The First Genome Survey of the Antarctic Krill (Euphausia superba) Provides a Valuable Genetic Resource for Polar Biomedical Research

 , ,
, ,  , and
, and
Abstract
:1. Introduction
2. Results
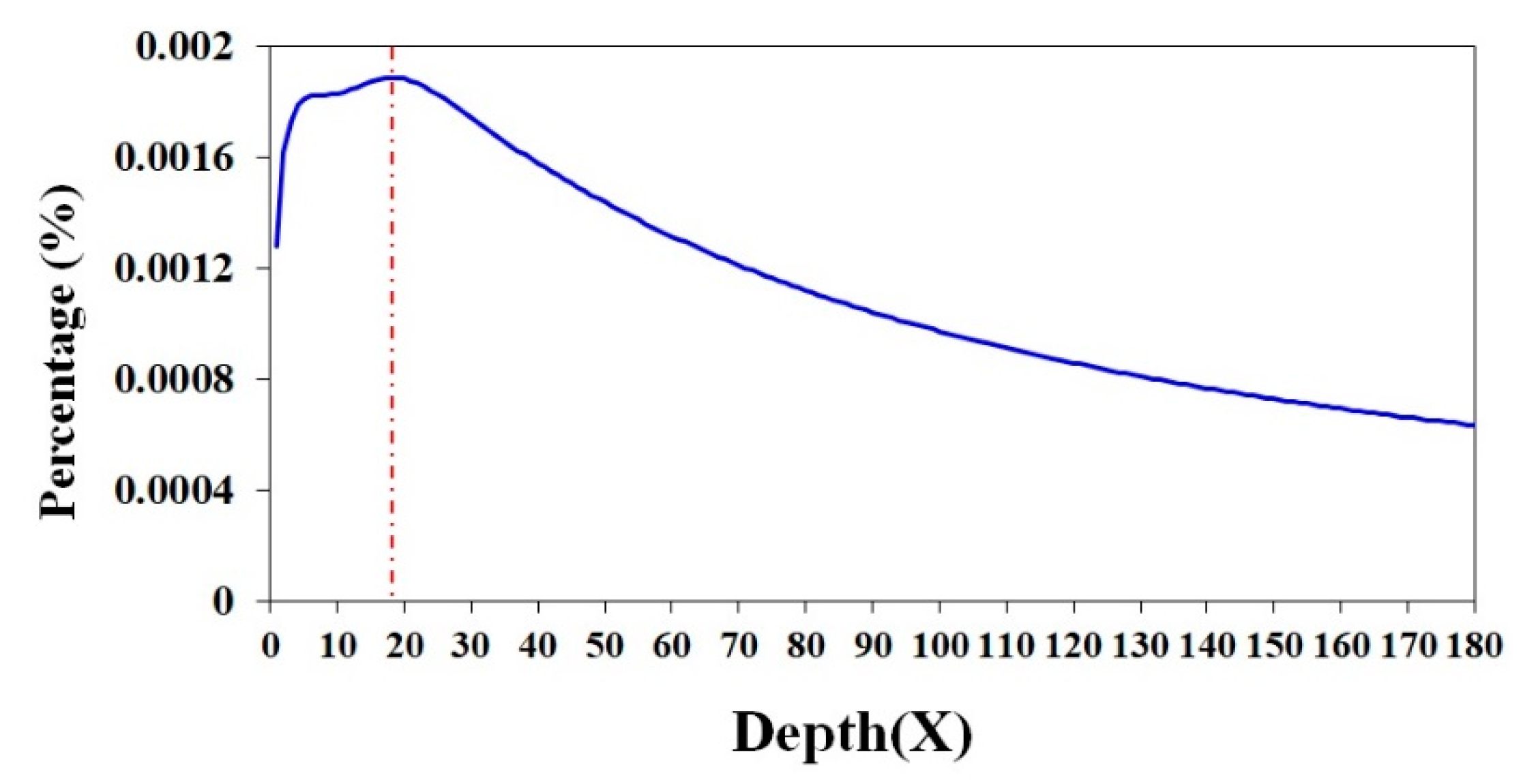
2.1. A Genome Survey of the Antarctic Krill
2.2. Assembly of Extracted Partial Mitochondrial Genome
2.2.1. Annotation and Analysis of Our Extracted Mitochondrial Genes
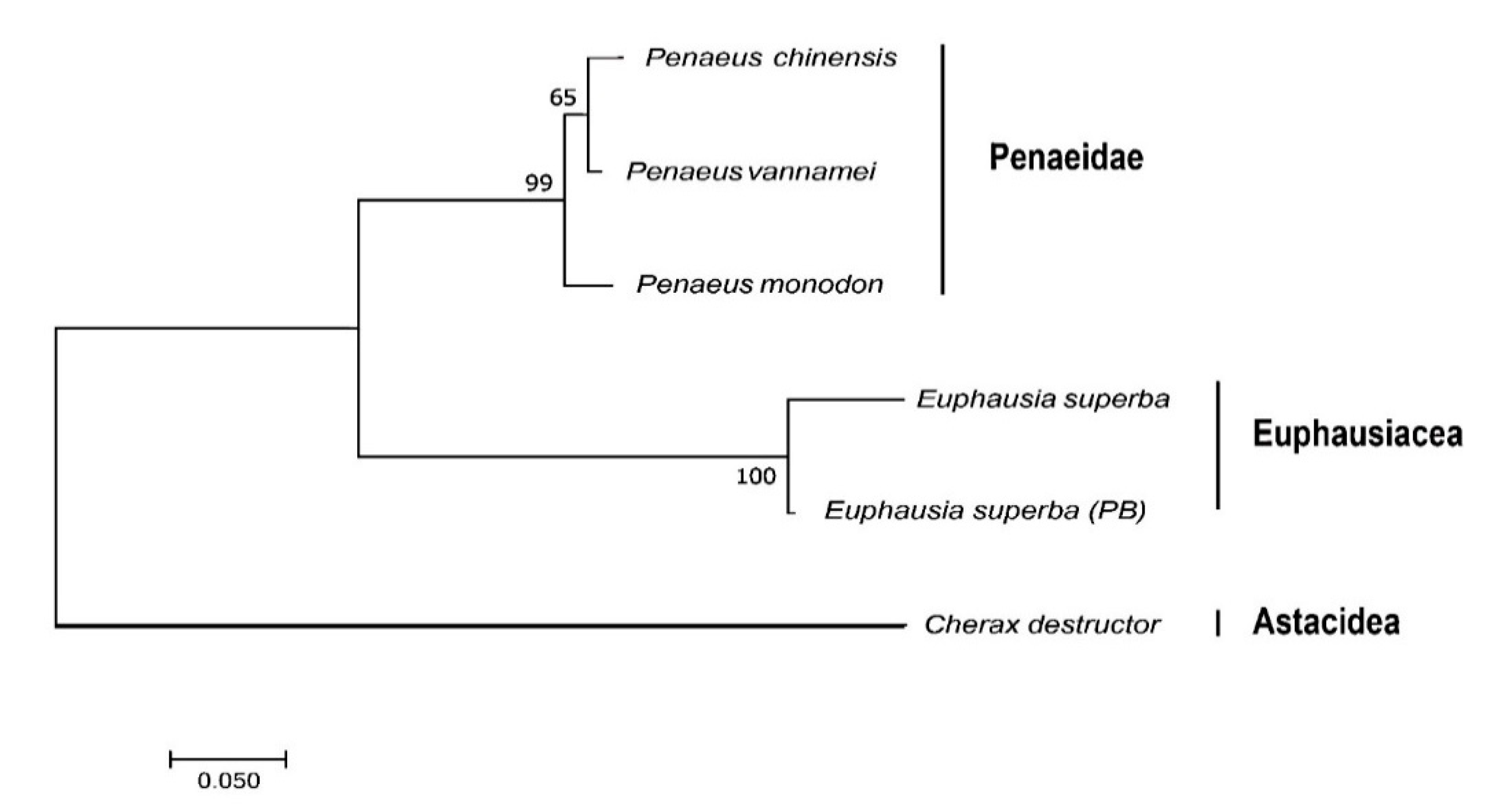
2.2.2. Multiple Sequence Alignment and Phylogenetic Analysis of the Representative Mitochondrial Gene nad4L
2.3. Assemblies of Reported Transcriptomes of the Antarctic Krill and the Whiteleg Shrimp
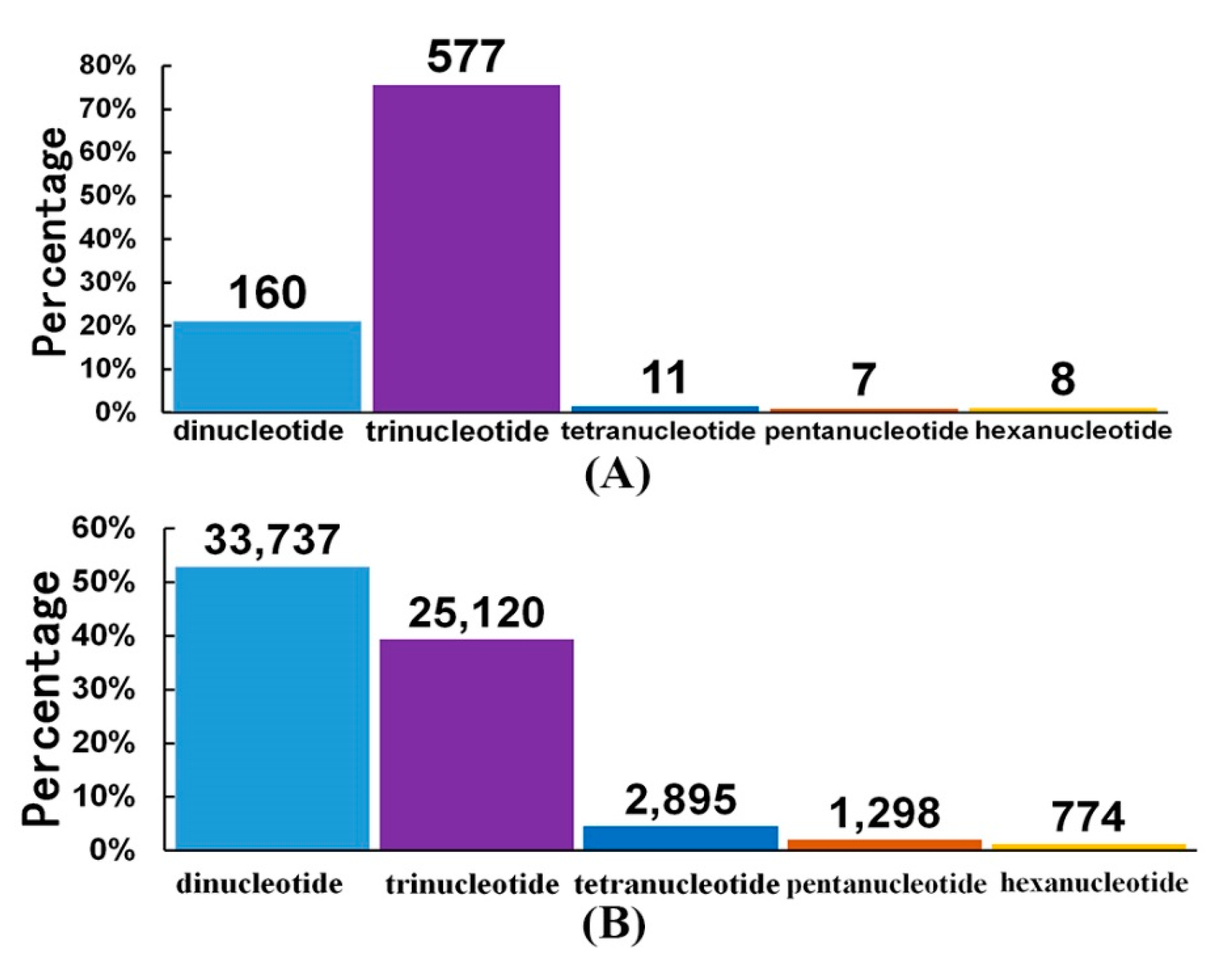
2.4. High-throughput SSR Identification in the Antarctic Krill
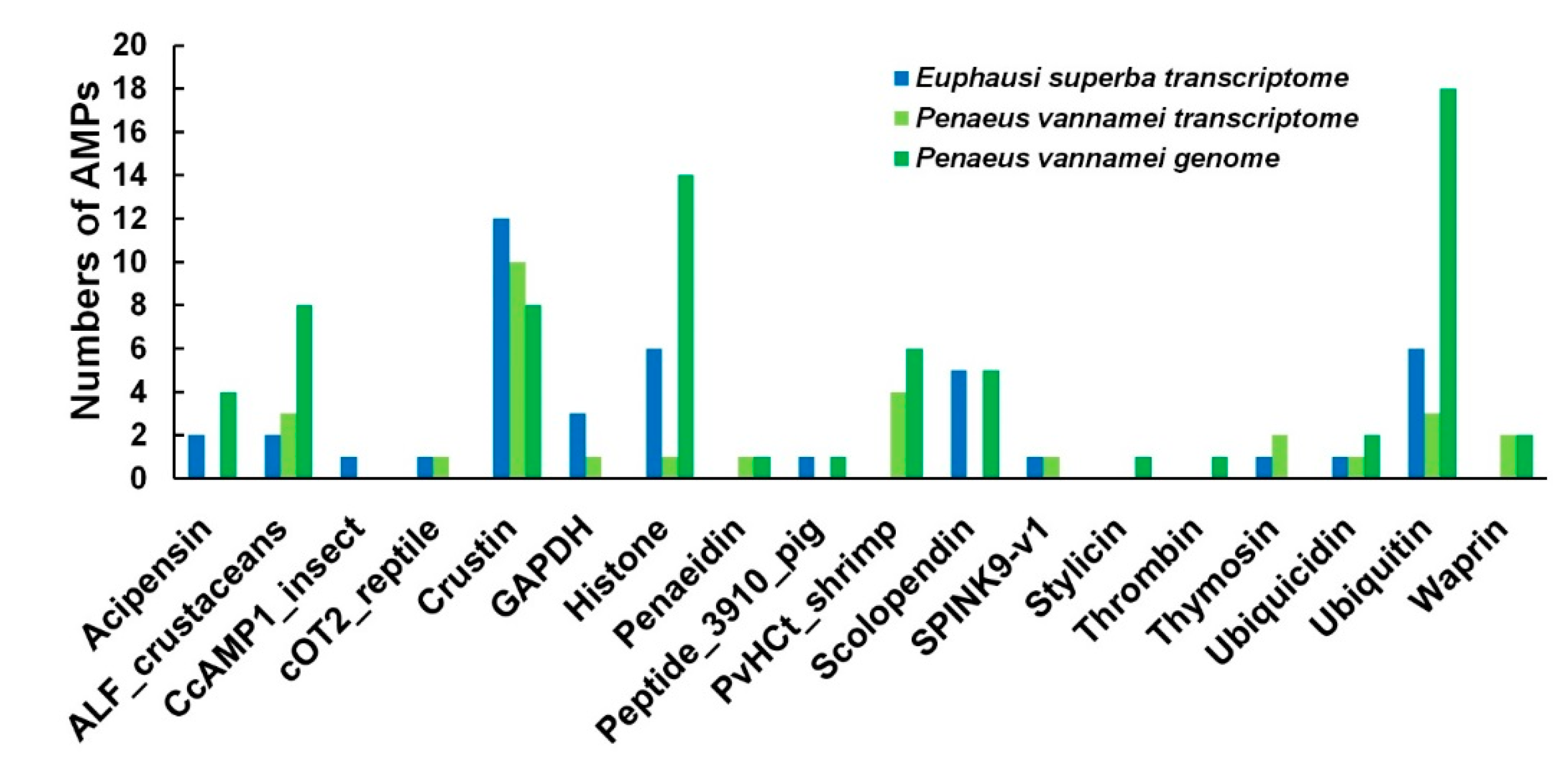
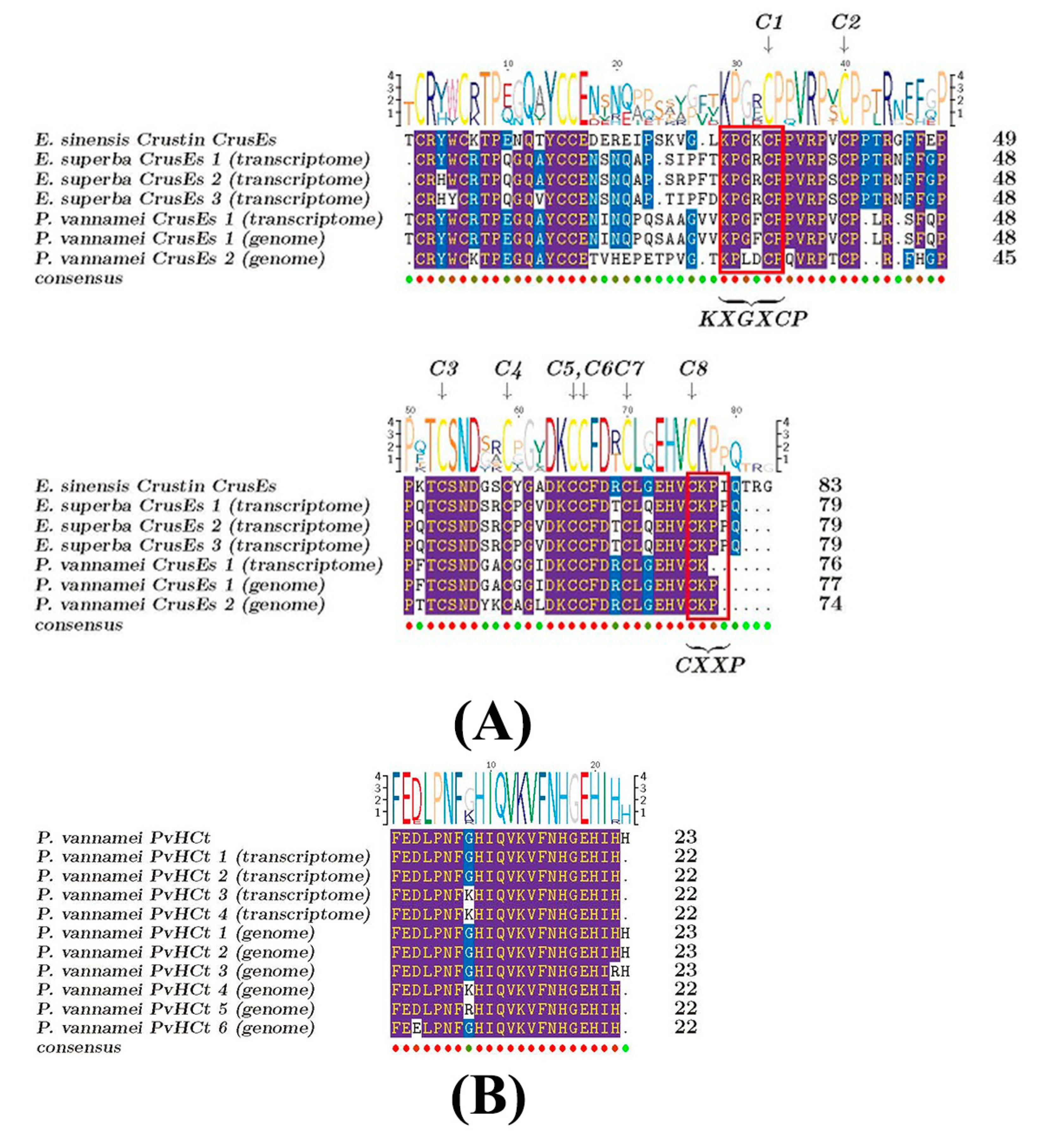
2.5. Comparisons of AMPs between the Antarctic Krill and the Whiteleg Shrimp
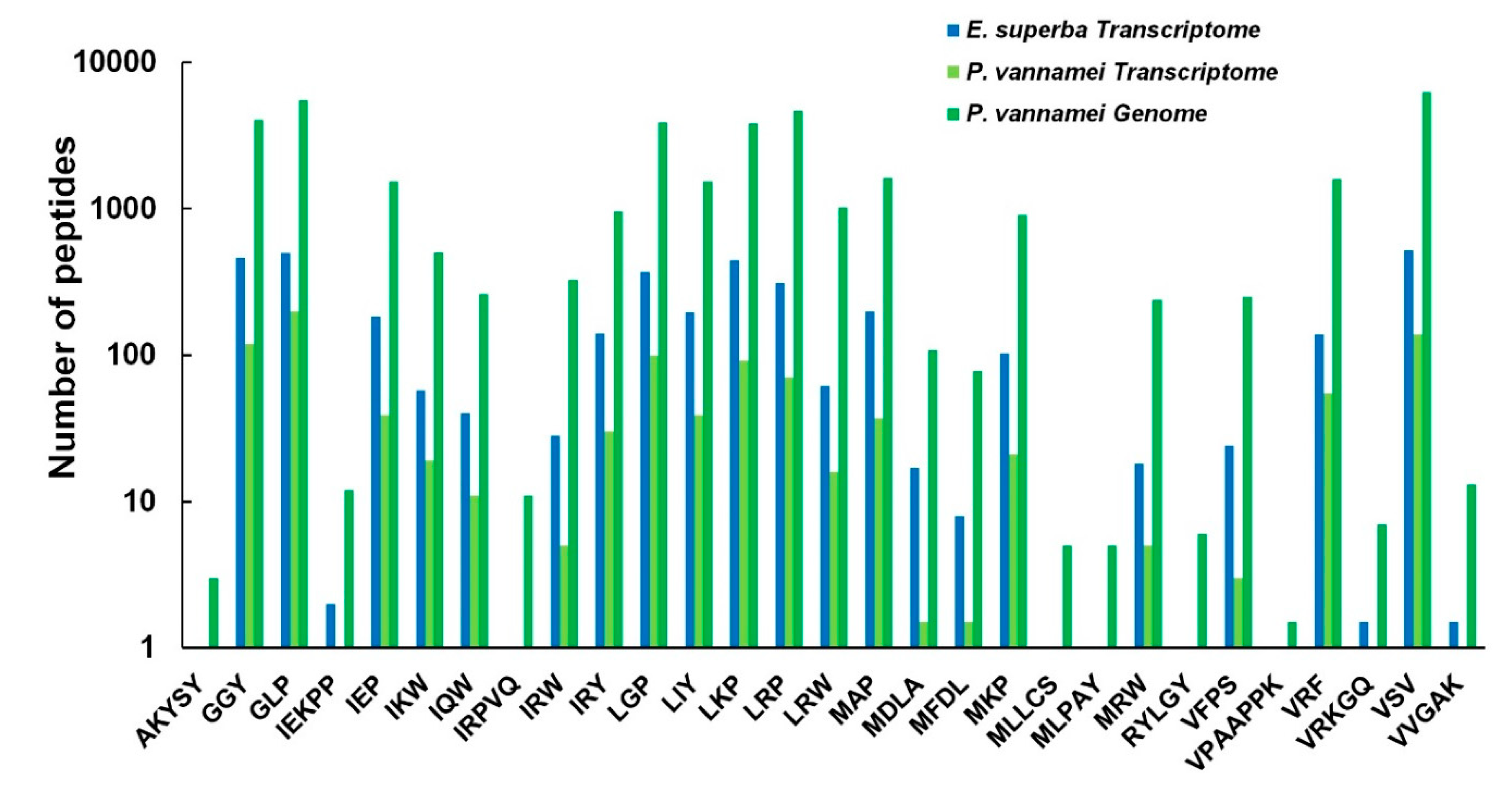
2.6. Prediction and Analysis of AHTPs in both Crustacean Species
3. Discussion
3.1. Importance to Characterize the Genome Size, Mitochondrial Genome and SSRs in the Antarctic Krill
3.2. Similarities and Differences of AMPs between the Two Examined Crustacean Species
3.3. Conservations of AHTPs between the Two Crustacean Species
4. Materials and Methods
4.1. Genomic DNA Extraction and Genome Sequencing for the Antarctic Krill
4.2. Assembly of the Antarctic Krill Mitochondrial Genome and Transcriptomes
4.3. Functional Annotation of the Extracted Mitochondrial Genome and the Reported Transcriptomes
4.4. Phylogenetic Analysis and Multiple Sequence Alignment
4.5. SSR Analysis
4.6. AMP Analysis
4.7. AHTP Analysis
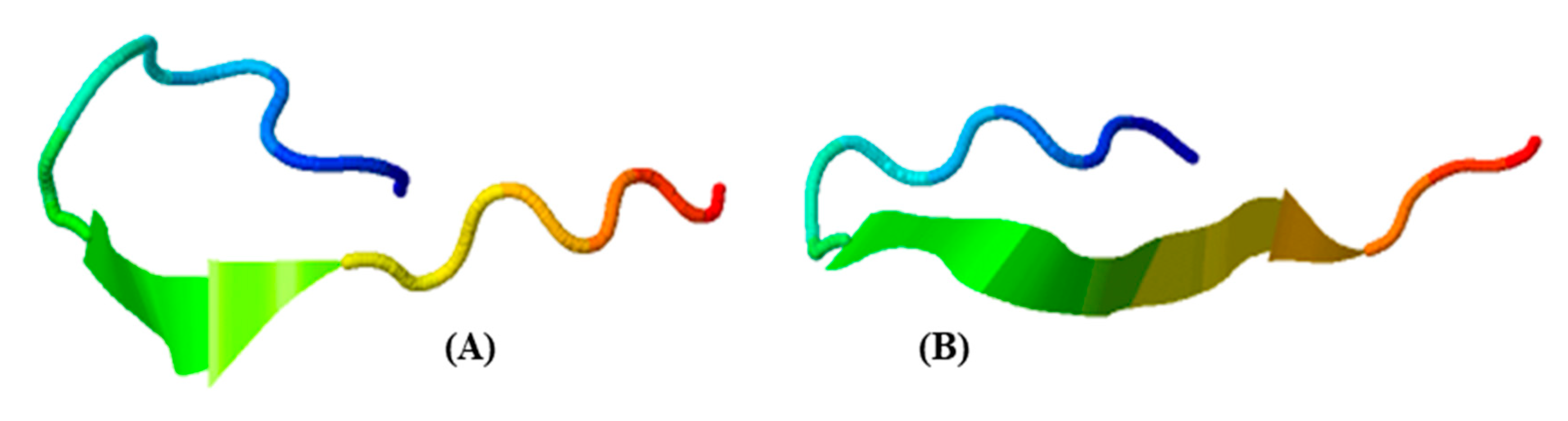
4.8. Tertiary Structure Prediction
5. Conclusions
Supplementary Materials
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Ma, C.; Ma, H.; Xu, G.; Feng, C.; Ma, L.; Wang, L. De novo sequencing of the Antarctic krill (Euphausia superba) transcriptome to identify functional genes and molecular markers. J. Genet. 2018, 97, 995–999. [Google Scholar] [CrossRef]
- Ikeda, T.; Dixon, P. The influence of feeding on the metabolic activity of Antarctic krill (Euphausia superba Dana). Polar Biol. 1984, 3, 1–9. [Google Scholar] [CrossRef]
- Sales, G.; Deagle, B.E.; Calura, E.; Martini, P.; Biscontin, A.; De Pitta, C.; Kawaguchi, S.; Romualdi, C.; Meyer, B.; Costa, R. KrillDB: A de novo transcriptome database for the Antarctic krill (Euphausia superba). PLoS ONE 2017, 12, e0171908. [Google Scholar] [CrossRef] [Green Version]
- Friedlaender, A.S.; Johnston, D.W.; Fraser, W.R.; Burns, J.; Costa, D.P. Ecological niche modeling of sympatric krill predators around Marguerite Bay, Western Antarctic Peninsula. Deep Sea Res. Part II Top. Stud. Oceanogr. 2011, 58, 1729–1740. [Google Scholar] [CrossRef]
- Nicol, S.; Foster, J.; Kawaguchi, S. The fishery for Antarctic krill–recent developments. Fish Fish. 2012, 13, 30–40. [Google Scholar] [CrossRef]
- Shen, X.; Wang, H.; Ren, J.; Tian, M.; Wang, M. The mitochondrial genome of Euphausia superba (Prydz Bay) (Crustacea: Malacostraca: Euphausiacea) reveals a novel gene arrangement and potential molecular markers. Mol. Biol. Rep. 2010, 37, 771. [Google Scholar] [CrossRef]
- Machida, R.J.; Miya, M.U.; Yamauchi, M.M.; Nishida, M.; Nishida, S. Organization of the mitochondrial genome of Antarctic krill Euphausia superba (Crustacea: Malacostraca). Mar. Biotechnol. 2004, 6, 238–250. [Google Scholar] [CrossRef]
- Zhang, X.; Yuan, J.; Sun, Y.; Li, S.; Gao, Y.; Yu, Y.; Liu, C.; Wang, Q.; Lv, X.; Zhang, X. Penaeid shrimp genome provides insights into benthic adaptation and frequent molting. Nat. Commun. 2019, 10, 356. [Google Scholar] [CrossRef] [Green Version]
- Yi, Y.; You, X.; Bian, C.; Chen, S.; Lv, Z.; Qiu, L.; Shi, Q. High-throughput identification of antimicrobial peptides from amphibious mudskippers. Mar. Drugs 2017, 15, 364. [Google Scholar] [CrossRef] [Green Version]
- Tincu, J.A.; Taylor, S.W. Antimicrobial peptides from marine invertebrates. Antimicrob. Agents Chemother. 2004, 48, 3645–3654. [Google Scholar] [CrossRef] [Green Version]
- Sperstad, S.V.; Haug, T.; Blencke, H.-M.; Styrvold, O.B.; Li, C.; Stensvag, K. Antimicrobial peptides from marine invertebrates: Challenges and perspectives in marine antimicrobial peptide discovery. Biotechnol. Adv. 2011, 29, 519–530. [Google Scholar] [CrossRef]
- Zhao, L.; Yin, B.; Liu, Q.; Cao, R. Purification of antimicrobial peptide from Antarctic Krill (Euphausia superba) and its function mechanism. J. Ocean. Univ. China 2013, 12, 484–490. [Google Scholar] [CrossRef]
- Yi, Y.; Lv, Y.; Zhang, L.; Yang, J.; Shi, Q. High throughput identification of antihypertensive peptides from fish proteome datasets. Mar. Drugs 2018, 16, 365. [Google Scholar] [CrossRef] [Green Version]
- Jia, K.; Bian, C.; Yi, Y.; Li, Y.; Jia, P.; Gui, D.; Zhang, X.; Lin, W.; Sun, X.; Lv, Y.; et al. Whole genome sequencing of Chinese white dolphin (Sousa chinensis) for high-throughput screening of antihypertensive peptides. Mar. Drugs 2019, 17, 504. [Google Scholar] [CrossRef] [Green Version]
- Park, S.Y.; Je, J.-Y.; Kang, N.; Han, E.J.; Um, J.H.; Jeon, Y.-J.; Ahn, G.; Ahn, C.-B. Antihypertensive effects of Ile–Pro–Ile–Lys from krill (Euphausia superba) protein hydrolysates: Purification, identification and in vivo evaluation in spontaneously hypertensive rats. Eur. Food Res. Technol. 2017, 243, 719–725. [Google Scholar] [CrossRef]
- Zhao, Y.-Q.; Zhang, L.; Tao, J.; Chi, C.-F.; Wang, B. Eight antihypertensive peptides from the protein hydrolysate of Antarctic krill (Euphausia superba): Isolation, identification, and activity evaluation on human umbilical vein endothelial cells (HUVECs). Food Res. Int. 2019, 121, 197–204. [Google Scholar] [CrossRef]
- Yu, Y.; Zhang, X.; Yuan, J.; Li, F.; Chen, X.; Zhao, Y.; Huang, L.; Zheng, H.; Xiang, J. Genome survey and high-density genetic map construction provide genomic and genetic resources for the Pacific White Shrimp Litopenaeus vannamei. Sci. Rep. 2015, 5, 15612. [Google Scholar] [CrossRef] [Green Version]
- Buchfink, B.; Xie, C.; Huson, D.H. Fast and sensitive protein alignment using DIAMOND. Nat. Methods 2015, 12, 59–60. [Google Scholar] [CrossRef]
- Kanehisa, M.; Goto, S. KEGG: Kyoto encyclopedia of genes and genomes. Nucleic Acids Res. 2000, 28, 27–30. [Google Scholar] [CrossRef]
- Consortium, G.O. The Gene Ontology (GO) database and informatics resource. Nucleic Acids Res. 2004, 32, D258–D261. [Google Scholar] [CrossRef] [Green Version]
- Saitou, N.; Nei, M. The neighbor-joining method: A new method for reconstructing phylogenetic trees. Mol. Biol. Evol. 1987, 4, 406–425. [Google Scholar]
- Felsenstein, J. Confidence limits on phylogenies: An approach using the bootstrap. Evolution 1985, 39, 783–791. [Google Scholar] [CrossRef]
- Kumar, S.; Stecher, G.; Tamura, K. MEGA7: Molecular evolutionary genetics analysis version 7.0 for bigger datasets. Mol. Biol. Evol. 2016, 33, 1870–1874. [Google Scholar] [CrossRef] [Green Version]
- Gao, Y.; Zhang, X.; Wei, J.; Sun, X.; Yuan, J.; Li, F.; Xiang, J. Whole transcriptome analysis provides insights into molecular mechanisms for molting in Litopenaeus vannamei. PLoS ONE 2015, 10, e0144350. [Google Scholar] [CrossRef] [Green Version]
- Petit, V.W.; Rolland, J.-L.; Blond, A.; Cazevieille, C.; Djediat, C.; Peduzzi, J.; Goulard, C.; Bachère, E.; Dupont, J.; Destoumieux-Garzón, D. A hemocyanin-derived antimicrobial peptide from the penaeid shrimp adopts an alpha-helical structure that specifically permeabilizes fungal membranes. Biochim. Biophys. Acta 2016, 1860, 557–568. [Google Scholar] [CrossRef] [Green Version]
- Mu, C.; Zheng, P.; Zhao, J.; Wang, L.; Zhang, H.; Qiu, L.; Gai, Y.; Song, L. Molecular characterization and expression of a crustin-like gene from Chinese mitten crab, Eriocheir sinensis. Dev. Comp. Immunol. 2010, 34, 734–740. [Google Scholar] [CrossRef]
- Ranganathan, S.; Simpson, K.J.; Shaw, D.C.; Nicholas, K.R. The whey acidic protein family: A new signature motif and three-dimensional structure by comparative modeling. J. Mol. Graph. Model. 1999, 17, 106–113. [Google Scholar] [CrossRef]
- Destoumieux, D.; Munoz, M.; Bulet, P.; Bachere, E. Penaeidins, a family of antimicrobial peptides from penaeid shrimp (Crustacea, Decapoda). Cell. Mol. Life Sci. 2000, 57, 1260–1271. [Google Scholar] [CrossRef]
- Jeffery, N.W. The first genome size estimates for six species of krill (Malacostraca, Euphausiidae): Large genomes at the north and south poles. Polar Biol. 2012, 35, 959–962. [Google Scholar] [CrossRef]
- Lucassen, M.; Koschnick, N.; Eckerle, L.; Pörtner, H.-O. Mitochondrial mechanisms of cold adaptation in cod (Gadus morhua L.) populations from different climatic zones. J. Exp. Biol. 2006, 209, 2462–2471. [Google Scholar] [CrossRef] [Green Version]
- Sundaray, J.K.; Rasal, K.D.; Chakrapani, V.; Swain, P.; Kumar, D.; Ninawe, A.S.; Nandi, S.; Jayasankar, P. Simple sequence repeats (SSRs) markers in fish genomic research and their acceleration via next-generation sequencing and computational approaches. Aquacult. Int. 2016, 24, 1089–1102. [Google Scholar] [CrossRef]
- Perez, F.; Ortiz, J.; Zhinaula, M.; Gonzabay, C.; Calderon, J.; Volckaert, F.A. Development of EST-SSR markers by data mining in three species of shrimp: Litopenaeus vannamei, Litopenaeus stylirostris, and Trachypenaeus birdy. Mar. Biotechnol. 2005, 7, 554–569. [Google Scholar] [CrossRef]
- Li, S.; Zhao, B. Isolation, purification, and detection of the antimicrobial activity of the antimicrobial peptide CcAMP1 from Coridius chinensis (Hemiptera: Dinidoridae). Acta Entomol. Sin. 2015, 58, 610–616. [Google Scholar]
- Kim, H.S.; Park, C.B.; Kim, M.S.; Kim, S.C. cDNA cloning and characterization of buforin I, an antimicrobial peptide: A cleavage product of histone H2A. Biochem. Biophys. Res. Commun. 1996, 229, 381–387. [Google Scholar] [CrossRef]
- Park, C.B.; Kim, M.S.; Kim, S.C. A novel antimicrobial peptide from Bufo bufo gargarizans. Biochem. Biophys. Res. Commun. 1996, 218, 408–413. [Google Scholar] [CrossRef]
- Seo, J.-K.; Lee, M.J.; Go, H.-J.; Do Kim, G.; Do Jeong, H.; Nam, B.-H.; Park, N.G. Purification and antimicrobial function of ubiquitin isolated from the gill of Pacific oyster, Crassostrea gigas. Mol. Immunol. 2013, 53, 88–98. [Google Scholar] [CrossRef]
- Krusong, K.; Poolpipat, P.; Supungul, P.; Tassanakajon, A. A comparative study of antimicrobial properties of crustinPm1 and crustinPm7 from the black tiger shrimp Penaeus monodon. Dev. Comp. Immunol. 2012, 36, 208–215. [Google Scholar] [CrossRef]
- Yu, A.-Q.; Shi, Y.-H.; Wang, Q. Characterisation of a novel type i crustin involved in antibacterial and antifungal responses in the red claw crayfish, Cherax quadricarinatus. Fish. Shellfish Immunol. 2016, 48, 30–38. [Google Scholar] [CrossRef]
- Rolland, J.A.M.; Dupont, J.; Lefevre, F.; Bachère, E.; Romestand, B. Stylicins, a new family of antimicrobial peptides from the Pacific blue shrimp Litopenaeus stylirostris. Mol. Immunol. 2010, 47, 1269–1277. [Google Scholar] [CrossRef] [Green Version]
- Amparyup, P.; Donpudsa, S.; Tassanakajon, A. Shrimp single WAP domain (SWD)-containing protein exhibits proteinase inhibitory and antimicrobial activities. Dev. Comp. Immunol. 2008, 32, 1497–1509. [Google Scholar] [CrossRef]
- Papareddy, P.; Rydengård, V.; Pasupuleti, M.; Walse, B.; Mörgelin, M.; Chalupka, A.; Malmsten, M.; Schmidtchen, A. Proteolysis of human thrombin generates novel host defense peptides. PLoS Pathog. 2010, 6, e1000857. [Google Scholar] [CrossRef] [Green Version]
- Low, B.W.; Ng, N.K.; Yeo, D.C. First record of the invasive Chinese mitten crab, Eriocheir sinensis H. Milne Edwards, 1853 (Crustacea: Brachyura: Varunidae) from Singapore. BioInvas. Rec 2013, 2, 73–78. [Google Scholar] [CrossRef]
- Thanh, N.M.; Ponzoni, R.W.; Nguyen, N.H.; Vu, N.T.; Barnes, A.; Mather, P.B. Evaluation of growth performance in a diallel cross of three strains of giant freshwater prawn (Macrobrachium rosenbergii) in Vietnam. Aquaculture 2009, 287, 75–83. [Google Scholar] [CrossRef]
- Benzie, J.; Ballment, E.; Forbes, A.; Demetriades, N.; Sugama, K.; Moria, S. Mitochondrial DNA variation in Indo-Pacific populations of the giant tiger prawn, Penaeus monodon. Mol. Ecol. 2002, 11, 2553–2569. [Google Scholar] [CrossRef]
- Eckert, R.L.; Green, H. Structure and evolution of the human involucrin gene. Cell 1986, 46, 583–589. [Google Scholar] [CrossRef]
- McGrath, J.; Eady, R.; Pope, F. Anatomy and organization of human skin. Rook’s Textb. Dermatol. 2004, 10, 9781444317633. [Google Scholar]
- Sotiropoulou, P.A.; Blanpain, C. Development and homeostasis of the skin epidermis. Cold Spring Harb. Perspect. Biol. 2012, 4, a008383. [Google Scholar] [CrossRef] [Green Version]
- Saiga, A.; Iwai, K.; Hayakawa, T.; Takahata, Y.; Kitamura, S.; Nishimura, T.; Morimatsu, F. Angiotensin I-converting enzyme-inhibitory peptides obtained from chicken collagen hydrolysate. J. Agric. Food Chem. 2008, 56, 9586–9591. [Google Scholar] [CrossRef]
- Kim, S.-K.; Byun, H.-G.; Park, P.-J.; Shahidi, F. Angiotensin I converting enzyme inhibitory peptides purified from bovine skin gelatin hydrolysate. J. Agric. Food Chem. 2001, 49, 2992–2997. [Google Scholar] [CrossRef]
- Fu, Y.; Young, J.F.; Rasmussen, M.K.; Dalsgaard, T.K.; Lametsch, R.; Aluko, R.E.; Therkildsen, M. Angiotensin I–converting enzyme–inhibitory peptides from bovine collagen: Insights into inhibitory mechanism and transepithelial transport. Food Res. Int. 2016, 89, 373–381. [Google Scholar] [CrossRef]
- Zhuang, Y.; Sun, L.; Li, B. Production of the angiotensin-I-converting enzyme (ACE)-inhibitory peptide from hydrolysates of jellyfish (Rhopilema esculentum) collagen. Food. Bioproc. Tech. 2012, 5, 1622–1629. [Google Scholar] [CrossRef]
- Fahmi, A.; Morimura, S.; Guo, H.-C.; Shigematsu, T.; Kida, K.; Uemura, Y. Production of angiotensin I converting enzyme inhibitory peptides from sea bream scales. Process. Biochem. 2004, 39, 1195–1200. [Google Scholar] [CrossRef]
- Liu, Z.-Y.; Chen, D.; Su, Y.-C.; Zeng, M.-Y. Optimization of hydrolysis conditions for the production of the angiotensin-I converting enzyme inhibitory peptides from sea cucumber collagen hydrolysates. J. Aquat. Food Prod. Technol. 2011, 20, 222–232. [Google Scholar] [CrossRef]
- Chen, Y.; Chen, Y.; Shi, C.; Huang, Z.; Zhang, Y.; Li, S.; Li, Y.; Ye, J.; Yu, C.; Li, Z. SOAPnuke: A MapReduce acceleration-supported software for integrated quality control and preprocessing of high-throughput sequencing data. Gigascience 2017, 7, gix120. [Google Scholar] [CrossRef] [Green Version]
- Li, R.; Yu, C.; Li, Y.; Lam, T.-W.; Yiu, S.-M.; Kristiansen, K.; Wang, J. SOAP2: An improved ultrafast tool for short read alignment. Bioinformatics 2009, 25, 1966–1967. [Google Scholar] [CrossRef] [Green Version]
- Bankevich, A.; Nurk, S.; Antipov, D.; Gurevich, A.A.; Dvorkin, M.; Kulikov, A.S.; Lesin, V.M.; Nikolenko, S.I.; Pham, S.; Prjibelski, A.D. SPAdes: A new genome assembly algorithm and its applications to single-cell sequencing. J. Comput. Biol. 2012, 19, 455–477. [Google Scholar] [CrossRef] [Green Version]
- Mount, D.W. Using the basic local alignment search tool (BLAST). Cold Spring Harb. Protoc. 2007, 2007, pdb.top17. [Google Scholar] [CrossRef]
- Jung, J.; Kim, J.I.; Jeong, Y.-S.; Yi, G. AGORA: Organellar genome annotation from the amino acid and nucleotide references. Bioinformatics 2018, 34, 2661–2663. [Google Scholar] [CrossRef]
- Haas, B.J.; Papanicolaou, A.; Yassour, M.; Grabherr, M.; Blood, P.D.; Bowden, J.; Couger, M.B.; Eccles, D.; Li, B.; Lieber, M. De novo transcript sequence reconstruction from RNA-seq using the Trinity platform for reference generation and analysis. Nat. Protoc. 2013, 8, 1494–1512. [Google Scholar] [CrossRef]
- Pertea, G.; Huang, X.; Liang, F.; Antonescu, V.; Sultana, R.; Karamycheva, S.; Lee, Y.; White, J.; Cheung, F.; Parvizi, B. TIGR Gene Indices clustering tools (TGICL): A software system for fast clustering of large EST datasets. Bioinformatics 2003, 19, 651–652. [Google Scholar] [CrossRef] [Green Version]
- Langmead, B.; Salzberg, S.L. Fast gapped-read alignment with Bowtie 2. Nat. Methods 2012, 9, 357–359. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, B.; Dewey, C.N. RSEM: Accurate transcript quantification from RNA-Seq data with or without a reference genome. BMC Bioinform. 2011, 12, 323. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Conesa, A.; Götz, S.; García-Gómez, J.M.; Terol, J.; Talón, M.; Robles, M. Blast2GO: A universal tool for annotation, visualization and analysis in functional genomics research. Bioinformatics 2005, 21, 3674–3676. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Boeckmann, B.; Bairoch, A.; Apweiler, R.; Blatter, M.-C.; Estreicher, A.; Gasteiger, E.; Martin, M.J.; Michoud, K.; O’Donovan, C.; Phan, I. The SWISS-PROT protein knowledgebase and its supplement TrEMBL in 2003. Nucleic Acids Res. 2003, 31, 365–370. [Google Scholar] [CrossRef]
- Katoh, K.; Standley, D.M. MAFFT multiple sequence alignment software version 7: Improvements in performance and usability. Mol. Biol. Evol. 2013, 30, 772–780. [Google Scholar] [CrossRef] [Green Version]
- Beitz, E. TEXshade: Shading and labeling of multiple sequence alignments using LATEX2 epsilon. Bioinformatics 2000, 16, 135–139. [Google Scholar] [CrossRef] [Green Version]
- Wang, G.; Li, X.; Wang, Z. APD3: The antimicrobial peptide database as a tool for research and education. Nucleic Acids Res. 2015, 44, D1087–D1093. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Yan, R.; Roy, A.; Xu, D.; Poisson, J.; Zhang, Y. The I-TASSER Suite: Protein structure and function prediction. Nat. Methods 2015, 12, 7–8. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| K-mer | K_num | K_depth | Genome Size | Clean Base (bp) | Depth (X) |
|---|---|---|---|---|---|
| 17 | 758,531,899,196 | 18 | 42,140,661,066 | 902,660,212,000 | 21 |
| Parameter | Value |
|---|---|
| Total Number (unigene) | 16,797 |
| Total Length (bp) | 10,715,598 |
| Mean Length (bp) | 637 |
| N50 (bp) | 923 |
| GC (%) | 37.63 |
| Parameter | Value |
|---|---|
| Total Number (unigene) | 3,768 |
| Total Length (bp) | 2,165,058 |
| Mean Length (bp) | 574 |
| N50 (bp) | 759 |
| GC (%) | 50.95 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Y.; Bian, C.; Liu, Z.; Wang, L.; Xue, C.; Huang, H.; Yi, Y.; You, X.; Song, W.; Mao, X.; et al. The First Genome Survey of the Antarctic Krill (Euphausia superba) Provides a Valuable Genetic Resource for Polar Biomedical Research. Mar. Drugs 2020, 18, 185. https://doi.org/10.3390/md18040185
Huang Y, Bian C, Liu Z, Wang L, Xue C, Huang H, Yi Y, You X, Song W, Mao X, et al. The First Genome Survey of the Antarctic Krill (Euphausia superba) Provides a Valuable Genetic Resource for Polar Biomedical Research. Marine Drugs. 2020; 18(4):185. https://doi.org/10.3390/md18040185
Chicago/Turabian StyleHuang, Yuting, Chao Bian, Zhaoqun Liu, Lingling Wang, Changhu Xue, Hongliang Huang, Yunhai Yi, Xinxin You, Wei Song, Xiangzhao Mao, and et al. 2020. "The First Genome Survey of the Antarctic Krill (Euphausia superba) Provides a Valuable Genetic Resource for Polar Biomedical Research" Marine Drugs 18, no. 4: 185. https://doi.org/10.3390/md18040185