
Artificial Intelligence and Machine Learning Approaches in Digital Education: A Systematic Revision


Department of Computer Science and Media Technology, Malmö University, 20506 Malmö, Sweden
*
Author to whom correspondence should be addressed.
Information 2022, 13(4), 203; https://doi.org/10.3390/info13040203
Submission received: 26 March 2022
/
Revised: 6 April 2022
/
Accepted: 15 April 2022
/
Published: 17 April 2022
(This article belongs to the Special Issue Artificial Intelligence Applications for Education)
Abstract
:The use of artificial intelligence and machine learning techniques across all disciplines has exploded in the past few years, with the ever-growing size of data and the changing needs of higher education, such as digital education. Similarly, online educational information systems have a huge amount of data related to students in digital education. This educational data can be used with artificial intelligence and machine learning techniques to improve digital education. This study makes two main contributions. First, the study follows a repeatable and objective process of exploring the literature. Second, the study outlines and explains the literature’s themes related to the use of AI-based algorithms in digital education. The study findings present six themes related to the use of machines in digital education. The synthesized evidence in this study suggests that machine learning and deep learning algorithms are used in several themes of digital learning. These themes include using intelligent tutors, dropout predictions, performance predictions, adaptive and predictive learning and learning styles, analytics and group-based learning, and automation. artificial neural network and support vector machine algorithms appear to be utilized among all the identified themes, followed by random forest, decision tree, naive Bayes, and logistic regression algorithms.
Keywords:
AI; ML; DL; digital education; literature review; dropouts; intelligent tutors; performance prediction1. Introduction
Artificial intelligence (AI), including machine learning (ML) and deep learning (DL), are considered to be game-changers across many industries and sectors, such as telecommunication, construction, transportation, healthcare, manufacturing, advertising, and education [1,2,3]. AI will have an increasingly important role in higher education as it allows students to have a personalized approach to learning issues based on their own unique experiences and preferences. AI-based digital learning solutions can adapt to individual students’ level of knowledge, learning rates, and desired goals to get the most out of their education. Furthermore, it has the potential to analyze students’ previous learning histories to identify weaknesses and offer courses best suited for an improved personalized learning experience [4,5]. At the same time, the use of AI can reduce the time needed for routine administrative tasks, allowing teachers in higher education to focus more on teaching and research [6].
The advent of the COVID-19 pandemic has accelerated the use of digitization in university education [7]. All higher education institutions were forced to switch to digital channels for teaching. Therefore, educational institutions, including students, are discussing this new paradigm shift and its effects on the post-COVID-19 era. AI can open new possibilities for digital education in terms of augmenting teaching [8] and facilitating future digital education. Digital education refers to “teaching and learning activities which make use of digital technology as part of in-person, blended, and fully online learning contexts” [9]. Digital education is seen as the effective integration of digital technologies in student learning and teaching [10,11]. As a part of digital technologies, AI deals with intelligent applications and machines to solve real-world problems. ML is a subset of AI that provides the ability to learn and improve from experiences and data automatically, whereas DL is a subset of ML methods; it provides the ability to analyze different factors and structures similar to human brain thinking to solve complex problems [12]. Thus, it is of utmost importance to carefully analyze these challenges from an academic perspective. The objective of this study is to systematically explore the current state of the art regarding the application of AI in higher education, including both ML and DL. The study proposes two main contributions. First, the study follows a repeatable and objective process of exploring the literature (see Section 3). Second, the study outlines and explains the literature’s themes related to the use of AI-based algorithms in digital education (see Section 4.2). It is essential to highlight that the scope of the study is limited to higher education.
The remainder of this paper is structured as follows. Section 2 explains the related work, and Section 3 shows the systematic revision method used to explore the literature in an objective and repeatable manner. Section 4 explains the study demographics and themes related to AI in digital education identified in the literature, and is followed by the conclusion and future work in Section 5.
2. Related Work
We have identified ten literature reviews relevant to the use of AI in digital education, but they differ in terms of the methodology usd and approaches taken. Table 1 provides an overview of and the limitations for each study.
Murad et al. [13] present several methods for recommending systems for online learning so as to better design learning management systems (LMS) using natural language processing technologies. These methods include collaborative filtering and content-based, demographic, utility-based, knowledge-based, community-based, and hybrid approaches. The most frequently used methods are content-based and collaborative filtering for the recommendations of books and courses. The paper presents a preliminary study towards a broader research objective of designing LMS and extracted the literature published between 2013 and 2018. Sciarrone et al. [14] present a preliminary study about the design, implementation, and delivery of LMS. The study provides an overview of learning analytics to integrate data with learning. The study concluded that learning analytical models are the most-highlighted models in the literature. Such models have four steps: capturing useful data, and reporting, predicting, acting, and refining the learning environment based on the data. The study does not discuss specific ML algorithms that can be used with the model. Similarly, Romero et al. [15] provide an overview of educational data mining by discussing the key concepts in this field. Both studies did not follow the systematic literature review guidelines and provided summaries as well as clarifications of available learning analytics, and of the educational data mining field and its techniques [14,15]. Furthermore, Romero et al. [16] presented another reflective literature review study to provide an overview of educational data mining. The study demonstrated several methods: prediction, clustering, outlier detecting, relationship mining, social network analysis, process mining, text mining, a distillation of data for human judgment, discovery with models, knowledge tracing, and non-negative matrix factorization. However, the study did not focus on ML algorithms, nor did it follow systematic literature review guidelines.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Literature review studies.
| Paper(s) | Systematic | Overview | Limitation(s) |
|---|---|---|---|
| [13] | Yes | A preliminary study to explore the recommendation systems for designing a smart learning management system for digital learning. |
|
| [14] | No | The study gives an overview of learning management systems. |
|
| [17] | No | The study addresses the strengths and opportunities in the field of education using artificial intelligence in education. |
|
| [15] | No | A reflective study to provide an overview of educational data mining and the knowledge discovery process with adaptation and methods needed in the field. |
|
| [18] | No | The study shows the field of e-learning in terms of its definitions and characteristics with a brief survey of the most popular ML and data analytics used in the field. |
|
| [16] | No | This paper provides the current state of knowledge in educational data mining for researchers, instructors, and advanced students. |
|
| [19] | No | The study focuses on the application and effects of AI in administration, instruction, and learning. |
|
| [20] | No | The study provides an overview of the applications of artificial intelligence and deep learning in teaching and learning. |
|
| [21] | No | An exploratory study that reviews different data mining methods and trends applied in educational data mining. |
|
| [22] | Yes | The study proposes ways to predict and reduce the high dropout rate in digital learning. |
|
Roll et al. [17] performed a literature review of the existing trends within AI in education, published within the International Journal of Artificial Intelligence in Education (IJAIED). The search results are limited to the years 1994, 2004, and 2014. This study was not conducted systematically and does not account for research trends published beyond the IJAIED context.
Moubayed et al. [18] explored the e-learning field in terms of its definitions and characteristics with a brief survey of the most popular ML and data analytics used in the area.
Chen et al. [19] assess the impact of AI in education in a literature review study. This qualitative research provides insights into the most prominent aspects of AI and different educational approaches. The study focuses on the application and effects of AI in administration, instruction, and learning. Guan at al. [20] presented a reflective study on AI that examines the themes and their evolution, highlighting that profiling and analytics are gaining attention lately. The study provides an overview of the application of artificial intelligence and deep learning in teaching and learning. However, the study lacks focus on the use of ML algorithms for digital education. Kumar et al. [21] presented a survey-based study that analyzed educational data to develop models for improving academic performances and improving institutional effectiveness.
The majority of the literature reviews identified in the Table 1 did not explore the literature systematically [14,15,16,17,18,19,20,21]. The two systematic literature review studies either examined the limited literature concerning a time-frame (2013–2018) [13], or had a narrow focus on predicting the student dropouts from digital courses [22]. Therefore, we performed a systematic revision to explore the AI literature on digital education objectively and with a repeatable process. The detailed account of the systematic revision methodology is explained in Section 3 below.
3. Research Methodology
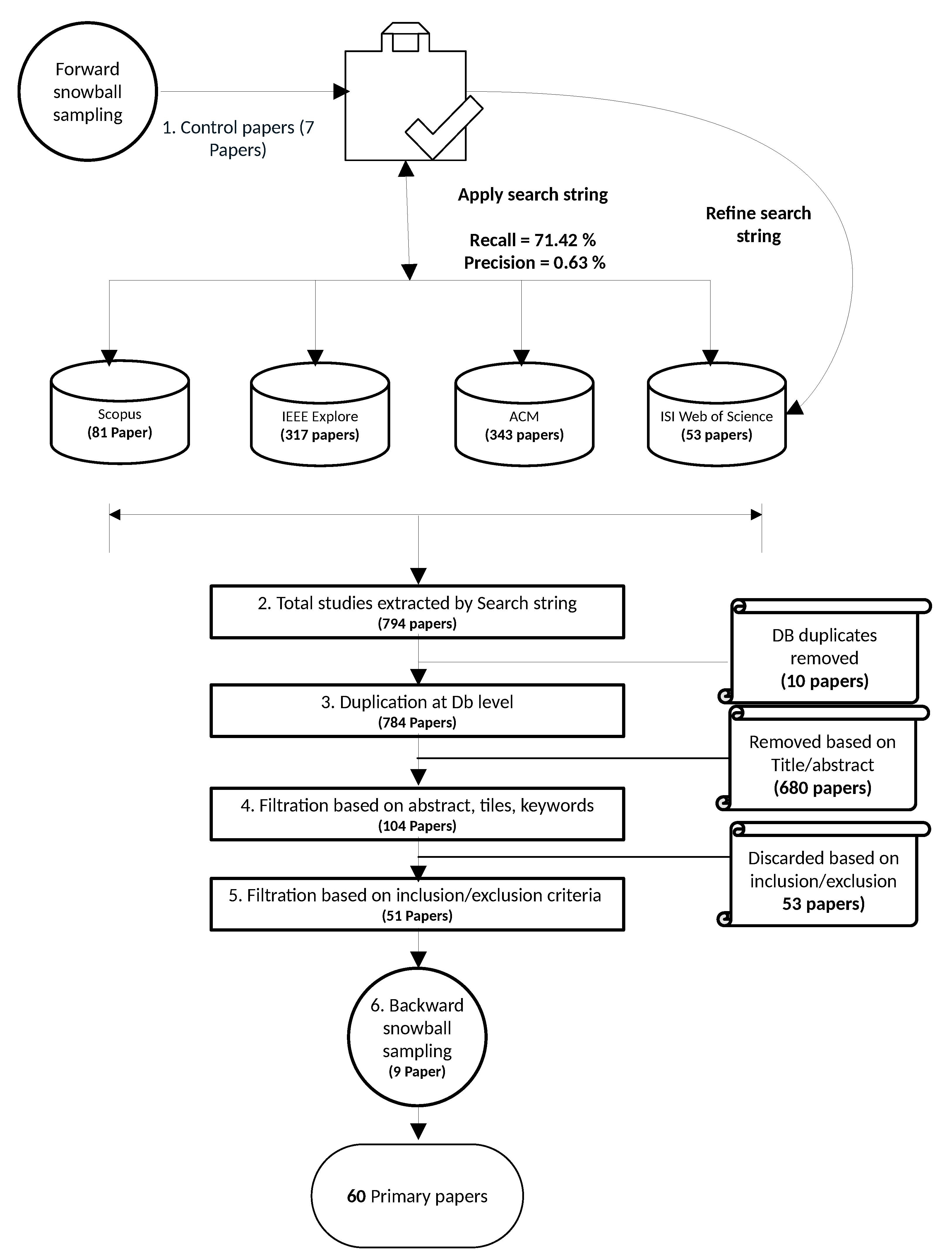
This section outlines the systematic revision research methodology [23]. The systematic revision methodology provides the overview of a research area in a repeatable and objective way. The process includes formulating research questions, search queries in relevant databases, data extraction after applying inclusion and exclusion criteria, and data analysis to answer the research questions [23]. A detailed account of the systematic revision research methodology used in this study is presented in Figure 1.
3.1. Research Questions
The following research questions were formulated to start the systematic revision. The first objective of the study, to explore the existing literature in a repeatable and objective manner, is covered by RQ1. The second objective of exploring the algorithms used in digital education is achieved with the help of RQ2.
- RQ1: What themes of AI-based education exist in the literature?
- RQ2: What kind of ML or DL models are currently used in digital education?
3.2. Systematic Revision Study Method: Primary Study Selection Process
We performed the following steps to complete the selection of the 60 primary studies shown in Figure 1:
- Identified seven control papers to verify the search string;
- Formulated the search string using the keywords and applied it to relevant data sources and evaluated the search string results using precision and recall;
- Extracted 794 papers from all data sources using the search string;
- Removed ten duplicated papers extracted from the selected data sources;
- Filtered 680 papers based on abstracts, titles, and keywords that did not adhere to the scope of the study;
- Filtered 53 papers by applying inclusion and exclusion criteria;
- Applied backward snowball sampling by scanning the reference list of 51 papers to identify 9 more papers.
3.3. Search String Formulation and Performance Evaluation
This section explains the keywords used in the search string and databases to extract the papers pertaining to the scope of this study. The search string is organized into three interventions:
- T1: Strings related to artificial intelligence, deep learning, and machine learning;
- T2: Strings related to teaching and learning;
- T3: Strings related to research methods.
(AI OR ML OR DL OR artificial intelligence OR machine learning OR deep learning) and (“teaching and learning” OR “distance learning”) and (literature review OR experiment OR case study OR challenge* OR benefit* OR IoT platform.)
The keywords related to T1 and T2 were derived from the seven control papers identified by the authors using the existing domain knowledge before starting the study. The control papers refer to the initial set of studies used to evaluate the performance of the search string. Moreover, T3 keywords were added to the search string to cover several research methods and explore the existing literature under the scope of the study. Beyer et al. [24], Kent et al. [25], and Wohlin et al. [26] explained that there is a possibility of missing out on keywords in the search string since the keywords are derived from a limited number of the studies. Therefore, they proposed multiple strategies to overcome the risk of subjectivity in formulating the search string. First, Kent et al. [25] explained the use of precision and recall in the information retrieval process (e.g., search string used to extract papers). Precision and recall are used as performance metrics for the information retrieval process. Precision can be defined as the fraction of retrieved documents that are relevant to the search string query. Recall refers to the fraction of the relevant documents that are successfully retrieved from the search string query [25]. Beyer et al. [24] proposed an acceptable range of precision (0.0% to 14.3%) and recall (0% to 87%) for search strings used in the information retrieval process. Second, Wohlin et al. [26] emphasized the importance of using the backward snowball sampling technique on the final set of studies to minimize the risk of missing out on studies when applying the search string query in the databases.
We have used both strategies mentioned above to evaluate the performance of the search string using precision and recall, and overcome the limitations of the missing keywords in the search string using backward snowball sampling (see Figure 1). First, we used seven control papers to evaluate the performance of the search string results using precision and recall. The precision (0.63%) and recall (71.42% ) calculated for the search strings used to extract papers lies in an acceptable range of precision (0.0% to 14.3%) and of recall (0% to 87%) for systematic revision studies [24]. Second, we combined the search string with backward snowball sampling to minimize the risk of missing out on important studies. Consequently, backward snowball sampling, which entails the scanning of the reference list of papers extracted from the search string (51 papers), found 9 additional papers (see Figure 1). We have used the following data sources to apply the search string and extract the relevant papers pertaining to the scope of the study (see Figure 1):
- IEEE Xplore;
- Web of Science;
- Scopus;
- ACM digital library.
3.4. Kappa Analysis and Filtration Criteria
Kappa analysis is used to measure inter-rater reliability for qualitative items when multiple raters are involved. The kappa value can be interpreted between no agreement and perfect (<0 = No agreement, 0–0.20 = Slight, 0.21–0.40 = Fair, 0.41–0.60 = Moderate, 0.61–0.80 = Substantial, 0.81–1.0 = Perfect) [27]. We chose to perform kappa analysis since multiple researchers were involved in applying the inclusion/exclusion criteria to the extracted papers. Consequently, this allowed authors to include or exclude papers objectively by achieving the substantial agreement level. The kappa analysis was performed in two steps. First, we randomly selected 35 articles from papers extracted from the search string before the first and second authors divided 392 papers each to apply the inclusion and exclusion criteria. This step was performed to check the inter-rater agreement level, also known as kappa analysis, to achieve objectivity when using the inclusion and exclusion criteria independently by the first and second author [28]. The first and second authors have applied the inclusion and exclusion criteria independently to 392 papers each to check the inter-rater agreement level [28]. Second, we calculated the kappa value (0.885), suggesting an almost perfect agreement between the researchers. Finally, we found two disagreements that were discussed and resolved. We have used the following criteria to decide whether or not to include or exclude a paper in this study. All articles must pass the quality threshold defined in Table 2.
3.5. Data Extraction and Synthesis Strategy
The data extraction properties formulated in Table 3 were discussed between the authors and finalized to perform the study. Furthermore, the authors created a spreadsheet with all the properties outlined in Table 3 to extract information from the papers. We performed thematic analysis (See Section 4.2) using the guidelines proposed by Cruzes et al. [29] to identify themes in the data [30].
3.6. Validity Threats
This section outlines the validity threats associated with the systematic review and the actions taken to mitigate those threats. Validity denotes the reliability of the results without introducing the subjective viewpoint of the researchers [31,32]. There was a risk of introducing subjectivity by the researchers in the study; we used the member checking technique to mitigate that risk. The first author developed a review protocol, and the remaining authors validated the study protocol before executing the study. One example of achieving objectivity in choosing the right set of studies related to the scope of the study was to check the inter-rater agreement level (kappa analysis) between the researchers (See Section 3.4). Reliability of the study refers to the extent to which the data and the analysis are dependent on a specific researcher. We considered multiple strategies to improve the reliability in finding the key studies pertaining to the scope of this systematic review study. First, the search string was put together based on the limited domain knowledge and known studies. This poses a threat of missing out on primary studies with a single search string for all selected databases. Therefore, we used seven control papers to measure the precision and recall of the search string. We refined our search string in all databases until we achieved the acceptable level of precision and recall for the search string (see Section 3.3). Second, we triangulated the data sources by choosing four different relevant databases to find the studies addressing the use of AI in teaching and learning. Third, we performed backward snowball sampling on the list of studies to identify any potential missing studies pertaining to the scope of the research and found more studies in that process (See Figure 1). Finally, the first two authors independently used the thematic analysis for the data analysis part and validated each other’s work to develop common themes in the study. We validated each other’s work to ensure the objectivity of the data so as to achieve reliable results.
4. Results and Discussion
The subsections below present the distribution of studies and a qualitative analysis of the data extracted from the studies based on the data extraction properties.
4.1. Distribution of Studies
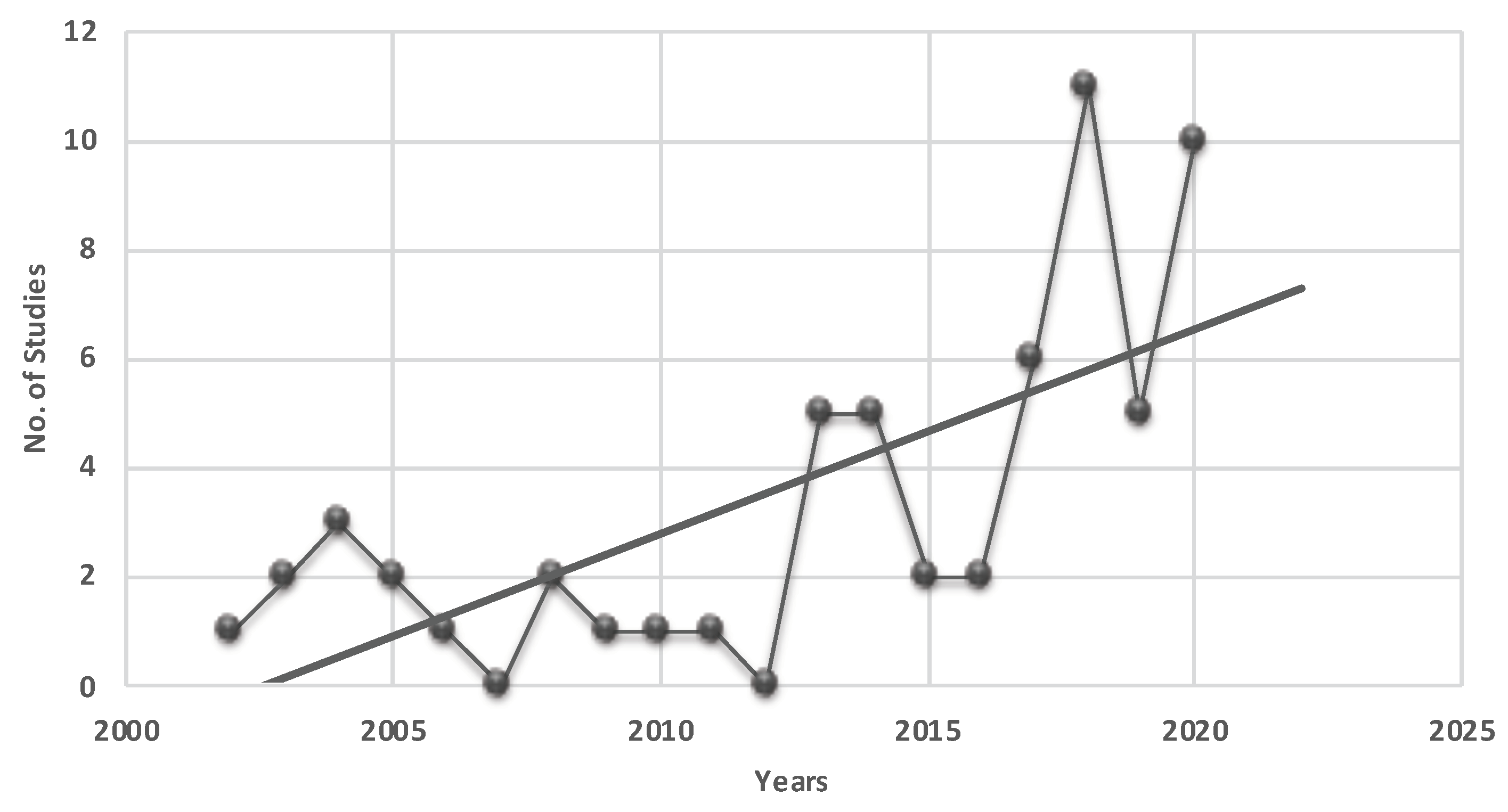
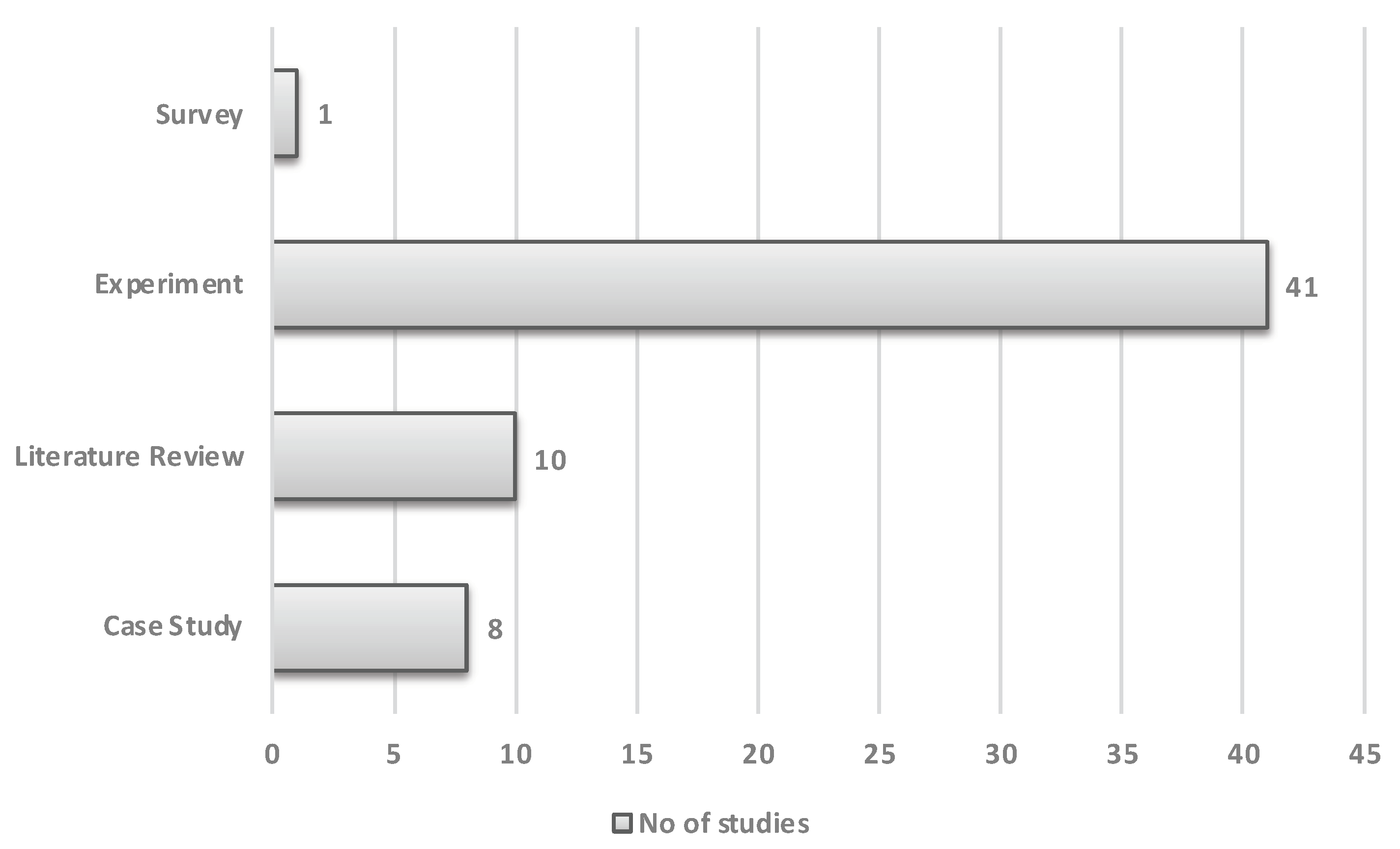
Figure 2 shows the distribution of 60 studies. The vertical axis indicates the number of studies, and the horizontal axis represents the year-span used in the search string to extract the papers pertaining to the scope of the study. The figure shows a linear pattern in the publication of studies. In particular, the use of AI in digital education after 2015 is becoming more prominent, as more and more researchers are attracted to conducting studies to explore the potential of AI/ML in education. It would not be surprising to see this trend continue to evolve as researchers explore personalized learning platforms. Figure 3 represents the research strategies employed in the published studies. The majority of studies used experiments (41) to compare the several ML models to predict the course dropouts or the performance of students in the courses (see Section 4.2). The ten literature reviews found were non-systematic and, therefore, paved the way for this systematic revision study to synthesize the research evidence.
4.2. Thematic Analysis
In this section, we performed a thematic analysis according to the guidelines provided by Cruzes et al. [29,33]. We performed the following steps to identify six distinct themes related to the studies addressing the use of AI in digital education. All the identified themes and their definitions are mentioned in Table 4. Furthermore, each theme is described in the subsections below. As for the thematic analysis, we performed the following steps:
- Extract data from the papers after completing the search review in the Excel sheet;
- Create tags for the interesting themes found in the data;
- Group the tags into distinct themes.
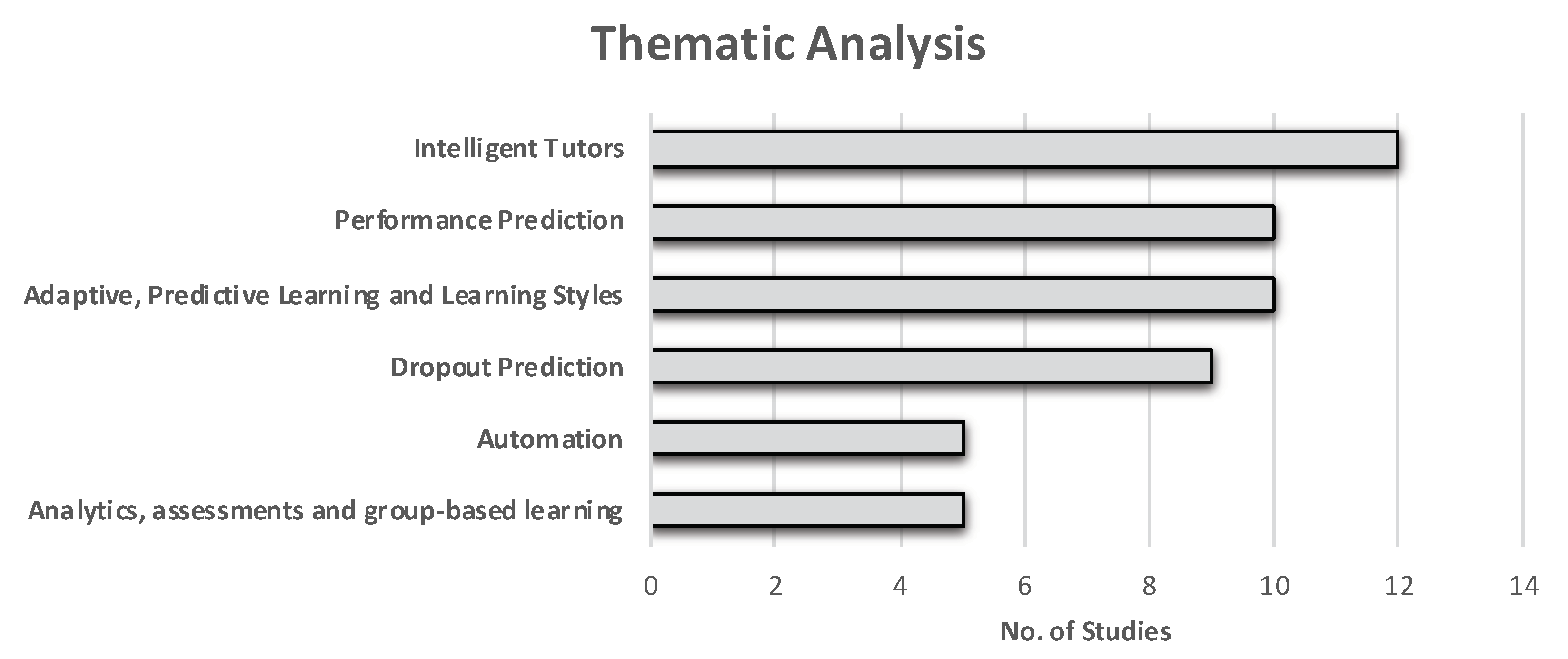
Figure 4 shows the classification of studies based on the themes identified in the process above. The vertical axis shows the six distinct themes from the literature, and the horizontal axis represents the number of studies categorized in each of these themes. Most papers were found in the “intelligent tutor” (twelve papers) theme, followed by “performance prediction”, “adaptive, predictive learning, and learning styles” (ten papers each). Furthermore, the themes “automation” and “analytics and assessments and group-based learning” contained five papers each.
4.2.1. Intelligent Tutors
This theme refers to intelligent tutoring systems used in online education. There are 12 studies found in this category, and most of them are proposed intelligent tutors; experiments were conducted to evaluate the tutors [34,35,36,37,38,39,40,41,42,43,44,45].
Butz et al. [34] presented a web-based intelligent tutoring system known as the Bayesian intelligent tutoring system (BITS). The tutoring system uses a Bayesian network to recommend learning goals and learning sequences for programming. For example, the student may be interested in learning File I/O without going through all the learning material. BITS can help students determine the minimum possible prerequisite knowledge to understand File I/O and show a link to the relevant concepts. Suraweera et al. [35] compared two intelligent tutors, namely, the knowledge-based entity relationship modeling (KERMIT) and entity relationship (ER) tutors. The two intelligent tutors were used by the student to learn entity relationship modeling by using KERMIT and the ER-Tutor. KERMIT uses constraint-based modeling (CBM) in order to model the domain knowledge and generate student models. The results show that students who interacted with KERMIT achieved significantly higher scores on the post-test as opposed to ER tutors. Alevenet et al. [36] presented a six-year-long project to develop the suite of authoring tools called cognitive tutor authoring tools (CTAT). CTAT has been used to build a diverse set of example-tracing tutors that have been used in a real educational setting without programming through drag-and-drop techniques. Example-tracing tutors evaluate student behavior by flexibly comparing it against examples of correct and incorrect problem-solving behaviors and provide step-by-step guidance on complex problems while recognizing multiple student strategies and maintaining multiple interpretations of student behavior.
Britt et al. [37] described an intelligent tutor called the source apprentice intelligent feedback mechanism (SAIF), which provides students with automatic feedback on their writing skills, such as plagiarism, uncited quotations, lack of citations, and limited content integration. SAIF uses latent semantic analysis to identify and encourage the student to revise their essays, which may lead to higher-quality essays. The results showed that the essays written after SAIF feedback included more explicit citations than essays written without using it. Vijay et al. [38] proposed a knowledge-based educational (KBEd) framework, which is used to capture, model, and codify laboratory teaching and assessment processes into an augmented reality (AR) technology. The results demonstrate that there is no significant difference between AR-trained students and on-campus learners when subjected to common experimental tasks. However, a small performance variation was noted between the two groups in terms of the AR tutors’ limited ability to understand the learner’s negligence, but the tutor showed the transferability of basic welding techniques from an AR environment to a laboratory environment in first-year engineering students with no prior experience of welding. Crowe et al. [39] conducted an exploratory case study with twenty subject-matter experts, including programmers, instructional designers, and content experts, for the development of a prototype knowledge-based scholarly writing software application that can be used in online learning. The results suggested that a prototype using Watson’s cloud-based application was determined to be feasible. The reason for this is that it is also possible to develop other distance-learning technologies for use as tools as well as curriculum applications, although the focus of the prototype was scholarly writing software.
Kim et al. [40] discussed an emotionally-aware AI smart classroom that delivers, through two modalities of an open learner model, automated real-time feedback to a presenter during a presentation to improve the effectiveness of the presentation, the presenter’s self-regulation, and their non-verbal and verbal communication skills. The foundations of the proposed system are based on prominent developments, theories, and empirical studies. The system uses deep learning to analyze a presenter’s multimodal visual and audio information to extract the intonation, body language, and hand gestures of the presenter. At the same time, the system receives scores from the audience to determine the quality of a presentation. Dahotre et al. [41] developed a prototype that semi-automatically generates API tutors from open-source code. The tutors enable students to have access to a large number of training materials. The results indicated that this approach increases student learning with high scores, while using less time for training compared to textbook-based training. Hsu et al. [42] proposed an intelligent question-answering bot entitled Xiao-Shih and improved its precision by using ML. The experimental results showed that the chatbot had a 0.833 precision of correct rate with a 0.044 response rate. Furthermore, the random forest algorithm appeared to improve the precision substantially in comparison to NLP. Haemaelaeinen et al. [45] compared five classification models, namely, linear regression (LR) and support vector machine (SVM) with numeric course data, and naive Bayes (NB), tree-augmented Bayesian nets (TAN), and Bayesian multinets (BMN) with categorical data. The results showed that K-nearest neighbors (KNN) achieved over 80% accuracy in predicting the outcome (pass or fail) of the two classes. Appsamy et al. [43] presented an API tutor recommendation system that integrates two algorithms: a content-based recommender (CBR) and a standard collaborative filtering (CF) algorithm. The system recommends suitable API tutors to users based on their needs. The results indicated that the ratings of the CBR were significantly higher than the ratings of CF-based recommendations. Gamboa et al. [44] proposed an intelligent tutoring system using a Bayesian net (BN), enabling its use as an e-learning tool. It is composed of several modules containing a user model, a knowledge base, an adaptation module, a pedagogical module, and a presentation module. BNs are used to assess a user’s preferences and state of knowledge to suggest pedagogical options for the tutor.
Takeaway: Several intelligent tutors are presented in the literature using ML models such as BN, CBR, and CF. These intelligent tutors assisted students by suggesting the right learning resources based on the students’ learning outcomes and by giving them feedback on their written assignments and verbal presentations.
4.2.2. Dropout Prediction
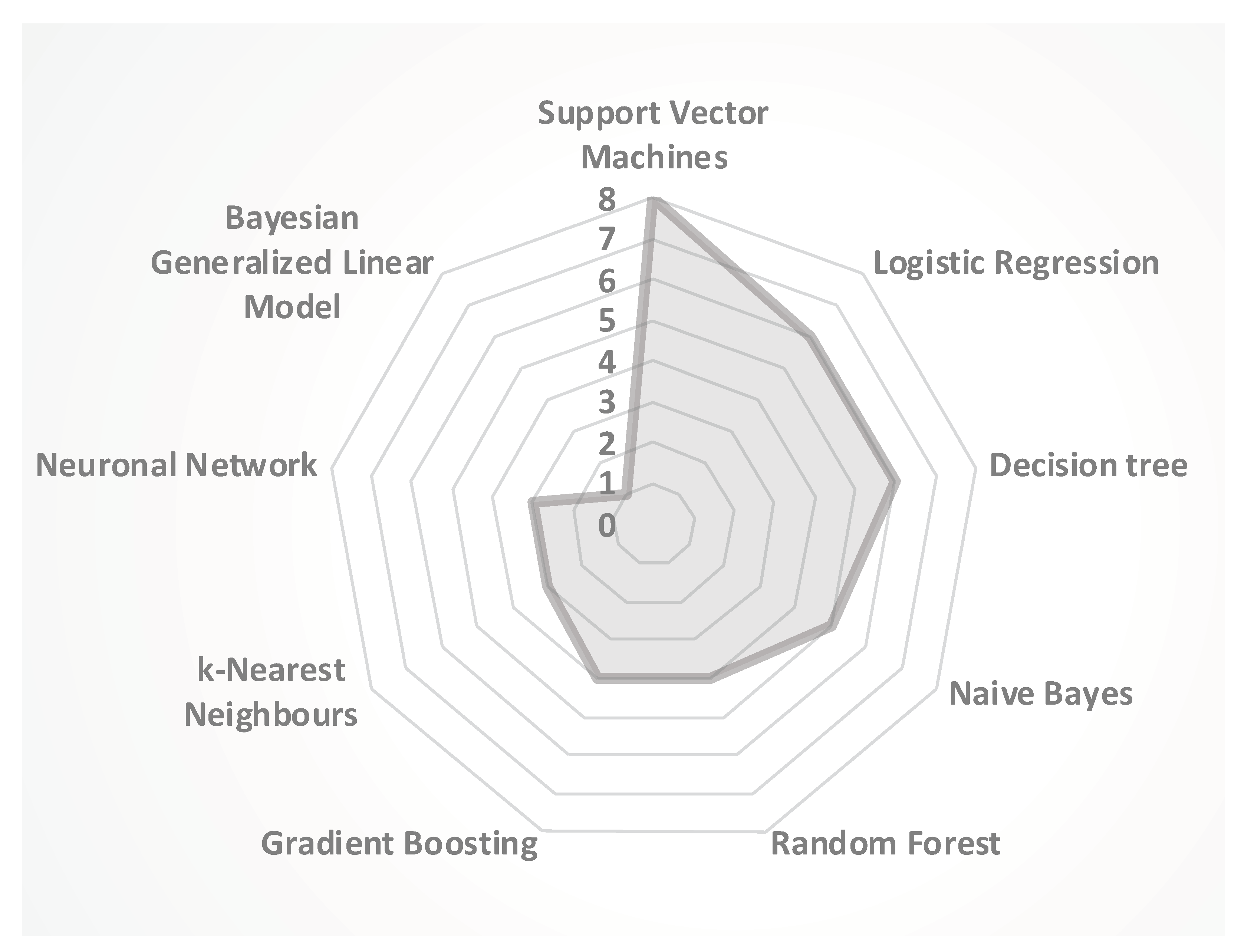
This theme consists of studies predicting student dropouts from online courses using ML models. The theme consists of nine papers using several ML algorithms to predict student dropouts from online courses [22,46,47,48,49,50,51,52,53]. We found eight experimental papers [46,47,48,49,50,51,52,53], one of which was a literature review [22]. However, that study does not adhere to the systematic literature review guidelines used in this study. Figure 5 shows the ML models used in the experiments. The most-used ML models to predict student dropouts from the online courses are SVM (eight papers), LR (six papers), DT (six papers), followed by NB (five papers). Moreover, four studies used random forest (RF) and gradient boosting (GB), followed by KNN and neural networks (NN), which were used in three papers each. The dataset varied from undergraduate to graduate courses offered online across several disciplines, such as computer networks, web development, informatics, and social sciences. The attributes used in the studies to train the models also varied a lot in the studies. These attributes may be classified as user features (e.g., total clicks, count of time, etc.), course features (e.g., number of enrollers, start time, end time, etc.), and demographic attributes (e.g., age, gender, work status, etc.). A detailed set of the attributes used in each study can be seen in Appendix A (see Table A1).
Alsolami et al.’s [46] results showed a dropout accuracy of 90% using the random forest model; the researchers suggested that the model can be used in online education to understand the early dropout prediction better. Thus, the model helps by making necessary adjustments to the courses. Cobos et al. [47] selected the Bayesian generalized linear model as the best algorithm because it consumed less time for training and was more stable than NN and RF. Kotsiantis et al. [48] did not find any statistical significant difference between the ML techniques (namely, DT, NN, NB, instance-based learning algorithms, LR, and SVM) used in the study. Lian et al. [49] claimed 89% accuracy in the dropout prediction task with a gradient boosting decision tree model (GBDT). Oliveira et al. [51] highlighted that the highest accuracy is delivered by the RF (88%). On the other hand, LR performed the worst, with an accuracy of 79%. Kostopoulos et al.’s [52] experimental results indicated a dropout predictive accuracy of 66.26% using NB based only on pre-university information (e.g., age, sex, education, work status, etc.) and 84.56% at the middle of the academic year.
Takeaway: The most commonly used ML model to predict student dropouts from online courses is Support Vector Machines. However, the RF, DT, and bayesian generalized linear model indicate the best student dropout results. The attributes used in the algorithms can be categorized into student features, course features, and demographics data.
4.2.3. Performance Prediction
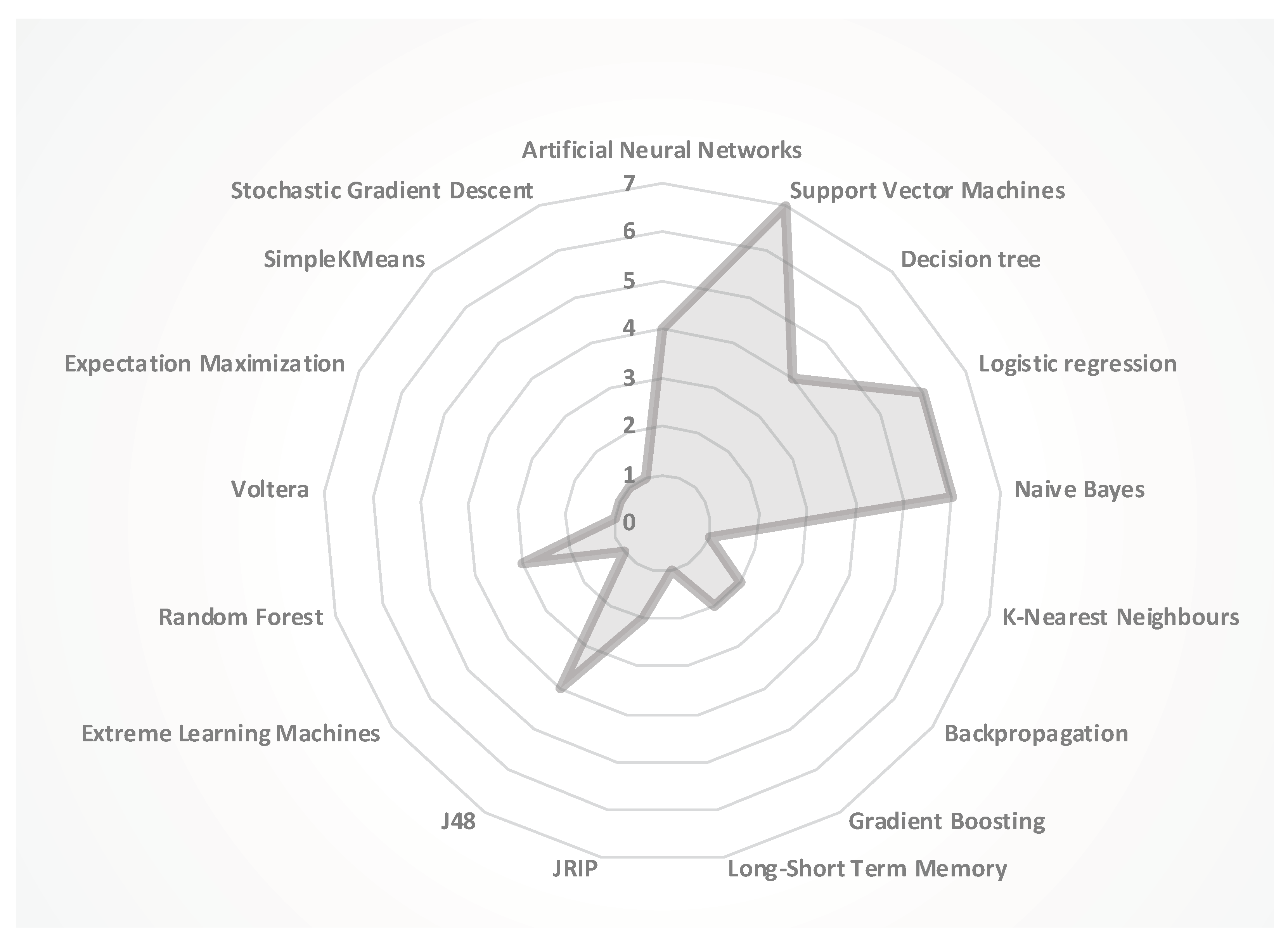
This theme consists of 10 papers using different ML models to predict student performance in online courses. All ten papers classified in this theme are experimental studies similar to the student dropout theme [54,55,56,57,58,59,60,61,62,63]. The number of machine models used in the studies can be seen in Figure 6. The majority of machine models used to predict student performance (e.g., grades) includes SVM (seven papers), LR (six papers), NB (six papers), ANN (four papers), DT (four papers), J48 (four papers), followed by RF (four papers). Furthermore, backpropagation (BP), GB, and JRIP were used in two studies each. KNN, LSTM, ELMs, voltera, expectation maximization, simpleKMeans, and SGD have been used in one study each. The details of the datasets and attributes used in each study are presented in Appendix B (see Table A2). The attributes used for predicting student performance can be classified into the following three categories:
- Past student performance (i.e., grades in the exam);
- Student engagement (e.g., duration count, number of learning material visits, search count activity, discussion participation, number of comments, commenting, exam attempts, etc.);
- Student demographic data (e.g., gender, age, skills, education level, working experience, etc.).
Tomasevic et al. [54] used ML techniques to predict the final exam results using data available before the final exam. The results showed that the highest precision was achieved using ANN by feeding the engagement and past performance data. Furthermore, the ANN results were followed by SVM, whereby the worst results were attained with the NB approach. Sekeroglu et al. [55] showed that higher results were obtained for BP, SVM, and GBC, as 87.78%, 83.20%, and 82.44%, respectively, in predicting student grades. The experiment conducted by Hussain et al. [56] showed that DT, J48, JRIP, and GBT were the most-appropriate algorithms for predicting low-engagement students during an open university assessment. De Albuquerque et al.’s [57] results showed that the MLP (a type of ANN) achieved 85% accuracy on average, and a maximum rate of 95% correct classifications. Deo et al.’s [58] experiment showed that the ELM model outperformed both the RF and Volterra models for the entire category of grades (e.g., C, F, etc.). Kotsiantis et al.’s [59] results of the post hoc analysis depict that NB shows the best results for the overall accuracy (72.48%) followed by the LR (72.32%), the BP (72.26%), and the SVM/SMO (72.17%). Lorenzo et al. [60] used several ML algorithms to predict the student’s video engagement, exercise engagement, and assignment engagement. SGD showed the best results for the video engagement indicator (89.09%), followed by the exercise engagement indicator (88.79%) and the assignment engagement indicator (85.39%). Jayaprakash et al.’s [61] study results showed that LR, SVM, and NBs outperform J48 in terms of recall. However, all three algorithms exhibit a very steady behavior when varying the overall sampling size. One possible explanation is that LR, support vector machine (i.e., linear), and NB are all high-bias and low-variance learners. Therefore, the representational power is low (all being linear models) and makes them steady, leading to low variance. Yoo et al.’s [62] comparison showed SVM is better and less sensitive to changes of the number of selected features, as opposed to J48 and NB, when predicting students’ project performance. Romero et al. [63] applied clustering algorithms with class-associated rule mining, instead of using only traditional classification models, to detect students at risk of failing at the end of the course and before the end of the course. The EM algorithm shows better accuracy in predicting students’ final performance from online discussion forum participation than the other classification algorithms in all eight datasets used in the study.
Takeaway: SVM is the most-used algorithm in the literature to predict students’ performance from online courses. Furthermore, SVM also showed better results in terms of predicting the students’ performance, together with ANN, NB, and LR. The most commonly used variables for the algorithms used in the studies can be categorized into students’ past performance, engagement activities, and demographic data.
4.2.4. Adaptive and Predictive Learning and Learning Styles
This theme consists of studies that use different algorithms for adaptive and predictive learning as well as for addressing different learning styles needed for digital education. For this theme (see Table 5), ten papers have been classified: six experiment-based studies [64,65,66,67,68,69], three case studies [70,71,72], and one survey-based study [73]. The ANN model is studied to generate adaptive lessons for an individual [64]. The model generates a set of documents that is adapted to learners’ needs by searching for the best route to connect the known concepts. The learner self-defines the learning goals, where selection algorithms aim to present the most suitable didactic plan based on the goal and considering the learner’s actual knowledge [64]. Learner modeling and resource modeling are important aspects to deploy adaptive mechanisms [73]. Thus, learning styles play an important role in modeling. The K-means algorithm is used to classify the online learners’ learning styles. These cluster analyses classify the data into several categories based on similarity. The learners are classified into the following categories: goal-type learners, task-based learners, self-learning learners, stable learners, and traditional learners [73]. A study on an ML method called determinantal point processes is used to sample a group of diverse questions for newcomers in massive open online courses (MOOC) to improve their personalized learning experiences [65]. Based on the known knowledge components of the newcomers, this method helps to select the first bulk of questions by not asking every newcomer the same questions. According to this research, this method outperforms uncertainty sampling by providing useful feedback to the newcomers in the MOOC system based on their strong and weak points [65]. An intelligent English-teaching platform is designed, where the decision tree algorithm and neural networks have been applied to generate an English-teaching assessment implementation model [72]. This approach develops a deep learning-assisted online system to help learners improve their English language skills and paves the way forward for personalized learning and teaching [72].
Using Bayesian nets for detecting students’ learning styles is proposed in order to deliver teaching materials to students [66]. This approach is evaluated with ten learners. The learning style model classifies students based on the number of scales, depending how they receive and process data. This study concludes that the Bayesian net helps to detect the students’ learning styles with high precision [66]. An adaptive recommendation -based online learning style (AROLS) is proposed by integrating a comprehensive learning style model for digital learning [67]. This approach provides recommendations based on learning styles by generating learner clusters. Afterwards, the similarity matrix and association rules for different learning resources are used based on browsing history by creating personalized recommendations [67].
The work of [68] covers the aspects of predicting the students’ outcomes by using the adaptive random forest classification algorithm and comparing the performance. Additionally, feature importance analysis is performed for predictive tasks. RF and adaptive random forest (ARF) are used to analyze the educational data with the aim of assessing the system’s capability of predicting the outcomes based on the historical input from students [68]. Another study provides a personalized learning with customized recommendations [69]. Their approach provides an adaptive learning path with self-perception, learning styles, and data on creativity with the utilization of the DT method for learner classifications, recommending the most-effective learning paths [69]. An application of AI is introduced for adaptive instruction [70]. The authors categorize three types of ML from an input–output perspective by distinguishing: (1) supervised learning, (2) unsupervised learning, and (3) reinforcement learning [70]. A grey-box approach is suggested for building pipelines for educational data [71]. Through a case study, the authors proposed a methodological paradigm for developing ML pipelines for predicting students’ learning performance [71].
Takeaway: The automatic customization of the learning content for the learner is important if we want to design adaptive learning mechanisms, which is followed by predictive and personalized learning, where the content tailored to the individual’s needs is based on prior knowledge, current skills, and interests, strengths, and weaknesses. Obviously, in addressing the learner’s needs, it is imperative to understand the user’s learning style, which is a set of an individual’s learning characteristics in terms of their choices and differences. All these learning concepts are important for digital learning and teaching; therefore, our study highlights the commonly used algorithms (whether ML or DL), which are presented in Table 5. This table also shows us that, within this theme, the most-used algorithms are K-means and RF.
4.2.5. Analytics, Assessments, and Group-Based Learning
This theme consists of studies related to analytics, assessments, and group-based learning, with the support of different algorithms. As presented in Table 6, this theme consists of five papers; all of them were experiment-based studies [74,75,76,77,78].
A multimodal learning analytics system (MMLA) is suggested for project-based learning to support group work [74]. This research automatically identifies some key aspects of students in project-based learning environments by incorporating support from the teachers and utilizing supervised ML methods and DL techniques to analyze data from different sources. Both neural networks and traditional regression approaches are used to classify the MMLA data to predict the students’ group performances in group-based learning environments [74]. A personalized ubiquitous e-teaching and e-learning framework is suggested to enhance the development, management, and delivery of both teaching and learning aspects for smart societies [75]. This framework has a number of components, such as a sentiment analyzer, user activity recognition and user identification components, and an adaptive content delivery mode adviser. Additionally, the framework includes a naive Bayes classifier, random forest, and a deep learning artificial neural network [75].
An innovative grouping approach is proposed by utilizing the genetic algorithm (GA) to enhance both the interaction and collaboration of students as well as to group peers based on degrees and social relationships [76]. The authors used different GA models in this study, which enabled the auto-grouping mechanisms to generate better learning results. This approach yields a high degree of heterogeneous grouping and stimulates the students for better learning [76]. An online classroom atmosphere system is proposed that uses deep learning technology to support learning and teaching [77]. This system evaluates the classroom atmosphere in real time by utilizing R-CNN and SVM. The study provides key insights about activities such as classroom time, classroom teachers, the actual number of people, attendance, and classroom atmosphere [77]. A new ML-based evaluation method is presented to assess the usability of e-learning systems. Support vector machines, neural networks, and decision trees, together with multiple linear regression, are utilized to predict and discover the usability of e-learning systems by identifying the most-important usability factors [78].
Takeaway: Group-based learning is an important component within the field of digital learning to enhance interaction and collaboration among peers. Analytics supports users’ group-based learning in terms of predicting their performance and assessing their work. Several ML and DL models have been used within this theme, but the most commonly used ones are SVM, RF, and NB; see Table 6 for details.
4.2.6. Automation
This theme refers to the studies related to specific algorithms used for automation, whether recommendation, proficiency, classification, or for indexing in digital learning. This theme is based on five studies: five experiment-based studies [67,79,80,81] and one case study [82].
A study by Mabrouk et al. [82] presents a hybrid intelligent recommendation system for online learning platforms. This system recommends the most-appropriate learning content and facilitates access to the content for learners by utilizing the classification and regression trees (CART) algorithm [82]. Another recommendation-based study by Chen et al. [67] shows how learner clusters are generated based on personalized recommendations of learning styles by using K-means. A study by Hasan et al. [79] presents experimental results related to automatic proficiency checking using features from an annotated learner database of Japanese learners in English. Furthermore, they have extracted implicit and explicit knowledge from learner data to support foreign language teaching and learning [79]. This study utilizes a number of ML algorithms, such as ID3, C4.5, Bayesian networks, and SVM, that identify non-trivial error-related features to predict the language proficiency level [79].
A study of the effectiveness of neural network learning techniques is used for automatic question classification in terms of classifying the questions into a number of levels [80]. According to Ting et al. [80], this approach was specifically used to classify multiple-choice questions, which are most commonly used in tests and exercises during online teaching. The experimental results were evaluated by precision, recall and F1 value, where they utilized ANNs and the least mean square (LMS) algorithm [80]. The automatic indexing of video lectures is studied by extracting topic hierarchies from text and audio transcripts [81]. Husain and Meena [81] proposed an approach to address the complementary strengths of slide text and audio transcript data using semi-supervised latent Dirichlet allocation (LDA) algorithm. This approach allows for the recognition of the words from video slides as seeds, and then uses these to train the model. The results show the efficacy of the proposed approach when indexing video lectures [81].
Takeaway: Automation is becoming an essential building block in digital education. It can help to control processes and minimize workload in repetitive tasks in the digital learning landscape. Thus, in order to address automation in digital education, in Table 7, we provide an overview of approaches and AI-based algorithms used within this theme, whether for the automatic recommendation of a learning content, for indexing video sequences, or for proficiency in language learning, which is specifically important for the globalization of learners.
5. Conclusions and Future Work
This paper reports the results of the systematic revision study to explore the existing literature for the use of AI-based approaches used in digital education. The key contribution of this study was to identify which themes and concepts are revolving around AI, and which ML- or DL-based models are mostly used in digital education. Furthermore, another significant contribution is to follow the systematic revision guidelines to systematically explore the literature by performing the thematic analysis. It is interesting to note that the majority of the studies found in this study are experiments. One possible reason is that the researchers are interested in comparing the results of different algorithms using digital education data such as student dropout or performance prediction. Furthermore, the yearly publication data related to ML or DL in digital education shows an increased interest in the research area from 2015 onwards. The researchers have been investigating the application of ML and DL in all fields. Similarly, the application of ML and DL in digital education is also seen as an emerging pattern in this study.
Concerning RQ1, the thematic analysis showed several learning themes revolving around AI-based digital education. These themes include intelligent tutors, dropout predictions, performance predictions, adaptive and predictive learning and learning styles, analytics and group-based learning, and automation. The three most-prominent themes are “intelligent tutors”, “performance prediction”, “adaptive and predictive learning and learning styles”, and “dropout prediction”, with twelve, ten, and nine papers, respectively. The remaining two themes are “automation” and “analytics, assessments, and group-based learning”, containing five papers each.
Regarding RQ2, an interesting result to note is that the artificial neural network and support vector machine algorithms appear to be utilized among all the identified themes and across two classes of problems of classification and regression. Second, the most-used algorithm found in this study is random forest, which is used in most themes except for “automation”. It is worth mentioning that DT, NB, and LR are used within three themes, namely, the “analytics, assessments, and group-based learning”, “dropout prediction”, and “performance prediction” themes.
Our results highlight several important insights for policy makers, educators, researchers and, indeed, higher education institutions that can help develop the potential of AI- and ML-supported technologies for digital education. We provide an extensive overview of six identified themes of digital education that enable a deepened understanding of the role of AI and ML in higher education. These general themes can improve the design and integration of specific AI-supported approaches into different educational modules and systems as well as pedagogical practices. Some of the ways in which our results are useful are, e.g., addressing and predicting learners’ dropout rates, identifying students’ performance issues in courses, and including learning analytics and automation capabilities in such systems. Likewise, assisting in the decision of which AI- and ML-supported approaches can be utilized for certain designs of intelligent tutors is another useful feature of our research results. Furthermore, the insights uncovered by our research can be utilized to design AI- and ML-supported courses by tailoring specific approaches set to innovate course curricula and, thereby, also increase the quality of digitalized higher education institutions and the prospects that they bring. As such, our findings serve as useful recommendations for policy makers and educators in digital education.
The future work of the study may be directed towards the investigation of empirical settings, with the aim of contextualizing the different ML models identified and proposing a design process for practitioners to apply ML models when designing digital education systems.
Author Contributions
Conceptualization, H.M. and B.V.; methodology, H.M.; validation, H.M., B.V. and A.J.; formal analysis, H.M. and B.V.; investigation, H.M. and B.V.; resources, H.M. and B.V.; data curation, H.M. and B.V.; writing—original draft preparation, H.M. and B.V.; writing—review and editing, H.M., B.V. and A.J.; visualization, H.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The lead author would like to thank all authors for their contributions in the study.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Contextual Details of the Student Dropout Theme
This appendix (see Table A1) contains the dataset and attributes used for ML models in the papers to predict student dropouts.
Table A1.
Student dropout prediction dataset and attributes used to train ML models.
| Ref. | Dataset | Attributes |
|---|---|---|
| [46] | The MOOC students dataset belongs to 39 courses and more than 100 thousand users connected with the system. | Browser_problem, Browser_access, Browser_video, Class_size, Server_problem, Server_access, Navigation. |
| [47] | MOOC data from Social Science and Science. | Num_events, Total_time num_sessions, Nav_events, Nav_time, Connected_days, Video_events, Video_time, Consecutive_inactivity_days, Problem_events, Problem_time, Num_diff_problems, Forum_events, Forum_time, Num_diff_videos. |
| [48] | The informatics course (INF) at Hellenic Open University is composed of 12 modules and leads to a Bachelor’s Degree. A total of 354 student records have been collected. | Sex, age, marital status, number of children, occupation, computer literacy, job associated with computers, 1st face-to-face meeting, 1st written assignment, 2nd face-to-face meeting, 2nd written assignment. |
| [49] | MOOC data from 39 courses | Count of time periods, total clicks, number of dropouts, number of courses, last access time, access count, course access interval, last access time, access times for categories, access interval for categories, last access time for categories, average-respond-time of categories, average respond time number of dropped courses, number of accesses, number of enrollers, last time, start time, total stay time, average stay time time elapsed, accessed counts, completed counts, total accessed, period counts, period span, period start, last access, start, completed counts. |
| [50] | The data was collected from a psychology MOOC with with 20,828 participants. | Number of requests, number of sessions, number of active days, number of page views number of page views per session, number of video views, number of video views per session, number of forum views, number of wiki views, number of homework page views, number of straight-through video plays, number of start–stops during video plays, number of skip-aheads during video plays, number of relistens during video plays, number of slow play rate uses, most common request time, number of requests from outside of course, number of screen pixels, most active day, country, operating system, browser. |
| [51] | The data collected from two postgraduate courses as part of Brazil’s Open University. The dataset comprises 200,166 records split into 115,407 for Course 1 and 84,762 for Course 2. A total of 166 students were enrolled in both courses. | Course view, Forum view, Forum view discussion, Resource view, Forum add post, Forum add discussion, Assign view, Assign submission, User view, URL view, Page view, Forum search. |
| [52] | The dataset used was provided by the Hellenic Open University (HOU) in an Introduction to Informatics module of the Computer Science course. | Gender male, Age, Marital status, Children, Work, Comp_Knowledge Presence in optional contact session, Test, Dropout. |
| [53] | Data collected from two introductory-level e-learning courses, namely, Computer Networks and Communications and Web Design, from the National Technical University of Athens, Greece. | Gender, Residency capital, Working experience, Educational level, English language literacy, Prior academic performance, Multiple choice test grade, Project grade, Project submission date, Section activity. |
Appendix B. Contextual Details of the Student Performance Prediction Theme
This appendix (see Table A2) contains the dataset and attributes used for ML models in the papers to predict students’ performance.
Table A2.
Students’ performance predictor dataset and attributes used to train ML models.
| Ref. | Dataset | Attributes |
|---|---|---|
| [56] | The study uses the anonymized Open University Learning Analytics Dataset (OULAD). It contains data about courses, students, and their interactions with a virtual learning environment (VLE) for seven selected courses (called modules). | Dataplus; Forumng; Glossary; Oucollaborate; Oucontent; Resource; Subpage; Homepage; URL; Score on the assessment. |
| [54] | The Open University Learning Analytics Dataset (OULAD) contains information about 22 module presentations and 32,593 students. The dataset includes different student-related data, such as their assessment results and logs of their interactions with the virtual learning environment (VLE), represented by daily summaries of student clicks on different resources [83]. | Gender; highest education; sum of clicks; score per assessment; no. of attempts; final exam score. |
| [55] | The Student Performance Dataset (SPD) and the Students’ Academic Performance Dataset (SAPD) are used in the study. SPD includes students’ performances as the output for Maths and Portuguese courses, according to 33 attributes related to parental status, home addresses, family size, etc. The SAPD consists of relatively similar attributes to SPD, but has, in total, 21 attributes and 3 outputs: good, average, and poor. | N/A explicitly |
| [57] | The dataset contains a total of 14,205 students evaluated in 2013. | Grade; period of study; School score; Student score in elementary school. |
| [58] | The student performance data collected over a six-year period in mid-level to advanced-level courses (engineering mathematics) at the Australian Regional University. | Exam score (two quizzes and three assignments). |
| [59] | Data collected from the informatics course of the Hellenic Open University (HOU). The course is composed of 12 modules and leads to a Bachelor’s Degree. | Sex; age; marital status; number of children; occupation number; computer literacy; job associated with computers; attributes from tutors’ records; 1st face-to-face meeting, absent; 1st written assignment number, fail; 2nd face-to-face meeting, absent; 2nd written assignment number, fail; 3rd face-to-face meeting, absent; 3rd written assignment number, fail; 4th face-to-face meeting, absent; 4th written assignment; class; final examination test. |
| [63] | Data from 114 university students during a first-year course in computer science. | Messages; threads; words; sentences; reads; time; AvgScoreMsg; centrality; prestige; number of selected attributes. |
| [60] | MOOC platform with 26,947 students enrolled in the Circuits and Electronics course. | (f1) % of lecture videos watched in chapter i, (f2) % of finger exercises answered; (f3) % of assignments submitted; (f4) normalized grade of finger exercises; (f5) normalized grade of assignments; (f6) value of video engagement indicator; (f7) value of exercise engagement indicator; (f8) value of assignment engagement indicator; (f9) normalized total grade of finger exercises; (f10) normalized total grade of assignments; (f11) Percentage of lecture videos totally or partially watched, chapter i + 1; (f12) % of finger exercises answered; (f13) % of assignments submitted; (f14) Difference between value of video engagement indicator, and % of lecture videos totally or partially watched; (f15) Difference between value of exercise engagement indicator, and % of finger exercises answered; (f16) Difference between value of assignment engagement indicator and percentage of assignments answered. |
| [61] | Data was collected at Marist College from courses taken by a student. | Online; age; gender; SAT_VERBAL; SAT_MATH; Aptitude_score; Full_time, Class, Cum_GPA, Enrollment, Academic_standing, RMN_Score_partial; R_sessions; R_Content_read. |
| [62] | Data from eight semesters of a computer science course, covering conversations of 370 students from the Moodle database. | Number of words programming; Number of sentences; Number of paragraphs; Number of messages. |
Appendix C. List of Studies Identified in the Review Process
This appendix (see Table A3) contains the list of all studies found in this systematic review using a search review process.
Table A3.
List of primary studies identified in review process.
| ID | Title | Ref. |
|---|---|---|
| S1 | A Comprehensive Survey on Educational Data Mining and Use of Data Mining Techniques for Improving Teaching and Predicting Student Performance | [21] |
| S2 | A Hybrid Approach for Dropout Prediction of MOOC Students using Machine Learning | [46] |
| S3 | A Learning Analytics Tool for Predictive Modeling of Dropout and Certificate Acquisition on MOOCs for Professional Learning | [47] |
| S4 | A machine learning-based usability evaluation method for eLearning systems | [78] |
| S5 | A Web-Based Intelligent Tutoring System for Computer Programming | [34] |
| S6 | A Neural Network for Generating Adaptive Lessons | [64] |
| S7 | An Intelligent Tutoring System for Entity Relationship Modelling | [35] |
| S8 | An Online Classroom Atmosphere Assessment System for Evaluating Teaching Quality | [77] |
| S9 | An overview and comparison of supervised data mining techniques for student exam performance prediction | [54] |
| S10 | Analysis of Online Learning Style Model Based on K-means Algorithm | [73] |
| S11 | Automated Test Assembly for Handling Learner Cold-Start in Large-Scale Assessments | [65] |
| S12 | Example-Tracing Tutors: A New Paradigm for Intelligent Tutoring Systems | [36] |
| S13 | Grouping Peers Based on Complementary Degree and Social Relationship Using Genetic Algorithm | [76] |
| S14 | Student Performance Prediction and Classification Using Machine Learning Algorithms | [55] |
| S15 | Supervised machine learning in multimodal learning analytics for estimating success in project-based learning | [74] |
| S16 | Student Engagement Predictions in an e-Learning System and Their Impact on Student Course Assessment Scores | [56] |
| S17 | Using neural networks to predict the future performance of students | [57] |
| S18 | UTiLearn: A Personalised Ubiquitous Teaching and Learning System for Smart Societies | [75] |
| S29 | Using Intelligent Feedback to improve Sourcing and Integration in Students Essays | [37] |
| S20 | Recommendation System for Smart LMS Using Machine Learning: A Literature Review | [13] |
| S21 | Preventing student dropout in distance learning using machine learning techniques | [48] |
| S22 | Machine learning and learning analytics: Integrating data with learning | [14] |
| S23 | Learner Corpus and its Application to Automatic Level Checking using Machine Learning Algorithms | [79] |
| S24 | Question Classification for E-learning by Artificial Neural Network | [80] |
| S25 | Machine learning application in MOOCs: Dropout prediction | [49] |
| S26 | Multimodal Fusion of Speech and Text using Semi-supervised LDA for Indexing Lecture Videos | [81] |
| S27 | Predicting and Reducing Dropout in Virtual Learning using Machine Learning Techniques: A Systematic Review | [22] |
| S28 | Modern Artificial Intelligence Model Development for Undergraduate Student Performance Prediction: An Investigation on Engineering Mathematics Courses | [58] |
| S29 | Predicting MOOC Dropout over Weeks Using Machine Learning Methods | [50] |
| S30 | LONET: An Interactive Search Network for Intelligent | [84] |
| S31 | Introducing knowledge based augmented reality environment in engineering learning –a comparative study | [38] |
| S32 | Knowledge Based Artificial Augmentation Intelligence Technology: Next Step in Academic Instructional Tools for Distance Learning | [39] |
| S33 | Predicting students’ performance in distance learning using machine learning techniques | [59] |
| S34 | Predicting students’ final performance from participation in on-line discussion forums | [63] |
| S35 | Predicting the decrease of engagement indicators in a MOOC | [60] |
| S36 | Towards an Intelligent Hybrid Recommendation System for E-Learning Platforms Using Data Mining | [82] |
| S37 | Towards Emotionally Aware AI Smart Classroom: Current Issues and Directions for Engineering and Education | [40] |
| S38 | Understanding the Student Dropout in Distance Learning | [51] |
| S39 | Using Bayesian Networks to Detect Students’ Learning Styles in a Web-based education system | [66] |
| S40 | Using Intelligent Tutors to Enhance Student Learning of Application Programming Interfaces | [41] |
| S41 | Xiao-Shih: The Educational Intelligent Question Answering Bot on Chinese-Based MOOCs | [42] |
| S42 | Enhanced learning resource recommendation based on online learning style model | [67] |
| S43 | Evolution and Revolution in Artificial Intelligence in Education | [17] |
| S44 | Evaluation of Algorithms for Recommending Intelligent Tutors to Computer Science Students | [43] |
| S45 | Early Alert of Academically At-Risk Students: An Open Source Analytics Initiative | [61] |
| S46 | Educational Data Mining: A Review of the State-of-the-Art | [15] |
| S47 | Early Dropout Prediction in Distance Higher Education Using Active Learning | [52] |
| S48 | Educational Stream Data Analysis: A Case Study | [68] |
| S49 | E-Learning: Challenges and Research Opportunities Using Machine Learning & Data Analytics | [18] |
| S50 | Designing Intelligent Tutoring Systems: A Bayesian Approach | [44] |
| S51 | Dropout prediction in e-learning courses through the combination of machine learning techniques | [53] |
| S52 | Design of online intelligent English teaching platform based on artificial intelligence techniques | [72] |
| S53 | Data mining for providing a personalized learning path in creativity: An application of decision trees | [69] |
| S54 | Data mining in education | [16] |
| S55 | Artificial Intelligence in Education: A Review | [19] |
| S56 | Can Online Discussion Participation Predict Group Project Performance? Investigating the Roles of Linguistic Features and Participation Patterns | [62] |
| S57 | Comparison of Machine Learning Methods for Intelligent Tutoring Systems | [45] |
| S58 | Application of Artificial Intelligence to Adaptive Instruction - Combining the Concepts | [70] |
| S59 | Building pipelines for educational data using AI and multimodal analytics: A grey-box approach | [71] |
| S60 | Artificial intelligence innovation in education: A twenty-year data-driven historical analysis | [20] |
References
- Reddy, S.; Allan, S.; Coghlan, S.; Cooper, P. A governance model for the application of AI in health care. J. Am. Med. Inform. Assoc. 2019, 27, 491–497. [Google Scholar] [CrossRef]
- Lee, J.; Davari, H.; Singh, J.; Pandhare, V. Industrial Artificial Intelligence for industry 4.0-based manufacturing systems. Manuf. Lett. 2018, 18, 20–23. [Google Scholar] [CrossRef]
- Langer, A. Analysis and Design of Next-Generation Software Architectures: 5G, IoT, Blockchain, and Quantum Computing; Springer International Publishing: New York, NY, USA, 2020. [Google Scholar]
- Kokku, R.; Sundararajan, S.; Dey, P.; Sindhgatta, R.; Nitta, S.; Sengupta, B. Augmenting classrooms with AI for personalized education. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 6976–6980. [Google Scholar]
- Maghsudi, S.; Lan, A.; Xu, J.; van Der Schaar, M. Personalized Education in the Artificial Intelligence Era: What to Expect Next. IEEE Signal Process. Mag. 2021, 38, 37–50. [Google Scholar] [CrossRef]
- Pokrivčáková, S. Preparing teachers for the application of AI-powered technologies in foreign language education. J. Lang. Cult. Educ. 2019, 7, 135–153. [Google Scholar] [CrossRef] [Green Version]
- Cone, L.; Brøgger, K.; Berghmans, M.; Decuypere, M.; Förschler, A.; Grimaldi, E.; Hartong, S.; Hillman, T.; Ideland, M.; Landri, P.; et al. Pandemic Acceleration: Covid-19 and the emergency digitalization of European education. Eur. Educ. Res. J. 2021. [Google Scholar] [CrossRef]
- Popenici, S.A.D.; Kerr, S. Exploring the impact of artificial intelligence on teaching and learning in higher education. Res. Pract. Technol. Enhanc. Learn. 2017, 12, 22. [Google Scholar] [CrossRef]
- VanLeeuwen, C.A.; Veletsianos, G.; Belikov, O.; Johnson, N. Institutional perspectives on faculty development for digital education in Canada. Can. J. Learn. Technol. 2020, 46, 2. [Google Scholar] [CrossRef]
- Dillenbourg, P. The Evolution of Research on Digital Education. Int. J. Artif. Intell. Educ. 2016, 26, 544–560. [Google Scholar] [CrossRef] [Green Version]
- Taglietti, D.; Landri, P.; Grimaldi, E. The big acceleration in digital education in Italy: The COVID-19 pandemic and the blended-school form. Eur. Educ. Res. J. 2021, 20, 423–441. [Google Scholar] [CrossRef]
- Rajendran, R.; Kalidasan, A. Convergence of AI, ML, and DL for Enabling Smart Intelligence: Artificial Intelligence, Machine Learning, Deep Learning, Internet of Things. In Challenges and Opportunities for the Convergence of IoT, Big Data, and Cloud Computing; IGI Global: Hershey, PA, USA, 2021; pp. 180–195. [Google Scholar]
- Murad, D.F.; Heryadi, Y.; Wijanarko, B.D.; Isa, S.M.; Budiharto, W. Recommendation system for smart LMS using machine learning: A literature review. In Proceedings of the 2018 International Conference on Computing, Engineering, and Design (ICCED), Bangkok, Thailand, 6–8 September 2018; pp. 113–118. [Google Scholar]
- Sciarrone, F. Machine learning and learning analytics: Integrating data with learning. In Proceedings of the 2018 17th International Conference on Information Technology Based Higher Education and Training (ITHET), Olhao, Portugal, 26–28 April 2018; pp. 1–5. [Google Scholar]
- Romero, C.; Ventura, S. Educational Data Mining: A Review of the State of the Art. IEEE Trans. Syst. Man, Cybern. Part C (Appl. Rev.) 2010, 40, 601–618. [Google Scholar] [CrossRef]
- Romero, C.; Ventura, S. Data mining in education: Data mining in education. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2013, 3, 12–27. [Google Scholar] [CrossRef]
- Roll, I.; Wylie, R. Evolution and Revolution in Artificial Intelligence in Education. Int. J. Artif. Intell. Educ. 2016, 26, 582–599. [Google Scholar] [CrossRef] [Green Version]
- Moubayed, A.; Injadat, M.; Nassif, A.; Lutfiyya, H.; Shami, A. E-Learning: Challenges and Research Opportunities Using Machine Learning Data Analytics. IEEE Access 2018, 6, 39117–39138. [Google Scholar] [CrossRef]
- Chen, L.; Chen, P.; Lin, Z. Artificial Intelligence in Education: A Review. IEEE Access 2020, 8, 75264–75278. [Google Scholar] [CrossRef]
- Guan, C.; Mou, J.; Jiang, Z. Artificial intelligence innovation in education: A twenty-year data-driven historical analysis. Int. J. Innov. Stud. 2020, 4, 134–147. [Google Scholar] [CrossRef]
- Anoopkumar, M.; Rahman, A.M. A Comprehensive Survey on Educational Data Mining and Use of Data Mining Techniques for Improving Teaching and Predicting Student Performance. In Advances in Innovative Engineering and Technologies; Candaian Arena of Applied Scientific Research Ltd.: Malaysia, 2015; pp. 59–88. Available online: https://www.researchgate.net/publication/301446618_A_Comprehensive_Survey_on_Educational_Data_Mining_and_Use_of_Data_Mining_Techniques_for_Improving_Teaching_and_Predicting_Student_Performance (accessed on 1 April 2022).
- Tamada, M.M.; de Magalhães Netto, J.F.; de Lima, D.P.R. Predicting and reducing dropout in virtual learning using machine learning techniques: A systematic review. In Proceedings of the 2019 IEEE Frontiers in Education Conference (FIE), Covington, KY, USA, 16–19 October 2019; pp. 1–9. [Google Scholar]
- Petersen, K.; Feldt, R.; Mujtaba, S.; Mattsson, M. Systematic mapping studies in software engineering. In Proceedings of the 12th International Conference on Evaluation and Assessment in Software Engineering (EASE) 12, Bari, Italy, 26–27 June 2008; pp. 1–10. [Google Scholar]
- Beyer, F.; Wright, K. Comprehensive Searching for Systematic Reviews: A Comparison of Database Performance; Centre for Reviews and Dissemination, University of York: York, UK, 2011. [Google Scholar]
- Kent, A.; Berry, M.M.; Luehrs, F.U., Jr.; Perry, J.W. Machine literature searching VIII. Operational criteria for designing information retrieval systems. Am. Doc. 1955, 6, 93–101. [Google Scholar] [CrossRef]
- Wohlin, C.; Prikladnicki, R. Systematic literature reviews in software engineering. Inf. Softw. Technol. 2013, 55, 919–920. [Google Scholar] [CrossRef]
- Landis, J.R.; Koch, G.G. The measurement of observer agreement for categorical data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef] [Green Version]
- Kundel, H.L.; Polansky, M. Measurement of Observer Agreement. Radiology 2003, 228, 303. [Google Scholar] [CrossRef]
- Cruzes, D.S.; Dybå, T.; Runeson, P.; Höst, M. Case Studies Synthesis: A Thematic, Cross-Case, and Narrative Synthesis Worked Example. Empir. Softw. Eng. 2014, 20, 1634–1665. [Google Scholar] [CrossRef] [Green Version]
- Ivarsson, M.; Gorschek, T. A method for evaluating rigor and industrial relevance of technology evaluations. Empir. Softw. Eng. 2011, 16, 365–395. [Google Scholar] [CrossRef]
- Yin, R.K. Case Study Research: Design and Methods, Applied Social Research Methods Series; Sage Publications, Inc.: Thousand Oaks, CA, USA, 2009. [Google Scholar]
- Runeson, P.; Höst, M.; Rainer, A.; Regnell, B. Case Study Research in Software Engineering: Guidelines and Examples; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Cruzes, D.S.; Dybå, T. Research synthesis in software engineering: A tertiary study. Inf. Softw. Technol. 2011, 53, 440–455. [Google Scholar] [CrossRef]
- Butz, C.; Hua, S.; Maguire, R. A Web-Based Intelligent Tutoring System for Computer Programming. In Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence (WI’04), Beijing, China, 20–24 September 2004; pp. 159–165. [Google Scholar]
- Suraweera, P.; Mitrovic, A. An intelligent tutoring system for entity relationship modelling. Int. J. Artif. Intell. Educ. 2004, 14, 375–417. [Google Scholar]
- Aleven, V.; McLaren, B.; Sewall, J.; Koedinger, K.R. Example-Tracing Tutors: A New Paradigm for Intelligent Tutoring Systems; Carnegie Mellon University: Pittsburgh, PA, USA, 2008. [Google Scholar]
- Britt, M.A.; Wiemer-Hastings, P.; Larson, A.A.; Perfetti, C.A. Using intelligent feedback to improve sourcing and integration in students’ essays. Int. J. Artif. Intell. Educ. 2004, 14, 359–374. [Google Scholar]
- Vijay, V.C.; Lees, M.; Vakaj, E. Introducing knowledge based augmented reality environment in engineering learning—A comparative study. In Proceedings of the 2020 IEEE Learning with MOOCS (LWMOOCS), Antigua Guatemala, Guatemala, 29 September–2 October 2020; pp. 131–143. [Google Scholar]
- Crowe, D.; LaPierre, M.; Kebritchi, M. Knowledge Based Artificial Augmentation Intelligence Technology: Next Step in Academic Instructional Tools for Distance Learning. Techtrends 2017, 61, 494–506. [Google Scholar] [CrossRef]
- Kim, Y.; Soyata, T.; Behnagh, R.F. Towards Emotionally Aware AI Smart Classroom: Current Issues and Directions for Engineering and Education. IEEE Access 2018, 6, 5308–5331. [Google Scholar] [CrossRef]
- Dahotre, A.; Krishnamoorthy, V.; Corley, M.; Scaffidi, C. Using Intelligent Tutors to Enhance Student Learning of Application Programming Interfaces. J. Comput. Sci. Coll. 2011, 27, 195–201. [Google Scholar]
- Hsu, H.; Huang, N. Xiao-Shih: The Educational Intelligent Question Answering Bot on Chinese-Based MOOCs. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 1316–1321. [Google Scholar]
- Appsamy, B.; Scaffidi, C. Evaluation of Algorithms for Recommending Intelligent Tutors to Computer Science Students. J. Comput. Sci. Coll. 2014, 30, 142–150. [Google Scholar]
- Gamboa, H.; Fred, A. Designing Intelligent Tutoring Systems: A Bayesian Approach. In Enterprise Information Systems III; Filipe, J., Sharp, B., Miranda, P., Eds.; Springer: New York, NY, USA, 2002. [Google Scholar]
- Hämäläinen, W.; Vinni, M. Comparison of Machine Learning Methods for Intelligent Tutoring Systems. In Intelligent Tutoring Systems; Ikeda, M., Ashley, K.D., Chan, T.W., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 525–534. [Google Scholar]
- Alsolami, F.J. A Hybrid Approach for Dropout Prediction of MOOC Students using Machine Learning. Int. J. Comput. Sci. Netw. Secur. 2020, 20, 54–63. [Google Scholar]
- Cobos, R.; Olmos, L. A Learning Analytics Tool for Predictive Modeling of Dropout and Certificate Acquisition on MOOCs for Professional Learning. In Proceedings of the 2018 IEEE International Conference on Industrial Engineering and Engineering Management (IEEM), Bangkok, Thailand, 16–19 December 2018; pp. 1533–1537. [Google Scholar]
- Kotsiantis, S.; Pierrakeas, C.; Pintelas, P. Preventing student dropout in distance learning using machine learning techniques. In Proceedings of the 7th International Conference on Knowledge-Based Intelligent Information and Engineering Systems (KES 2003), Oxford, UK, 3–5 September 2003; Volume 2774, pp. 267–274. [Google Scholar]
- Liang, J.; Li, C.; Zheng, L. Machine learning application in MOOCs: Dropout prediction. In Proceedings of the 2016 11th International Conference on Computer Science Education (ICCSE), Nagoya, Japan, 23–25 August 2016; pp. 52–57. [Google Scholar]
- Kloft, M.; Stiehler, F.; Zheng, Z.; Pinkwart, N. Predicting MOOC Dropout over Weeks Using Machine Learning Methods. In Proceedings of the EMNLP 2014 Workshop on Analysis of Large Scale Social Interaction in MOOCs, Doha, Qatar, 25–29 October 2014; pp. 60–65. [Google Scholar]
- d. Oliveira, M.M.; Barwaldt, R.; Pias, M.R.; Espíndola, D.B. Understanding the Student Dropout in Distance Learning. In Proceedings of the 2019 IEEE Frontiers in Education Conference (FIE), Cincinnati, OH, USA, 16–19 October 2019; pp. 1–7. [Google Scholar]
- Kostopoulos, G.; Kotsiantis, S.; Ragos, O.; Grapsa, T.N. Early dropout prediction in distance higher education using active learning. In Proceedings of the 2017 8th International Conference on Information, Intelligence, Systems Applications (IISA), Larnaca, Larnaca, Cyprus, 27–30 August 2017; pp. 1–6. [Google Scholar]
- Lykourentzou, I.; Giannoukos, I.; Nikolopoulos, V.; Mpardis, G.; Loumos, V. Dropout prediction in e-learning courses through the combination of machine learning techniques. Comput. Educ. 2009, 53, 950–965. [Google Scholar] [CrossRef]
- Tomasevic, N.; Gvozdenovic, N.; Vranes, S. An overview and comparison of supervised data mining techniques for student exam performance prediction. Comput. Educ. 2020, 143, 103676. [Google Scholar] [CrossRef]
- Sekeroglu, B.; Dimililer, K.; Tuncal, K. Student Performance Prediction and Classification Using Machine Learning Algorithms. In Proceedings of the 2019 8th International Conference on Educational and Information Technology (ICEIT 2019), Cambridge, UK, 2–4 March 2019; pp. 7–11. [Google Scholar]
- Hussain, M.; Zhu, W.; Zhang, W.; Abidi, S. Student Engagement Predictions in an e-Learning System and Their Impact on Student Course Assessment Scores. Comput. Intell. Neurosci. 2018, 2018, 6347186. [Google Scholar] [CrossRef] [Green Version]
- De Albuquerque, R.M.; Bezerra, A.A.; de Souza, D.A.; do Nascimento, L.B.P.; Sa, J.J.d.M.; do Nascimento, J.C. Using neural networks to predict the future performance of students. In Proceedings of the 2015 International Symposium on Computers in Education (SIIE), Setubal, Portugal, 25–27 November 2015; pp. 109–113. [Google Scholar]
- Deo, R.C.; Yaseen, Z.M.; Al-Ansari, N.; Nguyen-Huy, T.; Langlands, T.A.M.; Galligan, L. Modern Artificial Intelligence Model Development for Undergraduate Student Performance Prediction: An Investigation on Engineering Mathematics Courses. IEEE Access 2020, 8, 136697–136724. [Google Scholar] [CrossRef]
- Kotsiantis, S.; Pierrakeas, C.; Pintelas, P. Predicting students’ performance in distance learning using machine learning techniques. Appl. Artif. Intell. 2004, 18, 411–426. [Google Scholar] [CrossRef]
- Bote-Lorenzo, M.L.; Gómez-Sánchez, E. Predicting the decrease of engagement indicators in a MOOC. In Proceedings of the Seventh International Learning Analytics & Knowledge Conference, Vancouver, BC, Canada, 13–17 March 2017; pp. 143–147. [Google Scholar]
- Jayaprakash, S.M.; Moody, E.W.; Lauría, E.J.; Regan, J.R.; Baron, J.D. Early Alert of Academically at Risk Students: An Open Source Analytics Initiative. J. Learn. Anal. 2014, 1, 6–47. [Google Scholar] [CrossRef] [Green Version]
- Yoo, J.; Kim, J. Can Online Discussion Participation Predict Group Project Performance? Investigating the Roles of Linguistic Features and Participation Patterns. Int. J. Artif. Intell. Educ. 2014, 24, 8–32. [Google Scholar] [CrossRef] [Green Version]
- Romero, C.; López, M.I.; Luna, J.M.; Ventura, S. Predicting students’ final performance from participation in on-line discussion forums. Comput. Educ. 2013, 68, 458–472. [Google Scholar] [CrossRef]
- Seridi-Bou, H.; Sari, T.; Sellami, M. A Neural Network for Generating Adaptive Lessons. J. Comput. Sci. 2005, 1, 232–243. [Google Scholar] [CrossRef]
- Vie, J.J.; Popineau, F.; Bruillard, E.; Bourda, Y. Automated Test Assembly for Handling Learner Cold-Start in Large-Scale Assessments. Int. J. Artif. Intell. Educ. 2018, 28, 616–631. [Google Scholar] [CrossRef] [Green Version]
- García, P.; Amandi, A.; Schiaffino, S.; Campo, M. Using Bayesian networks to detect students’ learning styles in a web-based education system. In Proceedings of the ASAI, Rosario, Argentina, 29–30 August 2005; pp. 115–126. [Google Scholar]
- Chen, H.; Yin, C.; Li, R.; Rong, W.; Xiong, Z.; David, B. Enhanced learning resource recommendation based on online learning style model. Tsinghua Sci. Technol. 2020, 25, 348–356. [Google Scholar] [CrossRef]
- Casalino, G.; Castellano, G.; Mannavola, A.; Vessio, G. Educational Stream Data Analysis: A Case Study. In Proceedings of the 2020 IEEE 20th Mediterranean Electrotechnical Conference ( MELECON), Palermo, Italy, 16–18 June 2020; pp. 232–237. [Google Scholar]
- Lin, C.F.; Yeh, Y.c.; Hung, Y.H.; Chang, R.I. Data mining for providing a personalized learning path in creativity: An application of decision trees. Comput. Educ. 2013, 68, 199–210. [Google Scholar] [CrossRef]
- Roessingh, J.; Poppinga, G.; van Oijen, J.; Toubman, A. Application of Artificial Intelligence to Adaptive Instruction—Combining the Concepts. Lect. Notes Comput. Sci. 2019, 11597 LNCS, 542–556. [Google Scholar]
- Sharma, K.; Papamitsiou, Z.; Giannakos, M. Building pipelines for educational data using AI and multimodal analytics: A “grey-box” approach. Br. J. Educ. Technol. 2019, 50, 3004–3031. [Google Scholar] [CrossRef] [Green Version]
- Sun, Z.; Anbarasan, M.; Praveen Kumar, D. Design of online intelligent English teaching platform based on artificial intelligence techniques. Comput. Intell. 2020, 37, 1166–1180. [Google Scholar] [CrossRef]
- Li, R.; Yin, C. Analysis of online learning style model based on K-means algorithm. In Proceedings of the 3rd International Conference on Economics, Management, Law and Education (EMLE 2017), Zhengzhou, China, 25–26 November 2017; pp. 692–697. [Google Scholar]
- Spikol, D.; Ruffaldi, E.; Dabisias, G.; Cukurova, M. Supervised machine learning in multimodal learning analytics for estimating success in project-based learning. J. Comput. Assist. Learn. 2018, 34, 366–377. [Google Scholar] [CrossRef]
- Mehmood, R.; Alam, F.; Albogami, N.N.; Katib, I.; Albeshri, A.; Altowaijri, S.M. UTiLearn: A Personalised Ubiquitous Teaching and Learning System for Smart Societies. IEEE Access 2017, 5, 2615–2635. [Google Scholar] [CrossRef]
- Shih, T.K.; Gunarathne, W.K.T.M.; Ochirbat, A.; Su, H.M. Grouping Peers Based on Complementary Degree and Social Relationship Using Genetic Algorithm. ACM Trans. Internet Technol. 2018, 19, 1–29. [Google Scholar] [CrossRef]
- Liu, C.; Ge, J.; Chen, D.; Chen, G. An Online Classroom Atmosphere Assessment System for Evaluating Teaching Quality. In Proceedings of the 2018 IEEE International Conference of Safety Produce Informatization (IICSPI), Chongqing, China, 10–12 December 2018; pp. 127–131. [Google Scholar]
- Oztekin, A.; Delen, D.; Turkyilmaz, A.; Zaim, S. A machine learning-based usability evaluation method for eLearning systems. Decis. Support Syst. 2013, 56, 63–73. [Google Scholar] [CrossRef]
- Hasan, M.M.; Khaing, H.O. Learner Corpus and its Application to Automatic Level Checking using Machine Learning Algorithms. In Proceedings of the 2008 5th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology, Krabi, Thailand, 14–17 May 2008; pp. 25–28. [Google Scholar]
- Fei, T.; Heng, W.J.; Toh, K.C.; Qi, T. Question classification for E-learning by artificial neural network. In Proceedings of the 2003 Joint conference of the Fourth International Conference on Information, Communications and Signal Processing, 2003 and the Fourth Pacific Rim Conference on Multimedia, Singapore, 15–18 December 2003; Volume 3, pp. 1757–1761. [Google Scholar]
- Husain, M.; Meena, S.M. Multimodal Fusion of Speech and Text using Semi-supervised LDA for Indexing Lecture Videos. In Proceedings of the 2019 National Conference on Communications (NCC), Bangalore, India, 20–23 February 2019; pp. 1–6. [Google Scholar]
- Mabrouk, M.E.; Gaou, S.; Rtili, M.K. Towards an Intelligent Hybrid Recommendation System for E-Learning Platforms Using Data Mining. Int. J. Emerg. Technol. Learn. (iJET) 2017, 12, 52–76. [Google Scholar] [CrossRef] [Green Version]
- Kuzilek, J.; Hlosta, M.; Zdrahal, Z. Open university learning analytics dataset. Sci. Data 2017, 4, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Yen, N.Y.; Shih, T.K.; Jin, Q. LONET: An Interactive Search Network for Intelligent Lecture Path Generation. ACM Trans. Intell. Syst. Technol. 2013, 4, 1–27. [Google Scholar] [CrossRef]
Figure 1.
Systematic revision search process.

Figure 2.
Number of studies published to date since 2000.

Figure 3.
Research strategies used in the published studies.

Figure 4.
Classification of studies in thematic analysis.

Figure 5.
Algorithms used to predict students’ dropout rate in the courses.

Figure 6.
Algorithms used to predict students’ performance.

Table 2.
Inclusion/exclusion criteria.
| Inclusion Criteria | Exclusion Criteria |
|---|---|
| Studies addressing the use of AI/ML/DL in the teaching and learning. | Courses on machine learning. |
| AI/ML/DL used on data collected from teaching and learning platforms. | Digital learning systems without the use of AI techniques. |
| Studies using supervised, semi-supervised, and unsupervised learning methods are included. | No mention of AI/ML/DL uses in education. |
| Only peer-reviewed papers are included. | Articles not accessible in English. |
| All studies from 2000 to the present. | The study is not accessible as a full text. |
Table 3.
Data extraction properties.
| Data Extraction Property | Definition |
|---|---|
| General study information | Primary study ID, author(s), title, publication venue, date of publication, publication details for journal (volume and issue). |
| Type of paper | Problem identification, solution paper, survey, systematic review, experiment, case study. |
| Research questions | Clear description of research question or problem under investigation. |
| Main aims of the Study | What were the objectives behind conducting the study? |
| Study outcomes | Short description of study outcomes. |
Table 4.
Definition of identified themes from thematic analysis.
| Theme Name | Definition |
|---|---|
| Intelligent tutors | This theme refers to intelligent tutoring systems proposed or used in online education. |
| Dropout prediction | This theme consists of studies predicting student dropouts from online courses using ML models. |
| Performance prediction | This theme consists of papers using different ML models to predict student performance in online courses. |
| Adaptive and Predictive Learning and Learning Styles | This theme consists of studies that use different algorithms for adaptive and predictive learning as well as for addressing different learning styles. |
| Analytics, assessments, and group-based learning | This theme consists of studies related to analytics, assessments, and group-based learning with the support of different algorithms. |
| Automation | This theme refers to the studies related to specific algorithms used for automation, whether recommendation, proficiency, classification, or for indexing in digital learning. |
Table 5.
Algorithms and approaches used for adaptive and predictive learning and learning styles.
| Papers | Methodology | Algorithms |
|---|---|---|
| [64] | Experiment | Artificial neural network (ANN) |
| [73] | Survey | K-means |
| [65] | Experiment | Determinantal point processes (DPPs) |
| [72] | Case study | Decision tree classification, neural network |
| [66] | Experiment | Bayesian nets |
| [67] | Experiment | K-means clustering |
| [68] | Experiment | Random forest (RF) and adaptive random forest (ARF) |
| [69] | Experiment | Decision tree method |
| [70] | Case study | (1) Supervised learning, (2) unsupervised learning, and (3) reinforcement learning |
| [71] | Case study | Principal component analysis (PCA), support vector machine (SVM), random forest (RF), normalized root mean squared error (NRMSE) |
Table 6.
Algorithms and approaches used for analytics, assessments, and group-based learning.
| Papers | Methodology | Algorithms |
|---|---|---|
| [74] | Experiment | Naive Bayesian (NB), logistic regression (LR), support vector machine with linear kernel (SVML), support vector machine for regression (SVMR) |
| [75] | Experiment | Naive Bayes classifier (NBC), random forest (RF), and deep learning artificial neural network (ANN) |
| [76] | Experiment | Genetic algorithm (GA) |
| [77] | Experiment | R-CNN, SVM |
| [78] | Experiment | Support vector machine (SVM), neural networks (NN), decision trees (DT), linear regression (LR) |
Table 7.
Algorithms and approaches used for automatic recommendation, proficiency, classification, and indexing.
Table 7.
Algorithms and approaches used for automatic recommendation, proficiency, classification, and indexing.
| Papers | Methodology | Algorithms |
|---|---|---|
| [79] | Experiment | ID3, C4.5, Bayesian net and SVM |
| [80] | Experiment | ANN, least mean square (LMS) |
| [81] | Experiment | semi-supervised LDA algorithm |
| [82] | Case study | CART algorithm (classification and regression trees) |
| [67] | Experiment | K-means |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Munir, H.; Vogel, B.; Jacobsson, A. Artificial Intelligence and Machine Learning Approaches in Digital Education: A Systematic Revision. Information 2022, 13, 203. https://doi.org/10.3390/info13040203
AMA Style
Munir H, Vogel B, Jacobsson A. Artificial Intelligence and Machine Learning Approaches in Digital Education: A Systematic Revision. Information. 2022; 13(4):203. https://doi.org/10.3390/info13040203
Chicago/Turabian StyleMunir, Hussan, Bahtijar Vogel, and Andreas Jacobsson. 2022. "Artificial Intelligence and Machine Learning Approaches in Digital Education: A Systematic Revision" Information 13, no. 4: 203. https://doi.org/10.3390/info13040203
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.