
Abstract
In this article we report a computational semantic analysis of the presidential candidates’ speeches in the two major political parties in the USA. In Study One, we modeled the political semantic spaces as a function of party, candidate, and time of election, and findings revealed patterns of differences in the semantic representation of key political concepts and the changing landscapes in which the presidential candidates align or misalign with their parties in terms of the representation and organization of politically central concepts. Our models further showed that the 2016 US presidential nominees had distinct conceptual representations from those of previous election years, and these patterns did not necessarily align with their respective political parties’ average representation of the key political concepts. In Study Two, structural equation modeling demonstrated that reported political engagement among voters differentially predicted reported likelihoods of voting for Clinton versus Trump in the 2016 presidential election. Study Three indicated that Republicans and Democrats showed distinct, systematic word association patterns for the same concepts/terms, which could be reliably distinguished using machine learning methods. These studies suggest that given an individual’s political beliefs, we can make reliable predictions about how they understand words, and given how an individual understands those same words, we can also predict an individual’s political beliefs. Our study provides a bridge between semantic space models and abstract representations of political concepts on the one hand, and the representations of political concepts and citizens’ voting behavior on the other.
Similar content being viewed by others


Introduction
Words are powerful tools for humans to express their thoughts, beliefs, and ideologies. An important goal of education is to enable people, through the use and understanding of words, to arrive at accurate mental representations of key concepts about our world and society. Outside of the classroom, scientists, philosophers, and politicians frequently debate the meanings of words, which often reflect different individuals’ conceptions of the world. In the current studies, we use machine-learning techniques to investigate how changes in the representation of politically charged concepts can be predicted by environmental factors like political affiliation and time. Furthermore, we explore the ability of a complex measure of what a word means to predict an individual’s political affiliation.
In this article, we demonstrate that one way to discern the conceptual representations of presidential candidates and of their supporters is by capturing the history of words used in their speeches through big data computational modeling. Our computational models, as shown in this study, can capture the conceptual differences between the major political parties in the USA, and importantly, reflect the changes in conceptual alignment (and misalignment) between individual candidates’ mental representations and those of their parties for a wide range of political concepts. Additionally, we show that for some politically charged concepts, accuracy for predicting an unknown individual’s political affiliation can be as high as 80%, suggesting that there is considerable systematicity in how members of distinct political parties represent concepts.
Semantic space models and conceptual representation
In the current studies, we use computational approximations of word meaning, known as semantic space models, to investigate changes in conceptual representation over time and across political parties. Semantic space refers to the aggregate of the contextual dimensions about meanings of words, or more precisely, the totality of how words are used in utterances or speeches (see Jones, Willits, & Dennis, 2015 for a review). A contextual dimension is an index of how often a given context is relevant to a “target word”. A context could be a word (e.g., “border”), word phrases (“border control”), sentences (“The two parties have different opinions on what measures to take for border control”), or entire speeches or texts, all of which serve as the aggregated context for a target word or concept such as “immigration.” By learning the statistical relations from large sets of data, computational semantic space models can derive an accurate representation of word meanings or concepts expressed by words or phrases. In principle, a computational model of a semantic space can be derived from an exhaustive record of all the texts or speeches of an individual (e.g., all of Donald Trump’s speeches) or a group (e.g., all of the presidential candidates’ speeches in the Republican Party since Abraham Lincoln). In practice, such a model is typically built on a restricted set of texts or speeches, for a restricted time period, to reflect the semantic memory or conceptual representation history of individuals (e.g., Clinton vs. Trump) or groups (e.g., modern English speakers vs. English speakers of the Chaucer era).
To implement the computational models, researchers have developed algorithms that can effectively analyze semantic information distributed in text (i.e., the “distributional statistics”), specifically by learning the co-occurrence statistics that hold among words, phrases, sentences, paragraphs, or entire documents (see Li & Zhao, 2017, for a recent review). For example, one model may calculate the co-occurrence frequencies of a target word (“immigration”) with all the other words in a text or speech (which could include “immigrants,” “naturalization,” “deportation,” etc.) while another model may compute the co-occurrence frequencies of the word with all documents in which the word appears (e.g., all the Wikipedia pages that contain the word “immigration”). Previous co-occurrence-based models, most notably the Hyperspace Analogue to Language model (HAL; Lund & Burgess, 1996) and the Latent Semantic Analysis model (LSA; Landauer & Dumais, 1997), have used these methods to derive semantic representations. In such a representation, a word or a concept is a multi-dimensional vector based on co-occurrences, with each dimension corresponding to the target word’s context and the numerical value of the dimension to the strength of the co-occurrence between the context and the word. For example, HAL uses a variable moving window that scans through a large corpus of text and records the word-to-word co-occurrences. The resulting NwxNw matrix includes the frequency counts of how often each target word (n i ) co-occurs with other words (n j;i≠j ) in the sentences. A word’s meaning is then referenced to all the other words in the co-occurrence matrix, with row N i. representing the total contextual history of word ni. In the LSA model, the NwxND matrices are the frequencies of co-occurrence between words (Nw) and documents (ND), rather than NwxNw as in HAL. Thus, the semantic richness of a word or concept in this type of model depends on the complexity of the computed vectors or matrices.
HAL, LSA, and similar computational semantic space models have been well tested and extensively validated in the literature as powerful models to capture semantic representations of words and concepts (see Jones et al. 2015 for a recent review). Recently, Google’s word2vec has become a popular computational model for deriving semantic spaces (Mikolov et al., 2013a, b, c). Like other models, word2vec also exploits the distributional statistics from large text or speech corpora to compute semantic representations of words and concepts. Unlike other models, however, word2vec learns the distributional statistics by using a neural network algorithm, specifically the back-propagation algorithm (Rumelhart, Hinton, & Williams, 1986), according to which weight vectors are formed and adapted between the input nodes (the context) and the output nodes (the target) that are mediated through an intermediate layer of nodes (the “hidden units”). Using a set of computational heuristics (e.g., hierarchical softmax and negative sampling), word2vec effectively learns semantic representations and can handle large sets of text and speech data in an efficient manner. Given word2vec’s wide application and its tested reliability and efficiency, in this study we have adopted word2vec as the basis of our computational model for generating the semantic spaces of political concepts.
Computational modeling of individual beliefs and attitudes
Although much of the early semantic modeling effort was directed toward accurately capturing semantic representations in vector spaces (Burgess & Lund, 1997; Landauer & Dumais, 1997; Li, Burgess, & Lund, 2000), an implicit assumption of this work has been that the distributional statistics in text and speech reflect the organization of words and concepts in our mental space: words that are nearby in physical spaces (e.g., used together in speech, occurring in the same sentences or documents) are also words that are close in our mental space, because word usage reflects how our minds represent the word’s meanings. Words that co-occur together are most likely the words that evoke connected memories and associated ideas in our minds. These relationships are accurately reflected in the statistics captured by computational models as described.
The close correspondence between word meanings and language usage has motivated a new round of thinking about how computational models can capture individual differences in reading, writing, understanding, and knowledge in general (Landauer et al., 2013). Not surprisingly, computational semantic space models have also been successfully applied to account for patterns of brain activation, with a great deal of predictive accuracy and focal precision (Bullinaira & Levy, 2013; Mitchell et al., 2008; Schloss & Li, 2016), indicating that this data-driven approach is both psychologically and neurobiologically plausible. In a recent computational study, Caliskan et al. (2017) used a word-embedding model (GloVe, very similar to word2vec used in this study; see Method under Study One) and showed that the model can capture implicit human biases: semantic space vectors generated from the GloVe model’s text analyses showed stronger similarities (as measured by cosine similarity scores) between pairs of words that are stereotyped human associations, for example, between male names and words related to career versus female names and words related to family, and between male terms and science versus female terms and arts. These associations based on semantic space similarities reflect implicit human biases, which are in turn reflected in the statistical properties of human language in big-data text corpora. Caliskan et al.’s study demonstrated that proper semantic space modeling of the statistical properties of language and speech would provide us with the ability to identify not just the conceptual relationships of words but also, more generally, human attitudes and beliefs. This computational approach toward identifying semantic associations and ideological relations was also used in Holtzman et al. (2011), in which cable news transcripts were analyzed to reveal implicit biases of different television channels and newscasters, e.g., MSNBC versus FoxNews in associating words of positive versus negative valences with liberal versus conservative values. The Caliskan et al. and Holtzman et al. studies thus provide a sound basis for studying political attitudes and conceptual organization based on computational analysis of text corpora, as we attempt here.
Given the role of computational models in capturing word meaning and concept representation, in the first study we ask how such models can faithfully capture meaningful variations in the representation of politically charged abstract nouns across groups and individuals. In particular, we explore the semantic spaces generated from American presidential debates during the period 1999–2016, and model how key political concepts are organized in different political parties and in individual presidential candidates (referred to below as “political semantic spaces”). Abstract political concepts have been previously shown to reflect party affiliations in semantic space models: using the BEAGLE model (Jones & Mewhort, 2007) on a set of 80 words from the State of the Union addresses by Presidents Bush and Obama, Kievit-Kylar and Jones (2012) showed that the concepts of economy and education are much more connected in Obama’s speeches, whereas the concepts of war and terrorism had stronger connections in Bush’s speeches. Moreover, the same concepts (e.g., security) were differentially connected to different terms (e.g., to military security in Bush’s speeches vs. job security in Obama’s speeches). However, it is unclear whether these differences were due to party differences in general or to the specific times when the presidential addresses were given, for example during the Bush years when war on terror was the key policy versus the Obama years when a focus on the economy was a key issue.
The current study
In our study reported here, we focused on the presidential debates as documented in the American Presidency Project (Peters & Woolley, 2016). We chose the presidential debates as input data for the semantic space models because the candidates’ speech is relatively spontaneous. In these debate speeches, individual word choices occur in a matter of milliseconds and may be subject to subtle and potentially implicit associations that reflect more natural thoughts and beliefs than scripted speeches. Differences in the distributional statistics of individual words used by different candidates therefore should reflect important differences in how concepts are organized and structured. In Study One, we therefore constructed computational semantic space models from the presidential debates and compared the changing profiles in the conceptual organization in the Democratic versus the Republican Party, both generally and over time (from 1999 to present). We further identified how the 2016 presidential nominees align or misalign with the overall representations of their respective parties and with each other.
In Studies Two and Three, we explored a related idea with human subjects from Amazon’s Mechanical Turk (MTurk). We analyzed the reliability of MTurk participants’ survey responses as well as the relationship between reported political engagement and voting behavior in the 2016 American presidential election. We further explored the relationship between individuals’ political attitudes and behavior and their representation of political concepts. Specifically, we were interested in the possibility that systematic differences in the aggregate linguistic experiences of Democrats and Republicans will be reflected in how participants organize a subset of politically charged concepts that we also used in the computational Study One. A machine-learning algorithm was used to predict the political affiliations based on the conceptual representations of the individuals.
In sum, our research aims to provide a bridge between semantic space modeling and the representation of abstract political concepts. Specifically, we aimed to demonstrate that computational analyses of semantic spaces from text corpora can represent key individual and group differences in society, in this case, political attitudes and ideologies, and, more importantly, how such representations may evolve and change over time for the individuals (e.g., presidential candidates) and groups (their respective political parties). Furthermore, we aimed to underscore the complementary roles of individuals’ beliefs (i.e., reported political engagement or interest in political topics) and their mental associations among political concepts in predicting voter political affiliation and behavior. Thus, our study also served to link computational modeling with citizens’ political activism and behaviors.
Study One: Semantic space modeling of political concepts in presidential candidates’ speeches
Method
The meanings of politically charged words as used by the two major American political parties at different points in time as well as the 2016 presidential nominees and a population of voters were estimated separately, based on spontaneous speech from primary election debates, and then compared. We also compared the party alignment of major candidates from the 2016 election by feeding the debates into the model in chronological order and sampling the relationships between candidates and their respective political parties at different time-points. We used the learned semantic representations to identify words that are both disproportionately important to a single party and that are relatively equal in terms of their importance based on graph analyses of the centrality of each of the politically charged words in the semantic spaces. Finally, we compared word associations generated from human raters with those from computational models to identify similarities and differences between presidential candidates’ representations of these terms and non-political everyday representation of the same terms.
Input corpus and key terms
The input corpus to our computational model is based on publicly available presidential speeches and documents, all in machine-readable text format. We selected only primary Republican and Democratic presidential debate transcripts between the years 1999 and 2016 from the Presidential Document Archive of the American Presidency Project (http://www.presidency.ucsb.edu/index_docs.php), a non-profit and non-partisan document archive hosted at the University of California, Santa Barbara, CA (Peters & Woolley, 2016; http://www.presidency.ucsb.edu/). We did not use data from election years 2004 and 2012 because there was an incumbent who ended up winning the election, as we were more interested in tracking changes over time on political concepts based on party lines.
To select from this database the keywords/terms that represent the politically charged concepts, we used a combination of human judgment and computational analyses. The corpus was cleaned by identifying named entities and combining them into single words, removing stop words, removing inflections from nouns, verbs, and adverbs, and lemmatizing the resulting words using the POS (part of speech) tagger and named entity recognizer from Stanford Natural Language Toolkit, an open-source software for the analysis of language and speech corpora (http://nlp.stanford.edu/software). The words were first passed through an algorithm that (a) favored nouns that were used frequently in the debates and (b) avoided nouns that were used disproportionately by any single political party. This was achieved as follows: each word identified as a noun by the POS tagger was assigned a score, which was equal to the sum of the normalized frequency of that word in all of the debates for each party divided by the difference in these normalized frequency scores. This was to ensure that the selected nouns were both important and as non-partisan as possible because words that were used disproportionately by only one party received lower scores. A subset of high-scoring nouns was then manually selected by the researchers. We also included noun phrases because many political concepts are expressed by two or more words (e.g., “health care”). The noun phrases were first passed through an algorithm that identified sets of nouns that were more likely to co-occur with each other than with other words. The noun phrases were then combined into “single words” in the corpus so the model would learn a distinct representation for each noun phrase. The final list of words included a total of 213 single word and 397 word phrases as the key concepts. A subset of these – the 136 words as shown in Fig. 1 – is presented in Table 1. This subset of 136 words met one further criterion, which was that the word had to appear at least five times in the input to any semantic space. For example, when building a semantic space for Donald Trump, the word had to appear five or more times in Donald Trump’s speech. If comparing Donald Trump, Hillary Clinton, and the Republican and Democratic parties across all time points, then the word had to appear at least five times in each candidate’s speech, and in the documents corresponding to the parties and time points.

Similarity of political semantic spaces as a function of party and time of election. (A–C) The similarity matrices of each year, 2000, 2008, 2016, respectively; (D) is the multi-dimensional scaling display of the semantic spaces of three election times by party. DEM Democratic Party, REP Republican Party
Model algorithm
A three-layer artificial neural network as implemented in the word2vec model (Mikolov et al., 2013a, b, c; see also https://code.google.com/p/word2vec/) is used to learn the distributional statistics among words and contexts from the input corpus (see Input Corpus and Key Terms). Like other computational semantic space models, word2vec exploits the semantic information distributed in large-scale text or speech corpora, specifically by learning the co-occurrence statistics that hold among words and contexts (which could include words, phrases, sentences, or entire documents, as discussed in the Introduction). However, it learns the distributional statistics by using a neural network algorithm, specifically the back-propagation algorithm (Rumelhart et al., 1986), according to which the network updates its connection weights as follows: each time the network is presented with an input-to-output mapping, the discrepancy (or error) between the target output and the actual output is calculated; this error is then propagated back to the network so that the relevant connection weights can be updated relative to the amount of error present, so that over time the network’s connection weights will be optimized for producing the desired output given new input patterns.
There are two major mechanisms implemented in word2vec: (a) Skip-gram (SG): given a target word, the network predicts the context associated with the word (e.g., multiple words co-occurring with the target word), and (b) Continuous bag-of-word (CBOW): given a continuous set of word strings as the context, the network finds the target word that best fits in the context. In our modeling, we trained the model using both algorithms as implemented in Python’s Gensim package (Rehurek, 2010) and concatenated the representations into vectors with 4,000 dimensions. The decision to use concatenated vector representations was based on the consideration that (a) the two algorithms may be sensitive to different types of word associations (e.g., dominant, paradigmatic, vs. non-dominant associations), which may implicate different processing mechanisms (Jung-Beeman, 2005), and (b) previous work has suggested that concatenated vectors can in some cases provide increased accuracy in representing subtle semantic differences (Fyshe et al., 2013; Schloss & Li, 2016).Footnote 1 We used word2vec’s default settings, with a window size of five and a minimum word-count of five (words that were used less than five times were excluded) for all models reported below except for the time-course analysis. As reported in Fig. 2, we used the initial 2,000 dimensions from the Fyshe semantic spaces (Fyshe et al., 2013), and updated the vectors based on the BEAGLE model’s algorithm for updating semantic information (Jones & Mewhort, 2007). This implements an episodic memory model of semantic learning that simulates continuous changes over time. The purpose of this model was to plot gradual changes in the semantic space over the course of the presidential debates (see Fig. 2). Although we used a different learning algorithm for this analysis, we kept the same window size and minimum word cut-off threshold as in the word2vec models. Furthermore, we only used the debates from 2015–2016 for this analysis, and they were entered into the model in chronological order.

(A) Macro-changes in the political semantic spaces over time. Blue: similarity between semantic spaces within the Democratic (DEM) Party at two time points; Red: within the Republican (REP) Party at two time points; Gray: between parties at two time points. (B) Micro-changes in semantic spaces during the primary election period of the 2016 presidential election
Construction of political semantic spaces
To derive semantic space vectors based on documents of presidential debates, we initialized the vectors of all target words as follows: (a) vectors that did not correspond to the political concepts in Table 1 were assigned the Fyshe vector representation with 2,000 dimensions; and (b) vectors that were neither in the Fyshe model vocabulary nor in the list of words in Table 1 were assigned a random vector based on a normal distribution from the average value and standard deviation of each of the 2,000 dimensions in the Fyshe vectors that were used in our model (Fyshe et al., 2013). The Fyshe vectors were calculated from a generic, politically neutral, 16-billion word and 50-million document corpus (Callan and Hoy, 2009). When training the model, a single semantic space was constructed each time, but the political concepts were allowed to vary individually so that candidate-specific, party-specific, or time-specific semantic vectors could be constructed depending on the goal of each analysis. This was achieved by tagging each politically charged word with a unique marker, for example, “_c” for Hillary Clinton. Thus, the model treated “economy_c” (for Clinton) and “economy_t” (for Donald Trump) as separate words. This method then allowed us to compare the word “economy” as it was used by Clinton versus that used by Trump. Different numbers of words contributed to each analysis depending on the specific semantic space derived (and how they were tagged) as a function of party, candidate, and election year. For example, if the word “child_education_c” and “child_education_t” did not appear five times in Clinton’s and Trump’s speech, the concept “child_education” was excluded. The minimum word cut-off was to ensure that there was enough data to build an accurate representation of a given word. In cases where we compared entire political parties or political parties at certain time points, all speeches in the corresponding debates tagged as belonging to a specific party were entered into the model. When comparing Clinton and Trump to their respective parties, the speeches from Clinton or Trump would be separated from the speeches by other presidential candidates that entered into the model for the respective parties (e.g., “DEM_2016” for the Democratic Party 2016 that included speeches by Bernie Sanders, and “REP_2016” for the Republican Party 2016 that included speeches by Ted Cruz and Jeb Bush). For the analysis comparing the political parties across time depicted in Fig. 1, we used 135 of the terms from Table 1, i.e., all of them except “border” (which was not a frequently used word before September 11, 2001). For the analyses that included individual candidates, we used 53 terms (see Results section).
Analysis and display of semantic spaces
In addition to building the semantic spaces from the speech corpora as described, we used several statistical methods to analyze and visualize the vectors of key political concepts from the high-dimensional semantic spaces that varied by party, candidate, or time of election.
Similarity measures and comparisons
Both cosine similarity and the Euclidean distance were used as measures of similarity (see Fig. 1). The cosine similarity between two vectors is the cosine of the angle, a measure of geometric similarity of the two vectors in a high dimensional space, widely to reflect similarity of semantic representation of the language users (e.g., Landauer et al., 2013). The Euclidean distance is the standard measure of distance between two points in space. In general, we characterized the meaning of any single political concept as its cosine similarity with all other political concepts (of which there were 135 or 53, see previous section), and a semantic space as the entire set of these pairwise cosine similarities. To compare political semantic spaces, we used the Euclidean distance to measure (the square root of) the sum of the squared differences between pairwise political concepts in the two semantic spaces. While the individual cosine measures provide detailed information about which concepts move closer or farther apart at different time points across parties and individuals, the Euclidean distances characterize the aggregate of these changes.
Ordinary least squares regression (OLS)
Ordinary least squares (OLS) is a standard regression method used to evaluate linear relationships between a set of predictor variables and an outcome variable. In our case the outcome variable was the Euclidean distance between two concepts, and the predictor variables were the difference in time (0, 8, or 16 years) as a continuous variable, REP-REP and DEM-DEM as categorical variables, and it’s linear change over time as 1,2,3 for comparisons of the same concept over time as in REP_00-DEM_00, REP_08-DEM_08, and REP_16-DEM_16, respectively. That is, the last variable tested whether there was a linear increase or decrease in the distance between the same concept in the Republican and Democratic parties over the three big elections. For each of the 135 concepts, there were 15 (\( \left(\genfrac{}{}{0pt}{}{6}{2}\right) \)) Footnote 2 possible comparisons, resulting in 2,025 (=15×135) data points.
Multi-dimensional scaling (MDS)
MDS is a method that analyzes the multi-dimensional features of objects or groups with respect to their similarities or dissimilarities, and transforms the overall similarity into Euclidean distances on a two-dimensional plot, where Euclidean distance is the straight-line distance between two points in a plane. The farther apart two objects/groups are located on the MDS, the more dissimilar their multi-dimensional features are.
Graph/network centrality
Network centrality is a graph-theoretical measure of how important a node is to a network in terms of its connectivity to other nodes. In our analyses, the network nodes are individual words, and the edges are the connections with Euclidean distance values indicating the distance (edge length) between nodes. Words that are high in eigenvector centrality are considered to be important, or central, to the organization of the political concepts. This method was used to examine the concept centrality (see Results section), where we calculated the Euclidean distance between the semantic spaces of all terms in REP_2008, DEM_2008, REP_2016, DEM_2016, and in Trump and Clinton’s semantic spaces, and converted these to a graph structure where each concept was a node, and the Euclidean distance between concepts were weighted edges. The eigenvector centrality for each concept was then calculated.
Results
Figure 1 presents a snapshot of the overall political semantic spaces. Figure 1A–C are the similarity adjacency matrices for 135 semantic vectors of politically charged concepts (see Table 1 for the word list). Each matrix is symmetric and has three quadrants indicating different meanings: the bottom left lower triangle contains the pairwise cosine similarities between 135 concepts corresponding to the speeches from the Republican candidates; upper right is the same for the Democratic candidates (the same 135 concepts that appear in both groups); bottom right square shows the between-party cosine similarities. Figure 1D plots the multi-dimensional scaling (MDS) results of the semantic spaces for each major party (DEM, REP) in three major election years (2000, 2008, and 2016). The figure indicates very distinct profiles of semantic spaces for the two parties, and the DEM and the REP spaces are clearly divided on the MDS plot.
We further verified these trends across the political semantic spaces in a regression analysis to predict how different each of the individual 135 concepts would be between any two of the semantic spaces (see Table 2 and Fig. 1). The main effects of time difference (0, 8, or 16 years) and “between party” (a binary variable indicating whether the representation was calculated based on presidential debates from different parties) are shown in Table 2. The results suggest that the representation of a word is likely to be different across parties, p <.001, but not over time, p > .05. However, a second model, which included an interaction term for the time difference and between party variables, that provided a better overall fit, indicated the existence of a significant interaction between the variables (p <.001) such that the change in a word’s political meaning was more likely to be different if it was between parties and more time had passed, but more similar within the same party as more time had passed (i.e., the meanings of concepts have diverged over time between parties but could have consolidated to a greater degree within parties; see also Figs. 2 and 3). Both of these models included 135 random intercepts for each individual concept (not depicted in Table 2) and six random intercepts for the combinations of the three different election years and the two different parties (which are depicted in Table 2), indicating that our findings have accounted for variance specific to the stimuli used in this study and may generalize to other politically charged concepts and contexts. Second, a contrast on the beta coefficients comparing the random effects of the three Republican election years and the three Democratic election years (see Table 2) revealed that the expected change in meaning was smaller for the Republican semantic spaces than for the Democratic spaces (T=14.88, p <.001). This suggests that although the same party tended to use the same words more similarly than across parties (see also Fig. 4), there was greater internal similarity or consistency in the Republican Party than in the Democratic Party at different election time points in terms of the organization and representation of political concepts and ideologies.

(A) Euclidean distances of the semantic spaces of Clinton and Trump against the averaged Democratic (DEM) and Republican (REP) semantic spaces (2000 and 2008 collapsed). The Fyshe semantic spaces (dark gray) of the same 53 words are based on a 16-billion word, 50-million document corpus that covers everyday language use (i.e., politically neutral). (B) Pairwise comparisons of the seven political semantic spaces

(A) Concept centrality for Democratic (DEM, blue) vs. Republican (REP, red) parties. (B) Word cloud based on the centrality of each concept, weighted by frequency of use. Words that are more blue indicate more central concepts to the Democratic Party, words that are more red indicate more central concepts to the Republican Party, and words that are white or have lighter shades of blue and red are relatively less central to either party
Given the between-party differences over time, we are interested in whether political conceptual changes might occur at two different time scales: the “macro-changes” within an extended period of time (i.e., from 1999 to 2016), and the “micro-changes” within a short time span (e.g., the 12 months within 2016). Figure 2 shows the macro-changes (2A) and micro-changes (2B) with pairwise comparisons of the Euclidean distances in the semantic space similarity. The higher the bar, the more dissimilar the two semantic spaces are. For example, in Fig. 2A, the largest difference was between the Republican Party at 2000 and the Democratic Party at 2016 (i.e., REP_00 vs. DEM_16), followed by REP_08 versus DEM_16 and REP_16 versus DEM_16, indicating that the Democrats in the election year 2016 maximally differed from the early Republicans. Importantly, within the same party, the semantic spaces of REP_16 versus REP_00 were more dissimilar than those of REP_08 versus REP_00 (similarly for DEM spaces), suggesting that there is not only divergence between the political parties but also within each party over the last 16 years, which is consistent with our regression analysis. These patterns of macro-changes are suggestive of the increasingly more extreme conceptual views in each party.
Such changes can also occur in the micro-change landscape, as shown in Fig. 2B for the 2016 primary elections. The figure charted the dissimilarities between the semantic spaces from October 2015 to April 2016 by contrasting the monthly-based semantic spaces of the prominent party candidates (Trump, Clinton, and Sanders) with their respective parties, showing that (a) both Sanders and Trump were highly dissimilar with their respective party, while Clinton was more similar to the average Democrat; (b) both Clinton and Trump became more similar to their respective party over time; and (c) the changes occurred earlier for Clinton (end of 2015), while they occurred much later for Trump (April 2016).
The semantic space models of the macro- and micro-changes reflect quite closely the general picture of the political dynamics and are consistent with the public intuitions of an increasingly polarized political system in the USA. To corroborate this, we further compared the political semantic spaces with the Fyshe vectors (Fyshe et al., 2013), a semantic space that was based on distributional statistics from a very large corpus that likely reflect a more generic, politically neutral word usage. Figure 3 displays (a) the MDS plot of the DEM and REP spaces at two different times, against the Clinton, Trump, and Fyshe spaces, and (b) pairwise comparisons. Since we were particularly interested in how the 2016 presidential candidates were compared against previous candidates, we collaposed election years 2000 and 2008 in this analysis. Both the MDS analysis and the pairwise comparisons indicate that (a) politically charged semantic spaces were maximally different from the politically neutral semantic space of the same concepts (i.e., the Fyshe space being maximally dissimilar to the other spaces); (b) Trump’s semantic space was maximally different from the other political semantic spaces (in MDS plot), but more similar to the Fyshe space; and (c) Clinton’s semantic space was more similar to the DEM spaces than to the REP spaces, and more similar to both DEM and REP spaces than Trump’s. These model comparisons illustrate on the one hand the conceptual differences between the partisan ideologies and the general public’s concepts, and on the other the alignment (or misalignment) between the presidential candidates and their respective parties.
Finally, to see the specific conceptual contrasts between parties and candidates, we conducted a graph analysis of concept centrality (see Analysis and display of semantic spaces under Method). Figure 4 shows the results of this analysis on 53 key political concepts that had appeared at least five times in each presidential candidate’s speeches. In Fig. 4A, words are ordered and color-coded in their relative centrality, and the edges (thickness of lines) indicate how closely associated two words are to each other across semantic spaces. In Fig. 4B the size of each word is weighted by the relative frequency of use, but the order of the words is random. Thus, Fig. 4 shows what concepts are the most important to each party, and what other concepts may be associated with the concepts. To further identify the differences in word associations, we compared the politically central concepts (on the left side of the ring network in Fig. 4A) and their five most closely associated words (the “nearest neighbors”; see Table 3 for examples). We then compared the nearest neighbors of the associated words from Clinton and Trump’s semantic spaces with human word ratings from the University of South Florida (USF) Free Association Norms (Nelson et al., 1998; http://w3.usf.edu/FreeAssociation). The USF word associations were based on more than 6,000 human raters’ responses to over 5,000 words: the associations were generated by asking each rater to write down the first word that came to mind when presented with another word, the two of which should be strongly associated. Comparison of the political semantic spaces with daily human association ratings should reveal more clearly how the political concepts are differentially central to different parties. To further verify if the USF word associations (which were from participants in 1998) would be different from word associations generated by participants today, we used Amazon’s Mechanical Turk (MTurk) to collect free associations of the same 53 words (as in Fig. 4) from 324 participants (same participants as in Study Three; see below): ksimilarly as with the USF word-association task, participants were asked to write down the first three words that came to mind when given a word prompt.
Examination of the key concepts and their word associations show very clear distinctions between the political parties and the candidates on the one hand, and between the political semantic spaces and the non-political word associations on the other. For example, for Democrats, “health-care,” “education,” and “family” had higher centrality, whereas for Republicans “border,” “country,” and “military” were the most central. Furthermore, for Clinton, for example, “education” was most strongly associated with “women” and “family,” whereas for Trump, its closest associations were “money” and “Democrat”; for Clinton, “business” was related to “education” and “help,” whereas for Trump, “business” was associated with “deal” and “country” (e.g., Table 1). These data are highly consistent with the analyses of Kievit-Kylar and Jones (2012) on Obama’s versus Bush’s speeches (see Introduction). Interestingly, Trump treated many key notions to be highly associated with “deal” and “business” (including “family” and “education”), probably reflecting his views of these concepts from a business person’s perspective, whereas Clinton frequently associated many concepts with “women,” perhaps from her perspective of gender and equality. In both the USF Association Norms and the MTurk workers’ responses, the nearest neighbors are more “mundane” and non-politically oriented, such as “love” and “home” for “family” and “school” and “teacher” for “education.” Very similar word associations were observed in the USF norms and the MTurk data, showing that human raters did not differ between 1998 and 2016 for these terms. Our analyses above reflect deep-rooted conceptual differences between the candidates and between their parties, and between the political and non-political meanings of these terms, providing evidence for the use of free word associations to validate statistical relations captured in the semantic spaces.
Study Two: Voters’ self-reported political engagement and their voting behavior
Study One was primarily concerned with how the presidential candidates and their parties represented political concepts and the changing representations over time. In Study Two, we aimed to examine citizens as supporters of presidential candidates (i.e., voters), specifically by assessing how their self-reported political attitudes may directly impact their voting behaviors.
Method
Participants
Participants (N=397; 139 male, 224 female; 34 did not disclose) were recruited through MTurk (Buhrmester et al., 2011; Paolacci & Chandler, 2014; Paolacci et al., 2010). Criteria for inclusion of participants were that they were over 18 years of age, resided in the USA, and were native speakers of English. In addition, participants were required to have at least a 95% approval rating in MTurk, indicating successful completion of 95% of the MTurk tasks in which they enrolled. The average age of participants was 41 years (SD=12.9, range=18–80). With respect to educational background, approximately 46.1% of the participants indicated obtainment of a bachelor’s degree, while 29.2% indicated obtainment of a high school diploma or equivalent. About 16.9% held either a master’s or doctoral degree, and approximately 7.9% of participants did not disclose educational attainment. In terms of partisanship, 160 participants identified more strongly with Democratic values while 164 participants preferred Republican values, and the remaining participants identified as either moderate or independent. This study was carried out in accordance with the recommendations of the Institutional Review Board (IRB) of The Pennsylvania State University; informed consent was obtained from all participants.
Materials and measures
To assess participants’ engagement in politics, a brief four-item measure was administered to all participants. The items (see Table 5) measured individuals’ involvement in political discussions with others, reported concern about politics, and exposure to politically-related media. Items were administered using a 5-point Likert scale ranging from 1 – Strongly disagree to 5 – Strongly agree. An example item was: “I read, listen to, or watch politically-related news.” These items were used to measure self-reported political engagement (SRPE).
To examine the ability of SRPE to predict the likelihood of voting for either Trump or Clinton in the 2016 presidential election, two items were administered to participants on a sliding, continuous scale. The items were: “Please indicate the likelihood that you would vote for the following candidates: Hillary Clinton; Donald Trump.” Reported likelihood of voting for both candidates was recorded for all participants. Likelihood data for the two items could range from 0 to 100.
Procedure
All measures were administered within the MTurk platform using Qualtrics survey software (https://www.qualtrics.com/). Participants first completed a language history questionnaire (Li, Zhang, Tsai, & Puls, 2014), after which they completed a demographic inventory, followed by a sorting task for 50 abstract political concepts (discussed in Study Three) and free associations with the same words (discussed in Study One). Participants then completed the measure of SRPE and the items assessing reported likelihood of voting for both presidential candidates.
Data analysis
We specified structural equation models (SEMs) to examine the ability of participants’ SRPE to predict reported voting likelihood. SEM is a statistical analysis technique that systematically analyzes the relations among observed and latent variables. In particular, it provides an efficient estimation of a series of separate multiple regressions simultaneously by combining structural models that relate independent to dependent variables with measurement models that are derived from latent variable analysis. SEM models were specifically used in this study to examine the effect of a latent reported political engagement variable on voters’ likelihood of voting for either Clinton or Trump in the 2016 presidential election.
Analyses were conducted using Mplus (Version 7; Muthén & Muthén, 2005, 2012). A measurement model with each of the four SRPE items loading onto a latent SRPE factor was first specified. Then, the contribution of the latent SRPE factor to the reported likelihood of voting for either Clinton or Trump was examined. To account for the presence of non-normality among the questionnaire items, Shapiro-Wilk Ws = 0.30-0.33, ps<.05, maximum likelihood estimation with robust standard error estimates and a mean-adjusted chi-square statistic was used (MLM; Satorra & Bentler, 2001, 2010). Two separate SEM models were specified and evaluated, for the following reasons. First, as described below, while the correlation between scores on the two probability items was significant and negative, the magnitude of the correlation (i.e., r = −0.75; see Results) did not justify combining the variables into a single probability variable. In addition, a composite probability variable was created to explore the feasibility of a single SEM, whereby scores on the two separate probability items were summed. With this composite probability variable, the number of cases that summed to a range of 90–110 was 255, which was equal to only 64.9% of the sample, indicating a relative lack of overlap across the probability variables.
Results
Descriptive statistics for political engagement and voting likelihood measures are presented in Table 4. Reliability of the reported political engagement questionnaire items based on Cronbach’s alpha as an estimate of internal consistency was adequate (α=0.85). Representation of voters was approximately even across the two political parties. For example, of the participants, approximately 179 reported voting for Obama in the 2012 presidential election, while 149 reported voting for Romney (remaining participants reported “Other” or did not indicate voting). Similarly, approximately 148 reported voting for Obama and 134 reported voting for McCain in the 2008 presidential election.
Correlations among the four political engagement questionnaire items administered to participants are presented in Table 5. In general, scores on each of the items were moderately correlated with one another, ps <.05. In addition, scores on the two items assessing the probabilities of voting for both presidential candidates were significantly and negatively correlated, r = −0.75, p < .01.
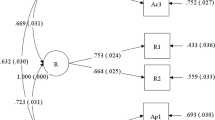
In the first SEM model, reported likelihood of voting for Clinton was predicted. The model demonstrated adequate fit to the data, χ 2(5)=8.53, p=.13, χ 2/df=1.71, CFI=0.99, TLI=0.99, RMSEA=0.04, SRMR=0.02. Figure 5 presents the structural equation model predicting reported likelihood of voting for Clinton. The results suggested that participants’ SRPE, consisting of reported engagement in political news and conversations with others, did not significantly predict the likelihood of voting for Clinton in the 2016 presidential election, β=0.03, t = 0.52, p >.05.

Structural equation model showing the contribution of the latent SRPE (self-reported political engagement) factor to reported likelihood of voting for Clinton. Inform, Read, Care, and Conv correspond to Items 1 through 4, respectively, as presented in Table 5. Standardized regression coefficients are presented. Bold lines indicate significant paths. Values in parentheses are standard errors
In the second SEM model, reported likelihood of voting for Trump was predicted. The model also demonstrated adequate fit to the data, χ 2(5)= 11.47, p=.04, χ 2/df=2.29, CFI=0.99, TLI=0.98, RMSEA=0.06, SRMR=0.02. Figure 6 presents the structural equation model predicting reported likelihood of voting for Trump. Participants’ SRPE significantly predicted the likelihood of voting for Trump in the 2016 presidential election, β=0.12, t=2.28, p<.05, suggesting that participants’ SRPE including their reported caring about politics was more related to voting for Trump than for Clinton in the 2016 election. Despite the finding that SRPE significantly predicted the likelihood of voting for Trump, the amount of variance accounted for in the reported likelihood of voting for Trump was quite small (R 2=0.02).

Structural equation model showing the contribution of the latent SRPE (self-reported political engagement) factor to reported likelihood of voting for Trump. Inform, Read, Care, and Conv correspond to Items 1 through 4, respectively, as presented in Table 5. Standardized regression coefficients are presented. Bold lines indicate significant paths. Values in parentheses are standard errors
Study Three: Predicting bipartisan political affiliations from word associations of political concepts
Method
Participants
Participants (N=324) for Study Three were a subset of those recruited in Study Two. In this study, we included participants who reported being more aligned with either the Democratic or the Republican party. We excluded participants who reported equal alignment, identified as independents, or did not report partisanship information. Additionally, all participants had a greater than 95% approval rating on MTurk. Demographic information for participants was similar to Study Two.
Materials and measures
Participants were asked to perform a “sorting task” by ordering 50 politically charged, abstract nouns (the same words in Study One minus three, see Fig. 4), as follows: (a) separating the words into (up to) ten groups, (b) ordering the words in each group so that words with more similar meanings were closer together and words with more dissimilar meanings were farther apart, and (c) ordering the groups of words so that more similar groups of words were closer together and groups with more dissimilar words were farther apart. This task is patterned after the sorting task used in other studies (Clariana, 2010; Spinozzi 1996), according to which participants sort a set of key concepts/terms by moving related terms close in proximity in space (e.g., on a computer screen). The sorting outcome is thought to reflect a snapshot of the relations of concepts or words in the participant’s mental representation. Additionally, participants were asked to report the extent to which they shared the Republican and Democratic Parties’ values (on a Likert scale ranging from 1 to5) as well as their political identification. Although the Likert scale was used to determine whether a particular subject was Republican or Democratic (which we converted to a binary variable), participants who identified as Independent were excluded.
Procedure
The procedure for this study was the same as in Study Two.
Data analysis
First, we determined each participant’s partisanship by binarizing the outcome of the two Likert scales asking participants to report the extent to which they identify with the Republican and Democratic Parties’ values by labeling the participant as “Republican” or “Democrat” depending on which party’s values they identified more strongly with. Then, we calculated distance matrices between all 50 political concepts from the sorting task by ordering the words along a single dimension, maintaining each participant’s within-word group ordering and then concatenating the groups of words according to the reported group ordering. Thus, the distance between any two distinct words was an integer between 1 and 49.
We then examined the extent to which reported distances of individual words with the other 49 words could be used to predict political party affiliation using a decision-tree algorithm. Decision-tree algorithms attempt to classify data based on a set of features by repeatedly searching for features that best split the data. Features can be categorical, such as “low,” “medium,” and “high,” or they can be numerical. In the current study, feature values were numerical distance values between words, and there were only two classes. The decision-tree algorithm attempts to find conditional rules that best split the data into Republicans and Democrats. For example, the algorithm might make a rule stating that if the distance between the words police and women was less than 20 words, it was more likely that the individual was a Republican and vice versa (see Fig. 7). The decision trees were allowed to make up to ten rules (i.e, a maximum depth of 10), and the leave-one-out cross-validation accuracy for the highest performing decision tree containing between 1 and 10 rules was reported. Decision trees tend to overfit data at higher depths, and, therefore, it is best to use cross-validation to determine which tree actually has the best predictive accuracy on untrained data, not the best fit to the trained data. We used leave-one-out cross-validation, where the model is repeatedly trained on all of the data points except for one (the left-out point; each data point is left out exactly one time), and then the learned model is used to predict the class/value of the left-out point. This leave-one-out cross-validation procedure for our 324 participants gives a chance performance for p <.05 at 176 or fewer correct (54.32%).

An example of a decision tree learned on one training iteration in which the decision tree attempted to predict political affiliation based on the distance between the word police and the other 49 concepts. In the figure, gini stands for Gini impurity, samples refers to the number of individuals in each split, value shows the number of Republicans (left) and Democrats (right), and class indicates the decision (or majority) that would occur at the split
Results
The results from our decision-tree analysis suggest that 43 out of 50 of the individual concepts’ distances among the 49 political concepts are good predictors of political party affiliation (see Table 6), with the first 7 words performing at chance, and with the word “police” obtaining the highest cross-validated accuracy (269 of 324 correct, 83.02% accuracy; see Fig. 7 for an example of one decision tree). The results suggest that there are considerable systematic differences in the way Democrats and Republicans understand and associate politically charged concepts.
General discussion
How are abstract political concepts represented by the political candidates and their respective parties? How are different conceptual representations related to citizens’ political beliefs and their voting behavior? In this study we address these questions by means of computational modeling of the large contexts in which words are used. Specifically, we constructed semantic space models to reflect the conceptual representation of individuals and groups, through distributional statistics in the co-occurrences of words and contexts. The findings from our computational models and analyses provide a generalized method for revealing what presidential candidates and their supporters understand a word to mean.
Semantic space models capture conceptual representations by incorporating the diverse contexts in which words are used. Such models capture the relations between target words and their usage history through analyses of large text or speech corpora, thereby reflecting word associations, conceptual organizations, and connected memories in general. Semantic space modeling has been widely applied to the domains of concept acquisition and representation in cognitive psychology and computational science, but has only begun to be examined in the context of political concept representations (e.g., Kievit-Kylar & Jones, 2012; Monroe, Colaresi, & Quinn, 2008; Murphy et al., 2012).
In the current study, we used a computational model, word2vec, to construct semantic spaces of key political concepts based on large sets of documents and public speeches given by the presidential candidates. Our models are able to capture the meaningful variations in how the Democrats and the Republicans represent the same political concepts, and the conceptual organizations and the dynamic changes within and across the political parties from 1999 to 2016. More importantly, the models also demonstrate, in light of the US presidential election in 2016, how the presidential candidates aligned or misaligned over time with their party’s general representation of these concepts, and how conceptual representations of political terms differ as a function of political affiliations in both presidential candidates and ordinary citizens.
A number of important findings from our computational models are noteworthy. First, not surprisingly, semantic spaces are more similar within parties than between parties. Within-party divergence seems to be less severe in the Republican semantic spaces than in the Democratic spaces across election years. Second, individual concepts have diverged over time, such that the meaning of a word in 2000 is different from the meaning of the same word in 2008 and in 2016, regardless of party affiliation. While the micro-changes indicate that candidates can change rapidly to converge with their parties, the macro-changes indicate that the two parties’ general representations of the same key political concepts, as well as those of their candidates, have drifted further and further apart (cf. Figs. 1 and 2 and Tables 1 and 2), suggesting that extreme political views and attitudes are gaining more dominance in the parties and hence making the average semantic spaces more distant between the political parties and their candidates. These statistical patterns are highly consistent with the public opinion of a polarized political system in the USA.
Further confirming this public intuition for the 2016 election is the very distinct semantic space of Trump, as compared with the semantic spaces of both political parties and the candidates (including Clinton). That Trump is an outsider in politics is shown not only by the huge gap between his semantic space and the other political semantic spaces, but also by how he injects non-traditional notions into political concepts (e.g., closely associating words such as “deal” with “education” and “government” in political debates). Finally, our concept centrality analyses show that a set of core political concepts including “economy,” “education,” “healthcare,” “security,” and the “world,” invoke different patterns of word associations and connectedness in the conceptual network, for both the political parties as a whole and for the recent US presidential candidates. Our word-association analyses also clearly indicate how the politically charged concepts are differentially central to different parties, and between supporters of different political candidates or voters who were likely to vote for different parties.
Our predictive models additionally indicate that reported political engagement among voters was found to significantly predict the likelihood of voting for Trump (but not for Clinton), suggesting key differences in the relationship between voters’ perceptions of their reported engagement with politics and the likelihood of them voting for a presidential candidate. That is, individuals who reported greater engagement with politics indicated a greater likelihood of voting for Trump than for Clinton, suggesting that individuals likely to vote for Trump believed themselves to be more politically informed through exposure to politically-related news and conversations with others about political topics. Broadly speaking and based on our data, those who voted for Trump may have been more interested and engaged in the effects of political decisions as well as the portrayal of perceived important political topics in the media. This may also partially explain why the reported political engagement outcomes did not significantly predict the likelihood of voting for Clinton, perhaps due to the influence of other non-engagement variables in the media. It is important to point out, however, that these models were based on participants’ perceptions of their engagement with politics and political topics rather than their actual engagement with or knowledge of them. Nevertheless, these findings suggest the complementary roles of individuals’ beliefs (i.e., reported political engagement or interest in political topics) in combination with their mental associations among political concepts in predicting voter political behavior. Our findings also support the combined use of computational semantic space modeling and traditional survey methodologies (in this case through MTurk) to provide a more complete picture of individuals’ political behaviors.
Finally, we were able to predict voters’ reported political affiliation with relatively high accuracy simply based on the way they organized a set of 50 political concepts. The results from our MTurk study suggest that these differences are systematic, and can achieve above 80% accuracy in predicting an individual’s political preferences based on the relative organization of a single concept. Given that the way individuals organize concepts predicted political beliefs, and that collecting samples of speech based on political affiliation revealed considerable differences in the organization of political concepts, it is plausible that greater exposure to one or the other political culture provides the necessary distributional statistics in the environment for individual variations in the representation of political concepts to occur. This is clearly consistent with the analyses of implicit media bias as reported by Holtzman et al. (2011), and, more generally, in implicit social biases based on gender, race, and cultural steoretypes as reported by Caliskan et al. (2017). We interpret these findings to suggest that the participants in our study may have biased the political content to which they exposed themselves, to a degree that was sufficient to create large discrepancies between semantic associations among those who aligned themselves with Republican and Democrat values. More generally, our results, along with those from Holtzman et al. (2011) and Caliskan et al. (2017), highlight the complex interdependence between language, speech, and culture, and furthermore suggest that simple statistical learning mechanisms may in part facilitate the way by which groups with different cultures may come to organize and understand the world differently at a linguistic, and, ultimately, conceptual level.
To conclude, Americans seem to speak two different “languages,” politically implying different meanings in their mental representation of concepts, and these differences have created sub-cultures in modern society that underline citizens’ political behaviors, along with a wide gulf that hinders effective political dialogues and communication.
Notes
To verify the differences between concatenated versus non-concatenated vectors, we also examined non-concatenated outputs using only the CBOW model (excluding the SG model), and using a stringent criterion of a minimum word count of ten; we found the same results under these different models.
This is a mathematical notation for the choose function to calculate all possible combinations of two items from a set of six items.
References
Buhrmester, M., Kwang, T., & Gosling, S. D. (2011). Amazon’s Mechanical Turk: A new source of inexpensive, yet high-quality, data? Perspectives on Psychological Science, 6(1), 3–5.
Burgess, C., & Lund, K. (1997). Modelling parsing constraints with high-dimensional context space. Language & Cognitive Processes, 12, 177–210.
Bullinaira, J., & Levy, J. (2013). Limiting factors for mapping corpus based semantic representations to brain activity. PLoS One, 8, e57191.
Callan, J., & Hoy, M. (2009). The ClueWeb09 Dataset. Available from http://lemurproject.org/clueweb09/
Caliskan, A., Bryson, J., & Narayanan, A. (2017). Semantics derived automatically from language corpora contain human-like biases. Science, 356, 183–186.
Clariana, R. B. (2010). Deriving group knowledge structure from semantic maps and from essays. In D. Ifenthaler, P. Pirnay-Dummer, & N. M. Seel (Eds.), Computer-based diagnostics and systematic analysis of knowledge (Chapter 7 (pp. 117–130). New York, NY: Springer.
Fyshe, A., Talukdar, P., Murphy, V., & Mitchell, T. (2013). Documents and dependencies: An exploration of vector space models for semantic composition. Proceedings of the 7th International Conference on Computational Natural Language Learning (CoNLL-2013), pp. 84–93.
Holtzman, N., Schott, J., Jones, M., Balota, D., & Yarkoni, T. (2011). Exploring media bias with semantic analysis tools: validation of the Contrast Analysis of Semantic Similarity (CASS). Behavior Research Methods, 43, 193–200.
Jones, M., & Mewhort, D. (2007). Representing word meaning and order information in a composite holographic lexicon. Psychological Review, 114, 1–37.
Jones, M., Willits, J., & Dennis, S. (2015). Models of semantic memory. In J. Busemeyer & J. Townsend (Eds.), Oxford handbook of mathematical and computational psychology (pp. 232–254). Oxford, UK: Oxford University Press.
Jung-Beeman, M. (2005). Bilateral brain processes for comprehending natural language. Trends in Cognitive Sciences, 9, 512–518.
Kievit-Kylar, B., & Jones, M. (2012). Visualizing multiple word similarity measures. Behavior Research Methods, 44, 656–674.
Landauer, T. K., & Dumais, S. T. (1997). A solution to Plato’s problem: The Latent Semantic Analysis theory of the acquisition, induction, and representation of knowledge. Psychological Review, 104, 211–240.
Landauer, T., McNamara, D., Dennis, S., & Kintsch, W. (2013). Handbook of latent semantic analysis. Mahwah, NJ: Erlbaum.
Li, P., & Zhao, X. (2017). Computational modeling. In A. M. B. de Groot & P. Hagoort (Eds.), Research methods in psycholinguistics: A practical guide. Malden, MA: Wiley.
Li, P., Burgess, C., & Lund, K. (2000). The acquisition of word meaning through global lexical co-occurrences. In E. V. Clark (Ed.), Proceedings of the Thirtieth Annual Child Language Research Forum (pp.167–178). Stanford, CA: Center for the Study of Language and Information.
Li, P., Zhang, F., Tsai, E., & Puls, B. (2014). Language History Questionnaire (LHQ 2.0): A new dynamic web-based research tool. Bilingualism: Language and Cognition, 17, 673–680.
Murphy, C., Burgess, C., Johnson, M., & Bowler, S. (2012). Heresthetics in ballot proposition arguments An investigation of California citizen initiative rhetoric. Journal of Language and Politics, 11, 135–156.
Lund, K., & Burgess, C. (1996). Producing high-dimensional semantic spaces from lexical co-occurrence. Behavior Research Methods, Instruments, & Computers, 28, 203–208.
Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013a). Efficient estimation of word representations in vector space. In Proceedings of Workshop at ICLR, 2013. (arXiv preprint arXiv:1301.3781).
Mikolov, T., Sutskever, I., Chen, K., Corrado, G., & Dean, J. (2013b). Distributed representations of words and phrases and their compositionality. In Advances in Neural Information Processing Systems (NIPS 2013), pp. 3111–3119.
Mikolov, T., Yih, W., & Zweig. G. (2013c). Linguistic regularities in continuous space word representations. In Proceedings of NAACL, pp. 746–751.
Mitchell, T. M., Shinkareva, S. V., Carlson, A., Chang, K., Malave, V. L., Mason, R. A., & Just, M. A. (2008). Predicting human brain activity associated with the meanings of nouns. Science, 320, 1191–1195.
Monroe, B., Colaresi, M., & Quinn, K. (2008). Fightin’ words: Lexical feature selection and evaluation for identifying the content of political conflict. Political Analysis, 16, 372–403.
Muthén, B. O., & Muthén, L. K. (2012). Software Mplus Version 7.
Muthén, L. K., & Muthén, B. O. (2005). Mplus: Statistical analysis with latent variables: User’s guide (pp. 1998–2012). Los Angeles: Muthén & Muthén.
Nelson, D. L., McEvoy, C. L., & Schreiber, T. A. (1998). The University of South Florida word association, rhyme, and word fragment norms. (http://www.usf.edu/FreeAssociation/.)
Paolacci, G., & Chandler, J. (2014). Inside the Turk: Understanding Mechanical Turk as a participant pool. Current Directions in Psychological Science, 23(3), 184–188.
Paolacci, G., Chandler, J., & Ipeirotis, P. G. (2010). Running experiments on Amazon Mechanical Turk. Judgment and Decision Making, 5(5), 411–419.
Peters, G., & Woolley, J. (2016). The American Presidency Project [Text Data]. Available from http://www.presidency.ucsb.edu/debates.php
Rehurek, R. (2010). Software framework for topic modelling with large corpora. Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks (LREC, Valetta, Malta).
Rumelhart, D., Hinton, G., & Williams, R. (1986). Learning representations by back-propagating errors. Nature, 323, 533–536.
Satorra, A., & Bentler, P. M. (2001). A scaled difference chi-square test statistic for moment structure analysis. Psychometrika, 66(4), 507–514.
Satorra, A., & Bentler, P. M. (2010). Ensuring positiveness of the scaled difference chi-square test statistic. Psychometrika, 75(2), 243–248.
Schloss, B., & Li, P. (2016). Disentangling narrow and coarse semantic networks in the brain: the role of computational models of word meaning. Behavior Research Methods. doi:10.3758/s13428-016-0807-0
Spinozzi, G. (1996). Categorization in monkeys and chimpanzees. Behavioural Brain Research, 74, 17–24.
Acknowledgements
We would like to thank Jane Hatzell, Ashley Evans, Sha Liu, and Tanner Quiggle for assisting with this research project. We also thank the Institute for CyberScience at Penn State University for the High Performance Computing resources. This work has been supported in part by a University Graduate Fellowship of the Pennsylvania State University. The data and opinions expressed in this article are those of the authors and do not represent the views of the Pennsylvania State University.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Li, P., Schloss, B. & Follmer, D.J. Speaking two “Languages” in America: A semantic space analysis of how presidential candidates and their supporters represent abstract political concepts differently. Behav Res 49, 1668–1685 (2017). https://doi.org/10.3758/s13428-017-0931-5
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13428-017-0931-5