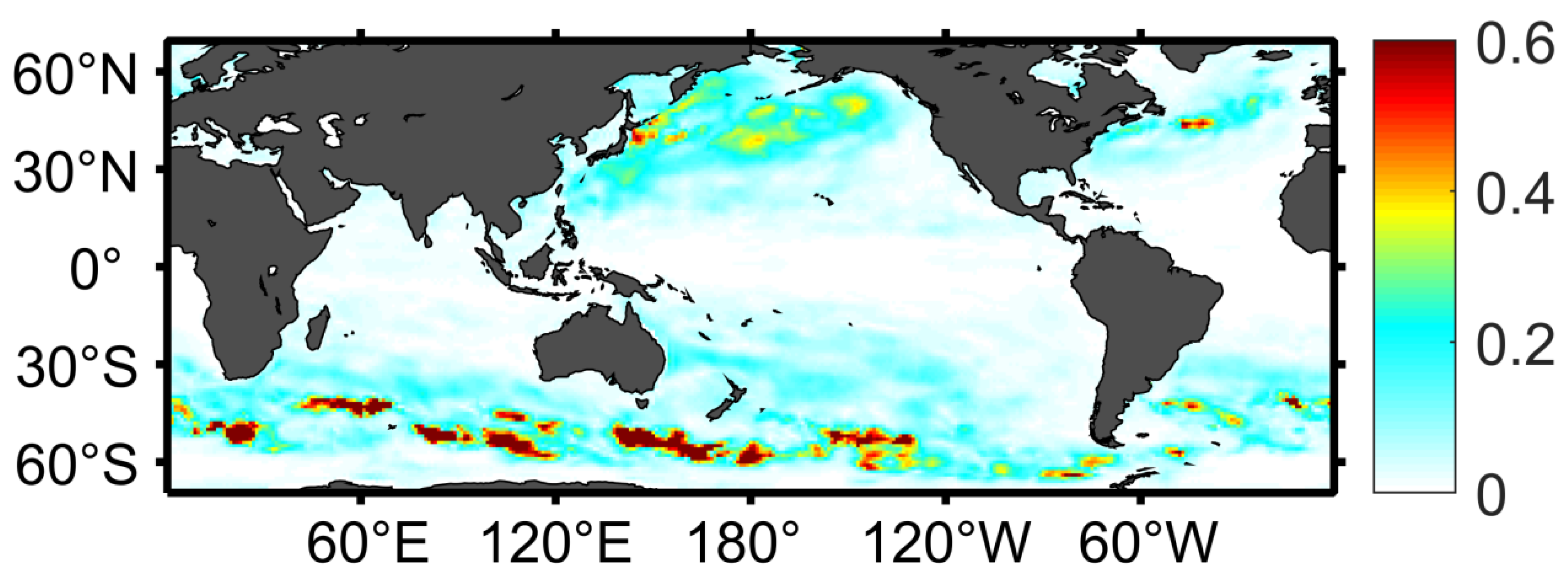
3.2.1. Spatial Distributions
3.2.2. Time Series
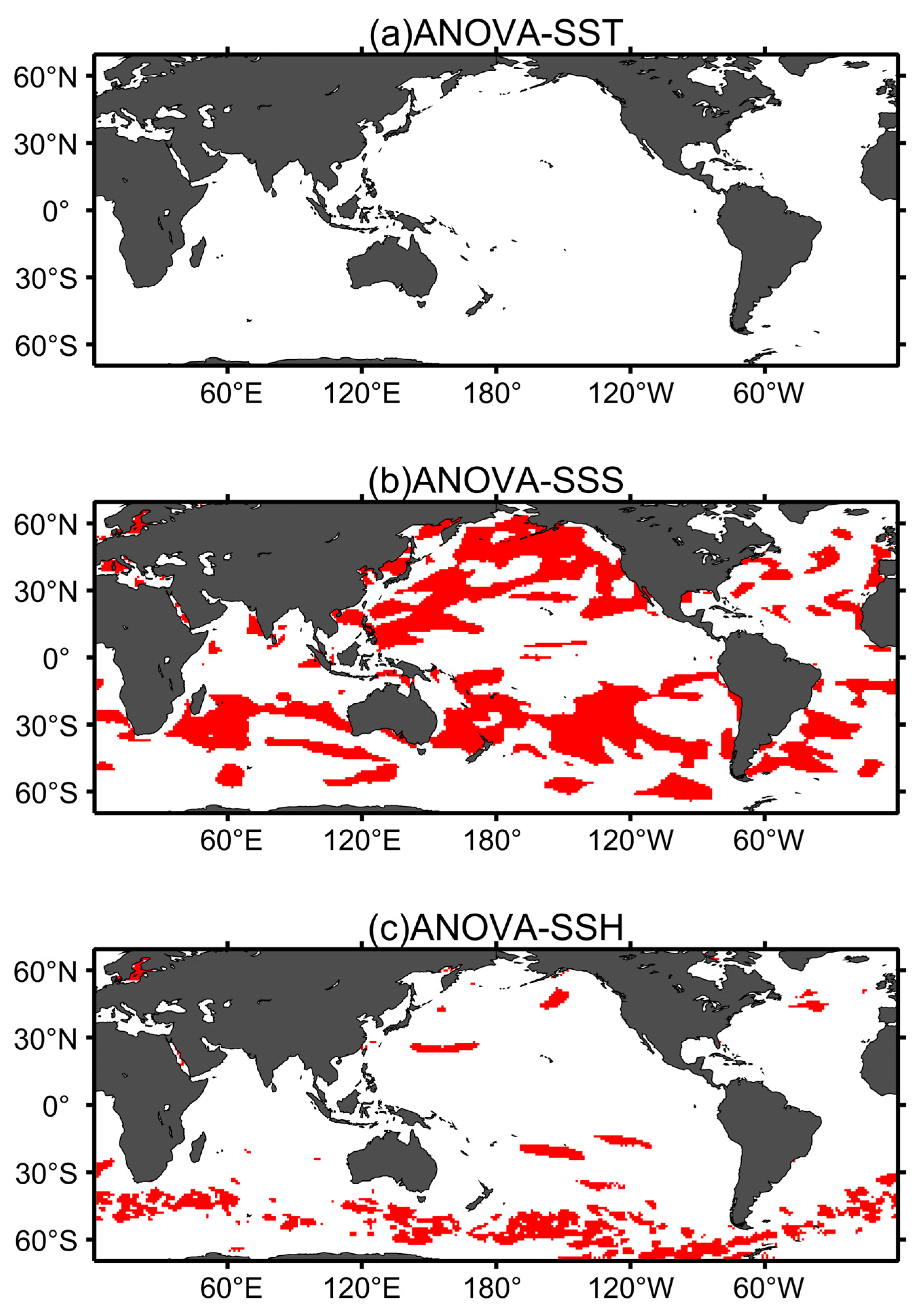
3.2.3. Significance Test
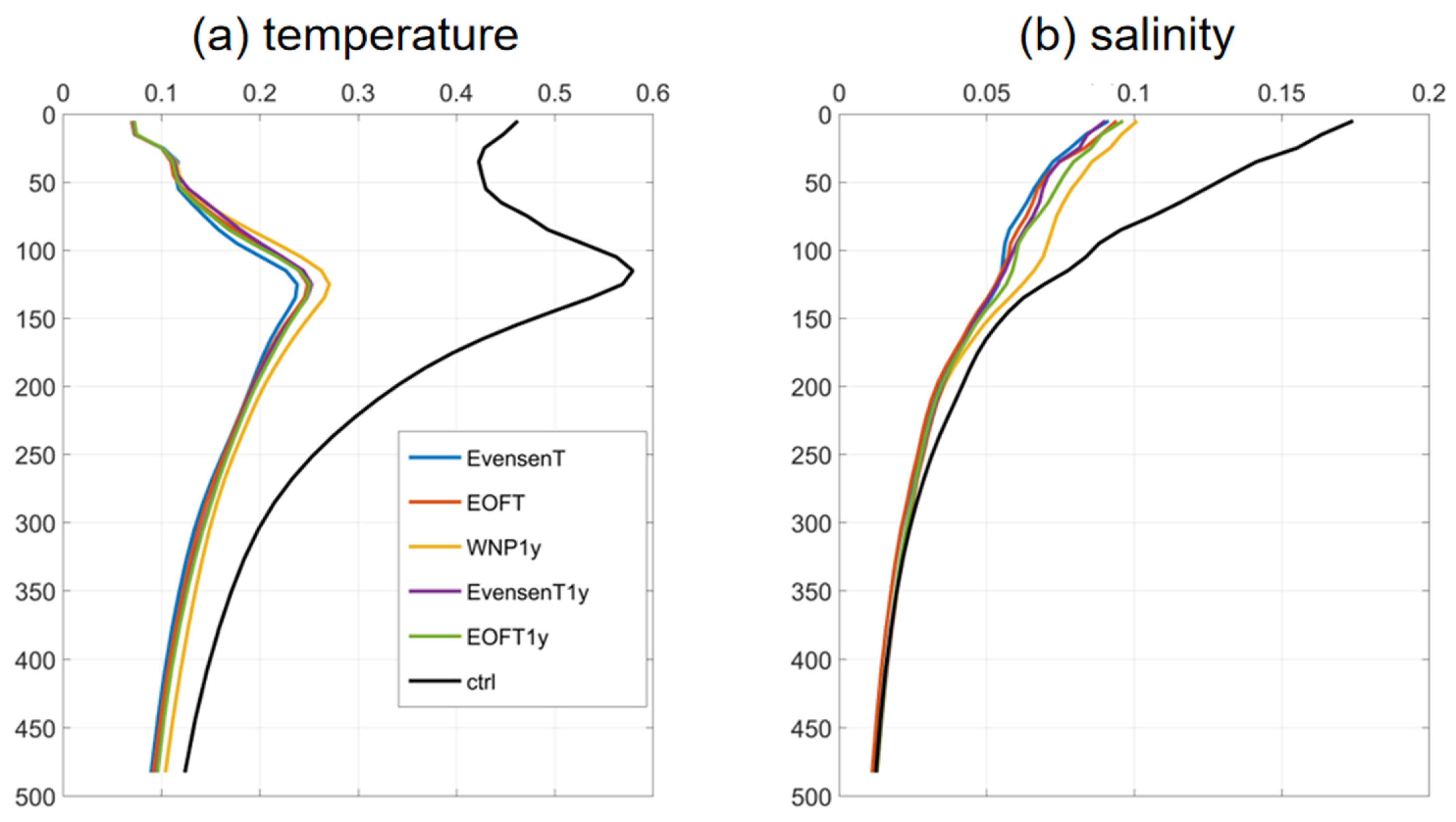
3.2.4. Vertical Distribution
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- LeDimet, F.X.; Talagrand, O. Variational algorithms for analysis and assimilation of meteorological observations: Theoretical aspects. Tellus A Dyn. Meteorol. Oceanogr. 1986, 38, 97–110. [Google Scholar] [CrossRef]
- Derber, J.C. Variational four-dimensional analysis using quasi-geostrophic constraints. Mon. Weather Rev. 1987, 115, 998–1008. [Google Scholar] [CrossRef] [Green Version]
- Talagrand, O.; Courtier, P. Variational assimilation of meteorological observations with the adjoint vorticity equation. Part I: Theory. Q. J. R. Meteorol. Soc. 1987, 113, 1311–1328. [Google Scholar] [CrossRef]
- Courtier, P.; Thepaut, J.N.; Hollingsworth, A. A strategy for operational implementation of 4D-Var, using an incremental approach. Q. J. R. Meteorol. Soc. 1994, 120, 1367–1388. [Google Scholar] [CrossRef]
- Peng, S.Q.; Xie, L.A. Effect of determining initial conditions by four-dimensional variational data assimilation on storm surge forecasting. Ocean Model. 2006, 14, 1–18. [Google Scholar] [CrossRef] [Green Version]
- Huang, X.-Y.; Xiao, Q.; Barker, D.; Zhang, X.; Michalakes, J.; Huang, W.; Henderson, T.; Bray, J.; Chen, Y.; Ma, Z.; et al. Four-Dimensional Variational Data Assimilation for WRF: Formulation and Preliminary Results. Mon. Weather Rev. 2009, 137, 299–314. [Google Scholar] [CrossRef] [Green Version]
- Kalnay, E.; Kanamitsu, M.; Kistler, R.; Collins, W.; Deaven, D.; Gandin, L.; Iredell, M.; Saha, S.; White, G.; Woollen, J.; et al. The NCEP/NCAR 40 -year reanalysis project. Bull. Am. Meteorol. Soc. 1996, 77, 437–471. [Google Scholar] [CrossRef] [Green Version]
- Behringer, D.; Ji, M.; Leetma, A. An improved coupled model for ENSO prediction and implications for ocean initialization. Part 1: The ocean data assimilation system. Mon. Weather Rev. 1998, 126, 1013–1021. [Google Scholar] [CrossRef]
- Mogensen, K.; Molteni, M.; Weaver, A. The NEMOVAR Ocean Data Assimilation System as implemented in the ECMWF Ocean Analysis System for System 4. In Technical Memorandum 668; ECMWF: Reading, UK, 2012. [Google Scholar]
- Zuo, H.; Balmaseda, M.; Mogensen, K. The new eddy-permitting ORAP5 ocean reanalysis: Description, evaluation and uncertainties in climate signals. Clim. Dyn. 2017, 49, 791–811. [Google Scholar] [CrossRef]
- Kalman, R.E. A new approach to linear filtering and prediction problems. J. Basic Eng. 1960, 82, 35–45. [Google Scholar] [CrossRef] [Green Version]
- Burgers, G.; van Leeuwen, P.J.; Evensen, G. Analysis scheme in the ensemble Kalman filter. Mon. Weather. Rev. 1998, 126, 1719–1724. [Google Scholar] [CrossRef]
- Evensen, G. Sequential data assimilation with a nonlinear quasi-geostrophic model using Monte Carlo methods to forecast error statistics. J. Geophys. Res. Ocean. 1994, 99, 10143–10162. [Google Scholar] [CrossRef]
- Martin, M.J.; Balmaseda, M.; Bertino, L.; Brasseur, P.; Brassington, G.; Cummings, J.; Oke, P.R. Status and future of data assimilation in operational oceanography. J. Oper. Oceanogr. 2015, 8, s28–s48. [Google Scholar] [CrossRef]
- Anderson, J.L. An ensemble adjustment Kalman filter for data assimilation. Mon. Weather Rev. 2001, 129, 2884–2903. [Google Scholar] [CrossRef] [Green Version]
- Anderson, J.L. A local least squares framework for ensemble filtering. Mon. Weather Rev. 2003, 131, 634–642. [Google Scholar] [CrossRef] [Green Version]
- Anderson, J.; Hoar, T.; Raeder, K.; Liu, H.; Collins, N.; Torn, R.; Avellano, A. The data assimilation research testbed: A community facility. Bull. Am. Meteorol. Soc. 2009, 90, 1283–1296. [Google Scholar] [CrossRef] [Green Version]
- Haugen, V.E.; Evensen, G. Assimilation of SLA and SST data into an OGCM for the Indian Ocean. Ocean Dyn. 2002, 52, 133–151. [Google Scholar] [CrossRef]
- Chen, D.; Zebiak, S.E.; Busalacchi, A.J. An improved procedure for El Nino forecasting: Implications for predictability. Science 1995, 269, 1699–1702. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, D.; Cane, M.A.; Zebiak, S.E.; Kaplan, A. The impact of sea level data assimilation on the Lamont model prediction of the 1997/98 El Nino. Geophys. Res. Lett. 1998, 25, 2837–2840. [Google Scholar] [CrossRef]
- Ballabrera, P.J.; Busalacchi, A.J.; Murtugudde, R. Application of a reduced-order Kalman filter to initialize a coupled atmosphereocean model: Impact on the prediction of El Niño. J. Clim. 2000, 14, 1720–1737. [Google Scholar] [CrossRef] [Green Version]
- Zebiak, S.E.; Cane, M.A. A model El Nino-Southern oscillation. Mon. Weather Rev. 1987, 115, 2262–2278. [Google Scholar] [CrossRef] [Green Version]
- Zheng, F.; Zhu, J.; Zhang, R.H.; Zhou, G. Improved ENSO forecasts by assimilating sea surface temperature observations into an intermediate coupled model. Adv. Atmos. Sci. 2006, 23, 615–624. [Google Scholar] [CrossRef]
- Zhang, S.; Harrison, M.; Rosati, A.; Wittenberg, A. System design and evaluation of coupled ensemble data assimilation for global oceanic climate studies. Mon. Weather Rev. 2007, 135, 3541–3564. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Rosati, A.; Harrison, M. Detection of multidecadal oceanic variability by ocean data assimilation in the context of a “perfect” coupled model. J. Geophys. Res. Ocean. 2009, 114, C12. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Rosati, A. An inflated ensemble filter for ocean data assimilation with a biased coupled GCM. Mon. Weather Rev. 2010, 138, 3905–3931. [Google Scholar] [CrossRef]
- Delworth, T.; Broccoli, A.; Rosati, A.; Stouffer, R.J.; Balaji, V.; Beesley, J.A.; Cooke, W.F.; Dixon, K.; Dunne, J.; Dunne, K.A.; et al. GFDL’s CM2 Global Coupled Climate Models. Part I: Formulation and Simulation Characteristics. J. Clim. 2006, 19, 643–674. [Google Scholar] [CrossRef]
- Yin, X.; Qiao, F.; Shu, Q. Using ensemble adjustment Kalman filter to assimilate Argo profiles in a global OGCM. Ocean Dyn. 2011, 61, 1017–1031. [Google Scholar] [CrossRef] [Green Version]
- Karspeck, A.R.; Danabasoglu, G.; Anderson, J.; Karol, S.; Collins, N.; Vertenstein, M.; Raeder, K.; Hoar, T.; Neale, R.; Edwards, J. A global coupled ensemble data assimilation system using the Community Earth System Model and the Data Assimilation Research Testbed. Q. J. R. Meteorol. Soc. 2018, 144, 2404–2430. [Google Scholar] [CrossRef]
- Karspeck, A.R.; Yeager, S.; Danabasoglu, G. An ensemble adjustment kalman filter for the CCSM4 ocean component. J. Clim. 2013, 26, 7392–7413. [Google Scholar] [CrossRef] [Green Version]
- Raeder, K.; Anderson, J.L.; Collins, N.; Hoar, T.J.; Kay, J.E.; Lauritzen, P.H.; Pincus, R. DART/CAM: An ensemble data assimilation system for CESM atmospheric models. J. Clim. 2012, 25, 6304–6317. [Google Scholar] [CrossRef]
- Zhang, Y.F.; Hoar, T.; Yang, Z.L.; Anderson, J.; Toure, A.; Rodell, M. Assimilation of MODIS snow cover through the Data Assimilation Research Testbed and the Community Land Model version 4. J. Geophys. Res. Atmos 2014, 119, 7091–7103. [Google Scholar] [CrossRef]
- Doucet, A.; De Freitas, N.; Gordon, N. An introduction to sequential Monte Carlo methods. In Sequential Monte Carlo Methods in Practice; Springer: Berlin/Heidelberg, Germany, 2001; pp. 3–14. [Google Scholar]
- Hoteit, I.; Pham, D.T.; Triantafyllou, G.; Korres, G. A new approximate solution of the optimal nonlinear filter for data assimilation in meteorology and oceanography. Mon. Weather Rev. 2008, 136, 317–334. [Google Scholar] [CrossRef]
- Wan, L.; Zhu, J.; Bertino, L.; Wang, H. Initial ensemble generation and validation for ocean data assimilation using HYCOM in the Pacific. Ocean Dyn. 2008, 58, 81–99. [Google Scholar] [CrossRef]
- Evensen, G. The ensemble Kalman filter: Theoretical formulation and practical implementation. Ocean Dyn. 2003, 53, 343–367. [Google Scholar] [CrossRef]
- Pham, D.T.; Verron, J.; Roubaud, M.C. A singular evolutive extended Kalman filter for data assimilation in oceanography. J. Mar. Syst. 1998, 16, 323–340. [Google Scholar] [CrossRef]
- Nerger, L.; Hiller, W.; Schröter, J. A comparison of error subspace Kalman filters. Tellus A Dyn. Meteorol. Oceanogr. 2005, 57, 715–735. [Google Scholar] [CrossRef]
- Hurrell, J.W.; Holland, M.M.; Gent, P.R.; Ghan, S.; Kay, J.E.; Kushner, P.J.; Lamarque, J.F.; Large, W.G.; Lawrence, D.; Lindsay, K.; et al. The Community Earth System Model: A framework for collaborative research. Bull. Am. Meteorol. Soc. 2013, 94, 1339–1360. [Google Scholar] [CrossRef]
- Yeager, S.; Karspeck, A.R.; Danabasoglu, G.; Tribbia, J.; Teng, H. A decadal prediction case study: Late 20th century North Atlantic Ocean heat content. J. Clim. 2012, 25, 5173–5189. [Google Scholar] [CrossRef]
- Meehl, G.; Goddard, L.; Boer, G.; Burgman, R.; Branstator, G.; Cassou, C.; Corti, S.; Danabasoglu, G.; Doblas-Reyes, F.; Hawkins, E.; et al. Decadal climate prediction: An update from the trenches. Bull. Am. Meteorol. Soc. 2014, 95, 243–267. [Google Scholar] [CrossRef] [Green Version]
- Karspeck, A.R.; Yeager, S.; Danabasoglu, G.; Teng, H. An evaluation of experimental decadal predictions using CCSM4. Clim. Dyn. 2015, 44, 907. [Google Scholar] [CrossRef]
- Neale, R.; Chen, C.C.; Gettelman, A.; Lauritzen, P.; Park, S.; Williamson, D.; Conley, A.; Garcia, R.; Kinnison, D.; Lamarque, J.F.; et al. Description of the NCAR Community Atmosphere Model (CAM 5.0). In Technical Note TN-486+STR; NCAR: Boulder, CO, USA, 2010. [Google Scholar]
- Danabasoglu, G.; Bates, S.; Briegleb, B.; Jayne, S.; Jochum, M.; Large, W.; Peacock, S.; Yeager, S. The CCSM4 ocean component. J. Clim. 2012, 25, 1361–1389. [Google Scholar] [CrossRef] [Green Version]
- Holland, M.; Bailey, D.; Briegleb, B.; Light, B.; Hunke, E. Improved sea ice shortwave radiation physics in CCSM4: The impact of melt ponds and aerosols on arctic sea ice. J. Clim. 2012, 25, 1413–1430. [Google Scholar] [CrossRef]
- Lawrence, D.; Oleson, K.; Flanner, M.; Thornton, P.; Swenson, S.; Lawrence, P.; Zeng, X.; Yang, Z.L.; Levis, S.; Sakaguchi, K.; et al. Parameterization improvements and functional and structural advances in version 4 of the Community Land Model. J. Adv. Modeling Earth Syst. 2011, 3, M03001. [Google Scholar] [CrossRef]
- Gaspari, G.; Cohn, S. Construction of correlation functions in two and three dimensions. Q. J. R. Meteorol. Soc. 1999, 125, 723–757. [Google Scholar] [CrossRef]
- Hoteit, I.; Hoar, T.; Gopalakrishnan, G.; Collins, N.; Anderson, J.; Cornuelle, B.; Köhl, A.; Heimbach, P. A MITgcm/DART ensemble analysis and prediction system with application to the Gulf of Mexico. Dyn. Atmos Ocean. 2013, 63, 1–23. [Google Scholar] [CrossRef]
- Pham, D.T. Stochastic methods for sequential data assimilation in strongly nonlinear systems. Mon. Weather Rev. 2001, 129, 1194–1207. [Google Scholar] [CrossRef]
- Hogg, R.; Ledolter, J. Engineering Statistics; MacMillan: New York, NY, USA, 1987. [Google Scholar]
- McHugh, M. Multiple comparison analysis testing in ANOVA. Biochem. Med. 2011, 21, 203–209. [Google Scholar] [CrossRef] [PubMed]
- Meroni, A.; Parodi, A.; Pasquero, C. Role of SST patterns on surface wind modulation of a heavy midlatitude precipitation event. J. Geophys. Res. Atmos 2018, 123, 9081–9096. [Google Scholar] [CrossRef]
- Ricchi, A.; Bonaldo, D.; Cioni, G.; Carniel, S.; Miglietta, M. Simulation of a flash-flood event over the Adriatic Sea with a high-resolution atmosphere -ocean-wave coupled system. Sci. Rep. 2021, 11, 9388. [Google Scholar] [CrossRef] [PubMed]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. in the ensemble | 20 |
| Covariance inflation | fixed factor (1.02) |
| Adaptive (Anderson, [17]) | |
| Localization | Gaspari and Cohn [47] |
| Horizontal half-width | 110 km |
| Vertical half-width | 600 m |
| Experiment | Generated Operation | Amplitude |
|---|---|---|
| EvensenT | Adding directly | 1 °C |
| EOFT | Adding directly | 1 °C |
| WNP1y | Adding directly and integrating the model for 1 year | 0.001 °C |
| EvensenT1y | Adding directly and integrating the model for 1 year | 0.001 °C |
| EOFT1y | Adding directly and integrating the model for 1 year | 0.001 °C |
| Control | No operation | None |
| SST | SSS | SSH | |
| p-Value | 0.9748 | 0.0036 | 0.0007 |
| 1-2 | 1-3 | 1-4 | 1-5 | 2-3 | 2-4 | 2-5 | 3-4 | 3-5 | 4-5 | |
| SSS | 0.9812 | 0.0053 | 0.9987 | 0.9715 | 0.0321 | 0.9987 | 1.0000 | 0.0136 | 0.0389 | 0.9970 |
| SSH | 0.9796 | 0.0054 | 0.9767 | 0.9694 | 0.0341 | 0.7755 | 1.0000 | 0.0005 | 0.0413 | 0.7373 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, S.; Shen, Z.; Chen, S.; Wang, R. Comparison of Perturbation Strategies for the Initial Ensemble in Ocean Data Assimilation with a Fully Coupled Earth System Model. J. Mar. Sci. Eng. 2022, 10, 412. https://doi.org/10.3390/jmse10030412
Deng S, Shen Z, Chen S, Wang R. Comparison of Perturbation Strategies for the Initial Ensemble in Ocean Data Assimilation with a Fully Coupled Earth System Model. Journal of Marine Science and Engineering. 2022; 10(3):412. https://doi.org/10.3390/jmse10030412
Chicago/Turabian StyleDeng, Shaokun, Zheqi Shen, Shengli Chen, and Renxi Wang. 2022. "Comparison of Perturbation Strategies for the Initial Ensemble in Ocean Data Assimilation with a Fully Coupled Earth System Model" Journal of Marine Science and Engineering 10, no. 3: 412. https://doi.org/10.3390/jmse10030412