Exploring Automated Classification Approaches to Advance the Assessment of Collaborative Problem Solving Skills


Abstract
:1. Introduction
1.1. Current Approaches for CPS Assessment
1.2. Machine-Driven Approaches for CPS Assessment
1.3. The Current Study
2. Materials and Methods
2.1. Participants
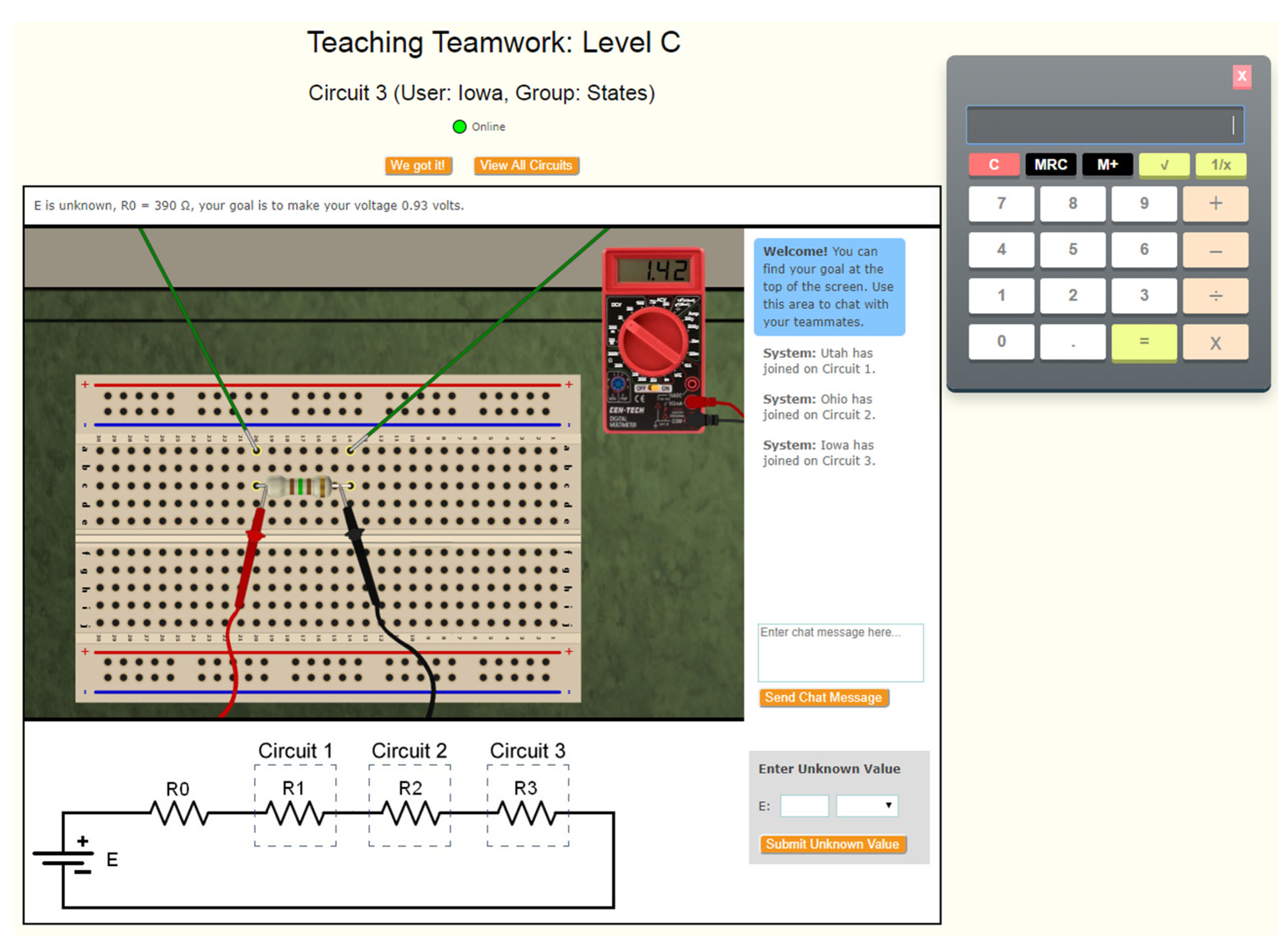
2.2. Task
2.3. Measures
2.4. CPS Ontology (Framework)
3. Analyses
3.1. Human Annotation
3.2. Automated Annotation
3.3. ClusterAnalysis
3.4. Validation Analyses
4. Results
4.1. Human Annotation Cluster Analysis
4.2. Human Annotation Validation Analyses
4.3. Automated Annotation Cluster Analysis
4.4. Automated Annotation Validation Analyses
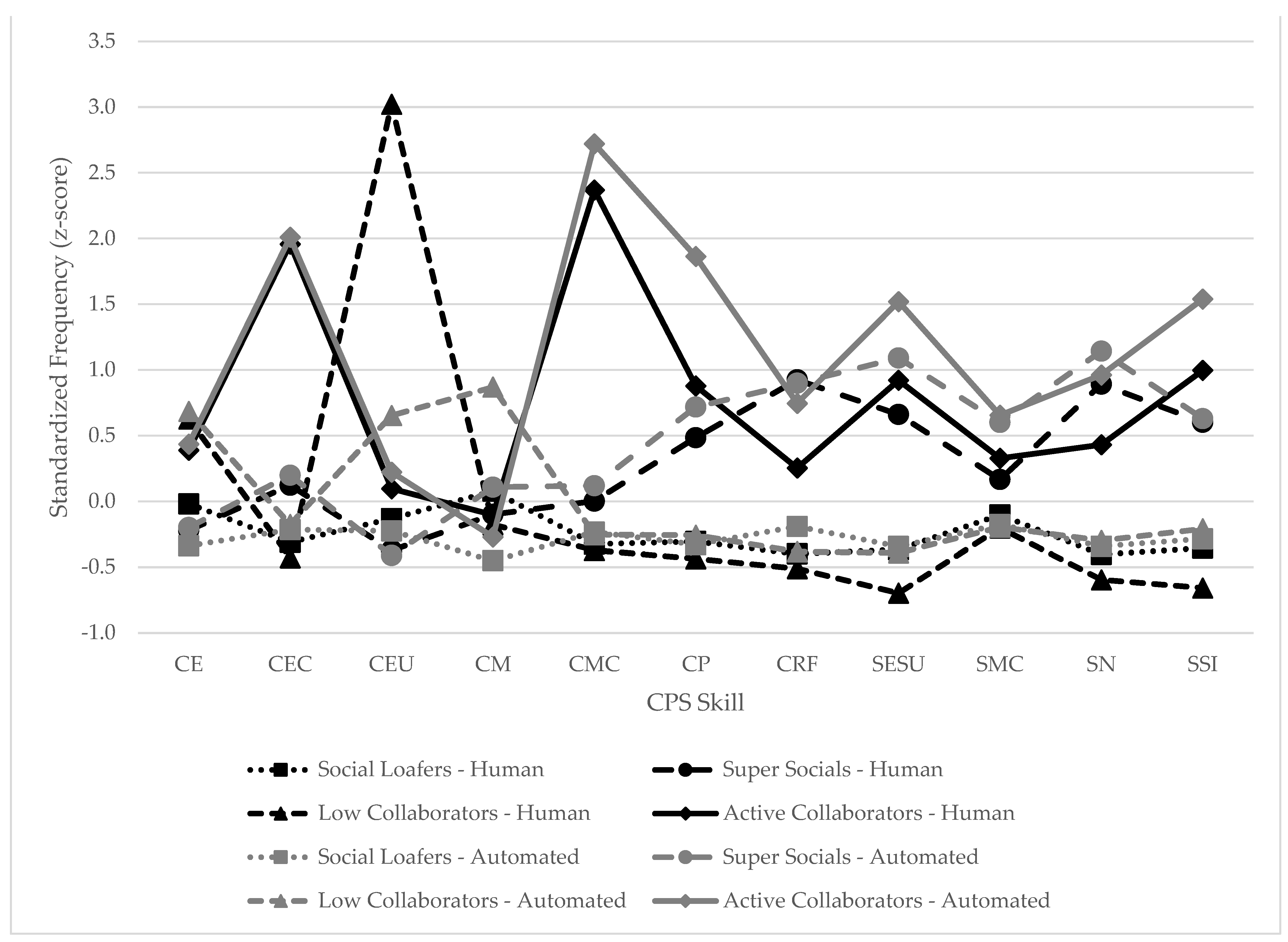
4.5. Comparing Clusters across Annotation Methods
5. Discussion
Limitations and Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Andrews-Todd, Jessica, and Carol M. Forsyth. 2020. Exploring Social and Cognitive Dimensions of Collaborative Problem Solving in an Open Online Simulation-Based Task. Computers in Human Behavior 104: 105759. [Google Scholar] [CrossRef]
- Andrews-Todd, Jessica, and Carol M. Forsyth. Forthcoming. Assessment of Collaborative Problem Solving Skills. In International Encyclopedia of Education. Edited by Rob Tierney, Fazal Rizvi and Kadriye Ercikan. New York: Elsevier.
- Andrews-Todd, Jessica, and Deirdre Kerr. 2019. Application of Ontologies for Assessing Collaborative Problem Solving Skills. International Journal of Testing 19: 172–87. [Google Scholar] [CrossRef]
- Andrews-Todd, Jessica, Carol M. Forsyth, Jonathan Steinberg, and André A. Rupp. 2018. Identifying Profiles of Collaborative Problem Solvers in an Online Electronics Environment. Paper presented at the 11th International Conference on Educational Data Mining, Buffalo, NY, USA, July 15–18; Edited by Kristy E. Boyer and Michael Yudelson. Buffalo: International Educational Data Mining Society, pp. 239–45. [Google Scholar]
- Andrews-Todd, Jessica, Jonathan Steinberg, and Yang Jiang. 2021. Stability of Collaborative Problem Solving Profile Membership across Tasks. Princeton: Educational Testing Servicem, Unpublished manuscript. [Google Scholar]
- Andrews-Todd, Jessica, Jonathan Steinberg, Samuel L. Pugh, and Sidney K. D’Mello. 2022. Comparing Collaborative Problem Solving Profiles Derived from Human and Semi-Automated Annotation. Paper presented at the 15th International Conference on Computer Supported Collaborative Learning—CSCL, Hiroshima, Japan, September 21; Edited by Armin Weinberger, Wenli Chen, Davinia Hernández-Leo and Bodong Chen. Hiroshima: International Society of the Learning Sciences, pp. 363–66. [Google Scholar]
- Barron’s Educational Series. 2017. Barron’s Profile of American Colleges, 33rd ed. Hauppauge: Barron’s Educational Series, Inc. [Google Scholar]
- Bojanowski, Piotr, Edouard Grave, Armand Joulin, and Tomas Mikolov. 2017. Enriching Word Vectors with Subword Information. Transactions of the Association for Computational Linguistics 5: 135–46. [Google Scholar] [CrossRef] [Green Version]
- Bowker, Albert H. 1948. A Test for Symmetry in Contingency Tables. Journal of the American Statistical Association 43: 572–74. [Google Scholar] [CrossRef] [PubMed]
- Brodt, Susan, and Leigh Thompson. 2001. Negotiating Teams: A Levels of Analysis Approach. Group Dynamics: Theory, Research, and Practice 5: 208–19. [Google Scholar] [CrossRef]
- Cai, Zhiqiang, Arthur C. Graesser, Carol M. Forsyth, Candice Burkett, Keith Millis, Patricia Wallace, Diane Halpern, and Heather Butler. 2011. “Trialog in ARIES: User Input Assessment in an Intelligent Tutoring System. Paper presented at the 3rd IEEE International Conference on Intelligent Computing and Intelligent Systems, Guangzhou, China, December 13–15; Edited by Wen Chen and Shaozi Li. Guangzhou: IEEE Press, pp. 429–33. [Google Scholar]
- Care, Esther, and Patrick Griffin. 2014. An Approach to Assessment of Collaborative Problem Solving. Research and Practice in Technology Enhanced Learning 9: 367–88. [Google Scholar]
- Care, Esther, Claire Scoular, and Patrick Griffin. 2016. Assessment of Collaborative Problem Solving in Education Environments. Applied Measurement in Education 29: 250–64. [Google Scholar] [CrossRef]
- Chung, Gregory K. W. K., Harold F. O’Neil, and Howard E. Herl. 1999. The Use of Computer-Based Collaborative Knowledge Mapping to Measure Team Processes and Team Outcomes. Computers in Human Behavior 15: 463–93. [Google Scholar] [CrossRef]
- Clark, Herbert H. 1996. Using Language. New York: Cambridge University Press. [Google Scholar]
- Clark, Herbert H., and Susan E. Brennan. 1991. Grounding in Communication. Perspectives on Socially Shared Cognition 13: 127–49. [Google Scholar]
- Cohen, Paul R. 1989. Planning and Problem Solving. In The Handbook of Artificial Intelligence. Edited by Paul R. Cohen and Edward. A. Feigenbaum. Boston: Addison-Wesley, pp. 513–62. [Google Scholar]
- Cover, Thomas, and Peter Hart. 1967. Nearest Neighbor Pattern Classification. IEEE Transactions on Information Theory 13: 21–27. [Google Scholar] [CrossRef] [Green Version]
- Davey, Tim, Steve Ferrara, Rich Shavelson, Paul Holland, Noreen Webb, and Lauress Wise. 2015. Psychometric Considerations for the Next Generation of Performance Assessment. Princeton: Educational Testing Service. [Google Scholar]
- Dowell, Nia M. M., Tristan M. Nixon, and Arthur C. Graesser. 2019. Group Communication Analysis: A Computational Linguistics Approach for Detecting Sociocognitive Roles in Multiparty Interactions. Behavior Research Methods 51: 1007–41. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dowell, Nia M. M., Yiwen Lin, Andrew Godfrey, and Christopher Brooks. 2020. Exploring the Relationship between Emergent Sociocognitive Roles, Collaborative Problem-Solving Skills, and Outcomes: A Group Communication Analysis. Journal of Learning Analytics 7: 38–57. [Google Scholar] [CrossRef] [Green Version]
- Eaton, Joshua A., Matthew-Donald D. Sangster, Molly Renaud, David J. Mendonca, and Wayne D. Gray. 2017. Carrying the Team: The Importance of One Player’s Survival for Team Success in League of Legends. Paper presented at the Human Factors and Ergonomics Society 2017 Annual Meeting, Rome, Italy, October 9–13; Los Angeles: SAGE Publications, vol. 61, pp. 272–76. [Google Scholar]
- Fiore, Stephen M., Art Graesser, Samuel Greiff, Patrick Griffin, Brian Gong, Patrick Kyllonen, Christine Massey, Harry O’Neil, Jim Pellegrino, Robert Rothman, and et al. 2017. Collaborative Problem Solving: Considerations for the National Assessment of Educational Progress. Alexandria: National Center for Education Statistics. [Google Scholar]
- Frensch, Peter A., and Joachim Funke. 1995. Complex Problem Solving: The European Perspective. Mahwah: Lawrence Erlbaum. [Google Scholar]
- Flor, Michael. 2012. Four Types of Context for Automatic Spelling Correction. Traitement Automatique Des Langues 53: 61–99. [Google Scholar]
- Flor, Michael, and Jessica Andrews-Todd. 2022. Towards Automatic Annotation of Collaborative Problem-Solving Skills in Technology-Enhanced Environments. Journal of Computer Assisted Learning, 1–14. [Google Scholar] [CrossRef]
- Flor, Michael, Su-Youn Yoon, Jiangang Hao, Lei Liu, and Alina von Davier. 2016. Automated Classification of Collaborative Problem Solving Interactions in Simulated Science Tasks. Paper presented at the 11th Workshop on Innovative Use of NLP for Building Educational Applications, San Diego, CA, USA, June 16; Edited by Joel Tetreault, Jill Burstein, Claudia Leacock and Helen Yannakoudakis. Stroudsburg: Association for Computational Linguistics, pp. 31–41. [Google Scholar]
- Forsyth, Carol, Jessica Andrews-Todd, and Jonathan Steinberg. 2020. “Are You Really a Team Player? Profiling of Collaborative Problem Solvers in an Online Environment. Paper presented at the 13th International Conference on Educational Data Mining, Irfane, Morocco, July 10–13; Edited by Anna N. Rafferty, Jacob Whitehill, Cristobal Romero and Violetta Cavalli-Sforza. Irfane: International Educational Data Mining Society, pp. 403–8. [Google Scholar]
- Gobert, Janice D., Michael A. Sao Pedro, Ryan S. J. D. Baker, Ermal Toto, and Orlando Montalvo. 2012. Leveraging Educational Data Mining for Real-Time Performance Assessment of Scientific Inquiry Skills within Microworlds. Journal of Educational Data Mining 4: 111–43. [Google Scholar]
- Graesser, Arthur C., Shulan Lu, George Tanner Jackson, Heather Hite Mitchell, Mathew Ventura, Andrew Olney, and Max M. Louwerse. 2004. AutoTutor: A Tutor with Dialogue in Natural Language. Behavior Research Methods, Instruments, & Computers 36: 180–92. [Google Scholar]
- Graesser, Arthur C., Zhiqiang Cai, Xiangen Hu, Peter W. Foltz, Samuel Greiff, Bor-Chen Kuo, Chen-Huei Liao, and David Williamson Shaffer. 2017. Assessment of Collaborative Problem Solving. In Design Recommendations for Intelligent Tutoring Systems: Volume 5—Assessment. Edited by Robert Sottilare, Arthur C. Graesser, Xiangen Hu and Gerald F. Goodwin. Orlando: U.S. Army Research Laboratory, vol. 275–85. [Google Scholar]
- Hao, Jiangang, Lei Chen, Michael Flor, Lei Liu, and Alina A. von Davier. 2017. CPS-Rater: Automated Sequential Annotation for Conversations in Collaborative Problem-Solving Activities. RR-17-58. Princeton: Educational Testing Service. [Google Scholar] [CrossRef] [Green Version]
- Hao, Jiangang, Lei Liu, Alina A. von Davier, and Patrick Kyllonen. 2015. Assessing Collaborative Problem Solving with Simulation Based Tasks. Paper presented at the 11th International Conference on Computer-Supported Collaborative Learning, Gothenburg, Sweden, June 7–11; Gothenburg: International Society for the Learning Sciences. [Google Scholar]
- Hao, Jiangang, Lei Liu, Alina A. von Davier, Patrick Kyllonen, and Christopher Kitchen. 2016. Collaborative Problem Solving Skills versus Collaboration Outcomes: Findings from Statistical Analysis and Data Mining. Paper presented at the 9th International Conference on Educational Data Mining, Raleigh, NC, USA, June 29–July 2; Edited by Tiffany Barnes, Min Chi and Mingyu Feng. Raleigh: International Educational Data Mining Society, pp. 382–87. [Google Scholar]
- Hao, Jiangang, Lei Liu, Patrick Kyllonen, Michael Flor, and Alina A. von Davier. 2019. Psychometric Considerations and a General Scoring Strategy for Assessments of Collaborative Problem Solving. ETS RR–19-41. ETS Research Report Series; Princeton: Educational Testing Service. [Google Scholar]
- Herborn, Katharina, Maida Mustafić, and Samuel Greiff. 2017. Mapping an Experiment-Based Assessment of Collaborative Behavior onto Collaborative Problem Solving in PISA 2015: A Cluster Analysis Approach for Collaborator Profiles. Journal of Educational Measurement 54: 103–22. [Google Scholar] [CrossRef] [Green Version]
- Hesse, Friedrich, Esther Care, Juergen Buder, Kai Sassenberg, and Patrick Griffin. 2015. A Framework for Teachable Collaborative Problem Solving Skills. In Assessment and Teaching of 21st Century Skills. Edited by Patrick Griffin and Esther Care. New York: Springer, pp. 37–56. [Google Scholar]
- Honey, Margaret A., and Margaret L. Hilton, eds. 2011. Learning Science through Computer Games and Simulations. Washington, DC: National Academies Press. [Google Scholar]
- Hsieh, I-Lin Gloria, and Harold F. O’Neil. 2002. Types of Feedback in a Computer-Based Collaborative Problem-Solving Group Task. Computers in Human Behavior 18: 699–715. [Google Scholar] [CrossRef]
- Hütter, Mandy, and Michael Diehl. 2011. Motivation Losses in Teamwork: The Effects of Team Diversity and Equity Sensitivity on Reactions to Free-Riding. Group Processes & Intergroup Relations 14: 845–56. [Google Scholar]
- Horwitz, Paul, Alina von Davier, John Chamberlain, Al Koon, Jessica Andrews, and Cynthia McIntyre. 2017. Teaching Teamwork: Electronics Instruction in a Collaborative Environment. Community College Journal of Research and Practice 41: 341–43. [Google Scholar] [CrossRef]
- Integrated Postsecondary Education Data System. 2019. Institutional Characteristics. U.S. Department of Education, National Center for Education Statistics. Available online: https://nces.ed.gov/ipeds/datacenter/DataFiles.aspx (accessed on 3 January 2019).
- Jurafsky, Daniel, and James H. Martin. 2008. Speech and Language Processing. Hoboken: Prentice-Hall. [Google Scholar]
- Kerr, Deirdre, Jessica J. Andrews, and Robert J. Mislevy. 2016. The In-Task Assessment Framework for Behavioral Data. In The Handbook of Cognition and Assessment: Frameworks, Methodologies, and Applications. Edited by André A. Rupp and Jacqueline P. Leighton. Hoboken: Wiley-Blackwell, pp. 472–507. [Google Scholar]
- Kerr, Norbert L. 1983. Motivation Losses in Small Groups: A Social Dilemma Analysis. Journal of Personality and Social Psychology 45: 819. [Google Scholar] [CrossRef]
- Kerr, Norbert L., and Steven E. Bruun. 1983. Dispensability of Member Effort and Group Motivation Losses: Free-Rider Effects. Journal of Personality and Social Psychology 44: 78. [Google Scholar] [CrossRef]
- Kirschner, Femke, Fred Paas, and Paul A. Kirschner. 2009. A Cognitive Load Approach to Collaborative Learning: United Brains for Complex Tasks. Educational Psychology Review 21: 31–42. [Google Scholar] [CrossRef]
- Landauer, Thomas K., Danielle S. McNamara, Simon Dennis, and Walter Kintsch. 2007. Handbook of Latent Semantic Analysis. Mahwah: Erlbaum. [Google Scholar]
- Landis, J. Richard, and Gary G. Koch. 1977. The Measurement of Observer Agreement for Categorical Data. Biometrics 33: 159–74. [Google Scholar] [CrossRef] [Green Version]
- Latané, Bibb, Kipling Williams, and Stephen Harkins. 1979. Many Hands Make Light the Work: The Causes and Consequences of Social Loafing. Journal of Personality and Social Psychology 37: 822–32. [Google Scholar] [CrossRef]
- Lenci, Alessandro. 2018. Distributional Models of Word Meaning. Annual Review of Linguistics 4: 151–71. [Google Scholar] [CrossRef] [Green Version]
- Lin, Kuen-Yi, Kuang-Chao Yu, Hsien-Sheng Hsiao, Yih-Hsien Chu, Yu-Shan Chang, and Yu-Hung Chien. 2015. Design of an Assessment System for Collaborative Problem Solving in STEM Education. Journal of Computers in Education 2: 301–22. [Google Scholar] [CrossRef] [Green Version]
- Lipponen, Lasse. 2000. Towards Knowledge Building: From Facts to Explanations in Primary Students’ Computer Mediated Discourse. Learning Environments Research 3: 179–99. [Google Scholar] [CrossRef]
- Lipponen, Lasse, Marjaana Rahikainen, Jiri Lallimo, and Kai Hakkarainen. 2003. Patterns of Participation and Discourse in Elementary Students’ Computer-Supported Collaborative Learning. Learning and Instruction 13: 487–509. [Google Scholar] [CrossRef]
- Liu, Lei, Alina A. von Davier, Jiangang Hao, Patrick Kyllonen, and Juan-Diego Zapata-Rivera. 2015. A Tough Nut to Crack: Measuring Collaborative Problem Solving. In Handbook of Research on Computational Tools for Real-World Skill Development. Edited by Yigal Rosen, Steve Ferrara and Maryam Mosharraf. Hershey: IGI-Global, pp. 344–59. [Google Scholar]
- Martin-Raugh, Michelle P., Patrick C. Kyllonen, Jiangang Hao, Adam Bacall, Dovid Becker, Christopher Kurzum, Zhitong Yang, Fred Yan, and Patrick Barnwell. 2020. Negotiation as an Interpersonal Skill: Generalizability of Negotiation Outcomes and Tactics across Contexts at the Individual and Collective Levels. Computers in Human Behavior 104: 105966. [Google Scholar] [CrossRef]
- Mayer, Richard E., and Merlin C. Wittrock. 1996. Problem-Solving Transfer. In Handbook of Educational Psychology. Edited by David C. Berliner and Robert C. Calfee. Mahwah: Lawrence Erlbaum, pp. 47–62. [Google Scholar]
- McGunagle, Doreen, and Laura Zizka. 2020. Employability Skills for 21st-Century STEM Students: The Employers’ Perspective. Higher Education, Skills and Work-Based Learning 10: 591–606. [Google Scholar] [CrossRef]
- Meier, Anne, Hans Spada, and Nikol Rummel. 2007. A Rating Scheme for Assessing the Quality of Computer-Supported Collaboration Processes. International Journal of Computer-Supported Collaborative Learning 2: 63–86. [Google Scholar] [CrossRef] [Green Version]
- Mesmer-Magnus, Jessica R., and Leslie A. DeChurch. 2009. Information Sharing and Team Performance: A Meta-Analysis. Journal of Applied Psychology 94: 535–46. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- OECD. 2013a. PISA 2012 Assessment and Analytical Framework: Mathematics, Reading, Science, Problem Solving and Financial Literacy. Paris: OECD Publishing. [Google Scholar]
- OECD. 2013b. PISA 2015 Collaborative Problem Solving Framework. Paris: OECD Publishing. [Google Scholar]
- O’Neil, Harold F. 1999. Perspectives on Computer-Based Performance Assessment of Problem Solving. Computers in Human Behavior 15: 225–68. [Google Scholar] [CrossRef]
- O’Neil, Harold F., Gregory K. W. K. Chung, and Richard S. Brown. 1995. Measurement of Teamwork Processes Using Computer Simulation. CSE Tech. Rep. No. 399. Los Angeles: National Center for Research on Evaluation, Standards, and Student Testing. [Google Scholar]
- Partnership of 21st Century Learning. 2016. Framework for 21st Century Learning. Available online: http://www.p21.org/storage/documents/docs/P21_framework_0816.pdf (accessed on 18 March 2022).
- Pugh, Samuel L., Arjun Rao, Angela E. B. Stewart, and Sidney K. D’Mello. 2022. Do Speech-Based Collaboration Analytics Generalize across Task Contexts? Paper presented at the LAK22: 12th International Learning Analytics and Knowledge Conference, online, March 21–25; pp. 208–18. [Google Scholar]
- Pugh, Samuel L., Shree Krishna Subburaj, Arjun Ramesh Rao, Angela E.B. Stewart, Jessica Andrews-Todd, and Sidney K. D’Mello. 2021. Say What? Automatic Modeling of Collaborative Problem Solving Skills from Student Speech in the Wild. Paper presented at the 14th International Conference on Educational Data Mining, virtual, June 29–July 2; Edited by I-Han Hsiao, Shaghayegh Sahebi, François Bouchet and Jill-Jênn Vie. Paris: International Educational Data Mining Society, pp. 55–67. [Google Scholar]
- Quellmalz, Edys S., and James W. Pellegrino. 2009. Technology and Testing. Science 323: 75–79. [Google Scholar] [CrossRef]
- Roschelle, Jeremy, and Stephanie D. Teasley. 1995. The Construction of Shared Knowledge in Collaborative Problem Solving. In Computer-Supported Collaborative Learning. Edited by Claire E. O’Malley. Berlin: Springer, pp. 69–97. [Google Scholar]
- Rosé, Carolyn, Yi-Chia Wang, Yue Cui, Jaime Arguello, Karsten Stegmann, Armin Weinberger, and Frank Fischer. 2008. Analyzing Collaborative Learning Processes Automatically: Exploiting the Advances of Computational Linguistics in Computer-Supported Collaborative Learning. International Journal of Computer-Supported Collaborative Learning 3: 237–71. [Google Scholar] [CrossRef] [Green Version]
- Rosen, Yigal, and Peter W. Foltz. 2014. Assessing Collaborative Problem Solving through Automated Technologies. Research and Practice in Technology Enhanced Learning 9: 389–410. [Google Scholar]
- Simoni, Mario, Marc Herniter, and Bruce Ferguson. 2004. Concepts to Questions: Creating an Electronics Concept Inventory Exam. In Proceedings of the 2004 American Society for Engineering Education Annual Conference & Exposition. Salt Lake City: American Society for Engineering Education. [Google Scholar]
- Stasser, Garold, and William Titus. 1985. Pooling of Unshared Information in Group Decision Making: Biased Information Sampling during Discussion. Journal of Personality and Social Psychology 48: 1467–78. [Google Scholar] [CrossRef]
- Stasser, Garold, Sandra I. Vaughan, and Dennis D. Stewart. 2000. Pooling Unshared Information: The Benefits of Knowing How Access to Information Is Distributed among Group Members. Organizational Behavior and Human Decision Processes 82: 102–16. [Google Scholar] [CrossRef]
- Steinberg, Jonathan, Jessica Andrews-Todd, and Carol Forsyth. 2018. The Influences of Communication and Group Dynamics on Collaborative Problem Solving Task Performance. NERA Conference Proceedings 10. Available online: https://opencommons.uconn.edu/nera-2018/10 (accessed on 18 March 2022).
- Steinberg, Jonathan, Jessica Andrews-Todd, Carolyn Forsyth, John Chamberlain, Paul Horwitz, Al Koon, Andre Rupp, and Laura McCulla. 2020. The Development of a Content Assessment of Basic Electronics Knowledge. RR-20-28. ETS Research Report Series; Princeton: Educational Testing Service. [Google Scholar]
- Stewart, Angela E. B., Hana Vrzakova, Chen Sun, Jade Yonehiro, Cathlyn Adele Stone, Nicholas D. Duran, Valerie Shute, and Sidney K. D’Mello. 2019. I Say, You Say, We Say: Using Spoken Language to Model Socio-Cognitive Processes during Computer-Supported Collaborative Problem Solving. Proceedings of the ACM on Human-Computer Interaction 3: 1–19. [Google Scholar] [CrossRef] [Green Version]
- Sun, Chen, Valerie J. Shute, Angela E. B. Stewart, Quinton Beck-White, Caroline R. Reinhardt, Guojing Zhou, Nicholas Duran, and Sidney K. D’Mello. 2022. The Relationship between Collaborative Problem Solving Behaviors and Solution Outcomes in a Game-Based Learning Environment. Computers in Human Behavior 128: 107120. [Google Scholar] [CrossRef]
- van Boxtel, Carla, Jos Van der Linden, and Gellof Kanselaar. 2000. Collaborative learning tasks and the elaboration of conceptual knowledge. Learning and Instruction 10: 311–30. [Google Scholar] [CrossRef]
- VanLehn, Kurt. 1996. Cognitive Skill Acquisition. Annual Review of Psychology 47: 513–39. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ward, Joe H., Jr. 1963. Hierarchical Grouping to Optimize an Objective Function. Journal of the American Statistical Association 58: 236–44. [Google Scholar] [CrossRef]
- Webb, Noreen M. 1991. Task-Related Verbal Interaction and Mathematics Learning in Small Groups. Journal for Research in Mathematics Education 22: 366–89. [Google Scholar] [CrossRef]
- Whorton, Ryan, Alex Casillas, Frederick L. Oswald, and Amy Shaw. 2017. Critical Skills for the 21st Century Workforce. In Building Better Students: Preparation for the Workforce. Edited by Jeremy Burrus, Krista D. Mattern, Bobby Naemi and Richard D. Roberts. New York: Oxford University Press, pp. 47–72. [Google Scholar]
- Wirth, Joachim, and Eckhard Klieme. 2003. Computer-Based Assessment of Problem Solving Competence. Assessment in Education: Principles, Policy & Practice 10: 329–45. [Google Scholar]
- Yuan, Jianlin, Yue Xiao, and Hongyun Liu. 2019. Assessment of Collaborative Problem Solving Based on Process Stream Data: A New Paradigm for Extracting Indicators and Modeling Dyad Data. Frontiers in Psychology 10: 369. [Google Scholar] [CrossRef] [Green Version]



{kind=link}
{kind=link}
| Task Level | External Voltage (E) | External Resistance (R0) | Goal Voltages |
|---|---|---|---|
| 1 | Known by all teammates | Known by all teammates | Same for all teammates |
| 2 | Known by all teammates | Known by all teammates | Different for all teammates |
| 3 | Unknown by teammates | Known by all teammates | Different for all teammates |
| 4 | Unknown by teammates | Unknown by teammates | Different for all teammates |
| Code | CPS Skill | CPS Sub-Skill | Count for Human Annotation | Count for Automated Annotation | Example |
|---|---|---|---|---|---|
| Social Dimensions (chat messages) | |||||
| SESU | Establishing Shared Understanding | Presentation Phase in Grounding | 3319 (6.5%) | 3629 (7.1%) | “What is your resistance?” |
| Acceptance Phase in Grounding | |||||
| SMC | Maintaining Communication | Rapport Building Communication | 1328 (2.6%) | 938 (1.8%) | “Good job yall” |
| Off-Topic Communication | |||||
| Inappropriate Communication | |||||
| SN | Negotiating | Express Agreement | 1153 (2.3%) | 942 (1.9%) | “Actually, no you can’t” |
| Express Disagreement | |||||
| Resolve Conflict | |||||
| SSI | Sharing Information | Share Own Information | 6182 (12.2%) | 6635 (13.1%) | “My goal is to make my voltage 3.5” |
| Share Task/Resource Information | |||||
| Share Understanding | |||||
| Cognitive Dimensions (chat messages) | |||||
| CRF | Representing and Formulating | Represent the Problem | 357 (0.7%) | 372 (0.7%) | “Given earlier fiddlings I’ve deduced that we can’t go lower than 20 DCV” |
| Formulate Hypotheses | |||||
| CP | Planning | Set Goals | 1070 (2.1%) | 1223 (2.4%) | “Use your resistance and your voltage to get the current. We know the formula, so we might be able to get E and work backwards” |
| Manage Resources | |||||
| Develop Strategies | |||||
| CMC | Monitoring communication | Monitor Success | 1194 (2.3%) | 959 (1.9%) | “Come on Tiger” |
| Monitor Group | |||||
| CEC | Executing communication | Suggest/Direct Actions | 1350 (2.7%) | 1252 (2.5%) | “Plum move yours to 150 as well” |
| Report Actions | |||||
| Non-Chat Activities | |||||
| CM | Monitoring actions | Monitor Success | 5973 (11.8%) | 5971 (11.8%) | Viewing board; opening zoom; submitting results |
| Monitor Group | |||||
| CE | Executing actions | Enact Strategies | 23,582 (46.4%) | 26,455 (52.1%) | Changing resistor value; using calculator |
| CEU | Exploring and Understanding | Explore the Environment | 5309 (10.4%) | 2441 (4.8%) | Changing resistor value prior to developing a plan |
| Understand the Problem | |||||
| Total events | 50,817 | 50,817 | |||
| Measure | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1. Executing actions | 0.96 ** | 0.11 * | 0.31 ** | 0.10 * | 0.12 * | −0.02 | −0.09 | −0.02 | −0.02 | 0.05 | 0.08 |
| 2. Executing chats | 0.06 | 0.88 ** | 0.07 | −0.02 | 0.51 ** | 0.46 ** | 0.22 ** | 0.52 ** | 0.19 ** | 0.25 ** | 0.51 ** |
| 3. Exploring & Understanding | 0.45 ** | −0.06 | 0.59 ** | −0.02 | 0.03 | −0.15 ** | −0.18 ** | −0.19 ** | −0.04 | −0.17 ** | −0.12 * |
| 4. Monitoring actions | 0.09 | −0.05 | 0.01 | 1.00 ** | −0.05 | −0.03 | −0.01 | −0.04 | −0.03 | 0.01 | −0.08 |
| 5. Monitoring chats | 0.10 * | 0.57 ** | 0.15 ** | −0.04 | 0.90 ** | 0.34 ** | 0.14 ** | 0.50 ** | 0.15 ** | 0.23 ** | 0.45 ** |
| 6. Planning | −0.03 | 0.42 ** | −0.08 | −0.04 | 0.36 ** | 0.83 ** | 0.37 ** | 0.48 ** | 0.19 ** | 0.28 ** | 0.42 ** |
| 7. Representing and Formulating | −0.09 | 0.12 * | −0.13 * | −0.03 | 0.14 ** | 0.41 ** | 0.53 ** | 0.39 ** | 0.20 ** | 0.36 ** | 0.37 ** |
| 8. Establish Shared Understanding | −0.06 | 0.52 ** | −0.13 ** | −0.04 | 0.42 ** | 0.53 ** | 0.46 ** | 0.93 ** | 0.26 ** | 0.50 ** | 0.64 ** |
| 9. Maintaining Communication | −0.02 | 0.10 | −0.02 | −0.01 | 0.13 ** | 0.24 ** | 0.09 | 0.31 ** | 0.95 ** | 0.15 ** | 0.28 ** |
| 10. Negotiating | −0.09 | 0.28 ** | −0.14 ** | −0.02 | 0.23 ** | 0.40 ** | 0.44 ** | 0.55 ** | 0.19 ** | 0.86 ** | 0.44 ** |
| 11. Sharing Information | 0.03 | 0.46 ** | 0.05 | −0.08 | 0.43 ** | 0.49 ** | 0.44 ** | 0.66 ** | 0.25 ** | 0.45 ** | 0.96 ** |
| Social Loafers (n = 224) | Super Socials (n = 99) | Low Collaborators (n = 21) | Active Collaborators (n = 34) | Total (n = 378) | |
|---|---|---|---|---|---|
| Code | Mean (SD) | Mean (SD) | Mean (SD) | Mean (SD) | Mean (SD) |
| Executing actions | 61.3 (54.5) | 50.4 (33.5) | 96.5 (102.8) | 83.5 (49.4) | 62.4 (54.5) |
| Executing chats | 2.2 (2.4) | 4.1 (2.9) | 1.7 (3.1) | 12.3 (7.9) | 3.6 (4.4) |
| Exploring and Understanding | 11.5 (12.8) | 6.9 (10.2) | 71.4 (18.0) | 15.9 (14.9) | 14.0 (19.0) |
| Monitoring actions | 17.0 (17.8) | 14.3 (11.0) | 13.0 (11.7) | 14.2 (11.0) | 15.8 (15.4) |
| Monitoring chats | 1.9 (2.0) | 3.2 (2.1) | 1.8 (1.9) | 12.1 (5.2) | 3.2 (3.8) |
| Planning | 1.7 (2.1) | 4.5 (3.8) | 1.3 (2.1) | 5.9 (6.3) | 2.8 (3.5) |
| Representing and Formulating | 0.4 (0.7) | 2.2 (1.8) | 0.2 (0.4) | 1.3 (1.4) | 0.9 (1.4) |
| Establishing Shared Understanding | 6.2 (4.1) | 13.5 (8.0) | 3.8 (3.6) | 15.4 (10.1) | 8.8 (7.1) |
| Maintaining Communication | 2.7 (9.0) | 4.8 (4.2) | 2.0 (2.7) | 6.0 (7.1) | 3.5 (7.7) |
| Negotiating | 1.9 (1.7) | 5.7 (3.4) | 1.3 (1.3) | 4.3 (3.4) | 3.1 (3.0) |
| Sharing Information | 12.6 (7.7) | 22.7 (8.6) | 9.4 (7.1) | 26.9 (16.2) | 16.4 (10.6) |
| Social Loafers (n = 192) | Super Socials (n = 64) | Low Collaborators (n = 99) | Active Collaborators (n = 23) | Total (n = 378) | |
|---|---|---|---|---|---|
| Code | Mean (SD) | Mean (SD) | Mean (SD) | Mean (SD) | Mean (SD) |
| Executing actions | 50.4 (31.4) | 58.4 (39.6) | 109.7 (82.4) | 95.2 (53.6) | 70.0 (58.0) |
| Executing chats | 2.4 (3.0) | 4.1 (3.0) | 2.6 (2.5) | 11.6 (8.4) | 3.3 (4.1) |
| Exploring & Understanding | 4.1 (5.6) | 2.2 (4.9) | 13.2 (15.2) | 8.7 (11.9) | 6.5 (10.3) |
| Monitoring actions | 8.8 (7.4) | 17.5 (12.4) | 29.2 (20.2) | 11.6 (9.6) | 15.8 (15.4) |
| Monitoring chats | 1.8 (2.0) | 2.9 (1.9) | 1.7 (1.8) | 11.0 (4.9) | 2.5 (3.1) |
| Planning | 2.1 (2.0) | 5.7 (3.1) | 2.4 (2.2) | 9.5 (6.3) | 3.2 (3.4) |
| Representing and Formulating | 0.7 (1.0) | 2.2 (1.7) | 0.5 (0.6) | 2.0 (1.8) | 1.0 (1.3) |
| Establishing Shared Understanding | 7.0 (4.5) | 17.8 (7.2) | 6.7 (4.3) | 21.0 (11.4) | 9.6 (7.5) |
| Maintaining Communication | 1.7 (2.0) | 5.3 (9.0) | 1.6 (2.4) | 5.5 (6.1) | 2.5 (4.6) |
| Negotiating | 1.6 (1.6) | 5.4 (3.0) | 1.7 (1.8) | 5.0 (3.1) | 2.5 (2.6) |
| Sharing Information | 14.4 (8.5) | 24.6 (9.3) | 15.2 (8.4) | 34.8 (19.7) | 17.6 (11.2) |
| Automated Annotation | |||||
|---|---|---|---|---|---|
| Human Annotation | Social Loafers | Super Socials | Low Collaborators | Active Collaborators | Total |
| Social Loafers | 147 | 5 | 72 | 0 | 224 |
| Super Socials | 32 | 55 | 8 | 4 | 99 |
| Low Collaborators | 6 | 0 | 15 | 0 | 21 |
| Active Collaborators | 7 | 4 | 4 | 19 | 34 |
| Total | 192 | 64 | 99 | 23 | 378 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Andrews-Todd, J.; Steinberg, J.; Flor, M.; Forsyth, C.M. Exploring Automated Classification Approaches to Advance the Assessment of Collaborative Problem Solving Skills. J. Intell. 2022, 10, 39. https://doi.org/10.3390/jintelligence10030039
Andrews-Todd J, Steinberg J, Flor M, Forsyth CM. Exploring Automated Classification Approaches to Advance the Assessment of Collaborative Problem Solving Skills. Journal of Intelligence. 2022; 10(3):39. https://doi.org/10.3390/jintelligence10030039
Chicago/Turabian StyleAndrews-Todd, Jessica, Jonathan Steinberg, Michael Flor, and Carolyn M. Forsyth. 2022. "Exploring Automated Classification Approaches to Advance the Assessment of Collaborative Problem Solving Skills" Journal of Intelligence 10, no. 3: 39. https://doi.org/10.3390/jintelligence10030039