
Molecular Genetic Analysis with Microsatellite-like Loci Reveals Specific Dairy-Associated and Environmental Populations of the Yeast Geotrichum candidum


 and
and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Yeast Isolates and Growth Conditions
2.2. DNA Extraction
2.3. Loci Selection
2.4. PCR Amplification
2.5. Data Treatment
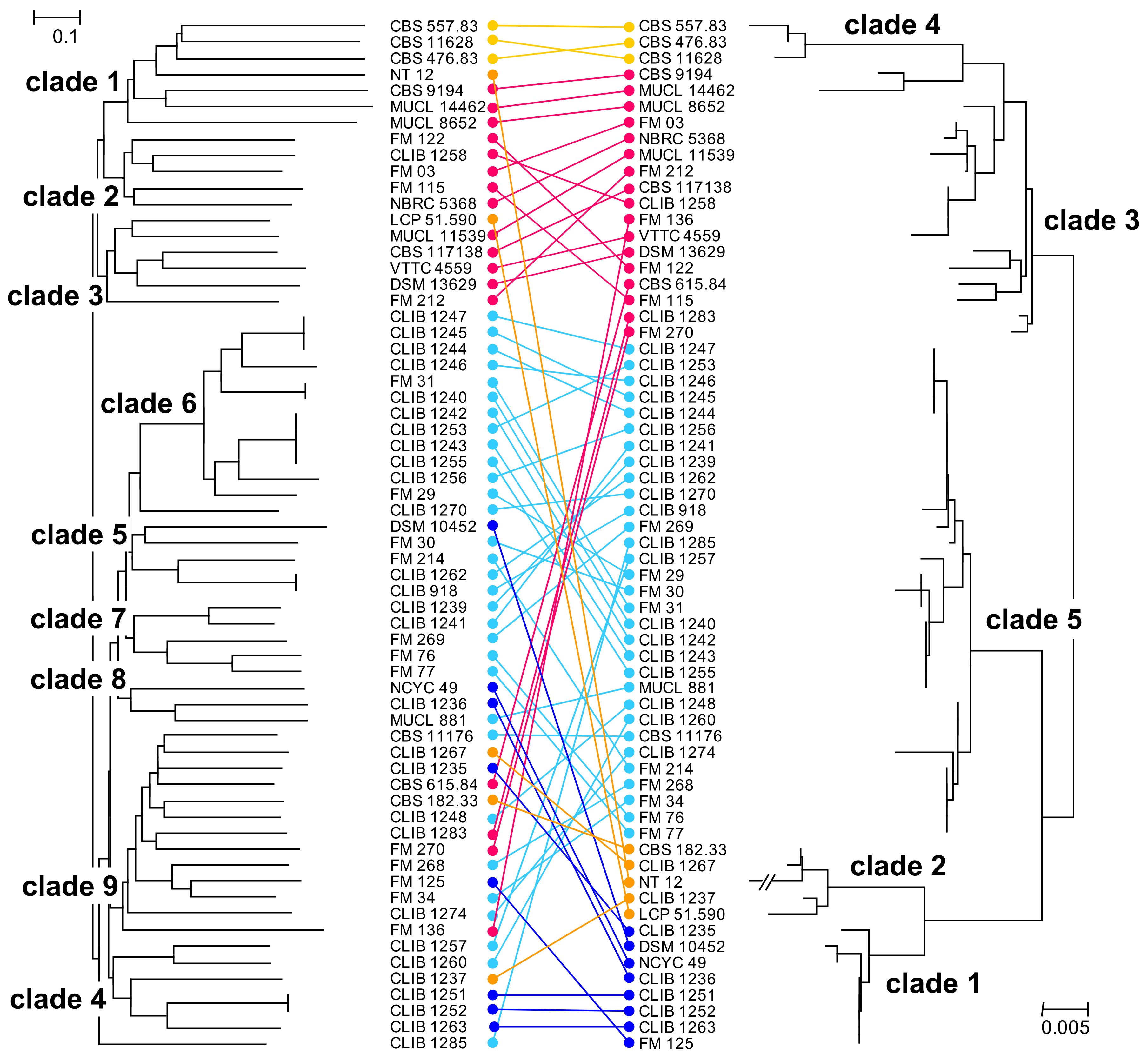
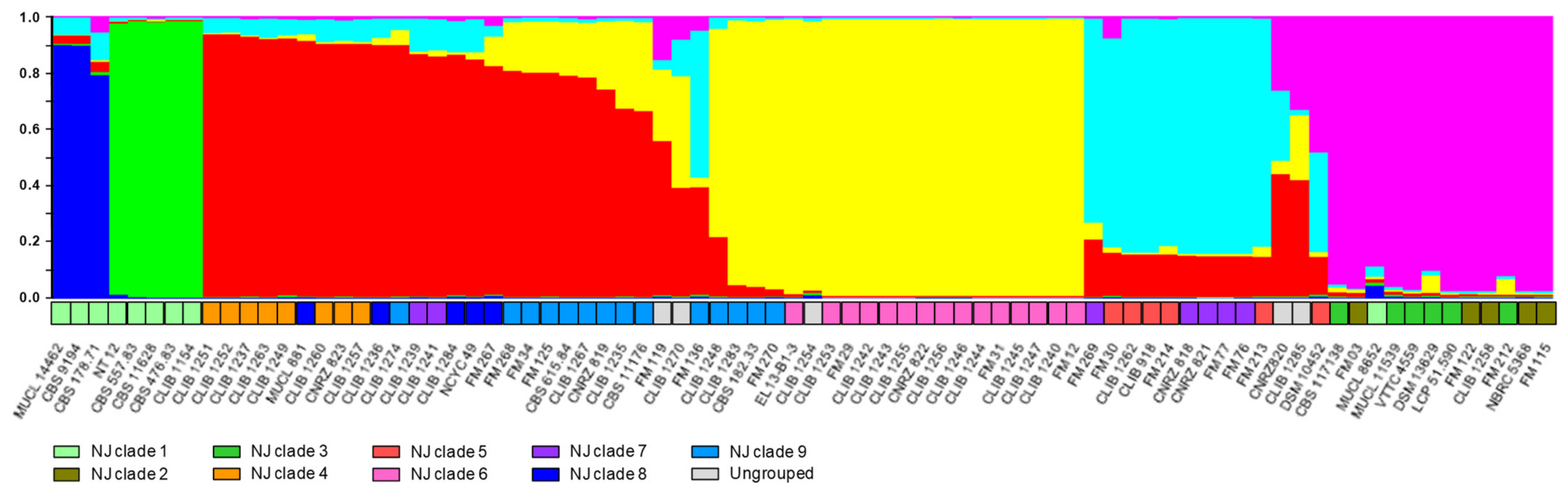
3. Results and Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Boutrou, R.; Guéguen, M. Interests in Geotrichum candidum for cheese technology. Int. J. Food Microbiol. 2005, 102, 1–20. [Google Scholar] [CrossRef]
- Fröhlich-Wyder, M.-T.; Arias-Roth, E.; Jakob, E. Cheese yeasts. Yeast 2018, 36, 129–141. [Google Scholar] [CrossRef]
- Marcellino, N.; Benson, D.R. The Good, The Bad, and the Ugly: Tales of Mold-Ripened Cheese. In Cheese and Microbes; American Society for Microbiology: Washington, WA, USA, 2014; pp. 95–131. ISBN 978-1-55581-586-8. [Google Scholar]
- Link, H.F. Observationes in Ordines Plantarum Naturales; Dissertatio, I. Magazin Der Gesellschaft Naturforschenden Freunde Berlin: Berlin, Germany, 1809; pp. 3–42. [Google Scholar]
- Morel, G.; Sterck, L.; Swennen, D.; Marcet-Houben, M.; Onesime, D.; Levasseur, A.; Jacques, N.; Mallet, S.; Couloux, A.; Labadie, K.; et al. Differential gene retention as an evolutionary mechanism to generate biodiversity and adaptation in yeasts. Sci. Rep. 2015, 5, 11571. [Google Scholar] [CrossRef]
- Ladevèze, S.; Haon, M.; Villares, A.; Cathala, B.; Grisel, S.; Herpoël-Gimbert, I.; Henrissat, B.; Berrin, J.-G. The yeast Geotrichum candidum encodes functional lytic polysaccharide monooxygenases. Biotechnol. Biofuels 2017, 10, 215. [Google Scholar] [CrossRef]
- Alper, I.; Frenette, M.; Labrie, S. Ribosomal DNA polymorphisms in the yeast Geotrichum candidum. Fungal Biol. 2011, 115, 1259–1269. [Google Scholar] [CrossRef]
- Alper, I.; Frenette, M.; Labrie, S. Genetic diversity of dairy Geotrichum candidum strains revealed by multilocus sequence typing. Appl. Microbiol. Biotechnol. 2013, 97, 5907–5920. [Google Scholar] [CrossRef]
- Jacques, N.; Mallet, S.; Laaghouiti, F.; Tinsley, C.R.; Casaregola, S. Specific populations of the yeast Geotrichum candidum revealed by molecular typing. Yeast 2017, 34, 165–178. [Google Scholar] [CrossRef]
- Legras, J.-L.; Merdinoglu, D.; Cornuet, J.-M.; Karst, F. Bread, beer and wine: Saccharomyces cerevisiae diversity reflects human history. Mol. Ecol. 2007, 16, 2091–2102. [Google Scholar] [CrossRef]
- Liti, G.; Carter, D.M.; Moses, A.M.; Warringer, J.; Parts, L.; James, S.A.; Davey, R.P.; Roberts, I.N.; Burt, A.; Koufopanou, V.; et al. Population genomics of domestic and wild yeasts. Nature 2009, 458, 337–341. [Google Scholar] [CrossRef] [Green Version]
- Peter, J.; De Chiara, M.; Friedrich, A.; Yue, J.-X.; Pflieger, D.; Bergström, A.; Sigwalt, A.; Barre, B.; Freel, K.; Llored, A.; et al. Genome evolution across 1,011 Saccharomyces cerevisiae isolates. Nature 2018, 556, 339–344. [Google Scholar] [CrossRef] [Green Version]
- Masneuf-Pomarede, I.; Salin, F.; Börlin, M.; Coton, E.; Coton, M.; Le Jeune, C.; Legras, J.-L. Microsatellite analysis ofSaccharomyces uvarumdiversity. FEMS Yeast Res. 2016, 16, fow002. [Google Scholar] [CrossRef] [Green Version]
- Legras, J.-L.; Erny, C.; Charpentier, C. Population Structure and Comparative Genome Hybridization of European Flor Yeast Reveal a Unique Group of Saccharomyces cerevisiae Strains with Few Gene Duplications in Their Genome. PLoS ONE 2014, 9, e108089. [Google Scholar] [CrossRef] [Green Version]
- Martiniuk, J.T.; Pacheco, B.; Russell, G.; Tong, S.; Backstrom, I.; Measday, V. Impact of Commercial Strain Use on Saccharomyces cerevisiae Population Structure and Dynamics in Pinot Noir Vineyards and Spontaneous Fermentations of a Canadian Winery. PLoS ONE 2016, 11, e0160259. [Google Scholar] [CrossRef] [Green Version]
- Tapsoba, F.; Legras, J.-L.; Savadogo, A.; Dequin, S.; Traore, A.S. Diversity of Saccharomyces cerevisiae strains isolated from Borassus akeassii palm wines from Burkina Faso in comparison to other African beverages. Int. J. Food Microbiol. 2015, 211, 128–133. [Google Scholar] [CrossRef]
- Bi, C.Y.T.; Amoikon, T.L.; Kouakou, C.A.; Noemie, J.; Lucas, M.; Grondin, C.; Legras, J.-L.; N’Guessan, F.K.; Djeni, T.N.; Djè, M.K.; et al. Genetic diversity and population structure of Saccharomyces cerevisiae strains isolated from traditional alcoholic beverages of Côte d’Ivoire. Int. J. Food Microbiol. 2019, 297, 1–10. [Google Scholar] [CrossRef]
- Albertin, W.; Setati, M.E.; Miot-Sertier, C.; Mostert, T.T.; Colonna-Ceccaldi, B.; Coulon, J.; Girard, P.; Moine, V.; Pillet, M.; Salin, F.; et al. Hanseniaspora uvarum from Winemaking Environments Show Spatial and Temporal Genetic Clustering. Front. Microbiol. 2016, 6, 1569. [Google Scholar] [CrossRef]
- Ezeronye, O.; Legras, J.-L. Genetic analysis of Saccharomyces cerevisiaes trains isolated from palm wine in eastern Nigeria. Comparison with other African strains. J. Appl. Microbiol. 2009, 106, 1569–1578. [Google Scholar] [CrossRef]
- Masneuf-Pomarede, I.; Juquin, E.; Miot-Sertier, C.; Renault, P.; Laizet, Y.; Salin, F.; Alexandre, H.; Capozzi, V.; Cocolin, L.; Colonna-Ceccaldi, B.; et al. The yeast Starmerella bacillaris (synonym Candida zemplinina) shows high genetic diversity in winemaking environments. FEMS Yeast Res. 2015, 15, fov045. [Google Scholar] [CrossRef] [Green Version]
- Tapsoba, F.; Savadogo, A.; Legras, J.; Zongo, C.; Traore, A.S. Microbial diversity and biochemical characteristics of Borassus akeassii wine. Lett. Appl. Microbiol. 2016, 63, 297–306. [Google Scholar] [CrossRef]
- Edwards, A.W.F. Distances between Populations on the Basis of Gene Frequencies. Biometrics 1971, 27, 873. [Google Scholar] [CrossRef]
- Kamvar, Z.N.; Tabima, J.F.; Grünwald, N.J. Poppr: An R package for genetic analysis of populations with clonal, partially clonal, and/or sexual reproduction. PeerJ 2014, 2, e281. [Google Scholar] [CrossRef] [Green Version]
- R Foundation for Statistical Computing R: A Language and Environment for Statistical Computing. Available online: https://www.R-project.org/ (accessed on 11 March 2021).
- R Studio Team. RStudio: Integrated Development for R; RStudio, Inc.: Boston, MA, USA, 2016; Available online: http://www.rstudio.com/ (accessed on 11 March 2021).
- Kumar, S.; Stecher, G.; Li, M.; Knyaz, C.; Tamura, K. MEGA X: Molecular Evolutionary Genetics Analysis across Computing Platforms. Mol. Biol. Evol. 2018, 35, 1547–1549. [Google Scholar] [CrossRef]
- Gao, H.; Williamson, S.; Bustamante, C.D. A Markov Chain Monte Carlo Approach for Joint Inference of Population Structure and Inbreeding Rates from Multilocus Genotype Data. Genetics 2007, 176, 1635–1651. [Google Scholar] [CrossRef] [Green Version]
- Jakobsson, N.; Rosenberg, N.A. CLUMPP: A Cluster Matching and Permutation Program for Dealing with Label Switching and Multimodality in Analysis of Population Structure. Bioinformatics 2007, 23, 1801–1806. [Google Scholar] [CrossRef] [Green Version]
- Mantel, N. The detection of disease clustering and a generalized regression approach. Cancer Res. 1967, 27, 209–220. [Google Scholar]
- de Vienne, D.M.; Giraud, T.; Martin, O.C. A congruence index for testing topological similarity between trees. Bioinformatics 2007, 23, 3119–3124. [Google Scholar] [CrossRef] [Green Version]
- Morel, G. La levure Geotrichum Candidum: Taxonomie, Biodiversité et Génome. Ph.D. Thesis, Université Paris Sud-Paris XI, Orsay, France, 2012. [Google Scholar]
- de Hoog, G.S.; Smith, M.-T. Galactomyces Redhead & Malloch. In The Yeasts: A Taxonomic Study; Kurtzman, C.P., Ed.; Elsevier: Amsterdam, The Netherlands, 2011; pp. 413–420. ISBN 978-0-444-52149-1. [Google Scholar]
- Sztajer, H.; Wang, W.; Lünsdorf, H.; Stocker, A.; Schmid, R.D. Purification and some properties of a novel microbial lactate oxidase. Appl. Microbiol. Biotechnol. 1996, 45, 600–606. [Google Scholar] [CrossRef]
- Schacherer, J.; Shapiro, J.A.; Ruderfer, D.M.; Kruglyak, L. Comprehensive polymorphism survey elucidates population structure of Saccharomyces cerevisiae. Nat. Cell Biol. 2009, 458, 342–345. [Google Scholar] [CrossRef] [Green Version]
- Pritchard, J.K.; Stephens, M.; Donnelly, P. Inference of population structure using multilocus genotype data. Genetics 2000, 155, 945–959. Available online: http://www.ncbi.nlm.nih.gov/pubmed/10835412 (accessed on 9 December 2021). [CrossRef]
- Gente, S.; Desmasures, N.; Panoff, J.-M.; Gueguen, M. Genetic diversity among Geotrichum candidum strains from various substrates studied using RAM and RAPD-PCR. J. Appl. Microbiol. 2002, 92, 491–501. [Google Scholar] [CrossRef] [Green Version]
- Perkins, V.; Vignola, S.; Lessard, M.-H.; Plante, P.-L.; Corbeil, J.; Dugat-Bony, E.; Frenette, M.; Labrie, S. Phenotypic and Genetic Characterization of the Cheese Ripening Yeast Geotrichum candidum. Front. Microbiol. 2020, 11, 737. [Google Scholar] [CrossRef]
- Almeida, P.; Barbosa, R.; Zalar, P.; Imanishi, Y.; Shimizu, K.; Turchetti, B.; Legras, J.-L.; Serra, M.; Dequin, S.; Couloux, A.; et al. A population genomics insight into the Mediterranean origins of wine yeast domestication. Mol. Ecol. 2015, 24, 5412–5427. [Google Scholar] [CrossRef]
- Coi, A.L.; Bigey, F.; Mallet, S.; Marsit, S.; Zara, G.; Gladieux, P.; Galeote, V.; Budroni, M.; Dequin, S.; Legras, J.L. Genomic signatures of adaptation to wine biological ageing conditions in biofilm-forming flor yeasts. Mol. Ecol. 2017, 26, 2150–2166. [Google Scholar] [CrossRef]
- Legras, J.-L.; Galeote, V.; Bigey, F.; Camarasa, C.; Marsit, S.; Nidelet, T.; Sanchez, I.; Couloux, A.; Guy, J.; Franco-Duarte, R.; et al. Adaptation of S. cerevisiae to Fermented Food Environments Reveals Remarkable Genome Plasticity and the Footprints of Domestication. Mol. Biol. Evol. 2018, 35, 1712–1727. [Google Scholar] [CrossRef]
- Albertin, W.; Chasseriaud, L.; Comte, G.; Panfili, A.; Delcamp, A.; Salin, F.; Marullo, P.; Bely, M. Winemaking and Bioprocesses Strongly Shaped the Genetic Diversity of the Ubiquitous Yeast Torulaspora delbrueckii. PLoS ONE 2014, 9, e94246. [Google Scholar] [CrossRef]
- Pérez-Ortín, J.E.; Querol, A.; Puig, S.; Barrio, E. Molecular Characterization of a Chromosomal Rearrangement Involved in the Adaptive Evolution of Yeast Strains. Genome Res. 2002, 12, 1533–1539. [Google Scholar] [CrossRef] [Green Version]
- Novo, M.; Bigey, F.; Beyne, E.; Galeote, V.; Gavory, F.; Mallet, S.; Cambon, B.; Legras, J.-L.; Wincker, P.; Casaregola, S.; et al. Eukaryote-to-eukaryote gene transfer events revealed by the genome sequence of the wine yeast Saccharomyces cerevisiae EC1118. Proc. Natl. Acad. Sci. USA 2009, 106, 16333–16338. [Google Scholar] [CrossRef] [Green Version]
- Marsit, S.; Sanchez, I.; Galeote, V.; Dequin, S. Horizontally acquired oligopeptide transporters favour adaptation of Saccharomyces cerevisiae wine yeast to oenological environment. Environ. Microbiol. 2016, 18, 1148–1161. [Google Scholar] [CrossRef]
- Almeida, P.; Barbosa, R.; Bensasson, D.; Gonçalves, P.; Sampaio, J. Adaptive divergence in wine yeasts and their wild relatives suggests a prominent role for introgressions and rapid evolution at noncoding sites. Mol. Ecol. 2017, 26, 2167–2182. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Isolate Name | Substrate of Isolation | Geographical Origin | Mating Type a | MLST Sequence Type b | MLST Clonal Complex b |
|---|---|---|---|---|---|
| CBS 178.71 | Soil polluted with oil | Germany | MATA/MATB | nd | nd |
| CBS 182.33 | Yoghurt | Italy | MATB | 6 | 2 |
| CBS 476.83 | Soil | Senegal | nd | 34 | 4 |
| CBS 557.83 | Peach | Egypt | nd | 35 | 4 |
| CBS 615.84 | Brie cheese | France | MATB | 20 | 3 |
| CBS 9194 | Fruitfly | Brazil | MATA | 8 | 3 |
| CBS 11176 | Bryndza cheese | Slovak republic, Žilina | MATB | 19 | 5 |
| CBS 11628 | Soil | South Africa, Western Cape | nd | 33 | 4 |
| CBS 117138 | Compost | Italy | nd | 14 | 3 |
| CLIB 918 | Pont-l’Évêque cheese | France, Calvados | MATA | 28 | 5 |
| CLIB 1154 | Flower | France, French Guiana | nd | nd | nd |
| CLIB 1235 | Camembert cheese | France, Orne | MATA | 5 | 1 |
| CLIB 1236 | Goat’s cheese | France, Manche | MATA | 7 | 1 |
| CLIB 1237 | Cow milk | France, Orne | MATA | 3 | 2 |
| CLIB 1239 | Mont d’Or cheese | France, Doubs | MATA | 29 | 5 |
| CLIB 1240 | Reblochon cheese | France, Haute-Savoie | MATB | 22 | 5 |
| CLIB 1241 | Mont d’Or cheese | France, Doubs | MATA | 29 | 5 |
| CLIB 1242 | Reblochon cheese | France, Haute-Savoie | MATA | 22 | 5 |
| CLIB 1243 | Reblochon cheese | France, Haute-Savoie | MATA | 22 | 5 |
| CLIB 1244 | Tomme de Savoie cheese | France, Haute-Savoie | MATB | 30 | 5 |
| CLIB 1245 | Reblochon cheese | France, Haute-Savoie | MATA | 30 | 5 |
| CLIB 1246 | Reblochon cheese | France, Haute-Savoie | MATB | 30 | 5 |
| CLIB 1247 | Tomme de Savoie cheese | France, Haute-Savoie | MATB | 30 | 5 |
| CLIB 1248 | Reblochon cheese | France, Haute-Savoie | MATA | 19 | 5 |
| CLIB 1249 | Mont d’Or cheese | France, Doubs | MATA/MATB | nd | nd |
| CLIB 1251 | Epoisses cheese | France, Côte-d’Or | MATA | 7 | 1 |
| CLIB 1252 | Epoisses cheese | France, Côte-d’Or | MATA | 7 | 1 |
| CLIB 1253 | Reblochon cheese | France, Haute-Savoie | MATB | 30 | 5 |
| CLIB 1254 | Reblochon cheese | France, Haute-Savoie | MATA/MATB | nd | nd |
| CLIB 1255 | Reblochon cheese | France, Haute-Savoie | MATA | 22 | 5 |
| CLIB 1256 | Reblochon cheese | France, Haute-Savoie | MATA | 29 | 5 |
| CLIB 1257 | Saint Nectaire cheese | France, Puy-de-Dôme | MATA | 21 | 5 |
| CLIB 1258 | Saint Nectaire cheese | France, Puy-de-Dôme | MATB | 14 | 3 |
| CLIB 1260 | Saint Nectaire cheese | France, Puy-de-Dôme | MATA | 19 | 5 |
| CLIB 1262 | Saint Nectaire cheese | France, Puy-de-Dôme | MATA | 29 | 5 |
| CLIB 1263 | Saint Nectaire cheese | France, Puy-de-Dôme | MATB | 7 | 1 |
| CLIB 1267 | Chaource cheese | France, Aube | MATA | 2 | 2 |
| CLIB 1270 | Saint Nectaire cheese | France, Puy-de-Dôme | MATA | 29 | 5 |
| CLIB 1274 | Reblochon cheese | France, Haute-Savoie | MATB | 16 | 5 |
| CLIB 1283 | Pont-l’Évêque cheese | France, Calvados | MATB | 10 | 3 |
| CLIB 1284 | Raw cream | France, Calvados | MATA/MATB | nd | nd |
| CLIB 1285 | Livarot cheese | France, Calvados | MATA | 25 | 5 |
| CNRZ 818 | unknown | unknown | nd | nd | nd |
| CNRZ 819 | unknown | unknown | nd | nd | nd |
| CNRZ 820 | unknown | unknown | nd | nd | nd |
| CNRZ 821 | unknown | unknown | nd | nd | nd |
| CNRZ 822 | unknown | unknown | nd | nd | nd |
| CNRZ 823 | unknown | unknown | nd | nd | nd |
| DSM 10452 | Sauerkraut | Germany | nd | 31 | 1 |
| DSM 13629 | Polyurethane | United Kingdom | nd | 38 | 3 |
| EL13-B1-3 | Refrigerator | France | nd | nd | nd |
| FM 03 | Cheese contaminant | unknown | MATB | 12 | 3 |
| FM 12 | unknown | unknown | nd | nd | nd |
| FM 29 | Cheese | Auvergne | MATB | 23 | 5 |
| FM 30 | Cheese | Auvergne | MATB | 24 | 5 |
| FM 31 | Cheese | Auvergne | MATB | 23 | 5 |
| FM 34 | Goat’s cheese | Auvergne | MATA | 18 | 5 |
| FM 76 | Raw milk | France, Normandie | MATB | 18 | 5 |
| FM 77 | unknown | unknown | MATB | 18 | 5 |
| FM 115 | unknown | unknown | MATB | 26 | 3 |
| FM 119 | unknown | unknown | MATA/MATB | nd | nd |
| FM 122 | unknown | unknown | MATA | 9 | 3 |
| FM 125 | unknown | unknown | MATA | 7 | 1 |
| FM 136 | unknown | unknown | MATA | 14 | 3 |
| FM 212 | Corn silage | France | MATB | 13 | 3 |
| FM 213 | unknown | unknown | MATA/MATB | nd | nd |
| FM 214 | Milk | France, Normandie | MATA | 18 | 5 |
| FM 267 | Stools | France, Normandie | MATA/MATB | nd | nd |
| FM 268 | Stools | France, Normandie | MATA | 18 | 5 |
| FM 269 | Stools | France, Normandie | MATA | 27 | 5 |
| FM 270 | Stools | France, Normandie | MATA | 11 | 3 |
| LCP 51.590 | Sand | Spain, Burgos | MATA | 4 | 2 |
| MUCL 881 | Milk | Belgium, Flemish Region | nd | 22 | 5 |
| MUCL 8652 | Wet hay | Belgium, Flemish Region | nd | 37 | 3 |
| MUCL 11539 | Polluted water | Great Britain | nd | 32 | 3 |
| MUCL 14462 | Squash | USA, Pierce county | nd | 39 | 3 |
| NBRC 5368 | Butter | Great Britain | nd | 36 | 3 |
| NCYC 49 | Milk | Great Britain | nd | 40 | 1 |
| NT 12 | Rain forest | Thailand | MATB | 1 | 2 |
| VTTC 4559 | Malting | Sweden | MATB | 15 | 3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tinsley, C.R.; Jacques, N.; Lucas, M.; Grondin, C.; Legras, J.-L.; Casaregola, S. Molecular Genetic Analysis with Microsatellite-like Loci Reveals Specific Dairy-Associated and Environmental Populations of the Yeast Geotrichum candidum. Microorganisms 2022, 10, 103. https://doi.org/10.3390/microorganisms10010103
Tinsley CR, Jacques N, Lucas M, Grondin C, Legras J-L, Casaregola S. Molecular Genetic Analysis with Microsatellite-like Loci Reveals Specific Dairy-Associated and Environmental Populations of the Yeast Geotrichum candidum. Microorganisms. 2022; 10(1):103. https://doi.org/10.3390/microorganisms10010103
Chicago/Turabian StyleTinsley, Colin R., Noémie Jacques, Marine Lucas, Cécile Grondin, Jean-Luc Legras, and Serge Casaregola. 2022. "Molecular Genetic Analysis with Microsatellite-like Loci Reveals Specific Dairy-Associated and Environmental Populations of the Yeast Geotrichum candidum" Microorganisms 10, no. 1: 103. https://doi.org/10.3390/microorganisms10010103