
Optimal Dividends for a Two-Dimensional Risk Model with Simultaneous Ruin of Both Branches


Institut für Mathematische Stochastik, Technische Universität Dresden, 01062 Dresden, Germany
*
Author to whom correspondence should be addressed.
†
These authors contributed equally to this work.
Risks 2022, 10(6), 116; https://doi.org/10.3390/risks10060116
Submission received: 21 April 2022
/
Revised: 23 May 2022
/
Accepted: 30 May 2022
/
Published: 2 June 2022
(This article belongs to the Special Issue Multivariate Risks)
{kind=link}
{kind=link}
{kind=link}
Abstract
:We consider the optimal dividend problem in the so-called degenerate bivariate risk model under the assumption that the surplus of one branch may become negative. More specific, we solve the stochastic control problem of maximizing discounted dividends until simultaneous ruin of both branches of an insurance company by showing that the optimal value function satisfies a certain Hamilton–Jacobi–Bellman (HJB) equation. Further, we prove that the optimal value function is the smallest viscosity solution of said HJB equation, satisfying certain growth conditions. Under some additional assumptions, we show that the optimal strategy lies within a certain subclass of all admissible strategies and reduce the two-dimensional control problem to a one-dimensional one. The results are illustrated by a numerical example and Monte Carlo simulated value functions.
1. Introduction
The problem of paying dividends optimally naturally arises when considering insurance risk processes. This is due to the fact that for any classical Cramér–Lundberg or even any spectrally negative Lévy risk model, the process either drifts to infinity with positive probability, or it faces ruin almost surely. As the assumption that an insurance company’s surplus grows to infinity is unrealistic, dividend payments are the natural choice to avoid this behavior.
In the univariate setting, optimal dividend payments are a well-studied field that was first introduced by De Finetti in De Finetti (1957) who considered the dividend barrier model. Later, in Gerber (1969), it was shown that in the Cramér–Lundberg risk model, the optimal strategy is always a band strategy. The study of dividends in this classical risk model has been continued with several extensions, see, e.g., the works Azcue and Muler (2005, 2010, 2012, 2014). The former three publications treat the cases of optimal dividend strategies with reinsurance, with investment in a Black–Scholes market, and the case of bounded dividend rates, respectively. The textbook Azcue and Muler (2014) gives a broad overview of how to use the theory of stochastic control and the dynamic programming approach to tackle dividend problems. In Thonhauser and Albrecher (2007), this approach is used to solve the problem of optimal dividend payments in the presence of a reward for later ruin. Additionlly in the field of (spectrally negative) Lévy risk models, there are several works regarding the dividend problem. See, e.g., Avram et al. (2007), where the optimal dividend policy for a spectrally negative Lévy process with and without bailout loans is considered and the optimal strategy among all barrier strategies is identified, or Loeffen (2008), where these results are extended by giving sufficient conditions on when the optimal strategy is indeed of barrier type. For a more thorough overview of the available tools, approaches, optimality results and optimal strategies in the univariate setting we refer to Albrecher and Thonhauser (2009); Avanzi (2009) and Schmidli (2008).
In multivariate risk theory, a popular model is the so-called degenerate bivariate risk model: Given a Poisson process with rate , define a claim process by
where are non-negative i.i.d. claim sizes with cdf F, independent of N. The degenerate model is then given via
where are the initial capitals of the two branches of the insurer, define constant premium rates, and define the proportion of each claim covered by the corresponding branch. As the claims need to be fully covered, we assume .
The degenerate model can be seen as an insurer-reinsurer model with proportional reinsurance, where the insurer covers proportion of each claim, while the reinsurer covers proportion . The model was first introduced in Avram et al. (2008a), where the authors derive the Laplace transform of the probability of ruin of at least one branch. Further on, the study of ruin probabilities in the degenerate model under different assumptions has been continued, see, e.g., Avram et al. (2008a, 2008b); Badescu et al. (2011); Hu and Jiang (2013); Palmowski et al. (2018). In addition, in the field of optimal dividends, the degenerate model has gained attention, e.g., in Czarna and Palmowski (2011) where dividends are paid according to an impulse or refraction control and ruin corresponds to exiting the positive quadrant. Under the same ruin assumption, in Azcue et al. (2018), it was shown that the optimal value function for general admissible strategies satisfies a certain Hamilton–Jacobi–Bellmann equation and the optimal strategy is described.
In the present work, we adapt the stochastic control approach used in Azcue et al. (2018) and consider the problem of paying dividends optimally under the assumption that one branch of the insurance company may have a negative surplus., i.e., we extend the set, where the insurance company is considered solvent to . We show that the optimal value function, which represents the expected discounted value of the paid dividends of the optimal strategy, may be characterized as the smallest viscosity solution of a certain Hamilton–Jacobi–Bellman (HJB) equation. Further, we show that in certain subcases, the optimal strategy lies within the subclass of so-called bang strategies, which reduces the bivariate optimization problem to a univariate one.
The paper is organized as follows. In Section 2 we specify our model and introduce necessary notations. Afterward, in Section 3 we derive the HJB equation and show that it is satisfied by the optimal value function. Section 4 is dedicated to the bang strategies, whereas in Section 5 we use Monte Carlo simulation to approximate the optimal strategy for a certain example.
2. Preliminaries
Throughout the whole paper we are going to use the bold version of any variable for the two-dimensional version of the same letter (e.g., ) without explicitly stating it again. All random quantities are defined on a filtered probability space and denote the probability measure and expectation, given that , respectively. The derivative of a function u with respect to the variable is denoted by or . For any set M we denote by the inner of M.
As mentioned before, in this paper, we consider the degenerate bivariate risk model defined in (2). In contrast to the assumptions in Azcue et al. (2018), we allow that one initial capital is negative as long as the other is not, i.e., we consider the solvency set . Without loss of generality, we assume that the second branch is equally or less profitable than the first one, i.e.,
Both branches pay dividends to their shareholders using part of their surpluses, where the dividend payment strategy represents the total amount of dividends paid by both branches up to time t. We define the associated controlled process with initial surplus as
This is mainly the model as the one considered in Azcue et al. (2018). The crucial difference to our work is, that in Azcue et al. (2018) the authors consider the ruin time
i.e., the first moment when at least one branch faces ruin, while we consider the time of simultaneous ruin
i.e., the first moment when both branches face ruin. Apart from the at-least-one ruin, the simultaneous ruin is a common assumption for bivariate risk models, which is considered, e.g., in Avram et al. (2008b), Palmowski et al. (2018) or Hu and Jiang (2013).
Corresponding to the new solvency set, we extend the concept of admissibility of a dividend strategy in comparison with Azcue et al. (2018):
Definition 1 (Admissible dividend payment strategy).
A bivariate dividend payment strategy is called admissible if it is a componentwise non-decreasing, càglàd stochastic process that is predictable with respect to the natural filtration of and if it satisfies
- (i)
- for ,
- (ii)
- if then for all , ,
- (iii)
- if then for all , .
The previous definition ensures that dividends are only paid as long as the associated controlled branch is non-negative. Moreover, it guarantees that no branch faces ruin due to dividend payments. Note that we set for .
Further, for any admissible dividend strategy and at any time point it holds that
which is a direct consequence of the definition of our ruin time.
For a given initial surplus , the set of all admissible dividend strategies is denoted by . Given any admissible dividend strategy , the associated controlled process is adapted to the natural filtration of and the ruin time is a stopping time with respect to this filtration. Moreover, the two-dimensional controlled risk process is of finite variation and by construction, ruin can only happen at the arrival of claims.
For a fixed dividend strategy , , the value function , which represents the cumulative expected discounted dividends, is defined as
where is a constant discount factor. On we assume to be zero. Our goal is to identify the optimal value function and the corresponding strategy, i.e., to solve the optimization problem defined by
for any .
3. The Optimal Value Function
We start our investigation of the optimal value function by collecting some properties that are going to be used later on. We emphasize that most results and proofs in this section are in large parts similar to either the one-dimensional case presented in Azcue and Muler (2014) or the degenerate model considered in Azcue et al. (2018). Therefore, our line of argument focuses on the differences.
Lemma 1.
For all the optimal value function is well-defined. If both , then the optimal value function satisfies
If the optimal value function satisfies
Equation (9) analogously holds for the case and with indices exchanged.
Proof.
The proofs for well-definedness and Inequality (8) are analog to the one-dimensional case presented in (Azcue and Muler 2014, Prop. 1.2). To show (9) assume that and . Define the strategy as the strategy that pays the maximum dividends possible at every . Obviously the ruin time is equal to the arrival time of the first claim, denoted by . In the first branch, we obtain for . The second branch can only pay dividends if . Hence, we need to wait at least until , before any dividend can be paid. Consequently, the resulting dividend process is given by . We get
which, by (7), implies the lower bound. The upper bound follows by a similar computation, since for any admissible dividend strategy we have and . □
Lemma 2.
The optimal value function V is componentwise increasing, locally Lipschitz, and satisfies
and
for any initial surplus and any .
In the case that and , we get
and if and , we get
for any .
Proof.
The property of being componentwise (non-strictly) increasing, the upper bounds in Equations (10) and (11), as well as Equations (12) and (13) can be proven exactly as in the proof of (Azcue et al. 2018, Lemma 3.2). Hence, we only show the lower bounds in (10) and (11), where due to analogy, we restrict to the former. If , , then the statement is a direct consequence of (12). Thus, we need to show that for it holds
W.l.o.g. we may assume that because otherwise, it follows that
since V is increasing and due to (12). The rest of the proof is done by construction. Given an , let be a strategy such that
We define a new strategy as follows:
- Dividends from branch two are paid according to strategy , i.e., .
- Branch one pays no dividends as long as its uncontrolled surplus is below . Once the surplus hits h, it pays h as a lump sum immediately, setting the controlled surplus to 0. Afterward it continues by paying dividends according to .
By construction we have . Moreover, for any we define the stopping time as the first time the process reaches s, i.e.,
where . Then it holds that
We conclude
By construction follows that
which implies
since was arbitrary. We note that , since the probability that is reached before the arrival of the first claim is strictly positive. Thus the proof is completed. □
Our next result is the Dynamic Programming Principle, which heuristically states that an optimal strategy must be optimal at any point in time.
Proposition 1 (Dynamic Programming Principle).
For any initial surplus and any stopping time τ it holds that
Proof.
We use the same strategy as in the proof of (Azcue and Muler 2014, Lemma 1.2): We show the statement for a fixed time , and then the general case follows using the arguments given in (Zhu 1992, chp. II.2).
Set
Then, by the same arguments as in (Azcue and Muler 2014, Lemma 1.2), we have for any and that
The proof of the inverse inequality is also similar to Azcue and Muler (2014), but more involved due to the new cases that appear if one initial capital is strictly negative. Therefore, we will go into detail here:
For any given , we fix such that
By Lemma 2 the optimal value function V is increasing and continuous in , and hence we can construct monotonically increasing sequences , with , , and such that if or , then
for , . W.l.o.g., in the following we solely use subscript i to simplify the notation. This is possible as we can always insert additional elements into the sequences. Hence, we get
Given we consider strategies such that
Based on these strategies we define a new strategy as follows:
- If , set and for all .
- If , set and for all .
- If and , choose i such that and . We distinguish three cases:
- −
- If and , then by assumption we have and . In , branch one immediately pays and branch two immediately pays as dividends at time T. Afterward we follow .
- −
- If and then by assumption . In , branch one immediately pays as dividends. Then we follow from surplus .
- −
- Similar to the previous case, if and , branch two pays as dividends and then we follow from surplus .
We now aim to derive the HJB equation. Therefore, recall the concept of the discounted infinitesimal generator, cf. (Azcue and Muler 2014, sct. 1.4), (Azcue et al. 2018, eq. (7)): Given a Markov process in and , set
for any real-valued, continuously differentiable function f on such that the above limit exists. For our considerations we choose , i.e., the controlled risk process stopped at ruin.
Let be constants and define the dividend strategy , that constantly pays dividends at rate from branch one and two, whenever the respective surplus is non-negative. Then clearly is admissible. Further, let be the first claim arrival time of . Using the same arguments as in (Azcue and Muler 2014, sct. 1.4), we derive
where is an integral operator given via
Moreover, set
The HJB equation, i.e., the integro-differential equation which is satisfied by the optimal value function, turns out to be
for any and in the following we explain its derivation:
As the case is completely similar to the derivation of the HJB equation in Azcue et al. (2018), we will only explain the differences in the new case, where one surplus is strictly negative. Due to symmetry we consider w.l.o.g. . Assume that V is continuously differentiable. Since , Equations (19) and (20) reduce to
Let such that and such that , if . From Proposition 1 with it follows that
This implies
and we conclude
Lastly, choosing either or letting we obtain that
which is (22) for . The case follows in complete analogy, where we obtain
Remark 1.
Note that at first sight, Equations (19)–(22) look very similar to Equations (8)–(12) in Azcue et al. (2018). The occurring indicator functions in (19) and (22) account only for the cases where one is strictly negative, which implies that on Equations (19), (21) and (22) superficially coincide with Equations (8), (10) and (12) in Azcue et al. (2018). The difference lies in the integral operator, as we need to allow to integrate up to the maximum instead of the minimum of and as f is only assumed to be zero on the pure negative quadrant, while it may be strictly positive outside.
As usual for this type of problem, there are cases where the value function may not be differentiable and thus it may not fulfill the HJB equation in the classical sense. Thus, subsequently, we use the notion of viscosity solutions: We follow the definition given in (Azcue et al. 2018, Def. 3.4) and call a function viscosity subsolution of (22) at a fixed point , if it is locally Lipschitz, and any continuously differentiable function with such that reaches its maximum in , satisfies
Moreover, a function is called a viscosity supersolution of (22) at a fixed point , if it is locally Lipschitz, and any continuously differentiable function with such that reaches its minimum in , satisfies
The functions and are also called test functions. A function is called viscosity solution at if it is both a viscosity sub- and supersolution.
The proof of Proposition 2 is naturally split into two parts that cover sub- and supersolution, respectively. The proof that V is a supersolution follows the idea of (Azcue and Muler 2014, Prop. 3.1). Mainly it uses the same arguments as the derivation of the HJB equation. For the sake of brevity the details will be omitted here. Proving that V is a viscosity subsolution follows the main ideas of (Azcue and Muler 2014, Prop. 3.1) as well and is done by contradiction. As our enlarged solvency set demands some additional care, we go a little more into detail here. For an easier understanding, we split the proof into Lemmas 3 and 4, which yield an immediate contradiction, showing that V is indeed a viscosity subsolution.
In the following, for notational simplicity, we abuse notation and define
Lemma 3.
Note that the minima (∧) inside the intervals in (26) and (27) are only relevant if or , respectively: If then (25) ensures that .
Proof of Lemma 3.
The proof follows the outline of the univariate case as presented in (Azcue and Muler 2014, Prop. 3.1) and consists in constructing a test function that fulfills the desired properties. □
Lemma 4.
Assume V is not a viscosity subsolution and let be as in Lemma 3. Then it holds that
Proof of Lemma 4.
In addition, this proof follows the outline given in (Azcue and Muler 2014, Prop. 3.1) and is similar to the proof of (Azcue et al. 2018, Thm. 3.5). However, there are some decisive extra arguments needed in our extended setting, which is why we go a bit into detail here.
Since is continuously differentiable, for any compact set we can find such that for any we have
Choose
and fix an admissible dividend policy for all t. Similar to the proof of (Azcue et al. 2018, Thm. 3.5) we define the stopping times
and set
where is, as usual, the ruin time of the controlled process . Clearly, for h small enough. Recall the sets , and from Lemma 3. Then by construction we have , and Hence,
and consequently (29) implies
Using a bivariate extension of (Azcue and Muler 2014, Prop. 2.13) we obtain
where
defines a zero mean martingale. Fix . If , then by construction of h we have for any . Hence, by admissibility of the strategy, no dividends can be paid from branch i and the respective integrals in (34) are zero. If on the other hand , then we may apply (26) or (27) to get
From (28), (30) and (31), we have
where the inequality for the second integral holds, since is in the union of some compact set M and . This is because, due to admissibility, we can not force a branch to go negative by a dividend payment and because claims occur along the line .
Now, the rest of the proof is completely similar to the proof of (Azcue and Muler 2014, Prop. 3.1): We use the Dynamic Programming Principle (Proposition 1) together with Equations (33), (35) and (36) to obtain the desired inequality
□
Remark 2.
A comparison of our proof and the proof of Theorem 3.5 in Azcue et al. (2018) exhibits some flaws in the latter. The authors state that
and later use the same stopping times , and as we do. This however is not enough, as
does not necessarily hold (see also (32)) and hence, the multivariate generalization of (Azcue and Muler 2014, Eq. (3.20)) fails.
Nevertheless, we emphasize that this does not affect the statement of (Azcue et al. 2018, Thm. 3.5) itself, as the proof may be fixed by adjusting the definition of as
for any , in order to show that (29) holds on the larger set .
The following proposition is also called verification result:
Proposition 3.
The optimal value function is the smallest viscosity solution u of (22) satisfying the growth conditions
and
for any and .
Proof.
Similar to (Azcue and Muler 2014, Prop. 4.4) one can show that for arbitrary and any viscosity supersolution of (22) satisfying (G1) and (G2), it holds that . Together with Proposition 2 this implies the statement. □
4. Bang Strategies
In this section, we choose a heuristic approach to define a class of strategies that appeal to be optimal. We show that in certain subcases, the optimal strategy indeed lies in this class and we reduce the control problem defined in (7) to a univariate one.
The idea behind the strategies is as follows: If we face ruin at time then it is desirable to have a relatively small surplus right before because it implies that we paid more dividends before ruin. As we allow that one branch of the process becomes negative, all possible dividends can be paid from one branch (at every ) to ensure that there is no capital “wasted” at the time of ruin. We thus consider strategies that pay dividends according to the following principles:
- One branch follows some admissible, one-dimensional dividend strategy,
- the other branch pays dividends as follows:
- (i)
- If the surplus is positive, the whole surplus is immediately paid as a lump sum.
- (ii)
- If the surplus is zero, all incoming premia are continuously paid as dividends.
- (iii)
- If the surplus is negative, no dividends are paid until the branch reaches zero again.
Inspired by the well-known Bang-bang controls (see, e.g., Rolewicz 1987, sct. 6.5) we call these strategies bang strategies as they always pay the maximum dividends possible from one branch. Let and fix such that in particular or . Formally, for any we set
where denotes the running supremum of . We define the class of bang strategies as
where by construction any strategy in is admissible. Clearly, for any the ruin time is equal to the ruin time of the first branch, denoted by , whereas for any the ruin time is equal to the ruin time of the second branch . This is, because any occurring claim affects both branches of our risk process and by construction of , any occurring claim leads to a negative surplus in the second or first branch, respectively. Further, for any univariate admissible strategy L defined on branch i it holds that
In the following, to facilitate reading, we are going to use the expression “strategy of type ” to refer to a strategy in and similarly for .
Our next goal is to show that the optimal strategy for the control problem (7) lies in . We start by proving that strategies of type and are the optimal choice for certain subsets of all admissible strategies. To do this, we define the sets
By construction, the controlled process can neither exit into nor exit into by a claim. Such a change can only happen by two events:
- (i)
- The process deterministically creeps from into , induced by the collected premia and by (3), or
- (ii)
- the process is forced to change from one set to the other by dividend payments (continuously or by a lump sum).
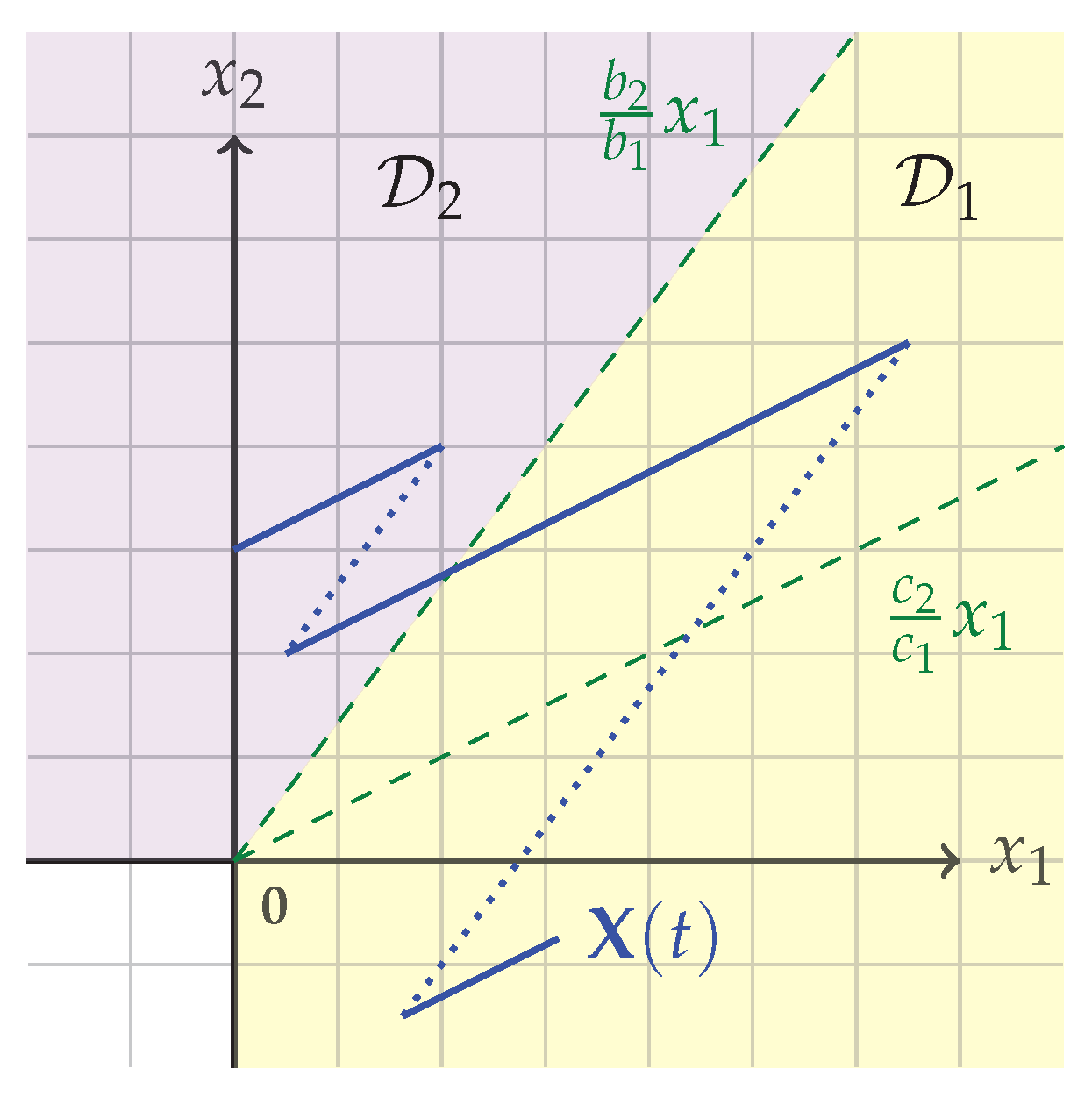
The sets and and a sample path of the process are shown in Figure 1.
Note that event (i) can be interpreted as a special case of event (ii) since it corresponds to paying no dividends at this particular time. Hence, changes between the sets are determined by the dividend policy.
For , , let be the set of all admissible strategies which ensure that stays in until ruin. By the previous reasoning the sets are well-defined.
Theorem 1.
The optimal strategy in is of type , whereas the optimal strategy in is of type .
Proof.
We show the statement for as the proof for the second case is similar. Let be any strategy in . Define another strategy as
with as in (38). Then and it holds that for any . Hence,
Moreover, by definition of and we have for all
which directly implies that . Hence, and the statement follows as was arbitrary. □
Remark 3.
Note that in contrast to the results in (Azcue et al. 2018, Section 4.3), Theorem 1 implies that a strategy that stays in until ruin can never be optimal in our setting.
Next, we show that under some additional assumptions a strategy of type is indeed optimal:
Theorem 2.
Let and let in . Then for any strategy there exists a strategy such that .
Before we begin with the proof of Theorem 2, we prove a preparatory lemma:
Lemma 5.
It holds that
Proof.
Now, we are ready to prove Theorem 2:
Proof of Theorem 2.
We start by showing the statement for the slightly stronger assumption that . Let be arbitrary. For any we define a strategy by
Note that is increasing by (3) and non-negative as . Moreover, admissibility of follows directly from admissibility of . By definition, is admissible and it is clear that for all . Hence, it remains to show that indeed . To accomplish this, we show
By (42) it holds that
and hence .
To show the second inequality in (44) we consider two separate cases. Let first . Then , which is equivalent to
Hence, in this case the minimum in (42) is attained by . Moreover, by definition of we have for any , and thus
If otherwhise , then analogously we have
and the minimum in (42) is attained by the second term. We use (46) to show
Note that, here we used to ensure that .
Moreover, it holds that (see (38))
With this and by (39) we have
since . We combine (47) and (48) and obtain
Finally, as the minimum in (42) is attained by the second term, this implies that
and hence the proof for is finished. Note that the additional restriction can be dropped, since in the case of , by admissibility, no dividends are paid by branch two until reaches zero. Hence, any admissible strategy on the second branch coincides with the strategy . Once the process reaches zero, we may apply the restricted result. □
Remark 4.
Note that the assumption in Theorem 2 does indeed impose a restriction to our model. As we assumed (3) throughout the whole paper, we can not simply exchange branches in order to obtain the case .
Unfortunately, even though is only used in (47), it is not possible to adapt the proof to obtain a similar result neither for the case , nor for and in the following we heuristically explain why.
The general idea of the proof is, given the arbitrary strategy , to construct another strategy that fulfills almost surely. (Actually, (42) and (43) ensure that (45) implies even .)
This construction relies heavily on the assumptions (3) and . Otherwise would not be admissible, as or , respectively. Moreover, in order to fulfill the second inequality in (44), is essential. We illustrate this using a counterexample: Assume and fix a strategy such that
- at , the first branch pays the whole initial capital as lump sum, while
- the second branch does not make any dividend payments at .
The following Corollary summarizes the important consequences of Theorems 1 and 2.
Corollary 1.
Let . Then for any , the optimal strategy is of type .
If then either the optimal strategy is of type , or the optimal strategy’s controlled process enters with positive probability, in which case it is optimal to continue with a strategy of type .
As explained in Remark 4 our approach for proving the optimality of bang strategies fails in the case as well as if . Even though in the latter case Corollary 1 does make a statement on the two possible behaviors of the optimal strategy, there remains an open question: If the optimal strategy’s controlled process enters with positive probability, then the corollary does not make any statement on how the optimal strategy behaves until this event.
As both of these problems could possibly be solved using other techniques, we leave them as open questions for future research.
- Value functions of bang strategies
Next we study properties of the value functions of strategies of type and . By symmetry, the classes are similar and we thus focus on the former.
For any the value function of the strategy can be expressed as
Note that if , then and hence, the expression can be dropped in the second integral of (49). If the initial capital of branch one is negative, then we may characterize the value of strategy explicitly in terms of :
Lemma 6.
For any , and any admissible strategy on branch one it holds that
In particular, as , is exponentially decreasing and
The result holds analogously for and strategies of type .
Proof.
Note that by construction branch two pays as a lump sum at the beginning and continues paying constantly as dividends, whenever the controlled process is positive. This construction ensures that . Consequently, if the first claim at time happens before branch one gets positive, i.e., if , then the value of the strategy is exactly the discounted value of the dividends paid from branch two until the first claim. If the first claim happens after , then the value of the strategy at is exactly plus the discounted dividends from branch two up to time . As and due to the lack of memory of the exponential distribution, we conclude that for any , it holds that
□
Remark 5.
The asymptotics as indicate that is not the optimal strategy on because as long as the surplus of branch one is negative, collapses to the trivial strategy, that always pays the highest dividend possible. However, if the initial capital is in , then the process never actually enters this set, as by construction of the occurrence of implies ruin.
The next Lemma gives sufficient conditions on when is preferable over and vice versa.
Lemma 7.
Let . If , then we have
If otherwise , and , then
Proof.
Assume that for some . Then obviously as branch one can always pay a lump sum of size h. We conclude by construction of that
The proof of the second case is completely analog. □
- The one-dimensional optimization problem
As the last step in this section, we formulate the one-dimensional optimization problem that arises for bang strategies. Let , , be the set of all admissible strategies (in the classical univariate sense, see Azcue and Muler 2014, chp. 1.2) acting on branch i with initial capital . For technical reasons, we allow to be negative and extend the definition, such that strategies are admissible if they do not pay any dividends, while branch i is negative. Define
and
Corollary 1 implies, that if and then the solution of (52) defines a solution to the original problem (7).
If on the other hand and , then either the optimal strategy can be defined through the solution of (53), or the optimal strategy ensures that the controlled process enters with positive probability, which brings us back to the first case. Hence, the maximum of the solutions to (52) and (53) is at minimum a good approximation to the solution of (7) if .
However, (52) and (53) are hard to solve explicitly, as (and ) and the expressions inside the indicator functions are strongly correlated, since all depend on the path of the underlying claim process . An approach to find approximate solutions to the problems in another subclass of the admissible strategies and using Monte Carlo simulations is presented in the following section.
5. Approximation Approach and Simulation Study
Given the theoretical results of the preceding section, we want to approximately solve the problems (52) and (53). As the approach is identical, we are going to discuss only the former case.
Assume that , while . We define the random process
such that we have (see (49))
The function depends explicitly on the initial value and the time s and implicitly on the random path of the claim process S. Let . Then is monotonically increasing with respect to and for any it holds that
almost surely. Equation (52) may be reformulated as
As mentioned before, due to the complicated dependency structure between and , this problem seems impossible to solve exactly and explicitly. However, similar problems have been treated before, e.g., in Thonhauser and Albrecher (2007), where the authors consider the problem (54) with constant, i.e., (see Thonhauser and Albrecher 2007, eq. (2)) a problem of type
It is shown, that in the case of unbounded dividend payments, the corresponding HJB equation is given by (cf. Thonhauser and Albrecher 2007, Eq. 36)
where is the cdf of the claims affecting branch one, i.e., . Moreover, it turns out that in the case of exponential claims, the optimal strategy is a barrier strategy, cf. (Thonhauser and Albrecher 2007, Prop. 11).
In the remainder of this section we will therefore restrict to barrier strategies as well. We say that an admissible strategy is of barrier type, if there exists a fixed surplus level , such that
- does not pay any dividends if ,
- pays continuously as dividends, while ,
- pays a lump sum of size as dividends, if .
The set of all barrier strategies acting on branch one with initial capital is denoted by . We consider
which is a slight modification of (52) (see also (54)) and solve it using Monte Carlo techniques.
In order to apply the results from Thonhauser and Albrecher (2007), we assume in the following that the claims of the driving compound Poisson process are exponentially distributed. Note that for modeling claim sizes there are more realistic distributions, such as the log-normal or the generalized Pareto distribution. However, the exponential distribution is a popular choice for claim sizes in Cramér–Lundberg risk models, as this case is particularly well-treatable since, e.g., ruin probabilities and excess of loss distributions at the time of ruin can be expressed in closed-form, see Asmussen and Albrecher (2010).
Let , , such that
By (Thonhauser and Albrecher 2007, Prop. 11) the barrier corresponding to the solution of (55) fulfills
where are the roots of the polynomial
such that . Hence, as , the barrier corresponding to the solution of (56) is likely to be contained in the set of solutions of (57) for .
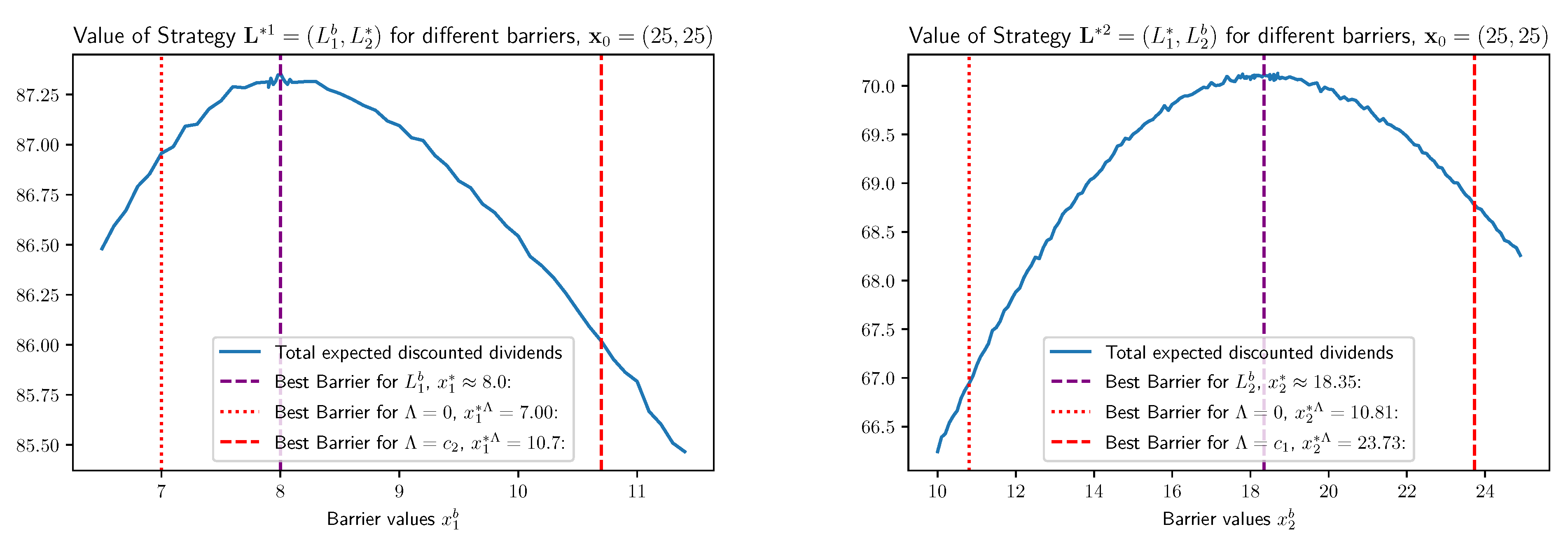
For our numerical study, we consider model (2) with parameters , , , , and such that in particular assumption (3) is fulfilled. Solving (57) for these parameters and yields . Similar to the previous reasoning, we can consider and approximate the corresponding optimal strategy in branch two by a barrier strategy. In this case we obtain for the optimal barrier .
Figure 2 shows the estimated discounted dividend values of strategy and with respect to different barriers and for an initial capital of , such that we always start by lump-sum payments in both branches. As expected, in both cases the optimal barrier for our model is strictly in between the optimal barriers for problem (55) with and ( for the case of ).
Figure 3 clearly shows that for our example is the preferable choice over for all initial values . Only on a subset of it yields a smaller expected value for the dividends, as already predicted in Lemma 6. However, in general, a global statement that is better than (or vice versa) is not true, as our last example indicates:
Example 1.
Consider a model, where . Then obviously claims happen along the line and, if , we have for all . By construction, we have for all and consequently Lemma 7 implies, that on , while on . This shows that a general statement on whether or is better for all can not hold in general.
Author Contributions
Conceptualization, P.L.S. and H.E.H.; methodology, P.L.S. and H.E.H.; software, P.L.S.; validation, P.L.S. and H.E.H.; formal analysis, P.L.S. and H.E.H.; investigation, P.L.S. and H.E.H.; resources, P.L.S.; data curation, P.L.S.; writing—original draft preparation, P.L.S. and H.E.H.; writing—review and editing, P.L.S. and H.E.H.; visualization, P.L.S.; project administration, P.L.S. and H.E.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Not applicable.
Acknowledgments
We gratefully acknowledge the support of our supervisor Anita Behme and her valuable comments on earlier versions of the present manuscript. Moreover, we thank three referees for suggestions and comments that helped improving this manuscript. We acknowledge the GWK support for funding this project by providing computing time through the Center for Information Services and HPC (ZIH) at TU Dresden.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Albrecher, Hansjörg, and Stefan Thonhauser. 2009. Optimality results for dividend problems in insurance. Revista de la Real Academia de Ciencias Exactas, Fisicas y Naturales. Serie A. Matematicas 103: 295–320. [Google Scholar] [CrossRef] [Green Version]
- Asmussen, Søren, and Hansjörg Albrecher. 2010. Ruin Probabilities, 2nd ed. Singapore: World Scientific. [Google Scholar]
- Avanzi, Benjamin. 2009. Strategies for dividend distribution: A review. North American Actuarial Journal 13: 217–51. [Google Scholar] [CrossRef]
- Avram, Florin, Zbigniew Palmowski, and Martijn R. Pistorius. 2007. On the optimal dividend problem for a spectrally negative Lévy process. The Annals of Applied Probability 17: 156–80. [Google Scholar] [CrossRef]
- Avram, Florin, Zbigniew Palmowski, and Martijn R. Pistorius. 2008a. A two-dimensional ruin problem on the positive quadrant. Insurance: Mathematics and Economics 42: 227–34. [Google Scholar] [CrossRef] [Green Version]
- Avram, Florin, Zbigniew Palmowski, and Martijn R. Pistorius. 2008b. Exit problem of a two-dimensional risk process from the quadrant: Exact and asymptotic results. The Annals of Applied Probability 18: 2421–49. [Google Scholar] [CrossRef]
- Azcue, Pablo, and Nora Muler. 2005. Optimal reinsurance and dividend distribution policies in the cramér-lundberg model. Mathematical Finance 15: 261–308. [Google Scholar] [CrossRef]
- Azcue, Pablo, and Nora Muler. 2010. Optimal investment policy and dividend payment strategy in an insurance company. The Annals of Applied Probability 20: 1253–302. [Google Scholar] [CrossRef] [Green Version]
- Azcue, Pablo, and Nora Muler. 2012. Optimal dividend policies for compound poisson processes: The case of bounded dividend rates. Insurance: Mathematics and Economics 51: 26–42. [Google Scholar] [CrossRef]
- Azcue, Pablo, and Nora Muler. 2014. Stochastic Optimization in Insurance: A Dynamic Programming Approach. Berlin and Heidelberg: Springer. [Google Scholar]
- Azcue, Pablo, Nora Muler, and Zbigniew Palmowski. 2018. Optimal dividend payments for a two-dimensional insurance risk process. European Actuarial Journal 9: 241–72. [Google Scholar] [CrossRef] [Green Version]
- Badescu, Andrei L., Eric C. K. Cheung, and Landy Rabehasaina. 2011. A two-dimensional risk model with proportional reinsurance. Journal of Applied Probability 48: 749–65. [Google Scholar] [CrossRef] [Green Version]
- Czarna, Irmina, and Zbigniew Palmowski. 2011. De Finetti’s dividend problem and impulse control for a two-dimensional insurance risk process. Stochastic Models 27: 220–50. [Google Scholar] [CrossRef]
- De Finetti, Bruno. 1957. Su un’impostazione alternativa della teoria collettiva del rischio. Transactions of the XVth International Congress of Actuaries 2: 433–43. [Google Scholar]
- Gerber, Hans U. 1969. Entscheidungskriterien für den zusammengesetzten Poisson-Prozess. Mitteilungen/Vereinigung Schweizerischer Versicherungsmathematiker 69: 185–228. [Google Scholar]
- Hu, Zechun, and Bin Jiang. 2013. On joint ruin probabilities of a two-dimensional risk model with constant interest rate. Journal of Applied Probability 50: 309–22. [Google Scholar] [CrossRef] [Green Version]
- Loeffen, Ronnie L. 2008. On optimality of the barrier strategy in de Finetti’s dividend problem for spectrally negative Lévy processes. The Annals of Applied Probability 18: 1669–80. [Google Scholar] [CrossRef]
- Palmowski, Zbigniew, Sergey Foss, Dmitry Korshunov, and Tomasz Rolski. 2018. Two-dimensional ruin probability for subexponential claim size. Probability and Mathematical Statistics 37: 319–35. [Google Scholar] [CrossRef] [Green Version]
- Rolewicz, Stefan. 1987. Functional Analysis and Control Theory. Berlin and Heidelberg: Springer. [Google Scholar]
- Schmidli, Hanspeter. 2008. Stochastic Control in Insurance. Berlin and Heidelberg: Springer. [Google Scholar]
- Thonhauser, Stefan, and Hansjörg Albrecher. 2007. Dividend maximization under consideration of the time value of ruin. Insurance: Mathematics and Economics 41: 163–84. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Hang. 1992. Dynamic Programming and Variational Inequalities in Singular Stochastic Control. Ph.D. thesis, Brown University, Providence, RI, USA. [Google Scholar]
Figure 1.
Visualization of the sets , and a sample path of .

Figure 2.
Expected discounted dividend payments of strategy and in dependence of the barriers chosen for strategies .
Figure 2.
Expected discounted dividend payments of strategy and in dependence of the barriers chosen for strategies .

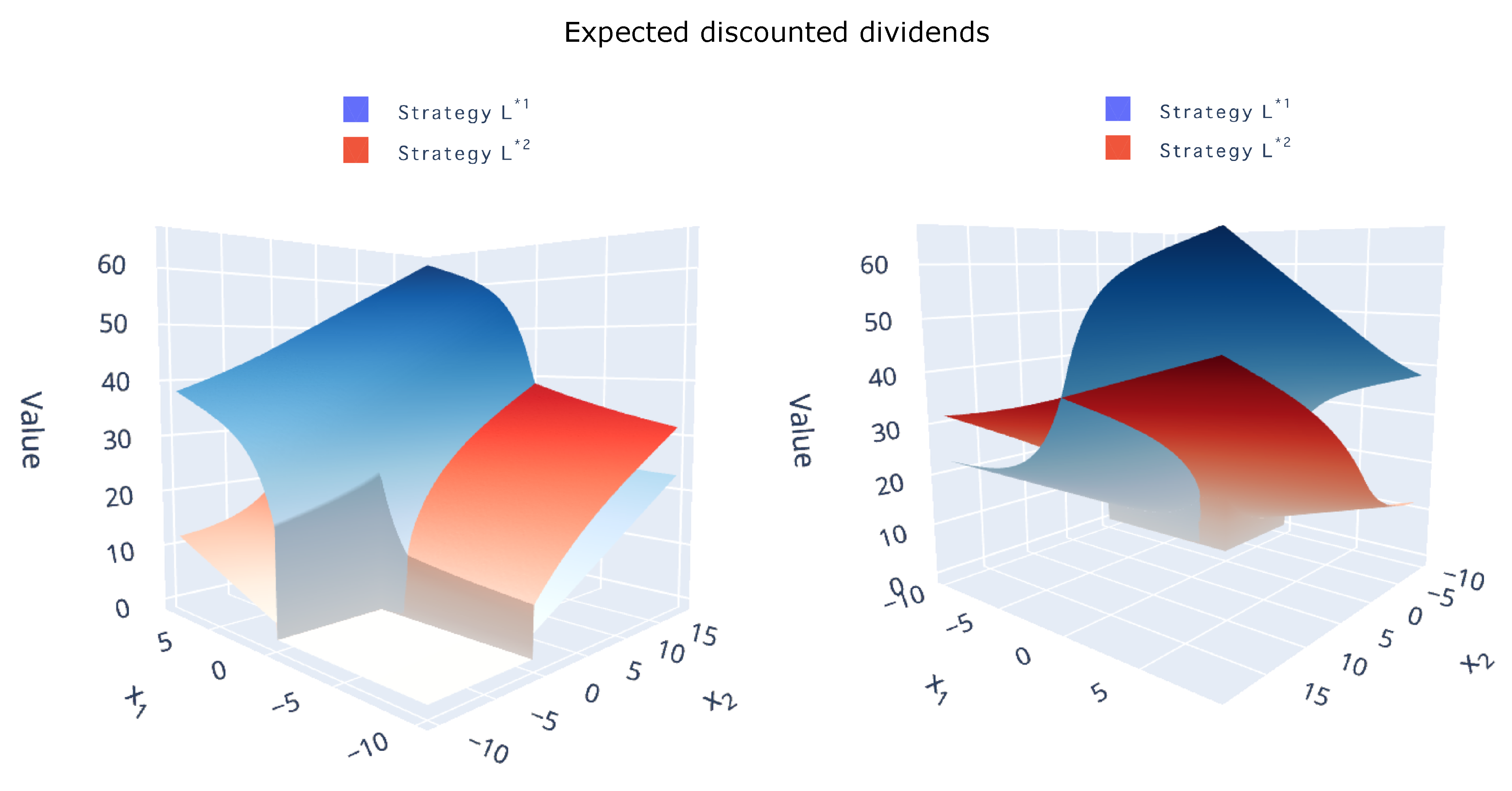
Figure 3.
Approximated value functions with the optimal barriers with respect to different initial values from several perspectives.
Figure 3.
Approximated value functions with the optimal barriers with respect to different initial values from several perspectives.

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Strietzel, P.L.; Heinrich, H.E. Optimal Dividends for a Two-Dimensional Risk Model with Simultaneous Ruin of Both Branches. Risks 2022, 10, 116. https://doi.org/10.3390/risks10060116
AMA Style
Strietzel PL, Heinrich HE. Optimal Dividends for a Two-Dimensional Risk Model with Simultaneous Ruin of Both Branches. Risks. 2022; 10(6):116. https://doi.org/10.3390/risks10060116
Chicago/Turabian StyleStrietzel, Philipp Lukas, and Henriette Elisabeth Heinrich. 2022. "Optimal Dividends for a Two-Dimensional Risk Model with Simultaneous Ruin of Both Branches" Risks 10, no. 6: 116. https://doi.org/10.3390/risks10060116
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.