
Abstract
A task is ideomotor (IM)-compatible when there is high conceptual similarity between the stimulus and the associated response (e.g., pressing a left key when an arrow points to the left). For such an easy task, can response selection operate automatically, bypassing the attentional bottleneck that normally constrains dual-task performance? To address this question, we manipulated the IM compatibility of a Task 2 that was performed concurrently with a non-IM-compatible Task 1, using the psychological refractory period procedure. Single-task trials, randomly intermixed with dual-task trials, served as a baseline against which to assess dual-task costs. The results indicated bottleneck bypassing (i.e., simultaneous response selection on both tasks) when Task 2 was IM-compatible, as evidenced by negligible dual-task costs on Task 2 (as well as on Task 1), very high percentages of response reversals, and weak correlations between Task-1 and Task-2 reaction times. These findings were supported by a fine-grained simulation analysis of inter-response intervals. We conclude that the perception of an IM-compatible stimulus directly activates the response code, which can then be selecting automatically, without recruiting central attention, consistent with A. G. Greenwald’s (Journal of Experimental Psychology, 94, 52-57, 1972) original theory of IM compatibility.
Similar content being viewed by others


Introduction
Dual-task costs are often attributed to a central bottleneck that prevents central stages of tasks (e.g., response selection) from operating at the same time (Pashler, 1994). One possible exception, however, has been proposed for pairs of ideomotor (IM)-compatible tasks, defined by Greenwald and Shulman (1973; hereafter G&S) as tasks for which “the stimulus resembles sensory feedback from the response” (p. 70). Because of the very high conceptual overlap between the stimulus and the response, IM-compatible tasks represent a special case of stimulus-response compatibility. G&S reported dual-task costs that were small, if not entirely absent, when their participants performed a shadowing task (i.e., repeating aloud a spoken work) while indicating the direction of a left/right-pointing arrow by a movement in the corresponding direction. Subsequent studies confirmed that dual-task costs can be very small, even without training, when both tasks are IM-compatible (Greenwald, 2003, 2004; Halvorson, Ebner, & Hazeltine, 2013; Halvorson & Hazeltine, 2015).
The assumption in previous studies that both tasks must be IM-compatible to enable bypassing – in the sense of performing in parallel the central stages (e.g., response selection) of the two tasksFootnote 1 – is, however, at odds with the typical definition of automaticity (Shiffrin & Schneider, 1977). An automatic task should not require limited resources and therefore should be able to proceed without them. So even when a non-IM-compatible task engages limited central resources, this should not interfere with the performance of an IM-compatible task. The present study addressed this issue.
Background
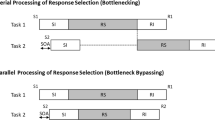
According to Pashler’s (1994) central bottleneck model, attention is allocated to the central operations (e.g., response selection) of only one task at a time: while Task-1 central processing is underway, Task-2 central processing is delayed (see Fig. 1A). This central limitation has been tested in numerous studies using the psychological refractory period (PRP) procedure, which involves varying the stimulus-onset asynchrony (SOA) between two stimuli (S1 and S2), each requiring a speeded response (R1 and R2). PRP studies show longer Task-2 reaction time (RT2) at short SOAs relative to long SOAs, a robust phenomenon called the PRP effect.

(A) Bottlenecking should produce large dual-task costs (represented by the dashed line), with R1 emitted before R2. (B) Bottleneck bypassing should produce little or no dual-task costs, with R2 typically occurring before R1. S = Stimulus, R = response
Ideomotor theory assumes that responses are centrally coded by the representations of their sensory feedback (Greenwald, 1970). From this, Greenwald (1972) hypothesized that “The stimulus of highly ideomotor-compatible combinations should effectively select the response without burdening limited-capacity decision processes” (p. 52). To test this hypothesis, G&S conducted two PRP experiments pairing an auditory-vocal (AV) task that was either IM-compatible (repeat aloud the auditory letter “A” or “B”) or non-IM-compatible (say “ONE” to “A” or “TWO” to “B”), along with a visual-manual (VM) task that was either IM-compatible (left/right movement to a left/right-pointing arrow) or not (left/right movement to the visual word “left” or “right”). After averaging RTs across the two tasks, G&S reported that PRP effects were absent when both were IM compatible but still present when at least one of them was not IM compatible.
Starting with G&S, the virtual elimination of dual-task interference has often been taken as a direct indication of bottleneck bypassing, where two responses are selected in parallel (e.g., Schumacher et al., 2001). Lien, Proctor, and Allen (2002) reported PRP effects ranging from 85 ms to 119 ms in experiments replicating G&S’s Experiment 2 and therefore argued against bypassing. Subsequent studies further debated whether pairing two IM-compatible tasks truly eliminates the PRP effect (e.g., Greenwald, 2003, 2004; Lien, McCann, Ruthruff, & Proctor, 2005).
Halvorson et al. (2013) investigated why dual-task costs are small when pairing two IM-compatible tasks. The first two experiments used two IM-compatible tasks: an AV task (letter shadowing) and a VM task (pressing a key positioned in the direction of an arrow). Substantial dual-task costs were found with the classical PRP instruction to prioritize Task 1 over Task 2 (Experiment 1). But, when the same stimuli and tasks were presented simultaneously, with instructions to treat them equally, near-perfect timesharing was found (Experiment 2). Experiment 3 was similar to Experiment 2 except that the AV task was to shadow a word and the VM task was to imitate the posture of images of hands. Dual-task costs on the IM-compatible VM Task 2 were small when both tasks were IM-compatible but large (200+ ms) when the AV Task 1 used an arbitrary (non-IM) stimulus-response mapping.
From these findings, Halvorson et al. (2013) concluded that the structure of the dual-task paradigm matters: elimination of dual-task costs requires simultaneous presentation of S1 and S2. They also concluded that “both tasks must be IM-compatible to nearly eliminate the dual-task cost” (Halvorson et al., 2013, p. 413). This latter conclusion seriously challenges the assumption of ideomotor theory that the mere presentation of a stimulus directly activates the associated response code. Indeed, Greenwald’s (1972) original paper explicitly asserted that “…highly efficient time sharing could be obtained even if one of the two simultaneous tasks is not highly ideomotor compatible” (p. 57).
The current study
We re-examined whether one IM-compatible task can operate automatically and thereby bypass the bottleneck, even when the other task is not IM compatible. True response-selection automaticity, as proposed by G&S’s original theory, suggests that it should be possible. However, the preponderance of evidence described above says it cannot (e.g., Greenwald, 2003; Halvorson et al., 2013). We suspect that this conclusion is incorrect due to over-reliance on dual-task costs as the primary indicator of bottleneck bypassing. Modest dual-task costs do not necessarily indicate the presence of a bottleneck. For instance, Hazeltine, Ruthruff, and Remington (2006) reported modest dual-task costs even though they argued that their participants selected two responses in parallel after dual-task training. Because peripheral conflicts were greatly minimized (the tasks shared neither the same sensory modality nor the same motor modality), Hazeltine et al. proposed that dual-task interference stemmed not from a central bottleneck, but rather from conflict between central codes of the tasks residing in working memory during parallel central processing.
Conversely, negligible dual-task costs do not provide conclusive evidence of bottleneck bypassing. When pairing two IM-compatible tasks, their respective central stages may be so short in duration that they rarely demand attention simultaneously, thus rendering the bottleneck latent (Ruthruff, Johnston, Van Selst, Whitsell, & Remington, 2003). Accordingly, one cannot unambiguously determine whether the central bottleneck was truly bypassed or merely latent. Indeed, both bottlenecking and bypassing predict basically the same thing: very small dual-task cost. Anderson, Taatgen, and Byrne (2005) nicely illustrated this impasse: they simulated Hazeltine, Teague, and Ivry’s (2002) report of an absence of dual-task cost after dual-task practice with a model incorporating a central bottleneck.
To overcome the theoretical impasse of pairing two fast tasks (see Anderson et al., 2005), we used an approach developed in our previous PRP studies on dual-task automatization: the slow/fast procedure, which pairs a slow Task 1 along with a fast Task 2. This slow/fast pairing avoids the latent-bottleneck problem by ensuring that Task-1 response is slow, which (as explained in more detail below) leads to very distinctive and testable predictions from bottlenecking versus bypassing (see Fig. 1; Maquestiaux, Laguë-Beauvais, Ruthruff, & Bherer, 2008; Maquestiaux, Ruthruff, Defer, & Ibrahime, 2018).
In addition to the PRP dual-task trials, we randomly intermixed single-task trials of Task 1 and single-task trials of Task 2. This encouraged participants to prepare both tasks before each trial (either task might be performed next), thus alleviating the impact of one potential drawback of the traditional PRP approach: excessive prioritization of Task 1.
Importantly, mixed single-task trials on Task 2 also provide a more precise baseline against which to assess RT2 lengthening at the shortest SOA (e.g., Schumacher et al., 2001). Traditionally, PRP studies have used the long SOA as a baseline, but this approach has a subtle problem. Prior to trial onset, participants presumably focus preparation on Task 1 (e.g., instantiating the S-R mapping in working memory), and then also prepare Task 2 with whatever resources are left over. At a long SOA, participants can finish Task 1 and then begin loading up preparation exclusively for Task 2, which would artificially speed up RT2. The same preparation boost is not possible at short SOAs because there is no spare time to prepare. The mixed single-task trials avoid this preparation confound because Task 2 appears at trial onset, leaving no spare time to boost preparation. So, our primary indicator of dual-task costs will be the RT2 difference between the shortest SOA and the single-task condition (although we still report the PRP effect, for the sake of completeness).
We probed for bottleneck bypassing versus bottlenecking with three distinct, converging indicators: dual-task costs, rates of response reversals (i.e., R2 before R1) at the shortest SOA, and RT1:RT2 correlations (see Maquestiaux et al., 2018). Bottleneck bypassing predicts negligible dual-task costs, frequent response reversals at short SOAs (because the fast Task 2 reliably wins the parallel race against the slower Task 1), and weak RT1:RT2 correlations at all SOAs (because the tasks are performed more or less independently). But bottlenecking predicts large dual-task costs (because Task-2 central processing is delayed), rare response reversals (i.e., R1 should almost always be emitted before R2) at all SOAs, and higher RT1:RT2 correlations at short SOAs (because random variation in Task-1 precentral and central stages is inherited by Task 2 after the bottleneck delay) than at long SOAs.
Method
Figure 2 shows the stimulus-response sets and trial types.

Stimulus-response sets (A) and event sequence within a trial (B)
Participants
Forty-eight undergraduate psychology students were recruited from the University of Franche-Comté in exchange for partial course credit. They were randomly assigned to the Task-2 non-IM group (n=24) or the Task-2 IM group (n=24). This sample size of 24 ensured that we had at least as much power as previous studies, which have used sample sizes ranging from 10 to 20 (n=12–16 in Halvorson et al., 2013; n=20 in Halvorson & Hazeltine, 2015; n=10–13 in Lien, Proctor, & Allen, 2002).
Apparatus and stimuli
The experiment was programmed with E-Prime and run on a laptop computer using an AZERTY keyboard, coupled with the PST Serial Response Box. Auditory stimuli were presented through headphones. Voice onset was detected by the voice key integrated within the box; the experimenter manually entered the participant’s vocal response using the box.
The 250-ms Task-1 tone was either low-pitched (400 Hz) or high-pitched (1,800 Hz). The visual Task 2 was IM compatible or non-IM compatible. For the IM version, the visual stimulus was a left-pointing arrow positioned on the left or a right-pointing arrow positioned on the right. The arrows measured 1.8 cm in width and 1.3 cm in height. For the non-IM version, the visual stimulus was a black circle (diameter of 2.2 cm) or triangle (3 cm in width and 2 cm in height) in the screen center.
Design and procedure
Participants responded vocally to the Task-1 tone (“bas” for low, “haut” for high). The Task-2 IM group (n=24) responded to the left arrow by pressing the E key with their left index finger and to the right arrow by pressing the P key with their right index finger. The Task-2 non-IM group (n=24) responded to the shapes using the same fingers.
Participants first performed familiarization trials on Task 1 and Task 2 separately (96 trials each). They then performed 16 familiarization trials followed by 288 experimental trials randomly intermixing PRP trials (192 trials) and single-task trials (48 for Task 1, 48 for Task 2). The 192 dual-task trials resulted from 12 repetitions of the 16 possible combinations of Task-1 stimulus, Task-2 stimulus, and SOA between Task-1 onset and Task-2 onset (15, 65, 250, and 1,500 ms). The 288 experimental trials were divided into nine blocks. During each 2-min block break, the computer provided performance feedback for the preceding block: Task-1 speed, Task-1 accuracy, and Task-2 accuracy. Participants were asked to copy the feedback scores onto a grid to ensure awareness of their performance and to promote efforts at improvement. They were informed that one stimulus or two would occur on each trial. They were also instructed to respond as fast and accurately as possible and were given the typical PRP instructions (i.e., emphasizing Task-1 speed).
Every trial began with a 500-ms black asterisk in the screen center. For AV single-task trials, the tone was then presented and participants had up to 2,500 ms to respond before timing out. Then, a 300-ms visual message indicated whether the response was correct. For VM single-task trials, the visual stimulus was presented and remained until response or 2,500 ms had elapsed. For dual-task trials, the tone was presented, followed after the SOA by the Task-2 stimulus (which remained until response or 2,500 ms had elapsed). Then, two successive 300-ms messages indicated whether the Task-1 and Task-2 responses were correct. If no response to a task was detected, an additional 200-ms message stated that fact. The intertrial interval was 800 ms.
Results
We removed trials for which RT was below 100 ms or above 2,500 ms on Task 1 (single-task: 0.7%; dual-task: 1.0%) or Task 2 (single-task: 0.1%; dual-task: 0.1%). Also, error trials were removed from RT analyses. The resulting mean RTs are shown in Fig. 3.

Mean reaction time on Task 1 and Task 2 as a function of stimulus-onset asynchrony (SOA), for the ideomotor (IM) Task-2 group and the non-IM Task-2 group. Dashed lines represent baseline (single-task) performance
Reaction times and error rates
AV Task 1
RT1 was shorter for the IM group than the non-IM group (621 ms vs. 686 ms), F(1, 46) = 4.53, p < .05; an easy Task 2 might allow people to better prepare for Task 1. There was a main effect of SOA, F(3, 138) = 35.60, p < .001, that was qualified by Task-2 compatibility group, F(3, 138) = 8.04, p < .001. From the longest to the shortest SOA, the mean RT1 increase was 118 ms for the non-IM group, F(3, 69) = 25.84, p < .001, but only 43 ms for the IM group, F(3, 69) = 9.81, p < .001.
The IM group committed more errors than the non-IM group (2.5% vs. 1.8%), F(1, 46) < 1. Task-1 error rates gradually increased from the longest SOA (1.50%) to the shortest SOA (3.01%), F(3, 138) = 5.79, p < .001. Task-2 compatibility group and SOA did not significantly interact, F(3, 138) < 1.
VM Task 2
Mean RT2 was 214 ms shorter for the IM group than the non-IM group (428 ms vs. 642 ms), F(1, 46) = 55.67, p < .001. RT2 significantly increased from the longest SOA (M = 420 ms) to the shortest SOA (M = 615 ms), F(3, 138) = 76.12, p < .001; the overall PRP effect was 195 ms. The PRP effect was much smaller for the IM group than for the non-IM group (94 ms vs. 295 ms), F(3, 138) = 19.82, p < .001.
Task-2 error rates were smaller with the IM Task 2 than the non-IM Task 2 (0.50% vs. 3.72%), F(1, 46) = 36.47, p < .001. Error rates were larger at the short SOAs (2.39% on average) than at the longest SOA (1.19%), F(3, 138) = 3.48, p < .05. Task-2 compatibility group and SOA did not significantly interact, F(3, 138) = 1.68, p = .18.
Three converging indicators of bypassing
Dual-task costs
Dual-task costs were measured with respect to the single-task baseline, rather than the long SOA, to avoid contamination from differential Task-2 preparation. On Task 2, the dual-task cost was large for the non-IM group but negligible for the IM group (194 ms vs. 3 ms), t(46) = 7.46, p < .05. On Task 1, the dual-task cost was larger for the non-IM group than for the IM group (80 ms vs. 13 ms), t(46) = 3.35, p < .01. The IM group’s dual-task cost did not differ significantly from 0 for Task 1 (13 ms), t(23) = 1.24, p = .22, or Task 2 (3 ms), t(23) < 1.
Response reversal rates
Figure 4 shows response reversal rates across SOAs. For bottleneck bypassing, the response order should routinely be reversed at short SOAs. Bottlenecking, in contrast, requires Task 2 to be processed after Task 1, making response reversals unlikely.

Percentages of response reversals at each stimulus onset asynchrony (SOA) for the non-ideomotor (IM) Task-2 group and the IM Task-2 group
The response reversal rate was more than twice as high for the IM Task-2 group than for the non-IM Task-2 group (45.4% vs. 20.9%), F(1, 46) = 27.73, p < .001. The main effect of SOA was significant, F(3, 138) = 182.25, p < .001, with the response reversal rate being virtually null at the longest SOA (0.05%) and gradually increasing up to the shortest SOA (59.5%). There was a significant interaction between SOA and Task-2 compatibility group, F(3, 138) = 20.86, p < .001, with a sharper increase in reversals at the shortest SOA for the IM group (79.2%) than the non-IM group (39.7%).
RT1:RT2 correlations
Figure 5 shows mean RT1:RT2 correlation coefficients as a function of SOA. Bottleneck bypassing predicts weak RT1:RT2 correlations at all SOAs, whereas bottlenecking predicts stronger correlations at short SOAs than long SOAs. The coefficient of correlation was weaker for the IM group than for the non-IM group (.28 vs. .48), F(1, 46) = 12.09, p < .01. There was a significant main effect of SOA, F(3, 138) = 26.27, p < .001, which was qualified by Task-2 compatibility group, F(3, 138) = 5.41, p < .01. For the non-IM group, correlations were stronger at short SOAs (average of .57) than the longest SOA (M = .18), F(3, 69) = 33.48, p < .001. But, for the IM group, the correlations at the 15-ms SOA (.24) and at the 65-ms SOA (.31) did not differ significantly from the coefficient correlation at the 1,500-ms SOA (.19); the only significant difference was between the 250-ms and 1,500-ms SOAs (.40 vs. .19), F(3, 69) = 4.37, p < .01. The small increase in correlations for the IM group at the 250-ms SOA might reflect occasional (but infrequent) bottlenecking. Note that bottlenecking would produce especially strong correlations for the IM Task 2 (which is low variability); yet the data show the exact opposite pattern.

Mean RT1:RT2 correlation coefficient as a function of stimulus onset asynchrony (SOA) for the non-ideomotor (IM) Task-2 group and the IM Task-2 group
Discussion
Previous studies have often implied that IM-compatible tasks cannot bypass the central bottleneck (Lien et al., 2002, 2005), or can do so only when both tasks are IM compatible (G&S; Halvorson et al. 2013; but see also Halvorson & Hazeltine 2015, 2019). However, according to Greenwald’s (1972) original conception of ideomotor compatibility, as well as the definition of automaticity, a single IM task should be sufficient to bypass the bottleneck. To test this possibility, we used three different indicators of bottleneck bypassing: dual-task costs, response reversal rates, and RT1:RT2 correlations. All three converged on the conclusion that a single IM Task 2 can bypass the bottleneck: negligible dual-task cost on Task 2 (4 ms), very high rates of response reversals at the shortest SOA (79.2%), and weak RT1:RT2 correlations (.28 overall). Thus, the perception of the IM-compatible stimulus directly activates the associated response code that can be selected without recruiting central attentional resources (i.e., automatically), allowing bottleneck bypassing even when the other task is not IM compatible. These findings, plainly consistent with Greenwald’s (1972) view of IM compatibility, also echo previous findings showing that response selection can become automatic following extensive single-task training (Maquestiaux et al., 2008, 2018).
In contrast to previous studies with conflicting results (e.g., G&S; Lien et al., 2002, 2005), we did not rely on only one indicator of bottleneck bypassing, but three. In addition, we used single-task trials (intermixed with dual-task trials) as a baseline, rather than long-SOA trials. The latter approach may have inflated dual-task costs in many previous PRP studies (e.g., Lien et al., 2002; G&S) because long-SOA RT2 is artificially fast due to heightened preparation.
Our slow/fast PRP approach sidesteps the latent-bottleneck problem, because Task 1 demands central operations for an extended period of time. In contrast, one can discount G&S’s findings of very small dual-task costs with two IM tasks, because both were performed very quickly (in less than 350 ms). Therefore, our findings provide clearer evidence of parallel central processing.
The data for the non-IM task, meanwhile, were consistent with frequent bottlenecking, consistent with previous studies (e.g., Pashler 1994). Surprisingly, these data also suggest a substantial amount of bypassing. Even though the non-IM group showed a dual-task cost of 194 ms on Task 2, it is relatively small given the long mean RT1 (686 ms) and previous PRP studies (typically showing 300+ ms PRP effects). Also, their percentage of response reversals at the shortest SOA was still surprisingly high (39.7%). Some reversals at short SOAs could reflect grouping of the two responses together (i.e., delaying R1 to emit it simultaneously with R2), but presumably not most because there was no evidence of the predicted RT1 delay. One speculation is that the inclusion of single-task trials within dual-task blocks increased preparation for Task 2, which allowed Task-2 to sporadically bypass the bottleneck.
Simulated versus observed inter-response intervals distributions
If the two tasks were truly performed independently at the 15-ms SOA, then the distribution of RTs from the dual-task trials, and their IRIs, should mimic that from the mixed single-task trials. Following Hazeltine et al. (2006), we tested this fine-grained prediction by simulating fully automatic response selection. For each of the 48 participants, we paired each of their 48 single-task trials on Task 1 with each of their 48 single-task trials on Task 2, resulting in 2,304 simulated dual-task trials. For each trial, we then calculated the simulated IRI at the 15-ms SOA: 15 ms + RT2 – RT1. Note that the IRI is a continuous (and much richer) version of the categorical “response reversal” rate discussed above (i.e., negative IRIs are response reversals). Then, we filtered the simulated data in exactly the same way as for the actual dual-task data (eliminating outliers and errors).
Figure 6 depicts the results of these simulations. Bottlenecking should cause the observed IRI distributions to be shifted well to the right of the simulated distribution. This prediction was confirmed for the non-IM group, as evidenced by a significant difference between the means of the two distributions (38 ms vs. -79 ms), t(23) = 4.66, p < .001. Bottleneck bypassing, meanwhile, predicts nearly perfect overlap between the simulated and observed IRI distributions. Consistent with this prediction for the IM group, the means between the observed and simulated distributions did not differ significantly (-160 ms vs. -150 ms), t(23) < 1. Furthermore, the standard deviations between the two distributions did not differ for the IM group (180 ms vs. 188 ms), t(23) < 1. These simulations again demonstrate that selecting the response associated with the perception of an IM-compatible stimulus is automatic.

Simulated vs. observed histograms of inter-response intervals (IRIs) at the 15-ms stimulus onset asynchrony for the non-ideomotor (non-IM) Task-2 group and the ideomotor (IM) Task-2 group
Ideomotor compatibility versus task separability
Halvorson et al. (2013) proposed that the relationship between tasks plays a critical role in dual-task performance. When two tasks can be kept entirely separated, within distinct working-memory subsystems (visual vs. verbal), dual-task interference should be minimal. This intriguing visual-verbal account predicts that tasks do not necessarily need to be IM compatible to achieve minimal dual-task interference, provided that the visuospatial sketchpad holds codes exclusively from the VM task and the phonological loop holds codes exclusively from the AV task (for a similar proposal but regarding practiced tasks, see Maquestiaux et al., 2018).
To test this account, Hazeltine and Halvorson (2015) had participants perform a VM task and an AV task. These authors devised an ingenious manipulation of IM compatibility for each task (a between-subjects manipulation). The IM-compatible task required imitating the stimulus: the AV task was to repeat aloud an auditory stimulus (“cat” or “dog”) and the VM task was to press the same key as a pictured hand. The non-IM-compatible tasks required making the opposite response, such as saying “cat” when hearing “dog” and pressing the opposite key to the pictured hand. Consistent with the visual-verbal account, dual-task costs (summing the VM and AV RTs) were small for all groups (see also Halvorson & Hazeltine, 2019). The results are intriguing and arguably challenge the present conclusion that IM compatibility is the key factor. However, the opposite tasks might actually be nearly IM compatible. Responding to “cat” with an automatically primed associated “dog” is quite easy. Also, it might be easy to re-interpret the “index” hand image as actually indicating the middle finger, and vice versa. If either of these tasks was effectively IM compatible, then IM compatibility could still be the key factor.
To reconcile the present findings with the visual-verbal account, one needs to assume that the VM Task 2 is purely visual when IM compatible but uses verbal stores when non-IM compatible. Consistent with this assumption, mean RT1 (AV) was shorter when Task 2 was IM versus non-IM compatible; however, this could instead reflect greater Task-1 preparation when Task 2 is IM and therefore easier to prepare. Furthermore, the assumptions about modalities are questionable and there is no easy way to verify them. The non-IM task (pushing keys in response to shapes) could have been entirely visual. Likewise, the IM task might have been verbal. For example, participants might have increased the congruence between a left-pointing arrow and the left key by thinking “left.” Future studies are needed to evaluate the visual-verbal account and determine whether the key to bottleneck bypassing is task separability, IM compatibility, or both.
Conclusions
In sum, the present study makes the following empirical and theoretical contributions. First, we have shown that IM tasks can bypass the central bottleneck. Unlike previous work, which has generally focused exclusively on dual-task costs, we relied upon multiple converging indicators of bypassing: dual-task cost, response reversals, and RT1:RT2 correlations, along with a fine-grained analysis of simulated versus observed IRIs. This resolves the controversy regarding whether IM-compatible tasks can bypass the central bottleneck (e.g., G&S) or not (Lien et al., 2002). Second, contrary to the apparent consensus in the literature, we have shown that bottleneck bypassing is possible even when only task is IM compatible. Third, the above findings support G&S’s original conception of IM tasks as automatic, not requiring central attentional resources. Fourth, these findings indicate that central bottleneck is not structural, but rather can be overcome in select circumstances.
Notes
Here we assume that response selection intervenes between stimulus perception and response generation, even when IM compatible. This assumption fits with G&S’s assertion that the “translation process [response selection] is especially simple when S-R relationships are characterized by IM compatibility” (p. 70). Halvorson and Hazeltine (2019) also interpreted G&S this way: “When the stimulus cuing the action matches the environmental outcome of the action, the response code can be directly activated and response selection is highly efficient (Greenwald and Shulman, 1973)” (p. 2).
References
Anderson, J. R., Taatgen, N. A., & Byrne, M. D. (2005). Learning to achieve perfect timesharing: Architectural implications of Hazeltine, Teague, and Ivry (2002). Journal of Experimental Psychology, 31, 749-761.
Greenwald, A. G. (1970). Sensory feedback mechanisms in performance control: With special reference to the ideo-motor mechanism. Psychological Review, 77, 73-99.
Greenwald, A. G. (1972). On doing two things at once: Time sharing as a function of ideomotor compatibility. Journal of Experimental Psychology, 94, 52-57.
Greenwald, A. G. (2003). On doing two things at once: III. Confirmation of perfect timesharing when simultaneous tasks are ideomotor compatible. Journal of Experimental Psychology, 29, 859-868.
Greenwald, A. G. (2004). On doing two things at once: IV. Necessary and sufficient conditions: Rejoinder to Lien, Proctor, and Ruthruff (2003). Journal of Experimental Psychology: Human Perception and Performance, 3, 632-636.
Greenwald, A. G., & Shulman, H. G. (1973). On doing two things at once: II. Elimination of the psychological refractory period effect. Journal of Experimental Psychology, 101, 70-76.
Halvorson, K. M., Ebner, H., & Hazeltine, E. (2013). Investigating perfect timesharing: The relationship between IM-compatible tasks and dual-task performance. Journal of Experimental Psychology: Human Perception and Performance, 39, 413-432.
Halvorson, K. M., & Hazeltine, E. (2015). Do small dual-task costs reflect ideomotor compatibility or the absence of crosstalk? Psychonomic Bulletin & Review, 22, 1403-1409.
Halvorson, K. M., & Hazeltine, E. (2019). Separation of tasks into distinct domains, not set-level compatibility, minimizes dual-task interference. Frontiers in Psychology, 10:711.
Hazeltine, E., Ruthruff, E., & Remington, R. W. (2006). The role of input and output modality pairings in dual-task performance: Evidence for content-dependent central interference. Cognitive Psychology, 52, 291-345.
Hazeltine, E., Teague, D., & Ivry, R. (2002). Simultaneous dual-task performance reveals parallel response selection after practice. Journal of Experimental Psychology: Human Perception and Performance, 28, 527-545.
Lien, M.-C., McCann, R. S., Ruthruff, E., & Proctor, R. W. (2005). Dual-task performance with ideomotor-compatible tasks: Is the central processing bottleneck intact, bypassed, or shifted in locus? Journal of Experimental Psychology: Human Perception and Performance, 31, 122–144.
Lien, M.-C., Proctor, R. W., & Allen, P. A. (2002). Ideomotor compatibility in the psychological refractory period effect: 29 years of oversimplification. Journal of Experimental Psychology: Human Perception and Performance, 28, 396–409.
Maquestiaux, F., Laguë-Beauvais, M., Ruthruff, E., & Bherer, L. (2008). Bypassing the central bottleneck after single-task practice in the psychological refractory period paradigm: Evidence for task automatization and greedy resource recruitment. Memory & Cognition, 36, 1262-1282.
Maquestiaux, F., Ruthruff, E., Defer, A., & Ibrahime, S. (2018). Dual-task automatization: The key role of sensory-motor modality compatibility. Attention, Perception, & Psychophysics, 80, 752-772.
Pashler, H. (1994). Dual-task interference in simple tasks: Data and theory. Psychological Bulletin, 116, 220-244.
Ruthruff, E., Johnston, J. C., Van Selst, M., Whitsell, S., & Remington, R. (2003). Vanishing dual-task interference after practice: Has the bottleneck been eliminated or is it merely latent? Journal of Experimental Psychology: Human Perception and Performance, 29, 280-289.
Schumacher, E. H., Seymour, T. L., Glass, J. M., Fencsik, D. E., Lauber, E. J., Kieras, D. E., & Meyer, D. E. (2001). Virtually perfect time sharing in dual-task performance: Uncorking the central cognitive bottleneck. Psychological Science, 12, 101-108.
Shiffrin, R. M., & Schneider, W. (1977). Controlled and automatic human information processing: II. Perceptual learning, automatic attending, and a general theory. Psychological Review, 84, 127-190.
Author Notes
We are grateful for the assistance of José Lages with the simulation analysis.
This research was supported by a grant from Région Bourgogne Franche-Comté and a grant from Institut Universitaire de France to François Maquestiaux.
Author information
Authors and Affiliations
Corresponding author
Additional information
Open Access
The raw data are publicly available at https://sites.google.com/site/frmaquestiaux/home/data-sharing. The experiment was not preregistered.
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Maquestiaux, F., Lyphout-Spitz, M., Ruthruff, E. et al. Ideomotor compatibility enables automatic response selection. Psychon Bull Rev 27, 742–750 (2020). https://doi.org/10.3758/s13423-020-01735-6
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-020-01735-6