Place-cell capacity and volatility with grid-like inputs
- Center for Theoretical and Computational Neuroscience, University of Texas, United States
- Department of Neuroscience, University of Texas, United States
- Department of Brain and Cognitive Sciences and McGovern Institute, MIT, United States
- Department of Mathematics and Neuroscience, The University of Texas, United States
Abstract
What factors constrain the arrangement of the multiple fields of a place cell? By modeling place cells as perceptrons that act on multiscale periodic grid-cell inputs, we analytically enumerate a place cell’s repertoire – how many field arrangements it can realize without external cues while its grid inputs are unique – and derive its capacity – the spatial range over which it can achieve any field arrangement. We show that the repertoire is very large and relatively noise-robust. However, the repertoire is a vanishing fraction of all arrangements, while capacity scales only as the sum of the grid periods so field arrangements are constrained over larger distances. Thus, grid-driven place field arrangements define a large response scaffold that is strongly constrained by its structured inputs. Finally, we show that altering grid-place weights to generate an arbitrary new place field strongly affects existing arrangements, which could explain the volatility of the place code.
Introduction
As animals run around in a small familiar environment, hippocampal place cells exhibit localized firing fields at reproducible positions, with each cell typically displaying at most a single firing field (O’Keefe and Dostrovsky, 1971; Wilson and McNaughton, 1993). However, a place cell generates multiple fields when recorded in single large environments (Fenton et al., 2008; Park et al., 2011; Rich et al., 2014) or across multiple environments (Muller et al., 1987; Colgin et al., 2008), including different physical and nonphysical spaces (Aronov et al., 2017).
Within large spaces, the locations seem to be well-described by a random process (Rich et al., 2014; Cheng and Frank, 2011), and across spaces the place-cell codes appear to be independent or orthogonal (Muller et al., 1987; Colgin et al., 2008; Alme et al., 2014), also potentially consistent with a random process. However, a more detailed characterization of possible structure in these responses is both experimentally and theoretically lacking, and we hypothesize that there might be structure imposed by grid cells in place field arrangements, especially when spatial cues are sparse or unavailable.
Our motivation for this hypothesis arises from the following reasoning: grid cells (Hafting et al., 2005) are a critical spatially tuned population that provides inputs to place cells. Their codes are unique over very large ranges due to their modular, multi-periodic structure (Fiete et al., 2008; Sreenivasan and Fiete, 2011; Mathis et al., 2012). They appear to integrate motion cues to update their states and thus reliably generate fields even in the absence of external spatial cues (Hafting et al., 2005; McNaughton et al., 2006; Burak and Fiete, 2006; Burak and Fiete, 2009). Thus, it is possible that in the absence of external cues spatially reliable place fields are strongly influenced by grid-cell inputs.
To generate theoretical predictions under this hypothesis, we examine here the nature and strength of potential constraints on the arrangements of multiple place fields driven by grid cells. On the one hand, the grid inputs are nonrepeating (unique) over a very large range that scales exponentially with the number of grid modules (given roughly by the product of the grid periods), and thus rich (Fiete et al., 2008; Sreenivasan and Fiete, 2011; Mathis et al., 2012); are these unique inputs sufficient to enable arbitrary place field arrangements? On the other hand, this vast library of unique coding states lies on a highly nonlinear, folded manifold that simple read-outs might not be able to discriminate (Sreenivasan and Fiete, 2011). This nonlinear structure is a result of the geometric, periodically repeating structure of individual modules (Stensola et al., 2012); should we expect place field arrangements to be constrained by this structure?
These questions are important for the following reason: a likely role of place cells, and the view we espouse here, is to build consistent and faithful associations (maps) between external sensory cues and an internal scaffold of motion-based positional estimates, which we hypothesize is derived from grid inputs. This perspective is consistent with the classic ideas of cognitive maps (O’Keefe and Nadel, 1978; Tolman, 1948; McNaughton et al., 2006) and also relates neural circuitry to the computational framework of the simultaneous localization and mapping (SLAM) problem for robots and autonomously navigating vehicles (Leonard and Durrant-Whyte, 1991; Milford et al., 2004; Cadena et al., 2016; Cheung et al., 2012; Widloski and Fiete, 2014; Kanitscheider and Fiete, 2017a; Kanitscheider and Fiete, 2017b; Kanitscheider and Fiete, 2017c). We can view the formation of a map as ‘decorating’ the internal scaffold with external cues. For this to work across many large spaces, the internal scaffold must be sufficiently large, with enough unique states and resolution to build appropriate maps.
A self-consistent place-cell map that associates a sufficiently rich internal scaffold with external cues can enable three distinct inferences: (1) allow external cues to correct errors in motion-based location estimation (Welinder et al., 2008; Burgess, 2008; Sreenivasan and Fiete, 2011; Hardcastle et al., 2014), through cue-based updating; (2) predict upcoming external cues over novel trajectories through familiar spaces by exploiting motion-based updating (Sanders et al., 2020; Whittington et al., 2020); and (3) drive fully intrinsic error correction and location inference when external spatial cues go missing and motion cues are unreliable by imposing self-consistency (Sreenivasan and Fiete, 2011).
In what follows, we characterize which arrangements of place fields are realizable based on grid-like inputs in a simple perceptron model, in which place cells combine their multiple inputs and make a decision on whether to generate a field (‘1’ output) or not (‘0’ output) by selecting input weights and a firing threshold (Figure 1A,B). However, in contrast to the classical perceptron results, which are derived under the assumption of random inputs that are in general position (a property related to the linear independence of the inputs), grid inputs to place cells are structured, which adds substantial complexity to our derivations.
Figure 1
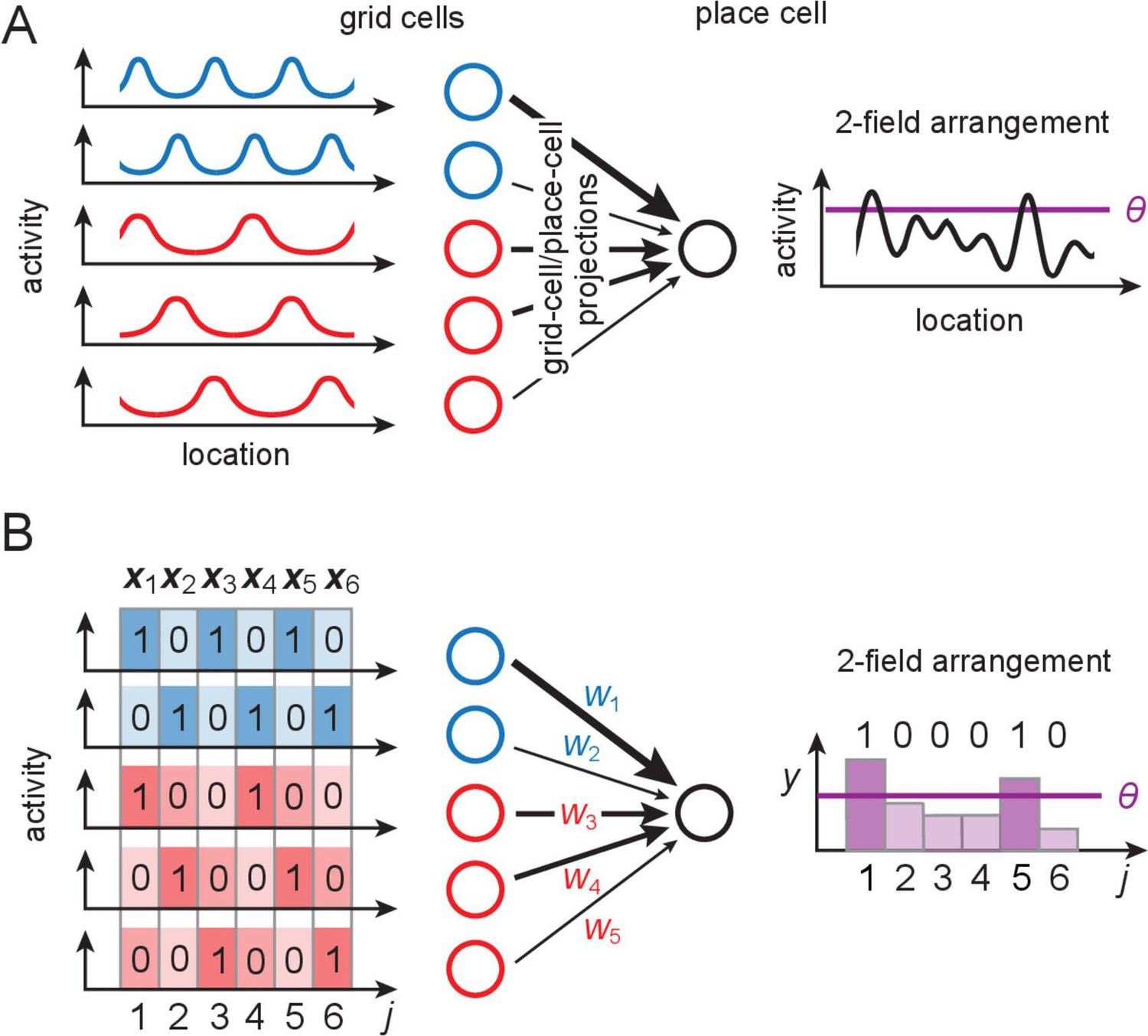
The grid-like code and modeling place cells as perceptrons.
(A) Grid-like inputs and a conceptual view of a place cell as a perceptron: each place cell combines its feedforward inputs, including periodic drive from grid cells (responses simplified here to one spatial dimension) of various periods and phases (blue and red cells are from modules with different periods) to generate location-specific activity that might be multiply peaked across large spaces. Can these place fields be arranged arbitrarily? (B) Idealization of a place cell as a perceptron: in discretized 1-D space, the grid-like inputs are discrete patterns that for simplicity we consider to be binary; place fields are assigned at locations where the weighted input sum exceeds a threshold . A place field arrangement can be considered as a set of binarized output labels (1 for each field, 0 for non-field locations) for the set of input patterns. We count field arrangements over the range of locations where the grid-like inputs have unique states; for two modules with periods , this range is 6 (the LCM of the grid periods). LCM = least common multiple; GCD = greatest common divisor.
We show analytically that each place cell can realize a large repertoire of arrangements across all possible space where the grid inputs are unique. However, these realizable arrangements are a special and vanishing subset of all arrangements over the same space, suggesting a constrained structure. We show that the capacity of a place cell or spatial range over which all field arrangements can be realized equals the sum of distinct grid periods, a small fraction of the range of positions uniquely encoded by grid-like inputs. Overall, we show that field arrangements generated from grid-like inputs are more robust to noise than those driven by random inputs or shuffled grid inputs.
Together, our results imply that grid-like inputs endow place cells with rich and robust spatial scaffolds, but that these are also constrained by grid-cell geometry. Rigorous proofs supporting all our mathematical results are provided in Appendix 1. Portions of this work have appeared previously in conference abstract form (Yim et al., 2019).
Modeling framework
Place cells as perceptrons
The perceptron model (Rosenblatt, 1958) idealizes a neuron as computing a weighted sum of its inputs () based on learned input weights () and applying a threshold () to generate a binary response that is above or below threshold. A perceptron may be viewed as separating its high-dimensional input patterns into two output categories () (Figure 2A), with the categorization depending on the weights and threshold so that sufficiently weight-aligned input patterns fall into category 1 and the rest into category 0:
(1)
Figure 2
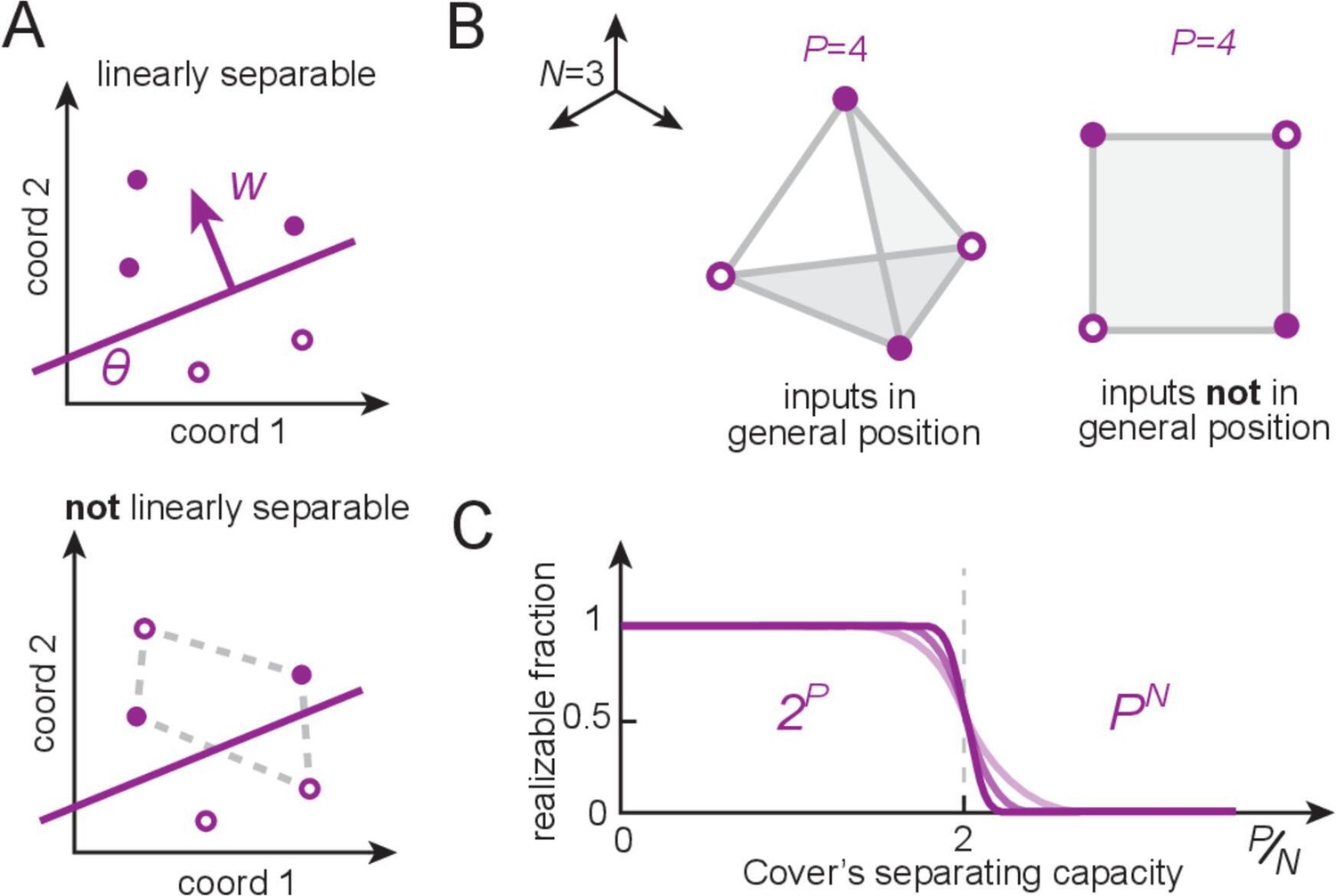
Linear separability, counting dichotomies, and separating capacity for perceptrons.
(A) A set of patterns (locations given by circles) that are assigned positive and negative labels (filled versus open), called a dichotomy of the patterns, is realizable by a perceptron if positive examples can be linearly separated (by a hyperplane) from the rest. The perceptron weights encode the direction normal to the separating hyperplane, and the threshold sets its distance from the origin. (B) An example with input dimension (the input dimension is the length of each input pattern vector, which equals the number of input neurons). When placed randomly, random real-valued patterns optimally occupy space and are said to be in general position (left); these patterns define a tetrahedron and all dichotomies are linearly separable. By contrast, structured inputs may occupy a lower-dimensional subspace and thus not lie in general position (right). This square configuration exhibits unrealizable dichotomies (as in A, bottom). (C) Cover’s results (Cover, 1965): for patterns in general position, the number of realizable dichotomies is , and thus the fraction of realizable dichotomies relative to all dichotomies is 1, when the number of patterns is smaller than the input dimension (). The fraction drops rapidly to zero when the number of patterns exceeds twice the input dimension (the separating capacity).
If each partitioning of inputs into the categories is called a dichotomy, then the only dichotomies ‘realizable’ by a perceptron are those in which the inputs are linearly separable – that is, the set of inputs in category 0 can be separated from those in category 1 by some linear hyperplane (Figure 2). Cover’s counting theorem (Cover, 1965; Vapnik, 1998) provides a count of how many dichotomies a perceptron can realize if input patterns are random (more specifically, in general position). A set of patterns in an -dimensional space is in general position if no subset of size smaller than is affinely dependent. In other words, no subset of points lies in a -dimensional plane for all . (Figure 2B) and establishes that for patterns, every dichotomy is realizable by a perceptron – this is the perceptron capacity (Figure 2C). For , exactly half of the possible dichotomies are realizable; when for fixed , the realizable dichotomies become a vanishing fraction of the total (Figure 2C).
Here, to characterize the place-cell scaffold, we model a place cell as a perceptron receiving grid-like inputs (Figure 1B). Across space, a particular ‘field arrangement’ is realizable by the place cell if there is some set of input weights and a threshold (Lee et al., 2020) for which its summed inputs are above threshold at only those locations and below it at all others (Figure 1A,B). We call an arrangement of exactly fields a ‘K-field arrangement.’.
In the following, we answer two distinct but related questions: (1) out of all potential field arrangements over the entire set of unique grid inputs, how many are realizable, and how does the realizable fraction differ for grid-like inputs compared to inputs with matched dimension but different structure? This is akin to perceptron function counting (Cover, 1965) with structured rather than general-position inputs and covers constraints within and across environments. We consider all arrangements regardless of sparsity, on one extreme, and -field (highly sparse) arrangements on the other; these cases are analytically tractable. We expect the regime of sparse firing to interpolate between these two regimes. (2) Over what range of positions is any field arrangement realizable? This is analogous to computing the perceptron-separating capacity (Cover, 1965) for structured rather than general-position inputs.
Although the structured rather than random nature of the grid code adds complexity to our problem, the symmetries present in the code also allow for the computation of some more detailed quantities than typically done for random inputs, including capacity computations for dichotomies with a prescribed number of positive labels (K-field arrangements).
Results
Our approach, summarized in Figure 3, is as follows: we define a mapping from space to grid-like input codes (Figure 3A,B), and a generalization to what we call modular-one-hot codes (Figure 3B). We explore the geometric structure and symmetries of these codes (Figure 3C). Next, we show how separating hyperplanes placed on these structured inputs by place-cell perceptrons permits the realization of some dichotomies (Figure 3D) and thus some spatial field arrangements (Figure 3E), but not others, and obtains mathematical results on the number of realizable arrangements and the separating capacity.
Figure 3

Our overall approach.
(A, B) Locations (indexed by ) map onto grid-like coding states (, defining the grid-like codebook) through the assignment of spatially periodic responses to grid cells, with different cells in a module having different phases and different modules having different periods. (This example: periods 2,3.) (C) The patterns in the grid-like codebook form some nonrandom, geometric structure. (D) The geometric structure defines which dichotomies are realizable by separating hyperplanes. (E) A realizable dichotomy in the abstract codebook pattern space, when mapped back to spatial locations, corresponds to a realizable field arrangement. Shown is a place field arrangement realized by the separating hyperplane from (D). Similarly, an unrealizable field arrangement can be constructed by examination of (D): it would consist of, for instance, fields at locations only (or, e.g., at only): vertices that cannot be grouped together by a single hyperplane.
The structure of grid-like input patterns
Grid cells have spatially periodic responses (Figure 1A,B). Cells in one grid module exhibit a common spatial period but cover all possible spatial phases. The dynamics of each module are low-dimensional (Fyhn et al., 2007; Yoon et al., 2013), with the dynamics within a module supporting and stabilizing a periodic phase code for position. Thus, we use the following simple model to describe the spatial coding of grid cells and modules: a module with spatial period (in units of the spatial discretization) consists of cells that tile all possible phases in the discretized space while maintaining their phase relationships with each other. Each grid cell’s response is a -valued periodic function of a discretized 1D location variable (indexed by ); cell in module fires (has response 1) whenever , and is off (has response 0) otherwise (Figure 1B). The encoding of location across all Mm modules is thus an -dimensional vector , where . Nonzero entries correspond to co-active grid cells at position . The total number of unique grid patterns is , which grows exponentially with for generic choices of the periods (Fiete et al., 2008). We refer to as the ‘full range’ of the code. We call the full ordered set of unique coding states the grid-like ‘codebook’ .
Because includes all unique grid-like coding states across modules, it includes all possible relative phase shifts or ‘remappings’ between grid modules (Fiete et al., 2008; Monaco et al., 2011). Thus, this full-range codebook may be viewed as the union of all grid-cell responses across all possible space and environments. We assume implicitly that 2D grid modules do not rotate relative to each other across space or environments. Permitting grid modules to differentially rotate would lead to more input pattern diversity, more realizable place patterns, and bigger separating capacity than in our present computations.
The grid-like code belongs to a more general class that we call ‘modular-one-hot’ codes. In a modular-one-hot code, cells are divided into modules; within each module only one cell is allowed to be active (the within-module code is one-hot), but there are no other constraints on the code. With modules of sizes , the modular-one-hot codebook contains unique patterns, with for a corresponding grid-like code. When are pairwise coprime, and the grid-like and modular-one-hot codebooks contain identical patterns. However, even in this case, modular-one-hot codes may be viewed as a generalization of grid-like codes as there is no notion of a spatial ordering in the modular-one-hot codes, and they are defined without referring to a spatial variable.
Of our two primary questions introduced earlier, question (1) on counting the size of the place-cell repertoire (the number of realizable field arrangements) depends only on the geometry of the grid coding states, and not on their detailed spatial embedding (i.e., it depends on the mappings in Figure 3B–D, but not on the mapping between Figure 3A,B,D,E). In other words, it does not depend on the spatial ordering of the grid-like coding states and can equivalently be studied with the corresponding modular-one-hot code instead, which turns out to be easier. Question (2), on place-cell capacity (the spatial range over which any place field arrangement is realizable), depends on the spatial embedding of the grid and place codes (and on the full chain of Figure 3A-E). For , this would correspond to a particular rather than random subset of , thus we cannot use the general properties of this generalized version of the grid-like code.
Alternative codes
In what follows, we will contrast place field arrangements that can be obtained with grid-like or modular-one-hot codes with arrangements driven by alternatively coded inputs. To this end, we briefly define some key alternative codes, commonly encountered in neuroscience, machine learning, or in the classical theory of perceptrons. For these alternative codes, we match the input dimension (number of cells) to the modular-one-hot inputs (unless stated otherwise).
Random codes , used in the standard perceptron results, consist of real-valued random vectors. These are quite different from the grid-like code and all the other codes we will consider, in that the entries are real-valued rather than -valued like the rest. A set of up to random input patterns in dimensions is linearly independent; thus, they have no structure up to this number.
Define the one-hot code as the set of vectors with a single nonzero element whose value is 1. It is a single-module version of the modular-one-hot code or may be viewed as a binarized version of the random patterns since patterns in dimensions are linearly independent. In the one-hot code, all neurons are equivalent, and there is no modularity or hierarchy.
Define the ‘binary’ code as all possible binary activity patterns of neurons (Figure 4B, right). We distinguish -valued codes from binary codes. In the binary code, each cell represents a specific position (register) according to the binary number system. Thus, each cell represents numbers at a different resolution, differing in powers of 2, and the code has no neuron permutation invariance since each cell is its own module; thus, it is both highly hierarchical and modular.
Figure 4
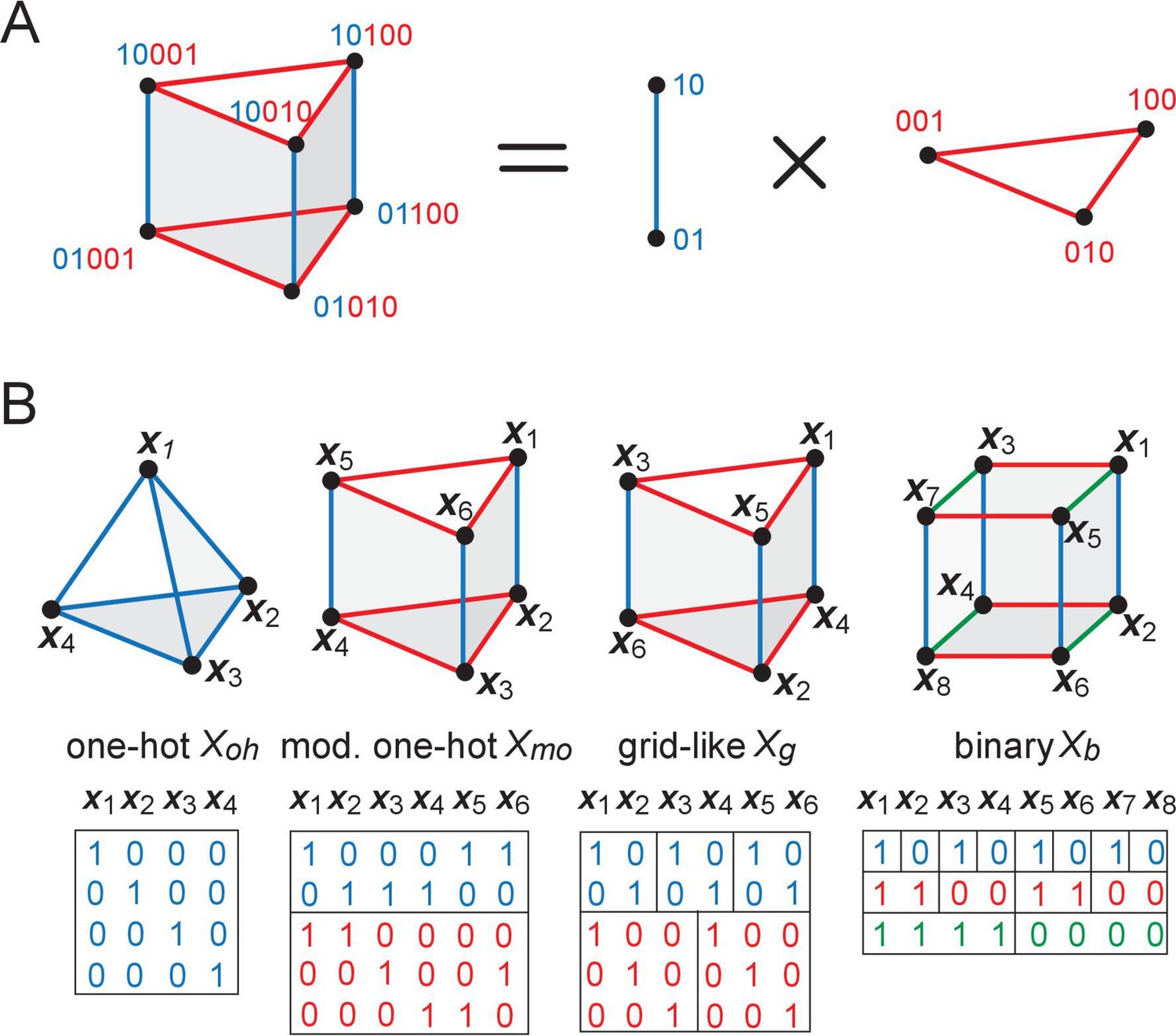
The geometry of structured inputs.
(A) Though the grid-like input patterns in the example Figure 1B are 5D, they have a simplified structure that can be embedded as a 3D triangular prism given by the product of a 2-graph (blue, middle) and 3-graph (red, right) because of the independently updating modular structure of the code. (B) Different codebooks and their geometries. At one end of the spectrum (left), one-hot codes consist of a single module; they are not hierarchical, and their geometry is always an elementary simplex (left). Grid cells and modular-one-hot codes (middle) have an intermediate level of hierarchy and consist of an orthogonal product of simplices. At the opposite end, the binary code (right) is the most hierarchical, consisting of as many modules as cells; the code has a hypercube geometry: vertices (codewords or patterns) on each face of the hypercube are far from being in general position.
The grid-like and modular-one-hot codes exhibit an intermediate degree of modularity (multiple cells make up a module). If the modules are of a similar size, the code has little hierarchy.
The geometry of grid-like input patterns
We first explore question . The modular-one-hot codebook is invariant to permutations of neurons (input matrix rows) within modules, but rows cannot be swapped across modules as this would destroy the modular structure. It is also invariant to permutations of patterns (input matrix columns ). Further, the codebook includes all possible combinations of states across modules, so that modules function as independent encoders. These symmetries are sufficient to define the geometric arrangement of patterns in , and the geometry in turn will allow us to count the number of field arrangements that are realizable by separating hyperplanes.
To make these ideas concrete, consider a simple example with module sizes (corresponding to the periods in the grid-like code), as in Figure 1B and Figure 3B. Independence across modules causes the code to have a product structure in the code: the codebook consists of six states that can be obtained as products of the within-module states: = , where and are the coding states within the size-2 and size-3 modules, respectively. We represent the two states in the size-2 module by two vertices, connected by an edge, which shows allowed state transitions within the module (Figure 4A, right). Similarly, the three states in the size-3 module and transitions between them are represented by a triangular graph (Figure 4A, right). The product of this edge graph and the triangle graph yields the full codebook . The resulting product graph (Figure 4A, left) is an orthogonal triangular prism with vertices representing the combined patterns.
This geometric construction generalizes to an arbitrary number of modules and to arbitrary module sizes (periods) , : by permutation invariance of neurons within modules, and independence of modules, the patterns of the codebook and thus of the corresponding grid-like codebook always lie on the vertices of some convex polytope (e.g., the triangular prism), given by an orthogonal product of simplicies (e.g., the line and triangle graphs). Each simplex represents one of the modules, with simplex dimension for module size (period) (see Place-cell capacity and volatility with grid-like inputs).
This geometric construction provides some immediate results on counting: in a convex polytope, any vertex can be separated from all the rest by a hyperplane; thus, all one-field arrangements are realizable. Pairs of vertices can be separated from the rest by a hyperplane if and only if the pair is directly connected by an edge (Figure 3D). Thus, we can now count the set of all realizable two-field arrangements as the number of adjacent vertices in the polytope. Unrealizable two-field arrangements, which consist geometrically of positive labels assigned to nonadjacent vertices, correspond algebraically to firing fields that are not separated by integer multiples of either of the grid periods (Figure 3D,E).
Moreover, note that the convex polytopes obtained for the grid-like code remain qualitatively unchanged in their geometry if the nonzero activations within each module are replaced by graded tuning curves as follows: convert all neural responses within a module into graded values by convolution along the spatial dimension by a kernel that has no periodicity over distances smaller than the module period (thus, the kernel cannot, for instance, be flat or contain multiple bumps within one module period). This convolution can be written as a matrix product with a circulant matrix of full rank and dimension equal to the full range . Thus, the rank of the convolved matrix remains equal to the rank of . Moreover, maintains the modular structure of : it has the same within-module permutation invariance and across-module independence. Thus, the resulting geometry of the code – that it consists of convex polytopes constructed from orthogonal products of simplices – remains unchanged. As a result, all counting derivations, which are based on these geometric graphs, can be carried out for -valued codes without any loss of generalization relative to graded tuning curves. (However, the conversion to graded tuning will modify the distances between vertices and thus affect the quantitative noise robustness of different field arrangements, as we will investigate later.) Later, we will also show that the counting results generalize to higher dimensions and higher-resolution phase representations within each module.
Given this geometric characterization of the grid-like and modular-one-hot codes, we can now compute the number of realizable field arrangements it is possible to obtain with separating hyperplanes.
Counting realizable place field arrangements
For modular-one-hot codes (but not for random codes), it is possible to specify any separating hyperplane using only non-negative weights and an appropriate threshold. This is an interesting property in the neurobiological context because it means that the finding that projections from entorhinal cortex to hippocampus are excitatory (Steward and Scoville, 1976; Witter et al., 2000; Shepard, 1998) does not further constrain realizable field arrangements.
It is also an interesting property mathematically, as we explore below: combined with the within-module permutation invariance property of modular-one-hot codes, the non-negative weight observation allows us to map the problem onto Young diagrams (Figure 5), which enables two things: (1) to move from considering separating hyperplanes geometrically, where infinitesimal variations represent distinct hyperplanes even if they do not change any pattern classifications, to considering them topologically, where hyperplane variations are considered as distinct only if they change the classification of any patterns, and (2) to use counting results previously established for Young diagrams.
Figure 5

Counting realizable place field arrangements.
(A) Geometric structure of a modular-one-hot code with two modules of periods and . (B–D) Because cells within a module can be freely permuted, we can arrange the cells in order of increasing weights and keep this ordering fixed during counting, without loss of generality. We arrange the cells in modules 1 and 2 along the ordinate and abcissa in increasing weight order (solid blue and red lines, respectively). Because the weights can all be assumed to be non-negative for modular-one-hot codes, the threshold can be interpreted as setting a summed-weight budget: no cell (weight) combinations (purple regions with purple-white circles) below the threshold (diagonal purple line) can contribute to a place field arrangement, while all cell combinations with larger summed weights (unmarked regions) can. Increasing the threshold (from B to C) decreases the number of permitted combinations, as does decreasing the weights (B to D). Weight changes (B, from solid to dashed lines) and threshold changes (C, solid to dashed line), so long as they do not change which lines are to the bottom-left of the threshold, do not affect the number of permitted combinations, reflecting the topological structure of the counting problem. (E) With Young diagrams (each corresponding to B–D above), we extract the purely topological part of the problem, stripping away analog weights to simplify counting. A Young diagram consists of stacks of blocks in rows of nonincreasing width within a grid of a maximum width and height. The number of realizable field arrangements is simply the total number and multiplicity of distinct Young diagrams that can be built of the given height and width (see Appendix 3), which in our case is given by the periods of the two modules.
Let us consider the field arrangements permitted by combining grid-like inputs from two modules, of periods and , (Figure 5A). The total number of distinct grid-cell modules is estimated to be between 5 and 8 (Stensola et al., 2012). Further, there is a spatial topography in the projection of grid cells to the hippocampus, such that each local patch of the hippocampus likely receives inputs from 2, and likely no more than 3, grid modules (Witter and Groenewegen, 1984; Amaral and Witter, 1989; Witter and Amaral, 1991; Honda et al., 2012; Witter et al., 2000). We denote cells by their outgoing weights ( is the weight from cell in module ) and arrange the weights along the axes of a coordinate space, one axis per module, in order of increasing size (Figure 5B). Since modular-one-hot codes are invariant to permutation of the cells within a module, we can assume a fixed ordering of cells and weights in counting all realizable arrangements, without loss of generality. The threshold (dark purple line) sets which combination of summed weights can contribute to a place field arrangement: no cell combinations below the boundary (purple region) have too small a summed weight and cannot contribute, while all cell combinations with larger summed weights (white region) can (Figure 5B). Decreasing the threshold (from Figure 5B to C) or increasing weights (from Figure 5B,C to D) a sufficient amount so some cells cross the threshold increases the number of combinations. But changes that do not cause cells to move past the threshold do not change the combinations (Figure 5B, solid versus dashed gray lines).
Young diagrams extract this topological information, stripping away geometric information about analog weights (Figure 5E). A Young diagram consists of stacks of blocks in rows of nonincreasing width, with maximum width and height given in this case by the two module periods, respectively. The number of realizable field arrangements turns out to be equivalent to the total number of Young diagrams that can be built of the given maximum height and width (see Appendix 3). With this mapping, we can leverage combinatorial results on Young diagrams (Fulton and Fulton, 1997; Postnikov, 2006) (commonly used to count the number of ways an integer can be written as a sum of non-negative integers).
As a result, the total number of separating hyperplanes (K-field arrangements for all ) across the full range can be written exactly as (see Appendix 3).
(2)
where are Stirling numbers of the second kind and are the poly-Bernoulli numbers (Postnikov, 2006; Kaneko, 1997). Assuming that the two periods have a similar size , this number scales asymptotically as (de Andrade et al., 2015).
(3)
Thus, the number of realizable field arrangements with distinct modular-one-hot input patterns in a -dimensional space grows nearly as fast as , (Table 1, row 2, columns 1–3). The total number of dichotomies over these input patterns scales as Thus, while the number of realizable arrangements over the full range is very large, it is a vanishing fraction of all potential arrangements (Table 1, row 2, column 4).
Table 1
Number and fraction of realizable dichotomies with binary, modular-one-hot ( modules) and one-hot input codes with the same input cell budget ().
| # cells | # input patts (L) | # lin dichot | Frac lin dichot | |
|---|---|---|---|---|
| Binary | 2λ | 22λ | 22λ2 | |
| = | << | << | >> | |
| Modular-one-hot | 2λ | λ2 | ||
| = | << | << | >> | |
| One-hot | 2λ | 2λ | 22λ | 1 |
If modules were to contribute to each place field’s response, then all realizable field arrangements still would correspond to Young diagrams; however, not all diagrams would correspond to realizable arrangements. Thus, counting Young diagrams would yield an upper bound on the number of realizable field arrangements but not an exact count (see Appendix 3). The latter limitation is not a surprise: Due to the structure of the grid-like code (a product of simplices), the enumeration of realizable dichotomies with arbitrarily many input modules is expected to be at least as challenging as that of Boolean functions. Counting the number of linearly separable Boolean functions of arbitrary (input) dimension (Peled and Simeone, 1985; Hegedüs and Megiddo, 1996) is hard.
Nevertheless, we can provide an exact count of the number of realizable -dichotomies for arbitrarily many input modules if is small ( and 4). This may be biologically relevant since place fields tend to fire sparsely even on long tracks and across environments. In this case, the number of realizable small- field arrangements scales as (the exact expression is derived analytically in Appendix 3)
(4)
The scaling approximation becomes more accurate for periods that are large relative to the spatial discretization (see Appendix 3). Since the total number of K-dichotomies scales as , the fraction of realizable K-dichotomies scales as , which for vanishes as a power law as soon as .
We can compare this result with the number of K-field arrangements realizable by one-hot codes. Since any arrangement is realizable with one-hot codes, it suffices to simply count all K-field arrangements. The full range of a one-hot code with cells is , thus the number of realizable K-field arrangements is , where the last scaling holds for . In short, a one-hot code enables arrangements, while the corresponding modular-one-hot code with cells enables field arrangements, for a ratio of realizable fields with modular-one-hot versus one-hot codes. Once again, as in the case where we counted arrangements without regard to sparseness, the grid-like code enables far more realizable K-field arrangements than one-hot codes.
In summary, place cells driven by grid inputs can achieve a very large number of unique coding states that grows exponentially with the number of modules. We have derived this result for and all K-field arrangements, on one hand, and for arbitrary but ultra-sparse (small-) field arrangements. It is difficult to obtain an exact result for sparse field arrangements for which is a small but finite fraction of ; however, we expect that regime should interpolate between these other two; it will be interesting and important for future work to shed light on this intermediate regime. In all cases, the number of realizable arrangements is large but a vanishingly small fraction of all arrangements, and thus forms a highly structured subset. This suggests that place cells, when driven by grid-cell inputs, can form a very large number of field arrangements that seem essentially unrestricted, but individual cells actually have little freedom in where to place their fields.
Comparison with other input patterns
How does the number of realizable place field arrangements differ for input codes with different levels of modularity and hierarchy? We directly compare codes with the same neuron budget (input dimension ) by taking , where for simplicity, we set for all modules in the modular-one-hot codes. This is because the modular-one-hot codes include all permutations of states in each module, the number of unique input states with equal-sized modules still equals the product of periods , as when the periods are different and coprime. The one-hot code generates far fewer distinct input patterns () than the modular-one-hot code, which in turn generates fewer input patterns than the binary code () (Table 1, column 2). This is due to the greater expressive power afforded by modularity and hierarchy.
Next, we compare results across codes for , the case for which we have an explicit formula counting the total number of realizable field arrangements for any , and which is also best supported by the biology.
How many dichotomies are realizable with these inputs? As for the modular-one-hot codes, the patterns of and fall on the vertices of a convex polytope. For , that polytope is just a -dimensional simplex (Figure 4C, left), thus any subset of vertices () lies on a -dimensional face of the simplex and is therefore a linearly separable dichotomy. Thus, all dichotomies of are realizable and the fraction of realizable dichotomies is 1 (Table 1, columns 3 and 4). For , the polytope is a hypercube; it therefore consists of square faces, a prototypical configuration of points not in general position (not linearly separable, Figure 2B and Figure 4, right) even when the number of patterns is small relative to the input dimension (number of cells). Counting the number of linearly separable dichotomies on vertices of a hypercube (also called linear Boolean functions) has attracted much interest (Peled and Simeone, 1985; Hegedüs and Megiddo, 1996). It is an NP-hard combinatorial problem, so no exact solution exists. However, in the limit of large dimension (), the number of linearly separable dichotomies scales as (Zuev, 1989), a much larger number than for one-hot inputs (Table 1, column 3). However, this number is a strongly vanishing fraction of all hypercube dichotomies (Table 1, column 4).
For modular-one-hot codes with modules, the polytopes contain -dimensional hypercubes and not all patterns are thus in general position. We determined earlier that the total number of realizable dichotomies with modules scales as , permitting a direct comparison with the one-hot and binary codes (Table 1, row 2).
Finally, we may compare grid-like codes with random (real-valued) codes, which are the standard inputs for the classical perceptron results. For a fixed input dimension, it is possible to generate infinitely many real-valued patterns, unlike the finite number achievable by -valued codes. We thus construct a random codebook with the same number, , of input patterns as the modular-one-hot code. We then determine the input dimension required to obtain the same number of realizable field arrangements as the grid-like code. The number of realizable dichotomies of the random code with patterns scales as according to an asymptotic expansion of Cover’s function counting theorem (Cover, 1965). For this number to match , the number of realizable field arrangements with a one-hot-modular code (of two modules of size each requires) . This is a comparable number of input cells in both codes, which is an interesting result because unlike for random codes the grid-like input patterns are not in general position, the states are confined to be -valued, and the grid input weights can be confined to be non-negative.
In sum, the more modular a code, the larger the set of realizable field arrangements, but these are also increasingly special subsets of all possible arrangements and are strongly structured by the inputs, with far from random or arbitrary configurations. Modular-one-hot codes are intermediate in modularity. Therefore, grid-driven place-cell responses occupy a middle ground between pattern richness and constrained structure.
Place-cell-separating capacity
We now turn to question (2) from above: what is the maximal range of locations, , over which all field arrangements are realizable? Once we reference a spatial range, the mapping of coding states to spatial locations matters (specifically, the fact that locations in the range are spatially contiguous matters, but given the fact that the code is translationally invariant [Fiete et al., 2008], the origin of this range does not). We thus call the ‘contiguous-separating capacity’ of a place cell (though we will refer to it as separating capacity, for short); it is the analogue of Cover’s separating capacity (Cover, 1965), but for grid-like inputs with the addition of a spatial contiguity constraint.
We provide three primary results on this question. (1) We establish that for grid-structured inputs, the separating capacity equals the rank of the input matrix. (2) We establish analytically a formula for the rank of grid-like input matrices with integer periods and generalize the result to real-valued periods. (3) We show that this rank, and thus the separating capacity for generic real-valued module periods, asymptotically approaches the sum . Our results are verified by numerical simulation and counting (proofs provided in Supporting Information Appendix).
We begin with a numerical example, using periods {3,4} (Figure 6A): the full range is , while we see numerically that the contiguous-separating capacity is . Although the separating capacity with grid-structured inputs is smaller than with random inputs, it is notably not much smaller (Figure 6B, black versus cyan curves), and it is actually larger than for random inputs if the read-out weights are constrained to be non-negative (Figure 6B, pink curves). Later, we will further show that the larger random-input capacity of place cells with unrestricted weights comes at the price of less robustness: the realizable fields have smaller margins. Next, we analytically characterize the separating capacity of place cells with grid-like inputs.
Figure 6
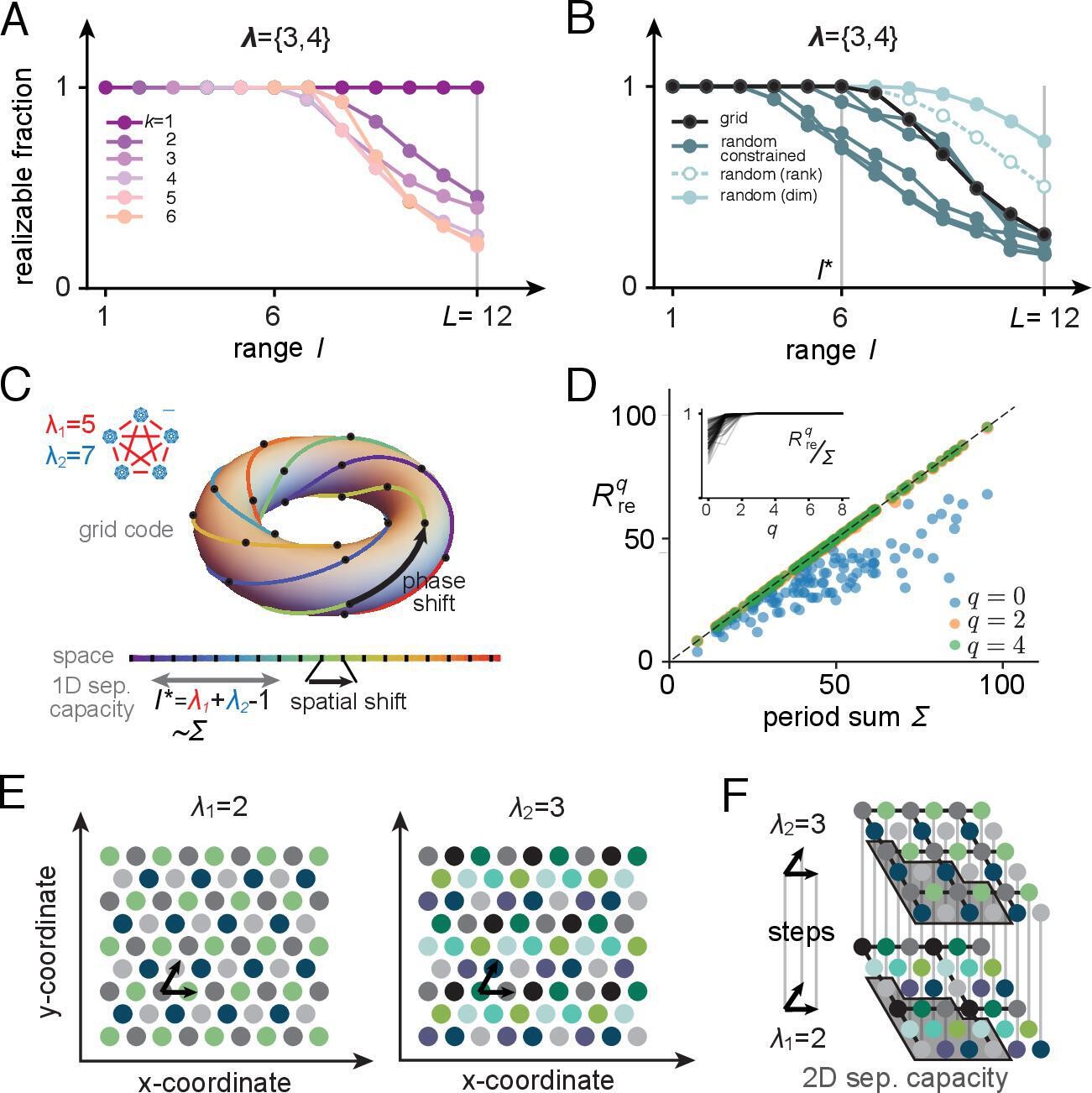
Place-cell-separating capacity.
(A) Fraction of K-field arrangements that are realizable with grid-like inputs as a function of range ( indicates the full range; in this example, grid periods are and ). (B) Fraction of realizable field arrangements (summed over ) as a function of range for grid cells (black); for random inputs, range refers to number of input patterns (solid cyan: random with matching input dimension; open/dashed cyan: random with input dimension equal to rank of the grid-like input matrix; dark teal: same as open cyan, but with weights constrained to be non-negative, as for grid-like inputs). With the non-negative weight constraint for random inputs, different specific input configurations produce quite different results, introducing considerable variability in separating capacity (unlike the unconstrained random input case or the grid code case for which results are exact rather than statistical). (C) The grid code is generated by iterated application of a phase-shift operator as a function of one-step updates in position over a contiguous 1D range. This feature of the code leads to a separating capacity that achieves its optimal value, given by the rank of the input matrix. (D) Separating capacity as a function of the sum of module periods for real-valued periods (randomly drawn from with , 100 realizations), showing the quality of the integer approximation at different resolutions. Integer approximations to the real-value periods at successively finer resolutions quickly converge, with results from and nearly indistinguishable from each other. Inset: ratio of separating capacity to sum of periods ( as a function of resolution quickly approaches 1 from below as increases). (E, F) Capacity results generalize to multidimensional spatial settings: (E) in 2D, grid-cell-activity patterns lie on a hexagonal lattice (all circles of one color mark the activity locations of one grid cell). For grid periods , this code utilizes 4 two-periodic cells and 9 three-periodic cells, respectively. (F) Full range of the 2D grid-like code from (E). The set of contiguous locations over which any place field arrangement is realizable (the 2D separating capacity) is shown in gray.
Separating capacity equals rank of grid-like inputs
For inputs in general position, the separating capacity equals the rank of the input matrix (plus 1 when the threshold is allowed to be nonzero), and the rank equals the dimension (number of cells) of the input patterns – the input matrix is full rank. When inputs are in general position, all input subsets of size equaling the separating capacity have the same rank. But when input patterns are not in general position, some subsets can have smaller ranks than others even when they have the same size. Thus, when input patterns are not in general position the separating capacity is only upper bounded by the rank of the full input matrix. In turn, the rank is only upper bounded by the number of cells (the input matrix need not be full rank).
For the grid-like code, all codewords can be generated by the iterated application of a linear operator to a single codeword: a simultaneous one-unit phase shift by a cyclic permutation in each grid module is such an operator , which can be represented by a block-form permutation matrix. The sequence of patterns generated by applying to a grid-like codeword with the same module structure represents contiguous locations (Figure 6C).
The separating capacity for inputs generated by iterated application of the same linear operation saturates its bound by equaling the rank of the input pattern matrix. Since a code , generated by some linear operator with starting codeword is translation invariant, the number of dimensions spanned by these patterns strictly increases until some value , after which the dimension remains constant. By definition, is therefore the rank of the input pattern matrix. It follows that any contiguous set of patterns is linearly independent, and thus in general position, which means that the separating capacity of such a pattern matrix is .
For place cells, it follows that whenever , with the rank of the grid-like input matrix, all field arrangements are realizable, while for any , there will be nonrealizable field arrangements (Supporting Information Appendix). Therefore, the contiguous-separating capacity for place cells is . This is an interesting finding: the separating capacity of a place cell fed with structured grid-like inputs approaches the same capacity as if fed with general-position inputs of the same rank. Next, we compute the rank for grid-like inputs under increasingly general assumptions.
Grid input rank converges to sum of grid module periods
Integer periods
For integer-valued periods , the rank of the matrix consisting of the multi-periodic grid-like inputs can be determined through the inclusion-exclusion principle (see Section B.4):
(5)
where is the ith of the k-element subsets of . To gain some intuition for this expression, note that if the periods were pairwise coprime, all the GCDs would be 1 and this formula would quite simply produce , where is defined as the sum of the module periods. If the periods are not pairwise coprime, the rank is reduced based on the set of common factors, as in (5), which satisfies the following inequality: . When the periods are large (), the rank approaches . Large integers () evenly spaced or uniformly randomly distributed over some range tend not to have large common factors (Cesaro, 1881). As a result, even for non-coprime periods, the rank scales like and approaches (see below for more elaboration).
Real-valued periods
Actual grid periods are real- rather than integer-valued, but with some finite resolution. To obtain an expression for this case, consider the sequence of ranks defined as
(6)
where denotes the floor operation, is an effective resolution parameter that takes integer values (the larger , the finer the resolution of the approximation to a real-valued period), and the periods are real numbers. The rank of the grid-like input matrix with real-valued periods is given by , if this limit exists. A finer resolution (higher ) corresponds to representing phases with higher resolution within each module, and thus intuitively to scaling the number of grid cells in each module by .
Suppose that the periods are drawn uniformly from an interval of the reals, which we take without loss of generality to be . Then the values are integers in and as above we have that . In the infinite resolution limit (), the probability scales asymptotically as , independent of (Cesaro, 1881), which means that large randomly chosen large integers tend not to have large common factors. This implies that with probability 1, the limit is well-defined and equals , the sum of the input grid module periods.
When assessed numerically at different resolutions (), the approach of the finite-resolution rank to the real-valued grid period rank is quite rapid (Figure 6D). Thus, the separating capacity does not depend sensitively on the precision of the grid periods. It is also invariant to the resolution with which phases are represented within each module.
In summary, the place-cell-separating capacity with real-valued grid periods and high-resolution phase representations within each module equals the rank of the grid-like input matrix, which itself approaches , the sum of the module periods. Thus, a place cell can realize any arrangement of fields over a spatial range given by the sum of module periods of its grid inputs.
It is interesting that the contiguous-separating capacity of a place cell fed with grid-like inputs not in general position approaches the same capacity as if fed with general-position inputs of the same rank. On the other hand, the contiguous-separating capacity is very small compared to the total range over which the input grid patterns are unique: since each local region of hippocampus receives input from 2 to 3 modules (Witter and Groenewegen, 1984; Amaral and Witter, 1989; Witter and Amaral, 1991; Witter et al., 2000; Honda et al., 2012), the range over which any field arrangement is realizable is at most 2–3 times the typical grid period. By contrast, the total range of locations over which the grid inputs provide unique codes scales as the product of the periods. The result implies that once field arrangements are freely chosen in a small region, they impose strong constraints on a much larger overall region and across environments. We explore this implication in more detail below.
Generalization to higher dimensions
We have already argued that our counting arguments hold for realistic tuning curve shapes with graded activity profiles. This follows from the fact that convolution of the grid-like codes with appropriate smoothing kernels does not change the general geometric arrangement of codewords relative to each other as these convolution operations preserve within-module permutation symmetries and across-module independence in the code. We have also shown that the contiguous-separating capacity results apply to real-valued grid periods with dense phase encodings within each module.
Here, we describe the generalization to different spatial dimensions. Consider a -dimensional grid-like code consisting of cells in the mth module to produce a one-hot phase code for (discrete) positions along each dimension (Figure 6E). Since the counting results rely only on the existence of a modular-one-hot code and not any mapping from real spaces to coding states, this code across multiple modules is equivalent to a modular-one-hot coding for states, with modules of size each. All the counting results from before therefore hold, with the simple substitution in the various formulae.
The contiguous-separating capacity in -dimensions is defined as the maximum volume over which all field arrangements are realizable. Like the 1D separating capacity results, this volume depends upon the mapping of physical space to grid-like codes. We are able to show that for grid modules with periods the generalized separating capacity is (see Section B.4; Figure 6F). This result follows from essentially the same reasoning as for 1D environments, but with the use of -dimensional phase-shift operators.
Robustness of field arrangements to noise and nongrid inputs
An important quality of field arrangements that is neglected when merely counting the number of realizable arrangements or determining the separating capacity is robustness: these computations consider all realizable field arrangements, but field arrangements are practically useful only if they are robust so that small amounts of perturbation or noise in the inputs or weights do not render them unrealizable. Above, we showed that grid-like codes enable many dichotomies despite being structurally constrained, but that random analog-valued codes as well as more hierarchical codes permit even more dichotomies. Here, we show that the dichotomies realized by grid codes are substantially more robust to noise and thus more stable.
The robustness of a realizable dichotomy in a perceptron is given by its margin: for a given linear decision boundary, the margin is the smallest datapoint-boundary distance for each class, summed for the two classes. The maximum margin is the largest achievable margin for that dataset. The larger the maximum margin, the more robust the classification. We thus compare maximum margins (herein simply referred to as margins) across place field arrangements, when the inputs are grid-like or not.
Perceptron margins can be computed using quadratic programming on linear support vector machines (Platt, 1998). We numerically solve this problem for three types of input codes (permitting a nonzero threshold and imposing no weight constraints): the grid-like code ; the shuffled grid-like code – a row- and column-shuffled version of the grid-like code that breaks its modular structure; and the random code of uniformly distributed random inputs (Figure 7). To make distance comparisons meaningful across codes, all patterns (columns) involve the same number of neurons (dimension), have the same total activity level (unity L1 norm), and the number of input patterns is the same across codes, and chosen to equal , the full range of the corresponding grid-like code. To compute margins, we consider only the realizable dichotomies on these patterns.
Figure 7
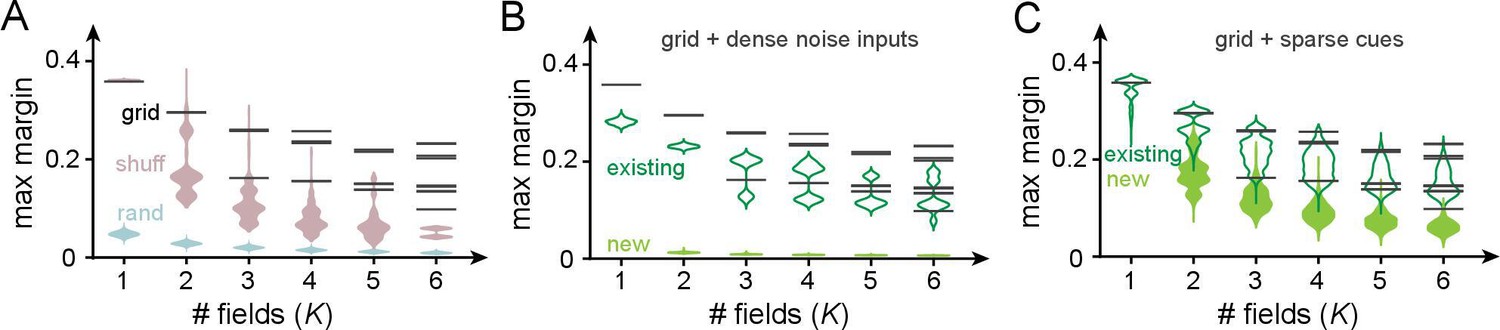
Robustness of place field arrangements to noise and nongrid inputs.
In (A–C), grid periods are ; the number of input patterns is set to for all input codes. Input patterns are normalized to have unity L1 norm in all cases. Maximum margins are determined by using SVC in scikit-learn (Pedregosa et al., 2011) (with thresholds and no weight constraints). (A) Black bars: the maximum margins of all realizable arrangements with grid-like inputs (bars have high multiplicity: across the very large number of realizable field arrangements, the set of distinct maximum margins is small and discrete because of the regular geometric structure of the grid-like code). Pink: margins for shuffled grid inputs that break the code’s modularity (shuffling neurons across modules for each pattern; 10 shuffles per and sampling 1000 realizable field arrangements per shuffle). Blue: margins for random inputs in general position (inputs sampled i.i.d. uniformly from ; 10 realizations of a random matrix per , 1000 realizable field arrangements sampled per realization). (B) Effect of noise on margins. We added dense noise inputs (100 non-negative i.i.d. random inputs at each location) to the place cell, in addition to the 74 grid-like inputs. (The expected value of each random input was 20% of the population mean of the grid inputs; thus, the summed random input was on average the size of the summed grid input.) Black: noise-free margins as in (A). Empty green violins: margins of existing field arrangements modestly shrink in size. Solid green violins: margins of some newly created field arrangements: these are small and thus unstable. (C) Effect of sparse spatial inputs (plots as in C). (We added 100 sparse inputs per location; each sparse input had fields placed randomly across the full range , so that the summed sparse input was on average the size of the summed grid input. The combined grid and nongrid input at each location was normalized to 1.)
The margins of all realizable place field arrangements with grid-like inputs are shown in Figure 7A (black); the margin values for all arrangements are discretized because of the geometric arrangements of the inputs, and each black bar has a very high multiplicity. The grid-like code produces much larger-margin field arrangements than shuffled versions of the same code and random codes (Figure 7A, pink and blue). The higher margins of the grid-like compared to the shuffled grid-like code show that it is the structured geometry and modular nature of the code that produce well-separated patterns in the input space (Figure 4B) and create wide margins and field stability. In other words, place field arrangements formed by grid inputs, though smaller in number than arrangements with differently coded inputs, should be more robust and stable against potential noise in neural activations or weights.
Next, we directly consider how different kinds of nongrid inputs, driving place cells in conjunction with grid-like inputs, affect our results on place field robustness. We examine two distinct types of added nongrid input: (1) spatially dense noise that is meant to model sources of uncontrolled variation in inputs to the cell and (2) spatially sparse and reliable cues meant to model spatial information from external landmarks.
After the addition of dense noise, previously realizable grid-driven place field arrangements remain realizable and their margins, though somewhat lowered, remain relatively large (Figure 7B, empty green violins). In other words, grid-driven place field arrangements are robust to small, dense, and spatially unreliable inputs, as expected given their large margins. Note that because the addition of dense i.i.d. noise to grid-like input patterns pushes them toward general position, and general-position inputs enable more realizable arrangements, the noise-added versions of grid-like inputs also give rise to some newly realizable field arrangements (Figure 7B, full green violins). However, as with arrangements driven purely by random inputs, these new arrangements have small margins and are relatively not robust. Moreover, since by definition noise inputs are assumed to be spatially unreliable, the newly realizable arrangements will not persist across trials.
Next, the addition of sparse spatial inputs (similar to the one-hot codes of Table 1, though the sparse inputs here are nearly but not strictly orthogonal) leaves previous field arrangements largely unchanged and their margins substantially unmodified (Figure 7C, empty green violins). In addition, a few more field arrangements become realizable and these new arrangements also have large margins (Figure 7C, full green violins). Thus, sufficiently sparse spatial cues can drive additional stable place fields that augment the grid-driven scaffold without substantially modifying its structure. Plasticity in weights from these sparse cue inputs can drive the learning of new fields without destabilizing existing field arrangements.
In sum, grid-driven place arrangements are highly robust to noise. Combining grid-cell drive with cue-driven inputs can produce robust maps that combine internal scaffolds with external cues.
High volatility of field arrangements with grid input plasticity
Our results on the fraction of realizable place field arrangements and on place-cell-separating capacity with grid-like inputs imply that place cells have highly restricted flexibility in laying down place fields (without direct drive from external spatially informative cues) over distances greater than , the sum of the input grid module periods. Selecting an arrangement of fields over this range then constrains the choices that can be made over all remaining space in the same environment and across environments. Conversely, changing the field arrangement in any space by altering the grid-place weights should affect field arrangements everywhere.
We examine this question quantitatively by constructing realizable K-field arrangements (with grid-like responses generated as 1D slices through 2D grids [Yoon et al., 2016]), then attempting to insert one or a few new fields (Figure 8A,B). Inserting even a single field at a randomly chosen location through Hebbian plasticity in the grid-place weights tends to produce new additional fields at uncontrolled locations, and also leads to the disappearance of existing fields (Figure 8A,B).
Figure 8
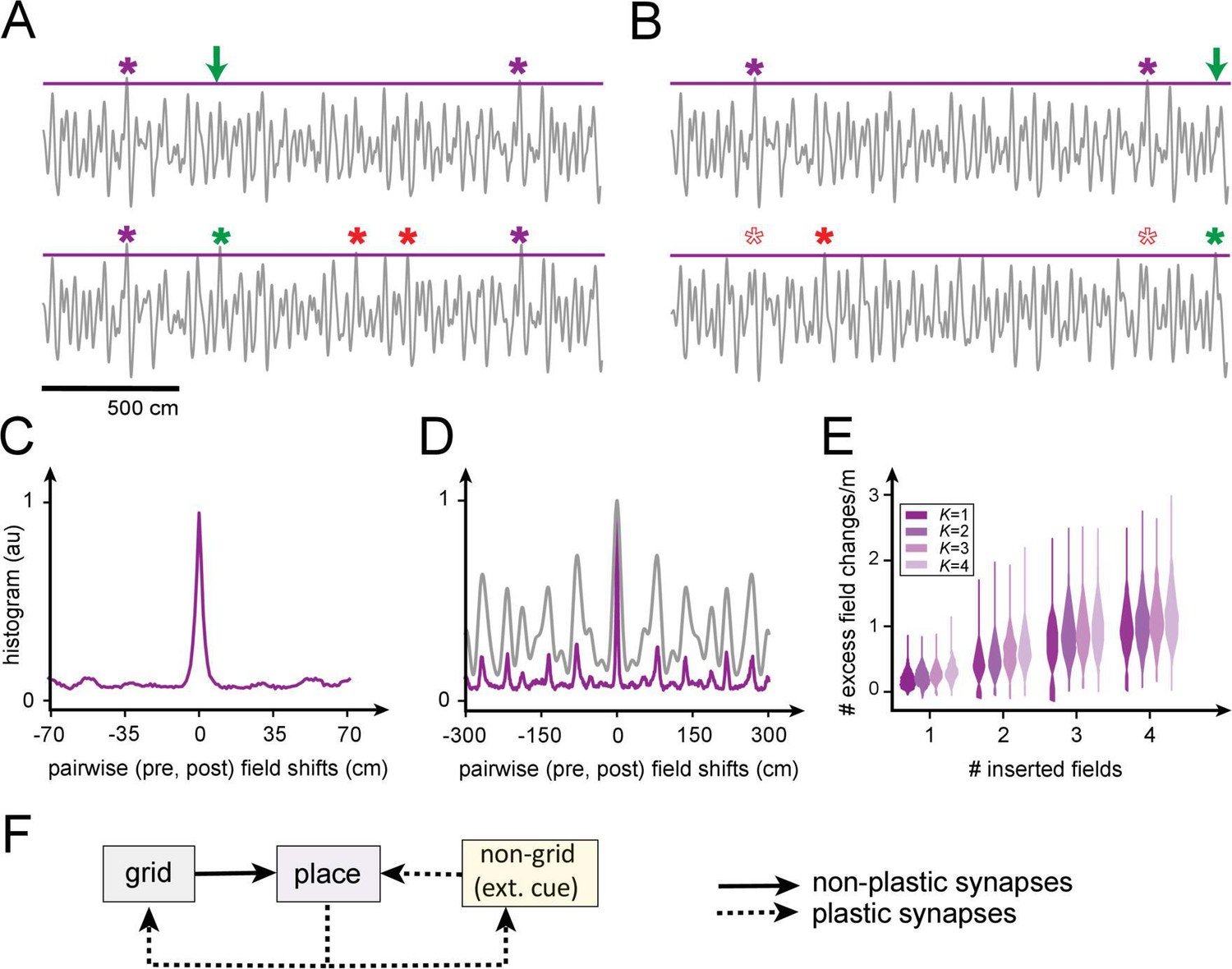
Predicted volatility of place field arrangements.
(A) Top: original field arrangement over a 20 m space (gray line: summed inputs to place cell; purple stars: original field locations; green arrow: location where new field will be induced by Hebbian plasticity in grid-place weights). Bottom: after induction of the new field (green star), two new uncontrolled fields appear (red stars). (B) Similar to (A): the insertion of a new field at a random location (green star) leads to one uncontrolled new field (red star) and the loss of two original fields (empty red stars). (C) Histogram of changes, after single-field insertion, in pairwise inter-field intervals (spacings): the primary off-target effect of field insertion is for other fields to appear or disappear, but existing fields do not tend to move. (D) A spatially extended version of (C) (purple), together with the (vertically rescaled) autocorrelation of the grid inputs to the cell (gray): new fields tend to appear at spacings corresponding to peaks in the input autocorrelation function. (E) Sum of uncontrolled field insertions or deletions per meter, in response to inserted fields when starting with a K-field arrangement over 20 m. (F) High place field volatility resulting from plasticity in the grid-to-place synapses suggests the possibility that grid-place weights might be relatively rigid (nonplastic).
Interestingly, though field insertion affects existing arrangements through the uncontrolled appearance or disappearance of other fields, it does not tend to produce local horizontal displacements of existing fields (Figure 8C): fields that persist retain their firing locations or they disappear entirely, consistent with the surprising finding of a similar effect in experiments (Ziv et al., 2013).
The locations of fields, including of uncontrolled field additions, are well-predicted by the structure (autocorrelation) of that cell’s grid inputs (Figure 8D). This multi-peaked autocorrelation function, with large separations between the tallest peaks, reflects the multi-periodic nature of the grid code and explains why fields tend to appear or disappear at remote locations rather than shifting locally: modest weight changes in the grid-like inputs modestly alter the heights of the peaks, so that some of the well-separated tall peaks fall below threshold for activation while others rise above.
Quantitatively, insertion of a single field at an arbitrary location in a 20 m span grid-place weight plasticity results in the insertion or deletion, on average, of uncontrolled fields per meter. The insertion of four fields anywhere over 20 m results in an average of one uncontrolled field per meter (Figure 8E).
Thus, if a place cell were to add a field in a new environment or within a large single environment by modifying the grid-place weights, our results imply that it is extremely likely that this learning will alter the original grid-cell-driven field arrangements (scaffold). By contrast, adding fields that are driven by spatially specific external cues, though plasticity in the cue input-to-place cell synapses, may not affect field arrangements elsewhere if the cues are sufficiently sparse (unique); in this case, the added field would be a ‘sensory’ field rather than an internally generated or ‘mnemonic’ one.
In sum, the small separating capacity of place cells according to our model may provide one explanation for the high volatility of the place code across tens of days (Ziv et al., 2013) if grid-place weights are subject to any plasticity over this timescale. Alternatively, to account for the stability of spatial representations over shorter timescales, our results suggest that external cue-driven inputs to place cells can be plastic but the grid-place weights, and correspondingly, the internal scaffold, may be fixed rather than plastic (Figure 8F). In experiments that induce the formation of a new place field through intracellular current injection (Bittner et al., 2015), it is notable that the precise location of the new field was not under experimental control: potentially, an induced field might only be able to form where an underlying (near-threshold) grid scaffold peak already exists to help support it, and the observed long plasticity window could enable place cells to associate a plasticity-inducing cue with a nearby scaffold peak.
This alternative is consistent with the finding that entorhinal-hippocamapal connections stabilize long-term spatial and temporal memory (Brun et al., 2008; Brun et al., 2002; Suh et al., 2011).
Finally, we note that the robustness of place field arrangements obtained with grid-like inputs is not inconsistent with the volatility of field arrangements to the addition or deletion of new fields through grid-place weight plasticity. Grid-driven place field arrangements are robust to random i.i.d. noise in the inputs and weights, as well as the addition of nongrid sparse inputs. On the other hand, the volatility results involve associative plasticity that induces highly nonrandom weight changes that are large enough to drive constructive interference in the inputs to add a new field at a specific location. This nonrandom perturbation, applied to the distributed and globally active grid inputs, results in global output changes.
Discussion
Grid-driven hippocampal scaffolds provide a large representational space for spatial mapping
We showed that when driven by grid-like inputs, place cells can generate a spatial response scaffold that is influenced by the structural constraints of the grid-like inputs. Because of the richness of their grid-like inputs, individual place cells can generate a large library of spatial responses; however, these responses are also strongly structured so that the realizable spatial responses are a vanishingly small fraction of all spatial responses over the range where the grid inputs are unique. However, realizable spatial field arrangements are robust, and place cells can then ‘hang’ external sensory cues onto the spatial scaffold by associative learning to form distinct maps spatial maps for multiple environments. Note that our results apply equally well to the situation where grid states are incremented based on motion through arbitrary Euclidean spaces, not just spatial ones (Killian et al., 2012; Constantinescu et al., 2016; Aronov et al., 2017; Klukas et al., 2020).
Summary of mathematical results
Mathematically, formulating the problem of place field arrangements as a perceptron problem led us to examine the realizable (linearly separable) dichotomies of patterns that lie not in general position but on the vertices of convex regular polytopes, thus extending Cover’s results to define capacity for a case with geometrically structured inputs (Cover, 1965). Input configurations not in general position complicate the counting of linearly separable dichotomies. For instance, counting the number of linearly separable Boolean functions, which is precisely the problem of counting the linearly separable dichotomies on the hypercube, is NP-hard (Peled and Simeone, 1985; Hegedüs and Megiddo, 1996).
We showed that the geometry of grid-cell inputs is a convex polytope, given by the orthogonal product of simplices whose dimensions are set by the period of each grid module divided by the resolution. Grid-like codes are a special case of modular-one-hot codes, consisting of a population divided into modules with only one active cell (group) at a time per module.
Exploiting the symmetries of modular-one-hot codes allowed us to characterize and enumerate the realizable K-field arrangements for small fixed . Our analyses relied on combinatorial objects called Young diagrams (Fulton and Fulton, 1997). For the special case of modules, we expressed the number of realizable field arrangements exactly as a poly-Bernoulli number (Kaneko, 1997). Note that with random inputs, by contrast, it is not well-posed to count the number of realizable K-field arrangements when is fixed since the solution will depend on the specific configuration of input patterns. While we have considered two extreme cases analytically, one with no constraints on place field sparsity and the other with very few fields, it remains an outstanding question of interest to examine the case of sparse but not ultra-sparse field arrangements in which the number of fields is proportional to the full range, with a constant small prefactor (Itskov and Abbott, 2008). Finding results in this regime would involve restricting our count of all possible Young diagrams to a subset with a fixed filled-in area (purple area in Figure 5). This constraint makes the counting problem significantly harder.
We showed using analytical arguments that our results generalize to analog or graded tuning curves, real-valued periods, and dense phase representations per module. We also showed numerically that our qualitative results hold when considering deviations from the ideal, like the addition of noise in inputs and weights. The relatively large margins of the place field arrangements obtained with grid-like inputs make the code resistant to noise. In future work, it will be interesting to further explore the dependence of margins, and thus the robustness of the place field arrangements, on graded tuning curve shapes and the phase resolution per module.
Robustness, plasticity, and volatility
As described in the section on separating capacity, once grid-place weights are set over a relatively small space (about the size of the sum of the grid module periods), they set up a scaffold also outside of that space (within and across environments). Associating an external cue with this scaffold would involve updating the weights from the external sensory inputs to place cells that are close to or above threshold based on the existing scaffold. This does not require relearning grid-place weights and does not cause interference with previously learned maps.
By contrast, relearning the grid-place weights for insertion of another grid-driven field rearranges the overall scaffold, degrading previously learned maps (volatility: Ziv et al., 2013). If we consider a realizable field arrangement in a small local region of space then impose some desired field arrangement in a different local region of space through Hebbian learning, we might ask what the effect would be in the first region. Our results on field volatility provide an answer: if the first local region is of a size comparable to the sum of the place cell’s input grid periods, then any attempt to choose field locations in a different local region of space (e.g., a different environment) will almost surely have a global effect that will likely affect the arrangement of fields in the first region. A similar result might hold true if the first region is actually a disjoint set of local regions whose individual side lengths add up to the sum of input grid periods. This prediction might be consistent with the observed volatility of place fields over time even in familiar environments (Ziv et al., 2013).
Our volatility results alternatively raise the intriguing possibility that grid-place weights, and thus the scaffold, might be largely fixed and not especially plastic, with plasticity confined to the nongrid sensory cue-driven inputs and in the return projections from place to grid cells. The experiments of Rich et al., 2014 – in which place cells are recorded on a long track, the animal is then exposed to an extended version of the track, but the original fields do not shift – might be consistent with this alternative possibility. These are two rather strong and competing predictions that emerge from our model, each consistent with different pieces of data. It will be very interesting to characterize the nature of plasticity in the grid-to-place weights in the future.
Alternative models of spatial tuning in hippocampus
This work models place cells as feedforward-driven conjunctions between (sparse) external sensory cues and (dense) motion-based internal position estimates computed in grid cells and represented by multi-periodic spatial tuning curves. In considering place-cell responses as thresholded versions of their feedforward inputs including from grid cells, our model follows others in the literature that make similar assumptions (Hartley et al., 2000; Solstad et al., 2006; Sreenivasan and Fiete, 2011; Monaco et al., 2011; Cheng and Frank, 2011; Whittington et al., 2020). These models do not preclude the possibility that place cells feed back to correct grid-cell states, and some indeed incorporate such return projections (Sreenivasan and Fiete, 2011; Whittington et al., 2020; Agmon and Burak, 2020). It will be interesting in future work to analyze how such return projections affect the capacity of the combined system.
Our assumptions and model architecture are quite different from those of a complementary set of models, which take the view that grid-cell activity is derived from place cells (Kropff and Treves, 2008; Dordek et al., 2016; Stachenfeld et al., 2017). Our assumptions also contrast with a third set of models in which place-cell responses are assumed to emerge largely from locally recurrent weights within hippocampus (Tsodyks et al., 1996; Samsonovich and McNaughton, 1997; Battista and Monasson, 2020; Battaglia and Treves, 1998). One challenge for those models is in explaining how to generate stable place fields through velocity integration across multiple large environments: the capacity (number of fixed points) of many fully connected neural integrator models in the style of Hopfield networks tends to be small – scaling as states with neurons (Amit et al., 1985; Gardner, 1988; Abu-Mostafa and Jacques, 1985; Sompolinsky and Kanter, 1986; Samsonovich and McNaughton, 1997; Battaglia and Treves, 1998; Battista and Monasson, 2020; Monasson and Rosay, 2013) because of the absence of modular structures (Fiete et al., 2014; Sreenivasan and Fiete, 2011; Chaudhuri and Fiete, 2019; Mosheiff and Burak, 2019). There are at least two reasons why a capacity roughly equal to the number of place cells might be too small, even though the number of hippocampal cells is large: (1) a capacity equal to the number of place cells would be quickly saturated if used to tile 2D spaces: 106 states from 106 cells supply 103 states per dimension. Assuming conservatively a spatial resolution of 10 cm per state, this means no more than 100 m of coding capacity per linear dimension, with no excess coding states for error correction (Fiete et al., 2008; Sreenivasan and Fiete, 2011). (2) The hippocampus sits atop all sensory processing cortical hierarchies and is believed to play a key role in episodic memory in addition to spatial representation and memory. The number of potential cortical coding states is vastly larger than the number of place cells, suggesting that the number of hippocampal coding states should grow more rapidly than linearly in the number of neurons, which is possible with our grid-driven model but not with nonmodular Hopfield-like network models with pairwise weights between neurons.
Even if our assumption that place cells primarily derive their responses from grid-like inputs combined with external cue-derived nongrid inputs is correct, place cells may nevertheless deviate from our simple perceptron model if the place response involves additional layers of nonlinear processing. There are many ways in which this can happen: place cells are likely not entirely independent of each other, interacting through population-level competition and other recurrent interactions. Dendritic nonlinearities in place cells act as a hidden layer between grid-cell input and place cell firing (Poirazi and Mel, 2001; Polsky et al., 2004; Larkum et al., 2007; Spruston, 2008; Larkum et al., 2009; Harnett et al., 2012; Harnett et al., 2013; Stuart et al., 2016). Or, if we identify our model place cells as residing in CA1, then CA3 would serve as an intermediate and locally recurrent processing layer. In principle, hidden layers that generated a one-hot encoding for space from the grid-like inputs and then drove place cells as perceptrons would make all place field arrangements realizable. However, such an encoding would require a very large number of hidden units (equal to the full range of the grid code, while the grid code itself requires only the logarithm of this number). Additionally, place cells may exhibit richer input-output transformations than a simple pointwise nonlinearity, for instance, through cellular temporal dynamics including adaptation or persistent firing. Finding ways to include these effects in the analysis of place field arrangements is a promising and important direction for future study.
In sum, combining modular grid-like inputs produces a rich spatial scaffold of place fields, on which to associate external cues, much larger than possible with nonmodular recurrent dynamics within hippocampus. Nevertheless, the allowed states are strongly constrained by the geometry of the grid-cell drive. Further, our results suggest either high volatility in the place scaffold if grid-to-place-cell weights exhibit synaptic plasticity, or suggest the possibility that grid-to-place-cell weights might be random and fixed.
Numerical methods
Random, weight-constrained random, and shuffled inputs
Entries of the random input matrix are uniformly distributed variables in . To compare separating capacity (Figure 4) of random codes with the grid-like code, we consider matrices of the same input dimension (number of neurons) as the grid-cell matrix, or alternatively of the same rank as the grid-cell matrix, then use Cover’s theorem to count the realizable dichotomies (Cover, 1965). Weight-constrained random inputs (Figure 4B–D) are random inputs with non-negative weights imposed during training.
To compare margins (Figure 7), we use matrices with the same input dimension and number of patterns. As margins scale linearly with the norm of the patterns, to keep comparisons fair the input columns (patterns) are normalized to have unity L1 norm.
Nongrid inputs
To test how nongrid inputs affect our results (Figure 7C,D), the grid-like inputs from two modules with periods and are augmented by 100 additional inputs. In Figure 7C, each nongrid dense noisy input is a random variable selected uniformly and identically at each location from the uniform interval , where , and is the population mean of the grid inputs. In Figure 7D, each nongrid sparse input is a random variable with nonzero responses across the full range . We set . In all cases, input columns (patterns with grid and nongrid inputs combined) are finally normalized to have unity L1 norm. Results are based on 1000 realizations (samples) of the nongrid inputs.
Grid-like inputs with graded tuning curves
We generate periodic grid-like activity with graded tuning curves as a function of 1D space in cell of module with period as follows Sreenivasan and Fiete, 2011:
(7)
where the phase of module is . The ith cell in a module has a preferred activity phase drawn randomly and uniformly from (0,1). The tuning width is defined in terms of phase, thus in real space the width of the activity bump grows linearly with the module period. We set (thus the full-width at half-max of the phase tuning curve equals 3/8 of the period, similar to grid cells).
Finally, to simulate quasi-periodic grid responses in 1D, we first generate 2D responses with Gaussian tuning on a hexagonal lattice, with the same field width as above. 1D responses of grid cells from the same module are then generated as parallel 1D slices of this lattice as in Yoon et al., 2016, with phases uniformly drawn at random.
Appendix 1
The geometry of the grid code
In this Appendix, we introduce the geometrical framework for the study of place cells modeled as perceptrons reading out the activity of grid cells. First, we define the space of grid-like inputs via symmetry considerations and without considering explicitly their relation to spatial locations. Second, we discuss linearly separable dichotomies in the space of grid-like inputs, whose geometric arrangements are not in general position. Third, we show that the geometry of grid-like inputs is that of a polytope that can be decomposed as an orthogonal product of simplices.
The space of grid-like inputs
We model grid-cell activity via spatial patterns that take value 1 whenever the cell is active and take value 0 otherwise (Fyhn et al., 2004; Fiete et al., 2008). To model the periodic spatial response of grid cells, we assume that the activity pattern of a grid cell defines a periodic lattice with integer period . For simplicity, we consider 1D model for which the spatial patterns are -periodic vectors and for which the set of activity patterns is given by the lattices , . We refer to the index as the phase index of the grid-cell spatial pattern. Our key results will generalize to lattices of arbitrary dimension , for which the set of spatial patterns is given by the hypercube lattices , with phase indices in .
Within a population, grid cells can have distinct periods and arbitrary phases. To model this heterogeneity, we consider a population of grid cells with possible integer spatial periods , thereby defining modules of grid cells. We assume that each module comprises all possible grid-cell-activity patterns, that is, grid cells labeled by the phase indices , . For convenience, we index each cell by its module index and its phase index , , so that the actual component index of cell , , is . By construction of our model, at every spatial position, each module has a single active cell. Thus, at each spatial position, the grid-like input is specified by column vectors of dimension , the total number of grid cells.
In principle, the inputs to place cells are defined as spatial locations. Here, by contrast, we consider grid-like inputs as the inputs to place cells, without requiring these patterns to be spatial encodings. This approach is mathematically convenient as it allows us to exploit the many symmetries of the set of grid-like inputs denoted by . The set contains as many grid-like inputs as there are choices of phase indices in each module, that is, :
(8)
Here follow two examples of grid-like inputs enumerated in lexicographical order for and .
(9)
Observe that, albeit inspired by the spatial activity of grid cells, the set of patterns has broader relevance than suggested by its use for modeling grid-like inputs. In fact, the set of patterns describes any modular winner-take-all activity, whereby cells are pooled in modules with only one cell active at a time – the winner of the module.
In the following, we consider that linear read-outs of grid-like inputs determine the activity of downstream cells, called place cells (O’Keefe and Dostrovsky, 1971). The set of these linear read-outs is the vector space spanned by the grid-like inputs . The dimension of the vector space specifies the dimensionality of the grid code. The following proposition characterizes and shows that its dimension is simply related to the periods .
Proposition 1
The set of grid-like inputs specified by grid modules with integer periods span the vector space
(10)
In particular, the embedding dimension of the grid code is .
Proof. Let us denote by a matrix formed by collecting all the column vectors from . The vector space is the range of the matrix , which is also the orthogonal complement of . A vector in belongs to if and only if . By construction of the matrix :
(11)
where im refers to the index of the active cell in module . The latter characterization implies that
(12)
In turn, a vector of the orthogonal complement of , that is, in the range of , is determined by for all in . From the above characterization of , this means that is in the range of , that is, in , if and only if for all such that , we have
(13)
Substituting in the above relation, we have that for all in ,
(14)
which is equivalent to for all , . The above relation entirely specifies the range of the activity matrix , that is, , as a vector space of dimension .
Linear read-outs of grid-like inputs
We model the response of a place cell as that of a perceptron, which takes grid-like inputs in as inputs (Rosenblatt, 1958). Such a perceptron is parametrized by a decision threshold and by a vector of read-out weights , where the vertical separators delineate the grid-cell modules with periods , . By convention, we consider that a place cell is active for grid-like inputs such that and inactive otherwise. Thus, in the perceptron framework, a place cell has a multi-field structure if it is active on a set of several grid-like inputs , with (Rich et al., 2014). Considering grid-like inputs as inputs allows one to restrict the class of perceptrons under consideration.
Proposition 2
Every realizable multi-field structure can be implemented by a perceptron with non-negative weights, or with zero threshold.
Proof. If is the total number of modules and 1 is the -dimensional column vectors of 1, for all grid-like inputs in we have . Thus, for all perceptron and for all real µ, we have
(15)
where is the place-cell-activity level for grid-cell pattern in . Consequently, setting , and defines a new perceptron with non-negative weights, which operates the same classification as the perceptron is equivalent to The result directly follows from a similar argument by observing that for all grid-populations pattern in
(16)
which implies that if the perceptron models and achieve the same linear classification.
Our goal is to study the multi-field structure of place-cell perceptrons, which amounts to characterize the two-class linear classifications of grid-like inputs . The study of linear binary classifications has a long history in machine learning. Given a collection of input patterns, there are possible assignments of binary labels to these patterns, also referred to as dichotomies. In general, not all dichotomies can be linearly classified by a perceptron. Those dichotomies that can be classified are called linearly separable. An important question is to compute the number of linearly separable dichotomies, which depends on the geometrical arrangement of the inputs presented to the perceptron. Remarkably, Cover’s function counting theorem specifies the exact number of linearly separable dichotomies for inputs represented as points in a -dimensional space (Cover, 1965). For inputs in general position, the number of dichotomies realizable by a zero-threshold perceptron is given by
(17)
which shows that all dichotomies are possible as long as . A collection of points in an -dimensional space is in general position if no subset of points lies on a -dimensional plane for all . In our modeling framework, the inputs are collections of points representing grid-like inputs . As opposed to Cover’s theorem assumptions, these grid-like inputs are not in general position as soon as we consider grid code with more than one module. For instance, it is not hard to see that for , the patterns , , and are not in general position for being the vertices of a square, therefore lying in a 2D plane. Nongeneric arrangements of grid-like inputs are due to symmetries that are inherent to the modular structure of the grid code. We expect such symmetries to heavily restrict the set of linearly separable dichotomies, therefore constraining the multi-field structure of a place cell perceptron.
We justify the above expectation by discussing the problem of linear separability for two codes that are related to the grid code. These two codes are the ‘one-hot’ code, whereby a single cell is active for all input pattern, and the ‘binary’ code, whereby the set of input patterns enumerate all possible binary vectors of activity. Exemplars of grid-like inputs for the one-hot code and the binary code are given for input cells by
(18)
From a geometrical point of view, a set of points representing the grid-like inputs is linearly separable if there is a hyperplane separating the points from the other points . The existence of a hyperplane separating a single point from all other points is straightforward when the set of patterns correspond to the vertices of a convex polytope. Then, every vertex can be linearly separated from the other points for being an extreme point. It turns out that both the population patterns of the one-hot code and of the binary code represent the vertices of a convex polytope: a simplex for the single-cell code and a hypercube for the binary code. However, because these vertices are in general position for the single-cell code but not for the binary code, the fraction of linearly separable dichotomies drastically differs for the two codes.
Let us first consider the points whose coordinates are given by . The convex hull of is the canonical -dimensional simplex. Thus, any sets of vertices, , specifies a -dimensional face of the simplex, and as such, is a linearly separable -dichotomy. This immediately shows that all dichotomies are linearly separable. This result follows from the fact that the points in are in general position. Let us then consider the points whose coordinates are given by . The convex hull of is the canonical -dimensional hypercube. Thus, by contrast with , the points in are not in general position. As a result, there are dichotomies that are not linearly separable as shown by considering. For instance, the pair , and the pair , can be linearly separated from the other points of the hypercube. Determining the number of linearly separable sets of hypercube vertices is a hard combinatorial problem that has attracted a lot of interest (Peled and Simeone, 1985; Hegedüs and Megiddo, 1996). Unfortunately, there is no efficient characterization of that number as a function of the dimension . However, it is known that out of the possible dichotomies, the total number of linearly separable dichotomies scales as in the limit of large dimension (Irmatov, 1993). This shows that only a vanishingly small fraction of hypercube dichotomies are also linearly separable.
Grid code convex polytope
It is beneficial to gain geometric intuition about grid-like inputs to characterize their linearly separable dichotomies. As binary vectors of length , grid-like inputs form a subset of the vertices of the -dimensional hypercube. Just as for the one-hot and binary codes, linear separability of sets of grid-like inputs can be seen as a geometric problem about polytopes. To clarify this point, let us denote by the convex hull of grid-like inputs . By definition, we have
(19)
where in denotes the ith column of . The convex hull turns out to have a simple geometric structure.
Proposition 3
For integer periods , the convex hull generated by , the set of grid-cell-population patterns, determines a -dimensional polytope , with , defined as where , , denotes the -simplex specified by the points: .
Before proving the product decomposition of , let us make a couple of observations. First, observe that all the vectors in satisfies , so that all edges , with , in , lie in the same hyperplane of the vector space . By Proposition 1, has dimension , this implies that the dimension of the polytope is at most . Second, observe that the set is left unchanged by the symmetry operators , , where cyclically shifts downward the mth module coordinates of the vectors in . The operators admit the matrix representation
(20)
where denotes the identity matrix in . Notice that the matrices satisfy showing that the operators are isometries in . Moreover, observe that for all , in , there are integers of such that . This shows that each vector in plays the same role in defining the geometry of , and thus is vertex-transitive. In particular, every vector in represents an extreme point of the convex hull . As a result, is a polytope with as many vertices as the cardinality of , that is, . The product decomposition of the polytope then follows from a simple recurrence argument over the number of modules .
Appendix 1—figure 1
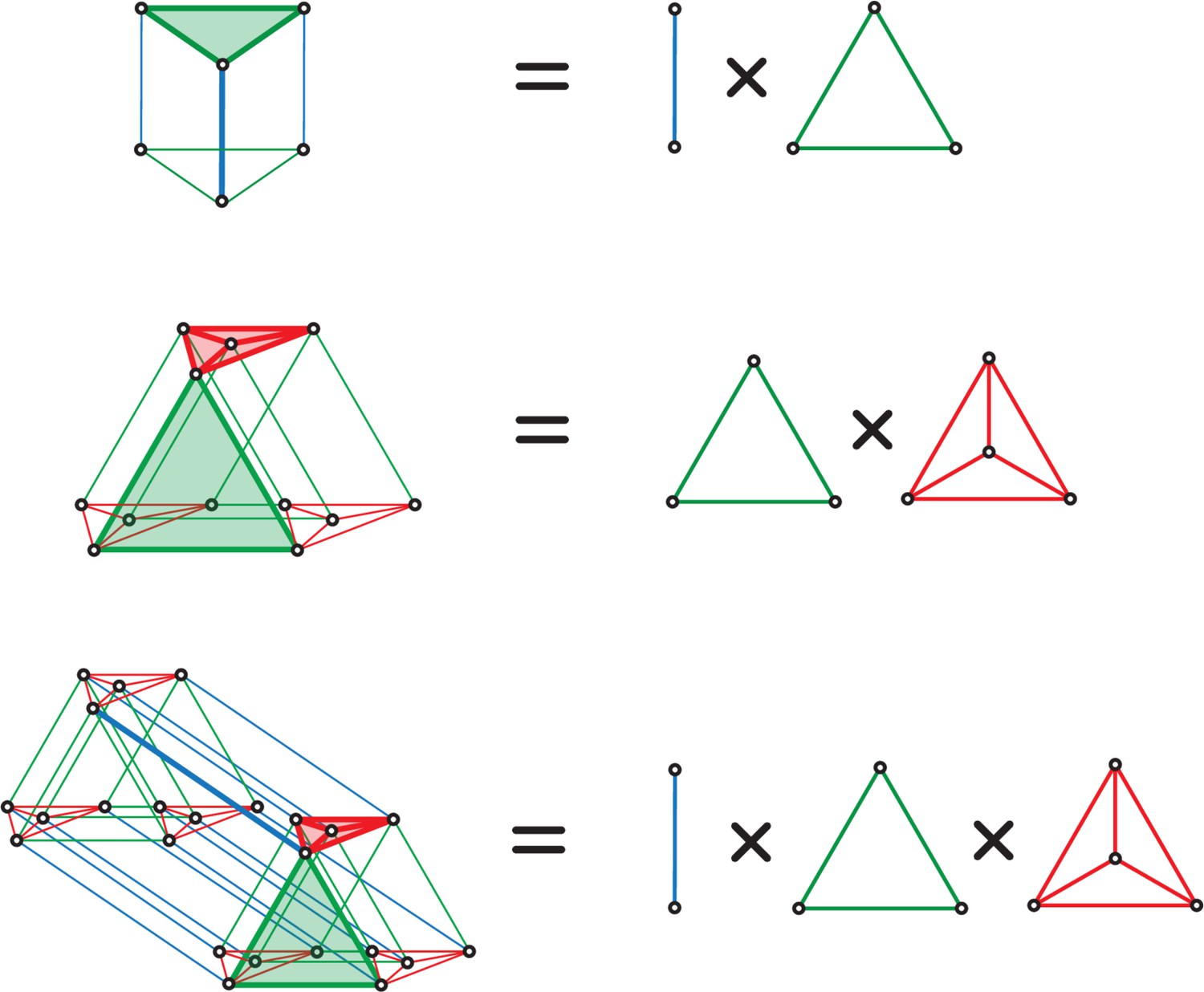
Simplicial decomposition.
The convex hull generated by the grid code activity patterns is a product of simplices.
Proof. In order to relate the geometrical structure of to that of simplices, let us introduce , , the elementary unit vector corresponding to the -th coordinate of . The set has the following product structure
(21)
where is the set of vectors for modules with periods . The product structure of the set transfers to the convex hull it generates. Specifically, we have
(22)
(23)
(24)
(25)
where we have recognized that the convex hull of the set of elementary basis vectors , , is precisely the canonical -simplex. Thus, we have shown that . Proceeding by recurrence on the number of modules, one obtains the announced decomposition of the convex hull as a product , where , , is the canonical -simplex.
The above orthogonal decomposition suggests that the problem of determining the linearly separable dichotomies of grid-like inputs is related to that of determining the linearly separable Boolean functions. Indeed, the polytope defined by grid-like inputs with modules contains -dimensional hypercubes, for which many dichotomies are not linearly separable. As counting the linearly separable Boolean functions is a notoriously hard combinatorial problem, it is unlikely that one can find a general characterization of the linearly separable dichotomies of grid-like inputs. However, it is possible to give some explicit results for the case of two modules or for the case of -dichotomies for small cardinality .
Appendix 2
Combinatorics of linearly separable dichotomies
In this Appendix, we establish combinatorial results about the properties and the cardinality of linearly separable dichotomies of grid-like inputs. First, we show that linearly separable dichotomies can be partitioned in classes, each indexed by a combinatorial object called Young diagram. Second, we exploit related combinatorial objects, called Young tableaux, to show that not all Young diagrams correspond to linearly separable dichotomies. Third, we utilize Young diagrams to characterize dichotomies for which one class of labeled patterns has small cardinality . Fourth, we count the exact number of linearly separable dichotomies for grid-like inputs with two modules.
Relation to Young diagrams
To count linearly separable dichotomies, we first show that these dichotomies can be partitioned in classes that are indexed by Young diagrams. Young diagrams are useful combinatorial objects that have been used to study, e.g., the properties of the group representations of the symmetric group and of the general linear group. Young diagrams are formally defined as follows:
Definition 1
A d-dimensional Young diagram is a subset D of lattice points in the positiveorthant of a d-dimensional integral lattice, which satisfies the following:
If and , then .
For any positive integer i ≤ d, and any non negative integers, m, p, with m > p, the restriction of D to the hyperplane ni = m is a (d−1)-dimensional Young diagram that covers the (d − 1)-dimensional Young diagram formed by the restriction of S to the hyperplane ni = p.
Moreover, the size of the diagram D, denoted by |D|, is defined as the number of lattice points in D.
Young diagrams have been primarily studied for d = 2 because their use allows oneto conveniently enumerate the partitions of the integers. For d = 2, there are differentconventions for representing Young diagrams pictorially. Hereafter, we follow the Frenchnotations, where Young diagrams are left justified lattice rows, whose length decreaseswith height. For the sake of clarity, Fig. 1a depicts the 5 Young diagrams associated to thepartitions of 4: 4, 3 + 1, 2 + 2, 2 + 1 + 1 and 1 + 1 + 1 + 1: Young diagrams have been less studiedfor dimensions d ≥ 3 and only a few of their combinatorial properties are known. Fig. 1brepresents a 3-dimensional diagram, together with two 2-dimensional restrictions (red edgesfor n3 = 1 and yellow edges for n3 = 3). Observe that these restrictions are 2-dimensionalYoung diagrams, and that the restriction corresponding to n3 = 1 covers the restriction corresponding to n3 = 3. Young diagrams can equivalently be viewed as arrays of boxesrather than lattice points in the positive orthant. This corresponds to identifying each latticepoint with the unit cube .
Before motivating the use of Young diagrams, let us make a few remarks about the set ofdichotomies that can be realized by a perceptron with fixed weight vector (ω, θ). First, recallthat with no loss of generality we can restrict the weight vectors ω to be nonnegative byProposition 2. Second, by permutation invariance, there is no loss of generality in consideringa perceptron (ω, θ) for which the weight vector.
(26)
is such that the weights are ordered within each module: , for all . We refer to weight vectors having this module-specific, increasing order propertyas being a modularly ordered weight vector. Bearing these observations in mind, the following proposition establishes the link between Young diagrams and perceptrons.
Proposition 4
Given integer periods , for all modularly ordered, non-negative, weight vectors and for all thresholds , the lattice set
(27)
is a -dimensional Young diagram in .
In other words, under assumption of modularly ordered, non-negative weights, the phase indices of inactive grid cells form a Young diagram.
Proof. The Young diagram properties directly follow from the ordering of weights within modules. For instance, it is easy to see that if for the component-wise partial order in , then implies . Indeed, we necessarily have
(28)
By the above proposition, given a grid code with modules, every perceptron acting on that grid code can be associated to a unique -dimensional Young diagram after ordering the components of within each module. Conversely, if a -dimensional Young diagram can be associated to a perceptron with modularly ordered, non-negative weights, we say that is realizable. Then a natural question to ask is: are all -dimensional Young diagrams realizable by perceptrons? It turns out that perceptrons exhaustively enumerate all -dimensional Young diagrams if , but there are unrealizable Young diagrams as soon as .
Relation to Young tableaux
Understanding why there are unrealizable Young diagrams as soon as involves using combinatorial objects that are closely related to Young diagrams, called Young tableaux.
Definition 2
Given a Young diagram , a Young tableau is obtained by labeling the lattice points – or filling in the boxes – of with the integers such that each number occurs exactly once and such that the entries are increasing across each row (to the right) and across each column (to the top).
Here are two examples of Young tableaux that are distinct labeling of the same Young diagram:
Appendix 2—scheme 1

Examples of Young tableaux.
Just as Young diagrams, Young tableaux are naturally associated to perceptrons. The following arguments specify the correspondence between perceptrons and Young tableaux. Given a perceptron with modularly ordered, non-negative weights, let us order all patterns in by increasing level of perceptron activity. Specifically, set and define iteratively for , ,
(29)
With no loss of generality, we can assume that all patterns achieve distinct levels of activity, so that there is a unique minimizer for all , . With that assumption, the sequence , , enumerates unambiguously all patterns in by increasing level of activity. The Young tableau associated to the perceptron , denoted by , is then obtained by labeling lattice points of the Young diagram by increasing level of activity as in the sequence , . One can check that such labeling yields a tableau as the resulting labels increase along each rows (to the right) and columns (to the top). Within this framework, we say that a Young tableau is realizable if there is a perceptron such that . Finally, let us define the sequence of thresholds , , such that , , and for
(30)
Then, observe that for all , , the set of active patterns is linearly separable for threshold satisfying . In fact, the sequence represents all the linearly separable dichotomies realizable by changing the threshold of a perceptron with weight vector . This fact will be useful to prove the following proposition, which justifies considering Young tableaux.
Proposition 5
All -dimensional Young diagrams are realizable if and only if all -dimensional Young tableaux are realizable.
Observe that the above proposition does not mention the periods . This is because the proposition deals with the correspondence between -dimensional Young diagrams and -dimensional Young tableaux for all possible assignments of periods.
Proof. In this proof, we use prime notations for quantities relating to modules and regular notations for quantities relating to modules. For instance, denotes an arbitrary assignment of periods and denotes its first components . With this preamble, we give the ‘if’ part of proof in and the ‘only if’ part in .
(i) Given a -dimensional Young tableau with diagram , let us consider the smallest periods such that . The ‘if’ part of the proof will follow from showing that if all -dimensional tableaux with Young diagram are realizable, than all -dimensional Young diagrams whose restriction to is are realizable. To prove this property, observe that all the -dimensional Young diagrams with restriction are obtained as finite sequences of -dimensional Young diagrams , for some specifying the minimum period in the mth dimension. For all such sequences, consider a tableau labeling such that for all , , the labels of are smaller than the labels . Such a tableau is always possible because of the nested property of the sequence of diagrams , . Now, suppose that the Young tableau is realizable. This means that there is a perceptron acting on the grid-like inputs in such that . With no loss of generality, the weight vector specifies a sequence of patterns , , and a sequence of thresholds , , such that enumerates the elements of by increasing level of activity and for all , the set of active patterns defined in (29) is linearly separable if and only if . Then by construction, the diagrams , , are realized by a perceptron , where every is such that . We are now in a position to construct a -module perceptron realizing the sequence . To do so, it is enough to specify the components of the Mth module of a weight vector since the other components will coincide with . One can check that choosing defines an admissible increasing sequence of non-negative weights.
(ii) For the ‘only if’ part, let us consider an arbitrary -dimensional Young tableau , with diagram such that . Then let us consider the -dimensional Young diagram obtained via the sequence of -dimensional diagrams , where for all , , is a singleton containing the lattice point labeled by . Moreover, let us consider the smallest periods such that . Now, suppose that all -dimensional Young diagrams are realizable. Then, there is a perceptron acting on with modularly ordered, non-negative weights such that . This means that for all , , the diagram is realized by the perceptron , where collect the components of that correspond to first modules. Then, let us consider the pattern represented by the lattice point in the singleton . Remember that a pattern is identified to the lattice point , whose coordinates are given by the phase of the active neuron within each module. Then, by the increasing property of the weights, we necessarily have , which implies that the Young tableaux is realized by the perceptron .
It is straightforward to check that all 1D Young tableaux are realizable, so that all 2D Young diagrams are realizable. However, the following counterexample shows that not all 2D Young tableaux are realizable, so that -dimensional Young diagrams with are not all realizable.
Counterexample 1. The 2D Young tableaux defined as
is not realizable.
Proof. Suppose there is a perceptron with modularly ordered, non-negative, weight vector realizing . By convention, we consider that the first module corresponds to the horizontal axis and the second module corresponds to the vertical axis. The labeling of implies order relations among read-out activities via . Specifically, the activities can be listed by increasing order as . We are going to show that such an order is impossible by contradiction. To do so, let us introduce the weight differences , associated to the first module and the weight differences , associated to the second module. These differences satisfy incompatible order relations. Specifically: the sequence in implies that the cost to go right, that is, , is less than the cost to go up, that is, . Otherwise, the label 2 would be on top the label 1. Thus, we necessarily have . The same reasoning for the sequence implies , so that we have The sequence implies , and the sequence implies , so that we have . Thus, assuming that is realizable leads to considering weights for which and —a contradiction.
Linearly separable dichotomies for realizable Young diagrams
Consider a Young -dimensional diagram that can be realized by a perceptron with modularly ordered, non-negative weights. Such a Young diagram is the lattice set whose points represent the phase indices of inactive grid-like inputs. Indeed, if , we have , which means that the perceptron is inactive for the grid-like input in obtained by setting for all . Thus, the perceptron implements the dichotomy for which the inactive grid-like inputs are exactly represented by . Are there more dichotomies associated to ? Answering this question requires revisiting the correspondence between perceptrons and Young diagrams. The key property in establishing this correspondence is the assumption of modularly ordered weights. In Section B.1, we justified that such an assumption incurs no loss of generality by permutation invariance of the grid cells within each modules. Thus, each Young diagram is in fact associated to the class of perceptrons
(31)
where denotes the set of permutation matrix stabilizing the modules of periods . Clearly, for , the perceptron generally implements a distinct dichotomy than that of . As a result, there is a class of dichotomies indexed by the Young diagram , which we denote by .
Evaluating the cardinality of via simple combinatorial arguments first requires a crude description of the geometry of , and specifically of its degenerate symmetries. For all , , let us denote the restriction of to the hyperplane by
(32)
By definition of the Young diagrams, we have for all . We say that a Young diagram exhibits a degenerate symmetry along the mth dimension whenever two consecutive restrictions coincide: . To make the notion of degeneracy more precise, let us consider the equivalence relation on defined by . Given in , the equivalence class of is then . Let us denote the total number of such equivalence classes by km, . Then, the set can be partitioned in km classes, , where the classes are listed by decreasing order of Young diagrams. For instance C1 comprises all the indices for which the restriction along the mth dimension yields the same Young diagram as . We denote the cardinality of the thus-ordered equivalence classes by , , so that we have . We refer to the as the degeneracy indices. Degenerate symmetries correspond to degeneracy indices . We are now in a position to determine the cardinality of :
Proposition 6
For integer periods , let us consider a realizable Young diagram in . Then, the class of linearly separable dichotomies with Young diagram , denoted by , has cardinality
(33)
where , are the degeneracy indices of the Young diagram along the mth dimension.
Proof. A dichotomy is specified by enumerating the set of inactive grid-like inputs in . Each pattern can be conveniently represented as a lattice point in by considering the phase indices of the active cell in the modules of pattern . Thus, a generic dichotomy is just a configuration of lattice points in . The class of dichotomies comprises all lattice-point configurations in obtained by permutations of the indices along the dimensions:
(34)
where we define
(35)
and where denotes the set of permutation of . Let us denote a generic lattice-point configuration in by . By permuting the indices of the points in , each transformation is actually permuting , , the restrictions of the lattice-point configuration along the mth dimension. The partial order defined by inclusion is preserved by permutations in the sense that given in , , we have if and only if . In particular, km, the number of restriction classes induced by the relation , is invariant to permutations, and so are their cardinalities. These cardinalities specify the degeneracy indices of along the mth dimension. Thus, all configurations obtained via permutation of have the same degeneracy indices as . Moreover, for a Young diagram , these degeneracy indices simply count the equivalence classes formed by restrictions of identical size along the same dimension. Thus, the number of dichotomies in is determined as the number of ways to independently assign the indices to km restriction classes of size for all , . For each , this number is given by the multinomial coefficient: .
As opposed to the case of random configurations in general position, the many symmetries of the grid-like inputs in allow one to enumerate dichotomies of specific cardinalities. We define the cardinality of a dichotomy by the size of the set of active pattern it separates. Thus, a perceptron realizing a -dichotomy is one for which exactly patterns in are such that . Proposition 7 reduces the problem of counting realizable -dichotomies to that of enumerating realizable Young diagrams of size . Such an enumeration depends on the number of modules , which sets the dimensionality of the Young diagrams, as well as the periods , . Unfortunately, even without considering the constraint of being a realizable Young diagram, there is no convenient way to enumerate Young diagrams of fixed size for general dimension . However, for low cardinality, for example, , there are only a few Young diagrams such that , and it turns out that all of them are realizable. In the following, and without aiming at exhaustivity, we exploit the latter fact to characterize the sets of -dichotomies for and to compute their cardinalities.
There are possible -dimensional Young diagram of size 2, according to the dimension along which the two lattice points are positioned. The Young diagram extending along the mth dimension, , has degeneracy indices and or and for . As a result, the number of 2-dichotomies of grid-like inputs is given by
(36)
There are two types of Young diagram of size 3, type for which the three lattice points span one dimension and type for which the lattice points span two dimensions. There are possible M-dimensional Young diagram of type . The degeneracy indices for the Young diagram extending along the mth dimension, , are and , and and for , yielding
(37)
There are possible -dimensional Young diagram of type , as many as choices of two dimensions among . The degeneracy indices of the Young diagram extending along dimensions and , , are and , and , and and for , yielding
(38)
(39)
As a result, the number of 3-dichotomies of grid-like inputs is given by
(40)
Appendix 2—figure 1
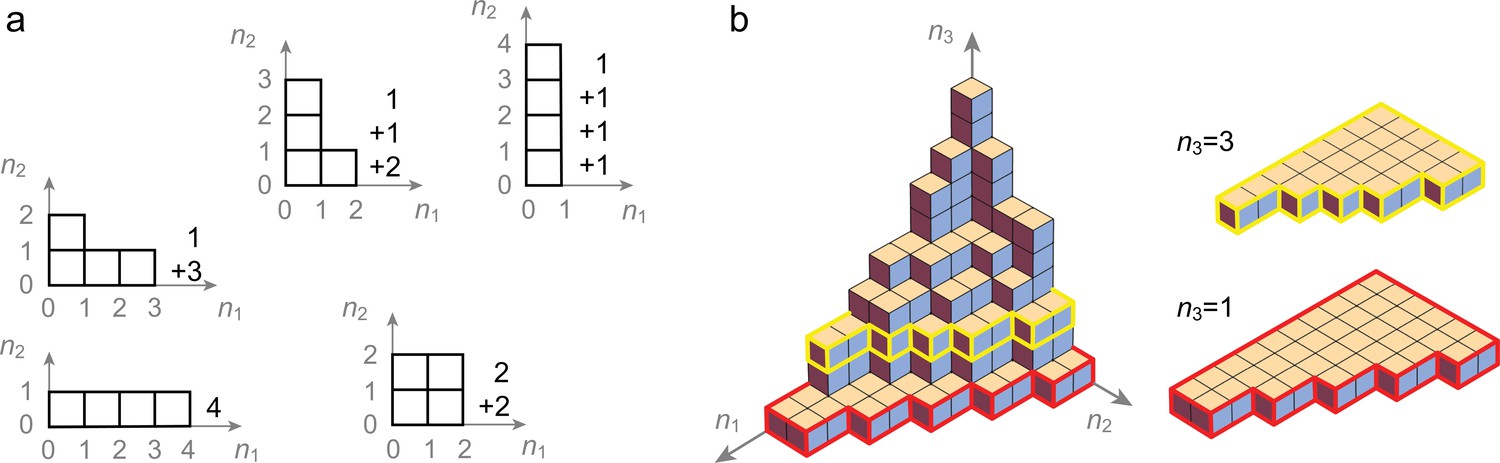
Multidimensional Young diagrams.
a. Lattice representations of the 2-dimensional Young diagrams of size 4, depicting the integer partitions of 4. b. Lattice representation of a 3-dimensional Young diagram with two 2-dimensional Young diagrams defined as horizontal restrictions.
Appendix 2—figure 2
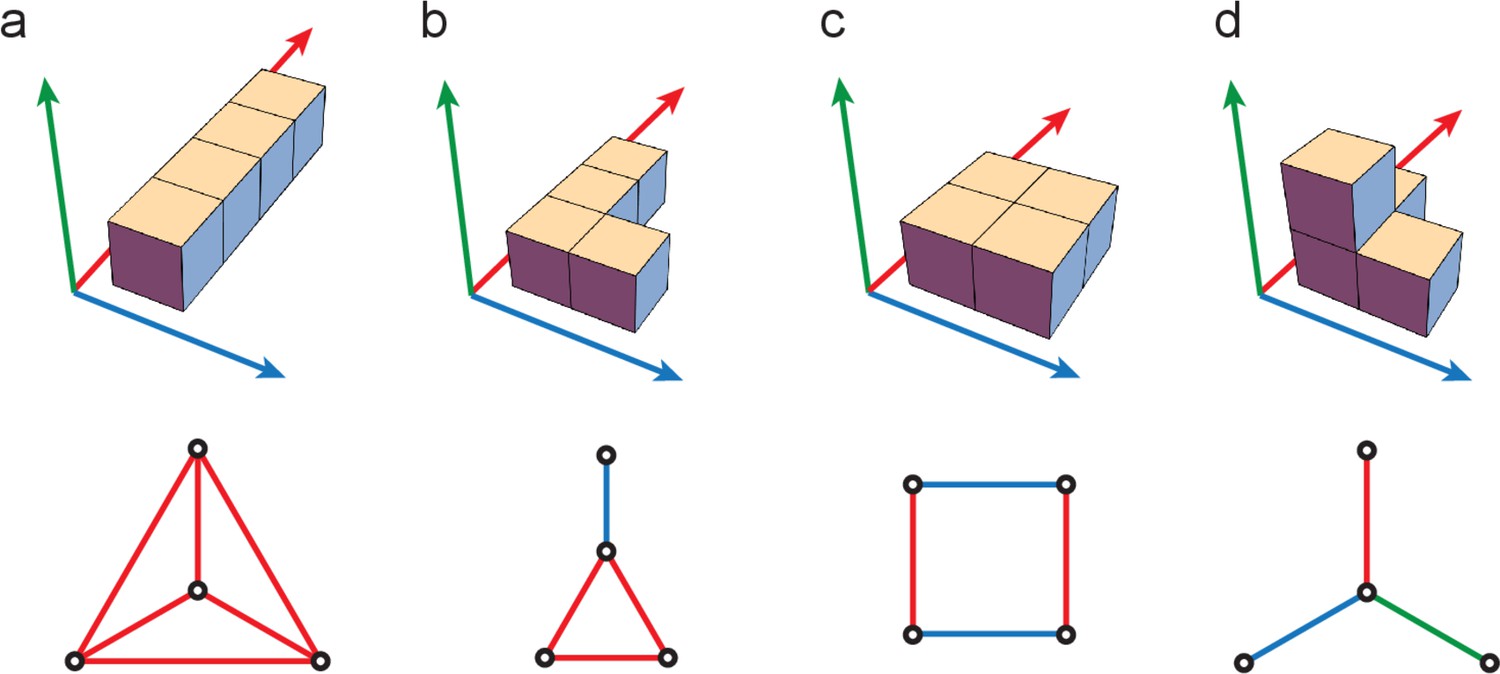
Linearly separable 4-dichotomies.
Top: there are four possible Young diagrams a, b, c, and d, of size 4, spanning at most three dimensions. Lattice points lying along the mth dimension represent grid-like inputs in whose coordinates only differ in the mth module. Bottom: Graphical edge structure arising from embedding a Young diagram within , the convex polytope defined by grid-like inputs.
A similar analysis reveals that there are four types of Young diagrams of size 4, which span up to three dimensions if . These Young diagrams, denoted by , , , and , are represented in Figure 6, where degeneracy indices can be read graphically. As a result, the number of 4-dichotomies of grid-like inputs is given by where the number of type-specific dichotomies is given by
(41)
(42)
(43)
(44)
The classification of dichotomies via Young diagrams also illuminates the geometrical structure of linearly separable -dichotomies, at least for small . In particular, 2-dichotomies are linearly separable if they involve two lattice points forming an edge of the convex polytope, that is, if these points correspond to patterns in whose coordinates only differ in one module. Similarly, 3-dichotomies are linearly separable if and only if they involve three lattice points representing patterns in whose coordinates only differ in one module or they involve two pairs of lattice points representing patterns in whose coordinates only differ in one module. Thus, corresponds to the case of three lattice points specifying a clique of convex-polytope edges, while corresponds to the case of three lattice points specifying two convex-polytope edges. We illustrate the four geometrical structures of the linearly separable 4-dichotomies in Figure 6.
Numbers of dichotomies for two modules
For two modules of period and , recall that each grid pattern in is a -dimensional vector, which is entirely specified by the indices of its two active neurons: , , . Thus, it is convenient to consider a set of grid patterns as a collection of points in the discrete lattice . From Proposition 4, we know that linearly separable dichotomies are made of those sets of grid patterns for which a Young diagram can be formed via permutations of rows and columns in the lattice (see Figure 7). By convention, we consider that the marked lattice points forming a Young diagram define the set of active grid patterns. The remaining unmarked lattice points define the set of inactive grid patterns. To each 2D Young diagrams in the lattice corresponds a class of linearly separable dichotomies. Counting the total number of linearly separable dichotomies when will proceed in two steps: (i) we first give a slightly stronger result than Proposition about the cardinality of the classes of dichotomies associated to a Young diagram, and (ii) we evaluate the total number of dichotomies by summing class cardinalities over the set of Young diagrams.
Proposition 7
For two integer periods and , let us consider a Young diagram in the lattice . Without loss of generality, can be specified via the degeneracy indices , and , chosen such that
(45)
Then, the class of linearly separable dichotomies with Young diagram , denoted by , has cardinality
(46)
where we have and .
Appendix 2—figure 3

Counting 2-module Young diagram.
Linearly separable dichotomies (left panel) can be associated to a unique Young diagram (middle panel). These Young diagrams are entirely specified by their frontier path, separating active positions from inactive ones. Enumerating all possible frontier paths allows one to count all the linearly separable dichotomies for two modules.
Proof. Consider a Young diagram in with inactive patterns. The diagram is uniquely defined by the row partition , , where ri denotes the occupancy of row , or equivalently by the column partition , , where sj denotes the occupancy of column . The occupancies and entirely define restrictions along each dimension and each set of occupancies along a dimension is invariant to row and column permutations. The corresponding degeneracy indices can be determined straightforwardly by counting the number of rows or columns with a given occupancy, that is, within a given equivalence class. Denoting the necessarily identical number of rows classes and columns classes by , Proposition yields directly the announced result.
Proposition 8
For two integer periods and , the number of linearly separable dichotomies in is
(47)
where denotes the Stirling numbers of the second kind and where denotes the poly-Bernoulli numbers.
Proof. Our goal is to evaluate the total number of dichotomies . To achieve this goal, we will exploit the combinatorics of 2D Young diagrams to specify as
(48)
where runs over all possible Young diagrams. Because of the multinomial nature of the cardinalities , it is advantageous to adopt an alternative representation for Young diagrams. This alternative representation will require utilizing the frontier of a Young diagram. Given a Young diagram with distinct nonempty rows and distinct nonempty columns, we define its frontier as the path joining the lattice points and , via lattice positions in separating the active region from the inactive region (see Figure 7). Such a path is uniquely defined via downward steps of size and rightward steps of sizes , which satisfy and . Clearly, the frontier of determines the cardinality of via (46). To evaluate in (48), we partition Young diagrams based on , the number of distinct row and column sizes. For , we have and , corresponding to Young diagram, the empty diagram, where all patterns are inactive. For , there is a single row and column size, corresponding to Young diagrams where the active patterns are arranged in a rectangle, with edge lengths and . Nonempty rectangular diagrams correspond to and , and thus contribute
(49)
(50)
to the sum (48). The contribution of diagrams with general -frontier, denoted by , follows from the multinomial theorem, where one ensures that frontiers with less than downward and rightward steps do not get repeated. These -frontiers correspond to sequences of downward and rightward steps for which no step has zero size, except possibly for the first downward step emanating from and the last rightward step arriving at . Under these conditions, the downward and rightward steps can be chosen independently, so that we can write , where the factors and only depend on the downward steps and rightward steps, respectively. Let us focus on the downward steps alone, that is, on the term . The admissible sequences of steps satisfy , with . From the multinomial theorem, we have
(51)
where the first term of the right-hand side is and the second term of the right-hand side collects the contribution of sequences that are not -frontiers. The latter term can be evaluated explicitly via the exclusion-inclusion principle yielding
(52)
(53)
(54)
where we have used the multinomial theorem for the last equality. Together with (51), the above equation allows one to specify in terms of the Sterling numbers of the second kind, denoted by , as
(55)
(56)
(57)
(58)
(59)
where the last equality follows from a well-known identity about Stirling numbers of the second kind. Then, the overall number of dichotomies follows from the fact that the frontier has at most distinct values of row/column sizes, which implies
(60)
where we have recognized the definition of the poly-Bernoulli numbers . These numbers are defined via the generating function
(61)
where denotes the poly-logarithm.
Poly-Bernoulli numbers were originally introduced by Kaneko to enumerate the set of binary -by- matrices that are uniquely reconstructible from their row and column sums (Kaneko, 1997). The use of poly-Bernoulli numbers to enumerate permutations of Young tableaux was pioneered by Postnikov while investigating totally Grassmannian cells (Postnikov, 2006). While studying the asymptotics of the extremal excedance set statistic, de Andrade et al., 2015 obtained the asymptotics of the poly-Bernoulli numbers along the diagonal:
(62)
Appendix 3
Spatial embedding of the grid code
In this Appendix, we address the limitations entailed by spatially embedding grid-like inputs. First, we define the grid-cell-activity matrix that specifies the spatial assignment of grid-like inputs for 1D space. Second, we show that the contiguous-separating capacity, defined as the maximum spatial extent over which all possible dichotomies are linearly separable, is determined by the rank of the grid-cell-activity matrix. Third, we generalize our results about the separating capacity to spaces of arbitrary dimensions.
Grid-cell-activity matrix for 1D space
The fundamental object of our combinatorial analysis is the polytope whose vertices have all possible grid-cell patterns as coordinates. Thanks to the many symmetries of this polytope, we can enumerate linearly separable dichotomies of grid-like inputs. However, such an approach makes no explicit reference the actual physical space that these grid-like inputs encode. Making these reference consists in specifying a mapping between spatial positions and grid-like inputs. Unfortunately, this generally involves breaking many of the polytope symmetries, precluding any combinatorial analysis. It is especially true if one considers spaces encoded by a subset of grid-cell patterns, as opposed to the full set , a situation that leads to considering nonsymmetrical polytopes.
Let us explain this point by considering the case of a discrete 1D space where each position is marked by an integer in . In this setting, positional information about is encoded by modules of grid cells with integer periods . Recall that each module comprises cells, each active at a distinct phase within the period , and that the corresponding repertoire of grid-like inputs has cardinality . Because the spatial activity of grid cells is periodic and because we consider a finite number of grid cells, the mappings between spatial positions and grid-like inputs are necessarily periodic functions . Let us denote by the period of . It is then convenient to consider the functions as matrices, called grid-cell-activity matrices, whose jth column is the pattern in that encodes the jth spatial position in , seen as the element in . In particular, the matrices have rows, each row corresponding to the periodic activity of a grid cell. Moreover, at every position , , each module has a single active cell. For the sake of clarity, here follows a concrete example of grid-cell-activity matrix for :
(63)
As the labelling of grid cells is arbitrary within a module, grid-population activity is actually represented by a class of matrices, which is invariant to permutation of the grid cells , , within a module . Here, with no loss of generality, we consider the class representatives obtained by ordering the grid cells by increasing phase within each module. This convention allows us to simply define the activity matrix via the introduction of a spatial shift operator . We define the shift operator as the linear operator that cyclically increments the phases by one unit within each module, that is,
(64)
where is the canonical circulant permutation matrix of order . We refer to as a shift operator because its action on any vector of corresponds to a positional shift by one unit of space: if , , denotes the jth column of , then if , and . Thus, we can define the grid-cell-activity matrix as the matrix obtained by enumerating in order the grid-cell patterns , , up to redundancies. Such a definition of the grid-cell-activity matrix prominently features the relation between the symmetries of the grid code and those of the actual physical space. In particular, it clearly shows that the formulation of our problem is invariant to rotation of the discretized space , that is, by shift in . We show that grid-cell-activity matrix can be similarly defined for lattice space of higher dimensions in Section C.3, including the relevant case of the 2D hexagonal lattice.
A key observation is that the periodicity , that is, the number of positions univocally tagged by grid-like inputs, is directly related to the periods via the Chinese remainder theorem. Indeed, by the Chinese remainder theorem, the first redundant grid-like input occurs for , therefore specifying the number of columns of the activity matrix. Thus, for pairwise coprime periods , , we have and the columns of the activity matrix exhaustively enumerate all grid-like inputs in . As a result, all the combinatorial results obtained for the full set of patterns directly apply over the full linear space for pairwise coprime periods. In particular, for pairwise coprime periods, we have by Proposition 1.
Unfortunately, our combinatorial results do not directly extend to a spatial context for integer periods that are not pairwise coprime or for incomplete spaces , . For non-coprime periods, we have , as exemplified by the grid-cell-activity matrix for given by
(65)
which comprises only four of the eight patterns of . Independent of the coprimality of the periods, the grid-cell-activity matrix over incomplete spaces is simply obtained by deleting the columns corresponding to the missing positions. In particular, we clearly have . Excluding some grid-like inputs has two opposite implications: (i) the total number of dichotomies is reduced in keeping with considering a smaller space but (ii) some dichotomies that were previously not linearly separable can become realizable. Disentangling these opposite implications is obscured by the many broken symmetries of the polytope formed by the subset patterns under consideration. For this reason, we essentially resort to studying spatial embedding of the grid code numerically. Such numerical analysis reveals, perhaps not surprisingly, that a key role is played by the embedding dimension of the grid code, especially in relation to the concept of contiguous-separating capacity.
Contiguous-separating capacity
We define the contiguous-separating capacity of a grid code as the maximum physical extent over which all possible dichotomies are linearly separable. Classically, for -dimensional inputs in general position, the separating capacity is defined as the maximum number of patterns for which all possible dichotomies are linearly separable, without any reference to contiguity. Within this context, Cover’s counting function theorem implies that the separating capacity equals the dimension of the input space. Should the grid-like inputs be in general position in the input space, the separating capacity would thus be equal to . However, being in general position requires that any submatrix formed by columns of be of rank for . This property does not hold for grid-cell-activity matrices. Moreover, we are interested in a stronger notion of separating capacity as we require that the grid-like inputs achieving separating capacity represent contiguous spatial position. Thankfully, the spatial symmetry of the grid-cell-activity matrices allows us to show that even under these restrictions the separating capacity is indeed .
Proposition 9
The contiguous-separating capacity of the generic grid-cell-activity matrix is equal to .
Proof.
The proof proceeds in two steps. With no loss of generality, we only consider linear classification via perceptron with zero threshold.
(i) By permutation and shift invariance, it is enough to consider contiguous columns of starting from the first column . From the definition of , the contiguous columns can be generated in terms of the shift operator as the sequence: . Let us consider the sequence defined by . Posit . If there is an integer such that , then necessarily dk is constant for , and is equal to . As and , the preceding observation implies that for . This shows that the contiguous columns , , are linearly independent, and thus are in general position in the input space. By Cover’s counting function theorem, all dichotomies obtained by labeling the positions with are linearly separable.
(ii) Considering an extra position, that is, including the column , produces at least a dichotomy that is not linearly separable. We proceed by contradiction. Assume that all dichotomies of the positions, that is, of the columns with , are linearly separable. By Cover’s counting function theorem, this is equivalent to assuming that all dichotomies of the first positions, that is, of the columns with , can be achieved by an -dimensional hyperplane passing through . In other words, for all -dichotomies in , there is a weight vector such that for and such that . However, by linear dependence, there are nonzero coefficients ai such that , so that for any -dichotomy, we can find achieving that dichotomy and such that
(66)
Considering a dichotomy for which for nonzero coefficients yields
(67)
which is a contradiction with (66).
The above proposition specifies as the contiguous-separating capacity for 1D spatial model. This rank also specifies the dimension of the space containing the subset of grid-like inputs to be linearly classified. For pairwise coprime periods , Proposition 1 shows that . The following proposition generalizes this result to generic integer periods.
Proposition 10
Let denote the grid-cell-activity matrix specified by M grid modules with integer periods . The rank of the activity matrix Aλ is given by
(68)
where is a subset of integer periods and denotes the cardinality of the set . If the periods are pairwise coprime, the above formula yields .
Proof. The proof will proceed in three steps.
(i) The first step is to realize that , where the vector spaces , , are generated by the rows of the mth module of the activity matrix. Then, the exclusion-inclusion principle applied to the sum of yields an expression for Aλ as the alternated sum:
(69)
(70)
By definition of the activity matrix, the space is generated by row vectors, which are cyclically permuted versions of the -periodic vector . In particular, these row vectors can be enumerated by iterated application of , the canonical -dimensional circulant permutation operator. The resulting sequence actually forms a basis of , identified to the space of -periodic vectors of length , and thus . The announced formula will follow from evaluation of the dimension of the intersection of the vector spaces .
(ii) The second step is to observe that one can specify the set of spaces , , as the span of vectors chosen from a common basis of , where we recall that . We identify such a common basis by considering the action of the operator on -dimensional periodic vectors. As a circulant permutation operator, admits a diagonal matrix representation in the basis of eigenvectors , ,
(71)
associated to the eigenvalue , where . Moreover, clearly preserves periodicity when acting on row vectors in , so that the spaces , , are stable by . As a consequence, each space can be represented as the span of a subset of the eigenvectors of . In principle, the existence of a basis spanning the spaces , , allows one to compute the dimension of the intersections of these spaces by counting the number of common basis elements in their span.
(iii)The last step is to show that counting the number of common basis elements in the subsets of yields the announced formula. Proving this point relies on elementary results from the theory of cyclic groups. Let us first consider the basis elements generating , which are the elements that are -periodic. These basis elements are precisely those for which , that is, in the cyclic group . Considering the integers as elements of , we can then specify the basis vectors generating by invoking the subgroup structure of the cyclic groups. Specifically, the basis elements generating are indexed by the elements of the unique subgroup of order in . Thus, as expected, the number of basis elements equates the otherwise known dimension of . Let us then consider the basis elements generating the intersection space , , which are the elements that are both -periodic and -periodic. These basis elements correspond to those indices for which we have and in the cyclic group , that is, for which in . By the subgroup structure of cyclic groups, the basis elements generating are thus indexed by the elements of the unique subgroup of order in . Thus, we have . The above reasoning generalizes straightforwardly to any set of indices , , leading to
(72)
Specifying the dimension of the intersection spaces in (69) derived from the exclusion-inclusion principle yields the rank formula given in (68).
Generalization to higher dimensional lattices
Our two results about (i) the number of dichotomies for grid code with two modules and about (ii) the separating capacity for an arbitrary number of modules generalize to an arbitrary number of dimensions. The generalization of (i) is straightforward as our results bear on the set of grid-like inputs with no reference to physical space. The only caveat has to do with the fact that for -dimensional lattice, each module , , contains cells so that has to be substituted for in formula (47). It turns out that the generalization of (ii) proceeds in the exact same way, albeit in a less direct fashion. In the following, we prove that the separating capacity for a -dimensional lattice model, including the 2D hexagonal lattice, is still given by the rank of the corresponding activity matrix.
A couple of remarks are in order before justifying the generalization of (ii):
First, let us specify how to construct activity matrices in d-dimensional space by considering a simple example. Consider the hexagonal-lattice model for two modules with . As illustrated in Figure 1, there are four possible 2-periodic lattices and nine possible 3-periodic lattices, each lattice representing the spatial activity pattern of a grid cell. Combining the encoding of the two modules yield a periodic lattice, with lattice mesh comprising positions. Every position within the mesh size is uniquely labeled by the grid-like input, and any subset of positions with larger cardinality has redundancy. Observe moreover that the lattice mesh is equivalent to that of a (2, 3)-square lattice, and in fact, the activity matrix for an (2, 3)-hexagonal lattice model is the same as that for a (2, 3)-square lattice. As a result, the spatial dependence of the grid-cell population is described by a matrix in with the following block structure:
(73)
In the above matrix , the top-two block rows represent the activity of 2-periodic cells, while the bottom-three block rows represent the activity of 3-periodic cells. By convention, we consider blocks and , comprising respectively two and three cells, represent the activity of grid cells along the horizontal -axis. There are two rows of blocks and three rows of blocks to encode 2-periodicity and 3-periodicity, respectively, along the vertical -axis. It is straightforward to generalize this hierarchical block structure to construct an activity matrix for arbitrary periods and arbitrary square-lattice dimension . In particular, the matrix has rows and columns.
Appendix 3—figure 1
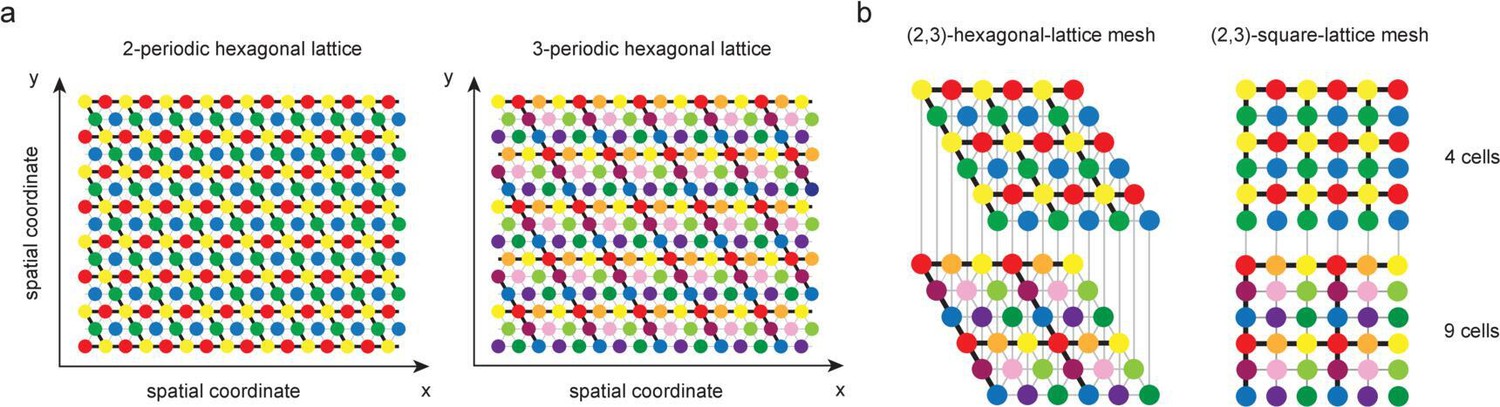
Hexagonal and square lattice in two dimensions.
(a) In two dimensions, 2-periodic and 3-periodic modules comprise respectively four and nine possible grid-cell-activity pattern. For instance, red, green, blue, and yellow patterns in the leftmost lattice correspond to the four possible patterns of activity that a 2-periodic cell can exhibit on an hexagonal lattice. (b) The maximum lattice mesh over which each position is uniquely encoded by the grid-like code is given as . Moreover, the hexagonal symmetry plays no role in our capacity calculations and one can consider a square lattice of positions instead.
Second, let us define the notion of contiguous-separating capacity for -dimensional lattice with . In one dimension, we define the contiguous-separating capacity as the maximum spatial extent for which all dichotomies involving its discrete set of positions are linearly separable. We generalize this notion for arbitrary dimensions by defining the contiguous-separating capacity as the maximum connected component of -dimensional positions for which all dichotomies are possible. Observe that thus-defined, we are rather oblivious about the geometric arrangement of this connected components. This is due to the fact that in dimension , the contiguous-separating capacity can be achieved by many distinct arrangements.
After these preliminary remarks, we can now prove the following proposition.
Proposition 11
The contiguous-separating capacity of the generic grid-cell-activity matrix is equal to , where we have
(74)
Proof. We only justify the formula for the case as similar arguments apply for all integers (see Remark after this proof). The proof will proceed in two steps: (i) we justify the formula for and (ii) we justify that the contiguous-separating capacity equals .
(i) We follow the same strategy as for dimension 1 to establish the rank formula for via exclusion-inclusion principle. The key point is to exhibit a basis of vectors in , with , which spans all the vector spaces , , where denotes the space of periodic functions on the -lattice mesh. To specify such a basis, we consider the two operators and acting on the grid-like inputs and representing the one-unit shift along horizontal -axis and along the vertical -axis, respectively. A basis of the space of periodic functions on the -lattice mesh is generated by iterated action of and on the activity lattice of a -periodic cell, that is, on a -row vector of the mth module of . Specifically, a basis of is given by the vectors , with and . Moreover, the operators and commute on , as by construction, shifting lattices by yields the same lattice as the one obtained by shifting the original lattice by . Thus, if and are diagonalizable, they can be diagonalized in the same basis , . Close inspection of the operators and reveals that they admit matrix representations that are closely related to the canonical -dimensional circulant matrix :
(75)
Concretely, the operator cyclically shifts columns within each blocks , whereas the operator cyclically shifts the blocks within . Considering the basis of eigenvector , , of , we define the basis , , as , where wi is the eigenvalue associated to . We have
(76)
(77)
which shows that is indeed a basis diagonalizing and . Moreover, as and stabilize the space , the basis spans the space , as well as all the spaces defined as intersections of subsets of . Consider the set of indices , , specifying the intersection . By the same reasoning as for dimension 1, the basis elements spanning are those eigenvectors that are -periodic in both -direction and -direction. As and , posing , this is equivalent to in . By the subgroup structure of cyclic group, the basis elements generating are thus indexed by where and are elements of the unique subgroup of order in . There are such basis elements, showing that
(78)
The rank formula follows immediately from expressing via the exclusion-inclusion principle.
(ii) Just as for , we follow the same strategy as for dimension 1 to show that the contiguous-separating capacity equals . The only caveat to address is that the grid-like inputs, that is, the columns of , are generated by the action of two shift operators instead of one. Specifically, starting from the first column of , we can generate all subsequent columns by action of the operators and , whose matrix representations are given by
(79)
(80)
Notice that and commute. By the same reasoning as for dimension 1, we know that the separating capacity cannot exceed . Then, to prove that the separating capacity equals , it is enough to exhibit a linearly independent set of contiguous positions with cardinality . Let us exhibit such positions. Mirroring the 1D case, let us consider the sequence defined by
(81)
The above sequence is strictly increasing by unit step until some l1, after which it remains constant at value
(82)
Let us then consider the sequence
(83)
The above sequence is also strictly increasing by unit step until some l2, after which it remains constant at value
(84)
Moreover, V2 admits for basis the vectors , and , . We can iterate this construction by repeated action of the operator , yielding a sequence of number lk and a sequence of space . Necessarily, the sequence lk becomes eventually zero as
(85)
Let us consider the smallest for which , than the set of vectors
(86)
is linearly independent by construction and generates the range of . In particular, we necessarily have . Observing that these vectors correspond to a connected component of positions concludes the proof.
Remark
Although we do not give the proof for arbitrary spatial dimension , let us briefly comment on extending the above arguments to higher dimension. Such a generalization is straightforward but requires the utilization of tensor calculus. For integer periods and generic dimension , the activity tensor can be defined as
(87)
where is the canonical basis vector associated to the coordinate in , with considered as an element of , and where is the linear form associated to the coordinate in . In tensorial form, the operators , , representing unit shift along the kth dimension, have the simple form such that
(88)
where is considered as an element of . The generalization to arbitrary -dimension follows from realizing that , , where is the eigenvector of associated to , form a basis diagonalizing all the operators , with .
Data availability
The authors confirm that the data supporting the findings of this study are available within the article. Implementation details and code are available at: https://github.com/myyim/placecellperceptron copy archived at https://archive.softwareheritage.org/swh:1:rev:8e03b880f47a1f0b7934afd91afb167f669ceeab.
References
-
Information capacity of the Hopfield modelIEEE Trans Inform Theory 31:461–464.https://doi.org/10.1109/TIT.1985.1057069
-
Storing Infinite Numbers of Patterns in a Spin-Glass Model of Neural NetworksPhysical Review Letters 55:1530–1533.https://doi.org/10.1103/PhysRevLett.55.1530
-
Conjunctive input processing drives feature selectivity in hippocampal CA1 neuronsNature Neuroscience 18:1133–1142.https://doi.org/10.1038/nn.4062
-
Do We Understand the Emergent Dynamics of Grid Cell ActivityJournal of Neuroscience 26:9352–9354.https://doi.org/10.1523/JNEUROSCI.2857-06.2006
-
Accurate Path Integration in Continuous Attractor Network Models of Grid CellsPLOS Computational Biology 5:e1000291.https://doi.org/10.1371/journal.pcbi.1000291
-
Past, Present, and Future of Simultaneous Localization and Mapping: Toward the Robust-Perception AgeIEEE Transactions on Robotics 32:1309–1332.https://doi.org/10.1109/TRO.2016.2624754
-
BookBipartite expander Hopfield networks as self-decoding high-capacity error correcting codesIn: Wallach H, Larochelle H, Beygelzimer A, Alché-Buc F, Fox E, Garnett R, editors. Advances in Neural Information Processing Systems 32. Curran Associates. pp. 7686–7697.
-
Maintaining a cognitive map in darkness: The need to fuse boundary knowledge with path integrationPLOS Computational Biology 8:e1002651.https://doi.org/10.1371/journal.pcbi.1002651
-
Understanding memory through hippocampal remappingTrends in Neurosciences 31:469–477.https://doi.org/10.1016/j.tins.2008.06.008
-
Geometrical and statistical properties of systems of linear inequalities with applications in pattern recognitionIEEE Transactions on Electronic Computers EC-14:326–334.https://doi.org/10.1109/PGEC.1965.264137
-
Asymptotics of the extremal excedance set statisticEuropean Journal of Combinatorics 46:75–88.https://doi.org/10.1016/j.ejc.2014.11.008
-
What Grid Cells Convey about Rat LocationThe Journal of Neuroscience 28:6858–6871.https://doi.org/10.1523/JNEUROSCI.5684-07.2008
-
BookYoung Tableaux: With Applications to Representation Theory and GeometryCambridge University Press.https://doi.org/10.1017/CBO9780511626241
-
ConferenceError accumulation and landmark-based error correction in grid cellsNeuroscience 2014.
-
On the geometric separability of Boolean functionsDiscrete Applied Mathematics 66:205–218.https://doi.org/10.1016/0166-218X(94)00161-6
-
Pattern capacity of a perceptron for sparse discriminationPhysical Review Letters 101:018101.https://doi.org/10.1103/PhysRevLett.101.018101
-
Making our way through the world: Towards a functional understanding of the brain’s spatial circuitsCurrent Opinion in Systems Biology 3:186–194.https://doi.org/10.1016/j.coisb.2017.04.008
-
ConferenceTraining recurrent networks to generate hypotheses about how the brain solves hard navigation problemsNIPS. pp. 4529–4538.
-
Efficient and flexible representation of higher-dimensional cognitive variables with grid cellsPLOS Computational Biology 16:e1007796.https://doi.org/10.1371/journal.pcbi.1007796
-
Dendritic Spikes in Apical Dendrites of Neocortical Layer 2/3 Pyramidal NeuronsThe Journal of Neuroscience 27:8999–9008.https://doi.org/10.1523/JNEUROSCI.1717-07.2007
-
Mobile robot localization by tracking geometric beaconsIEEE Trans Robot Autom 7:376–382.https://doi.org/10.1109/70.88147
-
Optimal Population Codes for Space: Grid Cells Outperform Place CellsNeural Computation 24:2280–2317.https://doi.org/10.1162/NECO00319
-
Path integration and the neural basis of the ’cognitive mapNature Reviews. Neuroscience 7:663–678.https://doi.org/10.1038/nrn1932
-
Modular realignment of entorhinal grid cell activity as a basis for hippocampal remappingThe Journal of Neuroscience 31:9414–9425.https://doi.org/10.1523/JNEUROSCI.1433-11.2011
-
Spatial firing patterns of hippocampal complex-spike cells in a fixed environmentJournal of Neuroscience 7:1935–1950.https://doi.org/10.1523/JNEUROSCI.07-07-01935.1987
-
Scikit-learn: Machine Learning in PythonJournal of Machine Learning Research 12:2825–2830.
-
Polynomial-time algorithms for regular set-covering and threshold synthesisDiscrete Applied Mathematics 12:57–69.https://doi.org/10.1016/0166-218X(85)90040-X
-
BookSequential Minimal Optimization: A Fast Algorithm for Training Support Vector MachinesMicrosoft Research Technical Report MSR-TR-98-14.
-
Computational subunits in thin dendrites of pyramidal cellsNature Neuroscience 7:621–627.https://doi.org/10.1038/nn1253
-
The perceptron: a probabilistic model for information storage and organization in the brainPsychological Review 65:386–408.https://doi.org/10.1037/h0042519
-
Path integration and cognitive mapping in a continuous attractor neural network modelThe Journal of Neuroscience 17:5900–5920.https://doi.org/10.1523/JNEUROSCI.17-15-05900.1997
-
From grid cells to place cells: A mathematical modelHippocampus 16:1026–1031.https://doi.org/10.1002/hipo.20244
-
Temporal Association in Asymmetric Neural NetworksPhysical Review Letters 57:2861–2864.https://doi.org/10.1103/PhysRevLett.57.2861
-
Pyramidal neurons: dendritic structure and synaptic integrationNature Reviews Neuroscience 9:206–221.https://doi.org/10.1038/nrn2286
-
Grid cells generate an analog error-correcting code for singularly precise neural computationNature Neuroscience 14:1330–1337.https://doi.org/10.1038/nn.2901
-
The hippocampus as a predictive mapNature Neuroscience 20:1643–1653.https://doi.org/10.1038/nn.4650
-
Cells of origin of entorhinal cortical afferents to the hippocampus and fascia dentata of the ratThe Journal of Comparative Neurology 169:347–370.https://doi.org/10.1002/cne.901690306
-
BookDendrites (Third edn)Oxford University Press.https://doi.org/10.1093/acprof:oso/9780198745273.001.0001
-
BookHow does the brain solve the computational problems of spatial navigation?In: Derdikman D, Knierim JJ, editors. Space, and Timeand Thememinipthermation Shippocampaformation. Springer. pp. 373–407.https://doi.org/10.1007/978-3-7091-1292-214
-
Laminar origin and septotemporal distribution of entorhinal and perirhinal projections to the hippocampus in the catThe Journal of Comparative Neurology 224:371–385.https://doi.org/10.1002/cne.902240305
-
Entorhinal cortex of the monkey: V. Projections to the dentate gyrus, hippocampus, and subicular complexThe Journal of Comparative Neurology 307:437–459.https://doi.org/10.1002/cne.903070308
-
Anatomical organization of the parahippocampal-hippocampal networkAnnals of the New York Academy of Sciences 911:1–24.https://doi.org/10.1111/j.1749-6632.2000.tb06716.x
-
Specific evidence of low-dimensional continuous attractor dynamics in grid cellsNature Neuroscience 16:1077–1084.https://doi.org/10.1038/nn.3450
-
Long-term dynamics of CA1 hippocampal place codesNature Neuroscience 16:264–266.https://doi.org/10.1038/nn.3329
-
BookAsymptotics of the Logarithm of the Number of Threshold Functions of the Algebra of LogicWalter de Gruyter.
Article and author information
Author details
Thibaud Taillefumier

Funding
Simons Foundation (Simons Collaboration on the Global Brain)
- Man Yi Yim
- Ila R Fiete
Howard Hughes Medical Institute (Faculty Scholars Program)
- Ila R Fiete
Alfred P. Sloan Foundation (Alfred P. Sloan Research Fellowship FG-2017-9554)
- Thibaud Taillefumier
Office of Naval Research (S&T BAA Award N00014-19-1-2584)
- Ila R Fiete
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
This work was supported by the Simons Foundation through the Simons Collaboration on the Global Brain, the ONR, the Howard Hughes Medical Institute through the Faculty Scholars Program to IRF, and the Alfred P Sloan Research Fellowship FG-2017-9554 to TT. We thank Sugandha Sharma, Leenoy Meshulam, and Luyan Yu for comments on the manuscript.
Version history
- Received: September 2, 2020
- Accepted: April 28, 2021
- Accepted Manuscript published: May 24, 2021 (version 1)
- Accepted Manuscript updated: May 26, 2021 (version 2)
- Version of Record published: July 21, 2021 (version 3)
Copyright
© 2021, Yim et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 1,267
- views
-
- 267
- downloads
-
- 8
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Place-cell capacity and volatility with grid-like inputs
eLife 10:e62702.
https://doi.org/10.7554/eLife.62702
Further reading
-
- Computational and Systems Biology
- Genetics and Genomics
We propose a new framework for human genetic association studies: at each locus, a deep learning model (in this study, Sei) is used to calculate the functional genomic activity score for two haplotypes per individual. This score, defined as the Haplotype Function Score (HFS), replaces the original genotype in association studies. Applying the HFS framework to 14 complex traits in the UK Biobank, we identified 3619 independent HFS–trait associations with a significance of p < 5 × 10−8. Fine-mapping revealed 2699 causal associations, corresponding to a median increase of 63 causal findings per trait compared with single-nucleotide polymorphism (SNP)-based analysis. HFS-based enrichment analysis uncovered 727 pathway–trait associations and 153 tissue–trait associations with strong biological interpretability, including ‘circadian pathway-chronotype’ and ‘arachidonic acid-intelligence’. Lastly, we applied least absolute shrinkage and selection operator (LASSO) regression to integrate HFS prediction score with SNP-based polygenic risk scores, which showed an improvement of 16.1–39.8% in cross-ancestry polygenic prediction. We concluded that HFS is a promising strategy for understanding the genetic basis of human complex traits.
-
- Computational and Systems Biology
Revealing protein binding sites with other molecules, such as nucleic acids, peptides, or small ligands, sheds light on disease mechanism elucidation and novel drug design. With the explosive growth of proteins in sequence databases, how to accurately and efficiently identify these binding sites from sequences becomes essential. However, current methods mostly rely on expensive multiple sequence alignments or experimental protein structures, limiting their genome-scale applications. Besides, these methods haven’t fully explored the geometry of the protein structures. Here, we propose GPSite, a multi-task network for simultaneously predicting binding residues of DNA, RNA, peptide, protein, ATP, HEM, and metal ions on proteins. GPSite was trained on informative sequence embeddings and predicted structures from protein language models, while comprehensively extracting residual and relational geometric contexts in an end-to-end manner. Experiments demonstrate that GPSite substantially surpasses state-of-the-art sequence-based and structure-based approaches on various benchmark datasets, even when the structures are not well-predicted. The low computational cost of GPSite enables rapid genome-scale binding residue annotations for over 568,000 sequences, providing opportunities to unveil unexplored associations of binding sites with molecular functions, biological processes, and genetic variants. The GPSite webserver and annotation database can be freely accessed at https://bio-web1.nscc-gz.cn/app/GPSite.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}