
Abstract
The present study investigated the role of object-centered reference systems in memories of objects' locations. Participants committed to memory the locations and orientations of either 11 human avatars (Experiment 1) or 11 animal models (Experiment 2) displayed in a desktop virtual environment and then completed judgments of relative directions, in which they pointed to objects from imagined vantage points corresponding to the locations of the objects. Results showed that, with avatars, performance was better when the imagined heading was congruent with the facing direction of the avatar located at the imagined vantage point. With animal models, no such facilitation was found. For both types of stimuli, performance was better for the learning view than for the novel 135° view. Results demonstrate that memories of the locations of objects are affected by object-centered reference systems and are consistent with conjectures that spatial memories are hierarchies of spatial reference systems, with higher levels corresponding to larger scales of space.
Similar content being viewed by others

Many human activities, ranging from retrieving a cell phone from a purse to making one’s way to work and back home, depend on the ability to remember the locations of objects in the environment. Spatial location is relative, and hence an object’s location must be specified with respect to another object, environmental feature, or abstract coordinate system, using a spatial reference system. For the purposes of understanding human spatial memory, two major systems of spatial reference are typically distinguished, egocentric and allocentric reference systems. Egocentric reference systems specify location with respect to the observer’s body. Allocentric reference systems specify object locations in terms of structures outside of the observer’s body, such as landmarks, environmental features, and other objects.
A large body of research has investigated the relative importance of egocentric and allocentric spatial reference systems in human spatial memory. An emerging consensus is that both types of reference systems are employed at various times and for various purposes, although models differ in when and where each type of representation is used (e.g., Burgess, 2008; Mou, McNamara, Valiquette, & Rump, 2004; Sholl, 2001; Waller & Hodgson, 2006; Wang & Spelke, 2002). For example, according to the theoretical framework proposed by Mou et al., locomotion to and around objects and through apertures is guided by relatively transient egocentric representations, whereas wayfinding in large-scale space relies primarily on enduring allocentric representations of the spatial layout of the environment.
A relatively unexplored topic is the role of the spatial properties of the objects that compose the layout in the encoding and retrieval of spatial memories. The spatial structure of objects can be defined in object-centered reference systems (e.g., Marr, 1982; Rock, 1973). Many objects, such as the human body, have natural facets that may define front and back, right and left, or top and bottom. These facets confer encoding and retrieval efficiencies under some circumstances (e.g., Bryant & Tversky, 1999; Franklin & Tversky, 1990). The goal of the present project was to determine whether retrieval of interobject spatial relations would be influenced by object-centered reference systems.
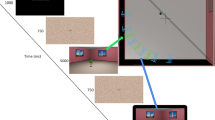
Participants in our experiments memorized locations and orientations of virtual human models (avatars, Experiment 1) or animal models (Experiment 2) in a desktop virtual environment (Fig. 1). Participants then performed judgments of relative direction (JRD), a perspective-taking task in which participants point to objects from imagined standing locations and headings. The question we asked was whether performance in this task would be affected by the facing directions of individual objects; in particular, we wanted to know whether performance would be influenced by the congruence between the imagined heading defined by the task and the actual facing direction of the object located at the imagined standing location.

a Example of an avatar layout in the virtual environment in Experiment 1. From left to right and front to back are lawyer, librarian, actress, designer, soldier, clown, doctor, dancer, manager, teacher, and cashier. b Example of an animal layout in the virtual environment in Experiment 2. From left to right and front to back are cow, cat, bird, monkey, penguin, giraffe, rabbit, honeybee, pig, frog, and duck. These two scenes correspond to layout a in Fig. 2
Marchette and Shelton (2010) examined how object-centered spatial reference systems influenced participants’ representations of interobject spatial relations. They had participants learn displays of symmetric objects, elongated objects that were randomly oriented, or elongated objects that shared a common orientation different from the learning perspective. Results showed that when the display was composed of commonly oriented elongated objects, participants used the orientation defined by the objects’ coincident orientations as the dominant reference direction in memory. This effect also occurred when the objects were agents with conceptually defined front–back axes (e.g., stuffed animals). Marchette and Shelton also investigated whether performance was affected by the congruence between the imagined heading and the orientation of the object located at the imagined standing location but found no evidence of such an effect.
One important difference between our study and Marchette and Shelton’s (2010) experiments is that we used human avatars in Experiment 1. Effects of object orientation may be greater for avatars because they are more similar physically to human bodies and may more strongly imply the potential for social interaction (these ideas are elaborated in the General Discussion section). The second major difference was that participants in our study had to memorize orientations of the objects, as well as their locations. We speculated that any effect of object-centered reference systems at the individual object level would be small. Therefore, participants’ voluntary attention to the orientation information could help to strengthen the memory trace and the influence of orientation on performance.
Experiment 1
Method
Participants
Thirty-two people (16 of them male, mean age of 24 years), with normal or corrected-to-normal vision, from the local community participated in this experiment for course credit or monetary compensation.
Materials and design
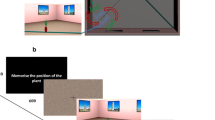
Eleven unique avatars were displayed in a 3-D virtual environment presented on a 20-in. iMac desktop computer (Fig. 1). Each avatar stood on a green plate. Avatars were physically distinctive and shared no obvious semantic associations. Eleven career names were assigned to the avatars such that names and physical appearances corresponded as closely as possible. The stationary learning perspective was defined as 0° (Fig. 2). The configuration of the avatar layout remained constant, but the locations of the avatars were randomized for each participant. The layout was set in a round room, with the wall covered with a brick pattern and the floor covered with a random carpet texture.

The two layouts used in the experiments. Each participant learned one layout from the heading of 0°. For the same triplet of objects in JRD, the facing direction of the anchoring object was the same as the imagined heading in one layout for one group of participants but differed by 135° in the other layout for the other group of participants
Participants’ memories were assessed with JRDs. Participants were asked to imagine occupying the position of one avatar (the anchoring avatar), and facing a second avatar and to point to a third avatar. The first two avatars established the imagined heading. The correct pointing angle to the third avatar was defined as the angle between the imagined heading and the line formed by the first and the third avatars.
The JRD task consisted of test trials on imagined headings of 0° and 135° and fillers on other imagined headings. Test trials were classified into two different conditions: same, in which the facing direction of the anchoring avatar was the same as the imagined heading, and different, in which the facing direction of the anchoring avatar was different from the imagined heading by 135° (clockwise or counterclockwise). Six pointing directions were used (45°, 90°, 135°, 225°, 270°, 315°). Fillers for six other imagined headings (45°, 90°, 180°, 225°, 270°, 315°) were included so that participants would experience more than two. Trials were presented in two blocks, identical except for randomized order. In each block, there were 2 (imagined heading) × 2 (imagined heading and anchoring avatar facing direction same or different) × 6 (pointing angle) = 24 test trials for imagined headings of 0° and 135° and 12 filler trials for the other six imagined headings.
Participants were randomly assigned to two counterbalancing groups, with 8 male and 8 female participants in each group. The configuration of the avatar layout was the same for the two groups, but avatars’ facing directions were manipulated to be different so that, for the same test triplet in the JRD task, the facing direction of the anchoring avatar corresponded to the imagined heading for one group but was different from the imagined heading by 135° for the other group (Fig. 2).
Procedure
After providing informed consent, participants were instructed to use the joystick and practiced the JRD task with several small objects. Participants then learned the avatars’ career names. Each avatar and its career name were presented simultaneously on the monitor, and participants were told to associate them together. To test participants’ memory for career names, the avatars were displayed individually, and participants were required to say the corresponding name in the presence of the experimenter. Only after participants retrieved each avatar name correctly three times could they proceed to learn locations and orientations of the avatars in a layout.
All participants learned the layout from the direction of 0°. The learning procedure consisted of study-and-test cycles: The avatar layout was displayed for 60 s, during which time participants tried to remember both the location and orientation of each avatar; all the avatars then disappeared, but the green plates remained in view; then one of the plates became white, which instructed participants to report the name of the avatar located on that plate. This procedure was repeated until participants successfully identified the location of each avatar correctly at least 3 times. Participants normally studied the layout 3–5 times to reach that criterion. After participants successfully demonstrated that they had learned the locations of the avatars, they were tested on the avatars’ orientations. The avatars were displayed on their correct locations, but in random orientations. Participants were asked to rotate each avatar to its correct facing direction by pressing appropriate keys on the keyboard. Participants went through the 11 avatars in a random order each time. Participants passed the orientation test when they got the facing direction of each avatar correct at least 3 times. If participants made mistakes in the orientation test, they were allowed to study the avatar layout for an additional 30 s before being tested again. After participants had passed both the location test and the orientation test, they were allowed to study the layout for another 60 s and were tested on the locations and orientations one more time.
After the learning stage, participants were led to another room for the JRD task. Participants were seated on a chair in front of a 17-in. Dell laptop computer. Participants completed four practice trials involving buildings on the Vanderbilt campus before starting the memory test. Each trial was initiated by pulling the trigger on the joystick. Trials were presented in text, with all three avatars named at the same time (e.g., “Imagine you occupy the position of Lawyer, Facing Doctor. Point to Actress”). Responses were recorded when the joystick was deflected by more than 30°. Accuracy was emphasized, but not to the complete exclusion of speed (“take as much time as you need, but no more, to make your pointing response accurate”). Pointing error was defined as the absolute angular difference between the actual pointing direction of the target avatar and the judged pointing direction. Response time was defined as the time between the display of the task text and participants’ responses. Participants were able to rest 1 min between blocks. Trials were randomized within each block, with the restriction that the same heading was never tested twice in succession.
Results
Analyses were performed on means per participant per condition, collapsing across pointing direction and block. Pointing error and response time were analyzed in mixed model analyses of variance, with terms for counterbalancing group, gender, imagined heading, and same–different condition. Counterbalancing group and gender were between-participants variables. Imagined heading and same–different condition were within-participants variables. Mean angular error and response time are plotted as a function of heading and same–different condition in Fig. 3a, b.

Mean angular error and response time as a function of heading and same/different condition in Experiment 1a, b and in Experiment 2c, d. Black bars represent the same condition, in which the anchoring object's facing direction was the same as the to–be-imagined heading. Gray bars represent the different condition, in which the anchoring object's facing direction differed from the to-be-imagined heading by 135°. Error bars represent ± 1 standard error of the mean
In pointing error, the effect of same–different condition was marginally significant, F(1, 28) = 3.150, p = .087, η 2 = .101. The interaction between same–different condition and heading was not significant, F(1, 28) = 0.900, p = .351, η 2 = .031. A priori planned t tests showed that for 0°, pointing error was lower in the same condition than in the different condition, t(31) = 2.598, p = .014, η 2 = .179; for 135°; this effect was in the same direction but not significant, t(31) = 0.592, p = .558, η 2 = .011.
The effect of heading was significant, F(1, 28) = 29.374, p < .001, η 2 = .512, with pointing error lower for the heading of 0° than for that of 135°. The three-way interaction between group, gender, and same–different condition was significant, F(1, 28) = 5.055, p = .033, η 2 = .153. This interaction did not compromise any of the other effects.
In response time, the effect of same–different condition was significant, F(1, 28) = 6.353, p = .018, η 2 = .185. A priori planned t tests showed that for both imagined headings, pointing latency was significantly or marginally significantly shorter in the same condition than in the different condition [0° heading, t(31) = 1.835, p = .076, η 2 = .098; 135° heading, t(31) = 2.097, p = .044, η 2 = .124].
The effect of heading was significant, F(1, 28) = 46.298, p < .001, η 2 = .623, with shorter pointing latency for the learning perspective than for the novel 135° perspective. The three-way interaction between gender, heading, and same–different condition was significant, F(1, 28) = 4.926, p = .035, η 2 = .150, but did not compromise the interpretation of the other effects.
Discussion
The results of Experiment 1 revealed that performance was facilitated by the congruence between the imagined heading and the facing direction of the avatar at the imagined standing location. Although this effect was of modest size and modulated to some extent by imagined heading, performance was consistently better when the imagined heading and avatar facing direction were the same than when they were different. To our knowledge, this is the first demonstration of such an effect in the spatial memory literature. Performance was also better for the familiar imagined heading of 0° than for the novel imagined heading of 135°, showing that participants’ memories were orientation dependent (e.g., McNamara, 2003).
Why did Marchette and Shelton (2010) not find similar results? Our experiment differed in several ways from theirs, but a potentially important difference was the nature of the objects: human avatars versus nonhuman objects. To investigate whether the nature of the objects composing the layout played a role, we replicated Experiment 1 but used animal models as the objects.
Experiment 2
Method
Twenty-eight people (8 females in each counterbalancing group) from the local community, with an average age of 21 years, participated in this experiment for course credit or monetary compensation. Materials, design, and procedure were the same as in Experiment 1, except that animal models were used as objects (Fig. 1b).
Results
Angular error and response time were analyzed as in Experiment 1; means are plotted as a function of heading and same– different condition in Fig. 3c, d.
In pointing error, the effect of same–different condition was significant, F(1, 24) = 4.848, p = .038, η 2 = .168, but in the opposite direction to that in Experiment 1. The interaction between same–different condition and heading was marginally significant, F(1, 24) = 3.391, p = .078, η 2 = .124. A priori planned t tests showed that for 0°, pointing error was not different in the same and different conditions, t(27) = −.229, p = .821, η 2 = .002; for 135°, pointing error was lower in the different condition than in the same condition, t(27) = 2.528, p = .018, η 2 = .191.
In response time, neither the same–different condition nor the interaction between same–different condition and heading was significant [main effect, F(1, 24) = 1.530, p = .228, η 2 = .060; interaction, F(1, 24) = 1.228, p = .279, η 2 = .049]. A priori planned t tests revealed no significant differences between the same and different conditions.
There were significant main effects of heading in pointing error and in response time [pointing error, F(1, 24) = 35.052, p < .001, η 2 = .594; response time, F(1, 24) = 38.589, p < .001, η 2 = .617], such that performance was better for the familiar heading of 0°.
In response time, the three-way interaction between same–different condition, heading, and counterbalancing group was significant, F(1, 24) = 5.032, p = .034, η 2 = .173. This interaction did not compromise any of the other effects.
Discussion
The results of Experiment 2 revealed that when animal models were the to-be-remembered objects, there was no benefit of congruence between the imagined heading and the orientation of the anchoring animal. This finding likely explains the discrepancy between the results of Experiment 1 and those of Marchette and Shelton (2010).
One odd result of Experiment 2 was that the same–different effect in pointing error was reversed for the imagined heading of 135°. In the 135°-different condition, the anchoring animal faced either 0° or 270°. An analysis of those items for which pointing directions were equivalent showed that pointing error was lower in the former than in the latter case, suggesting that there was a benefit to retrieving the location of an animal model when its heading matched the learning heading, even if its heading did not match the imagined heading. A post hoc analysis revealed that the same effect occurred in Experiment 1. This effect does not compromise the findings here but further highlights the role of object-centered reference frames in spatial memory and is worthy of additional investigation.
General discussion
This study examined whether retrieval of interobject spatial relations would be influenced by object-centered reference systems. In particular, the study tested whether performance in judgments of relative direction would be influenced by the congruence between the imagined heading required in a test trial and the facing direction of the object located at the imagined vantage point. When avatars were the to-be-remembered objects, participants performed better when the imagined heading was the same as the facing direction of the avatar at the imagined standing location. This facilitation effect did not occur when animal models were used as the stimuli.
Participants in the present experiment were required to memorize both the locations and the orientations of the objects. We assume that participants represented the locations of the objects in memory using spatial reference systems that had a dominant reference direction parallel to the learning perspective (e.g., Greenauer & Waller, 2008; Mou & McNamara, 2002; Shelton & McNamara, 2001). We further assume that objects’ orientations were represented by embedding object-centered reference systems within this representation of location.
One possible explanation of the facilitation observed when the imagined heading in JRD corresponded to an avatar’s facing direction is founded on the notion of embodiment (e.g., Barsalou, 2008). The hypothesis is that the mental processes involved in imagining one’s body at a particular location, facing a particular direction, are facilitated by correspondences between one’s physical body and the avatar’s body. Tversky and Hard (2009) showed that the mere presence of a potential actor in a scene encouraged observers to take the person’s perspective when describing the locations of objects. The absence of facilitation for animal models in Experiment 2 would be attributed to weaker affinities between the human body and the animal models.
A second possible explanation attributes the facilitation to the manner in which interobject spatial relations are represented in memory (e.g., Mou et al., 2004). The social interaction implied by facing direction might have led participants to be more likely to represent the spatial relation between two avatars if one was facing the other. In the same condition, the spatial relation between the anchoring avatar and the facing avatar could be retrieved (because the former is facing the latter), whereas in the different condition, this spatial relation might need to be inferred, producing costs in performance (e.g., Klatzky, 1998). The absence of facilitation in Experiment 2 and in Marchette and Shelton’s (2010) study would be attributed to weak or absent correspondences between facing direction and social interaction for animal models and other nonhuman objects.
Our conjecture is that the congruence between the imagined heading and the avatar’s facing direction affected JRD performance because object-centered reference systems for individual avatars were represented in spatial memory. Is it possible that these effects were caused, instead, by reference systems at larger scales? If avatars were grouped by facing direction and if, for each group, a local reference direction were defined, parallel to the avatars’ common facing direction, the congruence effect might have been produced by the same processes that produced the overall benefit for the learning view (e.g., Greenauer & Waller, 2010; Kelly & McNamara, 2010). The present experiment was not designed to test such an explanation, but we doubt that it can account for the present findings. We conducted an ad hoc test of this hypothesis by examining the same–different effect in each of the two layouts (Fig. 2) for each imagined heading (0° and 135°). By happenstance, the three locations in the 0° condition are more spatially contiguous in Layout A than in Layout B, whereas the three locations in the 135° condition are more spatially contiguous in Layout B than in Layout A. To the extent that avatars with a common facing direction are more likely to be grouped if they are also spatially contiguous, the same–different effect should be larger in Layout A than in Layout B for 0° but larger in Layout B than in Layout A for 135°. In fact, none of these interactions was significant, and the results were not consistent across pointing error and response time. These results indicate that the same–different effect was not caused by grouping of avatars on the basis of facing direction. The absence of the same–different effect in Experiment 2 also indicates that objects were not grouped on the basis of shared facing direction.
In summary, a growing body of evidence shows that spatial memories are affected by object-centered reference systems. Marchette and Shelton (2010) demonstrated that object-centered reference frames influenced the selection of the dominant reference direction in memory, and the present findings showed that even at the level of individual objects, object-centered reference frames affected performance in a perspective-taking task. Collectively, these findings are consistent with the conjecture that spatial memories are hierarchies of spatial reference systems, with higher levels corresponding to larger scales of space (e.g., McNamara, Sluzenski, & Rump, 2008; Meilinger & Vosgerau, 2010).
References
Barsalou, L. W. (2008). Grounded cognition. Annual Review of Psychology, 59, 617–645.
Bryant, D., & Tversky, B. (1999). Mental representations of perspective and spatial relations from diagrams and models. Journal of Experimental Psychology. Learning, Memory, and Cognition, 25, 137–156.
Burgess, N. (2008). Spatial cognition and the brain. Annals of the New York Academy of Sciences, 1124, 77–97.
Franklin, N., & Tversky, B. (1990). Searching imagined environments. Journal of Experimental Psychology. General, 119, 63–76.
Greenauer, N., & Waller, D. (2008). Intrinsic array structure is neither necessary nor sufficient for nonegocentric coding of spatial layouts. Psychonomic Bulletin & Review, 15, 1015–1021.
Greenauer, N., & Waller, D. (2010). Micro- and macroreference frames: Specifying the relations between spatial categories in memory. Journal of Experimental Psychology. Learning, Memory, and Cognition, 36, 938–957.
Kelly, J. W., & McNamara, T. P. (2010). Reference frames during the acquisition and development of spatial memories. Cognition, 116, 409–420.
Klatzky, R. L. (1998). Allocentric and egocentric spatial representations: Definitions, distinctions, and interconnections. In C. Freksa, C. Habel, & K. F. Wender (Eds.), Spatial cognition: An interdisciplinary approach to representing spatial knowledge (pp. 1–17). Berlin: Springer.
Marchette, S. A., & Shelton, A. L. (2010). Object properties of frame of reference in spatial memory representations. Spatial Cognition and Computation, 10, 1–27.
Marr, D. (1982). Vision: A computational investigation into the human representation and processing of visual information. New York: Holt.
McNamara, T. P. (2003). How are the locations of objects in the environment represented in memory? In C. Freksa, W. Brauer, C. Habel, & K. F. Wender (Eds.), Spatial cognition III: Routes and navigation, human memory and learning, spatial representation and spatial learning, LNAI 2685 (pp. 174–191). Berlin: Springer.
McNamara, T. P., Sluzenski, J., & Rump, B. (2008). Human spatial memory and navigation. In H. L. Roediger III (Ed.), Cognitive psychology of memory (Vol. 2 of learning and memory: A comprehensive reference) (pp. 157–178). Oxford: Elsevier.
Meilinger, T., & Vosgerau, G. (2010). Putting egocentric and allocentric into perspective. In C. Hölscher, T. F. Shipley, M. O. Belardinelli, J. A. Bateman, & N. S. Newcombe (Eds.), Spatial cognition VII, LNAI 6222 (pp. 207–221). Berlin: Springer.
Mou, W., & McNamara, T. P. (2002). Intrinsic frames of reference in spatial memory. Journal of Experimental Psychology. Learning, Memory, and Cognition, 28, 162–170.
Mou, W., McNamara, T. P., Valiquette, C. M., & Rump, B. (2004). Allocentric and egocentric updating of spatial memories. Journal of Experimental Psychology. Learning, Memory, and Cognition, 30, 142–157.
Rock, I. (1973). Orientation and form. New York: Academic Press.
Shelton, A. L., & McNamara, T. P. (2001). Systems of spatial reference in human memory. Cognitive Psychology, 43, 274–310.
Sholl, M. J. (2001). The role of a self-reference system in spatial navigation. In D. Montello (Ed.), Proceedings of the COSIT international conference: Vol. 2205. Spatial information theory: Foundations of geographic information science (pp. 217–232). Berlin: Springer.
Tversky, B., & Hard, B. M. (2009). Embodied and disembodied cognition: Spatial perspective-taking. Cognition, 110, 124–129.
Waller, D., & Hodgson, E. (2006). Transient and enduring spatial representations under disorientation and self-rotation. Journal of Experimental Psychology. Learning, Memory, and Cognition, 32, 867–882.
Wang, R. F., & Spelke, E. S. (2002). Human spatial representation: Insights from animals. Trends in Cognitive Sciences, 6, 376–382.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Chen, X., McNamara, T. Object-centered reference systems and human spatial memory. Psychon Bull Rev 18, 985–991 (2011). https://doi.org/10.3758/s13423-011-0134-5
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-011-0134-5