
Remote Sensing Image Scene Classification Using Multi-Scale Completed Local Binary Patterns and Fisher Vectors


Abstract
:
1. Introduction
2. Related Works
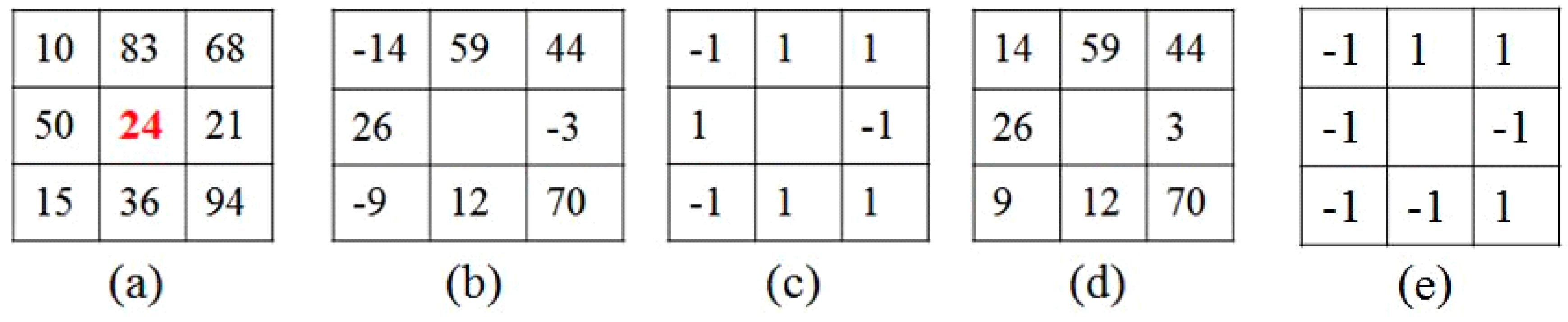
2.1. Completed Local Binary Patterns
2.2. Fisher Vector
3. Proposed Feature Representation Method
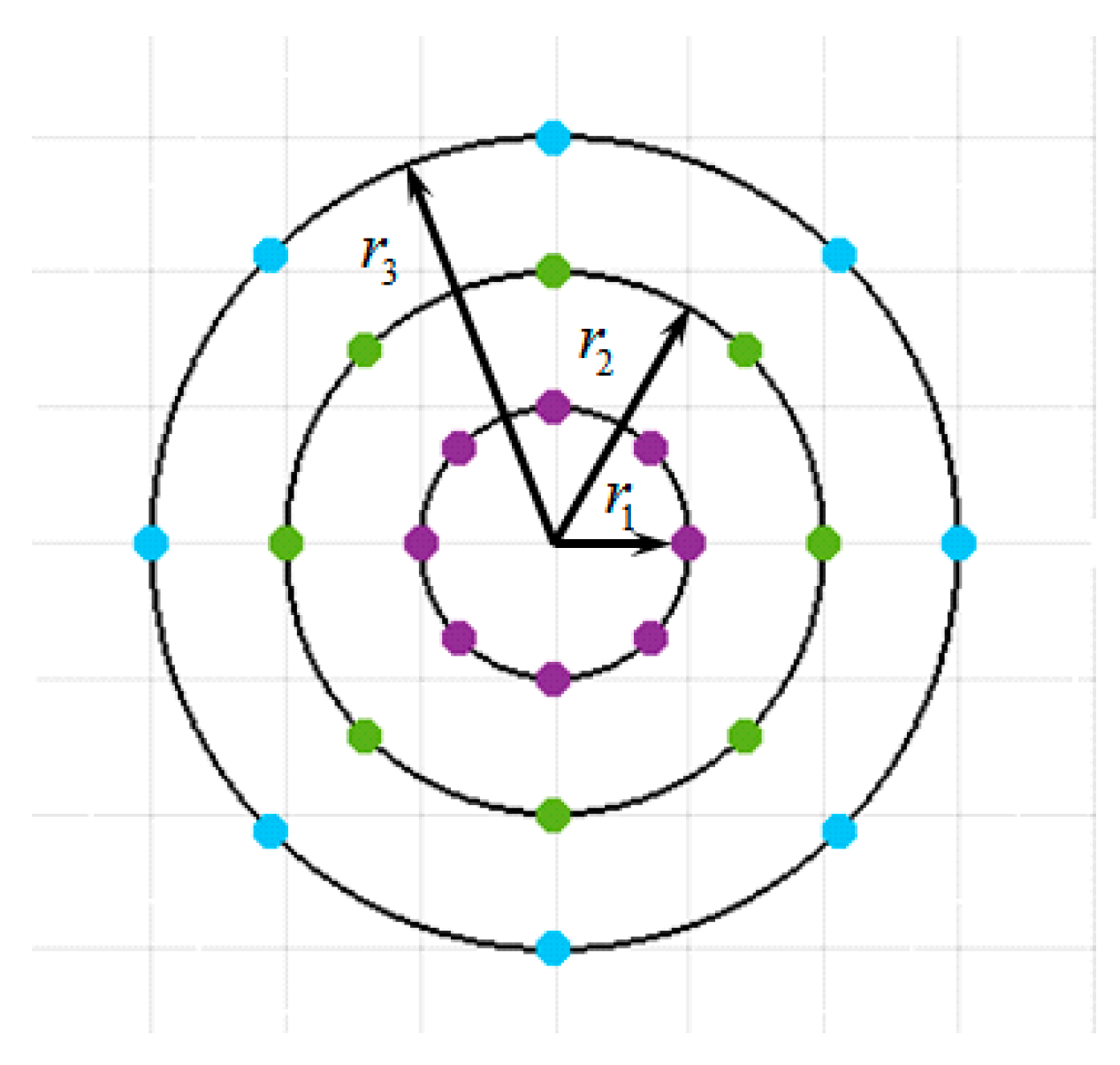
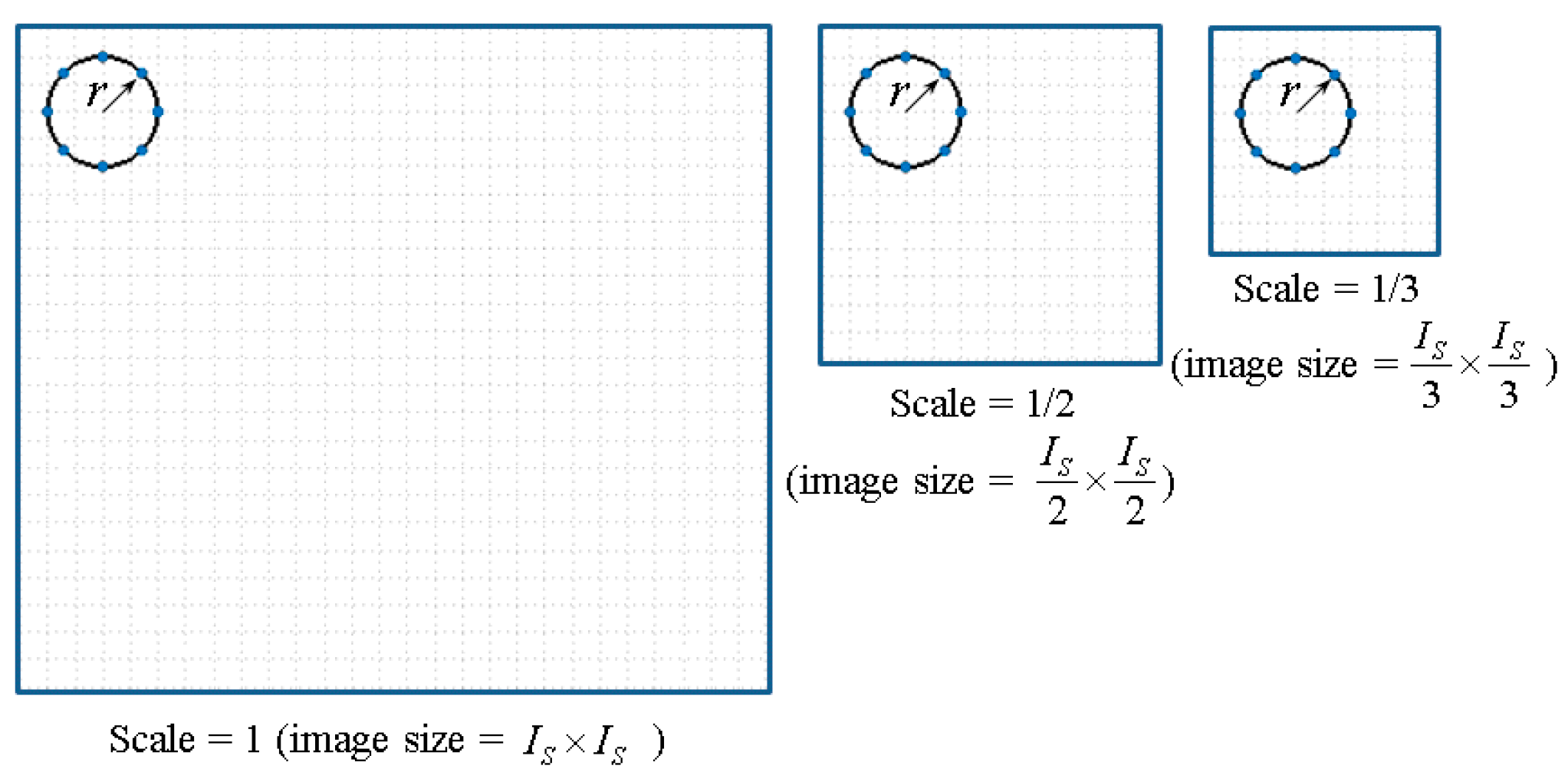
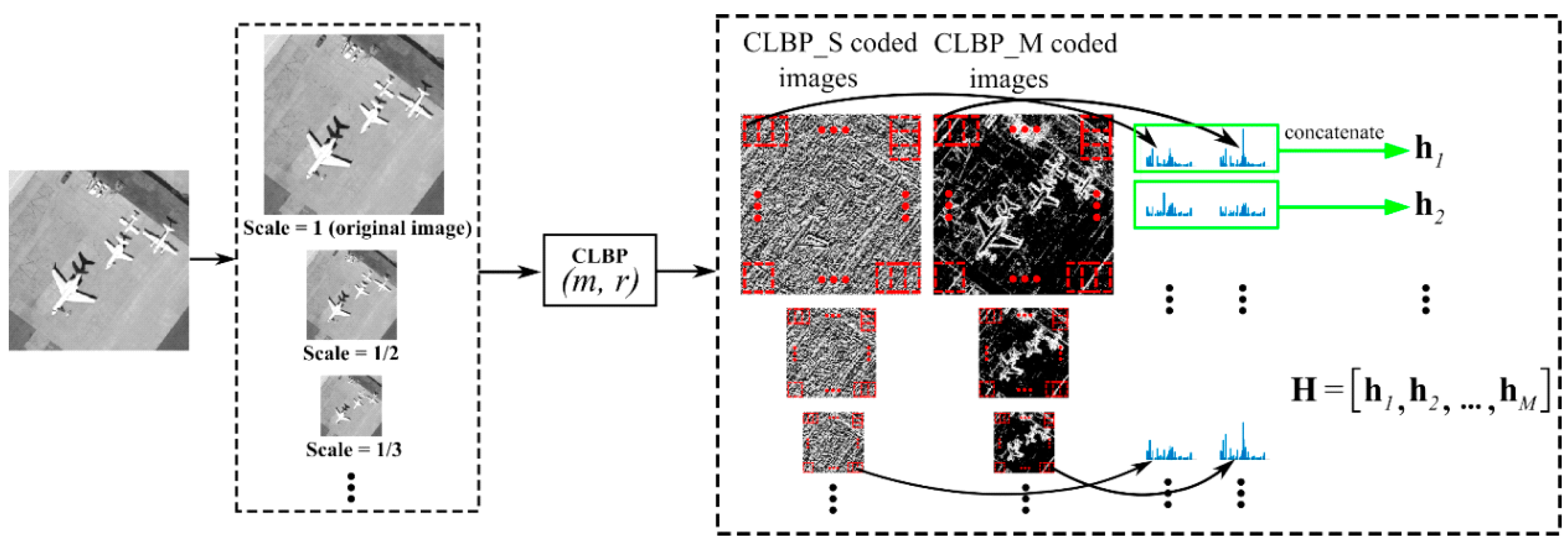
3.1. Two Implementations of Multi-Scale Completed Local Binary Patterns
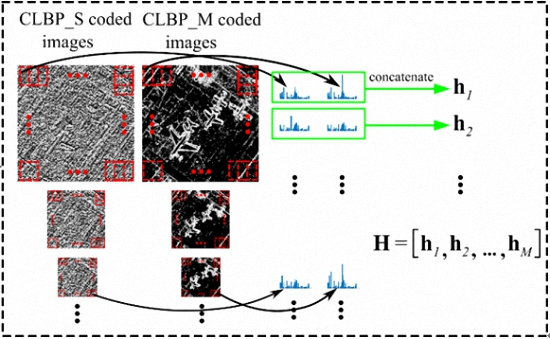
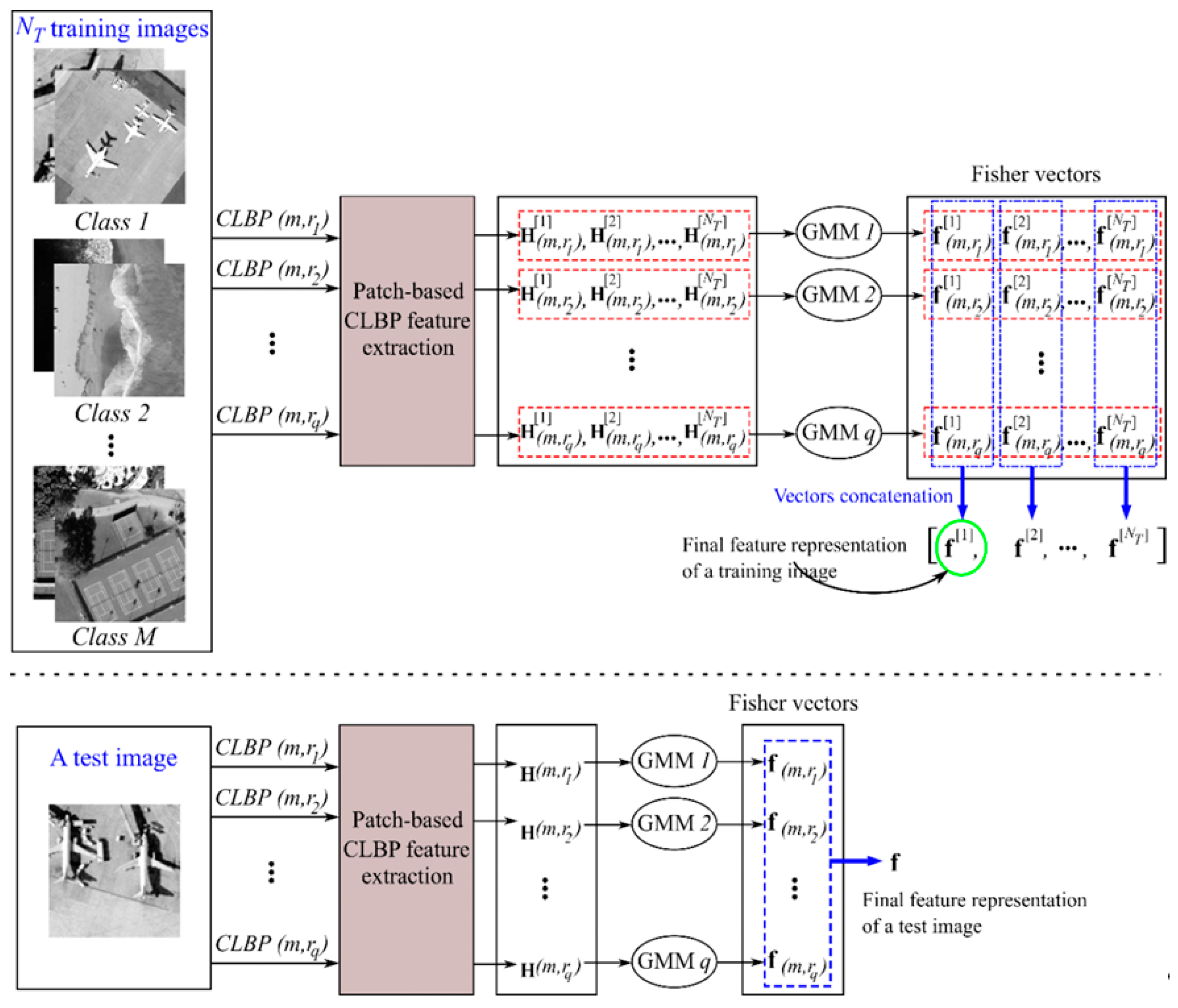
3.2. Patch-Based MS-CLBP Feature Extraction
3.3. A Fisher Kernel Representation
4. Experiments
4.1. Experimental Data and Setup
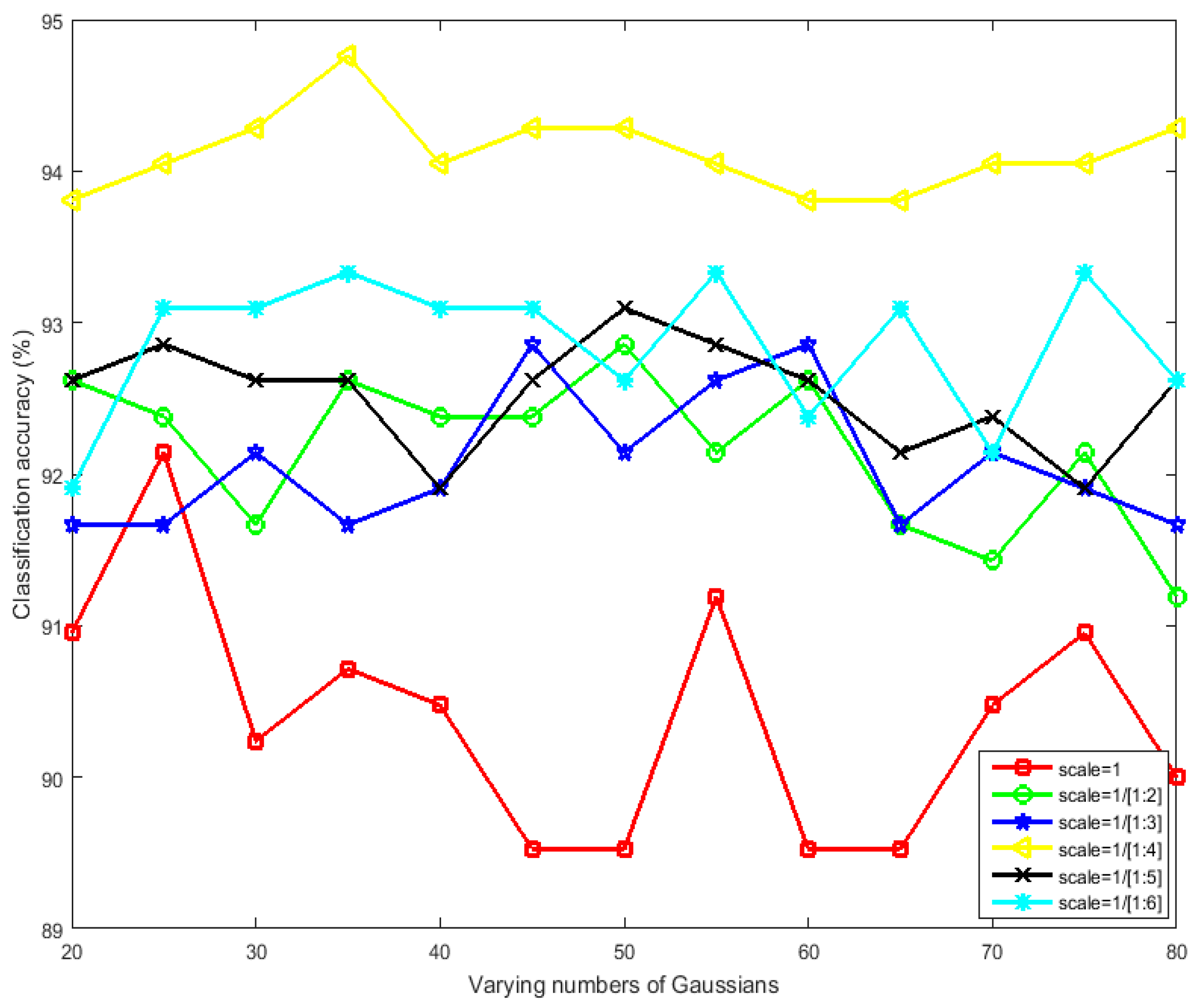
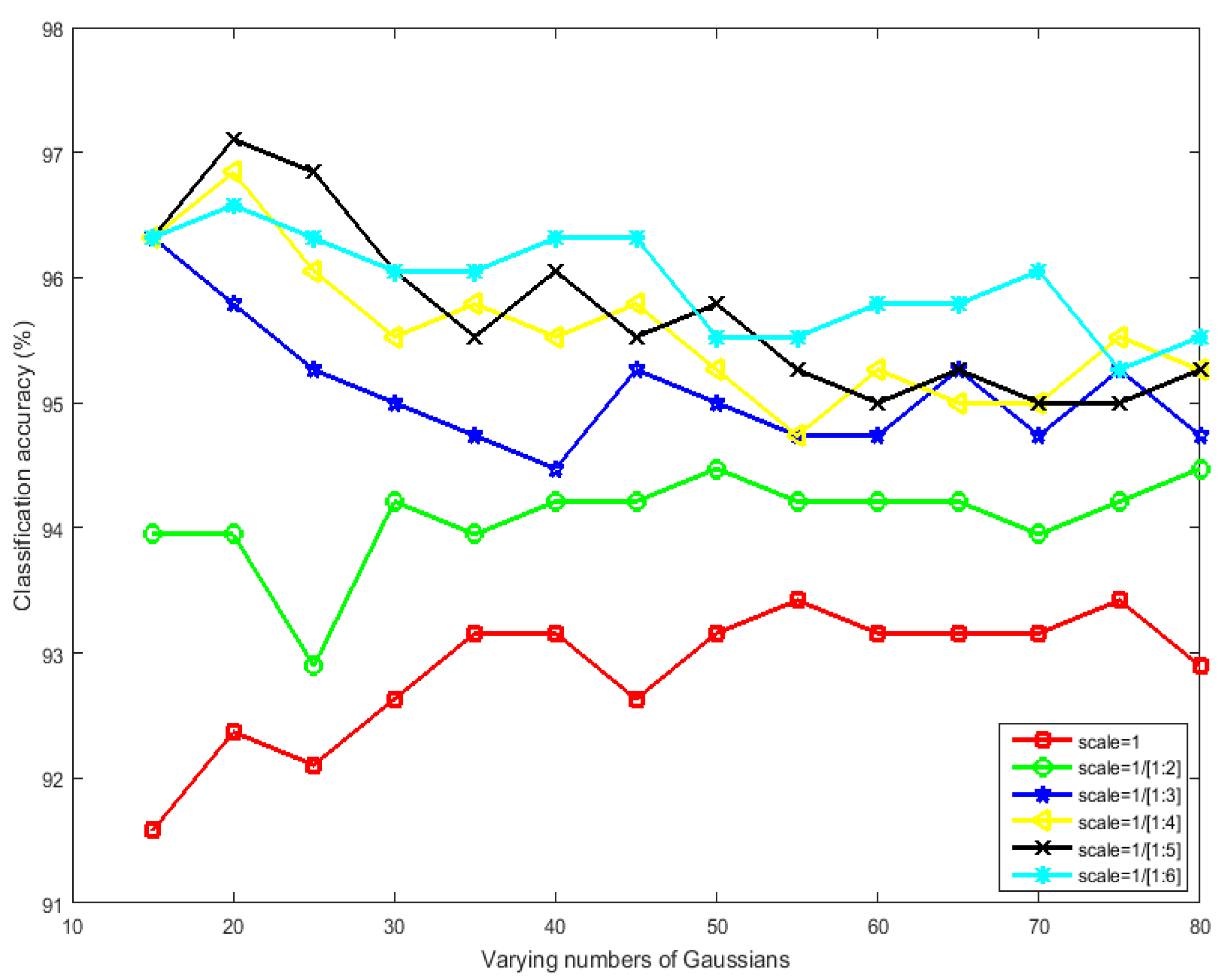
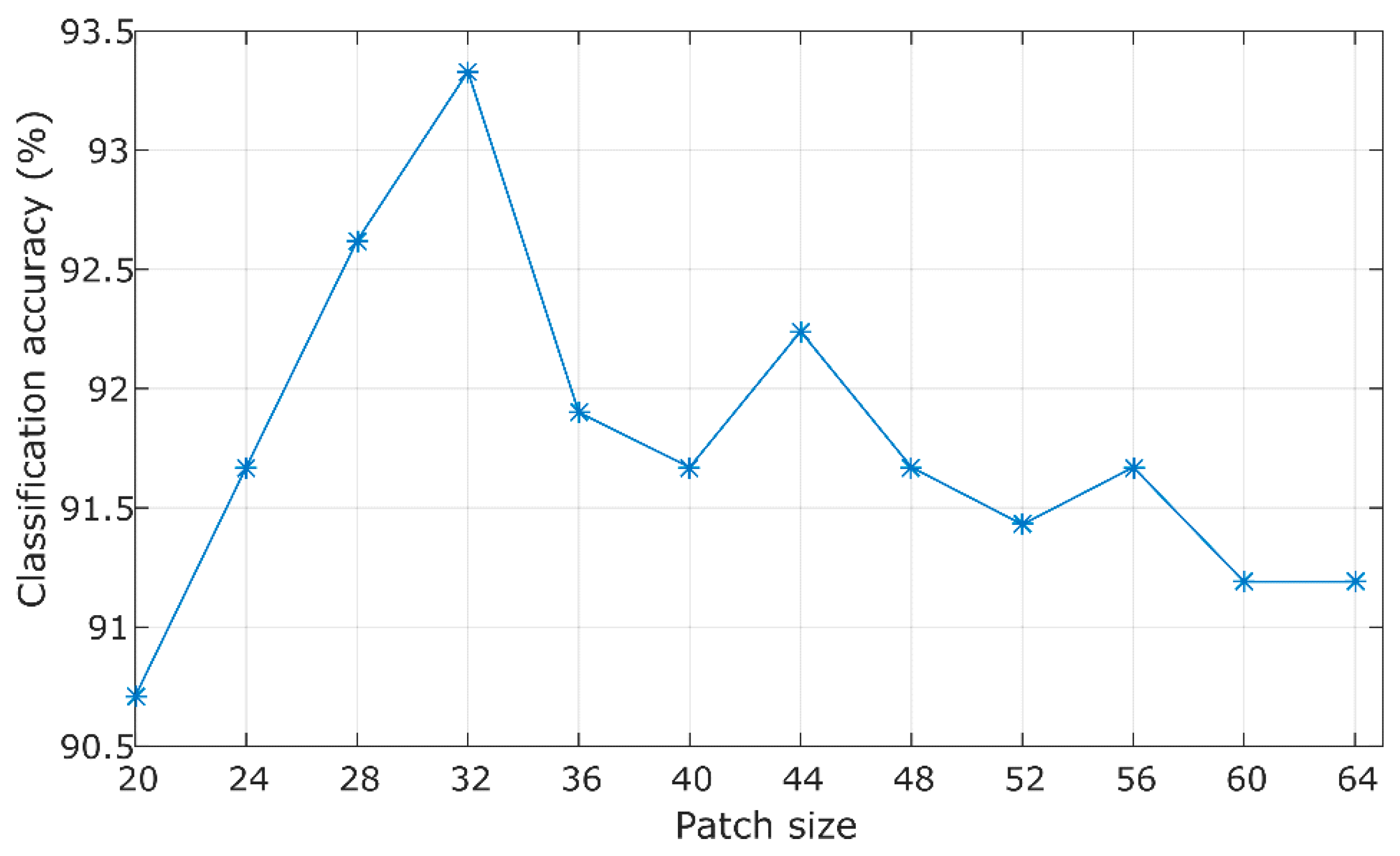
4.2. Parameters Setting
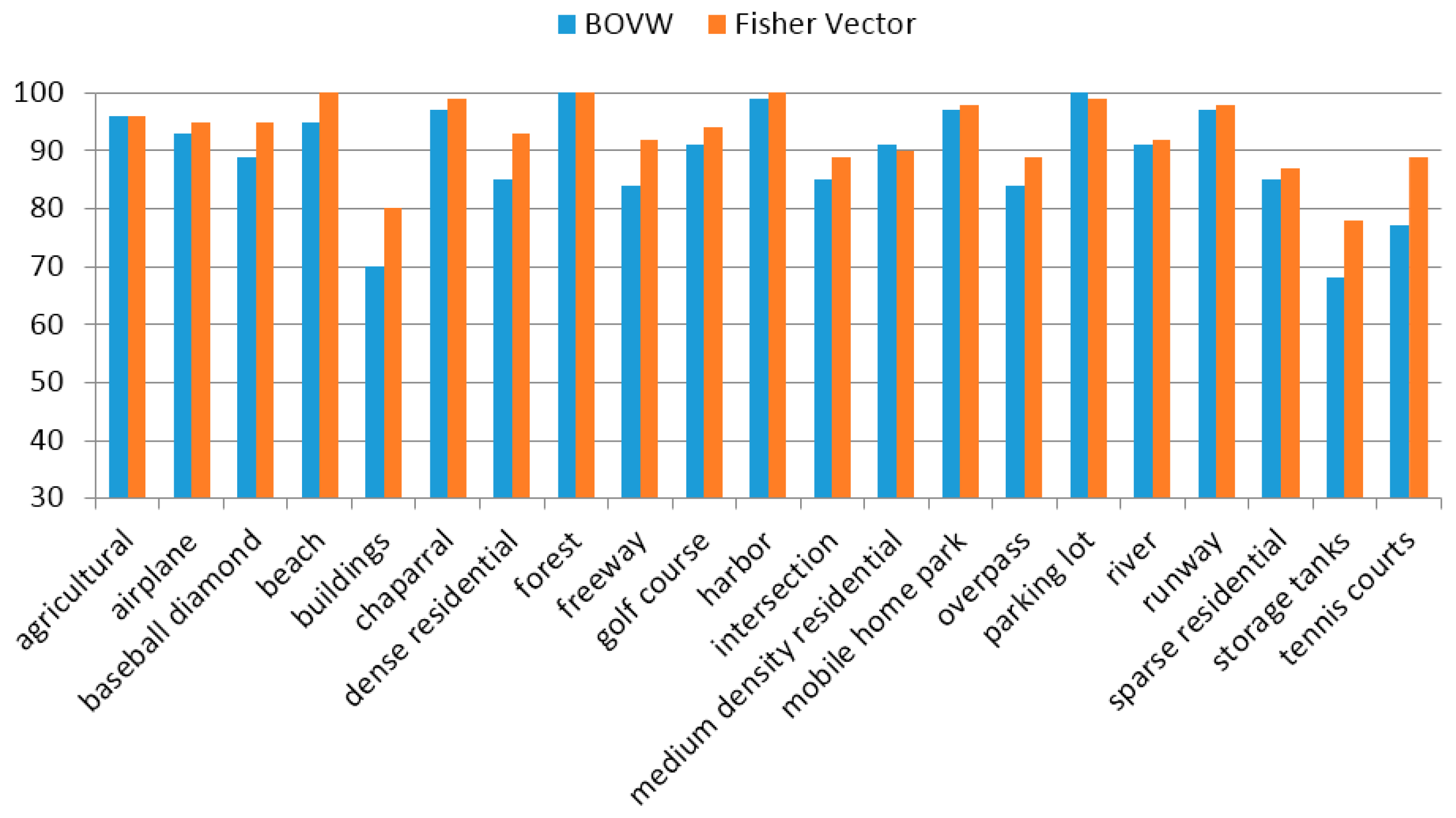
4.3. FV Representation vs. BOVW Model
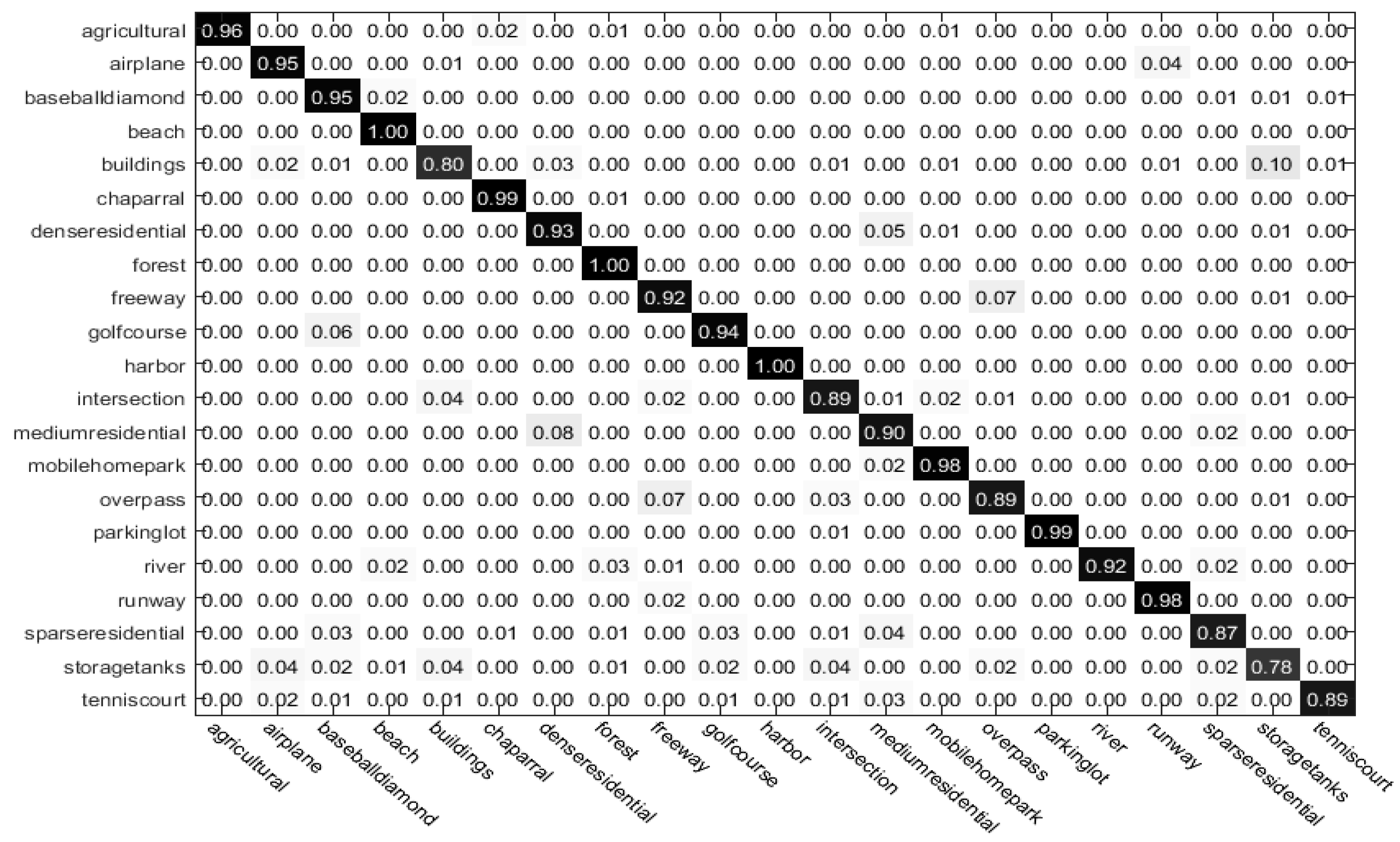
4.4. Comparison to the State-of-the-Art Methods
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| LBP | Local binary patterns |
| CLBP | Completed local binary patterns |
| MS-CLBP | Multi-scale completed local binary patterns |
| FV | Fisher vector |
| ELM | Extreme learning machine |
| KELM | Kernel-based extreme learning machine |
| BOVW | Bag-of-visual-words |
| SPM | Spatial pyramid matching |
| SIFT | Scale-invariant feature transform |
| EGTD | Enhanced Gabor texture descriptor |
| GMM | Gaussian mixture model |
| CLBP_S | Completed local binary patterns sign component |
| CLBP_M | Completed local binary patterns magnitude component |
| RBF | Radial basis function |
| USGS | United States Geological Survey |
| PCA | Principal component analysis |
References
- Yang, J.; Jiang, Y.-G.; Hauptmann, A.G.; Ngo, C.-W. Evaluating bag-of-visual-words representations in scene classification. In Proceedings of the International Workshop on Workshop on Multimedia Information Retrieval, the 15th ACM International Conference on Multimedia, Augsburg, Bavaria, Germany, 23–28 September 2007; pp. 197–206.
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond bags of features: spatial pyramid matching for recognizing natural scene categories. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; pp. 2169–2178.
- Yang, Y.; Newsam, S. Spatial pyramid co-occurrence for image classification. In Proceedings of the International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 1465–1472.
- Zhou, L.; Zhou, Z.; Hu, D. Scene classification using a multi-resolution bag-of-features model. Pattern Recognit. 2013, 46, 424–433. [Google Scholar] [CrossRef]
- Zhao, L.-J.; Tang, P.; Huo, L.-Z. Land-use scene classification using a concentric circle-structured multiscale bag-of-visual-words model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 4620–4631. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant key points. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Risojevic, V.; Babic, Z. Aerial image classification using structural texture similarity. In Proceedings of the IEEE International Symposium on Signal Processing and Information Technology (ISSPIT), Bilbao, Spain, 14–17 December 2011; pp. 190–195.
- Risojević, V.; Momić, S.; Babić, Z. Gabor descriptors for aerial image classification. In Adaptive and Natural Computing Algorithms; Springer: Berlin, Germany; Heidelberg, Germany, 2011; pp. 51–60. [Google Scholar]
- Oliva, A.; Torralba, A. Modeling the shape of the scene: A holistic representation of the spatial envelope. Int. J. Comput. Vis. 2001, 42, 145–175. [Google Scholar] [CrossRef]
- Zheng, X.; Sun, X.; Fu, K.; Wang, H. Automatic annotation of satellite images via multifeature joint sparse coding with spatial relation constraint. IEEE Geosci. Remote Sens. Lett. 2013, 10, 652–656. [Google Scholar] [CrossRef]
- Risojevic, V.; Babic, Z. Fusion of global and local descriptors for remote sensing image classification. IEEE Geosci. Remote Sens. Lett. 2013, 10, 836–840. [Google Scholar] [CrossRef]
- Goodfellow, I.; Courville, A.; Bengio, Y. Deep Learning. Book in Preparation for MIT Press; The MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Bengio, Y. Learning deep architectures for AI. Found. Trends Mach. Learn. 2009, 2, 1–127. [Google Scholar] [CrossRef]
- Yue, J.; Zhao, W.; Mao, S.; Liu, H. Spectral—Spatial classification of hyperspectral images using deep convolutional neural networks. Remote Sens. Lett. 2015, 6, 468–477. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Image net classification with deep convolutional neural networks. In Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc.: San Diego, CA, USA, 2012; pp. 1106–1114. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9.
- Chen, C.; Zhang, B.; Su, H.; Li, W.; Wang, L. Land-use scene classification using multi-scale completed local binary patterns. Signal Image Video Process. 2015, 10, 1–8. [Google Scholar] [CrossRef]
- Guo, Z.; Zhang, L.; Zhang, D. A Completed modeling of local binary pattern operator for texture classification. IEEE Trans Image Process. 2010, 19, 1657–1663. [Google Scholar] [PubMed]
- Perronnin, F.; Sánchez, J.; Mensink, T. Improving the Fisher Kernel for Large-Scale Image Classification. Computer Vision—ECCV 2010 Lecture Notes in Computer Science; Springer-Verlag: Berlin, Germany, 2010; pp. 143–156. [Google Scholar]
- Huang, G.-B.; Zhou, H.; Ding, X.; Zhang, R. Extreme Learning Machine for Regression and Multiclass Classification. IEEE Trans. Syst. Man Cybern. 2012, 42, 513–529. [Google Scholar] [CrossRef] [PubMed]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Li, W.; Chen, C.; Su, H.; Du, Q. Local binary patterns and extreme learning machine for hyperspectral imagery classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 3681–3693. [Google Scholar] [CrossRef]
- Krapac, J.; Verbeek, J.; Jurie, F. Modeling spatial layout with fisher vectors for image categorization. In Proceedings of International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 1487–1494.
- Sánchez, J.; Perronnin, F.; Mensink, T.; Verbeek, J. Image classification with the fisher vector: Theory and practice. Int. J. Comput. Vis. 2013, 105, 222–245. [Google Scholar] [CrossRef]
- Liu, C. Maximum likelihood estimation from incomplete data via EM-type Algorithms. In Advanced Medical Statistics; World Scientific Publishing Co.: Hackensack, NJ, USA, 2003; pp. 1051–1071. [Google Scholar]
- Jaakkola, T.S.; Haussler, D. Exploiting generative models in discriminative classifiers. Adv. Neural Inf. Process. Syst. 1999, 11, 487–493. [Google Scholar]
- Perronnin, F.; Dance, C. Fisher kernels on visual vocabularies for image categorization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8.
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 3–5 November 2010; pp. 270–279.
- Dai, D.; Yang, W. Satellite image classification via two-layer sparse coding with biased image representation. IEEE Geosci. Remote Sens. Lett. 2011, 8, 173–176. [Google Scholar] [CrossRef]
- Sheng, G.; Yang, W.; Xu, T.; Sun, H. High-resolution satellite scene classification using a sparse coding based multiple feature combination. Int. J. Remote Sens. 2012, 33, 2395–2412. [Google Scholar] [CrossRef]
- Ren, J.; Zabalza, J.; Marshall, S.; Zheng, J. Effective feature extraction and data reduction in remote sensing using hyperspectral imaging [applications corner]. IEEE Sign. Process. Mag. 2014, 31, 149–154. [Google Scholar] [CrossRef]
- Chen, C.; Li, W.; Tramel, E.W.; Fowler, J.E. Reconstruction of hyperspectral imagery from random projections using multi hypothesis prediction. IEEE Trans. Geosci. Remote Sens. 2014, 52, 365–374. [Google Scholar] [CrossRef]
- Cheriyadat, A.M. Unsupervised feature learning for aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2014, 52, 439–451. [Google Scholar] [CrossRef]
- Zhang, F.; Du, B.; Zhang, L. Saliency-guided unsupervised feature learning for scene classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2175–2184. [Google Scholar] [CrossRef]
- Shao, W.; Yang, W.; Xia, G.-S.; Liu, G. A hierarchical scheme of multiple feature fusion for high-resolution satellite scene categorization. In Lecture Notes in Computer Science Computer Vision Systems; Springer: Berlin, Germany; Heidelberg, Germany, 2013; pp. 324–333. [Google Scholar]
- Chen, S.; Tian, Y. Pyramid of spatial relatons for scene-level land use classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1947–1957. [Google Scholar] [CrossRef]
- Cvetković, S.; Stojanović, M.B.; Nikolić, S.V. Multi-channel descriptors and ensemble of extreme learning machines for classification of remote sensing images. Sign. Process. 2015, 39, 111–120. [Google Scholar] [CrossRef]
- Keiller, N.; Waner, O.; Jefersson, A.; Dos, S. Improving spatial feature representation from aerial scenes by using convolutional networks. In Proceedings of the SIBGRAPI Conference on Graphics, Patterns and Images, Salvador, 26–29 August 2015; pp. 44–51.
- Zhang, F.; Du, B.; Zhang, L. Scene classification via a gradient boosting random convolutional network framework. IEEE Trans. Geosci. Remote Sens. 2016, 54, 1793–1802. [Google Scholar] [CrossRef]
- Keiller, N.; Otavio, P.; Jefersson, S. Towards better exploiting convolutional neural networks for remote sensing scene classification. ArXiv E-Prints, 2016; arXiv:1602.01517. http://arxiv.org/abs/1602.01517. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Accuracy(Mean ± std) |
|---|---|
| BOVW [28] | 76.8 |
| SPM [28] | 75.3 |
| BOVW + Spatial Co-occurrence Kernel [28] | 77.7 |
| Color Gabor [28] | 80.5 |
| Color histogram (HLS) [28] | 81.2 |
| Structural texture similarity [7] | 86.0 |
| Unsupervised feature learning [33] | 81.7 ± 1.2 |
| Saliency-Guided unsupervised feature learning [34] | 82.7 ± 1.2 |
| Concentric circle-structured multiscale BOVW [5] | 86.6 ± 0.8 |
| Multifeature concatenation [35] | 89.5 ± 0.8 |
| Pyramid-of-Spatial-Relatons (PSR) [36] | 89.1 |
| MCBGP + E-ELM [37] | 86.52 ± 1.3 |
| ConvNet with specific spatial features [38] | 89.39 ± 1.10 |
| gradient boosting randomconvolutional network [39] | 94.53 |
| GoogLeNet [40] | 92.80 ± 0.61 |
| OverFeatConvNets [40] | 90.91 ± 1.19 |
| MS-CLBP [17] | 90.6 ± 1.4 |
| MS-CLBP + BOVW | 89.27 ± 2.9 |
| The Proposed | 93.00 ± 1.2 |
| Method | Accuracy (Mean ± std) |
|---|---|
| Bag of colors [25] | 70.6 ± 1.5 |
| Tree of c-shapes [25] | 80.4 ± 1.8 |
| Bag of SIFT [25] | 85.5 ± 1.2 |
| Multifeature concatenation [25] | 90.8 ± 0.7 |
| LTP-HF [23] | 77.6 |
| SIFT + LTP-HF + Color histogram [23] | 93.6 |
| MS-CLBP [1] | 93.4 ± 1.1 |
| MS-CLBP + BOVW | 89.29 ± 1.3 |
| The Proposed | 94.32 ± 1.2 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, L.; Chen, C.; Li, W.; Du, Q. Remote Sensing Image Scene Classification Using Multi-Scale Completed Local Binary Patterns and Fisher Vectors. Remote Sens. 2016, 8, 483. https://doi.org/10.3390/rs8060483
Huang L, Chen C, Li W, Du Q. Remote Sensing Image Scene Classification Using Multi-Scale Completed Local Binary Patterns and Fisher Vectors. Remote Sensing. 2016; 8(6):483. https://doi.org/10.3390/rs8060483
Chicago/Turabian StyleHuang, Longhui, Chen Chen, Wei Li, and Qian Du. 2016. "Remote Sensing Image Scene Classification Using Multi-Scale Completed Local Binary Patterns and Fisher Vectors" Remote Sensing 8, no. 6: 483. https://doi.org/10.3390/rs8060483