Combining Fractional Cover Images with One-Class Classifiers Enables Near Real-Time Monitoring of Fallows in the Northern Grains Region of Australia




Abstract
:
1. Introduction
2. Materials
2.1. Study Area
2.2. Remotely-Sensed Data and Cropland Map
2.3. Reference Data
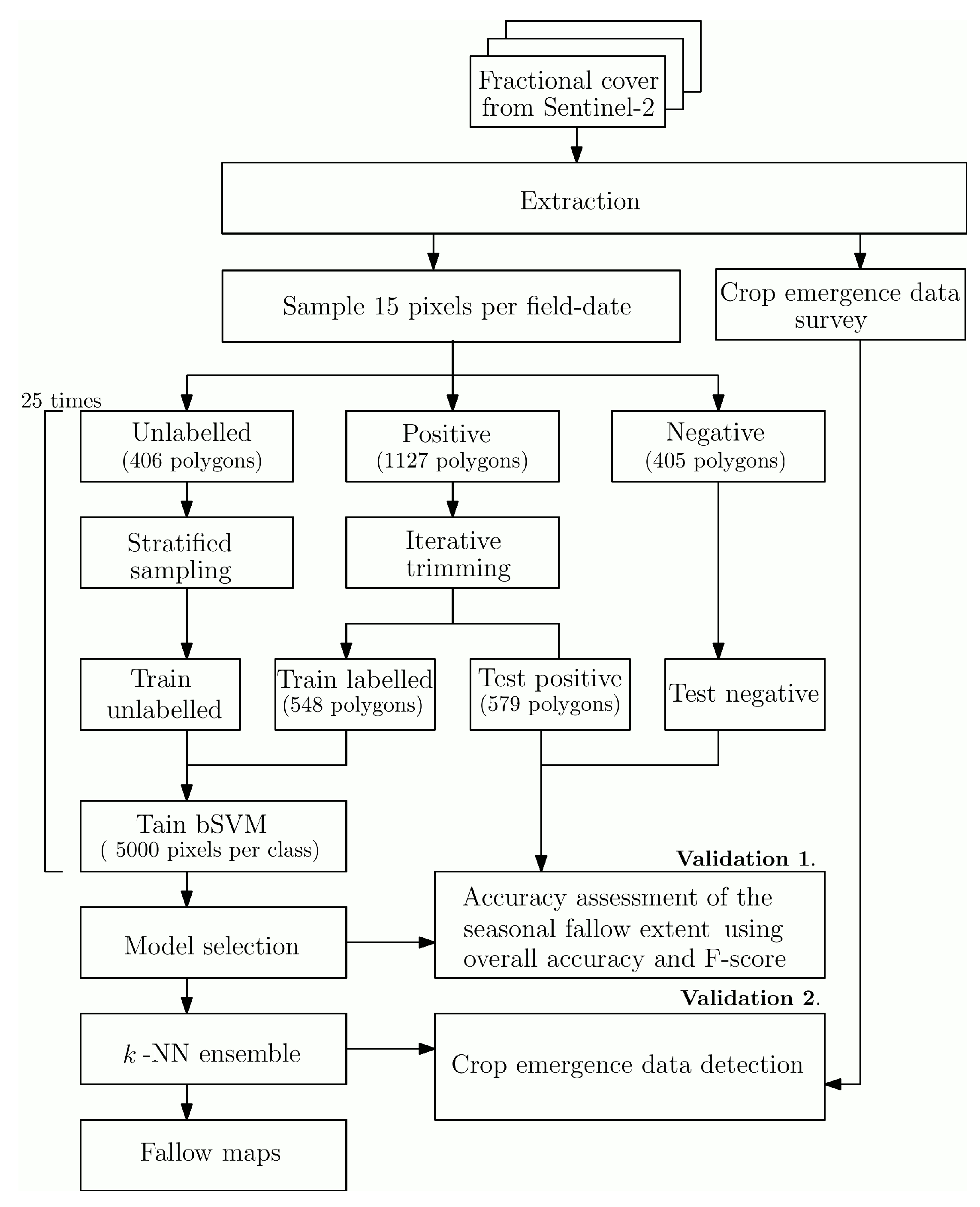
3. Methods
3.1. Data Pre-Processing And Resampling
3.2. Classification Method
3.3. Model Selection
3.4. Assessing the Model Performance and Building an Ensemble
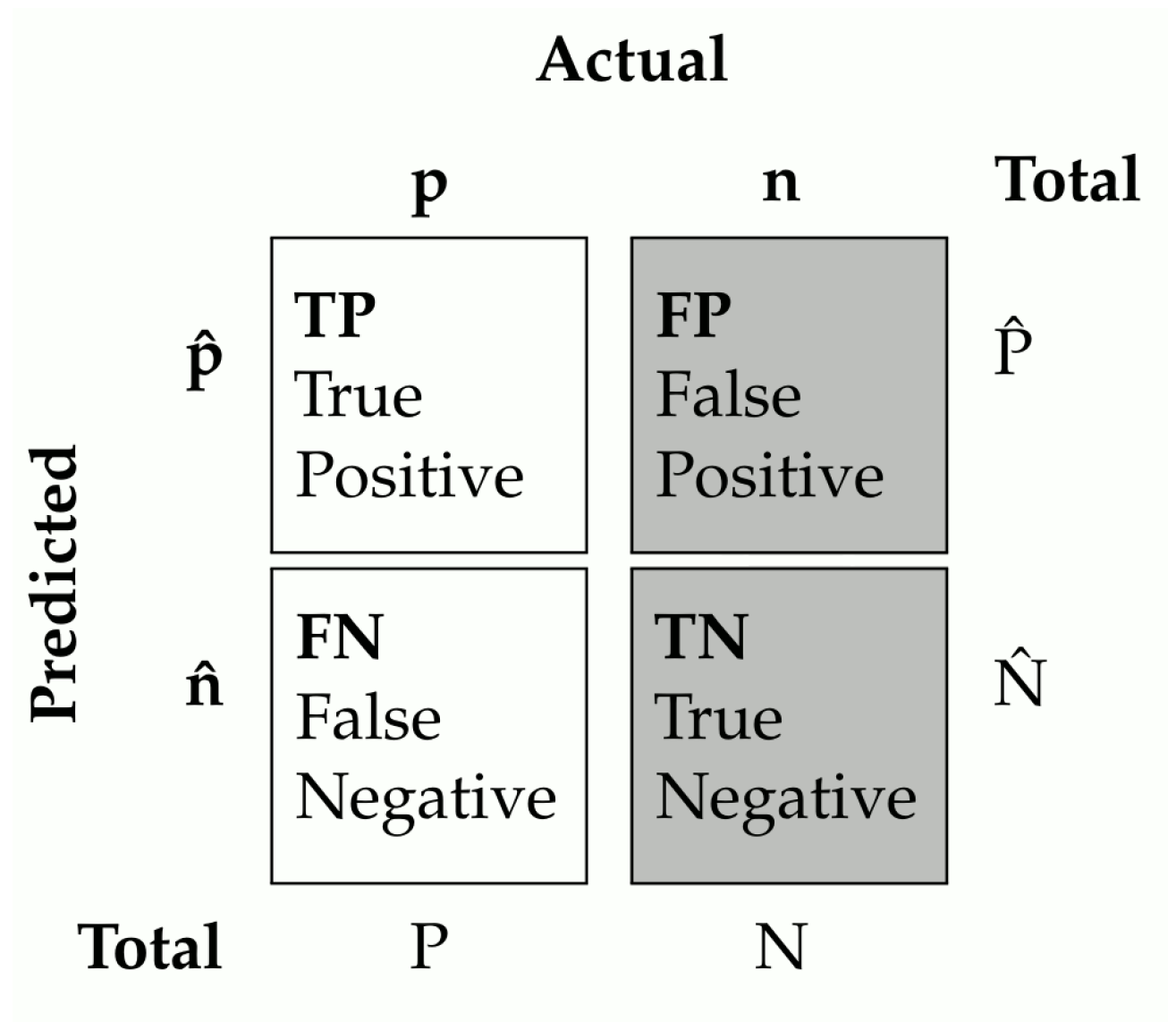
3.4.1. Validating Seasonal Fallow Predictions
3.4.2. Building an Ensemble
3.4.3. Validating Near Real-Time Performances
3.5. Mapping the Seasonal Fallow Dynamics
4. Results
4.1. Model Selection: puF vs. min.dist
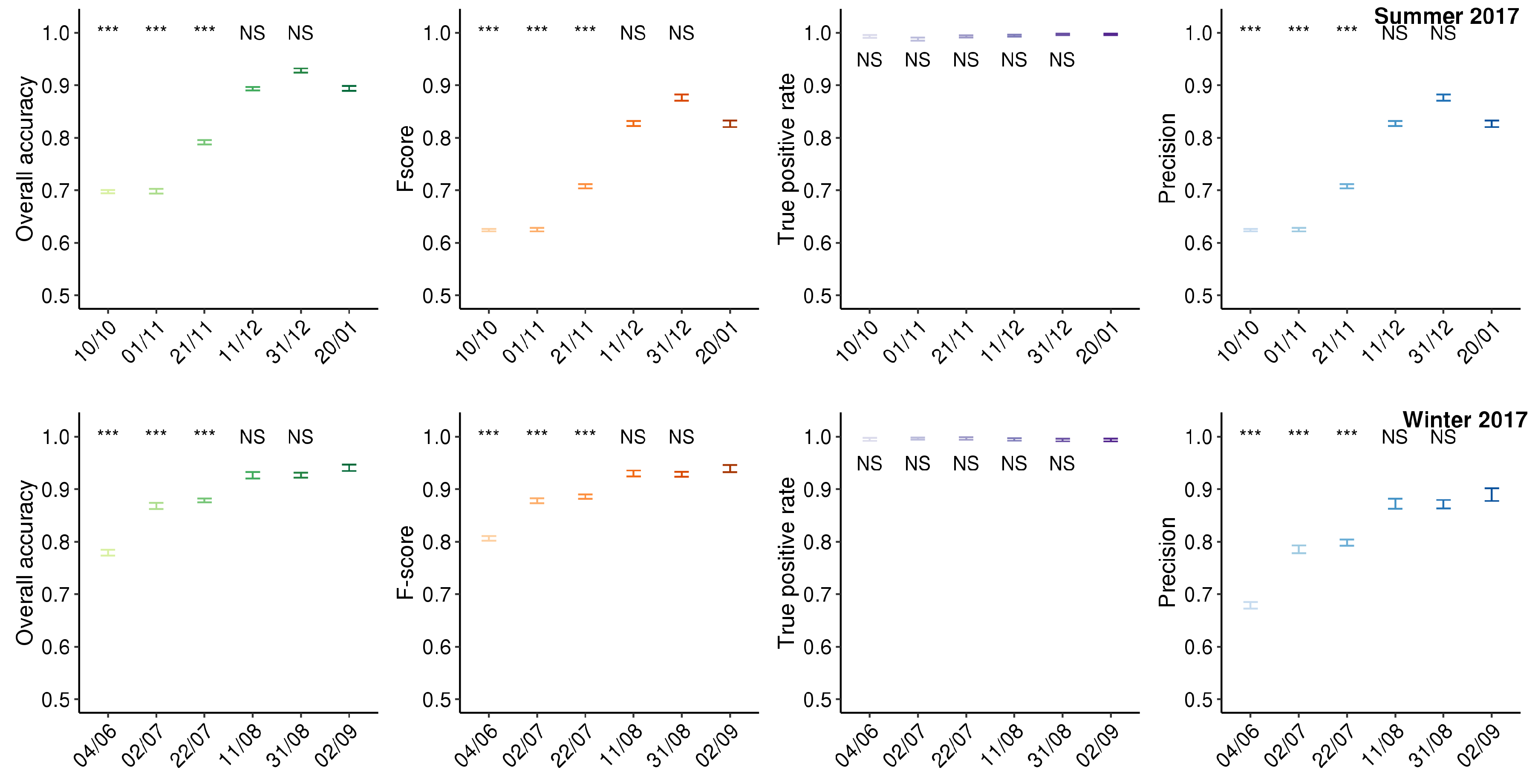
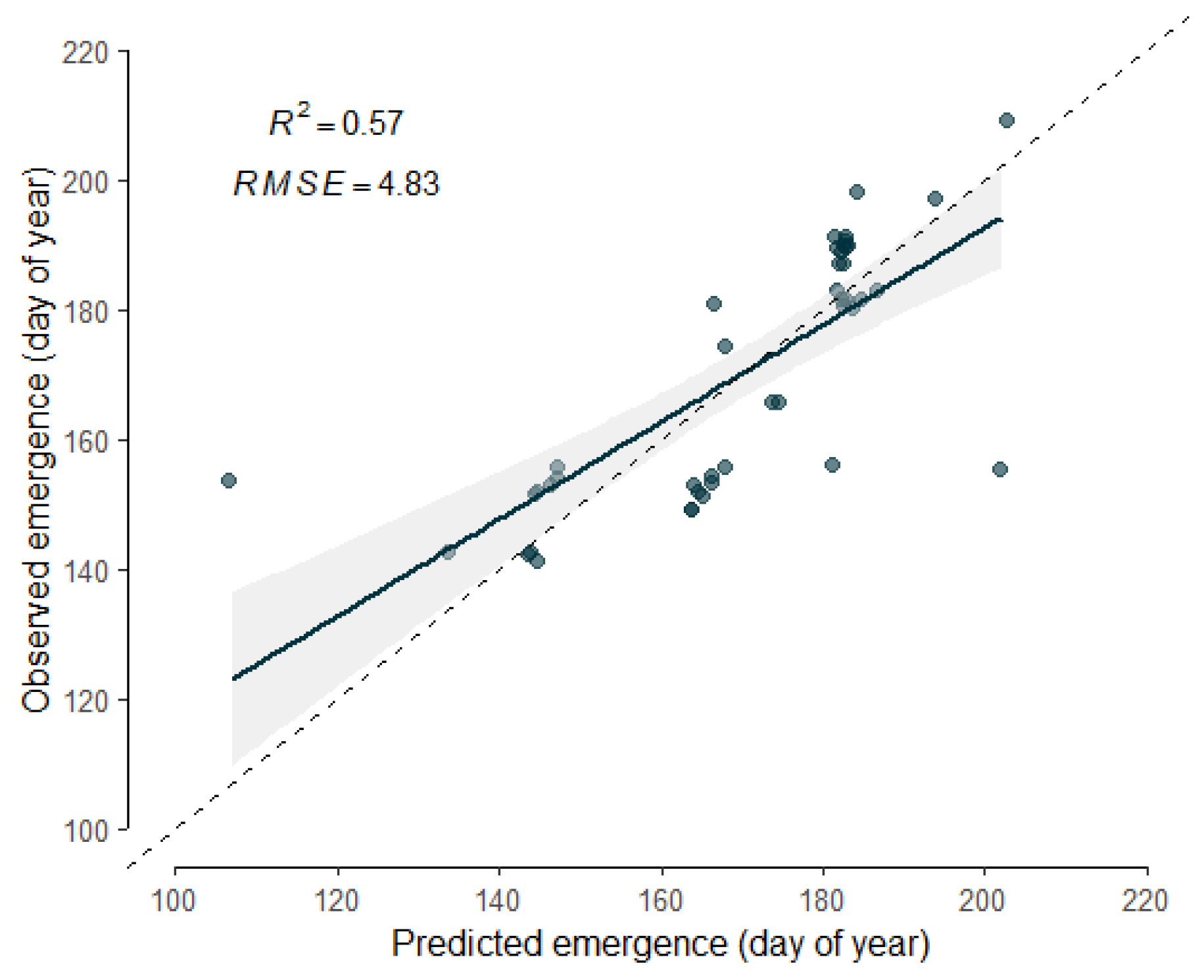
4.2. Accuracy of Seasonal Fallow Maps and Crop Emergence Detection
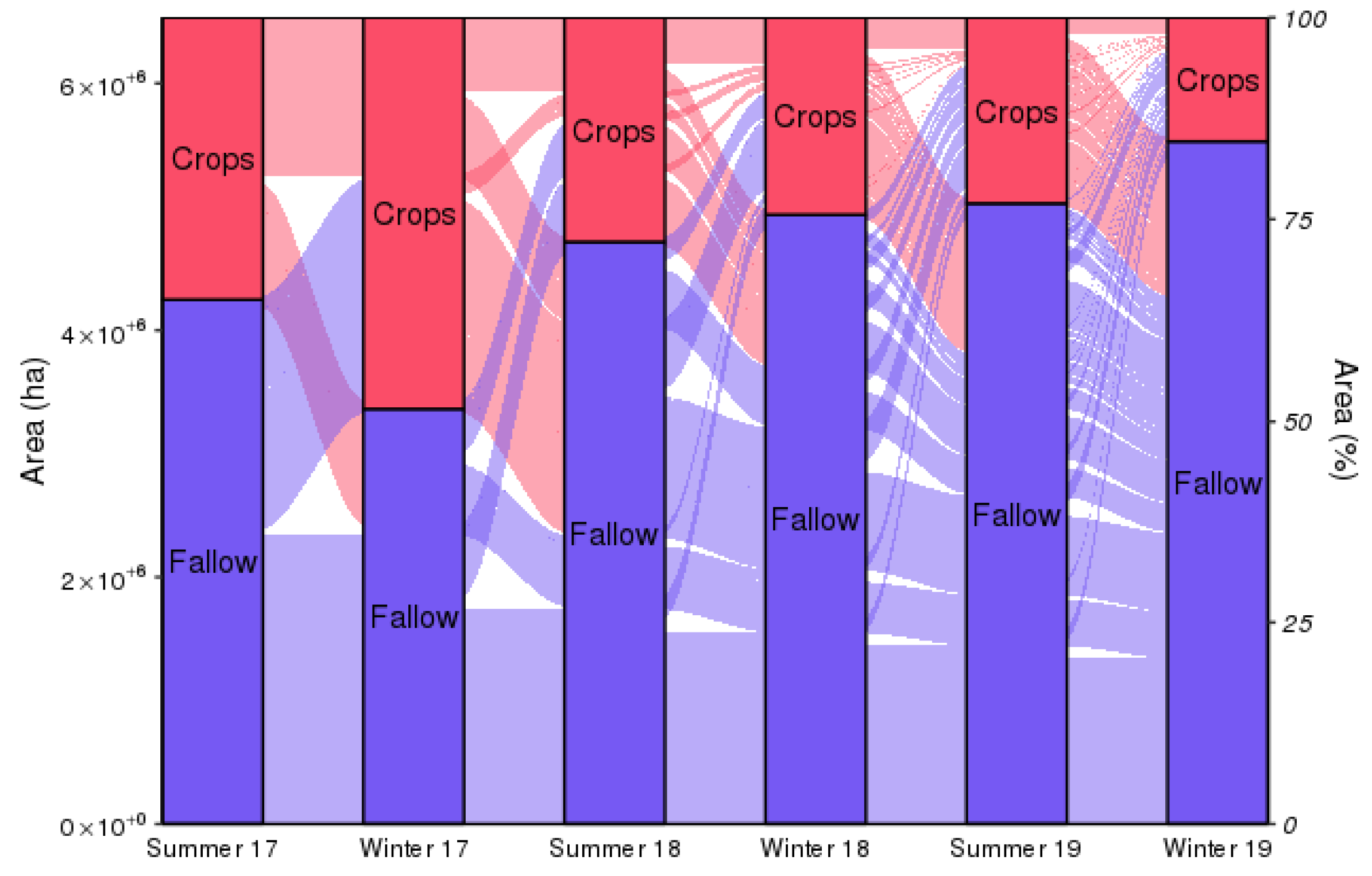
4.3. Mapping the Seasonal Fallow Extent and the Cropping Dynamics
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- French, R. The effect of fallowing on the yield of wheat. I. The effect on soil water storage and nitrate supply. Aust. J. Agric. Res. 1978, 29, 653–668. [Google Scholar] [CrossRef]
- French, R. The effect of fallowing on the yield of wheat. II. The effect on grain yield. Aust. J. Agric. Res. 1978, 29, 669–684. [Google Scholar] [CrossRef]
- Siebert, S.; Portmann, F.T.; Döll, P. Global patterns of cropland use intensity. Remote Sens. 2010, 2, 1625–1643. [Google Scholar] [CrossRef] [Green Version]
- Wu, Z.; Thenkabail, P.S.; Mueller, R.; Zakzeski, A.; Melton, F.; Johnson, L.; Rosevelt, C.; Dwyer, J.; Jones, J.; Verdin, J.P. Seasonal cultivated and fallow cropland mapping using MODIS-based automated cropland classification algorithm. J. Appl. Remote Sens. 2014, 8, 083685. [Google Scholar] [CrossRef] [Green Version]
- Melton, F.; Rosevelt, C.; Guzman, A.; Johnson, L.; Zaragoza, I.; Verdin, J.; Thenkabail, P.; Wallace, C.; Mueller, R.; Willis, P.; et al. Fallowed Area Mapping for Drought Impact Reporting: 2015 Assessment of Conditions in the California Central Valley; NASA AMES Research Center: Mountain View, CA, USA, 2015.
- Gumma, M.K.; Thenkabail, P.S.; Teluguntla, P.; Rao, M.N.; Mohammed, I.A.; Whitbread, A.M. Mapping rice-fallow cropland areas for short-season grain legumes intensification in South Asia using MODIS 250 m time-series data. Int. J. Digit. Earth 2016, 9, 981–1003. [Google Scholar] [CrossRef] [Green Version]
- Tong, X.; Brandt, M.; Hiernaux, P.; Herrmann, S.; Rasmussen, L.V.; Rasmussen, K.; Tian, F.; Tagesson, T.; Zhang, W.; Fensholt, R. The forgotten land use class: Mapping of fallow fields across the Sahel using Sentinel-2. Remote Sens. Environ. 2020, 239, 111598. [Google Scholar] [CrossRef]
- Bégué, A.; Arvor, D.; Bellon, B.; Betbeder, J.; De Abelleyra, D.; PD Ferraz, R.; Lebourgeois, V.; Lelong, C.; Simões, M.; R Verón, S. Remote sensing and cropping practices: A review. Remote Sens. 2018, 10, 99. [Google Scholar] [CrossRef] [Green Version]
- Fritz, S.; See, L.; Bayas, J.C.L.; Waldner, F.; Jacques, D.; Becker-Reshef, I.; Whitcraft, A.; Baruth, B.; Bonifacio, R.; Crutchfield, J.; et al. A comparison of global agricultural monitoring systems and current gaps. Agric. Syst. 2019, 168, 258–272. [Google Scholar] [CrossRef]
- Wardlow, B.D.; Egbert, S.L.; Kastens, J.H. Analysis of time-series MODIS 250 m vegetation index data for crop classification in the US Central Great Plains. Remote Sens. Environ. 2007, 108, 290–310. [Google Scholar] [CrossRef] [Green Version]
- Boryan, C.; Yang, Z.; Mueller, R.; Craig, M. Monitoring US agriculture: The US department of agriculture, national agricultural statistics service, cropland data layer program. Geocarto Int. 2011, 26, 341–358. [Google Scholar] [CrossRef]
- Löw, F.; Biradar, C.; Dubovyk, O.; Fliemann, E.; Akramkhanov, A.; Narvaez Vallejo, A.; Waldner, F. Regional-scale monitoring of cropland intensity and productivity with multi-source satellite image time series. GISci. Remote Sens. 2018, 55, 539–567. [Google Scholar] [CrossRef]
- Estel, S.; Kuemmerle, T.; Alcántara, C.; Levers, C.; Prishchepov, A.; Hostert, P. Mapping farmland abandonment and recultivation across Europe using MODIS NDVI time series. Remote Sens. Environ. 2015, 163, 312–325. [Google Scholar] [CrossRef]
- Teluguntla, P.; Thenkabail, P.S.; Xiong, J.; Gumma, M.K.; Congalton, R.G.; Oliphant, A.; Poehnelt, J.; Yadav, K.; Rao, M.; Massey, R. Spectral matching techniques (SMTs) and automated cropland classification algorithms (ACCAs) for mapping croplands of Australia using MODIS 250-m time-series (2000–2015) data. Int. J. Digit. Earth 2017, 10, 944–977. [Google Scholar] [CrossRef] [Green Version]
- Gumma, M.K.; Thenkabail, P.S.; Deevi, K.C.; Mohammed, I.A.; Teluguntla, P.; Oliphant, A.; Xiong, J.; Aye, T.; Whitbread, A.M. Mapping cropland fallow areas in myanmar to scale up sustainable intensification of pulse crops in the farming system. GISci. Remote Sens. 2018, 55, 926–949. [Google Scholar] [CrossRef]
- Wallace, C.S.; Thenkabail, P.; Rodriguez, J.R.; Brown, M.K. Fallow-land Algorithm based on Neighborhood and Temporal Anomalies (FANTA) to map planted versus fallowed croplands using MODIS data to assist in drought studies leading to water and food security assessments. GISci. Remote Sens. 2017, 54, 258–282. [Google Scholar] [CrossRef] [Green Version]
- Tong, X.; Brandt, M.; Hiernaux, P.; Herrmann, S.M.; Tian, F.; Prishchepov, A.V.; Fensholt, R. Revisiting the coupling between NDVI trends and cropland changes in the Sahel drylands: A case study in western Niger. Remote Sens. Environ. 2017, 191, 286–296. [Google Scholar] [CrossRef] [Green Version]
- Shao, Y.; Lunetta, R.S. Comparison of support vector machine, neural network, and CART algorithms for the land-cover classification using limited training data points. ISPRS J. Photogramm. Remote Sens. 2012, 70, 78–87. [Google Scholar] [CrossRef]
- Zhu, Z.; Gallant, A.L.; Woodcock, C.E.; Pengra, B.; Olofsson, P.; Loveland, T.R.; Jin, S.; Dahal, D.; Yang, L.; Auch, R.F. Optimizing selection of training and auxiliary data for operational land cover classification for the LCMAP initiative. ISPRS J. Photogramm. Remote Sens. 2016, 122, 206–221. [Google Scholar] [CrossRef] [Green Version]
- Heydari, S.S.; Mountrakis, G. Effect of classifier selection, reference sample size, reference class distribution and scene heterogeneity in per-pixel classification accuracy using 26 Landsat sites. Remote Sens. Environ. 2018, 204, 648–658. [Google Scholar] [CrossRef]
- Foody, G.M.; Mathur, A. Toward intelligent training of supervised image classifications: Directing training data acquisition for SVM classification. Remote Sens. Environ. 2004, 93, 107–117. [Google Scholar] [CrossRef]
- Foody, G.M.; Mathur, A.; Sanchez-Hernandez, C.; Boyd, D.S. Training set size requirements for the classification of a specific class. Remote Sens. Environ. 2006, 104, 1–14. [Google Scholar] [CrossRef]
- Zheng, B.; Myint, S.W.; Thenkabail, P.S.; Aggarwal, R.M. A support vector machine to identify irrigated crop types using time-series Landsat NDVI data. Int. J. Appl. Earth Obs. Geoinf. 2015, 34, 103–112. [Google Scholar] [CrossRef]
- Song, X.; Fan, G.; Rao, M. Svm-based data editing for enhanced one-class classification of remotely sensed imagery. IEEE Geosci. Remote Sens. Lett. 2008, 5, 189–193. [Google Scholar] [CrossRef]
- Chen, X.; Yin, D.; Chen, J.; Cao, X. Effect of training strategy for positive and unlabelled learning classification: Test on Landsat imagery. Remote Sens. Lett. 2016, 7, 1063–1072. [Google Scholar] [CrossRef]
- Waldner, F.; Chen, Y.; Lawes, R.; Hochman, Z. Needle in a haystack: Mapping rare and infrequent crops using satellite imagery and data balancing methods. Remote Sens. Environ. 2019, 233, 111375. [Google Scholar] [CrossRef]
- Sanchez-Hernandez, C.; Boyd, D.S.; Foody, G.M. One-class classification for mapping a specific land-cover class: SVDD classification of fenland. IEEE Trans. Geosci. Remote Sens. 2007, 45, 1061–1073. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; Guo, Q.; Elkan, C. A positive and unlabeled learning algorithm for one-class classification of remote-sensing data. IEEE Trans. Geosci. Remote Sens. 2010, 49, 717–725. [Google Scholar] [CrossRef]
- Muñoz-Marí, J.; Bovolo, F.; Gómez-Chova, L.; Bruzzone, L.; Camp-Valls, G. Semisupervised one-class support vector machines for classification of remote sensing data. IEEE Trans. Geosci. Remote Sens. 2010, 48, 3188–3197. [Google Scholar] [CrossRef] [Green Version]
- Mack, B.; Roscher, R.; Waske, B. Can i trust my one-class classification? Remote Sensing 2014, 6, 8779–8802. [Google Scholar] [CrossRef] [Green Version]
- Isbell, R.F. A Classification System for Australian Soils (Third Approximation); CSIRO Division of Soils: Townsville, Australia, 1993.
- Bell, M.; Seymour, N.; Stirling, G.; Stirling, A.; Van Zwieten, L.; Vancov, T.; Sutton, G.; Moody, P. Impacts of management on soil biota in Vertosols supporting the broadacre grains industry in northern Australia. Soil Res. 2006, 44, 433–451. [Google Scholar] [CrossRef] [Green Version]
- Russell, J.; Jones, P. Continuous, alternate and double crop systems on a Vertisol in subtropical Australia. Aust. J. Exp. Agric. 1996, 36, 823–830. [Google Scholar] [CrossRef]
- Hochman, Z.; Prestwidge, D.; Carberry, P.S. Crop sequences in Australia’s northern grain zone are less agronomically efficient than implied by the sum of their parts. Agric. Syst. 2014, 129, 124–132. [Google Scholar] [CrossRef]
- Verburg, K.; Bond, W.J.; Hunt, J.R. Fallow management in dryland agriculture: Explaining soil water accumulation using a pulse paradigm. Field Crop. Res. 2012, 130, 68–79. [Google Scholar] [CrossRef]
- Cantero-Martinez, C.; O’Leary, G.; Connor, D. Stubble retention and nitrogen fertilisation in a fallow-wheat rainfed cropping system. 1. soil water and nitrogen conservation, crop growth and yield. Soil Tillage Res. 1995, 34, 79–94. [Google Scholar] [CrossRef]
- Whitbread, A.; Davoren, C.; Gupta, V.; Llewellyn, R. Long-term cropping system studies support intensive and responsive cropping systems in the low-rainfall Australian Mallee. Crop. Pasture Sci. 2015, 66, 553–565. [Google Scholar] [CrossRef] [Green Version]
- Flood, N.; Danaher, T.; Gill, T.; Gillingham, S. An operational scheme for deriving standardised surface reflectance from Landsat TM/ETM+ and SPOT HRG imagery for Eastern Australia. Remote Sens. 2013, 5, 83–109. [Google Scholar] [CrossRef] [Green Version]
- Nalli, N.R.; Minnett, P.J.; Van Delst, P. Emissivity and reflection model for calculating unpolarized isotropic water surface-leaving radiance in the infrared. I: Theoretical development and calculations. Appl. Opt. 2008, 47, 3701–3721. [Google Scholar] [CrossRef]
- Chappell, A.; Zobeck, T.M.; Brunner, G. Using bi-directional soil spectral reflectance to model soil surface changes induced by rainfall and wind-tunnel abrasion. Remote Sens. Environ. 2006, 102, 328–343. [Google Scholar] [CrossRef]
- Danaher, T.; Collett, L. Development, optimisation and multi-temporal application of a simple Landsat based water index. Proceeding of the 13th Australasian Remote Sensing and Photogrammetry Conference, Canberra, Australia, 21–24 November 2006; Volume 2024. [Google Scholar]
- Muir, J.; Schmidt, M.; Tindall, D.; Trevithick, R.; Scarth, P.; Stewart, J. Guidelines for Field Measurement of Fractional Ground Cover: A Technical Handbook Supporting the Australian Collaborative Land Use and Management Program; Queensland Department of Environment and Resource Management for the Australian Bureau of Agricultural and Resource Economics and Sciences: Canberra, Australia, 2011.
- Guerschman, J.P.; Scarth, P.F.; McVicar, T.R.; Renzullo, L.J.; Malthus, T.J.; Stewart, J.B.; Rickards, J.E.; Trevithick, R. Assessing the effects of site heterogeneity and soil properties when unmixing photosynthetic vegetation, non-photosynthetic vegetation and bare soil fractions from Landsat and MODIS data. Remote Sens. Environ. 2015, 161, 12–26. [Google Scholar] [CrossRef]
- Flood, N. Comparing Sentinel-2A and Landsat 7 and 8 using surface reflectance over Australia. Remote Sens. 2017, 9, 659. [Google Scholar] [CrossRef] [Green Version]
- ABARES. The Australian Land Use and Management Classification; Version 8; Australian Bureau of Agricultural and Resource Economics and Sciences: Canberra, Australia, 2016.
- Waldner, F.; Bellemans, N.; Hochman, Z.; Newby, T.; de Abelleyra, D.; Verón, S.R.; Bartalev, S.; Lavreniuk, M.; Kussul, N.; Le Maire, G.; et al. Roadside collection of training data for cropland mapping is viable when environmental and management gradients are surveyed. Int. J. Appl. Earth Obs. Geoinf. 2019, 80, 82–93. [Google Scholar] [CrossRef]
- Radoux, J.; Defourny, P. Automated image-to-map discrepancy detection using iterative trimming. Photogramm. Eng. Remote Sens. 2010, 76, 173–181. [Google Scholar] [CrossRef]
- Chacón, J.E.; Duong, T. Multivariate Kernel Smoothing and Its Applications; Chapman and Hall/CRC: Boca Raton, FL, USA, 2018. [Google Scholar]
- Liu, B.; Dai, Y.; Li, X.; Lee, W.S.; Yu, P.S. Building text classifiers using positive and unlabeled examples. In Proceedings of the Third IEEE International Conference on Data Mining (ICDM 2003), Melbourne, FL, USA, 22 November 2003; pp. 179–186. [Google Scholar]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Mack, B.; Waske, B. In-depth comparisons of MaxEnt, biased SVM and one-class SVM for one-class classification of remote sensing data. Remote Sens. Lett. 2017, 8, 290–299. [Google Scholar] [CrossRef]
- Stehman, S.V. Selecting and interpreting measures of thematic classification accuracy. Remote Sens. Environ. 1997, 62, 77–89. [Google Scholar] [CrossRef]
- Goutte, C.; Gaussier, E. A probabilistic interpretation of precision, recall and F-score, with implication for evaluation. In Proceedings of the European Conference on Information Retrieval, Santiago de Compostela, Spain, 21–23 March 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 345–359. [Google Scholar]
- Piiroinen, R.; Fassnacht, F.E.; Heiskanen, J.; Maeda, E.; Mack, B.; Pellikka, P. Invasive tree species detection in the Eastern Arc Mountains biodiversity hotspot using one class classification. Remote Sens. Environ. 2018, 218, 119–131. [Google Scholar] [CrossRef]
- Lee, W.S.; Liu, B. Learning with positive and unlabeled examples using weighted logistic regression. ICML 2003, 3, 448–455. [Google Scholar]
- Shanahan, J.G.; Roma, N. Improving SVM text classification performance through threshold adjustment. In Proceedings of the European Conference on Machine Learning, Cavtat-Dubrovnik, Croatia, 22–26 September 2003; Springer: Berlin/Heidelberg, Germany, 2003; pp. 361–372. [Google Scholar]
- ABARES. Australian Crop Report; Number 192; Australian Bureau of Agricultural and Resource Economics and Sciences: Canberra, Australia, 2019. Available online: https://www.agriculture.gov.au/abares/research-topics/agricultural-commodities/australian-crop-report (accessed on 27 February 2020).
- ABARES. Australian Crop Report; Number 188; Australian Bureau of Agricultural and Resource Economics and Sciences: Canberra, Australia, 2018. Available online: https://www.agriculture.gov.au/abares/research-topics/agricultural-commodities/australian-crop-report (accessed on 27 February 2020).
- Van Niel, T.G.; McVicar, T.R. Determining temporal windows for crop discrimination with remote sensing: A case study in south-eastern Australia. Comput. Electron. Agric. 2004, 45, 91–108. [Google Scholar] [CrossRef]
- Llewellyn, R.; Ronning, D.; Clarke, M.; Mayfield, A.; Walker, S.; Ouzman, J. Impact of Weeds in Australian Grain Production; Grains Research and Development Corporation: Canberra, Australia, 2016. [Google Scholar]
- Sadeh, Y.; Zhu, X.; Chenu, K.; Dunkerley, D. Sowing date detection at the field scale using CubeSats remote sensing. Comput. Electron. Agric. 2019, 157, 568–580. [Google Scholar] [CrossRef]
- JECAM. JECAM Guidelines for Cropland and Crop Type Definition and Field Data Collection; Technical Report, Last Checked: 12.12.2017; Joint Experiment on Crop Assessment and Monitoring. 2014. Available online: http://jecam.org/wp-content/uploads/2018/10/JECAM_Guidelines_for_Field_Data_Collection_v1_0.pdf (accessed on 27 February 2020).
- Hunt, J.R.; Lilley, J.M.; Trevaskis, B.; Flohr, B.M.; Peake, A.; Fletcher, A.; Zwart, A.B.; Gobbett, D.; Kirkegaard, J.A. Early sowing systems can boost Australian wheat yields despite recent climate change. Nat. Clim. Chang. 2019, 9, 244. [Google Scholar] [CrossRef]
- Lewis, A.; Oliver, S.; Lymburner, L.; Evans, B.; Wyborn, L.; Mueller, N.; Raevksi, G.; Hooke, J.; Woodcock, R.; Sixsmith, J.; et al. The Australian geoscience data cube—Foundations and lessons learned. Remote Sens. Environ. 2017, 202, 276–292. [Google Scholar] [CrossRef]
- Borchani, H.; Varando, G.; Bielza, C.; Larrañaga, P. A survey on multi-output regression. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2015, 5, 216–233. [Google Scholar] [CrossRef] [Green Version]
- Rasmussen, P.E.; Allmaras, R.; Rohde, C.; Roager, N. Crop Residue Influences on Soil Carbon and Nitrogen in a Wheat-Fallow System 1. Soil Sci. Soc. Am. J. 1980, 44, 596–600. [Google Scholar] [CrossRef]
- Llewellyn, R.S.; D’Emden, F.H.; Kuehne, G. Extensive use of no-tillage in grain growing regions of Australia. Field Crop. Res. 2012, 132, 204–212. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Symbol | Values |
|---|---|---|
| Confidence level | 0.001, 0.0025, 0.005, 0.0075, 0.01 | |
| Regularisation term for unlabelled data | 0.1 to 9.1 by step of 1.0 | |
| Regularisation term for positive data | 1, 2, 4, 6, 8, 10, 20, 100 | |
| Kernel width | 1 to 10 by step of 1 |
| Season | Survey Date | Overall Accuracy | F-Score | ||
|---|---|---|---|---|---|
| puF Method | min.dist Method | puF Method | min.dist Method | ||
| Winter 2017 | 09–02 | ||||
| Summer 2018 | 02–09 | ||||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, L.; Waldner, F.; Scarth, P.; Mack, B.; Hochman, Z. Combining Fractional Cover Images with One-Class Classifiers Enables Near Real-Time Monitoring of Fallows in the Northern Grains Region of Australia. Remote Sens. 2020, 12, 1337. https://doi.org/10.3390/rs12081337
Zhao L, Waldner F, Scarth P, Mack B, Hochman Z. Combining Fractional Cover Images with One-Class Classifiers Enables Near Real-Time Monitoring of Fallows in the Northern Grains Region of Australia. Remote Sensing. 2020; 12(8):1337. https://doi.org/10.3390/rs12081337
Chicago/Turabian StyleZhao, Liya, François Waldner, Peter Scarth, Benjamin Mack, and Zvi Hochman. 2020. "Combining Fractional Cover Images with One-Class Classifiers Enables Near Real-Time Monitoring of Fallows in the Northern Grains Region of Australia" Remote Sensing 12, no. 8: 1337. https://doi.org/10.3390/rs12081337