1. Introduction
Over the last two decades, the use of health impact assessment for incorporating the issue of health in planning and decision-making, has been and is on an increase [
1]. According to WHO, health impact assessment is a method to assess the health impacts of policies, plans, and projects in diverse economic sectors, through quantitative and qualitative techniques. The policy, plan, or project is briefly named a scenario hereafter, most of which affect the health through their effect on environmental health indices. The impact assessment (IA) methods that evaluate the impact of a scenario on environmental indices, followed by, the impact of changes in environmental indices on health, are known as the environmental health impact assessment (EHIA) [
2]. Due to the widespread effects of transportation on health, the major focus of EHIA is on transportation [
3,
4]. Most of these EHIA assess the air quality impacts, mainly due to the availability of models, essential information, and the extent of air quality impacts on health [
5]. An efficient EHIA must be capable of compute the impacts of various scenarios and prioritize them [
6]. Development of such capabilities requires quantitative methods [
7,
8,
9]. The quantitative methods typically determine the impact by estimating the number of occurred or avoided cases as a result of change in pollutant concentration.
In general, quantitative EHIA for air quality consists of two stages: (1) determining the pollutant concentration (e.g., PM
2.5); and (2) computing the impact of human exposure to pollution. Ideally, quantitative EHIA could be achieved by monitoring the population exposed to air population, which in fact is impossible due to cost and time restrictions especially at urban scale [
10]. The initial studies concerning the effect of air pollution on health are run through urban monitoring stations to estimate the concentration of pollutants [
11]. These stations only estimate large-scale spatial variations. During the past decade, some studies have proven significant and small-scale pollutants variability in urban regions [
12]. The differences of some pollutants concentrations (e.g., PM
2.5) in intra city are similar to that of the inter cities [
13]. Consequently, quantitative assessment of exposure requires the modeling of pollutant concentration with appropriate spatial resolution [
14,
15]. Dispersion and land use regression (LUR) models are applied to improve the spatial resolution of pollutant concentration [
10,
16,
17].
In general, to develop regression models, the data derived from air pollution monitoring stations are applied. Due to inefficient number of monitoring stations, located in certain places in a given city, occurrence of substantial errors in regression models in regions where the urban pattern is different from the location of urban monitoring stations is inevitable [
18,
19]. The LUR models fail to model small-scale pollutant variability due to interactions between emission sources and meteorological processes [
20,
21]. These limitations make the regression models unable to determine the true contribution of transportation on air pollution [
22]. By comparing the dispersion models to the regression models, the first has greater spatial and temporal resolutions. Dispersion models make it possible to assess the impact of a particular source of pollution on air pollution, and health thereof in an efficient manner. According to Brauer et al. (2008) and Michanowicz (2015), dispersion models require numerous high-density data including temporally and spatially separated emissions data and intensive computation, which has led to their rare adoption in epidemiological and impact assessment studies [
23,
24]. Unlike dispersion models regression models, require fewer inputs and computation [
25], therefore, they are widely used in epidemiological and impact assessment studies.
To overcome the drawbacks and take advantage of different modeling methods, especially for environmental health impact assessments, the integration of these models has become more common [
24,
26,
27]. Most of the available studies apply dispersion model output as dependent variable in order to develop the landuse regression model [
28,
29,
30]. Adopting dispersion models for generating regression models can improve the spatial and temporal resolutions and increase the accuracy by incorporating source-meteorology interaction information [
12,
20,
26]. Despite the advances made in modeling pollutants concentrations, a limited use of these models is reported for quantitative EHIA. Most of the applied practical EHIAs (75%) for air pollution are qualitative [
31], indicating that conventional models are not capable to meet EHIAs requirements.
Numerous parameters are required to determine the PM
2.5 concentration and to estimate the exposure impact in quantitative EHIA in transportation scenarios. These parameters are the results of various studies, modeling, and computation and consist of: traffic parameters, especially after the implementation of a scenario, are merely a result of traffic modeling; the parameters of meteorological data, which are associated with uncertainty; and the parameters of concentration-response coefficient and total adverse health outcome the derived from analysis of limited population. Accordingly, the abovementioned parameters are generally uncertain, diverse, descriptive, and heterogeneous [
9,
32,
33,
34]. Thus, a significant part of academic research focus on modeling uncertainty in IA [
35,
36].
Neither conventional dispersion models nor LUR are capable of considering the uncertainty of the parameters applied in EHIA. These models are not flexible to apply heterogeneous, descriptive, and uncertain data. The amount of required data together with considering their uncertainty and their computational mass are the major contributors to the practicality of air pollution prediction model and health metric [
2,
33,
37,
38]. Applying fuzzy inference systems in EHIA provide the possibility of establishing an appropriate model from the available heterogeneous, descriptive, and uncertain data. Moreover, the flexibility of such models in applying qualitative and quantitative data contributes to their practical state in different stages of planning and decision-making, like informing the decision makers, developing, assessing, and selecting the scenarios [
39].
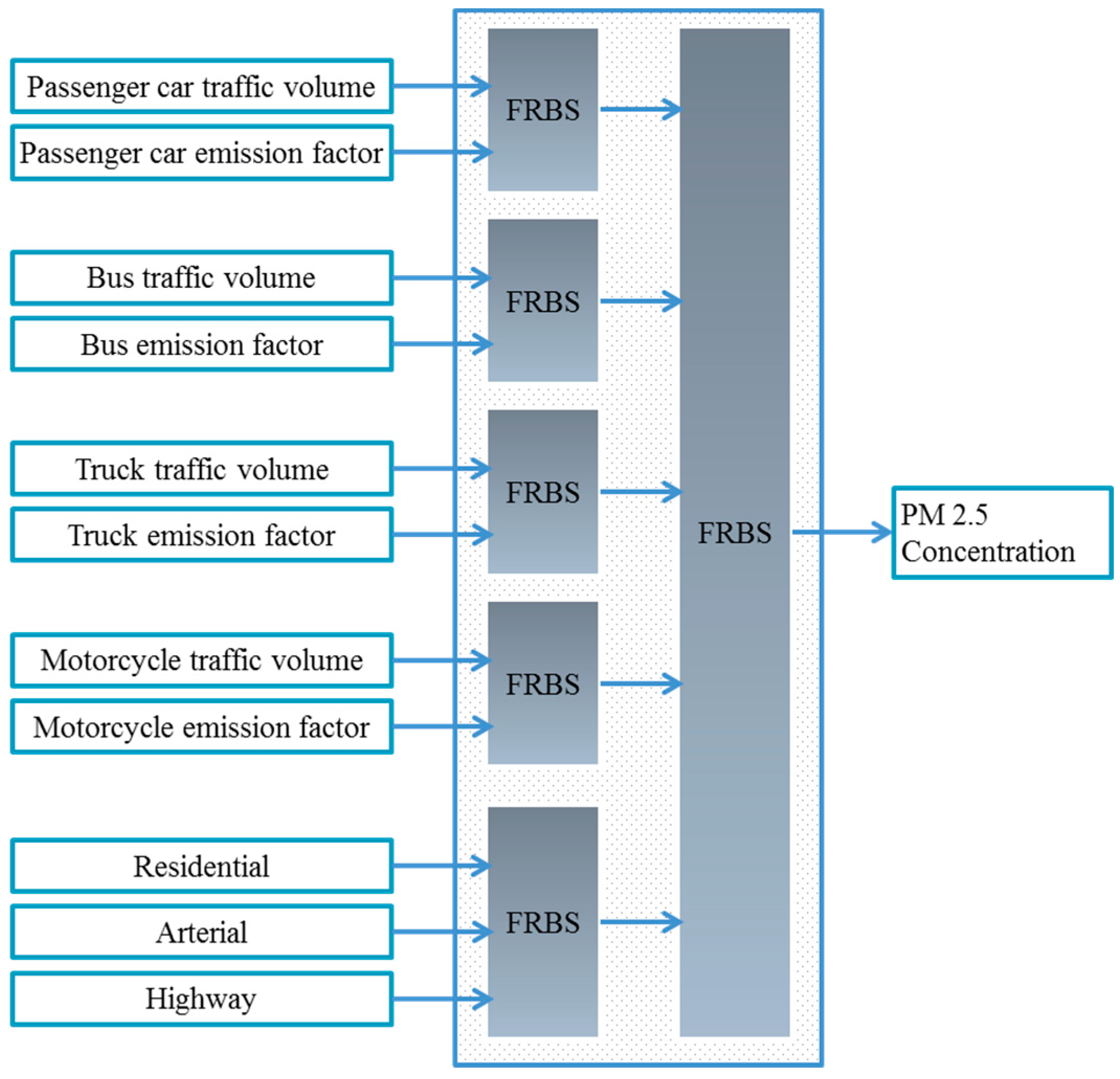
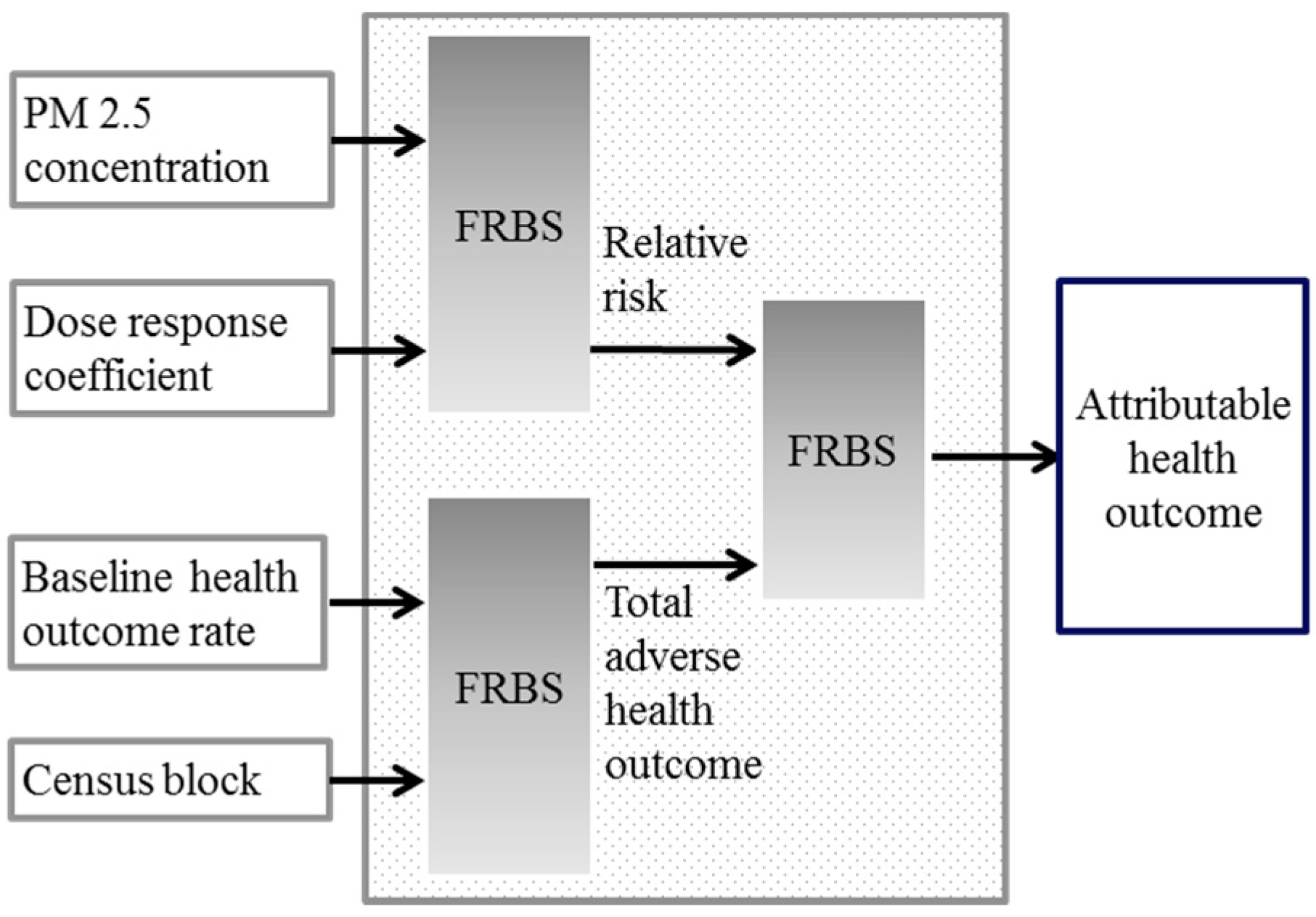
In this paper, a hybrid fuzzy model is proposed to quantitatively assess the environmental health impacts of transportation scenarios. In this model, the data from an air dispersion model are applied in establishing a hierarchical fuzzy inference system in order to determine the suspended particles concentration (i.e., PM2.5). In addition, another hierarchical fuzzy inference system is developed based on epidemiological evidence, applied in estimating the health outcome caused by PM2.5 concentration. Due to the nature of the EHIA, flexibility and performance constitute the core of developing such models. Linguistic modeling is applied to create the essential flexibility and hierarchical structure, and NSGA2 multi-objective optimization algorithm is applied to enhance the models’ performance. To evaluate these proposed models, three traffic scenarios are examined in the city of Isfahan, Iran.
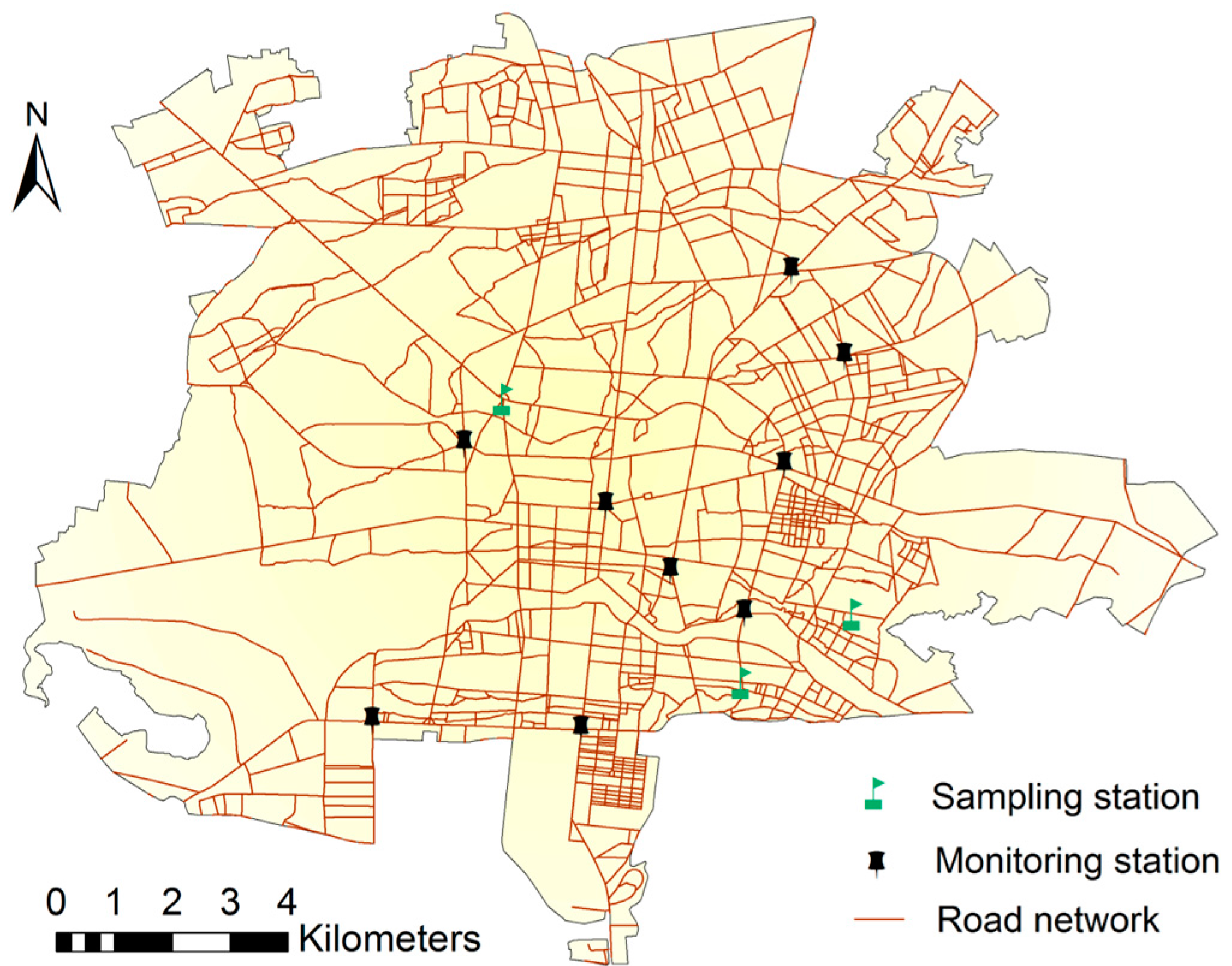
2. Transportation and Air Pollution in the City of Isfahan
The city of Isfahan, located in the center of Iran with population of about two million and an urban area of 200 km
2, is one of the most polluted metropolises. The adverse environmental and health outcomes caused by air pollution have experienced a growing trend. However, there exist few studies on assessing the cause–effect relationship of involved parameters in air pollution in this city [
40]. According to these studies, transportation systems are responsible for about 70% of total emissions in Isfahan [
41,
42]. Similar to many other developing cities, PM
2.5 is generated mainly through transportation systems [
43,
44] which contribute to an increase in permissible level of Air Quality Index [
45,
46,
47]. Recent studies reveal that even normal concentration of PM
2.5 is far more harmful than the commonly known pollutants, such as SO
2 and CO [
48]. Studies and epidemiological evidence concerning the effect of PM
2.5 on health are more extensive than studies made on other pollutants [
49,
50]. Selecting suspended particle as pollution predictor prevents recounting pollutants. Accordingly, WHO has advised using PM
2.5 for quantitative assessment of air pollution [
51].
The following three traffic scenarios are examined and their effects on PM
2.5 and health outcome are quantified:
Current condition is considered as the baseline scenario. Dispersion model and hierarchical fuzzy inference system are developed and tested based on this scenario. The classification of current transport fleet according to the emission standard is tabulated in
Table 1.
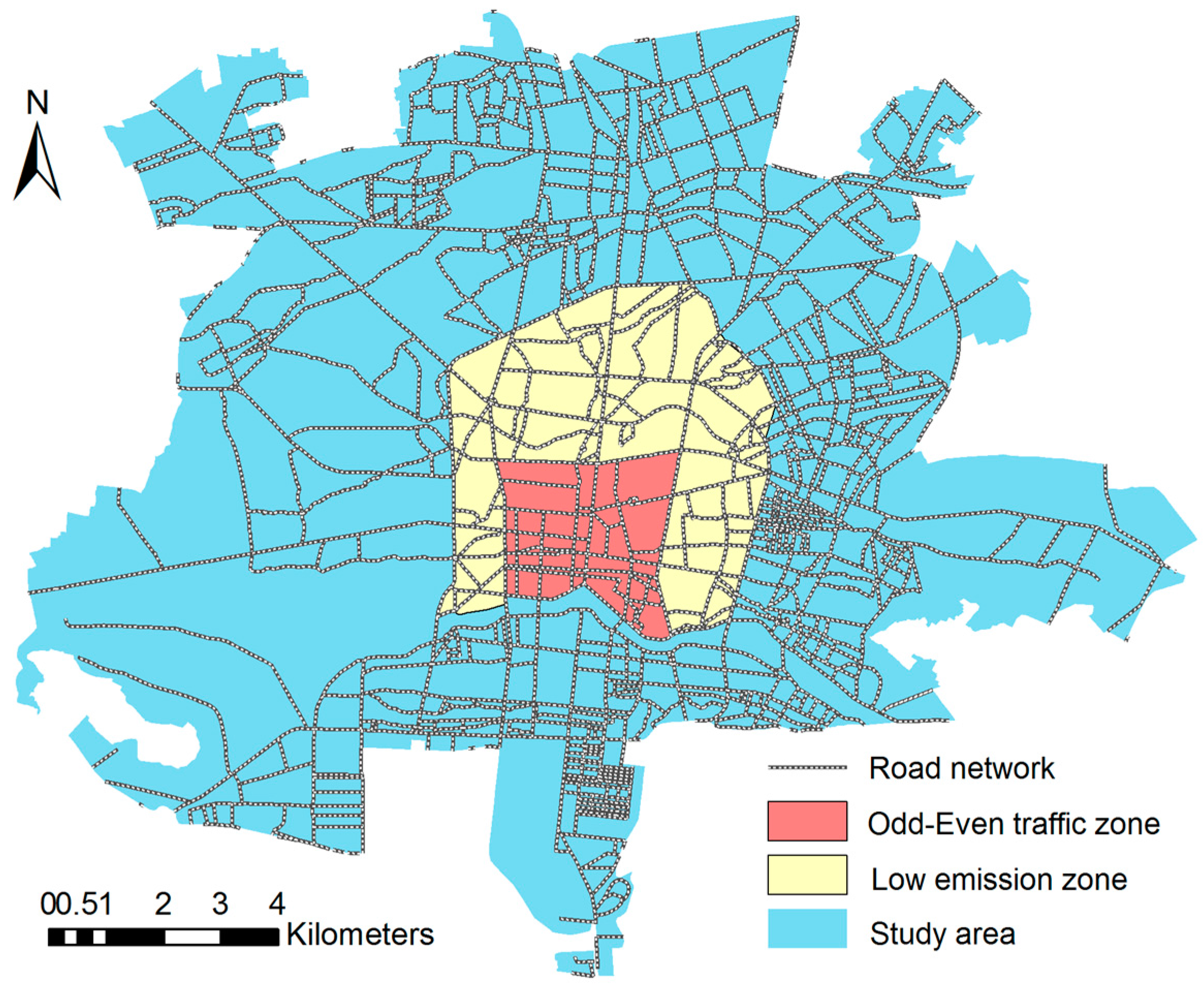
Odd/Even scenario is one of the most important plans proposed to cope with air pollution in Isfahan. This plan, however, is not successful in practice. Lack of supervision in Odd/Even zone, lack of police and citizen acceptability and cooperation, and the nature of the plan are the main reasons of failure [
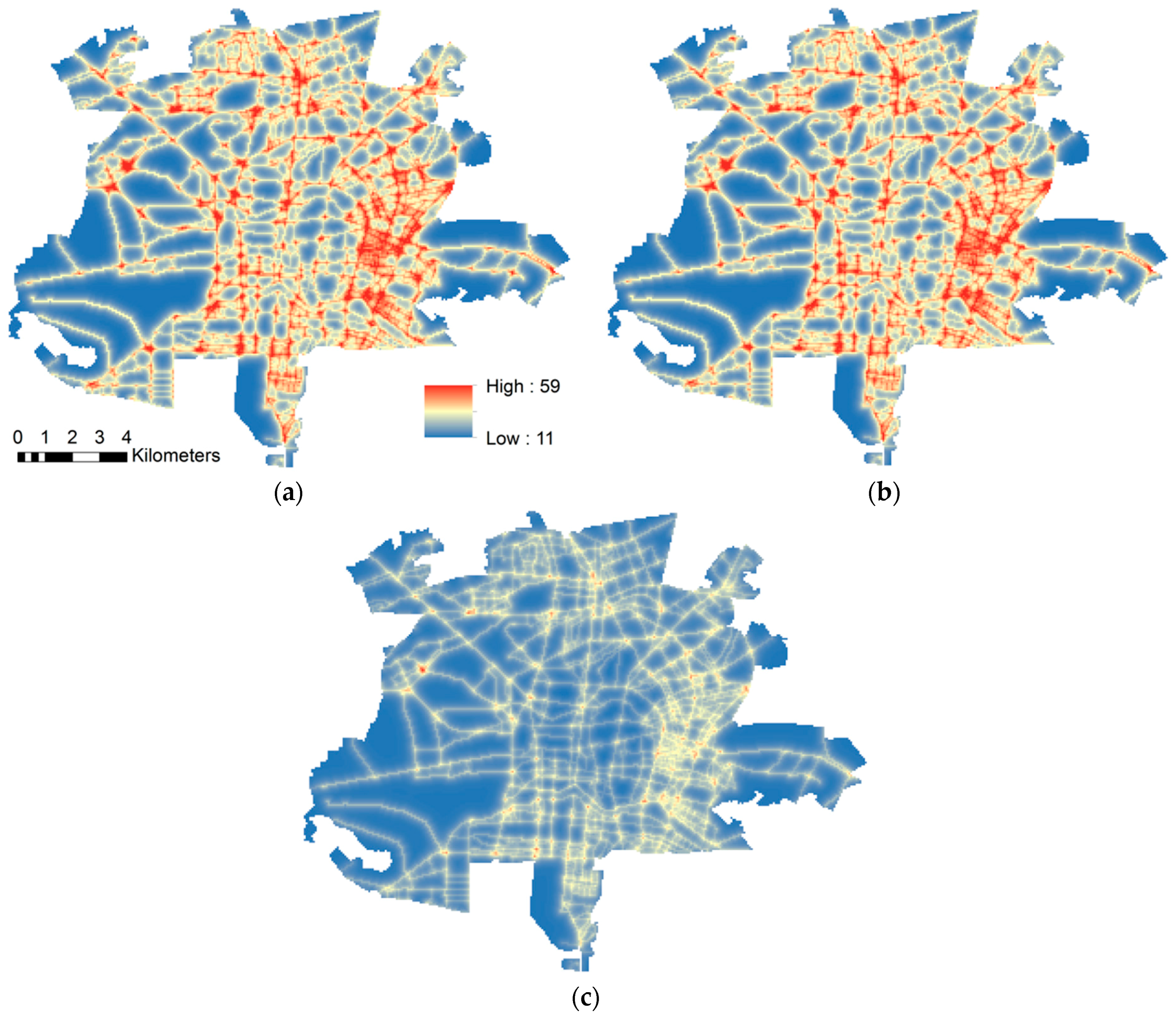
52]. Modeling by Transport and Traffic Department of Isfahan Municipality has determined what the traverse of transport fleet would be if the plan fully implemented (
Figure 1).
Low emission zone [
53] plan is widely applied in many countries to reduce air pollution. The studies run on the main parameters affecting air pollution in Isfahan, have presented three preliminary proposals with the objective of establishing LEZ: (1) restriction for old diesel vehicles; (2) restriction on motorcycle traffic in downtown; and (3) traffic ban for passenger cars and vans with respect to their emission levels in different zones (
Figure 2). Modeling by the Transport and Traffic Department of Isfahan Municipality has determined the changes of traffic if LEZ scenario will be fully implemented.
5. Conclusions
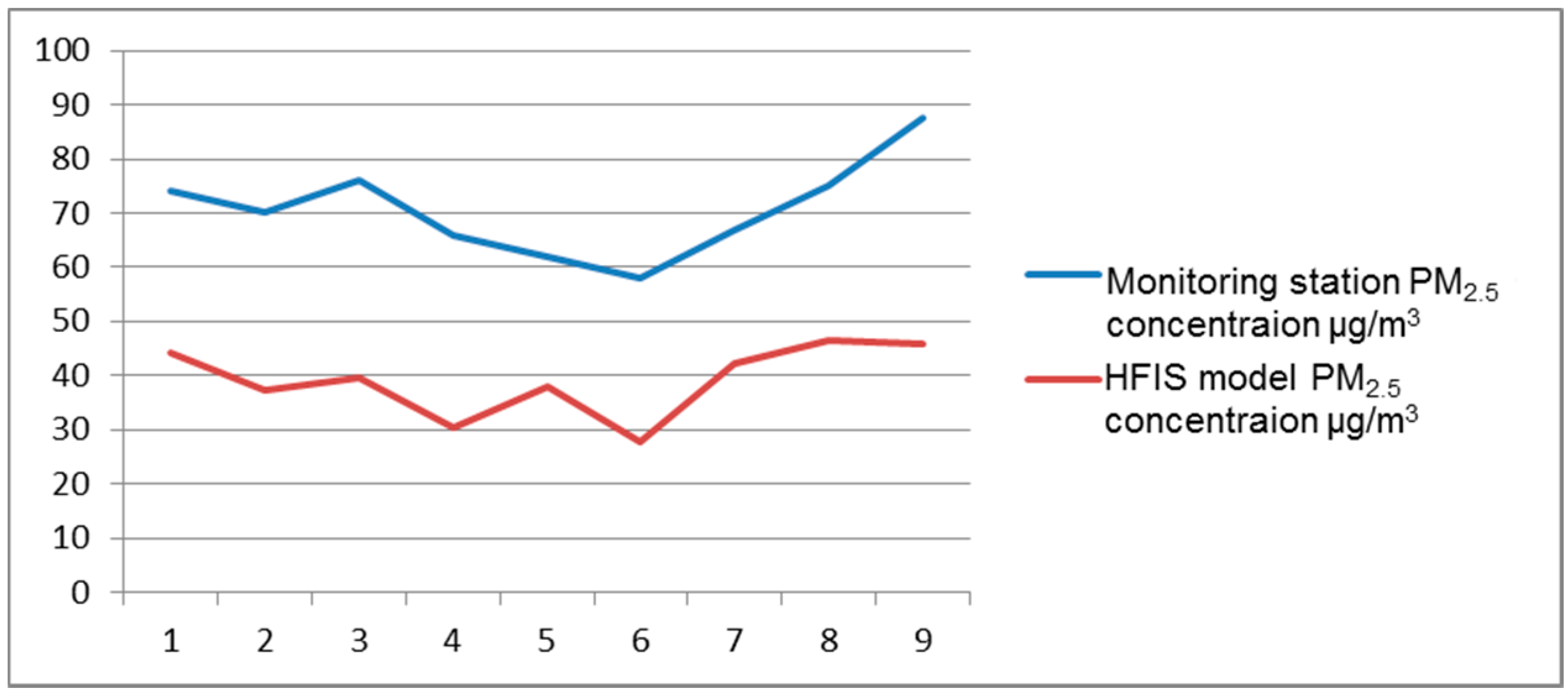
A new quantitative modeling approach for environmental health impact assessment of transportation scenarios was proposed in this study, where optimized hierarchical fuzzy inference systems was employed for modeling the impacts of traffic on PM2.5 concentrations and the effects of traffic related PM2.5 on health.
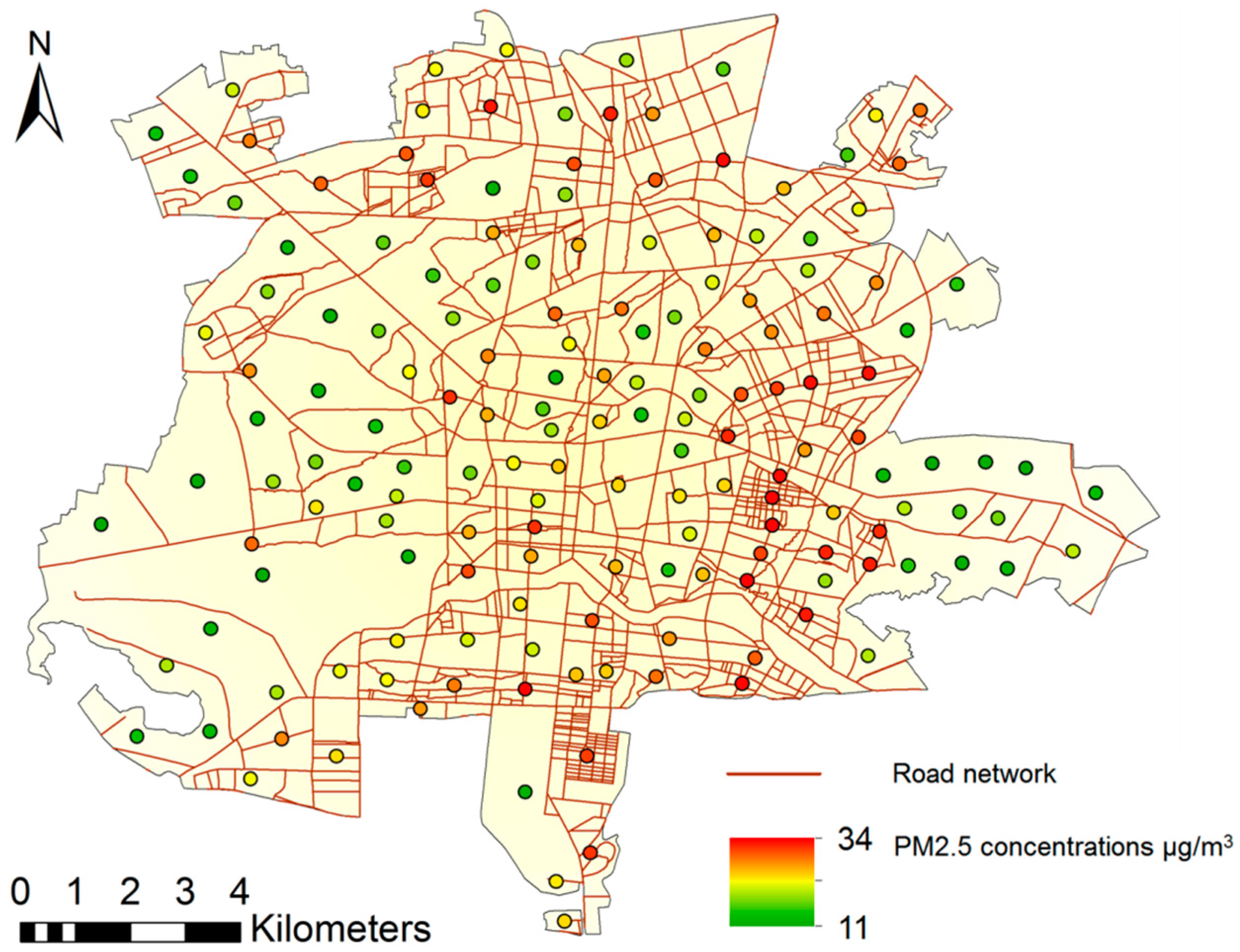
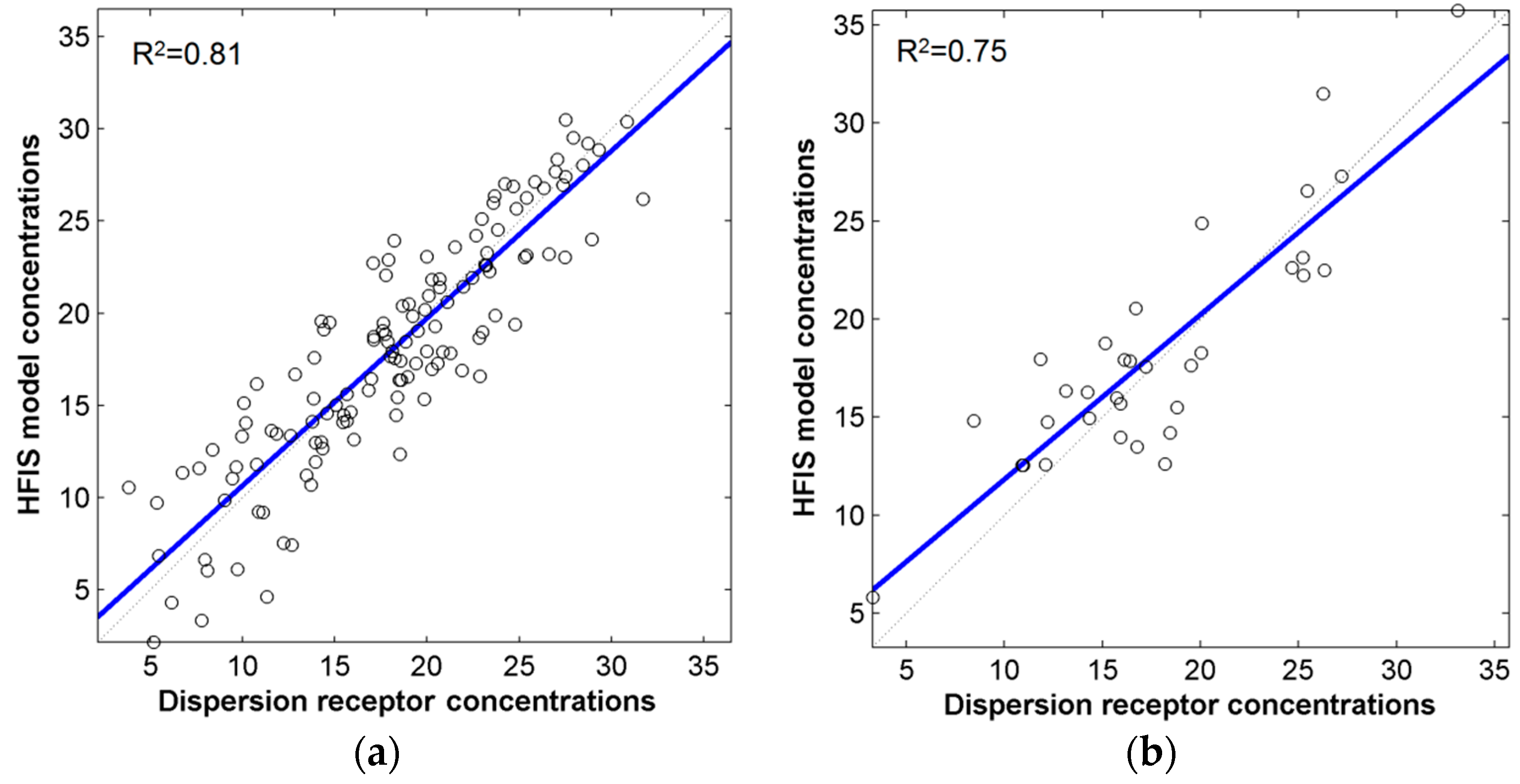
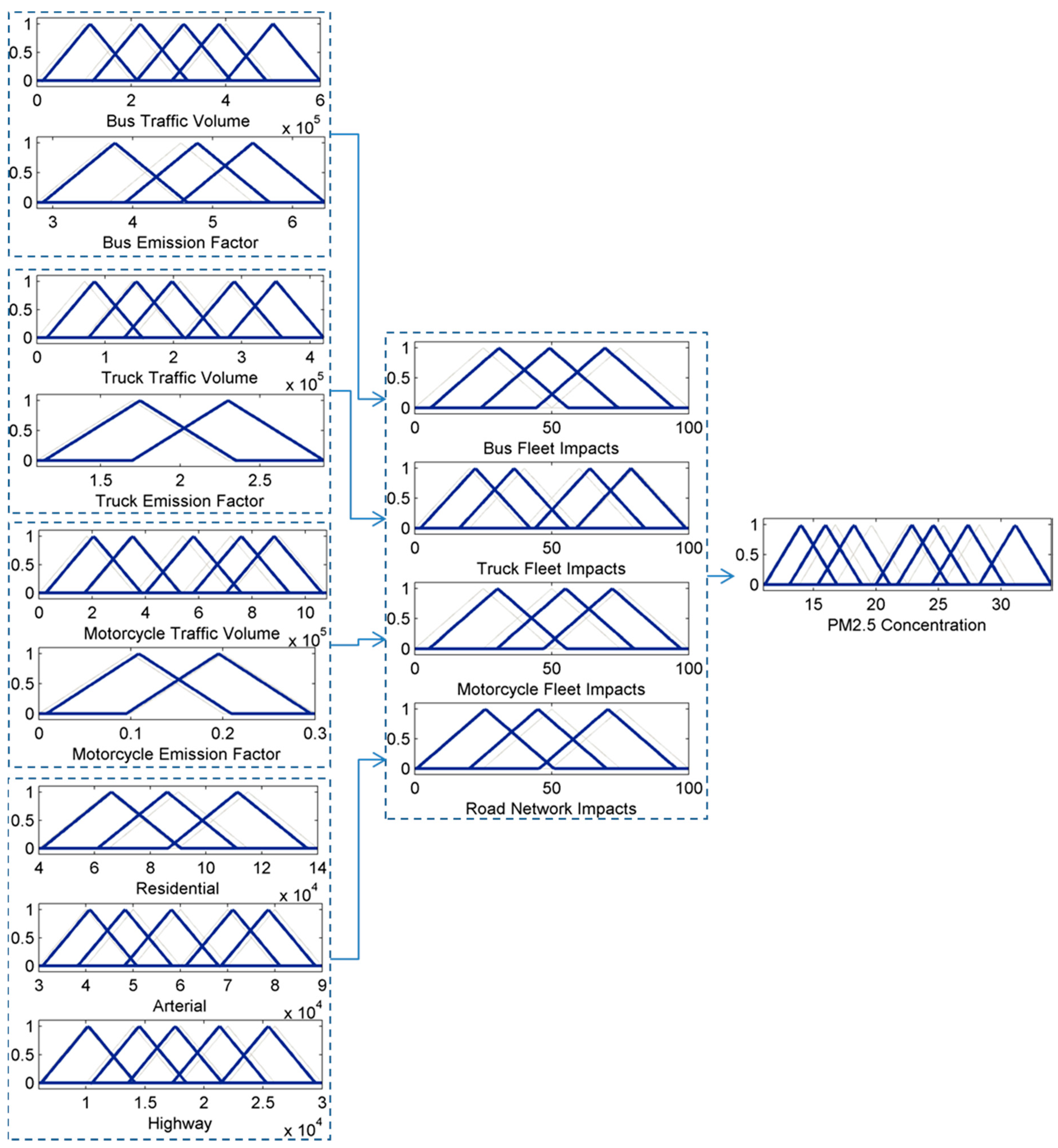
AERMOD dispersion receptors were used as dependent variables, and transportation parameters were used as independent variables to develop the hierarchical fuzzy inference system for modeling PM2.5 concentration (HFISPM). Integration of HFIS and dispersion model is one of the main contributions of this article. Compared to conventional models, the HFIS has several advantages, like appropriate processing requirements, selectable inputs, consideration of interaction between emissions and meteorological processes, and modeling the casual relationship among transportation parameters and air pollution. Due to the capability of applying qualitative and quantitative data, this proposed model could be adopted in environmental health impact assessment. High spatial resolution of derived PM2.5 map can provide essential information to assess the impacts of various scenarios on health.
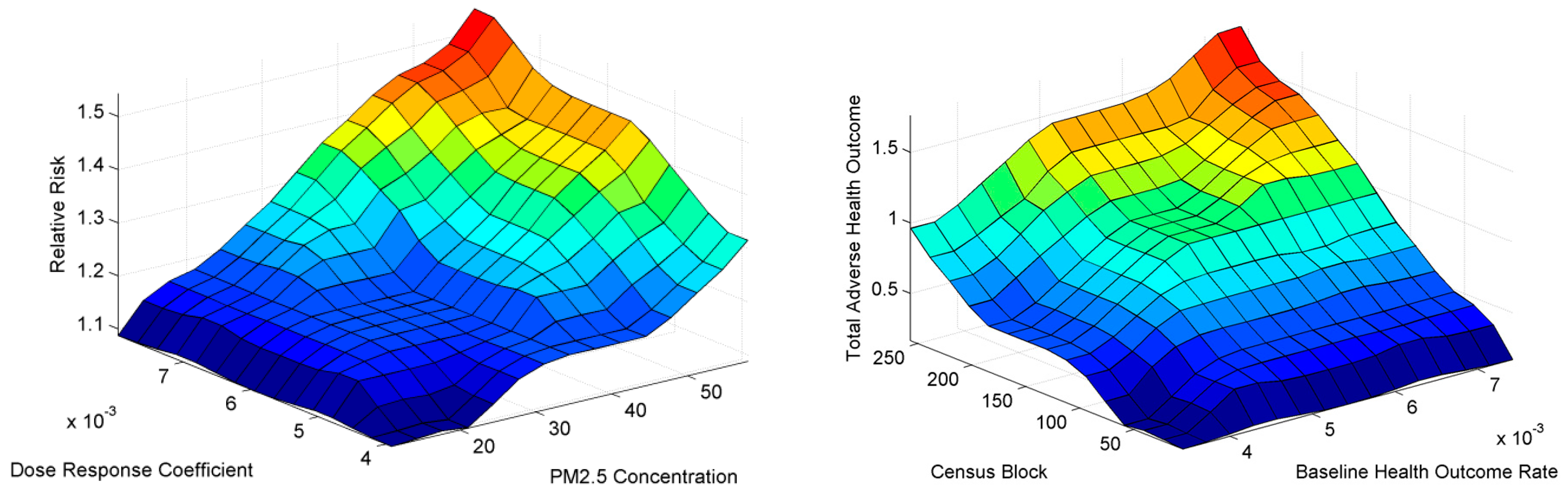
This proposed hierarchical fuzzy inference system for modeling health outcome was developed based on the epidemiological equations. Although these relations are frequently applied in health impact assessment, they are subject of debate in many related studies. The capability of learning and tuning of relationships in this proposed approach enables the modeling of the uncertainty of relationships among parameters and the uncertainty associated with parameter values in a simultaneous manner.
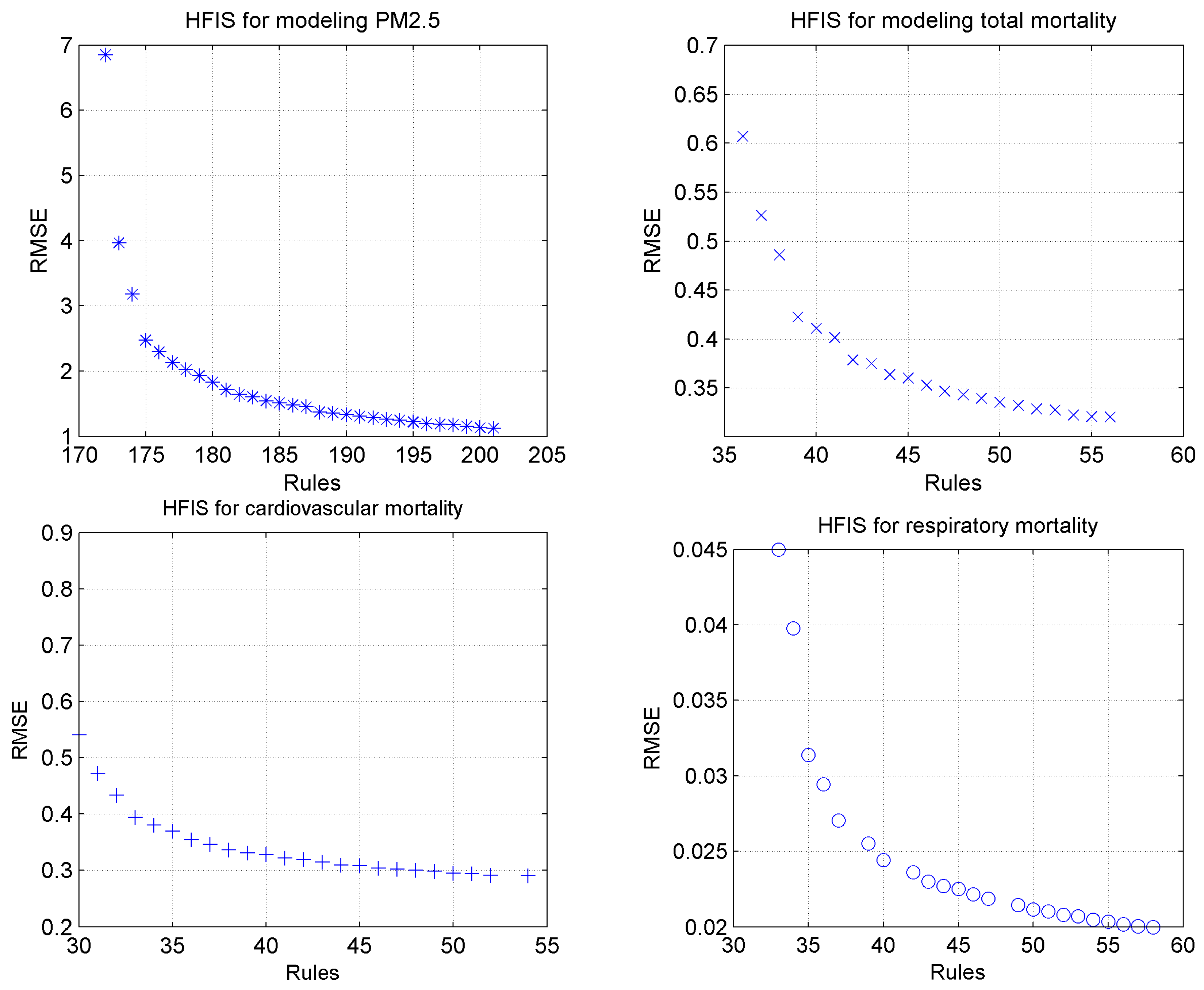
In order to design the fuzzy inference systems according to the problem requirements, to be able to overcome the exponential increase of rules, and to increase accuracy, two solutions were applied. The first solution is to select the topology of the hierarchical fuzzy inference system according to the problem. The second solution is the concurrent determination of the membership functions and rule set through learning. These two solutions have led to a better cooperation between the generated rules in knowledge base of models, maximization of accuracy, and minimization of system complexity.
Three traffic scenarios, the current condition, Odd/Even, and LEZ, were assessed here. The modeling results indicate that LEZ has the most advantages associated with air pollution and health. Applying hierarchical fuzzy inference system in EHIA can provide better understanding of the issue for planners and decision makers. Moreover, decision makers can assess the impact of changes in each parameter better.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}