Small Manhole Cover Detection in Remote Sensing Imagery with Deep Convolutional Neural Networks

Abstract
:1. Introduction
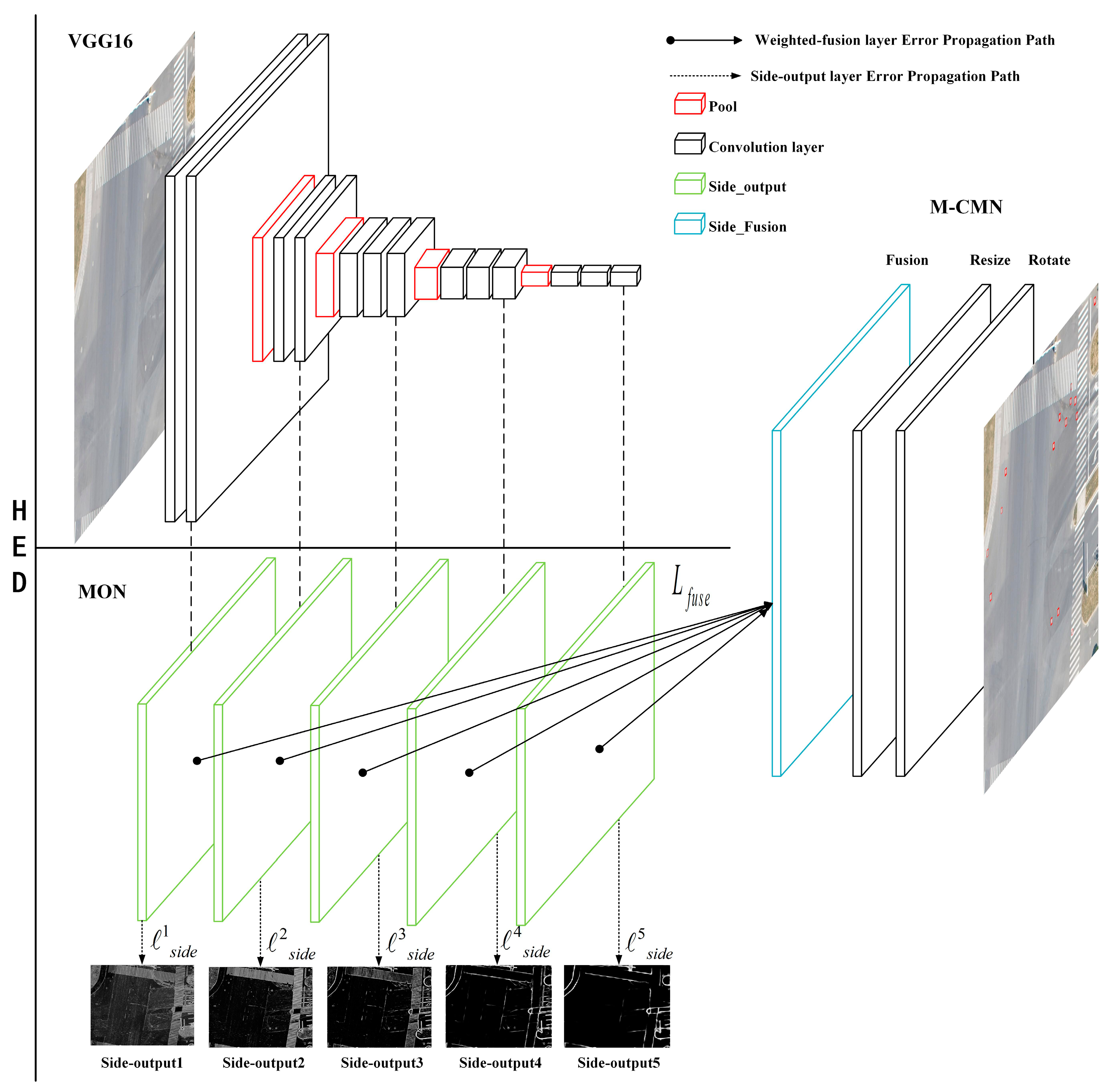
2. Multi-scale CNN for Manhole Cover Object Detection
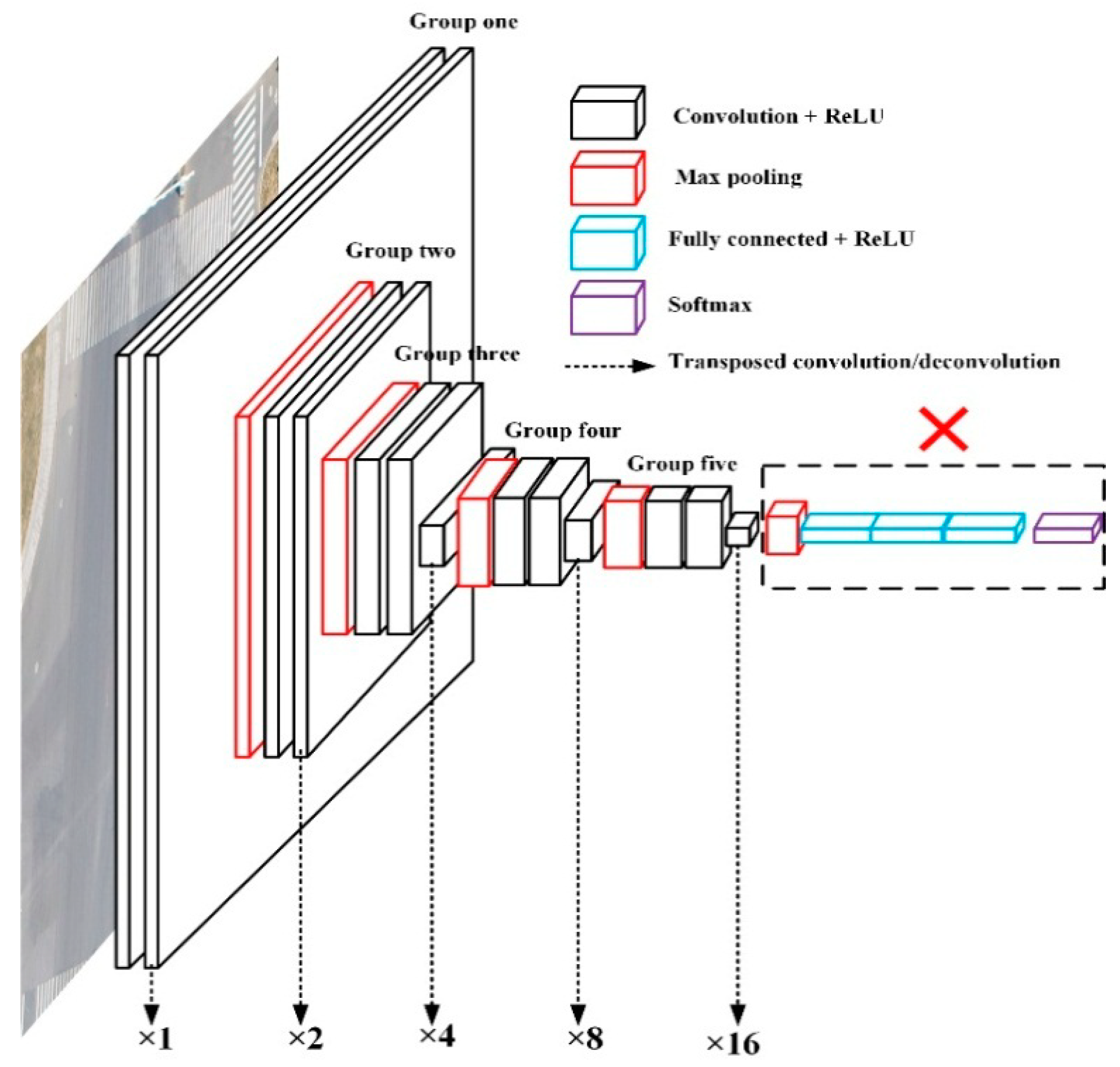
2.1. Details on VGG16 Architecture
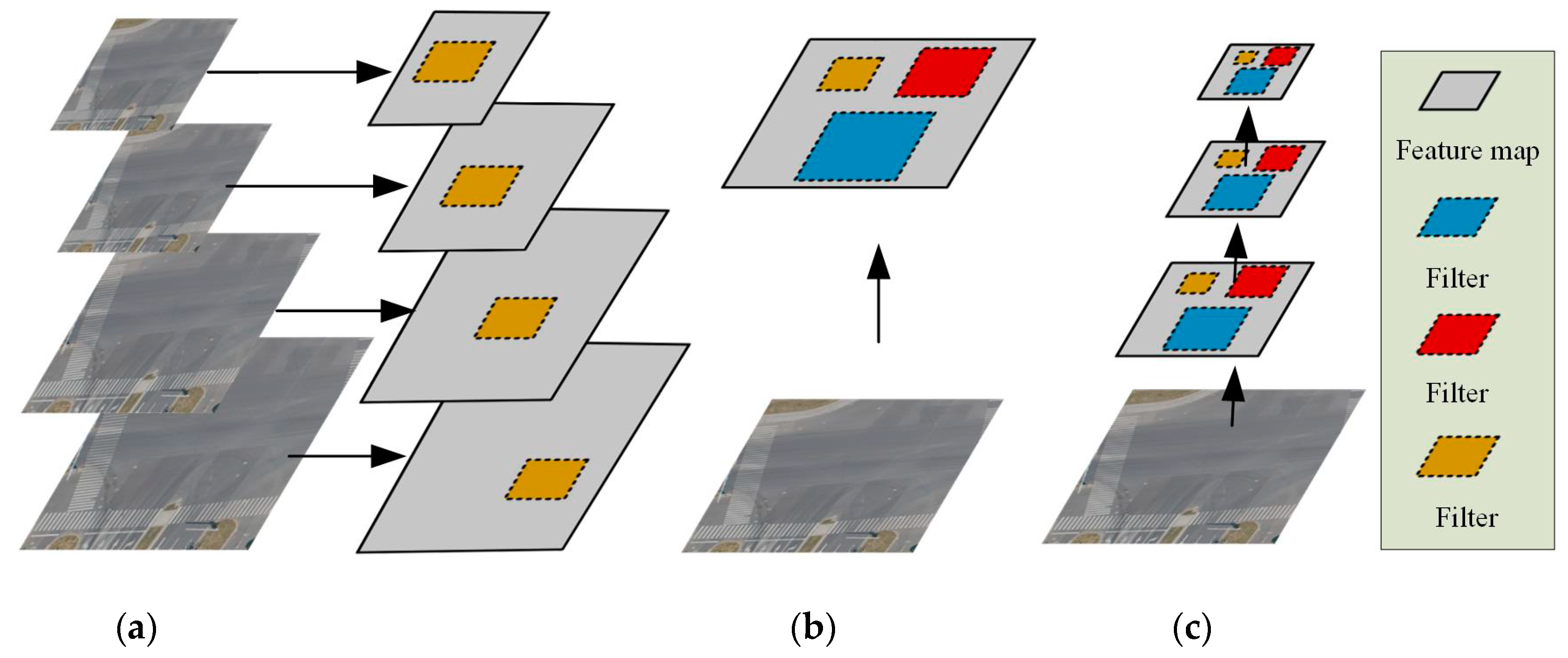
2.2. Multi-scale Output Network (MON)
2.3. Multi-level Convolution Matching Network (M-CMN)
3. Experimental Results
3.1. Dataset
3.2. Model and Parameters
3.3. Results
4. Discussion
4.1. Can Increasing the Depth of the Backbone Network Improve Small Object Detection Performance?
4.2. Can Multi-scale and Multi-level Feature Fusion Improve the Performance of Small Object Detection?
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Yu, J.; Lin, W. The Application of High Precision Mobile Measurement System in Urban Component Survey. Sci. Surv. Mapp. 2016, 8, 147–148. [Google Scholar]
- Li, X.; Tang, J.; Li, H. The Application of Mobile Mapping Technology in Digital Urban Component Census. Lang Resour. Her. 2017, 14, 53–57. [Google Scholar]
- Song, Y.; Zeng, F.; Gao, Z. Application of vehicle panoramic photogrammetry in the investigation of urban parts. Sci. Surv. Mapp. 2016, 11, 40–43. [Google Scholar]
- Deng, Z.; Sun, H.; Zhou, S.; Zhao, J.; Lei, L.; Zou, H. Multi-scale object detection in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2018, 145, 3–22. [Google Scholar] [CrossRef]
- Ding, P.; Zhang, Y.; Deng, W.J.; Jia, P.; Kuijper, A. A light and faster regional convolutional neural network for object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2018, 141, 208–218. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. arXiv, 2014; arXiv:1311.2524v4. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-Based Convolutional Networks for Accurate Object Detection and Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 142–158. [Google Scholar] [CrossRef]
- Hwang, J.J.; Liu, T.L. Pixel-wise Deep Learning for Contour Detection. arXiv, 2015; arXiv:1504.01989. [Google Scholar]
- Zhao, F.; Xia, L.; Kylling, A.; Li, R.Q.; Shang, H.; Xu, M. Detection flying aircraft from Landsat 8 OLI data. ISPRS J. Photogramm. Remote Sens. 2018, 141, 176–184. [Google Scholar] [CrossRef]
- Zhong, Y.; Han, X.; Zhang, L. Multi-class geospatial object detection based on a position-sensitive balancing framework for high spatial resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2018, 138, 281–294. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. arXiv, 2015; arXiv:1504.08083. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Xie, S.; Tu, Z. Holistically-Nested Edge Detection. Int. J. Comput. Vis 2015, 125, 3–18. [Google Scholar] [CrossRef]
- Yan, Z.; Zhang, H.; Piramuthu, R.; Jagadeesh, V. HD-CNN: Hierarchical Deep Convolutional Neural Networks for Large Scale Visual Recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2740–2748. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Duarte, D.; Nex, F.; Kerle, N.; Vosselman, G. Multi-Resolution Feature Fusion for Image Classification of Building Damages with Convolutional Neural Networks. Remote Sens. 2018, 10, 1636. [Google Scholar] [CrossRef]
- Zhang, C.; Sargent, I.; Pan, X.; Li, H.; Gardiner, A.; Hare, J.; Atkinson, P.M. An object-based convolutional neural network (OCNN) for urban land use classification. Remote Sens. Environ. 2018, 216, 57–70. [Google Scholar] [CrossRef]
- Lecun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 2014, 1, 541–551. [Google Scholar] [CrossRef]
- Dollar, P.; Tu, Z.; Belongie, S. Supervised Learning of Edges and Object Boundaries. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; pp. 1964–1971. [Google Scholar]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. DSSD: Deconvolutional Single Shot Detector. arXiv, 2017; arXiv:1701.06659. [Google Scholar]
- Li, Z.; Zhou, F. FSSD: Feature Fusion Single Shot Multibox Detector. arXiv, 2017; arXiv:1712.00960. [Google Scholar]
- Cheng, G.; Han, J.; Zhou, P. Learning Rotation-Invariant and Fisher Discriminative Convolutional Neural Networks for Object Detection. IEEE Trans. Image Process. 2018, 28, 265–278. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J. Learning Rotation-Invariant Convolutional Neural Networks for Object Detection in VHR Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Li, K.; Cheng, G.; Bu, S.; You, X. Rotation-Insensitive and Context-Augmented Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2337–2348. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layers | C1 | C2 | C3 | C4 | C5 | Fully Connected |
|---|---|---|---|---|---|---|
| 16 | Conv3-64 | Conv3-128 | Conv3-256 | Conv3-512 | Conv3-512 | FC-4096 |
| Conv3-64 | Conv3-128 | Conv3-256 | Conv3-512 | Conv3-512 | FC-4096 | |
| Max pool | Max pool | Conv1-256 | Conv1-512 | Conv1-512 | FC-1000 | |
| Max pool | Max pool | Max pool | Soft-max |
| Layer | C1_2 | P1 | C2_2 | P2 | C3_3 | P3 | C4_3 | P4 | C5_3 | P5 |
|---|---|---|---|---|---|---|---|---|---|---|
| RF | 5 | 6 | 14 | 16 | 32 | 36 | 68 | 76 | 140 | 156 |
| Stride | 1 | 2 | 2 | 4 | 4 | 8 | 8 | 16 | 16 | 32 |
| Method | Faster R-CNN | YOLOv3 | SSD | DSSD | FSSD |
|---|---|---|---|---|---|
| Precision | 0.7108 | 0.7034 | 0.6720 | 0.8058 | 0.8039 |
| Recall | 0.7481 | 0.7858 | 0.8369 | 0.8159 | 0.8506 |
| F1-score | 0.7289 | 0.7395 | 0.7454 | 0.8108 | 0.8266 |
| Speed (fps) | 6.2 | 76 | 52 | 7.8 | 69 |
| Method | Ours-fusion | Ours-fusion 2 | Ours-fusion 3 | Ours-fusion 4 | |
| Precision | 0.7626 | 0.6928 | 0.8640 | 0.9486 | |
| Recall | 0.8008 | 0.9658 | 0.9272 | 0.6949 | |
| F1-score | 0.7812 | 0.8068 | 0.8946 | 0.8022 | |
| Speed (fps) | 18 | 16 | 14.2 | 11.6 |
| Method | Faster R-CNN | YOLOv3 | SSD | DSSD | FSSD |
|---|---|---|---|---|---|
| True Positive | 3256 | 3420 | 3642 | 3551 | 3702 |
| False Negative | 1096 | 932 | 710 | 801 | 650 |
| False Positive | 1325 | 1442 | 1778 | 856 | 903 |
| Method | Ours-fusion | Ours-fusion2 | Ours-fusion3 | Ours-fusion4 | |
| True Positive | 3485 | 4203 | 4035 | 3024 | |
| False Negative | 767 | 149 | 317 | 1328 | |
| False Positive | 1085 | 1864 | 635 | 164 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, W.; Cheng, D.; Yin, P.; Yang, M.; Li, E.; Xie, M.; Zhang, L. Small Manhole Cover Detection in Remote Sensing Imagery with Deep Convolutional Neural Networks. ISPRS Int. J. Geo-Inf. 2019, 8, 49. https://doi.org/10.3390/ijgi8010049
Liu W, Cheng D, Yin P, Yang M, Li E, Xie M, Zhang L. Small Manhole Cover Detection in Remote Sensing Imagery with Deep Convolutional Neural Networks. ISPRS International Journal of Geo-Information. 2019; 8(1):49. https://doi.org/10.3390/ijgi8010049
Chicago/Turabian StyleLiu, Wei, Dayu Cheng, Pengcheng Yin, Mengyuan Yang, Erzhu Li, Meng Xie, and Lianpeng Zhang. 2019. "Small Manhole Cover Detection in Remote Sensing Imagery with Deep Convolutional Neural Networks" ISPRS International Journal of Geo-Information 8, no. 1: 49. https://doi.org/10.3390/ijgi8010049