
Vis–NIR Spectroscopy Combined with GAN Data Augmentation for Predicting Soil Nutrients in Degraded Alpine Meadows on the Qinghai–Tibet Plateau

Abstract
:1. Introduction
2. Materials and Methods
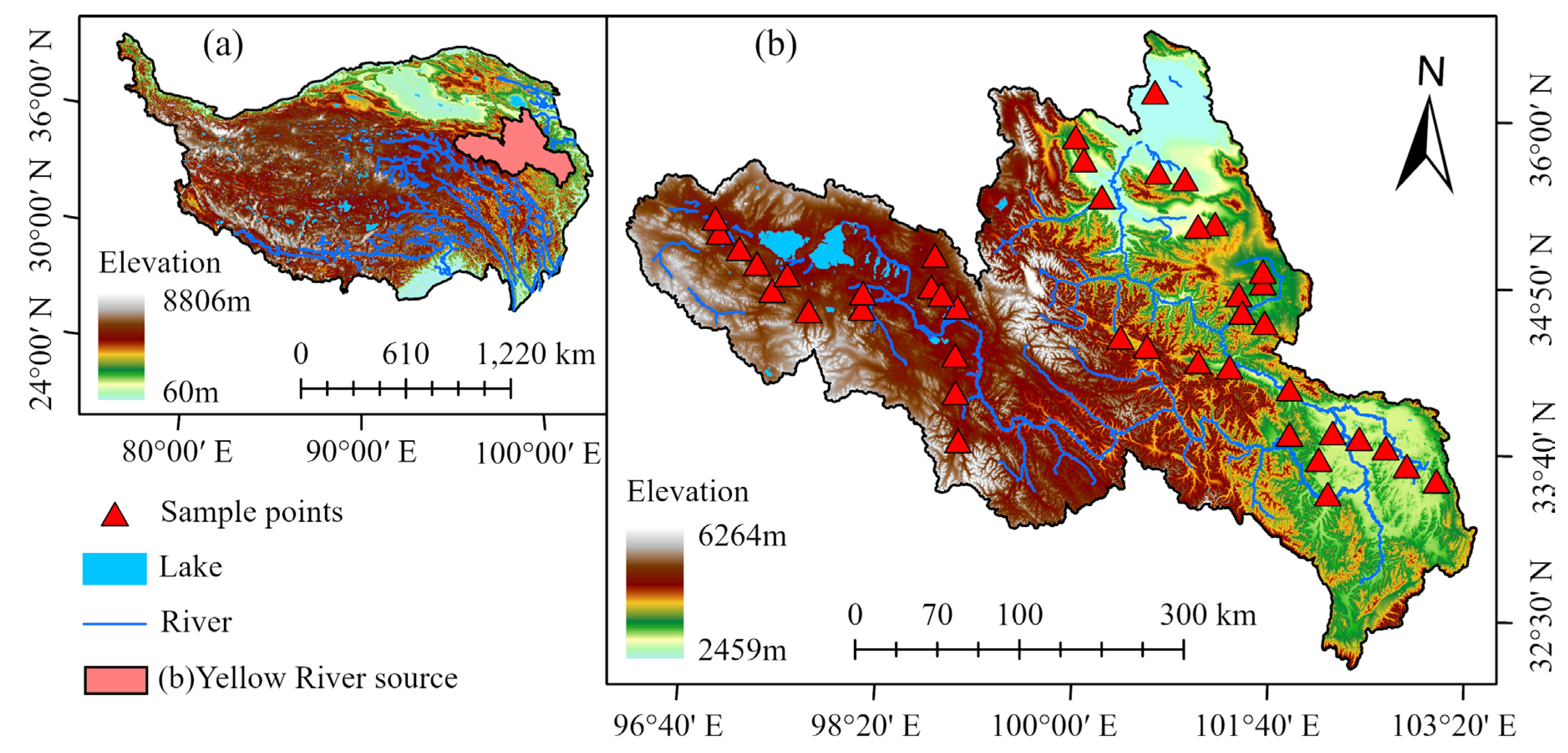
2.1. Overview of the Study Area
2.2. Soil Data Collection in Pika-Disturbed Areas
2.3. Spectral Data Preprocessing
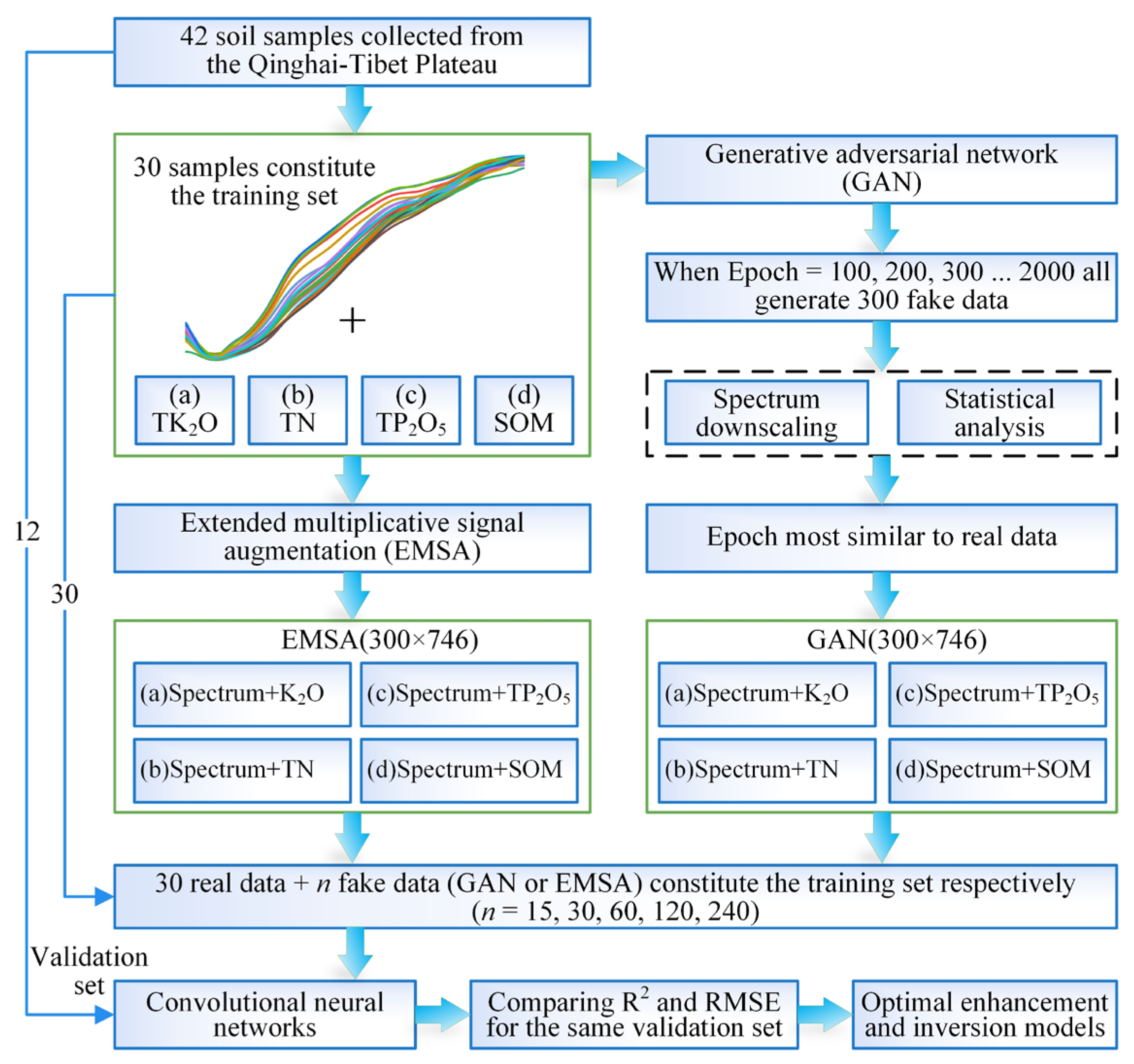
2.4. Data Augmentation and Evaluation Methods
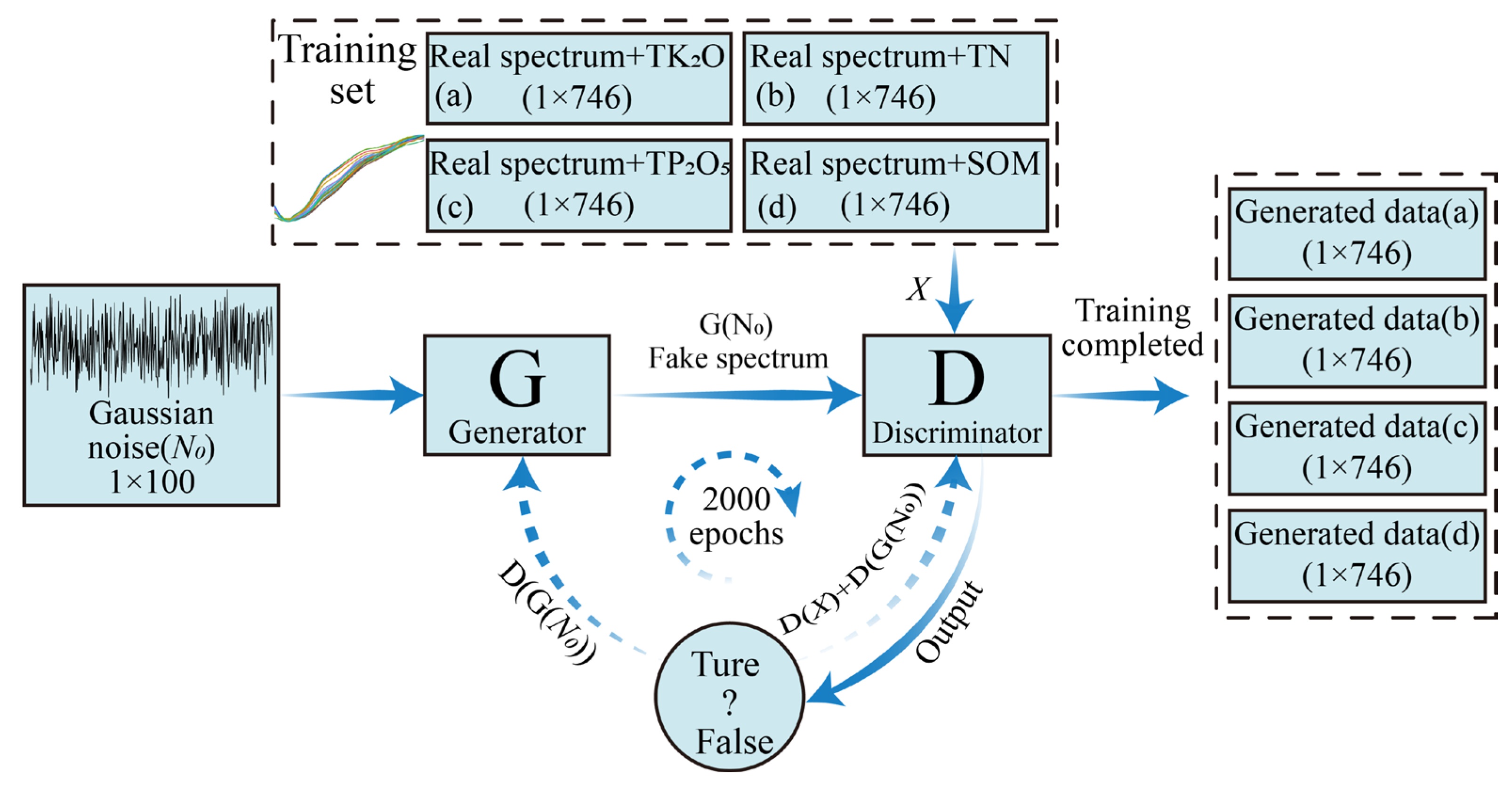
2.4.1. Generative Adversarial Networks (GAN)
- 1.
- To illustrate the method of combining spectral and nutrient data, the spectral matrix for each soil sample was defined as and the soil parameter matrix as , where n is the number of bands and is 745, x is the spectral reflectance of the corresponding band, and y is the corresponding soil nutrient content;
- 2.
- In order to generate spectral data and nutrient data simultaneously using GAN, X and Y need to be unified in an interval. First, X was normalized to speed up the convergence of the GAN model. Secondly, the four types of nutrient data were scaled between 0 and 1. The specific steps are: , , , ;
- 3.
- The pre-processed data were combined into a new matrix, P. As the four nutrients differed in content and chemical properties, the four types of nutrient data were combined with the spectral data separately in order to generate each type of nutrient data with the corresponding spectral data more accurately. In the end, four new matrices of size 42 × 951 were obtained. They were: , ;
- 4.
- The four merged sets of data were each fed into the GAN for training and a specified number of fake data were generated. Finally, the generated soil nutrient data were subjected to the opposite process to that in 3.
2.4.2. Extended Multiplicative Signal Augmentation (EMSA)
- 1.
- Use EMSC to calculate the physical parameters for each spectrum in the training set;
- 2.
- Calculate the standard deviation of each parameter ();
- 3.
- In order to obtain an augmented spectrum from the measured spectrum, a set of deviations are taken from the normal distribution using the zero mean and the respective standard deviation of each parameter;
- 4.
- Add the calculated deviation to each parameter (e.g., );
- 5.
- Calculate the new spectral data as:
2.4.3. Evaluation Methods for GAN-Generated Data
2.5. Principal Component Analysis (PCA)
- 1.
- Define the spectral matrix , where n is the number of samples and m is the number of bands;
- 2.
- Find the mean of X by row, then subtract from to give:
- 3.
- Calculate the inverse matrix C of X, ;
- 4.
- Calculate the eigenvalues () and eigenvectors () of C. Then arrange the eigenvectors in order from largest to smallest eigenvalues. This forms the new matrix ;
- 5.
- Finally, the contribution of each PC was calculated based on the feature vector:
2.6. Statistical Analysis
2.7. CNN Modeling and Accuracy Analysis
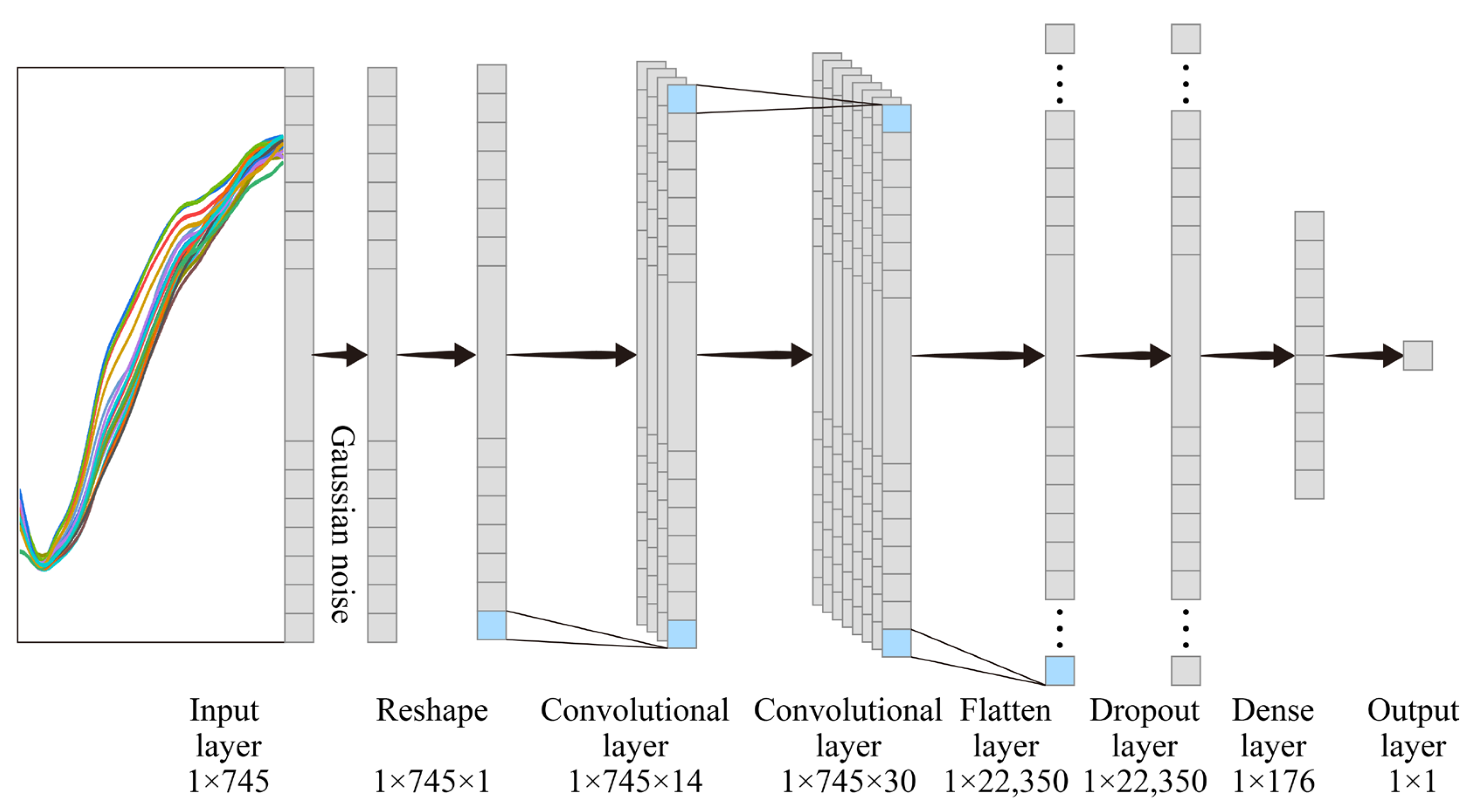
2.7.1. Convolutional Neural Network (CNN)
2.7.2. Predictive Accuracy Evaluation
2.8. Training Set Expansion Method
3. Results
3.1. Analysis of the Generated Spectral Data
3.1.1. Analysis of GAN-Generated Spectral Curves
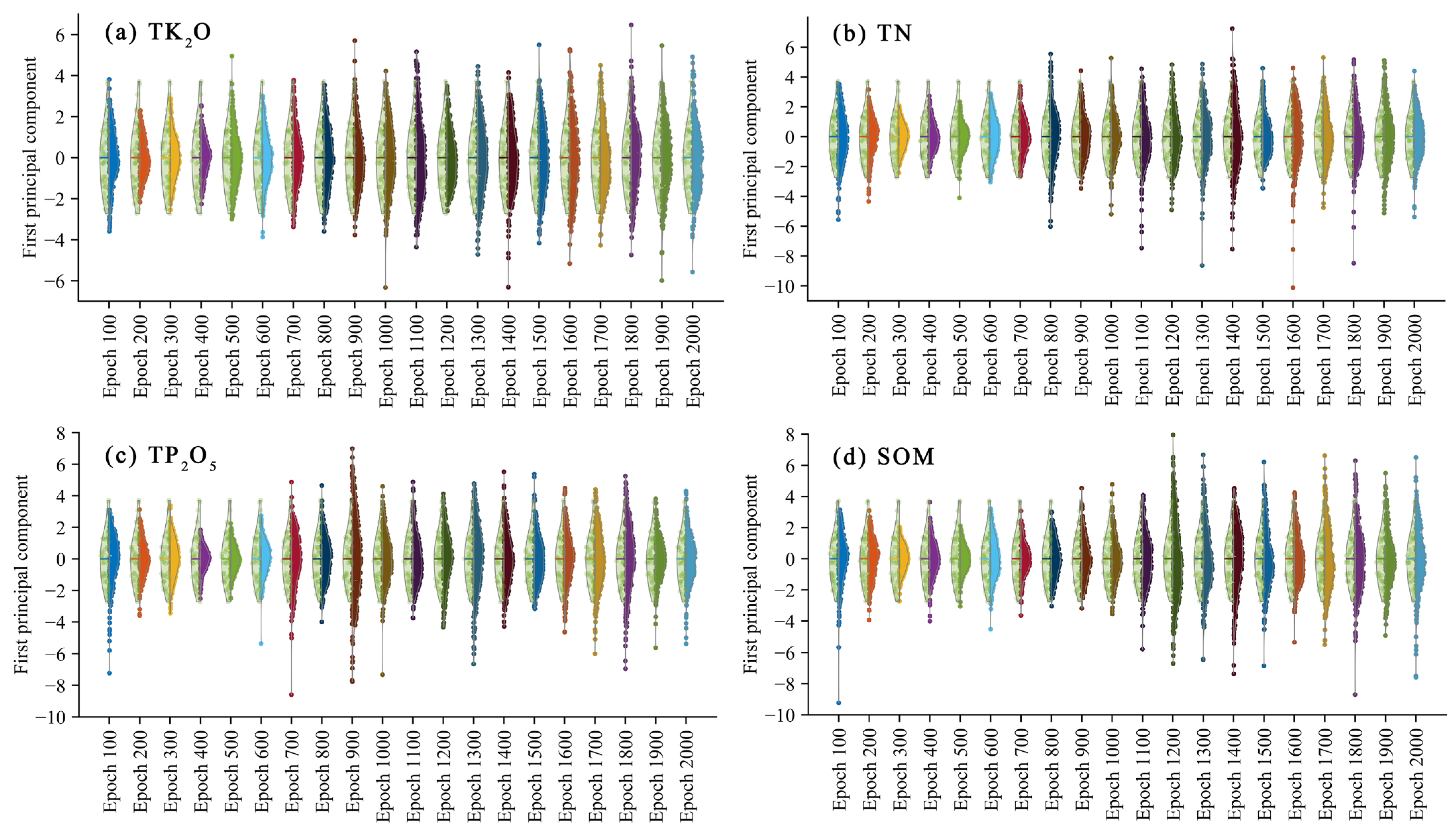
3.1.2. PCA Analysis of GAN-Generated Spectra
3.2. Analysis of Generated Nutrient Data
3.3. Impact of Data Augmentation on CNN
4. Discussion
5. Conclusions
- 1.
- The analysis revealed that the spectral data generated by GAN had a lot of noise when the number of iterations was small. However, as the number of iterations increased, the shape and smoothness of the fake spectra approached that of the real data, and the diversity and realism increased, surpassing the real data after epoch = 1200.
- 2.
- Comparing the maximum, minimum, mean, median, and standard deviation of the four types of nutrient data generated by GAN with the real data revealed that TK2O was closest to the real data at epoch = 1800 and TN, TP2O5, and SOM at 1400. The spectra and nutrients at this time were the most suitable for subsequent augmented modeling.
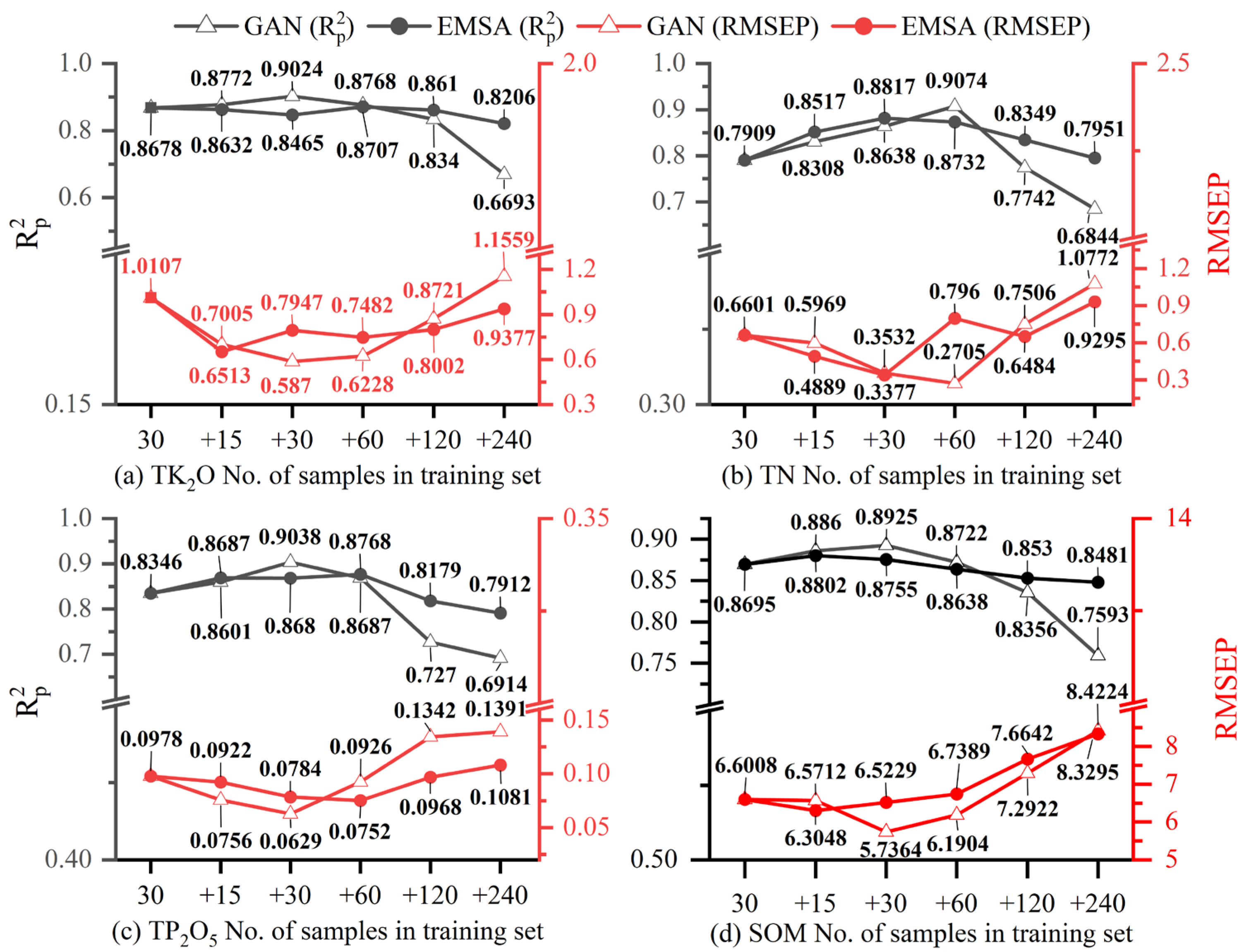
- 3.
- The model was trained by adding 15, 30, 60, 120, and 240 fake data samples to the real data. The effects of GAN and EMSA on the CNN model and the same validation set showed the same pattern of variation, i.e., the model performance improved and then deteriorated with the continuous addition of fake data, and the maximum improvement in model performance was higher for GAN than EMSA.
- 4.
- Based on the previous conclusion to reduce the interval of augmented data, the reasonable ranges for adding GAN data to real TK2O, TN, TP2O5, and SOM data were 30–40, 50–60, 30–35, and 25–35, respectively. The accuracy changes of the TK2O, TN, TP2O5, and SOM prediction models are as follows: the of the validation set increased by 4.08%, 14.73%, 8.29%, and 4.61%, and the RMSEP decreased by 41.68%, 59.02%, 35.69%, and 18.96%, respectively.
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lehmann, J.; Bossio, D.A.; Kögel-Knabner, I.; Rillig, M.C. The concept and future prospects of soil health. Nat. Rev. Earth Environ. 2020, 1, 544–553. [Google Scholar] [CrossRef] [PubMed]
- Chorover, J.; Kretzschmar, R.; Garcia-Pichel, F.; Sparks, D.L. Soil biogeochemical processes within the critical zone. Elements 2007, 3, 321–326. [Google Scholar] [CrossRef]
- Banerjee, S.; van der Heijden, M.G.A. Soil microbiomes and one health. Nat. Rev. Microbiol. 2023, 21, 6–20. [Google Scholar] [CrossRef] [PubMed]
- Hayashi, K. Nitrogen cycling and management focusing on the central role of soils: A review. Soil Sci. Plant Nutr. 2022, 68, 514–525. [Google Scholar] [CrossRef]
- Berhe, A.A.; Barnes, R.T.; Six, J.; Marin-Spiotta, E. Role of soil erosion in biogeochemical cycling of essential elements: Carbon, nitrogen, and phosphorus. Annu. Rev. Earth Planet. Sci 2018, 46, 521–548. [Google Scholar] [CrossRef]
- Wu, J.; Wang, H.; Li, G.; Ma, W.; Wu, J.; Gong, Y.; Xu, G. Vegetation degradation impacts soil nutrients and enzyme activities in wet meadow on the qinghai-tibet plateau. Sci. Rep. 2020, 10, 21271. [Google Scholar] [CrossRef]
- Li, H.; Qiu, Y.; Yao, T.; Han, D.; Gao, Y.; Zhang, J.; Ma, Y.; Zhang, H.; Yang, X. Nutrients available in the soil regulate the changes of soil microbial community alongside degradation of alpine meadows in the northeast of the qinghai-tibet plateau. Sci. Total Environ. 2021, 792, 148363. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.-d.; Dong, S.-k.; Shen, H.; Xiao, J.-n.; Li, S.; Gao, X.-x.; Wu, S.-n. Degradation significantly decreased the ecosystem multifunctionality of three alpine grasslands: Evidences from a large-scale survey on the qinghai-tibetan plateau. J. Mt. Sci. 2021, 18, 357–366. [Google Scholar] [CrossRef]
- Jianyun, Z.; Chuanli, J.; Wenhui, L.; Yuanyuan, D.; Guorong, L. Pika disturbance intensity observation system via multidimensional stereoscopic surveying for monitoring alpine meadow. J. Appl. Remote Sens. 2022, 16, 044524. [Google Scholar]
- Bardgett, R.D.; van der Putten, W.H. Belowground biodiversity and ecosystem functioning. Nature 2014, 515, 505–511. [Google Scholar] [CrossRef]
- Chen, H.; Ju, P.; Zhu, Q.; Xu, X.; Wu, N.; Gao, Y.; Feng, X.; Tian, J.; Niu, S.; Zhang, Y.; et al. Carbon and nitrogen cycling on the qinghai–tibetan plateau. Nat. Rev. Earth Environ. 2022, 3, 701–716. [Google Scholar] [CrossRef]
- Qiu, J. China: The third pole. Nature 2008, 454, 393–396. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.; Xue, X.; Peng, F.; You, Q.; Hao, A. Meta-analysis of the effects of grassland degradation on plant and soil properties in the alpine meadows of the qinghai-tibetan plateau. Glob. Ecol. Conserv. 2019, 20, e00774. [Google Scholar] [CrossRef]
- Zhao, J.; Jiang, C.; Ding, Y.; Peng, J. Alpine vegetation coverage mutation and its attribution analysis based on avhrr ndvi data. Proc. SPIE 2023, 12551, 726–731. [Google Scholar]
- Zhang, L.; Su, F.; Yang, D.; Hao, Z.; Tong, K. Discharge regime and simulation for the upstream of major rivers over tibetan plateau. J. Geophys. Res. Atmos. 2013, 118, 8500–8518. [Google Scholar] [CrossRef]
- López-Pujol, J.; Zhang, F.-M.; Sun, H.-Q.; Ying, T.-S.; Ge, S. Centres of plant endemism in china: Places for survival or for speciation? J. Biogeogr. 2011, 38, 1267–1280. [Google Scholar] [CrossRef]
- Zhang, A.; Li, X.; Wu, S.; Li, L.; Jiang, Y.; Wang, R.; Ahmed, Z.; Zeng, F.; Lin, L.; Li, L. Spatial pattern of c:N:P stoichiometry characteristics of alpine grassland in the altunshan nature reserve at north qinghai-tibet plateau. Catena 2021, 207, 105691. [Google Scholar] [CrossRef]
- Harris, R.B. Rangeland degradation on the qinghai-tibetan plateau: A review of the evidence of its magnitude and causes. J. Arid. Environ. 2010, 74, 1–12. [Google Scholar] [CrossRef]
- Peng, F.; Xue, X.; Li, C.; Lai, C.; Sun, J.; Tsubo, M.; Tsunekawa, A.; Wang, T. Plant community of alpine steppe shows stronger association with soil properties than alpine meadow alongside degradation. Sci. Total Environ. 2020, 733, 139048. [Google Scholar] [CrossRef]
- Zong, N.; Shi, P.; Zheng, L.; Zhou, T.; Cong, N.; Hou, G.; Song, M.; Tian, J.; Zhang, X.; Zhu, J. Restoration effects of fertilization and grazing exclusion on different degraded alpine grasslands: Evidence from a 10-year experiment. Ecol. Eng. 2021, 170, 106361. [Google Scholar] [CrossRef]
- Sparks, D.L.; Page, A.L.; Helmke, P.A.; Loeppert, R.H. Methods of Soil Analysis, Part 3: Chemical Methods; John Wiley & Sons: Hoboken, NJ, USA, 2020; Volume 14. [Google Scholar]
- Sun, J.; Wang, G.; Zhang, H.; Xia, L.; Zhao, W.; Guo, Y.; Sun, X. Detection of fat content in peanut kernels based on chemometrics and hyperspectral imaging technology. Infrared Phys. Technol. 2020, 105, 103226. [Google Scholar] [CrossRef]
- Caporaso, N.; Whitworth, M.B.; Fisk, I.D. Near-infrared spectroscopy and hyperspectral imaging for non-destructive quality assessment of cereal grains. Appl. Spectrosc. Rev. 2018, 53, 667–687. [Google Scholar] [CrossRef] [Green Version]
- Chen, H.; Chen, A.; Xu, L.; Xie, H.; Qiao, H.; Lin, Q.; Cai, K. A deep learning cnn architecture applied in smart near-infrared analysis of water pollution for agricultural irrigation resources. Agric. Water Manag. 2020, 240, 106303–106310. [Google Scholar] [CrossRef]
- Zeng, J.; Guo, Y.; Han, Y.; Li, Z.; Yang, Z.; Chai, Q.; Wang, W.; Zhang, Y.; Fu, C. A review of the discriminant analysis methods for food quality based on near-infrared spectroscopy and pattern recognition. Molecules 2021, 26, 749. [Google Scholar] [CrossRef] [PubMed]
- Kawamura, K.; Nishigaki, T.; Andriamananjara, A.; Rakotonindrina, H.; Tsujimoto, Y.; Moritsuka, N.; Rabenarivo, M.; Razafimbelo, T. Using a one-dimensional convolutional neural network on visible and near-infrared spectroscopy to improve soil phosphorus prediction in madagascar. Remote Sens. 2021, 13, 1519. [Google Scholar] [CrossRef]
- Kawamura, K.; Nishigaki, T.; Tsujimoto, Y.; Andriamananjara, A.; Rabenaribo, M.; Asai, H.; Rakotoson, T.; Razafimbelo, T. Exploring relevant wavelength regions for estimating soil total carbon contents of rice fields in madagascar from vis-nir spectra with sequential application of backward interval pls. Plant Prod. Sci. 2021, 24, 1–14. [Google Scholar] [CrossRef]
- Kawamura, K.; Tsujimoto, Y.; Nishigaki, T.; Andriamananjara, A.; Rabenarivo, M.; Asai, H.; Rakotoson, T.; Razafimbelo, T. Laboratory visible and near-infrared spectroscopy with genetic algorithm-based partial least squares regression for assessing the soil phosphorus content of upland and lowland rice fields in madagascar. Remote Sens. 2019, 11, 506. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Li, M.; Ji, R.; Wang, M.; Zheng, L. Comparison of soil total nitrogen content prediction models based on vis-nir spectroscopy. Sensors 2020, 20, 7078. [Google Scholar] [CrossRef]
- Xie, S.; Ding, F.; Chen, S.; Wang, X.; Li, Y.; Ma, K. Prediction of soil organic matter content based on characteristic band selection method. Spectrochim. Acta Part A: Mol. Biomol. Spectrosc. 2022, 273, 120949. [Google Scholar] [CrossRef]
- Zhou, P.; Zhang, Y.; Yang, W.; Li, M.; Liu, Z.; Liu, X. Development and performance test of an in-situ soil total nitrogen-soil moisture detector based on near-infrared spectroscopy. Comput. Electron. Agric. 2019, 160, 51–58. [Google Scholar] [CrossRef]
- Morellos, A.; Pantazi, X.-E.; Moshou, D.; Alexandridis, T.; Whetton, R.; Tziotzios, G.; Wiebensohn, J.; Bill, R.; Mouazen, A.M. Machine learning based prediction of soil total nitrogen, organic carbon and moisture content by using vis-nir spectroscopy. Biosyst. Eng. 2016, 152, 104–116. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Han, J.; Xie, J.; Wang, H.; Tong, W.; Ba, Y. Assessing heavy metal concentrations in earth-cumulic-orthic-anthrosols soils using vis-nir spectroscopy transform coupled with chemometrics. Spectrochim. Acta Part A: Mol. Biomol. Spectrosc. 2020, 226, 117639. [Google Scholar] [CrossRef]
- Mao, Y.; Liu, J.; Cao, W.; Ding, R.; Fu, Y.; Zhao, Z. Research on the quantitative inversion model of heavy metals in soda saline land based on visible-near-infrared spectroscopy. Infrared Phys. Technol. 2021, 112, 103602. [Google Scholar] [CrossRef]
- Zhou, P.; Yang, W.; Li, M.; Wang, W. A new coupled elimination method of soil moisture and particle size interferences on predicting soil total nitrogen concentration through discrete nir spectral band data. Remote Sens. 2021, 13, 762. [Google Scholar] [CrossRef]
- Ng, W.; Minasny, B.; Mendes, W.d.S.; Dematte, J.A.M. Estimation of effective calibration sample size using visible near infrared spectroscopy: Deep learning vs machine learning. Soil Discuss. 2019, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Padarian, J.; Minasny, B.; McBratney, A.B. Using deep learning to predict soil properties from regional spectral data. Geoderma Reg. 2019, 16, e00198. [Google Scholar] [CrossRef]
- Qiu, Z.; Chen, J.; Zhao, Y.; Zhu, S.; He, Y.; Zhang, C. Variety identification of single rice seed using hyperspectral imaging combined with convolutional neural network. Appl. Sci. 2018, 8, 212. [Google Scholar] [CrossRef] [Green Version]
- Yang, B.; Chen, C.; Chen, F.; Chen, C.; Tang, J.; Gao, R.; Lv, X. Identification of cumin and fennel from different regions based on generative adversarial networks and near infrared spectroscopy. Spectrochim. Acta A Mol. Biomol. Spectrosc. 2021, 260, 119956. [Google Scholar] [CrossRef]
- Wang, C.; Xiao, Z. Lychee surface defect detection based on deep convolutional neural networks with gan-based data augmentation. Agronomy 2021, 11, 1500. [Google Scholar] [CrossRef]
- Li, H.; Zhang, L.; Sun, H.; Rao, Z.; Ji, H. Discrimination of unsound wheat kernels based on deep convolutional generative adversarial network and near-infrared hyperspectral imaging technology. Spectrochim. Acta A Mol. Biomol. Spectrosc. 2022, 268, 120722. [Google Scholar] [CrossRef]
- Jannik Bjerrum, E.; Glahder, M.; Skov, T. Data augmentation of spectral data for convolutional neural network (cnn) based deep chemometrics. arXiv 2017, arXiv:1710.01927. [Google Scholar]
- Blazhko, U.; Shapaval, V.; Kovalev, V.; Kohler, A. Comparison of augmentation and pre-processing for deep learning and chemometric classification of infrared spectra. Chemom. Intell. Lab. Syst. 2021, 215, 104367. [Google Scholar] [CrossRef]
- Hahn, A.; Tummala, M.; Scrofani, J. Extended semi-supervised learning gan for hyperspectral imagery classification. In Proceedings of the 2019 13th International Conference on Signal Processing and Communication Systems (ICSPCS), Gold Coast, Australia, 16–18 December 2019; pp. 1–6. [Google Scholar]
- Jin, J.; Wang, G.; Zhang, J.; Yang, Q.; Liu, C.; Liu, Y.; Bao, Z.; He, R. Impacts of climate change on hydrology in the yellow river source region, china. J. Water Clim. Change 2018, 11, 916–930. [Google Scholar] [CrossRef]
- Luo, D.; Jin, H.; Wu, Q.; Bense, V.F.; He, R.; Ma, Q.; Gao, S.; Jin, X.; Lü, L. Thermal regime of warm-dry permafrost in relation to ground surface temperature in the source areas of the yangtze and yellow rivers on the qinghai-tibet plateau, sw china. Sci. Total Environ. 2018, 618, 1033–1045. [Google Scholar] [CrossRef]
- Xu, M.; Kang, S.; Chen, X.; Wu, H.; Wang, X.; Su, Z. Detection of hydrological variations and their impacts on vegetation from multiple satellite observations in the three-river source region of the tibetan plateau. Sci. Total Environ. 2018, 639, 1220–1232. [Google Scholar] [CrossRef]
- Wan, B.; Mei, X.; Hu, Z.; Guo, H.; Chen, X.; Griffiths, B.S.; Liu, M. Moderate grazing increases the structural complexity of soil micro-food webs by promoting root quantity and quality in a tibetan alpine meadow. Appl. Soil Ecol. 2021, 168, 104161. [Google Scholar] [CrossRef]
- Devianti; Sufardi; Bulan, R.; Sitorus, A. Vis-nir spectra combined with machine learning for predicting soil nutrients in cropland from aceh province, indonesia. Case Stud. Chem. Environ. Eng. 2022, 6, 100268. [Google Scholar] [CrossRef]
- Recena, R.; Fernández-Cabanás, V.M.; Delgado, A. Soil fertility assessment by vis-nir spectroscopy: Predicting soil functioning rather than availability indices. Geoderma 2019, 337, 368–374. [Google Scholar] [CrossRef]
- Cipullo, S.; Nawar, S.; Mouazen, A.M.; Campo-Moreno, P.; Coulon, F. Predicting bioavailability change of complex chemical mixtures in contaminated soils using visible and near-infrared spectroscopy and random forest regression. Scientific Reports 2019, 9, 4492. [Google Scholar] [CrossRef] [Green Version]
- Aggarwal, A.; Mittal, M.; Battineni, G. Generative adversarial network: An overview of theory and applications. Int. J. Inf. Manag. Data Insights 2021, 1, 100004. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Baek, J.Y.; Yoo, Y.S.; Bae, S.H. Adversarial learning with knowledge of image classification for improving gans. IEEE Access 2019, 7, 56591–56605. [Google Scholar] [CrossRef]
- Gui, J.; Sun, Z.; Wen, Y.; Tao, D.; Ye, J. A review on generative adversarial networks: Algorithms, theory, and applications. IEEE Trans. Knowl. Data Eng. 2021, 35, 3313–3332. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, Y.; Wei, Y.; An, D. Near-infrared hyperspectral imaging technology combined with deep convolutional generative adversarial network to predict oil content of single maize kernel. Food Chem. 2022, 370, 131047. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.; Adam, B.J. A method for stochastic optimization. Cornell university. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Martens, H.; Stark, E. Extended multiplicative signal correction and spectral interference subtraction: New preprocessing methods for near infrared spectroscopy. J. Pharm. Biomed. Anal. 1991, 9, 625–635. [Google Scholar] [CrossRef] [PubMed]
- Solheim, J.H.; Zimmermann, B.; Tafintseva, V.; Dzurendová, S.; Shapaval, V.; Kohler, A. The use of constituent spectra and weighting in extended multiplicative signal correction in infrared spectroscopy. Molecules 2022, 27, 1900. [Google Scholar] [CrossRef]
- MacDonald, G.K.; Bennett, E.M.; Potter, P.A.; Ramankutty, N. Agronomic phosphorus imbalances across the world’s croplands. Proc. Natl. Acad. Sci. USA 2011, 108, 3086–3091. [Google Scholar] [CrossRef] [Green Version]
- Stenberg, B.; Viscarra Rossel, R.A.; Mouazen, A.M.; Wetterlind, J. Chapter five—Visible and near infrared spectroscopy in soil science. Adv. Agron. 2010, 107, 163–215. [Google Scholar]
- Ruggiero, L.; Amalfitano, C.; Di Vaio, C.; Adamo, P. Use of near-infrared spectroscopy combined with chemometrics for authentication and traceability of intact lemon fruits. Food Chem. 2022, 375, 131822. [Google Scholar] [CrossRef]
- Teng, G.E.; Wang, Q.Q.; Kong, J.L.; Dong, L.Q.; Cui, X.T.; Liu, W.W.; Wei, K.; Xiangli, W.T. Extending the spectral database of laser-induced breakdown spectroscopy with generative adversarial nets. Opt. Express 2019, 27, 6958–6969. [Google Scholar] [CrossRef]
- Liu, S.; Kokot, S.; Will, G. Photochemistry and chemometrics—An overview. J. Photochem. Photobiol. C: Photochem. Rev. 2009, 10, 159–172. [Google Scholar] [CrossRef]
- Ren, S.; Jia, Y. Near-infrared data classification at phone terminal based on the combination of pca and cs-rbfsvc algorithms. Spectrochim. Acta Part A: Mol. Biomol. Spectrosc. 2023, 287, 122080. [Google Scholar] [CrossRef] [PubMed]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Chollet, F. Keras 2015. Available online: https://github.com/keras-team/keras (accessed on 3 November 2022).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-learn: Machine learning in python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. Scipy 1.0: Fundamental algorithms for scientific computing in python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Blazhko, U. Available online: https://github.com/BioSpecNorway/EMSA (accessed on 3 November 2022).
- Heil, K.; Schmidhalter, U. An evaluation of different nir-spectral pre-treatments to derive the soil parameters c and n of a humus-clay-rich soil. Sensors 2021, 21, 1423. [Google Scholar] [CrossRef]
- Qi, H.; Paz-Kagan, T.; Karnieli, A.; Jin, X.; Li, S. Evaluating calibration methods for predicting soil available nutrients using hyperspectral vnir data. Soil and Tillage Research 2018, 175, 267–275. [Google Scholar] [CrossRef]
- Yu, X.; Liu, Q.; Wang, Y.; Liu, X.; Liu, X. Evaluation of mlsr and plsr for estimating soil element contents using visible/near-infrared spectroscopy in apple orchards on the jiaodong peninsula. CATENA 2016, 137, 340–349. [Google Scholar] [CrossRef]
- Wenjun, J.; Zhou, S.; Jingyi, H.; Shuo, L. In situ measurement of some soil properties in paddy soil using visible and near-infrared spectroscopy. PloS ONE 2014, 9, e105708. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guo, P.; Li, T.; Gao, H.; Chen, X.; Cui, Y.; Huang, Y. Evaluating calibration and spectral variable selection methods for predicting three soil nutrients using vis-nir spectroscopy. Remote Sens. 2021, 13, 4000. [Google Scholar] [CrossRef]
- Gao, F.; Yang, Y.; Wang, J.; Sun, J.; Yang, E.; Zhou, H. A deep convolutional generative adversarial networks (dcgans)-based semi-supervised method for object recognition in synthetic aperture radar (sar) images. Remote Sens. 2018, 10, 846. [Google Scholar] [CrossRef] [Green Version]
- Douzas, G.; Bacao, F. Effective data generation for imbalanced learning using conditional generative adversarial networks. Expert Syst. Appl. 2018, 91, 464–471. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sample Set | No. of Sample | ||
|---|---|---|---|
| Real Data | Fake Data | All | |
| Validation set | 12 | 0 | 12 |
| Training set-0 | 30 | 0 | 30 |
| Training set-1 | 30 | 15 | 45 |
| Training set-2 | 30 | 30 | 60 |
| Training set-3 | 30 | 60 | 90 |
| Training set-4 | 30 | 120 | 150 |
| Training set-5 | 30 | 240 | 270 |
| Spectral Data | Contribution Rate of PC 1 (%) | |||
|---|---|---|---|---|
| TK2O | TN | TP2O5 | SOM | |
| Epochs 100 | 92.3428 | 94.5622 | 94.4856 | 93.5099 |
| Epochs 200 | 88.2185 | 95.1557 | 93.9276 | 92.6306 |
| Epochs 300 | 89.5419 | 89.3859 | 93.6082 | 89.8450 |
| Epochs 400 | 91.1020 | 92.9954 | 89.3382 | 93.2153 |
| Epochs 500 | 96.3471 | 91.7921 | 91.8749 | 92.2119 |
| Epochs 600 | 96.6341 | 96.9554 | 95.9055 | 96.6859 |
| Epochs 700 | 96.6916 | 96.3283 | 97.6449 | 95.9690 |
| Epochs 800 | 97.2386 | 96.7172 | 96.5586 | 97.1831 |
| Epochs 900 | 96.8385 | 95.4957 | 95.2677 | 97.2630 |
| Epochs 1000 | 96.0832 | 97.2015 | 94.7501 | 97.6678 |
| Epochs 1100 | 97.3020 | 97.3502 | 96.1348 | 97.8660 |
| Epochs 1200 | 97.0517 | 97.3077 | 97.0092 | 96.9983 |
| Epochs 1300 | 96.8244 | 95.6088 | 97.3126 | 97.2169 |
| Epochs 1400 | 95.7257 | 96.7516 | 97.0826 | 96.4738 |
| Epochs 1500 | 97.3150 | 97.4158 | 93.6527 | 96.2250 |
| Epochs 1600 | 96.7321 | 94.3487 | 96.8070 | 96.8517 |
| Epochs 1700 | 96.8459 | 97.9589 | 96.6976 | 97.0083 |
| Epochs 1800 | 97.1099 | 95.1054 | 95.7284 | 95.3972 |
| Epochs 1900 | 93.9653 | 95.7423 | 90.2857 | 95.5565 |
| Epochs 2000 | 96.1429 | 93.4147 | 88.9370 | 92.8778 |
| Real | 89.5203 | 89.5203 | 89.5203 | 89.5203 |
| EMSA | 98.2737 | 97.9811 | 98.2256 | 98.4410 |
| Variety | Sample Types | Epoch | No. of Sample | Minimum (g/kg) | Maximum (g/kg) | Average (g/kg) | Median (g/kg) | Standard Deviation (g/kg) |
|---|---|---|---|---|---|---|---|---|
| TK2O | Real data | / | 30 | 13.790 | 21.610 | 18.995 | 19.570 | 2.167 |
| GAN data | 1800 | 300 | 13.207 | 22.940 | 19.065 | 19.582 | 2.377 | |
| TN | Real data | / | 30 | 0.450 | 3.760 | 2.085 | 2.150 | 0.754 |
| GAN data | 1400 | 300 | 0.125 | 4.210 | 2.123 | 2.171 | 0.829 | |
| TP2O5 | Real data | / | 30 | 1.020 | 1.590 | 1.254 | 1.235 | 0.147 |
| GAN data | 1400 | 296 | 0.731 | 1.999 | 1.250 | 1.200 | 0.227 | |
| SOM | Real data | / | 30 | 4.070 | 71.090 | 34.467 | 32.885 | 15.201 |
| GAN data | 1400 | 300 | 4.698 | 72.409 | 34.409 | 32.804 | 15.100 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, C.; Zhao, J.; Ding, Y.; Li, G. Vis–NIR Spectroscopy Combined with GAN Data Augmentation for Predicting Soil Nutrients in Degraded Alpine Meadows on the Qinghai–Tibet Plateau. Sensors 2023, 23, 3686. https://doi.org/10.3390/s23073686
Jiang C, Zhao J, Ding Y, Li G. Vis–NIR Spectroscopy Combined with GAN Data Augmentation for Predicting Soil Nutrients in Degraded Alpine Meadows on the Qinghai–Tibet Plateau. Sensors. 2023; 23(7):3686. https://doi.org/10.3390/s23073686
Chicago/Turabian StyleJiang, Chuanli, Jianyun Zhao, Yuanyuan Ding, and Guorong Li. 2023. "Vis–NIR Spectroscopy Combined with GAN Data Augmentation for Predicting Soil Nutrients in Degraded Alpine Meadows on the Qinghai–Tibet Plateau" Sensors 23, no. 7: 3686. https://doi.org/10.3390/s23073686