
A New Linear Regression Kalman Filter with Symmetric Samples


1
School of Mathematics, Renmin University of China, Beijing 100872, China
2
Department of Mathematical Sciences, Tsinghua University, Beijing 100084, China
3
Department of Mathematics and Gonda Brain Research Center, Bar-Ilan University, Ramat-Gan 52900, Israel
4
Yanqi Lake Beijing Institute of Mathematical Sciences and Applications (BIMSA), Huairou, Beijing 101400, China
*
Author to whom correspondence should be addressed.
†
These authors contributed equally to this work.
Symmetry 2021, 13(11), 2139; https://doi.org/10.3390/sym13112139
Submission received: 9 October 2021
/
Revised: 25 October 2021
/
Accepted: 27 October 2021
/
Published: 10 November 2021
(This article belongs to the Section Mathematics)
Abstract
:Nonlinear filtering is of great significance in industries. In this work, we develop a new linear regression Kalman filter for discrete nonlinear filtering problems. Under the framework of linear regression Kalman filter, the key step is minimizing the Kullback–Leibler divergence between standard normal distribution and its Dirac mixture approximation formed by symmetric samples so that we can obtain a set of samples which can capture the information of reference density. The samples representing the conditional densities evolve in a deterministic way, and therefore we need less samples compared with particle filter, as there is less variance in our method. The numerical results show that the new algorithm is more efficient compared with the widely used extended Kalman filter, unscented Kalman filter and particle filter.
1. Introduction
We aim to seek the optimal estimate of the state based on noisy observations in nonlinear filtering problems, which have a long history that can be traced back to the 1960s. In 1960, Kalman proposed the famous Kalman filter (KF) [1] and one year later, Kalman and Bucy proposed the Kalman–Bucy filter [2]. However, we need to assume that the filtering system is linear and Gaussian in KF. For general nonlinear filtering problems, we usually cannot obtain the optimal estimates. Therefore, approximations are required in order to derive suboptimal but still efficient estimators.
One direction is to approximate the nonlinear system. For instance, we approximate the original system by linear system using first-order Taylor expansions in the extended Kalman filter (EKF) [3]. Second-order variants of EKF can be found in [4]. In [5], the state is extended and then the nonlinear system is approximated by bilinear system using Carleman approach. Obviously, in these methods, the continuity of the system is required, and the estimations are sensitive to the specific point used for the expansion.
Instead, we can approximate the conditional density function rather than the system, since the optimal estimate is completely determined by the conditional density. For example, in particle filter (PF) [6] and its variants, we use the empirical distribution of some particles to approximate the real conditional distribution. For continuous filtering systems, the posterior density function satisfies the Duncan–Mortensen–Zakai equation [7,8,9] and there are many works aiming to solve this equation such as the direct method [10] and Yau–Yau method [11,12,13].
If we approximate the conditional density by single Gaussian distribution, and use KF formulas in updating step, then we can obtain a class of the so-called Nonlinear Kalman Filters [4]. However, we still need linearization in case of nonlinear systems, and one suitable way to perform such linearization is statistical linearization in the form of statistical linear regression [14]. In this sample-based approach, we represent the related densities by a set of random or deterministic selected samples. The class of Nonlinear Kalman Filters which make use of statistical linear regression are called Linear Regression Kalman Filters (LRKFs) [14]. For more details about LRKF, readers are referred to the work in [15]. The unscented Kalman filter (UKF) [16] is the most commonly used LRKF, which use a fixed number of deterministic sigma-points to capture the information of the conditional densities. Intuitively, the LRKF can be viewed as a hybrid of PF and KF, where the particles are obtained in a deterministic way. There are some heuristic algorithms that combine PF and KF directly in many practical applications such as target tracking [17,18].
The key problem in LRKF is how to select the points, which can be determined by minimizing some distance between original density and its Dirac mixture density formed by these points. In this paper, we propose a new LRKF which uses Kullback–Leibler (K-L) divergence as the measure. Motivated by the work [19] and considering the symmetry of Gaussian distribution, we approximate the standard normal density by the Dirac mixture density formed by any given number of symmetric points. Now, we only need to solve a optimization problem. There are many PFs based on MCMC sampling in recent decades. However, only a few papers have improved particle sampling by variational inference, as it is difficult to calculate the K-L divergence between discrete densities. With the rise of a large number of generative models in machine learning, more and more approximate algorithms related to variational inference are produced, and Stein variational gradient decent (SVGD) is an important one [20,21]. SVGD drives the discrete particles to approximate the continuous posterior density function by kernel functions, so that the K-L divergence between the continuous density and its Dirac mixture approximation by discrete points is minimized by using gradient descent. We then obtain the points which can approximate non-standard Gaussian density functions by Mahalanobis transformation [22]. At last, using the framework of LRKF, we can obtain the estimation result. Inheriting the advantages of LRKF, we can handle discontinuous filtering systems by the proposed algorithm and we do not need to compute the Jacobian matrix.
The first contribution of this work is that we introduce K–L divergence to measure the distance of the continuous density and its Dirac mixture approximation formed by any given number of symmetric samples. Besides, we use SVGD to solve the corresponding optimization problem motivated by frequently uses of variational inference in machine learning. It can be seen from the numerical simulations that our algorithm shows great efficiency compared with classical EKF, UKF, and PF.
Notations: represents the Euclidean norm. denotes the Dirac delta function, i.e.,
which is also constrained to satisfy the identity
denotes the Gaussian density function with mean m and positive definite covariance P, i.e.,
where n is the dimension of x and is the determinant of P.
2. Preliminaries
The discrete time filtering system considered here is as follows:
where is the state of the stochastic nonlinear dynamic system (1) at discrete time instant k, is the noisy measurement (or observation) generated according to the model (), and and are Gaussian white noise processes with and . Here we need to assume that , and the initial state are independent of each other. The density function of the initial state is . denotes the history of the observations up to time instant k, i.e.,
We aim to seek the optimal estimate of state based on the observation history in the sense of minimum mean square error.
Definition 1 (Minimum mean square error estimate([3])). Let be an estimate of random variable x. Then the minimum mean square error estimate of x is
Jazwinski proved that the minimum mean square error estimate of state based on is its conditional expectation in the following theorem.
Theorem 1
(Theorem 5.3 in [3]). Let the estimate of be a functional on . Then, the minimum mean square error estimate of state is its conditional mean .
Obviously, if we can obtain the conditional density of based on , i.e., , then we can simply compute . The evolution of the conditional density function is given in the following theorem.
Theorem 2
([19]). Consider the filtering problem (1)–() from time step to step k. The evolution of the conditional density function contains iterative two steps:
- In the prediction step, employing the system model (1) and the Chapman–Kolomogorov equation, we can obtainwhere
- In the updating step, when the latest measurement arrives, using Bayes’ rule, we havewhere the likelihood function is obtained according towith
The initial value of the conditional density function is . Then according to Theorem 2, we have the evolution framework of which is shown in the following Figure 1.
Unfortunately, we cannot obtain the conditional density function analytically in most cases, although we have the recursive evolution equations of conditional density functions. Therefore, we cannot get the optimal estimate , and we need to resort to some approximation techniques.
2.1. Nonlinear Kalman Filtering Based on Statistical Linearization
One important approximative Bayesian estimation technique is used in the class of Nonlinear Kalman Filter. These filters assume that both and are well approximated by Gaussian distributions. The detailed procedures are listed as follows [19].
- 1.
- Initialization: The initial density of is approximated by Gaussian:with the initial meanand initial covariance
- 2.
- Prediction: The apriori density function is approximated bywith predicted state meanand predicted state covariance matrixrespectively.
- 3.
- Updating: The Bayesian filter step (5) can be reformulated in form of the joint density according toHere, this joint density is approximated by Gaussianthen according to Theorem A2 in Appendix A, posterior state meanand posterior state covariance matrixwhere the measurement meanthe measurement covariance matrixas well as the cross-covariance matrix of predicted state and measurement
However, we cannot obtain the closed form integrals in the above equations in general cases.
2.2. The Linear Regression Kalman Filter
If the state densities in the integrals of the Nonlinear Kalman Filter can be replaced by proper Dirac mixture densities formed by some samples, then we can easily compute these integrals. That is, the statistical linearization is turned into an approximate statistical linear regression, and this is exactly what the LRKF does.
The Dirac mixture approximation of an arbitrary density of by L samples is
with samples and positive scalar weights , for which
Therefore, the information of the density is approximately encoded in the Dirac mixture parameters, which can be determined by minimizing certain distance between and .
2.3. The Smart Sampling Kalman Filter
One of the LRKFs is the smart sampling Kalman Filter proposed in [15]. As the goal in LRKF is to approximate Gaussian densities and by Dirac mixture densities, They first consider to approximate an N-dimensional standard normal distribution by Dirac mixture approximation using equal weights and symmetric samples in the following manner:
Then, given a non-standard Gaussian distribution
we can use the Mahalanobis transformation [22] to obtain the Dirac mixture approximation. More explicitly, by transforming the samples in (22) according to
where is the square root of using Cholesky decomposition, we have the Dirac mixture approximation of (23) as follows:
Moreover, this transformation can be also understood from the property of Gaussian random variables listed in Theorem A1.
By approximating the approximated a priori density in (10) and posterior density in (14) using (24) and (25), we can get the desired filtering result under the framework of LRKF. Now the key is how to determine the samples in (22) so that they approximate a multivariate standard normal distribution in an optimal way. In [19], a combination of the Localized Cumulative Distribution and the modified Cramér–von Mises distance is adapted.
3. The New Linear Regression Kalman Filter
Apparently, in the framework of LRKF, we need to approach the goal through the formulation of an optimization problem with respect to the appropriate chosen distance metric between original density and its Dirac mixture approximation. Instead of the distance measure adapted in [19], we can minimize the K–L divergence between the multivariate standard normal distribution and its approximation
formed by samples
3.1. Kullback–Leibler Divergence and Stein Variational Gradient Descent
K–L divergence, , is used to measure how one probability distribution is different from the reference probability distribution. Based on definition, it is known that, the K–L divergence between the Dirac mixture approximation density defined in (26) and standard normal distribution is
The new algorithm requires that the initial particles are calculated in advance. Therefore we can divided the new algorithm into two parts. The first part is pre-calculation which is implemented off-line, while we use LRKF to get the estimates of the states in the on-line part. In the first part, particle sampling is regarded as a variational inference problem. SVGD is used to capture and store the most important statistical locus of the target distribution.
For all our experiments, we use kernel , and take the bandwidth to be , where “med” is the median of the pairwise distance between the current points . We must point out that the different kernel functions may lead to different numerical results, here we choose this kernel to approximate the Gaussian distribution better. Details of the SVGD can be found in the references [20,21].
The procedures of this off-line algorithm is listed in Algorithm 1.
| Algorithm 1:Off-Line Computation |
|
3.2. On-Line Filtering Algorithm
With the ready off-line data , we can obtain the estimate of state by the following procedures [19].
- when , and are the initial mean and covariance of initial density , respectively. The initial particles are generated according to
- For , given , and , letthen we have
- when the measurement arrives, letand computewithThe particles are updated according to
The on-line procedures are summarized in Algorithm 2.
Combining Algorithms 1 and 2, we obtain the new LRKF (NLRKF).
| Algorithm 2: On-Line Computation |
|
4. Experiments
4.1. Settings
We run our simulations on CPU clusters with Intel Core i9-9880H(2.3CGz/L3 16M) equipped with 16 GB memory.
The total time step is K. We run the simulations for 100 times and assume that the is the estimation result of real state at time step k in the i-th experiment. In order to measure the performances of the numerical algorithms over time, we define the Root Mean Square Error (RMSE) and the mean error at time step k as follows:
is the average estimation error at time k while is the accumulated average estimation error till to time k.
4.2. Numerical Example
We consider the classic cubic sensor here and the model is as follows:
where , , , , and with . The continuous and continuous-discrete cubic sensor problems have been investigated in [5,11,12], and it has been proved that there cannot exist a recursive finite-dimensional filter driven by the observations for continuous cubic sensor system [23].
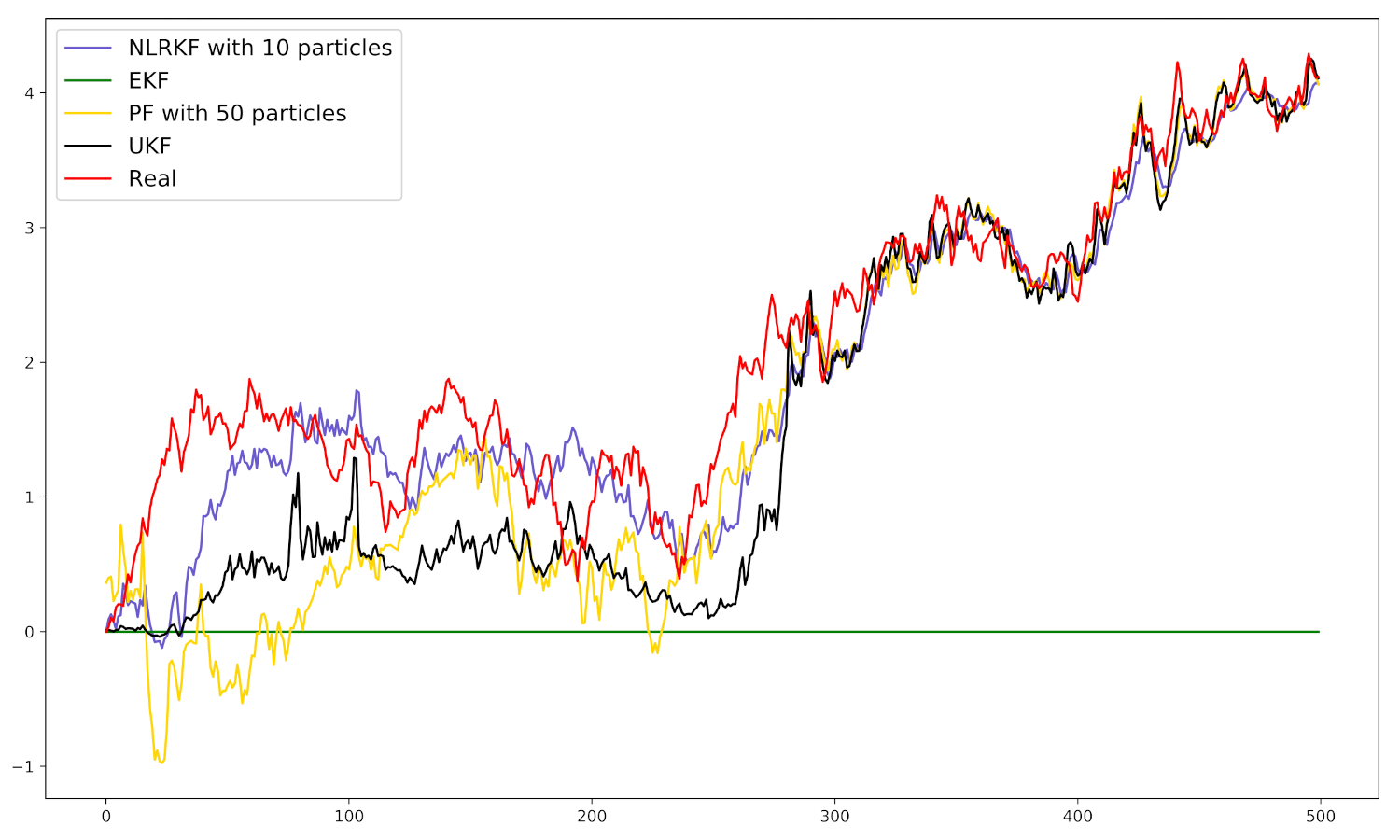
We compare our NLRKF with classical EKF, UKF, and PF. We first use 10 symmetric points (or particles) for our NLRKF and 50 particles for PF. The performance in one experiment is shown in Figure 2. Apparently, EKF totally fails to track the real state and other algorithms can track the real state well with different accuracies.
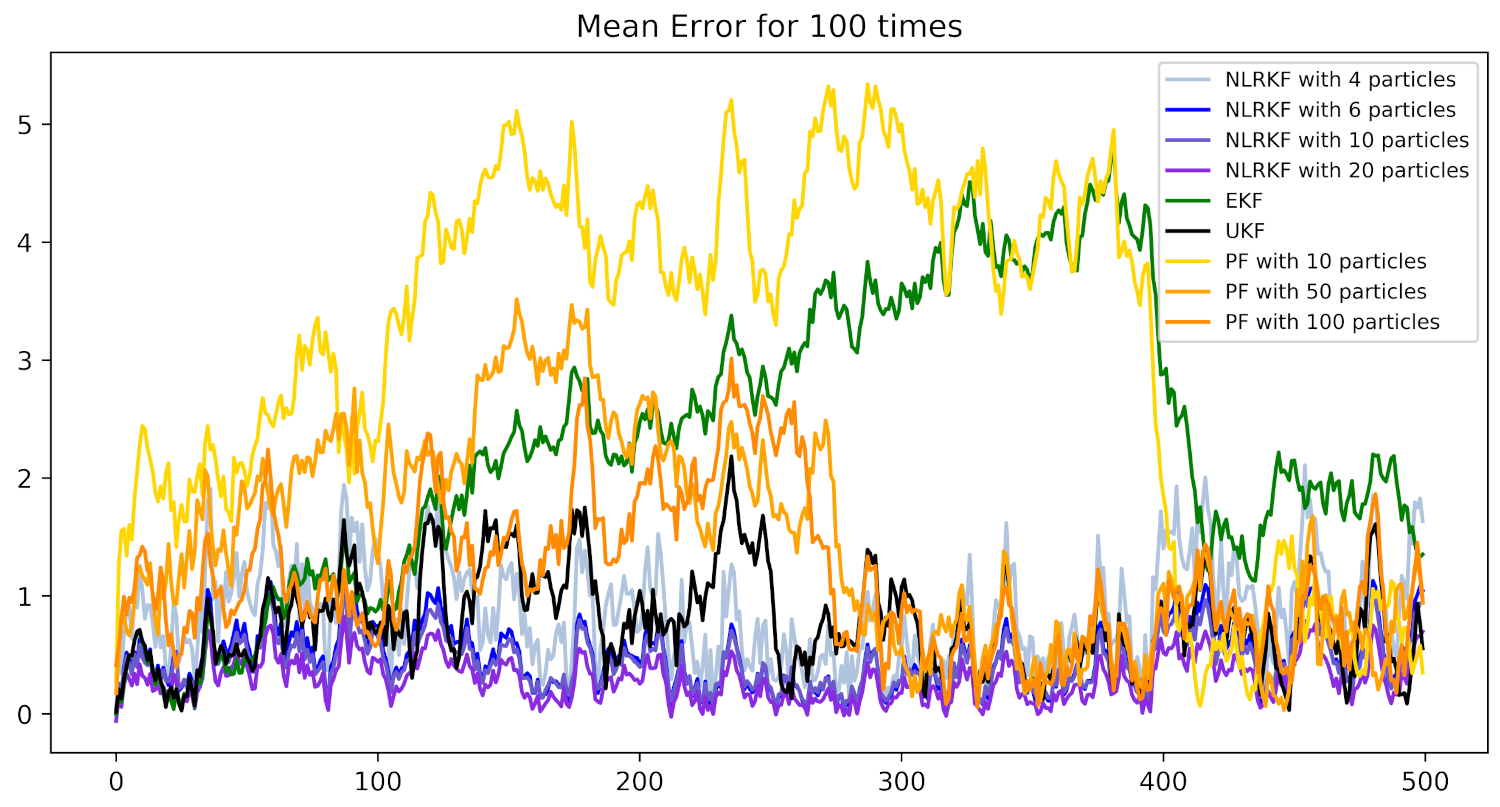
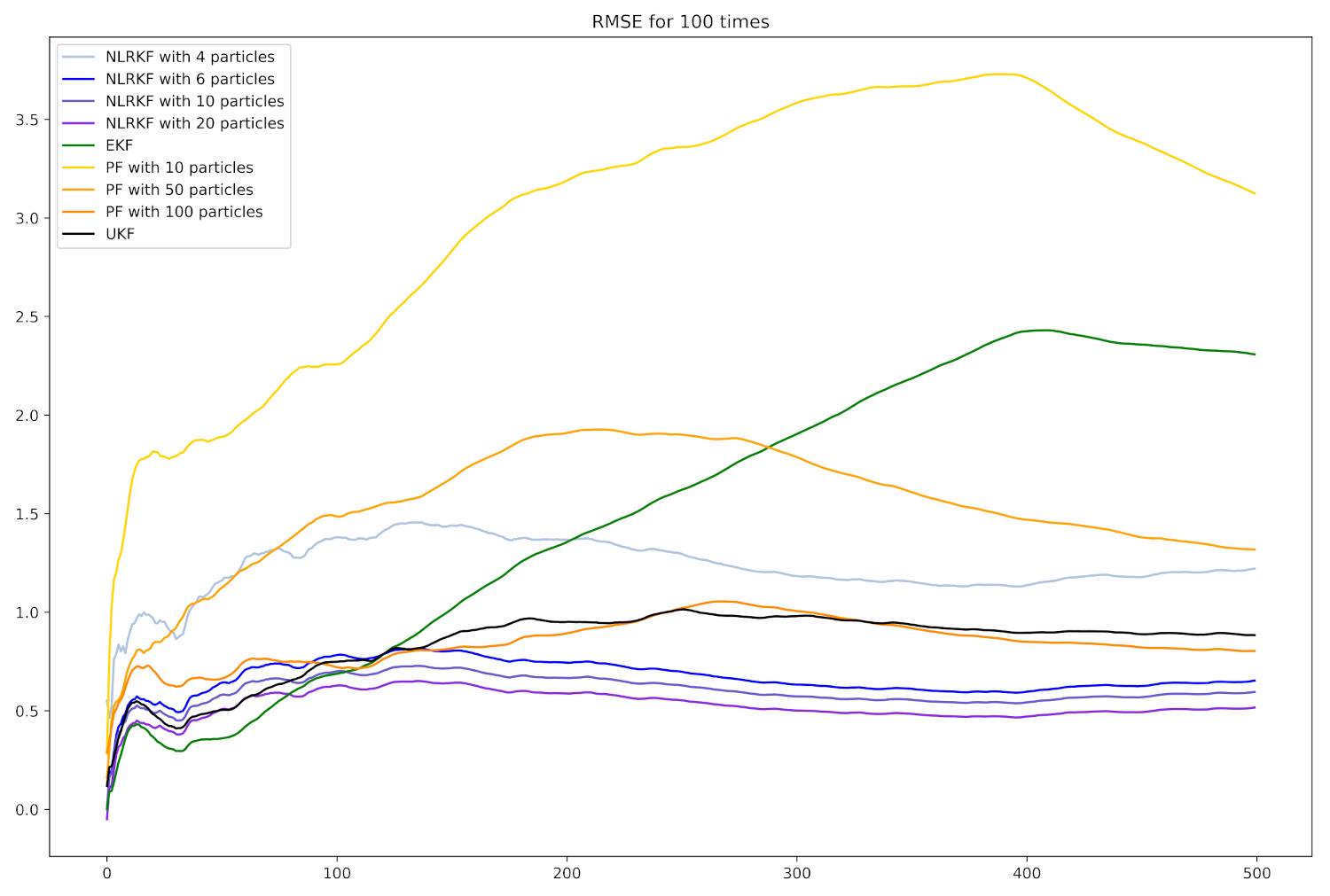
To further explore the performance of different algorithms based on 100 experiments, we plot the evolutions of mean error and RMSE over time in Figure 3 and Figure 4. As can be seen from these two figures, NLRKF with 20 particles performs best, followed by NLRKF with 10 particles and 6 particles. UKF is better than PF.
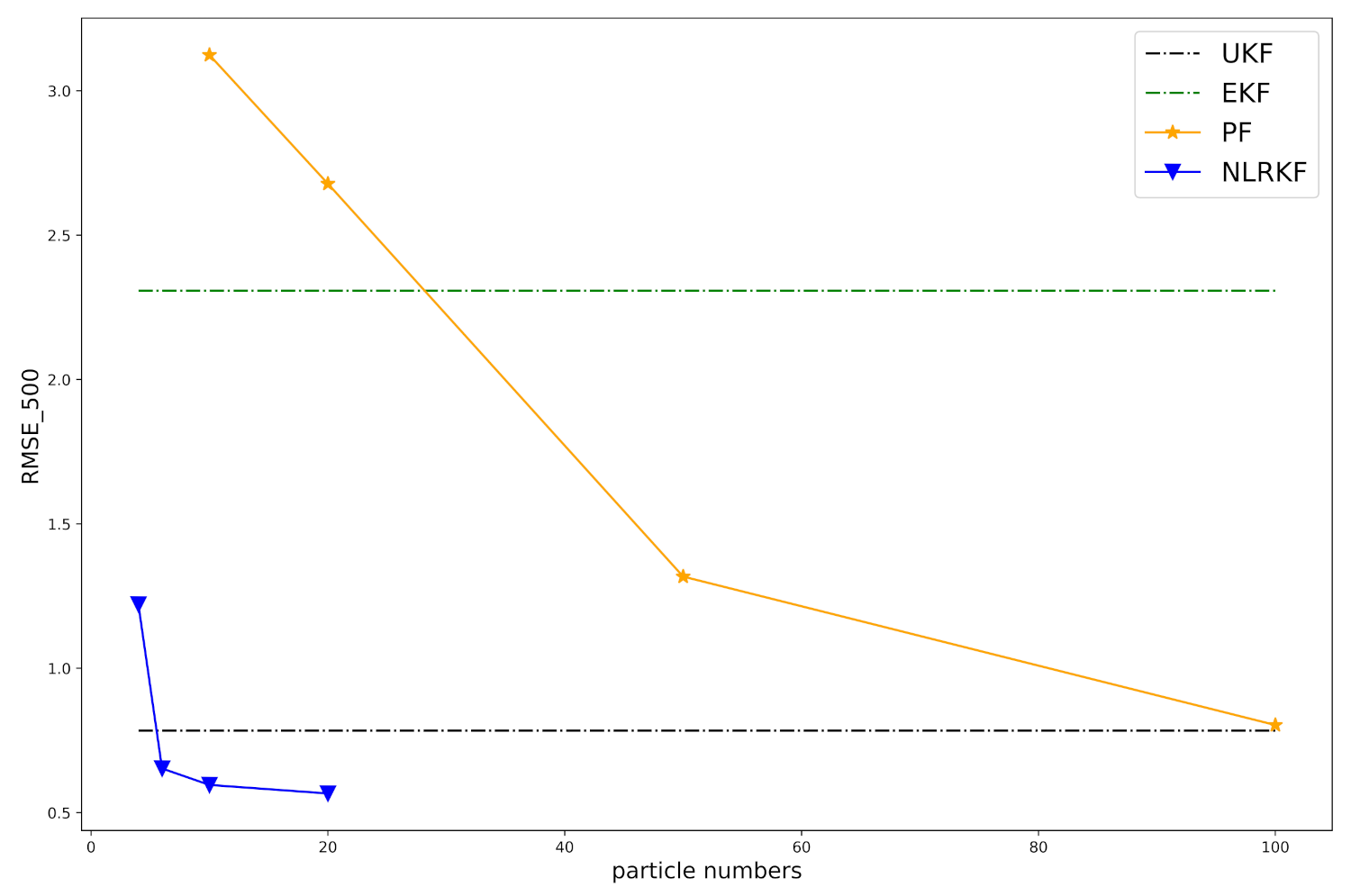
The total estimation error and costing times of different methods based on 100 experiments are listed in Table 1, in which represents the number of particles or points used in NLRKF and is the number of particles used in PF. We can know that NLRKFs with , and 6 particles are the three best performing algorithms considering both RMSE and costing times. We also display the connection of RMSE and number of particles in Figure 5. UKF and EKF are independent of the number of particles, so the two lines are horizontal. The NLRKF surpasses other methods with just 6 particles.
5. Conclusions
In this paper, we proposed a new LRKF using K–L divergence and symmetric samples. The numerical simulation results show that our algorithm is accurate and efficient. However, the proposed algorithm requires the explicit model of the filtering system. Besides, this algorithm is under the framework of nonlinear Kalman filter, i.e., we approximate the conditional density by single Gaussian density. The approximation can lead to large errors when the conditional density is highly non-Gaussian. How to remove this framework and deterministically propagate the points are our future works.
Author Contributions
Conceptualization, X.C.; methodology, X.C.; software, J.K.; validation, J.K.; formal analysis, X.C. and J.K.; investigation, J.K. and X.C.; resources, S.S.-T.Y.; data curation, J.K.; writing—original draft preparation, X.C.; writing—review and editing, M.T. and S.S.-T.Y.; visualization, J.K. and X.C.; supervision, M.T. and S.S.-T.Y.; project administration, S.S.-T.Y.; funding acquisition, M.T. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National Natural Science Foundation of China NSFC (grant no. 11961141005), Israel Science Foundation (joint ISF-NSFC grant) (grant no 20551), Tsinghua University start-up fund, and Tsinghua University Education Foundation fund (042202008).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
All data in the simulations are generated according to Equations (36) and (37).
Acknowledgments
The authors thank the editor and anonymous reviewers for their helpful comments and constructive suggestions. S. S.-T. Yau is grateful to the National Center for Theoretical Sciences (NCTS) for providing an excellent research environment while part of this research was done.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Properties of Gaussian Random Variables
It was noted that the density function of Gaussian random variable is characterized by two parameters, the mean and covariance. We list some properties of Gaussian random variables here.
Theorem A1
(Theorem 2.11 in [3]). Let the p-dimensional Gaussian random vector . Let , where is a constant matrix, is a constant vector, and is a vector. Then .
Theorem A2
Then, the conditional density of x given y is normal with mean
and covariance matrix
References
- Kalman, R.E. A new approach to linear filtering and prediction problem. ASME Trans. J. Basic Eng. Ser. D 1960, 82, 35–45. [Google Scholar] [CrossRef] [Green Version]
- Kalman, R.E.; Bucy, R.S. New results in linear filtering and prediction theory. ASME Trans. J. Basic Eng. Ser. D 1961, 83, 95–108. [Google Scholar] [CrossRef]
- Jazwinski, A.H. Stochastic Processes and Filtering Theory; Academic Press: New York, NY, USA; London, UK, 1970. [Google Scholar]
- Simon, D. Optimal State Estimation: Kalman, H Infinity, and Nonlinear Approaches; John Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Luo, X.; Chen, X.; Yau, S.S.T. Suboptimal linear estimation for continuous–discrete bilinear systems. Syst. Control Lett. 2018, 119, 92–100. [Google Scholar] [CrossRef]
- Gordon, N.J.; Salmond, D.J.; Smith, A.F.M. Novel Approach to Nonlinear/Non-Gaussian Bayesian State Estimation. Radar Signal Process. IEE Proc. F 1993, 140, 107–113. [Google Scholar] [CrossRef] [Green Version]
- Duncan, T.E. Probability Densities for Diffusion Processes with Applications to Nonlinear Filtering Theory and Detection Theory; Technical Report; Stanford University: Stanford, CA, USA, 1967. [Google Scholar]
- Mortensen, R.E. Optimal Control of Continuous Time Stochastic Systems. Ph.D. Thesis, University of California, Berkley, CA, USA, 1966. [Google Scholar]
- Zakai, M. On the optimal filtering of diffusion process. Z. Wahrsch. Verw. Geb. 1969, 11, 230–243. [Google Scholar] [CrossRef]
- Chen, X.; Shi, J.; Yau, S.S.T. Real-time solution of time-varying yau filtering problems via direct method and gaussian approximation. IEEE Trans. Autom. Control 2019, 64, 1648–1654. [Google Scholar] [CrossRef]
- Luo, X.; Yau, S.S.T. Hermite spectral method to 1-D forward Kolmogorov equation and its application to nonlinear filtering problems. IEEE Trans. Autom. Control 2013, 58, 2495–2507. [Google Scholar] [CrossRef]
- Shi, J.; Chen, X.; Yau, S.S.T. A Novel Real-Time Filtering Method to General Nonlinear Filtering Problem Without Memory. IEEE Access 2021, 9, 119343–119352. [Google Scholar] [CrossRef]
- Yau, S.T.; Yau, S.S.T. Real time solution of the nonlinear filtering problem without memory II. SIAM J. Control Optim. 2008, 47, 163–195. [Google Scholar] [CrossRef]
- Lefebvre, T.; Bruyninckx, H.; De Schutter, J. Kalman filters for non-linear systems: A comparison of performance. Int. J. Control 2004, 77, 639–653. [Google Scholar] [CrossRef]
- Steinbring, J.; Hanebeck, U.D. LRKF revisited: The smart sampling Kalman filter (S2KF). J. Adv. Inf. Fusion 2014, 9, 106–123. [Google Scholar]
- Julier, S.J.; Uhlmann, J.K. Unscented filtering and nonlinear estimation. Proc. IEEE 2004, 92, 401–422. [Google Scholar] [CrossRef] [Green Version]
- Majumdar, J.; Dhakal, P.; Rijal, N.S.; Aryal, A.M.; Mishra, N.K. Article: Implementation of Hybrid Model of Particle Filter and Kalman Filter based Real-Time Tracking for handling Occlusion on Beagleboard-xM. Int. J. Comput. Appl. 2014, 95, 31–37. [Google Scholar]
- Morelande, M.R.; Kreucher, C.M.; Kastella, K. A Bayesian Approach to Multiple Target Detection and Tracking. IEEE Trans. Signal Process. 2007, 55, 1589–1604. [Google Scholar] [CrossRef] [Green Version]
- Steinbring, J.; Pander, M.; Hanebeck, U.D. The smart sampling Kalman filter with symmetric samples. arXiv 2015, arXiv:1506.03254. [Google Scholar]
- Liu, Q.; Wang, D. Stein variational gradient descent: A general purpose bayesian inference algorithm. arXiv 2016, arXiv:1608.04471. [Google Scholar]
- Liu, Q. Stein variational gradient descent as gradient flow. arXiv 2017, arXiv:1704.07520. [Google Scholar]
- Härdle, W.K.; Simar, L. Applied Multivariate Statistical Analysis; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Hazewinkel, M.; Marcus, S.; Sussmann, H.J. Nonexistence of finite-dimensional filters for conditional statistics of the cubic sensor problem. Syst. Control Lett. 1983, 3, 331–340. [Google Scholar] [CrossRef] [Green Version]
Figure 1.
The evolutions of the posterior density functions.

Figure 2.
Estimation results in one experiment. The horizontal axis is time step k and the vertical axis is for real state and for filtering algorithms.
Figure 2.
Estimation results in one experiment. The horizontal axis is time step k and the vertical axis is for real state and for filtering algorithms.

Figure 3.
Mean Errors of different filtering algorithms. The horizontal axis is time step k and the vertical axis is defined in (35).
Figure 3.
Mean Errors of different filtering algorithms. The horizontal axis is time step k and the vertical axis is defined in (35).

Figure 4.
RMSE of different filtering algorithms. The horizontal axis is time step k and the vertical axis is defined in (35).
Figure 4.
RMSE of different filtering algorithms. The horizontal axis is time step k and the vertical axis is defined in (35).

Figure 5.
of filtering algorithms w.r.t. the number of particles or samples.


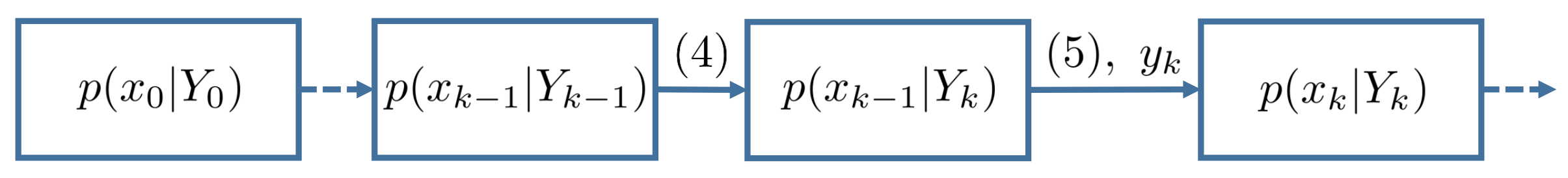{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
The and costing times of different filtering algorithms based on 100 experiments.
| Method | Costing Time (s) | |
|---|---|---|
| EKF | 2.3076 | 0.0206 |
| UKF | 0.7840 | 0.1390 |
| NLRKF () | 1.2212 | 0.0406 |
| NLRKF () | 0.6529 | 0.0729 |
| NLRKF () | 0.5959 | 0.0879 |
| NLRKF () | 0.5663 | 0.1218 |
| PF () | 3.1242 | 0.1163 |
| PF () | 1.3175 | 0.1892 |
| PF () | 0.8034 | 0.2672 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Chen, X.; Kang, J.; Teicher, M.; Yau, S.S.-T. A New Linear Regression Kalman Filter with Symmetric Samples. Symmetry 2021, 13, 2139. https://doi.org/10.3390/sym13112139
AMA Style
Chen X, Kang J, Teicher M, Yau SS-T. A New Linear Regression Kalman Filter with Symmetric Samples. Symmetry. 2021; 13(11):2139. https://doi.org/10.3390/sym13112139
Chicago/Turabian StyleChen, Xiuqiong, Jiayi Kang, Mina Teicher, and Stephen S.-T. Yau. 2021. "A New Linear Regression Kalman Filter with Symmetric Samples" Symmetry 13, no. 11: 2139. https://doi.org/10.3390/sym13112139
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.