1. Introduction
Severely unbalanced cases are highly likely to appear in decisive problems. Equally distributed class data are supposedly mandatory in prediction to avoid misclassification [
1]. However, this unbalanced phenomenon has been one of the main obstacles in prediction issues [
2]. According to Wang et al. [
3], substantially unbalanced datasets allegedly create imprecise classification models, especially for the minority classes. Furthermore, a study conducted by Provost et al. [
4] stated that the dataset can be in a ratio of one to one hundred thousand from one class to another. Several previous studies on unbalanced data have been conducted. The effect of unbalanced data has appeared in studies on oil spills [
5], telecommunication risk management [
6], text recognition [
7], fraud characteristics in cellular communication [
8], and email spam problems [
9].
Aiming to overcome the unbalanced data problem, several earlier studies have been conducted. Batista et al. [
10] used a method reducing the dominant group and increasing the smaller ones. Cristianini et al. [
11] did a fine-tuning of the weights of the classes. Chawla et al. [
12] performed a study about the synthetic minority over-sampling technique.
Fuzzy c-Means clustering (FCM) is a widely used algorithm for the unbalanced data problem. According to Jain et al. [
13], essentially, clustering has a fundamental target for achieving the phenomena from unspecified output problems. One study applied an FCM-based algorithm to the unbalanced data [
14]. Further, a combination of FCM with Support Vector Machine (SVM) classification outperformed the model using only SVM classification [
15]. Meanwhile, an FCM clustering-based algorithm for resampling the preprocessing method for unbalanced data was also applied before the classification step for a biomedical dataset [
16].
Artificial Neural Networks (ANNs) are one the most commonly used classification algorithms [
17,
18]. However, they usually suffer from the generalization problem [
19]. Some studies have used multiple classifiers as part of the solutions for solving the generalization problem, instead of the individual model. There is a relationship between diversity and generalization [
20]. Furthermore, diversity can produce several alternatives to a specific issue and gives the possibility to select a decision [
21]. An investigation into the importance of diversity to ensemble modelling has been made by applying an entropy-based algorithm [
22], a regression model [
23], and an evaluation of numbers of neural networks [
24]. A study previously conducted by Tumer et al. [
25] also remarkably revealed a strong relation between diversity and ensemble evaluation.
Several methods have been proposed for ensemble techniques. Averaging is one of the commonly used ensemble techniques. Averaging methods can be classified into simple or weighted averaging. However, according to earlier studies, weighted averaging is not remarkably better than a simple averaging method [
26,
27,
28], where a simple averaging method works by directly taking the average value from the outputs generated by the classifiers. Furthermore, more advanced studies have been conducted on ensemble techniques [
29,
30,
31].
Fundamentally, an ensemble of classifiers has the purpose of reaching a generalization of the aforementioned models. Further, combining several models produces a better generalization compared with combining all models [
32]. In order to realize this condition, an optimization technique should be applied. The Genetic Algorithm (GA), based on natural selection and evolution, is one of the most robust optimizing algorithms that has been applied in huge optimization applications. Hornby et al. [
33] applied GA for designing an antenna for aerospace applications. GA has also been applied to produce an ensemble of models. Padilha et al. [
34] used GA to produce an ensemble from several SVM-based models. In a recent study, a combination of random sampling to balance classes using GA based on an ensemble of several classification methods was applied by Haque et al. [
35].
The emergency medical service (EMS) is one of the most critical parts of healthcare. Furthermore, the pre-hospital EMS contributes to the decisive medical system [
36]—the response and treatment from the EMS technicians is very decisive with regards to the patient’s survival rate [
37].
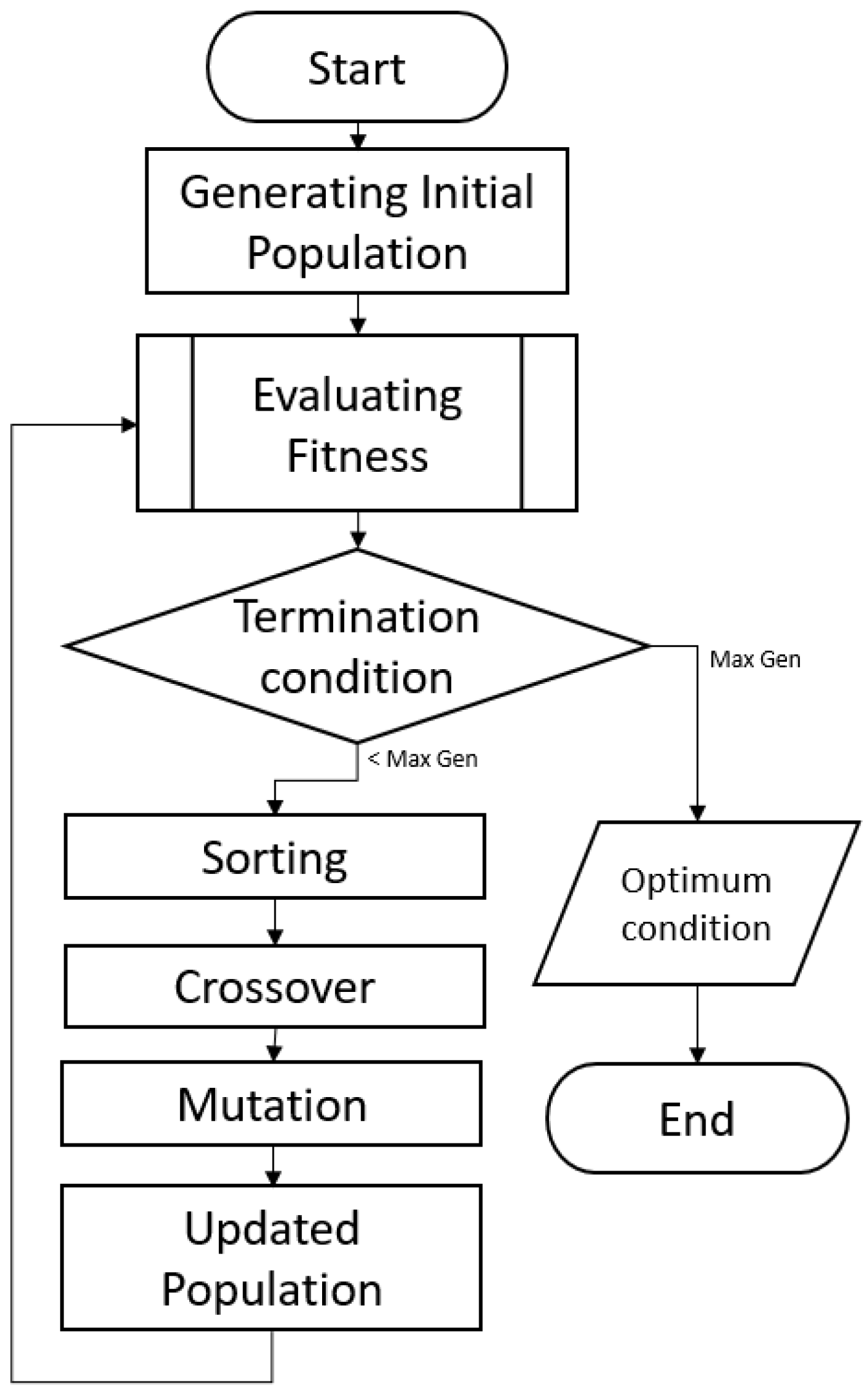
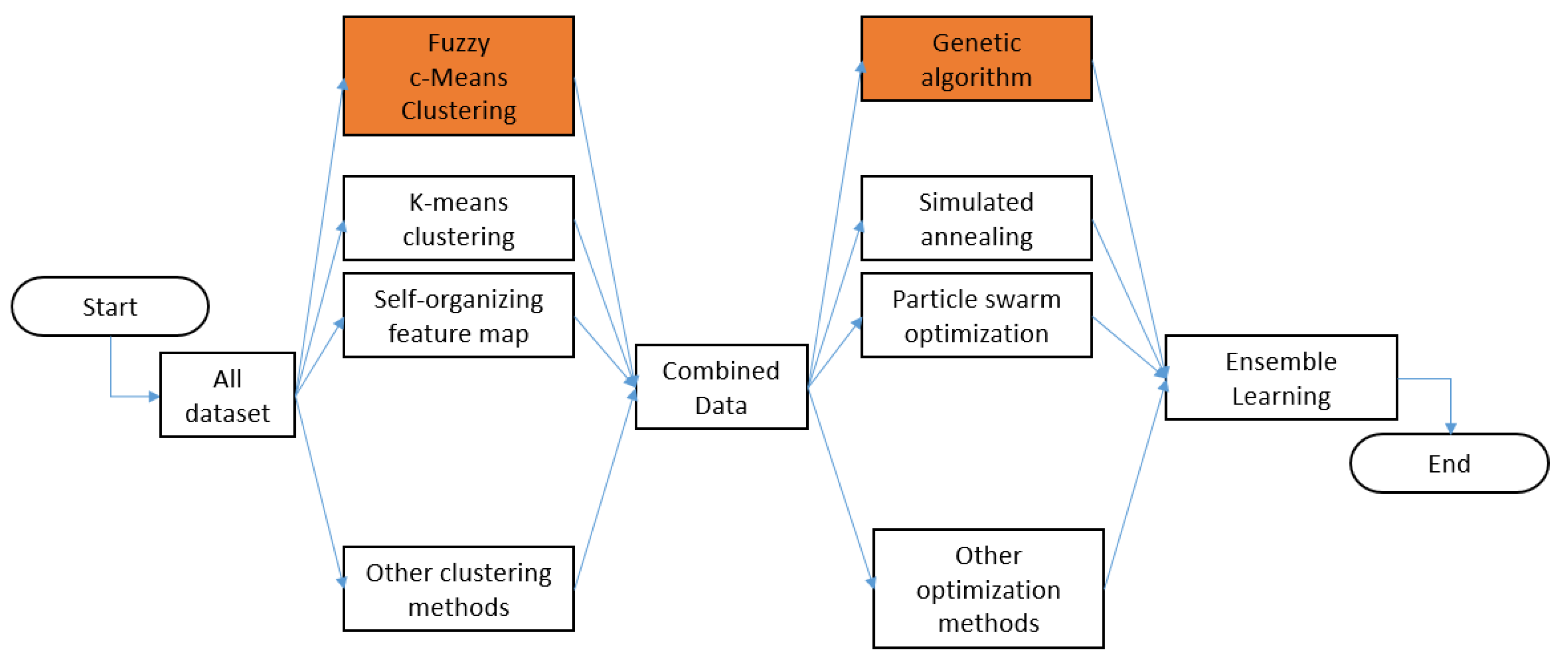
This study aims to predict the survival/nonsurvival rate from highly unbalanced emergency medical service data. An FCM algorithm is applied to equally separate the classes before the classification step. Furthermore, ANNs are utilized as a classifier in combination with a GA optimizer.
3. Results and Discussion
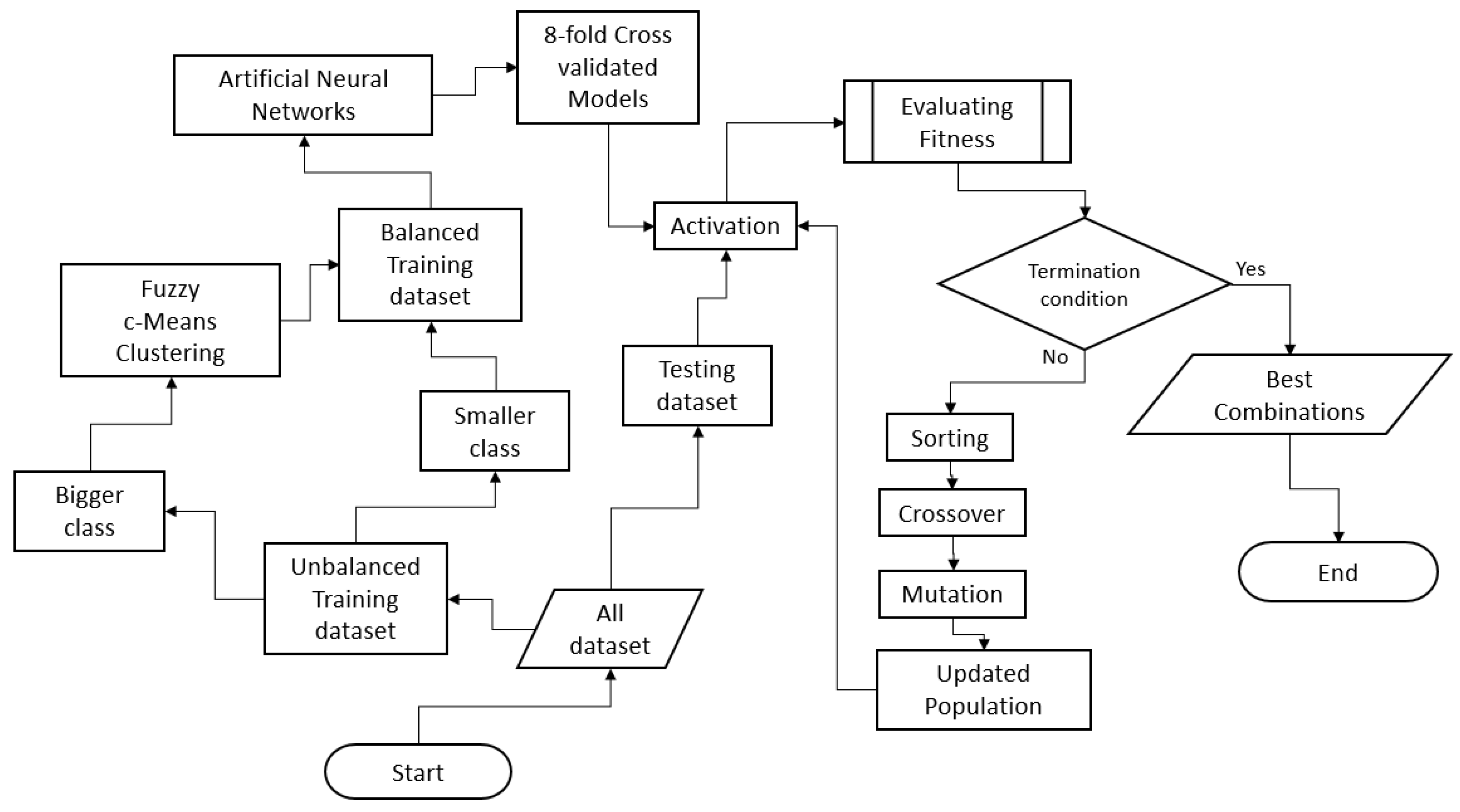
This study evaluates a big dataset relating to the emergency medical service. The first preprocessing step is to filter the age- and time-related parameters. The second filter is conducted using simple linguistic filtering. This filter is utilized to select data correlating the input and output based on how the input data correlates to the output results. Furthermore, an FCM clustering algorithm is performed in order to balance the dataset. The cross-validation-based ANN is selected as the classifier. The GA-based ensemble method is eventually performed to select the models based on the evaluation of the AUC.
Initially, this study evaluates highly unbalanced data from the emergency medical service. This system has about 100 to 1 data distribution from one class to another. The raw data after the first filter is used consists of 4,408,187 patient datapoints. Based on the data distribution, the second filter is applied. For the lower limit data, this works by removing the data less than the mean minus one standard deviation. Similarly, the higher limit data is also terminated by removing that which is more than the sum of the mean and three standard deviations. This second filter reduces the total amount of data to 3,129,733 cases. From the whole dataset, the portions corresponding to survival and nonsurvival are 3,103,387 and 26,346, respectively. The data is prepared for training and testing by taking half of each class (rounded)—1,551,693 datapoints from the survival class and 13,173 from the nonsurvival class are randomly selected. This strategy is utilized to investigate the performance of the ensemble technique after the training model.
In order to evaluate the behavior of the input parameters relative to the output from the large-set data class—the survival class—this study proposes simple linguistic terms by associating them with specific ranges of numbers. This evaluation uses five normalization units. For example, in the response time parameter, from having the original sequence between 3 and 20 min, the normalized unit will change to 1 to 5. The lowest to the highest units will be very short, short, normal, long, and very long. On other hand, for the age parameter, the linguistic terms are young, adult, middle-age, middle-old, and oldest-old. These linguistic terms are applied to normalize the training data with the purpose of avoiding unordinary input–output behavior.
After setting each linguistic parameter, the combination from all input parameters relating to the survival-only output is investigated. For example, how frequently will the combination of male middle-old patients with very short response time, short on-scene time, and normal transportation time result in survival? This algorithm will also filter the combinations that appear with low frequency. These possibilities are ranked based on the frequency with which they appear, as shown in
Table 2. The best-ranked combination possibilities will correspond to the original dataset sequences. Furthermore, cumulative summation is performed to filter the data to about 95 percent of the original training data size for a total of 1,473,777 cases from the most frequent 328 combinations.
The clustering algorithm is performed sequentially for the best possibilities previously formed by the linguistic terms. In this study, the purpose of the data classification method is to make the bigger class close to the size of the smaller class—13,173 patient datapoints. For example, if the survival data is divided into ten clusters, each of the survival clusters will randomly send 1317 datapoints to make a total of 13,170 survival class members to form the new balanced training dataset.
For classification, the ANN is selected as the classifier. The structure of the ANN is designed to be a system with three hidden layers. In order to generate diversity, all of the hidden neurons are set randomly between five and fifty neurons with initial weights also randomly selected. Further, the backpropagation learning algorithm is applied. The output of the classification—either nonsurvival or survival—is normalized to zero or one, respectively.
The eight models are generated based on the cross-validation method. In this study, the testing data is held outside its evaluation for all the clusters. This benefits the ensemble performance estimator. As can be seen from
Table 3, the 8-fold cross validation result performs with a relatively small standard deviation, showing good generalization.
GA is applied with random initial activation of the models set as the chromosomes, generated by the single neural network. In this study, the chromosome length and the bit number are defined as the number of models. The AUC of the model is selected as the fitness function, with a higher AUC showing a better evaluation. The number of chromosomes is set to 4 for the reproduction. The highest and the second-highest AUC models will be stored for the crossover candidates. These two models will be the parents for the next new chromosomes with the addition of the randomly initiated chromosomes in the crossover step.
A single crossover point for the half part of the chromosome is used for the crossover system. In this study, this method will only change for the third and the fourth chromosomes—the randomly initiated chromosomes—for their half part. For example, the last four bits of the first chromosome will replace the first four bits of the third chromosome. Similarly, the last four bits from the second-best chromosome will replace the first four bits of the fourth-best chromosome.
After the crossover procedure, the mutation algorithm is applied. The mutation is generated by random integer, placing either a zero or one in the mutated chromosome bit. This method generates a chance for some bits to avoid being mutated bits. This study also evaluates two methods of mutation. The first one is the all chromosome mutation possibility, with a small mutation rate of 0.1, and another way is the leave-best-out mutation, which has a much greater mutation rate of 0.95.
The all chromosome mutation system works essentially with the possibility that all bits from all chromosomes can be mutated, whereas leave-best-out mutation works similar to the whole chromosome mutation with the exception of the best chromosome bits—those with the highest AUC—which withstand the mutation. This event will only be able to reshape the second to the last chromosome bits. This also means that no best chromosome bit will be mutated. This procedure has the purpose of holding the best chromosome as the highest ranking and also as the best parent for generating the next offspring.
The next procedure is the fitness function evaluation. If, after the crossover and mutation, there is any chromosome sorted by the AUC as better than the previous best chromosome, this new chromosome will be placed as the top chromosome and become a parent along with the second best; the second best can be the previous best model or one of the new randomly generated chromosomes. This situation highly likely generates a better offspring, due to the mating of the best parent chromosomes. The termination condition is set to 200 generations.
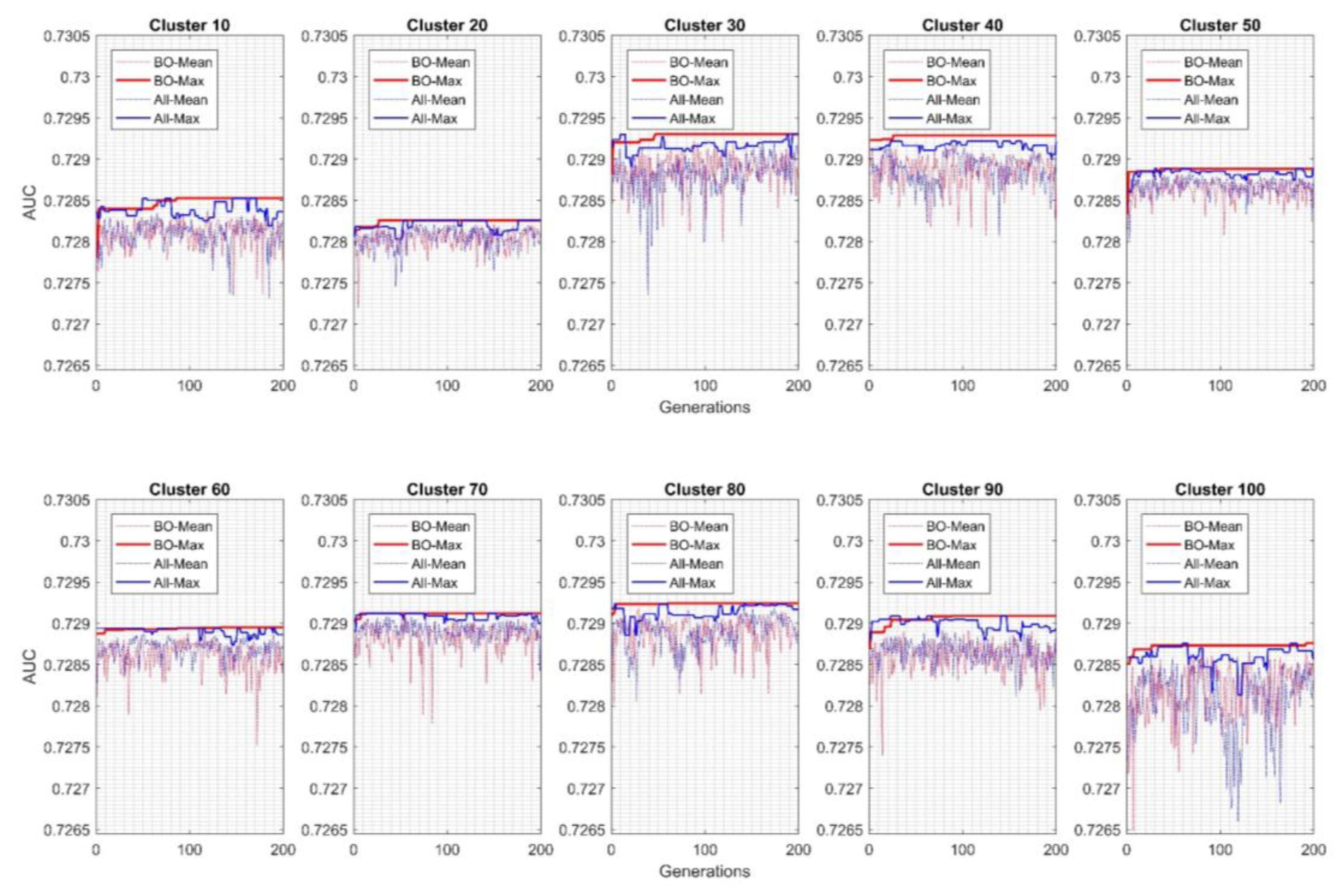
For results of intra-cluster EGFNM with different mutation rate systems are shown in
Figure 3. The all chromosome mutation method in some clusters (10, 30, and 90) is faster in increasing the fitness function using the
AUC compared with the leave-best-out method. However, the leave-best-out method provides better stability and accuracy for most of the cases. The cluster evaluation shows that Cluster 30 and Cluster 40 have the relative highest—yet similar—results. However, the
AUC for Cluster 30 is slightly better.
Table 4 shows comparisons and details about the unbalanced, best single model, and the intra-cluster EGFNM results. It shows that the unbalanced
AUC equals 0.67974, while the random cluster has 0.7177, and the best single model is a model for Cluster 40, marked in bold, with an AUC of 0.72806. Furthermore, the importance of applying GA as an optimizer is due to its ability to evaluate all possible solutions to decide which of them generates the best combination. For this study, the GA is set to have four population selections each with a chromosome length set to eight, an equal-part single-point crossover for the two highest
AUC models, and a leave-best-out 95% mutation rate. As a result, the intra-cluster EGFNM, applying the GA-based method as the ensemble technique, produces the best result when four models from Cluster 30 are selected—namely, the second, third, fifth, and sixth out of eight models are activated—producing 0.7293 of the AUC, as shown underline in
Table 4.
The evaluation of the inter-cluster EGFNM is described in the following. In order to have consistent evaluation, the inter-cluster EGFNM evaluation is also reduced to evaluate only eight clusters from the initial ten clusters. This means only the eight best clusters, excluding Clusters 10 and 20, are used in the ensemble models. The ANN structure of these models can be seen in
Table 5.
Similarly, for the intra-cluster evaluation, the result shows that the combination of the best model from Clusters 30, 50, 60, 80, 90 and 100 produces the highest
AUC of 0.73038. However, if all clusters are combined, the result is slightly reduced to 0.73037. This condition, as well the intra-cluster method, indicates that the best combination is not formed by combining the best models. Instead, some of the models will provide the best ensemble learner. This finding supports the study by Zhou et al., in 2002, which concluded that combining several models can generate a better result than combining all the models [
32].
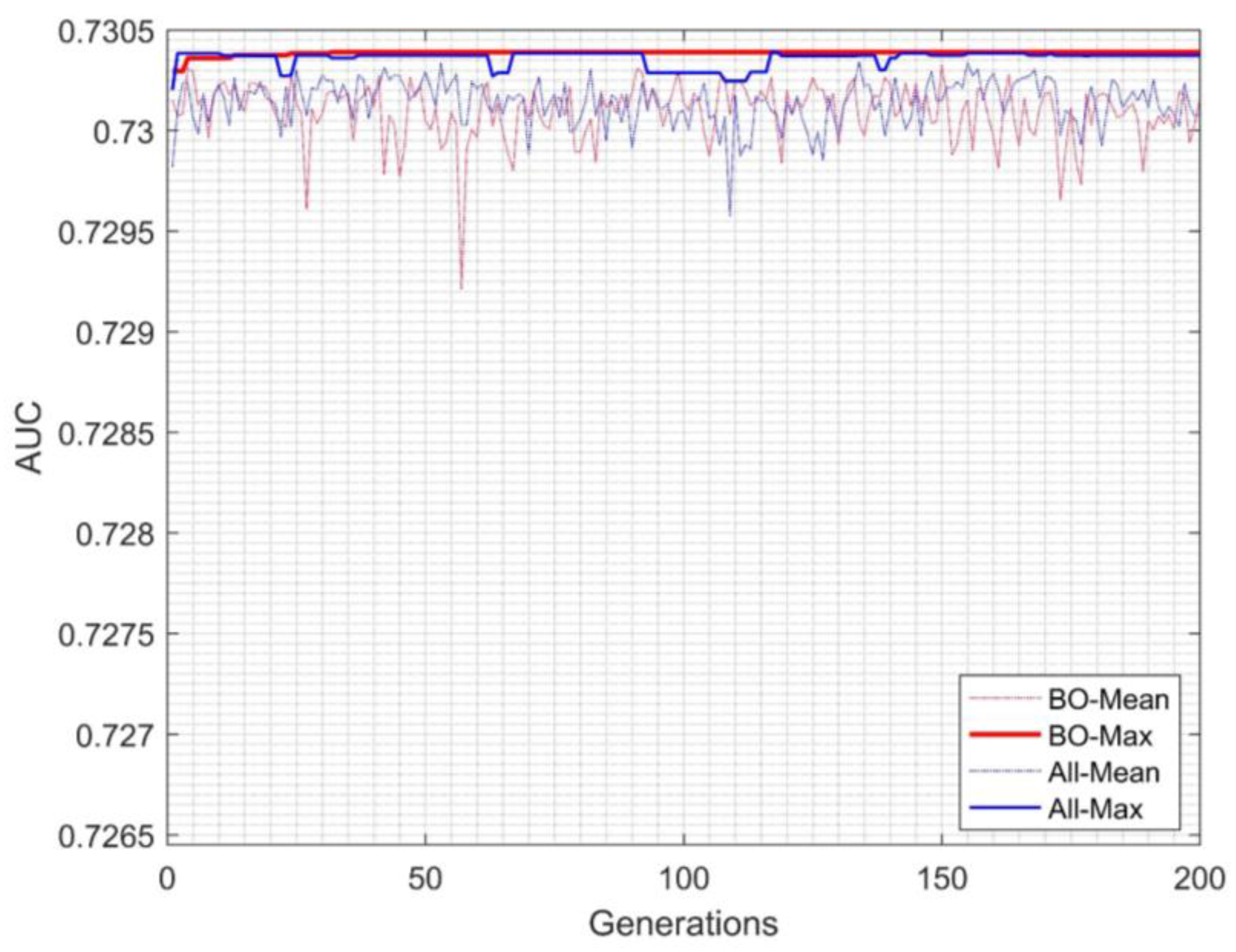
The inter-cluster EGFNM evaluation
AUC for each generation with different mutation methods can be seen in
Figure 4. As can be seen, the leave-best-out method also generates better accuracy and stability compared to the all chromosome mutation method.
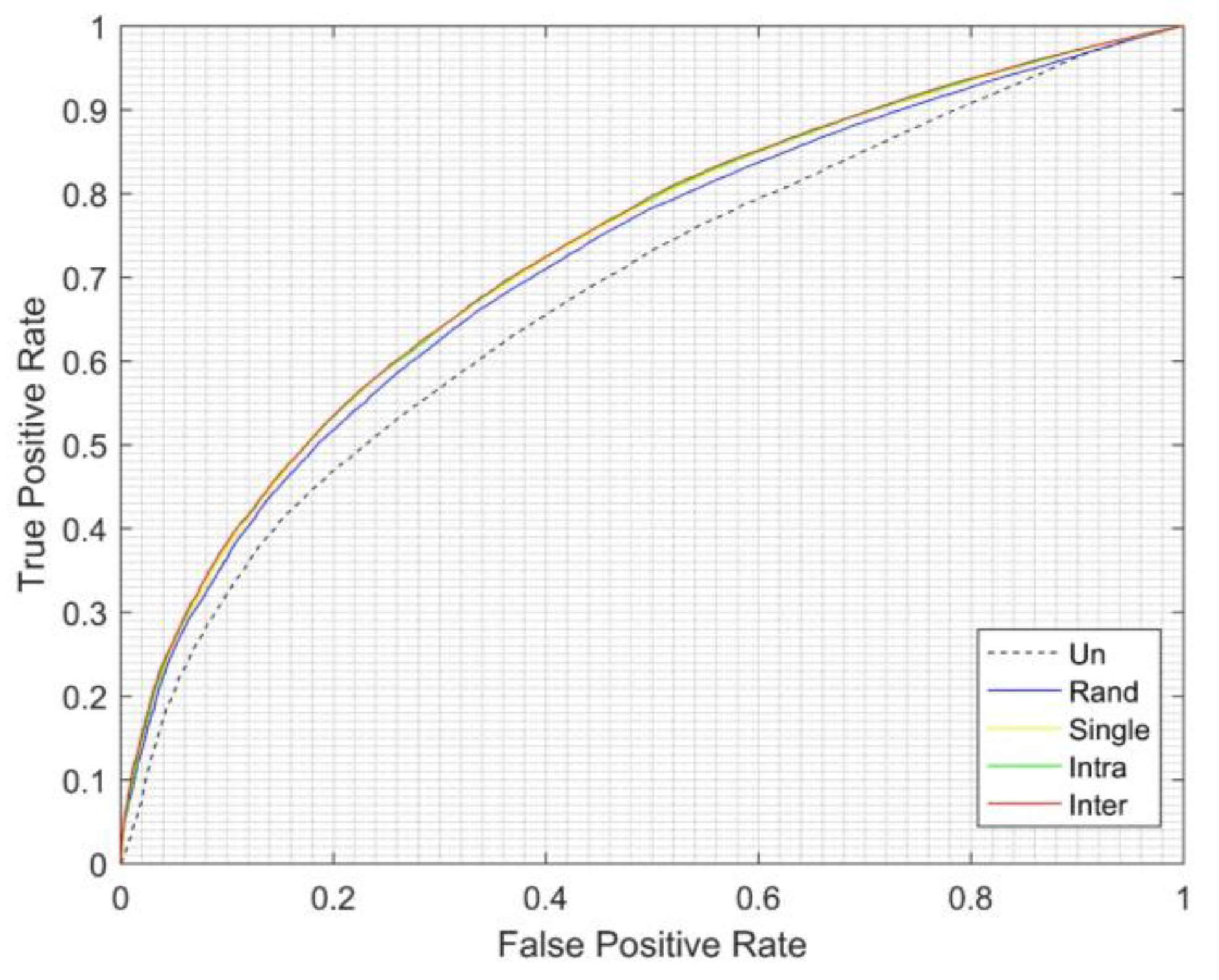
The entire ROC curves of the unbalanced, best single model, best intra-cluster EGFNM, and best inter-cluster EGFNM results are shown in
Figure 5. The result shows that the clustering methods provide an improvement compared to the result from the unbalanced training. Further, the GA-based ensemble techniques show that inter-cluster EGFNM produces a better result compared with intra-cluster EGFNM.
In order to validate the optimum result produced by the EGFNM, a simple binary evaluation is created, called the binary-allocated model. This method will be used as the evaluation reference, due to the fact that the related method can evaluate all combination
AUCs with no possibility of missing the best result. An evaluation of the binary system ensemble technique can be seen in
Figure 6. For a simple visualization, a 5-bit combination system is shown. The activated model is marked by ‘1’, while the deactivated model marked by ‘0’. This system is similar to the EGFNM chromosome. As can be seen, there are 31 out of 32 possibilities for the ensemble models, excluding the first combination, ‘[0 0 0 0 0]’, where no model is activated. This figure also illustrates all combinations with the corresponding evaluation of the
AUC results.
However, this method is computationally highly expensive when facing longer bit combinations. As shown in
Figure 7, the trend of the line is increasing with longer combinations. This situation will consume huge amounts of physical computer memory in order to evaluate the best
AUC possibility.
In this study, an 8-bit combination evaluation is used, and the validation procedure can be compared with 8-bit binary system ensemble evaluation. The EGFNM method is set to 200 generations.
Table 6 shows the number of generations both for EGFNM intra- and inter-cluster models can reach the maximum
AUC, as previously described in
Table 2 for the intra-cluster EGFNM
AUC, validating the results. It shows that within 100 generations, except for intra-cluster EGFNM Clusters 60 and 100, the models reach the optimum
AUC achieved by the binary system evaluation. The inter-cluster evaluation uses only the eight best clustering models for the activation candidates.
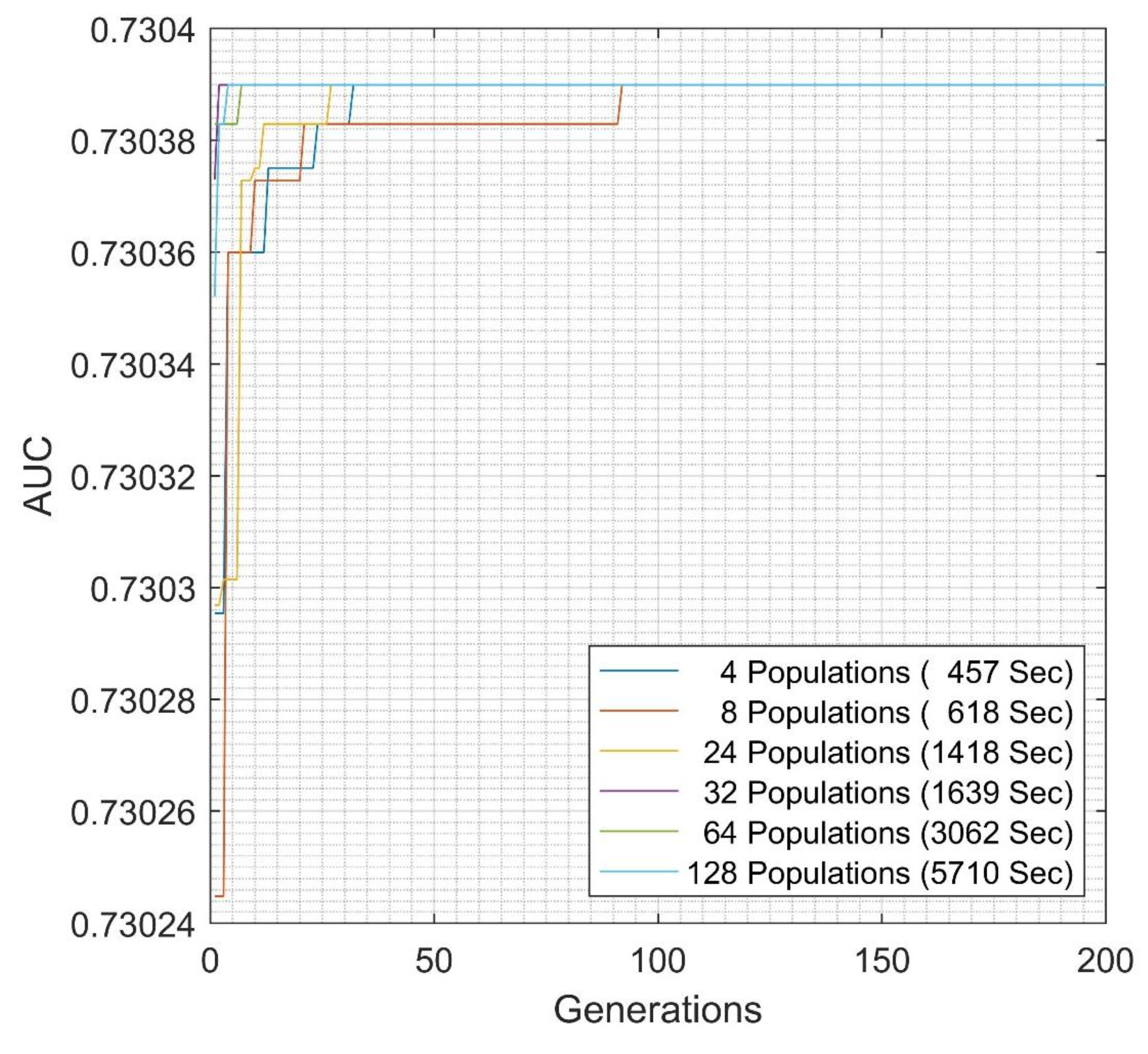
In order to evaluate the relationship between the population size, fitness function, and estimated time, several evaluations are conducted. As shown in
Figure 8, it can be concluded that the higher populations in the evaluation give a higher chance to achieve the optimum fitness function with shorter generations. Preliminary population sizes of 32, 64 and 128 converge relatively earlier than when utilizing a population size of 4, 8, or 24. This condition will accelerate the model selection in the ensemble learning to the best combinations. Furthermore, the computational resources available will determine use of the binary system combination or ability to perform evaluation of larger populations. However, EGFNM works remarkably more efficiently in storing the data into memory compared with the binary combination when dealing with limited calculation resources.


 and
and 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}