
Abstract
Laughter is an auditory stimulus that powerfully conveys positive emotion. We investigated how laughter influenced the visual perception of facial expressions. We presented a sound clip of laughter simultaneously with a happy, a neutral, or a sad schematic face. The emotional face was briefly presented either alone or among a crowd of neutral faces. We used a matching method to determine how laughter influenced the perceived intensity of the happy, neutral, and sad expressions. For a single face, laughter increased the perceived intensity of a happy expression. Surprisingly, for a crowd of faces, laughter produced an opposite effect, increasing the perceived intensity of a sad expression in a crowd. A follow-up experiment revealed that this contrast effect may have occurred because laughter made the neutral distractor faces appear slightly happy, thereby making the deviant sad expression stand out in contrast. A control experiment ruled out semantic mediation of the laughter effects. Our demonstration of the strong context dependence of laughter effects on facial expression perception encourages a reexamination of the previously demonstrated effects of prosody, speech content, and mood on face perception, as they may be similarly context dependent.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Although recognizing a facial expression seems effortless, it requires integration of multiple visual features (Smith, Cottrell, Gosselin, & Schyns, 2005). Because expression perception is vital for social interactions, the visual system likely incorporates expression-relevant information from other sensory modalities. The auditory modality may provide especially strong crossmodal cues to facial expressions, since vocalizations tend to accompany affective states.
Indeed, researchers have demonstrated that emotion-related speech sounds such as prosody (see below), as well as less explicit emotion-conveying sounds such as music (e.g., Spreckelmeyer, Kutas, Urbach, Altenmüller, & Münte, 2006), can influence the perception of facial expressions. For example, when a face and voice are concurrently presented, the visual and auditory forms of information both contribute to emotion perception proportionally to their expressive strength (Massaro & Egan, 1996). Additionally, emotion classification improves when emotionally congruent faces and voices are bimodally (vs. unimodally) presented (de Gelder & Vroomen, 2000; Kreifelts, Ethofer, Grodd, Erb, & Wildgruber, 2007). These results suggest that concurrent visual and auditory information facilitates emotion judgments, but the results do not necessarily provide evidence of crossmodal interactions in facial expression perception.
More relevant to the present study, visual classification of happy and fearful faces is speeded when emotionally congruent voices are presented concurrently (Dolan, Morris, & de Gelder, 2001). Similarly, visual classification across the continuum of happy and sad faces is biased by concurrently presented happy and sad voices (de Gelder & Vroomen, 2000). These findings suggest that emotion-conveying prosody crossmodally influences visual classification of facial expressions. Ethofer et al. (2006) showed that emotion-conveying voices also influence visual perception of facial expressions, by asking participants to rate expressions ranging from fearful to happy on a schematic scale of negative to positive expressions. They found that simultaneously presented fearful voices made the participants rate the neutral to fearful faces as more fearful, but there was no effect of happy voices.
Although previous research has provided clear evidence of auditory–visual interactions in facial expression perception, researchers have only investigated these auditory effects on single, isolated faces. However, people typically see emotional faces in social as well as dyadic contexts, and it is unclear whether crossmodal effects obtained with a single face would generalize to a crowd of faces. Although such a generalization may seem intuitive, neural responses are different when multiple faces simultaneously fall within the large receptive fields of face-selective visual neurons, as compared to when only a single face falls within those receptive fields (Desimone, 1991; Kastner et al., 2001; Sweeny, Grabowecky, & Suzuki, 2009; Zoccolan, Cox, & DiCarlo, 2005). It is thus possible that crossmodal effects might differ for a single face and a crowd of faces. Furthermore, instead of prosody, which can be interpreted differently, depending on cultural and linguistic contexts (e.g., Scherer, Banse, & Wallbott, 2001), we used laughter, which universally and strongly conveys positive emotion.
We present a surprising demonstration that laughter produces opposite effects on perceived facial expressions, depending on whether one views a single emotional face or an emotional face in a crowd of faces.
Experiment 1: Effects of laughter on perception of a single face versus multiple faces
Method
Participants
The participants in all experiments were Northwestern University undergraduate students, gave informed consent to participate for partial course credit, had normal or corrected-to-normal visual acuity and normal hearing, and were tested individually in a dimly lit room. A group of 18 (10 female, 8 male) students participated in this experiment.
Stimuli and procedure
The participants were shown brief displays of schematic faces (~100 ms, varied between 94 and 106 ms because of the 75-Hz monitor refresh rate). Each face (subtending 1.15° [horizontal] by 1.49° [vertical] of visual angle) assumed one of three expressions, denoted by the curvature of the mouth; an upward-curved mouth indicated a happy face, a flat mouth indicated a neutral face, and a downward-curved mouth indicated a sad face. The curved mouths (0.80° × 0.14°) and the flat mouth (0.86° × 0.06°) were of the same length.
On crowd trials, eight schematic faces were arranged in a circular array (5.50° radius) around a central fixation point. A third of the crowd trials contained a happy face (in one of eight randomly selected locations) presented among seven neutral faces; another third of the crowd trials contained a sad face presented among seven neutral faces; and the remaining crowd trials contained eight neutral faces. On single-face trials, a happy, sad, or neutral face was presented alone (in one of eight randomly selected locations) without the additional crowd of seven neutral faces.
Participants were told that every display contained either a happy or sad face and that their task was to report the perceived intensity of the happy or sad expression. Because of the brief stimulus duration, even neutral faces appeared happy or sad, presumably due to neural noise (Sweeny, Grabowecky, Kim, & Suzuki, 2011). Using visual stimuli identical to those used in the present study, we previously assessed response confidence and verified that participants indeed perceived negative and positive expressions, even when neutral faces were briefly presented (Sweeny et al., 2011).
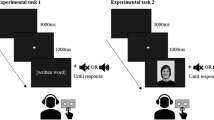
On half of the trials, the visual display (100 ms) was presented simultaneously with a sound clip of a child laughing (1,000 ms, 67 dB SPL). The sound carried no information about the location or expression of the faces. A blank display (1,000 ms) followed, to allow the laughter clip to play for its full duration. No sound was presented on the remaining trials. All conditions were randomly intermixed across 96 trials, after 10 practice trials had been given prior to the experiment. The trial sequence and timing are shown in Fig. 1.

Each trial began with a central fixation marker. After 1,000 ms, the face display, showing either a single emotional face (right) or an emotional face among seven neutral faces (left), was presented for ~100 ms. On half of the trials, a sound was presented (laughter in Exp. 1, or the spoken word “laugh” in Exp. 3) simultaneously with the face display. A fixation screen was subsequently displayed for 1,000 ms to allow the sound clip to play its full duration. Participants were then shown a response screen to use when indicating the curvature that most closely matched the mouth of the emotional face that they had seen. The trial ended once a response was entered on the keyboard. The next trial began after 3,700 ms
Rather than using a symbolic response scale (Ethofer et al., 2006), we more directly probed auditory effects on visual perception by using a curvature-matching task. The response screen consisted of 10 curved segments, arranged from left to right in the order of a strongly downward-curved (labeled “1”) to a strongly upward-curved (labeled “10”) segment. The numerical curvature labels were proportional to the vertical stretch of the curved segments, which linearly increased from 0.14° (for curves labeled “5” and “6”) to 0.22° (for curves labeled “1” and “10”). Participants pressed a key to indicate the curvature that most closely resembled the mouth of the perceived face. For example, when they perceived a slightly upward-curved mouth, they might press “6,” whereas when they perceived a strongly downward-curved mouth, they might press “3.” The actual mouth curvature was always “6” for a happy face or “5” for a sad face. We presented these as the minimum curvatures in the response scale because previous research (Sweeny et al., 2011), along with our pilot results, demonstrated that perceived mouth curvatures tend to be exaggerated in brief viewing. The response scale was thus appropriate for the range of perceived curvatures.
The visual stimuli were displayed on a color CRT monitor (1,024 × 768 pixels, 75 Hz) at a viewing distance of 100 cm, and were presented using MATLAB with the Psychophysics Toolbox (Brainard, 1997; Pelli, 1997). Sounds were presented through Sennheiser HD256 headphones (10-Hz to 20,000-Hz frequency response).
Results
To determine how laughter influenced the perceived intensity of each facial expression, we computed the differences in the average expression ratings between the laughter and no-sound trials for each participant and each expression (see Table 1 for all of the mean curvature ratings).Footnote 1 Positive values indicate that laughter made a face appear happier, whereas negative values indicate that laughter made a face appear sadder. The reported t statistics are Bonferroni corrected in all experiments.
For single-face trials, laughter significantly increased the perceived intensity of the happy face, t(17) = 3.34, p < .05, d = 0.79, without significantly influencing the perceived intensity of the neutral or the sad face, t(17) < 1.15, n.s. (left panel in Fig. 2). This pattern of results was confirmed by a contrast analysis with 1, –.5, and –.5 as the weights assigned to the happy, neutral, and sad expressions, respectively, t(17) = 2.54, p < .02, d = 0.60.

Effects of laughter on the expression ratings (mouth curvature ratings) of the happy, neutral, and sad faces, for the single-face (left panel) and crowd (right panel) trials. Positive values indicate that laughter made a face appear happier, whereas negative values indicate that laughter made a face appear sadder, with zero indicating no effect (as compared to the no-sound trials). The error bars represent ±1 SEM. * p < .05. ** p < .01 (Bonferroni corrected)
For crowd trials, in contrast, laughter significantly increased the perceived intensity of the sad face, t(17) = –4.32, p < .01, d = –1.02, without significantly influencing the perceived intensity of the happy or the neutral face, t(17) < 2.23, n.s. (right panel in Fig. 2). This pattern of results was confirmed by a contrast analysis with .5, .5, and –1 as the weights assigned to the happy, neutral, and sad facial expressions, respectively, t(17) = 6.61, p < .0001, d = 1.56.
These differential effects of laughter on single-face and crowd trials were further confirmed by a significant ANOVA interaction between facial expression and visual context, F(2, 16) = 7.45, p < .003, η 2 = .31.
Overall, simultaneously presented laughter exaggerated a happy expression for a single face and exaggerated a sad expression in a crowd of neutral faces. The fact that laughter produced expression-specific and opposite effects depending on the visual context makes explanations based on response bias and arousal unlikely.
Experiment 2: Why does laughter exaggerate a sad expression in a crowd?
We investigated why laughter increases the perceived intensity of a sad face in a crowd. We hypothesized that laughter might make the crowd of neutral faces appear slightly happy, thereby enhancing the negativity of the sad target face via increased emotion contrast. This possibility is hinted at by a trend in Experiment 1, in which laughter tended to make the crowd of neutral faces appear slightly happier, t(17) = 2.23, p < .05 (without Bonferroni correction), d = 0.52. If this hypothesis is true, making the mouths of the neutral distractor faces upward curved by an equivalent amount should exaggerate the perceived intensity of the deviant sad expression to the same extent as laughter did in Experiment 1.
Method
Participants
A group of 10 new students (6 female, 4 male) participated.
Stimuli and procedure
The stimuli and procedures were the same as in Experiment 1, except that only crowd trials were presented, with each display containing a sad face presented among seven distractor faces. On a third of the trials, the seven distractor faces were neutral, as in Experiment 1: the neutral-crowd condition. On another third of the trials, the distractor faces had a slightly happy expression, deviated from neutral by a half-curvature step (0.80° × 0.07°), approximately equivalent to the intensity of upward curvature induced by laughter on the crowd of neutral faces in Experiment 1: the slightly-happy-crowd condition. On the remaining trials, the distractor faces had a “full” happy expression equivalent to the happy faces used in Experiment 1: the full-happy-crowd condition. The full-happy-crowd condition was included to see whether a larger curvature contrast might make the sad face appear sadder to a greater degree.
Participants indicated the perceived curvature of the mouth of the sad face. Because all of the targets were sad faces, the matching scale only contained downward curves, ranging from 1 (slightly downward curved) to 5 (strongly downward curved). The trial sequence was identical to that of Experiment 1, except that no sounds were presented. All face displays were randomly intermixed across 96 trials.
Results
To determine how the happy expression of the crowd influenced the perceived intensity of the target sad face, we computed the difference in the average expression ratings between each of the happy-crowd conditions and the neutral-crowd condition. In this way, the measure was comparable to that computed in Experiment 1. In particular, negative values indicated that a happy crowd made the target sad face appear sadder (see Table 2 for all of the mean curvature ratings).
Both the slightly happy crowd [t(9) = 4.06, p < .01, d = 1.28] and the full-happy crowd [t(9) = 5.21, p < .01, d = 1.64] made the sad target face appear sadder (Fig. 3). Furthermore, comparing Fig. 2 (right panel) with Fig. 3 illustrates that laughter in Experiment 1 and the slightly happy crowd in this experiment made the target sad face appear sadder to similar degrees, t(26) = 0.29, n.s. This supports the hypothesis that laughter exaggerated the sad expression in the crowd of neutral faces by making the neutral faces appear slightly happy. Slightly happy and full-happy crowds made the sad face appear sadder to similar degrees [t(9) = 1.49, n.s.], suggesting that the exaggeration of the sad target face by emotion contrast was not strongly sensitive to the degree of the emotion contrast.

Effects of happy crowd expressions—either slightly happy or full happy (see main text for details)—on the expression ratings (mouth curvature ratings) of the sad target face. Negative values indicate that the happy crowd expressions made the sad target face appear sadder (as compared to the neutral crowd expressions), with zero indicating no effect. The error bars represent ±1 SEM. ** p < .01 (Bonferroni corrected)
Experiment 3: Are laughter effects mediated by a perceptual interaction or semantic association?
How does laughter influence perceived facial expressions? Does the specific acoustic profile of laughter crossmodally influence the visual processing of facial expressions, or is the effect of laughter mediated by abstract semantic interactions? To test these possibilities, we replaced laughter with the spoken word “laugh.” If the specific acoustic profile of laughter drives the crossmodal effect, the spoken word “laugh” should produce no effect. In contrast, if listening to laughter activates the concept of a laugh, which in turn influences facial expression perception through semantic associations, the spoken word “laugh” should produce effects similar to those of laughter.
Method
Participants, stimuli, and procedure
A group of 18 new students (12 female, 6 male) participated. The stimuli and procedure were identical to those of Experiment 1, except that the spoken word “laugh” replaced the laughter. The word, spoken with neutral emotion (presenting no prosodic information), was recorded from the Merriam-Webster online dictionary (female voice).
Results
We determined how the spoken word “laugh” influenced the perceived intensity of expressions in single-face and crowd trials. As in Experiment 1, we analyzed the changes in average expression ratings between “laugh” and no-sound trials (see Table 3 for all of the mean curvature ratings).
The spoken word “laugh” did not influence average expression ratings, regardless of facial expression or visual context (Fig. 4). All effects of the spoken word “laugh” were nonsignificant, even without Bonferroni correction [t(17)s < 1.43, n.s.], and no interaction between facial expression and visual context was obtained, F(2, 16) = 0.70, n.s. Furthermore, the between-experiments (laughter effect from Exp. 1 vs. null effect with “laugh”) interaction was significant for the single-face condition, F(2, 33) = 4.18, p = .024, η2 = .20, and marginal for the crowd condition, F(2, 33) = 2.35, p = .11, η2 = .13.

Effects of the spoken word “laugh” on the expression ratings (mouth curvature ratings) of happy, neutral, and sad faces, for single-face (left panel) and crowd (right panel) trials. Positive values indicate that the spoken word “laugh” made a face appear happier, whereas negative values indicate that “laugh” made a face appear sadder, with zero indicating no effect (as compared to the no-sound trials). The error bars represent ±1 SEM
Taken together, these results suggest that the effects of laughter are mediated by crossmodal perceptual associations between the acoustics of laughter and facial expressions, and are unlikely to be mediated by an abstract semantic association.
Discussion
We investigated how hearing laughter influenced visual perception of happy, neutral, and sad facial expressions. Importantly, we determined how crossmodal effects of laughter depended on visual context by comparing the effects of laughter on the perception of a single face and of a face presented in a crowd.
When a single face was briefly presented, laughter increased the perceived intensity of a congruent happy expression without affecting the intensity of a neutral or sad expression. This result extends previous findings that emotion-conveying prosody both facilitates classification and biases expression perception for a congruent facial expression (de Gelder & Vroomen, 2000; Dolan et al., 2001; Kreifelts et al., 2007; Massaro & Egan, 1996). Laughter and positively valenced prosody both activate similar brain regions, including the middle temporal gyrus (MTG), middle superior temporal gyrus, anterior rostral prefrontal cortex, and superior temporal sulcus (Belin, Zatorre, Lafaille, Ahad, & Pike, 2000; Grandjean et al., 2005; Kotz et al., 2003; Kreifelts et al., 2007; Szameitat et al., 2010). Furthermore, the left MTG and left anterior fusiform gyrus are more strongly activated by simultaneously presented faces and voices than by either stimulus presented unimodally (Park et al., 2010; Pourtois, de Gelder, Bol, & Crommelinck, 2005). It is thus plausible that the congruency effects of laughter and prosody on the perceived expression of a single face might involve similar processes (e.g., mediated by MTG).
Surprisingly, the congruency effect of laughter became a contrast effect when an emotional face was presented in a crowd of neutral faces. Laughter substantially increased the perceived intensity of the incongruent sad expression, whereas it did not significantly affect the perception of the happy or neutral expressions. To our knowledge, such an auditory–visual contrast effect has not been reported. We have provided evidence suggesting that this contrast effect occurred as a result of laughter causing the neutral distractor faces to appear slightly happy, thus comparatively increasing the perceived negativity of the sad face. It is possible that a similar mechanism might explain the fact that the enhancing effect of laughter on a single happy face was eliminated when the happy face was presented in a neutral crowd. Even if laughter made the happy face in a crowd appear happier, this effect might have been diminished because laughter also made the distractor faces appear happy, decreasing the emotional contrast between target and distractors.
Irrespective of the underlying mechanisms, the fact that the same laughter produced opposite effects on a single face and a face in a crowd indicates that neither effect is likely to be attributable to simple response bias. Furthermore, we have evidence against the possibility that the laughter effects are explained by induced arousal. First, it is unclear why high arousal would selectively make a happy face appear happier in the single-face condition without affecting the appearances of either a sad face or a neutral face. Second, although the spoken word “laugh” does not elicit as high arousal as laughter, it would have increased arousal relative to the no-sound trials. Thus, if arousal alone could explain the laughter effect, the spoken word “laugh” would have produced a weaker but similar pattern of effects relative to actual laughter. However, this was not the case (cf. Figs. 2 and 4). Third, in a pilot study we replaced laughter with the sound of a crying child (highly arousing but negative in valence), and it produced no significant crossmodal effects, even without correction for multiple comparisons [t(5) < 1.69, n.s.]. Although a null result with a small sample size needs to be interpreted with caution, the pattern of nonsignificant variations produced by the crying sound did not resemble the effects of laughter. Thus, induced arousal alone is unlikely to account for the laughter effects.
Because we defined facial expressions using mouth curvature (in order to measure crossmodal effects of laughter on a clearly defined visual feature), it is possible that laughter directly influenced curvature perception rather than influencing the perception of facial expression. However, prior results from experiments using similar stimuli suggested that a curved arc presented as the mouth within a facial context is processed as an integral part of the face (e.g., Suzuki & Cavanagh, 1995; Sweeny et al., 2011). We also conducted a pilot study, which was the same as Experiment 1 except that the curved arcs were presented without any facial context. Laughter produced no effects on the perception of the upward-curved or downward-curved arcs, irrespective of visual context [t(17) < 1.42, all effects nonsignificant even without Bonferroni correction].
In summary, laughter produces a congruency effect for a single emotional face, making a happy face appear happier, but produces a contrast effect for an emotional face in a crowd, making a sad face appear sadder. These crossmodal effects of laughter cannot be explained by induced arousal, semantic activation of the concept of laughter, or the induction of a general positive mood from listening to laughter, which would have similarly affected the laughter trials and the randomly intermixed no-sound trials. These results suggest that the strongly context-dependent crossmodal effects of laughter are mediated by perceptual interactions between the acoustic processing of laughter and visual processing of facial expressions. An implication of our results is that crossmodal effects of emotion-conveying sounds on perceived facial expressions may generally depend on visual context. It may thus be informative to reexamine the previously reported effects of prosody, speech content (e.g., O’Sullivan, Ekman, Friesen, & Scherer, 1985), and mood (e.g., Bouhuys, Bloem, & Groothuis, 1995; Leppänen, Milders, Bell, Terriere, & Hietanen, 2004) on the perception of facial expressions using both a single face and a crowd of faces.
Notes
Our previous study using similar stimuli showed that the perceived intensities of both happy and sad expressions were diminished when a happy or a sad face was presented among a neutral crowd (Sweeny et al., 2011), presumably due to mandatory long-range averaging of facial expressions (Sweeny et al., 2009). As is shown in Tables 1 and 3, we replicated this expression-dampening effect of a neutral crowd in Experiments 1 and 3 (see the cells corresponding to “Simultaneous sound = None,” and note that the expression ratings for both happy and sad faces are closer to 5.5 [neutral] in the crowd condition than in the single-face condition). Because the effect of a neutral crowd is to reduce the intensity of any target expression (happy or sad), the laughter effect in the crowd condition (selectively enhancing a sad expression) is qualitatively different than the expression-dampening effect of a neutral crowd per se.
References
Belin, P., Zatorre, R. J., Lafaille, P., Ahad, P., & Pike, B. (2000). Voice-selective areas in human auditory cortex. Nature, 403, 309–312.
Bouhuys, A. L., Bloem, G. M., & Groothuis, T. G. G. (1995). Induction of depressed and elated mood by music influences the perception of facial emotional expressions in healthy subjects. Journal of Affective Disorders, 33, 215–226.
Brainard, D. H. (1997). The psychophysics toolbox. Spatial Vision, 10, 433–436. doi:10.1163/156856897X00357
de Gelder, B., & Vroomen, J. (2000). The perception of emotions by ear and by eye. Cognition and Emotion, 14, 289–311.
Desimone, R. (1991). Face-selective cells in the temporal cortex of monkeys. Journal of Cognitive Neuroscience, 3, 1–8.
Dolan, R. J., Morris, J. S., & de Gelder, B. (2001). Crossmodal binding of fear in voice and face. Proceedings of the National Academy of Sciences, 98, 10006–10010.
Ethofer, T., Anders, S., Erb, M., Droll, C., Royen, L., Saur, R., … Wildgruber, D. (2006). Impact of voice on emotional judgment of faces: An event-related fMRI study. Human Brain Mapping, 27, 707–714.
Grandjean, D., Sander, D., Pourtois, G., Schwartz, S., Seghier, M. L., Scherer, K. R., & Vuilleumier, P. (2005). The voices of wrath: Brain responses to angry prosody in meaningless speech. Nature Neuroscience, 8, 145–146.
Kastner, S., De Weerd, P., Pinsk, M. A., Elizondo, M. I., Desimone, R., & Ungerleider, L. G. (2001). Modulation of sensory suppression: Implications for receptive field sizes in the human visual cortex. Journal of Neurophysiology, 86, 1398–1411.
Kotz, S. A., Meyer, M., Alter, K., Besson, M., Cramon, D., & Friederici, A. D. (2003). On the lateralization of emotional prosody: An event-related functional MR investigation. Brain and Language, 86, 366–376.
Kreifelts, B., Ethofer, T., Grodd, W., Erb, M., & Wildgruber, D. (2007). Audiovisual integration of emotional signals in voice and face: An event-related fMRI study. NeuroImage, 37, 1445–1456.
Leppänen, J. M., Milders, M., Bell, J. S., Terriere, E., & Hietanen, J. K. (2004). Depression biases the recognition of emotionally neutral faces. Psychiatry Research, 128, 123–133. doi:10.1016/j.psychres.2004.05.020
Massaro, D., & Egan, P. B. (1996). Perceiving affect from the voice and face. Psychonomic Bulletin & Review, 3, 215–221.
O’Sullivan, M., Ekman, P., Friesen, W., & Scherer, K. (1985). What you say and how you say it: The contribution of speech content and voice quality to judgments of others. Journal of Personality and Social Psychology, 48, 54–62.
Park, J.-Y., Gu, B.-M., Kang, D.-H., Shin, Y.-W., Choi, C.-H., Lee, J.-M., & Kwon, J. S. (2010). Integration of cross-modal emotional information in the human brain: An fMRI study. Cortex, 46, 161–169.
Pourtois, G., de Gelder, B., Bol, A., & Crommelinck, M. (2005). Perception of facial expressions and voices and of their combination in the human brain. Cortex, 41, 49–59.
Pelli, D. G. (1997). The VideoToolbox software for visual psychophysics: Transforming numbers into movies. Spatial Vision, 10, 437–442. doi:10.1163/156856897X00366
Scherer, K., Banse, R., & Wallbott, H. G. (2001). Emotion inferences from vocal expression correlate across languages and cultures. Journal of Cross-Cultural Psychology, 32, 76–92.
Smith, M. L., Cottrell, G. W., Gosselin, F., & Schyns, P. (2005). Transmitting and decoding facial expressions. Psychological Science, 16, 184–189.
Spreckelmeyer, K. N., Kutas, M., Urbach, T. P., Altenmüller, E., & Münte, T. F. (2006). Combined perception of emotion in pictures and musical sounds. Brain Research, 1070, 160–170. doi:10.1016/j.brainres.2005.11.075
Suzuki, S., & Cavanagh, P. (1995). Facial organization blocks access to low-level features: an object inferiority effect. Journal of Experimental Psychology. Human Perception and Performance, 21, 901–913.
Sweeny, T., Grabowecky, M., & Suzuki, S. (2009). Within-hemifield perceptual averaging of facial expressions predicted by neural averaging. Journal of Vision, 9(3), 2:1–11. doi:10.1167/9.3.2
Sweeny, T. D., Grabowecky, M., Kim, Y. J., & Suzuki, S. (2011). Internal curvature signal and noise in low- and high-level vision. Journal of Neurophysiology, 105, 1236–1257.
Szameitat, D. P., Kreifelts, B., Alter, K., Szameitat, A. J., Sterr, A., Grodd, W., & Wildgruber, D. (2010). It is not always tickling: Distinct cerebral responses during perception of different laughter types. NeuroImage, 53, 1264–1271.
Zoccolan, D., Cox, D. D., & DiCarlo, J. J. (2005). Multiple object response normalization in monkey inferotemporal cortex. Journal of Neuroscience, 25, 8150–8164.
Author note
This study was supported by the National Institutes of Health Grants R01 EY018197, EY018197-02S1, and EY021184, as well as National Science Foundation Grant BCS0643191.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Sherman, A., Sweeny, T.D., Grabowecky, M. et al. Laughter exaggerates happy and sad faces depending on visual context. Psychon Bull Rev 19, 163–169 (2012). https://doi.org/10.3758/s13423-011-0198-2
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-011-0198-2