A Graph Convolutional Network-Based Deep Reinforcement Learning Approach for Resource Allocation in a Cognitive Radio Network




Abstract
:1. Introduction
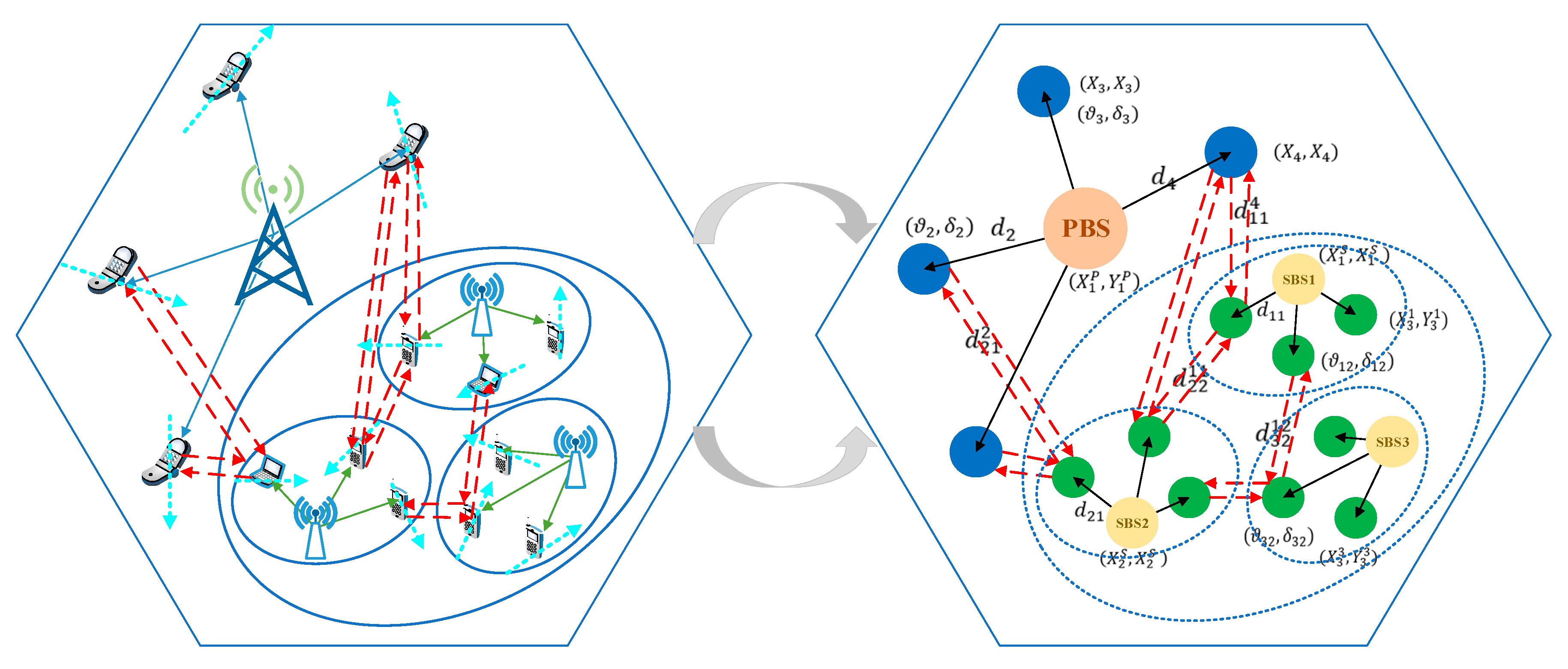
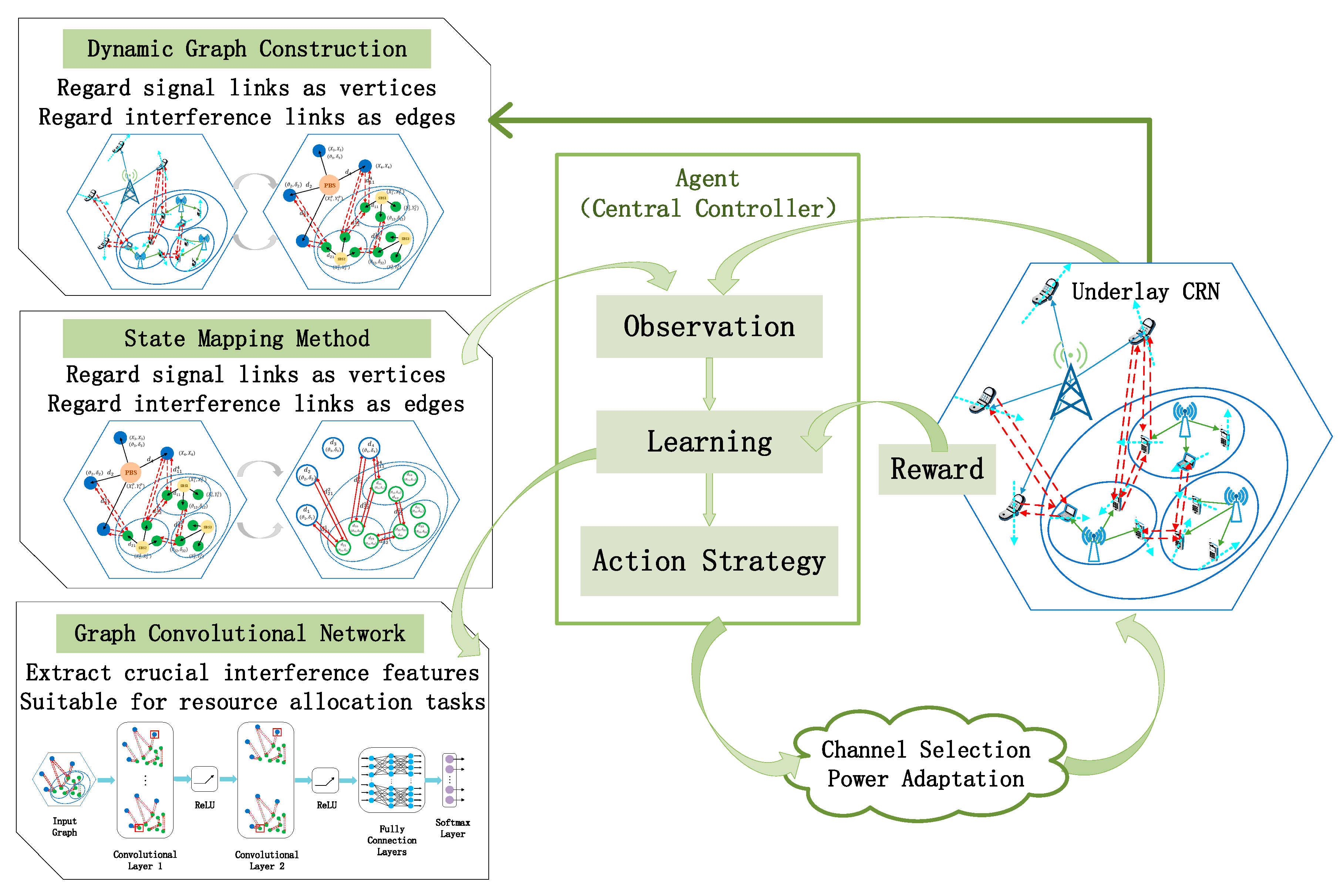
- We propose a method of constructing the topology of the underlay CRN based on a dynamic graph. The dynamics of the communication graph is mainly reflected in two aspects: One is to adopt the random walk model to simulate the users’ movements, which indicates the dynamics of the position of vertices; the other is the dynamics of the topology caused by the different resource occupation results. Moreover, a novel mapping method is also presented. We regard the signal links as vertices and interference links as edges. This simplifies the complexity of the graph, and is more suitable for extracting the desired interference information.
- Considering that it is difficult to obtain accurate CSI, we suggest an RL algorithm that utilizes graph data as state inputs. To make the state conditions looser, we model the path loss based on the user distance information inherent in the graph. Hence, the state can be defined by the user distance distribution and resource occupation, which substitute CSI. Additionally, the actions are two-objective, including channel selection and power adaptation, to achieve spectrum sharing and interference mitigation.
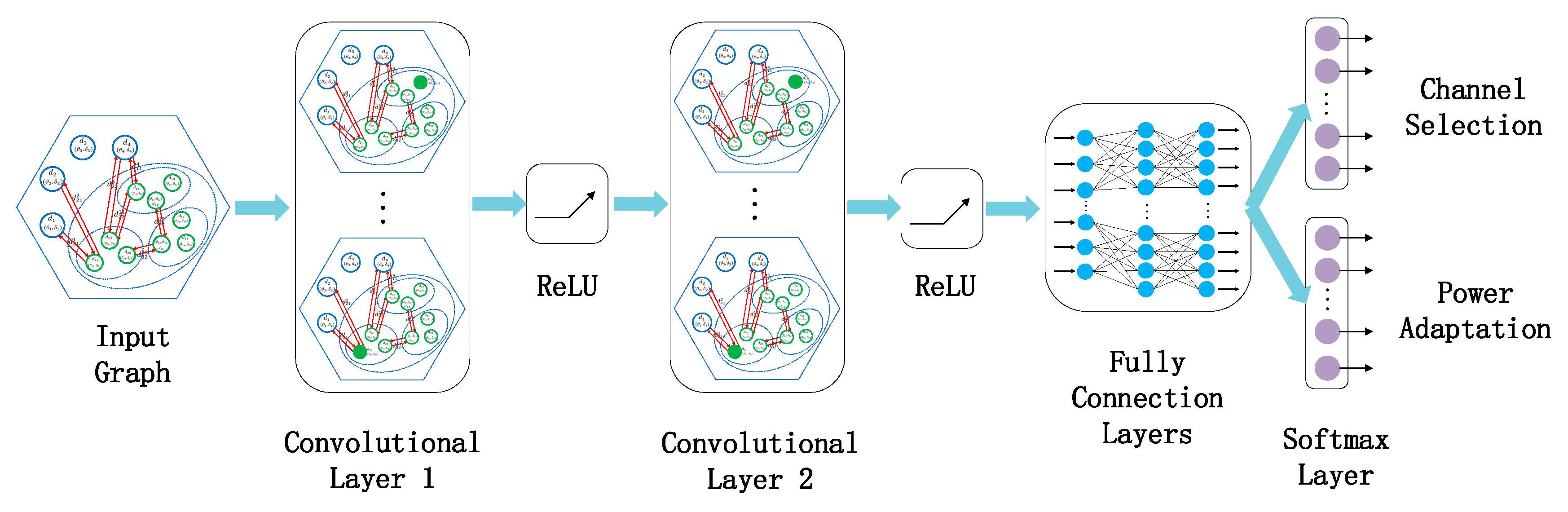
- We explore the performance of the resource allocation strategies with the “GCN+DRL” framework. Here, we design an end-to-end model by stacking the graph convolutional layers, to learn the structural information and attribute the information of the CRN communication graph. In this design, the convolutional layers are mainly used to extract interference features, and the fully connected layers are responsible for allocating the channel and power. The end-to-end learning model can automatically extract effective features, avoiding the mismatch between features and tasks. In this way, the reward of RL can simultaneously guide the learning process of feature representation and resource assignment.
2. System Model and Problem Formulation
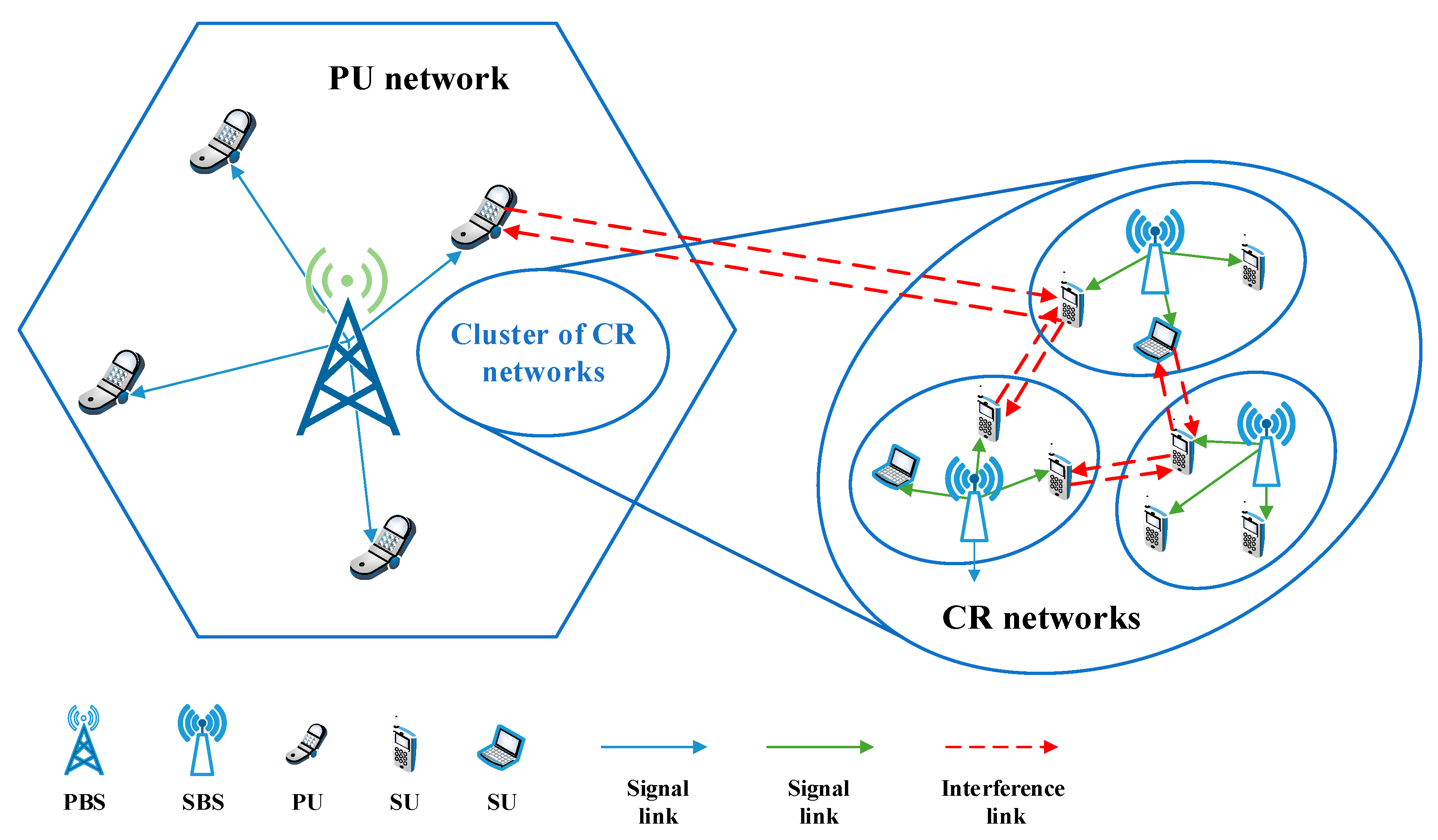
2.1. System Model
2.1.1. Path Loss Model
2.1.2. Dynamic Graph Construction Based on Users’ Mobility Model
2.2. Problem Formulation
3. Graph Convolutional Network-Based Deep Reinforcement Learning Approach for Resource Allocation in Cognitive Radio Network
3.1. Preliminaries
3.1.1. Reinforcement Learning
3.1.2. Graph Neural Networks
3.2. Definition of RL Elements of the CRN Environment
- Agent: Based on the “GCN+DRL” framework, a central controller is treated as the agent. In other words, our work adopts a centralized RL algorithm. Interacting with the environment, the agent has the ability to learn and make decisions. The central controller is responsible for scheduling spectrum and power resource for PUs and SUs in the underlay CRN.
- State: The state in the RL framework represents the information that the agent can acquire from the environment. To design effective states for the resource allocation problem in a CRN environment, the important insight is that, the sum data rate of the CRNs is significantly influenced by the CCI. Further, the CCI, including co-layer interference among SUs and cross-layer interference between SUs and PUs, is the result of the user distance distribution and resource occupation.
- Action: An action is a valid resource allocation process to satisfy users’ request. At every single step, we define the actions as channel and power allocation of all PUs and SUs, which can be expressed as:where is the channel selection matrix and is the power selection matrix. The values of the actions will be determined by the interaction with the environment. A reasonable resource selection achieves spectrum sharing and interference mitigation, while satisfying the constraints of the optimization problem mentioned above. In the channel selection process, and represent the occupation of the RB by the PU and the SU, respectively. In the power selection process, is denoted as the set of the power levels, and, and represent whether the power level is chosen by the PU and the SU. The specific forms of these two matrices are as follows:
- Reward: Instead of following a predefined label, the learning agent optimizes the behavior of the algorithm by constantly receiving rewards from the external environment. The principle of the “reward” mechanism is to tell the agent how good the current action is doing relatively. That is to say, the reward function guides the optimizing direction of the algorithm. Hence, if we correlate the design of the reward function with the optimization goal, the performance of the system will be improved driven by the reward.
3.3. Resource Allocation Algorithm Based on a Graph Convolutional Network
3.3.1. State Mapping Method Based on a Dynamic Graph
3.3.2. End-to-End Learning Model Integrated Feature Extraction and Policy Generation
3.3.3. Learning Process based on the Policy Gradient Algorithm
| Algorithm 1: Resource Allocation Algorithm Based GCN+DRL in the Underlay CRN |
| begin |
| Initialization: |
| Each user is dropped randomly with an arbitrary speed and direction of movement |
| The parameter of CRN system model is initialized, and CSI is set to a random value |
| All RBs are initialized to the idle state |
| The policy network parameter is initialized |
| Processing: |
| For in Z, do |
| Initialize the underlay CRN environment |
| For in , do |
| Construct the graph of current CRN topology |
| Observe the state from the communication graph, including user distance distribution and resource occupation |
| Select channel , according to the |
| Select power level , according to the |
| Perform channel selection and power control, and obtain the reward according to the data rate of the CR networks |
| Check SINR to guarantee QoS of users according to constraints |
| Establish the actual interference links based on the resource allocation result |
| End for |
| Calculate the loss of channel selection and power adaptation, and |
| Calculate the total loss |
| Update the network parameter with the gradient descent method |
| End for |
| end |
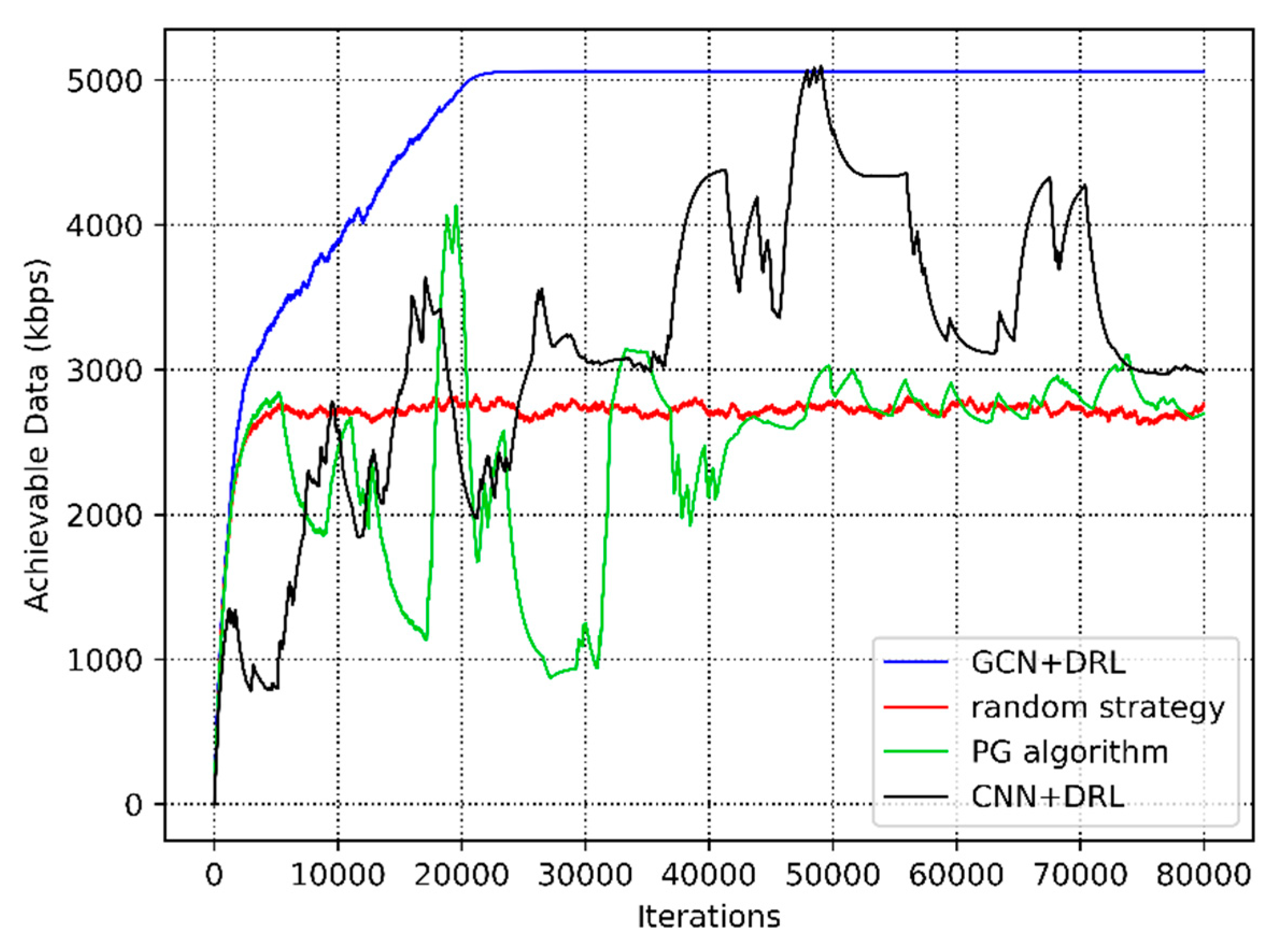
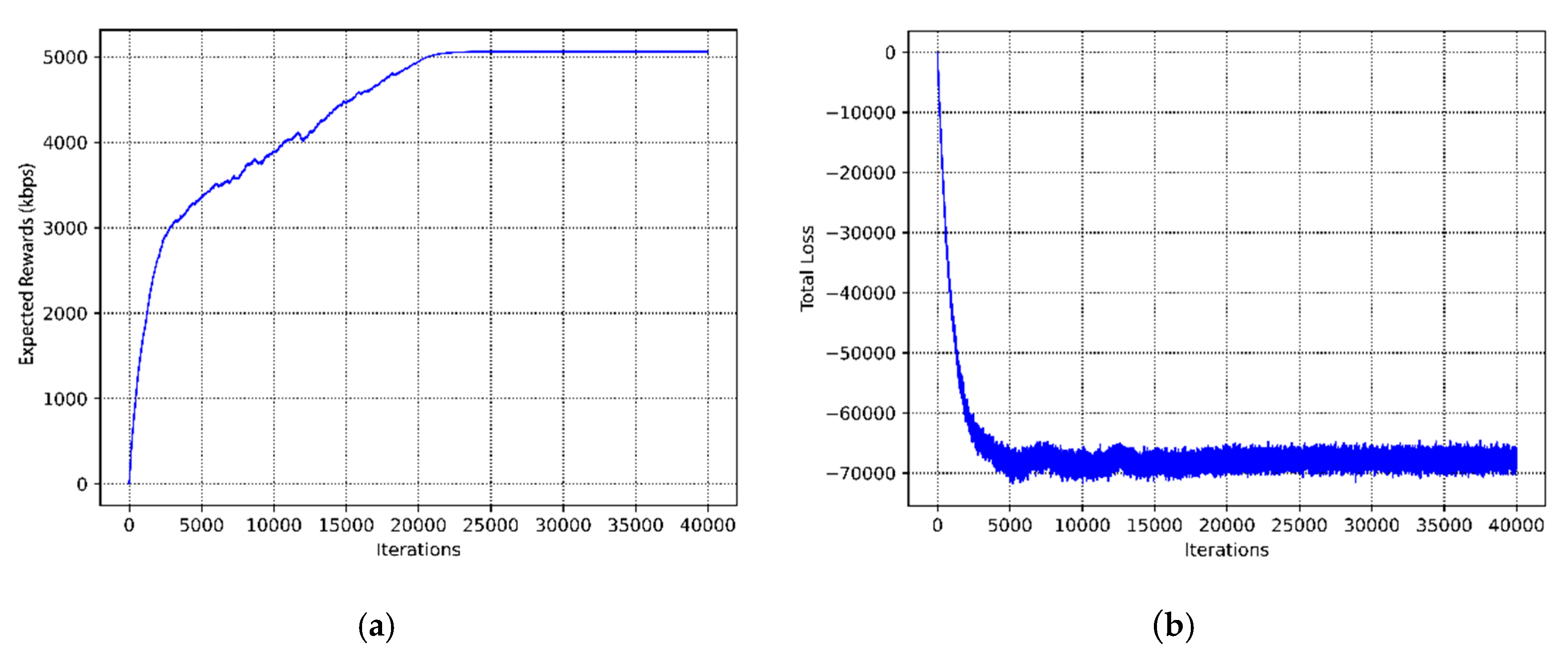
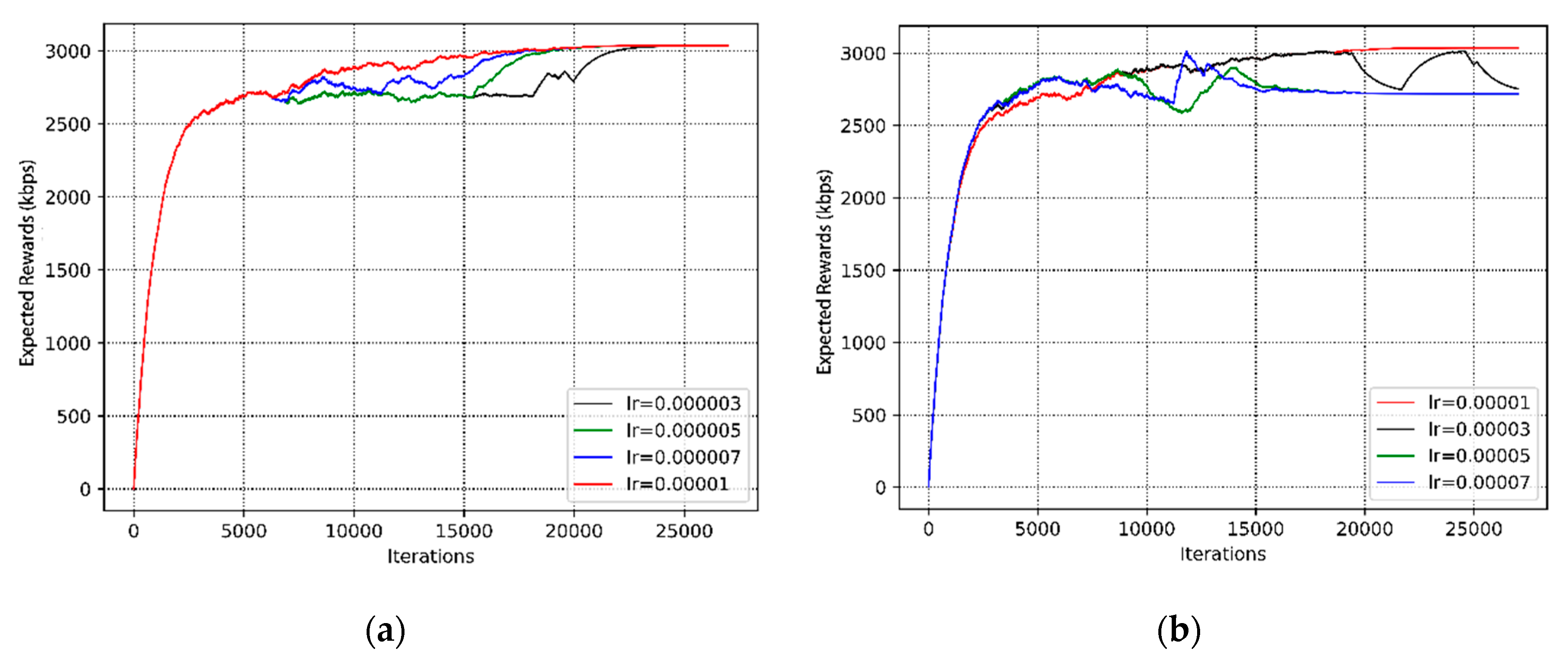
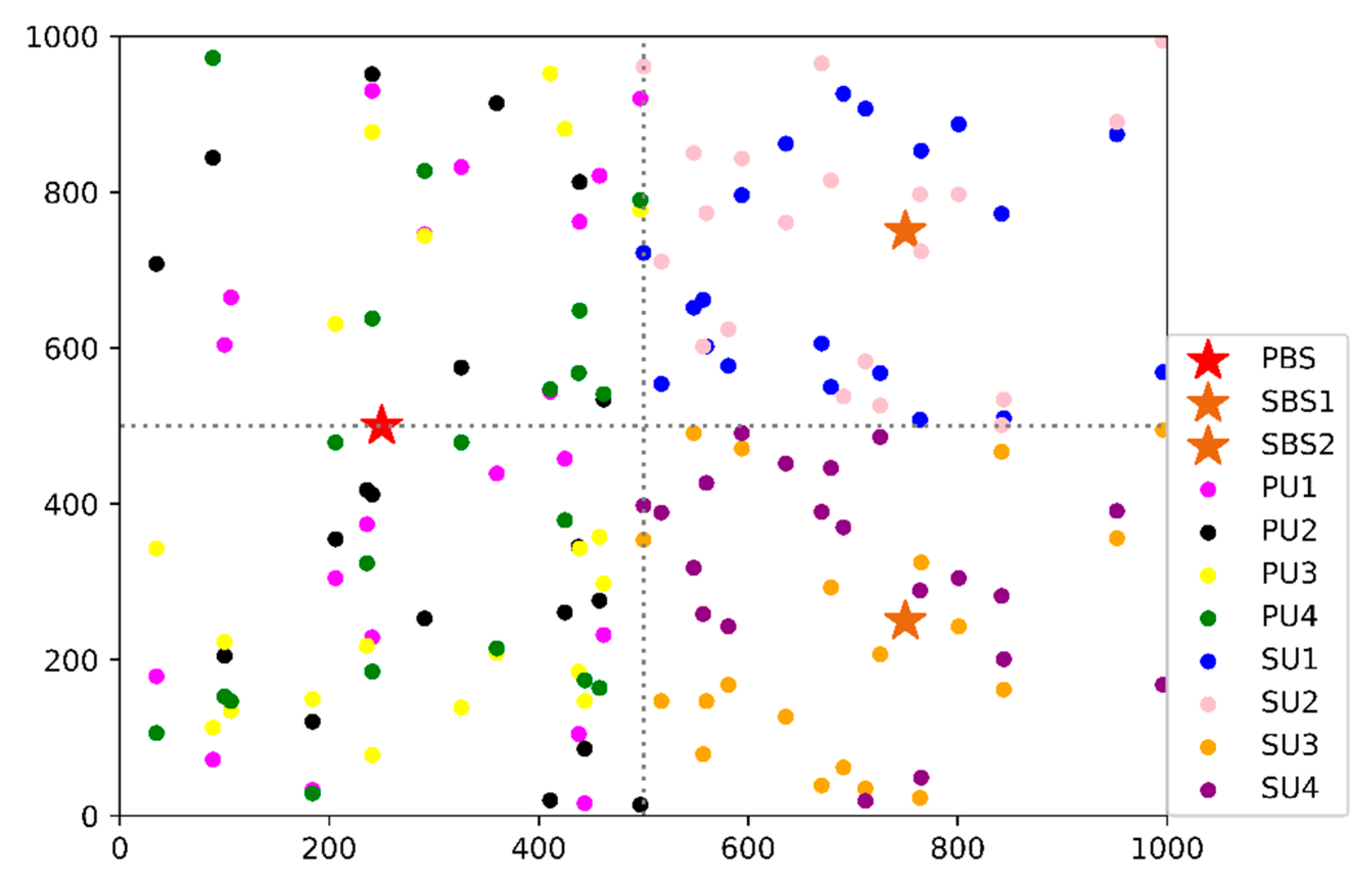
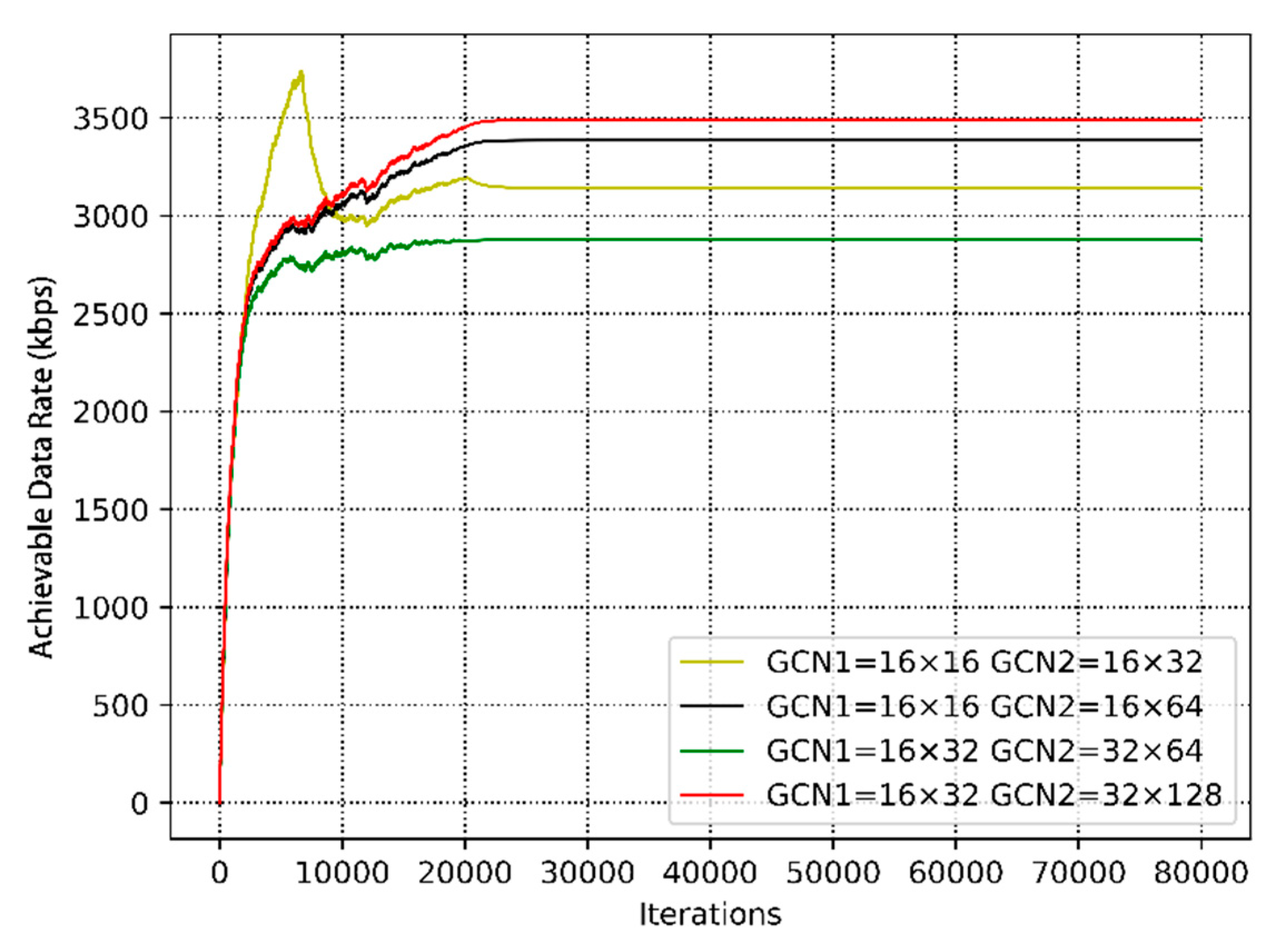
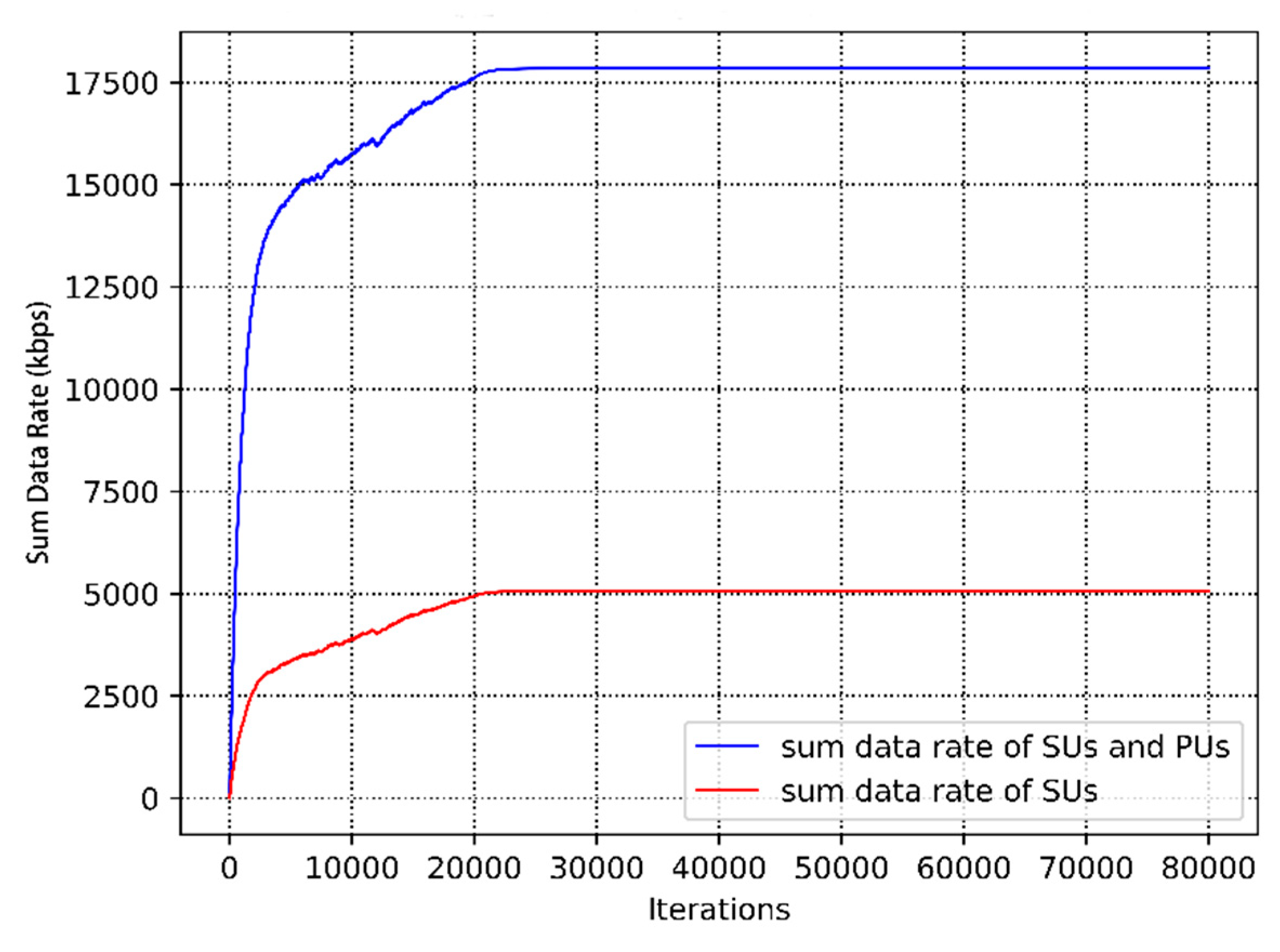
4. Simulation and Evaluation
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notations | Variables | Descriptions |
|---|---|---|
| the distances from PBS to PUs | ||
| the distances between PUs | ||
| the distances between PUs and SUs | ||
| is the transpose matrix of . | ||
| the distances from SBSs to SUs | ||
| the distances between SUs under the same SBS | ||
| the distances between SUs covered by different SBSs | ||
| Notations | Variables | Descriptions |
|---|---|---|
| indicator variables that represent the status of the resource blocks occupied by PUs | ||
| indicator variables that represent the status of the resource blocks occupied by SUs |
References
- Jiang, C.; Zhang, H.; Ren, Y.; Han, Z.; Chen, K.; Hanzo, L. Machine learning paradigms for next-generation wireless networks. IEEE Wirel. Commun. 2017, 24, 98–105. [Google Scholar] [CrossRef] [Green Version]
- Wang, D.; Song, B.; Chen, D.; Du, X. Intelligent cognitive radio in 5G: AI-based hierarchical cognitive cellular networks. IEEE Wirel. Commun. 2019, 26, 54–61. [Google Scholar] [CrossRef]
- Du, X.; Lin, F. Improving sensor network performance by deploying mobile sensors. In Proceedings of the 24th IEEE International Performance, Computing, and Communications Conference, Phoenix, AZ, USA, 7–9 April 2005. [Google Scholar]
- Wang, D.; Zhang, W.; Song, B.; Du, X.; Guizani, M. Market-based model in CR-IoT: A Q-probabilistic multi-agent reinforcement learning approach. IEEE Trans. Cogn. Commun. Netw. 2020, 6, 179–188. [Google Scholar] [CrossRef]
- Abbas, N.; Nasser, Y.; Ahmad, K.E. Recent advances on artificial intelligence and learning techniques in cognitive radio networks. EURASIP J. Wirel. Commun. 2015, 1, 174. [Google Scholar] [CrossRef] [Green Version]
- Tanab, M.E.; Hamouda, W. Resource allocation for underlay cognitive radio networks: A survey. IEEE Commun. Surv. Tutor. 2017, 19, 1249–1276. [Google Scholar] [CrossRef]
- Haykin, S. Cognitive radio: Brain-empowered wireless communications. IEEE J. Sel. Areas Commun. 2005, 23, 201–220. [Google Scholar] [CrossRef]
- Yang, H.; Chen, C.; Zhong, W. Cognitive multi-cell visible light communication with hybrid underlay/overlay resource allocation. IEEE Photon. Technol. Lett. 2018, 30, 1135–1138. [Google Scholar] [CrossRef]
- Kachroo, A.; Ekin, S. Impact of secondary user interference on primary network in cognitive radio systems. In Proceedings of the 2018 IEEE 88th Vehicular Technology Conference, Chicago, IL, USA, 27–30 August 2018. [Google Scholar]
- Xu, W.; Qiu, R.; Cheng, J. Fair optimal resource allocation in cognitive radio networks with co-channel interference mitigation. IEEE Access 2018, 6, 37418–37429. [Google Scholar] [CrossRef]
- Wang, S.; Ge, M.; Zhao, W. Energy-efficient resource allocation for OFDM-based cognitive radio networks. IEEE Trans. Commun. 2013, 61, 3181–3191. [Google Scholar] [CrossRef]
- Marques, A.G.; Lopez-Ramos, L.M.; Giannakis, G.B.; Ramos, J. Resource allocation for interweave and undelay CRs under probability-of-interference constraints. IEEE J. Sel. Areas Commun. 2012, 30, 1922–1933. [Google Scholar] [CrossRef]
- Peng, M.; Zhang, K.; Jiang, J.; Wang, J.; Wang, W. Energy-efficient resource assignment and power allocation in heterogeneous cloud radio access networks. IEEE Trans. Veh. Technol. 2015, 64, 5275–5287. [Google Scholar] [CrossRef]
- Satria, M.B.; Mustika, I.W. Resource allocation in cognitive radio networks based on modified ant colony optimization. In Proceedings of the 2018 4th International Conference on Science and Technology, Yogyakarta, Indonesia, 7–8 August 2018. [Google Scholar]
- Khan, H.; Yoo, S.J. Multi-objective optimal resource allocation using particle swarm optimization in cognitive radio. In Proceedings of the 2018 IEEE Seventh International Conference on Communications and Electronics, Hue, Vietnam, 18–20 July 2018. [Google Scholar]
- Mallikarjuna, G.C.P.; Vijaya, K.T. Blocking probabilities, resource allocation problems and optimal solutions in cognitive radio networks: A survey. In Proceedings of the 2018 International Conference on Electrical, Electronics, Communication, Computer, and Optimization Techniques, Msyuru, India, 14–15 December 2018. [Google Scholar]
- He, A.; Bae, K.K.; Newman, T.R.; Gaeddert, J.; Kim, K.; Menon, R.; Morales-Tirado, L.; Neel, J.J.; Zhao, Y.; Reed, J.H. A survey of artificial intelligence for cognitive radios. IEEE Trans. Veh. Technol. 2010, 59, 1578–1592. [Google Scholar] [CrossRef]
- Zhou, X.; Sun, M.; Li, G.Y.; Juang, B.F. Intelligent wireless communications enabled by cognitive radio and machine learning. China Commun. 2018, 15, 16–48. [Google Scholar]
- Puspita, R.H.; Shah, S.D.A.; Lee, G.M.; Roh, B.H.; Kang, S. Reinforcement learning based 5G enabled cognitive radio networks. In Proceedings of the 2019 International Conference on Information and Communication Technology Convergence, Jeju Island, Korea, 16–18 October 2019. [Google Scholar]
- AlQerm, I.; Shihada, B. Enhanced online Q-learning scheme for energy efficient power allocation in cognitive radio networks. In Proceedings of the 2019 IEEE Wireless Communications and Networking Conference, Marrakesh, Morocco, 15–18 April 2019. [Google Scholar]
- Zhang, H.; Yang, N.; Wei, H.; Long, K.; Leung, V.C.M. Power control based on deep reinforcement learning for spectrum sharing. IEEE Trans. Wirel. Commun. 2020, 19, 4209–4219. [Google Scholar] [CrossRef]
- Kaur, A.; Kumar, K. Energy-efficient resource allocation in cognitive radio networks under cooperative multi-agent model-free reinforcement learning schemes. IEEE Trans. Netw. Serv. Man. 2020, 17, 1337–1348. [Google Scholar] [CrossRef]
- Shen, Y.; Shi, Y.; Zhang, J.; Letaief, K.B. A graph neural network approach for scalable wireless power control. In Proceedings of the 2019 IEEE Globecom Workshops, Waikoloa, HI, USA, 9–13 December 2019. [Google Scholar]
- Cui, W.; Shen, K.; Yu, W. Spatial deep learning for wireless scheduling. IEEE J. Sel. Areas Commun. 2019, 37, 1248–1261. [Google Scholar] [CrossRef] [Green Version]
- Lee, M.; Yu, G.; Li, G.Y. Graph embedding based wireless link scheduling with few training samples. arXiv 2019, arXiv:1906.02871. Available online: https://arxiv.org/abs/1906.02871v1 (accessed on 7 June 2019).
- Goldsmith, A. Wireless Communications; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Yu, P.S. A comprehensive survey on graph neural networks. IEEE Trans. Neur. Net. Lear. Available online: https://ieeexplore.ieee.org/document/9046288 (accessed on 24 March 2020). [CrossRef] [Green Version]
- Zhang, Z.; Cui, P.; Zhu, W. Deep learning on graphs: A survey. IEEE Trans. Knowl. Data Eng. Available online: https://ieeexplore.ieee.org/document/9039675 (accessed on 17 March 2020). [CrossRef] [Green Version]
- Zhou, J.; Cui, G.; Zhang, Z.; Yang, C.; Liu, Z.; Wang, L.; Li, C.; Sun, M. Graph neural networks: A review of methods and applications. arXiv 2018, arXiv:1812.08434. Available online: https://arxiv.org/abs/1812.08434 (accessed on 10 July 2019).
- Bruna, J.; Zaremba, W.; Szlam, A.; Lecun, Y. Spectral networks and locally connected networks on graphs. arXiv 2013, arXiv:1312.6203. Available online: https://arxiv.org/abs/1312.6203 (accessed on 21 May 2014).
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional neural networks on graphs with fast localized spectral filtering. arXiv 2016, arXiv:1606.09375. Available online: https://arxiv.org/abs/1606.09375 (accessed on 5 February 2017).
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. Available online: https://arxiv.org/abs/1609.02907 (accessed on 22 February 2017).
- Nie, S.; Fan, Z.; Zhao, M.; Gu, X.; Zhang, L. Q-learning based power control algorithm for D2D communication. In Proceedings of the 2016 IEEE 27th Annual International Symposium on Personal, Indoor, and Mobile Radio Communications, Valencia, Spain, 4–8 September 2016. [Google Scholar]













| Parameter | Value |
|---|---|
| Cell radius | 500 m |
| BS antenna gain | 18 dBi |
| User antenna gain | 3 dBi |
| Carrier frequency | 2 GHz |
| Path loss model | 137.3 + 35.2 log(d(km)) (dB) |
| Noise power | −122 dBm |
| Interference temperature | 6 db |
| RB bandwidth | 180 kHz |
| Number of RBs | 8 |
| Transmission power | [3,13,23] dBm |
| Number of PUs | 4 |
| Number of CR network | 2 |
| Number of SUs per CR network | 2 |
| Direction of user movement | [0, 2] |
| Speed of user movement | 4.3 km/h |
| Discount factor | 0.995 |
| Random Strategy | PG Algorithm | CNN + DRL | GCN + DRL | |
|---|---|---|---|---|
| Neural networks used | GCN | MLP | CNN | GCN |
| DRL framework | 🗴 | 🗸 | 🗸 | 🗸 |
| Computational complexity | ||||
| Convergence time | 1590 s | 17,000 s | ≥30,880 s | 8800 s |
| Optimal solution | 🗴 | 🗴 | 🗴 | 🗸 |
| Scalability | 🗴 | 🗴 | 🗴 | 🗸 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, D.; Qin, H.; Song, B.; Han, B.; Du, X.; Guizani, M. A Graph Convolutional Network-Based Deep Reinforcement Learning Approach for Resource Allocation in a Cognitive Radio Network. Sensors 2020, 20, 5216. https://doi.org/10.3390/s20185216
Zhao D, Qin H, Song B, Han B, Du X, Guizani M. A Graph Convolutional Network-Based Deep Reinforcement Learning Approach for Resource Allocation in a Cognitive Radio Network. Sensors. 2020; 20(18):5216. https://doi.org/10.3390/s20185216
Chicago/Turabian StyleZhao, Di, Hao Qin, Bin Song, Beichen Han, Xiaojiang Du, and Mohsen Guizani. 2020. "A Graph Convolutional Network-Based Deep Reinforcement Learning Approach for Resource Allocation in a Cognitive Radio Network" Sensors 20, no. 18: 5216. https://doi.org/10.3390/s20185216