

A clustering effectiveness measurement model based on merging similar clusters
- Published
- Accepted
- Received
- Academic Editor
- Tzung-Pei Hong
- Subject Areas
- Algorithms and Analysis of Algorithms, Data Mining and Machine Learning
- Keywords
- Merging of similar clusters, Affinity propagation, Clustering evaluation, Internal evaluation indices, Optimal number of clusters
- Copyright
- © 2024 Duan and Zou
- Licence
- This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, reproduction and adaptation in any medium and for any purpose provided that it is properly attributed. For attribution, the original author(s), title, publication source (PeerJ Computer Science) and either DOI or URL of the article must be cited.
- Cite this article
- 2024. A clustering effectiveness measurement model based on merging similar clusters. PeerJ Computer Science 10:e1863 https://doi.org/10.7717/peerj-cs.1863
Abstract
This article presents a clustering effectiveness measurement model based on merging similar clusters to address the problems experienced by the affinity propagation (AP) algorithm in the clustering process, such as excessive local clustering, low accuracy, and invalid clustering evaluation results that occur due to the lack of variety in some internal evaluation indices when the proportion of clusters is very high. First, depending upon the “rough clustering” process of the AP clustering algorithm, similar clusters are merged according to the relationship between the similarity between any two clusters and the average inter-cluster similarity in the entire sample set to decrease the maximum number of clusters Kmax. Then, a new scheme is proposed to calculate intra-cluster compactness, inter-cluster relative density, and inter-cluster overlap coefficient. On the basis of this new method, several internal evaluation indices based on intra-cluster cohesion and inter-cluster dispersion are designed. Results of experiments show that the proposed model can perform clustering and classification correctly and provide accurate ranges for clustering using public UCI and NSL-KDD datasets, and it is significantly superior to the three improved clustering algorithms compared with it in terms of intrusion detection indices such as detection rate and false positive rate (FPR).
Introduction
The cluster analysis technique is widely used to perform data analysis, and it is an unsupervised learning method. Its main function is to perform the division of a set of unlabeled data into multiple clusters so that data points in the same cluster are as similar to each other as possible and those in other clusters are as different from each other as possible (Jain, Murty & Flynn, 1999). The classical K-means clustering algorithm (MacQueen, 1967), the K-medoids clustering algorithm (Park & Jun, 2009), and the fuzzy C-means clustering algorithm (Dunnâ, 1974) are common clustering techniques. Unlike these classical clustering algorithms, the affinity propagation (AP) algorithm (Frey & Dueck, 2007) does not need cluster center initialization, and it is fast and stable. It can outperform classical clustering algorithms, especially when large datasets need to be processed. Studies show that the AP clustering when performed on datasets with complex structures, parameters p greatly affect the clustering, and the resulting number of clusters is often higher than the actual value (Wang, Chang & Du, 2021; Li et al., 2021). Therefore, it is necessary to further analyze and evaluate the range and rationality of the number of clusters if the AP clustering algorithm is used. In addition, the evaluation of clustering quality is very important for cluster analysis. Commonly used evaluation methods determine the best clustering and classification results by comparing cluster validity indices (Liang, Han & Yang, 2020). The current study is focused on addressing the research question: What is the rationale behind utilizing the AP clustering algorithm to determine the optimal range of clusters, and how does this impact the quality of clustering compared to commonly used evaluation methods?
Researchers typically classify cluster validity indices (CVIs) into two groups, namely, internal indices and external indices. The main difference between these two groups of indices is whether external information is used. External CVIs require that standard class labels be before known because their main purpose is to perform the selection of the optimal clustering algorithm for a particular dataset. On the other hand, internal CVIs are usually used to select the optimum number of clusters for a given dataset without prior knowledge. In fact, prior knowledge about the class is not frequently available. Therefore, CVIs are the only option for clustering evaluation in such cases (Guan & Loew, 2020). For example, the optimal number of clusters may vary for different indices without the prior information. Which evaluation index has a K value with more reference value? This has become an important research topic in the field of cluster analysis. Classical internal CVIs such as DB, CH, XB, and IGP (Huang et al., 2013; Guangli et al., 2022) have been widely used. Studies have shown that these classical evaluation indices can effectively handle spherical clusters with simple structures, but it is difficult to achieve good results when they are used to process the data of non-spherical clusters. For this reason, researchers have successively proposed a series of evaluation indices, such as S_Dbw, CDbw, and DBCV (Liang, Han & Yang, 2020). To a certain extent, these evaluation indices solve the problem in the evaluation of clustering quality for non-spherical clusters. However, when the data becomes more complex, the cluster density varies or clusters overlap each other, some evaluation indices will be limited to a certain extent. Therefore, improving the existing evaluation indices or designing more scientific and reasonable evaluation indices has become a crucial research direction for the subject topic of clustering evaluation.
First, considering the deficiencies of the AP clustering algorithm and internal CVIs in their applications, the original AP clustering algorithm is improved by merging similar clusters to reduce the greater number of clusters Kmax. Then, through a comparative study of the classical internal evaluation indices, a new method for calculating intra-cluster cohesion, inter-cluster overlap coefficient, and inter-cluster dispersion is given, and a new internal evaluation index is proposed. Subsequently, a model for evaluating clustering quality is designed on the basis of the improved AP clustering algorithm. Finally, the performance of this model is verified using the UCI data and NSL-KDD intrusion detection data. In summary, this study has the following contributions:
-
This article proposes an enhanced AP clustering algorithm that reduces the number of resulting clusters by merging similar ones.
-
This article proposes a novel internal evaluation index to calculate the intra-cluster cohesion, inter-cluster overlap coefficient, and inter-cluster dispersion.
-
This article proposed to verify the performance of the improved AP clustering method using the detection rate, correct classification rate, and accuracy metrics such as FNR, and false positive rate (FPR) on the UCI and NSL-KDD datasets.
The remainder of the article is structured as follows:
The overview of the existing literature is given in ‘Related Work’; the current status of the research regarding the AP clustering model is given in ‘Materials & Methods Current Research Status’; while the proposed effective clustering measurement model is given in ‘A New Clustering Effectiveness Measurement Model’. Next, comprehensive experiments with results and comparisons with other algorithms are presented in ‘Experiments and Results’. Lastly, the proposed research is concluded with future research implications in ‘Conclusion’.
Related Work
Chandra, Canale & Dunson (2023) proposed Bayesian clustering (Lamb) along with a set of low-dimensional latent variables. The proposed model is highly amenable to scaling the posterior inference and avoids the limitations of high dimensionality under mild assumptions. More complex data structures that do not involve real-valued vectors and allow for kernel misspecification can be handled by the proposed model’s application.
The AP model, with its propagation capability, has been proposed to cluster low and high-influence indices (Geng et al., 2019). The application of the proposed model has been used to select and refine input indices. The model has great discriminant ability by screening the high-influence factors. However, due to excessive clustering, the AP model faces certain issues of low accuracy, excessive clustering, and invalid clustering results. Recent work Duan & Zou (2023) proposes a model by reducing the clustering and optimizing the maximum clustering number. The proposed model has been evaluated on the NSL-KDD dataset to demonstrate its strength for correct clustering partitioning.
The AP model has shown its applications in various research areas. AP clustering demonstrates high performance and low complexity for real-time and joint transmission in cloud radio access networks. The application of the AP model has shown normalized execution time and provides highly effective energies and spectral properties compared with existing clustering models (Park et al., 2021). The proposed AP model has the potential to be considered for more realistic joint transmissions, owing to the various arrival times.
Performing clustering on real-world large-scale data is a complex and time-consuming process. Lin et al. (2019) proposed a bottom-up clustering (BUC) technique to revolutionize convolutional neural networks. The proposed technique involved similarity within the same identity and diversity among different density factors. Identity over samples is used to group similar samples into one identity, and the data volume of each cluster is balanced by using bottom-up clustering. The results show that the proposed technique is superior to semi-supervised learning and transfer learning techniques. Clustering models are of paramount importance due to their various applications. For example, the hierarchical clustering approach is used to categorize airports into a number of clusters (Sheridan et al., 2020). Detection of anomalous flights leverages the airports and safety measures. Event flights had an average anomalous score compared to non-event flights.
Materials & Methods Current Research Status
To facilitate the description of the AP clustering algorithm, various internal indices for clustering evaluation, and the algorithm proposed in this paper, the following sample set is created: X = {x1, x2, …, xi,…, xN}, where N is the total number of samples, and the sample xi = {xi1, xi2,…, xil}, where l denotes the feature dimensionality of samples. X is divided into K clusters. Therefore, X = {C1, C2, …, CK}. The resulting set of cluster centers (centroids) is V = {v1, v2,…, vK}, ni is the number of samples in the ith cluster, and c is the mean center of the sample set.
AP algorithm
Frey & Dueck (2007) proposed the AP algorithm for clustering in SCIENCE in 2007. The main rationale behind the proposal of this clustering algorithm was to involve all data points as potential cluster centers and connect them to form a network. During its implementation, the cluster center of each data point is calculated through the transmission of information along each edge in the network (Wang, Chang & Du, 2021). The basic structure of the AP clustering algorithm is given as follows:
First, the similarity s between sample pairs is determined based on the Euclidean distance formula, and the similarity matrix S for all samples is obtained. Next, the availability a, and responsibility r of the samples are iteratively updated. When the number of iterative updates exceeds the preset value or the updating of representative points ceases after multiple iterations, the AP clustering algorithm terminates. At this point, the remaining samples can be assigned to the appropriate clusters to complete the clustering process. The operation process of the AP clustering algorithm is detailed below.
Step 1: Use the opposite number of the Euclidean distance as the similarity s (i,k) between the samples xi and xk to obtain the similarity matrix S. (1)
where p (k) is the value on the diagonal of S that expresses the tendency of the sample xk to be selected as the cluster center. The larger the p (k) value, the greater the probability of the sample xk being selected as the representative of cluster centers. In this paper, reference is made to the practice recommended in Halkidi & Vazirgiannis (2001), i.e., taking the median of the similarity matrix S as the default value of the bias parameter p when no prior knowledge is available.
This article involves two key parameters bias parameter and damping parameter. A damping factor between 0 and 1 is applied to control the numerical oscillation. The data points in a sample have the same possibility for becoming the clustering center and the parametric value of all data points is set to the same value of P. Certain parametric values of the noise level in data, convergence criteria, affinity matrix construction, and similarity matric could affect the proposed approach.
The parameter selection for the AP algorithm is based on a combination of domain knowledge and empirical experimentation. The outcome of the proposed approach can be affected by bias and damping parametric values. For example, a higher preference value encourages more data points to become exemplars and a lower bias value makes it more challenging and results in fewer and larger clusters. Similarly, a lower damping factor value makes faster convergence but can result in instability or oscillation in the cluster assignments.
Step 2: Transmit information, iteratively update the availability a, and responsibility r, and generate a representative cluster center. The responsibility r(i,k) represents the degree of responsibility of xk to xi. The larger the value of r(i,k), the greater the probability of xk becoming the center of xi’s cluster. The availability a(i,k) represents the degree of availability of xi to xk. The larger the value of a(i,k), the higher the possibility of xi’s cluster choosing xk as its center. The methods for iteratively updating the responsibility r and availability a are given in Eqs. (2) and (3). (2)
where a(i,k′) denotes the degree of availability of samples other than xk to xi; s(i,k′) denotes the degree of responsibility of samples other than xk to xi, i.e., the degree of completion of all samples other than xk for the ownership of xi; r(i,k) is the cumulative evidence proving that xk has become the center of xi. (3)
where r(k,k) denotes the self-responsibility of xk, a(k,k) denotes the self-availability of xk; r(i′,k) denotes the similarity level of xk serving as the centroids of all samples other than xi; a(i,k) represents the degree of possibility of taking all availability values greater than or equal to 0 plus the self-availability value of xk as the cluster center.
Oscillations can occur when the responsibility r and availability a are updated. The damping parameter λ is introduced to reduce the amplitude of oscillation, eliminate oscillations, and correct r(i,k) and a(i,k) during iterations to make the iterative process more stable. The damping parameter is set to λ ∈[0, 1), and the number of iterations is t. The corrected iterative processes are expressed by Eqs. (4) and (5).
(4) (5)
where r(i,k)t and r(i,k)t+1 denote the degrees of responsibility for the tth and t +1th iterations, and a(i,k)t and a(i,k)t+1 denote the degrees of availability for the tth and t +1th iterations.
Step 3: Determine the cluster-center representative. Select the sample xk with the largest sum of responsibility r(i,k) and availability a(i,k) as the representative point of the cluster to which xi belongs. The condition that the number of clusters k should satisfy is given in Eq. (6). (6)
From the operation process described above, it can be seen that the bias parameter p appears when the responsibility r(i,k) is calculated in Step 1. As the value of p increases, r(i,k) and a(i,k) increase, and the probability of the candidate representative points becoming cluster centers also increases accordingly. It can be known that when the value of p is large and there are a large number of candidate representative points, the tendency of more candidate representative points to be cluster centers will become increasingly obvious. However, the current theoretical basis for determining the value of p is inadequate, which leads to the fact that the AP clustering algorithm usually takes the locally optimal solution or the approximate global optimum as its final result (Zhou et al., 2021). The practice of taking the median of similarity values as the value of p has a certain reference value (Li et al., 2017). Still, the resulting value of K is often greater than the correct number of clusters, and the clustering accuracy of this method appears insufficient. Therefore, it is necessary to further analyze and evaluate the clustering quality using appropriate evaluation indices to achieve more ideal results. In addition, when the sample size is huge, the AP clustering algorithm will experience problems such as insufficient storage space and long running time, and when it is used to process non-cluster-shaped sample sets, it will usually produce a large number of local clusters. Depending on a locally linear embedding (LLE) hybrid kernel function, an innovative AP clustering method was proposed in Sun et al. (2018), In addition to it, a new hybrid kernel was introduced to measure similarity and construct the similarity matrix for AP clustering. However, when the values of upper bounds for clustering obtained by this AP clustering method are large, this method will still face the problem of long running time. In a study Gan, Xiuhong & Xiaohui (2015), the merge process was integrated into the AP clustering algorithm to merge the two clusters satisfying the condition that the minimum inter-cluster distance is less than the average distance between clusters in the entire dataset, thus improving the performance of the proposed algorithm and solving the problem of unsatisfactory clustering results with non-cluster-shaped datasets. However, because this algorithm uses the minimum inter-cluster distance, sample data with low similarity may be assigned to one cluster in the merge process.
Internal evaluation indices
Internal evaluation indices have been widely used to perform the evaluation of the clustering quality for data without classification labels by measuring the intra-cluster and inter-cluster similarities after clustering using only the attributes of the dataset in question, and no external information is needed in such an evaluation process. High-quality clustering can achieve high intra-cluster compactness and good inter-cluster separation. These indices are usually achieved through certain forms of combination based on the selection of values for intra-cluster and inter-cluster distances (by taking extreme values or by weighting after taking extreme values). Commonly used internal evaluation indices and their characteristics are analyzed below.
Davies–Bouldin index
(7)where K represents the number of clusters, Ci denotes the i-th cluster, ni is the number of samples of the i-th cluster, vi refers to the cluster center of the i-th cluster, d(x, vi) is the Euclidean distance between the sample x and the cluster center vi, and d(vi, vj) represents the Euclidean distance between the cluster centers vi and vj.
The Davies–Bouldin (DB) index of a sample set is obtained by taking the sum of the average distances between the samples in two adjacent clusters and the centers of the two clusters as the intra-cluster distance (Davies & Bouldin, 1979). The smaller the value of the DB index, the lower the similarity between clusters and the better the clustering quality. This index is suitable for evaluating datasets that are characterized by high intra-cluster compactness and great inter-cluster distance, but when the degree of inter-cluster overlap in a dataset is high (for example, when data points are distributed in a circular pattern), it is very difficult to complete clustering evaluation accurately using this index.
Xie-Beni index
(8)where N represents the total number of samples, and uij refers to the fuzzy membership degree of sample xj and cluster Ci.
In the Xie-Beni (XB) index, the numerator represents the intra-cluster compactness for fuzzy partitioning, and the denominator represents inter-cluster separation (Xie & Beni, 1991). This index takes into account the geometric structure of the dataset to be processed, calculates the intra-cluster correlation, and considers the inter-cluster distance. To achieve the best clustering result, the difference in the same cluster must be very small. The greater the value of the numerator, the higher the degree of inter-cluster separation. However, when the number of clusters is excessively large, the numerator of the XB index gradually decreases with the increase in K. As the value of K increases, the numerator of the XB index tends to 0, the value of the denominator increases continuously, and the XB index will lose the ability to judge due to its excessive monotony.
V.P.C. and V.P.E.
(9) (10)
Bezdek proposed two evaluation indices: partition coefficient (VPC) and partition entropy (VPE) (Bezdek, 1974b; Bezdek, 1974a). For both indices, the availability uij is used as the main criterion for evaluating the clustering quality. For VPC, the closer the samples in a cluster are to the cluster center, the closer the value of uij is to 1. Therefore, the greater the value of VPC, the better the clustering quality. VPE is opposite to VPC. The maximum value of uij is 1, and the value of uij will become 0 after the log is taken. For this reason, the value of VPE will not be negative. Therefore, the smaller the value of VPE, the better. The disadvantage of VPC and VPE is that they do not consider the spatial structure of clusters, and they are susceptible to the effects of noise and overlap between clusters.
VH&H
(11) (12)
Lin, Huang & Huang (2015) improved the XB index from the perspective of entropy and proposed the index VH&H. The numerator of VH&H represents the degree of compactness, and the denominator represents the degree of separation. vs and vk denote the shortest distance between cluster centers. It can be seen that, for the degree of separation in this index, the log is taken to reduce the influence of the shortest distance between cluster centers. Because a negative value may occur after the log is taken, it is necessary to take an absolute value. Unlike the XB index, VH&H introduces the concept of entropy into the degree of separation. According to this characteristic, the w in Eq. (12) is used as the weight of the degree of separation. This weight is the result of summing the entropies ps and pk in the two clusters with the shortest distance between their centers.
xj and xl are samples belonging to clusters Cs and Ck, and usj and ukl denote the degrees of availability of xj and xl to Cs and Ck. When the clusters Cs and Ck with the shortest distance between their centers overlap each other, the entropies ps and pk of the two clusters will be high, i.e., the weight w will be large. Therefore, the degree of separation between the two clusters can be higher. To prevent either ps or pk from affecting the final calculation result excessively, both ps and pk need to be normalized. VH&H has a high tolerance to overlapping between clusters, but it cannot evaluate samples with non-uniform densities stably.
A new clustering effectiveness measurement model
The proposed clustering effectiveness measurement model is mainly based on two parts namely, the improved AP clustering algorithm and new internal CVIs. Since the number of clusters produced by the AP clustering algorithm for non-cluster-shaped datasets is higher as compared to the actual number of clusters, the upper bound for clustering, Kmax, is reduced by merging similar clusters, and new internal evaluation indices based on intra-cluster cohesion and inter-cluster dispersion have been designed to address the shortcomings of the commonly used internal evaluation indices mentioned above. The description of the AP clustering algorithm is given in the following subsection.
Improved AP clustering algorithm
This study adopts the merging idea as described in a study Gan, Xiuhong & Xiaohui (2015). First, the AP clustering algorithm is used to perform the rough clustering of samples. Then, the initial clusters are merged based on similarity, and the upper limit of the number of clusters is reduced to compress the range of clusters and improve clustering accuracy. The general idea is to, on the basis of initial clustering performed by the AP clustering algorithm, calculate the ratio α of the similarity between any two clusters to the average similarity between clusters in the entire sample set. α represents the relationship between any two clusters and the entire sample set in terms of structural similarity. The smaller the value of α is, the closer any two clusters are to each other. If the lowest value of α is within the specified threshold range after complete traversals, the two clusters will be merged. If not, they will endure unmodified. The definitions and equations of the new algorithm are given below.
Definition 1 The Euclidean distance between any two points in space can be defined as: (13)
where i =1,2, …, N; j =1,2, …, N; l represents the feature dimensionality of samples.
Definition 2 The similarity between any two clusters can be defined as taking the sum of the distances between all sample pairs in the two clusters. (14)
where xt and xu denote any samples in the ith and jth clusters, respectively.
Definition 3 The average similarity between clusters in a sample set can be defined as the average similarity between two clusters in the entire sample set. (15)
where C2K represents the number of combinations of any two clusters arbitrarily selected from K clusters.
Definition 4 Inter-cluster similarity ratio can be defined as the ratio of the similarity between any two clusters to the average similarity between clusters in the entire sample set.
(16) (17)
If the inter-cluster similarity ratio αij is less than or equal to a given threshold W, the ith and jth clusters will be merged. Otherwise, they will remain unchanged. The reference range of W used in this paper is [0.3, 0.5]. The specific value of W can be set by users.
New CVIs
Intra-cluster and inter-cluster similarities are the main elements of the evaluation. Optimal clustering minimizes inter-cluster similarity while maximizing intra-cluster similarity. In this paper, the product of inter-cluster relative density and intra-cluster compactness is used to represent intra-cluster cohesion. The inter-cluster separation is represented by the ratio of the shortest distance between two clusters to the product of the distance between cluster centers and the inter-cluster overlap coefficient.
Halkidi & Vazirgiannis (2001) mentioned several indices for the evaluation of clustering algorithms. However, our current study identifies five indices that are particularly suitable for evaluating the Affinity Propagation (AP) algorithm. These indices have demonstrated superior performance in similar studies. For instance, the author stated that intra-cluster cohesion is best suited for unsupervised clustering algorithms (Estiri, Omran & Murphy, 2018). The selection of a small set of indices allows for a more focused and in-depth analysis of clustering performance. This enables us to conduct a targeted evaluation of the clustering algorithm’s performance, aligning with our primary interest in the current research.
The definitions and equations of the new indices are given below.
Intra-cluster cohesion
From the perspective of intra-cluster similarity, the shorter the distance between data points in the same cluster, the better. Intra-cluster cohesion (hereinafter referred to as coh) is defined as follows: (18)
The product of inter-cluster relative density (hereinafter referred to as den) and intra-cluster compactness (hereinafter referred to as com) is used to represent intra-cluster cohesion. Specifically, den(i) denotes the inter-cluster relative density of the cluster Ci and is used to measure the ratio of the density of the cluster Ci to that of other clusters, and com(i) denotes the intra-cluster compactness of the cluster Ci and is used to measure the degree of concentration of data points in the cluster. The greater the product of den(i) and com(i), the greater the value of Coh(i), the higher the intra-cluster cohesion, and the better the clustering result.
Inter-cluster relative density
The density of low-dimensional samples is usually determined by dividing the number of data points by the occupied area, volume, or space. However, for high-dimensional data, the volume of the data space will increase exponentially, and variations in the measure of distance between any two points in a Euclidean space will become increasingly smaller (Bezdek, 1974a; Lin, Huang & Huang, 2015). In the structural analysis of a high-dimensional data space, the center of the data space is often “empty.” For this reason, the original density calculation method will become invalid. The standard deviation of samples to be clustered can reflect data sparsity. The smaller the standard deviation, the denser the data. The greater the standard deviation, the more discrete the data distribution. Therefore, a new density calculation method is proposed to calculate density by dividing the number of data points in a cluster by the standard deviation of the cluster. The formula for calculating inter-cluster relative density is as follows: (19)
where the numerator represents the density of the cluster Ci, ni is the number of samples in the cluster Ci, σi is the standard deviation of the cluster Ci; the denominator represents the average density of other clusters except the cluster Ci, and N is the total number of data points in the sample set. A greater value of den(i) means that the density of cluster Ci is higher than the average density of other clusters.
Intra-cluster compactness
According to the common sense of probability, the probabilities that an approximately normally distributed dataset exists in the confidence intervals (μ−σ, μ + σ), (μ−2σ, μ+2σ), and (μ−3σ, μ+3σ) are 68.26%, 95.44%, and 99.74%, respectively. Considering this property, the ratio between the numbers of samples in different intervals of the same cluster is used to calculate intra-cluster compactness. The equations for calculating intra-cluster compactness are as follows:
(20) (21) (22)
where f(x,vi,σi) is used to measure the similarity or distance at data point x, and cluster center vi with σi that represents a scale parameter to adjust the measurement scale. num (x, vi, σi) denotes the number of data points within a radius of σi with vi as the center. The ratio of the number of data points within σi to that within 3σi is used to represent the degree of concentration of samples in cluster Ci. A larger value of this ratio means that more data points in cluster Ci are densely distributed around the cluster center vi. When intra-cluster compactness increases continuously and tends to 1, it means that the data points within the current cluster are extremely similar to each other.
Inter-cluster dispersion
To minimize the similarity between clusters, the data points in different clusters should be kept as far away from each other as possible. In this paper, the ratio of the shortest distance between two clusters to the product of the distance between cluster centers and the inter-cluster overlap coefficient (hereinafter referred to as overlap) is used to represent inter-cluster dispersion (hereinafter referred to as disp). Inter-cluster dispersion is defined as follows: (23)
where xi and xj denote any samples in clusters Ci and Cj, and vi and vj denote the centers of the two clusters. The greater the value of this ratio, the more dispersed the clusters, the clearer the cluster boundaries, and the better the clustering quality. In the equation above, the overlap coefficient overlap ij represents the degree of concentration of data points in the overlapping area between clusters Ci and Cj. The overlap coefficient has several practical applications in a range of research areas. For example, in text document clustering, documents belong to several multiple topics. The overlap coefficient metric is used to analyze the extent to which topics overlap, and potentially reveal the areas of semantic ambiguity. Similarly, the level of ambiguity in object recognition is determined by using the overlap coefficient metric in image segmentation (Zou et al., 2004). The overlap coefficient is used in the fractional segmentation of MR images for reproducibility and accuracy.
The overlap coefficient is defined as follows:
(24) (25) (26) (27)
where xa denotes the data in the cluster Ci or cluster Cj; ni and nj denote the number of data points in Ci and the number of data points in Cj; f(xa, Ci, Cj) represents the contribution of the sample xa to the degree of concentration in the overlapping area between clusters Ci and Cj; uia and uja are the degrees of availability of xa to clusters Ci and Cj (Dunnâ, 1974); and H is the threshold at which xa falls within the overlapping area. The default value of H used in this paper is 0.3. As shown in Fig. 1, xb and xc are located inside Ci and Cj, respectively, xb ∈Ci, and xc ∈ Cj. The availability of xb and xc is very clear, i.e., —uib- ujb— >H, — uic- ujc— >H. Compared with the availability of xb and xc, the availability of the data point xa located in the overlapping area between the two clusters (as shown in Fig. 1) is closer to uia and uja, i.e., —uia- uja— ≤H. f(xa, Ci, Cj) determines the inter-cluster overlap coefficient by calculating the degree of concentration of fuzzy data points in the overlapping area.
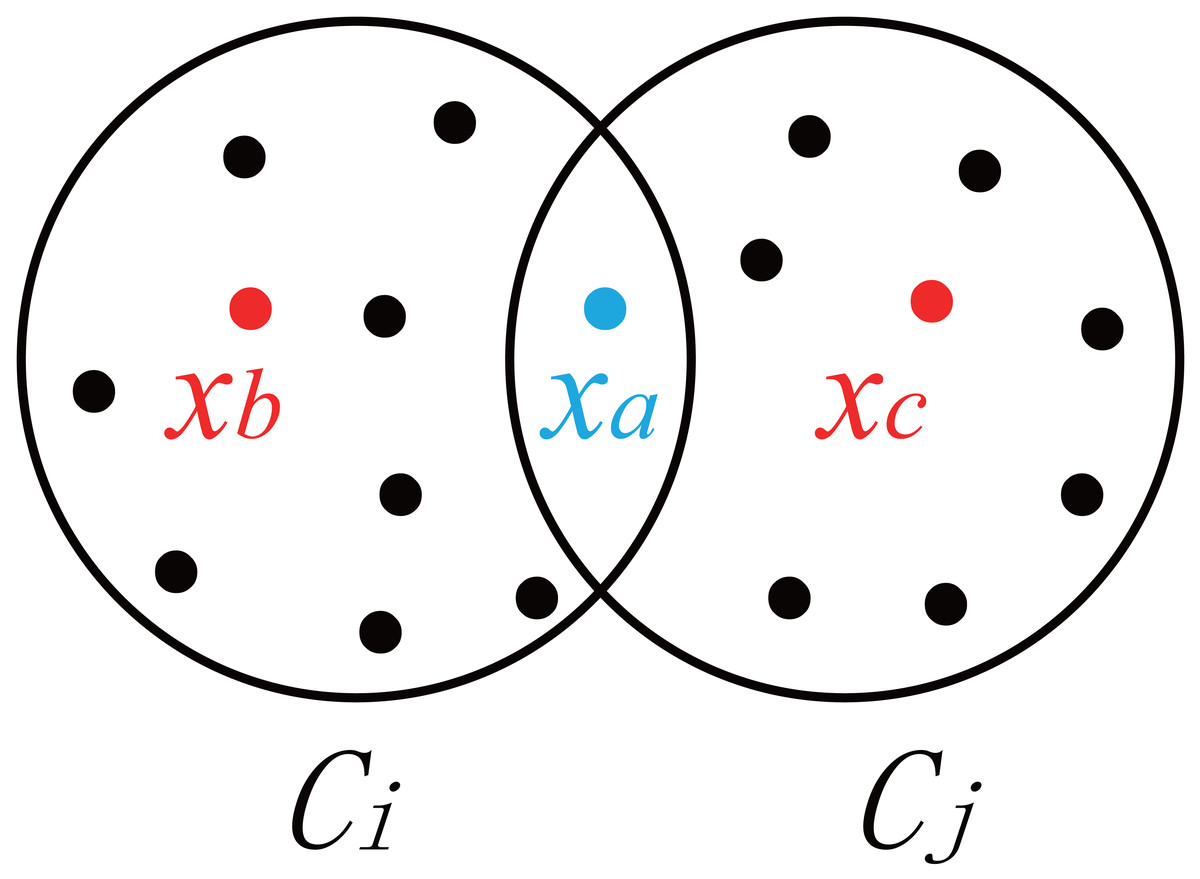
Figure 1: Degree of dispersion of samples in clusters.
{kind=link}
Specifically, when —uia- uja— ≤ H, data points will fall within the overlapping area. In this case, e1−|uia−uja| is taken to increase the influence of data points in the overlapping area. Otherwise, zero is taken. From Eqs. (24) and (25), it can be known that the smaller the cumulative sum of the degrees of concentration in the overlapping areas between clusters, the smaller the overlap coefficient, and the clearer the division of clusters.
New internal evaluation indices
The new internal evaluation indices introduced herein include intra-cluster cohesion and inter-cluster dispersion. They are used to determine the optimal number of clusters for the final CVI. This evaluation index is defined as follows: (28)
where C2k is the number of combinations of any two clusters arbitrarily selected from K clusters, Coh(i) and Coh(j) denote the intra-cluster cohesion of the cluster Ci and that of the cluster Cj, Disp(i,j) denotes the inter-cluster dispersion between clusters Ci and Cj. Both Coh and Disp are positively correlated with the quality of clustering. Therefore, the evaluation index CVI(K) will achieve optimal results when the product of the intra-cluster cohesion and inter-cluster dispersion of Ci and Cj reaches the maximum value.
The optimal number of clusters
Based on the nature of the CVI, it is evident that a higher index value indicates better clustering quality, except for the Xie-Beni (XB) index, which achieves improved clustering quality when the index reaches its lowest possible value. However, Therefore, the optimal number of clusters Kopt is the number of clusters when CVI(K) reaches the maximum value. (29)
where K ∈[2, Kmax], and Kmax are given by the improved AP clustering algorithm proposed herein.
Clustering effectiveness measurement model based on merging similar clusters
In this article, the original AP clustering algorithm is improved by merging similar clusters, and a clustering effectiveness measurement model based on merging similar clusters (hereinafter referred to as the CEMS) is proposed based on the new evaluation indices presented herein. The structure of the CEMS is shown in Fig. 2.
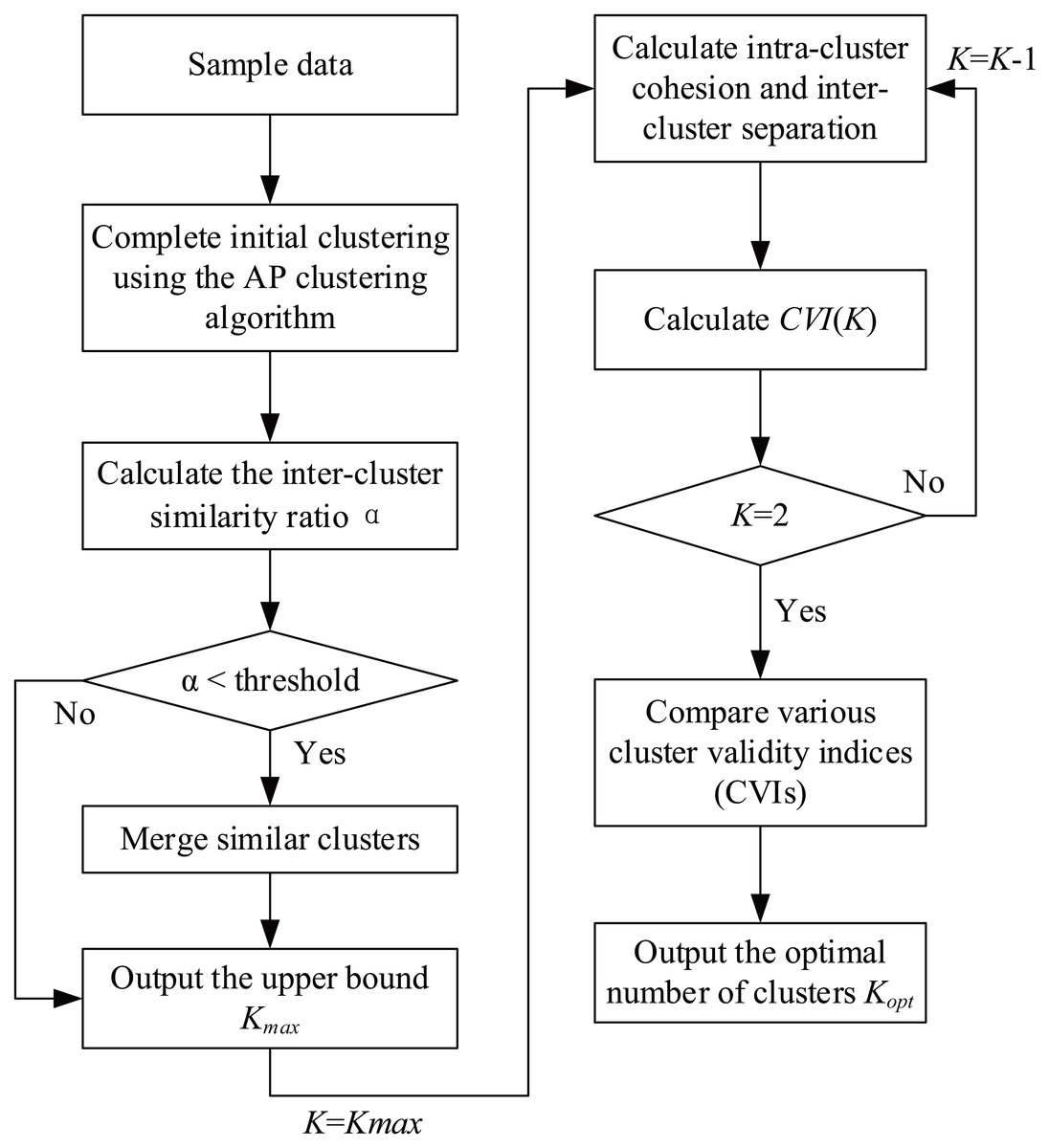
Figure 2: CEMS process flowchart.
{kind=link}
The operation process of the CEMS consists of 10 steps intended to merge similar clusters and determine the optimal number of clusters. These steps are described below.
(1) Calculate the similarity matrix S of dataset X using Eq. (1).
(2) Calculate and update the responsibility and availability using Eqs. (2) and (3), set the damping parameter and the number of iterations, and use Eqs. (4) and (5) to correct the responsibility and availability during iterations and reduce the amplitude of oscillation.
(3) Select the data point with the maximum sum of responsibility r and availability a according to Eq. (6), set the selected data point as the representative point of the cluster to which it belongs, repeat Step (2), obtain the representative points of all clusters, and complete the clustering of non-representative points based on similarity.
(4) Calculate the similarity between any two clusters and the average similarity between clusters in the entire sample set using Eqs. (14) and (15).
(5) Calculate the inter-cluster similarity ratio using Eq. (16) and use Eq. (17) to merge clusters that satisfy the required condition.
(6) Repeat steps (4) and (5), update clusters based on the new inter-cluster similarity ratio, and obtain the maximum number of clusters Kmax at the end of the iterative process.
(7) Take Kmax as the initial value of the parameter K in the CVI, i.e., K = Kmax.
(8) Calculate inter-cluster relative density (den), intra-cluster compactness (com), and inter-cluster overlap coefficient (overlap) using Eqs. (19), (20), and (24), calculate intra-cluster cohesion (coh) and inter-cluster dispersion (disp) using Eqs. (18) and (23), and calculate the CVI using Eq. (28).
(9) Let K =K-1 and repeat steps (7) and (8) until K = 2 to obtain a set of CVI values, i.e., CVI _K = {CVI (2), CVI (3),…, CVI (Kmax-1), CVI (Kmax)}.
(10) Select the parameter K corresponding to the maximum value of CVI according to Eq. (29), and output it as the optimal number of clusters Kopt.
Experiments and Results
The experimental environment is as follows: Intel(R) Core(TM) i7-10750H CPU @2.6 GHz 2.59 GHz, 16 GB RAM, Microsoft Windows 10 (64-bit) Professional, and the test platform is Matlab (Liang & Cheng, 2020). The experiments conducted include the CEMS effectiveness test and practicality test. Specifically, the first experiment is designed to perform the comparative test of the number of clusters using the improved AP clustering algorithm in combination with the CVI and commonly used internal evaluation indices. Its purpose is to verify the effectiveness of the improved AP clustering algorithm and the CVI. The details of the datasets used are listed in Table 1.
| Dataset | Sample size | Number of features | Standard number of clusters |
|---|---|---|---|
| Iris | 150 | 4 | 3 |
| Wine | 178 | 13 | 3 |
| Thyroid | 215 | 5 | 2 |
| Yeast | 1,484 | 8 | 10 |
| Glass | 214 | 9 | 6 |
| Dermatology | 366 | 34 | 6 |
The second experiment is designed to further verify the functional integrity of the CEMS from the perspectives of intrusion detection rate, correct classification rate, FNR, and FPR using the NSL-KDD dataset (Liu, Lu & Zhang, 2020). The intrusion detection rate is used to measure the actual proportion of intrusions that are correctly identified by the proposed method. Correct classification rate and accuracy are interchangeably used. Accuracy measures the overall proportion of correctly classified instances. False negative rate (FNR) is used to measure the proportion of actual intrusions that are incorrectly classified, while false positive rate (FPR) measures those non-intrusion instances that have been incorrectly classified as intrusions.
The NSL-KDD dataset is structured into distinct categories based on network traffic types. The NSL-KDD dataset is widely employed to evaluate the effectiveness of intrusion detection systems. This dataset does not include duplicate records. Each record in this dataset possesses 42 attributes: 41 attributes are about the characteristics of the dataset and one attribute represents the type of attack. This data is owned by the Canadian Institute for Cybersecurity and can be accessed from “https://www.unb.ca/cic/datasets/nsl.html”. Test sets (T1, T2, and T3) are employed for CEMS testing. For example, in T1, there are 3,070 “Normal” connections, 308 instances of “Dos” (Denial-of-Service), 234 “Probe” instances, 121 “R2L” instances (unauthorized access from a remote machine), and 42 “U2R” instances (unauthorized access to root). Similarly, values for the T2 and T3 test sets are also provided.
CEMS effectiveness test
In this section, a comparative experiment on the maximum number of clusters for the UCI dataset was conducted using the improved AP clustering algorithm and the original AP clustering algorithm. The settings of these two algorithms are as follows: the damping factor λ = 0.85, the number of iterations t = 1,500, and the threshold of inter-cluster similarity ratio for the improved AP clustering algorithm W = 0.3. The results are given in Table 2. The clustering results were evaluated using the CVI and classical internal evaluation indices. The comparison results are summarized in Table 3.
| Standard number of clusters | Original AP clustering algorithm | Improved AP clustering algorithm | |
|---|---|---|---|
| Iris | 3 | 8 | 6 |
| Wine | 3 | 9 | 6 |
| Thyroid | 2 | 7 | 4 |
| Yeast | 10 | 23 | 18 |
| Glass | 6 | 20 | 15 |
| Dermatology | 6 | 17 | 12 |
| Standard number of clusters | DB. | XB | VC | VPE | VH&H | CVI | |
|---|---|---|---|---|---|---|---|
| Iris | 3 | 2 | 2 | 3 | 3 | 3 | 3 |
| Wine | 3 | 3 | 9 | 4 | 3 | 3 | 3 |
| Thyroid | 2 | 5 | 8 | 2 | 2 | 2 | 2 |
| Yeast | 10 | 10 | 10 | 8 | 7 | 10 | 10 |
| Glass | 6 | 2 | 8 | 2 | 2 | 15 | 6 |
| Dermatology | 6 | 4 | 4 | 2 | 2 | 14 | 5 |
As shown in Table 2, the values of upper bounds for the improved AP clustering algorithm on the UCI dataset are all smaller than those for the original AP clustering algorithm, indicating that the former can effectively compress the clustering space.
As shown in Table 3, the accuracy of the CVI concerning the number of clusters is 83.33%, and the accuracy levels of other indices are 33.33%, 16.67%, 33.33%, 50%, and 66.67%, respectively. It is obvious that the accuracy of the CVI is significantly higher than the accuracy levels of the other five indices. It is to be noted that during the test on the Glass dataset, all indices except the CVI failed to achieve accurate classification. During the test on the Dermatology dataset, all indices failed to achieve accurate classification, and the CVI divided the data points in this dataset into five clusters. Compared with the number of clusters determined by other indices, the number of clusters determined by the CVI is closer to the standard number of clusters. In general, the CVI performs best on this dataset. It indicated that CVI better performed on the high dimensional datasets due to the thorough exploitation of spectral dimension reduction, optimization of data architecture, and reduction in the overlapping between various clusters. As a result of it, the clustering performance is improved.
Application of the CEMS in intrusion detection
To test the performance of the CEMS, 20% of the KDDTrain+ samples in the NSL-KDD intrusion detection dataset were experimentally selected to create a training set with 25,196 samples, and 50% of the KDDTest+ samples were selected and divided into three test sets with 11,272 samples in total. The samples in the training and test sets contain four network intrusions, namely, Dos, Probe, R2L, and U2R (Chen & Wang, 2022). The formats of the samples were converted by one-hot encoding (Zhang et al., 2019), and the feature dimensionality of the datasets was reduced using the dimensionality reduction method. The details of pre-processed data are listed in Table 4.
| Data type | Training set | Test set T1 | Test set T2 | Test set T3 |
|---|---|---|---|---|
| Normal | 19,106 | 3,070 | 3,025 | 3,052 |
| Dos | 5,180 | 308 | 321 | 315 |
| Probe | 612 | 234 | 250 | 220 |
| R2L | 258 | 121 | 111 | 105 |
| U2R | 40 | 42 | 52 | 46 |
Relationship between the CVI and K
The improved AP clustering algorithm was run with the parameters listed above. The maximum number of clusters in training is set as Kmax = 28, denoted along the x-axis. The CVI values corresponding to different values of K are shown in Fig. 3, denoted along the y-axis. When 2 ≤K ≤20, the CVI value increases continuously. When K ∈ as mentioned in Li et al. (2017), the increase in the CVI value slows down. When K = 24, the CVI value reaches its peak.
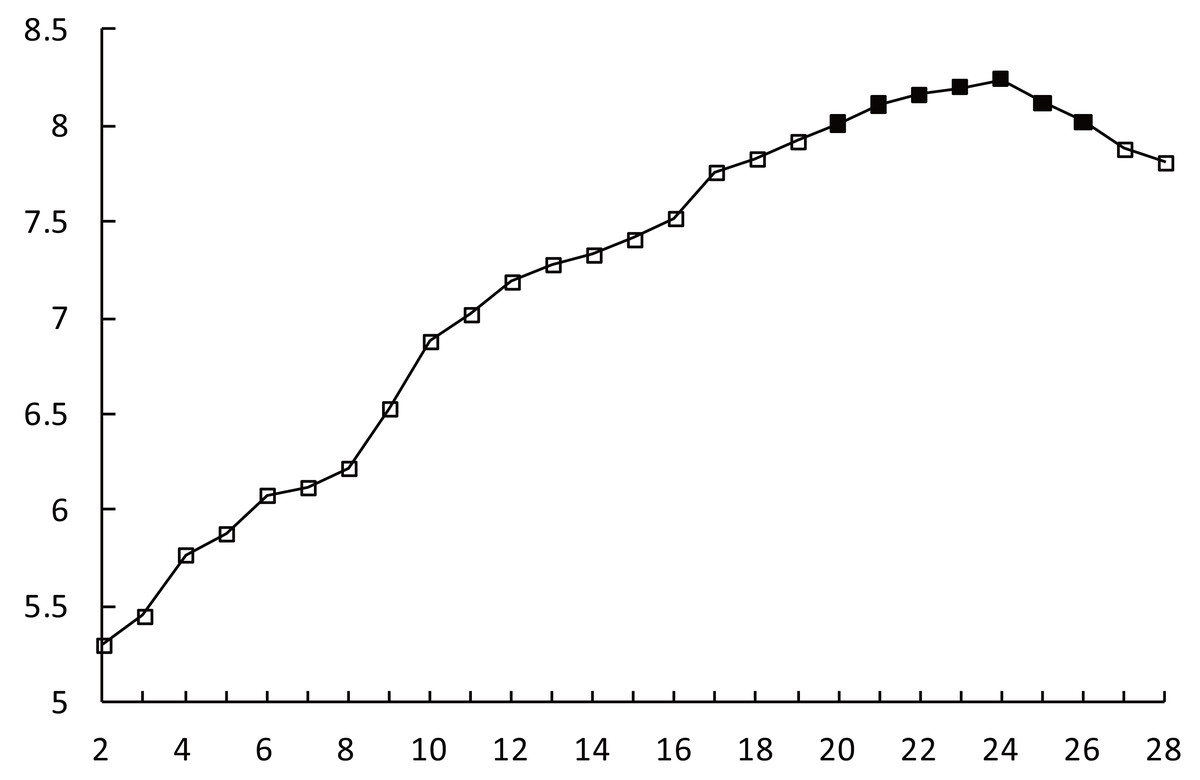
Figure 3: CVI-K relationship.
{kind=link}
As the value of K continues to increase, the CVI value decreases slowly. When K = 27, the rate of decrease in the CVI value increases. Considering the rules of variation in the CVI, the set of multiple numbers of clusters corresponding to the process of the CVI slowly increasing to the maximum value and then slowly decreasing from the maximum value is defined as the optimal clustering space denoted as Kopt ∈ as mentioned in Davies & Bouldin (1979).
Indices for intrusion detection in the optimal clustering space
In this section, the effectiveness of the indices for intrusion detection in the optimal clustering space Kopt ∈ was verified using three test sets (Davies & Bouldin, 1979).
Table 5 presents various indices for three test sets (T1–T3). Clusters 20–26 are provided with their corresponding detection rate, correct classification rate, false negative rate (FNR), and false positive rate (FPR) values. From the values listed in Table 5 and the line charts in Fig. 4, it can be seen that when K = 22, the detection rates and FNR of the three test sets reach extreme values at the same time, and the average detection rate and FNR are 94.13% and 4.76%, respectively; when 21 ≤ K ≤ 23, the correct classification rates of the test sets reach the maximum values successively, with an average of 93.40%; when K = 21 and K = 22, the FPR of the three test sets reach the minimum values, with an average of 4.36%.
| K | Detection rate | Correct classification rate | FNR | FPR | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T1 | T2 | T3 | T1 | T2 | T3 | T1 | T2 | T3 | T1 | T2 | T3 | |
| 20 | 93.82 | 92.87 | 93.81 | 92.13 | 92.25 | 92.87 | 5.26 | 5.27 | 5.3 | 5.35 | 5.26 | 5.43 |
| 21 | 94.11 | 93.33 | 94.03 | 92.67 | 93.29 | 93.08 | 4.98 | 4.93 | 4.98 | 4.16 | 4.28 | 4.64 |
| 22 | 94.45 | 93.64 | 94.29 | 93.03 | 93.02 | 94.16 | 4.83 | 4.71 | 4.73 | 4.65 | 4.71 | 4.13 |
| 23 | 93.88 | 92.58 | 93.85 | 93.42 | 92.25 | 93.43 | 5.55 | 5.08 | 5.23 | 4.92 | 5.39 | 4.85 |
| 24 | 93.41 | 92.31 | 93.41 | 93.11 | 92.14 | 93.18 | 6.23 | 5.99 | 5.73 | 5.12 | 4.94 | 5.04 |
| 25 | 93.33 | 91.83 | 93.22 | 92.52 | 91.57 | 92.51 | 6.88 | 6.89 | 6.68 | 5.26 | 5.33 | 5.33 |
| 26 | 93.82 | 91.64 | 92.69 | 92.61 | 91.48 | 92.11 | 6.96 | 6.83 | 6.93 | 5.03 | 4.94 | 5.58 |
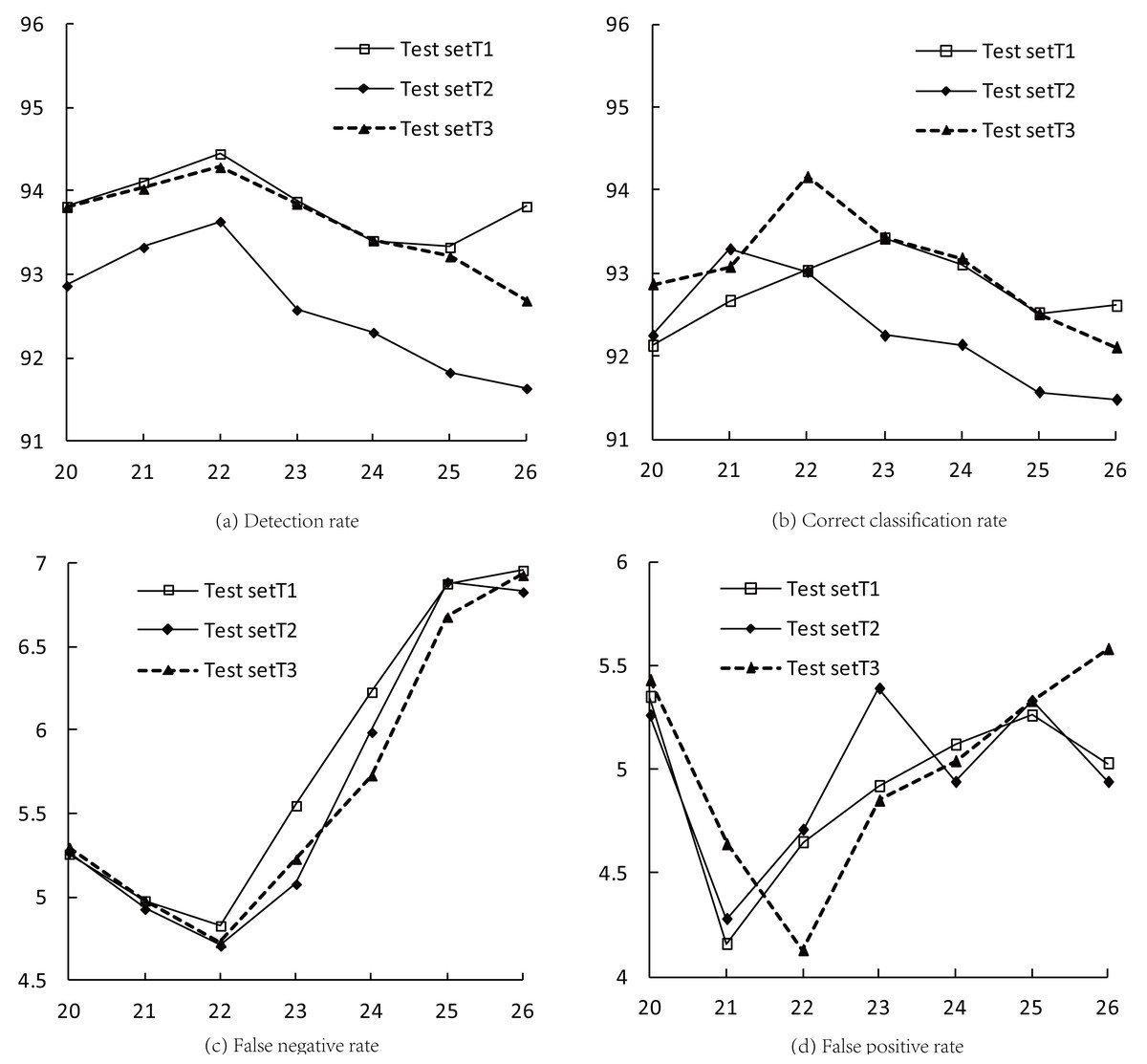
Figure 4: Indices for intrusion detection in the optimal clustering space.
{kind=link}
Time complexity analysis
The AP algorithm exhibits quadratic complexity, meaning that as the size of a dataset or the number of data points increases, the computational demand of the AP algorithm grows quadratically. Performance peaks of the algorithm were observed at a specific cluster (K = 22), indicating that as the number of clusters increases, the computational requirements of the AP algorithm also escalate. Therefore, due to the quadratic time complexity of the AP algorithm, it is crucial to carefully consider its application, especially with large datasets.
Comparison between the CEMS and other algorithms
The performance comparison of CEMS and other algorithms is presented in Tables 6 to 9. Specifically, Table 6 showcases the comparison of detection rates (Mohammadi et al., 2019; Su et al., 2020), while Table 7 displays the comparison of correct classification rates (Zou & Yang, 2018a; Zou & Yang, 2018b).
| K | K-medoids+ | Reference [33]+ | Reference [34]+ | CEMS | |
|---|---|---|---|---|---|
| 20 | 91.49 | 92.73 | 92.81 | 93.50 | |
| 21 | 91.86 | 93.46 | 93.52 | 93.82 | |
| 22 | 92.64 | 93.13 | 93.63 | 94.13 | |
| 23 | 92.35 | 92.75 | 93.26 | 93.44 | |
| 24 | 92.07 | 92.62 | 92.83 | 93.04 | |
| 25 | 91.85 | 92.33 | 92.64 | 92.79 | |
| 26 | 91.59 | 91.69 | 91.91 | 92.72 |
| K | K-medoids+ | Reference [35]+ | Reference [36]+ | CEMS |
|---|---|---|---|---|
| 20 | 90.50 | 92.03 | 92.47 | 92.42 |
| 21 | 91.43 | 92.31 | 92.62 | 93.01 |
| 22 | 91.88 | 92.26 | 92.88 | 93.40 |
| 23 | 91.42 | 91.86 | 93.05 | 93.03 |
| 24 | 91.13 | 91.62 | 92.41 | 92.81 |
| 25 | 90.79 | 91.27 | 92.22 | 92.20 |
| 26 | 90.62 | 90.70 | 91.46 | 92.07 |
For further verification of the CVI and compare the clustering quality of the CEMS and that of other algorithms horizontally, the K-medoids clustering algorithm and two improved density-based clustering algorithms (Zou & Yang, 2018a; Zou & Yang, 2018b) were combined with the CVI and recorded as “K-medoids+,” “Reference (Zou & Yang, 2018a)+,” and “Reference (Zou & Yang, 2018b)+.” Four intrusion detection indices were horizontally compared within the range of Kopt ∈ as mentioned in Davies & Bouldin (1979). The k-medoids algorithm attempts to minimize the distance between two points and its centroid. For the K-medoids+ algorithm, the average value was taken after it was run 500 times.
By observing the data in Tables 6 and 7, it can be found that, after the other three algorithms are combined with the CVI, the detection rate, as well as the correct classification rate, can receive their highest values when 21 ≤ K ≤ 23, and the detection rate of the CEMS is significantly higher than those of the other three algorithms within the whole range given above. The correct classification rate of the CEMS is consistent with that of the algorithm proposed in Zou & Yang (2018b) when K = 23 and the CEMS outperforms the other three algorithms in the ranges of 20 ≤K 23 and 25x K ≤ 26. As shown in Tables 6 and 7 the proposed CEMS achieved the best performance in terms of detection rate and accuracy (%) on the NSL-KDD dataset. Results clearly show that the detection and classification performances of the proposed CEMS are more effective compared with the rest of the clustering algorithms.
From the data in Table 8, it can be seen that the FNR of the other three clustering algorithms can reach the minimum values when 21 ≤ K ≤ 23, and the minimum FNR of the CEMS is 4.76%, which is slightly lower than that of “Reference Zou & Yang (2018b)+” and significantly lower than those of the other two algorithms. The performance of the CEMS is better compared with the K-medoid, and clustering models in Reference Zou & Yang (2018a) and Reference Zou & Yang (2018b). False negatives are either due to poor detection probabilities or failure in connecting clusters that are too far apart. However, in the current study, the proposed CEMS’s reduced FNR indicates its robust and efficacious performance.
| K | K-medoids+ | Reference [35]+ | Reference [36]+ | CEMS |
|---|---|---|---|---|
| 20 | 8.33 | 7.23 | 5.33 | 5.28 |
| 21 | 7.96 | 6.86 | 5.12 | 4.96 |
| 22 | 7.62 | 7.22 | 4.97 | 4.76 |
| 23 | 7.58 | 7.59 | 5.56 | 5.29 |
| 24 | 7.87 | 7.87 | 6.11 | 5.98 |
| 25 | 7.83 | 8.13 | 6.94 | 6.82 |
| 26 | 8.67 | 8.47 | 7.11 | 6.91 |
| K | K-medoids+ | Reference [35]+ | Reference [36]+ | CEMS |
|---|---|---|---|---|
| 20 | 5.39 | 5.52 | 5.64 | 5.35 |
| 21 | 4.48 | 4.74 | 4.78 | 4.36 |
| 22 | 4.57 | 4.63 | 4.68 | 4.5 |
| 23 | 5.13 | 5.09 | 5.21 | 5.05 |
| 24 | 4.95 | 5.06 | 5.03 | 5.03 |
| 25 | 5.21 | 5.26 | 5.16 | 5.31 |
| 26 | 5.35 | 5.19 | 5.22 | 5.18 |
By observing the data in Table 9, it can be known that the FPR of the other three algorithms can reach the minimum values when 21 ≤ K ≤ 22; when 20 ≤ K ≤ 23, the FPR of the CEMS is slightly lower than those of the other three algorithms; and when 24 ≤ K ≤ 26, the average FPR of the CEMS is basically consistent with those of “K-medoids+” and “Reference Zou & Yang (2018a)+” and slightly higher than that of “Reference Zou & Yang (2018b)+”.
The experimental results above show that the CVI has a high universality and can accurately assess the results from clustering and give an optimal number of clusters after it is combined with other clustering algorithms. During the comparative test, the CEMS could improve the intrusion detection rate and correct classification rate at a low FPR and significantly reduce the FNR, indicating that its overall performance is more desirable than that of the other three clustering algorithms.
The current research shows promising results on both the UCI and NSL-KDD datasets. This suggests that the findings of this study may be generalized to other datasets with similar characteristics. However, the applicability of the proposed research may be limited if new datasets have different features.
This research show cases correct classification and clustering, demonstrating that the proposed approach was effectively applied. The use of internal evaluation indices has further strengthened confidence in the internal validity of this study. It demonstrates that the observed effects and their association are genuinely attributed to the performance of the CEMS algorithm. This implies that the proposed research was well-designed and conducted with minimized potential for biases in the experimental design.
Conclusion
In this article, an improved AP clustering algorithm is proposed, which uses the ratio of the similarity between any two clusters to the average similarity between clusters in the entire sample set as a reference, reduces the upper limit of the number of clusters by merging similar clusters, and solves some problems with the original AP clustering algorithm, such as excessively large number of clusters and low accuracy. In addition, several new internal evaluation indices are proposed, the product of inter-cluster relative density and intra-cluster compactness is used to improve intra-cluster cohesion, and the inter-cluster overlap coefficient is used to enhance inter-cluster separation and mitigate the effects of uneven distribution of data points and overlap between clusters. Internal evaluation indices show a better solution to issues with classical ones: monotony and excessive clusters. The findings show that CEMS is practical and versatile as CVIs enhance accuracy with other algorithms.
In future work, we will set thresholds for parameters such as the bias parameter p, the inter-cluster similarity ratio w, and the inter-cluster overlap coefficient H, increase the correct classification rate, and seek a better balance between high detection rate and low FPR to improve the CEMS.
Since lower FPR is desirable, we further need to conduct more experiments to achieve the highest accuracy with just over 1% false positives. In future works, we plan to conduct an extensive study of clustering algorithms to give an enhanced detection and classification solution by using real-time datasets.
The proposed method can be extended by applying a post-processing step to merge clusters based on a similarity threshold. Using techniques such as agglomerative clustering with the suitable linkage method to combine clusters with sufficient similarity. Further, a hierarchical approach can be combined with the AP algorithm which can give us more control over the number of resulting clusters, allowing us to merge similar clusters at different hierarchy levels.